Genomic and Biotechnological Characterization of the Heavy-Metal Resistant, Arsenic-Oxidizing Bacterium Ensifer sp. M14

 , ,
, ,  ,
,  ,
,
Abstract
1. Introduction
2. Materials and Methods
2.1. Genome Sequencing, Assembly, and Annotation
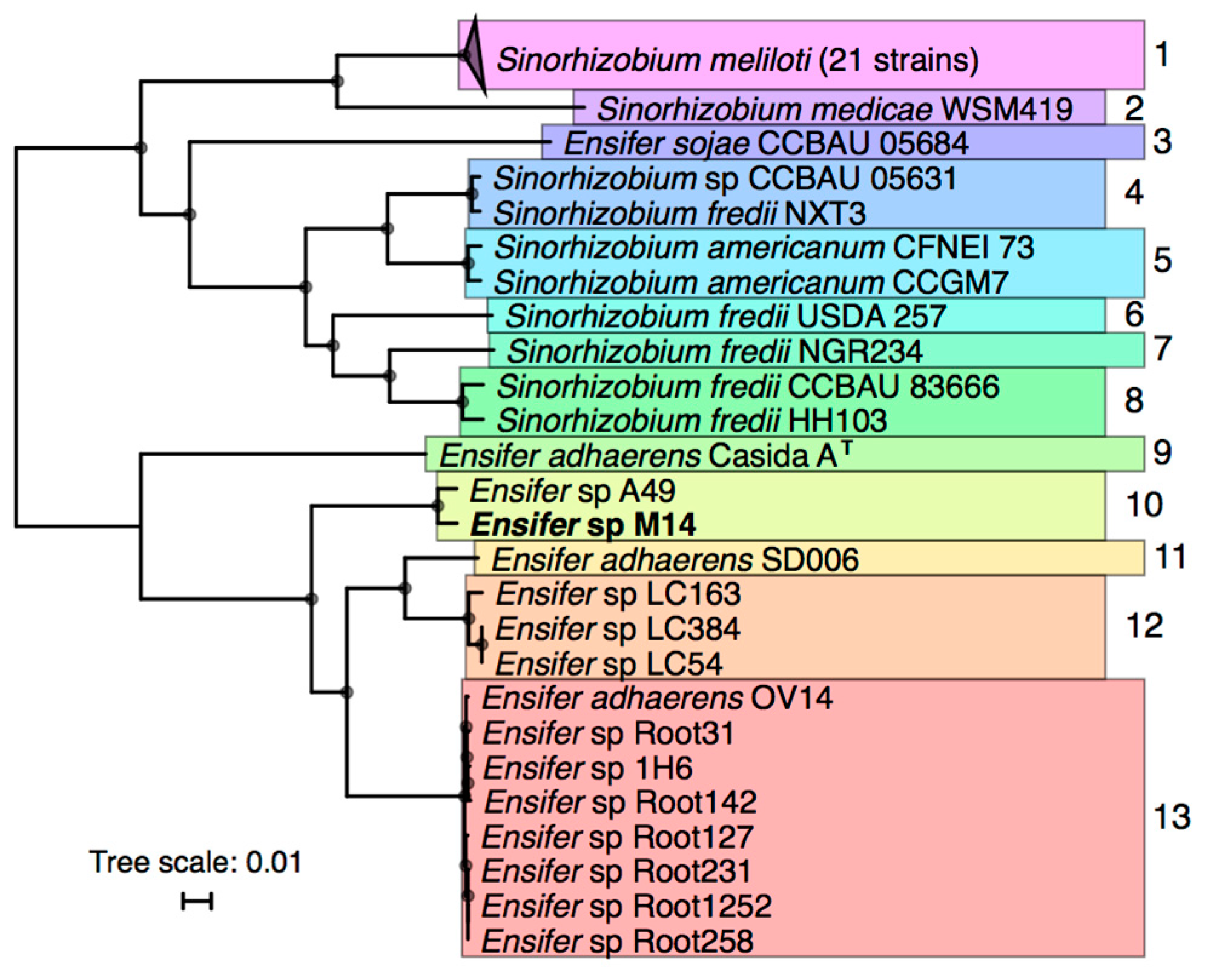
2.2. Phylogenetic Analysis
2.3. Sinorhizobium/Ensifer Pangenome Calculation
2.4. Comparative Genomics of Arsenic Oxidizing Bacteria
2.5. Identification of Prophage Loci
2.6. Identification of Putative Antibiotic Resistance Genes
2.7. Analysis of the Antimicrobial Susceptibility Patterns
2.8. Search for Symbiotic Proteins
2.9. Cluster of Orthologous Genes Functional Annotation
2.10. In Silico Metabolic Reconstruction and Constraint-Based Modelling
2.11. Prediction of Secondary Metabolism
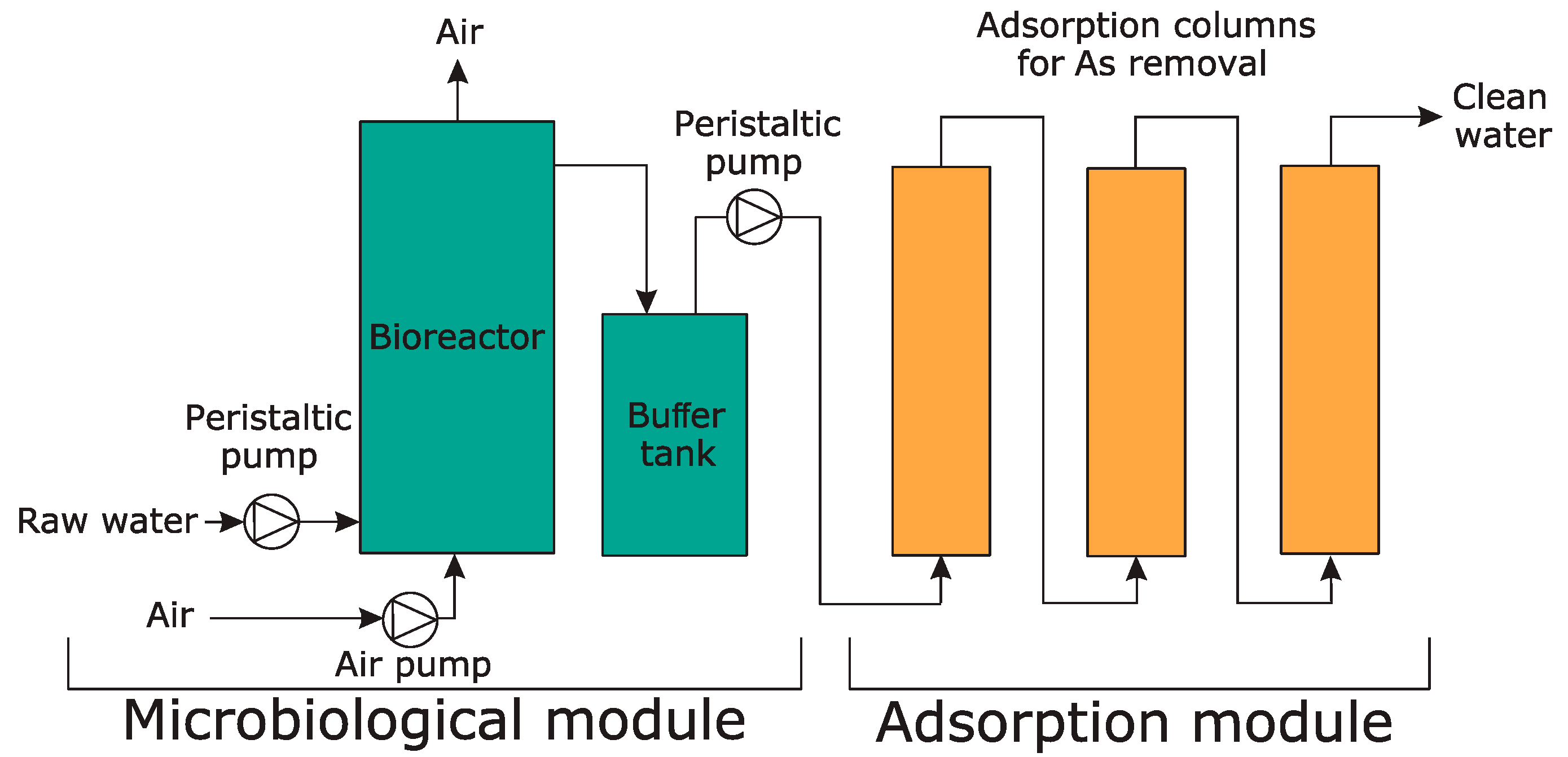
2.12. Construction of a Pilot-Scale Installation for Arsenic Bioremediation
2.13. Installation Start-Up
2.14. Biological and Chemical Analyses
3. Results and Discussion
3.1. Sequencing of the Ensifer sp. M14 Genome
3.2. Taxonomic Analysis of Ensifer sp. M14
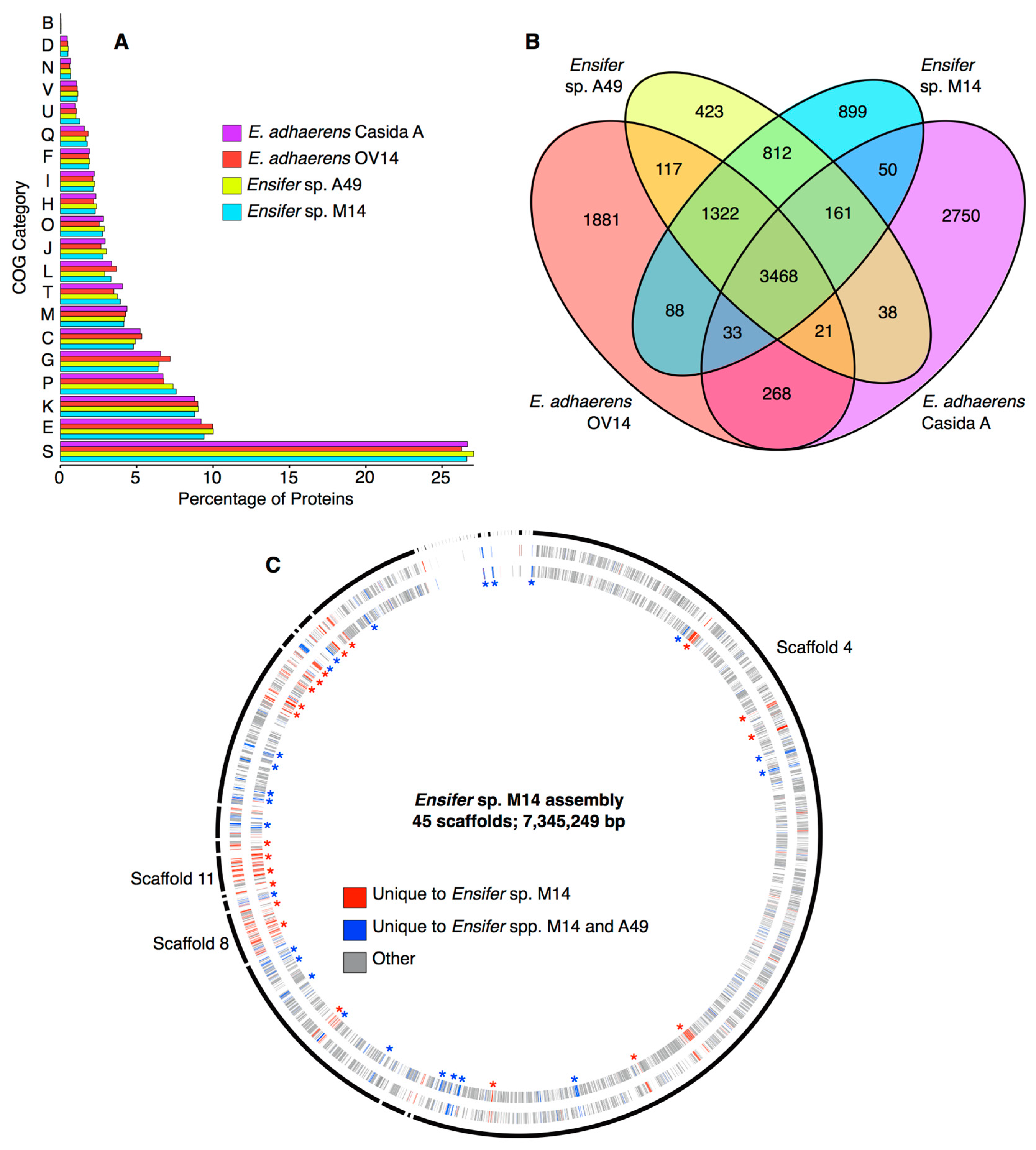
3.3. Identification of Unique Features of the Ensifer sp. M14 Genome
3.4. Metabolism of Ensifer sp. M14
3.4.1. Phosphate Transport
3.4.2. Sulfur Metabolism
3.4.3. One-Carbon Metabolism
3.4.4. Iron Transport and Metabolism
3.4.5. Halotolerance
3.4.6. Heavy Metal Resistance
3.5. Biosafety Considerations of Ensifer sp. M14
3.6. Development of a Pilot-Scale Installation for Arsenic Bioremediation
3.7. The Activity and Characterization of the Microbiological Module of the Pilot-Scale Installation
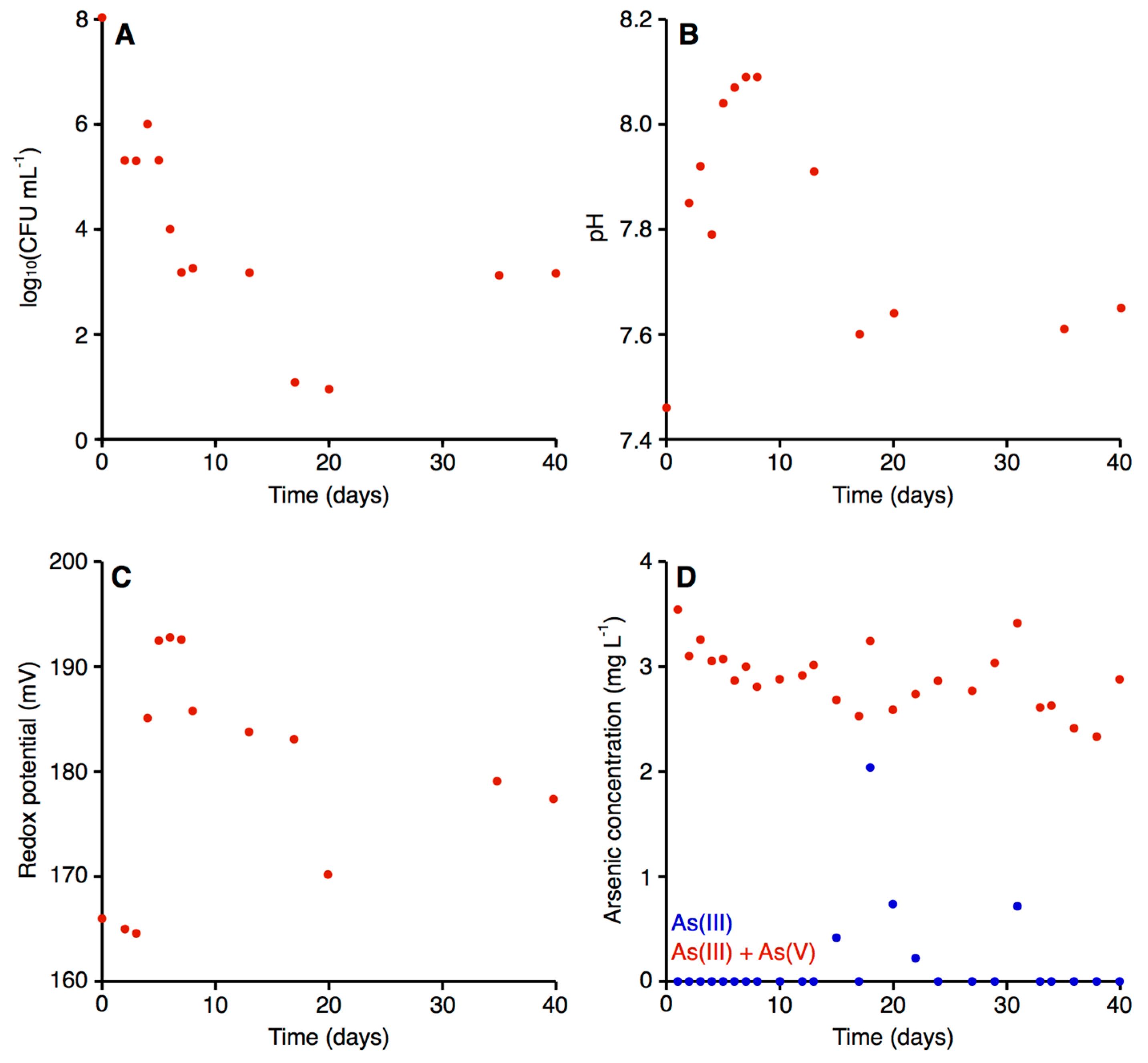
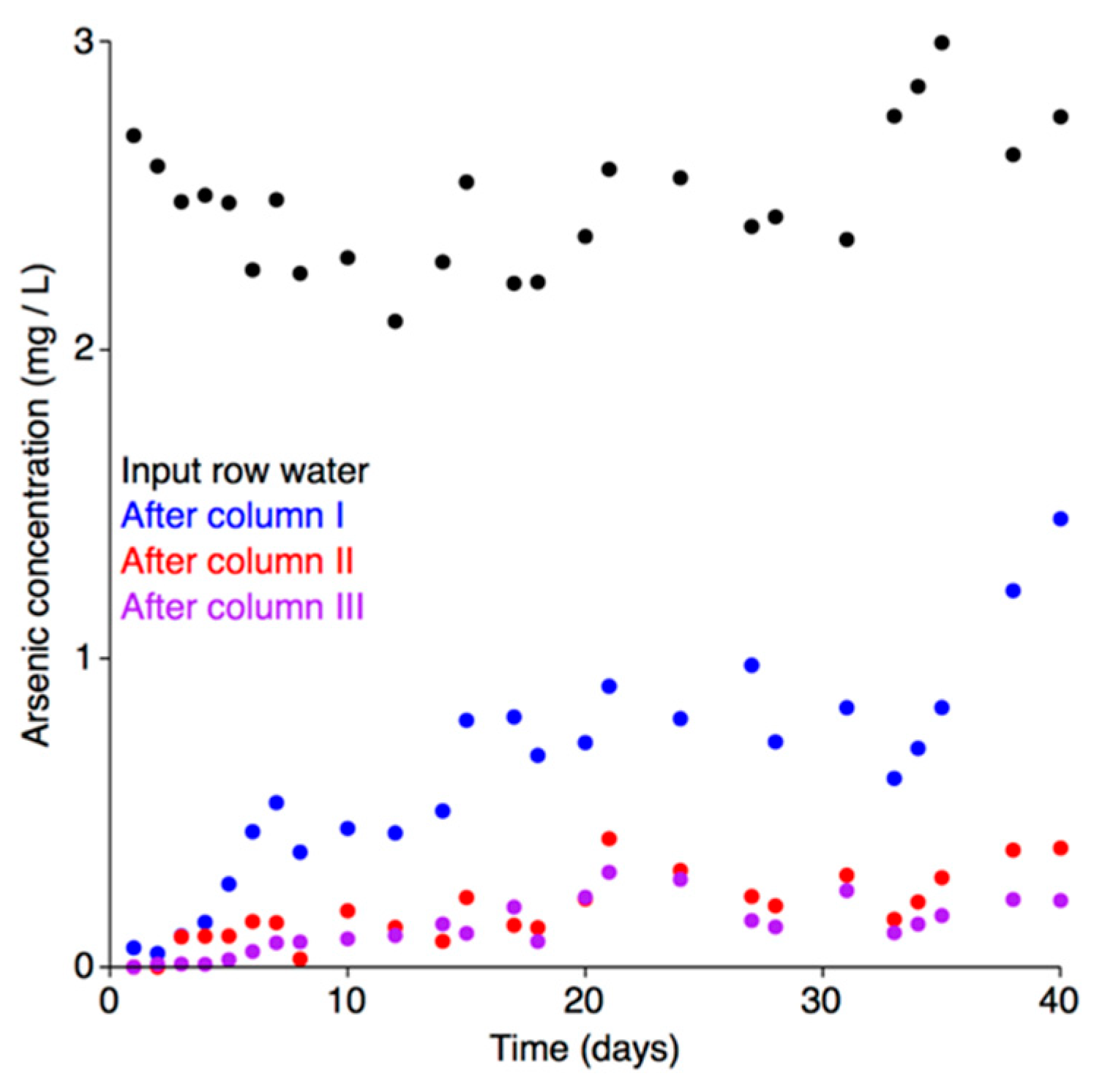
3.7.1. Microbial Growth and Efficiency of Arsenic Biooxidation in the Bioreactor
3.7.2. Physical and Chemical Characterization of the Bioreactor
3.8. Effectiveness of the Adsorption Module of the Pilot-Scale Installation
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Alisi, C.; Musella, R.; Tasso, F.; Ubaldi, C.; Manzo, S.; Cremisini, C.; Sprocati, A.R. Bioremediation of diesel oil in a co-contaminated soil by bioaugmentation with a microbial formula tailored with native strains selected for heavy metals resistance. Sci. Total Environ. 2009, 407, 3024–3032. [Google Scholar] [CrossRef] [PubMed]
- Kuppusamy, S.; Thavamani, P.; Megharaj, M.; Lee, Y.B.; Naidu, R. Polyaromatic hydrocarbon (PAH) degradation potential of a new acid tolerant, diazotrophic P-solubilizing and heavy metal resistant bacterium Cupriavidus sp. MTS-7 isolated from long-term mixed contaminated soil. Chemosphere 2016, 162, 31–39. [Google Scholar] [CrossRef] [PubMed]
- Yu, D.; Yang, J.; Teng, F.; Feng, L.; Fang, X.; Ren, H. Bioaugmentation treatment of mature landfill leachate by new isolated ammonia nitrogen and humic acid resistant microorganism. J. Microbiol. Biotechnol. 2014, 24, 987–997. [Google Scholar] [CrossRef] [PubMed]
- Pepper, I.L.; Gentry, T.J.; Newby, D.T.; Roane, T.M.; Josephson, K.L. The role of cell bioaugmentation and gene bioaugmentation in the remediation of co-contaminated soils. Environ. Health Perspect. 2002, 110 (Suppl. 6), 943–946. [Google Scholar] [CrossRef] [PubMed]
- Feng, Z.; Li, X.; Lu, C.; Shen, Z.; Xu, F.; Chen, Y. Characterization of Pseudomonas mendocina LR capable of removing nitrogen from various nitrogen-contaminated water samples when cultivated with Cyperus alternifolius L. J. Biosci. Bioeng. 2012, 114, 182–187. [Google Scholar] [CrossRef] [PubMed]
- Lee, P.K.H.; Warnecke, F.; Brodie, E.L.; Macbeth, T.W.; Conrad, M.E.; Andersen, G.L.; Alvarez-Cohen, L. Phylogenetic microarray analysis of a microbial community performing reductive dechlorination at a TCE-contaminated site. Environ. Sci. Technol. 2012, 46, 1044–1054. [Google Scholar] [CrossRef] [PubMed]
- Drewniak, L.; Matlakowska, R.; Sklodowska, A. Arsenite and arsenate metabolism of Sinorhizobium sp. M14 living in the extreme environment of the Zloty Stok gold mine. Geomicrobiol. J. 2008, 25, 363–370. [Google Scholar] [CrossRef]
- Drewniak, L.; Krawczyk, P.S.; Mielnicki, S.; Adamska, D.; Sobczak, A.; Lipinski, L.; Burec-Drewniak, W.; Sklodowska, A. Physiological and metagenomic analyses of microbial mats involved in self-purification of mine waters contaminated with heavy metals. Front. Microbiol. 2016, 7, 1252. [Google Scholar] [CrossRef] [PubMed]
- Debiec, K.; Krzysztoforski, J.; Uhrynowski, W.; Sklodowska, A.; Drewniak, L. Kinetics of arsenite oxidation by Sinorhizobium sp. M14 under changing environmental conditions. Int. Biodeterior. Biodegrad. 2017, 119, 476–485. [Google Scholar] [CrossRef]
- Drewniak, L.; Dziewit, L.; Ciezkowska, M.; Gawor, J.; Gromadka, R.; Sklodowska, A. Structural and functional genomics of plasmid pSinA of Sinorhizobium sp. M14 encoding genes for the arsenite oxidation and arsenic resistance. J. Biotechnol. 2013, 164, 479–488. [Google Scholar] [CrossRef] [PubMed]
- Dziewit, L.; Bartosik, D. Comparative analyses of extrachromosomal bacterial replicons, ientification of chromids, and experimental evaluation of their indispensability. Methods Mol. Biol. 2015, 1231, 15–29. [Google Scholar] [CrossRef] [PubMed]
- Romaniuk, K.; Dziewit, L.; Decewicz, P.; Mielnicki, S.; Radlinska, M.; Drewniak, L. Molecular characterization of the pSinB plasmid of the arsenite oxidizing, metallotolerant Sinorhizobium sp. M14—Insight into the heavy metal resistome of sinorhizobial extrachromosomal replicons. FEMS Microbiol. Ecol. 2017, 93, fiw215. [Google Scholar] [CrossRef] [PubMed]
- Doyle, J.; Doyle, J. A rapid DNA isolation procedure for small quantities of fresh leaf tissue. Phytochem. Bull. 1987, 19, 11–15. [Google Scholar]
- Joint Genome Institute JGI Bacterial DNA Isolation CTAB Protocol. Available online: https://jgi.doe.gov/user-program-info/pmo-overview/protocols-sample-preparation-information/jgi-bacterial-dna-isolation-ctab-protocol-2012/ (accessed on 20 July 2018).
- Bankevich, A.; Nurk, S.; Antipov, D.; Gurevich, A.A.; Dvorkin, M.; Kulikov, A.S.; Lesin, V.M.; Nikolenko, S.I.; Pham, S.; Prjibelski, A.D.; et al. SPAdes: A new genome assembly algorithm and its applications to single-cell sequencing. J. Comput. Biol. 2012, 19, 455–477. [Google Scholar] [CrossRef] [PubMed]
- Vasilinetc, I.; Prjibelski, A.D.; Gurevich, A.; Korobeynikov, A.; Pevzner, P.A. Assembling short reads from jumping libraries with large insert sizes. Bioinformatics 2015, 31, 3262–3268. [Google Scholar] [CrossRef] [PubMed]
- Jain, C.; Rodriguez-R, L.M.; Phillippy, A.M.; Konstantinidis, K.T.; Aluru, S. High-throughput ANI analysis of 90K prokaryotic genomes reveals cear species boundaries. bioRxiv 2017, 225342. [Google Scholar] [CrossRef]
- Bosi, E.; Donati, B.; Galardini, M.; Brunetti, S.; Sagot, M.-F.; Lió, P.; Crescenzi, P.; Fani, R.; Fondi, M. MeDuSa: A multi-draft based scaffolder. Bioinformatics 2015, 31, 2443–2451. [Google Scholar] [CrossRef] [PubMed]
- Seemann, T. Prokka: Rapid prokaryotic genome annotation. Bioinformatics 2014, 30, 2068–2069. [Google Scholar] [CrossRef] [PubMed]
- Hyatt, D.; Chen, G.-L.; LoCascio, P.F.; Land, M.L.; Larimer, F.W.; Hauser, L.J. Prodigal: Prokaryotic gene recognition and translation initiation site identification. BMC Bioinform. 2010, 11, 119. [Google Scholar] [CrossRef] [PubMed]
- Laslett, D.; Canback, B. ARAGORN, a program to detect tRNA genes and tmRNA genes in nucleotide sequences. Nucleic Acids Res. 2004, 32, 11–16. [Google Scholar] [CrossRef] [PubMed]
- Kolbe, D.L.; Eddy, S.R. Fast filtering for RNA homology search. Bioinformatics 2011, 27, 3102–3109. [Google Scholar] [CrossRef] [PubMed]
- Kalvari, I.; Argasinska, J.; Quinones-Olvera, N.; Nawrocki, E.P.; Rivas, E.; Eddy, S.R.; Bateman, A.; Finn, R.D.; Petrov, A.I. Rfam 13.0: Shifting to a genome-centric resource for non-coding RNA families. Nucleic Acids Res. 2018, 46, D335–D342. [Google Scholar] [CrossRef] [PubMed]
- Huerta-Cepas, J.; Forslund, K.; Coelho, L.P.; Szklarczyk, D.; Jensen, L.J.; von Mering, C.; Bork, P. Fast genome-wide functional annotation through orthology assignment by eggNOG-mapper. Mol. Biol. Evol. 2017, 34, 2115–2122. [Google Scholar] [CrossRef] [PubMed]
- Page, A.J.; Cummins, C.A.; Hunt, M.; Wong, V.K.; Reuter, S.; Holden, M.T.G.; Fookes, M.; Falush, D.; Keane, J.A.; Parkhill, J. Roary: Rapid large-scale prokaryote pan genome analysis. Bioinformatics 2015, 31, 3691–3693. [Google Scholar] [CrossRef] [PubMed]
- Löytynoja, A. Phylogeny-aware alignment with PRANK. Methods Mol. Biol. 2014, 1079, 155–170. [Google Scholar] [CrossRef] [PubMed]
- Stamatakis, A. RAxML version 8: A tool for phylogenetic analysis and post-analysis of large phylogenies. Bioinformatics 2014, 30, 1312–1313. [Google Scholar] [CrossRef] [PubMed]
- Letunic, I.; Bork, P. Interactive tree of life (iTOL) v3: An online tool for the display and annotation of phylogenetic and other trees. Nucleic Acids Res. 2016, 44, W242–W245. [Google Scholar] [CrossRef] [PubMed]
- Buchfink, B.; Xie, C.; Huson, D.H. Fast and sensitive protein alignment using DIAMOND. Nat. Methods 2015, 12, 59–60. [Google Scholar] [CrossRef] [PubMed]
- Luo, C.; Rodriguez-R, L.M.; Konstantinidis, K.T. MyTaxa: An advanced taxonomic classifier for genomic and metagenomic sequences. Nucleic Acids Res. 2014, 42, e73. [Google Scholar] [CrossRef] [PubMed]
- Hao, X.; Lin, Y.; Johnstone, L.; Liu, G.; Wang, G.; Wei, G.; McDermott, T.; Rensing, C. Genome sequence of the arsenite-oxidizing strain Agrobacterium tumefaciens 5A. J. Bacteriol. 2012, 194, 903. [Google Scholar] [CrossRef] [PubMed]
- Henkel, C.V.; den Dulk-Ras, A.; Zhang, X.; Hooykaas, P.J.J. Genome sequence of the octopine-type Agrobacterium tumefaciens strain Ach5. Genome Announc. 2014, 2, e00225-14. [Google Scholar] [CrossRef] [PubMed]
- Rudder, S.; Doohan, F.; Creevey, C.J.; Wendt, T.; Mullins, E. Genome sequence of Ensifer adhaerens OV14 provides insights into its ability as a novel vector for the genetic transformation of plant genomes. BMC Genom. 2014, 15, 268. [Google Scholar] [CrossRef] [PubMed]
- Österman, J.; Marsh, J.; Laine, P.K.; Zeng, Z.; Alatalo, E.; Sullivan, J.T.; Young, J.P.W.; Thomas-Oates, J.; Paulin, L.; Lindström, K. Genome sequencing of two Neorhizobium galegae strains reveals a noeT gene responsible for the unusual acetylation of the nodulation factors. BMC Genom. 2014, 15, 500. [Google Scholar] [CrossRef] [PubMed]
- Andres, J.; Arsène-Ploetze, F.; Barbe, V.; Brochier-Armanet, C.; Cleiss-Arnold, J.; Coppée, J.-Y.; Dillies, M.-A.; Geist, L.; Joublin, A.; Koechler, S.; et al. Life in an arsenic-containing gold mine: Genome and physiology of the autotrophic arsenite-oxidizing bacterium Rhizobium sp. NT-26. Genome Biol. Evol. 2013, 5, 934–953. [Google Scholar] [CrossRef] [PubMed]
- Arkin, A.P.; Cottingham, R.W.; Henry, C.S.; Harris, N.L.; Stevens, R.L.; Maslov, S.; Dehal, P.; Ware, D.; Perez, F.; Canon, S.; et al. KBase: The United States Department of Energy Systems Biology Knowledgebase. Nat. Biotechnol. 2018, 36, 566–569. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Stoeckert, C.J.; Roos, D.S. OrthoMCL: Identification of ortholog groups for eukaryotic genomes. Genome Res. 2003, 13, 2178–2189. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Hu, Y.; Gong, J.; Lin, Y.; Johnstone, L.; Rensing, C.; Wang, G. Genome sequence of the highly efficient arsenite-oxidizing bacterium Achromobacter arsenitoxydans SY8. J. Bacteriol. 2012, 194, 1243–1244. [Google Scholar] [CrossRef] [PubMed]
- Muller, D.; Médigue, C.; Koechler, S.; Barbe, V.; Barakat, M.; Talla, E.; Bonnefoy, V.; Krin, E.; Arsène-Ploetze, F.; Carapito, C.; et al. A tale of two oxidation states: Bacterial colonization of arsenic-rich environments. PLoS Genet. 2007, 3, e53. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Gong, J.; Hu, Y.; Cai, L.; Johnstone, L.; Grass, G.; Rensing, C.; Wang, G. Genome sequence of the moderately halotolerant, arsenite-oxidizing bacterium Pseudomonas stutzeri TS44. J. Bacteriol. 2012, 194, 4473–4474. [Google Scholar] [CrossRef] [PubMed]
- O’Leary, N.A.; Wright, M.W.; Brister, J.R.; Ciufo, S.; Haddad, D.; McVeigh, R.; Rajput, B.; Robbertse, B.; Smith-White, B.; Ako-Adjei, D.; et al. Reference sequence (RefSeq) database at NCBI: Current status, taxonomic expansion, and functional annotation. Nucleic Acids Res. 2016, 44, D733–D745. [Google Scholar] [CrossRef] [PubMed]
- Akhter, S.; Aziz, R.K.; Edwards, R.A. PhiSpy: A novel algorithm for finding prophages in bacterial genomes that combines similarity- and composition-based strategies. Nucleic Acids Res. 2012, 40, e126. [Google Scholar] [CrossRef] [PubMed]
- McArthur, A.G.; Waglechner, N.; Nizam, F.; Yan, A.; Azad, M.A.; Baylay, A.J.; Bhullar, K.; Canova, M.J.; De Pascale, G.; Ejim, L.; et al. The comprehensive antibiotic resistance database. Antimicrob. Agents Chemother. 2013, 57, 3348–3357. [Google Scholar] [CrossRef] [PubMed]
- Kahlmeter, G.; Brown, D.F.J.; Goldstein, F.W.; MacGowan, A.P.; Mouton, J.W.; Odenholt, I.; Rodloff, A.; Soussy, C.-J.; Steinbakk, M.; Soriano, F.; et al. European Committee on Antimicrobial Susceptibility Testing (EUCAST) Technical notes on antimicrobial susceptibility testing. Clin. Microbiol. Infect. 2006, 12, 501–503. [Google Scholar] [CrossRef] [PubMed]
- EUCAST European Committee on Antimicrobial Susceptibility Testing. Available online: http://www.eucast.org (accessed on 20 July 2018).
- Eddy, S.R. A new generation of homology search tools based on probabilistic inference. Genome Inform. 2009, 23, 205–211. [Google Scholar] [CrossRef] [PubMed]
- Finn, R.D.; Coggill, P.; Eberhardt, R.Y.; Eddy, S.R.; Mistry, J.; Mitchell, A.L.; Potter, S.C.; Punta, M.; Qureshi, M.; Sangrador-Vegas, A.; et al. The Pfam protein families database: Towards a more sustainable future. Nucleic Acids Res. 2016, 44, D279–D285. [Google Scholar] [CrossRef] [PubMed]
- Haft, D.H.; Selengut, J.D.; Richter, R.A.; Harkins, D.; Basu, M.K.; Beck, E. TIGRFAMs and genome properties in 2013. Nucleic Acids Res. 2012, 41, D387–D395. [Google Scholar] [CrossRef] [PubMed]
- Keating, S.M.; Bornstein, B.J.; Finney, A.; Hucka, M. SBMLToolbox: An SBML toolbox for MATLAB users. Bioinformatics 2006, 22, 1275–1277. [Google Scholar] [CrossRef] [PubMed]
- Bornstein, B.J.; Keating, S.M.; Jouraku, A.; Hucka, M. LibSBML: An API library for SBML. Bioinformatics 2008, 24, 880–881. [Google Scholar] [CrossRef] [PubMed]
- Schellenberger, J.; Que, R.; Fleming, R.M.T.; Thiele, I.; Orth, J.D.; Feist, A.M.; Zielinski, D.C.; Bordbar, A.; Lewis, N.E.; Rahmanian, S.; et al. Quantitative prediction of cellular metabolism with constraint-based models: The COBRA Toolbox v2.0. Nat. Protoc. 2011, 6, 1290–1307. [Google Scholar] [CrossRef] [PubMed]
- DiCenzo, G.; Mengoni, A.; Fondi, M. Tn-Core: Context-specific reconstruction of core metabolic models using Tn-seq data. bioRxiv 2017, 221325. [Google Scholar] [CrossRef]
- DiCenzo, G.C.; Checcucci, A.; Bazzicalupo, M.; Mengoni, A.; Viti, C.; Dziewit, L.; Finan, T.M.; Galardini, M.; Fondi, M. Metabolic modelling reveals the specialization of secondary replicons for niche adaptation in Sinorhizobium meliloti. Nat. Commun. 2016, 7, 12219. [Google Scholar] [CrossRef] [PubMed]
- DiCenzo, G.C.; Benedict, A.B.; Fondi, M.; Walker, G.C.; Finan, T.M.; Mengoni, A.; Griffitts, J.S. Robustness encoded across essential and accessory replicons of the ecologically versatile bacterium Sinorhizobium meliloti. PLoS Genet. 2018, 14, e1007357. [Google Scholar] [CrossRef] [PubMed]
- Blin, K.; Wolf, T.; Chevrette, M.G.; Lu, X.; Schwalen, C.J.; Kautsar, S.A.; Suarez Duran, H.G.; de los Santos, E.L.C.; Kim, H.U.; Nave, M.; et al. antiSMASH 4.0—Improvements in chemistry prediction and gene cluster boundary identification. Nucleic Acids Res. 2017, 45, W36–W41. [Google Scholar] [CrossRef] [PubMed]
- Debiec, K.; Rzepa, G.; Bajda, T.; Uhrynowski, W.; Sklodowska, A.; Krzysztoforski, J.; Drewniak, L. Granulated bog iron ores as sorbents in passive (bio)remediation systems for arsenic removal. Front. Chem. 2018, 6, 54. [Google Scholar] [CrossRef] [PubMed]
- Tardy, V.; Casiot, C.; Fernandez-Rojo, L.; Resongles, E.; Desoeuvre, A.; Joulian, C.; Battaglia-Brunet, F.; Héry, M. Temperature and nutrients as drivers of microbially mediated arsenic oxidation and removal from acid mine drainage. Appl. Microbiol. Biotechnol. 2018, 102, 2413–2424. [Google Scholar] [CrossRef] [PubMed]
- Williams, L.E.; Baltrus, D.A.; O’Donnell, S.D.; Skelly, T.J.; Martin, M.O. Complete genome sequence of the predatory bacterium Ensifer adhaerens Casida A. Genome Announc. 2017, 5, e01344-17. [Google Scholar] [CrossRef] [PubMed]
- Grissa, I.; Vergnaud, G.; Pourcel, C. CRISPRFinder: A web tool to identify clustered regularly interspaced short palindromic repeats. Nucleic Acids Res. 2007, 35, W52–W57. [Google Scholar] [CrossRef] [PubMed]
- Lycus, P.; Lovise Bøthun, K.; Bergaust, L.; Peele Shapleigh, J.; Reier Bakken, L.; Frostegård, Å. Phenotypic and genotypic richness of denitrifiers revealed by a novel isolation strategy. ISME J. 2017, 11, 2219–2232. [Google Scholar] [CrossRef] [PubMed]
- Casida, L.E. Ensifer adhaerens gen. nov., sp. nov.: A bacterial predator of bacteria in soil. Int. J. Syst. Bacteriol. 1982, 32, 339–345. [Google Scholar] [CrossRef]
- Krzywinski, M.; Schein, J.; Birol, I.; Connors, J.; Gascoyne, R.; Horsman, D.; Jones, S.J.; Marra, M.A. Circos: An information aesthetic for comparative genomics. Genome Res. 2009, 19, 1639–1645. [Google Scholar] [CrossRef] [PubMed]
- Geddes, B.A.; Oresnik, I.J. Physiology, genetics, and biochemistry of carbon metabolism in the alphaproteobacterium Sinorhizobium meliloti. Can. J. Microbiol. 2014, 60, 491–507. [Google Scholar] [CrossRef] [PubMed]
- Silver, S.; Phung, L.T. Genes and enzymes involved in bacterial oxidation and reduction of inorganic arsenic. Appl. Environ. Microbiol. 2005, 71, 599–608. [Google Scholar] [CrossRef] [PubMed]
- Hughes, M.F. Arsenic toxicity and potential mechanisms of action. Toxicol. Lett. 2002, 133, 1–16. [Google Scholar] [CrossRef]
- Voegele, R.T.; Bardin, S.; Finan, T.M. Characterization of the Rhizobium (Sinorhizobium) meliloti high- and low-affinity phosphate uptake systems. J. Bacteriol. 1997, 179, 7226–7232. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Z.-C.; Zaheer, R.; Finan, T.M. Regulation and properties of PstSCAB, a high-affinity, high-velocity phosphate transport system of Sinorhizobium meliloti. J. Bacteriol. 2006, 188, 1089–1102. [Google Scholar] [CrossRef] [PubMed]
- Elias, M.; Wellner, A.; Goldin-Azulay, K.; Chabriere, E.; Vorholt, J.A.; Erb, T.J.; Tawfik, D.S. The molecular basis of phosphate discrimination in arsenate-rich environments. Nature 2012, 491, 134–137. [Google Scholar] [CrossRef] [PubMed]
- Pickering, B.S.; Oresnik, I.J. Formate-dependent autotrophic growth in Sinorhizobium meliloti. J. Bacteriol. 2008, 190, 6409–6418. [Google Scholar] [CrossRef] [PubMed]
- Fuchs, G. Alternative pathways of carbon dioxide fixation: Insights into the early evolution of life? Annu. Rev. Microbiol. 2011, 65, 631–658. [Google Scholar] [CrossRef] [PubMed]
- Xiu, A.; Kong, Y.; Zhou, M.; Zhu, B.; Wang, S.; Zhang, J. The chemical and digestive properties of a soluble glucan from Agrobacterium sp. ZX09. Carbohydr. Polym. 2010, 82, 623–628. [Google Scholar] [CrossRef]
- Padan, E.; Tzubery, T.; Herz, K.; Kozachkov, L.; Rimon, A.; Galili, L. NhaA of Escherichia coli, as a model of a pH-regulated Na+/H+antiporter. Biochim. Biophys. Acta Bioenerg. 2004, 1658, 2–13. [Google Scholar] [CrossRef] [PubMed]
- Rathore, D.S.; Lopez-Vernaza, M.A.; Doohan, F.; Connell, D.O.; Lloyd, A.; Mullins, E. Profiling antibiotic resistance and electro-transformation potential of Ensifer adhaerens OV14; a non-Agrobacterium species capable of efficient rates of plant transformation. FEMS Microbiol. Lett. 2015, 362, fnv126. [Google Scholar] [CrossRef] [PubMed]
- Nikaido, H. Multidrug resistance in bacteria. Annu. Rev. Biochem. 2009, 78, 119–146. [Google Scholar] [CrossRef] [PubMed]
- Xiong, X.H.; Han, S.; Wang, J.H.; Jiang, Z.H.; Chen, W.; Jia, N.; Wei, H.L.; Cheng, H.; Yang, Y.X.; Zhu, B.; et al. Complete genome sequence of the bacterium Ketogulonicigenium vulgare Y25. J. Bacteriol. 2011, 193, 315–316. [Google Scholar] [CrossRef] [PubMed]
- Martin, F.A.; Posadas, D.M.; Carrica, M.C.; Cravero, S.L.; O’Callaghan, D.; Zorreguieta, A. Interplay between two RND systems mediating antimicrobial resistance in Brucella suis. J. Bacteriol. 2009, 191, 2530–2540. [Google Scholar] [CrossRef] [PubMed]
- Barakat, M.A. New trends in removing heavy metals from industrial wastewater. Arab. J. Chem. 2011, 4, 361–377. [Google Scholar] [CrossRef]
- Lièvremont, D.; N’negue, M.A.; Behra, P.; Lett, M.C. Biological oxidation of arsenite: Batch reactor experiments in presence of kutnahorite and chabazite. Chemosphere 2003, 51, 419–428. [Google Scholar] [CrossRef]
- Hong, J.; Silva, R.A.; Park, J.; Lee, E.; Park, J.; Kim, H. Adaptation of a mixed culture of acidophiles for a tank biooxidation of refractory gold concentrates containing a high concentration of arsenic. J. Biosci. Bioeng. 2016, 121, 536–542. [Google Scholar] [CrossRef] [PubMed]
- Kamde, K.; Pandey, R.A.; Thul, S.T.; Dahake, R.; Shinde, V.M.; Bansiwal, A. Microbially assisted arsenic removal using Acidothiobacillus ferrooxidans mediated by iron oxidation. Environ. Technol. Innov. 2018, 10, 78–90. [Google Scholar] [CrossRef]
- Wang, G.; Xie, S.; Liu, X.; Wu, Y.; Liu, Y.; Zeng, T. Bio-oxidation of a high-sulfur and high-arsenic refractory gold concentrate using a two-stage process. Miner. Eng. 2018, 120, 94–101. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, X.; Zhu, M.; Tan, W. Effects of dissolved oxygen and carbon dioxide under oxygen-rich conditions on the biooxidation process of refractory gold concentrate and the microbial community. Miner. Eng. 2015, 80, 37–44. [Google Scholar] [CrossRef]
- Wang, S.; Zhao, X. On the potential of biological treatment for arsenic contaminated soils and groundwater. J. Environ. Manag. 2009, 90, 2367–2376. [Google Scholar] [CrossRef] [PubMed]
- Katsoyiannis, I.A.; Zouboulis, A.I. Application of biological processes for the removal of arsenic from groundwaters. Water Res. 2004, 38, 17–26. [Google Scholar] [CrossRef] [PubMed]
- Polish Minister of Health. Regulation of the Polish Minister of Health on the Quality of Water Intended for Human Consumption; No. 1989; Polish Minister of Health: Warsaw, Poland, 2015.
- Goncharuk, V.V.; Bagrii, V.A.; Mel’nik, L.A.; Chebotareva, R.D.; Bashtan, S.Y. The use of redox potential in water treatment processes. J. Water Chem. Technol. 2010, 32, 1–9. [Google Scholar] [CrossRef]
- Debiec, K.; Rzepa, G.; Bajda, T.; Zych, L.; Krzysztoforski, J.; Sklodowska, A.; Drewniak, L. The influence of thermal treatment on bioweathering and arsenic sorption capacity of a natural iron (oxyhydr)oxide-based adsorbent. Chemosphere 2017, 188, 99–109. [Google Scholar] [CrossRef] [PubMed]
- Polish Ministry of the Environment. Regulation on the Conditions to Be Met during Introducing Sewage into Waters or into the Ground, and in on Substances Particularly Harmful to the Aquatic Environment; No. 06.137.984; Polish Ministry of the Environment: Warsaw, Poland, 2006.
- Zuniga-Soto, E.; Mullins, E.; Dedicova, B. Ensifer-mediated transformation: An efficient non-Agrobacterium protocol for the genetic modification of rice. Springerplus 2015, 4, 600. [Google Scholar] [CrossRef] [PubMed]
- Kanehisa, M.; Sato, Y.; Kawashima, M.; Furumichi, M.; Tanabe, M. KEGG as a reference resource for gene and protein annotation. Nucleic Acids Res. 2016, 44, D457–D462. [Google Scholar] [CrossRef] [PubMed]
- Moriya, Y.; Itoh, M.; Okuda, S.; Yoshizawa, A.C.; Kanehisa, M. KAAS: An automatic genome annotation and pathway reconstruction server. Nucleic Acids Res. 2007, 35, W182–W185. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Length | 7,345,249 bp |
| G + C content | 61.47% |
| CDS | 6874 |
| rRNA | 3 |
| tRNA | 53 |
| Miscellaneous RNA | 33 |
| Scaffolds | 45 |
| Scaffold N50 (L50) | 4400,487 (1) |
| CDS with COG terms *,† | 64.00% |
| CDS with GO terms * | 28.70% |
| CDS with KEGG pathway terms * | 35.50% |
| CDS with eggNOG annotations *,¥ | 80.50% |
| CDS with no similarity * | 9.40% |
| Scaffold | Gene ID | CARD Database Hit | Predicted Resistance to | Tested Antibiotics |
|---|---|---|---|---|
| Scaffold_4 | BLJAPNOD_00187- | acrAB | Fluoroquinolone | CIP (S); MXF (S) |
| BLJAPNOD_00188 | Tetracyclines | TE (S/R) | ||
| Scaffold_4 | BLJAPNOD_00458 | cmlA/floR | Chloramphenicol | C (R) |
| Scaffold_4 | BLJAPNOD_00485- | acrAB-TolC | Tetracyclines | TE (S/R) |
| BLJAPNOD_00487 | Cephalosporins | CFM (S); CRO (S); CTX (S) | ||
| Penams | AMP (R) | |||
| Phenicols | C (R) | |||
| Rifamycins | RD (R) | |||
| Fluoroquinolones | CIP (S); MXF (S) | |||
| Scaffold_4 | BLJAPNOD_00960 | aph(3′)-IIa | Aminoglycosides | CN (S) |
| Scaffold_4 | BLJAPNOD_01284 | adeF | Fluoroquinolones | CIP (S); MXF (S) |
| Tetracyclines | TE (S/R) | |||
| Scaffold_4 | BLJAPNOD_02256 | blaOXA | Cephalosporins | CFM (S); CRO (S); CTX (S) |
| Penams | AMP (R) | |||
| Scaffold_4 | BLJAPNOD_02798 | aph(6)-Ic | Aminoglycosides | CN (S) |
| Scaffold_7 | BLJAPNOD_04982 | aph(3′′)-Ib | Aminoglycosides | CN (S) |
| Scaffold_8 | BLJAPNOD_05149- | acrAB-TolC | Tetracyclines | TE (S/R) |
| BLJAPNOD_05151 | Cephalosporins | CFM (S); CRO (S); CTX (S) | ||
| Penams | AMP (R) | |||
| Phenicols | C (R) | |||
| Rifamycins | RD (R) | |||
| Fluoroquinolones | CIP (S); MXF (S) | |||
| Scaffold_14 | BLJAPNOD_05841- | acrAB | Fluoroquinolone | CIP (S); MXF (S) |
| BLJAPNOD_05842 | Tetracyclines | TE (S/R) | ||
| Scaffold_17 | BLJAPNOD_06442 | dfrA12 | Trimethoprim | TM (S) |
| Scaffold_18 | BLJAPNOD_06615 | aph(6)-Ic | Aminoglycosides | CN (S) |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
DiCenzo, G.C.; Debiec, K.; Krzysztoforski, J.; Uhrynowski, W.; Mengoni, A.; Fagorzi, C.; Gorecki, A.; Dziewit, L.; Bajda, T.; Rzepa, G.; et al. Genomic and Biotechnological Characterization of the Heavy-Metal Resistant, Arsenic-Oxidizing Bacterium Ensifer sp. M14. Genes 2018, 9, 379. https://doi.org/10.3390/genes9080379
DiCenzo GC, Debiec K, Krzysztoforski J, Uhrynowski W, Mengoni A, Fagorzi C, Gorecki A, Dziewit L, Bajda T, Rzepa G, et al. Genomic and Biotechnological Characterization of the Heavy-Metal Resistant, Arsenic-Oxidizing Bacterium Ensifer sp. M14. Genes. 2018; 9(8):379. https://doi.org/10.3390/genes9080379
Chicago/Turabian StyleDiCenzo, George C, Klaudia Debiec, Jan Krzysztoforski, Witold Uhrynowski, Alessio Mengoni, Camilla Fagorzi, Adrian Gorecki, Lukasz Dziewit, Tomasz Bajda, Grzegorz Rzepa, and et al. 2018. "Genomic and Biotechnological Characterization of the Heavy-Metal Resistant, Arsenic-Oxidizing Bacterium Ensifer sp. M14" Genes 9, no. 8: 379. https://doi.org/10.3390/genes9080379
APA StyleDiCenzo, G. C., Debiec, K., Krzysztoforski, J., Uhrynowski, W., Mengoni, A., Fagorzi, C., Gorecki, A., Dziewit, L., Bajda, T., Rzepa, G., & Drewniak, L. (2018). Genomic and Biotechnological Characterization of the Heavy-Metal Resistant, Arsenic-Oxidizing Bacterium Ensifer sp. M14. Genes, 9(8), 379. https://doi.org/10.3390/genes9080379