
Research on Frequent Itemset Mining of Imaging Genetics GWAS in Alzheimer’s Disease

 ,
, 

Abstract
:1. Introduction
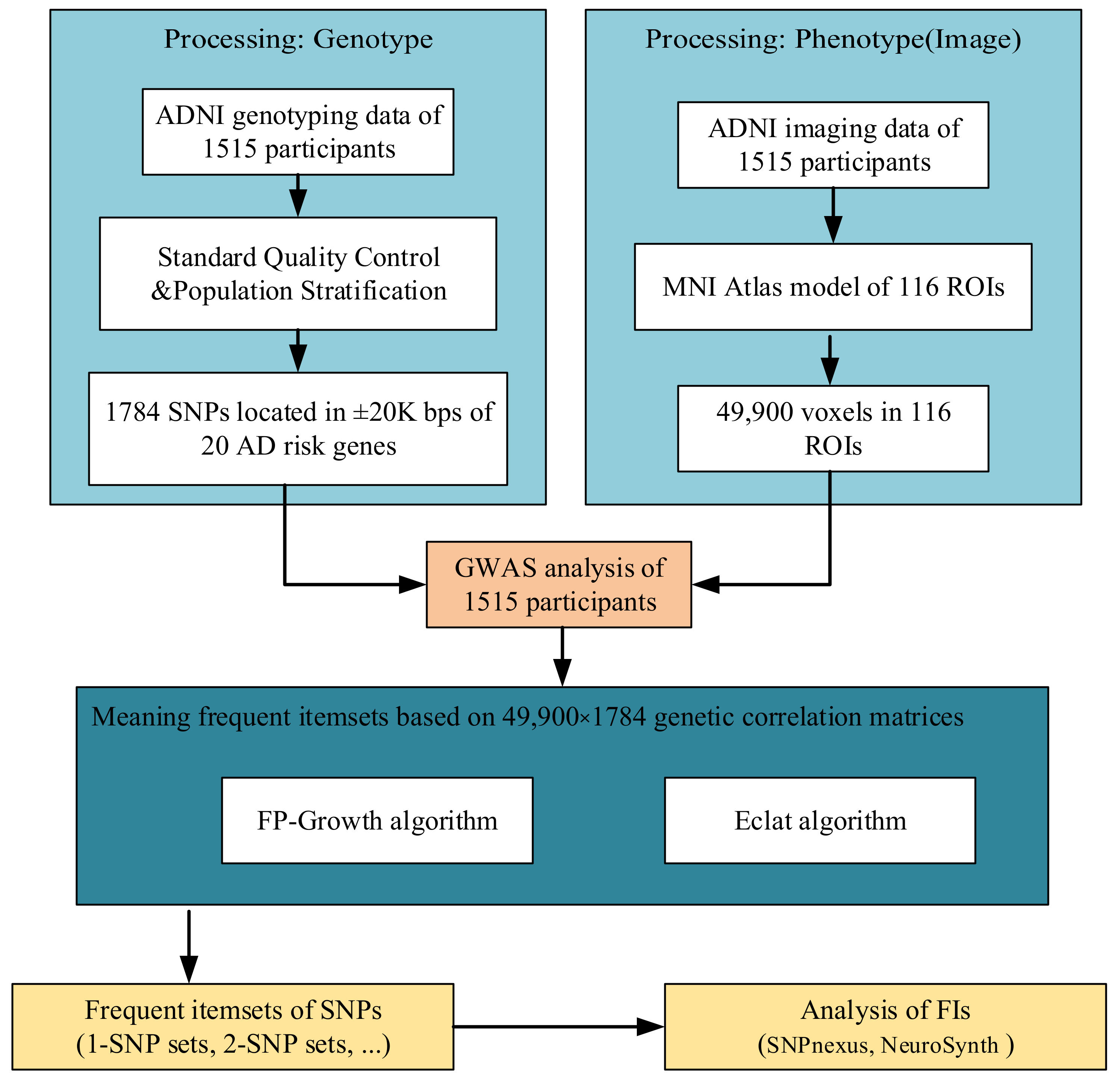
2. Materials and Methods
2.1. Data Source
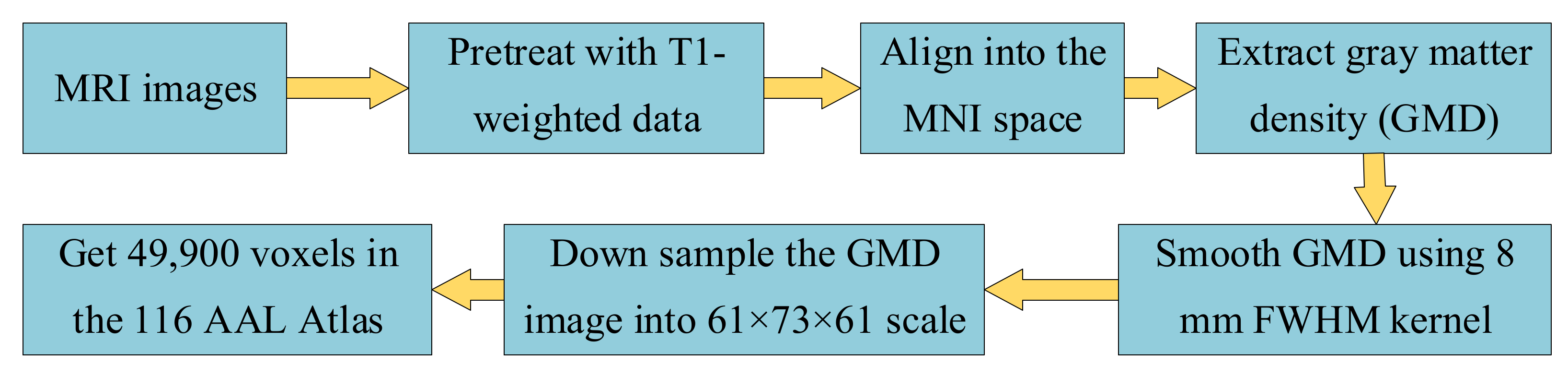
2.2. Data Processing and Correlation Matrix
2.3. Frequent Itemsets Mining
2.4. Construct Confidence of Frequent Itemsets
2.5. Statistical Analysis of SNPs
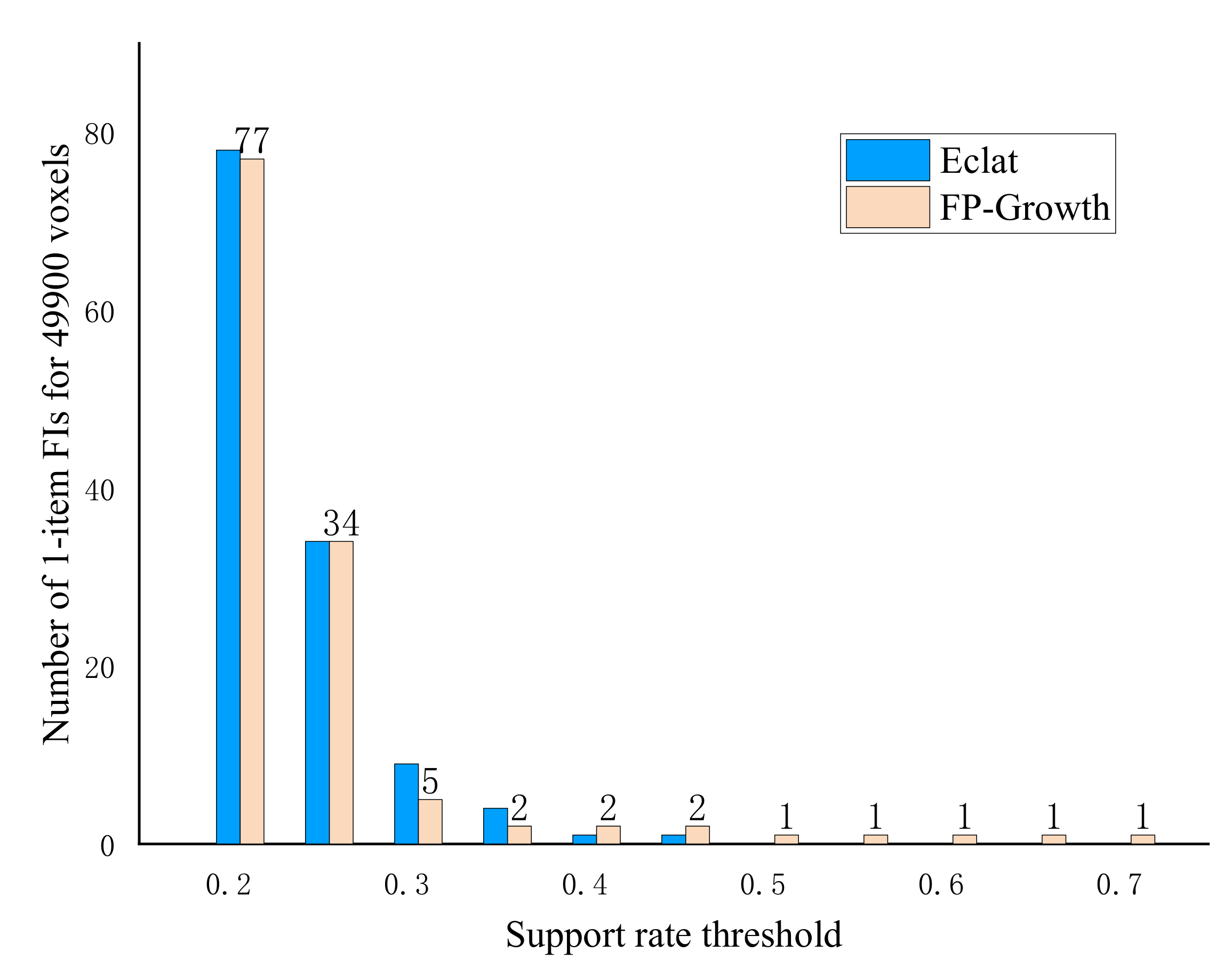
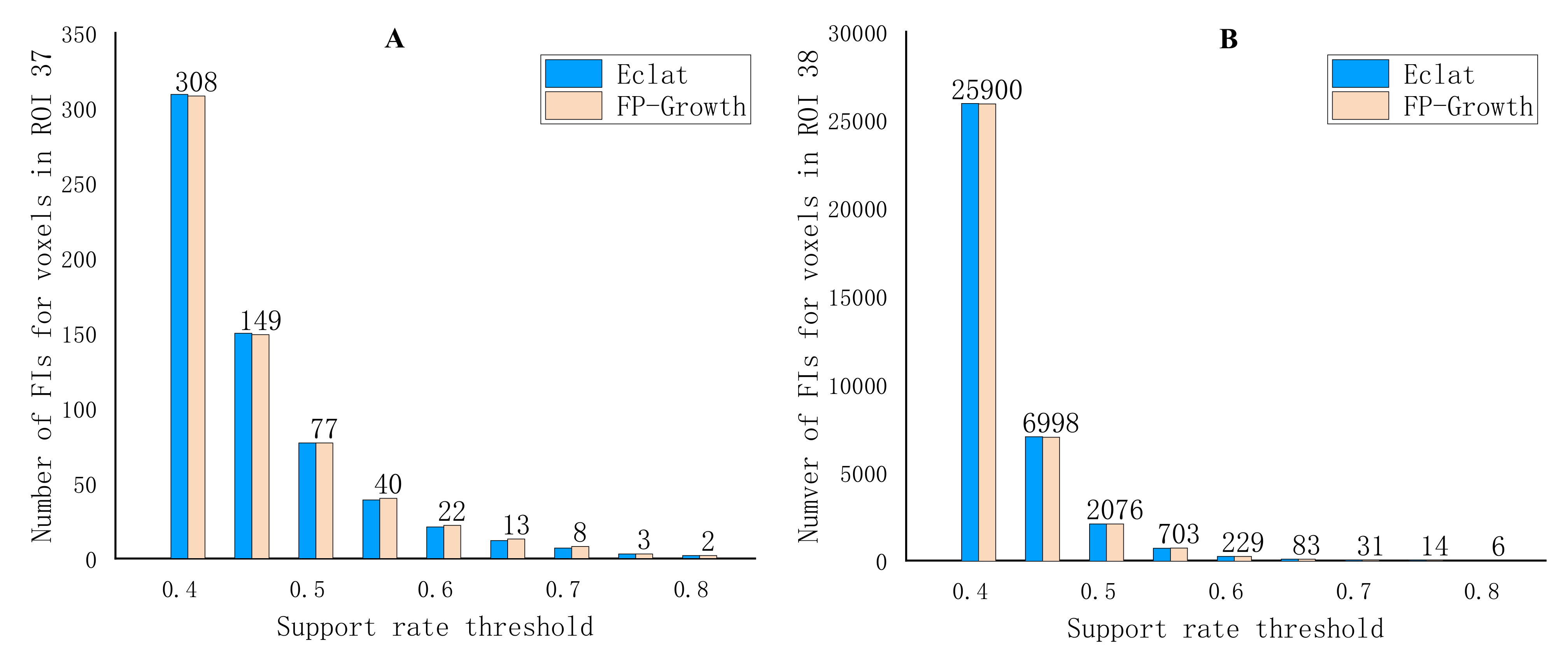
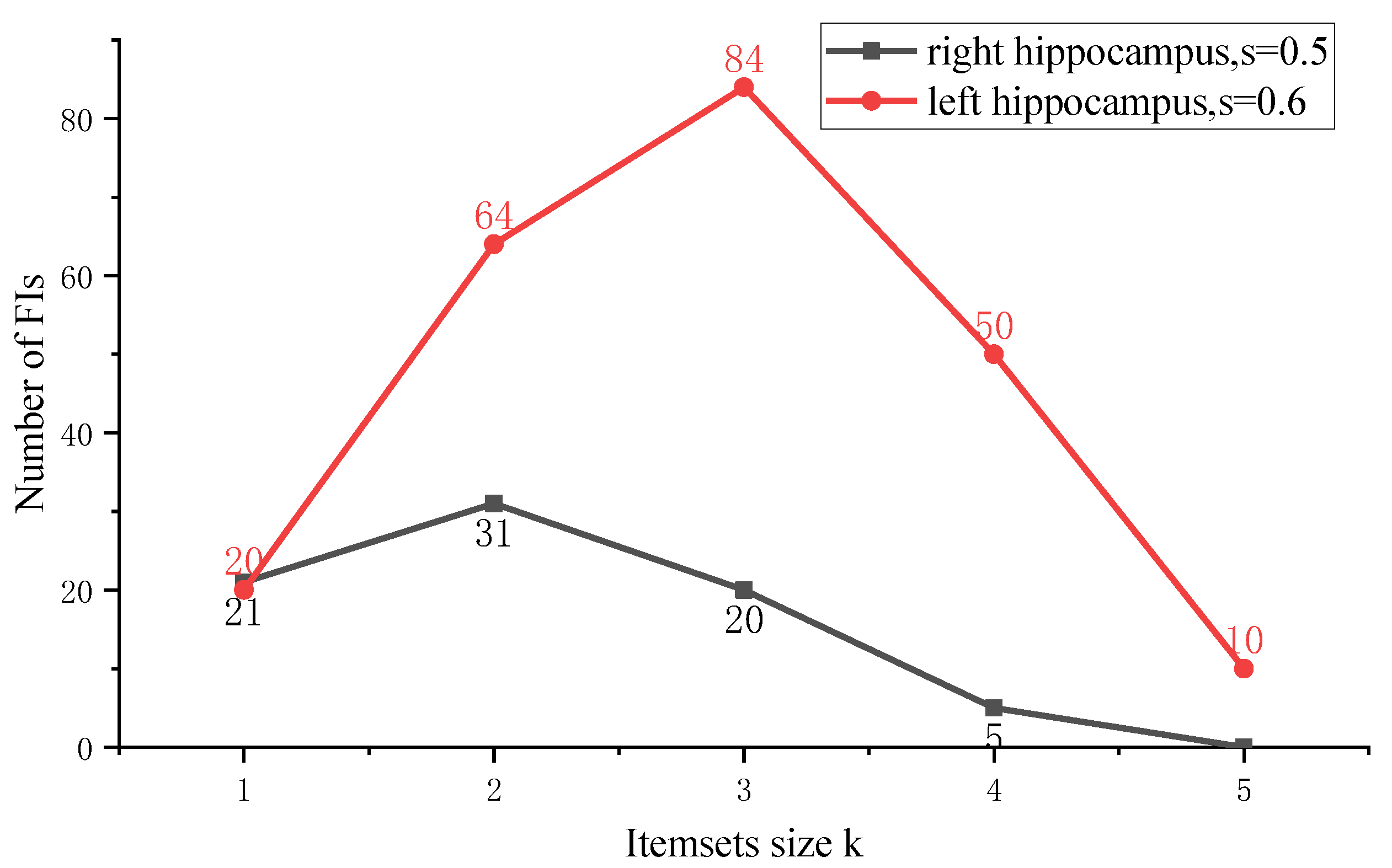
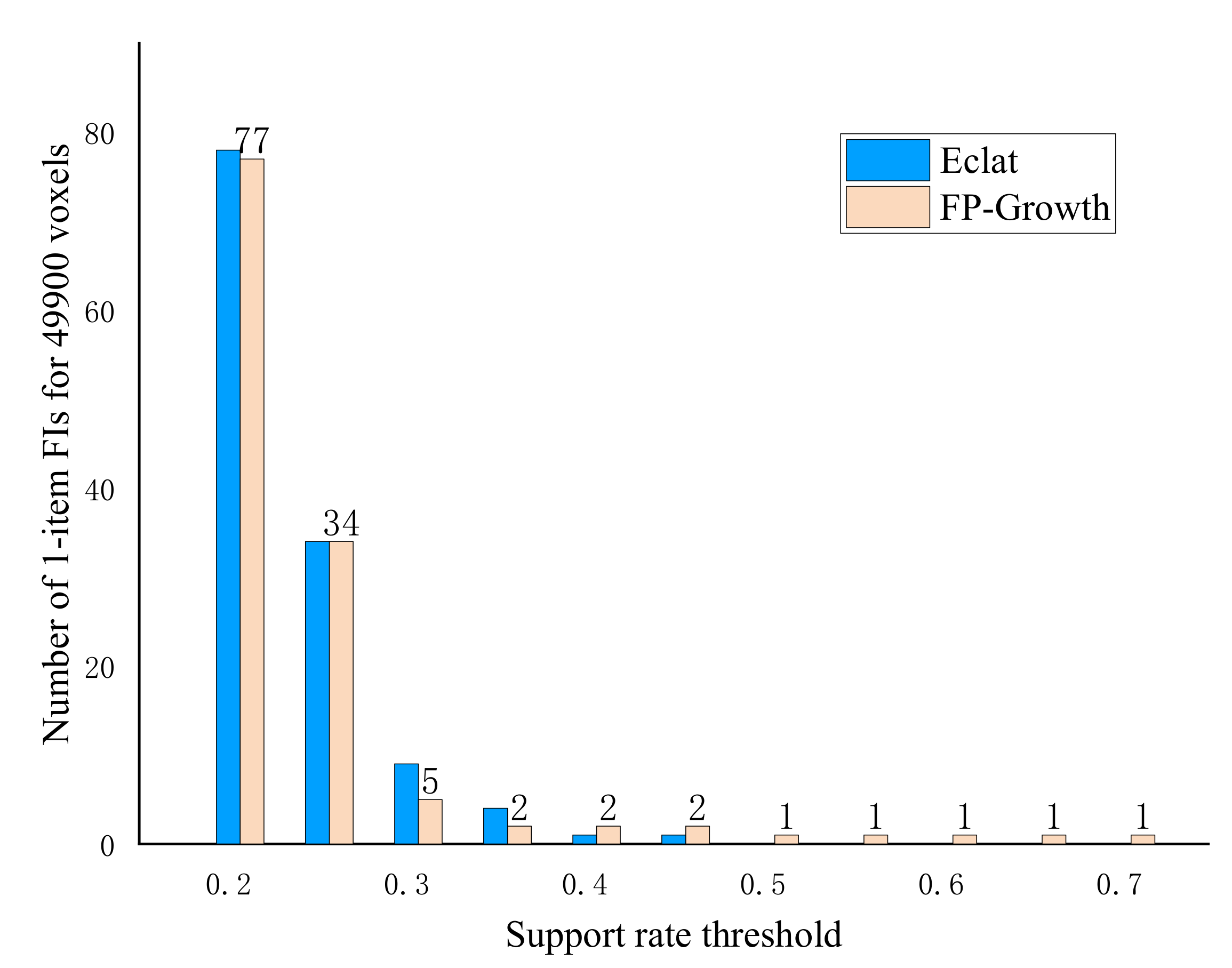
3. Results
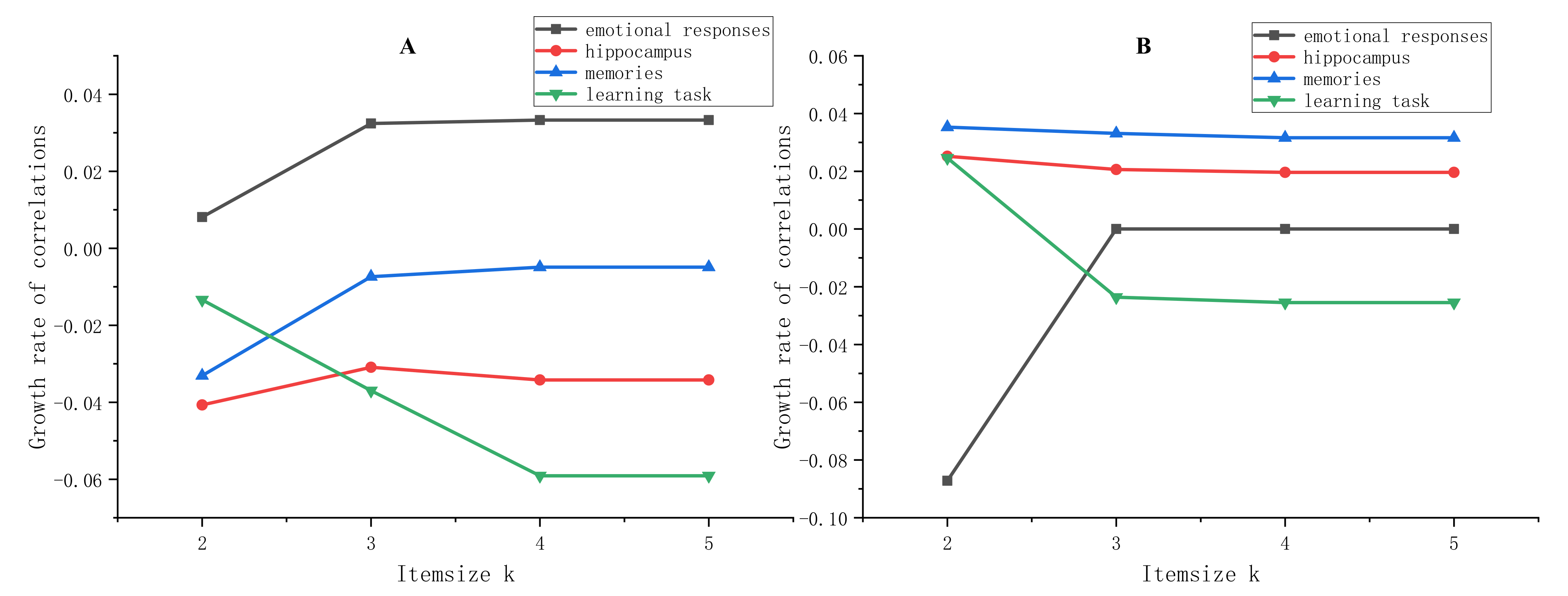
4. Discussion
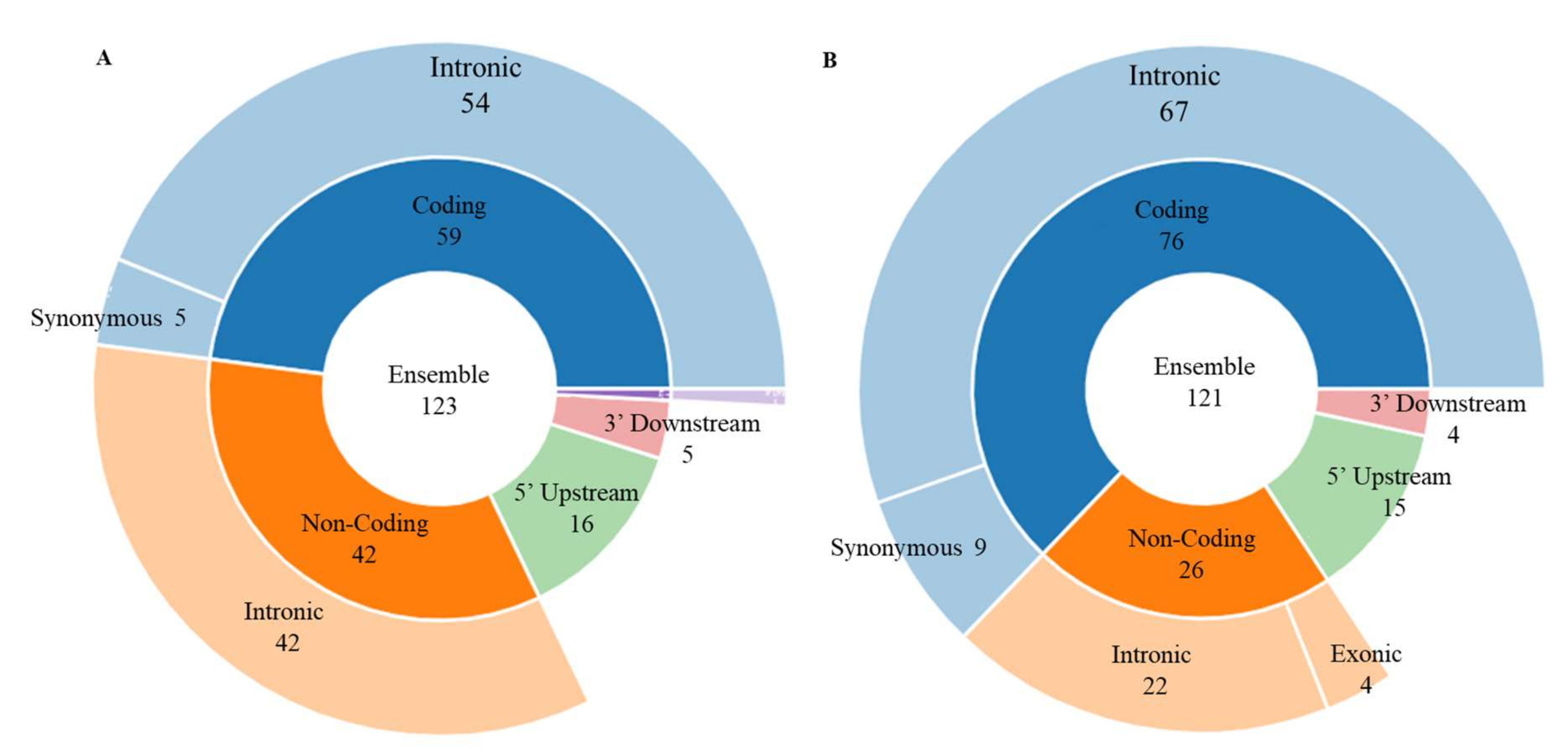
4.1. 1-Item FI: (rs10498633)
4.2. k-Item FI: (k = 2, 3, 4, 5)
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yuting, L.; Xufeng, Y.; Xixi, B.; Song, X.; Gang, H. Research Progresses of imaging genomics in Alzheimer’s dseases. Chin. J. Med. Imaging Technol. 2020, 36, 1243–1246. [Google Scholar] [CrossRef]
- Jiang, W.; King, T.Z.; Turner, J.A. Imaging Genetics Towards a Refined Diagnosis of Schizophrenia. Front. Psychiatry 2019, 10, 494. [Google Scholar] [CrossRef]
- Newton-Cheh, C.; Hirschhorn, J.N. Genetic association studies of complex traits: Design and analysis issues. Mutat. Res. 2005, 573, 54–69. [Google Scholar] [CrossRef]
- Stein, J.L.; Hua, X.; Lee, S.; Ho, A.J.; Leow, A.D.; Toga, A.W.; Saykin, A.J.; Shen, L.; Foroud, T.; Pankratz, N.J.N. Voxelwise genome-wide association study (vGWAS). NeuroImage 2010, 53, 1160–1174. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Szymczak, S.; Biernacka, J.M.; Cordell, H.J.; Gonzalez-Recio, O.; Konig, I.R.; Zhang, H.; Sun, Y.V. Machine learning in genome-wide association studies. Genet. Epidemiol. 2009, 33, S51–S57. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.-T.; Sung, P.-Y.; Lin, P.-L.; Yu, Y.-W.; Chung, R.-H. A multi-SNP association test for complex diseases incorporating an optimal P-value threshold algorithm in nuclear families. BMC Genom. 2015, 16, 381. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Ferreira, T.; Morris, A.P.; Medland, S.; Madden, P.A.F.; Heath, A.C.; Martin, N.; Montgomery, G.; Weedon, M.; Genetic Investigation of ANthropometric Traits (GIANT) Consortium; et al. Conditional and joint multiple-SNP analysis of GWAS summary statistics identifies additional variants influencing complex traits. Nat. Genet. 2012, 44, 369–375. [Google Scholar] [CrossRef] [PubMed]
- Lu, Z.-H.; Zhu, H.; Knickmeyer, R.; Sullivan, P.F.; Williams, S.N.; Zou, F.; Alzheimer’s Disease Neuroimaging Initiative. Multiple SNP Set Analysis for Genome-Wide Association Studies through Bayesian Latent Variable Selection. Genet. Epidemiol. 2015, 39, 664–677. [Google Scholar] [CrossRef] [Green Version]
- Montanez, C.A.C.; Fergus, P.; Chalmers, C.; Malim, N.H.A.H.; Abdulaimma, B.; Reilly, D.; Falciani, F. SAERMA: Stacked Autoencoder Rule Mining Algorithm for the Interpretation of Epistatic Interactions in GWAS for Extreme Obesity. IEEE Access 2020, 8, 112379–112392. [Google Scholar] [CrossRef]
- Mutalib, S.; Mohamed, A.; Abdul-Rahman, S. A Study on Frequent Itemset Mining for Identifying Associated Multiple SNPs. J. Comput. Sci. Comput. Math. 2019, 9, 1–6. [Google Scholar] [CrossRef]
- Reynolds, T.; Johnson, E.C.; Huggett, S.B.; Bubier, J.A.; Palmer, R.H.C.; Agrawal, A.; Baker, E.J.; Chesler, E.J. Interpretation of psychiatric genome-wide association studies with multispecies heterogeneous functional genomic data integration. Neuropsychopharmacology 2021, 46, 86–97. [Google Scholar] [CrossRef] [PubMed]
- Scheltens, P.; Blennow, K.; Breteler, M.M.; De, S.B.; Frisoni, G.B.; Salloway, S.; Van der Flier, W.M. Alzheimer’s disease. Lancet 2016, 388, 13. [Google Scholar] [CrossRef]
- Sudre, G.; Choudhuri, S.; Szekely, E.; Bonner, T.; Goduni, E.; Sharp, W.; Shaw, P. Estimating the Heritability of Structural and Functional Brain Connectivity in Families Affected by Attention-Deficit/Hyperactivity Disorder. JAMA Psychiatry 2017, 74, 76–84. [Google Scholar] [CrossRef] [PubMed]
- Hashem, S.; Nisar, S.; Bhat, A.A.; Yadav, S.K.; Azeem, M.W.; Bagga, P.; Fakhro, K.; Reddy, R.; Frenneaux, M.P.; Haris, M. Genetics of structural and functional brain changes in autism spectrum disorder. Transl. Psychiatry 2020, 10, 229. [Google Scholar] [CrossRef] [PubMed]
- Lee, W.H.; Rodrigue, A.; Glahn, D.C.; Bassett, D.S.; Frangou, S. Heritability and Cognitive Relevance of Structural Brain Controllability. Cereb. Cortex 2020, 30, 3044–3054. [Google Scholar] [CrossRef] [PubMed]
- Chee, C.-H.; Jaafar, J.; Aziz, I.A.; Hasan, M.H.; Yeoh, W. Algorithms for frequent itemset mining: A literature review. Artif. Intell. Rev. 2018, 52, 2603–2621. [Google Scholar] [CrossRef] [Green Version]
- Aguiar, V.; Seoane, J.A.; Freire, A.; Guo, L. GA-based data mining applied to genetic data for the diagnosis of complex diseases. In Soft Computing Methods for Practical Environment Solutions: Techniques and Studies; IGI Global: Philadelphia, PA, USA, 2010; pp. 219–239. [Google Scholar]
- Yao, X.; Risacher, S.L.; Nho, K.; Saykin, A.J.; Wang, Z.; Shen, L.; Alzheimer’s Disease Neuroimaging Initiative. Targeted genetic analysis of cerebral blood flow imaging phenotypes implicates the INPP5D gene. Neurobiol. Aging 2019, 81, 213–221. [Google Scholar] [CrossRef] [Green Version]
- Karch, C.M.; Goate, A.M. Alzheimer’s disease risk genes and mechanisms of disease pathogenesis. Biol. Psychiatry 2015, 77, 43–51. [Google Scholar] [CrossRef] [Green Version]
- Stage, E.; Duran, T.; Risacher, S.L.; Goukasian, N.; Do, T.M.; West, J.D.; Wilhalme, H.; Nho, K.; Phillips, M.; Elashoff, D.; et al. The effect of the top 20 Alzheimer disease risk genes on gray-matter density and FDG PET brain metabolism. Alzheimers Dement. 2016, 5, 53–66. [Google Scholar] [CrossRef] [PubMed]
- Van Cauwenberghe, C.; Van Broeckhoven, C.; Sleegers, K. The genetic landscape of Alzheimer disease: Clinical implications and perspectives. Genet. Med. 2016, 18, 421–430. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lambert, J.C.; Ibrahim-Verbaas, C.A.; Harold, D.; Naj, A.C.; Sims, R.; Bellenguez, C.; DeStafano, A.L.; Bis, J.C.; Beecham, G.W.; Grenier-Boley, B.; et al. Meta-analysis of 74,046 individuals identifies 11 new susceptibility loci for Alzheimer’s disease. Nat. Genet. 2013, 45, 1452–1458. [Google Scholar] [CrossRef] [Green Version]
- Chang, C.C.; Chow, C.C.; Tellier, L.C.A.M.; Vattikuti, S.; Purcell, S.M.; Lee, J.J. Second-generation PLINK: Rising to the challenge of larger and richer datasets. GigaScience 2015, 4, s13742-015. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Bhuiyan, M.A.; Hasan, M.A. Frequent Pattern Mining Algorithms: A Survey. In Frequent Pattern Mining; Aggarwal, C.C., Han, J., Eds.; Springer, Cham: New York, NY, USA, 2014; pp. 19–64. [Google Scholar] [CrossRef]
- Han, J.; Pei, J.; Yin, Y. Mining frequent patterns without candidate generation. ACM Sigmod Rec. 2000, 29, 1–12. [Google Scholar] [CrossRef]
- Zaki, M.J. Scalable Algorithms for Association Mining. IEEE Trans. Knowl. Data Eng. 2000, 12, 372–390. [Google Scholar] [CrossRef] [Green Version]
- Claude, C.; Arshad, K.; Lemoine, N.R. SNPnexus: A web database for functional annotation of newly discovered and public domain single nucleotide polymorphisms. Bioinformatics 2009, 25, 655–661. [Google Scholar]
- Yarkoni, T.; Poldrack, R.A.; Nichols, T.E.; Van Essen, D.C.; Wager, T.D. Large-scale automated synthesis of human functional neuroimaging data. Nat. Methods 2011, 8, 665–670. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Oscanoa, J.; Sivapalan, L.; Gadaleta, E.; Dayem Ullah, A.Z.; Lemoine, N.R.; Chelala, C. SNPnexus: A web server for functional annotation of human genome sequence variation (2020 update). Nucleic. Acids Res. 2020, 48, W185–W192. [Google Scholar] [CrossRef]
- Jansen, I.E.; Savage, J.E.; Watanabe, K.; Bryois, J.; Williams, D.M.; Steinberg, S.; Sealock, J.; Karlsson, I.K.; Hägg, S.; Athanasiu, L. Genome-wide meta-analysis identifies new loci and functional pathways influencing Alzheimer’s disease risk. Nat. Genet. 2019, 51, 404–413. [Google Scholar] [CrossRef]
- Dutta, S.S. Hippocampus Functions. 2021. Available online: https://www.news-medical.net/health/Hippocampus-Functions.aspx (accessed on 1 November 2021).
- Mu, Y.; Gage, F.H. Adult hippocampal neurogenesis and its role in Alzheimer’s disease. Mol. Neurodegener. 2011, 6, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- West, M.J.; Coleman, P.D.; Flood, D.G.; Troncoso, J.C. Differences in the pattern of hippocampal neuronal loss in normal ageing and Alzheimer’s disease. Lancet 1994, 344, 769–772. [Google Scholar] [CrossRef]
- Yan, J.; Raja, V.V.; Huang, Z.; Amico, E.; Nho, K.; Fang, S.; Sporns, O.; Wu, Y.-c.; Saykin, A.; Goñi, J. Brain-wide structural connectivity alterations under the control of Alzheimer risk genes. Int. J. Comput. Biol. Drug Des. 2020, 13, 58–70. [Google Scholar] [CrossRef]
- Jun, G.; Ibrahim-Verbaas, C.A.; Vronskaya, M.; Lambert, J.C.; Chung, J.; Naj, A.C.; Kunkle, B.W.; Wang, L.S.; Bis, J.C.; Bellenguez, C.; et al. A novel Alzheimer disease locus located near the gene encoding tau protein. Mol. Psychiatry 2016, 21, 108–117. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.S.; Yang, Y.X.; Xu, W.; Wang, H.F.; Tan, L.; Zuo, C.T.; Dong, Q.; Tan, L.; Suckling, J.; Yu, J.T.; et al. Associations of Alzheimer’s disease risk variants with gene expression, amyloidosis, tauopathy, and neurodegeneration. Alzheimers Res. Ther. 2021, 13, 15. [Google Scholar] [CrossRef]
- Mitsis, G.D.; Iannetti, G.D.; Smart, T.S.; Tracey, I.; Wise, R.G. Regions of interest analysis in pharmacological fMRI: How do the definition criteria influence the inferred result? Neuroimage 2008, 40, 121–132. [Google Scholar] [CrossRef] [PubMed]
- Schubert, C.R.; Carmichael, L.L.; Murphy, C.; Klein, B.E.; Klein, R.; Cruickshanks, K.J. Olfaction and the 5-year incidence of cognitive impairment in an epidemiological study of older adults. J. Am. Geriatr. Soc. 2008, 56, 1517–1521. [Google Scholar] [CrossRef] [Green Version]
- Attems, J.; Jellinger, K. Olfactory tau pathology in Alzheimer disease and mild cognitive impairment. Clin. Neuropathol. 2006, 25, 265. [Google Scholar]
- Murphy, C. Olfactory and other sensory impairments in Alzheimer disease. Nat. Rev. Neurol. 2019, 15, 11–24. [Google Scholar] [CrossRef]
- Zou, Y.M.; Lu, D.; Liu, L.P.; Zhang, H.H.; Zhou, Y.Y. Olfactory dysfunction in Alzheimer’s disease. Neuropsychiatr. Dis. Treat. 2016, 12, 869–875. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Chen, X.; Zheng, W.; Xia, M.; Han, Y.; Song, H.; Li, K.; He, Y.; Wang, Z. Altered Functional Connectivity of Insular Subregions in Alzheimer’s Disease. Front. Aging Neurosci. 2018, 10, 107. [Google Scholar] [CrossRef] [Green Version]
- Fathy, Y.Y.; Hoogers, S.E.; Berendse, H.W.; van der Werf, Y.D.; Visser, P.J.; de Jong, F.J.; van de Berg, W.D.J. Differential insular cortex sub-regional atrophy in neurodegenerative diseases: A systematic review and meta-analysis. Brain Imaging Behav. 2020, 14, 2799–2816. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kitamura, J.; Nagai, M.; Ueno, H.; Ohshita, T.; Kikumoto, M.; Toko, M.; Kato, M.; Dote, K.; Yamashita, H.; Kario, K.J.A.D.; et al. The Insular Cortex, Alzheimer Disease Pathology, and Their Effects on Blood Pressure Variability. Alzheimer Dis. Assoc. Disord. 2020, 34, 282–291. [Google Scholar] [CrossRef]
- Dimitrova, L.I.; Dean, S.L.; Schlumpf, Y.R.; Vissia, E.M.; Nijenhuis, E.R.S.; Chatzi, V.; Jäncke, L.; Veltman, D.J.; Chalavi, S.; Reinders, A. A neurostructural biomarker of dissociative amnesia: A hippocampal study in dissociative identity disorder. Psychol. Med. 2021, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Averill, C.L.; Satodiya, R.M.; Scott, J.C.; Wrocklage, K.M.; Schweinsburg, B.; Averill, L.A.; Akiki, T.J.; Amoroso, T.; Southwick, S.M.; Krystal, J.H.; et al. Posttraumatic Stress Disorder and Depression Symptom Severities Are Differentially Associated with Hippocampal Subfield Volume Loss in Combat Veterans. Chronic Stress 2017, 1, 1–11. [Google Scholar] [CrossRef]
- Dubois, B.; Feldman, H.H.; Jacova, C.; Hampel, H.; Molinuevo, J.L.; Blennow, K.; DeKosky, S.T.; Gauthier, S.; Selkoe, D.; Bateman, R. Advancing research diagnostic criteria for Alzheimer’s disease: The IWG-2 criteria. Lancet Neurol. 2014, 13, 614–629. [Google Scholar] [CrossRef]
- Babcock, K.R.; Page, J.S.; Fallon, J.R.; Webb, A.E. Adult Hippocampal Neurogenesis in Aging and Alzheimer’s Disease. Stem Cell Rep. 2021, 16, 681–693. [Google Scholar] [CrossRef] [PubMed]
- Blanken, A.E.; Hurtz, S.; Zarow, C.; Biado, K.; Honarpisheh, H.; Somme, J.; Brook, J.; Tung, S.; Kraft, E.; Lo, D. Associations between hippocampal morphometry and neuropathologic markers of Alzheimer’s disease using 7 T MRI. NeuroImage Clin. 2017, 15, 56–61. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nikolenko, V.N.; Oganesyan, M.V.; Rizaeva, N.A.; Kudryashova, V.A.; Nikitina, A.T.; Pavliv, M.P.; Shchedrina, M.A.; Giller, D.B.; Buligin, K.V.; Sinelnikov, M.Y. Amygdala: Neuroanatomical and Morphophysiological Features in Terms of Neurological and Neurodegenerative Diseases. Brain Sci. 2020, 10, 502. [Google Scholar] [CrossRef] [PubMed]
- Robinson, J.L.; Richardson, H.; Xie, S.X.; Suh, E.; Van Deerlin, V.M.; Alfaro, B.; Loh, N.; Porras-Paniagua, M.; Nirschl, J.J.; Wolk, D.J.B. The development and convergence of co-pathologies in Alzheimer’s disease. Brain 2021, 144, 953–962. [Google Scholar] [CrossRef] [PubMed]
- Ma, D.; Fetahu, I.S.; Wang, M.; Fang, R.; Li, J.; Liu, H.; Gramyk, T.; Iwanicki, I.; Gu, S.; Xu, W. The fusiform gyrus exhibits an epigenetic signature for Alzheimer’s disease. Clin. Epigenetics 2020, 12, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Tombini, M.; Assenza, G.; Ricci, L.; Lanzone, J.; Boscarino, M.; Vico, C.; Magliozzi, A.; Di Lazzaro, V. Temporal Lobe Epilepsy and Alzheimer’s Disease: From Preclinical to Clinical Evidence of a Strong Association. J. Alzheimer’s Dis. Rep. 2021, 5, 243–261. [Google Scholar] [CrossRef] [PubMed]
- Scharf, J.M.; Yu, D.; Mathews, C.A.; Neale, B.M.; Stewart, S.E.; Fagerness, J.A.; Evans, P.; Gamazon, E.; Edlund, C.K.; Service, S.K.; et al. Genome-wide association study of Tourette’s syndrome. Mol. Psychiatry 2013, 18, 721–728. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rodenas-Cuadrado, P.; Ho, J.; Vernes, S.C. Shining a light on CNTNAP2: Complex functions to complex disorders. Eur. J. Hum. Genet. 2014, 22, 171–178. [Google Scholar] [CrossRef] [PubMed]
- Sepulveda-Diaz, J.E.; Alavi Naini, S.M.; Huynh, M.B.; Ouidja, M.O.; Yanicostas, C.; Chantepie, S.; Villares, J.; Lamari, F.; Jospin, E.; van Kuppevelt, T.H.; et al. HS3ST2 expression is critical for the abnormal phosphorylation of tau in Alzheimer’s disease-related tau pathology. Brain 2015, 138, 1339–1354. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Smits, N.C.; Kobayashi, T.; Srivastava, P.K.; Skopelja, S.; Ivy, J.A.; Elwood, D.J.; Stan, R.V.; Tsongalis, G.J.; Sellke, F.W.; Gross, P.L.; et al. HS3ST1 genotype regulates antithrombin’s inflammomodulatory tone and associates with atherosclerosis. Matrix Biol. 2017, 63, 69–90. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characters | CN | SMC | EMCI | LMCI | AD |
|---|---|---|---|---|---|
| Number of samples | 353 | 89 | 273 | 504 | 296 |
| Gender(M/F) | 187/166 | 36/53 | 153/120 | 309/195 | 166/130 |
| Age (year, Mean ± SD) | 74.9 ± 5.7 | 72.2 ± 5.7 | 71.3 ± 7.1 | 74.0 ± 7.6 | 74.7 ± 7.6 |
| Education (year, Mean ± SD) | 16.1 ± 2.7 | 16.8 ± 2.6 | 16.1 ± 2.6 | 16.0 ± 2.9 | 15.5 ± 2.9 |
| NO. | SNP | Support Rate |
|---|---|---|
| 1 | rs6014724 | 0.46 |
| 2 | rs11731587 | 0.39 |
| 3 | rs7806 | 0.36 |
| 4 | rs6024860 | 0.35 |
| 5 | rs1060743 | 0.34 |
| 6 | rs4243693 | 0.34 |
| 7 | rs7790238 | 0.33 |
| 8 | rs7219391 | 0.31 |
| 9 | rs386274 | 0.30 |
| 10 | rs6092321 | 0.30 |
| Begin: |
| If (FPT is a single path or empty): |
| For each subset of item in path (return FI and its support judge by s) |
| Else: |
| ( |
| For each item i in chain of pointers |
| ( |
| Generate conditional pattern base Pi = (i) ∪ P and get its support |
| Extract conditional FP-tree FPTi from chain of pointers in Pi |
| If (FPTi ≠ ∅) recursion FP-Growth (FPTi, Pi, s) |
| ) |
| ) |
| end |
| Begin: |
| in FP ( |
| FPi = ∅ |
| in FP and j > i ( |
| into FPi |
| Recurve Eclat(FPi, s) |
| ) |
| ) |
| end |
| Right Hippocampus | Left Hippocampus | ||
|---|---|---|---|
| 3-Item, 4-Item and 5-Item FIs (Top 5) | Support Rate | 3-Item, 4-Item and 5-Item FIs (Top 5) | Support Rate |
| rs1047389, rs11731587, rs10277969 | 0.65 | rs10277969, rs2242065, rs10498633 | 0.72 |
| rs1047389, rs10498633, rs10277969 | 0.63 | rs10277969, rs2242065, rs1047389 | 0.71 |
| rs1047389, rs11731587, rs16881446 | 0.60 | rs2242065, rs10498633, rs1047389 | 0.71 |
| rs11731587, rs10498633, rs10277969 | 0.58 | rs7563345, rs10498633, rs1047389 | 0.70 |
| rs1047389, rs11731587, rs10498633 | 0.58 | rs2242065, rs10498633, rs6082 | 0.70 |
| rs1047389, rs11731587, rs10498633, rs10277969 | 0.56 | rs10277969, rs2242065, rs10498633, rs6082 | 0.67 |
| rs1047389, rs11731587, rs16881446, rs10277969 | 0.54 | rs10277969, rs2242065, rs10498633, rs1047389 | 0.67 |
| rs1047389, rs10277969, rs1918296, rs886969 | 0.53 | rs7563345, rs2242065, rs10498633, rs6082 | 0.65 |
| rs1047389, rs11731587, rs10277969, rs1918296 | 0.52 | rs10277969, rs2242065, rs10498633, rs7563345 | 0.65 |
| rs1047389, rs10498633, rs10277969, rs1918296 | 0.51 | rs10277969, rs2242065, rs7000615, rs1047389 | 0.65 |
| NULL | NULL | rs10277969, rs7563345, rs2242065, rs10498633, rs6082 | 0.63 |
| rs10277969, rs1047389, rs2242065, rs10498633, rs6082 | 0.62 | ||
| rs10277969, rs1047389, rs7563345, rs2242065, rs10498633 | 0.62 | ||
| rs10277969, rs1047389, rs2242065, rs10498633, rs7000615 | 0.61 | ||
| rs1047389, rs7563345, rs2242065, rs10498633, rs6082 | 0.61 | ||
| 2-Item FIs (Top 5) in ROI 37 | Confidence | 2-Item FIs (Top 5) in ROI 37 | Confidence |
|---|---|---|---|
| rs10498633 to rs10277969 | 0.90 (0.74/0.82) | rs10277969 to rs10498633 | 0.84 (0.74/0.88) |
| rs1047389 to rs10277969 | 0.94 (0.74/0.79) | rs10277969 to rs1047389 | 0.84 (0.74/0.88) |
| rs11731587 to rs1047389 | 0.97 (0.71/0.73) | rs1047389 to rs11731587 | 0.90 (0.71/0.79) |
| rs11731587 to rs10277969 | 0.92 (0.67/0.73) | rs10277969 to rs11731587 | 0.76 (0.67/0.88) |
| rs10277969 to rs1918296 | 0.76 (0.67/0.88) | rs1918296 to rs10277969 | 0.99 (0.67/0.68) |
| Activated Brain ROIs: | Activated Hippocampus Subregions: | ||
|---|---|---|---|
| NO. | ROI | NO. | Subregion |
| 1 | Frontal_Inf_Orb | 1 | Hippocampal-amygdaloid Transition area |
| 2 | Olfactory | 2 | Cornu ammonis 1 |
| 3 | Insula | 3 | Pre subiculum |
| 4 | Hippocampus | 4 | Cornu ammonis 4 |
| 5 | Para Hippocampal | 5 | Para subiculum |
| 6 | Amygdala | 6 | Hippocampal fissure |
| 7 | Fusiform | ||
| 8 | Temporal_Pole_Sup | ||
| 9 | Temporal_Pole_Mid | ||
| 10 | Temporal_Inf | ||
| Association Rules | Confidence | |
|---|---|---|
| Right Hippocampus | Left Hippocampus | |
| rs10498633 to rs10277969 | 0.90 | 0.86 |
| rs10498633, rs10277969 to rs1047389 | 0.85 | 0.91 |
| rs10498633, rs10277969, rs1047389 to rs11731587 | 0.88 | 0.87 |
| rs10498633, rs10277969, rs1047389, rs11731587 to rs2242065 | -- * | -- |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, H.; Cao, L.; Gao, Y.; Luo, H.; Meng, X.; Wang, Y.; Li, J.; Liu, W. Research on Frequent Itemset Mining of Imaging Genetics GWAS in Alzheimer’s Disease. Genes 2022, 13, 176. https://doi.org/10.3390/genes13020176
Liang H, Cao L, Gao Y, Luo H, Meng X, Wang Y, Li J, Liu W. Research on Frequent Itemset Mining of Imaging Genetics GWAS in Alzheimer’s Disease. Genes. 2022; 13(2):176. https://doi.org/10.3390/genes13020176
Chicago/Turabian StyleLiang, Hong, Luolong Cao, Yue Gao, Haoran Luo, Xianglian Meng, Ying Wang, Jin Li, and Wenjie Liu. 2022. "Research on Frequent Itemset Mining of Imaging Genetics GWAS in Alzheimer’s Disease" Genes 13, no. 2: 176. https://doi.org/10.3390/genes13020176
APA StyleLiang, H., Cao, L., Gao, Y., Luo, H., Meng, X., Wang, Y., Li, J., & Liu, W. (2022). Research on Frequent Itemset Mining of Imaging Genetics GWAS in Alzheimer’s Disease. Genes, 13(2), 176. https://doi.org/10.3390/genes13020176