
Genomic Variation Shaped by Environmental and Geographical Factors in Prairie Cordgrass Natural Populations Collected across Its Native Range in the USA

 ,
,
Abstract
1. Introduction
2. Materials and Methods
2.1. Plant Materials
2.2. Genotyping-by-Sequencing
2.3. Ploidy Levels
2.4. Population Structure and Genetic Diversity
2.5. Environmental and Geographical Variables
2.6. Mantel Tests and Canonical Correlation Analyses
3. Results
3.1. SNP Discovery
3.2. Ploidy Levels
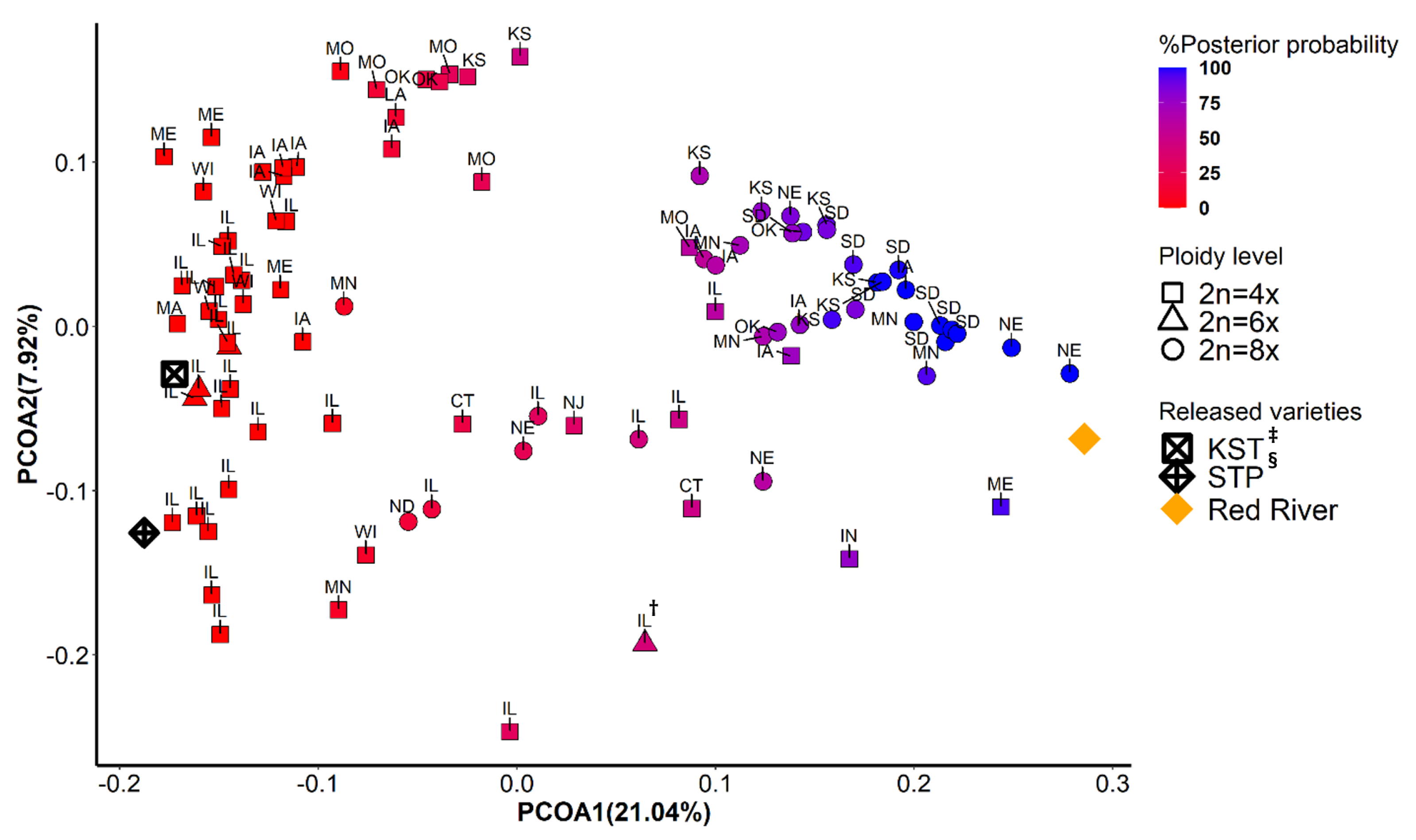
3.3. Population Structure
3.4. Analysis of Molecular Variance and Heterozygosity
3.5. Mantel Tests and Canonical Correlation Analyses
4. Discussion
4.1. Intraspecific Genetic Diversity
4.2. Genetic and Geographical/Environmental Associations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| POP ID | State | n | Ploidy Level (x = 10) | Ecoregion † | USDA Hardiness Zone ‡ | Average Annual Minimum Temperature (°C) | Latitude | Longitude | Imputed (%) ** | West Deme (%) *** | East Deme (%) *** | Deme Membership |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PC09-102 | CT | 2 | 4x | NCZ | HZ7a | −17.8 to −15.0 | 41°210.09 N | 71°5433.08 W | 19 | 48 | 52 | East |
| PC19-101 | IA | 2 | 4x | WCBP | HZ5a | −28.9 to −26.1 | 41°557.77 N | 92°3457.55 W | 3 | 0 | 100 | East |
| PC19-102 | IA | 2 | 4x | WCBP | HZ5a | −28.9 to −26.1 | 41°5623.29 N | 92°3435.82 W | 3 | 0 | 100 | East |
| PC19-103 | IA | 2 | 4x | WCBP | HZ5a | −28.9 to −26.1 | 42°029.81 N | 93°2538.27 W | 2 | 0 | 100 | East |
| PC19-105 | IA | 3 | 4x | WCBP | HZ5a | −28.9 to −26.1 | 42°3942.72 N | 94°1336.54 W | 5 | 0 | 100 | East |
| PC19-106 * | IA | 2 | 8x | WCBP | HZ5a | −28.9 to −26.1 | 43°458.56 N | 94°2652.32 W | 17 | 57 | 43 | West |
| PC19-107 | IA | 2 | 8x | WCBP | HZ5a | −28.9 to −26.1 | 43°55.98 N | 94°3214.99 W | 8 | 77 | 23 | West |
| PC19-108 | IA | 2 | 8x | WCBP | HZ5a | −28.9 to −26.1 | 42°1948.21 N | 96°1937 W | 13 | 100 | 0 | West |
| PC19-109 | IA | 2 | 4x | WCBP | HZ5a | −28.9 to −26.1 | 42°1220.6 N | 96°155.22 W | 9 | 13 | 87 | East |
| PC19-110 | IA | 2 | 4x | WCBP | HZ5a | −28.9 to −26.1 | 41°4733.84 N | 96°233.19 W | 6 | 74 | 26 | West |
| PC19-111 | IA | 4 | 4x | WCBP | HZ5a | −28.9 to −26.1 | 42°127 N | 93°436 W | 6 | 0 | 100 | East |
| PC19-112 | IA | 2 | 8x | WCBP | HZ5a | −28.9 to −26.1 | 42°155.93 N | 94°2719.83 W | 4 | 63 | 37 | West |
| IL-100 | IL | 2 | 4x | CCBP | HZ6a | −23.3 to −20.6 | 39°4023.7 N | 89°919.68 W | 9 | 0 | 100 | East |
| IL-102 | IL | 2 | 4x | CCBP | HZ5b | −26.1 to −23.3 | 40°355 N | 88°1419 W | 27 | 0 | 100 | East |
| IL-104 | IL | 2 | 4x | CCBP | HZ5b | −26.1 to −23.3 | 40°1045 N | 88°4431 W | 11 | 0 | 100 | East |
| IL-105 | IL | 2 | 4x | CCBP | HZ5b | −26.1 to −23.3 | 40°5441 N | 87°5636 W | 14 | 30 | 70 | East |
| IL-106 | IL | 2 | 4x | CCBP | HZ5b | −26.1 to −23.3 | 40°3924 N | 88°112 W | 22 | 0 | 100 | East |
| IL-99 | IL | 2 | 4x | CCBP | HZ6a | −23.3 to −20.6 | 39°45 N | 88°423 W | 9 | 0 | 100 | East |
| PC17-102 | IL | 3 | 6x | CCBP | HZ5b | −26.1 to −23.3 | 40°038.74 N | 88°114.88 W | 3 | 0 | 100 | East |
| PC17-103 | IL | 2 | 6x | CCBP | HZ5b | −26.1 to −23.3 | 40°038.85 N | 88°114.44 W | 12 | 41 | 59 | East |
| PC17-104 | IL | 2 | 6x | CCBP | HZ5b | −26.1 to −23.3 | 40°038.97 N | 88°114.14 W | 9 | 0 | 100 | East |
| PC17-105 | IL | 2 | 4x | CCBP | HZ5b | −26.1 to −23.3 | 40°648.09 N | 88°855.1 W | 13 | 48 | 52 | East |
| PC17-106 | IL | 2 | 8x | CCBP | HZ5b | −26.1 to −23.3 | 40°1258 N | 88°618 W | 6 | 44 | 56 | East |
| PC17-107 | IL | 2 | 4x | CCBP | HZ5b | −26.1 to −23.3 | 40°1328.89 N | 88°544.07 W | 8 | 0 | 100 | East |
| PC17-108 | IL | 2 | 4x | CCBP | HZ5b | −26.1 to −23.3 | 40°1750.2 N | 88°06.81 W | 18 | 0 | 100 | East |
| PC17-109 | IL | 2 | 4x | CCBP | HZ5b | −26.1 to −23.3 | 40°316.85 N | 88°1216.12 W | 13 | 0 | 100 | East |
| PC17-111 | IL | 3 | 4x | CCBP | HZ5a | −28.9 to −26.1 | 41°4950.99 N | 89°264.28 W | 13 | 60 | 40 | West |
| PC17-114 | IL | 2 | 4x | CCBP | HZ5b | −26.1 to −23.3 | 40°017.16 N | 88°036.08 W | 5 | 0 | 100 | East |
| PC17-115 * | IL | 2 | 4x | CCBP | HZ5b | −26.1 to −23.3 | 41°295.16 N | 90°1921.66 W | 2 | 0 | 100 | East |
| PC17-116 | IL | 2 | 6x | CCBP | HZ5b | −26.1 to −23.3 | 40°038.68 N | 88°113.51 W | 10 | 0 | 100 | East |
| PC17-117 | IL | 2 | 8x | CCBP | HZ5b | −26.1 to −23.3 | 39°577.84 N | 88°022.96 W | 12 | 31 | 69 | East |
| PC17-118 | IL | 2 | 4x | IRVH | HZ6a | −23.3 to −20.6 | 38°5726.79 N | 88°2951.04 W | 3 | 0 | 100 | East |
| PC17-119 | IL | 2 | 4x | CCBP | HZ6a | −23.3 to −20.6 | 39°3814.77 N | 88°1855.89 W | 9 | 0 | 100 | East |
| PC17-120 | IL | 2 | 4x | IRVH | HZ6a | −23.3 to −20.6 | 39°2736.18 N | 91°213.92 W | 11 | 2 | 98 | East |
| PC17-124 | IL | 2 | 4x | IRVH | HZ5b | −26.1 to −23.3 | 40°5219.48 N | 90°3646.59 W | 6 | 0 | 100 | East |
| PC17-126 | IL | 2 | 4x | CCBP | HZ5b | −26.1 to −23.3 | 40°2822.61 N | 87°4444.54 W | 6 | 0 | 100 | East |
| PC17-128 | IL | 4 | 4x | CCBP | HZ5b | −26.1 to −23.3 | 40°1247.45 N | 88°1159.33 W | 3 | 0 | 100 | East |
| PC17-129 | IL | 2 | 4x | CCBP | HZ5b | −26.1 to −23.3 | 40°440.17 N | 88°1450.64 W | 37 | 0 | 100 | East |
| PC17-130 | IL | 4 | 4x | CCBP | HZ5b | −26.1 to −23.3 | 40°646.58 N | 88°128.77 W | 11 | 0 | 100 | East |
| PC17-136 | IL | 2 | 4x | CCBP | HZ5b | −26.1 to −23.3 | 40°13.71 N | 88°131.42 W | 6 | 0 | 100 | East |
| PC17-144 | IL | 2 | 8x | IRVH | HZ6a | −23.3 to −20.6 | 39°1228.08 N | 88°2932.58 W | 13 | 17 | 83 | East |
| PC17-146 | IL | 2 | 4x | CCBP | HZ6a | −23.3 to −20.6 | 39°2930.45 N | 89°78.33 W | 4 | 0 | 100 | East |
| PC20-109 * | IL | 2 | 8x | FH | HZ6a | −23.3 to −20.6 | 39°541.43 N | 96°3614.75 W | 7 | 100 | 0 | West |
| PC18-101 | IN | 2 | 4x | ECBP | HZ5b | −26.1 to −23.3 | 40°1454.29 N | 87°333.53 W | 12 | 77 | 23 | West |
| PC20-101 | KS | 2 | 8x | FH | HZ6a | −23.3 to −20.6 | 39°416.1 N | 96°3218.89 W | 7 | 67 | 33 | West |
| PC20-102 | KS | 2 | 4x | FH | HZ6b | −20.6 to −17.8 | 37°1938.15 N | 97°024.84 W | 2 | 47 | 53 | East |
| PC20-103 | KS | 2 | 8x | FH | HZ6a | −23.3 to −20.6 | 39°338.25 N | 96°2253.91 W | 1 | 96 | 4 | West |
| PC20-104 * | KS | 2 | 8x | FH | HZ6b | −20.6 to −17.8 | 37°4433.7 N | 96°5038.12 W | 1 | 100 | 0 | West |
| PC20-110 | KS | 2 | 8x | CGP | HZ6a | −23.3 to −20.6 | 38°5432.13 N | 97°1444.54 W | 3 | 92 | 8 | West |
| PC22-101 | LA | 4 | 4x | SWTP | HZ8a | −12.2 to −9.40 | 32°5354 N | 91°5927 W | 9 | 12 | 88 | East |
| PC25-101 | MA | 2 | 4x | NCZ | HZ6b | −20.6 to −17.8 | 42°3337.2 N | 70°5518.96 W | 5 | 0 | 100 | East |
| PC23-101 | ME | 2 | 4x | APH | HZ5b | −26.1 to −23.3 | 43°5513.93 N | 69°5149.57 W | 11 | 95 | 5 | West |
| PC23-102 | ME | 2 | 4x | APH | HZ5b | −26.1 to −23.3 | 44°164.57 N | 69°10.65 W | 9 | 0 | 100 | East |
| PC23-103 | ME | 2 | 4x | APH | HZ5b | −26.1 to −23.3 | 44°2926.19 N | 68°11.51 W | 18 | 0 | 100 | East |
| PC23-104 | ME | 2 | 4x | APH | HZ5b | −26.1 to −23.3 | 44°3139.58 N | 67°5314.11 W | 9 | 0 | 100 | East |
| PC27-101 | MN | 2 | 4x | LAP | HZ3b | −37.2 to −34.4 | 47°3525.52 N | 95°4716.76 W | 8 | 9 | 91 | East |
| PC27-102 * | MN | 2 | 8x | LAP | HZ4a | −34.4 to −31.7 | 47°4840.55 N | 96°3638.84 W | 5 | 70 | 30 | West |
| PC27-103 | MN | 2 | 8x | LAP | HZ3b | −37.2 to −34.4 | 48°3051.67 N | 96°5313.16 W | 29 | 8 | 92 | East |
| PC27-104 | MN | 2 | 8x | LAP | HZ4a | −34.4 to −31.7 | 46°4027.03 N | 96°2530.67 W | 9 | 100 | 0 | West |
| PC27-106 | MN | 2 | 8x | WCBP | HZ4b | −31.7 to −28.9 | 45°95.72 N | 95°5741.39 W | 12 | 94 | 6 | West |
| PC27-108 | MN | 2 | 8x | WCBP | HZ4b | −31.7 to −28.9 | 44°3236.86 N | 94°1741.97 W | 11 | 67 | 33 | West |
| PC29-101 | MO | 2 | 4x | CIP | HZ5b | −26.1 to −23.3 | 39°4637.08 N | 93°2416.02 W | 10 | 60 | 40 | West |
| PC29-102 | MO | 2 | 4x | CIP | HZ6a | −23.3 to −20.6 | 39°4535.76 N | 92°4116.86 W | 4 | 14 | 86 | East |
| PC29-103 | MO | 4 | 4x | CIP | HZ5b | −26.1 to −23.3 | 39°4253.7 N | 92°751.66 W | 6 | 3 | 97 | East |
| PC29-104 * | MO | 2 | 4x | CIP | HZ6a | −23.3 to −20.6 | 37°5142.63 N | 94°1337.97 W | 4 | 29 | 71 | East |
| PC29-106 | MO | 2 | 4x | CIP | HZ6b | −20.6 to −17.8 | 37°5112.95 N | 94°1855.53 W | 21 | 26 | 74 | East |
| PC38-101 | ND | 2 | 8x | NGP | HZ4a | −34.4 to −31.7 | 47°2733 N | 98°4958 W | 18 | 14 | 86 | East |
| PC31-101 | NE | 4 | 8x | CGP | HZ5b | −26.1 to −23.3 | 40°4613.63 N | 97°456.22 W | 3 | 85 | 15 | West |
| PC31-102 | NE | 2 | 8x | CGP | HZ5b | −26.1 to −23.3 | 40°4428 N | 99°3335 W | 9 | 100 | 0 | West |
| PC31-103 | NE | 2 | 8x | CGP | HZ5a | −28.9 to −26.1 | 40°535.91 N | 100°341.99 W | 7 | 100 | 0 | West |
| PC31-104 | NE | 2 | 8x | CGP | HZ5a | −28.9 to −26.1 | 41°222.28 N | 100°2519.84 W | 12 | 27 | 73 | East |
| PC31-105 | NE | 4 | 8x | CGP | HZ5a | −28.9 to −26.1 | 41°52.18 N | 100°3216.07 W | 9 | 61 | 39 | West |
| PC34-101 | NJ | 2 | 4x | ACPB | HZ6b | −20.6 to −17.8 | 40°010.56 N | 74°378.49 W | 17 | 34 | 66 | East |
| PC20-105 | NY | 2 | 4x | CIP | HZ6b | −20.6 to −17.8 | 37°4355.63 N | 94°4229.07 W | 3 | 30 | 70 | East |
| PC20-107 | NY | 2 | 8x | FH | HZ6a | −23.3 to −20.6 | 39°09.24 N | 96°3130.42 W | 4 | 78 | 22 | West |
| PC40-101 | OK | 2 | 4x | CIP | HZ6b | −20.6 to −17.8 | 36°5132.52 N | 94°5447.76 W | 8 | 18 | 82 | East |
| PC40-102 * | OK | 2 | 4x | CIP | HZ6b | −20.6 to −17.8 | 36°5225.5 N | 95°045.24 W | 4 | 23 | 77 | East |
| PC40-103 | OK | 2 | 8x | CGP | HZ7a | −17.8 to −15.0 | 36°4943.56 N | 97°43.47 W | 2 | 89 | 11 | West |
| PC40-104 | OK | 2 | 8x | CGP | HZ7a | −17.8 to −15.0 | 36°4943.92 N | 97°43.3 W | 10 | 75 | 25 | West |
| PC46-101 | SD | 2 | 8x | WCBP | HZ4b | −31.7 to −28.9 | 43°4026.68 N | 96°4841 W | 25 | 78 | 22 | West |
| PC46-102 | SD | 2 | 8x | NGP | HZ4b | −31.7 to −28.9 | 43°325.52 N | 96°4950.69 W | 7 | 100 | 0 | West |
| PC46-103 | SD | 2 | 8x | NGP | HZ4b | −31.7 to −28.9 | 43°2626.69 N | 96°4934.73 W | 14 | 100 | 0 | West |
| PC46-104 * | SD | 2 | 8x | NGP | HZ4b | −31.7 to −28.9 | 43°2317.41 N | 96°4934.67 W | 4 | 95 | 5 | West |
| PC46-105 | SD | 2 | 8x | NGP | HZ4b | −31.7 to −28.9 | 43°1034.77 N | 96°4932.57 W | 10 | 99 | 1 | West |
| PC46-106 | SD | 2 | 8x | NGP | HZ4b | −31.7 to −28.9 | 42°581.2 N | 96°4934.73 W | 19 | 86 | 14 | West |
| PC46-107 | SD | 2 | 8x | NGP | HZ5a | −28.9 to −26.1 | 42°4811 N | 96°4935.19 W | 12 | 85 | 15 | West |
| PC46-108 | SD | 2 | 8x | NWGP | HZ4b | −31.7 to −28.9 | 43°5639.15 N | 98°1617.77 W | 12 | 100 | 0 | West |
| PC46-109 | SD | 2 | 8x | SCP | HZ5a | −28.9 to −26.1 | 43°2655.46 N | 100°141.2 W | 11 | 100 | 0 | West |
| PC55-101 | WI | 3 | 4x | WCBP | HZ5a | −28.9 to −26.1 | 43°3127 N | 89°2951 W | 11 | 0 | 100 | East |
| PC55-102 | WI | 2 | 4x | NCHF | HZ4b | −31.7 to −28.9 | 44°312.62 N | 90°523.37 W | 12 | 10 | 90 | East |
| PC55-103 | WI | 2 | 4x | NCHF | HZ4b | −31.7 to −28.9 | 44°3940.94 N | 91°314.96 W | 36 | 0 | 100 | East |
| PC55-104 * | WI | 4 | 4x | NCHF | HZ4a | −34.4 to −31.7 | 45°3021.77 N | 92°112.12 W | 5 | 0 | 100 | East |
| PC55-105 | WI | 2 | 4x | DA | HZ4b | −31.7 to −28.9 | 43°2646.02 N | 90°4648.11 W | 18 | 0 | 100 | East |
| KST ¶ | - | - | 4x | - | - | - | - | - | 11 | 0 | 100 | East |
| Red River | - | - | 8x | - | - | - | - | - | 12 | 100 | 0 | West |
| STP *§ | - | - | 4x | - | - | - | - | - | 9 | 0 | 100 | East |


References
- Guo, J.; Thapa, S.; Voigt, T.; Rayburn, A.L.; Boe, A.; Lee, D.K. Phenotypic and Biomass Yield Variations in Natural Populations of Prairie Cordgrass (Spartina pectinata Link) in the USA. BioEnergy Res. 2015, 8, 1371–1383. [Google Scholar] [CrossRef]
- Lemus, R.; Lal, R. Bioenergy Crops and Carbon Sequestration. Crit. Rev. Plant Sci. 2005, 24, 1–21. [Google Scholar] [CrossRef]
- McLaughlin, S.B.; de la Torre Ugarte, D.G.; Garten, C.T.; Lynd, L.R.; Sanderson, M.A.; Tolbert, V.R.; Wolf, D.D. High-Value Renewable Energy from Prairie Grasses. Environ. Sci. Technol. 2002, 36, 2122–2129. [Google Scholar] [CrossRef] [PubMed]
- Sanderson, M.A.; Adler, P.R. Perennial forages as second generation bioenergy crops. Int. J. Mol. Sci. 2008, 9, 768–788. [Google Scholar] [CrossRef] [PubMed]
- Samson, F.; Knopf, F. Prairie Conservation in North America. BioScience 1994, 44, 418–421. [Google Scholar] [CrossRef]
- Hufford, K.M.; Mazer, S.J. Plant ecotypes: Genetic differentiation in the age of ecological restoration. Trends Ecol. Evol. 2003, 18, 147–155. [Google Scholar] [CrossRef]
- Montalvo, A.M.; Williams, S.L.; Rice, K.J.; Buchmann, S.L.; Cory, C.; Handel, S.N.; Nabhan, G.P.; Primack, R.; Robichaux, R.H. Restoration biology: A population biology perspective. Restor. Ecol. 1997, 5, 277–290. [Google Scholar] [CrossRef]
- Weaver, J.E. North American Prairie. 1954. Available online: https://digitalcommons.unl.edu/agronweaver/15/ (accessed on 5 May 2018).
- Weaver, J.E. Extent of Communities and Abundance of the Most Common Grasses in Prairie. Bot. Gaz. 1960, 122, 25–33. [Google Scholar] [CrossRef]
- Mobberley, D.G. Taxonomy and Distribution of the Genus Spartina; Iowa State University: Ames, IA, USA, 1953. [Google Scholar]
- Potter, L.; Bingham, M.; Baker, M.; Long, S. The potential of two perennial C4 grasses and a perennial C4 sedge as ligno-cellulosic fuel crops in NW Europe. Crop establishment and yields in E. England. Ann. Bot. 1995, 76, 513–520. [Google Scholar] [CrossRef]
- Boe, A.; Lee, D. Genetic variation for biomass production in prairie cordgrass and switchgrass. Crop Sci. 2007, 47, 929–934. [Google Scholar] [CrossRef]
- Boe, A.; Owens, V.; Gonzalez-Hernandez, J.; Stein, J.; Lee, D.; Koo, B. Morphology and biomass production of prairie cordgrass on marginal lands. GCB Bioenergy 2009, 1, 240–250. [Google Scholar] [CrossRef]
- Dokyoung, L.; Parrish, A. Prairie Cordgrass (Spartina Pectinata) Cultivar ‘Savoy’ for a Bioenergy Feedstock Production. U.S. Patent 9,241,471, 26 January 2016. [Google Scholar]
- Jensen, N. Plant Guide for Prairie Cordgrass (Spartina Pectinata Bosc ex Link). 2006. Available online: https://www.nrcs.usda.gov/Internet/FSE_PLANTMATERIALS/publications/nypmcpg11942.pdf/ (accessed on 15 June 2021).
- Church, G.L. Cytotaxonomic Studies in the Gramineae Spartina, Andropogon and Panicum. Am. J. Bot. 1940, 27, 263–271. [Google Scholar] [CrossRef]
- Marchant, C.J. Evolution in Spartina (Gramineae): II. Chromosomes, basic relationships and the problem of S. ×townsendii agg. J. Linn. Soc. Lond. Bot. 1968, 60, 381–409. [Google Scholar] [CrossRef]
- Marchant, C.J. Evolution in Spartina (Gramineae): III. Species chromosome numbers and their taxonomic significance. J. Linn. Soc. Lond. Bot. 1968, 60, 411–417. [Google Scholar] [CrossRef]
- Kim, S.; Rayburn, A.L.; Boe, A.; Lee, D.K. Neopolyploidy in Spartina pectinata Link: 1. Morphological analysis of tetraploid and hexaploid plants in a mixed natural population. Plant Syst. Evol. 2012, 298, 1073–1083. [Google Scholar] [CrossRef]
- Kim, S.; Rayburn, A.L.; Lee, D.K. Genome Size and Chromosome Analyses in Prairie Cordgrass. Crop Sci. 2010, 50, 2277–2282. [Google Scholar] [CrossRef]
- Kim, S.; Rayburn, A.L.; Parrish, A.; Lee, D.K. Cytogeographic Distribution and Genome Size Variation in Prairie Cordgrass (Spartina pectinata Bosc ex Link). Plant Mol. Biol. Report. 2012, 30, 1073–1079. [Google Scholar] [CrossRef]
- Kim, S.; Rayburn, A.L.; Voigt, T.B.; Ainouche, M.L.; Ainouche, A.K.; Lee, D.K. Chloroplast DNA Intraspecific Phylogeography of Prairie Cordgrass (Spartina pectinata Bosc ex Link). Plant Mol. Biol. Report. 2013, 31, 1376–1383. [Google Scholar] [CrossRef]
- Ainouche, M.L.; Baumel, A.; Salmon, A.; Yannic, G. Hybridization, polyploidy and speciation in Spartina (Poaceae). New Phytol. 2003, 161, 165–172. [Google Scholar] [CrossRef]
- Ainouche, M.; Chelaifa, H.; Ferreira, J.; Bellot, S.; Aïnouche, A.; Salmon, A. Erratum from—Polyploid evolution in spartina: Dealing with highly redundant hybrid genomes. In Polyploidy and Genome Evolution; Springer: Berlin/Heidelberg, Germany, 2012; pp. 225–243. [Google Scholar]
- Birky, C.W. Transmission Genetics of Mitochondria and Chloroplasts. Annu. Rev. Genet. 1978, 12, 471–512. [Google Scholar] [CrossRef] [PubMed]
- Petit, R.J.; Kremer, A.; Wagner, D.B. Finite island model for organelle and nuclear genes in plants. Heredity 1993, 71, 630–641. [Google Scholar] [CrossRef]
- Elshire, R.J.; Glaubitz, J.C.; Sun, Q.; Poland, J.A.; Kawamoto, K.; Buckler, E.S.; Mitchell, S.E. A robust, simple genotyping-by-sequencing (GBS) approach for high diversity species. PLoS ONE 2011, 6, e19379. [Google Scholar] [CrossRef] [PubMed]
- Poland, J.A.; Brown, P.J.; Sorrells, M.E.; Jannink, J.L. Development of high-density genetic maps for barley and wheat using a novel two-enzyme genotyping-by-sequencing approach. PLoS ONE 2012, 7, e32253. [Google Scholar]
- Emerson, K.J.; Merz, C.R.; Catchen, J.M.; Hohenlohe, P.A.; Cresko, W.A.; Bradshaw, W.E.; Holzapfel, C.M. Resolving postglacial phylogeography using high-throughput sequencing. Proc. Natl. Acad. Sci. USA 2010, 107, 16196–16200. [Google Scholar] [CrossRef]
- Escobar, J.S.; Scornavacca, C.; Cenci, A.; Guilhaumon, C.; Santoni, S.; Douzery, E.J.P.; Ranwez, V.; Glémin, S.; David, J. Multigenic phylogeny and analysis of tree incongruences in Triticeae (Poaceae). BMC Evol. Biol. 2011, 11, 181. [Google Scholar] [CrossRef]
- Grattapaglia, D.; Silva-Junior, O.B.; Kirst, M.; de Lima, B.M.; Faria, D.A.; Pappas, G.J. High-throughput SNP genotyping in the highly heterozygous genome of Eucalyptus: Assay success, polymorphism and transferability across species. BMC Plant Biol. 2011, 11, 65. [Google Scholar] [CrossRef]
- Morris, G.P.; Grabowski, P.P.; Borevitz, J.O. Genomic diversity in switchgrass (Panicum virgatum): From the continental scale to a dune landscape. Mol. Ecol. 2011, 20, 4938–4952. [Google Scholar] [CrossRef] [PubMed]
- Degnan, J.H.; Rosenberg, N.A. Gene tree discordance, phylogenetic inference and the multispecies coalescent. Trends Ecol. Evol. 2009, 24, 332–340. [Google Scholar] [CrossRef] [PubMed]
- Eckert, A.; Carstens, B. Does gene flow destroy phylogenetic signal? The performance of three methods for estimating species phylogenies in the presence of gene flow. Mol. Phylogenet. Evol. 2008, 49, 832–842. [Google Scholar] [CrossRef]
- Pollard, D.A.; Iyer, V.N.; Moses, A.M.; Eisen, M.B. Widespread discordance of gene trees with species tree in Drosophila: Evidence for incomplete lineage sorting. PLoS Genet. 2006, 2, e173. [Google Scholar] [CrossRef] [PubMed]
- Doyle, J.J.; Doyle, J.L. A Rapid DNA Isolation Procedure for Small Quantities of Fresh Leaf Tissue. Phytochem. Bull. 1987, 19, 11–15. [Google Scholar]
- Melo, A.T.O.; Bartaula, R.; Hale, I. GBS-SNP-CROP: A reference-optional pipeline for SNP discovery and plant germplasm characterization using variable length, paired-end genotyping-by-sequencing data. BMC Bioinform. 2016, 17, 29. [Google Scholar] [CrossRef] [PubMed]
- Bolger, A.M.; Lohse, M.; Usadel, B. Trimmomatic: A flexible trimmer for Illumina sequence data. Bioinformatics 2014, 30, 2114–2120. [Google Scholar] [CrossRef]
- Rognes, T.; Flouri, T.; Nichols, B.; Quince, C.; Mahé, F. VSEARCH: A versatile open source tool for metagenomics. PeerJ 2016, 4, e2584. [Google Scholar] [CrossRef]
- Bishop, J.W.; Kim, S.; Villamil, M.B.; Lee, D.; Rayburn, A.L. Meiotic pairing as an indicator of genome composition in polyploid prairie cordgrass (Spartina pectinata Link). Genetica 2017, 145, 235–240. [Google Scholar] [CrossRef] [PubMed]
- Crawford, J.; Brown, P.J.; Voigt, T.; Lee, D.K. Linkage mapping in prairie cordgrass (Spartina pectinata Link) using genotyping-by-sequencing. Mol. Breed. 2016, 36. [Google Scholar] [CrossRef]
- Rayburn, A.L.; McCloskey, R.; Tatum, T.C.; Bollero, G.A.; Jeschke, M.R.; Tranel, P.J. Genome Size Analysis of Weedy Amaranthus Species. Crop Sci. 2005, 45, 2557–2562. [Google Scholar] [CrossRef]
- Lee, M.S.; Rayburn, A.L.; Lee, D.K. Genesis and Identification of Octoploids Generated from Tetraploid Prairie Cordgrass. Crop Sci. 2016, 56, 2973–2982. [Google Scholar] [CrossRef]
- Bradbury, P.J.; Zhang, Z.; Kroon, D.E.; Casstevens, T.M.; Ramdoss, Y.; Buckler, E.S. TASSEL: Software for association mapping of complex traits in diverse samples. Bioinformatics 2007, 23, 2633–2635. [Google Scholar] [CrossRef]
- Money, D.; Gardner, K.; Migicovsky, Z.; Schwaninger, H.; Zhong, G.Y.; Myles, S. LinkImpute: Fast and accurate genotype imputation for nonmodel organisms. G3 Genes Genomes Genet. 2015, 5, 2383–2390. [Google Scholar] [CrossRef]
- Raj, A.; Stephens, M.; Pritchard, J.K. fastSTRUCTURE: Variational inference of population structure in large SNP data sets. Genetics 2014, 197, 573–589. [Google Scholar] [CrossRef] [PubMed]
- Jombart, T.; Devillard, S.; Balloux, F. Discriminant analysis of principal components: A new method for the analysis of genetically structured populations. BMC Genet. 2010, 11, 1–15. [Google Scholar] [CrossRef]
- Wilkinson, L. ggplot2: Elegant Graphics for Data Analysis by WICKHAM, H. Biometrics 2011, 67, 678–679. [Google Scholar] [CrossRef]
- Paradis, E.; Blomberg, S.; Bolker, B.; Brown, J.; Claude, J.; Cuong, H.S.; Desper, R. Package ‘ape’. Anal. Phylogenet. Evol. Version. 2019. Available online: http://ape.mpl.ird.fr/ (accessed on 22 August 2017).
- Kamvar, Z.N.; Tabima, J.F.; Grünwald, N.J. Poppr: An R package for genetic analysis of populations with clonal, partially clonal, and/or sexual reproduction. PeerJ 2014, 2, e281. [Google Scholar] [CrossRef]
- Goudet, J. Hierfstat, a package for r to compute and test hierarchical F-statistics. Mol. Ecol. Notes 2005, 5, 184–186. [Google Scholar] [CrossRef]
- Weir, B.S.; Cockerham, C.C. Estimating F-Statistics for the Analysis of Population Structure. Evolution 1984, 38, 1358–1370. [Google Scholar] [CrossRef] [PubMed]
- Hijmans, R.J.; Phillips, S.; Leathwick, J.; Elith, J.; Hijmans, M.R.J. Package ‘dismo’. Circles 2017, 9, 1–68. [Google Scholar]
- Omernik, J.M. Ecoregions of the Conterminous United States. Ann. Assoc. Am. Geogr. 1987, 77, 118–125. [Google Scholar] [CrossRef]
- Legendre, P.; Fortin, M.J. Comparison of the Mantel test and alternative approaches for detecting complex multivariate relationships in the spatial analysis of genetic data. Mol. Ecol. Resour. 2010, 10, 831–844. [Google Scholar] [CrossRef]
- Oksanen, J.; Kindt, R.; Legendre, P.; O’Hara, B.; Simpson, G.L.; Solymos, P.; Stevens, M.H.H.; Wagner, H. Vegan: Community Ecology Package. 2008. Available online: https://cran.r-project.org/web/packages/vegan (accessed on 22 August 2017).
- Vincenty, T. Direct and Inverse Solutions of Geodesics on the Ellipsoid with Application of Nested Equations. Surv. Rev. 1975, 23, 88–93. [Google Scholar] [CrossRef]
- Wallace, J.R.; Wallace, M.J.R. Package ‘Imap’. 2010. Available online: https://cran.r-project.org/web/packages/Imap/ (accessed on 22 August 2017).
- Legendre, P.; Borcard, D.; Peres-Neto, P.R. Analyzing beta diversity: Partitioning the spatial variation of community composition data. Ecol. Monogr. 2005, 75, 435–450. [Google Scholar] [CrossRef]
- Manel, S.; Schwartz, M.K.; Luikart, G.; Taberlet, P. Landscape genetics: Combining landscape ecology and population genetics. Trends Ecol. Evol. 2003, 18, 189–197. [Google Scholar] [CrossRef]
- McRae, B.H. Isolation by Resistance. Evolution 2006, 60, 1551–1561. [Google Scholar] [CrossRef]
- Legendre, P.; Legendre, L.F.J. Numerical Ecology; Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar]
- Wartenberg, D. Canonical Trend Surface Analysis: A Method for Describing Geographic Patterns. Syst. Zool. 1985, 34, 259. [Google Scholar] [CrossRef]
- Gonzalez, I.; Déjean, S.; Martin, P.; Baccini, A. CCA: AnRPackage to Extend Canonical Correlation Analysis. J. Stat. Softw. 2008, 23. [Google Scholar] [CrossRef]
- Menzel, U. CCP: Significance Tests for Canonical Correlation Analysis (CCA). Available online: https://cran.r-project.org/web/packages/CCP/ (accessed on 22 August 2017).
- Lauenroth, W.K.; Burke, I.C.; Gutmann, M.P. The structure and function of ecosystems in the central North American grassland region. Great Plains Res. 1999, 9, 223–259. [Google Scholar]
- Huff, D.R.; Quinn, J.A.; Higgins, B.; Palazzo, A.J. Random amplified polymorphic DNA (RAPD) variation among native little bluestem [Schizachyrium scoparium(Michx.) Nash] populations from sites of high and low fertility in forest and grassland biomes. Mol. Ecol. 1998, 7, 1591–1597. [Google Scholar] [CrossRef]
- Narasimhamoorthy, B.; Saha, M.C.; Swaller, T.; Bouton, J.H. Genetic Diversity in Switchgrass Collections Assessed by EST-SSR Markers. BioEnergy Res. 2008, 1. [Google Scholar] [CrossRef]
- Price, D.L.; Salon, P.R.; Casler, M.D. Big Bluestem Gene Pools in the Central and Northeastern United States. Crop Sci. 2012, 52, 189–200. [Google Scholar] [CrossRef]
- Grabowski, P.P.; Morris, G.P.; Casler, M.D.; Borevitz, J.O. Population genomic variation reveals roles of history, adaptation and ploidy in switchgrass. Mol. Ecol. 2014, 23, 4059–4073. [Google Scholar] [CrossRef]
- Casler, M.D.; Stendal, C.A.; Kapich, L.; Vogel, K.P. Genetic Diversity, Plant Adaptation Regions, and Gene Pools for Switchgrass. Crop Sci. 2007, 47, 2261–2273. [Google Scholar] [CrossRef]
- Lovell, J.T.; MacQueen, A.H.; Mamidi, S.; Bonnette, J.; Jenkins, J.; Napier, J.D.; Sreedasyam, A.; Healey, A.; Session, A.; Shu, S.; et al. Genomic mechanisms of climate adaptation in polyploid bioenergy switchgrass. Nature 2021, 590, 438–444. [Google Scholar] [CrossRef] [PubMed]
- Evans, J.; Sanciangco, M.D.; Lau, K.H.; Crisovan, E.; Barry, K.; Daum, C.; Hundley, H.; Jenkins, J.; Kennedy, M.; Kunde-Ramamoorthy, G.; et al. Extensive genetic diversity is present within North American switchgrass germplasm. Plant Genome 2018, 11, 170055. [Google Scholar] [CrossRef]
- Dewey, L.H. Three New Weeds of the Mustard Family; U.S. Dept. of Agriculture, Division of Botany: Washington, DC, USA, 1897. [Google Scholar] [CrossRef]
- Hansen, M.J.; Clevenger, A.P. The influence of disturbance and habitat on the presence of non-native plant species along transport corridors. Biol. Conserv. 2005, 125, 249–259. [Google Scholar] [CrossRef]
- Boe, A.; Bortnem, R. Morphology and Genetics of Biomass in Little Bluestem. Crop Sci. 2009, 49, 411–418. [Google Scholar] [CrossRef]
- Casler, M.D.; Vogel, K.P.; Taliaferro, C.M.; Wynia, R.L. Latitudinal Adaptation of Switchgrass Populations. Crop Sci. 2004, 44, 293–303. [Google Scholar] [CrossRef]
- McMillan, C. Ecotypic Differentiation within Four North American Prairie Grasses. II. Behavioral Variation within Transplanted Community Fractions. Am. J. Bot. 1965, 52, 55–65. [Google Scholar] [CrossRef]
- Porter, C.L. An Analysis of Variation Between Upland and Lowland Switchgrass, Panicum Virgatum L., in Central Oklahoma. Ecology 1966, 47, 980–992. [Google Scholar] [CrossRef]
- Hall, S.A. Modern Pollen Influx in Tallgrass and Shortgrass Prairies, Southern Great Plains, USA. Grana 1994, 33, 321–326. [Google Scholar] [CrossRef][Green Version]
- Moncada, K.M.; Ehlke, N.J.; Muehlbauer, G.J.; Sheaffer, C.C.; Wyse, D.L.; DeHaan, L.R. Genetic variation in three native plant species across the state of Minnesota. Crop Sci. 2007, 47, 2379–2389. [Google Scholar] [CrossRef]
- Aspinwall, M.J.; Lowry, D.B.; Taylor, S.H.; Juenger, T.E.; Hawkes, C.V.; Johnson, M.V.V.; Kiniry, J.R.; Fay, P.A. Genotypic variation in traits linked to climate and aboveground productivity in a widespread C4grass: Evidence for a functional trait syndrome. New Phytol. 2013, 199, 966–980. [Google Scholar] [CrossRef] [PubMed]
- Hoyt, C.A. Pollen signatures of the arid to humid grasslands of North America. J. Biogeogr. 2000, 27, 687–696. [Google Scholar] [CrossRef]
- Borchert, J.R. The Climate of the Central North American Grassland. Ann. Assoc. Am. Geogr. 1950, 40, 1–39. [Google Scholar] [CrossRef]
- Cathey, H.M. USDA Plant Hardiness Zone Map; USDA-ARS Misc. Pub.: Annapolis, MD, USA, 1990. [Google Scholar] [CrossRef]
- Bailey, R.G. Identifying ecoregion boundaries. Environ. Manag. 2004, 34, S14–S26. [Google Scholar] [CrossRef]



| DF † | Sums of Squares | Mean Squares | Percentage of Variance Component | ||
|---|---|---|---|---|---|
| Model 1 | Ploidy levels | 2 | 4325 | 2162 **,‡ | 2.8 |
| Populations/ploidy level | 93 | 101,614 | 1093 ** | 32.9 | |
| Samples/populations/ploidy level | 91 | 49,761 | 547 *** | 64.3 | |
| Model 2 | Demes | 1 | 16,886 | 16,886 * | 14.3 |
| Ploidy levels/demes | 3 | 7073 | 2358 ** | 4.6 | |
| Populations/Ploidy levels/demes | 91 | 143,274 | 1574 ** | 81.1 |
| N | Ho | He | Ht | Fis | Fst | |
|---|---|---|---|---|---|---|
| Overall | 96 | 0.27 | 0.22 | 0.24 | −0.212 | 0.050 |
| East deme | 61 | 0.21 | 0.19 | 0.20 | −0.133 | 0.045 |
| West deme | 35 | 0.35 | 0.26 | 0.27 | −0.369 | 0.053 |
| Between two demes | 0.079 |
| Canonical Axes | Canonical Correlation (r) | Variance Explained (%) | F Value | p Value (Prob > F) |
|---|---|---|---|---|
| I | 0.92 | 37.8 | 3.5 | <0.001 |
| II | 0.87 | 21 | 2.8 | <0.001 |
| III | 0.83 | 14.7 | 2.3 | <0.001 |
| IV | 0.78 | 10.9 | 1.9 | <0.001 |
| V | 0.71 | 6.9 | 1.4 | <0.01 |
| VI | 0.57 | 3.4 | 1.1 | <0.33 |
| (I) | (II) | (III) | |
|---|---|---|---|
| Genetic | |||
| PCOA1 | −0.123 | 0.618 | −0.032 |
| PCOA2 | −0.178 | 0.578 | −0.297 |
| PCOA3 | 0.947 | 0.147 | −0.143 |
| PCOA4 | −0.07 | 0.304 | 0.123 |
| PCOA5 | −0.193 | −0.141 | −0.358 |
| PCOA6 | −0.057 | −0.01 | −0.171 |
| PCOA7 | 0.057 | −0.035 | −0.521 |
| PCOA8 | 0.08 | 0.287 | 0.548 |
| PCOA9 | −0.016 | −0.031 | −0.297 |
| PCOA10 | −0.044 | −0.256 | 0.241 |
| Environmental/Geographical † | |||
| LAT | 0.166 | −0.183 | −0.601 |
| LONG | 0.805 | −0.419 | −0.057 |
| ALT | −0.421 | 0.483 | 0.135 |
| MAT | −0.058 | 0.192 | 0.604 |
| MAP | 0.394 | −0.291 | 0.179 |
| SDAT | −0.417 | −0.017 | −0.499 |
| SDAP | 0.252 | 0.231 | 0.135 |
| MTWM | −0.26 | 0.426 | 0.545 |
| MTCM | 0.154 | 0.195 | 0.608 |
| MPWM | −0.052 | 0.096 | −0.094 |
| MPDM | 0.601 | −0.463 | 0.233 |
| MTSP | 0.042 | 0.186 | 0.592 |
| MTSU | −0.337 | 0.164 | 0.561 |
| MTAU | −0.207 | 0.327 | 0.588 |
| MTWI | 0.127 | 0.112 | 0.591 |
| MPSP | 0.549 | −0.323 | 0.222 |
| MPSU | 0.158 | −0.063 | 0.197 |
| MPAU | −0.06 | −0.108 | −0.085 |
| MPWI | 0.617 | −0.384 | 0.198 |
| EF | 0.181 | 0.496 | −0.178 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, J.; Brown, P.J.; Rayburn, A.L.; Butts-Wilmsmeyer, C.J.; Boe, A.; Lee, D. Genomic Variation Shaped by Environmental and Geographical Factors in Prairie Cordgrass Natural Populations Collected across Its Native Range in the USA. Genes 2021, 12, 1240. https://doi.org/10.3390/genes12081240
Guo J, Brown PJ, Rayburn AL, Butts-Wilmsmeyer CJ, Boe A, Lee D. Genomic Variation Shaped by Environmental and Geographical Factors in Prairie Cordgrass Natural Populations Collected across Its Native Range in the USA. Genes. 2021; 12(8):1240. https://doi.org/10.3390/genes12081240
Chicago/Turabian StyleGuo, Jia, Patrick J. Brown, Albert L. Rayburn, Carolyn J. Butts-Wilmsmeyer, Arvid Boe, and DoKyoung Lee. 2021. "Genomic Variation Shaped by Environmental and Geographical Factors in Prairie Cordgrass Natural Populations Collected across Its Native Range in the USA" Genes 12, no. 8: 1240. https://doi.org/10.3390/genes12081240
APA StyleGuo, J., Brown, P. J., Rayburn, A. L., Butts-Wilmsmeyer, C. J., Boe, A., & Lee, D. (2021). Genomic Variation Shaped by Environmental and Geographical Factors in Prairie Cordgrass Natural Populations Collected across Its Native Range in the USA. Genes, 12(8), 1240. https://doi.org/10.3390/genes12081240