1. Introduction
Accurate and exhaustive annotation of human gene variants is important for every application of NGS technology, including development of therapies, selection of an effective individualized therapy, and comparing multiple samples in biological/clinical studies. Currently, according to Genetests [
1], more than 68,000 genetic tests are offered in clinics, resulting in an equally large and rapidly growing amount of experimentally sequenced data that requires analysis and interpretation. Among the many types of annotations that can be assigned to each sequenced NGS variant, of particular interest are those predicting if a variant has a benign or deleterious phenotypic effect. However, causative relationships between genes and phenotypes are very complex, depending on many connections and influences, and there are major challenges in obtaining the associations [
2]. In the following paragraphs, we briefly overview the state-of-the-art approaches in annotating with phenotypic effects, focusing mostly on an array of predicted pathogenicity scores, and on population allele frequencies, as it is also very popular for estimation of pathogenicity. We list their main limitations and describe an approach proposed in this work with an eye to solving those limitations, followed by a brief overview of the method’s results.
In total, almost 100 million single nucleotide variants (SNV) are possible in the human gene-coding ‘exome’ space, of which around 83 million are non-synonymous nsSNVs and around 15 million are short splice-site ssSNVs. About 6 million SNVs (or ~6% of total) have been annotated with alternative allele frequency (AAF), obtained through large population sequencing projects [
3] such as ExAC [
4] and gnomAD [
5]. The prime limitation of using AAF, apart from the known issue of strong population bias, is that in practice it is intrinsically difficult to choose where to assign a frequency threshold for discriminating between benign and pathogenic variants; the histogram of AAF values follows a very steep (γ) distribution, with 85% of all sequenced variants being singletons or ultra-rare. Applying a single threshold for all genes (e.g., 0.1%) does not achieve clear-cut separation. The recently-proposed approach [
6] of using a different threshold for each gene can partially alleviate this problem, but the sub-distributions in genes are of the same type as the combined distribution.
Another source of annotations is evidence on mutation effects from clinical and biological studies, but currently, the coverage of the variant space by such studies is very limited. For example, ClinVar [
7] annotations cover ca. 0.5% of the total possible variation. For the remaining majority, the best extant alternative is to use annotations from various variant effect prediction (VEP) tools.
The first group of VEP methods (e.g., GERP++, SiPhy, bStatistic) [
8] is based on nucleotide conservation in alignments of genetic sequences in mammalian species. It uses the statistical property of rare variants being typically less evolutionarily conserved and having higher predicted pathogenicity than frequent ones [
9]. The second group of VEP methods predicts the functional impact of mutations (e.g., MutationTaster, Eigen, fitCons) [
9]. A third group are approaches based on structural information from protein 3D structures (e.g., Polyphen, SuSPect, SNAP2) [
10]. A fourth group of ensemble methods (e.g., REVEL [
9], CADD [
11]) uses combinations of predictive scores of several types. Notably, the tools from the last group have shown better predictive performance than any from the first three groups [
12]. For example, in a study [
13] using The Cancer Genome Atlas (TCGA), a dataset comprised of 10,000 tumor samples across 33 cancer types, it was shown that improved prediction results were obtained by combining scores of all types, where the results were confirmed in 78% of cases by in vitro functional tests. When the methods in these four VEP groups are compared [
14], it seems the main limitation is that even for the best tools, errors of more than 10% are common [
15], which goes alongside low specificity in the range of 25–83% [
16,
17].
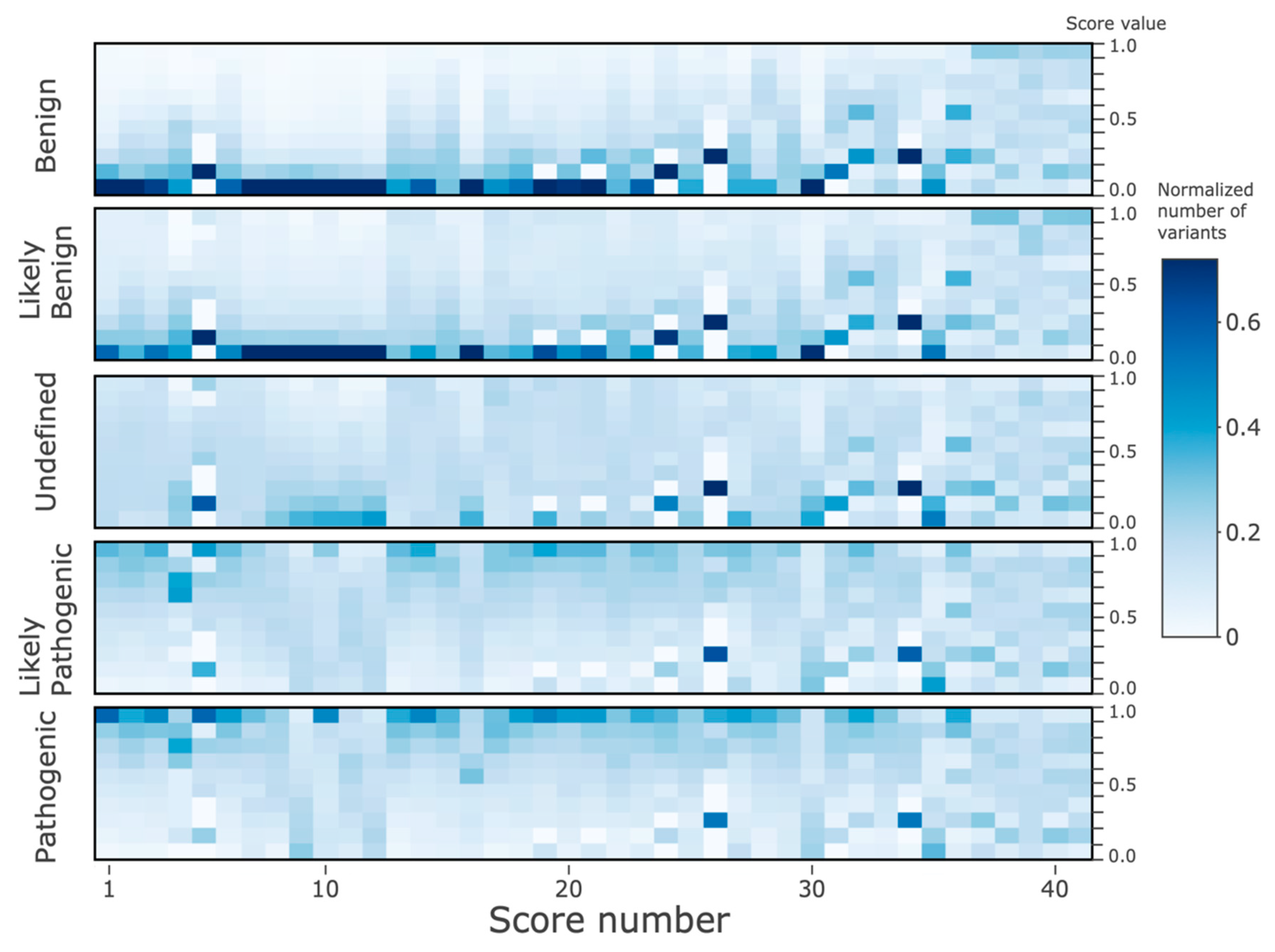
It is interesting to note that nearly all these methods provide for each variant a single continuous score value, which is usually converted to range from 0 (benign) to 1 (deleterious). A high-value continuous score for a variant implies a higher probability of it having a deleterious phenotypic effect; thus, such scores do not provide directly interpretable annotation, which is usually preferred for use in practice. Deriving a binary annotation from such score (i.e., to differentiate pathogenic or benign) requires applying a threshold in the range from 0 to 1 (e.g., 0.5). However, the common practice of using a single threshold for all genes is questionable, as the pathogenicity score values for both pathogenic and benign variants are typically very diffusely distributed over the whole 0–1 range, as can be seen e.g., in the results presented in this work. In reality, the situation is further complicated by the need to obtain thresholds for each individual gene [
6]; for example, variants in essential genes typically require a lower threshold compared to those in mutation-tolerant genes. To remedy this issue, we use in training here a gene indispensability score [
18] to account for differences due to highly varying degrees of gene mutation-tolerance or involvement in a number of protein-protein interactions or cellular networks [
18]. Another known limitation is that there is a very large degree of contradiction between them [
19], making it very difficult to derive a consensus annotation from a long list of scores for a variant—i.e., without using a very advanced computational technique, as is done here.
In contrast to the continuous scores produced by a large majority of existing methods, categorical classes such as ‘Pathogenic’, ‘Likely_benign’, or ‘Uncertain_significance’ are easier to interpret and can be used directly, i.e., without the need for any threshold determination. To the best of our knowledge, so far, no study has developed a method able to classify variants by categorical effect annotations across the entire coding genome and with sufficiently high accuracy.
The method of consensus variant effect prediction (or cVEP) proposed in this work attempts to obtain annotations of gene variants by determining a consensus of the 39 impact prediction scores compiled in dbNSFP [
20]. The inclusion of scores in the database by its authors was based on comparison of their performance in a competition involving a large number of scores in a series of test cases for predicting variant impacts for new data not yet included in the ClinVar database. Thus, this selection of scores is unbiased, merit-based, and represents the current state-of-the-art in the field. Although each of the scores are based on their own respective knowledge domains, such as cross-species sequence conservation or functional impact of mutations, there often exists considerable overlap between scores if any part of data they use for training is obtained from the same source. It is very difficult to determine degrees of overlap from the associated publications; however, novel machine learning algorithms can effectively address the problem of redundancy in training information, as well as other notorious problems such as over- and under-fitting of input data in models, or highly unbalanced datasets. For example, random forest (RF) algorithms such as distributed random forest (DRF) [
21], and gradient boosting machines (GBMs) [
22] are known to deal well with redundancy by being specially designed for related techniques, such as determining feature importance, which evaluates the degree of unique contribution from each score. The approach used here is a stacked ensemble of base-learners. Described simply: a Generalized Linear Model (GLM) determines which features are the most non-contradictory to the target of prediction; a GBM determines the largest unique and orthogonal contributions; and a DRF takes all contributions from features that are consistently in line with the target. Additionally, since there remains a lack of consensus regarding which method is best for predicting the effect annotation, we provide a ranking of the methods by their contribution to correct predictions.
A Stacked Ensemble of Supervised Learners (SESL) is a two-level machine learning algorithm that combines several prediction algorithms, or base-learners, using a process called stacking (also known as meta- or super-learning). Unlike bagging and boosting approaches, which are also used for combining base-learners, the goal in stacking is to combine a (preferably diverse) set of learners together. It has been shown [
23] that a super-learner ensemble represents an asymptotically optimal system for learning. Among stacking algorithms, super-learning is distinguished by the direct implementation of cross-validation and for tuning parameter selection in the algorithm. The method classified variants into five putative annotation categories: pathogenic, likely pathogenic, uncertain significance, likely benign, benign. This classification is in accordance with the standards and guidelines of the American College of Medical Genetics and Genomics (ACMG) and of the Association of Molecular Pathology (AMP) [
24]. The predicted class annotations are trained and cross-validated on multiple categories of ClinVar data, which are rather accurate, since the ACMG/AMP expanded guideline for inclusion requires each variant classification to have certainty of better than 90% from experimental clinical/biological evidence [
25].
To summarize the results of the study: first, we illustrate how variant class discrimination improves with increasing dimensions of input data. Then, we describe a meta-learning consensus method that combines a selection of the best-performing functional impact effects and sequence conservation and pathogenicity scores, along with one gene-level score. We then train and cross-validate the consensus ensemble meta-model on a dataset of known effect annotations derived from the ClinVar database. We provide rankings for the ability of these scores to make correct predictions, both individually and in combination, derived from feature importance in the base models. We apply the ensemble model to predict effect annotation classes for human exonic variants in all chromosomes. Finally, to demonstrate the potential of the method for use in applications, we provide data on applying it to several highly pathogenic genes.
2. Materials and Methods
2.1. Machine Learning Algorithm
To perform SESL we use the H2O tool [
26], which is an open source, in-memory, distributed, fast, scalable machine learning and predictive analytics tool that allows users to build machine learning models for big data analysis, implemented as a package in the statistical environment R. The ‘meta-learning’ algorithm, implemented here using the
h2o.stackedEnsemble function of the H2O tool (version 3.0), finds an optimal combination of the following three base learners: generalized linear model (GLM) [
27], gradient boosting machine (GBM) [
22], and distributed random forest (DRF) [
21].
The popular GLM method is a well-known generalization of linear regression for response variables. More recently developed DRF and GBM methods both build collections of decision trees. A decision tree captures interactions among different features, with the interactions order controlled by a tree depth parameter–higher order for higher depths. There are significant differences in these algorithms: briefly, DRF averages multiple decision trees, created on different random samples of rows and columns; GBM builds the model in a stage-wise fashion. The algorithms are non-linear, robust for noisy data, and provide importance of each predictor in the models. Here, the base-models use ‘multinomial’ distribution for class prediction; the types of distributions used for continuous combination are given in
Supplementary Materials.
The key parameters (
max_depth,
ntrees,
max_after_balance_size,
learn_rate/sample_rate,
min_rows) for DRF, GBM, and GLM were chosen using the grid search in the parameter space to produce fits with the lowest logarithmic score and with its achieved stability in the five-fold cross-validations. The logarithmic score [
28] method is connected to Shannon entropy and Kullback–Leibler divergence, denoted by the term
logloss (Equation (1)) in H2O documentation. It measures the performance of a multinomial classification model during minimization.
Logloss for a perfect model would be equal to 0, and it increases as the predicted probability diverges from the actual label. For the multi-class classification, the sum of
logloss values for each class prediction in the observation is taken:
where
yc,o is a binary indicator (0 or 1) of whether class label
c is the correct classification for observation
o;
pc,o—the model’s predicted probability that observation
o is of class
c.
Since there were a different number of points for each class, the learning was performed with balancing classes. The meta-learner used GLM with nonnegative weights. When the algorithms were learning categorical values, instead of the R2, the McFadden’s pseudo R-squared, or likelihood-ratio index, was used. It is a statistical measure of closeness of the predicted and input data are in the fits. The log likelihood of the intercept model is treated as a total sum of squares, and the log likelihood of the full model is treated as the sum of squared errors. The ratio of the likelihoods scaled to 0–1 range gives the level of improvement offered by the full model over the intercept model. When comparing two models, McFadden’s ratio is higher for the model with the greater likelihood.
2.2. Datasets
The gnomAD [
5] dataset extends the ExAC [
4] dataset from 60,706 to 125,748 unrelated individuals of a diverse set of ethnicities, including European, African, Latino, South Asian, East Asian. It contains allele frequencies of the sequenced genetic (mostly exome) variants. ClinVar [
7] is a public archive of the relationships of human variations and phenotypes, with supporting evidence. Its interpretations of the clinical significance of germline and somatic variants for reported conditions are based on “ground-truth”-clinical and biological evidence. The archive located at the National Center for Biotechnology Information (NCBI) is maintained according to standards and guidelines of the American College of Medical Genetic and Genomics (ACMG) and the Association for Molecular Pathology (AMP) [
25]. Here, the ‘ClinVar dataset’ is the subset of the gnomAD dataset of 227,232 nsSNVs having non-empty ClinVar annotations. The dbNSFP [
20] is a database integrating annotations from multiple sources, including allele frequencies from ExAC, gnomAD, clinical annotations from ClinVar, and functional and conservation annotations [
20]. Its current academic version (“a”-branch) compiled prediction scores for 84,013,490 non-synonymous SNVs (nsSNVs), from 29 functional prediction algorithms (
SIFT,
SIFT4G,
Polyphen2-HDIV,
Polyphen2-HVAR,
LRT,
MutationTaster2,
MutationAssessor,
FATHMM,
MetaSVM,
MetaLR,
CADD,
VEST4,
PROVEAN,
FATHMM-MKL coding,
FATHMM-XF coding,
fitCons,
LINSIGHT,
DANN,
GenoCanyon,
Eigen,
Eigen-PC,
M-CAP,
REVEL,
MutPred,
MVP,
MPC,
PrimateAI,
GEOGEN2,
ALoFT), 9 conservation scores (
bStatistic,
phyloP100way_vertebrate,
phyloP30way_mammal,
phyloP17way_primate,
phastCons100way_vertebrate,
phastCons30way_mammal,
phastCons17way_primate,
GERP++ and SiPhy) and other annotations (
Table S1).
Each of the curated training, prediction, and validation datasets contained the following annotations from the dbNSFP4.0 [
20]: 39 functional annotation scores (
Table 1, the sources are listed in
Table S1); the gene-level
Gene_indispensability score, a probability prediction of whether the gene is essential (from 0 to 1) [
18]; and two pairs of AAF fields for the exome and control samples:
gnomAD_exomes_AF of all exome samples (125,748 samples);
gnomAD_exomes_POPMAX_AF is the maximum across populations;
gnomAD_exomes_controls_AF is for the ‘controls’ subset (54,704 samples;
gnomAD_exomes_controls_POPMAX_AF is the maximum in the ‘controls’ subset.
The
Gene_indispensability score was included due to its adding a significant improvement in predictive performance, particularly for rare variants and VUSs. It is well known that a moderately deleterious variant in a non-essential gene can often exhibit itself as non-pathogenic, as e.g., such can be located in a mutation-tolerant gene, or in a truncated dis-functional gene having a duplicate functional gene; whereas such a variant in an essential gene is usually very pathogenic, since such genes are involved in several cellular networks, leading to a major cell function disruption. The original model [
18] derives an ‘
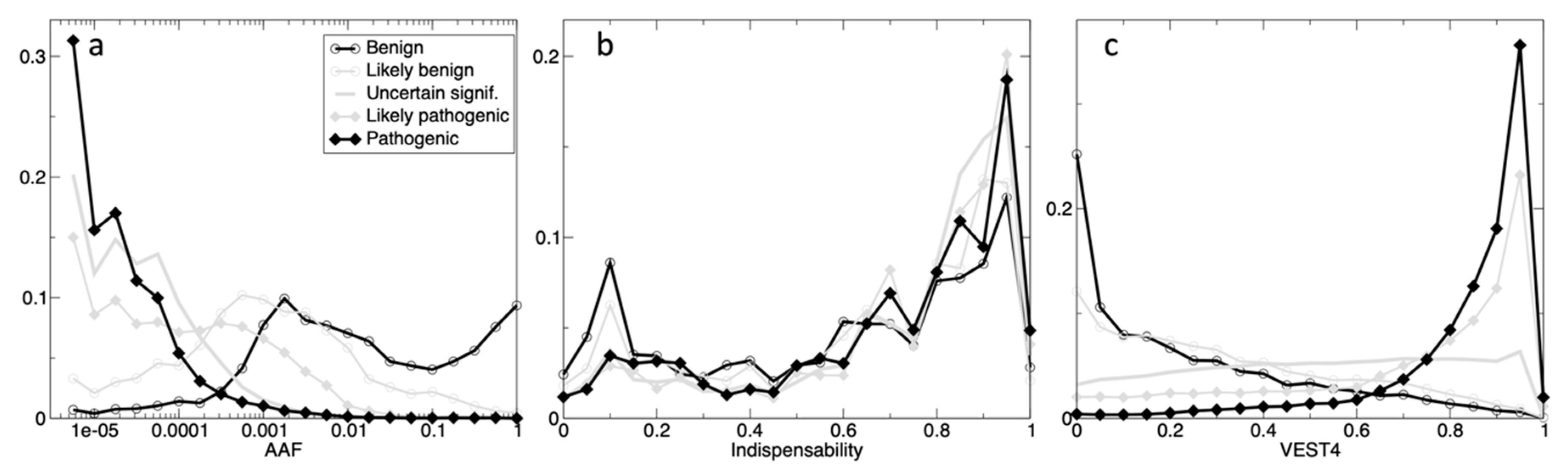
Indispensability’ score from the degree-centralities and other characteristics in a ‘multinet’ of the networks: protein-protein interactions (PPI), phosphorylation, signaling, metabolic, genetic, regulatory, essentiality, LoF-tolerance, number of PPI interfaces, dN/dS ratios, paralogs, etc. The score value is higher e.g., for variants in oncogenes and tumor suppressors, while it is near 0 in duplicated and mutation-tolerant genes.
2.3. Training, Prediction, and Validation Procedures
The 40 scores (
Table 1) and the indispensability were derived from the dbNSFP. Since the
LINSIGHT (x31) score was missing for most of the gnomAD variants, it was replaced with a ‘Mean’ of 39 scores available for each variant (excl. indispensability).
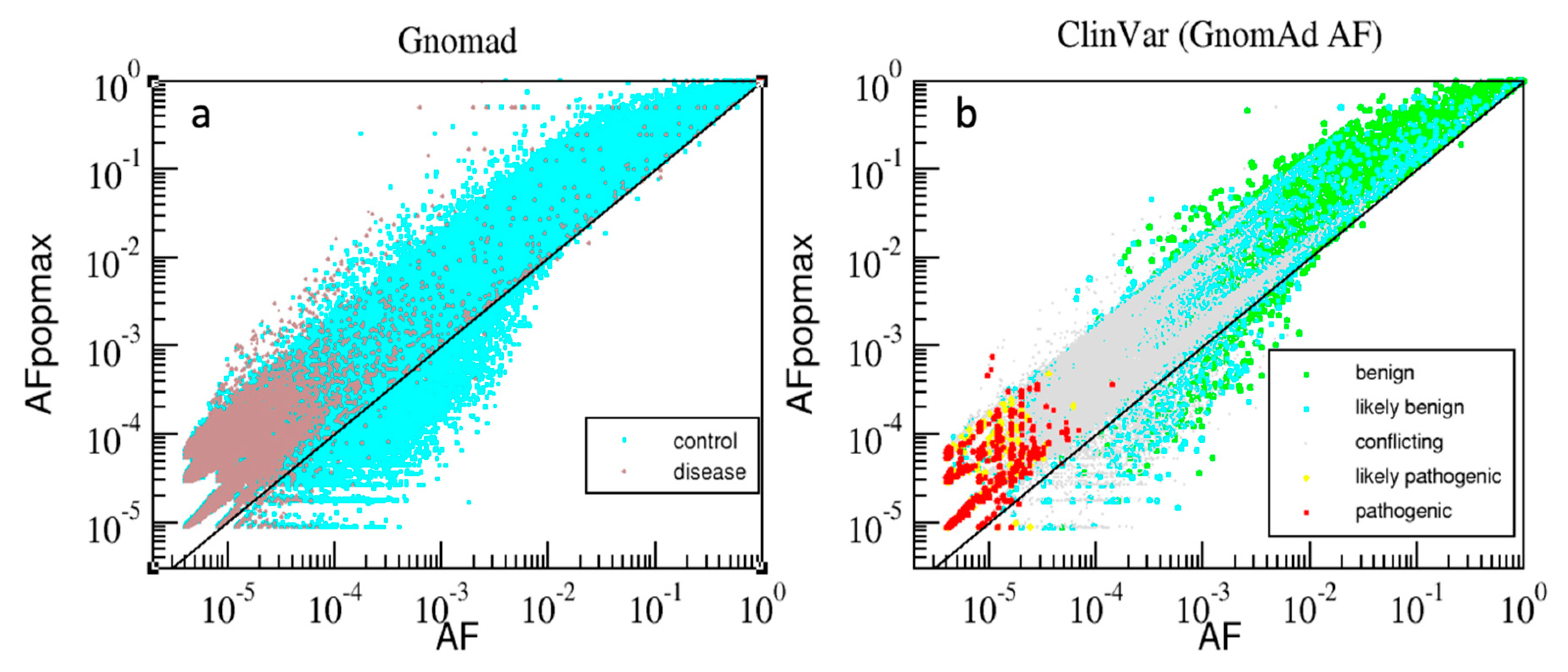
The combined “gnomAD-AAF” dataset consisted of 5,502,403 variants having gnomAD_exome_AF annotations. This dataset was further subdivided into ‘Control’, with non-zero gnomAD_exome_control_AF annotations (3,451,486 variants for 54,704 samples from individuals not associated with any disease), and ‘Disease’, which included the remaining 2,050,917 variants (i.e., annotated with gnomAD_exome_AF but not with gnomAD_exome_control_AF). There were two AAF versions used: gnomAD_exome_AF and gnomAD_exome_AFpopmax.
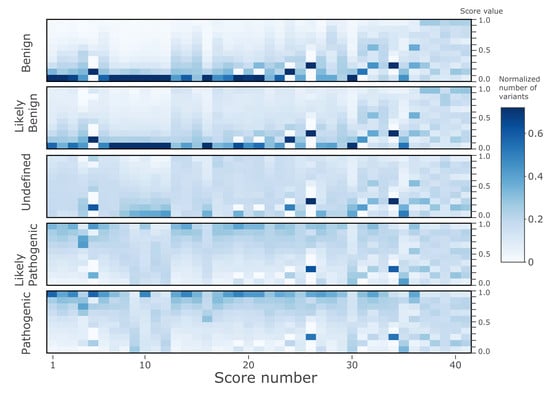
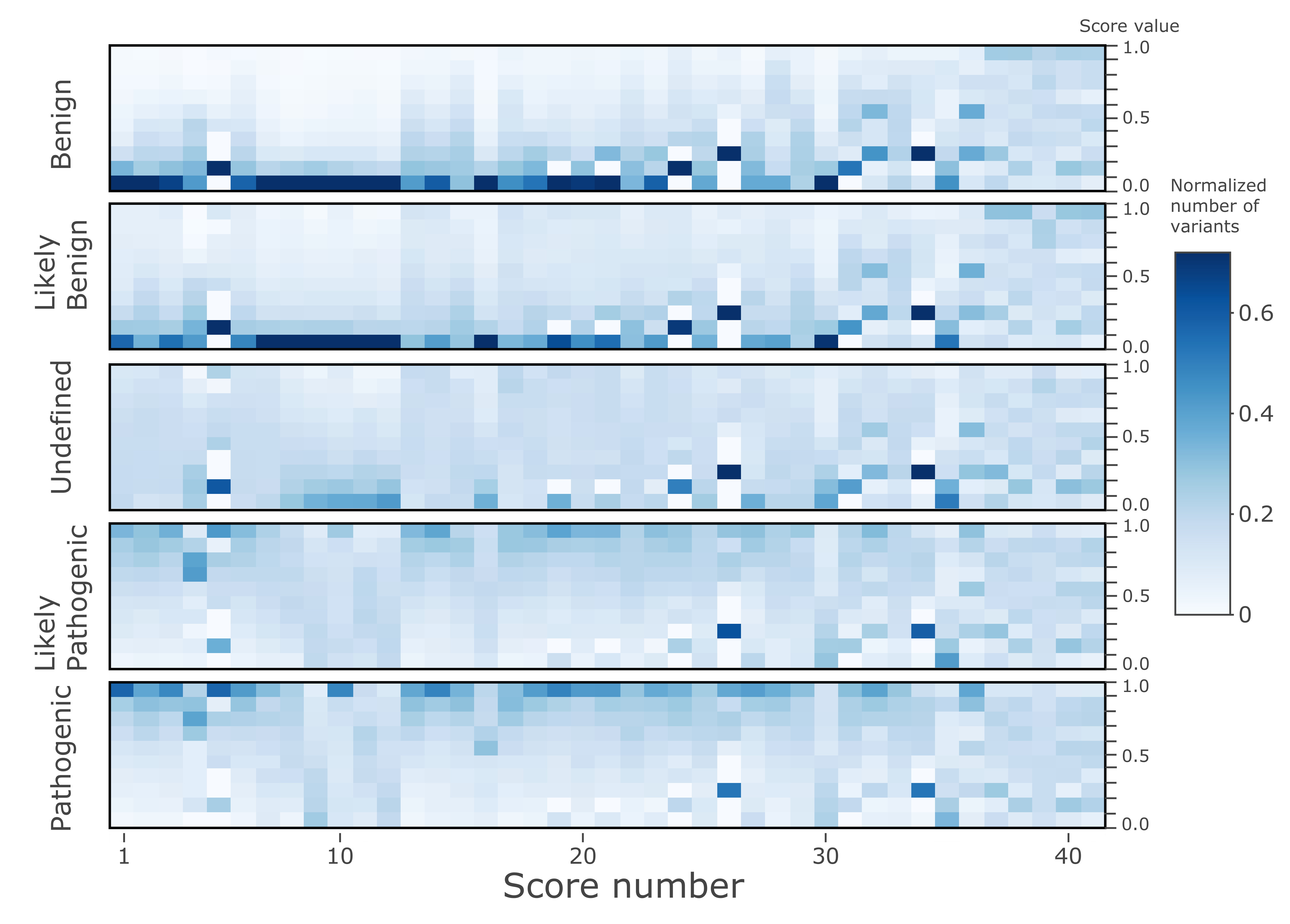
All nsSNV variants listed in the dbNSFP4.0 were classified into the categories by the ClinVar annotations. The ‘training’ (and cross-validation) dataset comprised the variants with ClinVar annotations (133,514 variants) across five classes: ‘Benign’ (35,659 variants, denoted by “2” label in calculations), ‘Likely_benign’ (21,931 variants, labelled as “1”), ‘Uncertain_significance’ (18,716 variants, labelled as “0”), ‘Likely_pathogenic’ (21,510 variants, labelled as “−1”), and ‘Pathogenic’ (35,698 variants, labelled as “−2”). Note that to improve the imbalance between the classes the original ClinVar categories Benign/Likely_benign and Likely_benign were merged into the ‘Likely_benign’ class, and similarly, ClinVar’s Pathogenic/Likely_pathogenic and Likely_pathogenic were merged into the ‘Likely_pathogenic’ class; the ‘Uncertain_significance’ class was down-sampled seven times randomly.
After training of the models of the ‘training’ dataset, cVEP classes were extended to the ‘prediction’ dataset, comprised of all remaining nsSNVs contained in the dbNSFP4.0, i.e., 84,013,490 human nsSNVs in the human coding genome split by the chromosome regions. The resulting output database is provided (link below). In addition, the results illustrate the dependence of the cVEP classifications on the indispensability, and differences in individual genes of two pathogenic types.
4. Discussion
The main advantage of the proposed approach is of a practical computational nature. We do not suggest replacing the plethora of existing scores in favor of one new score. On the contrary, we suggested above the use of a combination of several top-ranking scores, which were shown to have the highest predictive capacity. Nonetheless, the advantage of using a consensus score becomes very clear when attempting to sort a list of sequenced WES variants by several pathogenicity scores. When sorting separately by several scores in a sequence of steps, and applying a realistic threshold (e.g., 0.5) for filtering on each step, usually all variants become completely filtered out after several steps. Here we overcome this challenge and provide a means of ‘sorting’ any subset of variants (and without using any thresholds), because the consensus score has incorporated contributions from all used scores. To give quantitative references: in the consensus approach, since the correlations between the target annotations and each individual score are in the 75–82% range (
Table 2), and since the cVEP predictions have 98% match with the target, the resulting annotations are in line with the input scores to the nearly same degree as the targets (i.e., 73–80% correlation). The method minimized the prediction errors of each input feature, thus producing for the consensus several times smaller error values, i.e., smaller false-positive (FP) and false-negative (FN) rates. The quantitative comparison of the recent methods given here [
15] allows directly comparing the FP/FN-rates of other methods with the cVEP rates obtained here, since many of them (with the exception of REVEL, which is trained on a dataset containing many new rare variants [
9]) are also trained on the ClinVar dataset. This study [
15] cited FP rates in the 10–40% range for several very popular scores (VEST3, metaLR, metaSVM, M-CAP, fathm-MKL, Eigen, GenoCanyon, REVEL); in contrast, 2% FP error was observed for the cVEP 2-class classification, which is much smaller. The improvement in error is achieved by using the super-learning two-level method with base-learners having different depths, and by taking into account the importance and redundancy of each score’s contribution to the target prediction.
Another novelty here is that the method finds a consensus of all continuous value scores in the form of a categorical value, which is compatible with the ACMG/AMP standards and guidelines for use in clinical practice. This categorical classification has the advantage of allowing its direct use in WES applications for performing one-score ranking of variants without any thresholds. Such an approach was proposed long ago by researchers in this field, but the present paper makes a meaningful step towards implementing it for the first time. This categorization is a definite improvement, allowing for more than just binary (pathogenic, benign) classifications and including ‘likely’ and ‘uncertain’ classes, thereby addressing biological complexities somewhat better.
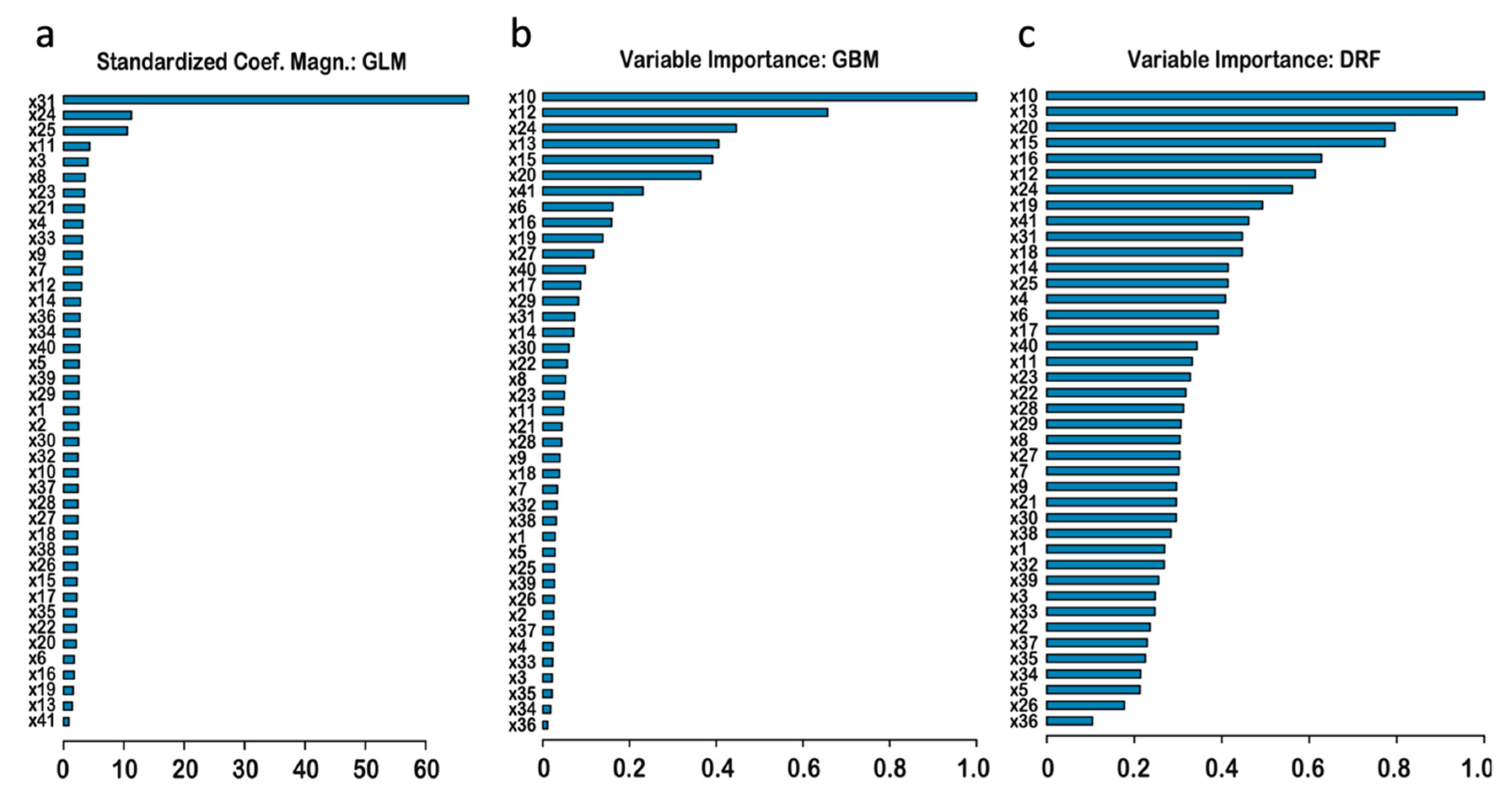
A novel gene indispensability score was included in the predictors for several important reasons. On the one hand, there are a considerable number of potentially deleterious variants (i.e., those having high values for their continuous pathogenicity scores) located in mutation-tolerant genes. Such variants that also have high population allele frequencies could be assumed neutral based on that measure alone, and, consequently, could be associated with no negative effects in cells; as a result, they could be grouped into the ‘
Benign’ class in the ClinVar database. On the other hand, moderately deleterious variants (i.e., those having medium-level pathogenicity scores) in essential genes can be potentially associated with very adverse effects in cells, and thus included in the ‘
Pathogenic’ ClinVar class. A relatively large number of such cases could be a major source of error when training an algorithm based on pathogenicity scores alone. However, here such effects are partially accounted for by the indispensability score, and it is not surprising that this score contributed significantly to the improvement in accuracy; when ranking features by importance, that score (x41) was listed in the top ten. The addition of the indispensability has reduced the total amount of classification errors more than five-fold (
Table S5): from an initial ca. 10% (without
Indispensability) to the current ca. 2%. Similarly, this work obtained feature rankings by importance for the first time, which can be used as a guide when selecting scores for variant filtering.
To list limitations of the approach, first of all, it would clearly be preferable to use annotations based on actual clinical or experimental evidence from in vitro or in vivo test results to determine variant effects instead of any prediction method. However, such data are currently unavailable for more than 99% of all potential nsSNVs. This situation is very likely to improve in the future; for example, it might become possible to obtain direct measures of pathogenicity using high-throughput in vitro cell screening assays of synthetic mutations, e.g., using the CRISPR approach [
29], leading to a rapid increase in the percentage of evidence annotations. However, there are some types of variants, such as null mutations, that appear to be too pathogenic to exist in a living cell or whose effects might remain below the screen’s detectability level.
Secondly, it is important to note that as with other similar tools, this method cannot replace methods that are currently mainstream for distinguishing pathogenic somatic variants from germline ones, e.g., using sequence data from family trios, or from direct evidence on variant-disease association, or information on genomic structure.
Thirdly, it is important to note the limitation of using ClinVar annotations for training. In GWAS studies, when a causal and common connection between clinical phenotype and genotype is derived initially from a small cohort, the results frequently become invalid or are contradicted when more data is added from new studies, leading to these contradictory annotations subsequently becoming reclassified in ClinVar [Song 2016]. The current state of the continuous classification process can be seen in the (re)distribution of the classes of ClinVar annotations, including undefined or contradictory interpretations. Nonetheless, since the ACMG/AMP expanded guidelines require certainty of better than 90% from experimental clinical/biological evidence (the remaining <10% may be (re)classified as contradictory or uncertain), the large majority of the resulting database is not contradictory. In fact, it is well-established that the pathogenic/benign/likely status annotations derived from evidence-based data submitted to ClinVar are very useful for variant filtering and ranking. In this work, we ‘propagate’ using machine-learning techniques, the knowledge from known variant impacts into the unknown, thus covering all variants with predicted annotations.
Fourthly, annotation with pathogenicity is just one biologically-relevant dimension; others include the connections and associations of a variant to diverse phenotypes and diseases, and annotations like population allele frequency. Interpretation of variant impact is afflicted by multiple levels of complexity due to diverse direct and indirect influences on the effects of a mutation, to the interconnectedness of cell processes in an organism, and to the accumulation of multiple effects during the life of an organism or over the long course of evolution. However, such complex topics are mostly beyond the scope of this work. Nonetheless, we partially explored here the evolutionary connection between three characteristics of a gene variant: allele frequency, mammalian family conservation, and pathogenicity effects. It is undeniable that pathogenic variants are less conserved in families and less frequent in genetic sequences, while beneficial and benign mutations are more prevalent in populations.
Finally, new evidence and bioinformatic databases continuously appear that address the question of variant impact from new and different angles; perhaps, the future will bring more direct and more effective approaches. In this study, we focused only on the scores that are explicitly termed ‘pathogenicity prediction’ and on non-synonymous exome SNPs. Adding gain/loss-of-function (GOF/LOF) annotation might improve computational interpretation of variant effects. Similar to nsSNV mutations, GOF/LOF for a variant is not directly causative of pathogenicity, as these can lead to all types of impacts—making effects by such mutations genes more or less pathogenic, or neutral. Currently, GOF/LOF annotation remains challenging or incomplete; it remains to be seen whether it will be possible to add these scores to the combination, and whether doing so will provide improvement of accuracy, or if such scores should only be used separately. Although our approach is extensible to adding short slice-site exome mutations, regulatory and other variants in non-coding areas, but such future work would require a different set of input scores, and, possibly, a different approach, e.g., doing it in groups by diseases or traits. One such example of non-coding variant annotation methods, DIVAN [
30] is an ensemble learning framework with feature selection. It is able to identify non-coding disease-specific risk variants using thousands of epigenomic annotations, such as histone marks. It evaluates and annotates variants with respect to 45 different diseases/traits.
Although the results of this work are immediately useful, we suggest treating this attempt to classify all variants as exploratory, and to use the predictions with a degree of caution similar as for other predictive scores. The cVEP labels should be considered putative and treated as predictions only, which should not to be confused with the annotations based on actual evidence from clinical and biological data, such as in ClinVar database. In contrast to the pathogenicity scores, produced by a number of other predictive tools in the form of a continuous value ranging from 0 to 1 (e.g., 0.65), we produced the consensus predictions as five multinomial classes corresponding to the respective ClinVar labels. This is done to facilitate for the reader interpretation of the results in this work, but we did not intend to claim that we produced evidence level annotations. All told, with the advantages of the approach summarized below, the predictions might be especially useful for the large number of ultra-rare and singleton germline or rare somatic variants, which have no AAF or biological/clinical evidence due to their rarity.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}