Sequence Composition Underlying Centromeric and Heterochromatic Genome Compartments of the Pacific Oyster Crassostrea gigas


 , , ,
, , ,  and
and 
Abstract
1. Introduction
2. Materials and Methods
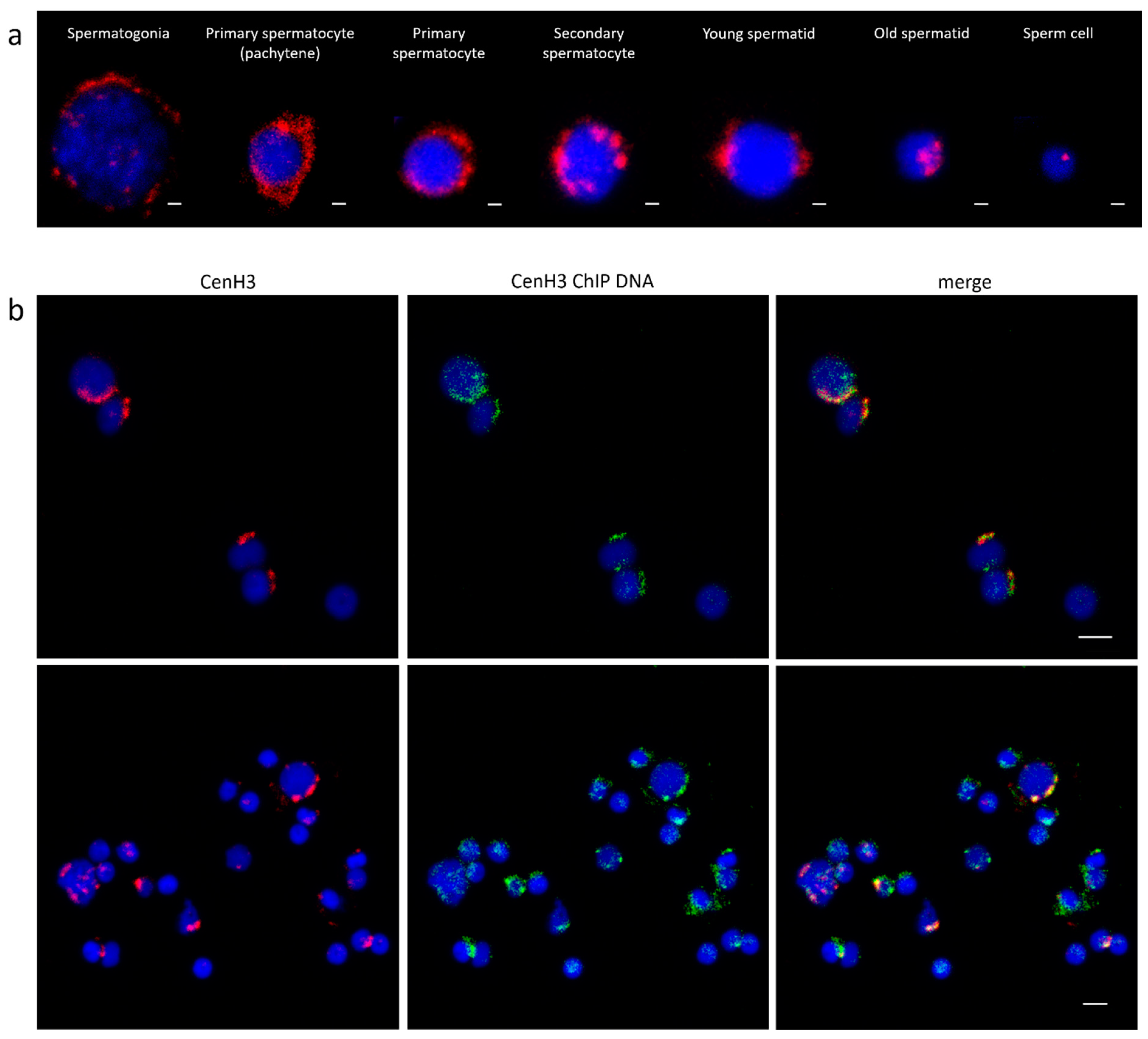
2.1. Cg-CenH3 Gene Detection and Antibody Synthesis
2.2. DNA Barcoding
2.3. Native Chromatin Isolation and Micrococcal Nuclease Digestion
2.4. ChIP Experiments
2.5. Sequencing, Read Clustering, and ChIP-Seq Data Analysis
2.6. Mitotic Chromosomes and Gonadal Suspension Preparations
2.7. Probe Labelling
2.8. Fluorescent In Situ Hybridization (FISH)
2.9. Immunofluorescence (IF)
2.10. IF-FISH
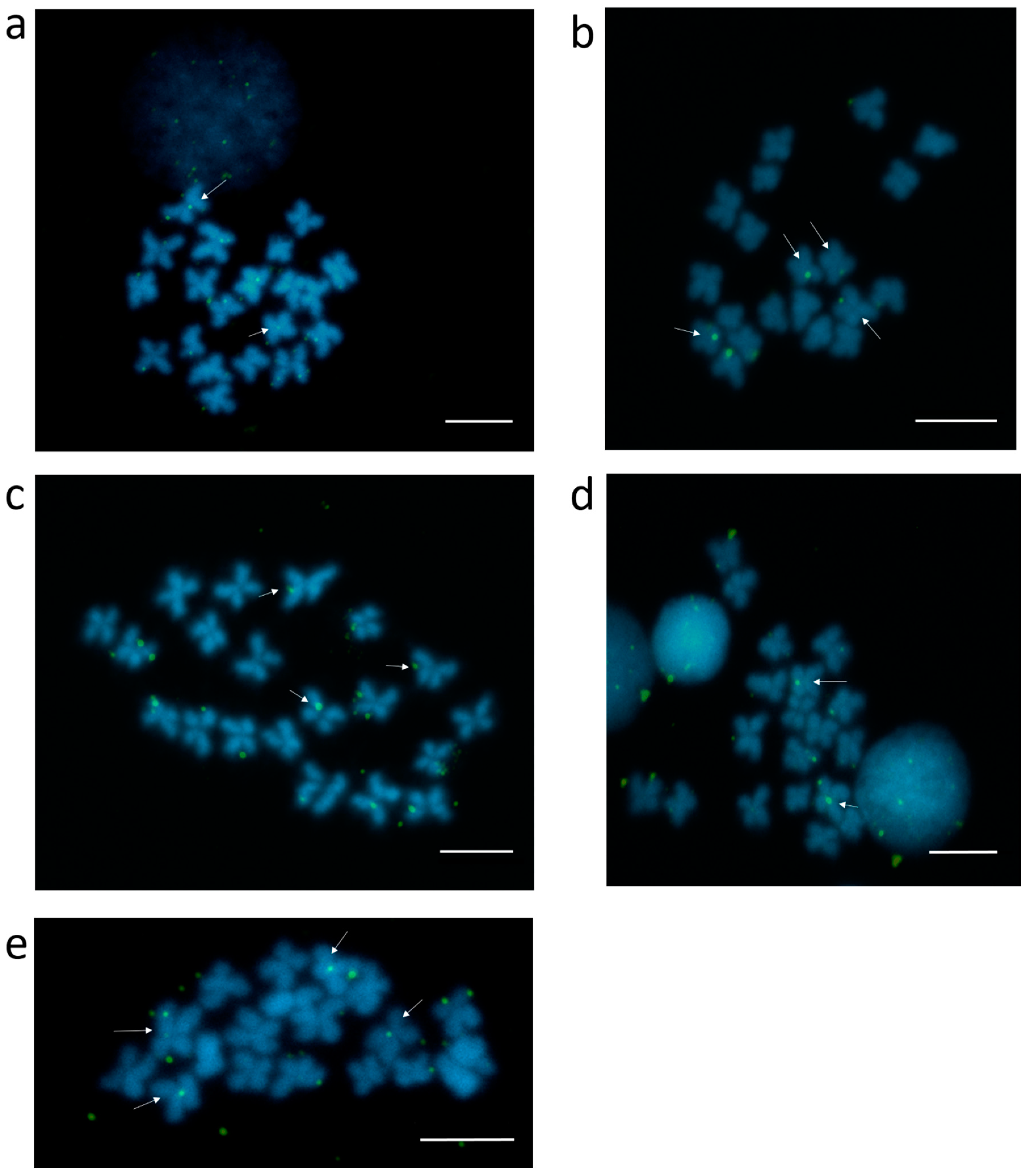
2.11. Localization of Cg170 on Pseudochromosomes
3. Results
3.1. DNA Repeat Content of the C. gigas Genome
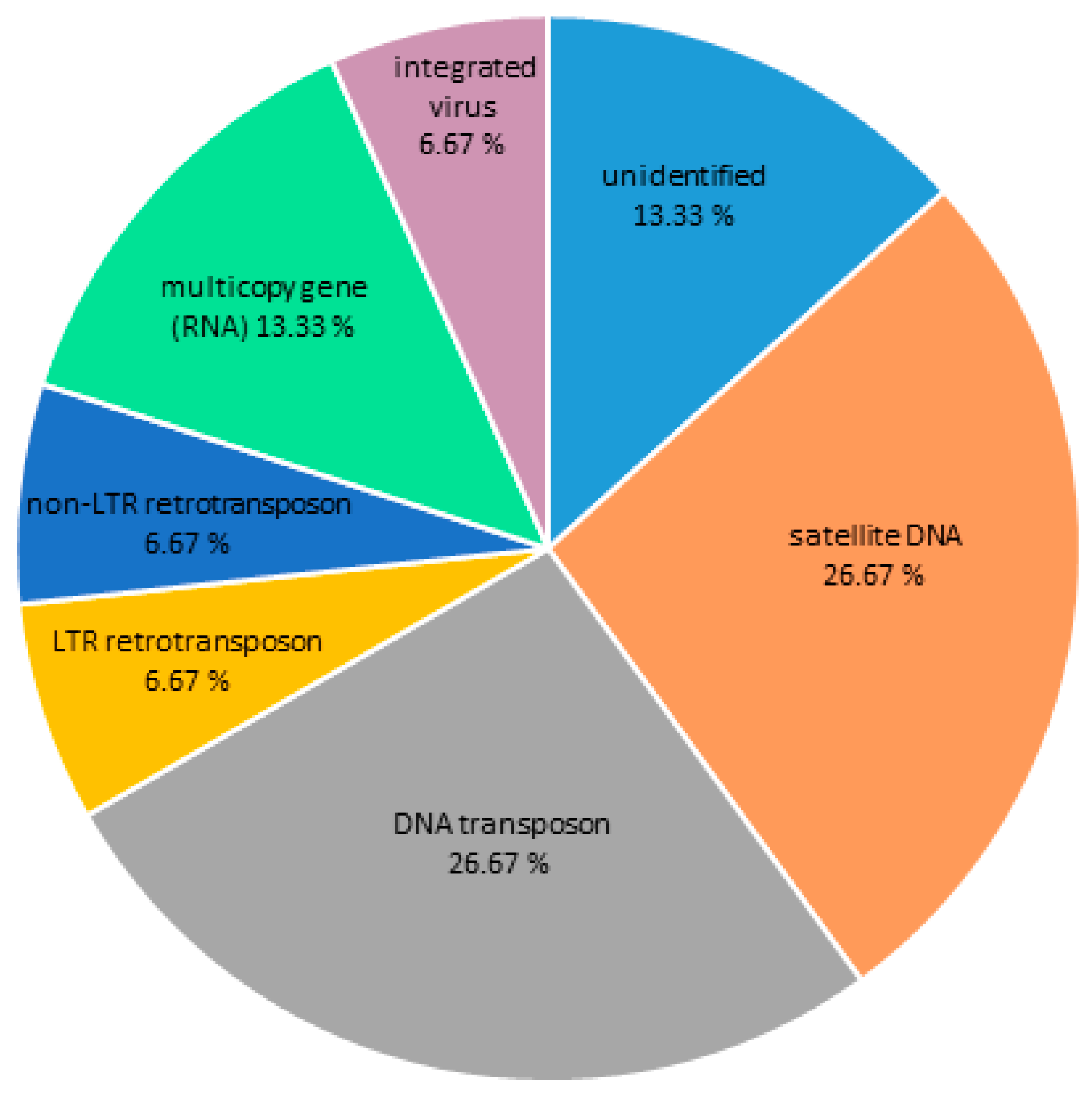
3.2. Centromeric Sequences of C. gigas
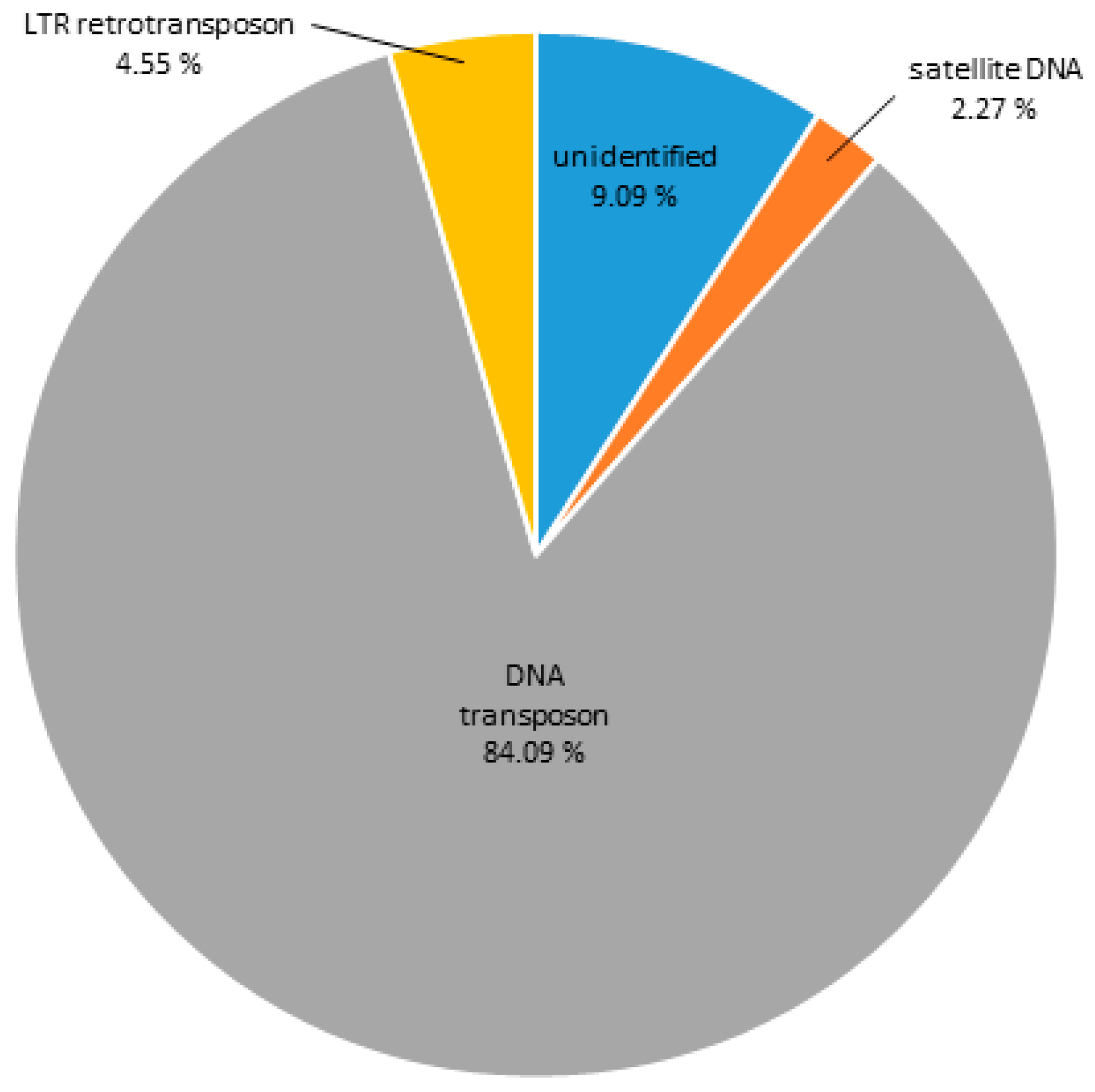
3.3. Heterochromatic Sequences of C. gigas
4. Discussion
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Vaughn, C.C.; Hoellein, T.J. Bivalve Impacts in Freshwater and Marine Ecosystems. Annu. Rev. Ecol. Evol. Syst. 2018, 49, 183–208. [Google Scholar] [CrossRef]
- Zhang, G.; Fang, X.; Guo, X.; Li, L.; Luo, R.; Xu, F.; Yang, P.; Zhang, L.; Wang, X.; Qi, H.; et al. The Oyster Genome Reveals Stress Adaptation and Complexity of Shell Formation. Nature 2012, 490, 49–54. [Google Scholar] [CrossRef] [PubMed]
- Plohl, M.; Meštrović, N.; Mravinac, B. Centromere Identity from the DNA Point of View. Chromosoma 2014, 123, 313–325. [Google Scholar] [CrossRef] [PubMed]
- McKinley, K.L.; Cheeseman, I.M. The Molecular Basis for Centromere Identity and Function. Nat. Rev. Mol. Cell Biol. 2016, 17, 16–29. [Google Scholar] [CrossRef] [PubMed]
- Malik, H.S.; Henikoff, S. Major Evolutionary Transitions in Centromere Complexity. Cell 2009, 138, 1067–1082. [Google Scholar] [CrossRef] [PubMed]
- Jiang, J.; Birchler, J.A.; Parrott, W.A.; Dawe, R.K. A Molecular View of Plant Centromeres. Trends Plant Sci. 2003, 8, 570–575. [Google Scholar] [CrossRef]
- Šatović, E.; Vojvoda Zeljko, T.; Plohl, M. Characteristics and Evolution of Satellite DNA Sequences in Bivalve Mollusks. Eur. Zool. J. 2018, 85, 95–104. [Google Scholar] [CrossRef]
- Clabby, C.; Goswami, U.; Flavin, F.; Wilkins, N.P.; Houghton, J.A.; Powell, R. Cloning, Characterization and Chromosomal Location of a Satellite DNA from the Pacific Oyster, Crassostrea gigas. Gene 1996, 168, 205–209. [Google Scholar] [CrossRef]
- Wang, Y.; Xu, Z.; Guo, X. A Centromeric Satellite Sequence in the Pacific Oyster (Crassostrea gigas Thunberg) Identified by Fluorescence In Situ Hybridization. Mar. Biotechnol. 2001, 3, 486–492. [Google Scholar] [CrossRef]
- López-Flores, I.; de la Herrán, R.; Garrido-Ramos, M.A.; Boudry, P.; Ruiz-Rejón, C.; Ruiz-Rejón, M. The Molecular Phylogeny of Oysters Based on a Satellite DNA Related to Transposons. Gene 2004, 339, 181–188. [Google Scholar] [CrossRef]
- Luchetti, A.; Šatović, E.; Mantovani, B.; Plohl, M. RUDI, a Short Interspersed Element of the V-SINE Superfamily Widespread in Molluscan Genomes. Mol. Genet. Genomics 2016, 291, 1419–1429. [Google Scholar] [CrossRef] [PubMed]
- Thomas-Bulle, C.; Piednoël, M.; Donnart, T.; Filée, J.; Jollivet, D.; Bonnivard, É. Mollusc Genomes Reveal Variability in Patterns of LTR-Retrotransposons Dynamics. BMC Genomics 2018, 19, 821. [Google Scholar] [CrossRef] [PubMed]
- Šatović, E.; Luchetti, A.; Pasantes, J.J.; García-Souto, D.; Cedilak, A.; Mantovani, B.; Plohl, M. Terminal-Repeat Retrotransposons in Miniature (TRIMs) in Bivalves. Sci. Rep. 2019, 9. [Google Scholar] [CrossRef] [PubMed]
- Gaffney, P.M.; Pierce, J.C.; Mackinley, A.G.; Titchen, D.A.; Glenn, W.K. Pearl, a Novel Family of Putative Transposable Elements in Bivalve Mollusks. J. Mol. Evol. 2003, 56, 308–316. [Google Scholar] [CrossRef]
- Kourtidis, A.; Drosopoulou, E.; Pantzartzi, C.N.; Chintiroglou, C.C.; Scouras, Z.G. Three New Satellite Sequences and a Mobile Element Found inside HSP70 Introns of the Mediterranean Mussel (Mytilus galloprovincialis). Genome 2006, 49, 1451–1458. [Google Scholar] [CrossRef] [PubMed]
- Šatović, E.; Plohl, M. Tandem Repeat-Containing MITE Elements in the Clam Donax trunculus. Genome Biol. Evol. 2013, 5, 2549–2559. [Google Scholar] [CrossRef] [PubMed]
- Šatović, E.; Plohl, M. Two New Miniature Inverted-Repeat Transposable Elements in the Genome of the Clam Donax trunculus. Genetica 2017, 145, 379–385. [Google Scholar] [CrossRef]
- Meštrović, N.; Mravinac, B.; Pavlek, M.; Vojvoda-Zeljko, T.; Šatović, E.; Plohl, M. Structural and Functional Liaisons between Transposable Elements and Satellite DNAs. Chromosom. Res. 2015, 23, 583–596. [Google Scholar] [CrossRef]
- Dias, G.B.; Heringer, P.; Svartman, M.; Kuhn, G.C.S.S. Helitrons Shaping the Genomic Architecture of Drosophila: Enrichment of DINE-TR1 in α- and β-Heterochromatin, Satellite DNA Emergence, and piRNA Expression. Chromosom. Res. 2015, 23, 597–613. [Google Scholar] [CrossRef]
- Luchetti, A. TerMITEs: Miniature Inverted-Repeat Transposable Elements (MITEs) in the Termite Genome (Blattodea: Termitoidae). Mol. Genet. Genomics 2015, 290, 1499–1509. [Google Scholar] [CrossRef]
- Plohl, M.; Petrović, V.; Luchetti, A.; Ricci, A.; Šatović, E.; Passamonti, M.; Mantovani, B. Long-Term Conservation vs High Sequence Divergence: The Case of an Extraordinarily Old Satellite DNA in Bivalve Mollusks. Heredity (Edinb) 2010, 104, 543–551. [Google Scholar] [CrossRef] [PubMed]
- Šatović, E.; Vojvoda Zeljko, T.; Luchetti, A.; Mantovani, B.; Plohl, M. Adjacent Sequences Disclose Potential for Intra-Genomic Dispersal of Satellite DNA Repeats and Suggest a Complex Network with Transposable Elements. BMC Genomics 2016, 17, 997. [Google Scholar] [CrossRef] [PubMed]
- Thomas, J.; Pritham, E.J. Helitrons, the Eukaryotic Rolling-Circle Transposable Elements. Microbiol. Spectr. 2015, 3, 1–32. [Google Scholar] [CrossRef]
- Nicetto, D.; Zaret, K.S. Role of H3K9me3 Heterochromatin in Cell Identity Establishment and Maintenance. Curr. Opin. Genet. Dev. 2019, 55, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Sullivan, B.A.; Karpen, G.H. Centromeric Chromatin Exhibits a Histone Modification Pattern That Is Distinct from Both Euchromatin and Heterochromatin. Nat. Struct. Mol. Biol. 2004, 11, 1076–1083. [Google Scholar] [CrossRef] [PubMed]
- Havenhand, J.N.; Li, X.X. Karyotype, Nucleolus Organiser Regions and Constitutive Heterochromatin in Ostrea angasi (Molluscae: Bivalvia): Evidence of Taxonomic Relationships within the Ostreidae. Mar. Biol. 1997, 127, 443–448. [Google Scholar] [CrossRef]
- Cross, I.; Díaz, E.; Sánchez, I.; Rebordinos, L. Molecular and Cytogenetic Characterization of Crassostrea angulata Chromosomes. Aquaculture 2005, 247, 135–144. [Google Scholar] [CrossRef]
- Petrović, V.; Pérez-García, C.; Pasantes, J.J.; Šatović, E.; Prats, E.; Plohl, M. A GC-Rich Satellite DNA and Karyology of the Bivalve Mollusk Donax trunculus: A Dominance of GC-Rich Heterochromatin. Cytogenet. Genome Res. 2009, 124, 63–71. [Google Scholar] [CrossRef]
- Petkevičiūtė, R.; Stunžėnas, V.; Stanevičiūtė, G. Comments on Species Divergence in the Genus Sphaerium (Bivalvia) and Phylogenetic Affinities of Sphaerium nucleus and S. corneum var. mamillanum Based on Karyotypes and Sequences of 16S and ITS1 RDNA. PLoS ONE 2018, 13, e0191427. [Google Scholar] [CrossRef]
- Bouilly, K.; Chaves, R.; Leitao, A.; Benabdelmouna, A.; Guedes-Pinto, H. Chromosomal Organization of Simple Sequence Repeats in Chromosome Patterns. J. Genet. 2008, 87, 119–125. [Google Scholar] [CrossRef]
- Sedlazeck, F.J.; Lee, H.; Darby, C.A.; Schatz, M.C. Piercing the Dark Matter: Bioinformatics of Long-Range Sequencing and Mapping. Nat. Rev. Genet. 2018, 19, 329–346. [Google Scholar] [CrossRef] [PubMed]
- Gagnaire, P.-A.; Lamy, J.-B.; Cornette, F.; Heurtebise, S.; Dégremont, L.; Flahauw, E.; Boudry, P.; Bierne, N.; Lapègue, S. Analysis of Genome-Wide Differentiation between Native and Introduced Populations of the Cupped Oysters Crassostrea gigas and Crassostrea angulata. Genome Biol. Evol. 2018, 10, 2518–2534. [Google Scholar] [CrossRef] [PubMed]
- Bouilly, K.; Chaves, R.; Fernandes, M.; Guedes-Pinto, H. Histone H3 Gene in the Pacific Oyster, Crassostrea gigas Thunberg, 1793: Molecular and Cytogenetic Characterisations. Comp. Cytogenet. 2010, 4, 111–121. [Google Scholar] [CrossRef]
- Liu, J.; Li, Q.; Kong, L.; Yu, H.; Zheng, X. Identifying the True Oysters (Bivalvia: Ostreidae) with Mitochondrial Phylogeny and Distance-Based DNA Barcoding. Mol. Ecol. Resour. 2011, 11, 820–830. [Google Scholar] [CrossRef] [PubMed]
- Folmer, O.; Black, M.; Hoeh, W.; Lutz, R.; Vrijenhoek, R. DNA Primers for Amplification of Mitochondrial Cytochrome c Oxidase Subunit I from Diverse Metazoan Invertebrates. Mol. Mar. Biol. Biotechnol. 1994, 3, 294–299. [Google Scholar] [CrossRef] [PubMed]
- Novák, P.; Robledillo, L.Á.; Koblížková, A.; Vrbová, I.; Neumann, P.; Macas, J. TAREAN: A Computational Tool for Identification and Characterization of Satellite DNA from Unassembled Short Reads. Nucleic Acids Res. 2017, 45, e111. [Google Scholar] [CrossRef]
- Novák, P.; Neumann, P.; Pech, J.; Steinhaisl, J.; Macas, J. RepeatExplorer: A Galaxy-Based Web Server for Genome-Wide Characterization of Eukaryotic Repetitive Elements from next-Generation Sequence Reads. Bioinformatics 2013, 29, 792–793. [Google Scholar] [CrossRef]
- Kowar, T.; Zakrzewski, F.; Macas, J.; Kobližková, A.; Viehoever, P.; Weisshaar, B.; Schmidt, T. Repeat Composition of CenH3-Chromatin and H3K9me2-marked Heterochromatin in Sugar Beet (Beta vulgaris). BMC Plant Biol. 2016, 16, 120. [Google Scholar] [CrossRef]
- Zhang, W.; Zuo, S.; Li, Z.; Meng, Z.; Han, J.; Song, J.; Pan, Y.B.; Wang, K. Isolation and Characterization of Centromeric Repetitive DNA Sequences in Saccharum spontaneum. Sci. Rep. 2017, 7, 1–12. [Google Scholar] [CrossRef]
- Martínez-Expósito, M.J.; Pasantes, J.J.; Méndez, J. NOR Activity in Larval and Juvenile Mussels (Mytilus galloprovincialis Lmk.). J. Exp. Mar. Biol. Ecol. 1994, 175, 155–165. [Google Scholar] [CrossRef]
- Franco, A.; Heude Berthelin, C.; Goux, D.; Sourdaine, P.; Mathieu, M. Fine Structure of the Early Stages of Spermatogenesis in the Pacific Oyster, Crassostrea gigas (Mollusca, Bivalvia). Tissue Cell 2008, 40, 251–260. [Google Scholar] [CrossRef] [PubMed]
- Pérez-García, C.; Morán, P.; Pasantes, J.J. Cytogenetic Characterization of the Invasive Mussel Species Xenostrobus securis Lmk. (Bivalvia: Mytilidae). Genome 2011, 54, 771–778. [Google Scholar] [CrossRef] [PubMed]
- Murgarella, M.; Puiu, D.; Novoa, B.; Figueras, A.; Posada, D.; Canchaya, C. A First Insight into the Genome of the Filter-Feeder Mussel Mytilus galloprovincialis. PLoS ONE 2016, 11, e0151561. [Google Scholar] [CrossRef]
- Silva, B.S.M.L.; Heringer, P.; Guilherme, B.D.; Svartman, M.; Kuhn, G.C.S. De Novo Identification of Satellite DNAs in the Sequenced Genomes of Drosophila virilis and D. americana Using the RepeatExplorer and TAREAN Pipeline. PLoS ONE 2019, 14, e0223466. [Google Scholar] [CrossRef] [PubMed]
- Abdurashitov, M.A.; Gonchar, D.A.; Chernukhin, V.A.; Tomilov, V.N.; Tomilova, J.E.; Schostak, N.G.; Zatsepina, O.G.; Zelentsova, E.S.; Evgen′ev, M.B.; Degtyarev, S.K. Medium-Sized Tandem Repeats Represent an Abundant Component of the Drosophila virilis Genome. BMC Genomics 2013, 14, 771. [Google Scholar] [CrossRef] [PubMed]
- Zelentsova, E.S.; Vashakidze, R.P.; Krayev, A.S.; Evgen′ev, M.B. Dispersed Repeats in Drosophila virilis: Elements Mobilized by Interspecific Hybridization. Chromosoma 1986, 93, 469–476. [Google Scholar] [CrossRef]
- Xiong, W.; Dooner, H.K.; Du, C. Rolling-Circle Amplification of Centromeric Helitrons in Plant Genomes. Plant J. 2016, 88, 1038–1045. [Google Scholar] [CrossRef]
- Gong, Z.; Wu, Y.; Koblížková, A.; Torres, G.A.; Wang, K.; Iovene, M.; Neumann, P.; Zhang, W.; Novák, P.; Robin Buell, C.; et al. Repeatless and Repeat-Based Centromeres in Potato: Implications for Centromere Evolution. Plant Cell 2012, 24, 3559–3574. [Google Scholar] [CrossRef]
- Mehra, M.; Gangwar, I.; Shankar, R. A Deluge of Complex Repeats: The Solanum Genome. PLoS ONE 2015, 10, e0133962. [Google Scholar] [CrossRef]
- Long, E.O.; Dawid, I.B. Repeated Genes in Eukaryotes. Ann. Rev. Biochem. 1980, 49, 727–764. [Google Scholar] [CrossRef]
- Stupar, R.M.; Song, J.; Tek, A.L.; Cheng, Z.; Dong, F.; Jiang, J. Highly Condensed Potato Pericentromeric Heterochromatin Contains rDNA-Related Tandem Repeats. Genetics 2002, 162, 1435–1444. [Google Scholar] [PubMed]
- Lim, K.Y.; Matyášek, R.; Lichtenstein, C.P.; Leitch, A.R. Molecular Cytogenetic Analyses and Phylogenetic Studies in the Nicotiana Section Tomentosae. Chromosoma 2000, 109, 245–258. [Google Scholar] [CrossRef] [PubMed]
- Jo, S.H.; Koo, D.H.; Kim, J.F.; Hur, C.G.; Lee, S.; Yang, T.J.; Kwon, S.Y.; Choi, D. Evolution of Ribosomal DNA-Derived Satellite Repeat in Tomato Genome. BMC Plant Biol. 2009, 9, 42. [Google Scholar] [CrossRef] [PubMed]
- Almeida, C.; Fonsêca, A.; dos Santos, K.G.B.; Mosiolek, M.; Pedrosa-Harand, A. Contrasting Evolution of a Satellite DNA and Its Ancestral IGS rDNA in Phaseolus (Fabaceae). Genome 2012, 55, 683–689. [Google Scholar] [CrossRef] [PubMed]
- Pérez-García, C.; Morán, P.; Pasantes, J.J. Karyotypic Diversification in Mytilus Mussels (Bivalvia: Mytilidae) Inferred from Chromosomal Mapping of rRNA and Histone Gene Clusters. BMC Genet. 2014, 15, 84. [Google Scholar] [CrossRef]
- García-Souto, D.; Pérez-García, C.; Morán, P.; Pasantes, J.J. Divergent Evolutionary Behavior of H3 Histone Gene and rDNA Clusters in Venerid Clams. Mol. Cytogenet. 2015, 8, 1–10. [Google Scholar] [CrossRef] [PubMed]
- García-Souto, D.; Ríos, G.; Pasantes, J.J. Karyotype Differentiation in Tellin Shells (Bivalvia: Tellinidae). BMC Genet. 2017, 18, 66. [Google Scholar] [CrossRef] [PubMed]
- García-Souto, D.; Qarkaxhija, V.; Pasantes, J.J. Resolving the Taxonomic Status of Chamelea gallina and C. striatula (Veneridae, Bivalvia): A Combined Molecular Cytogenetic and Phylogenetic Approach. BioMed Res. Int. 2017, 2017, 7638790. [Google Scholar] [CrossRef] [PubMed]
- García-Souto, D.; Pasantes, J.J. Cytogenetics in Arctica islandica (Bivalvia, Arctidae): The Longest Lived Non-Colonial Metazoan. Genes (Basel) 2018, 9, 299. [Google Scholar] [CrossRef]
- Layat, E.; Sáez-Vásquez, J.; Tourmente, S. Regulation of Pol I-Transcribed 45S rDNA and Pol III-Transcribed 5S rDNA in Arabidopsis. Plant Cell Physiol. 2012, 53, 267–276. [Google Scholar] [CrossRef]
- Robicheau, B.M.; Susko, E.; Harrigan, A.M.; Snyder, M. Ribosomal RNA Genes Contribute to the Formation of Pseudogenes and Junk DNA in the Human Genome. Genome Biol. Evol. 2017, 9, 380–397. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Zhao, H.; Zhang, T.; Zeng, Z.; Zhang, P.; Zhu, B.; Han, Y.; Braz, G.T.; Casler, M.D.; Schmutz, J.; et al. Amplification and Adaptation of Centromeric Repeats in Polyploid Switchgrass Species. New Phytol. 2018, 218, 1645–1657. [Google Scholar] [CrossRef] [PubMed]
- Scherthan, H.; Weich, S.; Schwegler, H.; Heyting, C.; Härle, M.; Cremer, T. Centromere and Telomere Movements during Early Meiotic Prophase of Mouse and Man are Associated with the Onset of Chromosome Pairing. J. Cell Biol. 1996, 134, 1109–1125. [Google Scholar] [CrossRef] [PubMed]
- Colaco, S.; Modi, D. Genetics of the Human Y Chromosome and Its Association with Male Infertility. Reprod. Biol. Endocrinol. 2018, 16, 1–24. [Google Scholar] [CrossRef] [PubMed]
- Matsunaga, S.; Takata, H.; Morimoto, A.; Hayashihara, K.; Higashi, T.; Akatsuchi, K.; Mizusawa, E.; Yamakawa, M.; Ashida, M.; Matsunaga, T.M.; et al. RBMX: A Regulator for Maintenance and Centromeric Protection of Sister Chromatid Cohesion. Cell Rep. 2012, 1, 299–308. [Google Scholar] [CrossRef] [PubMed]
- Cho, Y.; Ideue, T.; Nagayama, M.; Araki, N.; Tani, T. RBMX Is a Component of the Centromere Noncoding RNP Complex Involved in Cohesion Regulation. Genes Cells 2018, 23, 172–184. [Google Scholar] [CrossRef] [PubMed]
- Wiland, E.; Fraczek, M.; Olszewska, M.; Kurpisz, M. Topology of Chromosome Centromeres in Human Sperm Nuclei with High Levels of DNA Damage. Sci. Rep. 2016, 6, 1–12. [Google Scholar] [CrossRef]
- Gosálvez, J.; Kjelland, M.E.; López-Fernández, C. Sperm DNA in Grasshoppers: Structural Features and Fertility Implications. J. Orthoptera Res. 2010, 19, 243–252. [Google Scholar] [CrossRef][Green Version]
- Champroux, A.; Damon-Soubeyrand, C.; Goubely, C.; Bravard, S.; Henry-Berger, J.; Guiton, R.; Saez, F.; Drevet, J.; Kocer, A. Nuclear Integrity but Not Topology of Mouse Sperm Chromosome Is Affected by Oxidative DNA Damage. Genes 2018, 9, 501. [Google Scholar] [CrossRef]
- Maheshwari, S.; Ishii, T.; Brown, C.T.; Houben, A.; Comai, L. Centromere Location in Arabidopsis Is Unaltered by Extreme Divergence in CENH3 Protein Sequence. Genome Res. 2017, 27, 471–478. [Google Scholar] [CrossRef]
- Su, H.; Liu, Y.; Liu, C.; Shi, Q.; Huang, Y.; Han, F. Centromere Satellite Repeats Have Undergone Rapid Changes in Polyploid Wheat Subgenomes. Plant Cell 2019, 31, 2035–2051. [Google Scholar] [CrossRef] [PubMed]
- Yan, H.; Ito, H.; Nobuta, K.; Ouyang, S.; Jin, W.; Tian, S.; Lu, C.; Venu, R.C.; Wang, G.L.; Green, P.J.; et al. Genomic and Genetic Characterization of Rice Cen3 Reveals Extensive Transcription and Evolutionary Implications of a Complex Centromere. Plant Cell 2006, 18, 2123–2133. [Google Scholar] [CrossRef] [PubMed]
- Chang, C.-H.; Chavan, A.; Palladino, J.; Wei, X.; Martins, N.M.C.; Santinello, B.; Chen, C.-C.; Erceg, J.; Beliveau, B.J.; Wu, C.-T.; et al. Islands of Retroelements Are Major Components of Drosophila Centromeres. PLoS Biol. 2019, 17, e3000241. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Repeat | % of the Genome |
|---|---|
| satellite | 2.56 |
| Cg170 satDNA | 1.76 |
| mobile elements | 2.07 |
| Ty3 gypsy | 0.09 |
| DIRS | 0.04 |
| LINE | 0.11 |
| Penelope | 0.04 |
| 45S rDNA | 0.40 |
| mitochondria | 0.02 |
| Unclassified | 15.64 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tunjić Cvitanić, M.; Vojvoda Zeljko, T.; Pasantes, J.J.; García-Souto, D.; Gržan, T.; Despot-Slade, E.; Plohl, M.; Šatović, E. Sequence Composition Underlying Centromeric and Heterochromatic Genome Compartments of the Pacific Oyster Crassostrea gigas. Genes 2020, 11, 695. https://doi.org/10.3390/genes11060695
Tunjić Cvitanić M, Vojvoda Zeljko T, Pasantes JJ, García-Souto D, Gržan T, Despot-Slade E, Plohl M, Šatović E. Sequence Composition Underlying Centromeric and Heterochromatic Genome Compartments of the Pacific Oyster Crassostrea gigas. Genes. 2020; 11(6):695. https://doi.org/10.3390/genes11060695
Chicago/Turabian StyleTunjić Cvitanić, Monika, Tanja Vojvoda Zeljko, Juan J. Pasantes, Daniel García-Souto, Tena Gržan, Evelin Despot-Slade, Miroslav Plohl, and Eva Šatović. 2020. "Sequence Composition Underlying Centromeric and Heterochromatic Genome Compartments of the Pacific Oyster Crassostrea gigas" Genes 11, no. 6: 695. https://doi.org/10.3390/genes11060695
APA StyleTunjić Cvitanić, M., Vojvoda Zeljko, T., Pasantes, J. J., García-Souto, D., Gržan, T., Despot-Slade, E., Plohl, M., & Šatović, E. (2020). Sequence Composition Underlying Centromeric and Heterochromatic Genome Compartments of the Pacific Oyster Crassostrea gigas. Genes, 11(6), 695. https://doi.org/10.3390/genes11060695