High Contiguity de novo Genome Sequence Assembly of Trifoliate Yam (Dioscorea dumetorum) Using Long Read Sequencing

 ,
,  , and
, and 
Abstract
1. Introduction
2. Materials and Methods
2.1. Sampling and Sequencing
2.2. Genome Assembly and Polishing
2.3. Genome Sequence Annotation
2.4. Assembly and Annotation Assessment
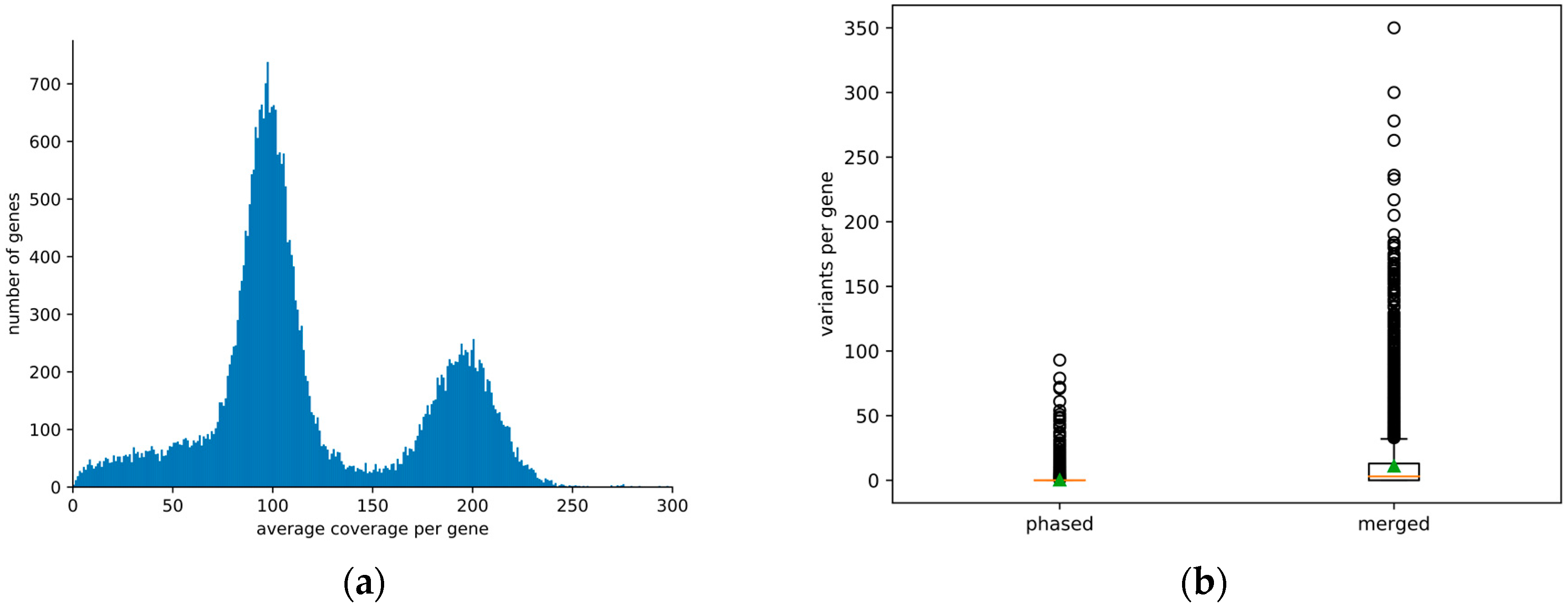
3. Results
4. Discussion
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Viruel, J.; Forest, F.; Paun, O.; Chase, M.W.; Devey, D.; Couto, R.S.; Segarra-Moragues, J.G.; Catalan, P.; Wilkin, P. A nuclear Xdh phylogenetic analysis of yams (Dioscorea Dioscoreaceae) congruent with plastid trees reveals a new Neotropical lineage. Bot. J. Linn. Soc. 2018, 187, 232–246. [Google Scholar] [CrossRef]
- Sefa-Dedeh, S.; Afoakwa, E.O. Biochemical and textural changes in trifoliate yam Dioscorea dumetorum tubers after harvest. Food Chem. 2002, 79, 27–40. [Google Scholar] [CrossRef]
- Alozie, Y.E.; Akpanabiatu, M.; Eyong, E.U.; Umoh, I.B.; Alozie, G. Amino Acid Composition of Dioscorea dumetorum Varities. Pak. J. Nutr. 2009, 8, 103–105. [Google Scholar]
- Ferede, R.; Maziya-Dixon, B.; Alamu, O.E.; Asiedu, R. Identification and quantification of major carotenoids of deep yellow-fleshed yam (tropical Dioscorea dumetorum). J. Food Agric. Environ. 2010, 8, 160–166. [Google Scholar]
- Nimenibo-Uadia, R.; Oriakhi, A. Proximate, Mineral and Phytochemical Composition of Dioscorea dumetorium Pax. J. Appl. Sci. Environ. Manag. 2017, 21, 771–774. [Google Scholar]
- Iwu, M.M.; Okunji, C.O.; Ohiaeri, G.O.; Akah, P.; Corley, D.; Tempesta, M.S. Hypoglycaemic activity of dioscoretine from tubers of Dioscorea dumetorum in normal and alloxan diabetic rabbits. Plant. Med. 1990, 56, 264–267. [Google Scholar] [CrossRef]
- Siadjeu, C.; Panyoo, E.A.; Toukam, G.M.S.; Bell, J.M.; Nono, B.; Medoua, G.N. Influence of Cultivar on the Postharvest Hardening of Trifoliate Yam (Dioscorea dumetorum) Tubers. Adv. Agric. 2016, 2658983. [Google Scholar] [CrossRef]
- Tamiru, M.; Natsume, S.; Takagi, H.; White, B.; Yaegashi, H.; Shimizu, M.; Yoshida, K.; Uemura, A.; Oikawa, K.; Abe, A.; et al. Genome sequencing of the staple food crop white Guinea yam enables the development of a molecular marker for sex determination. BMC Biol. 2017, 15, 86. [Google Scholar] [CrossRef]
- Cormier, F.; Lawac, F.; Maledon, E.; Gravillon, M.C.; Nudol, E.; Mournet, P.; Vignes, H.; Chaïr, H.; Arnau, G. A reference high-density genetic map of greater yam (Dioscorea alata L.). Theor. Appl. Genet. 2019, 132, 1733–1744. [Google Scholar] [CrossRef]
- Ngo Ngwe, M.F.; Omokolo, D.N.; Joly, S. Evolution and Phylogenetic Diversity of Yam Species (Dioscorea spp.): Implication for Conservation and Agricultural Practices. PLoS ONE 2015, 10, e0145364. [Google Scholar] [CrossRef]
- Magwe-Tindo, J.; Wieringa, J.J.; Sonke, B.; Zapfack, L.; Vigouroux, Y.; Couvreur, T.L.P.; Scarcelli, N. Complete plastome sequences of 14 African yam species (Dioscorea spp.). Mitochondrial DNA Part B-Resour. 2019, 4, 74–76. [Google Scholar] [CrossRef]
- Miege, J. Nombres chromosomiques et répartition géographique de quelques plantes tropicales et équatoriales. Revue de Cytologie et de Biologie Végétales 1954, 15, 312–348. [Google Scholar]
- Hui-Chen, C.; Mei-Chen, C.; Ping-Ping, L.; Chih-Tsun, T.; Fang-Ping, D. A cytotaxonomic study on Chinese Dioscorea, L.—The chromosome numbers and their relation to the origin and evolution of the genus. J. Syst. Evol. 1985, 23, 11–18. [Google Scholar]
- Siadjeu, C.; Mayland-Quellhorst, E.; Albach, D.C. Genetic diversity and population structure of trifoliate yam (Dioscorea dumetorum Kunth) in Cameroon revealed by genotyping-by-sequencing (GBS). BMC Plant Biol. 2018, 18, 359. [Google Scholar] [CrossRef]
- Rosso, M.G.; Li, Y.; Strizhov, N.; Reiss, B.; Dekker, K.; Weisshaar, B. An Arabidopsis thaliana T-DNA mutagenised population (GABI-Kat) for flanking sequence tag based reverse genetics. Plant Mol. Biol. 2003, 53, 247–259. [Google Scholar] [CrossRef]
- Vurture, G.W.; Sedlazeck, F.J.; Nattestad, M.; Underwood, C.J.; Fang, H.; Gurtowski, J.; Schatz, M.C. GenomeScope: Fast reference-free genome profiling from short reads. Bioinformatics 2017, 33, 2202–2204. [Google Scholar] [CrossRef]
- Sun, H.; Ding, J.; Piednoel, M.; Schneeberger, K. findGSE: Estimating genome size variation within human and Arabidopsis using k-mer frequencies. Bioinformatics 2018, 34, 550–557. [Google Scholar] [CrossRef]
- Liu, B.; Shi, Y.; Yuan, J.; Hu, X.; Zhang, H.; Li, N.; Li, Z.; Chen, Y.; Mu, D.; Fan, W. Estimation of genomic characteristics by analyzing k-mer frequency in de novo genome projects. arXiv 2013, arXiv:1308.2012. [Google Scholar]
- Marcais, G.; Kingsford, C. A fast, lock-free approach for efficient parallel counting of occurrences of k-mers. Bioinformatics 2011, 27, 764–770. [Google Scholar] [CrossRef]
- Pucker, B. Mapping-based genome size estimation. bioRxiv 2019. [Google Scholar] [CrossRef]
- Ranallo-Benavidez, T.R.; Jaron, K.S.; Schatz, M.C. GenomeScope 2.0 and Smudgeplots: Reference-free profiling of polyploid genomes. bioRxiv 2019, 747568. [Google Scholar] [CrossRef] [PubMed]
- Koren, S.; Walenz, B.P.; Berlin, K.; Miller, J.R.; Bergman, N.H.; Phillippy, A.M. Canu: Scalable and accurate long-read assembly via adaptive k-mer weighting and repeat separation. Genome Res. 2017, 27, 722–736. [Google Scholar] [CrossRef] [PubMed]
- Li, H. Minimap2: Pairwise alignment for nucleotide sequences. Bioinformatics 2018, 34, 3094–3100. [Google Scholar] [CrossRef]
- Vaser, R.; Sović, I.; Nagarajan, N.; Šikić, M. Fast and accurate de novo genome assembly from long uncorrected reads. Genome Res. 2017, 27, 737–746. [Google Scholar] [CrossRef] [PubMed]
- Li, H. Aligning sequence reads, clone sequences and assembly contigs with BWA-MEM. arXiv 2013, arXiv:1303.3997. [Google Scholar]
- Walker, B.J.; Abeel, T.; Shea, T.; Priest, M.; Abouelliel, A.; Sakthikumar, S.; Cuomo, C.A.; Zeng, Q.; Wortman, J.; Young, S.K.; et al. Pilon: An integrated tool for comprehensive microbial variant detection and genome assembly improvement. PLoS ONE 2014, 9, e112963. [Google Scholar] [CrossRef]
- Pucker, B.; Holtgräwe, D.; Rosleff Sörensen, T.; Stracke, R.; Viehöver, P.; Weisshaar, B. A De Novo Genome Sequence Assembly of the Arabidopsis thaliana Accession Niederzenz-1 Displays Presence/Absence Variation and Strong Synteny. PLoS ONE 2016, 11, e0164321. [Google Scholar] [CrossRef]
- Tang, H.; Zhang, X.; Miao, C.; Zhang, J.; Ming, R.; Schnable, J.C.; Schnable, P.S.; Lyons, E.; Lu, J. ALLMAPS: Robust scaffold ordering based on multiple maps. Genome Biol. 2015, 16, 3. [Google Scholar] [CrossRef]
- Pucker, B.; Holtgräwe, D.; Weisshaar, B. Consideration of non-canonical splice sites improves gene prediction on the Arabidopsis thaliana Niederzenz-1 genome sequence. BMC Res. Notes 2017, 10, 667. [Google Scholar] [CrossRef]
- Simão, F.A.; Waterhouse, R.M.; Ioannidis, P.; Kriventseva, E.V.; Zdobnov, E.M. BUSCO: Assessing genome assembly and annotation completeness with single-copy orthologs. Bioinformatics 2015, 31, 3210–3212. [Google Scholar] [CrossRef]
- Keller, O.; Kollmar, M.; Stanke, M.; Waack, S. A novel hybrid gene prediction method employing protein multiple sequence alignments. Bioinformatics 2011, 27, 757–763. [Google Scholar] [CrossRef] [PubMed]
- Smit, A.F.A.; Hubley, R.; Green, P. RepeatMasker Open-4.0. Available online: http://www.repeatmasker.org (accessed on 2 December 2018).
- Pucker, B.; Feng, T.; Brockhington, S. Next generation sequencing to investigate genomic diversity in Caryophyllales. bioRxiv 2019. [Google Scholar] [CrossRef]
- Altschul, S.F.; Gish, W.; Miller, W.; Myers, E.W.; Lipman, D.J. Basic local alignment search tool. J. Mol. Biol. 1990, 215, 403–410. [Google Scholar] [CrossRef]
- Cheng, C.Y.; Krishnakumar, V.; Chan, A.; Thibaud-Nissen, F.; Schobel, S.; Town, C.D. Araport11: A complete reannotation of the Arabidopsis thaliana reference genome. Plant J. 2017, 89, 789–804. [Google Scholar] [CrossRef] [PubMed]
- Jones, P.; Binns, D.; Chang, H.Y.; Fraser, M.; Li, W.; McAnulla, C.; McWilliam, H.; Maslen, J.; Mitchell, A.; Nuka, G.; et al. InterProScan 5: Genome-scale protein function classification. Bioinformatics 2014, 30, 1236–1240. [Google Scholar] [CrossRef] [PubMed]
- Lowe, T.M.; Eddy, S.R. tRNAscan-SE: A program for improved detection of transfer RNA genes in genomic sequence. Nucleic Acids Res. 1997, 25, 955–964. [Google Scholar] [CrossRef] [PubMed]
- Chan, P.P.; Lowe, T.M. tRNAscan-SE: Searching for tRNA Genes in Genomic Sequences. In Gene Prediction: Methods and Protocols; Kollmar, M., Ed.; Springer: Berlin/Heidelberg, Germany, 2019; Volume 1962, pp. 1–14. [Google Scholar]
- Nawrocki, E.P.; Eddy, S.R. Infernal 1.1: 100-fold faster RNA homology searches. Bioinformatics 2013, 29, 2933–2935. [Google Scholar] [CrossRef]
- Kalvari, I.; Argasinska, J.; Quinones-Olvera, N.; Nawrocki, E.P.; Rivas, E.; Eddy, S.R.; Bateman, A.; Finn, R.D.; Petrov, A.I. Rfam 13.0: Shifting to a genome-centric resource for non-coding RNA families. Nucleic Acids Res. 2018, 46, D335–D342. [Google Scholar] [CrossRef]
- Flynn, J.M.; Hubley, R.; Goubert, C.; Rosen, J.; Clark, A.G.; Feschotte, C.; Smit, A.F. RepeatModeler2: Automated genomic discovery of transposable element families. bioRxiv 2019. [Google Scholar] [CrossRef]
- Pucker, B.; Ruckert, C.; Stracke, R.; Viehover, P.; Kalinowski, J.; Weisshaar, B. Twenty-Five Years of Propagation in Suspension Cell Culture Results in Substantial Alterations of the Arabidopsis Thaliana Genome. Genes 2019, 10, 671. [Google Scholar] [CrossRef]
- Baasner, J.S.; Howard, D.; Pucker, B. Influence of neighboring small sequence variants on functional impact prediction. bioRxiv 2019. [Google Scholar] [CrossRef]
- Emms, D.M.; Kelly, S. OrthoFinder: Phylogenetic orthology inference for comparative genomics. Genome Biol. 2019, 20, 238. [Google Scholar] [CrossRef] [PubMed]
- Ruggieri, V.; Alexiou, K.G.; Morata, J.; Argyris, J.; Pujol, M.; Yano, R.; Nonaka, S.; Ezura, H.; Latrasse, D.; Boualem, A.; et al. An improved assembly and annotation of the melon (Cucumis melo L.) reference genome. Sci. Rep. 2018, 8, 8088. [Google Scholar] [CrossRef] [PubMed]
- Mignouna, H.D.; Abang, M.M.; Asiedu, R. Harnessing modern biotechnology for tropical tuber crop improvement: Yam (Dioscorea spp.) molecular breeding. Afr. J. Biotechnol. 2003, 2, 12. [Google Scholar]
- Mignouna, H.D.; Abang, M.M.; Asiedu, R. Genomics of Yams, a Common Source of Food and Medicine in the Tropics. In Genomics of Tropical Crop Plants; Moore, P.H., Ming, R., Eds.; Springer: New York, NY, USA, 2008; pp. 549–570. [Google Scholar] [CrossRef]
- Michael, T.P.; Jupe, F.; Bemm, F.; Motley, S.T.; Sandoval, J.P.; Lanz, C.; Loudet, O.; Weigel, D.; Ecker, J.R. High contiguity Arabidopsis thaliana genome assembly with a single nanopore flow cell. Nat. Commun. 2018, 9, 541. [Google Scholar] [CrossRef]
- Paajanen, P.; Kettleborough, G.; Lopez-Girona, E.; Giolai, M.; Heavens, D.; Baker, D.; Lister, A.; Cugliandolo, F.; Wilde, G.; Hein, I.; et al. A critical comparison of technologies for a plant genome sequencing project. Gigascience 2019, 8, giy163. [Google Scholar] [CrossRef]
- Salmela, L.; Walve, R.; Rivals, E.; Ukkonen, E. Accurate self-correction of errors in long reads using de Bruijn graphs. Bioinformatics 2017, 33, 799–806. [Google Scholar] [CrossRef]
- Knuth, R. Dioscoreaceae. In Das Pflanzenreich; Engelr, A., Ed.; Engelmann, W.: Leipzig, Germany, 1924. [Google Scholar]
- Viruel, J.; Segarra-Moragues, J.G.; Raz, L.; Forest, F.; Wilkin, P.; Sanmartin, I.; Catalan, P. Late Cretaceous-Early Eocene origin of yams (Dioscorea, Dioscoreaceae) in the Laurasian Palaearctic and their subsequent Oligocene-Miocene diversification. J. Biogeogr. 2016, 43, 750–762. [Google Scholar] [CrossRef]
- Wendel, J.F.; Jackson, S.A.; Meyers, B.C.; Wing, R.A. Evolution of plant genome architecture. Genome Biol. 2016, 17, 37. [Google Scholar] [CrossRef]
- Pucker, B.; Brockington, S.F. Genome-wide analyses supported by RNA-Seq reveal non-canonical splice sites in plant genomes. BMC Genom. 2018, 19, 980. [Google Scholar] [CrossRef]
- Pucker, B.; Holtgräwe, D.; Stadermann, K.B.; Frey, K.; Huettel, B.; Reinhardt, R.; Weisshaar, B. A chromosome-level sequence assembly reveals the structure of the Arabidopsis thaliana Nd-1 genome and its gene set. PLoS ONE 2019, 14, e0216233. [Google Scholar] [CrossRef] [PubMed]
- Barton, H. Yams: Origins and Development. Encyclopaedia Glob. Archaeol. 2014, 7943–7947. [Google Scholar]
- Treche, S.; Delpeuch, F. Physiologie Vegetale—Mise en evidence de l’apparition d’un epaississement membranaire dans le parenchyme des tubercules de Dioscorea dumetorum au cours de la conservation. Comptes Rendus de l’Académie des Sciences. Série D: Sciences Naturelles 1979, 288, 67–70. [Google Scholar]
- Price, E.J.; Wilkin, P.; Sarasan, V.; Fraser, P.D. Metabolite profiling of Dioscorea (yam) species reveals underutilised biodiversity and renewable sources for high-value compounds. Sci. Rep. 2016, 6, 29136. [Google Scholar] [CrossRef]


{kind=link}
| Initial Assembly | Racon1 | Medaka2 | Pilon3 | Final | |
|---|---|---|---|---|---|
| Number of contigs | 1172 | 1172 | 1215 | 1215 | 924 |
| Max. contig length (bp) | 20,187,448 | 20,424,333 | 17,910,017 | 17,878,854 | 17,878,854 |
| Assembly size (bp) | 501,985,705 | 508,061,170 | 507,215,754 | 506,184,192 | 485,115,345 |
| Assembly size without N (bp) | 501,985,705 | 508,061,170 | 507,215,754 | 506,184,192 | 485,115,345 |
| GC content | 37.74% | 37.66% | 37.87% | 37.59% | 37.57% |
| N50 (bp) | 3,896,882 | 3,930,287 | 2,598,889 | 2,593,751 | 3,190,870 |
| N90 (bp) | 136,614 | 138,199 | 137,206 | 136,754 | 156,407 |
| BUSCO (complete) | 85.70% | 89.80% | 91.90% | 92.30% | 92.30% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Siadjeu, C.; Pucker, B.; Viehöver, P.; Albach, D.C.; Weisshaar, B. High Contiguity de novo Genome Sequence Assembly of Trifoliate Yam (Dioscorea dumetorum) Using Long Read Sequencing. Genes 2020, 11, 274. https://doi.org/10.3390/genes11030274
Siadjeu C, Pucker B, Viehöver P, Albach DC, Weisshaar B. High Contiguity de novo Genome Sequence Assembly of Trifoliate Yam (Dioscorea dumetorum) Using Long Read Sequencing. Genes. 2020; 11(3):274. https://doi.org/10.3390/genes11030274
Chicago/Turabian StyleSiadjeu, Christian, Boas Pucker, Prisca Viehöver, Dirk C. Albach, and Bernd Weisshaar. 2020. "High Contiguity de novo Genome Sequence Assembly of Trifoliate Yam (Dioscorea dumetorum) Using Long Read Sequencing" Genes 11, no. 3: 274. https://doi.org/10.3390/genes11030274
APA StyleSiadjeu, C., Pucker, B., Viehöver, P., Albach, D. C., & Weisshaar, B. (2020). High Contiguity de novo Genome Sequence Assembly of Trifoliate Yam (Dioscorea dumetorum) Using Long Read Sequencing. Genes, 11(3), 274. https://doi.org/10.3390/genes11030274