1. Introduction
Due to innovation in the areas of genome sequencing and ’omics analysis, biological data is entering the age of big data. As opposed to other fields of research, biological data sets tend to have large feature quantity, but much smaller sample counts, such as in a GWAS population where there are typically hundreds to thousands of genotypes, but millions of SNPs. The number of independent features of biological systems is large, and would require many lifetimes of the entire scientific community to sufficiently study [
1]. The ability to determine which features are influential to a particular phenotype, be it SNPs, gene expression, or interactions between multiple molecular pathways, is essential in reducing the full feature space to a subset that is feasible to analyze.
Many methods exist to determine feature importance and feature selection, such as Pearson Correlation, Mutual Information (MI), Sequential Feature Selection (SFS) [
2], Lasso, and Ridge Regression. Random Forest [
3] is a commonly used machine learning method for making predictions, and while not classically defined as a feature selection method, it is useful in scoring feature importance. During the training phase, decision trees are built, where a subset of features is examined at each decision point and the one that best divides the data is chosen. Feature importance is calculated for each feature based on its location and effectiveness within the tree structures. By using random subsets of the training data for each tree and considering random features for each decision point, Random Forest prevents over fitting. Because of the nature of decision trees, the importance of any chosen feature is inherently conditional on the features that were chosen previously. In this way the Random Forest can account for some of the interconnected dependencies that occur in biological systems. As a non-linear model, Random Forest has been applied to a range of biological data problems, including GWAS, genomic prediction, gene expression networks and SNP imputation [
4].
Iterative Random Forest [
5] (iRF) is an algorithmic advancement of Random Forest (RF), which takes advantage of Random Forests ability to produce feature importance and produces a more accurate model by iteratively creating weighted forests. In each iteration, the importance scores from the previous iteration are used to weight features for the current forest. Until now, iRF was implemented solely as an R package [
6]. While useful for small projects, it was not designed for big data analysis. This paper describes the process of implementing a high-performance computing-enabled iRF, using MPI (Message Passing Interface) [
7]. This new implementation enabled the creation of Predictive Gene Expression Networks with 40,000 genes and quickly completed the feature importance calculations for 1.7 million
Arabidopsis thaliana SNPs in relation to a gene expression profile, as part of a genome-wide explainable-AI-based eQTL analysis.
2. Materials and Methods
2.1. Random Forest and Iterative Random Forest Methods
The base learner for the Random Forest (RF) and Iterative Random Forest (iRF) methods is the decision tree, also known as a binary tree. A decision tree starts with a set of data: samples, features, and a dependent variable. The goal is to divide the samples, through decisions based on the features, into subsets containing homogeneous dependent variable values, generally following the CART (Classification and Regression Trees) method [
8], where each decision divides one node into two child nodes. This is a greedy algorithm which will continue to divide the samples into child nodes, based on a scoring criterion, until a stopping criteria is met. Decision trees are weak learners and tend to over-fit to the data provided.
A Random Forest is an ensemble of decision trees. However, the trees in a Random Forest differ from standard decision trees in that each tree starts with a subset of the samples, chosen via random sampling with replacement. Also differing from standard decision trees, the features being considered at each node are a random subset, with the number of features provided by a parameter. Once a forest has been generated, the importance of each feature can be calculated from node impurity, such as the Gini index for classification or variance explained for regression, or permutation importance. Unlike a single decision tree, a Random Forest is a strong learner, because it averages many weak learners and avoids putting too much weight on outlier decisions. The number of trees in a forest is a parameter that is chosen by the user and influences the accuracy of the model.
Iterative Random Forest expands on the Random Forest method by adding an iterative boosting process, producing a similar effect to Lasso in a linear model framework. First, a Random Forest is created where features are unweighted and have an equal chance of being randomly sampled at any given node. The resulting importance scores for the features are then used to weight the features in the next forest, thus increasing the chance that important features are evaluated at any given node. This process of weighting and creating a new Random Forest is repeated
i times, where
i is set by the user. Due to the ability to easily follow the decisions that these models make, they have been deemed explainable-AI (X-AI) [
1], which differs from many standard machine and deep learning methods.
For both Random Forest and Iterative Random Forest, the total number of features, samples, trees, and iterations (for iRF) all influence run time to differing degrees. Most of the computation time is spent creating the decision trees, so run time scales with the number of trees. The number of samples influences the number of decisions within a tree needed to divide the data into homogeneous subsets. This influences the number of nodes created in a tree, and thus the run time per tree. Furthermore, the number of features influences the amount of time required to find the feature that best divides the samples at any given node. Finally, for iRF, a whole new forest must be generated for each iteration, though the run time for subsequent forests tends to diminish as many feature weights are set to zero. The number of iterations allows the user to find a balance between over- and under-parameterization of the model, by progressively eliminating features.
2.2. Implementation of iRF in C++
We used Ranger [
9], an open source Random Forest implementation in C++, as the core of our iRF implementation. Ranger already implements the decision tree and forest creation aspects, but implements neither the communication necessary for running on multiple compute nodes of a distributed HPC system, nor the iterative aspect of iRF.
Within our implementation, each decision tree is initialized with a random subset of the data sample vectors and is then built in an independent process. Groups of trees (sub-forests) are built on compute nodes and then sent to a master compute node that aggregates them into a full Random Forest. This is done by giving each sub-forest a randomly generated seed number which determines the random subset of data each tree in a sub-forest uses, allowing for a higher likelihood of unique random data subsets on each tree. Once in the form of a single Random Forest, Ranger’s functions for forest analysis are used, including feature importance aggregation.
On a distributed system, where parts of the forest are created on different compute nodes, the aggregation of results requires most of the inter-node communication. This process relies on MPI (the Message Passing Interface), an internode-communication standard for parallel programming, and Open-MPI [
10], an open source C library containing functions that follow the MPI standard.
To implement i iterations, the forest creation and aggregation is performed i times. After the completion of each iteration, the feature weights are written to a file. At the beginning of the next iteration, this file is read into an array that is used to create the weighted distribution from which features are sampled during the decision process at each node on each tree. This process, while potentially slow due to the file I/O, uses the preexisting functionality of weighted sampling from Ranger.
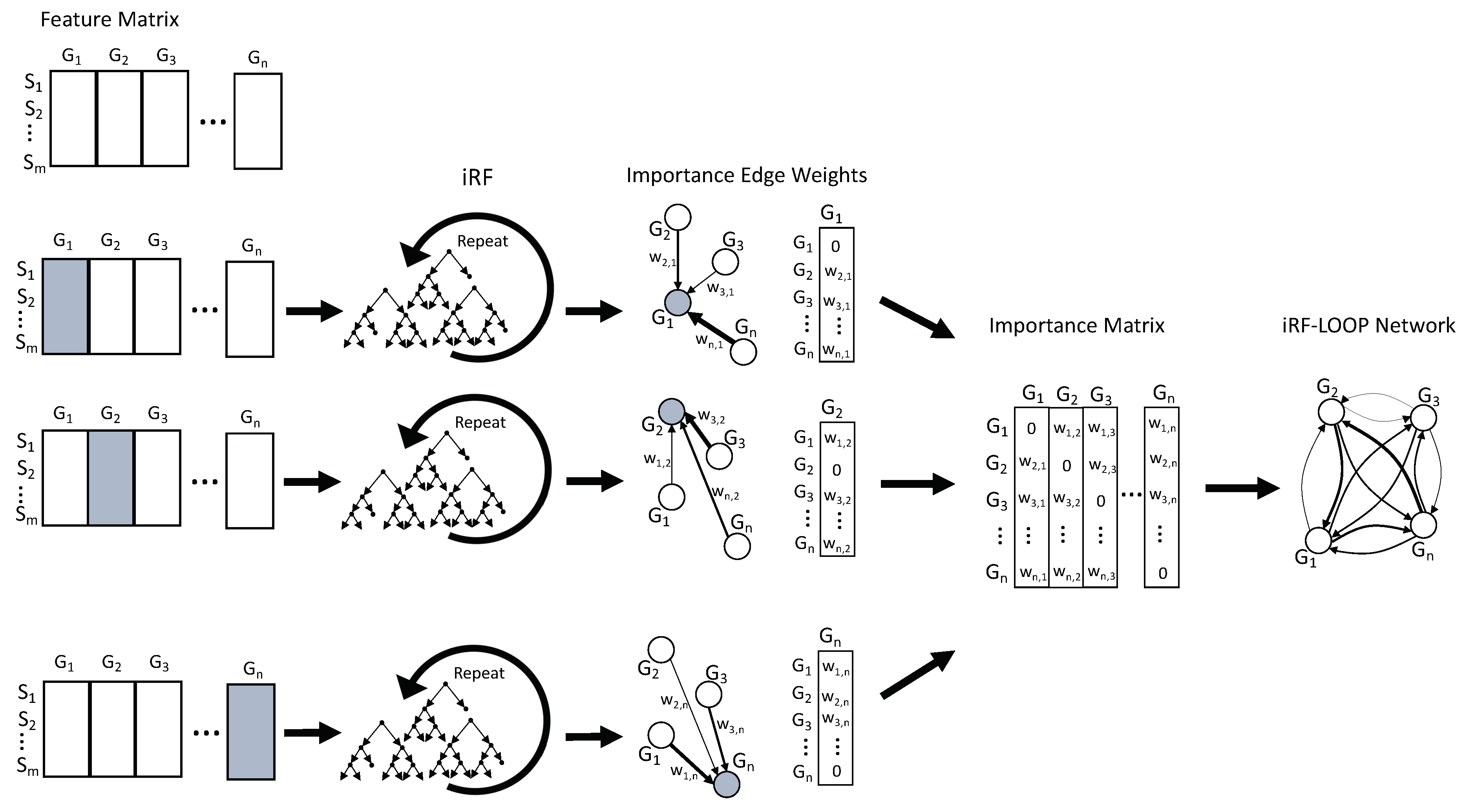
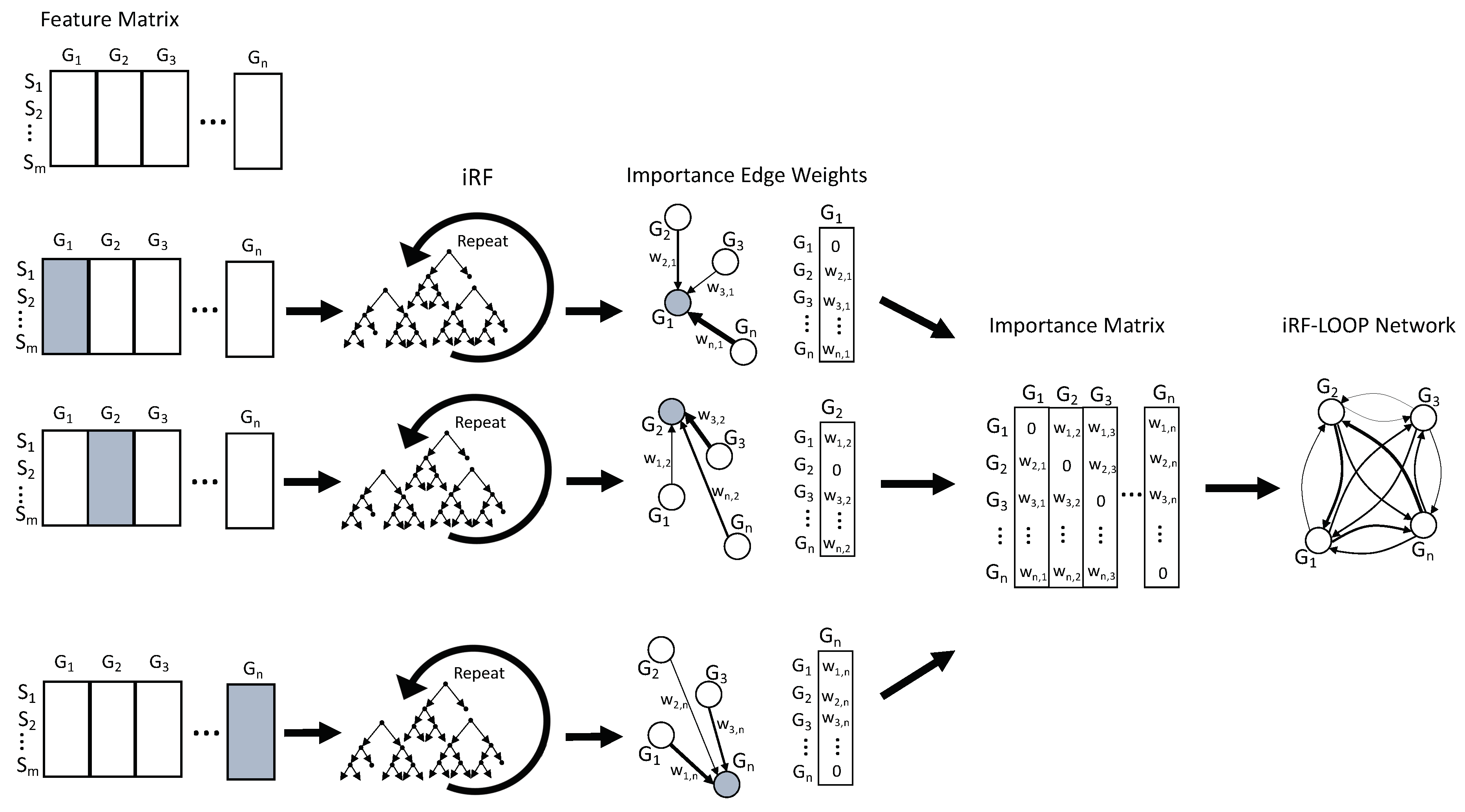
2.3. iRF-LOOP: iRF Leave One out Prediction
Given a data set of
n features and
m samples, iRF Leave One Out Prediction (iRF-LOOP) starts by treating one feature as the dependent variable (Y) and the remaining
n − 1 features as predictor matrix (X) of size
m x n − 1. Using an iRF model, the importance of each feature in X, for predicting Y, is calculated. The result is a vector, of size
n, of importance scores (the importance score of Y, for predicting itself, has been set to zero). This process is repeated for each of the
n features, requiring
n iRF runs. The
n vectors of importance scores are concatenated into an
n x n importance matrix. To keep importance scores on the same scale across the importance matrix, each column is normalized relative to the sum of the column. The normalized importance matrix can be viewed as a directional adjacency matrix, where values are edge weights between features. See
Figure 1 for a diagram of this process. Due to the nature of iRF, the adjacency matrix is not symmetric as feature A may predict feature B with a different importance than feature B predicts feature A.
2.4. Big Data: Showing the Scale of iRF with Arabidopsis thaliana SNP Data
A typical use case of iRF, with a matrix of features and a single target vector of outcomes, becomes comparable to an X-AI-based eQTL analysis, when the matrix of features is a set of single nucleotide polymorphisms (SNPs) and the dependent variable vector is a gene’s expression measured across samples. This analysis determines which set(s) of SNPs are important to variation in the gene’s expression.
We obtained
Arabidopsis thaliana SNP data from the Weigel laboratory at the Max Planck Institute for Developmental Biology, available at
https://1001genomes.org/data/GMI-MPI/releases/v3.1/. We filtered the SNPs using bcftools 1.9 [
11] to keep only those that were biallelic, had a minor allele frequency greater than 0.01, and had less than ten percent missing data across the population. This resulted in a set of 1.71 million SNPs for 1135 samples, from the original 11.7 million SNPs.
We obtained
Arabidopsis thaliana expression data [
12] from 727 samples and 24,175 genes. Of these 727 samples, 666 samples were also present in the SNP data set. The vector of gene expression values for gene AT1G01010 for those 666 samples was used as the dependent variable for iRF. The feature set was the full set of 1.71 million SNPs, for the same 666 samples. While this is not many samples, this is clearly many features.
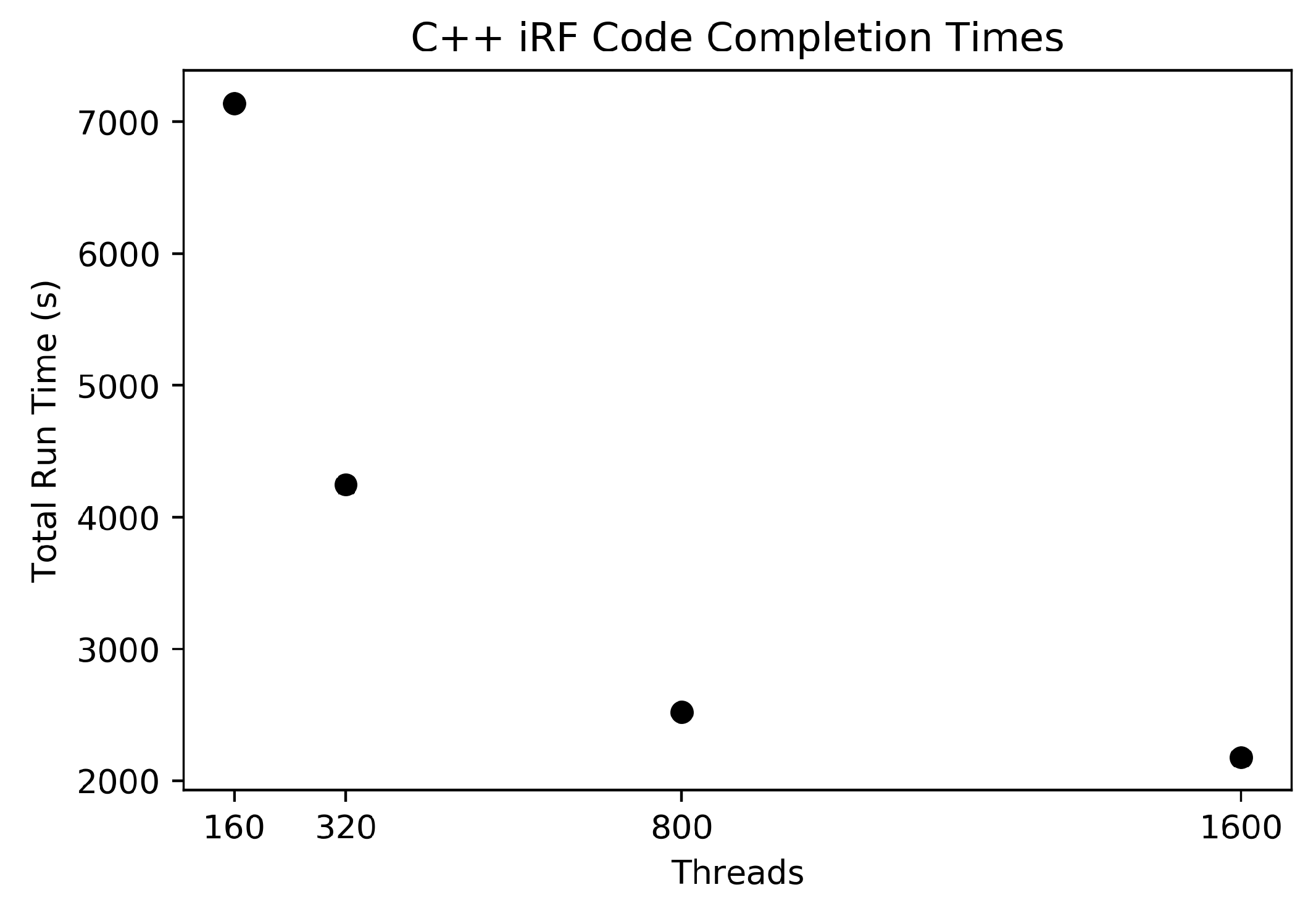
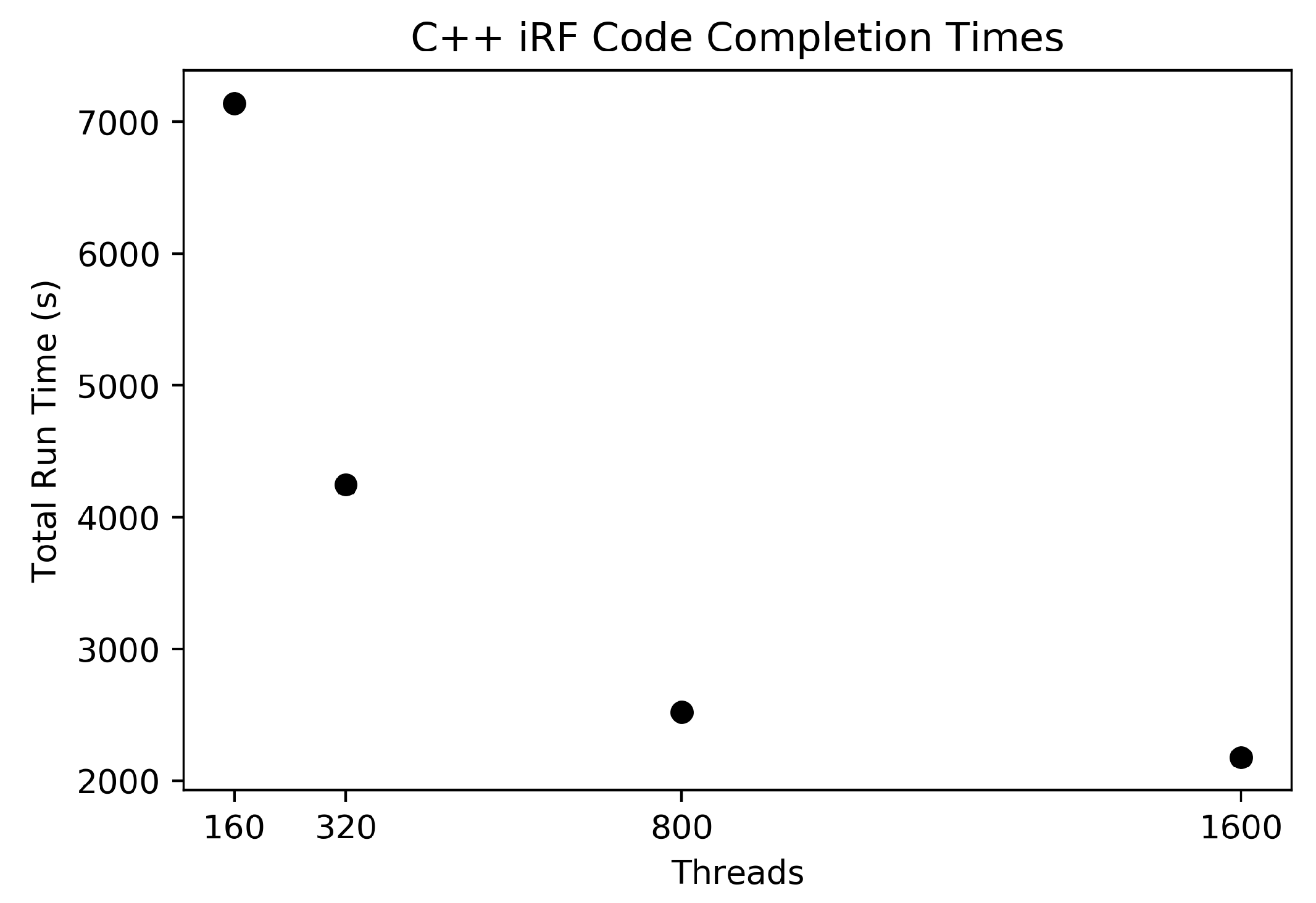
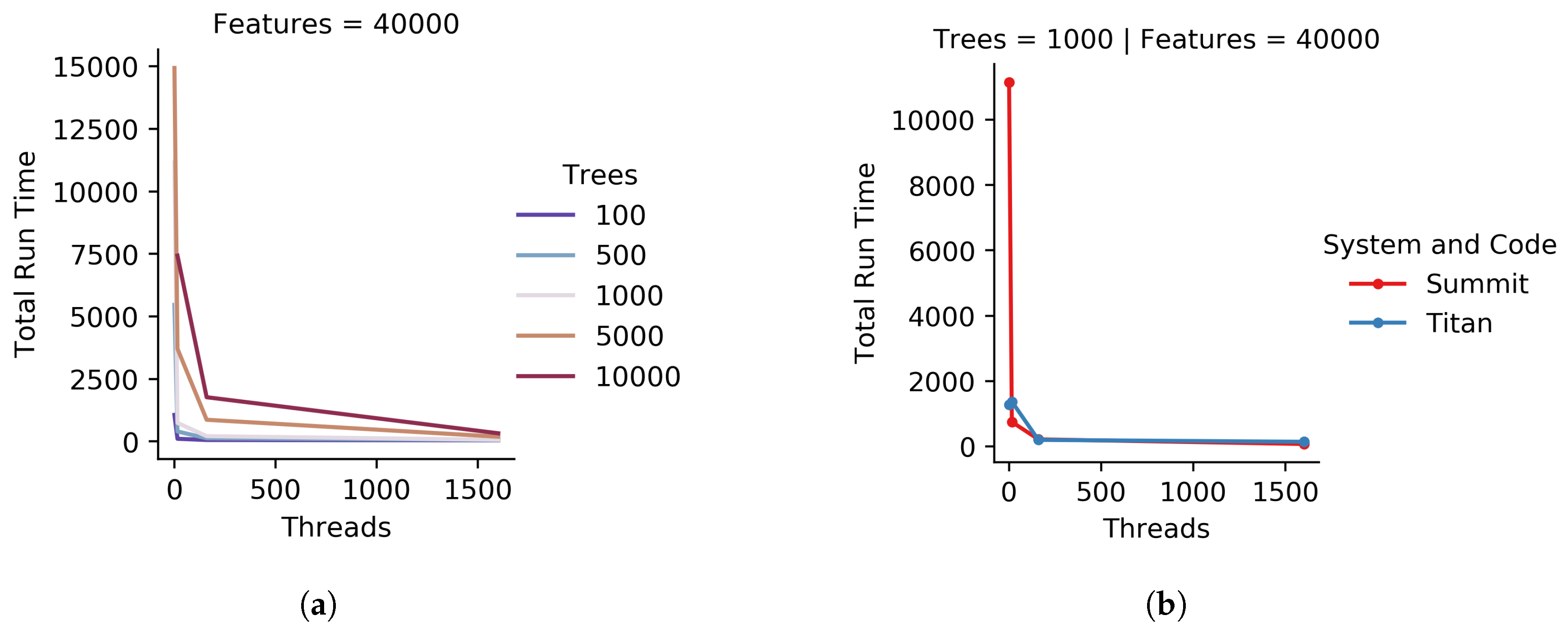
The C++ iRF code was run using these data as input with five iterations, each generating a forest containing 1000 trees. The number of trees was chosen as a value close to the square root of the number of features (a common setting for this parameter), where each feature has a 95% chance of being included in the feature subset within the first two layers in at least one tree. This helps to guarantee that all features are considered at least once across an iteration. HPC node quantities of 1, 2, 5, and 10 were used to show run time changes as the amount of resources increases.
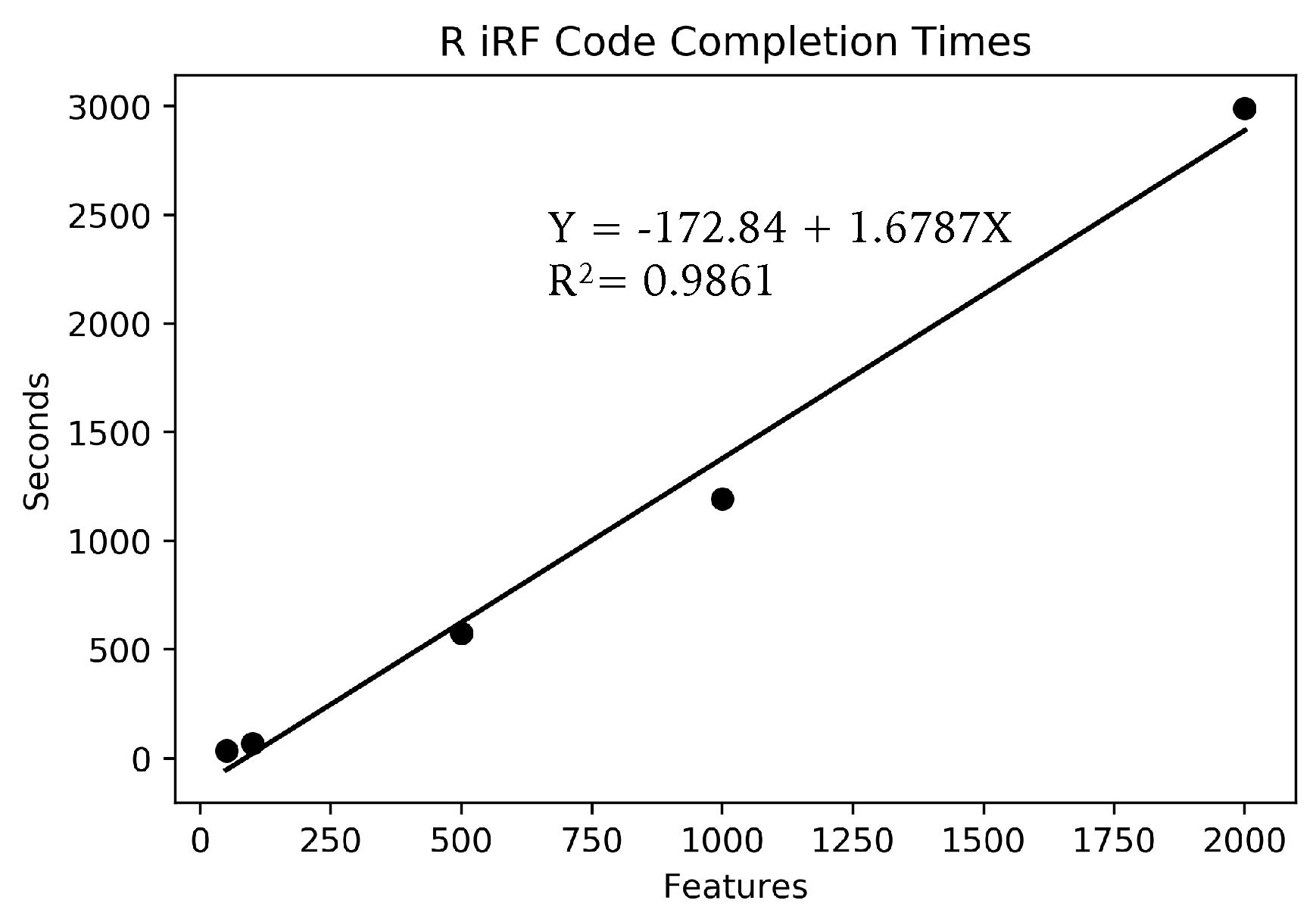
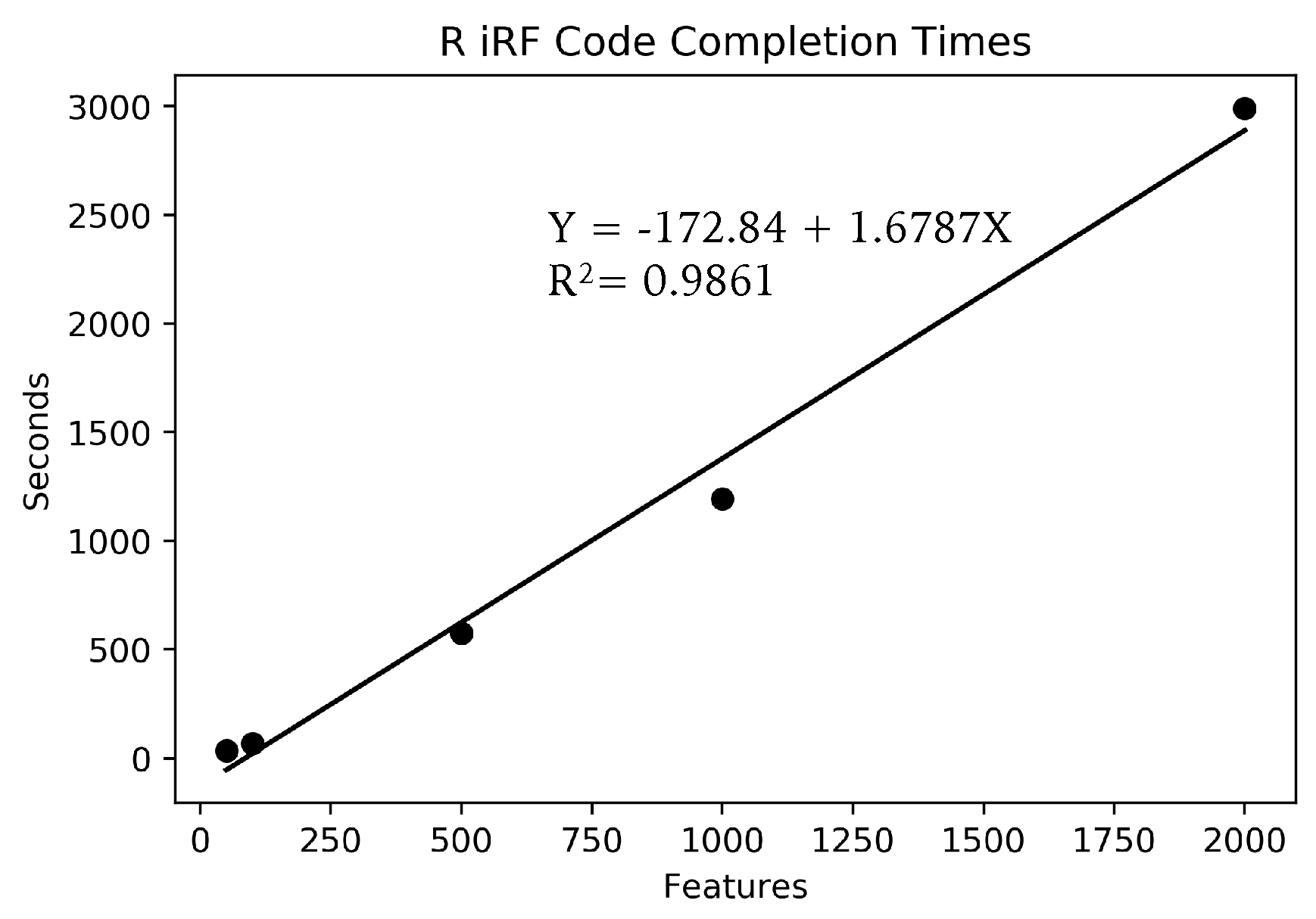
Due to the large number of SNPs, the full data could not fit in memory on a standard laptop, for use in the R iRF program. Instead, small subsets of features of sizes 2000, 1000, 500, 100 and 50 features were run, each using the full 666 samples and the same AT1G01010 gene expression dependent variable. Each feature set was run three times and averaged to account for the inherent stochasticity in the algorithm. Only one run was performed for each parameter set on Summit with the full data set due to limited compute time availability.
2.5. Using iRF-LOOP to Create Predictive Expression Networks
Given a matrix of gene expression data, there are a multitude of approaches for inferring which genes potentially regulate the expression of other genes, ranging in complexity from pairwise Pearson Correlations to advanced methods such as Aracne [
13], Genie3 [
14], and dynamic Bayesian networks (DBNs) [
15]. Due to the large number of features and the complexity of the interactions between them, Random Forest-type approaches are well suited to this task.
We applied iRF-LOOP to a matrix of gene expression data measured in 41,335 genes across 720 genotypes of
Populus trichocarpa (Black cottonwood). The RNAseq data [
16] from were obtained from the NCBI SRA database (SRA numbers: SRP097016– SRP097036;
www.ncbi.nlm.nih.gov/sra). Reads were aligned to the
Populus trichocarpa v.3.0 reference [
17]. Transcript per million (TPM) counts were then obtained for each genotype, resulting in a genotype–transcript matrix, as referenced in [
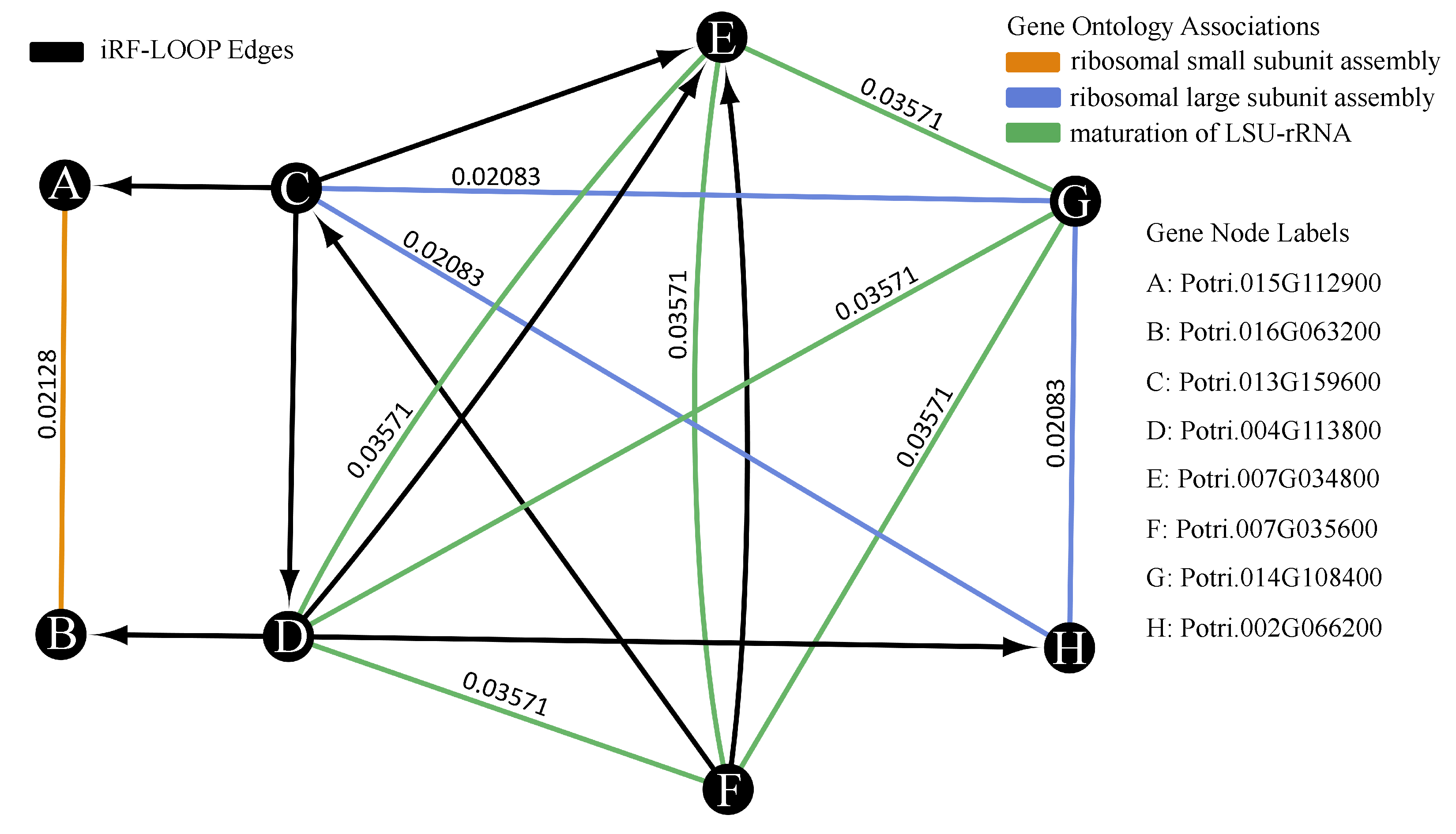
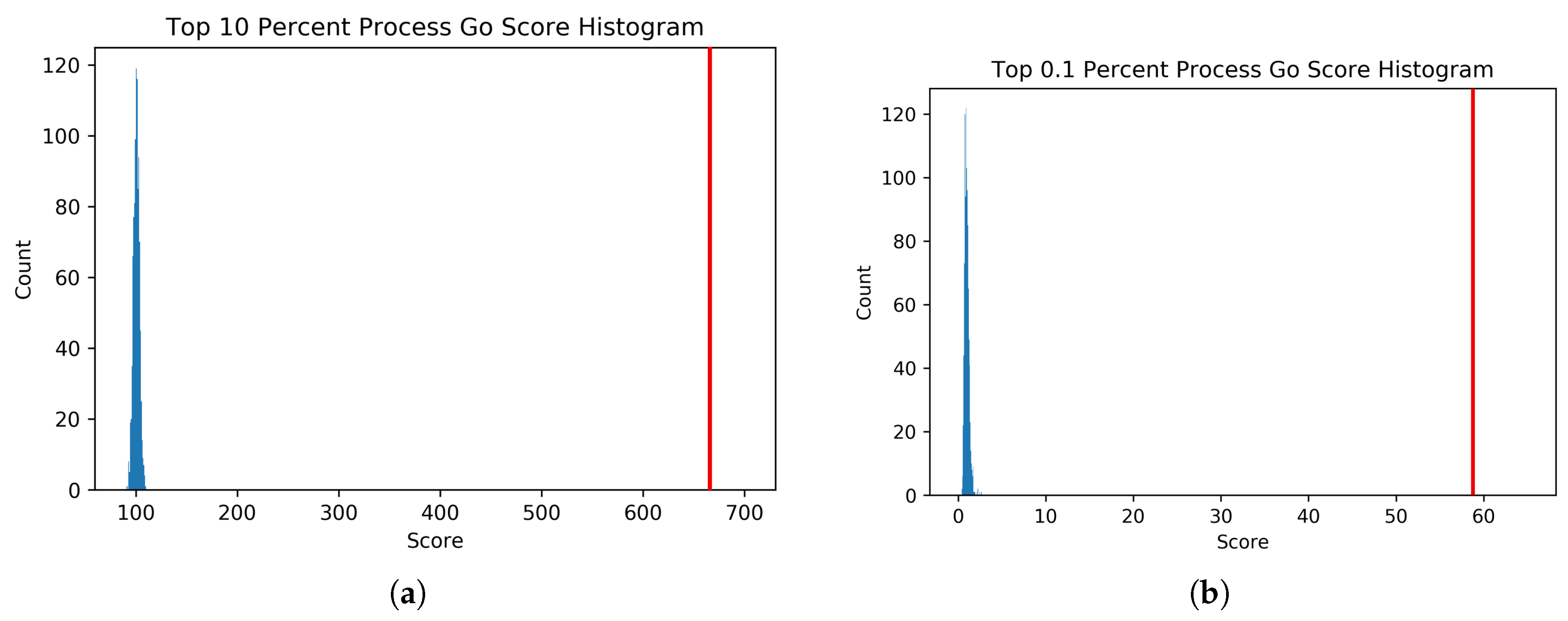
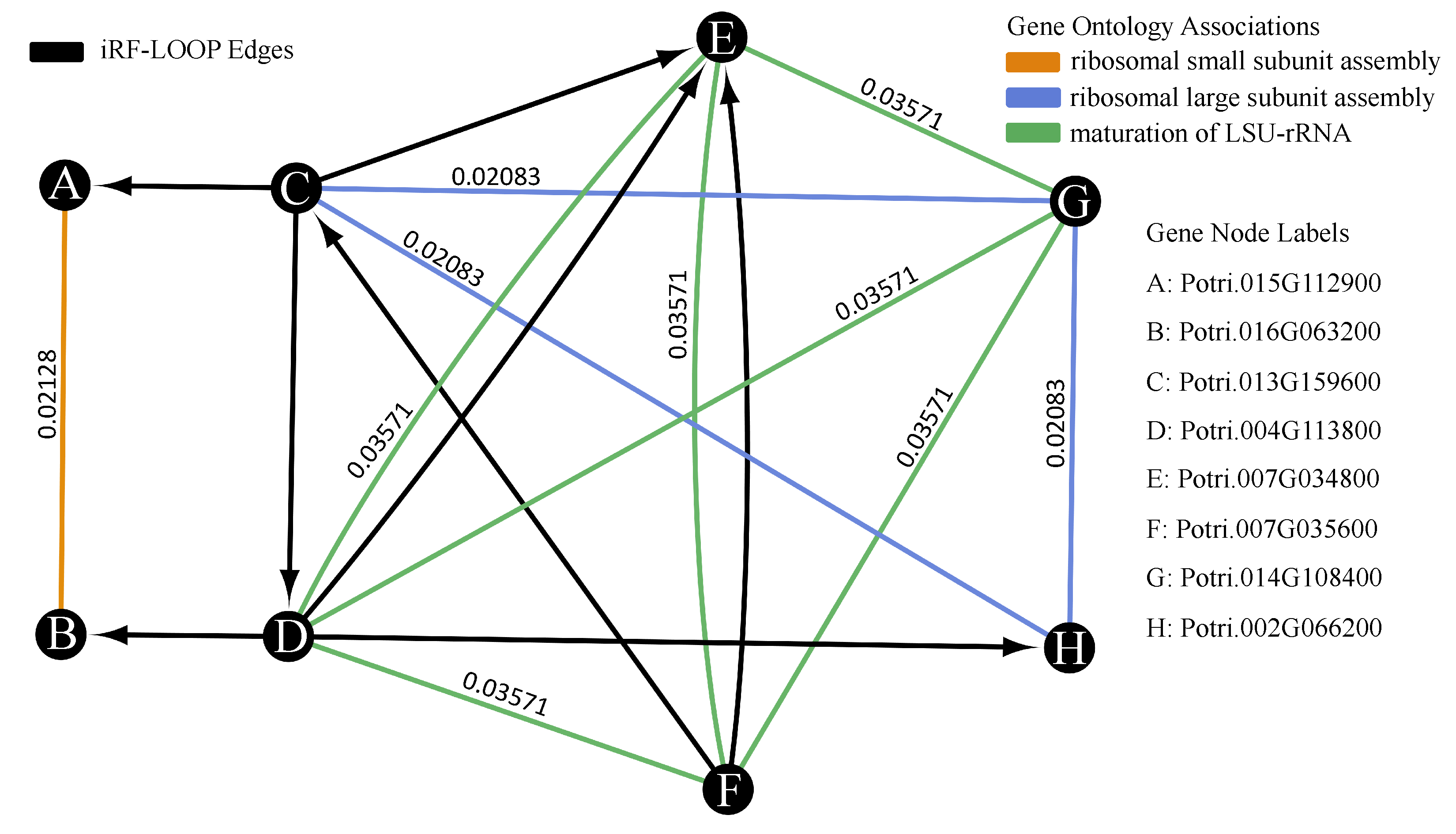
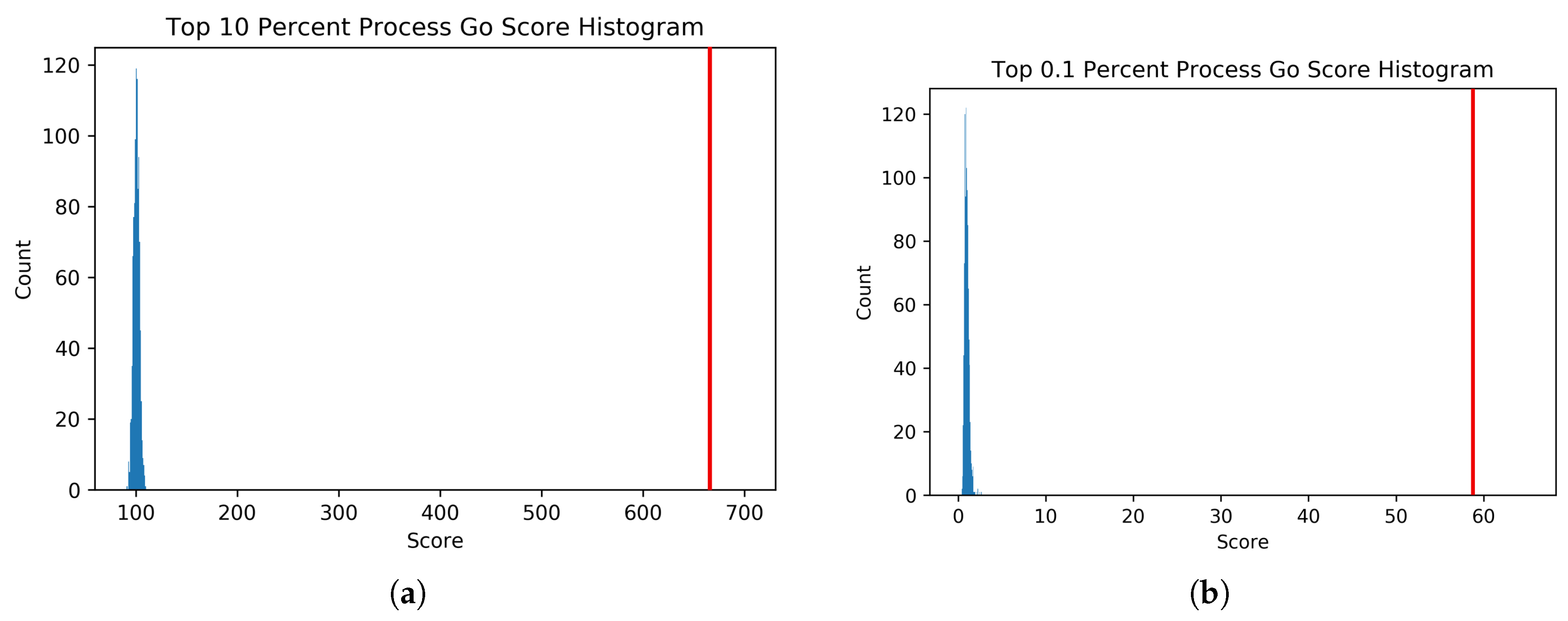
18]. The adjacency matrix resulting from iRF-LOOP represents a Predictive Expression Network (PEN) where a directed edge (AB) between and two genes (A and B) is weighted according to the importance of gene A’s expression in predicting gene B’s expression, conditional on all other genes in the iRF model. We removed zeros and produced four thresholded networks, keeping the top 10%, 5%, 1%, and 0.1% of edge scores, respectively.
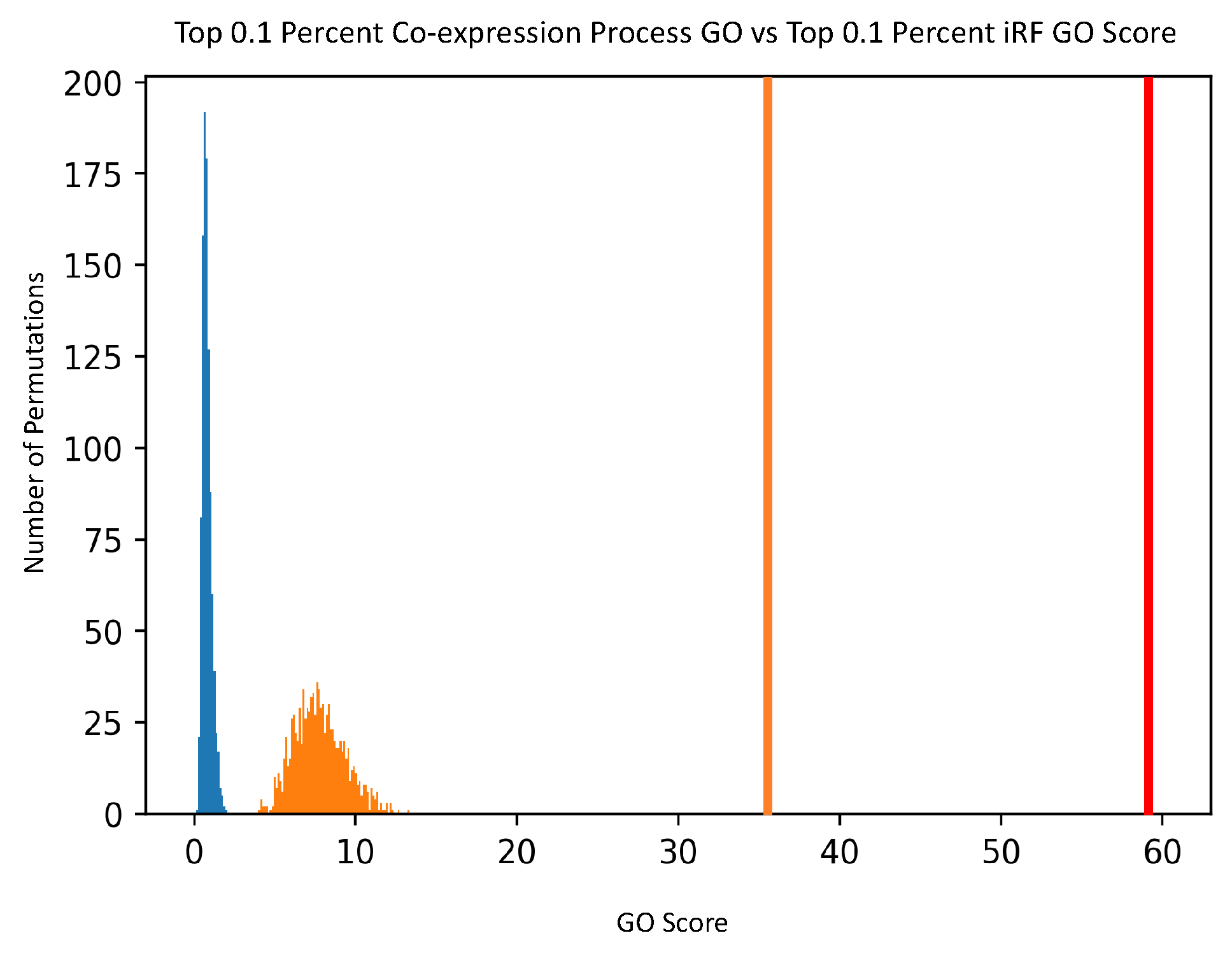
To determine the biological significance of the PEN produced by the iRF-LOOP, we compared each of the four thresholded networks to a network of known biological function, created from Gene Ontology (GO) annotations. GO is a standardized hierarchy of gene descriptions that captures the current knowledge of gene function. It is accepted that there is both missing information and some error, nevertheless it is useful as a broad truth set for large sets of genes. We calculated scores for each network by intersecting with the GO network. We then evaluated the probability of achieving such scores relative to random chance by creating null distributions of scores produced by random permutation of the iRF-LOOP networks and calculated t-statistics for each threshold.
We created a Populus trichocarpa GO network for the Biological Process (BP) GO terms, using annotations from [
19]. Genes are connected if they share one or more GO terms. Due to the hierarchical nature of the Gene Ontology, a term shared by only a few genes, indicates a very detailed and specific association, where the associations shared by many genes are generally broad categorizations. The edge weight between two genes equals
, where
n is the number of genes with the shared term. This weighting attempts to balance the scoring metric so that correctly identifying rare edges is not out weighted by simply capturing many generic GO terms. Genes that share a GO term create connected sets of genes, where each gene has an edge with each other gene in the set. A predicted network’s intersect score is a summation of all GO edge weights from edges that appear in both the GO and predicted networks. For example, if the predicted network has an edge between gene A and gene B, and the GO network also has an edge between gene A and B with a weight of X, then the intersect score would increase by X. If two genes share more than one GO term, then the largest weight is used for the edge. To avoid edges between very loosely associated genes, only GO terms with less than 1000 genes were used for this analysis. The resulting network provides the relationship between genes that share some level of known functionality.
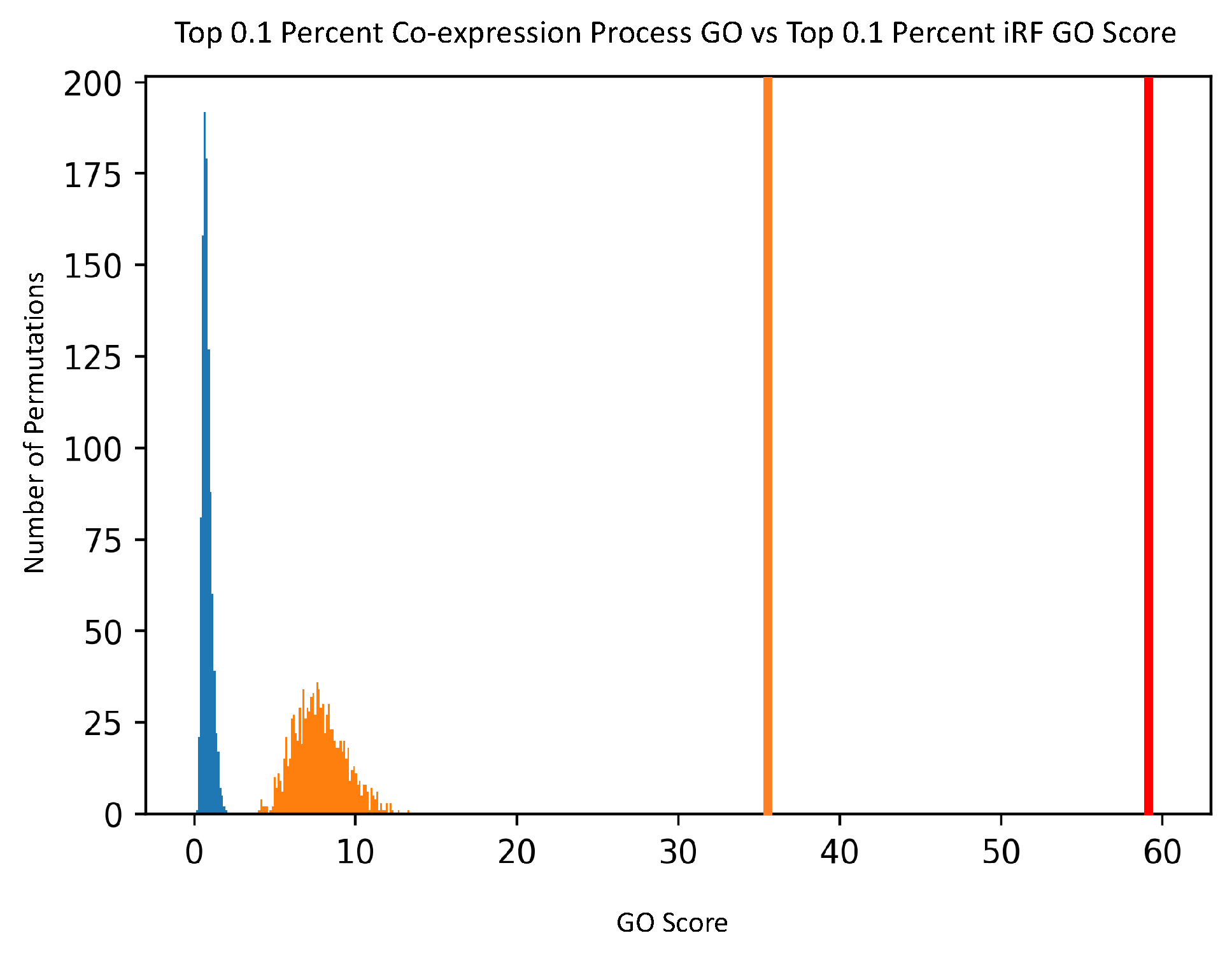
To generate the null distribution of intersect scores for each thresholded PEN, the node labels of each network were randomly permuted 1000 times, and each random network was scored against the GO network. From these null distributions, t-statistics were calculated for the score of each thresholded Predictive Expression Network.
For comparison purposes, the noted GO scoring process was also done on a Pearson’s Correlation-generated network, creating co-expression scores. The input data was the same expression data, and Pearson’s Correlation was calculated for each pair of genes. The top 0.1% of correlation values was then analyzed with the GO scoring process, and compared to the top 0.1% of edge scores from the PEN.
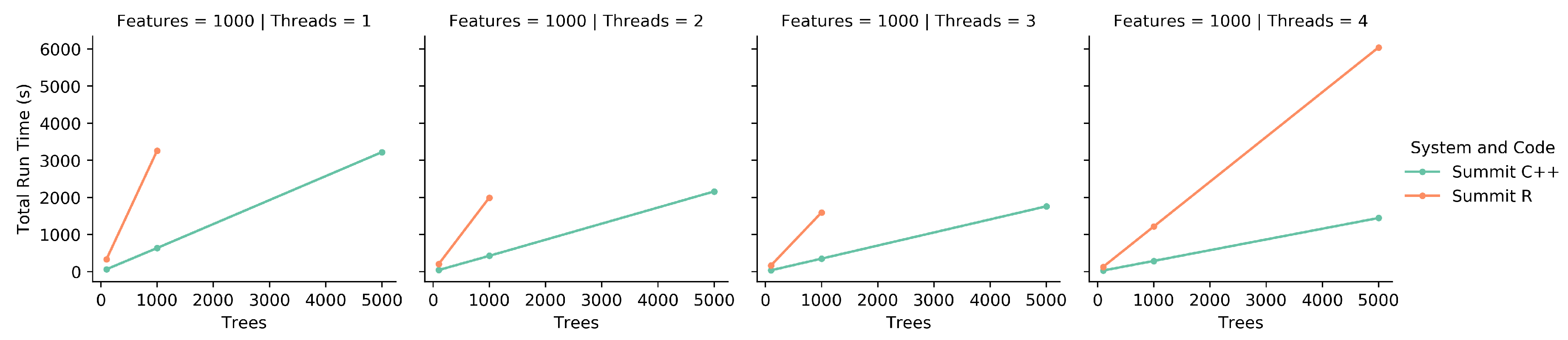
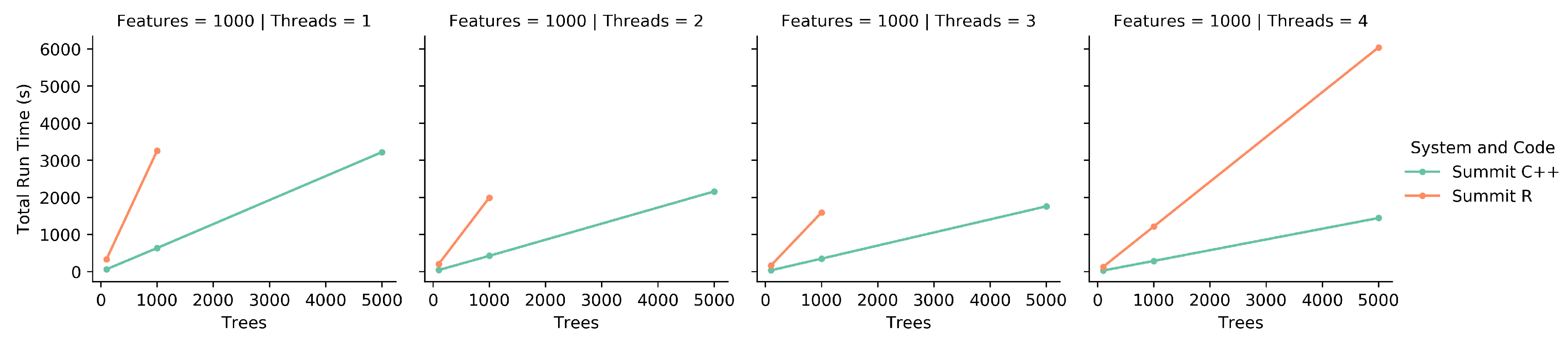
2.6. Comparison of R to C++ Code
To compare the original iRF R code to the new implementation, both were run on a single node of Summit with a variety of running parameters. These parameters included all combinations of 100, 1000, and 5000 trees and 1, 2, 3, and 4 threads for 1000 features. All combinations were run three times and the scores were averaged. Due to the R code’s doParallel [
20] back-end not being designed for an HPC system, the R code was limited to a single CPU on a node with up to four independent threads. For consistency, the new implementation was limited to the same resources. A subset of the
Populus trichocarpa expression data mentioned above was used as the feature set.
2.7. Computational Resources
The computational resources used in this work were Summit, Titan, and a 2015 MacBook Pro laptop. Summit is an Oak Ridge Leadership Computing Facility (OLCF) supercomputer located at Oak Ridge National Laboratory (ORNL). It is an IBM system with approximately 4600 nodes, each with two IBM POWER9 processors, each with 22 cores (176 hardware threads) and six NVIDIA VOLTAV100 GPUs, and 512 GB of DDR4 memory. Titan was a former OLCF supercomputer, recently decommission, and was a Cray system that had approximately 18,688 nodes, each with a 16-core AMD Opteron 6274 processor and 32 GB of DDR3 ECC memory. The 2015 MacBook Pro has a 3.1 GHz Intel Core i7 Processor and 16 GB of DDR3 memory.
4. Discussion
We have presented a high-performance computing-capable implementation of Iterative Random Forest. This implementation uses Ranger, C++, and MPI to use the resources available on multi-node computation resources. We have shown that our implementation can perform X-AI-based eQTL-type analyses with millions of SNPs and have shown its ability to scale with multiple parameters. Using iRF to complete a whole analysis of the 24,175 gene expression profiles for Arabidopsis thaliana, assuming each run took approximately the same time as the shown above, would take approximately 705 days using 5 nodes, or 84,680 compute node hours, or 18 h using 4600 Summit nodes. To complete the analysis for all 24,175 gene expression predictions on a laptop using the R code would take approximately 2191 years. While this comparison seems impressive, it should also be noted that for a larger feature set and larger number of trees the large resources will be even more appropriate as the scaling factor will be even less effected by overhead. For cases where the number of SNPs is 10 million and higher, the code should be even more efficient on HPC systems. However, as not everyone has access to the fastest computers in the world this code could still run efficiently on a smaller system using a smaller set of SNPs.
Using this new implementation, we developed iRF-LOOP and used it to produce Predictive Expression Networks which were shown to have biologically relevant information. The process of iRF-LOOP has the potential to be used for a wide variety of data analysis problems. With an appropriate amount of compute resources, it would be possible to build connected networks for each level of ’omics data available for a given species. The same concept could also be used to connect ’omics layers to each other as shown by using the SNPs in the X-AI-based eQTL analysis. This machine learning method is not limited to genetics or biology and has uses in other fields where systems can be represented as a matrix.
Downstream of any iRF analysis, there is the possibility of finding epistatic interactions among features from the resulting forests, using Random Intersection Trees (RIT) [
21]. This method works regardless of the data type for the features, where it can find sets of SNPs that influence gene expression or sets of genes that influence other gene’s expression, adding another set of nodes and groups to a Predictive Expression Network.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}