Multi-Temporal Agricultural Land-Cover Mapping Using Single-Year and Multi-Year Models Based on Landsat Imagery and IACS Data


Abstract
1. Introduction
- (1)
- How well do models based on a single year’s spectral information predict crops when tested on years not included in the model calibration process?
- (2)
- What is the prediction performance of models calibrated on spectral information from multiple years?
- (3)
- Is the accuracy of the classification models affected by field size?
2. Materials and Methods
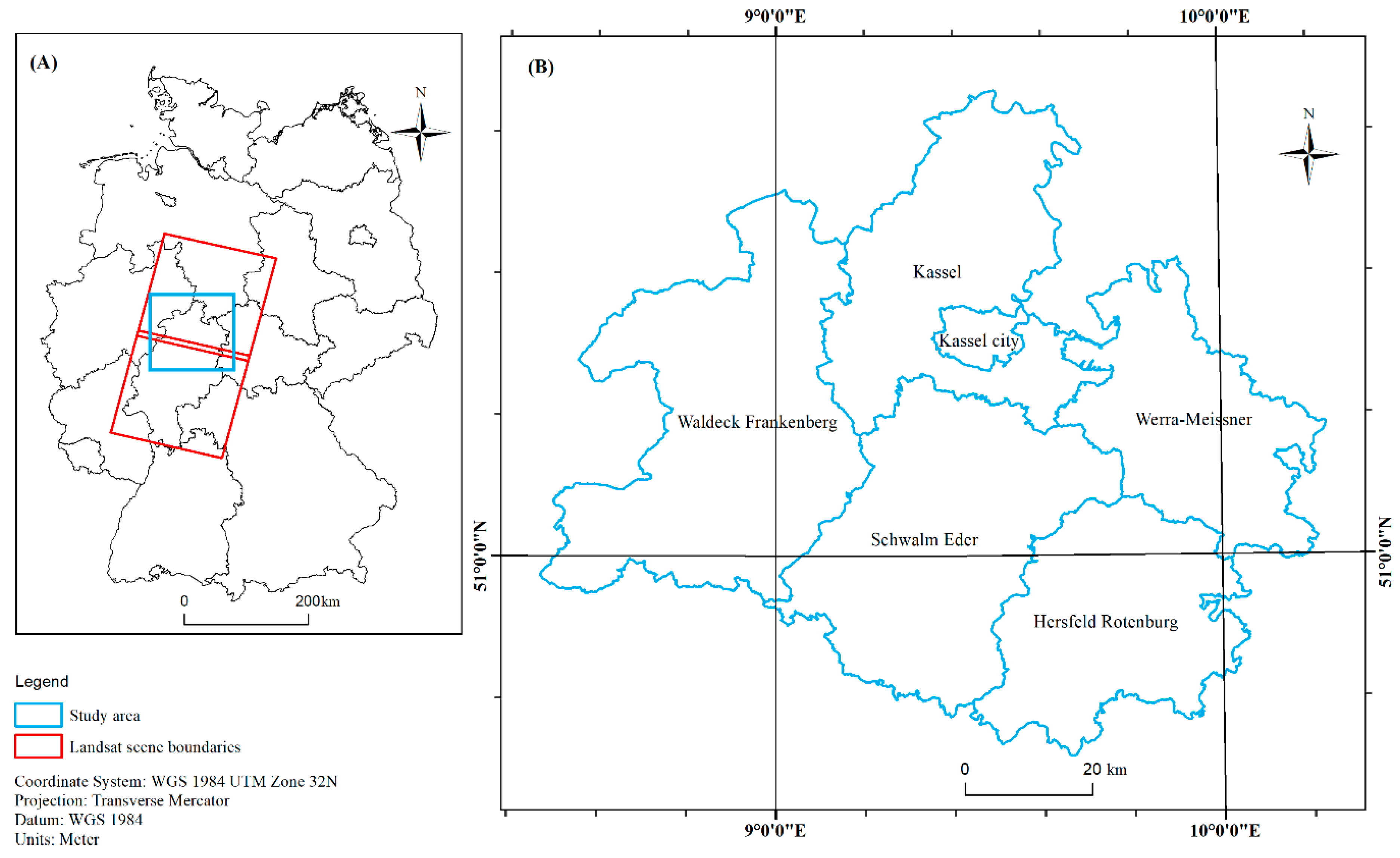
2.1. Study Area
2.2. Data
2.2.1. Satellite Data
2.2.2. Reference Data
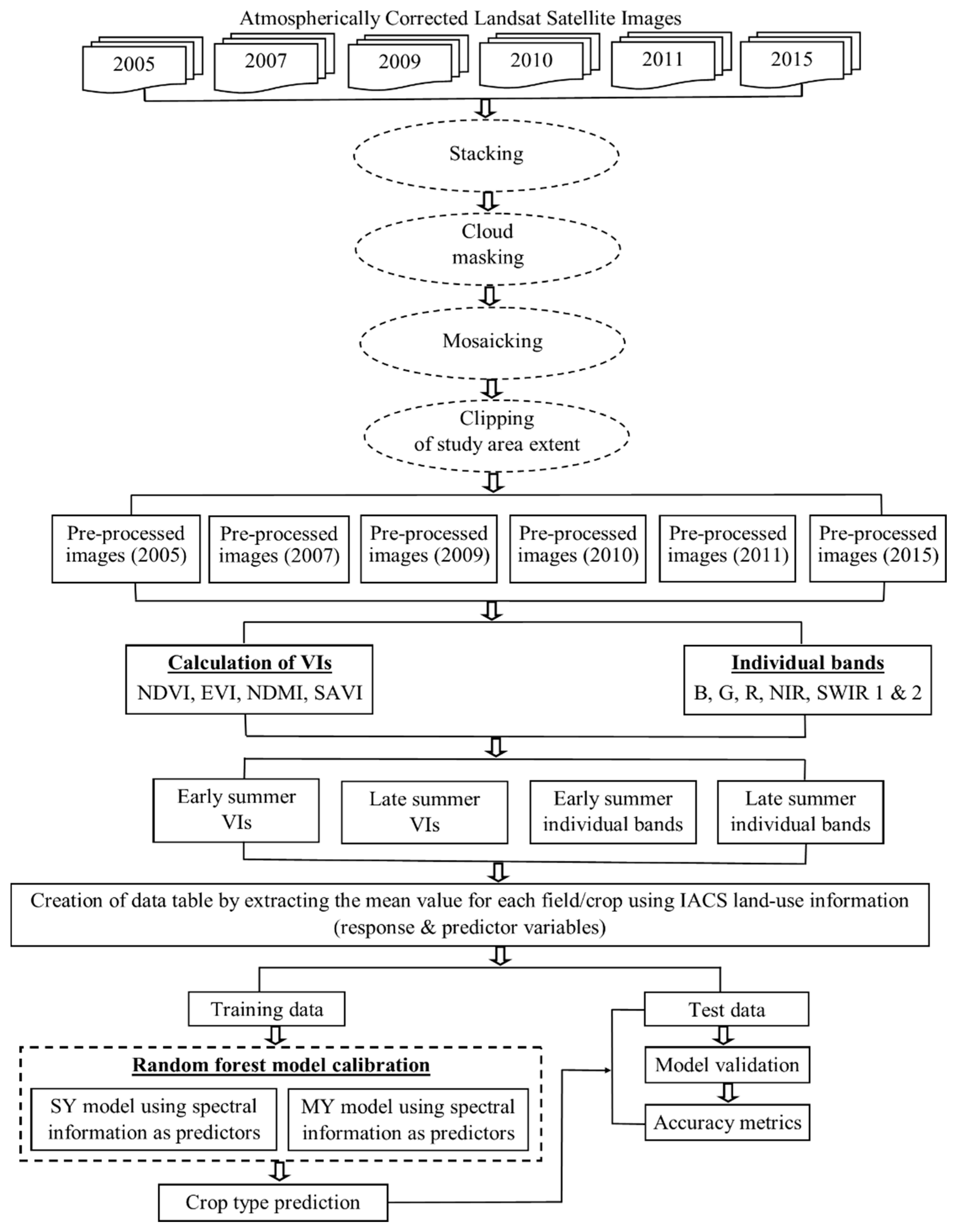
2.3. Data Processing
Image Pre-processing
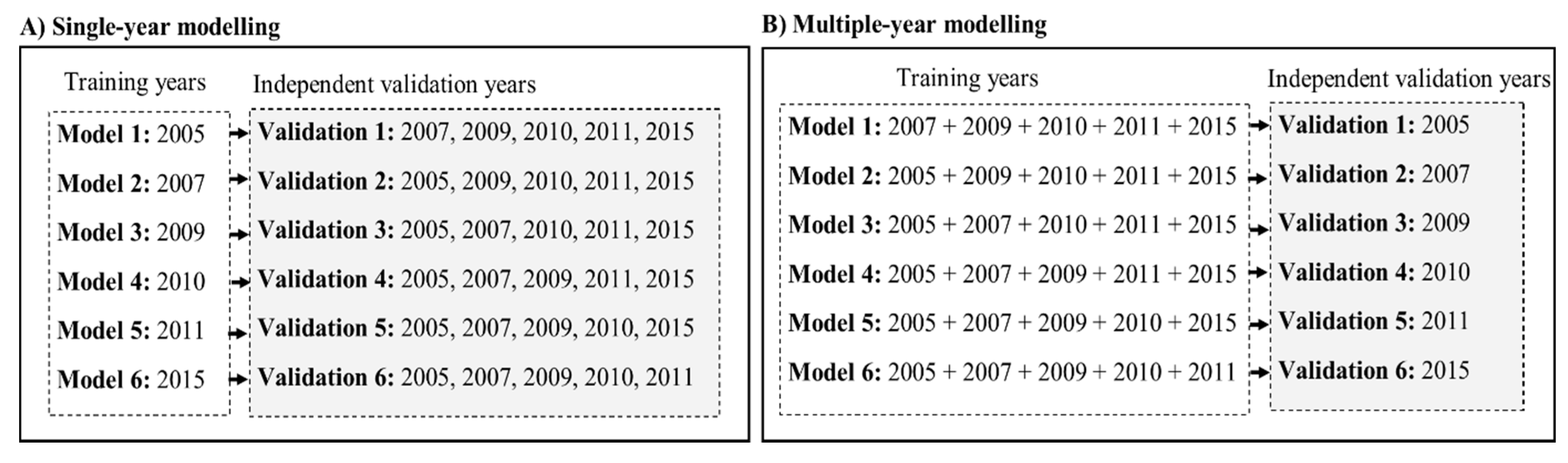
2.4. Model Calibration and Validation
2.4.1. Input Variables Used in the Model
2.4.2. Field-based Extraction of Spectral Information.
2.4.3. Crop Type Prediction Modelling
2.4.4. Accuracy Assessment
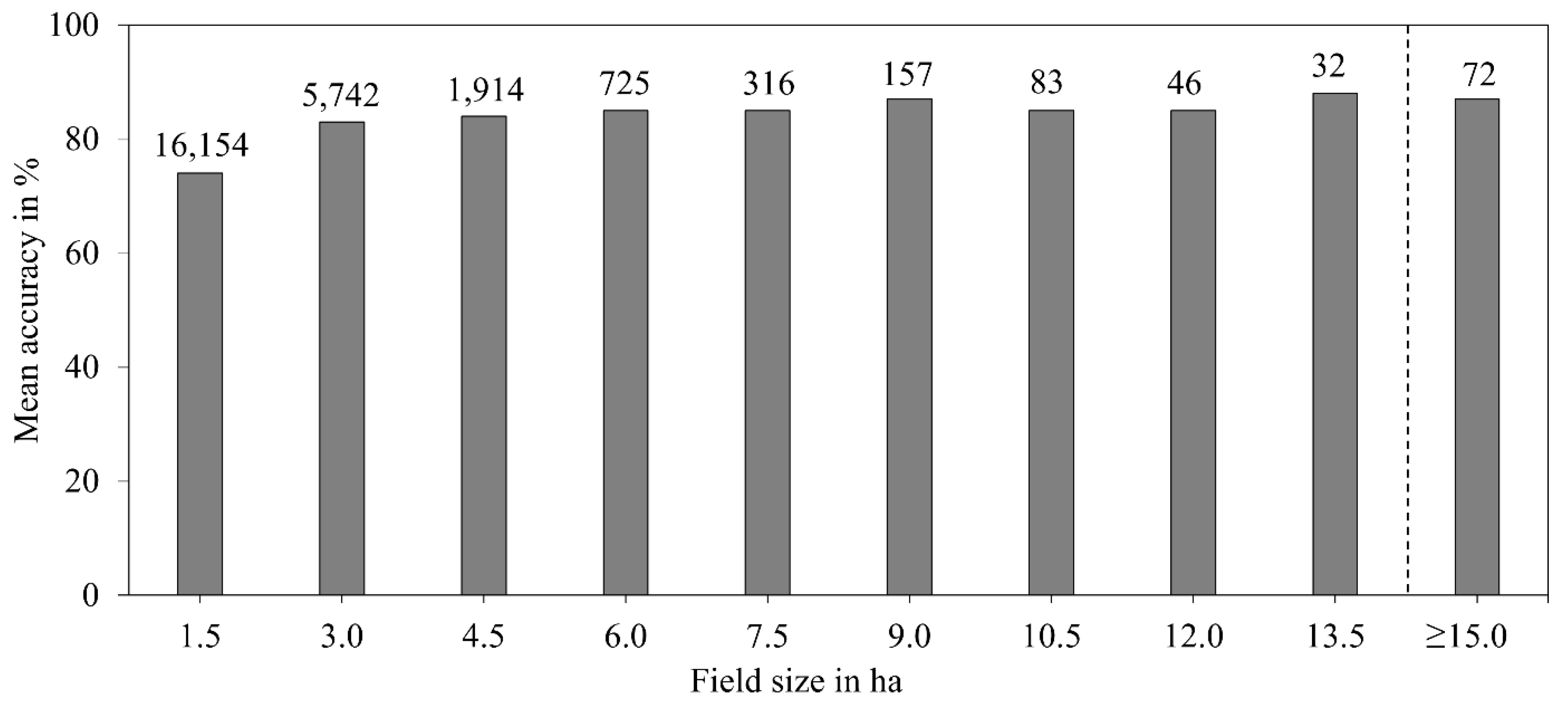
2.5. Relationship between Field Size and Accuracy
3. Results
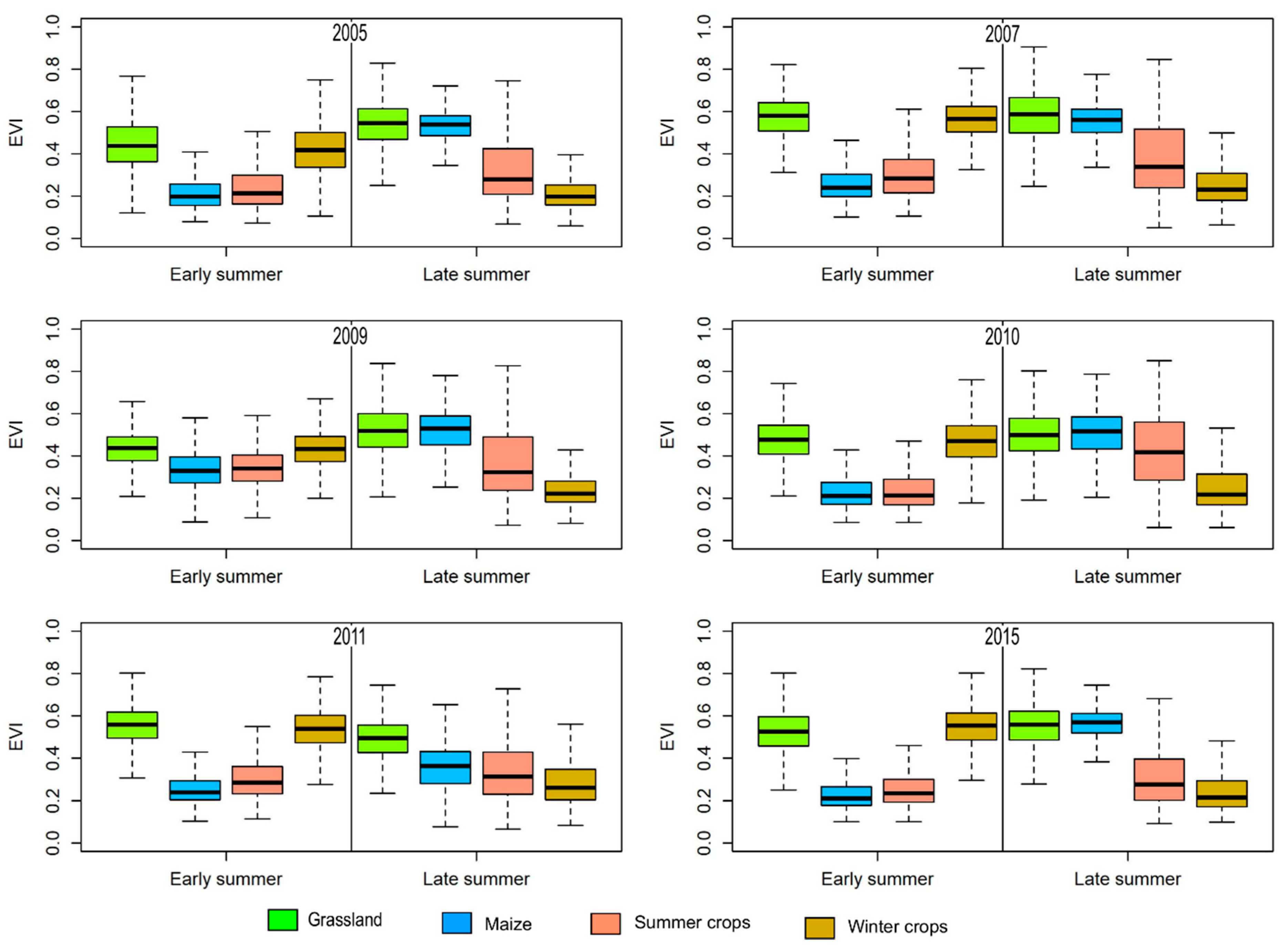
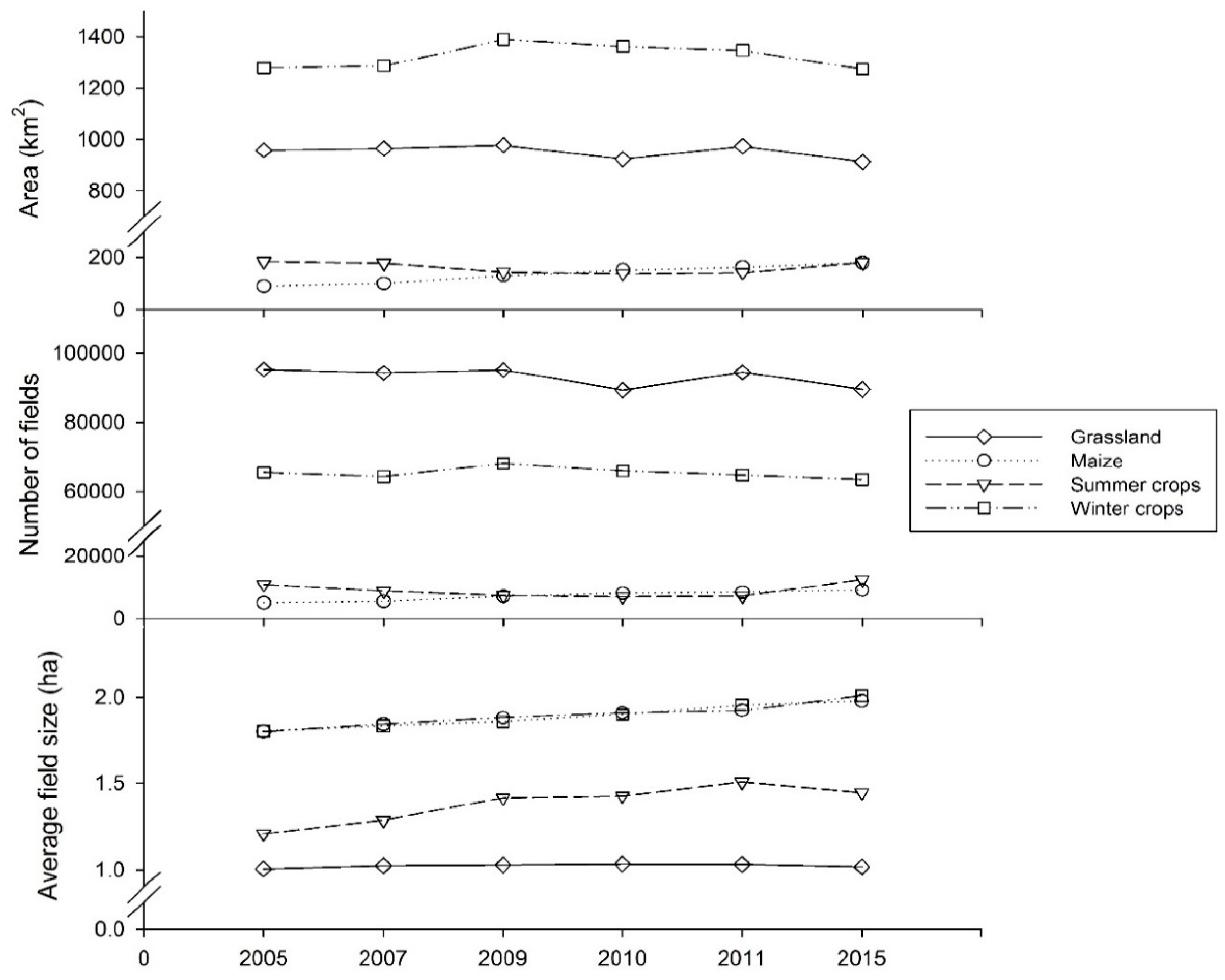
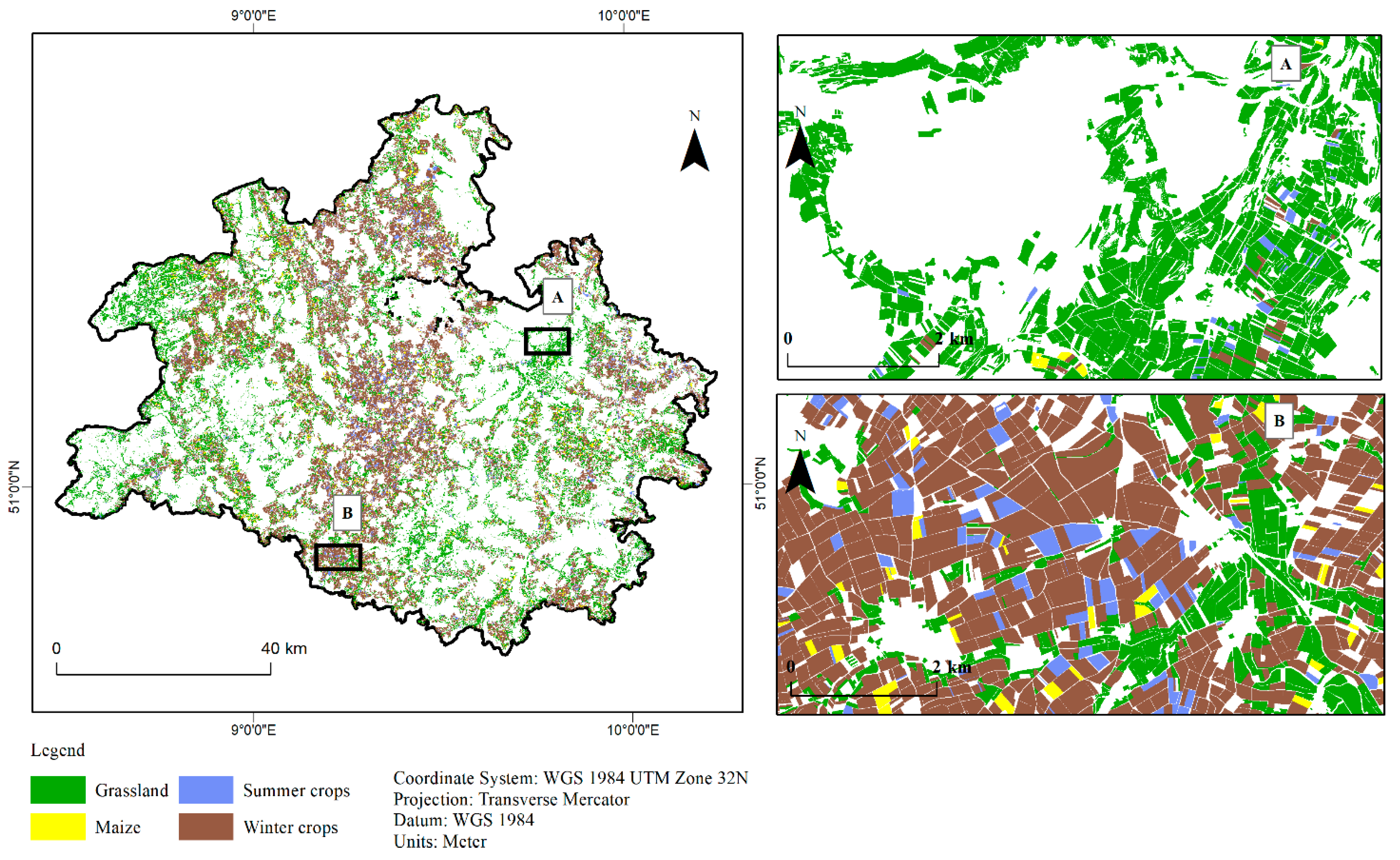
3.1. Agricultural Land Cover Data
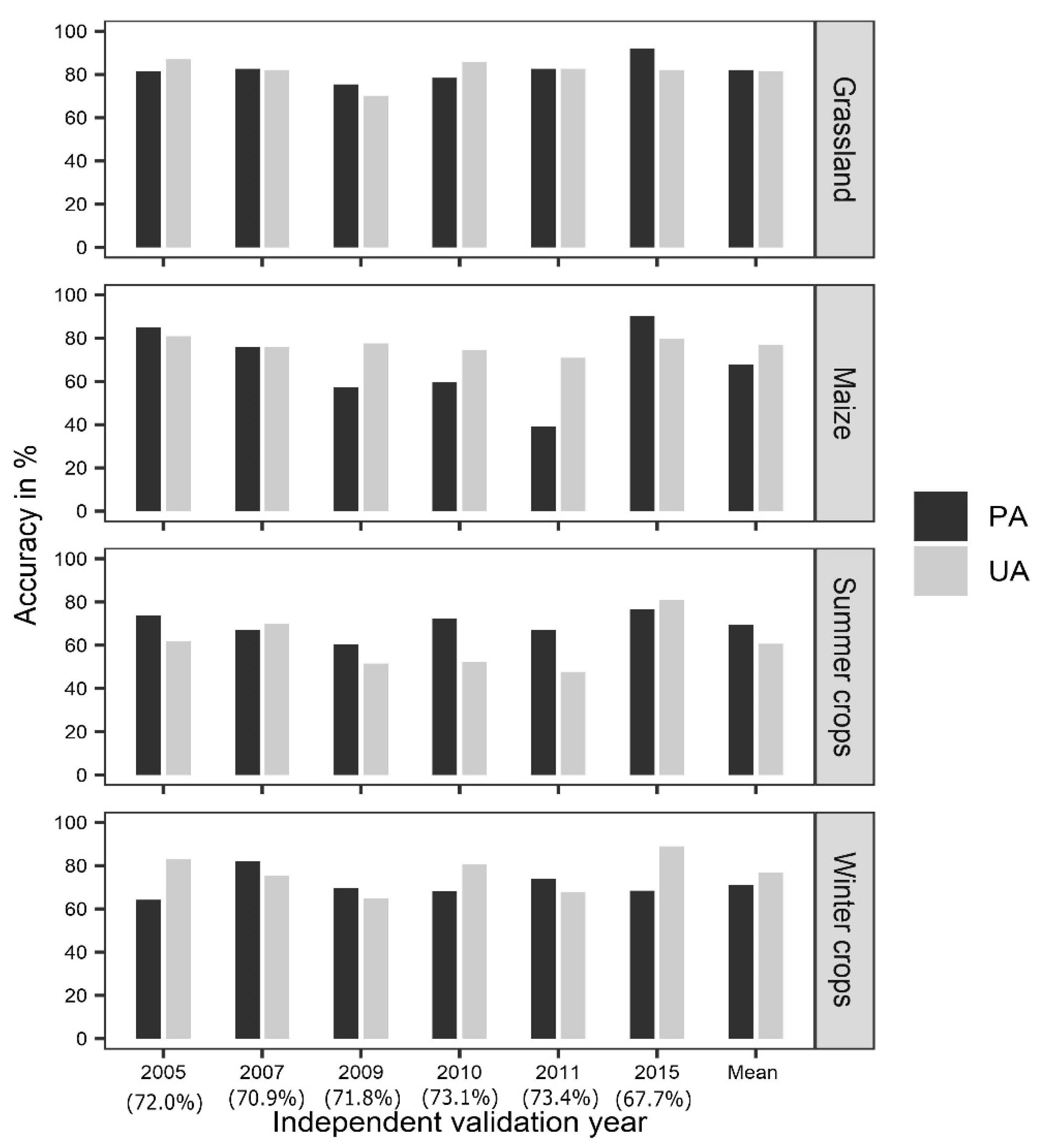
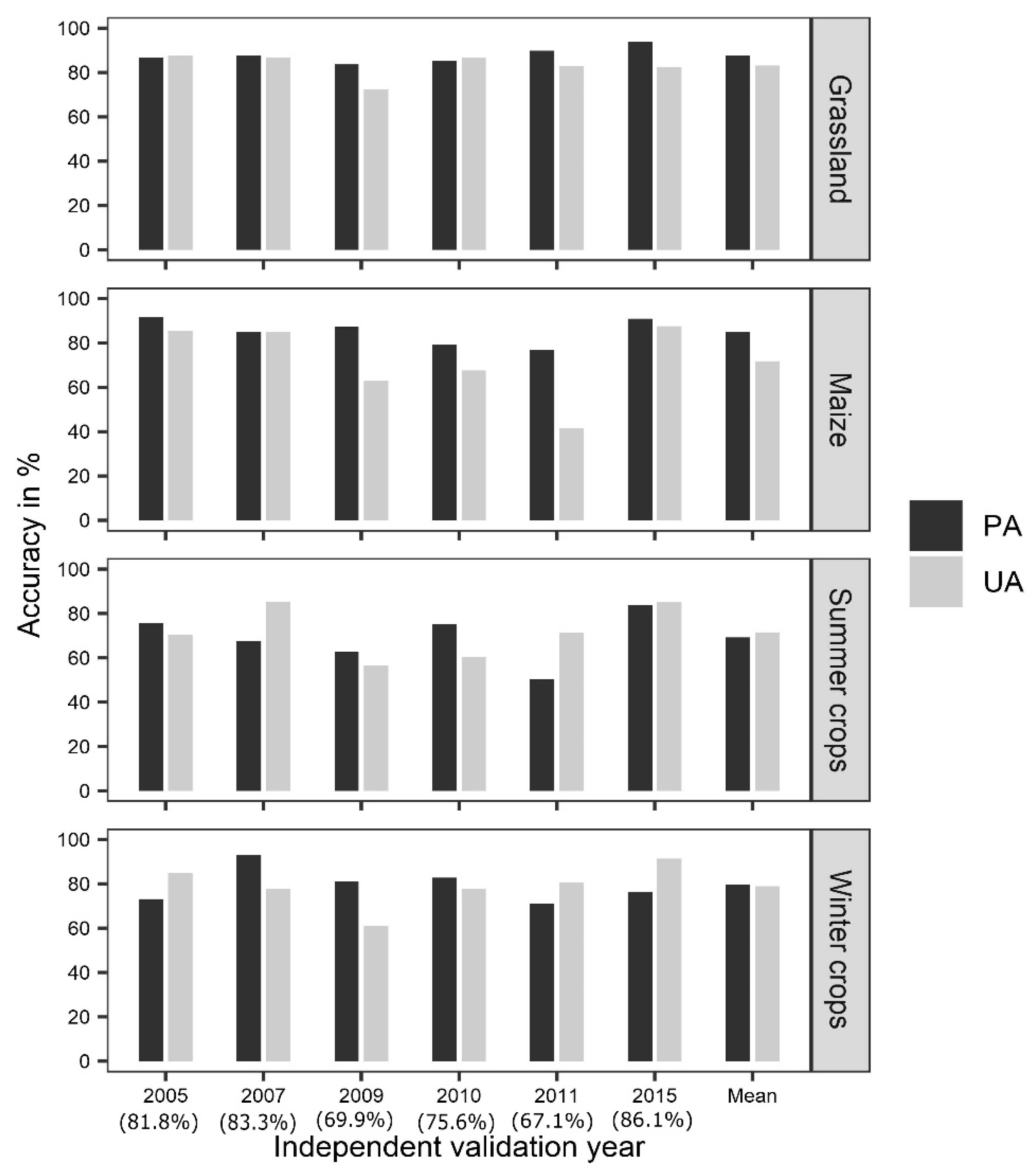
3.2. Assessment of the Modelling Approaches
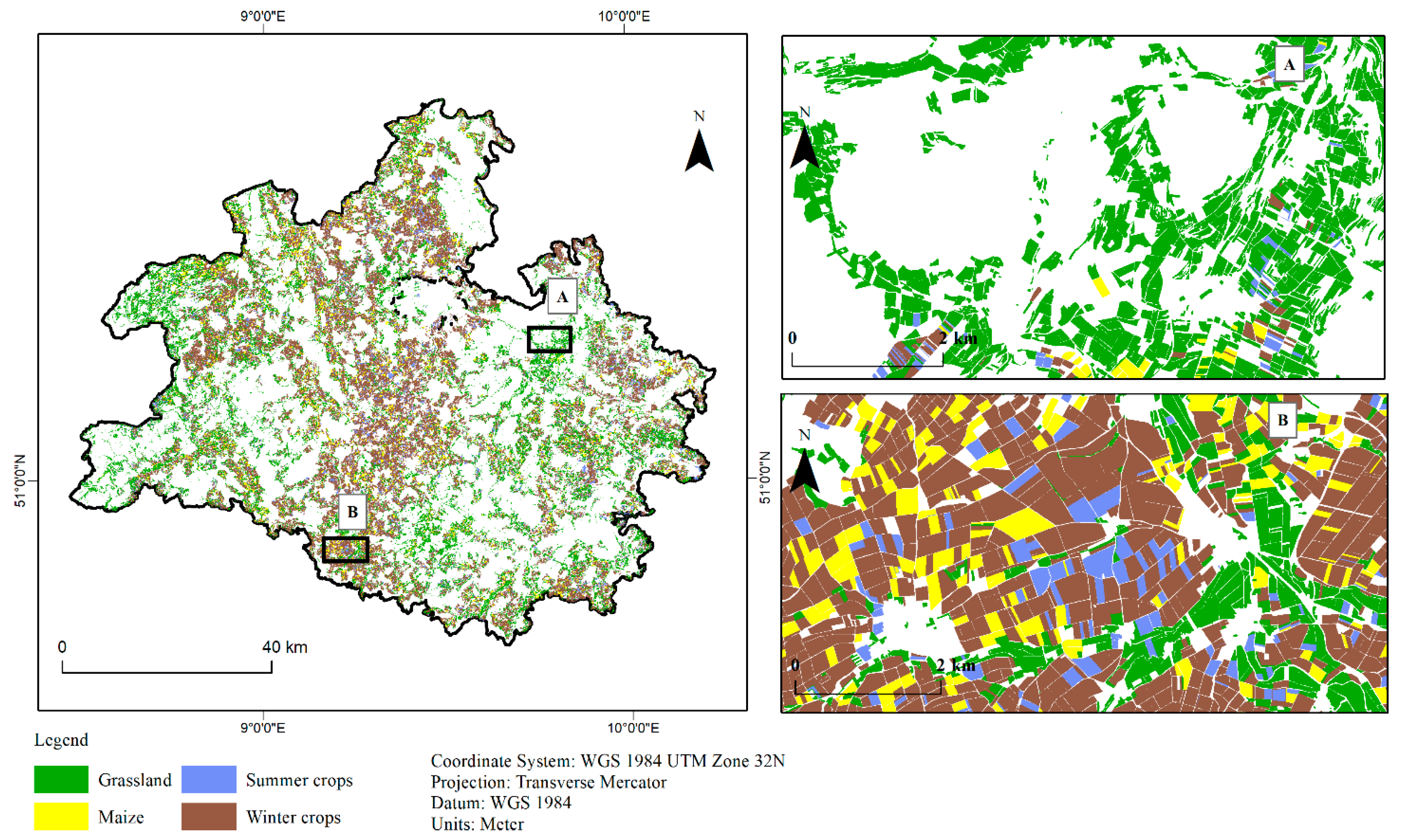
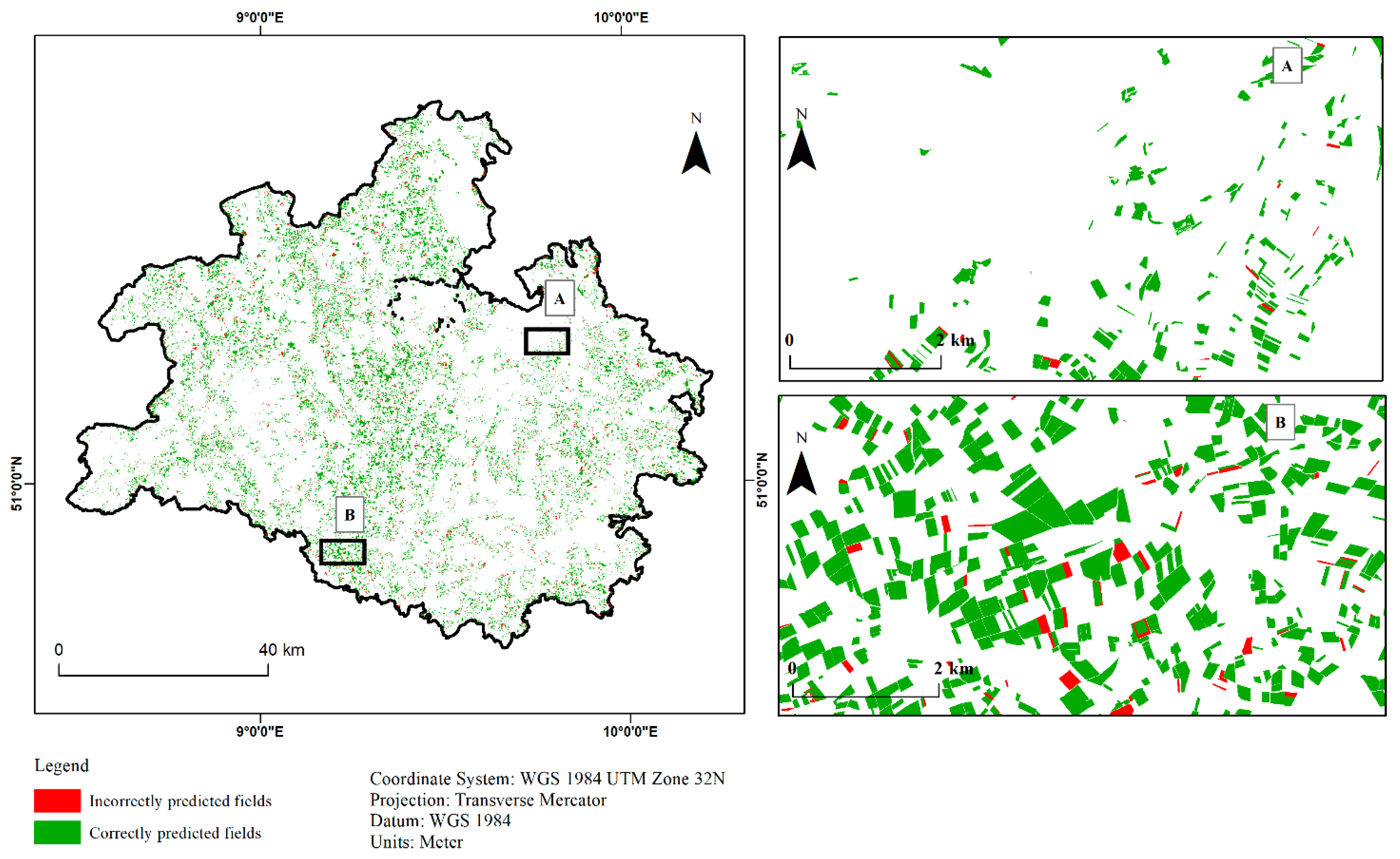
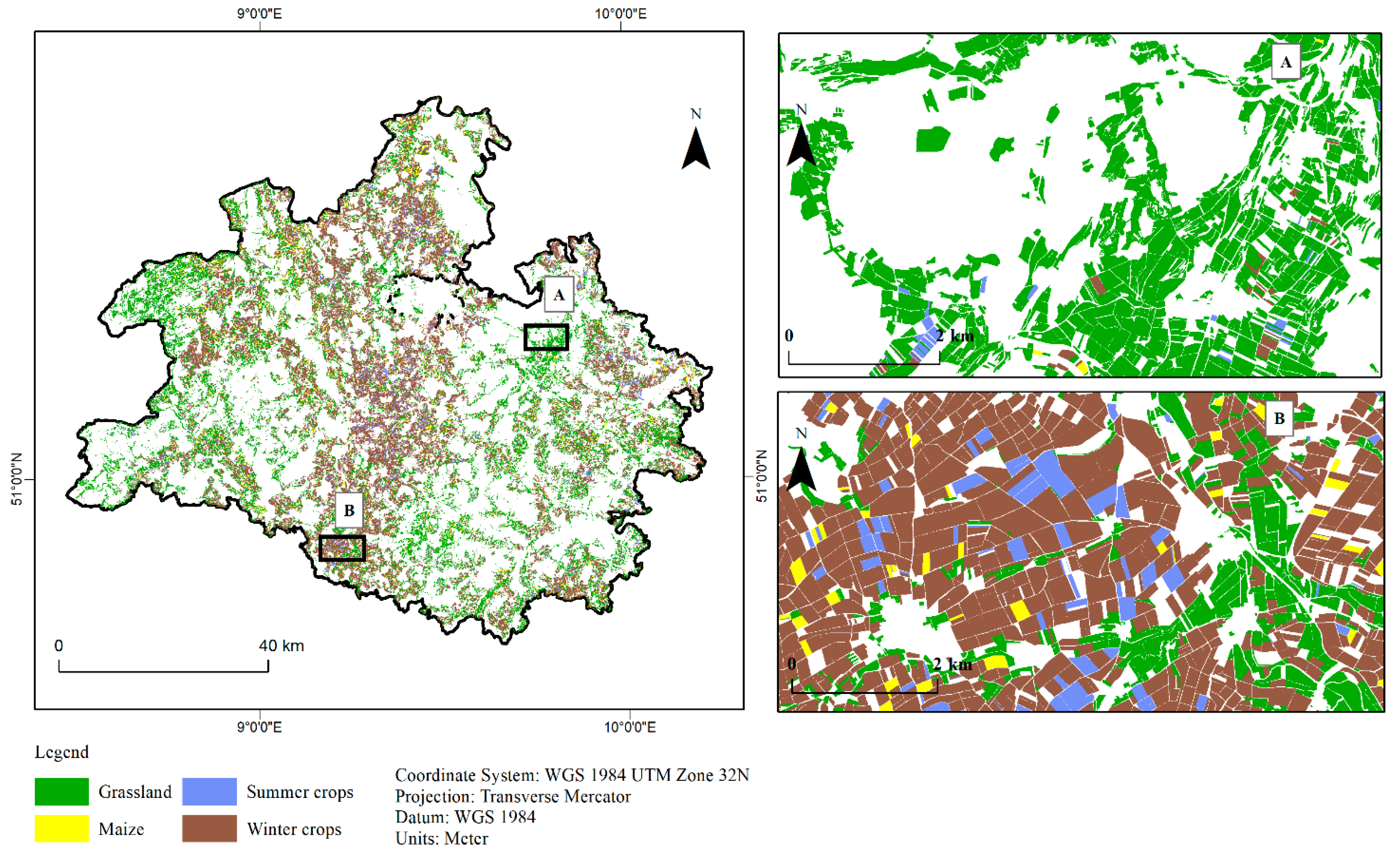
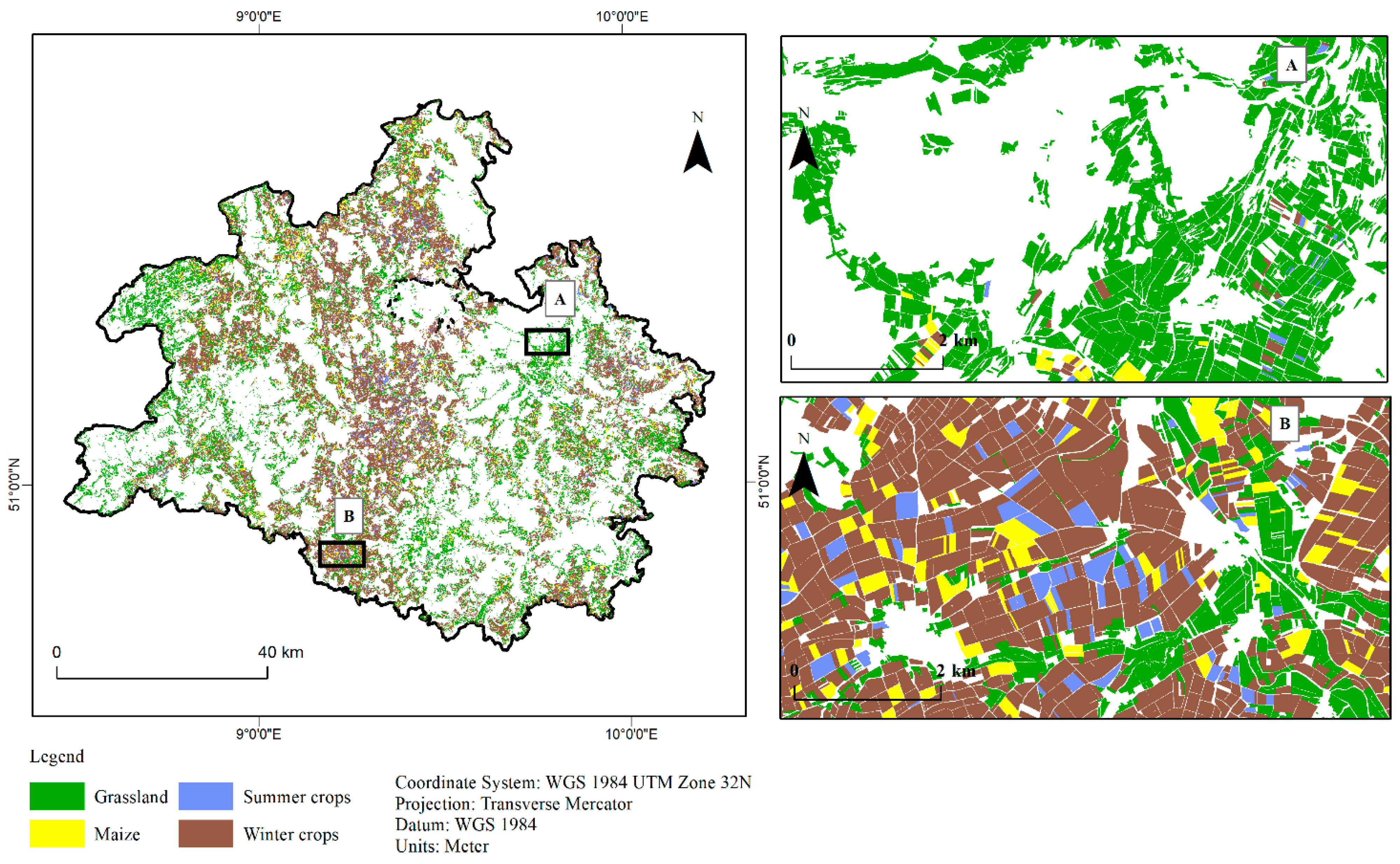
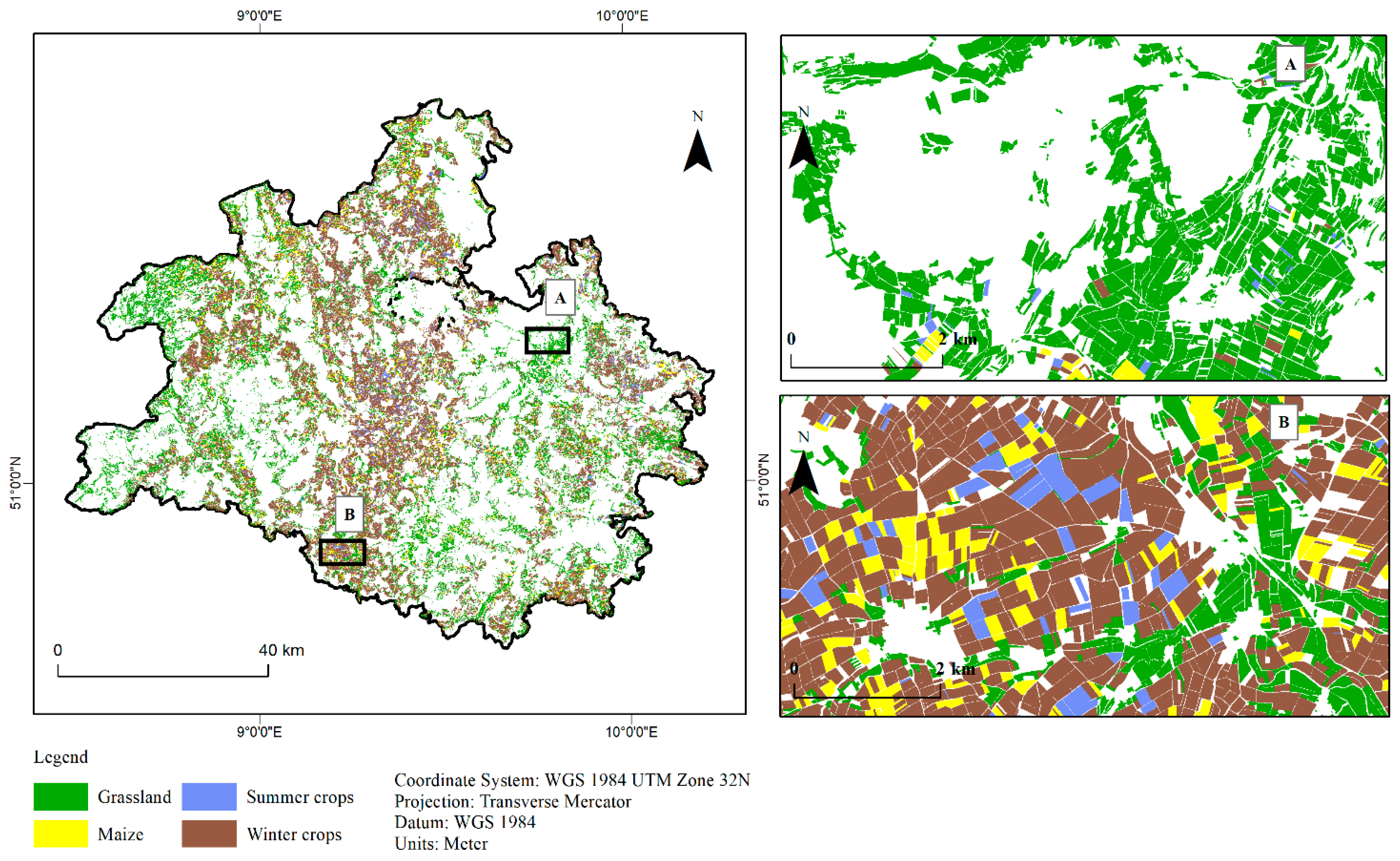
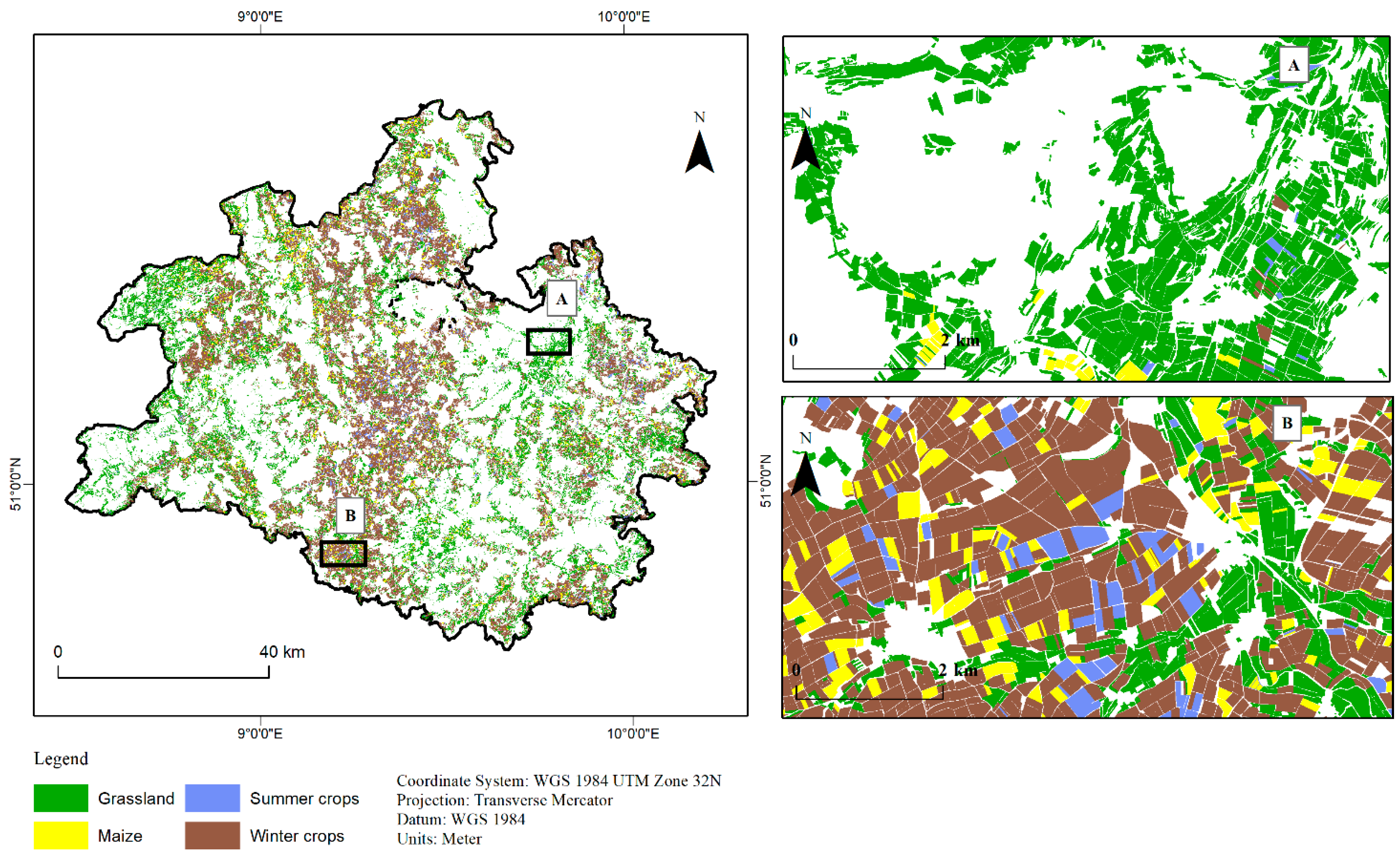
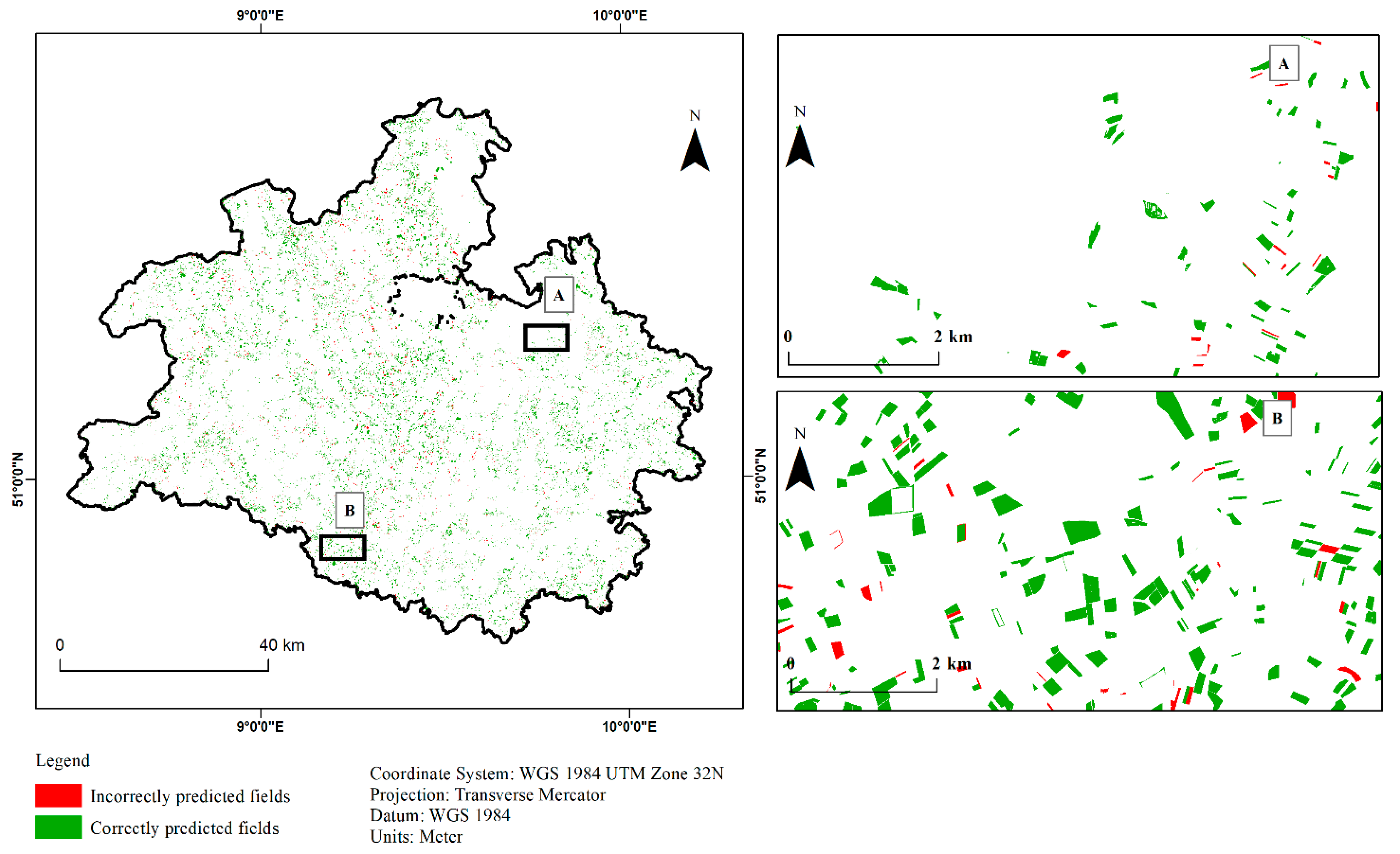
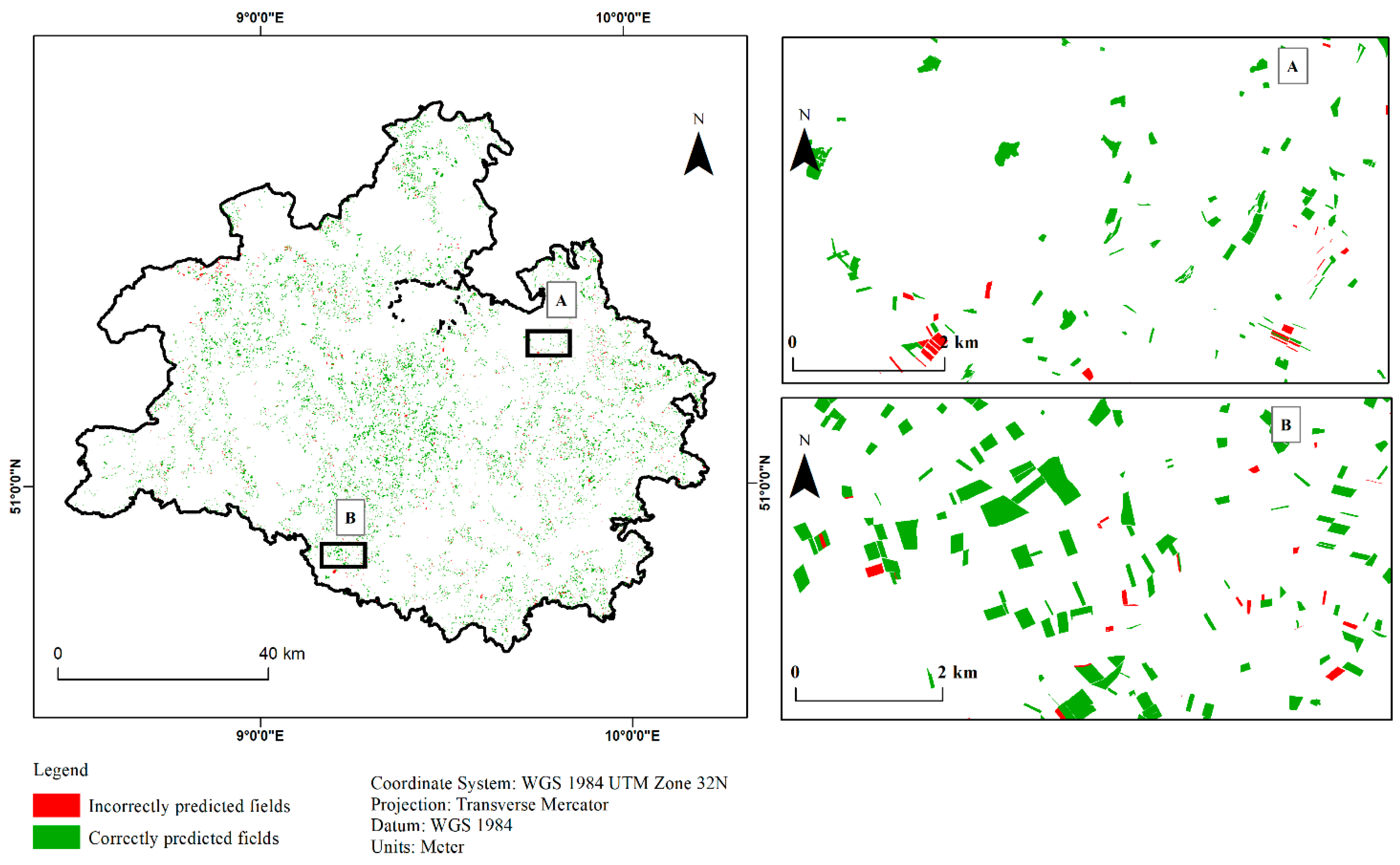
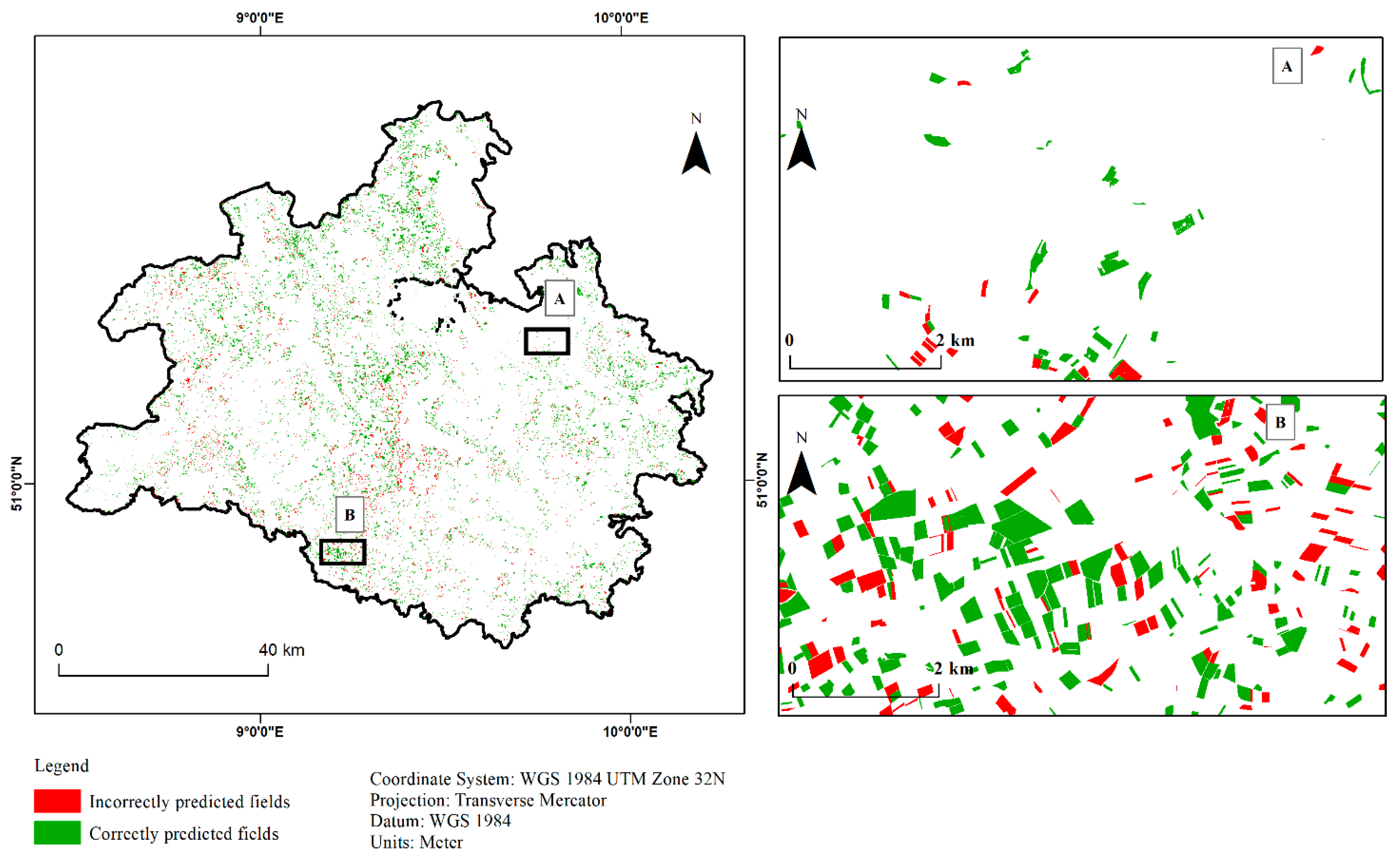
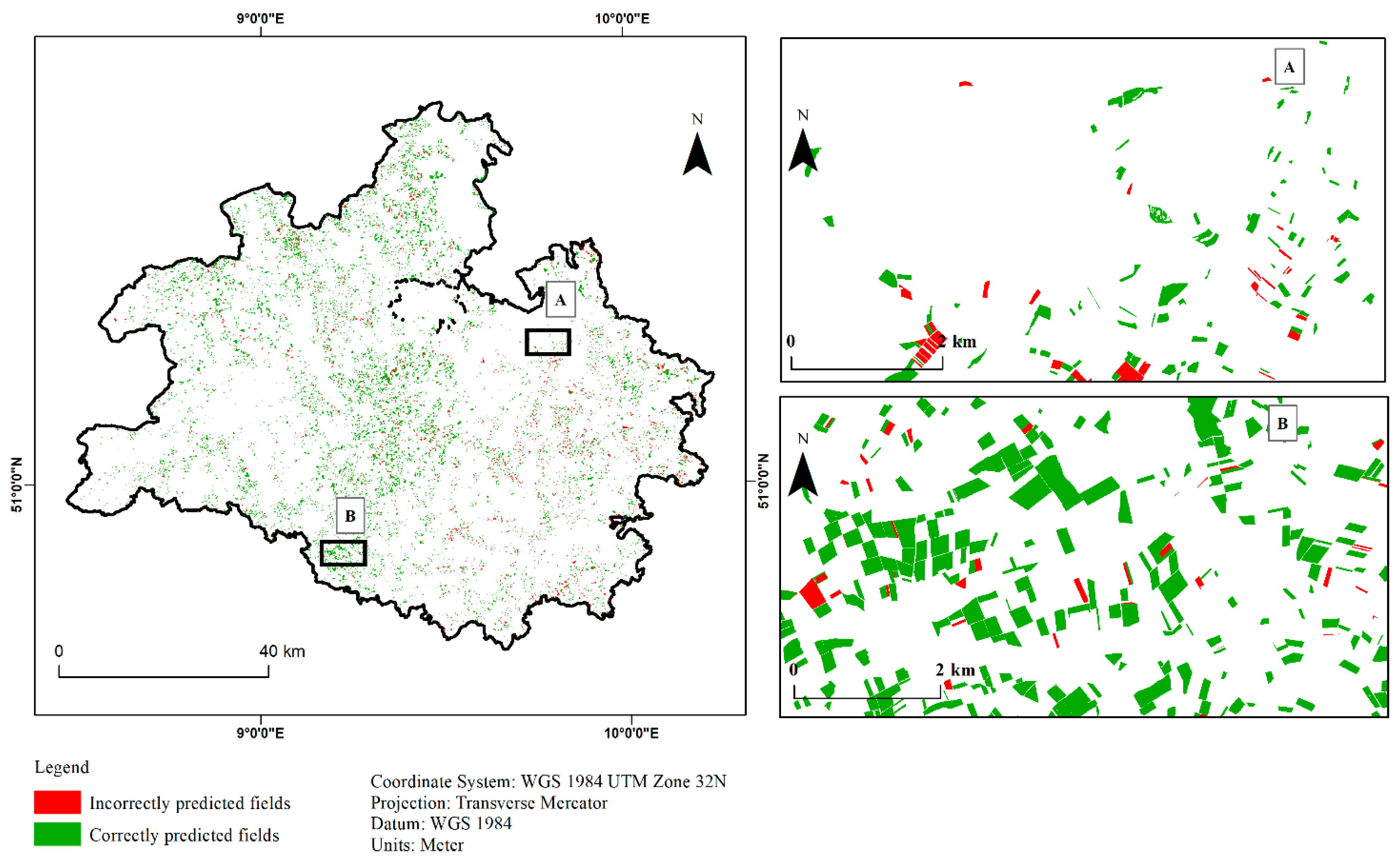
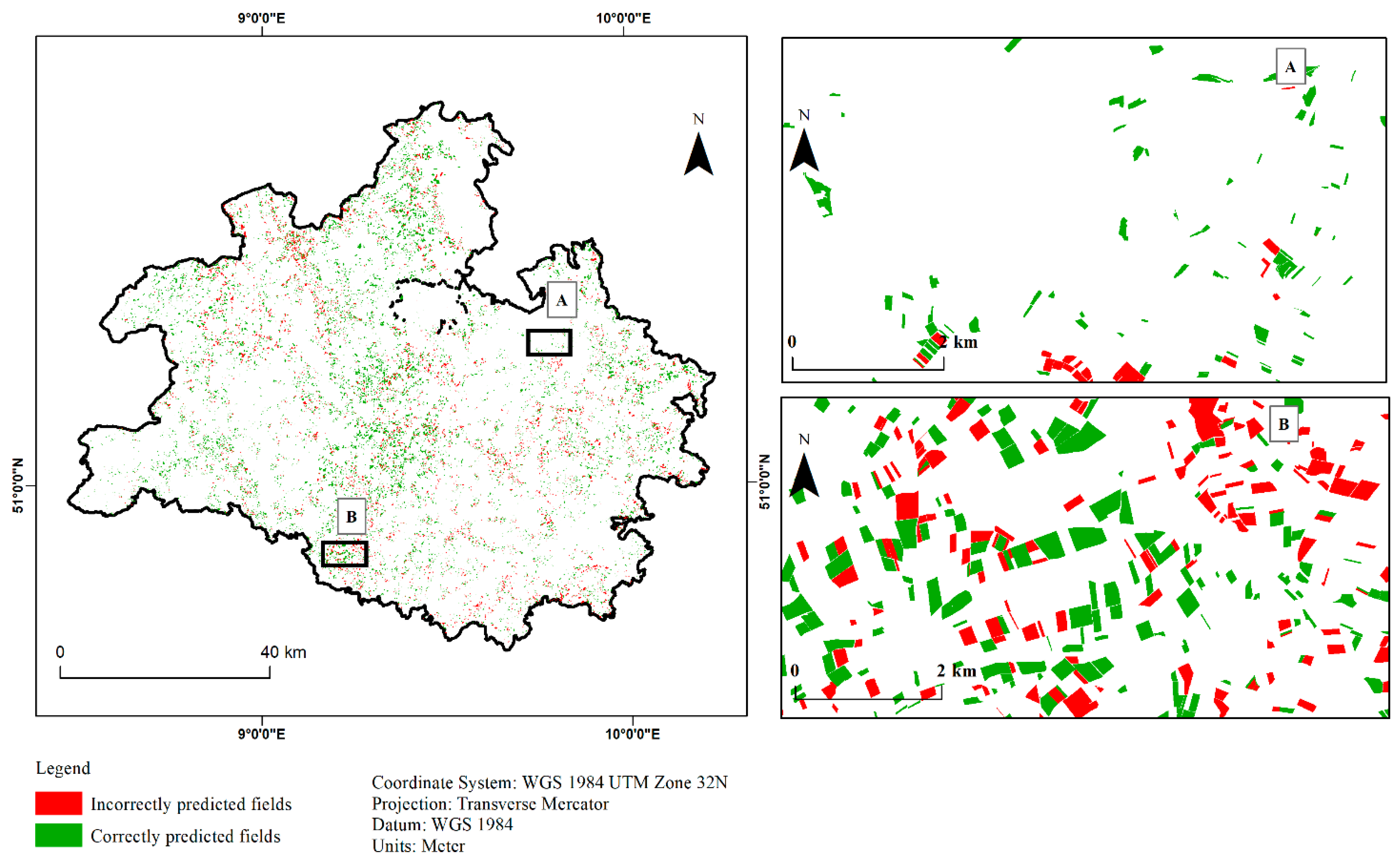
3.3. Classified Maps Based on Best Modelling Method
3.4. Relationship between Model Accuracy and Field Size
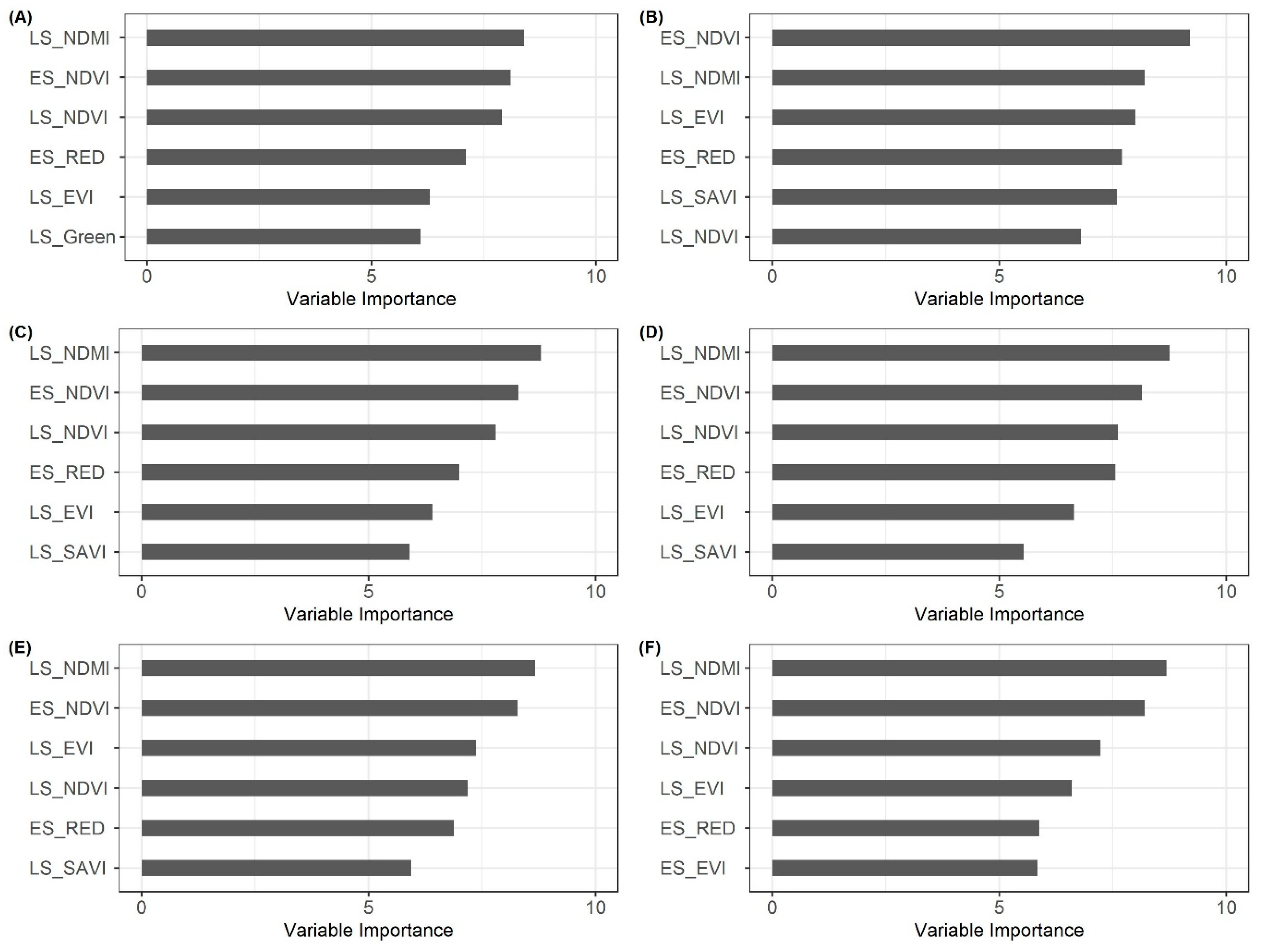
3.5. Importance of Predictor Variables
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | ||||||||
|---|---|---|---|---|---|---|---|---|
| GL | MZ | SC | WC | Total | UA (%) | CE (%) | ||
| Prediction | GL | 4339 | 137 | 270 | 214 | 4960 | 87.48 | 12.52 |
| MZ | 292 | 4527 | 442 | 33 | 5294 | 85.51 | 14.49 | |
| SC | 264 | 229 | 3792 | 1099 | 5384 | 70.43 | 29.57 | |
| WC | 105 | 48 | 496 | 3654 | 4303 | 84.92 | 15.08 | |
| Total | 5000 | 4941 | 5000 | 5000 | ||||
| PA (%) | 86.78 | 91.62 | 75.84 | 73.08 | ||||
| OE (%) | 13.22 | 8.38 | 24.16 | 26.92 | ||||
| OA (%) | 81.8 | |||||||
| Reference | ||||||||
|---|---|---|---|---|---|---|---|---|
| GL | MZ | SC | WC | Total | UA (%) | CE (%) | ||
| Prediction | GL | 4380 | 203 | 316 | 156 | 5055 | 86.65 | 13.35 |
| MZ | 158 | 3738 | 463 | 38 | 4397 | 85.01 | 14.99 | |
| SC | 68 | 358 | 3384 | 154 | 3964 | 85.37 | 14.63 | |
| WC | 394 | 90 | 837 | 4652 | 5973 | 77.88 | 22.12 | |
| Total | 5000 | 4389 | 5000 | 5000 | ||||
| PA (%) | 87.60 | 85.17 | 67.68 | 93.04 | ||||
| OE (%) | 12.40 | 14.83 | 32.32 | 6.96 | ||||
| OA (%) | 83.32 | |||||||
| Reference | ||||||||
|---|---|---|---|---|---|---|---|---|
| GL | MZ | SC | WC | Total | UA (%) | CE (%) | ||
| Prediction | GL | 4185 | 986 | 430 | 175 | 5776 | 72.45 | 27.55 |
| MZ | 166 | 4070 | 394 | 26 | 4656 | 87.41 | 12.59 | |
| SC | 345 | 889 | 3347 | 748 | 5329 | 62.81 | 37.19 | |
| WC | 304 | 531 | 1743 | 4051 | 6629 | 61.11 | 38.89 | |
| Total | 5000 | 6476 | 5914 | 5000 | ||||
| PA (%) | 83.70 | 62.85 | 56.59 | 81.02 | ||||
| OE (%) | 16.30 | 37.15 | 43.41 | 18.98 | ||||
| OA (%) | 69.91 | |||||||
| Reference | ||||||||
|---|---|---|---|---|---|---|---|---|
| GL | MZ | SC | WC | Total | UA (%) | CE (%) | ||
| Prediction | GL | 4262 | 376 | 179 | 91 | 4908 | 86.84 | 13.16 |
| MZ | 172 | 4990 | 956 | 185 | 6303 | 79.17 | 20.83 | |
| SC | 238 | 1830 | 4388 | 827 | 7283 | 60.25 | 39.75 | |
| WC | 328 | 171 | 307 | 3897 | 4703 | 82.86 | 17.14 | |
| Total | 5000 | 7367 | 5830 | 5000 | ||||
| PA (%) | 85.24 | 67.73 | 75.27 | 77.94 | ||||
| OE (%) | 14.76 | 32.27 | 24.73 | 22.06 | ||||
| OA (%) | 75.6 | |||||||
| Reference | ||||||||
|---|---|---|---|---|---|---|---|---|
| GL | MZ | SC | WC | Total | UA (%) | CE (%) | ||
| Prediction | GL | 4493 | 209 | 264 | 460 | 5426 | 82.81 | 17.19 |
| MZ | 141 | 3427 | 732 | 151 | 4451 | 76.99 | 23.01 | |
| SC | 108 | 4073 | 4644 | 363 | 9188 | 50.54 | 49.46 | |
| WC | 258 | 507 | 872 | 4026 | 5663 | 71.09 | 28.91 | |
| Total | 5000 | 8216 | 6512 | 5000 | ||||
| PA (%) | 89.86 | 41.71 | 71.31 | 80.52 | ||||
| OE (%) | 10.14 | 58.29 | 28.69 | 19.48 | ||||
| OA (%) | 67.09 | |||||||
| Reference | ||||||||
|---|---|---|---|---|---|---|---|---|
| GL | MZ | SC | WC | Total | UA (%) | CE (%) | ||
| Prediction | GL | 10,313 | 461 | 592 | 1163 | 12,529 | 82.31 | 17.69 |
| MZ | 183 | 8111 | 891 | 69 | 9254 | 87.65 | 12.35 | |
| SC | 305 | 296 | 9943 | 1134 | 11,678 | 85.14 | 14.86 | |
| WC | 199 | 53 | 464 | 7634 | 8350 | 91.43 | 8.57 | |
| Total | 11,000 | 8921 | 11,890 | 10,000 | ||||
| PA (%) | 93.75 | 90.92 | 83.62 | 76.34 | ||||
| OE (%) | 6.25 | 9.08 | 16.38 | 23.66 | ||||
| OA (%) | 86.1 | |||||||
References
- Tilman, D.; Balzer, C.; Hill, J.; Befort, B.L. Global food demand and the sustainable intensification of agriculture. Proc. Natl. Acad. Sci. USA 2011, 108, 20260–20264. [Google Scholar] [CrossRef] [PubMed]
- Nagy, A.; Fehér, J.; Tamás, J. Wheat and maize yield forecasting for the Tisza river catchment using MODIS NDVI time series and reported crop statistics. Comput. Electron. Agric. 2018, 151, 41–49. [Google Scholar] [CrossRef]
- See, L.; Fritz, S.; You, L.; Ramankutty, N.; Herrero, M.; Justice, C.; Becker-Reshef, I.; Thornton, P.; Erb, K.; Gong, P.; et al. Improved global cropland data as an essential ingredient for food security. Glob. Food Secur. 2015, 4, 37–45. [Google Scholar] [CrossRef]
- Gumma, M.K.; Thenkabail, P.S.; Teluguntla, P.; Rao, M.N.; Mohammed, I.A.; Whitbread, A.M. Mapping rice-fallow cropland areas for short-season grain legumes intensification in South Asia using MODIS 250 m time-series data. Int. J. Digit. Earth 2016, 9, 981–1003. [Google Scholar] [CrossRef]
- Funk, C.C.; Brown, M.E. Declining global per capita agricultural production and warming oceans threaten food security. Food Secur. 2009, 1, 271–289. [Google Scholar] [CrossRef]
- Pérez-Hoyos, A.; Rembold, F.; Kerdiles, H.; Gallego, J. Comparison of global land cover datasets for cropland monitoring. Remote Sens. 2017, 9, 1118. [Google Scholar] [CrossRef]
- Tatsumi, K.; Yamashiki, Y.; Canales Torres, M.A.; Taipe, C.L.R. Crop classification of upland fields using Random forest of time-series Landsat 7 ETM+ data. Comput. Electron. Agric. 2015, 115, 171–179. [Google Scholar] [CrossRef]
- Zhong, L.; Gong, P.; Biging, G.S. Efficient corn and soybean mapping with temporal extendability: A multi-year experiment using Landsat imagery. Remote Sens. Environ. 2014, 140, 1–13. [Google Scholar] [CrossRef]
- Castillejo-González, I. Mapping of Olive Trees Using Pansharpened QuickBird Images: An Evaluation of Pixel- and Object-Based Analyses. Agronomy 2018, 8, 288. [Google Scholar] [CrossRef]
- Foerster, S.; Kaden, K.; Foerster, M.; Itzerott, S. Crop type mapping using spectral-temporal profiles and phenological information. Comput. Electron. Agric. 2012, 89, 30–40. [Google Scholar] [CrossRef]
- Moeckel, T.; Dayananda, S.; Nidamanuri, R.R.; Nautiyal, S.; Hanumaiah, N.; Buerkert, A.; Wachendorf, M. Estimation of vegetable crop parameter by multi-temporal UAV-borne images. Remote Sens. 2018, 10, 805. [Google Scholar] [CrossRef]
- Wu, B.; Meng, J.; Li, Q.; Yan, N.; Du, X.; Zhang, M. Remote sensing-based global crop monitoring: Experiences with China’s CropWatch system. Int. J. Digit. Earth 2014, 7, 113–137. [Google Scholar] [CrossRef]
- Pittman, K.; Hansen, M.C.; Becker-Reshef, I.; Potapov, P.V.; Justice, C.O. Estimating global cropland extent with multi-year MODIS data. Remote Sens. 2010, 2, 1844–1863. [Google Scholar] [CrossRef]
- Waldhoff, G.; Lussem, U.; Bareth, G. Multi-Data Approach for remote sensing-based regional crop rotation mapping: A case study for the Rur catchment, Germany. Int. J. Appl. Earth Obs. Geoinf. 2017, 61, 55–69. [Google Scholar] [CrossRef]
- Habyarimana, E.; Piccard, I.; Catellani, M.; De Franceschi, P.; Dall’Agata, M. Towards Predictive Modeling of Sorghum Biomass Yields Using Fraction of Absorbed Photosynthetically Active Radiation Derived from Sentinel-2 Satellite Imagery and Supervised Machine Learning Techniques. Agronomy 2019, 9, 203. [Google Scholar] [CrossRef]
- Liu, J.; Feng, Q.; Gong, J.; Zhou, J.; Liang, J.; Li, Y. Winter wheat mapping using a random forest classifier combined with multi-temporal and multi-sensor data. Int. J. Digit. Earth 2018, 11, 783–802. [Google Scholar] [CrossRef]
- Maxwell, S.K.; Nuckols, J.R.; Ward, M.H.; Hoffer, R.M. An automated approach to mapping corn from Landsat imagery. Comput. Electron. Agric. 2004, 43, 43–54. [Google Scholar] [CrossRef]
- Yin, H.; Prishchepov, A.V.; Kuemmerle, T.; Bleyhl, B.; Buchner, J.; Radeloff, V.C. Mapping agricultural land abandonment from spatial and temporal segmentation of Landsat time series. Remote Sens. Environ. 2018, 210, 12–24. [Google Scholar] [CrossRef]
- Zheng, B.; Myint, S.W.; Thenkabail, P.S.; Aggarwal, R.M. A support vector machine to identify irrigated crop types using time-series Landsat NDVI data. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 103–112. [Google Scholar] [CrossRef]
- Waldner, F.; Hansen, M.C.; Potapov, P.V.; Löw, F.; Newby, T.; Ferreira, S.; Defourny, P. National-scale cropland mapping based on spectral-temporal features and outdated land cover information. PLoS ONE 2017, 12, e0181911. [Google Scholar] [CrossRef]
- Phiri, D.; Morgenroth, J. Developments in Landsat land cover classification methods: A review. Remote Sens. 2017, 9, 967. [Google Scholar] [CrossRef]
- Liu, D.; Xia, F. Assessing object-based classification: Advantages and limitations. Remote Sens. Lett. 2010, 1, 187–194. [Google Scholar] [CrossRef]
- Chen, D.; Stow, D. The Effect of Training Strategies on Supervised Classification at Different Spatial Resolutions. Photogramm. Eng. Remote Sens. 2002, 68, 1155–1162. [Google Scholar]
- Li, Q.; Wang, C.; Zhang, B.; Lu, L. Object-based crop classification with Landsat-MODIS enhanced time-series data. Remote Sens. 2015, 7, 16091–16107. [Google Scholar] [CrossRef]
- Zhu, L.; Radeloff, V.C.; Ives, A.R. Improving the mapping of crop types in the Midwestern U.S. by fusing Landsat and MODIS satellite data. Int. J. Appl. Earth Obs. Geoinf. 2017, 58, 1–11. [Google Scholar] [CrossRef]
- Chen, Y.; Lu, D.; Moran, E.; Batistella, M.; Dutra, L.V.; Sanches, I.D.; da Silva, R.F.B.; Huang, J.; Luiz, A.J.B.; de Oliveira, M.A.F. Mapping croplands, cropping patterns, and crop types using MODIS time-series data. Int. J. Appl. Earth Obs. Geoinf. 2018, 69, 133–147. [Google Scholar] [CrossRef]
- Foody, G.M.; Mathur, A.; Sanchez-Hernandez, C.; Boyd, D.S. Training set size requirements for the classification of a specific class. Remote Sens. Environ. 2006, 104, 1–14. [Google Scholar] [CrossRef]
- Botkin, D.B.; Estes, J.E.; MacDonald, R.M.; Wilson, M.V. Studying the Earth’s Vegetation from Space. Bioscience 1984, 34, 508–514. [Google Scholar] [CrossRef]
- Sonobe, R.; Yamaya, Y.; Tani, H.; Wang, X.; Kobayashi, N.; Mochizuki, K.I. Mapping crop cover using multi-temporal landsat 8 oli imagery. Int. J. Remote Sens. 2017, 38, 4348–4361. [Google Scholar] [CrossRef]
- Vuolo, F.; Neuwirth, M.; Immitzer, M.; Atzberger, C.; Ng, W.-T. How much does multi-temporal Sentinel-2 data improve crop type classification? Int. J. Appl. Earth Obs. Geoinf. 2018, 72, 122–130. [Google Scholar] [CrossRef]
- Zhao, Y.; Feng, D.; Yu, L.; Wang, X.; Chen, Y.; Bai, Y.; Hernández, H.J.; Galleguillos, M.; Estades, C.; Biging, G.S.; et al. Detailed dynamic land cover mapping of Chile: Accuracy improvement by integrating multi-temporal data. Remote Sens. Environ. 2016, 183, 170–185. [Google Scholar] [CrossRef]
- Xiao, X.; Boles, S.; Liu, J.; Zhuang, D.; Frolking, S.; Li, C.; Salas, W.; Moore, B. Mapping paddy rice agriculture in southern China using multi-temporal MODIS images. Remote Sens. Environ. 2005, 95, 480–492. [Google Scholar] [CrossRef]
- Manfron, G.; Delmotte, S.; Busetto, L.; Hossard, L.; Ranghetti, L.; Brivio, P.A.; Boschetti, M. Estimating inter-annual variability in winter wheat sowing dates from satellite time series in Camargue, France. Int. J. Appl. Earth Obs. Geoinf. 2017, 57, 190–201. [Google Scholar] [CrossRef]
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.P.; Gao, X.; Ferreira, L.G. Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Bill, R.; Nash, E.; Grenzdörffer, G. Integrated Administration and Control System. In Springer Handbook of Geographic Information System; Kresse, W., Danko, D.M., Eds.; Springer: Berlin, Germany, 2012; pp. 801–803. ISBN 978-3-540-72678-4. [Google Scholar]
- Boryan, C.; Yang, Z.; Mueller, R.; Craig, M. Monitoring US agriculture: The US department of agriculture, national agricultural statistics service, cropland data layer program. Geocarto Int. 2011, 26, 341–358. [Google Scholar] [CrossRef]
- Massey, R.; Sankey, T.T.; Congalton, R.G.; Yadav, K.; Thenkabail, P.S.; Ozdogan, M.; Sánchez Meador, A.J. MODIS phenology-derived, multi-year distribution of conterminous U.S. crop types. Remote Sens. Environ. 2017, 198, 490–503. [Google Scholar] [CrossRef]
- Griffiths, P.; Nendel, C.; Hostert, P. Intra-annual reflectance composites from Sentinel-2 and Landsat for national-scale crop and land cover mapping. Remote Sens. Environ. 2019, 220, 135–151. [Google Scholar] [CrossRef]
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. ISPRS Journal of Photogrammetry and Remote Sensing A review of supervised object-based land-cover image classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Queiroz Feitosa, R.; van der Meer, F.; van der Werff, H.; van Coillie, F.; et al. Geographic Object-Based Image Analysis—Towards a new paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef]
- Castilla, G.; Hernando, A.; Zhang, C.; McDermid, G.J. The impact of object size on the thematic accuracy of landcover maps. Int. J. Remote Sens. 2014, 35, 1029–1037. [Google Scholar] [CrossRef]
- Wagner, B. Spatial analysis of loess and loess-like sediments in the Weser-Aller catchment (Lower Saxony and Northern Hesse, NW Germany). Quarernary Sci. J. 2011, 60, 27–46. [Google Scholar] [CrossRef]
- HLNUG Hessian Agency for Nature Conservation, Environment and Geology. Available online: Atlas.umwelt.hessen.de (accessed on 9 November 2018).
- USGS Landsat Surface Reflectance Products. Available online: https://earthexplorer.usgs.gov/ (accessed on 24 July 2018).
- Masek, J.G.; Vermote, E.F.; Saleous, N.E.; Wolfe, R.; Hall, F.G.; Huemmrich, K.F.; Gao, F.; Kutler, J.; Lim, T.K. A landsat surface reflectance dataset for North America, 1990–2000. IEEE Geosci. Remote Sens. Lett. 2006, 3, 68–72. [Google Scholar] [CrossRef]
- Vermote, E.; Justice, C.; Claverie, M.; Franch, B. Preliminary analysis of the performance of the Landsat 8/OLI land surface reflectance product. Remote Sens. Environ. 2016, 185, 46–56. [Google Scholar] [CrossRef]
- Flood, N. Continuity of reflectance data between landsat-7 ETM+ and landsat-8 OLI, for both top-of-atmosphere and surface reflectance: A study in the australian landscape. Remote Sens. 2014, 6, 7952–7970. [Google Scholar] [CrossRef]
- Li, P.; Jiang, L.; Feng, Z. Cross-comparison of vegetation indices derived from landsat-7 enhanced thematic mapper plus (ETM+) and landsat-8 operational land imager (OLI) sensors. Remote Sens. 2014, 6, 310–329. [Google Scholar] [CrossRef]
- USGS Landsat Science Products-Landsat Surface Reflectance. Available online: https://www.usgs.gov/land-resources/nli/landsat/landsat-surface-reflectance?qt-science_support_page_related_con=0#qt-science_support_page_related_con (accessed on 10 May 2019).
- Hijmans, R.J.; van Etten, J.; Cheng, J.; Mattiuzzi, M.; Sumner, M.; Greenberg, J.A.; Lamigueiro, O.P.; Bevan, A.; Racine, E.B.; Shortridge, A. Package “raster”. R Package 2019, version 2.9-5. 1–60. [Google Scholar]
- Team, R.D.C. R Development Core Team R. R A Lang. Environ. Stat. Comput. 2015, 1, 409. [Google Scholar]
- Breiman, L. Random forest. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăgu, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Tucker, C.J. Red and photographic infrared linear combinations for monitoring vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef]
- Huete, A. A soil-adjusted vegetation index (SAVI). Remote Sens. Environ. 1988, 25, 295–309. [Google Scholar] [CrossRef]
- Gao, B.C. NDWI-A normalized difference water index for remote sensing of vegetation liquid water from space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Laborte, A.G.; Maunahan, A.A.; Hijmans, R.J. Spectral Signature Generalization and Expansion Can Improve the Accuracy of Satellite Image Classification. PLoS ONE 2010, 5, e10516. [Google Scholar] [CrossRef] [PubMed]
- Fletcher, R.S. Using Vegetation Indices as Input into Random Forest for Soybean and Weed Classification. Am. J. Plant Sci. 2016, 07, 2186–2198. [Google Scholar] [CrossRef]
- Cai, Y.; Guan, K.; Peng, J.; Wang, S.; Seifert, C.; Wardlow, B.; Li, Z. A high-performance and in-season classification system of field-level crop types using time-series Landsat data and a machine learning approach. Remote Sens. Environ. 2018, 210, 35–47. [Google Scholar] [CrossRef]











| Crop Types | Sowing Window | Peak Greenness | Harvesting Window |
|---|---|---|---|
| Grassland | Depending on the grassland management system | ||
| Maize | Late April | Mid-August | Mid-late September |
| Summer crops | Late March-Mid April | Mid-Late June | July-September |
| Winter crops | September-October | Mid-June | July-August |
| Date of Image Acquisition | |||
|---|---|---|---|
| Year | Satellite | Early Summer | Late Summer |
| 2005 | Landsat 5 TM | 03-Apr. (1), 21-Apr. (2) | 18-Aug. (2) |
| Landsat 7 ETM+ | 4-Apr. (2) | ||
| 2007 | Landsat 5 TM | 02-Apr. (2), 25-Apr. (1), 27-Apr. (1) | 16-Jul. (2), 01-Aug. (1), 24-Aug. (2) |
| Landsat 7 ETM+ | 26-Apr (2) | ||
| 2009 | Landsat 5 TM | 07-Apr. (2), 14-Apr. (2), 16-Apr. (2), 02-May (1), 25-May (1) | 06-Aug. (2), 20-Aug. (2) |
| Landsat 7 ETM+ | 05-Aug. (1), 22-Sep. (1) | ||
| 2010 | Landsat 5 TM | 17- Apr. (2), 19-Apr. (2) | 08-Jul. (1), 31-Jul. (1), 07-Aug. (2) |
| Landsat 7 ETM+ | 18-Apr. (2) | ||
| 2011 | Landsat 5 TM | 20-Apr. (1), 22-Apr. (2), 08-May (1) | 03-Aug. (1), 15-Oct. (1), 22-Oct. (1) |
| Landsat 7 ETM+ | 21-Apr. (2), 07-May(2) | 20-Aug. (1), 03-Sep. (2), 21-Sep (1), 28-Sep. (2) | |
| 2015 | Landsat 8 | 24-Apr. (2) | 30-Aug. (2) |
| Landsat 5 TM and 7 ETM+ | Landsat 8 | ||||
|---|---|---|---|---|---|
| Band Number | Band Name | Wavelength (μm) | Band Number | Band Name | Wavelength (μm) |
| Band 1 | Blue | 0.441–0.514 | Band 2 | Blue | 0.452–0.512 |
| Band 2 | Green | 0.519–0.601 | Band 3 | Green | 0.533–0.590 |
| Band 3 | Red | 0.631–0.692 | Band 4 | Red | 0.636–0.673 |
| Band 4 | NIR | 0.772–0.898 | Band 5 | NIR | 0.851–0.879 |
| Band 5 | SWIR-1 | 1.547–1.749 | Band 6 | SWIR-1 | 1.566–1.651 |
| Band 7 | SWIR-2 | 2.064–2.345 | Band 7 | SWIR-2 | 2.107–2.294 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kyere, I.; Astor, T.; Graß, R.; Wachendorf, M. Multi-Temporal Agricultural Land-Cover Mapping Using Single-Year and Multi-Year Models Based on Landsat Imagery and IACS Data. Agronomy 2019, 9, 309. https://doi.org/10.3390/agronomy9060309
Kyere I, Astor T, Graß R, Wachendorf M. Multi-Temporal Agricultural Land-Cover Mapping Using Single-Year and Multi-Year Models Based on Landsat Imagery and IACS Data. Agronomy. 2019; 9(6):309. https://doi.org/10.3390/agronomy9060309
Chicago/Turabian StyleKyere, Isaac, Thomas Astor, Rüdiger Graß, and Michael Wachendorf. 2019. "Multi-Temporal Agricultural Land-Cover Mapping Using Single-Year and Multi-Year Models Based on Landsat Imagery and IACS Data" Agronomy 9, no. 6: 309. https://doi.org/10.3390/agronomy9060309
APA StyleKyere, I., Astor, T., Graß, R., & Wachendorf, M. (2019). Multi-Temporal Agricultural Land-Cover Mapping Using Single-Year and Multi-Year Models Based on Landsat Imagery and IACS Data. Agronomy, 9(6), 309. https://doi.org/10.3390/agronomy9060309