
Low-Damage Grasp Method for Plug Seedlings Based on Machine Vision and Deep Learning

 ,
,
Abstract
1. Introduction
- A novel low-damage seedling grasp method is proposed, combining machine vision with deep learning.
- A lightweight grasp real-time position detection network (LRGN) is developed for real-time and accurate seedling grasping.
- The proposed method is validated on a self-built dataset, and its advantages are demonstrated over existing approaches.
2. Materials and Methods
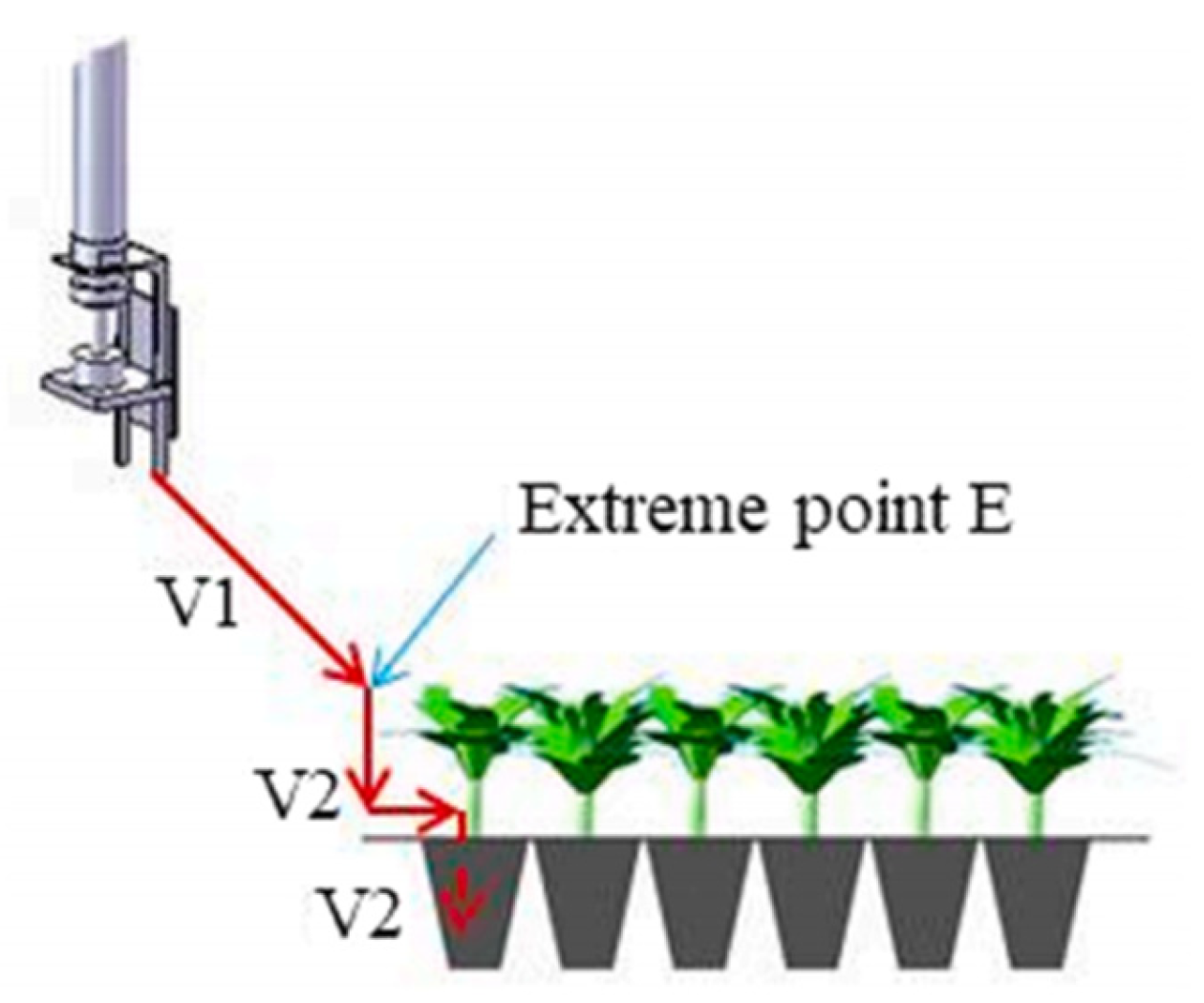
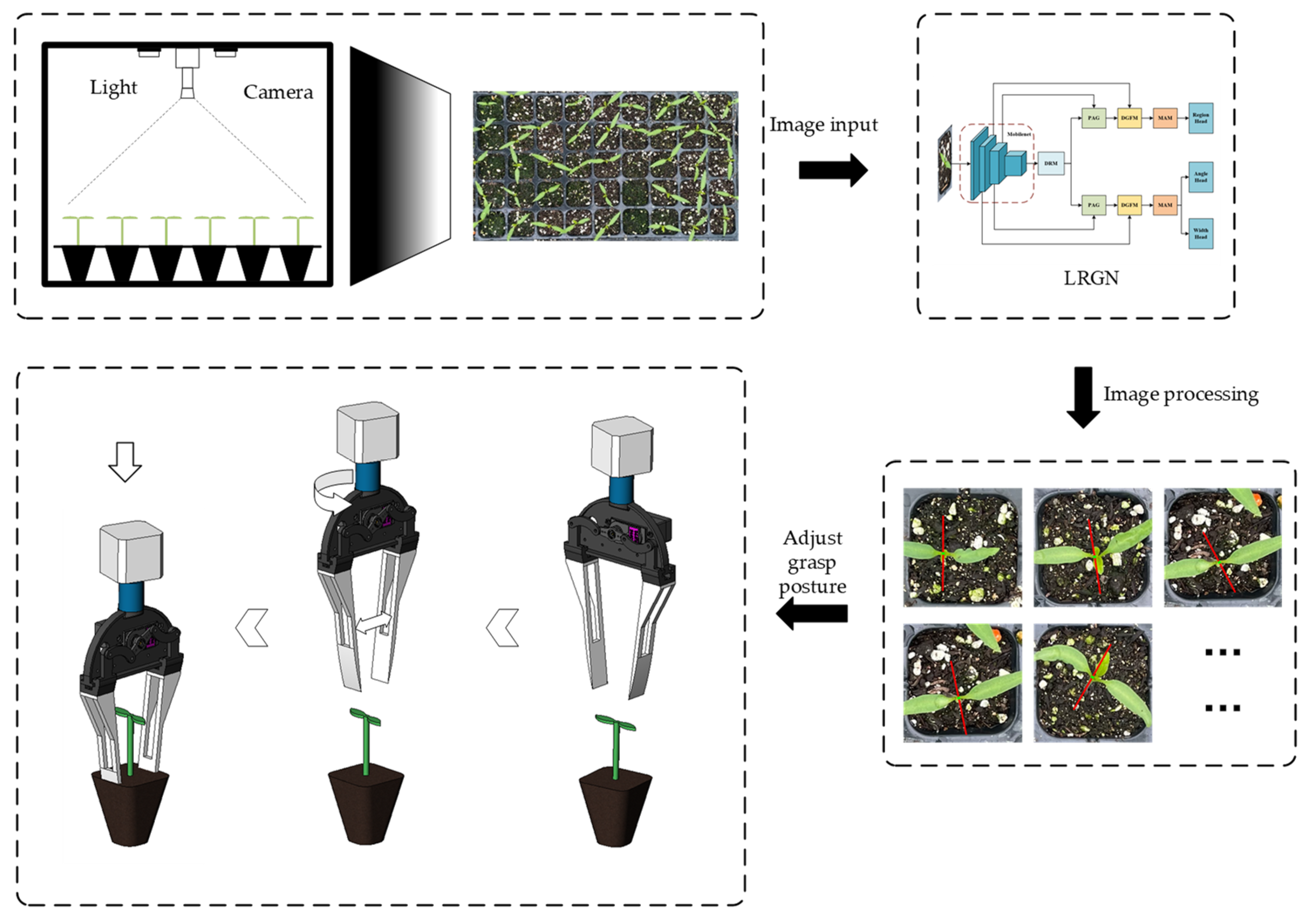
2.1. Overall Process Introduction
2.2. Image Data Collection
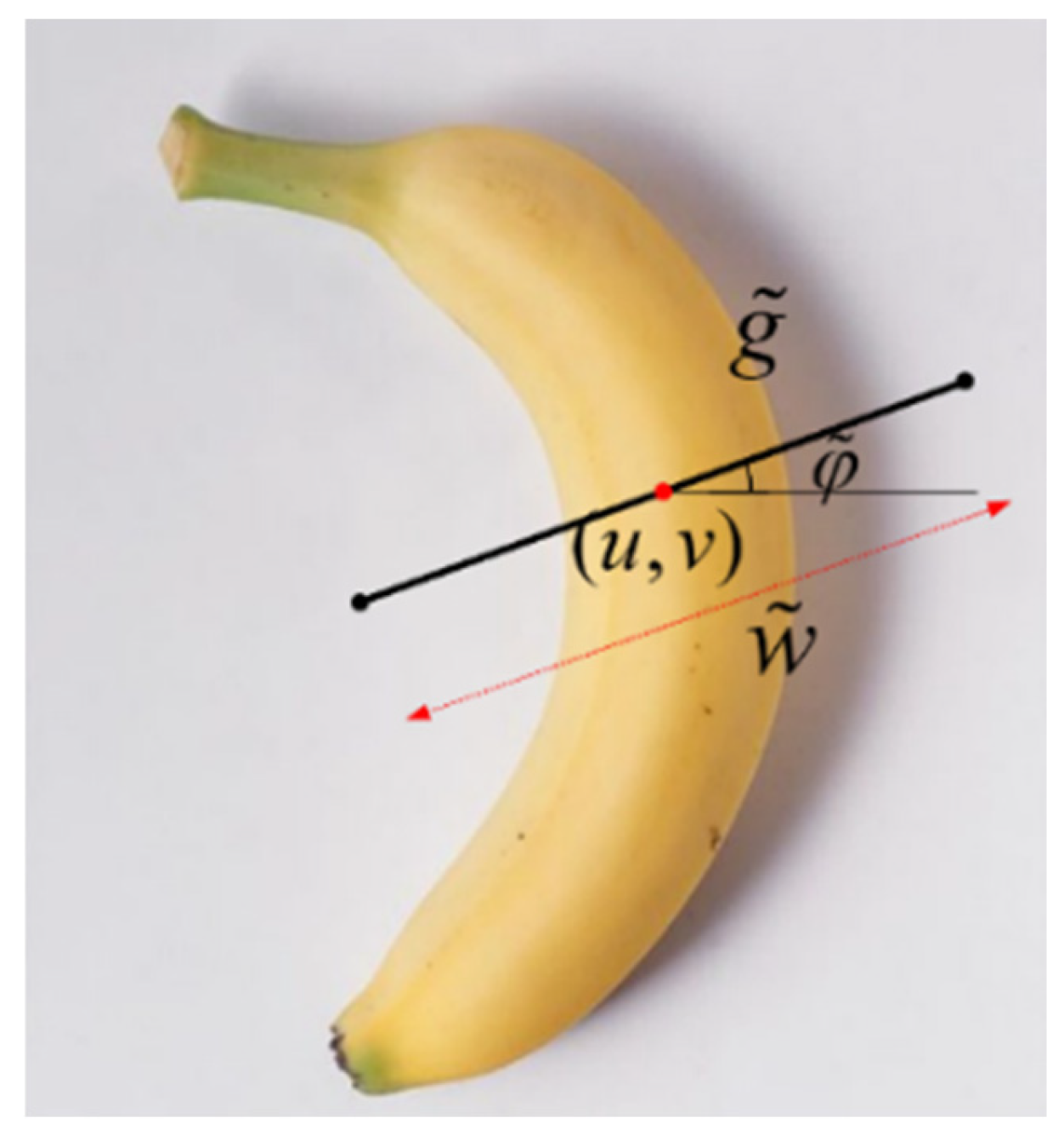
2.3. Grasping Representation of Two-Finger End-Effector
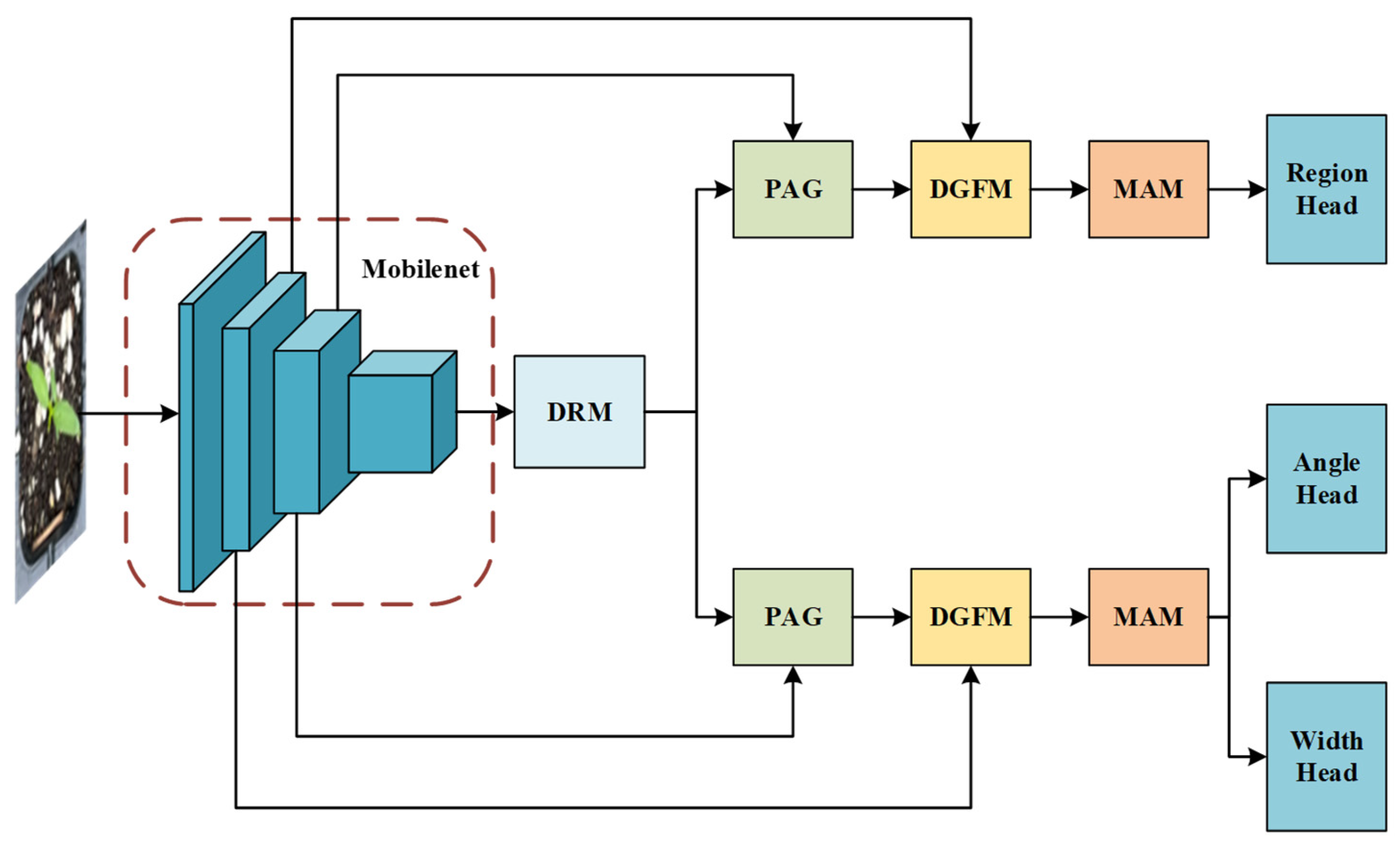
2.4. Grasp Detection Network
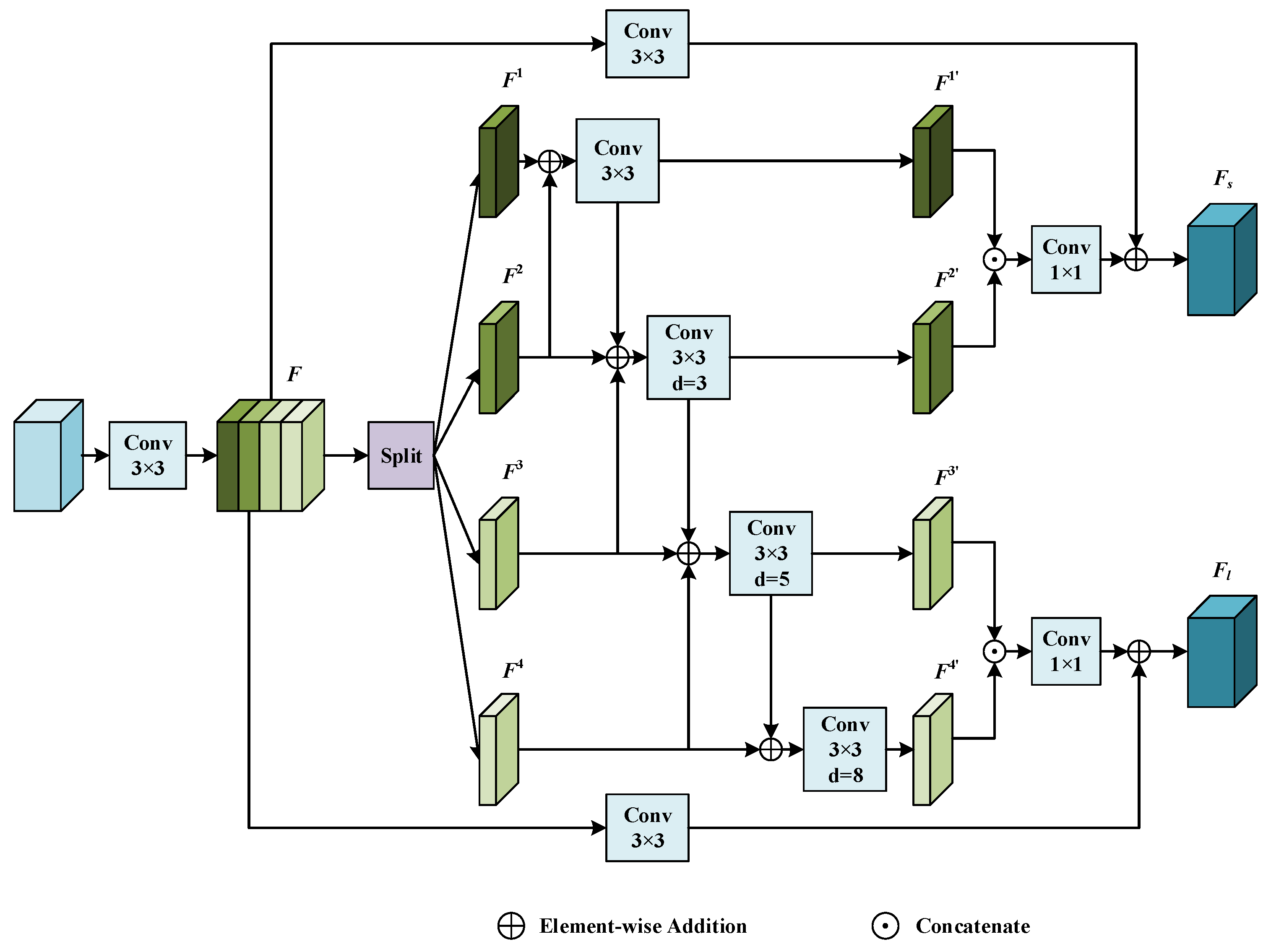
2.4.1. Dilated Refinement Module
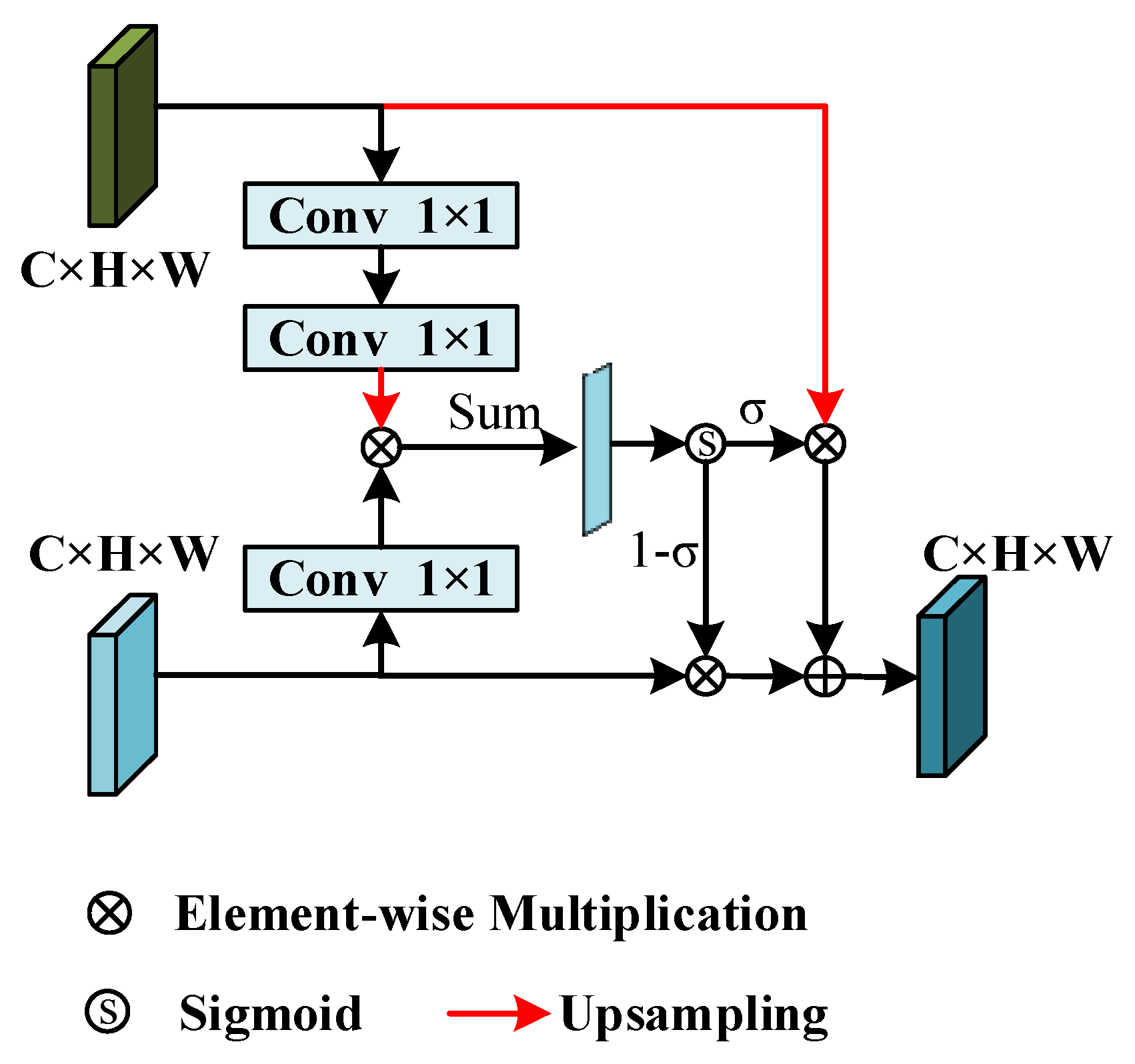
2.4.2. Pixel-Attention-Guided Fusion Module
2.4.3. Deep Guidance Fusion Module
2.4.4. Mixed Attention Module
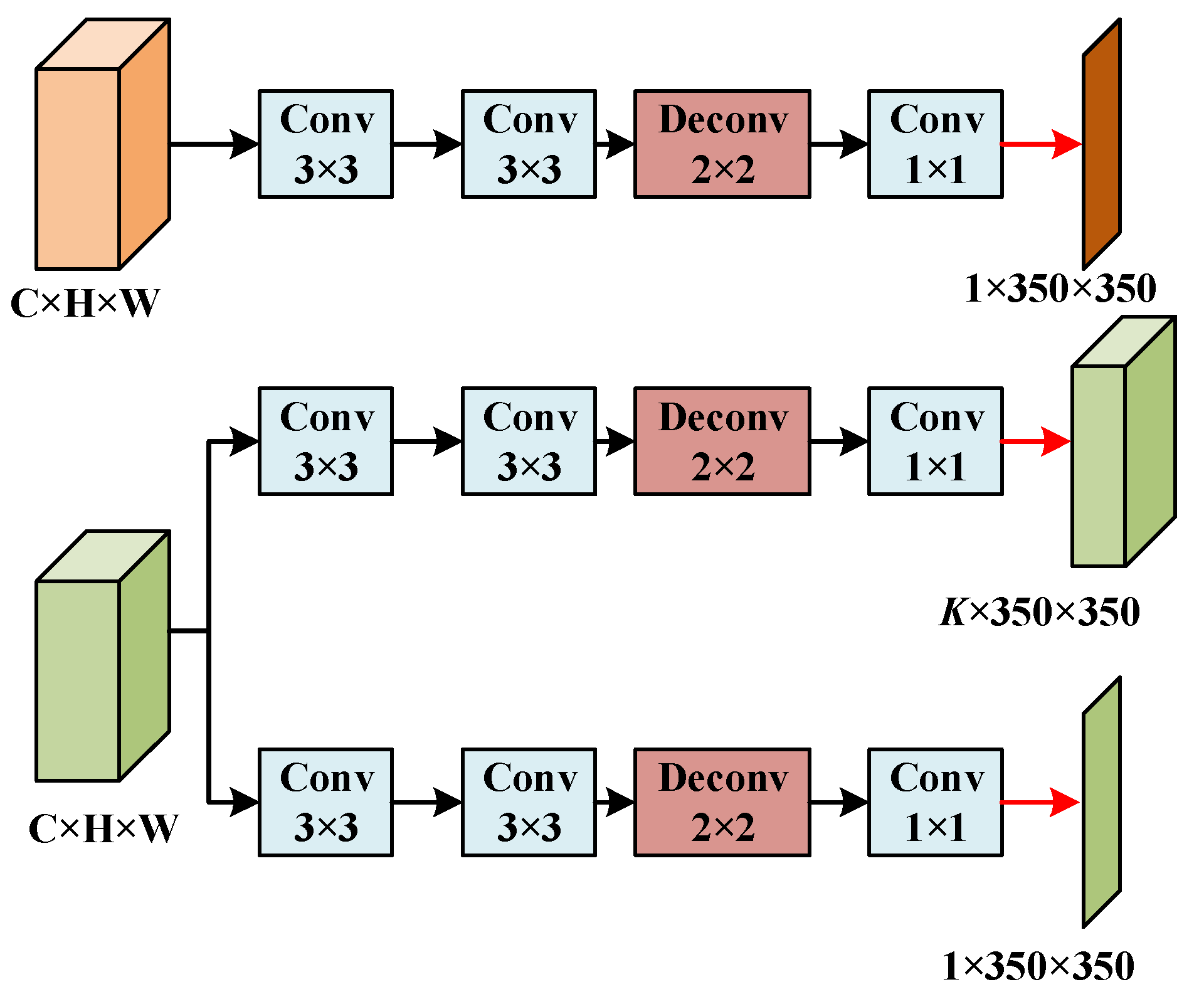
2.4.5. Prediction Output Head
2.5. Loss Function
3. Experimental Results and Analysis
3.1. Experimental Condition
3.2. Evaluation Metrics
3.3. Experimental Results
3.3.1. Cornell Dataset
3.3.2. Grasp Dataset of Plug Seedings
3.3.3. Ablation Experiment
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Peng, D. Mobile-based teacher professional training: Influence factor of technology acceptance. In Proceedings of the Foundations and Trends in Smart Learning. In Proceedings of 2019 International Conference on Smart Learning Environments, Denton, TX, USA, 18–20 March 2019; pp. 161–170. [Google Scholar]
- Zhao, X.; Guo, J.; Li, K.; Dai, L.; Chen, J. Optimal design and experiment of 2-DoF five-bar mechanism for flower seedling transplanting. Comput. Electron. Agric. 2020, 178, 105746. [Google Scholar] [CrossRef]
- Gao, G.; Feng, T.; Li, F. Design and optimization of operating parameters for potted anthodium transplant manipulator. Trans. CSAE 2014, 30, 34–42. [Google Scholar] [CrossRef]
- Wang, Y.; Yu, H. Experiment and analysis of impact factors for soil matrix intact rate of manipulator for picking-up plug seedlings. Nongye Gongcheng Xuebao/Trans. Chin. Soc. Agric. Eng. 2015, 31, 65–71. [Google Scholar] [CrossRef]
- Jin, X.; Tang, L.; Li, R.; Zhao, B.; Ji, J.; Ma, Y. Edge recognition and reduced transplantation loss of leafy vegetable seedlings with Intel RealsSense D415 depth camera. Comput. Electron. Agric. 2022, 198, 107030. [Google Scholar] [CrossRef]
- Liu, W.; Liu, J. Review of End-Effectors in Tray SeedlingsTransplanting Robot. J. Agric. Mech. Res. 2013, 35, 6–10. [Google Scholar] [CrossRef]
- Zhang, Z.; Lv, Q.; Chen, Q.; Xu, H.; Li, H.; Zhang, N.; Bai, Z. Status analysis of picking seedling transplanting mechanism automatic mechanism for potted flower. J. Jiangsu Univ. (Nat. Sci. Ed.) 2016, 37, 409–417. [Google Scholar]
- Kumi, F. Study on Substrate-Root Multiple Properties of Tomato Seedlings and Damage of Transplanting Pick-Up. Ph.D. Thesis, Jiangsu University, Zhenjiang, China, 2016. [Google Scholar]
- Ding, Y. Design and Experimental Study on Key Components of Automatic Transplanting Machine for Greenhouse Seedlings. Master’s Thesis, Zhejiang Sci-Tech University, Hangzhou, China, 2019. [Google Scholar]
- Lenz, I.; Lee, H.; Saxena, A. Deep learning for detecting robotic grasps. Int. J. Robot. Res. 2015, 34, 705–724. [Google Scholar] [CrossRef]
- Morrison, D.; Corke, P.; Leitner, J. Learning robust, real-time, reactive robotic grasping. Int. J. Robot. Res. 2020, 39, 183–201. [Google Scholar] [CrossRef]
- Tian, H.; Song, K.; Li, S.; Ma, S.; Yan, Y. Lightweight Pixel-Wise Generative Robot Grasping Detection Based on RGB-D Dense Fusion. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- Liu, D.; Tao, X.; Yuan, L.; Du, Y.; Cong, M. Robotic Objects Detection and Grasping in Clutter Based on Cascaded Deep Convolutional Neural Network. IEEE Trans. Instrum. Meas. 2022, 71, 1–10. [Google Scholar] [CrossRef]
- Xu, J.; Xiong, Z.; Bhattacharyya, S.P. PIDNet: A real-time semantic segmentation network inspired by PID controllers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–23 June 2023; pp. 19529–19539. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Wang, D.; Liu, C.; Chang, F.; Li, N.; Li, G. High-performance pixel-level grasp detection based on adaptive grasping and grasp-aware network. IEEE Trans. Ind. Electron. 2021, 69, 11611–11621. [Google Scholar] [CrossRef]
- Redmon, J.; Angelova, A. Real-time grasp detection using convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1316–1322. [Google Scholar]
- Kumra, S.; Kanan, C. Robotic grasp detection using deep convolutional neural networks. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 769–776. [Google Scholar]
- Asif, U.; Tang, J.; Harrer, S. GraspNet: An Efficient Convolutional Neural Network for Real-time Grasp Detection for Low-powered Devices. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI), Stockholm, Sweden, 13–19 July 2018; pp. 4875–4882. [Google Scholar]
- Wang, D. SGDN: Segmentation-based grasp detection network for unsymmetrical three-finger gripper. arXiv 2020, arXiv:2005.08222. [Google Scholar]
- Yu, Y.; Cao, Z.; Liu, Z.; Geng, W.; Yu, J.; Zhang, W. A two-stream CNN with simultaneous detection and segmentation for robotic grasping. IEEE Trans. Syst. Man Cybern. Syst. 2020, 52, 1167–1181. [Google Scholar] [CrossRef]
- Xu, R.; Chu, F.-J.; Vela, P.A. GKNet: Grasp keypoint network for grasp candidates detection. Int. J. Robot. Res. 2022, 41, 361–389. [Google Scholar] [CrossRef]
- Kumra, S.; Joshi, S.; Sahin, F. Antipodal robotic grasping using generative residual convolutional neural network. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 9626–9633. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–9 June 2023; pp. 1–5. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Images | Train | Test | Augmentation Techniques |
|---|---|---|---|---|
| Image Split | 3540 | 2832 | 708 | Scale, Flip, Crop |
| Object Split | 3540 | 2728 | 680 | Scale, Flip, Crop |
| Method | Accuracy/% | FPS | Params/M | |
|---|---|---|---|---|
| Image-Wise | Object-Wise | |||
| GG-CNN2 [11] | 73.00 | 69.00 | 52.62 | 0.06 |
| AlexNet [18] | 88.00 | 87.10 | 13.20 | 7.30 |
| ResNet-50 × 2 [19] | 89.21 | 88.96 | 9.70 | 25.56 |
| GraspNet [20] | 90.60 | 90.20 | 42.60 | 3.71 |
| SGDN [21] | 96.80 | 92.27 | 51.60 | 15.31 |
| TsGNet [22] | 93.13 | 92.99 | 147.00 | 0.20 |
| GKNet [23] | 96.90 | 95.70 | 41.70 | 15.74 |
| AFFGA-Net [17] | 99.09 | 98.64 | 66.70 | 68.11 |
| LRGN | 98.96 | 98.30 | 113.00 | 12.67 |
| Method | Accuracy/% | Flops/M | Params/M | Weight/MB | FPS |
|---|---|---|---|---|---|
| AFFGA-Net (resnet101) [17] | 97.94 | 82,520.14 | 68.11 | 266 | 50 |
| AFFGA-Net (xception) [17] | 92.98 | 79,844.55 | 63.48 | 249 | 55 |
| AFFGA-Net (drn) [17] | 96.25 | 129,618.7 | 45.97 | 181 | 69 |
| AFFGA-Net (mobilenet) [17] | 97.66 | 54,800.15 | 12.42 | 46.6 | 102 |
| GG-CNN2 [11] | 73.91 | 3097.55 | 0.06 | 0.26 | 53 |
| GR-ConvNet [24] | 96.49 | 32,368.61 | 1.9 | 7.28 | 96 |
| SGDN [21] | 97.65 | 62,455.23 | 15.31 | 152 | 51 |
| GKNet [23] | 96.77 | 56,420.67 | 15.74 | 73 | 41 |
| LRGN | 98.83 | 16,758.03 | 12.67 | 46.3 | 113 |
| Method | Jaccard Index | |||
|---|---|---|---|---|
| 0.25 | 0.30 | 0.35 | 0.40 | |
| LRGN | 99.42 | 98.83 | 96.49 | 94.15 |
| Baseline | DRM | PAG | DGFM | MAM | Accuracy/% | FPS |
|---|---|---|---|---|---|---|
| √ | 94.74 | 210 | ||||
| √ | √ | 95.91 | 181 | |||
| √ | √ | √ | 96.94 | 170 | ||
| √ | √ | √ | √ | 98.25 | 121 | |
| √ | √ | √ | √ | √ | 98.83 | 113 |
| Model | Accuracy/% | FPS | Params/M |
|---|---|---|---|
| +EMA | 98.71 | 106 | 12.65 |
| +CBAM | 98.56 | 114 | 12.64 |
| +ECA | 98.62 | 115 | 12.64 |
| +MAM | 98.83 | 113 | 12.67 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, F.; Ren, G.; Xiao, Z.; Sun, E.; Ma, G.; Chen, S.; Li, Z.; Zou, Z.; Wang, X. Low-Damage Grasp Method for Plug Seedlings Based on Machine Vision and Deep Learning. Agronomy 2025, 15, 1376. https://doi.org/10.3390/agronomy15061376
Yuan F, Ren G, Xiao Z, Sun E, Ma G, Chen S, Li Z, Zou Z, Wang X. Low-Damage Grasp Method for Plug Seedlings Based on Machine Vision and Deep Learning. Agronomy. 2025; 15(6):1376. https://doi.org/10.3390/agronomy15061376
Chicago/Turabian StyleYuan, Fengwei, Gengzhen Ren, Zhang Xiao, Erjie Sun, Guoning Ma, Shuaiyin Chen, Zhenlong Li, Zhenhong Zou, and Xiangjiang Wang. 2025. "Low-Damage Grasp Method for Plug Seedlings Based on Machine Vision and Deep Learning" Agronomy 15, no. 6: 1376. https://doi.org/10.3390/agronomy15061376
APA StyleYuan, F., Ren, G., Xiao, Z., Sun, E., Ma, G., Chen, S., Li, Z., Zou, Z., & Wang, X. (2025). Low-Damage Grasp Method for Plug Seedlings Based on Machine Vision and Deep Learning. Agronomy, 15(6), 1376. https://doi.org/10.3390/agronomy15061376