
Extraction of Cropland Based on Multi-Source Remote Sensing and an Improved Version of the Deep Learning-Based Segment Anything Model (SAM)


 , ,
, ,
Abstract
1. Introduction
2. Materials and Methods
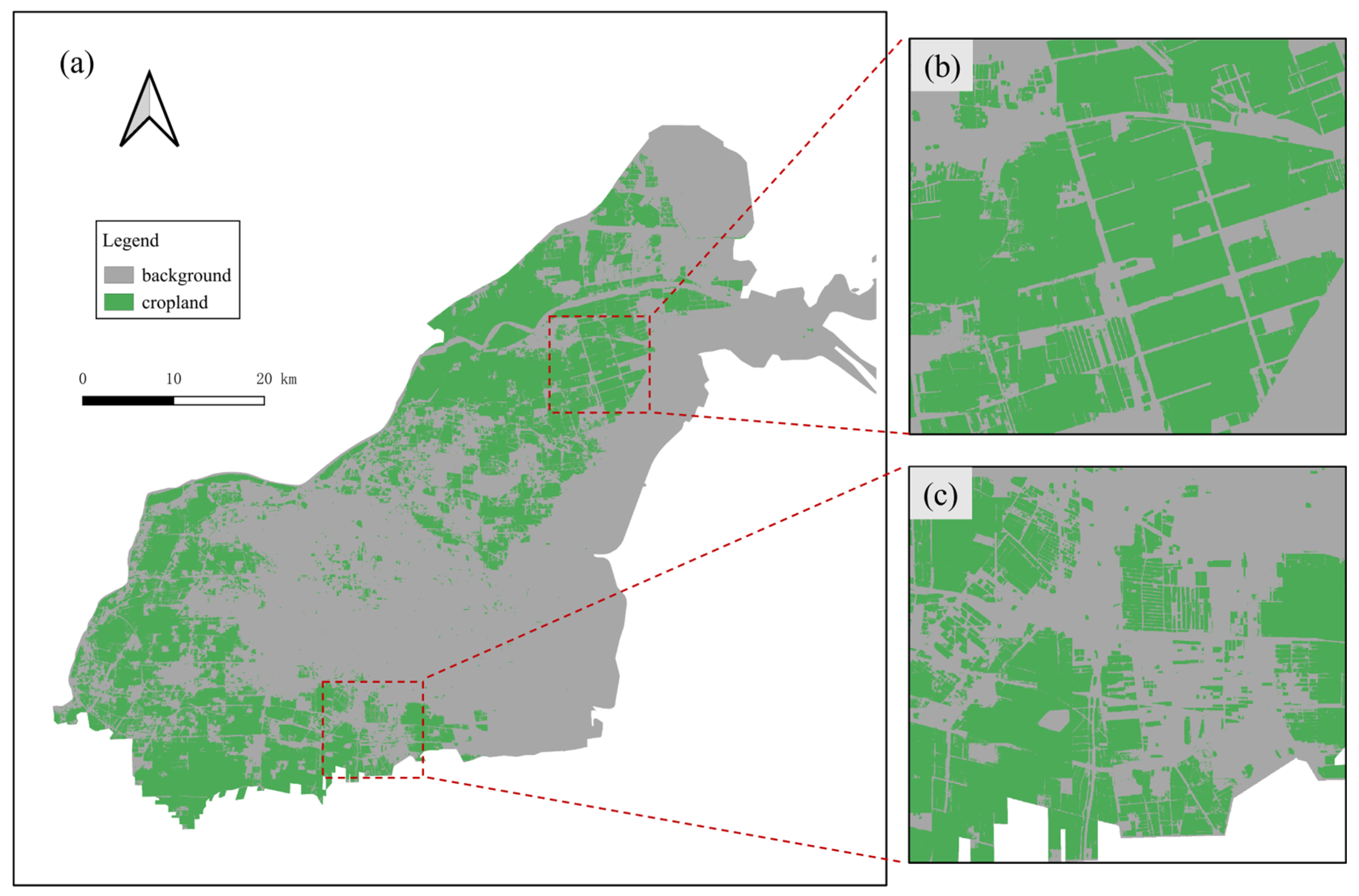
2.1. Study Area
2.2. Data
2.3. Method
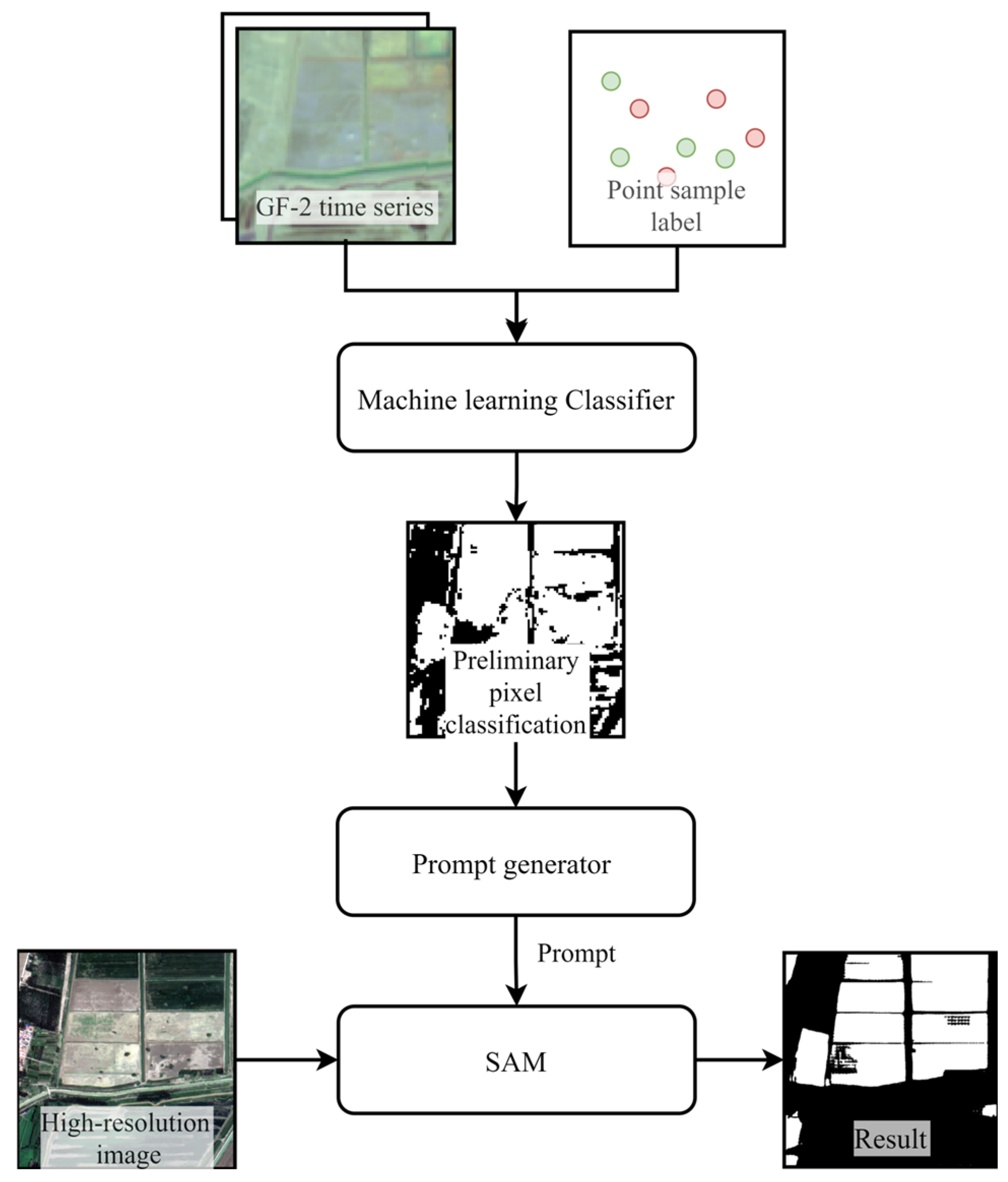
2.3.1. Preliminary Pixel Classification from Medium-Resolution Time Series Data
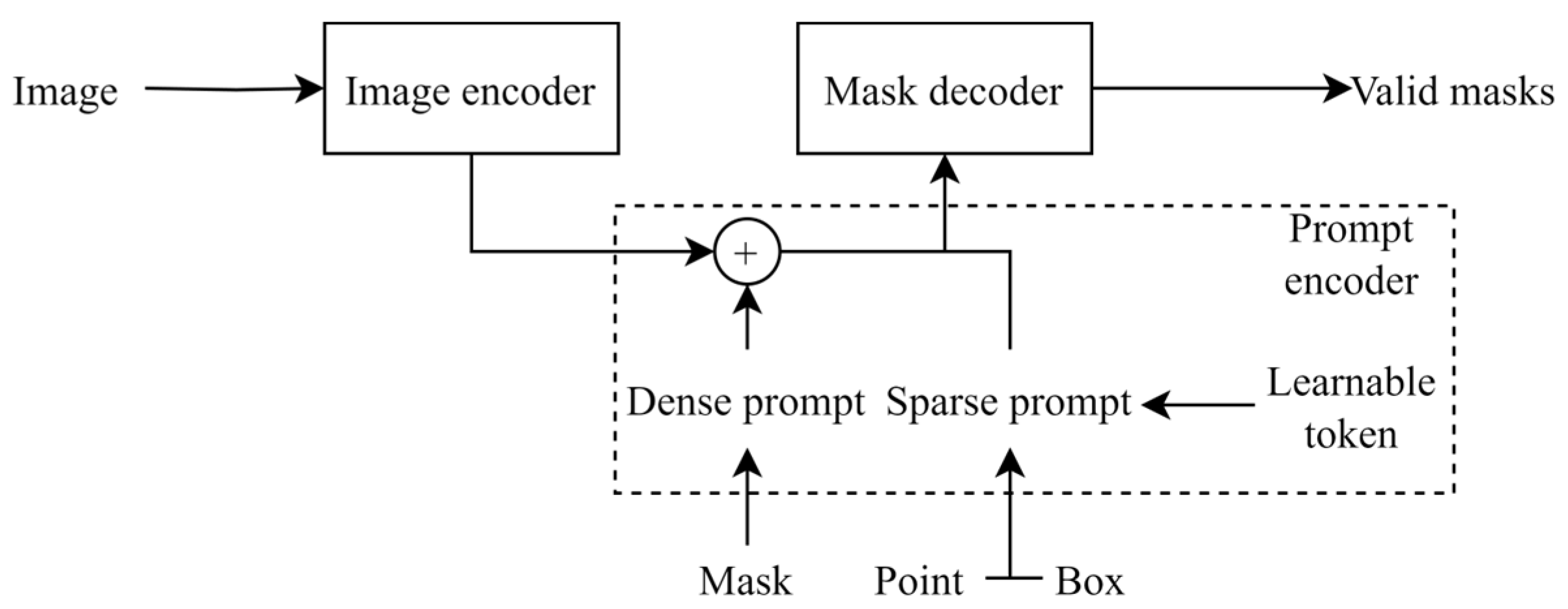
2.3.2. Brief Review of SAM
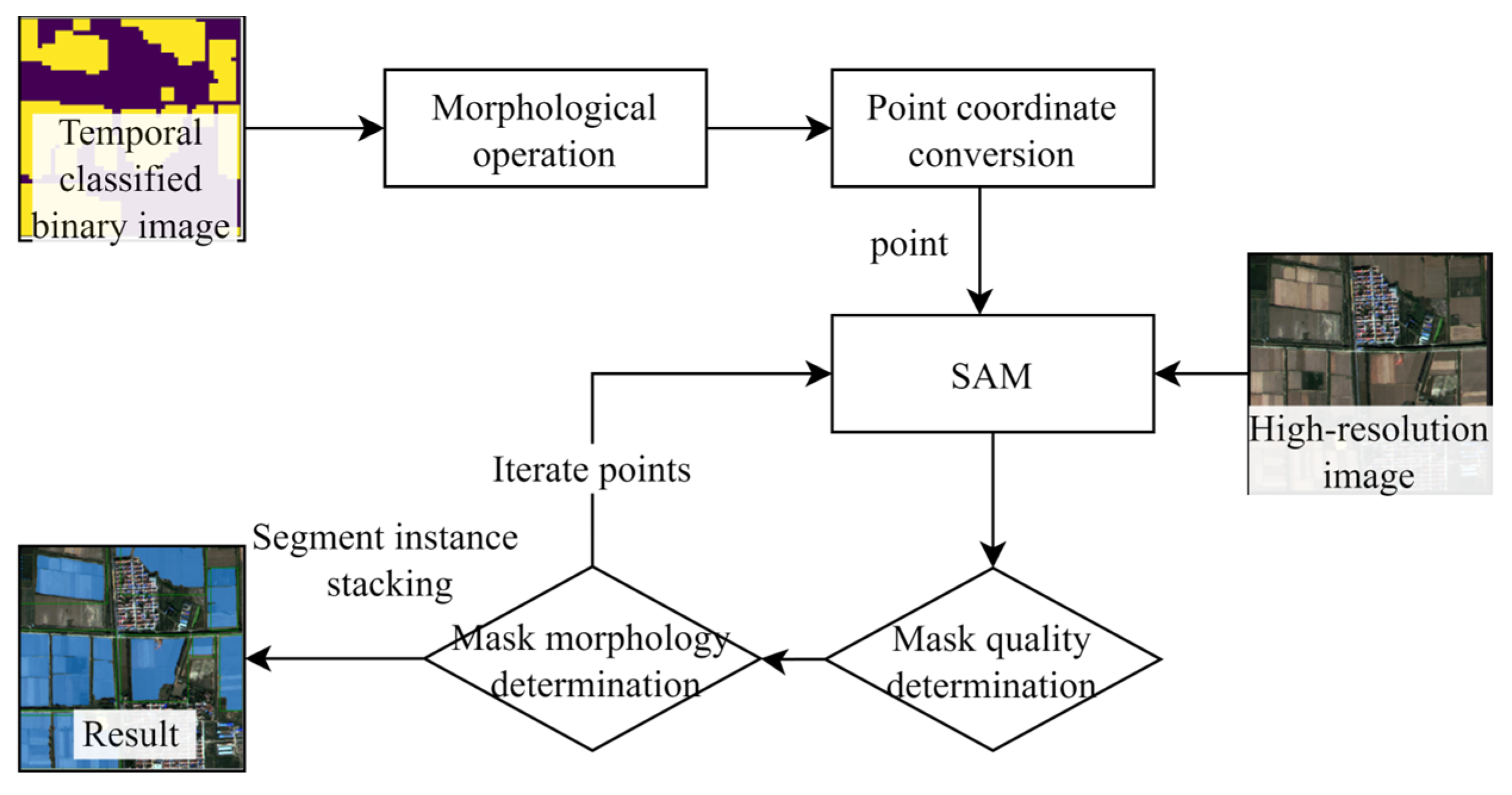
2.3.3. Auto Prompt Generation Module
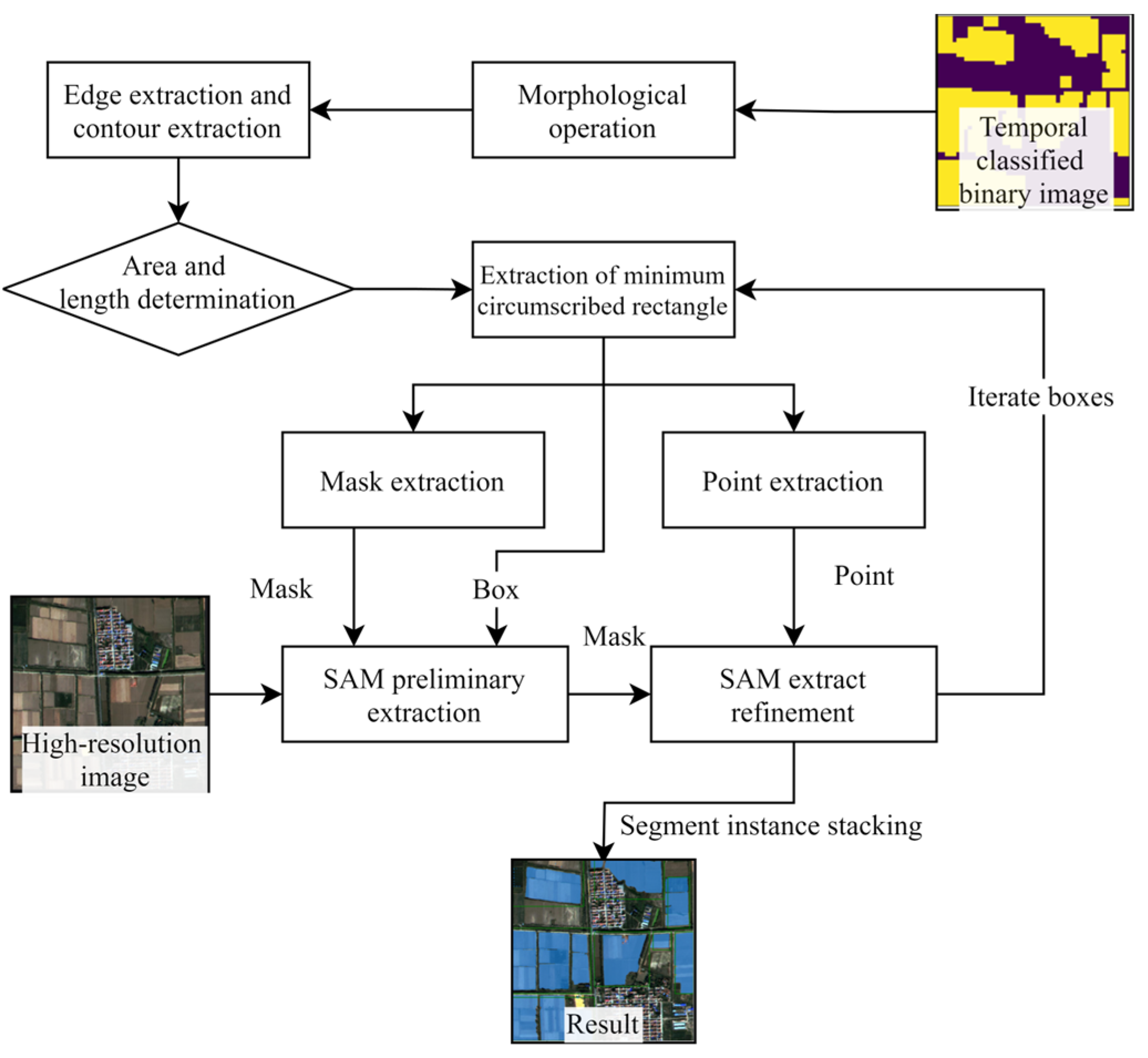
2.3.4. Box Prompt Generation Module
2.4. Implementation and Experimental Setup
2.4.1. Comparison of Semantic Segmentation Models
2.4.2. Box Module Ablation Test
2.4.3. Investigation of Improved SAM’s Best Performance
2.4.4. Performance Assessment
3. Results
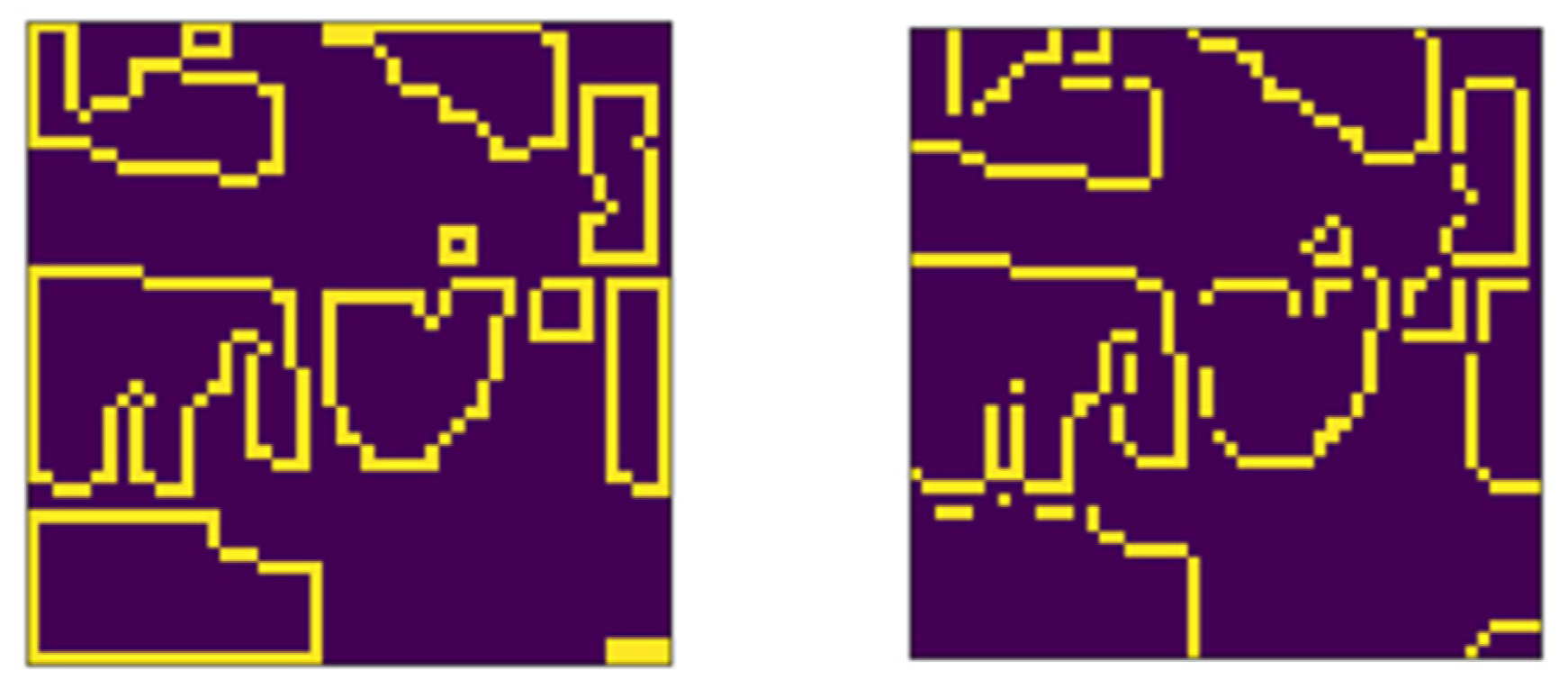
3.1. Sentinel-2 Time Series Data Pixel Classification
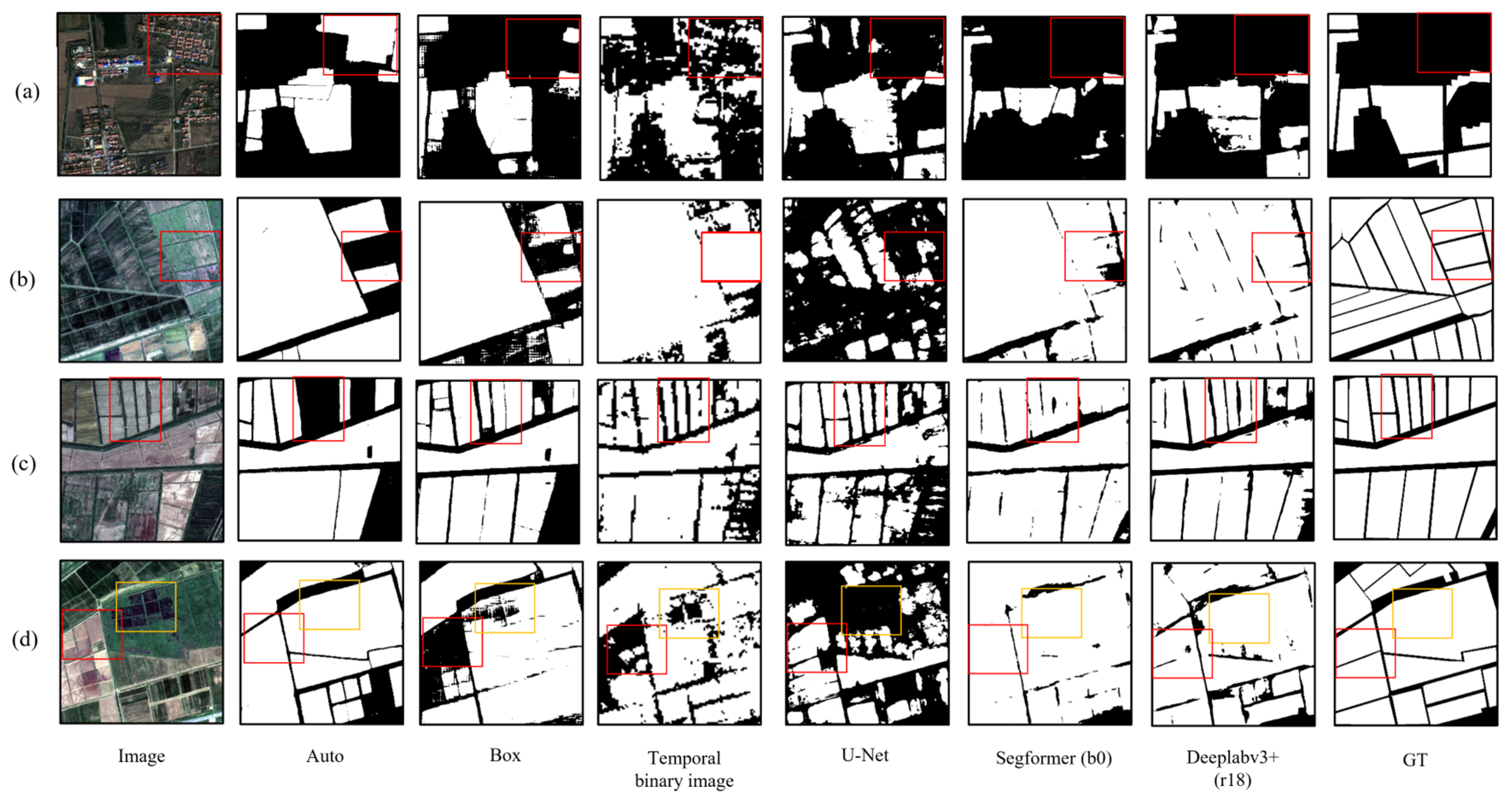
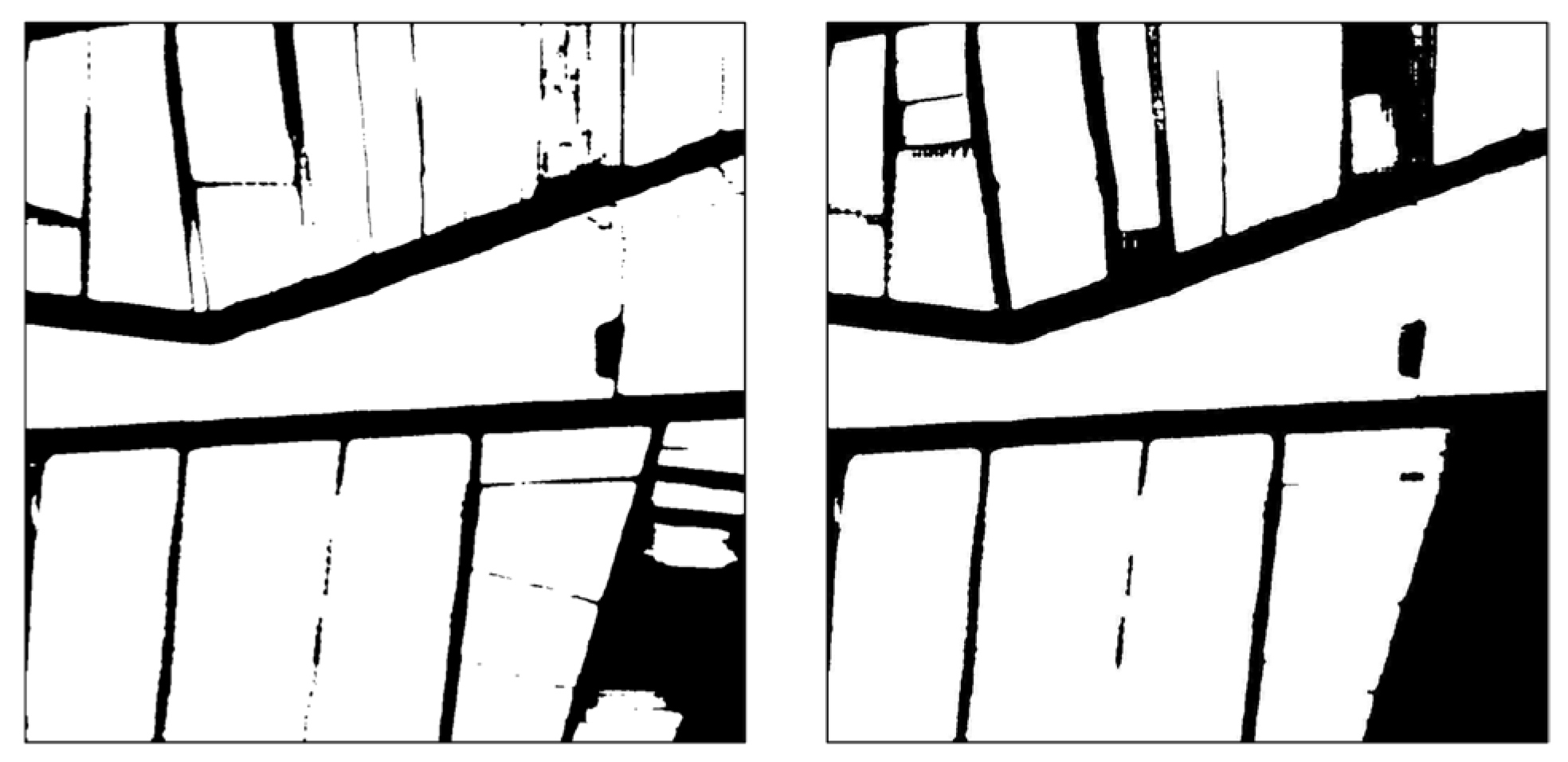
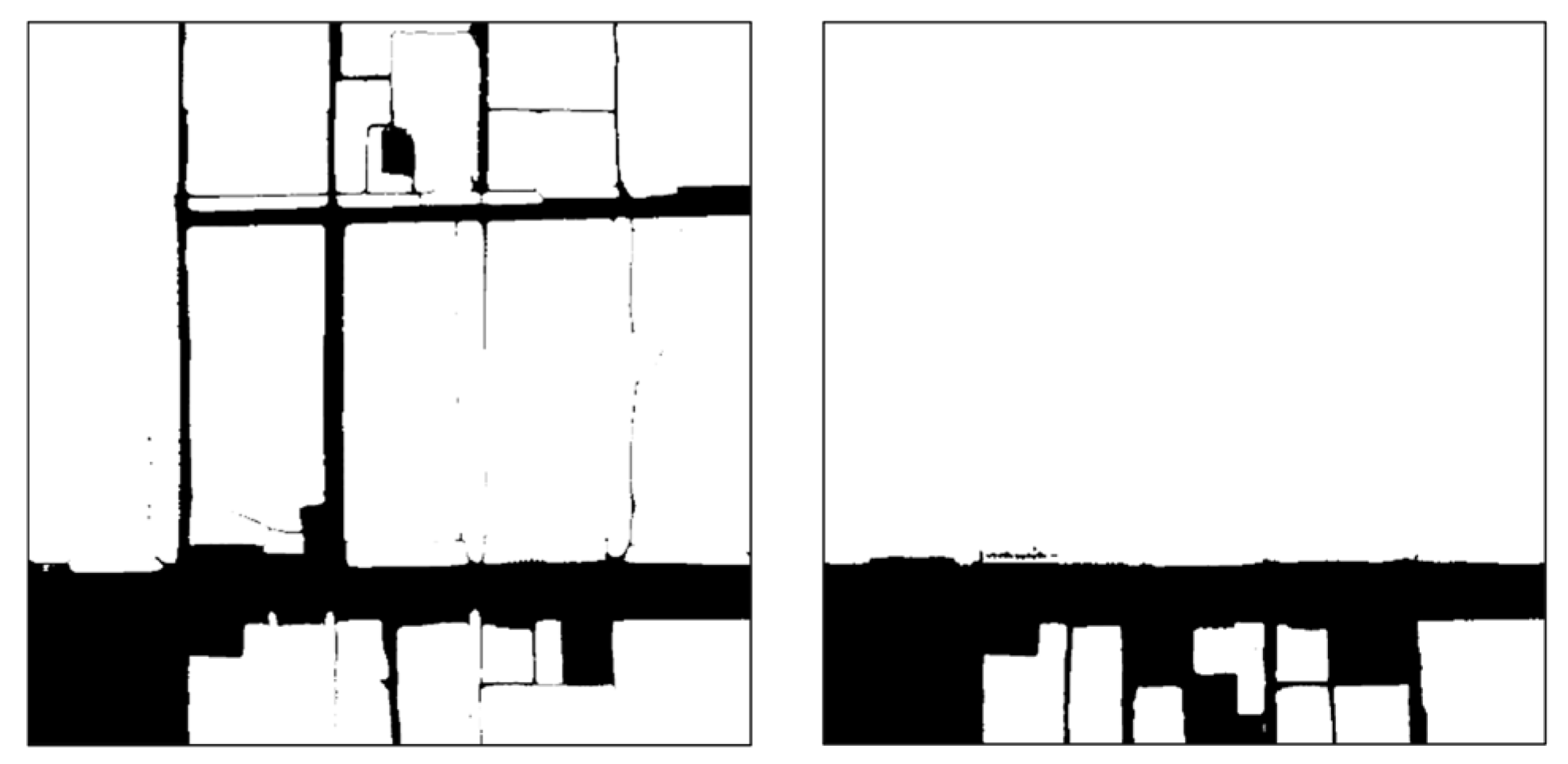
3.2. Comparison of Cropland Extraction Results
3.3. Ablation Experiment Results
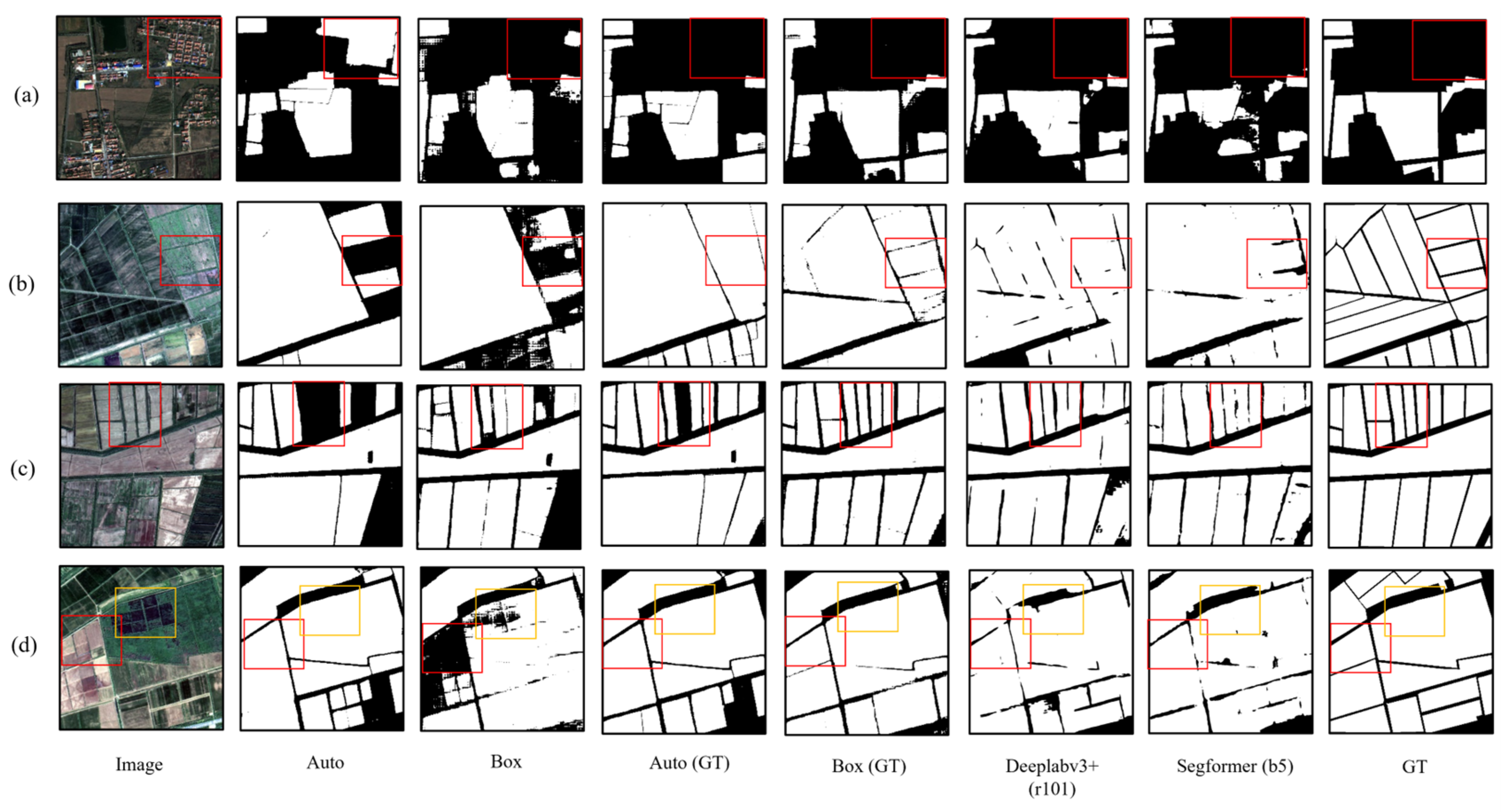
3.4. Improved SAM’s Best Performance
4. Discussion
4.1. Advantages of Improved SAM
4.2. Comparative Analysis of Box Module and Auto Module
4.3. Prospect
- (1)
- Increase the accuracy and reduce the variance of the prompt data source (temporal image pixel classification), without increasing the computational resources.
- (2)
- Optimize the extraction of cropland in large areas to address the boundary errors caused by block-based computing, and increase the computation efficiency.
- (3)
- Improve the stability of the prompt generation module so that it can effectively generate prompts and extract cropland, even when dealing with prompt data sources with certain bias and variance.
5. Conclusions
- (1)
- For the Auto module SAM, the mIoU is 0.679 and the OA is 0.810. As for the Box module SAM, its mIoU is 0.711 and its OA is 0.831. The performance of the Box module SAM is on a par with that of the small-parameter versions of Segformer and Deeplabv3+. Through visual analysis, it was found that the two SAMs, equipped with the introduced prompt modules, can generate cropland masks of higher quality and effectively distinguish roads between cropland parcels. The performance of the Auto module SAM is slightly weaker than that of the Box module SAM, yet it can produce cropland masks of even higher quality. The accuracy of cropland extraction for both SAM modules is affected by the precision of the prompt source data.
- (2)
- The accuracy of cropland extraction via the Auto module SAM is influenced by both the prompt accuracy and the IoU threshold, as well as by the stability threshold during the mask quality control process. A higher threshold can reduce the extraction of non-cropland features, yet it will correspondingly increase the cases of missing cropland prediction. A lower threshold has the opposite effect. The results of the ablation test analysis indicate that, compared with the single-stage prediction approach, the accuracy of cropland extraction in the multi-stage prediction approach of the Box module SAM is significantly enhanced. While point prompts can compensate for missing predictions in areas with scarce prompts, box prompts can roughly define the prediction area and boost the quality of the prediction mask.
- (3)
- The utilization of ground truth annotations as the prompt data source has been proven to enhance the performance of the SAMs based on the two prompt modules, with their segmentation accuracy surpassing that of the largest-parameter versions of Segformer and Deeplabv3+. Specifically, the mIoU of the Box module SAM is 0.920, and the OA is 0.958.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- See, L.; Fritz, S.; You, L.; Ramankutty, N.; Herrero, M.; Justice, C.; Becker-Reshef, I.; Thornton, P.; Erb, K.; Gong, P.; et al. Improved Global Cropland Data as an Essential Ingredient for Food Security. Glob. Food Secur. 2015, 4, 37–45. [Google Scholar] [CrossRef]
- Valjarević, A.; Morar, C.; Brasanac-Bosanac, L.; Cirkovic-Mitrovic, T.; Djekic, T.; Mihajlović, M.; Milevski, I.; Culafic, G.; Luković, M.; Niemets, L.; et al. Sustainable Land Use in Moldova: GIS & Remote Sensing of Forests and Crops. Land Use Policy 2025, 152, 107515. [Google Scholar] [CrossRef]
- Yan, L.; Roy, D.P. Conterminous United States Crop Field Size Quantification from Multi-Temporal Landsat Data. Remote Sens. Environ. 2016, 172, 67–86. [Google Scholar] [CrossRef]
- Persello, C.; Tolpekin, V.A.; Bergado, J.R.; de By, R.A. Delineation of Agricultural Fields in Smallholder Farms from Satellite Images Using Fully Convolutional Networks and Combinatorial Grouping. Remote Sens. Environ. 2019, 231, 111253. [Google Scholar] [CrossRef]
- Xu, L.; Yang, P.; Yu, J.; Peng, F.; Xu, J.; Song, S.; Wu, Y. Extraction of Cropland Field Parcels with High Resolution Remote Sensing Using Multi-Task Learning. Eur. J. Remote Sens. 2023, 56, 2181874. [Google Scholar] [CrossRef]
- Rydberg, A.; Borgefors, G. Integrated Method for Boundary Delineation of Agricultural Fields in Multispectral Satellite Images. IEEE Trans. Geosci. Remote Sens. 2001, 39, 2514–2520. [Google Scholar] [CrossRef]
- Zhong, L.; Hu, L.; Zhou, H. Deep Learning Based Multi-Temporal Crop Classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Xia, J.; Ghamisi, P.; Yokoya, N.; Iwasaki, A. Random Forest Ensembles and Extended Multiextinction Profiles for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 202–216. [Google Scholar] [CrossRef]
- Yoon, H.; Kim, S. Detecting Abandoned Farmland Using Harmonic Analysis and Machine Learning. ISPRS J. Photogramm. Remote Sens. 2020, 166, 201–212. [Google Scholar] [CrossRef]
- Wang, X.; Shu, L.; Han, R.; Yang, F.; Gordon, T.; Wang, X.; Xu, H. A Survey of Farmland Boundary Extraction Technology Based on Remote Sensing Images. Electronics 2023, 12, 1156. [Google Scholar] [CrossRef]
- Xu, L.; Ming, D.; Du, T.; Chen, Y.; Dong, D.; Zhou, C. Delineation of Cultivated Land Parcels Based on Deep Convolutional Networks and Geographical Thematic Scene Division of Remotely Sensed Images. Comput. Electron. Agric. 2022, 192, 106611. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Cao, X.; Zhou, F.; Xu, L.; Meng, D.; Xu, Z.; Paisley, J. Hyperspectral Image Classification With Markov Random Fields and a Convolutional Neural Network. IEEE Trans. Image Process. 2018, 27, 2354–2367. [Google Scholar] [CrossRef]
- Jeon, M.; Jeong, Y.-S. Compact and Accurate Scene Text Detector. Appl. Sci. 2020, 10, 2096. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. arXiv 2015, arXiv:1411.4038. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 833–851. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Jadhav, J.K.; Singh, R.P. Automatic Semantic Segmentation and Classification of Remote Sensing Data for Agriculture. Math. Models Eng. 2018, 4, 112–137. [Google Scholar] [CrossRef]
- Masoud, K.M.; Persello, C.; Tolpekin, V.A. Delineation of Agricultural Field Boundaries from Sentinel-2 Images Using a Novel Super-Resolution Contour Detector Based on Fully Convolutional Networks. Remote Sens. 2020, 12, 59. [Google Scholar] [CrossRef]
- Du, Z.; Yang, J.; Ou, C.; Zhang, T. Smallholder Crop Area Mapped with a Semantic Segmentation Deep Learning Method. Remote Sens. 2019, 11, 888. [Google Scholar] [CrossRef]
- Rußwurm, M.; Körner, M. Self-Attention for Raw Optical Satellite Time Series Classification. ISPRS J. Photogramm. Remote Sens. 2020, 169, 421–435. [Google Scholar] [CrossRef]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D Convolutional Neural Networks and Applications: A Survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Cai, Z.; Hu, Q.; Zhang, X.; Yang, J.; Wei, H.; Wang, J.; Zeng, Y.; Yin, G.; Li, W.; You, L.; et al. Improving Agricultural Field Parcel Delineation with a Dual Branch Spatiotemporal Fusion Network by Integrating Multimodal Satellite Data. ISPRS J. Photogramm. Remote Sens. 2023, 205, 34–49. [Google Scholar] [CrossRef]
- Hu, Y.; Hu, Q.; Li, J. CMINet: A Unified Cross-Modal Integration Framework for Crop Classification From Satellite Image Time Series. IEEE Trans. Geosci. Remote Sens. 2025, 63, 4402213. [Google Scholar] [CrossRef]
- Cui, B.; Yang, Q.; Yang, Z.; Zhang, K. Evaluating the Ecological Performance of Wetland Restoration in the Yellow River Delta, China. Ecol. Eng. 2009, 35, 1090–1103. [Google Scholar] [CrossRef]
- Sun, Y.; Chen, X.; Luo, Y.; Cao, D.; Feng, H.; Zhang, X.; Yao, R. Agricultural Water Quality Assessment and Application in the Yellow River Delta. Agronomy 2023, 13, 1495. [Google Scholar] [CrossRef]
- Ren, K.; Sun, W.; Meng, X.; Yang, G.; Du, Q. Fusing China GF-5 Hyperspectral Data with GF-1, GF-2 and Sentinel-2A Multispectral Data: Which Methods Should Be Used? Remote Sens. 2020, 12, 882. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Taunk, K.; De, S.; Verma, S.; Swetapadma, A. A Brief Review of Nearest Neighbor Algorithm for Learning and Classification. In Proceedings of the 2019 International Conference on Intelligent Computing and Control Systems (ICCS), Madurai, India, 15–17 May 2019; pp. 1255–1260. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y.; et al. Segment Anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Chen, K.; Liu, C.; Chen, H.; Zhang, H.; Li, W.; Zou, Z.; Shi, Z. RSPrompter: Learning to Prompt for Remote Sensing Instance Segmentation Based on Visual Foundation Model. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4701117. [Google Scholar] [CrossRef]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. arXiv 2021, arXiv:2105.15203. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2019, arXiv:1711.05101. [Google Scholar]
- Ma, A.; Chen, D.; Zhong, Y.; Zheng, Z.; Zhang, L. National-Scale Greenhouse Mapping for High Spatial Resolution Remote Sensing Imagery Using a Dense Object Dual-Task Deep Learning Framework: A Case Study of China. ISPRS J. Photogramm. Remote Sens. 2021, 181, 279–294. [Google Scholar] [CrossRef]
- Li, Z.; Chen, S.; Meng, X.; Zhu, R.; Lu, J.; Cao, L.; Lu, P. Full Convolution Neural Network Combined with Contextual Feature Representation for Cropland Extraction from High-Resolution Remote Sensing Images. Remote Sens. 2022, 14, 2157. [Google Scholar] [CrossRef]
- Mei, W.; Wang, H.; Fouhey, D.; Zhou, W.; Hinks, I.; Gray, J.M.; Van Berkel, D.; Jain, M. Using Deep Learning and Very-High-Resolution Imagery to Map Smallholder Field Boundaries. Remote Sens. 2022, 14, 3046. [Google Scholar] [CrossRef]
- Lu, R.; Zhang, Y.; Huang, Q.; Zeng, P.; Shi, Z.; Ye, S. A Refined Edge-Aware Convolutional Neural Networks for Agricultural Parcel Delineation. Int. J. Appl. Earth Obs. Geoinf. 2024, 133, 104084. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test Set OA | Cross-Validation OA | Test Set OA |
|---|---|---|
| LSTM | 0.947 | - |
| RF | 0.969 | 0.912 |
| XGBoost | 0.950 | 0.908 |
| KNN | 0.935 | 0.898 |
| mIoU | OA | F1 (Cropland) | F1 (Background) | Kappa | |
|---|---|---|---|---|---|
| Auto | 0.679 | 0.810 | 0.824 | 0.794 | 0.618 |
| Box | 0.711 | 0.831 | 0.839 | 0.823 | 0.662 |
| U-Net | 0.516 | 0.680 | 0.704 | 0.627 | 0.335 |
| Deeplabv3+ (r18) | 0.708 | 0.830 | 0.847 | 0.811 | 0.659 |
| Segformer (b0) | 0.716 | 0.835 | 0.839 | 0.829 | 0.669 |
| mIoU | OA | F1 (Cropland) | F1 (Background) | Kappa | |
|---|---|---|---|---|---|
| Box | 0.711 | 0.831 | 0.839 | 0.823 | 0.662 |
| Box (point, mask) | 0.540 | 0.712 | 0.762 | 0.634 | 0.416 |
| Box (box, mask) | 0.635 | 0.777 | 0.769 | 0.785 | 0.556 |
| mIoU | OA | F1 (Cropland) | F1 (Background) | Kappa | |
|---|---|---|---|---|---|
| Auto | 0.679 | 0.810 | 0.824 | 0.794 | 0.618 |
| Box | 0.711 | 0.831 | 0.839 | 0.823 | 0.662 |
| Deeplabv3 (r101) | 0.765 | 0.867 | 0.878 | 0.855 | 0.734 |
| Segformer (b5) | 0.753 | 0.860 | 0.864 | 0.855 | 0.719 |
| Auto (GT) | 0.815 | 0.898 | 0.903 | 0.893 | 0.796 |
| Box (GT) | 0.920 | 0.958 | 0.959 | 0.957 | 0.916 |
| Stability | 0.86 | 0.88 | 0.90 | |
|---|---|---|---|---|
| IoU | ||||
| 0.8 | 0.685 | 0.675 | 0.680 | |
| 0.82 | 0.685 | 0.679 | 0.675 | |
| 0.84 | 0.680 | 0.668 | 0.676 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tao, K.; Li, H.; Huang, C.; Liu, Q.; Zhang, J.; Du, R. Extraction of Cropland Based on Multi-Source Remote Sensing and an Improved Version of the Deep Learning-Based Segment Anything Model (SAM). Agronomy 2025, 15, 1139. https://doi.org/10.3390/agronomy15051139
Tao K, Li H, Huang C, Liu Q, Zhang J, Du R. Extraction of Cropland Based on Multi-Source Remote Sensing and an Improved Version of the Deep Learning-Based Segment Anything Model (SAM). Agronomy. 2025; 15(5):1139. https://doi.org/10.3390/agronomy15051139
Chicago/Turabian StyleTao, Kunjian, He Li, Chong Huang, Qingsheng Liu, Junyan Zhang, and Ruoqi Du. 2025. "Extraction of Cropland Based on Multi-Source Remote Sensing and an Improved Version of the Deep Learning-Based Segment Anything Model (SAM)" Agronomy 15, no. 5: 1139. https://doi.org/10.3390/agronomy15051139
APA StyleTao, K., Li, H., Huang, C., Liu, Q., Zhang, J., & Du, R. (2025). Extraction of Cropland Based on Multi-Source Remote Sensing and an Improved Version of the Deep Learning-Based Segment Anything Model (SAM). Agronomy, 15(5), 1139. https://doi.org/10.3390/agronomy15051139