
DSW-YOLO-Based Green Pepper Detection Method Under Complex Environments

Abstract
1. Introduction
- A green pepper detection dataset was constructed, covering various fruit sizes, counts, light intensities, occlusion types, and shooting angles.
- A lightweight C2f-Dilation-wise Residual-Reparam (C2f-DWRR) module was proposed. The dilated convolution in the Dilation-wise Residual (DWR) module was replaced with a Dilated Reparam Block (DRB) module and integrated into the C2f module through class inheritance, thereby replacing the original Bottleneck structure. Substituting the 6th and 8th layers of the YOLOv10 backbone with C2f-DWRR significantly improved P and R while reducing model size and parameters, thus achieving lightweight goals.
- The SimAM attention mechanism was integrated between the Backbone and Neck of YOLOv10n, and Complete Intersection Over Union Loss (CIOU) was replaced with Weighted Intersection over Union v3 (WIOUv3). These modifications notably enhanced performance in scenes involving occlusion, overlap, and congestion, minimizing false positives and missed detections without increasing additional parameters. The terminology utilized in this document is outlined in Table 1.
2. Materials and Methods
2.1. Image Acquisition
2.2. Dataset Construction
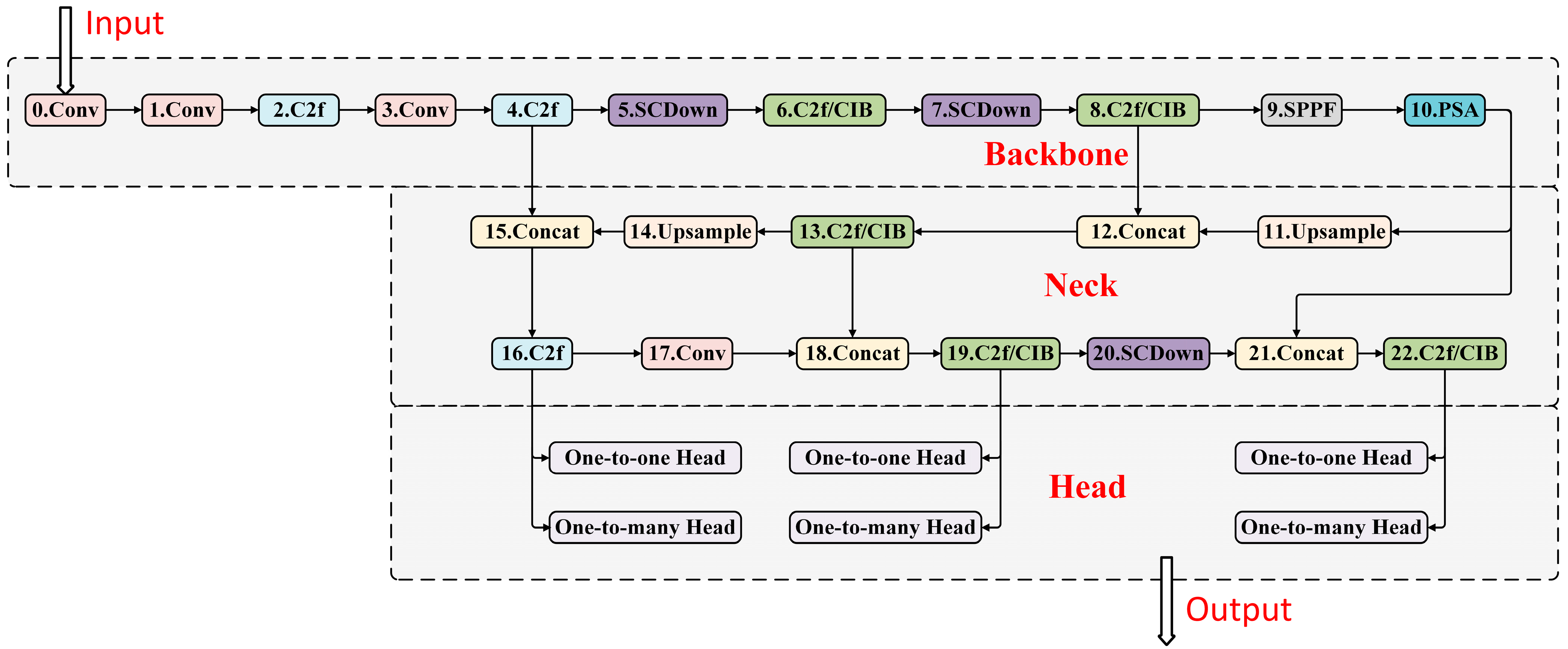
2.3. YOLOv10 Network Architecture
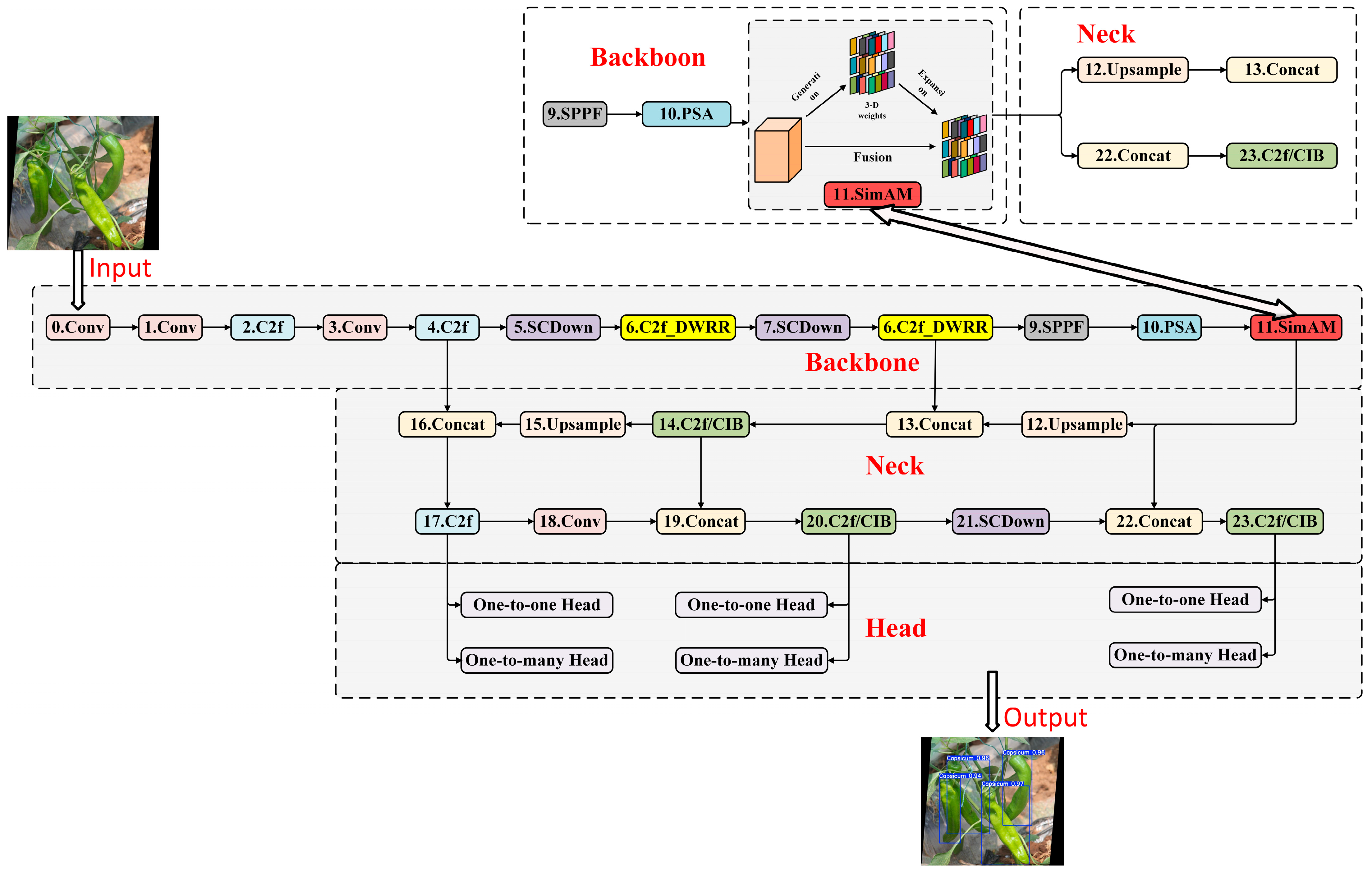
2.4. DSW-YOLO Network Architecture
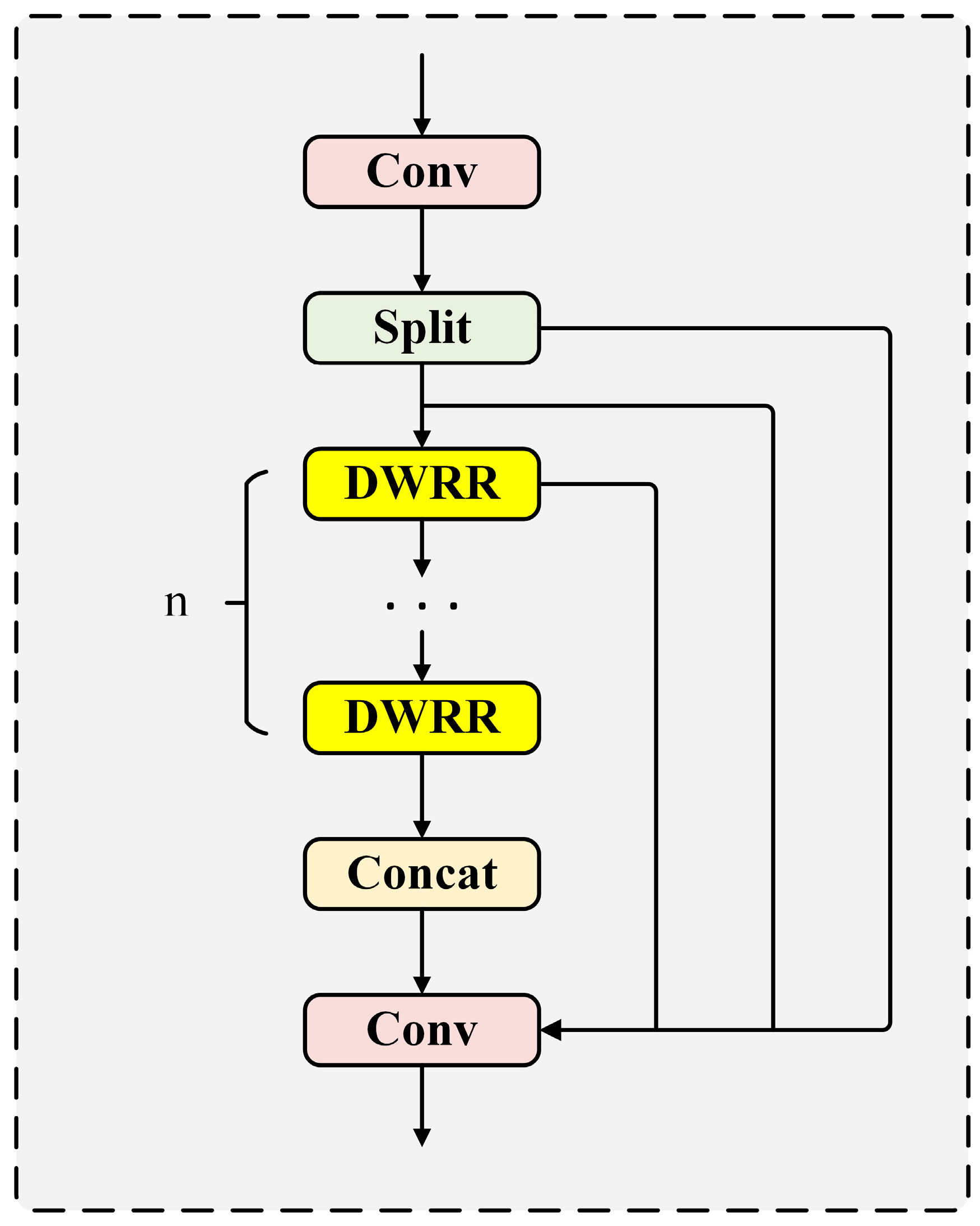
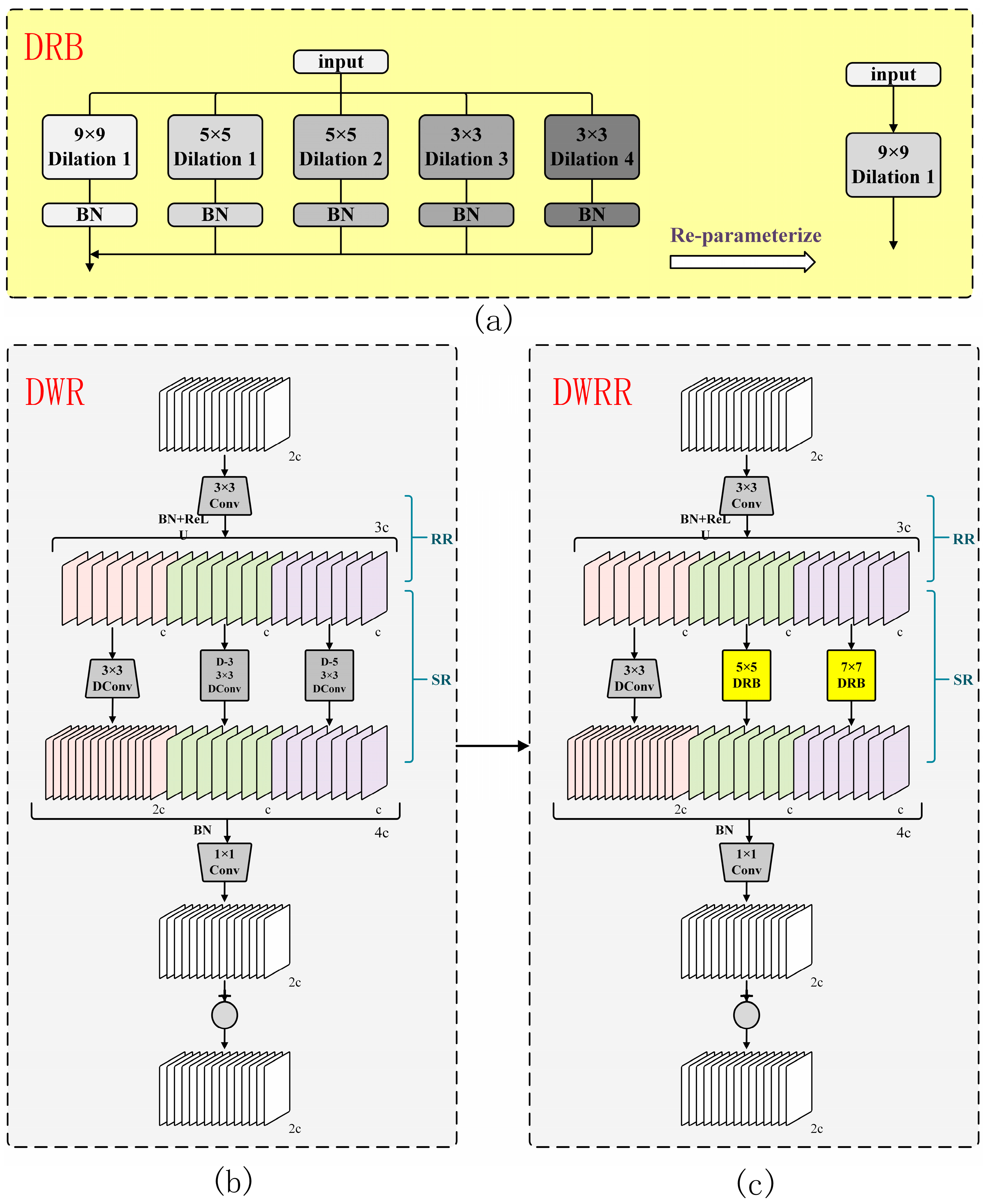
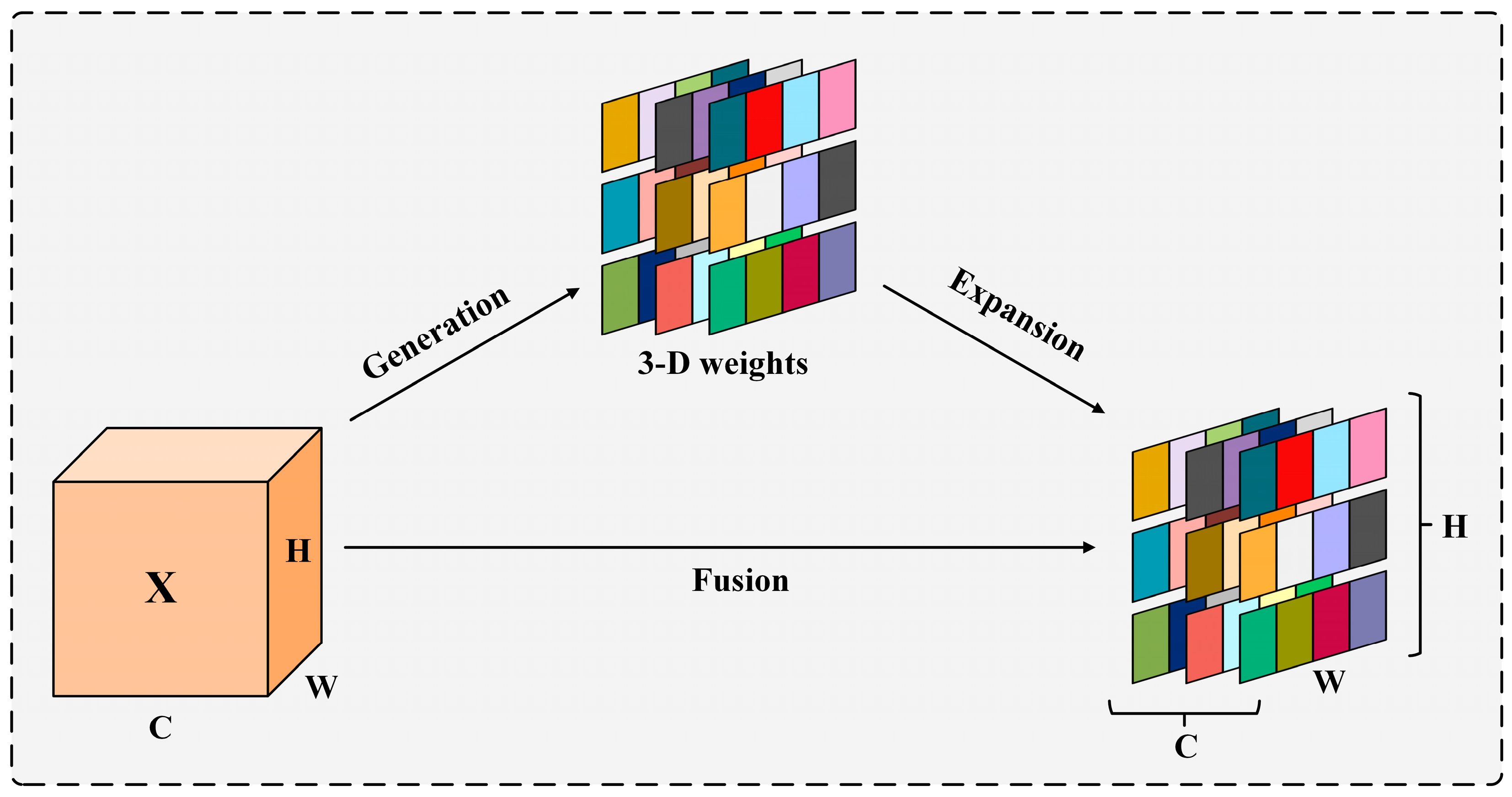
2.4.1. Construction of the C2f-DWRR Module
- (1)
- DRB module enhances multi-scale feature extraction capability: The DRB module can simultaneously capture fine-grained local features and broader spatial context by using gradually increasing dilation rates across multiple layers, thereby enhancing the ability to extract multi-scale features.
- (2)
- Trade-off between accuracy and efficiency: Compared to the higher computational cost of deep convolutions with larger input feature maps, DRB reduces the number of parameters and computational burden through reparameterization techniques, while almost maintaining the accuracy of feature extraction.
- (3)
- Maintaining the basic feature extraction characteristics of the DWR module: Although the computational efficiency is optimized, the first branch of the DWRR module still uses convolution layers with a dilation rate of zero, ensuring that the basic operations and feature extraction properties of the original structure are preserved. This balance between efficiency and functionality is crucial for ensuring that the model captures key features.
- DRB: DRB achieves a similar effect to large kernel convolution by using multiple smaller dilated kernels. The input first goes through a 9 × 9 kernel, followed by two 5 × 5 kernels and two 3 × 3 kernels with increasing dilation rates. Batch normalization (BN) boosts training efficiency and stability. This approach reconfigures the layers to act like a single large-kernel convolution, expanding the receptive field and improving spatial feature extraction while keeping the model efficient in terms of parameters and computation.
- DWR: The DWR module improves multi-scale information collection using a two-step process-Regional Residualization (RR) and Semantic Residualization (SR)-to capture detailed features. In the first step (RR), it generates multi-scale feature maps with 3 × 3 convolutions, BN, and ReLU, enhancing the ability to process information. In the second step (SR), these maps are grouped into clusters with similar features using morphological filtering. Convolutions with different dilation rates adjust the features, improving spatial analysis. The results are combined and passed through a 1 × 1 convolution to reduce complexity and parameters. Finally, the original input is added back to the output through a residual connection, boosting the network’s learning and stability. This design makes the DWR module ideal for high-precision, efficient deep learning tasks.
2.4.2. SimAM Attention Mechanism
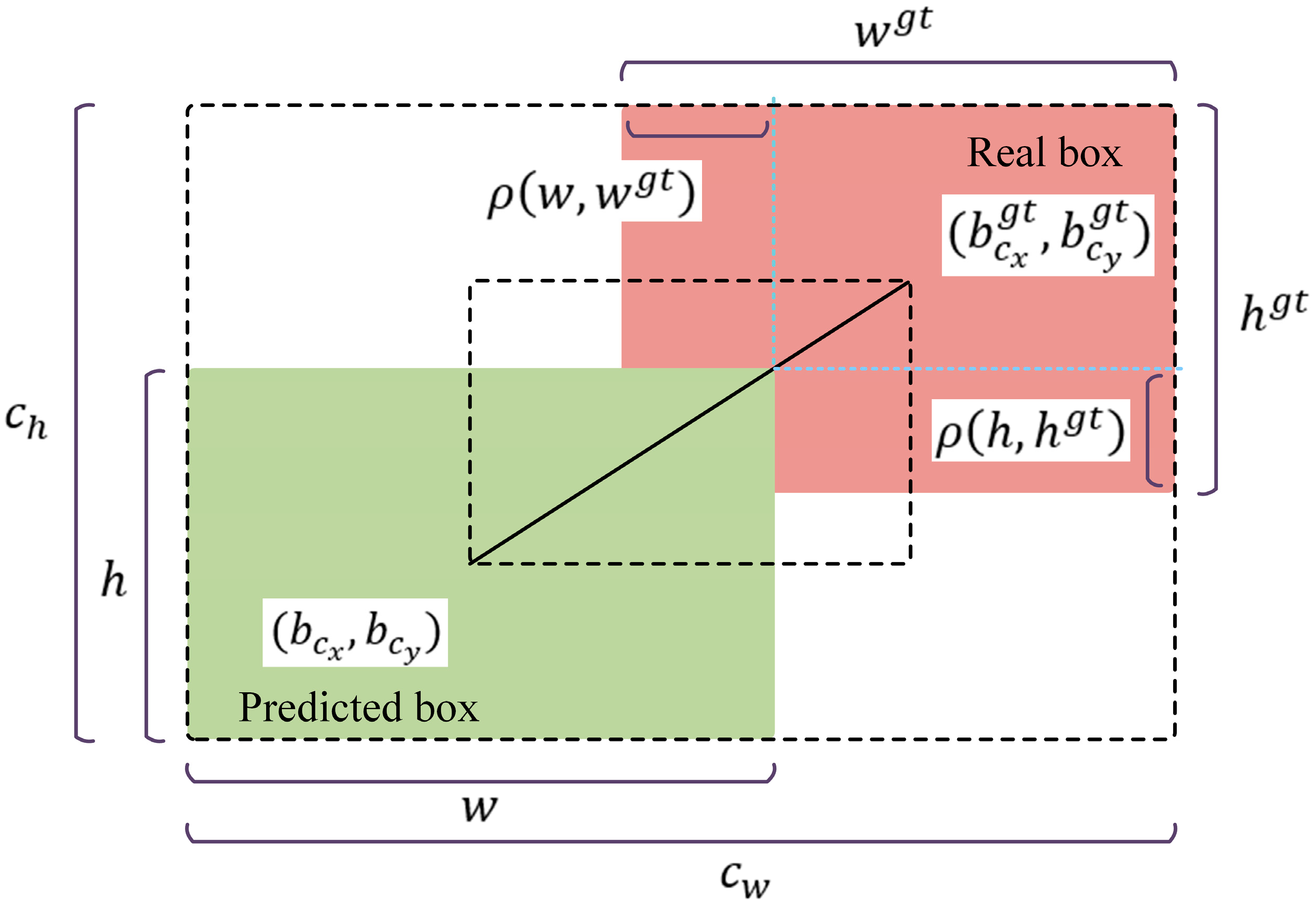
2.4.3. WIoUv3 Loss Function
2.5. Experimental Platform Configuration and Training Strategy
2.6. Evaluation Metrics
3. Results
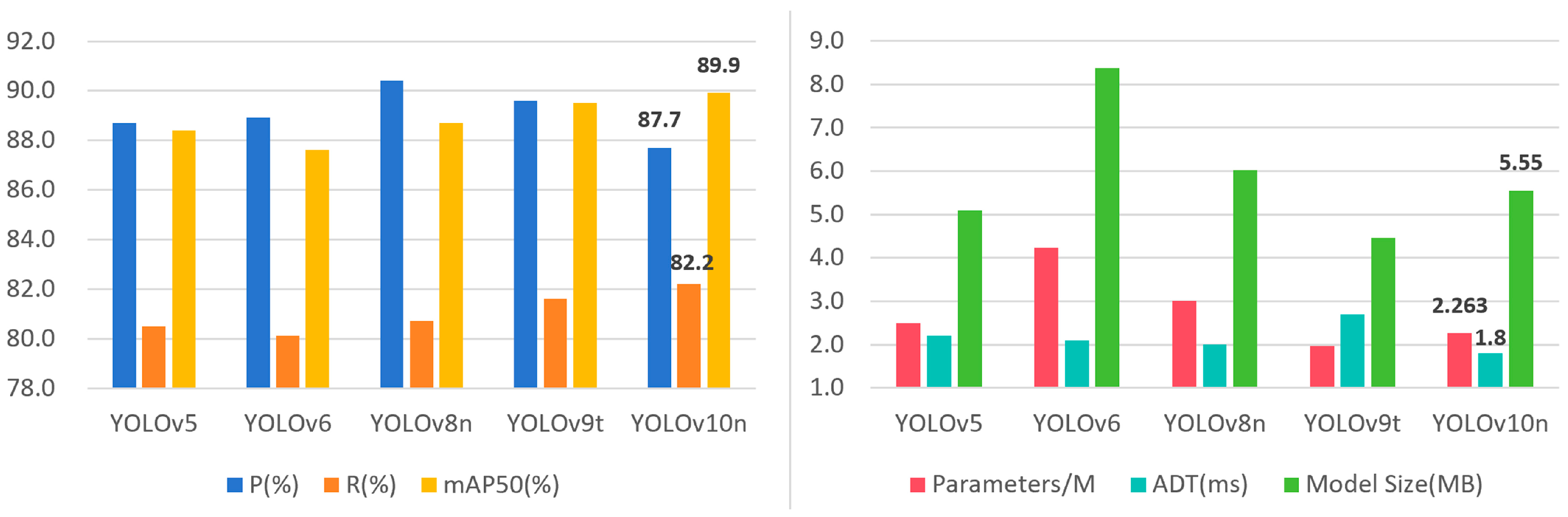
3.1. Analysis of Comparative Results of YOLO-Series Algorithms
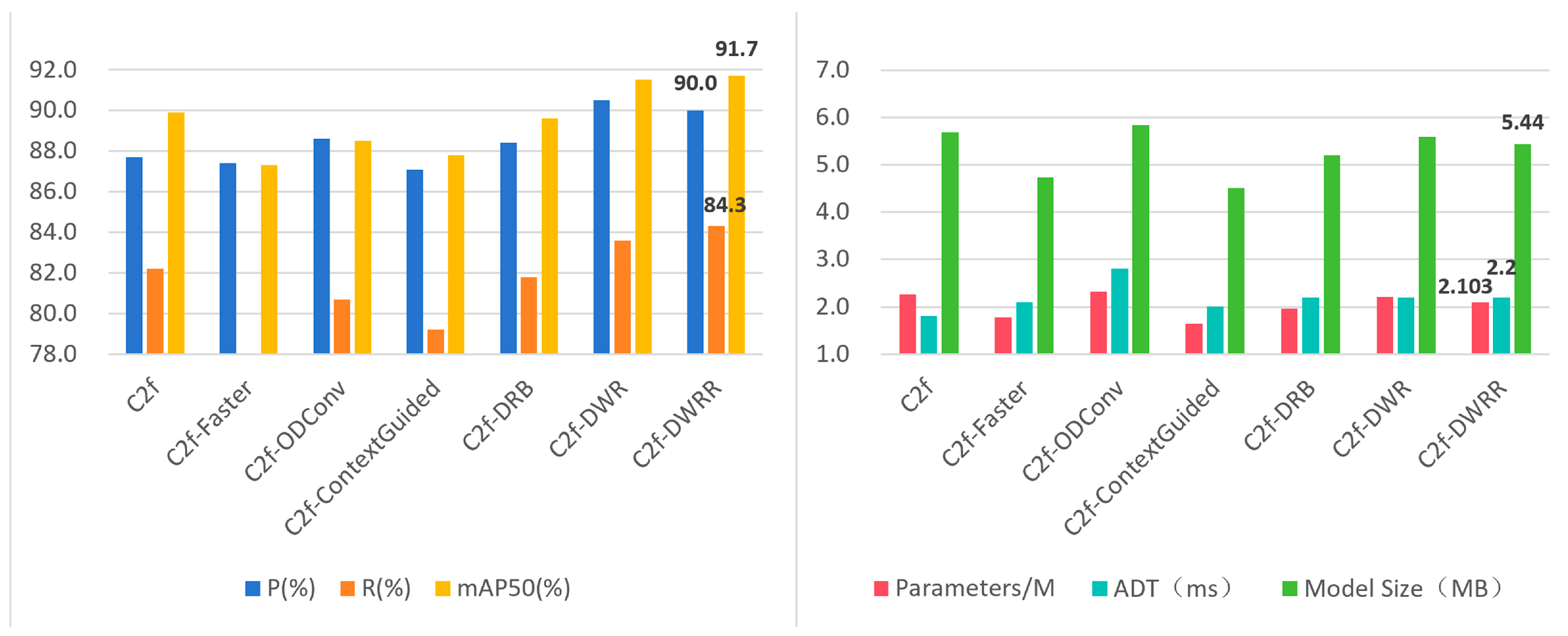
3.2. C2f Module Optimization Results and Analysis
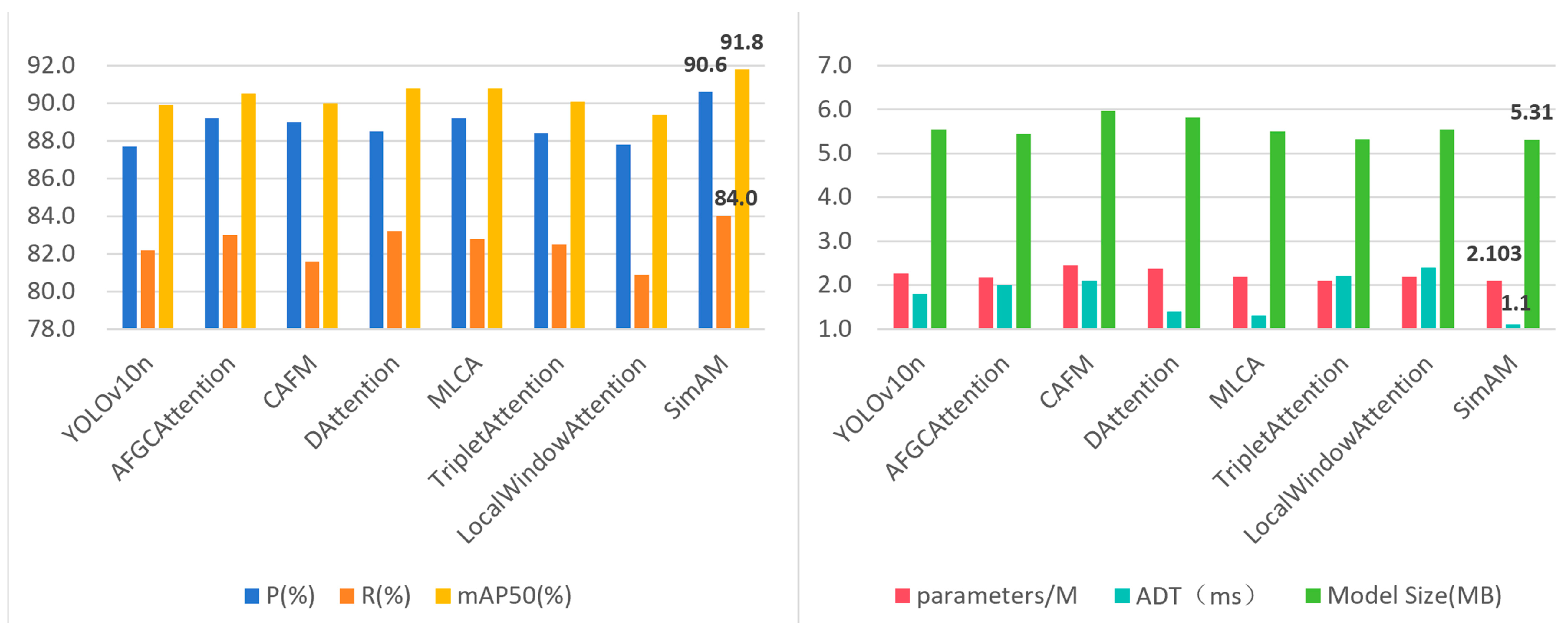
3.3. Attention Mechanism Optimization Results and Analysis
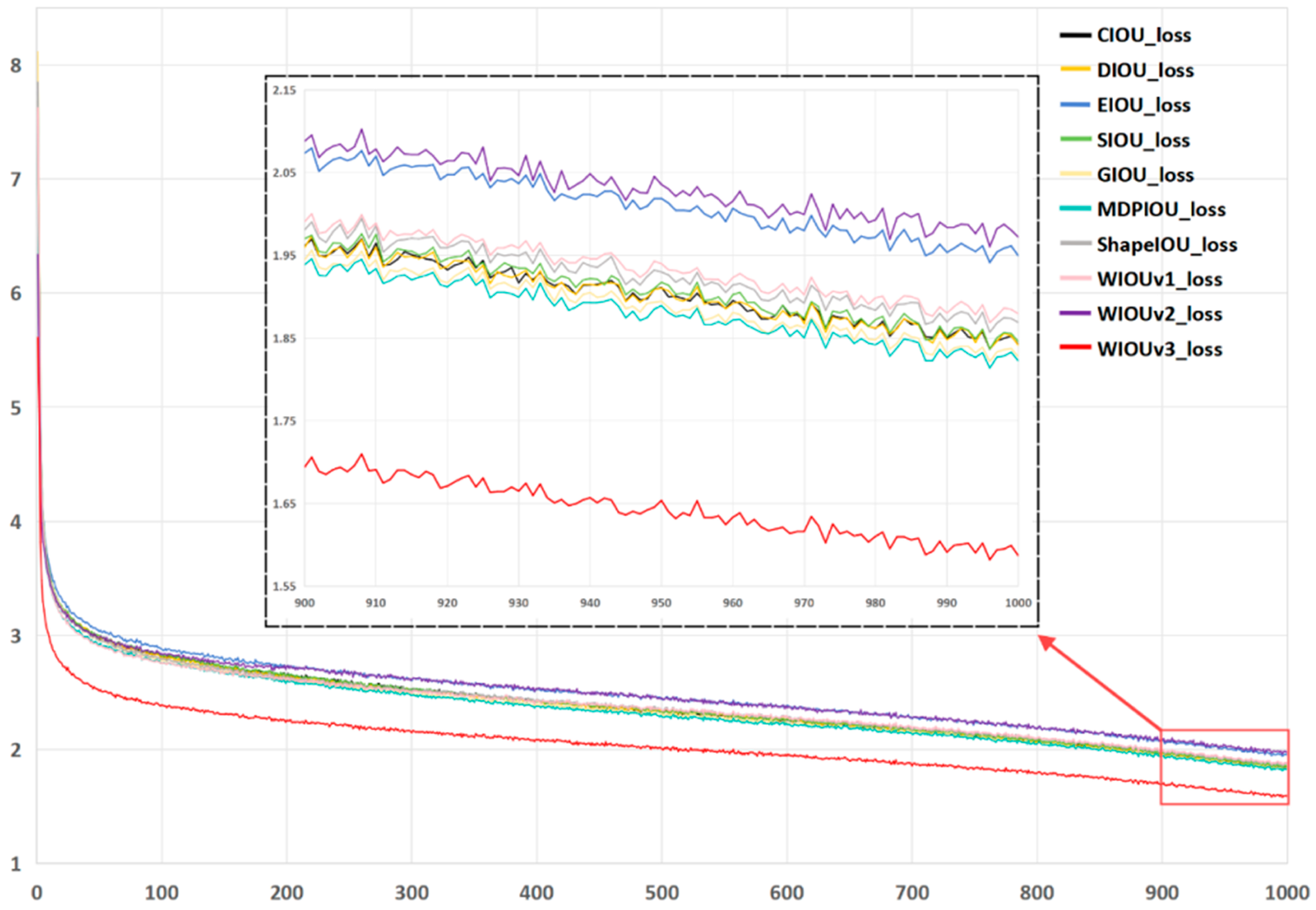
3.4. Loss Function Optimization Results and Analysis
3.5. Ablation Test
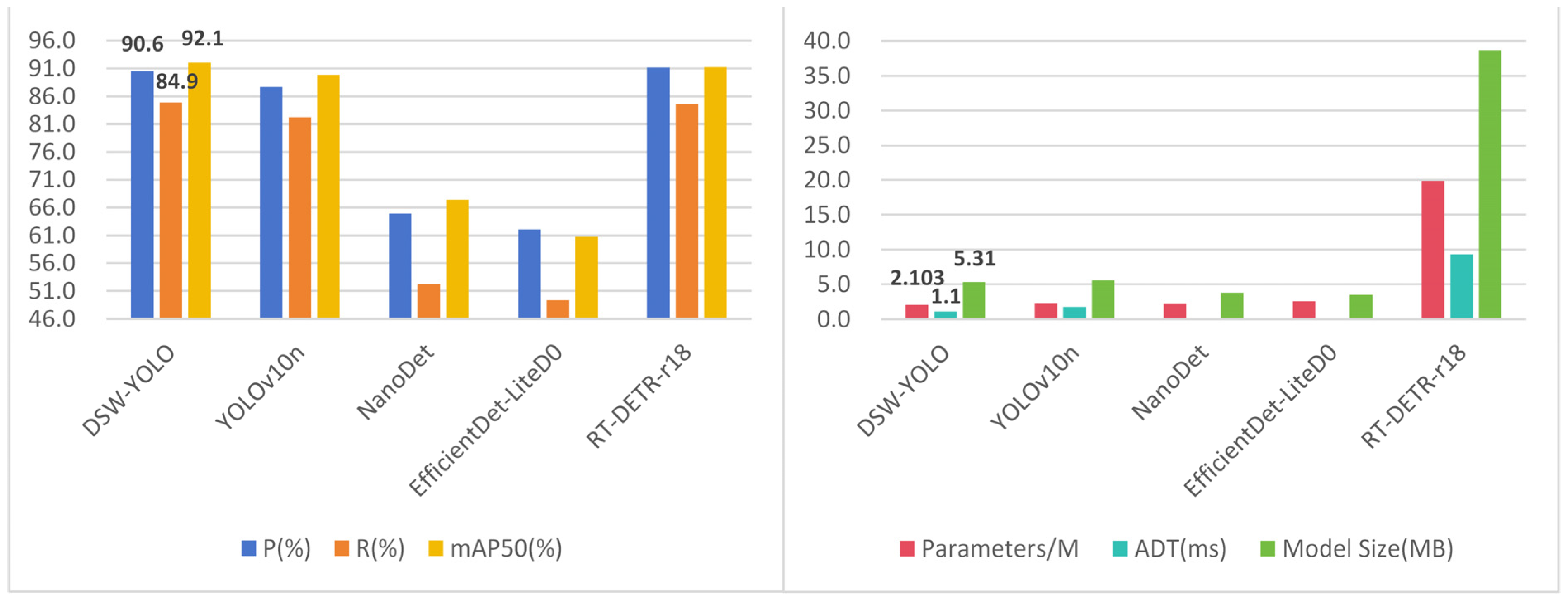
3.6. Final Optimized Model Analysis
4. Discussion
- (1)
- In the experiments of Section 2.4, this study analyzed the impact of different loss functions on the improved YOLOv10n model. It was observed that WIOUv1, WIOUv2, CIOU, and WIOUv3 exhibited a progressively optimized trend in convergence speed and loss values. WIOUv1 and WIOUv2 primarily adjust the weights of boundary regions while ignoring the optimization of central areas, which can lead to box drift [42]. CIOU, by introducing center point optimization and aspect ratio terms, enhances box stability. However, because CIOU places excessive emphasis on the center point and aspect ratio, it may result in unstable bounding-box optimization under dense object detection tasks like complex green pepper environments, affecting object differentiation and boundary accuracy [43]. In contrast, WIOUv3 refines weighted IoU and applies adaptive gradients, offering more comprehensive optimizations for boundaries, overlaps, and scale issues in dense-object scenarios, thus performing best in dense environments. In datasets with fewer dense targets, retaining CIOU could help lower computational complexity while maintaining detection performance.
- (2)
- In the ablation experiments of Section 2.5, the effectiveness of each module was validated by gradually integrating them. The results indicate that adding the SimAM attention mechanism alone decreases precision and increases parameter count and model size, whereas combining it with the C2f-DWRR module yields better precision, fewer parameters, and smaller model size than the baseline. The analysis suggests that SimAM attention aligns better with the C2f-DWRR module, which provides deeper feature extraction. Because the original C2f module has weaker feature extraction capabilities, SimAM alone cannot compensate for its limitations. Moreover, SimAM’s channel-by-channel computations may conflict with the C2f design, increasing computational load and consequently reducing model performance [44,45]. By contrast, C2f-DWRR leverages dilated convolutions and re-parameterization to capture more diverse local and global features, enhancing the quality of low-level features and, in turn, improving the effectiveness of SimAM. This finding underscores the critical importance of a well-chosen module combination for boosting model performance [46].
5. Conclusions
- (1)
- This study incorporates the C2f-DWRR module into the backbone network as a replacement for the original C2f module, thereby enhancing feature extraction capabilities while maintaining a lightweight design. This structural improvement significantly boosts detection performance under complex environmental conditions and offers both theoretical foundation and technical support for practical object recognition tasks in real-world agricultural scenarios.
- (2)
- The SimAM attention mechanism is integrated into the final layer of the backbone network, significantly enhancing feature representation while reducing detection latency. Notably, it does not increase the number of model parameters, providing a practical solution for object detection in resource-constrained environments.
- (3)
- The proposed DSW-YOLO model maintains stable detection of green pepper fruits under varying lighting conditions, occlusions, and scale changes, demonstrating excellent deployment adaptability and robustness. It is well suited for embedded platforms and can effectively support the vision system of green pepper harvesting robots in complex orchard environments.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zou, Z.; Zou, X. Geographical and ecological differences in pepper cultivation and consumption in China. Front. Nutr. 2021, 8, 718517. [Google Scholar] [CrossRef] [PubMed]
- Karim, K.M.R.; Rafii, M.Y.; Misran, A.B.; Ismail, M.F.B.; Harun, A.R.; Khan, M.M.H.; Chowdhury, M.F.N. Current and prospective strategies in the varietal improvement of chilli (Capsicum annuum L.) specially heterosis breeding. Agronomy 2021, 11, 2217. [Google Scholar] [CrossRef]
- Omolo, M.A.; Wong, Z.Z.; Mergen, A.K.; Hastings, J.C.; Le, N.C.; Reiland, H.A.; Case, K.A.; Baumler, D.J. Antimicrobial properties of chili peppers. J. Infect. Dis. Ther. 2014, 2, 145–150. [Google Scholar] [CrossRef]
- Saleh, B.; Omer, A.; Teweldemedhin, B. Medicinal uses and health benefits of chili pepper (Capsicum spp.): A review. MOJ Food Process Technol. 2018, 6, 325–328. [Google Scholar] [CrossRef]
- Azlan, A.; Sultana, S.; Huei, C.; Razman, M. Antioxidant, anti-obesity, nutritional and other beneficial effects of different chili pepper: A review. Molecules 2022, 27, 898. [Google Scholar] [CrossRef] [PubMed]
- Tang, Y.; Chen, M.; Wang, C.; Luo, L.; Li, J.; Lian, G.; Zou, X. Recognition and localization methods for vision-based fruit picking robots: A review. Front. Plant Sci. 2020, 11, 510. [Google Scholar] [CrossRef]
- McCool, C.; Sa, I.; Dayoub, F.; Lehnert, C.; Perez, T.; Upcroft, B. Visual detection of occluded crop: For automated harvesting. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 2506–2512. [Google Scholar] [CrossRef]
- Ji, W.; Chen, G.; Xu, B.; Meng, X.; Zhao, D. Recognition method of green pepper in greenhouse based on least-squares support vector machine optimized by the improved particle swarm optimization. IEEE Access 2019, 7, 119742–119754. [Google Scholar] [CrossRef]
- Ji, W.; Gao, X.; Xu, B.; Chen, G.; Zhao, D. Target recognition method of green pepper harvesting robot based on manifold ranking. Comput. Electron. Agric. 2020, 178, 105663. [Google Scholar] [CrossRef]
- Xu, D.; Zhao, H.; Lawal, O.M.; Lu, X.; Ren, R.; Zhang, S. An automatic jujube fruit detection and ripeness inspection method in the natural environment. Agronomy 2023, 13, 451. [Google Scholar] [CrossRef]
- Zhao, H.; Xu, D.; Lawal, O.; Zhang, S. Muskmelon maturity stage classification model based on CNN. J. Robot. 2021, 2021, 8828340. [Google Scholar] [CrossRef]
- Chen, P.; Yu, D. Improved Faster RCNN approach for vehicles and pedestrian detection. Int. Core J. Eng. 2020, 6, 119–124. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, S.; Wang, C.; Wang, L.; Zhang, Y.; Song, H. Segmentation method of Zanthoxylum bungeanum cluster based on improved Mask R-CNN. Agriculture 2024, 14, 1585. [Google Scholar] [CrossRef]
- Cai, C.; Xu, H.; Chen, S.; Yang, L.; Weng, Y.; Huang, S.; Dong, C.; Lou, X. Tree recognition and crown width extraction based on novel Faster-RCNN in a dense loblolly pine environment. Forests 2023, 14, 863. [Google Scholar] [CrossRef]
- Deng, R.; Cheng, W.; Liu, H.; Hou, D.; Zhong, X.; Huang, Z.; Xie, B.; Yin, N. Automatic identification of sea rice grains in complex field environment based on deep learning. Agriculture 2024, 14, 1135. [Google Scholar] [CrossRef]
- Shen, L.; Su, J.; Huang, R.; Quan, W.; Song, Y.; Fang, Y.; Su, B. Fusing Attention Mechanism with Mask R-CNN for Instance Segmentation of Grape Cluster in the Field. Front. Plant Sci. 2022, 13, 934450. [Google Scholar] [CrossRef]
- Lin, S.; Liu, M.; Tao, Z. Detection of underwater treasures using attention mechanism and improved YOLOv5. Trans. Chin. Soc. Agric. Eng. 2021, 37, 307–314. [Google Scholar] [CrossRef]
- Li, S.; Zhang, Z.; Li, S. GLS-YOLO: A lightweight tea bud detection model in complex scenarios. Agronomy 2024, 14, 2939. [Google Scholar] [CrossRef]
- Wang, N.; Cao, H.; Huang, X.; Ding, M. Rapeseed flower counting method based on GhP2-YOLO and StrongSORT algorithm. Plants 2024, 13, 2388. [Google Scholar] [CrossRef]
- Nan, Y.; Zhang, H.; Zeng, Y.; Zheng, J.; Ge, Y. Faster and accurate green pepper detection using NSGA-II-based pruned YOLOv5l in the field environment. Comput. Electron. Agric. 2023, 205, 107621. [Google Scholar] [CrossRef]
- Li, X.; Pan, J.; Xie, F.; Zeng, J.; Li, Q.; Huang, X.; Liu, D.; Wang, X. Fast and accurate green pepper detection in complex backgrounds via an improved Yolov4-tiny model. Comput. Electron. Agric. 2021, 191, 106547. [Google Scholar] [CrossRef]
- Bhargavi, T.; Sumathi, D. Significance of data augmentation in identifying plant diseases using deep learning. In Proceedings of the 2023 5th International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 23–25 January 2023; pp. 1099–1103. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J. YOLOv10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs beat YOLOs on real-time object detection. arXiv 2023, arXiv:2304.08069. [Google Scholar]
- Ding, X.; Zhang, Y.; Ge, Y.; Zhao, S.; Song, L.; Yue, X.; Shan, Y. UniRepLKNet: A Universal Perception Large-Kernel ConvNet for Audio Video Point Cloud Time-Series and Image Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024. [Google Scholar] [CrossRef]
- Wei, H.; Liu, X.; Xu, S.; Dai, Z.; Dai, Y.; Xu, X. DWRSeg: Rethinking efficient acquisition of multi-scale contextual information for real-time semantic segmentation. arXiv 2022, arXiv:2212.01173. [Google Scholar]
- Carrasco, M. Visual attention: The past 25 years. Vision Res. 2011, 51, 1484–1525. [Google Scholar] [CrossRef] [PubMed]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. SimAM: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the 38th International Conference on Machine Learning, PMLR 139, Virtual, 18–24 July 2021; pp. 11863–11874. Available online: https://proceedings.mlr.press/v139/yang21h.html (accessed on 12 November 2024).
- Webb, B.S.; Dhruv, N.T.; Solomon, S.G.; Tailby, C.; Lennie, P. Early and late mechanisms of surround suppression in striate cortex of macaque. J. Neurosci. 2005, 25, 11666–11675. [Google Scholar] [CrossRef]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding box regression loss with dynamic focusing mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Chen, J.; Kao, S.H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar] [CrossRef]
- Li, C.; Zhou, A.; Yao, A. Omni-dimensional dynamic convolution. arXiv 2022, arXiv:2209.07947. [Google Scholar]
- Wu, T.; Tang, S.; Zhang, R.; Cao, J.; Zhang, Y. CGNet: A light-weight context guided network for semantic segmentation. IEEE Trans. Image Process. 2020, 30, 1169–1179. [Google Scholar] [CrossRef]
- Sermanet, P.; Frome, A.; Real, E. Attention for fine-grained categorization. arXiv 2014, arXiv:1412.7054. [Google Scholar]
- Hu, S.; Gao, F.; Zhou, X.; Dong, J.; Du, Q. Hybrid convolutional and attention network for hyperspectral image denoising. IEEE Geosci. Remote Sens. Lett. 2024, 21, 5501605. [Google Scholar] [CrossRef]
- Xia, Z.; Pan, X.; Song, S.; Li, L.E.; Huang, G. Vision transformer with deformable attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4794–4803. [Google Scholar] [CrossRef]
- Wan, D.; Lu, R.; Shen, S.; Xu, T.; Lang, X.; Ren, Z. Mixed local channel attention for object detection. Eng. Appl. Artif. Intell. 2023, 123, 106442. [Google Scholar] [CrossRef]
- Misra, D.; Nalamada, T.; Arasanipalai, A.U.; Hou, Q. Rotate to attend: Convolutional triplet attention module. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 3139–3148. [Google Scholar] [CrossRef]
- Sun, H.; Wang, Y.; Wang, X.; Zhang, B.; Xin, Y.; Zhang, B.; Cao, X.; Ding, E.; Han, S. Maformer: A transformer network with multi-scale attention fusion for visual recognition. Neurocomputing 2024, 595, 127828. [Google Scholar] [CrossRef]
- Jiang, P.-T.; Zhang, C.-B.; Hou, Q.; Cheng, M.-M.; Wei, Y. LayerCAM: Exploring hierarchical class activation maps for localization. IEEE Trans. Image Process. 2021, 30, 5875–5888. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Cho, Y.J. Weighted intersection over union (wIoU) for evaluating image segmentation. Pattern Recognit. Lett. 2024, 185, 101–107. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar] [CrossRef]
- Sun, Y.; Hou, H. Stainless Steel Welded Pipe Weld Seam Defect Detection Method Based on Improved YOLOv5s. In Proceedings of the Fifth International Conference on Computer Vision and Data Mining (ICCVDM 2024), Changchun, China, 3 October 2024; p. 90. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, K.; Li, Z.; Hu, H.; Li, B.; Tan, W.; Lu, H.; Xiao, J.; Ren, Y.; Pu, S. Dynamic Feature Pyramid Networks for Detection. In Proceedings of the International Conference on Multimedia Computing and Systems, Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Meaning |
|---|---|
| C2f-DWRR | C2f-Dilation-wise Residual-Reparam |
| DWR | Dilation-wise Residual |
| DRB | Dilated Reparam Block |
| CIOU | Complete Intersection Over Union Loss |
| WIOUv3 | Weighted Intersection over Union v3 |
| NMS | non-maximum suppression |
| ECA | Efficient Channel Attention |
| DUC | Dense Upsampling Convolution |
| Green Pepper Image and Annotation Count in Different Environments | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Number | Environment Categories | Number of Images | Number of Annotations | ||||||
| Training | Val | Test | Total | Training | Val | Test | Total | ||
| 1 | Overcast + fruit_branch + fruit_branch + fruit_branch | 553 | 79 | 145 | 777 | 4013 | 627 | 1090 | 5730 |
| 2 | Overcast + fruit_fruit + fruit_fruit | 642 | 71 | 190 | 903 | 5551 | 550 | 1720 | 7821 |
| 3 | Overcast + fruit_leaf | 713 | 107 | 200 | 1020 | 5163 | 811 | 1517 | 7491 |
| 4 | Blurry_target | 264 | 41 | 79 | 384 | 2178 | 317 | 541 | 3036 |
| 5 | Backlighting + fruit_branch + fruit_branch | 318 | 36 | 81 | 435 | 2138 | 229 | 564 | 2931 |
| 6 | Backlighting + fruit_fruit | 293 | 40 | 90 | 423 | 3268 | 411 | 959 | 4638 |
| 7 | Backlighting + fruit_leaf | 320 | 46 | 93 | 459 | 2141 | 374 | 662 | 3177 |
| 8 | Unobstructed | 390 | 61 | 107 | 558 | 1806 | 285 | 537 | 2628 |
| 9 | Frontlighting + fruit_branch + fruit_fruit | 574 | 86 | 171 | 831 | 3576 | 473 | 1063 | 5112 |
| 10 | Frontlighting + fruit_fruit | 561 | 97 | 170 | 828 | 3830 | 680 | 1202 | 5712 |
| 11 | Frontlighting + fruit_leaf | 800 | 111 | 226 | 1137 | 5019 | 699 | 1356 | 7074 |
| Total | 5428 | 775 | 1552 | 7755 | 38,683 | 5456 | 11,211 | 55,350 | |
| Training Parameters | Values |
|---|---|
| Initial learning rate | 0.01 |
| Number of images per batch | 32 |
| Number of epochs | 1000 |
| Optimizer | SGD |
| Optimizer momentum | 0.937 |
| Optimizer weight decay rate | 0.0005 |
| Image input size | 640 × 640 |
| Number | Algorithm | P (%) | R (%) | mAP50 (%) | mAP50-95 (%) | Parameters/M | ADT (ms) | ModelSize (MB) |
|---|---|---|---|---|---|---|---|---|
| 1 | YOLOv5n | 88.7 | 80.5 | 88.4 | 64.3 | 2.503 | 2.2 | 5.09 |
| 2 | YOLOv6n | 88.9 | 80.1 | 87.6 | 65.2 | 4.234 | 2.1 | 8.38 |
| 3 | YOLOv8n | 90.4 | 80.7 | 88.7 | 65 | 3.006 | 2.0 | 6.03 |
| 4 | YOLOv9t | 89.6 | 81.6 | 89.5 | 66.5 | 1.971 | 2.7 | 4.46 |
| 5 | YOLOv10n | 87.7 | 82.2 | 89.9 | 65.9 | 2.263 | 1.8 | 5.55 |
| Number | Algorithm | P (%) | R (%) | mAP50 (%) | mAP50-95 (%) | Parameters /M | ADT (ms) | Model Size (MB) |
|---|---|---|---|---|---|---|---|---|
| 1 | C2f | 87.7 | 82.2 | 89.9 | 65.9 | 2.263 | 1.8 | 5.69 |
| 2 | C2f-Faster | 87.4 | 78.0 | 87.3 | 62.5 | 1.780 | 2.1 | 4.73 |
| 3 | C2f-ODConv | 88.6 | 80.7 | 88.5 | 64.3 | 2.317 | 2.8 | 5.84 |
| 4 | C2f-ContextGuided | 87.1 | 79.2 | 87.8 | 62.4 | 1.644 | 2.0 | 4.50 |
| 5 | C2f-DRB | 88.4 | 81.8 | 89.6 | 66.0 | 1.965 | 2.2 | 5.20 |
| 6 | C2f-DWR | 90.5 | 83.6 | 91.5 | 67.2 | 2.204 | 2.2 | 5.59 |
| 7 | C2f-DWRR | 90.0 | 84.3 | 91.7 | 69.3 | 2.103 | 2.2 | 5.44 |
| Number | Algorithm | P (%) | R (%) | mAP50 (%) | mAP50-95 (%) | Parameters /M | ADT (ms) | Model Size (MB) |
|---|---|---|---|---|---|---|---|---|
| 1 | YOLOv10n | 87.7 | 82.2 | 89.9 | 65.9 | 2.263 | 1.8 | 5.55 |
| 2 | YOLOv10n- C2f-DWRR | 90.0 | 84.3 | 91.7 | 69.3 | 2.103 | 2.2 | 5.31 |
| 3 | AFGCAttention | 89.2 | 83.0 | 90.5 | 67.0 | 2.169 | 2.0 | 5.44 |
| 4 | CAFM | 89.0 | 81.6 | 90.0 | 65.0 | 2.449 | 2.1 | 5.97 |
| 5 | DAttention | 88.5 | 83.2 | 90.8 | 67.4 | 2.370 | 1.4 | 5.82 |
| 6 | MLCA | 89.2 | 82.8 | 90.8 | 66.5 | 2.197 | 1.3 | 5.50 |
| 7 | TripletAttention | 88.4 | 82.5 | 90.1 | 65.5 | 2.103 | 2.2 | 5.32 |
| 8 | LocalWindow Attention | 87.8 | 80.9 | 89.4 | 64.5 | 2.197 | 2.4 | 5.55 |
| 9 | SimAM | 90.6 | 84.0 | 91.8 | 68.5 | 2.103 | 1.1 | 5.31 |
| Loss Function | P (%) | R (%) | mAP50 (%) | mAP50-95 (%) |
|---|---|---|---|---|
| CIOU | 90.6 | 84.0 | 91.8 | 68.5 |
| WIOU-V3 | 90.6 | 84.9 | 92.1 | 69.3 |
| DIOU | 91.3 | 83.6 | 91.9 | 68.9 |
| EIOU | 89.4 | 82.4 | 90.3 | 66.2 |
| SIOU | 89.8 | 83.9 | 91.9 | 68.3 |
| GIOU | 90.4 | 82.4 | 90.9 | 67.9 |
| MDPIOU | 89.5 | 84.9 | 91.8 | 68.8 |
| ShapeIOU | 89.5 | 84.1 | 91.0 | 67.7 |
| WIOU-V1 | 89.8 | 82.3 | 91.0 | 67.1 |
| WIOU-V2 | 89.6 | 83.7 | 91.5 | 68.4 |
| Number | Base Line | C2f- DWRR | SimAM | WIOUv3 | P (%) | R (%) | mAP50 (%) | mAP50-95 (%) | Parameters /M | ADT (ms) | Model Size (MB) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | ✔ | 87.7 | 82.2 | 89.9 | 65.9 | 2.263 | 1.8 | 5.55 | |||
| 2 | ✔ | ✔ | 90.0 | 84.3 | 91.7 | 69.3 | 2.103 | 2.2 | 5.31 | ||
| 3 | ✔ | ✔ | 86.7 | 80.3 | 88.5 | 63.9 | 2.907 | 2.6 | 7.96 | ||
| 4 | ✔ | ✔ | 89.4 | 81.5 | 90.1 | 65.4 | 2.265 | 2.3 | 5.56 | ||
| 5 | ✔ | ✔ | ✔ | 90.6 | 84.0 | 91.8 | 68.5 | 2.103 | 1.1 | 5.31 | |
| 6 | ✔ | ✔ | ✔ | ✔ | 90.6 | 84.9 | 92.1 | 69.3 | 2.103 | 1.1 | 5.31 |
| Algorithm | P (%) | R (%) | mAP50 (%) | mAP50-95 (%) | Parameters/M | ADT (ms) | Model Size (MB) |
|---|---|---|---|---|---|---|---|
| DSW-YOLO | 90.6 | 84.9 | 92.1 | 69.3 | 2.103 | 1.1 | 5.31 |
| YOLOv10n | 87.7 | 82.2 | 89.9 | 65.9 | 2.263 | 1.8 | 5.55 |
| NanoDet | 64.9 | 52.2 | 67.4 | 37.3 | 2.215 | None | 3.77 |
| EfficientDet -LiteD0 | 62.1 | 49.3 | 60.8 | 34.5 | 2.558 | None | 3.48 |
| RT-DETR-r18 | 91.2 | 84.6 | 91.3 | 71.3 | 19.873 | 9.3 | 38.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, Y.; Ren, G.; Zhang, J.; Du, Y.; Bao, G.; Cheng, L.; Yan, H. DSW-YOLO-Based Green Pepper Detection Method Under Complex Environments. Agronomy 2025, 15, 981. https://doi.org/10.3390/agronomy15040981
Han Y, Ren G, Zhang J, Du Y, Bao G, Cheng L, Yan H. DSW-YOLO-Based Green Pepper Detection Method Under Complex Environments. Agronomy. 2025; 15(4):981. https://doi.org/10.3390/agronomy15040981
Chicago/Turabian StyleHan, Yukuan, Gaifeng Ren, Jiarui Zhang, Yuxin Du, Guoqiang Bao, Lijun Cheng, and Hongwen Yan. 2025. "DSW-YOLO-Based Green Pepper Detection Method Under Complex Environments" Agronomy 15, no. 4: 981. https://doi.org/10.3390/agronomy15040981
APA StyleHan, Y., Ren, G., Zhang, J., Du, Y., Bao, G., Cheng, L., & Yan, H. (2025). DSW-YOLO-Based Green Pepper Detection Method Under Complex Environments. Agronomy, 15(4), 981. https://doi.org/10.3390/agronomy15040981