
TLDDM: An Enhanced Tea Leaf Pest and Disease Detection Model Based on YOLOv8


Abstract
1. Introduction
2. Materials and Methods
2.1. Data Collection
2.2. TLDDM Model Design
2.2.1. YOLOv8 Model
2.2.2. C2f-Faster-EMA
2.2.3. Deformable Attention
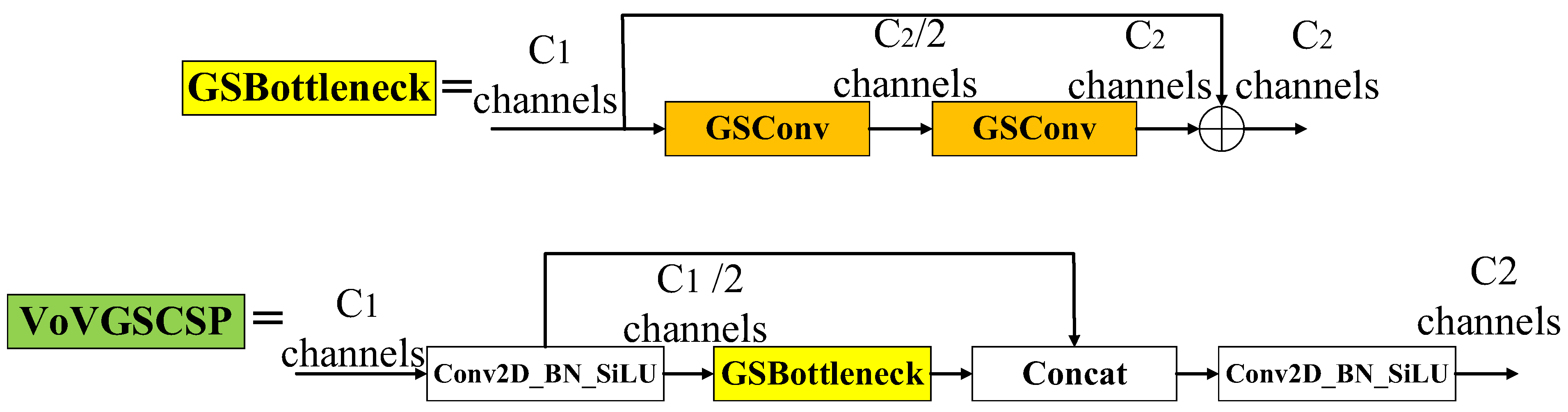
2.2.4. Slimneck
2.2.5. EfficientPHead: A Lightweight Detection Head
2.2.6. TLDDM Model
2.3. Model Evaluation
3. Results
3.1. Experimental Configuration
3.2. Ablation Experiment
3.3. Comparative Experiments
3.4. Comparison of Test Results
4. Discussions
4.1. Key Contributions
4.2. Comparative Analysis with Existing Methods
- (1)
- Comparison with Non-YOLO Algorithms
- (2)
- Comparison with YOLO Series Models
4.3. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dong, Z.; Li, J.; Zhao, Y. Investigation on the types of pests and diseases in Shangluo tea trees and the distribution of major pests and diseases. J. Shanxi Agric. Univ. 2018, 38, 33–37. [Google Scholar]
- Bao, W.; Fan, T.; Hu, G.; Liang, D.; Li, H. Detection and identification of tea leaf diseases based on AX-RetinaNet. Sci. Rep. 2022, 12, 2183. [Google Scholar] [CrossRef] [PubMed]
- Bauriegel, E.; Giebel, A.; Geyer, M.; Schmidt, U.; Herppich, W. Early detection of Fusarium infection in wheat using hyper-spectral imaging. Comput. Electron. Agric. 2011, 75, 304–312. [Google Scholar] [CrossRef]
- Prabira, K.; Nalini, K.; Amiya, K.; Santi, K. Deep feature based rice leaf disease identification using support vector machine. Comput. Electron. Agric. 2020, 175, 105527. [Google Scholar]
- Behmann, J.; Steinrücken, J.; Plümer, L. Detection of early plant stress responses in hyperspectral images. ISPRS J. Photogramm. Remote Sens. 2014, 93, 98–111. [Google Scholar] [CrossRef]
- Xie, C.; Yang, C.; He, Y. Hyperspectral imaging for classification of healthy and gray mold diseased tomato leaves with different infection severities. Comput. Electron. Agric. 2017, 135, 154–162. [Google Scholar] [CrossRef]
- Zhang, S.; Wu, X.; You, Z.; Zhang, L. Leaf image based cucumber disease recognition using sparse representation classification. Comput. Electron. Agric. 2017, 134, 135–141. [Google Scholar] [CrossRef]
- Hossain, S.; Mou, R.; Hasan, M.; Chakraborty, S.; Razzak, M. Recognition and detection of tea leaf’s diseases using support vector machine. In Proceedings of the 2018 IEEE 14th International Colloquium on Signal Processing & Its Applications (CSPA), Penang, Malaysia, 9–10 March 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Sun, Y.; Jiang, Z.; Zhang, L.; Dong, W.; Rao, Y. SLIC_SVM based leaf diseases saliency map extraction of tea plant. Comput. Electron. Agric. 2019, 157, 102–109. [Google Scholar] [CrossRef]
- Yuan, W.; Lan, L.; Xu, J.; Sun, T.; Wang, X.; Wang, Q.; Hu, J.; Wang, B. Smart Agricultural Pest Detection Using I-YOLOv10-SC: An Improved Object Detection Framework. Agronomy 2025, 15, 221. [Google Scholar] [CrossRef]
- Hu, G.; Wu, H.; Zhang, Y.; Wan, M. A low shot learning method for tea leaf’s disease identification—Sciencedirect. Comput. Electron. Agric. 2019, 163, 104852. [Google Scholar] [CrossRef]
- Hu, G.; Yang, X.; Zhang, Y.; Wan, M. Identification of tea leaf diseases by using an improved deep convolutional neural network. Sustain. Comput. Inform. Syst. 2019, 24, 100353. [Google Scholar] [CrossRef]
- Jiang, F.; Lu, Y.; Chen, Y.; Cai, D.; Li, G. Image recognition of four rice leaf diseases based on deep learning and support vector machine. Comput. Electron. Agric. 2020, 179, 105824. [Google Scholar] [CrossRef]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z. A survey of deep learning-based object detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Zhou, G.; Zhang, W.; Chen, A.; He, M.; Ma, X. Rapid detection of rice disease based on FCM-KM and faster R-CNN fusion. Adv. Neural Inf. Process. Syst. 2019, 7, 143190–143206. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part I 14: 21–37. Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition(CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wu, D.; Lv, S.; Jiang, M.; Song, H. Using channel pruning-based YOLO v4 deep learning algorithm for the real-time and accurate detection of apple flowers in natural environments. Comput. Electron. Agric. 2020, 178, 105742. [Google Scholar] [CrossRef]
- Liu, G.; Nouaze, J.; Mbouembe, T. YOLO-tomato: A robust algorithm for tomato detection based on YOLOv3. Sensors 2020, 20, 2145. [Google Scholar] [CrossRef]
- Dang, F.; Chen, D.; Lu, Y.; Li, Z. YOLOWeeds: A novel benchmark of YOLO object detectors for multi-class weed detection in cotton production systems. Comput. Electron. Agric. 2023, 205, 107655. [Google Scholar] [CrossRef]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Roy, A.M.; Bose, R.; Bhaduri, J. A fast accurate fine-grain object detection model based on YOLOv4 deep neural network. Neural. Comput. Appl. 2022, 34, 3895–3921. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.; Liao, H. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Sun, C.; Huang, C.; Zhang, H. Individual tree crown segmentation and crown width extraction from a heightmap derived from aerial laser scanning data using a deep learning framework. Front. Plant Sci. 2022, 13, 914974. [Google Scholar] [CrossRef]
- Dai, G.; Fan, J. An industrial-grade solution for crop disease image detection tasks. Front. Plant Sci. 2022, 13, 921057. [Google Scholar] [CrossRef]
- Nguyen, K.; Nguyen, H.; Tran, H.; Quach, L. Combining autoencoder and YOLOv6 model for classification and disease detection in chickens. In Proceedings of the 2023 8th International Conference on Intelligent Information Technology, New York, NY, USA, 24–26 February 2023; pp. 132–138. [Google Scholar]
- Zhao, K.; Zhao, L.; Zhao, Y.; Deng, H. Study on lightweight model of maize seedling object detection based on YOLOv7. Appl. Sci. 2023, 13, 7731. [Google Scholar] [CrossRef]
- Chen, J.; Kao, S.; He, H.; Zhuo, W.; Wen, S.; Lee, C.; Chan, S. Run, don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 12021–12031. [Google Scholar]
- Chen, J.; Ma, A.; Huang, L.; Li, H.; Zhang, H.; Huang, Y.; Zhu, T. Efficient and lightweight grape and picking point synchronous detection model based on key point detection. Comput. Electron. Agric. 2024, 217, 108612. [Google Scholar] [CrossRef]
- Duan, E.; Han, G.; Zhao, S.; Ma, Y.; Lv, Y.; Bai, Z. Regulation of Meat Duck Activeness through Photo period Based on Deep Learning. Animals 2023, 13, 3520. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.; Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 7132–7141. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Liu, B.; Huang, X.; Sun, L.; Wei, X.; Ji, Z.; Zhang, H. MCDCNet: Multi-scale constrained deformable convolution network for apple leaf disease detection. Comput. Electron. Agric. 2024, 222, 109028. [Google Scholar] [CrossRef]
- Xia, Z.; Pan, X.; Song, S.; Li, L.; Huang, G. Vision transformer with deformable attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4794–4803. [Google Scholar]
- Martinelli, F.; Matteucci, I. Partial Model Checking for the Verification and Synthesis of Secure Service Compositions. In Public Key Infrastructures, Services and Applications; EuroPKI 2013. Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8341. [Google Scholar]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles. arXiv 2022, arXiv:2206.02424. [Google Scholar]
- Sozzi, M.; Cantalamessa, S.; Cogato, A.; Kayad, A.; Marinello, F. Automatic Bunch Detection in White Grape Varieties Using YOLOv3, YOLOv4, and YOLOv5 Deep Learning Algorithms. Agronomy 2022, 12, 319. [Google Scholar] [CrossRef]
- Srivastav, S.; Guleria, K.; Sharma, S. Tea Leaf Disease Detection Using Deep Learning-based Convolutional Neural Networks. In Proceedings of the 2023 IEEE World Conference on Applied Intelligence and Computing (AIC), Sonbhadra, India, 29–30 July 2023; pp. 569–574. [Google Scholar]
- Liu, Y.; Zeng, F.; Diao, H.; Zhu, J.; Ji, D.; Liao, X.; Zhao, Z. YOLOv8 Model for Weed Detection in Wheat Fields Based on a Visual Converter and Multi-Scale Feature Fusion. Sensors 2024, 24, 4379. [Google Scholar] [CrossRef]
- Xue, Z.; Xu, R.; Bai, D.; Lin, H. YOLO-Tea: A Tea Disease Detection Model Improved by YOLOv5. Forests 2023, 14, 415. [Google Scholar] [CrossRef]
- Lin, J.; Bai, D.; Xu, R.; Lin, H. TSBA-YOLO: An Improved Tea Diseases Detection Model Based on Attention Mechanisms and Feature Fusion. Forests 2023, 14, 619. [Google Scholar] [CrossRef]
- Soeb, J.A.; Jubayer, F.; Tarin, T.A.; Al Mamun, M.R.; Ruhad, F.M.; Parven, A.; Mubarak, N.M.; Karri, S.L.; Meftaul, I.M. Tea leaf disease detection and identification based on YOLOv7 (YOLO-T). Sci. Rep. 2023, 13, 6078. [Google Scholar] [CrossRef] [PubMed]
- Bai, B.; Wang, J.; Li, J.; Yu, L.; Wen, J.; Han, Y. T-YOLO: A lightweight and efficient detection model for nutrient buds in complex tea-plantation environments. J. Sci. Food Agric. 2024, 104, 5698–5711. [Google Scholar] [CrossRef]
- Ye, R.; Shao, G.; Yang, Z.; Sun, Y.; Gao, Q.; Li, T. Detection Model of Tea Disease Severity under Low Light Intensity Based on YOLOv8 and EnlightenGAN. Plants 2024, 13, 1377. [Google Scholar] [CrossRef]
- Ye, R.; Shao, G.; He, Y.; Gao, Q.; Li, T. YOLOv8-RMDA: Lightweight YOLOv8 Network for Early Detection of Small Target Diseases in Tea. Sensors 2024, 24, 2896. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Train | Val | Test | |
|---|---|---|---|
| algal spot | 681 | 109 | 210 |
| brown blight | 612 | 81 | 174 |
| gray blight | 714 | 92 | 194 |
| healthy | 693 | 104 | 203 |
| helopeltis | 718 | 95 | 187 |
| redspot | 688 | 106 | 206 |
| Training Parameters | Value |
|---|---|
| Momentu | 0.937 |
| Weight_decay | 0.0005 |
| Batch_size | 16 |
| Learning_rate | 0.01 |
| Epochs | 101 |
| Model | C2f-Faster-EMA | DAttention | Slimneck | Efficient PHead | AP (%) | Fps | F1 | Size (MB) |
|---|---|---|---|---|---|---|---|---|
| YOLOv8n | 97.9 | 82.0 | 0.87 | 6.3 | ||||
| Model1 | ✔ | 98.0 | 64.1 | 0.97 | 5.5 | |||
| Model2 | ✔ | ✔ | 98.1 | 69.5 | 0.98 | 6.0 | ||
| Model3 | ✔ | ✔ | ✔ | 97.8 | 77.5 | 0.98 | 5.6 | |
| TLDDM | ✔ | ✔ | ✔ | ✔ | 98.0 | 98.2 | 0.98 | 4.3 |
| Model | Weight/MB | AP/% | fps | Precision/% | Recall/% |
|---|---|---|---|---|---|
| Faster R-CNN | 111.5 | 77.68 | 20 | 75.34 | 79.21 |
| SSD | 102.7 | 73.96 | 44 | 73.45 | 76.17 |
| YOLOv3tiny | 17.0 | 80.6 | 20.9 | 68.6 | 78.4 |
| YOLOv5n | 5.0 | 98.0 | 69.4 | 98.82 | 96.89 |
| YOLOv7tiny [30] | 11.7 | 97.1 | 88.3 | 90.69 | 94.16 |
| YOLOv8n | 6.0 | 97.9 | 82 | 98.3 | 96.8 |
| TLDDM | 4.3 | 98.0 | 98.2 | 98.34 | 96.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, J.; Zhang, Y.; Lin, S.; Han, H.; Yu, X. TLDDM: An Enhanced Tea Leaf Pest and Disease Detection Model Based on YOLOv8. Agronomy 2025, 15, 727. https://doi.org/10.3390/agronomy15030727
Song J, Zhang Y, Lin S, Han H, Yu X. TLDDM: An Enhanced Tea Leaf Pest and Disease Detection Model Based on YOLOv8. Agronomy. 2025; 15(3):727. https://doi.org/10.3390/agronomy15030727
Chicago/Turabian StyleSong, Jun, Youcheng Zhang, Shuo Lin, Huijie Han, and Xinjian Yu. 2025. "TLDDM: An Enhanced Tea Leaf Pest and Disease Detection Model Based on YOLOv8" Agronomy 15, no. 3: 727. https://doi.org/10.3390/agronomy15030727
APA StyleSong, J., Zhang, Y., Lin, S., Han, H., & Yu, X. (2025). TLDDM: An Enhanced Tea Leaf Pest and Disease Detection Model Based on YOLOv8. Agronomy, 15(3), 727. https://doi.org/10.3390/agronomy15030727