1. Introduction
Tea is one of the world’s most popular beverages [
1,
2]. The tea cultivation industry has been affected by pests. The main pests in tea plantations are tiny pests such as
Empoasca pirisuga (Matumura),
Halyomorpha halys (Stål),
Apolygus lucorum (Meyer-Dür), etc. [
3,
4]. These pests are predominantly distributed in East Asia and exhibit a broad host range, primarily affecting tea plants, fruit trees, and vegetable crops. Their damage mechanism involves sap feeding on leaves, leading to chlorosis, curling, and wilting of foliage, ultimately resulting in corresponding reductions in tea yield [
5,
6]. Therefore, employing safe and effective methods to monitor the occurrence of tea pests has become an important issue in tea production. Traditional monitoring methods for tea plant pests, such as manual inspection and light traps, have their respective limitations. Manual inspection not only proves resource-intensive but also faces challenges in accurately identifying pest infestations [
7,
8]. Light traps are constrained by high costs and complex installation requirements [
9,
10]. In light of this, the present study selected the cost-effective yellow sticky trap method as the primary monitoring approach. In the meantime, the rapid development of deep learning and machine vision technology has greatly improved the efficiency of pest monitoring. The main machine vision observation of insect pests is based on the mode of a camera with deep learning detection algorithms, i.e., through the field deployment of observation equipment, including a camera, to capture images of the insides of insect traps, followed by the use a deep learning model to count and recognizing insects in the images [
11,
12,
13]. These approaches been successfully applied for pest detection in many crops, such as corn, rice, and soybean [
14,
15,
16]. Hence, a machine vision-based deep learning algorithm is an tea pest detection approach with future development potential.
The performance of deep learning algorithms is highly dependent on the quality of training data [
17,
18]. However, the collection and annotation of tea pest data are costly, and publicly available datasets for yellow sticky traps are scarce, which severely limits the generalization capability and performance of models. Currently, solutions to address data insufficiency in pest detection primarily fall into two categories: generative methods and transfer learning methods. Generative methods primarily utilize techniques such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) to increase the diversity and volume of the dataset, thereby enhancing the model’s generalization ability and performance [
19,
20]. Those methods have been successfully applied in other pest detection studies [
21,
22]. The premise of the generative model’s capability is the need for a large amount of training data, which is contradictory to the few-shot learning problem. Therefore, this manuscript utilizes transfer learning to tackle the challenge of insufficient tea pest datasets. Transfer learning applies the effective features learned from a source domain to a target domain, significantly improving the model’s performance on new tasks [
23,
24]. This approach leverages rich feature information from the source domain to help the model in better extract features relevant to the target domain, especially in cases where the target domain has limited samples [
25,
26]. Transfer learning is gradually being used to solve some agricultural pest detection issues, such as researchers transferring pre-trained classification models from large datasets like ImageNet for the identification and prediction of major pests in agricultural crops like tomatoes and hemp [
27,
28]. The rise of cross-domain transfer learning has shattered the traditional constraint that there must be a direct logical link between the source domain and target domain [
29,
30] by offering a novel perspective. Cross-domain transfer learning is capable of managing knowledge transfer across domains with varying data types or feature representations, thereby enhancing task performance in the target domain, even when facing data scarcity. Tiny tea pests in the image resemble characters scattered across a yellow sheet of paper, exhibiting a high degree of similarity relative to textual characters in terms of feature representation, despite belonging to a different domain. This manuscript leverages the character domain in natural language as the source domain and tea pests in images as the target domain to implement cross-domain transfer learning. Since images of characters can be generated in large quantities, they provide an ample sample size to enhance the neural network’s ability to extract features of small targets. Consequently, transferring knowledge from the textual character domain to the tea pest domain not only improves the performance of tea pest detection but also mitigates the challenge of insufficient data in the tea pest dataset.
The small size of primary tea pests inevitably presents a challenge for small target detection in detection tasks. The current approaches to addressing small target recognition typically involve feature fusion, multi-scale feature extraction, and the incorporation of attention mechanisms [
31,
32]. From the perspective of feature extraction, in this study, through experimental exploration, we discovered that small target pests lose substantial information in deep convolutional network layers, leading to missed detections. The primary reason is that deep convolution acts as a band-pass filter, making it prone to filter out the information of small target tea pests during transmission [
33,
34]. This manuscript proposes a novel tea pest detection neural network called YOLOv8-FasterTea. Experimental results demonstrate that, on a small sample yellow board pest dataset, the mAP@.5 value of the model increased by approximately 6%, on average, after transfer learning. The YOLOv8-FasterTea model improved the mAP@.5 value by 3.7%, while the model size was reduced by 46.6%.
In summary, the research objectives of this paper focus on addressing three major challenges in tea pest monitoring: the lack of high-precision observation equipment, the scarcity of data samples, and the low accuracy of models in identifying small target pests. The main innovations and contributions of this research are outlined as follows:
This manuscript presents the design and implementation of a specialized intelligent device for tea pest detection that is capable of self-powered operation and real-time monitoring of tea pests. The device supports continuous pest biomass monitoring in remote and harsh outdoor tea plantation environments. Furthermore, a high-quality yellow board pest dataset, TeaPests, is constructed using this device.
The manuscript employs cross-domain transfer learning using script-generated natural language text images for pre-training of the model, effectively addressing the issue of a limited sample size in the target domain (tea pest identification).
This manuscript introduces a novel network architecture named YOLOv8-FasterTea. It is designed to reduce the depth of the network and minimize the loss of features for small target tea leaf pests, thereby enhancing the accuracy of pest identification. Compared to the traditional YOLOv8 model, this model demonstrates significant advantages in terms of higher precision and a more compact size in practical detection tasks.
This manuscript pledges to openly share the algorithm’s code and dataset to foster academic exchange. The resources can be accessed through the following link:
https://github.com/lycode1202/YOLOv8-FasterTea (accessed on 1 March 2025).
2. Materials and Methods
Tea pests pose unique computational challenges in terms of their detection due to their small size and ease of concealment, as well as the limited availability of annotated datasets. Conventional machine vision methods often struggle to localize and classify such small targets, especially in cluttered field conditions where rain, dust, light variations, and background interference can further degrade performance. To alleviate these problems, this study proposes a new multi-scale feature fusion framework that enhances the model’s ability to discriminate subtle pest features in a spatial hierarchy. Also, to address the problem of data scarcity, domain-adaptive data augmentation and cross-domain transfer learning strategies are integrated to achieve robust generalization, even with limited training samples. These approaches are complemented by hardware optimizations for field-deployed pest observation systems to ensure efficient data collection and power management in real-world agricultural environments. The specific technology roadmap is shown in
Figure 1.
2.1. Tea Tree Pest Monitoring System
A detailed description of the system architecture is provided in
Figure 2. In line with an environmentally friendly and energy-saving design philosophy, the system ingeniously employs solar panels in conjunction with voltage conversion modules to ensure hardware safety while achieving energy self-sufficiency. A Raspberry Pi 4B serves as the core for data processing, connected to the Internet via a 5G IoT card, ensuring the regular upload of monitoring data and providing robust data support for subsequent analysis and model training. Additionally, the system places special emphasis on the lightweight design of the model, facilitating its deployment directly on data collection nodes in later stages. Specific details about the system’s implementation are discussed in depth in subsequent sections.
2.1.1. Device Design and Realization
The tea tree pest monitoring device is composed of the following core components: a Raspberry Pi 4B mini-computer that serves as the brain of the system, responsible for data processing and coordination; a color, high-definition, industrial USB camera with a resolution of up to 12 million pixels, used to capture images of pests in the tea plantation; an efficient energy system composed of a 120 W solar panel and a 240 AH battery, ensuring the device’s continuous operation in outdoor environments; a precise power voltage regulation module, ensuring stable power supply under different voltage conditions; and a 5G outdoor network module for high-speed and stable data transmission. All components of the system are installed on a sturdy pole and horizontal steel arm structure to adapt to the challenges of the outdoor environment and ensure the stable long-term operation of the monitoring device. The mechanical design of the equipment is detailed in
Figure 3a.
As shown in the physical display of
Figure 3b, the tea tree pest monitoring device is installed on a 3-meter-high pole, with a sleeve in the middle of the pole to support the horizontal arm for installation of the monitoring camera and the pest observation steel plate. The high-definition camera is placed 50 cm away from the pest observation board. To enhance the tidiness of the wiring layout and the flexibility of the equipment’s operation, outlets are included at the bottom and sides, as well as universal joints mounted on each horizontal arm. In addition, the device is secured by a solid steel ground cage and a thick flange to ensure stability, ensuring that the device can operate safely and stably, even in adverse weather conditions. All key control devices, including the Raspberry Pi 4B and the power voltage regulation module, are safely enclosed in a stainless-steel distribution box on the pole, achieving good electromagnetic isolation and protection.
2.1.2. System Deployment
The tea pest monitoring system was deployed in a tea plantation located in a province in southwest China. The monitoring devices were meticulously placed at several key geographical locations within the tea plantation for continuous data collection around the clock. A total of three monitoring devices were deployed, with each device responsible for monitoring an area of approximately 20 square meters. The installation sites of the devices were selected based on the professional advice of tea experts, as these locations are hotspot areas where pests are more concentrated due to their living habits. This monitoring system was in continuous operation from 8 November 2023 to 8 July 2024, providing valuable long-term monitoring data for the research project over a period of 244 days.
2.2. Data Processing and Dataset Production
This manuscript is dedicated to collecting data related to tea plantation pests, spanning from November 2023 to April 2024. To efficiently gather data, the equipment utilizes an industrial USB camera with a resolution as high as 12 million pixels, equipped with a high-quality 5-megapixel lens free of distortion to capture clear images of pests. The camera is positioned at an optimal distance of 50 cm from the yellow sticky insect trap and takes continuous scheduled shots from 8 a.m. to 6 p.m. daily, ensuring the continuity and completeness of data collection.
Utilizing the 5G network, the tea pest monitoring devices achieved a stable network connection, allowing the Raspberry Pi 4B to smoothly upload the captured images to the image-bed server. Subsequently, researchers performed a series of data enhancement processes on the images, including rotation, cropping, and brightening, to further improve the quality of the dataset. After rigorous selection, a high-quality yellow board pest dataset was constructed, named TeaPests. The TeaPests has a total of 974 images. To enable the detection model to more accurately identify pests, researchers carried out meticulous annotation work on the dataset. The labels of the yellow board pest dataset were saved in TXT format; then, the dataset was divided into training, validation, and test sets in a ratio of 7:2:1. The specific details of the dataset are shown in
Table 1.
This manuscript also constructs a large-scale source-domain dataset for transfer learning, specifically a dataset of natural characters. Initially, a large number of natural language characters were generated using a Python script file, which were then compiled into a document file named “Words.doc”. Subsequently, a coding tool was utilized to convert each page of the document into a .jpg format image, culminating in the creation of the Words dataset.
The characters dataset encompasses a rich variety of natural language characters, including traditional punctuation marks, English letters, and diverse Chinese characters. Visual attributes such as the font size, thickness, and color of the characters in the images were assigned randomly, allowing the complex features of natural language characters to enhance the recognition accuracy of the small sample dataset of small target insects in the tea plantation. For instance, large characters like Chinese and English characters in the Words dataset can correspond to flies (Muscidae) and bees (Apidae) in the tea plantation, while small punctuation marks like commas and periods can correspond to mosquitoes (Culicidae) and whiteflies (Aleyrodidae). Through the use of this carefully designed dataset, the aim was to train a robust model capable of adapting to various complex scenarios, thereby addressing challenges such as small size, low contrast, and dull color of the objects to be detected in the source target. A total of 752 images of natural language characters were selected for training; a specific dataset effect comparison is shown in
Figure 4.
2.3. Cross-Domain Transfer Learning
Transfer learning involves learning common features between the source and target domains to achieve effective model transfer from the source to the target domain. To address this challenge, we used Python scripts to generate a series of simulated images that include a large number of punctuation marks, numbers, and characters, with backgrounds designed to mimic the yellow sticky boards used in tea plantations to attract flying insects. To more realistically simulate the representational characteristics of pests in tea plantations, we specifically designed the natural language characters generated in the images to vary in size, color, and font thickness, making the visual features of the natural language characters in the images similar to the tea pest targets in the tea plantation. Both possess the characteristics of being small, complex, and irregularly distributed, allowing the model pre-trained on character data to achieve more accurate detection in small sample pest dataset. At the same time, the natural language character dataset can greatly reduce the annotation cost through the use of automatic labeling technology; even creating a large-scale image dataset can be easily achieved with low resource consumption and time cost. This automated processing method not only reduces reliance on manual labor but also greatly shortens the data preparation cycle, providing strong support for the rapid construction and iteration of models.
We first trained the neural network using the character data generated by the aforementioned methods, then adjusted the neural network parameters for the actual insect dataset. The detailed process is shown in
Figure 4.
2.4. Deep Learning-Based Algorithm for Tea Pest Detection
2.4.1. YOLOv8
The YOLOv8 algorithm is the latest in a series of object detection models based on YOLO from Ultralytics, offering a new state-of-the-art (SOTA) model for tasks such as object detection, instance segmentation, and image classification [
35,
36]. The backbone incorporates the ELAN concept from YOLOv7 and replaces the C3 structure with the more gradient-rich C2f structure [
37]. For the neck, it introduces the PAN-FPN structure, effectively addressing the issue of position information that may be overlooked by traditional FPNs [
38]. The head part is changed to the currently mainstream decoupled head structure, separating the classification and detection heads, making the model more versatile and adaptable. As a result, the algorithm can adjust the number of channels for different scale models, greatly reducing the number of parameters and computational load and significantly improving model performance. This makes it highly suitable for the detection requirements of tea pests; hence, we chose YOLOv8 as the base model.
2.4.2. YOLOv8-FasterTea
To enhance the detection accuracy of small flying insect targets in images and ensure the model’s lightweight nature, this paper proposes an improved model specifically for tea tree pest detection based on the YOLOv8 network, named YOLOv8-FasterTea. This model makes targeted adjustments and optimizations based on the YOLOv8 algorithm to more effectively identify and locate pest positions. The specific structure of the model is detailed in
Figure 5. It not only improves detection accuracy but also significantly reduces the model’s size, providing a more accurate and lightweight solution for the monitoring and control of tea tree pests.
Figure 5 shows a comparison of network structure diagrams. In
Figure 5, it can be seen that YOLOv8-FasterTea replaces the original C2f module of the YOLOv8 network with a more lightweight Faster Block (FBlock) module. The traditional C2f structure increases the computational complexity and the number of parameters by connecting multiple bottlenecks in series, adding more skip connections, eliminating convolutional operations in the branches, and introducing additional split operations, which enriches the extraction of feature information. However, this structure has certain limitations in extracting features of small targets. To address this issue, this paper partially replaces this module with the FBlock module. A detailed introduction to the specific module is provided in later sections.
Considering the actual application scenario of pest detection in tea plantations, we chose to add a P2 small target layer while removing the original P5 detection layer in YOLOv8. This targeted improvement strategy not only optimizes the model’s resource allocation but also significantly enhances the accuracy and efficiency of small target flying insect detection. With the P2 small target layer, the model can more keenly capture subtle signs of pests in the tea plantation, which is crucial for early detection and prevention of pests. At the same time, removing the P5 detection layer not only simplifies the network structure but also reduces the model’s computational load, making the model faster in operation while maintaining high precision, making it more suitable for deployment in resource-constrained field environments. Such optimization makes the model more flexible and efficient in practical applications and capable of quickly responding to the needs of tea plantation pest detection.
2.4.3. Image Feature Extraction Module
Partial Convolution (PConv) is a novel operator that, compared to traditional operators, can reduce redundant computations and memory access, thereby more efficiently extracting spatial features [
39]. As a feature extraction module, PConv only applies regular convolution to a subset of the input channels for spatial feature extraction while keeping the remaining channels unchanged. The specific structure is shown in
Figure 6a. With this design, PConv has lower latency and fewer memory accesses than traditional convolution, with the specific computational formulas shown in Equations (
1) and (
2).
The FasterNet block, based on the partial convolution (PConv), was further designed to include two Pointwise Convolution (PWConv) layers following the PConv layer, with normalization and activation layers placed only after the intermediate layer to ensure the diversity of extracted features and lower latency. The specific structure of PWConv is shown in
Figure 6b.
2.4.4. Small-Target Deep Features
We explored the feature extraction process for small target objects using the YOLOv8 network. The following section analyzes and demonstrates the process of extracting deep features of small targets under YOLOv8.
Figure 7b illustrates the main process of the YOLOv8 network for feature extraction of small target objects. By carefully analyzing the feature maps generated in these steps, we were able to investigate the feature loss that occurs during the feature extraction process for small target objects. The research on the detection process is mainly divided into two parts: observation of specific stages of the backbone section and selective observation of certain stages of the neck section. A visualization of the feature map detection results is presented in
Figure 7.
Figure 7a presents the complete process of feature extraction from simulated images. In this case, layers L2–L9 are used as the basic feature layers of YOLOv8, and operations such as up-sampling or addition are performed after L9. The deep features of L2–L9 directly affect the final detection results. This manuscript focuses on the deep features of L2–L9. By observing the changes in the features of these layers, one can sense how the target information in the image is gradually captured and processed by the model. We generated target points of different sizes in images with dimensions of 640 × 640 pixels. Then, these images were input into the model to observe the differences in the feature extraction process for targets of different scales. Through this analysis, the aim was to explore at which stages the neural network’s ability to extract target features is weak so as to improve the model in a targeted manner and enhance its overall performance.
By observing
Figure 7b,c, it can be found that during feature extraction in the backbone stage of the neural network, as the number of convolutional neural network layers increases, the size of the feature maps gradually decreases, while their receptive field correspondingly expands. In this experiment, the small target information underwent high-level semantic information extraction in the backbone stage. Although some detailed information was not fully captured, there was no large-scale information loss overall. In light of this finding, we chose to retain the overall structure of the backbone part in our subsequent improvement work, making only a few modifications to ensure that the key feature information of small targets was effectively utilized and properly protected. In contrast, by examining the changes in feature maps during the feature extraction process in the neck part of the neural network, we found that the small target information suffered more severe information loss during the down-sampling process in the PAN-FPN stage. The phenomenon of information deficiency continued to intensify in the subsequent transmission process of the feature maps, ultimately affecting the model’s detection head’s ability to identify and locate small targets.
To more accurately evaluate the model’s perceptual ability for target features at different stages, this manuscript introduces a quantitative metric—the energy cluster ratio. This concept aims to measure the changes in the target’s attention in the image through the application a quantitative scientific method. We selected a 55 × 55 pixel area at the center of the feature map, calculated the energy value in that area, and compared it with the energy value of the remaining area of the entire feature map. The process of energy calculation involves summing the image matrix in a specific area, as shown in Equations (
3) and (
4).
By calculating the ratio between these two parts, we can quantitatively assess the model’s focus on the targets in the image, providing a strong reference for subsequent model optimization, as shown in
Figure 8.
Throughout the entire process of model feature extraction, the initial energy ratio of the target points remained at a relatively stable level. However, as the number of model layers increased, the energy ratio of these target points began to significantly decrease at Layer 4. At the same time, the energy ratio of larger-sized target points was consistently higher than that of smaller-sized target points throughout the process. This phenomenon reveals that when the model processes targets of different sizes, the smaller the target, the more obvious the information loss. To improve this situation, we considered removing the original P4 and P5 layers of the model and adding a P2 layer that enhances the fusion of small target information, thereby increasing the model’s sensitivity to these subtle features.
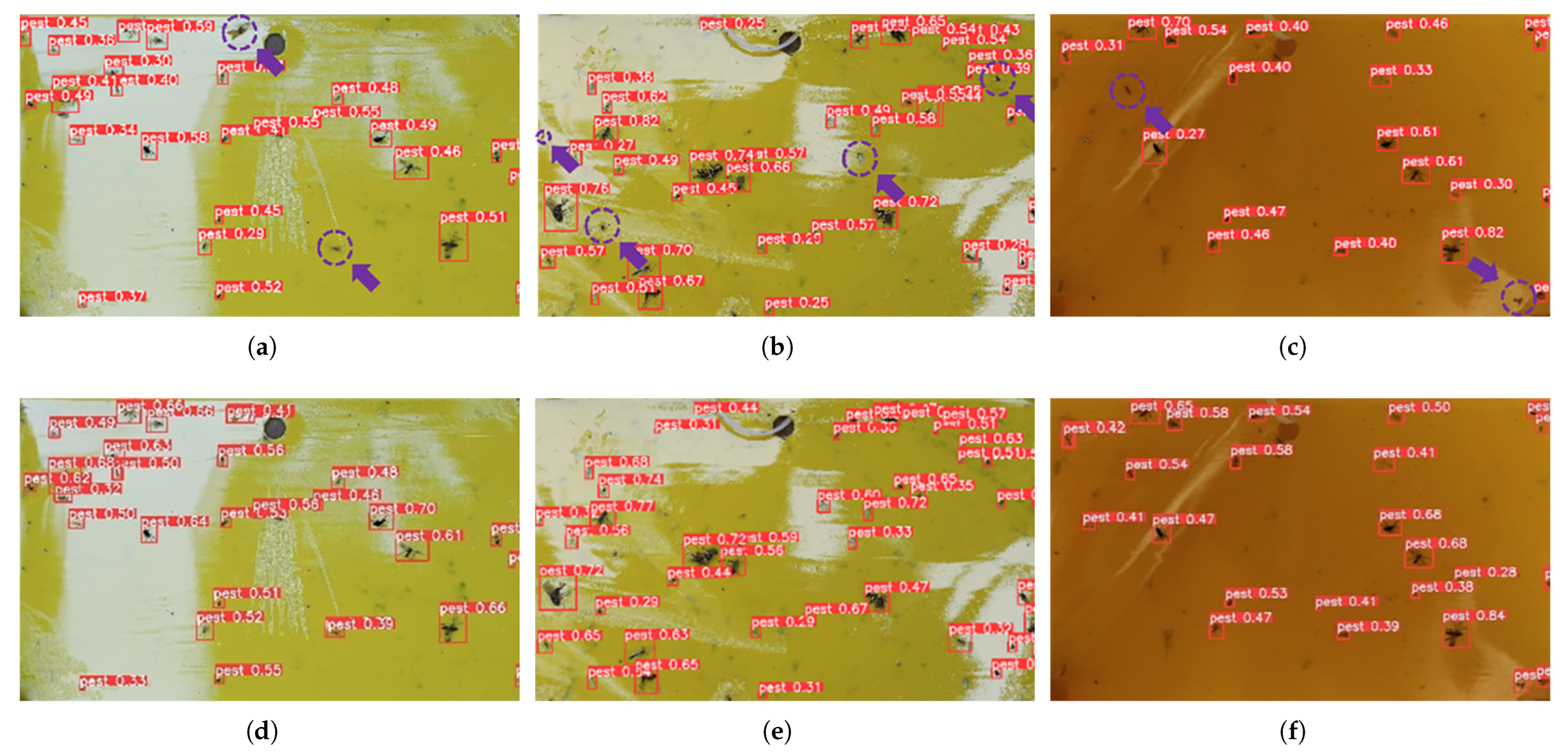
To further explore how transfer learning optimized the model’s detection process and the main reasons for the improvement in accuracy, we employed a heatmap visualization method. Heatmap visualization allows observers to quickly grasp the hot and cold spots in the dataset through changes in color intensity. The HiResCAM method [
40] was used for heatmap visualization of the detection images, with the accuracy threshold set at 0.5. These methods aim to deeply understand changes in the internal mechanism within the model and how these changes lead to significant performance improvements. The specific visualization results are shown in
Figure 9.
4. Discussion
Regarding the completed and future research efforts, this paper deems it necessary to engage in candid discussions concerning the following aspects:
(1) Visual device: Conventional vision devices, such as pest reporting lamps [
41,
42,
43], often encounter difficult in capturing detailed characteristic information due to equipment bottlenecks and technological limitations [
44,
45]. In field experiments, tea pests can effectively stick to yellow sticky boards. Meanwhile, the use of sticky boards reduces the dependence on chemical pesticides to a certain extent, in addition to implementing the concepts of green prevention and control and sustainable development of agriculture. Therefore, the use of sticky insect panels is a cost-effective method of pest observation [
46,
47]. In this study, we chose yellow sticky boards for tea pest detection and observation and developed real-time monitoring equipment that can realize long-term autonomous operation in complex outdoor environments. The equipment is built with stainless steel and equipped with a high-capacity solar panel of up to 240 AH. It is able to provide long-lasting power support for the edge computing device to ensure its continuous and stable operation. Thanks to its good materials and compact design, this device can easily adapt to various outdoor environments and realize rapid deployment. Finally, a dataset comprising 974 high-quality images was constructed utilizing this apparatus. Compared with commercially available products, the proposed apparatus demonstrates greater cost-effectiveness while integrating both simplicity and operational efficiency.
(2) The issue of small-sample learning: The small-sample problem has consistently been a challenging issue in deep learning detection tasks, and it is particularly evident in the tea-leaf pest detection application presented in this manuscript. In the application reported in this paper, the characters and tea leaf pests both had the characteristics of being small and dense, enabling the transfer of features from the character domain for the identification of tea leaf pests. The characters themselves were artificially created, and character data can be obtained in large quantities, making the sample size in the character domain very abundant. During the training process in the character domain, with abundant samples, the network’s ability to extract features of small and complex targets is effectively enhanced. Consequently, when transferring to the small sample domain of tea-leaf pests, the network only needs to use a small amount of tea-leaf pest data to adjust the background or target features to achieve better detection accuracy. Based on the aforementioned analysis, this study achieved a significant improvement in accuracy across pest detection datasets of varying scales by leveraging generated data. Notably, in the Pests-100 dataset, the mAP@.5 of the baseline model was enhanced by 5.5%. The cross-domain transfer learning methodology presented in this manuscript effectively resolves practical scientific challenges in pest identification, establishing a novel paradigm for few-shot learning research.
(3) The problem of small-target feature loss: Tea-leaf pests are mainly characterized as small” in images, with few pixel points and limited texture features. These pests occupy only a few pixels within an image, and as the number of convolutional network layers increases, information about the pests tends to be gradually lost, resulting in reduced visual detection accuracy. This study selected features from different layers to calculate feature significance indicators, thereby confirming this hypothesis. Based on the aforementioned research findings, this study designed and implemented the YOLOv8-FasterTea model. This model is based on YOLOv8 and reduces network depth by removing the P5 detection head, effectively minimizing the loss of small target features during transmission. Additionally, while YOLOv8-FasterTea connects the detection head to shallower feature layers, it also optimizes some C2f modules using the FasterNet block, significantly enhancing the model’s efficiency and accuracy in identifying small flying pest targets within tea plantations. On the Pests-100 small-scale pest detection dataset, the model demonstrated outstanding performance, with precision increasing by 1.8%, recall improving by 7.7%, and mAP@.5 significantly rising by 7.5%, while the model size was substantially reduced by 33.3%. These results indicate that, compared to baseline models of the same type, YOLOv8-FasterTea achieved significant optimization across all key performance metrics.




 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}