
RNN-Based Approach for Broccoli Harvest Time Forecast

 and
and
Abstract
1. Introduction
2. Materials and Methods
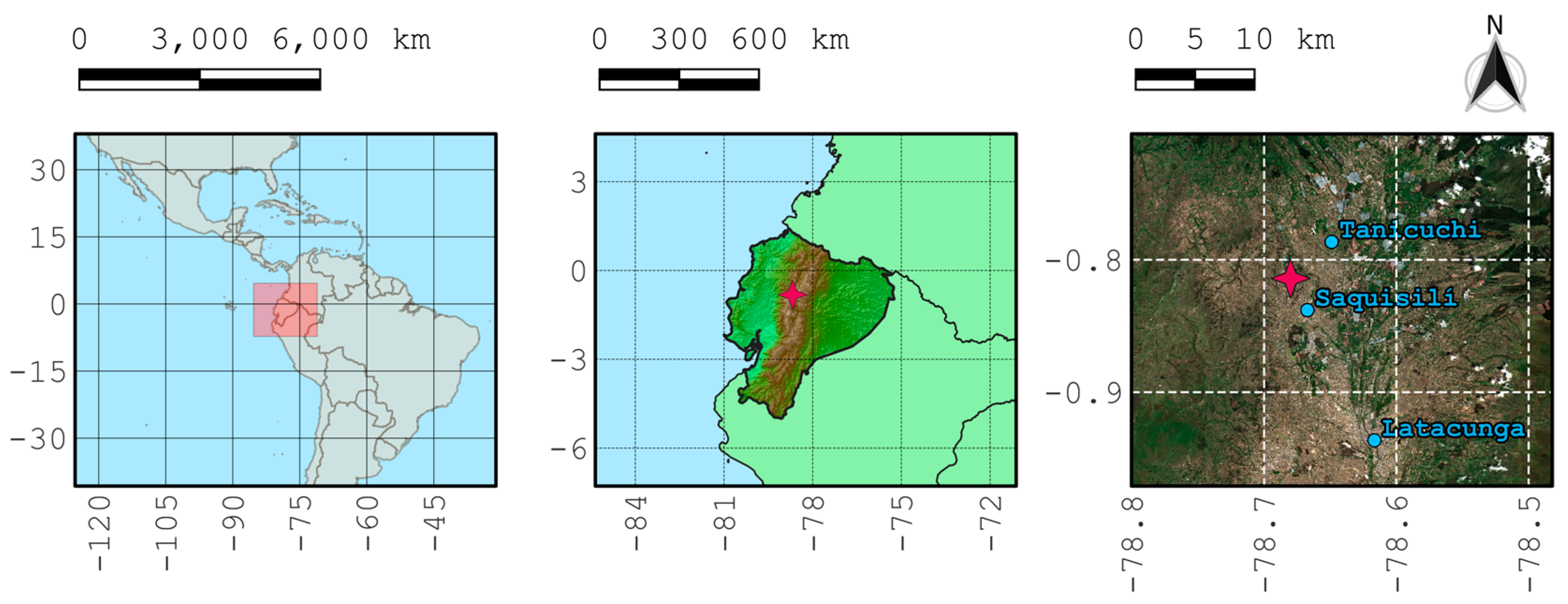
2.1. Data Sources
2.1.1. Broccoli Dataset
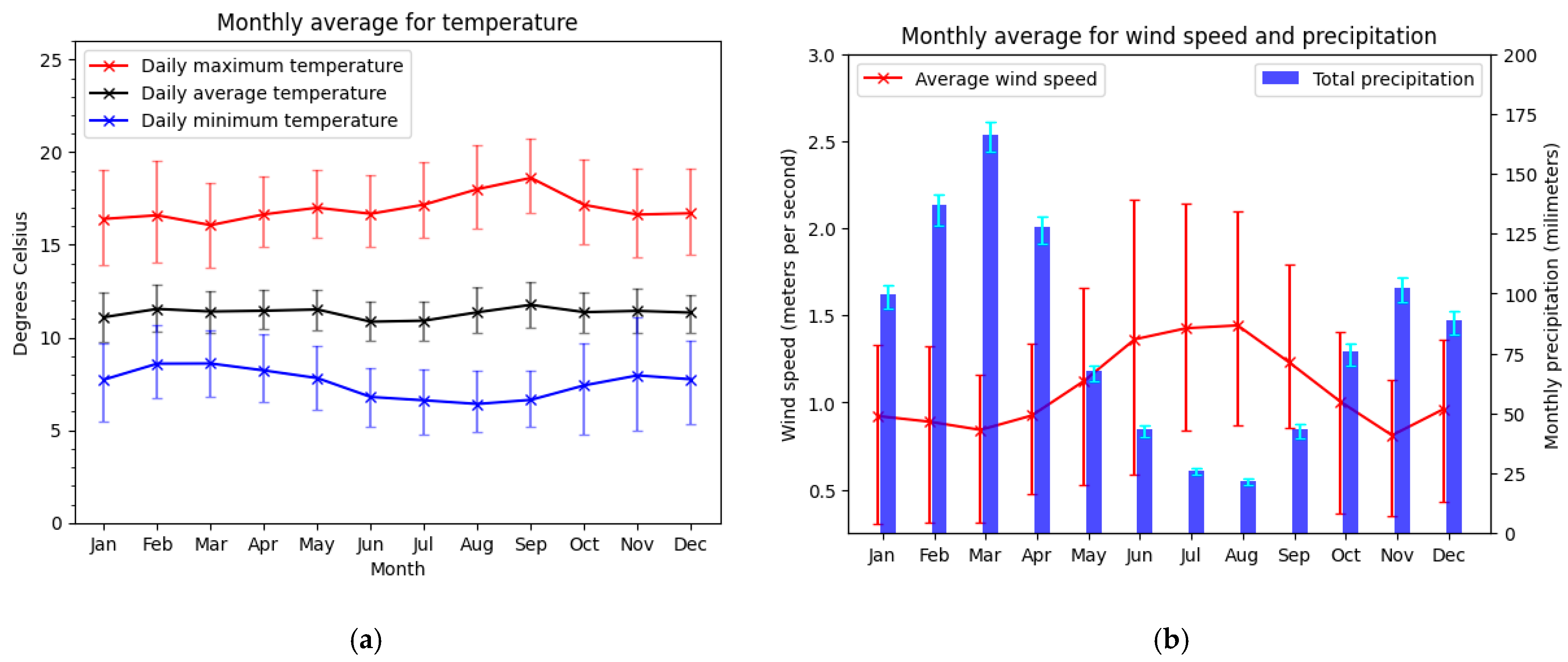
2.1.2. Weather Dataset
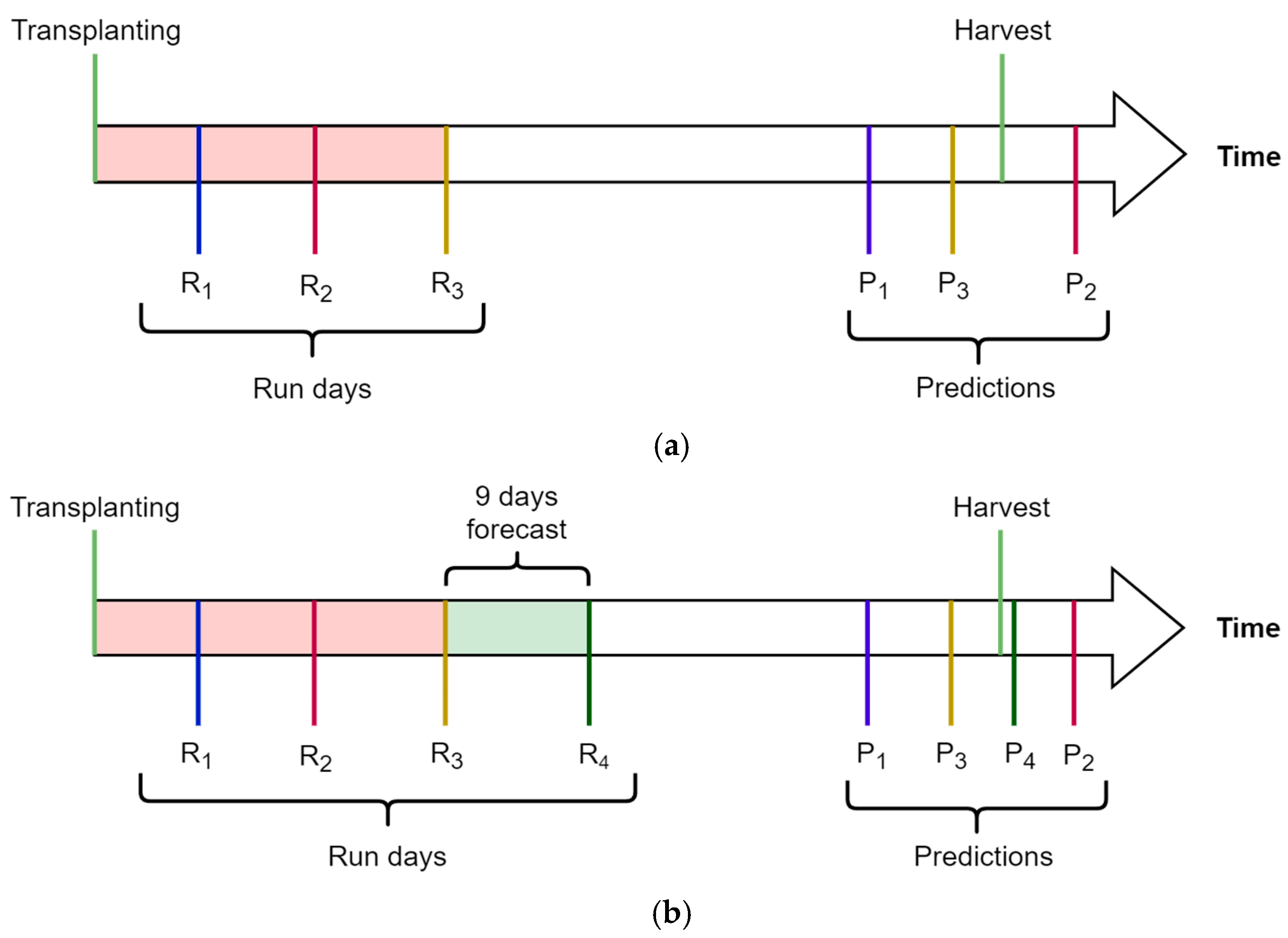
2.1.3. Forecast Dataset
2.2. Harvest Models
2.2.1. Persistence Model
2.2.2. Thermal Model
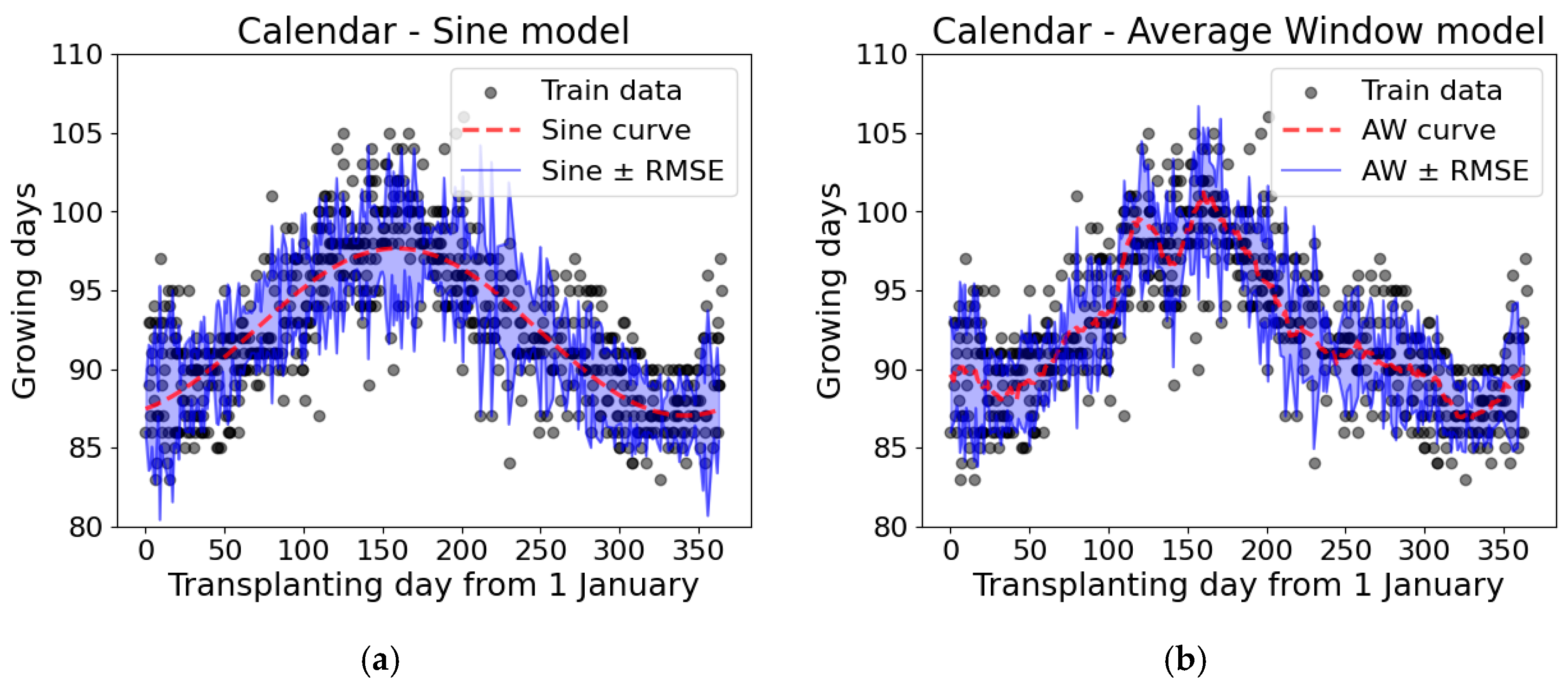
2.2.3. Calendar Model
2.2.4. RNN Model
2.3. Evaluation Metrics
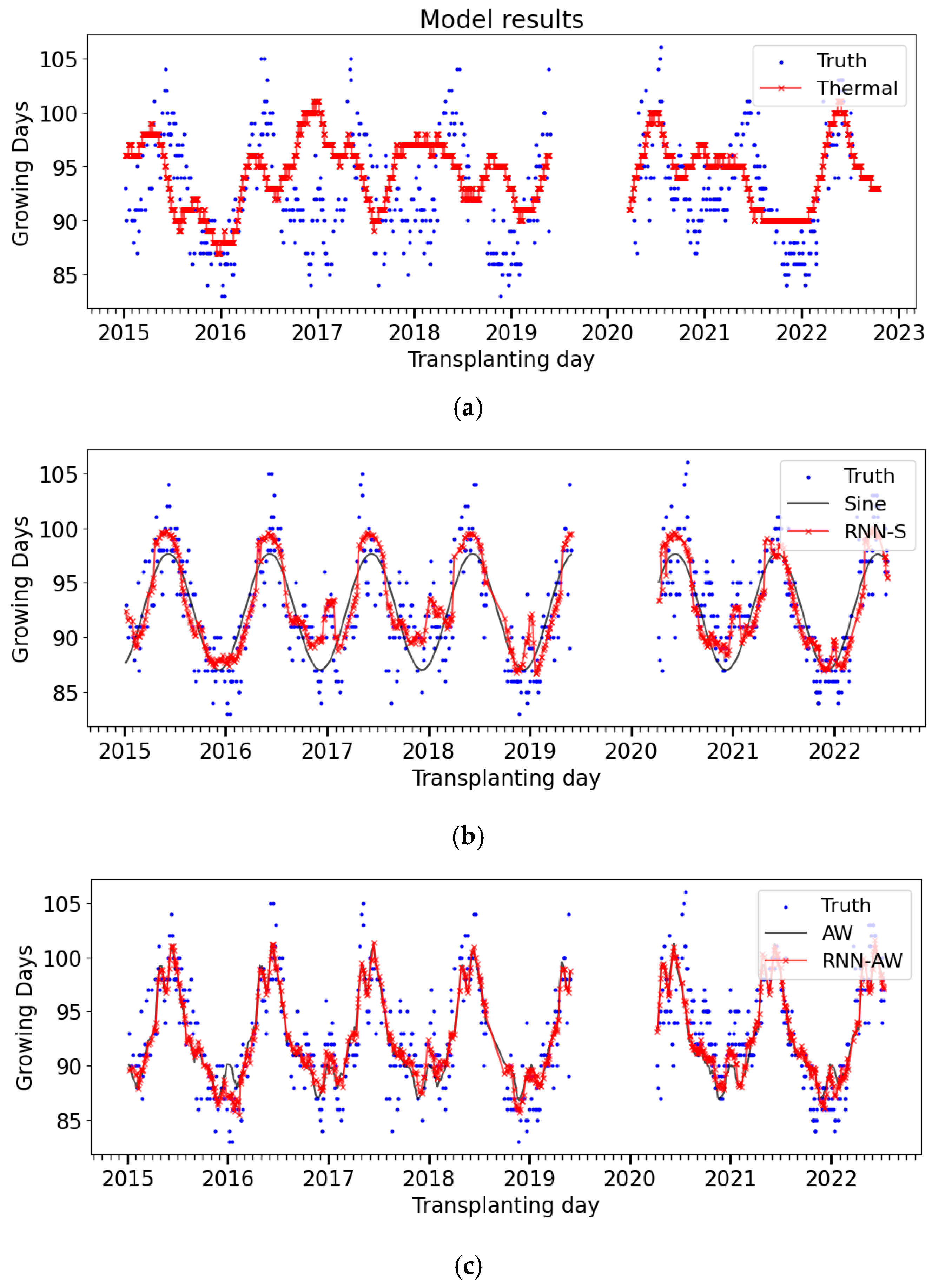
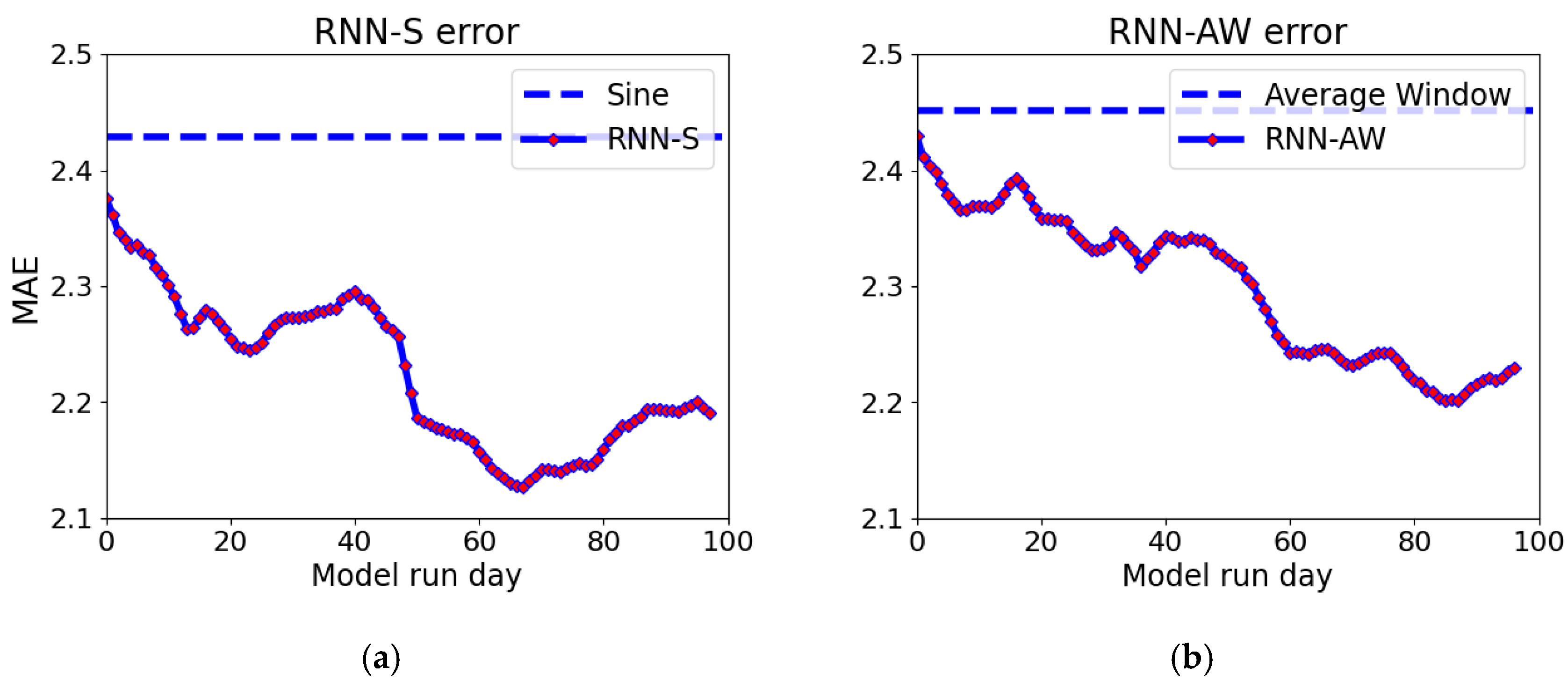
3. Results
3.1. Model Parameters
3.2. Model Performance
3.3. Forecast Extension
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | GEFS Forecast Day | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
| Average Temperature (C) | 3.72 | 3.66 | 3.68 | 3.71 | 3.73 | 3.74 | 3.75 | 3.74 | 3.75 |
| (0.68) | (0.67) | (0.7) | (0.71) | (0.73) | (0.73) | (0.74) | (0.75) | (0.76) | |
| Minimum Temperature (C) | 2.09 | 1.83 | 1.85 | 1.87 | 1.89 | 1.9 | 1.91 | 1.91 | 1.92 |
| (1.18) | (1.2) | (1.23) | (1.2) | (1.19) | (1.14) | (1.12) | (1.12) | (1.15) | |
| Maximum Temperature (C) | 7.53 | 7.56 | 7.6 | 7.63 | 7.65 | 7.67 | 7.68 | 7.67 | 7.67 |
| (1.51) | (1.55) | (1.56) | (1.55) | (1.56) | (1.55) | (1.55) | (1.56) | (1.57) | |
| Wind Speed (m/s) | 1.3 | 1.35 | 1.36 | 1.33 | 1.31 | 1.32 | 1.33 | 1.33 | 1.35 |
| (0.42) | (0.41) | (0.4) | (0.4) | (0.4) | (0.4) | (0.41) | (0.41) | (0.41) | |
| Total Precipitation (mm) | 4.59 | 5.9 | 5.76 | 5.59 | 5.53 | 5.29 | 5.29 | 5.14 | 5.21 |
| (2.92) | (2.95) | (2.93) | (2.92) | (2.9) | (2.89) | (2.89) | (2.91) | (2.92) | |
References
- Jin, X.; Kumar, L.; Li, Z.; Feng, H.; Xu, X.; Yang, G.; Wang, J. A Review of Data Assimilation of Remote Sensing and Crop Models. Eur. J. Agron. 2018, 92, 141–152. [Google Scholar] [CrossRef]
- Saiz-Rubio, V.; Rovira-Más, F. From Smart Farming towards Agriculture 5.0: A Review on Crop Data Management. Agronomy 2020, 10, 207. [Google Scholar] [CrossRef]
- Wheeler, T.R.; Hong, T.D.; Ellis, R.H.; Batts, G.R.; Morison, J.I.L.; Hadley, P. The Duration and Rate of Grain Growth, and Harvest Index, of Wheat (Triticum aestivum L.) in Response to Temperature and CO2. J. Exp. Bot. 1996, 47, 623–630. [Google Scholar] [CrossRef]
- Williams, J.R.; Jones, C.A.; Kiniry, J.R.; Spanel, D.A. The EPIC Crop Growth Model. Trans. ASAE 1989, 32, 0497–0511. [Google Scholar] [CrossRef]
- Ohishi, M.; Takahashi, M.; Fukuda, M.; Sato, F. Developing a Growth Model to Predict Dry Matter Production in Broccoli (Brassica oleracea L. var. italica) “Ohayou”. Hortic. J. 2023, 92, 77–87. [Google Scholar] [CrossRef]
- Lindemann-Zutz, K.; Fricke, A.; Stützel, H. Prediction of Time to Harvest and Its Variability of Broccoli (Brassica oleracea var. italica) Part II. Growth Model Description, Parameterisation and Field Evaluation. Sci. Hortic. 2016, 200, 151–160. [Google Scholar]
- Diputado, M.T., Jr.; Nichols, M.A. The Effect of Sowing Date and Cultivar on the Maturity Characteristics of Broccoli (Brassica oleraceae var. italica). Acta Hortic. 1989, 247, 59–66. [Google Scholar] [CrossRef]
- Wei-ming, L.; En-guo, W. Mathematical Modeling of Broccoli Cultivation and Growth Period and Yield of Flower Heads. In Computer and Computing Technologies in Agriculture VIII; Springer International Publishing: Cham, Switzerland, 2015; pp. 94–98. [Google Scholar]
- de Maria Mourao, I.; Brito, L.M. Empirical models for harvest date prediction in broccoli (Brassica oleracea L. var. italica Plenck). Acta Hortic. 2000, 239, 47–53. [Google Scholar] [CrossRef]
- Fujime, Y. Studies on Thermal Conditions of Curd Formation and Development in Cauliflower and Broccoli, with Special Reference to Abnormal Curd Development; Kagawa University: Takamatsu City, Japan, 1983. [Google Scholar]
- Tan, D.K.Y.; Wearing, A.H.; Rickert, K.G.; Birch, C.J. Detection of Floral Initiation in Broccoli (Brassica oleracea L. var. italica Plenck) Based on Electron Micrograph Standards of Shoot Apices. Aust. J. Exp. Agric. 1998, 38, 313–318. [Google Scholar]
- Tan, D.K.Y.; Birch, C.J.; Wearing, A.H.; Rickert, K.G. Predicting Broccoli Development: II. Comparison and Validation of Thermal Time Models. Sci. Hortic. 2000, 86, 89–101. [Google Scholar] [CrossRef]
- Czernecki, B.; Nowosad, J.; Jabłońska, K. Machine Learning Modeling of Plant Phenology Based on Coupling Satellite and Gridded Meteorological Dataset. Int. J. Biometeorol. 2018, 62, 1297–1309. [Google Scholar] [CrossRef]
- Gavahi, K.; Abbaszadeh, P.; Moradkhani, H. DeepYield: A Combined Convolutional Neural Network with Long Short-Term Memory for Crop Yield Forecasting. Expert Syst. Appl. 2021, 184, 115511. [Google Scholar] [CrossRef]
- Srivastava, A.K.; Safaei, N.; Khaki, S.; Lopez, G.; Zeng, W.; Ewert, F.; Gaiser, T.; Rahimi, J. Winter Wheat Yield Prediction Using Convolutional Neural Networks from Environmental and Phenological Data. Sci. Rep. 2022, 12, 3215. [Google Scholar] [CrossRef]
- Khaki, S.; Wang, L.; Archontoulis, S.V. A CNN-RNN Framework for Crop Yield Prediction. Front. Plant Sci. 2019, 10, 1750. [Google Scholar] [CrossRef]
- Haider, S.A.; Naqvi, S.R.; Akram, T.; Umar, G.A.; Shahzad, A.; Sial, M.R.; Khaliq, S.; Kamran, M. LSTM Neural Network Based Forecasting Model for Wheat Production in Pakistan. Agronomy 2019, 9, 72. [Google Scholar] [CrossRef]
- Boechel, T.; Policarpo, L.M.; Ramos, G.d.O.; da Rosa Righi, R.; Singh, D. Prediction of Harvest Time of Apple Trees: An RNN-Based Approach. Algorithms 2022, 15, 95. [Google Scholar] [CrossRef]
- Liu, S.-C.; Jian, Q.-Y.; Wen, H.-Y.; Chung, C.-H. A Crop Harvest Time Prediction Model for Better Sustainability, Integrating Feature Selection and Artificial Intelligence Methods. Sustain. Sci. Pract. Policy 2022, 14, 14101. [Google Scholar] [CrossRef]
- Jain, A.; Nandakumar, K.; Ross, A. Score Normalization in Multimodal Biometric Systems. Pattern Recognit. 2005, 38, 2270–2285. [Google Scholar] [CrossRef]
- NOAA Global Ensemble Forecast System (GEFS). Available online: https://registry.opendata.aws/noaa-gefs (accessed on 1 September 2023).
- Zhou, X.; Zhu, Y.; Hou, D.; Fu, B.; Li, W.; Guan, H.; Sinsky, E.; Kolczynski, W.; Xue, X.; Luo, Y.; et al. The Development of the NCEP Global Ensemble Forecast System Version 12. Weather Forecast. 2022, 37, 1069–1084. [Google Scholar] [CrossRef]
- Zimmerman, D.; Pavlik, C.; Ruggles, A.; Armstrong, M.P. An Experimental Comparison of Ordinary and Universal Kriging and Inverse Distance Weighting. Math. Geol. 1999, 31, 375–390. [Google Scholar] [CrossRef]
- Huth, R. Statistical Downscaling of Daily Temperature in Central Europe. J. Clim. 2002, 15, 1731–1742. [Google Scholar] [CrossRef]
- Holzworth, D.P. DEVEL: A Crop Development Modelling Tool; Queensland Department of Primary Industsries: Brisbane City, QLD, Australia, 1991. [Google Scholar]
- Swiler, L.P.; Roberts, R.M.; Sullivan, S.P.; Stucky-Mack, N.J.; Vugrin, K.W. Confidence Region Estimation Techniques for Nonlinear Regression: Three Case Studies; United States Department of Energy: Washington, DC, USA, 2005. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Tan, D.K.Y.; Birch, C.J.; Wearing, A.H.; Rickert, K.G. Predicting Broccoli Development I. Development Is Predominantly Determined by Temperature rather than Photoperiod. Sci. Hortic. 2000, 84, 227–243. [Google Scholar] [CrossRef]
- Tan, D.K.Y.; Birch, C.J.; Wearing, A.H.; Rickert, K.G. Modelling Broccoli Development, Yield and Quality. Available online: https://core.ac.uk/download/pdf/14983005.pdf (accessed on 24 November 2023).

| Statistics | Min. Temperature | Max. Temperature | Avg. Temperature | Total Precipitation | Wind Speed |
|---|---|---|---|---|---|
| Mean | 7.76 | 16.90 | 11.38 | 2.76 | 1.25 |
| Median | 7.77 | 17.00 | 11.37 | 0.95 | 1.15 |
| Standard deviation | 1.64 | 1.81 | 0.94 | 4.04 | 0.61 |
| Metric | Persistence | Thermal | Average Window | Sine | RNN-S (Day 50) | RNN-AW (Day 50) |
|---|---|---|---|---|---|---|
| MAE | 3.97 | 3.14 | 2.5 | 2.4 | 2.18 | 2.32 |
| RMSE | 4.77 | 3.92 | 3.22 | 3.12 | 2.82 | 3.01 |
| R2 | - | 0.32 | 0.53 | 0.56 | 0.63 | 0.60 |
| RD | RNN-S | RNN-AW | ||
|---|---|---|---|---|
| Field Only | Field with Forecast | Field Only | Field with Forecast | |
| 40 | 1.90 | 1.89 | 2.03 | 1.98 |
| 45 | 1.89 | 1.85 | 2.01 | 1.96 |
| 50 | 1.84 | 1.81 | 1.97 | 1.92 |
| 55 | 1.81 | 1.78 | 1.93 | 1.91 |
| 60 | 1.78 | 1.78 | 1.91 | 1.96 |
| 65 | 1.76 | 1.77 | 1.91 | 1.95 |
| 70 | 1.76 | 1.78 | 1.91 | 1.93 |
| RD | p-Value | |
|---|---|---|
| RNN-S | RNN-AW | |
| 40 | 0.53 | 0.97 |
| 45 | 0.50 | 0.98 |
| 50 | 0.52 | 0.95 |
| 55 | 0.58 | 0.90 |
| 60 | 0.61 | 0.84 |
| 65 | 0.78 | 0.72 |
| 70 | 0.79 | 0.78 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lohachov, M.; Korei, R.; Oki, K.; Yoshida, K.; Azechi, I.; Salem, S.I.; Utsumi, N. RNN-Based Approach for Broccoli Harvest Time Forecast. Agronomy 2024, 14, 361. https://doi.org/10.3390/agronomy14020361
Lohachov M, Korei R, Oki K, Yoshida K, Azechi I, Salem SI, Utsumi N. RNN-Based Approach for Broccoli Harvest Time Forecast. Agronomy. 2024; 14(2):361. https://doi.org/10.3390/agronomy14020361
Chicago/Turabian StyleLohachov, Mykhailo, Ryoji Korei, Kazuo Oki, Koshi Yoshida, Issaku Azechi, Salem Ibrahim Salem, and Nobuyuki Utsumi. 2024. "RNN-Based Approach for Broccoli Harvest Time Forecast" Agronomy 14, no. 2: 361. https://doi.org/10.3390/agronomy14020361
APA StyleLohachov, M., Korei, R., Oki, K., Yoshida, K., Azechi, I., Salem, S. I., & Utsumi, N. (2024). RNN-Based Approach for Broccoli Harvest Time Forecast. Agronomy, 14(2), 361. https://doi.org/10.3390/agronomy14020361