
Research on Winter Jujube Object Detection Based on Optimized Yolov5s



Abstract
1. Introduction
- (1)
- To search for a backbone network to replace Yolov5’s backbone to reduce the model size and network parameters;
- (2)
- To search for a neck structure to replace Yolov5’s neck to reduce the complexity of computation and network structure while maintaining sufficient accuracy;
- (3)
- To search for a knowledge migration method that provides an improved Yolov5s model with the learning capability of a complex model and brings performance improvements while compressing the model.
2. Materials and Methods
2.1. Image Data Acquisition
2.2. Image Data Expansion
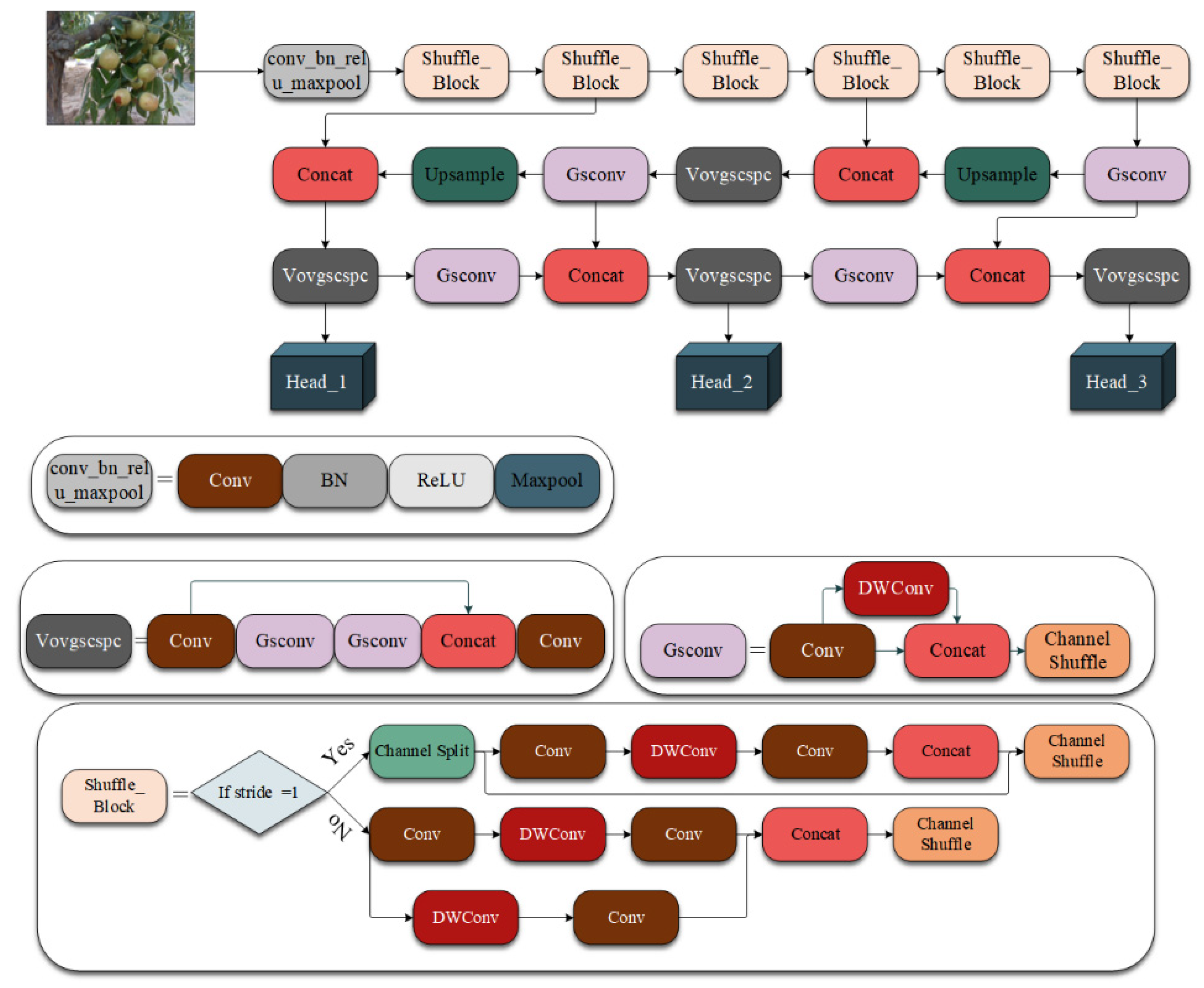
2.3. Winter Jujube Detection Method
2.3.1. Original Yolov5s Structure
2.3.2. ShuffleNet V2 Backbone
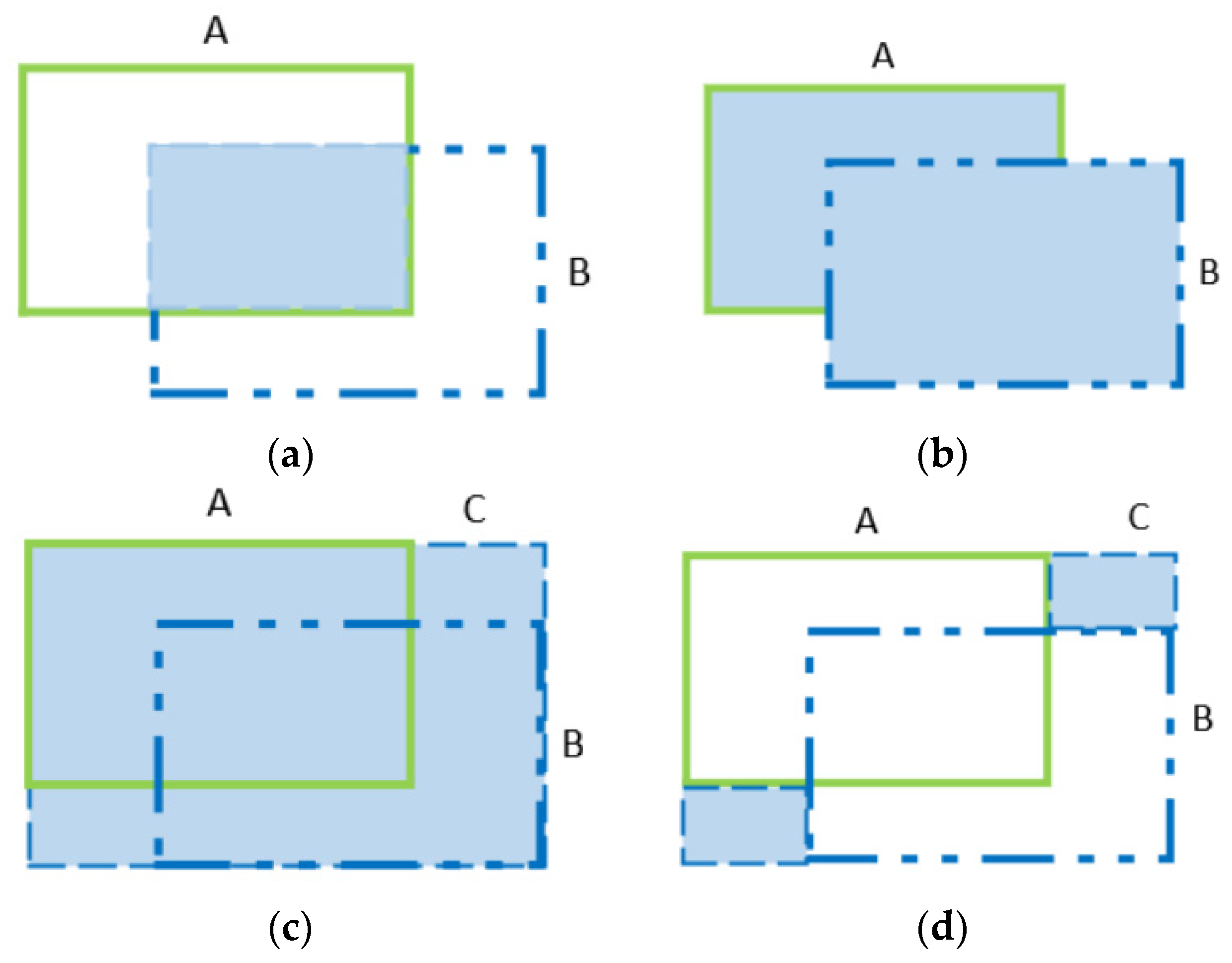
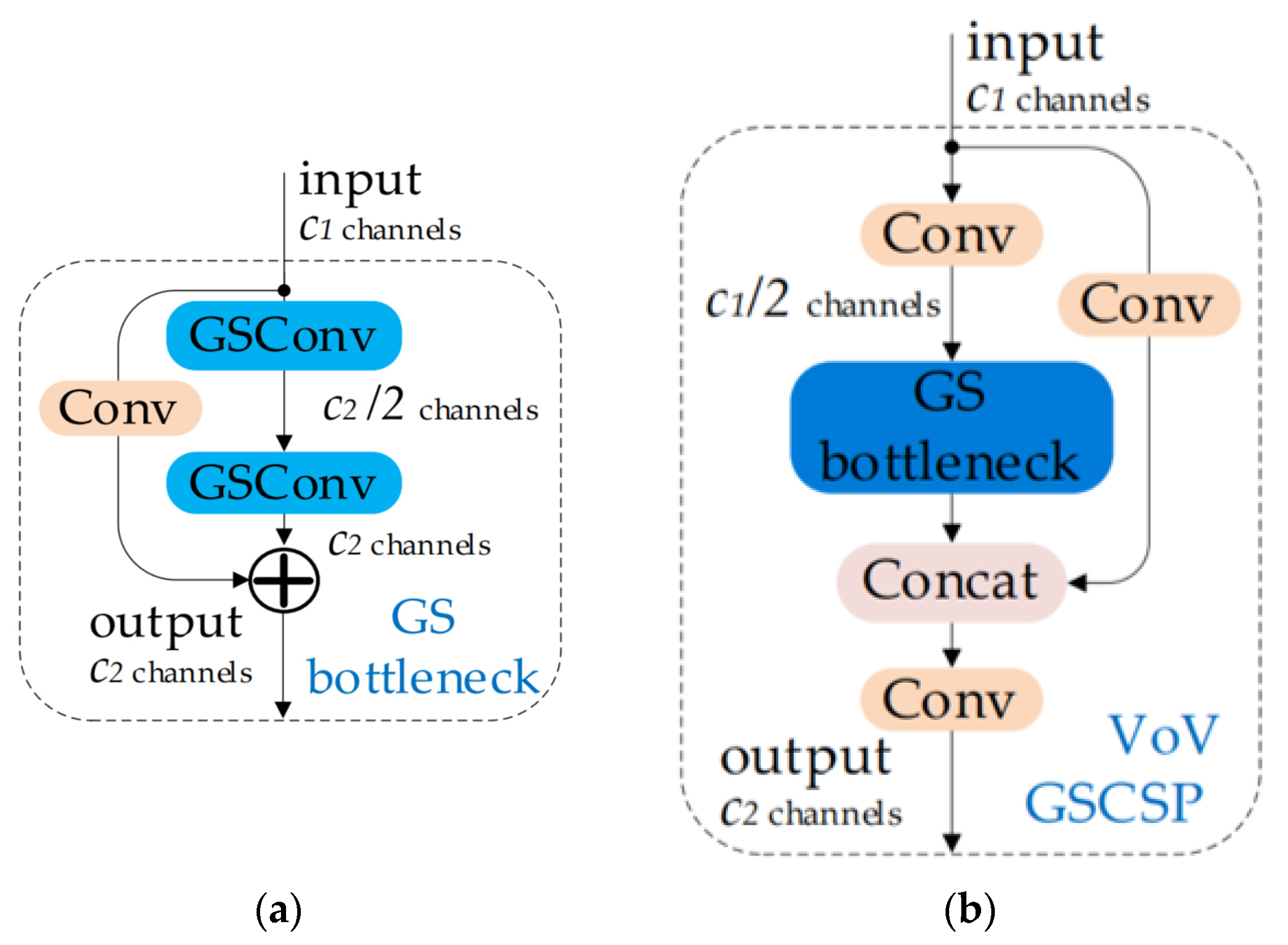
2.3.3. Slim-Neck
2.3.4. Optimized Method
2.4. Test Platform
2.5. Evaluation of Model Performance
3. Results
3.1. Improved Yolov5s Model Based on Ablation Experiment
3.2. Improved Yolov5s Model
3.3. Performance Comparison with Other Lightweight Backbone Networks
3.4. Further Optimized Yolov5s Model Based on Knowledge Distillation
3.5. Performance Comparison of Target Detection Using Different Algorithms
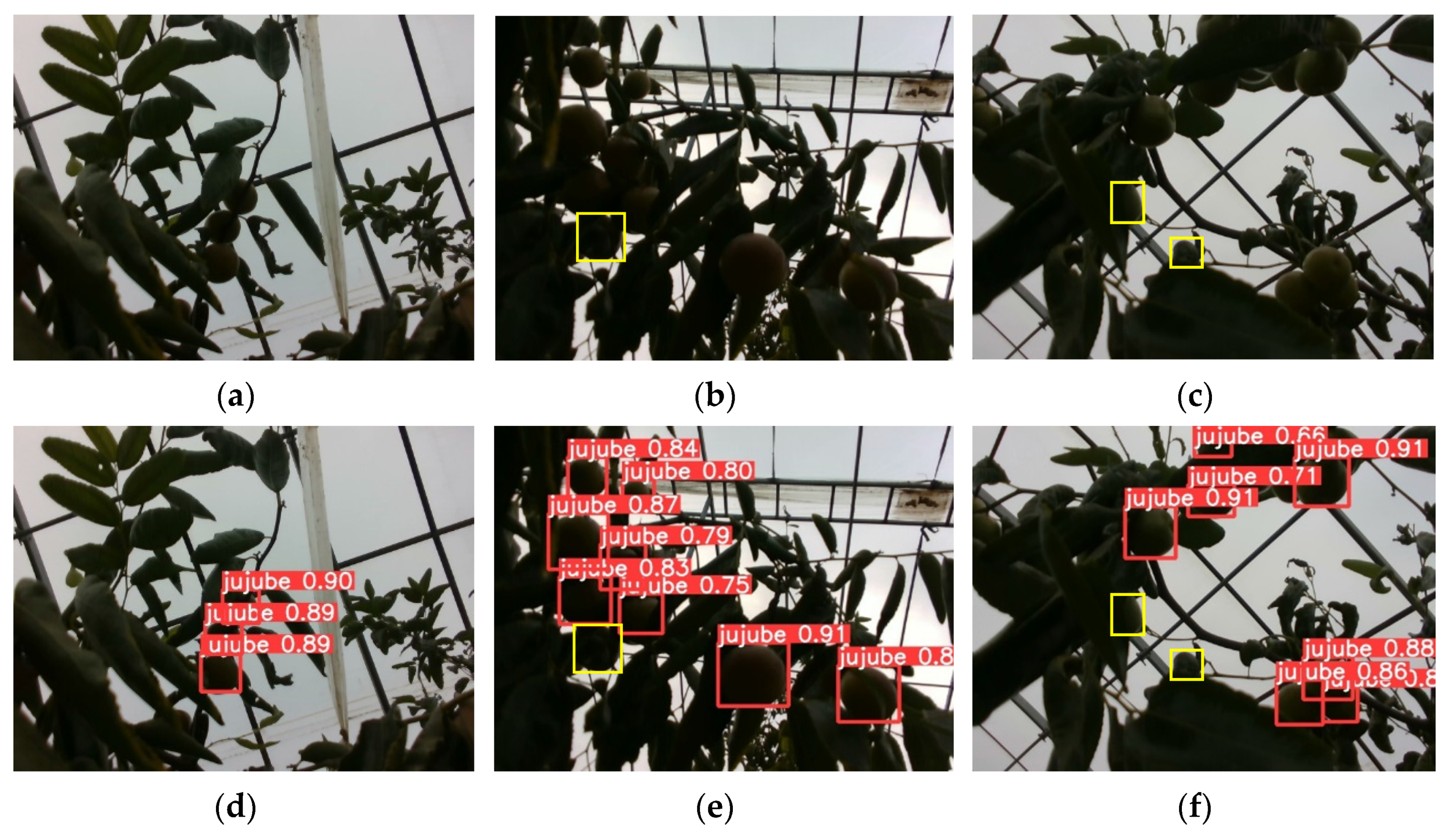
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Feng, J.; Liu, G.; Si, Y.; Wang, S.; Zhou, W. Construction of a laser vision system for an apple picking robot. Trans. Chin. Soc. Agric. Eng. 2013, 29, 32–37. [Google Scholar]
- Xie, E.; Ding, J.; Wang, W.; Zhan, X.; Xu, H.; Sun, P.; Li, Z.; Luo, P. Detco: Unsupervised contrastive learning for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 8392–8401. [Google Scholar]
- Zhao, M.; Jha, A.; Liu, Q.; Millis, B.A.; Mahadevan-Jansen, A.; Lu, L.; Landman, B.A.; Tyska, M.J.; Huo, Y. Faster Mean-shift: GPU-accelerated clustering for cosine embedding-based cell segmentation and tracking. Med. Image Anal. 2021, 71, 102048. [Google Scholar] [CrossRef] [PubMed]
- Zhao, M.; Liu, Q.; Jha, A.; Deng, R.; Yao, T.; Mahadevan-Jansen, A.; Tyska, M.J.; Millis, B.A.; Huo, Y. VoxelEmbed: 3D Instance Segmentation and Tracking with Voxel Embedding Based Deep Learning; Springer International Publishing: Cham, Switzerland, 2021; pp. 437–446. [Google Scholar]
- You, L.; Jiang, H.; Hu, J.; Chang, C.H.; Chen, L.; Cui, X.; Zhao, M. GPU-accelerated Faster Mean Shift with euclidean distance metrics. In Proceedings of the 2022 IEEE 46th Annual Computers, Software, and Applications Conference, Los Alamitos, CA, USA, 27 June–1 July 2022; pp. 211–216. [Google Scholar]
- Zheng, Z.; Hu, Y.; Yang, H.; Qiao, Y.; He, Y.; Zhang, Y.; Huang, Y. AFFU-Net: Attention feature fusion U-Net with hybrid loss for winter jujube crack detection. Comput. Electron. Agric. 2022, 198, 107049. [Google Scholar] [CrossRef]
- Zheng, Z.; Yang, H.; Zhou, L.; Yu, B.; Zhang, Y. HLU 2-Net: A residual U-structure embedded U-Net with hybrid loss for tire defect inspection. IEEE Trans. Instrum. Meas. 2021, 70, 1–11. [Google Scholar]
- Yang, Q.; Duan, S.; Wang, L. Efficient Identification of Apple Leaf Diseases in the Wild Using Convolutional Neural Networks. Agronomy 2022, 12, 2784. [Google Scholar] [CrossRef]
- Fu, L.; Yang, Z.; Wu, F.; Zou, X.; Lin, J.; Cao, Y.; Duan, J. YOLO-Banana: A lightweight neural network for rapid detection of banana bunches and stalks in the natural environment. Agronomy 2022, 12, 391. [Google Scholar] [CrossRef]
- Moreira, G.; Magalhães, S.A.; Pinho, T.; dos Santos, F.N.; Cunha, M. Benchmark of deep learning and a proposed hsv colour space models for the detection and classification of greenhouse tomato. Agronomy 2022, 12, 356. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Williams, H.A.; Jones, M.H.; Nejati, M.; Seabright, M.J.; Bell, J.; Penhall, N.D.; Barnett, J.J.; Duke, M.D.; Scarfe, A.J.; Ahn, H.S.; et al. Robotic kiwifruit harvesting using machine vision, convolutional neural networks, and robotic arms. Biosyst. Eng. 2019, 181, 140–156. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A real-time apple targets detection method for picking robot based on improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zhou, J.; Hu, W.; Zou, A.; Zhai, S.; Liu, T.; Yang, W.; Jiang, P. Lightweight detection algorithm of kiwifruit based on improved YOLOX-s. Agriculture 2022, 12, 993. [Google Scholar] [CrossRef]
- Sozzi, M.; Cantalamessa, S.; Cogato, A.; Kayad, A.; Marinello, F. Automatic bunch detection in white grape varieties using YOLOv3, YOLOv4, and YOLOv5 deep learning algorithms. Agronomy 2022, 12, 319. [Google Scholar] [CrossRef]
- Qiao, Y.; Hu, Y.; Zheng, Z.; Yang, H.; Zhang, K.; Hou, J.; Guo, J. A Counting Method of Red Jujube Based on Improved YOLOv5s. Agriculture 2022, 12, 2071. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1580–1589. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles. arXiv 2022, arXiv:2206.02424. [Google Scholar]
- Mehta, R.; Ozturk, C. Object detection at 200 frames per second. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018; Part V 15. pp. 659–675. [Google Scholar]
- Chen, G.; Choi, W.; Yu, X.; Han, T.; Chandraker, M. Learning efficient object detection models with knowledge distillation. Adv. Neural Inf. Process. Syst. 2017, 30, 1–10. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration | Parameter |
|---|---|
| CPU | AMD EPYC 7642 48-CoreProcessor |
| GPU | NVIDIA GeForce RTX 3090 |
| Accelerated environment | CUDA11.3 |
| Deep learning framework | Pytorch 1.10 |
| Programming language | Python 3.8 |
| Model | Precision (%) | Recall (%) | mAP (%) | F1 Score (%) | Parameters | Model Size (MB) | Fps |
|---|---|---|---|---|---|---|---|
| Yolov5s | 84.00 | 80.70 | 88.90 | 82.31 | 7,012,822 | 13.74 | 106.38 |
| Yolov5s + Shufflenetv2 | 83.40 | 81.40 | 87.90 | 82.38 | 842,358 | 2.06 | 114.94 |
| Yolov5s + GSconv | 87.70 | 81.80 | 89.50 | 84.64 | 6,581,366 | 13.58 | 111.11 |
| Yolov5s + VoVGSCSPC | 88.10 | 82.40 | 89.90 | 85.15 | 7,189,030 | 14.83 | 107.52 |
| Yolov5s + Shufflenetv2 + GSconv | 84.90 | 80.90 | 88.60 | 82.85 | 736,630 | 1.85 | 105.26 |
| Yolov5s + Shufflenetv2 + VoVGSCSPC | 85.10 | 80.60 | 88.70 | 82.78 | 889,422 | 2.19 | 111.11 |
| Yolov5s + Slim-neck | 88.20 | 82.30 | 89.40 | 85.14 | 6,737,702 | 13.96 | 107.52 |
| Yolov5s + Shufflenetv2 + Slim-neck | 86.30 | 81.10 | 89.40 | 83.61 | 787,230 | 1.91 | 109.89 |
| Model | Precision (%) | Recall (%) | mAP (%) | F1 Score (%) | Parameters | Model Size (MB) | Fps |
|---|---|---|---|---|---|---|---|
| Yolov5s | 84.00 | 80.70 | 88.90 | 82.31 | 7,012,822 | 13.74 | 106.38 |
| Yolov5s + Ghostnet + Slim-neck | 86.60 | 83.50 | 91.00 | 85.02 | 4,803,854 | 10.10 | 98.49 |
| Yolov5s + Mobilenetv3 + Slim-neck | 86.50 | 80.20 | 88.60 | 83.23 | 1,327,268 | 3.10 | 87.51 |
| Yolov5s + Shufflenet V2 + Slim-neck | 86.30 | 81.10 | 89.40 | 83.61 | 787,230 | 1.91 | 109.89 |
| Model | Precision (%) | Recall (%) | mAP (%) | F1 Score (%) | Parameters | Model Size (MB) | Fps |
|---|---|---|---|---|---|---|---|
| Yolov5m model | 91.40 | 83.70 | 91.20 | 87.38 | 20,852,934 | 42.24 | 50.76 |
| Improved Yolov5s model | 86.30 | 81.10 | 89.40 | 83.61 | 787,230 | 1.91 | 109.89 |
| Optimized Yolov5s model | 88.70 | 82.00 | 90.80 | 85.21 | 787,230 | 1.91 | 109.89 |
| Model | Precision (%) | Recall (%) | mAP (%) | F1 Score (%) | Parameters | Model Size (MB) | Fps |
|---|---|---|---|---|---|---|---|
| Yolov5s | 84.00 | 80.70 | 88.90 | 82.31 | 7,012,822 | 13.74 | 106.38 |
| Yolov3-tiny | 84.52 | 79.21 | 87.59 | 81.77 | 8,666,692 | 17.44 | 163.96 |
| Yolov4-tiny | 83.38 | 80.24 | 85.76 | 81.77 | 6,056,606 | 23.57 | 151.46 |
| Yolov7-tiny | 87.90 | 81.60 | 88.50 | 84.63 | 6,007,596 | 12.29 | 109.69 |
| SSD | 91.60 | 52.10 | 77.91 | 66.42 | 26,285,486 | 90.60 | 57.03 |
| Faster RCNN | 52.27 | 72.05 | 67.68 | 60.58 | 137,098,724 | 108.17 | 8.07 |
| Optimized Yolov5s model | 88.70 | 82.00 | 90.80 | 85.21 | 787,230 | 1.91 | 109.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, J.; Yu, C.; Shi, X.; Zheng, Z.; Yang, L.; Hu, Y. Research on Winter Jujube Object Detection Based on Optimized Yolov5s. Agronomy 2023, 13, 810. https://doi.org/10.3390/agronomy13030810
Feng J, Yu C, Shi X, Zheng Z, Yang L, Hu Y. Research on Winter Jujube Object Detection Based on Optimized Yolov5s. Agronomy. 2023; 13(3):810. https://doi.org/10.3390/agronomy13030810
Chicago/Turabian StyleFeng, Junzhe, Chenhao Yu, Xiaoyi Shi, Zhouzhou Zheng, Liangliang Yang, and Yaohua Hu. 2023. "Research on Winter Jujube Object Detection Based on Optimized Yolov5s" Agronomy 13, no. 3: 810. https://doi.org/10.3390/agronomy13030810
APA StyleFeng, J., Yu, C., Shi, X., Zheng, Z., Yang, L., & Hu, Y. (2023). Research on Winter Jujube Object Detection Based on Optimized Yolov5s. Agronomy, 13(3), 810. https://doi.org/10.3390/agronomy13030810