
A Soft Clustering Approach to Detect Socio-Ecological Landscape Boundaries Using Bayesian Networks

 , , ,
, , ,  ,
,  and
and
Abstract
1. Introduction
2. Methodology
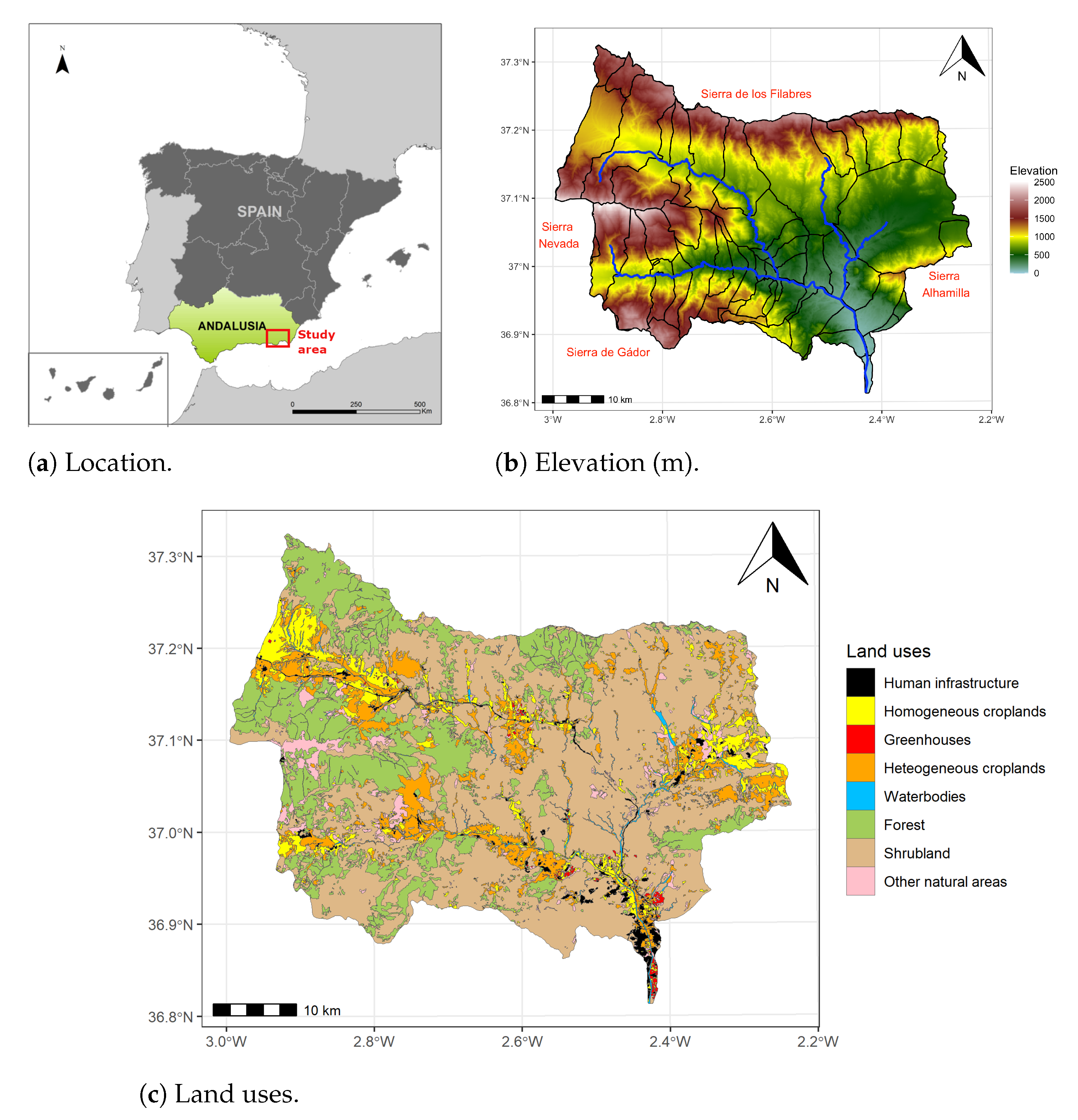
2.1. Study Area
2.2. Data Collection and Preprocessing
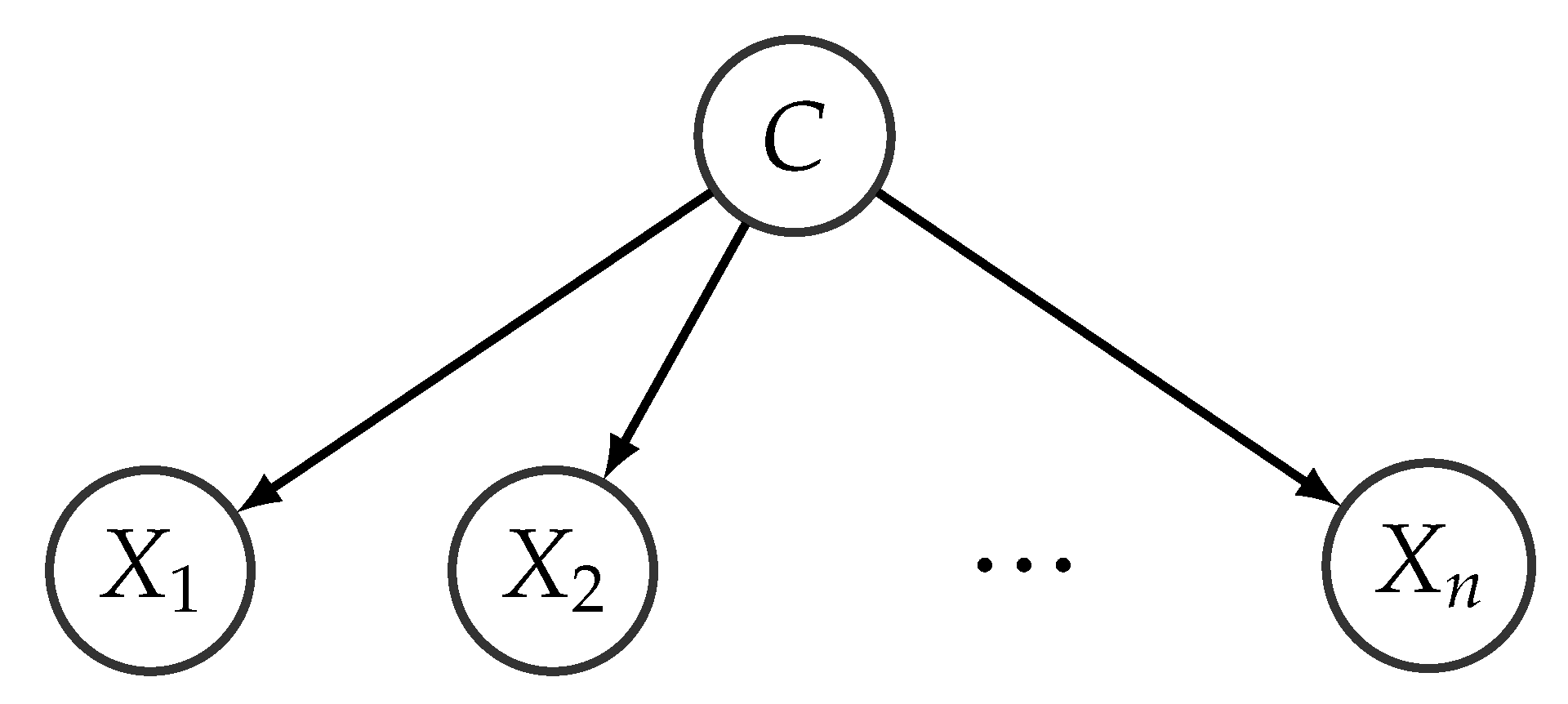
2.3. Hybrid Bayesian Networks
2.4. Unsupervised Classification Using Hybrid BNs
| Algorithm 1: Probabilistic clustering based on hybrid Bayesian networks for the landscape data set. |
 |
| Algorithm 2: LearnInitialModel. |
 |
| Algorithm 3: DataAugmentation. |
 |
| Algorithm 4: AddCluster. |
| Input: A model with n states in the hidden variable . Output: A new model M with states in the hidden variable H. 1 . 2 Let be the states of the hidden variable H in M. 3 Add a new state, to H. 4 Update the probability distribution of H by re-computing the probability of and as follows: 5 . 6 . 7 . 8 foreach feature in M do 9  10 return M. |
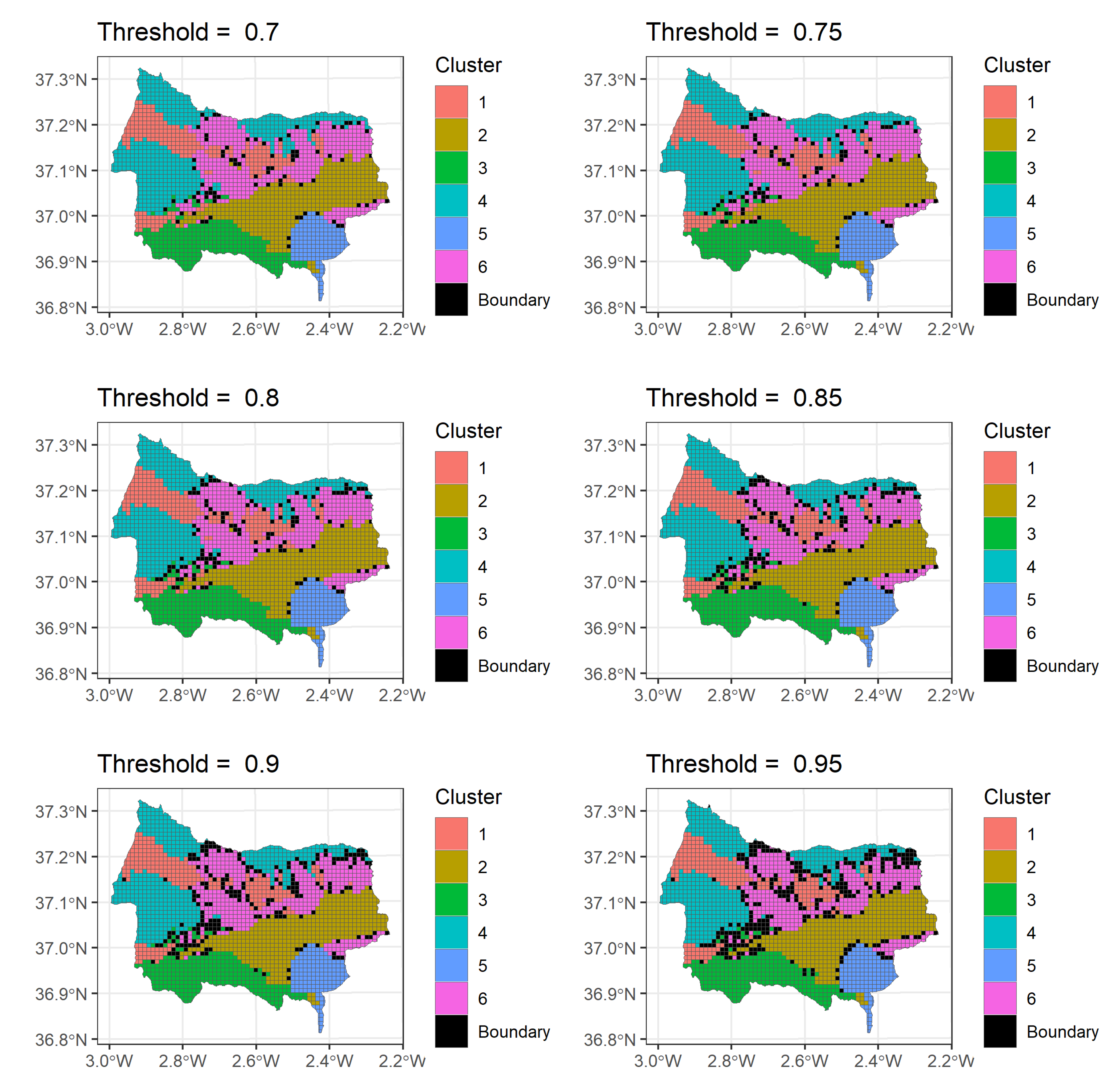
2.5. Boundary Detection
3. Results and Discussion
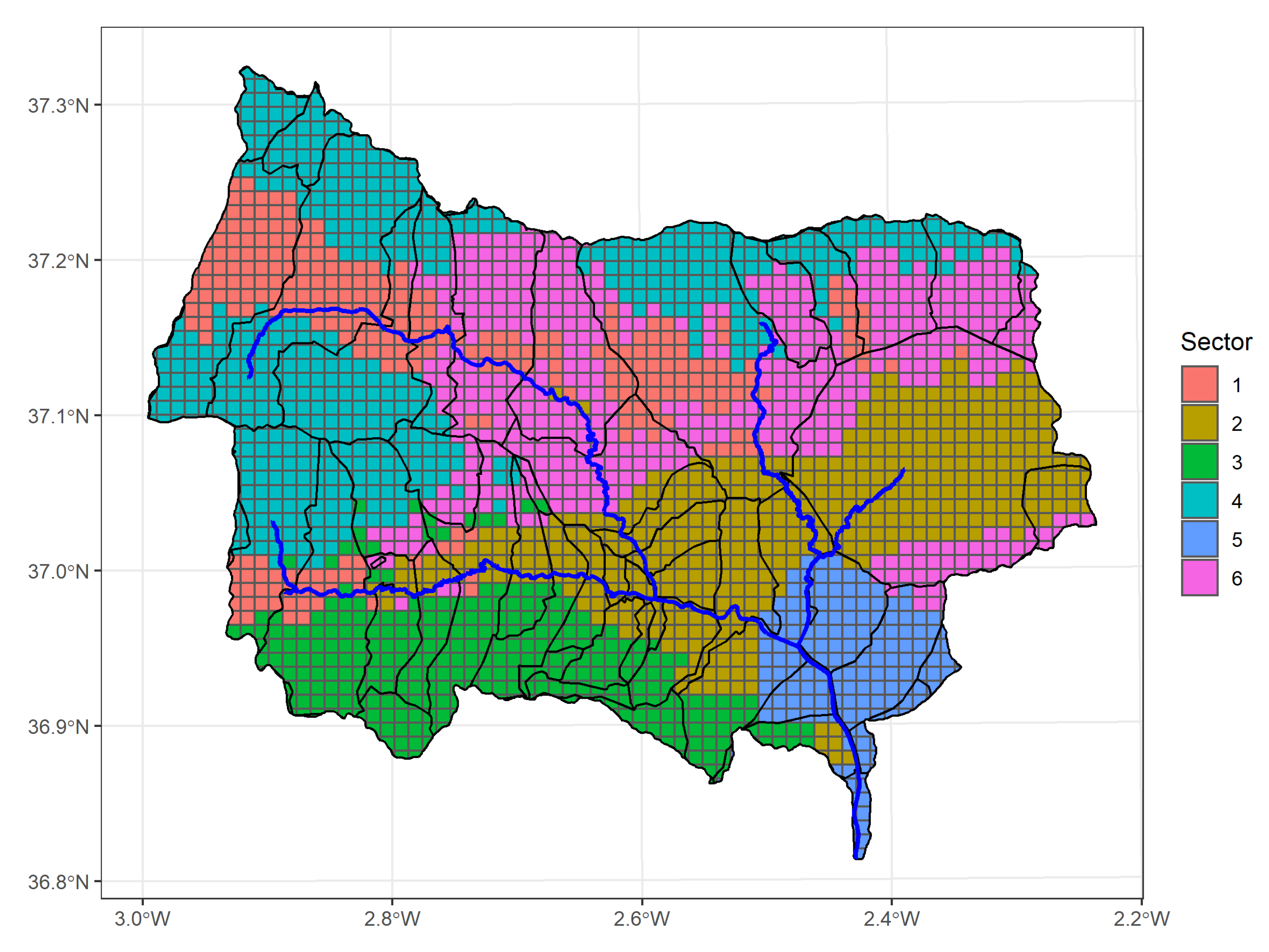
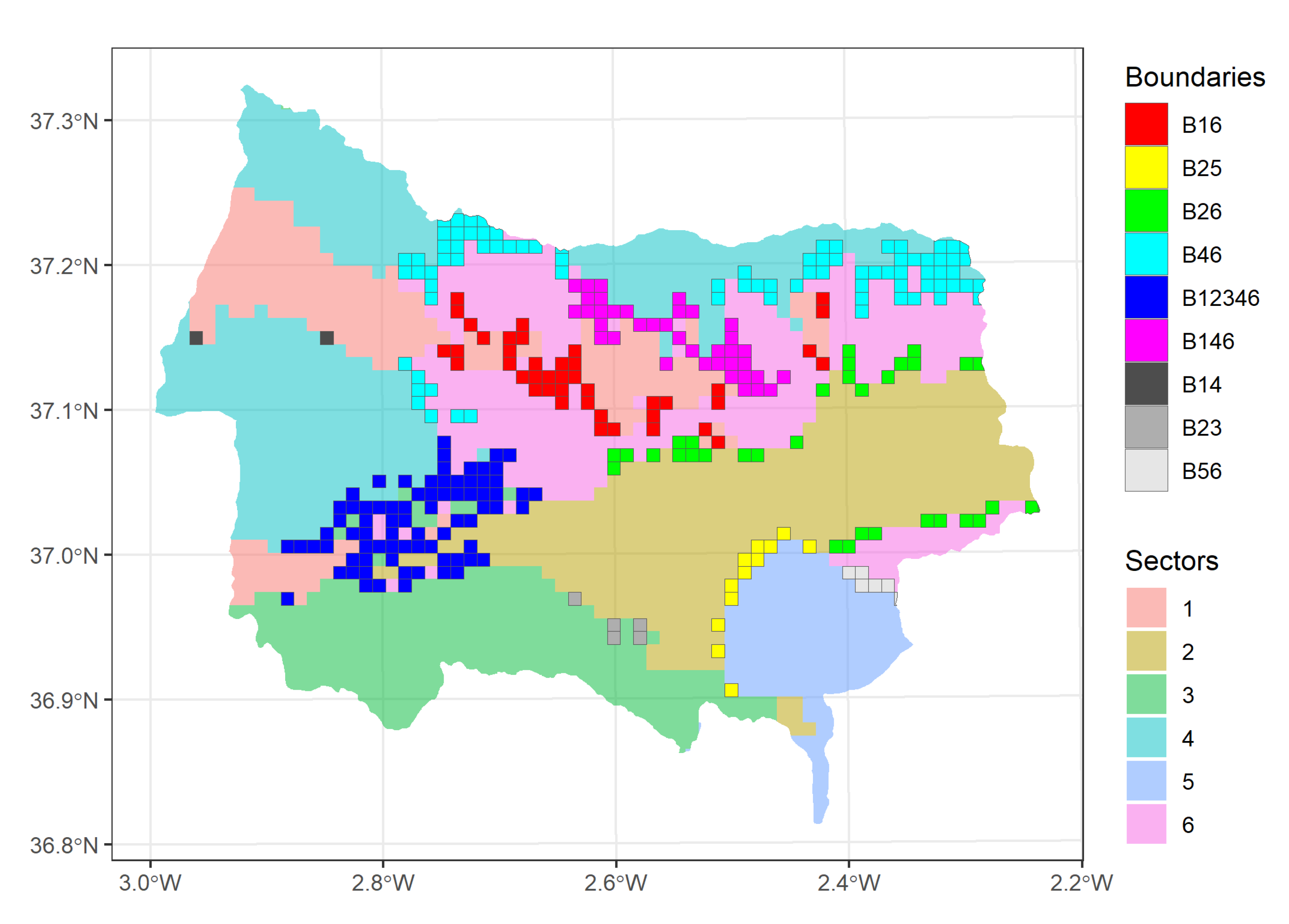
3.1. Socio-Ecological Sectors
- Sector 1 comprises grid cells located at the upper river courses. This cluster is characterized by a high percentage of homogeneous crops (, i.e., it is 1.45 standard deviations above the mean, on average) and high percentage of luvisols (). The presence of shrubland is scarce in this region (), occupying less than 15% of the sector.
- Sector 2 comprises inner lowland grid cells, characterized by the predominance of the sedimentary material, which occupies more than 90% of the sector (). Furthermore, the annual temperature, the minimum temperature of the coldest month and the evapotranspiration (ETP) take higher-than-average values (). In this sector shrubs and homogeneous crops (mainly extensive areas of olive crops) coexist.
- Sector 3 comprises grid cells located in Sierra de Gádor, the southernmost mountain range on the study area. This sector is characterized by a high percentage of karst landscape () and high percentage of lithosols (). In terms of land-use, this sector presents the lowest percentage of land occupied by both heterogeneous and homogeneous crops (≤3%).
- Sector 4 comprises grid cells located in the uppermost parts of Sierra Nevada and Sierra de los Filabres. This sector is characterized by low temperatures (both, annual and minimum of coldest month, with ) and ETP (), and high rainfall, especially summer rainfall and summer rainy days (). In terms of land-uses, this sector presents the highest percentage of land occupied by forest (>72%) in comparison with the remaining sectors ().
- Sector 5 comprises grid cells at the lowest elevation and is mainly characterized by the socio-economic and climatic variables. More specifically, the Income Per Capita (IPC) is two standard deviations above the mean; moreover, the population growth is higher than in the remaining sectors () whereas the proportion of population over 65 years old is lower (). Regarding the climatic variables, this sector shows high temperatures and ETP () and low amount of rainfall and rainy days ().
- Sector 6 is mainly located at the foothills of Sierra de los Filabres, Sierra Nevada and Sierra Alhamilla. This sector is characterized by a population with lower IPC (), higher proportion of older people () and higher emigration rate ().
3.2. Socio-Ecological Boundary Areas
- : This boundary zone separates Sectors 1 (upper river area) and 6 (foothills) and is mainly located along the middle course of the Nacimiento river, at a lower elevation than the other two sectors. From the socio-economic point of view, the boundary zone seems to be more similar to Sector 6 than 1, as the medians of most variables are closer and no statistically significant differences are found in many cases (Figure A2). In terms of lithology, while Sector 1 is predominantly sedimentary and Sector 6 is metamorphic, the boundary zone is mixed, showing statistically significant differences with both sectors. Concerning land-uses, Sector 1 is largely covered by herbaceous crops and Sector 6 by shrubland. However, the boundary zone is predominantly covered by forest, showing statistically significant differences with both sectors. Finally, regarding the climate variables, the lower elevation at which the boundary zone is located determines its hotter and drier conditions, with the hypothesis test performed yielding significant differences between the boundary and both sectors, in most cases.
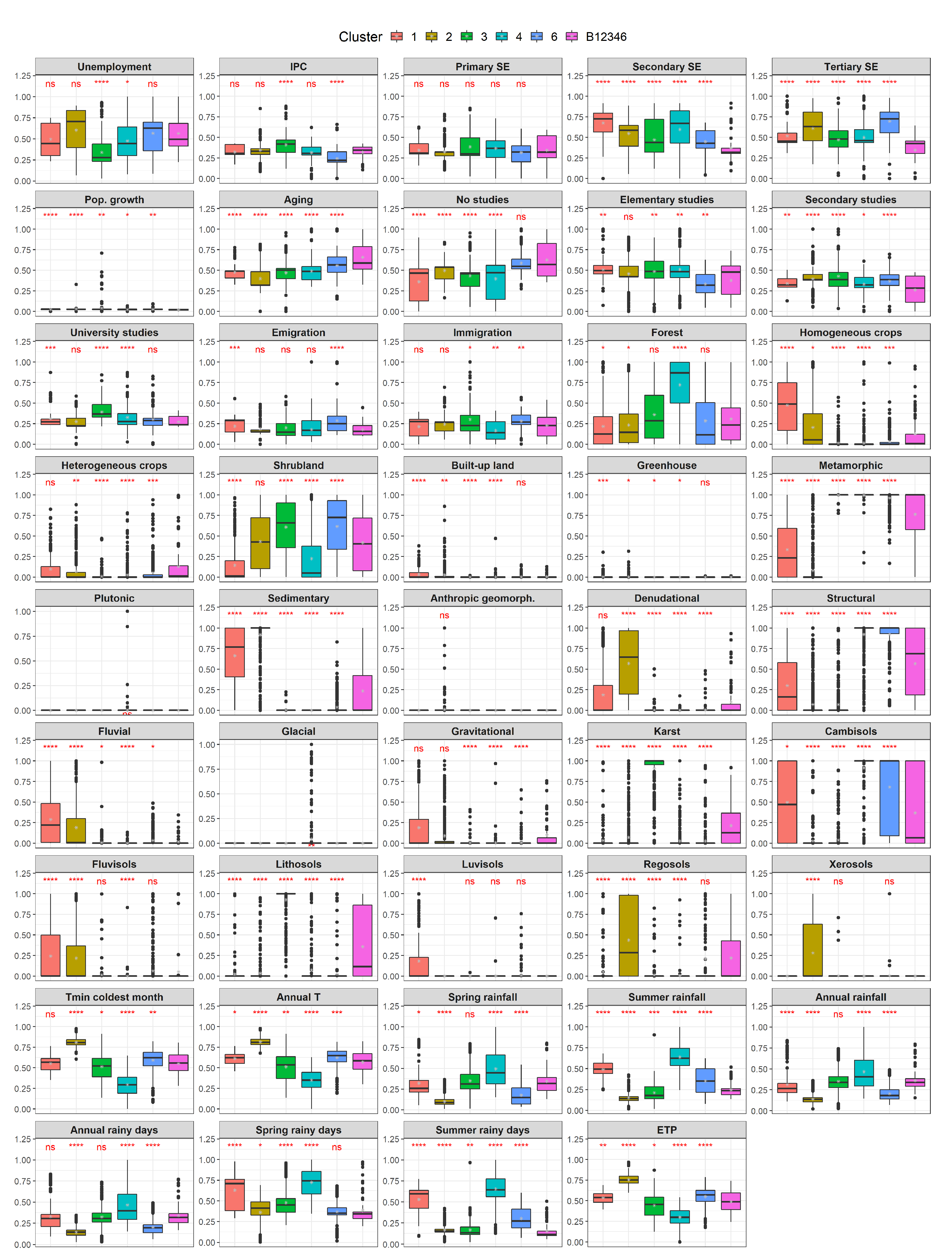
- : This boundary zone divides Sectors 2 (inner lowlands) and 5 (wealthier land). In general, the statistical test yielded significant differences regarding the socio-economic and climate variables (Figure A3). In terms of the economic variables (unemployment, IPC and sector employment), the boundary zone is more similar to Sector 5 than 2. Regarding the remaining social and climate variables, the boundary zone takes intermediate values between the two sectors, yielding statistically significant differences, in most cases.
- : This boundary zone divides Sectors 2 (inner lowlands) and 6 (foothills). The transition in altitude is reflected in the climatic conditions of the boundary area, as it shows intermediate values between both sectors, showing statistically significant differences between the boundary zone and each sector, in most cases (Figure A4). In terms of land-uses, significant differences were not found between the boundary zone and Sector 6, whereas Sector 2 and the boundary zone present significant differences regarding, homogeneous crops, shrubland and built-up land. Regarding the socio-economic variables, significant differences were found between the boundary zone and Sector 2 in five out of 13 variables and between the boundary area and Sector 6 in 10 out of 13 variables. Therefore, this boundary zone is more similar to Sector 2 from the socio-economic point of view and more similar to Sector 6 from the land-use point of view, but with warmer and drier climate conditions.
- : This boundary zone is located between Sectors 4 (high mountain) and 6 (foothills). As occurred in boundary , the transition in altitude causes a shift in the climate variables, with the boundary zone taking intermediate values with respect to the two sectors (Figure A5). Regarding land-uses, the boundary zone shows differences with the two sectors, presenting a higher coverage of homogeneous and heterogeneous crops, a coverage of forest similar to Sector 6 and a coverage of shrubland intermediate between the two sectors. Concerning the socio-economic variables, significant differences were found between the boundary zone and Sector 4 in all variables and between the boundary zone and Sector 6 in five out of 13 variables.
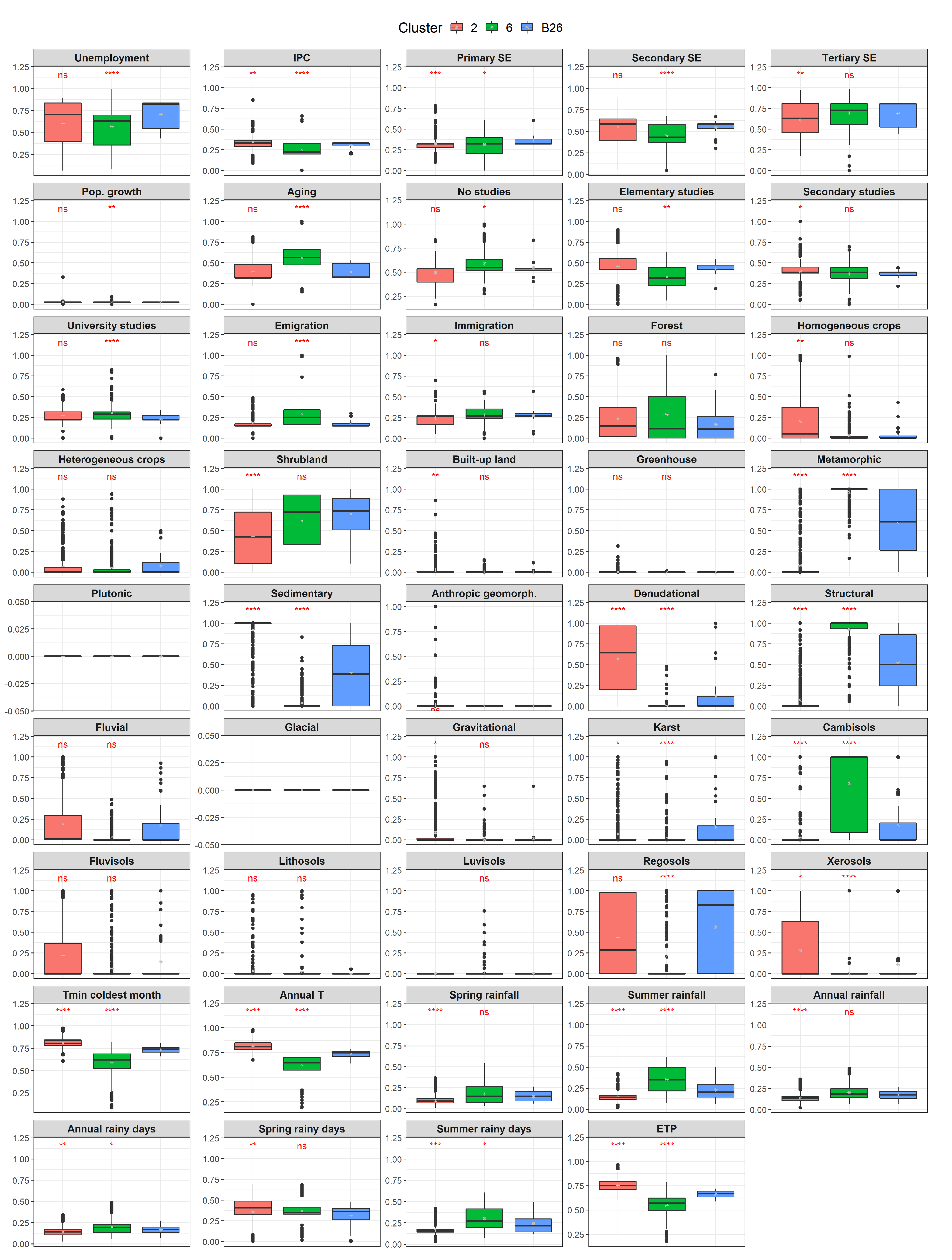
- : This boundary zone divides Sectors 1 (upper river courses), 4 (high mountains) and 6 (foothills). From the socio-economic point of view, it completely lies within one municipality, and therefore, the values of these variables in this zone hardly vary (Figure A6). Regarding land-uses, this boundary is more similar to Sector 6, due to its dominance of shrubland, and shows significant differences with the other two sectors in most variables. Concerning the climate variables, the boundary zone takes intermediate values between Sectors 4 and 6, with the statistical test yielding significant differences in all cases.
- : Finally, this boundary zone is a highly heterogeneous a complex area that divides a total of five sectors. It is located between two mountain ranges, Sierra de Gádor and Sierra Nevada, and covers part of the middle course of the main river of the catchment (Figure A7).
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Description of Variables

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | Variable | Definition | Range |
|---|---|---|---|
| Land use | Forest land | % of land occupied by forest trees or pastures, sometimes combined with shrubs | 0 = [0, 11] (n = 768) 1 = (11, 52] (n = 770) 2 = (52, 100] (n = 768) |
| Land use | Homogeneous cropland | % of land occupied by herbaceous or woody monocultures | 0 = 0 (n = 1299) 1 = (0, 15] (n = 505) 2 = (15, 100] (n = 502) |
| Land use | Heterogeneous cropland | % of the land occupied by mixtures of herbaceous and woody crops or mixtures of crops and natural vegetation | 0 = 0 (n = 1538) 1 = (0, 7] (n = 385) 2 = (7, 100] (n = 383) |
| Land use | Shrubland | % of land occupied by shrubs with absence of trees | 0 = [0, 11] (n = 768) 1 = (11, 63] (n = 768) 2 = (63, 100] (n = 770) |
| Land use | Human infrastructure | % of urban, industrial and commercial areas, landfills, mining deposits and communication infrastructures | 0 = 0 (n = 1851) 1 = (0, 5] (n = 228) 2 = (5, 100] (n = 227) |
| Land use | Greenhouse | % of high yield irrigated crops under controlled conditions | 0 = 0 (n = 2158) 1 = (0, 2] (n = 75) 2 = (2,100] (n = 73) |
| Soil | Cambisols | % of cambisols | 0 = 0 (n = 1092) 1 = (0, 99] (n = 361) 2 = (99, 100] (n = 853) |
| Soil | Fluvisols | % of fluvisols | 0 = 0 (n = 1867) 1 = (0, 57] (n = 220) 2 = (57, 100] (n = 219) |
| Soil | Lithosols | % of lithosols | 0 = 0 (n = 1809) 1 = (0, 99] (n = 228) 2 = (99, 100] (n = 269) |
| Soil | Luvisols | % of luvisols | 0 = 0 (n = 2182) 1 = (0, 45] (n = 63) 2 = (45, 100] (n = 61) |
| Soil | Regosols | % of regosols | 0 = 0 (n = 1719) 1 = (0, 88] (n = 294) 2 = (88, 100] (n = 293) |
| Soil | Xerosols | % of xerosols | 0 = 0 (n = 2008) 1 = (0, 76] (n = 150) 2 = (76, 100] (n = 148) |
| Geomorphology | Anthropic | % of anthropic geomorphological type | 0 = 0 (n = 2284) 1 = (0, 9] (n = 12) 2 = (9, 45] (n = 10) |
| Geomorphology | Gravitational | % of gravitational geomorphological type | 0 = 0 (n = 1921) 1 = (0, 29] (n = 193) 2 = (29, 100] (n = 192) |
| Geomorphology | Denudational | % of denudational geomorphological type | 0 = 0 (n = 1674) 1 = (0, 64] (n = 317) 2 = (64, 100] (n = 315) |
| Geomorphology | Structural | % of structural geomorphological type | 0 = 0 (n = 830) 1 = (0, 99] (n = 740) 2 = (99, 100] (n = 736) |
| Geomorphology | Fluvial | % of fluvial geomorphological type | 0 = 0 (n = 1598) 1 = (0, 23] (n = 355) 2 = (23, 100] (n = 353) |
| Geomorphology | Glacial | % of glacial geomorphological type | 0 = 0 (n = 2264) 1 = (0, 53] (n = 22) 2 = (53, 100] (n = 20) |
| Geomorphology | Karst | % of karst geomorphological type | 0 = 0 (n = 1666) 1 = (0, 74] (n = 321) 2 = (74, 100] (n = 319) |
| Lithology | Metamorphic | % of metamorphic rock | 0 = [0, 55] (n = 769) 1 = (55, 99] (n = 258) 2 = (99, 100] (n = 1279) |
| Lithology | Sedimentary | % of sedimentary rock | 0 = 0 (n = 1286) 1 = (0, 99] (n = 482) 2 = (99, 100] (n = 538) |
| Lithology | Plutonic | % of plutonic rock | 0 = 0 (n = 2299) 1 = (0, 12] (n = 4) 2 = (12, 83] (n = 3) |
| Group | Variable | Definition | Range |
|---|---|---|---|
| Social | Population natural growth | Growth of the population, computed as the difference between the number of births and deaths | [−25, 782] |
| Social | Aging | % of people older than 65 years | [6.73, 48.91] |
| Social | No studies | % of people who do not have any level of educational attainment, including illiterates (computed from people over 16) | [2.67, 72.06] |
| Social | Primary studies | % people whose maximum level of education attained is elementary school (computed from people over 16) | [4.51, 49.25] |
| Social | Secondary studies | % people whose maximum level of education attained is high school (computed from people over 16) | [16.18, 56.59] |
| Social | Tertiary studies | % people whose maximum level of education attained is a university degree (computed from people over 16) | [1.63, 16.33] |
| Social | Emigration | % of emigrants | [1.37, 21.45] |
| Social | Immigration | % of immigrants | [1.42, 15.33] |
| Economic | Income per capita | Average net income declared () | [5178, 18184] |
| Economic | Unemployment | % of workforce that is unemployed | [3.97, 43.48] |
| Economic | Primary sector employment | % of people working in the primary sector | [0, 59.5] |
| Economic | Secondary sector employment | % of people working in the secondary sector | [7.69, 43.95] |
| Economic | Tertiary sector employment | % of people working in the tertiary sector | [0, 26.92] |
| Climate | Coldest month temperature, | Minimum temperature of the averages of the minimum monthly temperatures (°C) over the period 1961–2000 | [0.7, 12.58] |
| Climate | Annual temperature | Average annual mean temperature (°C) over the period 1961–2000 | [7.32, 18.93] |
| Climate | Spring rainfall | Average spring total rainfall (mm) over the period 1961–2000 | [16.94, 56.56] |
| Climate | Summer rainfall | Average summer total rainfall (mm) over the period 1961–2000 | [3.32, 14.37] |
| Climate | Annual rainfall | Average annual total rainfall (mm) over the period 1961–2000 | [172, 639.49] |
| Climate | Annual number of rainfall days | Average number of annual rainy days over the period 1961–2000 | [8.21, 26.65] |
| Climate | Spring number of rainfall days | Average number of vernal rainy days over the period 1961–2000 | [2.08, 5.38] |
| Climate | Summer number of rainfall days | Average number of estival rainy days over the period 1961–2000 | [1.48, 6.12] |
| Climate | Evapotranspiration rate | Average annual evapotranspiration of reference (mm) over the period 1961–2000 | [541.99, 951.20] |
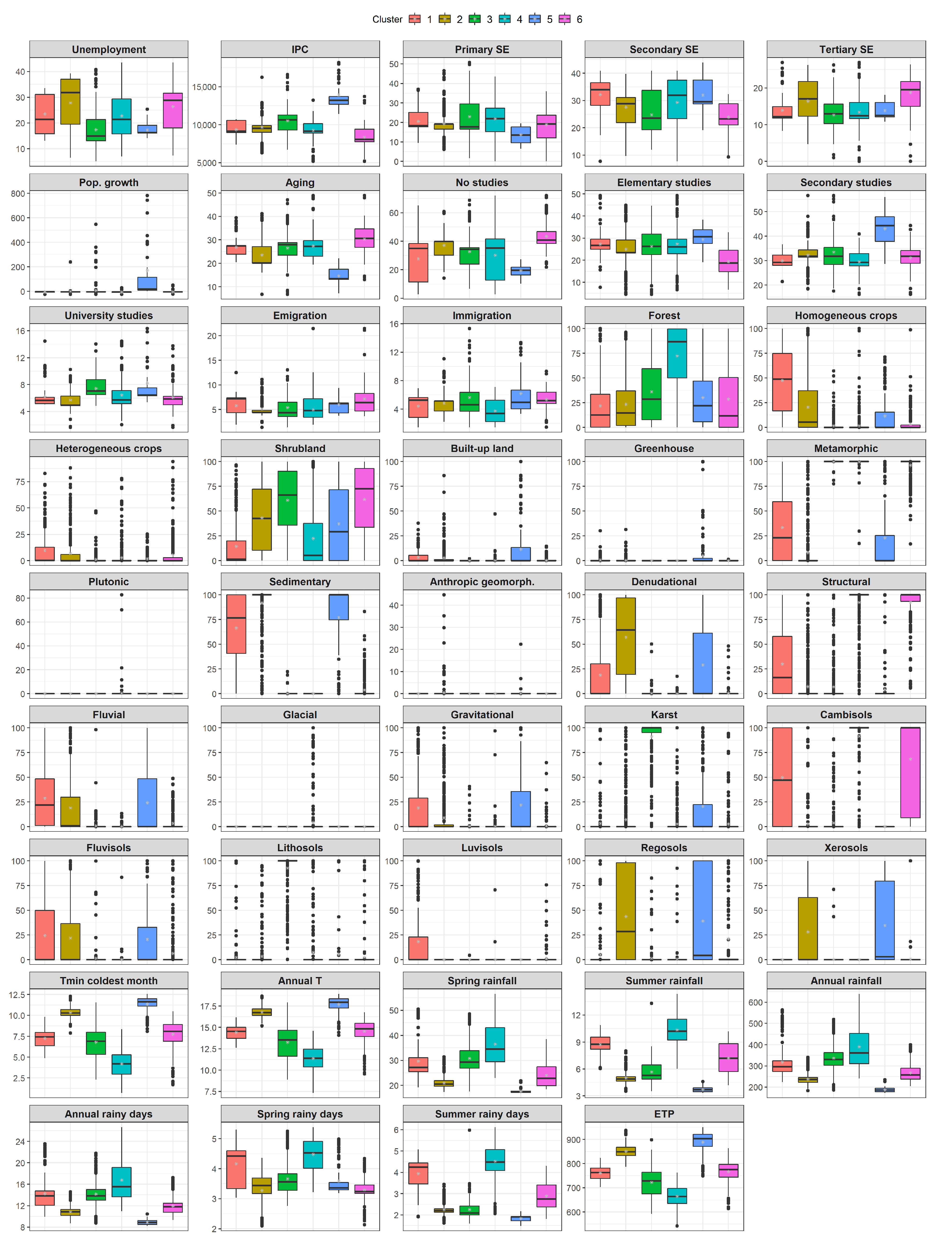
Appendix B. Socio-Ecological Variables by Sector

Appendix C. Comparison Sector-Boundary






References
- Plieninger, T.; Bieling, C. Resilience and the Cultural Landscape: Understanding and Managing Change in Human-Shaped Environments; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Rescia, A.J.; Willaarts, B.A.; Schmitz, M.F.; Aguilera, P.A. Changes in land-uses and management in two Nature Reserves in Spain: Evaluating the social-ecological resilience of cultural landscapes. Landsc. Urban Plan. 2010, 98, 26–35. [Google Scholar] [CrossRef]
- Rescia, A.; Pérez-Corona, M.E.; Arribas-Ureña, P.; Dover, J.W. Cultural landscapes as complex adaptive systems: The cases of northern Spain and northern Argentina. In Resilience and the Cultural Landscape: Understanding and Managing Change in Human-Shaped Environments; Cambridge University Press: Cambridge, UK, 2012; pp. 126–145. [Google Scholar]
- Maldonado, A.D.; Ramos-López, D.; Aguilera, P.A. A comparison of machine-learning methods to select socioeconomic indicators in cultural landscapes. Sustainability 2018, 10, 4312. [Google Scholar] [CrossRef]
- Parrott, L.; Quinn, N. A complex systems approach for multiobjective water quality regulation on managed wetland landscapes. Ecosphere 2016, 7, e01363. [Google Scholar] [CrossRef]
- Schmitz, M.F.; De Aranzabal, I.; Aguilera, P.; Rescia, A.; Pineda, F.D. Relationship between landscape typology and socioeconomic structure: Scenarios of change in Spanish cultural landscapes. Ecol. Model. 2003, 168, 343–356. [Google Scholar] [CrossRef]
- Ostrom, E. A general framework for analyzing sustainability of social-ecological systems. Science 2009, 325, 419–422. [Google Scholar] [CrossRef] [PubMed]
- Folke, C. Social-ecological systems and adaptive governance of the commons. Ecol. Res. 2007, 22, 14–15. [Google Scholar] [CrossRef]
- Hamann, M.; Biggs, R.; Reyers, B. Mapping social-ecological systems: Identifying green-loop and red-loop dynamics based on characteristic bundles of ecosystem service use. Glob. Environ. Chang. 2015, 34, 218–226. [Google Scholar] [CrossRef]
- Bogunovic, I.; Viduka, A.; Magdic, I.; Telak, L.J.; Francos, M.; Pereira, P. Agricultural and forest land-use impact on soil properties in Zagreb periurban area (Croatia). Agronomy 2020, 10, 1331. [Google Scholar] [CrossRef]
- Mendoza-Fernández, A.J.; Peña-Fernández, A.; Molina, L.; Aguilera, P.A. The role of technology in greenhouse agriculture: Towards a sustainable intensification in Campo de Dalías (Almería, Spain). Agronomy 2021, 11, 101. [Google Scholar] [CrossRef]
- Hardt, E.; dos Santos, R.F.; de Pablo, C.L.; Martín de Agar, P.; Pereira-Silva, E. Utility of landscape mosaics and boundaries in forest conservation decision making in the Atlantic Forest of Brazil. Landsc. Ecol. 2013, 28, 385–399. [Google Scholar] [CrossRef]
- Fortin, M.J.; Olson, R.; Ferson, S.; Iverson, L.; Hunsaker, C.; Edwards, G.; Levine, D.; Butera, K.; Klemas, V. Issues related to the detection of boundaries. Landsc. Ecol. 2000, 15, 453–466. [Google Scholar] [CrossRef]
- Dale, M.R.T.; Fortin, M.J. Spatial Analysis: A Guide for Ecologists; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Fortin, M.; Drapeau, P. Delineation of ecological boundaries: Comparison of approaches and significance test. Oikos 1995, 72, 323–332. [Google Scholar] [CrossRef]
- Polakowska, A.; Fortin, M.; Coutuier, A. Quantifying the spatial relationship between bird species distributions and landscape feature boundaries in southern Ontario, Canada. Landsc. Ecol. 2012, 27, 1481–1493. [Google Scholar] [CrossRef]
- Fortin, M.; Keitt, T.; Maurer, B.; Tapper, M.; Kaufman, D.; Blackburn, T. Species geographic ranges and distribution limits: Pattern analysis and statistical issues. Oikos 2005, 108, 7–17. [Google Scholar] [CrossRef]
- Fagan, W.; Fortin, M.J.; Soykan, C. Integrating edge detection and dynamic modeling in quantitative analyses of ecological boundaries. Bioscience 2003, 53, 730–738. [Google Scholar] [CrossRef]
- Camarero, J.; Gutiérrez, E.; Fortin, M. Spatial patterns of plant richness across treeline ecotones in the Pyrenees reveal different locations for richness and tree cover boundaries. Glob. Ecol. Biogeogr. 2006, 15, 182–191. [Google Scholar] [CrossRef]
- Jain, A.K.; Murty, M.M.; Flynn, P.J. Data clustering: A review. ACM Comput. Surv. 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Anderberg, M.R. Cluster Analysis for Applications; Academic Press: Cambridge, MA, USA, 1973. [Google Scholar]
- Ahmadi, A.; Moridi, A.; Han, D. Uncertainty assessment in environmental risk through Bayesian networks. J. Environ. Inform. 2015, 25. [Google Scholar] [CrossRef]
- Kelly, R.; Jakeman, A.J.; Barreteau, O.; Borsuk, M.; ElSawah, S.; Hamilton, S.; Henriksen, H.J.; Kuikka, S.; Maier, H.; Rizzoli, E.; et al. Selecting among five common approaches for integrated environmental assessment and management. Environ. Model. Softw. 2013, 47, 159–181. [Google Scholar] [CrossRef]
- Pearl, J. Probabilistic Reasoning in Intelligent Systems; Morgan-Kaufmann: San Mateo, CA, USA, 1988. [Google Scholar]
- Uusitalo, L. Advantages and challenges of Bayesian networks in environmental modelling. Ecol. Model. 2007, 203, 312–318. [Google Scholar] [CrossRef]
- Aguilera, P.A.; Fernández, A.; Fernández, R.; Rumí, R.; Salmerón, A. Bayesian networks in environmental modelling. Environ. Model. Softw. 2011, 26, 1376–1388. [Google Scholar] [CrossRef]
- Landuyt, D.; Broekx, S.; D’hondt, R.; Engelen, G.; Aertsens, J.; Geothals, P. A review of Bayesian belief networks in ecosystem service modelling. Environ. Model. Softw. 2013, 1–13. [Google Scholar] [CrossRef]
- McDonald, K.; Ryder, D.S.; Tighe, M. Developing best-practice Bayesian belief networks in ecological risk assessments for freshwaterand estuarine ecosystems: A quantitative review. J. Environ. Manag. 2015, 154, 190–200. [Google Scholar] [CrossRef] [PubMed]
- Phan, T.; Smart, J.C.; Capon, S.; Hadwen, W.; Sahin, O. Applications of Bayesian belief networks in water resource management: A systematic review. Environ. Model. Softw. 2016, 85, 98–111. [Google Scholar] [CrossRef]
- Kaikkonen, L.; Parviainen, T.; Rahikainen, M.; Uusitalo, L.; Lehikoinen, A. Bayesian networks in environmental risk assessment: A review. Integr. Environ. Assess. Manag. 2021, 17, 62–78. [Google Scholar] [CrossRef]
- Aguilera, P.A.; Fernández, A.; Ropero, R.F.; Molina, L. Groundwater quality assessment using data clustering based on hybrid Bayesian networks. Stoch. Environ. Res. Risk Assess. 2013, 27, 435–447. [Google Scholar] [CrossRef]
- Schmitz, M.; Pineda, F.; Castro, H.; Aranzabal, I.D.; Aguilera, P. Cultural Landscape and Socioeconomic Structure. Environmental Value and Demand for Tourism in a Mediterranean Territory; Consejería de Medio Ambiente, Junta de Andalucía: Sevilla, Spain, 2005. [Google Scholar]
- Moral, S.; Rumí, R.; Salmerón, A. Mixtures of truncated exponentials in hybrid Bayesian networks. In ECSQARU 2001, Proceedings of the European Conference on Symbolic and Quantitative Approaches to Reasoning and Uncertainty, Toulouse, France, 19–21 September 2001; Lecture Notes in Artificial Intelligence; Springer: BerlinHeidelberg, Germany, 2001; Volume 2143, pp. 156–167. [Google Scholar]
- Rumí, R.; Salmerón, A.; Moral, S. Estimating mixtures of truncated exponentials in hybrid Bayesian networks. Test 2006, 15, 397–421. [Google Scholar] [CrossRef]
- Rumí, R.; Salmerón, A. Approximate probability propagation with mixtures of truncated exponentials. Int. J. Approx. Reason. 2007, 45, 191–210. [Google Scholar] [CrossRef]
- Cobb, B.R.; Rumí, R.; Salmerón, A. Advances in Probabilistic Graphical Models; Studies in Fuzziness and Soft Computing; Chapter Bayesian Networks Models with Discrete and Continuous Variables; Springer: Berlin/Heidelberg, Germany, 2007; pp. 81–102. [Google Scholar]
- Friedman, N.; Geiger, D.; Goldszmidt, M. Bayesian Network Classifiers. Mach. Learn. 1997, 29, 131–163. [Google Scholar] [CrossRef]
- Fernández, A.; Gámez, J.A.; Rumí, R.; Salmerón, A. Data clustering using hidden variables in hybrid Bayesian networks. Prog. Artif. Intell. 2014, 2, 141–152. [Google Scholar] [CrossRef]
- Elvira-Consortium. Elvira: An environment for probabilistic graphical models. In Proceedings of the First European Workshop on Probabilistic Graphical Models (PGM’02), Cuenca, Spain, 6–8 November 2002; pp. 222–230. [Google Scholar]
- Tanner, M.A.; Wong, W.H. The calculation of posterior distributions by data augmentation. J. Am. Stat. Assoc. 1987, 82, 528–550. [Google Scholar] [CrossRef]
- Lauritzen, S.L. The EM algorithm for graphical association models with missing data. Comput. Stat. Data Anal. 1995, 19, 191–201. [Google Scholar] [CrossRef]
- Boillat, S.; Scarpa, F.M.; Robson, J.P.; Gasparri, I.; Aide, T.M.; Aguiar, A.P.D.; Anderson, L.O.; Batistella, M.; Fonseca, M.G.; Futemma, C.; et al. Land system science in Latin America: Challenges and perspectives. Curr. Opin. Environ. Sustain. 2017, 26, 37–46. [Google Scholar] [CrossRef]
- Frazier, A.; Wang, L. Modeling landscape structure response across a gradient of land cover intensity. Landsc. Ecol. 2013, 28, 233–246. [Google Scholar] [CrossRef]
- Cushman, S.; Gutzweiler, K.; Evans, J.; McGarigal, K. Spatial Complexity, Informatics, and Wildlife Conservation; Chapter The gradient paradigm: A conceptual and analytical framework for landscape ecology; Springer: Tokyo, Japan, 2010; pp. 83–108. [Google Scholar]
- Li, J.; Zhang, H.; Xu, E. Spatialization of Actual Grain Crop Yield Coupled with Cultivation Systems and Multiple Factors: From Survey Data to Grid. Agronomy 2020, 10, 675. [Google Scholar] [CrossRef]
- Strayer, D.; Power, M.; Fagan, W.; Pickett, S.T.; Belnap, J. A classification of ecological boundaries. Bioscience 2003, 53, 723–729. [Google Scholar] [CrossRef]
- Jacquez, G.; Maruca, S.; Fortin, M.J. From fields to objects: A review of geographic boundary analysis. Geogr. Syst. 2000, 2, 221–241. [Google Scholar] [CrossRef]
- Dallimer, M.; Strange, N. Why socio-political borders and boundaries matter in conservacion. Trends Ecol. Evol. 2015, 30, 132–139. [Google Scholar] [CrossRef] [PubMed]
- Martín-López, B.; Palomo, I.; García-Llorente, M.; Iniesta, I.; Castro, A.; García del Amo, D.; Gómez-Baggethun, E.; Montes, C. Delineating boundaries of social-ecological systems for landscape planning: A comprehensive spatial approach. Land Use Policy 2017, 66, 90–104. [Google Scholar] [CrossRef]
- Fitzpatrick, M.C.; Preisser, E.L.; Porter, A.; Elkinton, J.; Waller, L.A.; Carlin, B.P.; Ellison, A.M. Ecological boundary detection using Bayesian areal Wombling. Ecology 2010, 91, 3448–3455. [Google Scholar] [CrossRef] [PubMed]
- Hanberry, B.B.; Fraser, J.S. Visualizing current and future climate boundaries of the conterminous United States: Implications for forests. Forest 2019, 10, 280. [Google Scholar] [CrossRef]
- Han, Y.; Peng, J.; Meersmans, J.; Liu, Y.; Zhao, Z.; Mao, Q. Integrating spatial continuous wavelet transform and normalized difference vegetation index to map the agro-pastoral transitional zone in Northern China. Remote Sens. 2018, 10, 1928. [Google Scholar] [CrossRef]
- Hargrove, W.W.; Hoffman, F.M. Using multivariate clustering to characterize ecoregion borders. Comput. Sci. Eng. 1999, 1, 18–25. [Google Scholar] [CrossRef]
- Hargrove, W.W.; Hoffman, F.M. Potential of multivariate quantitative methods for delineation and visualization of ecoregions. Environ. Manag. 2004, 34, S39–S60. [Google Scholar] [CrossRef]
- Partington, K.; Cardille, J.A. Uncovering dominant land-cover patterns of Quebec: Representative landscapes, spatial clusters, and fences. Land 2013, 2, 756–773. [Google Scholar] [CrossRef]
- Safner, T.; Miller, M.P.; McRae, B.H.; Fortin, M.J.; Manel, S. Comparison of Bayesian clustering and edge detection methods for inferring boundaries in landscape genetics. Int. J. Mol. Sci. 2011, 12, 865–889. [Google Scholar] [CrossRef]
- Albanese, G.; Haukos, D. A network model framework for priorizing wetland conservation in the Great Plains. Landsc. Ecol. 2017, 32, 115–130. [Google Scholar] [CrossRef]
- Tenerelli, P.; Puffel, C.; Luque, S. Spatial assessment of aesthetic service in a complex mountain region: Combining visual landscape properties with crowdsourced geographic information. Landsc. Ecol. 2017, 32, 1097–1115. [Google Scholar] [CrossRef]
- Martens, W.J.M.; Rotmans, J. Transitions in a globalising world. Integr. Assess. Stud. 2002, 1, 135. [Google Scholar] [CrossRef]
- Hernandez-Ochoa, I.M.; Asseng, S. Cropping systems and climate change in humid subtropical environments. Agronomy 2018, 8, 19. [Google Scholar] [CrossRef]
- Pathak, T.B.; Maskey, M.L.; Dahlberg, J.A.; Kearns, F.; Bali, K.M.; Zaccaria, D. Climate change trends and impacts on California agriculture: A detailed review. Agronomy 2018, 8, 25. [Google Scholar] [CrossRef]
- Úbeda, X.; Alcañiz, M.; Borges, G.; Outeiro, L.; Francos, M. Soil Quality of abandoned agricultural terraces managed with prescribed fires and livestock in the municipality of Capafonts, Catalonia, Spain (2000–2017). Agronomy 2019, 9, 340. [Google Scholar] [CrossRef]
- Sahami, M. Learning limited dependence Bayesian classifiers. In Proceedings of the Second International Conference on Knowledge Discovery in Databases, Portland, OR, USA, 2–4 August 1996; pp. 335–338. [Google Scholar]





| Grid Cell | P() | P() | P() | Max. Prob. | |
|---|---|---|---|---|---|
| 1 | 0.5 | 0.25 | 0.25 | 1 | Boundary |
| 2 | 0.05 | 0.13 | 0.82 | 3 | 3 |
| ... | ... | ... | ... | ... | ... |
| 2306 | 0.71 | 0.18 | 0.11 | 1 | Boundary |
| Variable | Sector 1 | Sector 2 | Sector 3 | Sector 4 | Sector 5 | Sector 6 |
|---|---|---|---|---|---|---|
| IPC | −0.2 | −0.04 | 0.37 | −0.25 | 2.05 | −0.69 |
| Primary SE | 0.05 | −0.09 | 0.34 | 0.21 | −0.77 | −0.16 |
| Aging | 0.14 | −0.33 | 0.09 | 0.21 | −1.57 | 0.62 |
| No studies | −0.38 | 0.27 | −0.04 | −0.21 | −0.96 | 0.7 |
| Emigration | 0.05 | −0.2 | −0.1 | −0.28 | 0.14 | 0.6 |
| Forest | −0.47 | −0.43 | −0.08 | 0.93 | −0.24 | −0.29 |
| Homogeneous crops | 1.45 | 0.33 | −0.44 | −0.44 | −0.04 | −0.37 |
| Heterogeneous crops | 0.41 | 0.18 | −0.29 | −0.16 | −0.23 | 0.06 |
| Annual temperature | 0.06 | 1.01 | −0.41 | −1.17 | 1.37 | 0.11 |
| Annual rainfall | 0.18 | −0.68 | 0.36 | 0.94 | −1.21 | −0.37 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ropero, R.F.; Maldonado, A.D.; Uusitalo, L.; Salmerón, A.; Rumí, R.; Aguilera, P.A. A Soft Clustering Approach to Detect Socio-Ecological Landscape Boundaries Using Bayesian Networks. Agronomy 2021, 11, 740. https://doi.org/10.3390/agronomy11040740
Ropero RF, Maldonado AD, Uusitalo L, Salmerón A, Rumí R, Aguilera PA. A Soft Clustering Approach to Detect Socio-Ecological Landscape Boundaries Using Bayesian Networks. Agronomy. 2021; 11(4):740. https://doi.org/10.3390/agronomy11040740
Chicago/Turabian StyleRopero, Rosa F., Ana D. Maldonado, Laura Uusitalo, Antonio Salmerón, Rafael Rumí, and Pedro A. Aguilera. 2021. "A Soft Clustering Approach to Detect Socio-Ecological Landscape Boundaries Using Bayesian Networks" Agronomy 11, no. 4: 740. https://doi.org/10.3390/agronomy11040740
APA StyleRopero, R. F., Maldonado, A. D., Uusitalo, L., Salmerón, A., Rumí, R., & Aguilera, P. A. (2021). A Soft Clustering Approach to Detect Socio-Ecological Landscape Boundaries Using Bayesian Networks. Agronomy, 11(4), 740. https://doi.org/10.3390/agronomy11040740