Once the variables to be included in the average price for the season calculation had been determined (field prices published by the Regions, the Ministry, and the Exchanges, respectively), the next step was to decide on the relative importance or weighting assigned to these variables in the calculation formula for this price, which come from a source of information about citrus fruit field prices.
3.1.1. Structural Equation Modeling (SEM)
Firstly, structural equation modeling (SEM) was used, a method based on multivariate analysis (regression and path-analysis techniques), which allows the estimation of multiple and cross-referenced dependency relationships between observable and non-observable variables or latent variables [
29]. This technique is highly confirmatory, which means that the variables making up the proposed model have to be defined beforehand based on the research theory. The process includes two key stages: validating the measurement model and fitting the structural model [
30]. The former is achieved mainly through analysis of paths with latent variables. SEM is based on causal relationships that explain how changes in exogenous variables (ones that affect other variables but are not affected by any others) result in changes in endogenous variables (the ones the model seeks to explain and are determined by other variables). Causality between variables can be asserted through theoretical determination.
The best-known statistical procedure for investigating relations between sets of observed and latent variables is that of factor analysis [
31]. In using this, the researcher examines the covariation among a set of observed variables in order to gather information on their underlying latent constructs (factors). There are two basic types of factor analyses: exploratory factor analysis (EFA) and confirmatory factor analysis (CFA). EFA is designed for the situation where links between the observed and latent variables are unknown or uncertain. In contrast, CFA is used when the researcher has some knowledge of the underlying latent variable structure and he or she is interested in explaining the correlations in a data set as a result of a few underlying factors [
32]. The factor analytic model focuses solely on how, and the extent to which, the observed variables are linked to their underlying latent factors. Because the CFA model focuses solely on the link between factors and their measured variables, within the framework of SEM, it represents what has been termed a measurement model.
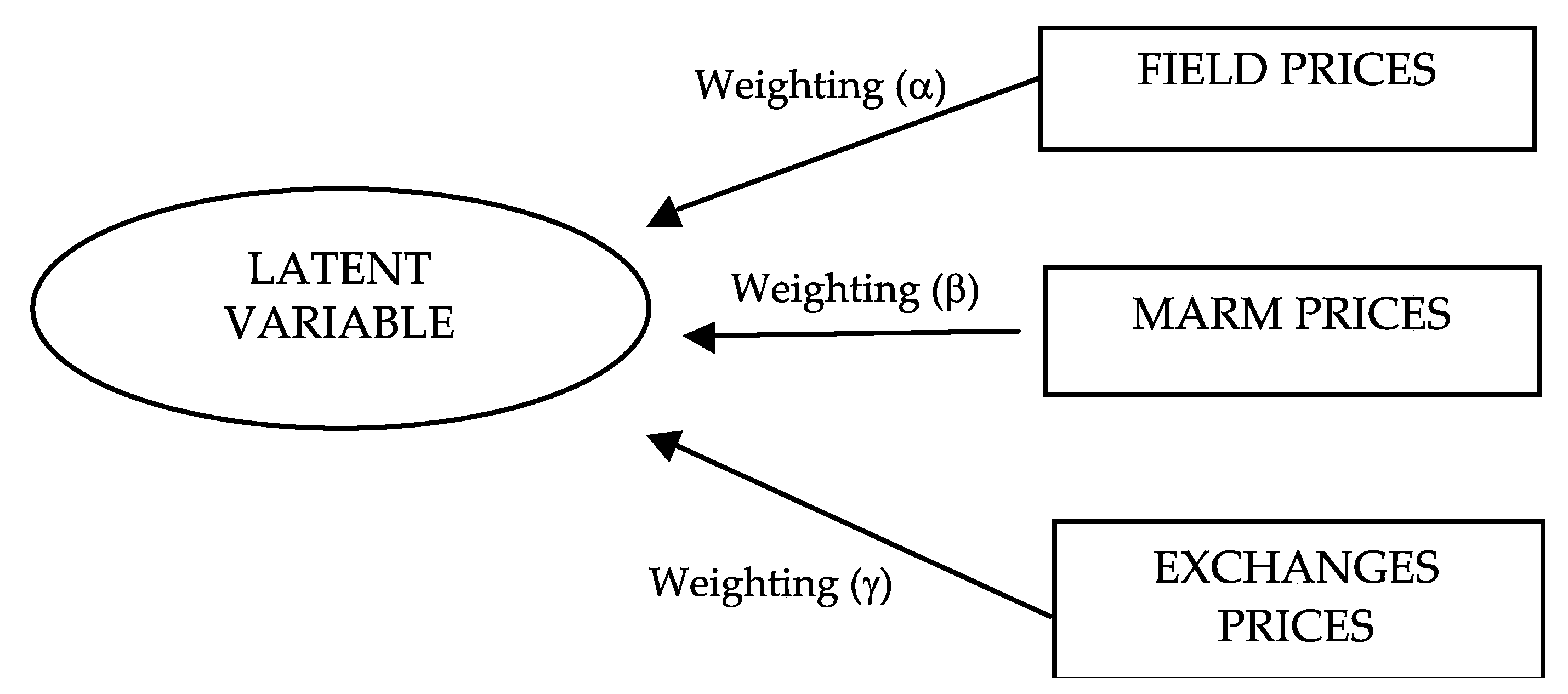
Our factor analysis sought to determine the underlying relationship between three series of data (FIELD prices, MARM prices, and prices in EXCHANGES) in order to establish a criterion for determining the weightings of each of the three sources used (coefficients
α,
β, and
γ in Equation (2)). The model can be represented in a diagram as shown in
Figure 2, where the rectangles signify the observed data (each of the three sources used in Equation (2)) and the oval stands for the unobserved data (latent variable). In short, it involved making a regression adjustment where the results obtained were expressed as a percentage in order to be able to make comparisons. AMOS software from SPSS was used.
The main problem for citrus fruit price data when using the above methodology was the non-independence of observations since the value of a datum in one week influenced the value for the following period. Thus, if the quotations (prices) of a variety in one week were 0.23 euro/kilo, the following datum was highly unlikely to have a value of 0.98 euro/kilo since it would be in the vicinity of its predecessor.
However, there was also a second problem due to the fact that the information available was extremely fragmented. In order to be able to use a weekly datum in the analysis, the three values from the three sources of information had to be present in the same week. Since in the case of the Exchange, there are only data from the last two years, the initial series that could be used in this price estimation analysis was restricted to that time period.
Finally, there were a total of 302 useful pieces of data for oranges and 180 useful pieces of data for mandarins out of all the data available. Each of these data thus indicated the value of the quotation for a season, a variety, and a date; hence, their individual analysis led to multiple weighting indexes for each variety depending on the season or period considered. To avoid this, global analyses were carried out for the various varieties on the assumption that all the data for the variety constitute a sample of the quotations for that variety in the seasons available. The results obtained for the data samples of oranges, mandarins, and joint sample (oranges and mandarins) are shown in
Table 5.
The results derived for the oranges sample show a weighting of 42.2% for Regional Ministry prices and 25% for MARM and Exchanges. This is a good fit for each of the variables considered (the sources of information) since the values of the R2 coefficients are very close to one. However, its overall quality is poor, as the RMSA index (the root mean square error approximation index is an estimator of the discrepancies of the data in the population corrected by the degrees of freedom and is the most frequently used global goodness of fit estimator) is always well above 0.08, which is considered to be the highest acceptable value. This poor quality is what means that the sum of the weights for the three variables is not always one. The paucity of data available for the individual variety groups makes it advisable to perform the analysis only on an aggregate basis (oranges, mandarins, and a joint sample of oranges and mandarins), as it is recommended that there be at least 50 observations in order to be able to assume the normality hypothesis in the data.
The results obtained with the aggregated data for mandarins show once again the relevance of Regional Ministry prices with a weight of 62%, a 15% weighting for the Exchanges, and 8% for the MARM. As was the case in the analysis of oranges, the partial fits are good, but as the RMSA index is higher than 0.08, it must be held that the global model lacks the requisite quality, which is why the sum of the weights for the three sources of information is not always one.
The analysis performed with all the data on oranges and mandarins (joint sample), for which 482 useful data are available, reveals once again the relevance of the Regional Ministries as a source of price data with a 51% weight followed by the Exchange prices weighted at 26% and finally the MARM with a weight of 18%.
In order to examine the impact of the data on the results, an analysis was conducted for the Clemenules variety (mandarin) comparing the results of the 74 available pieces of data with the ones in the first 27 of the series (
Table 6). In the former case, the Regional Ministries obtained a weighting of 54% and the Exchanges 31%, while in the latter case the Exchanges had a weighting of around 44% and the Regional Ministries’ relative weight fell to 37%. Consequently, we believe that the results of the weightings of the three sources are very sensitive to the data used.
When this analysis was performed again for the Navelina data (orange) by comparing the weights resulting from considering all the available data and some of them, for example the first 50, the results repeated the previous pattern (
Table 6). Thus, the weightings found were substantially different from the initial ones in that the relative weight of the Regional Ministries increased from 0.46 to 0.74 with the importance of the other two information sources at around 12%. The above two results thus indicate great sensitivity of the possible weightings to the quality of the data used.
Accordingly, and given the enormous dispersion found for the possible weightings of the sources used both between varieties and within the same variety depending on the data employed, it was decided to add another methodology to the above analysis via a consultation of experts to determine the weightings they attributed to each of the three sources of information being employed (coefficients α, β, and γ).
3.1.2. The Analytic Hierarchy Process (AHP)
Given the above results featuring poor overall quality models, multi-criteria tools were used involving subjective techniques of consultation with experts. In cases where the information is unreliable, insufficient, or simply does not exist, the use of subjective information constitutes an important advance in scientific knowledge. Qualitative methodologies could be a highly efficient resource for obtaining the information necessary for a quantitative economic model. This information proceeds from the knowledge and experience that tacitly resides in the judgement of individual experts. The analytic hierarchy process (AHP) [
33] is a decision-making method using pairwise comparisons and relies on the judgement of experts to derive priority scales or preferences. It is these scales that measure intangibles in relative terms. The comparisons are made using a scale of absolute judgements, and this scale represents how much more one element dominates another with respect to a given attribute. It is currently one of the most widely used methods for making choices between alternatives and consists of comparing each one in pairs, indicating preferences on a verbal scale. In short, the AHP provides a reference framework to structure a decision problem, represent and quantify its elements, relate these elements to general objectives, and evaluate alternative solutions.
Saaty [
34] argued that, to make a decision in an organized way and generate priorities, we need to decompose the decision into the following steps:
Define the problem and determine the kind of knowledge sought.
Structure the hierarchy map. At the top of this map is the decision problem or general objective, at the intermediate level the criteria, and at the lowest level the decision alternatives or options.
Construct the pairwise comparison matrix. In this matrix, each element in an upper level is used to compare the elements in the level immediately below it. The elements in each level are evaluated by means of pairwise comparison using a measurement scale from 1 to 9 as shown in
Figure 3, which also indicates the numerical correspondence of the verbally expressed preference.
The outcome of these comparisons is a square, reciprocal, and positive matrix called a pairwise comparison matrix, in which each component reflects the intensity of preferences compared to other aspects of the objective under consideration, i.e., the priorities between the different elements compared. In our case, the three elements considered were the three sources of price information (Regional Ministries, MARM, and Exchanges), and the aim was to quantify their level of importance on a scale of 100 points. Therefore, the matrix [3 × 3] reflects the preferences that the experts expressed using the Saaty scale. This matrix has two special features. Firstly, it has ones on the main diagonal because an element must be equally preferred to itself. Secondly, the elements of this matrix meet the condition that aij = 1/aji. In practice, and given the scale used to construct the expert pairwise preference matrix, it is only useful to learn which preference values are greater than one, since the symmetrical value in the matrix will be subtracted from this first value.
The relative weight is then calculated for each element. To do this, each column is added up, and the reciprocal of the total is obtained.
- 4.
Build the standardized matrix and calculate the priority vector. To do this, an auxiliary matrix is produced in which each cell is completed with the result of the total reciprocal for the value judgement. Adding each row gives the standardized total for each element. The main priorities vector is then derived from the average of the values of the standardized columns. Finally, the result is synthesized from the relative contribution of each alternative to each criterion and the relative level of preference is attributed to them in order to reach the decision problem or general goal.
The research process begins by asking the experts consulted to express their preference for one of the options for each pair analyzed and then asking them to evaluate this importance on the verbal scale shown (
Figure 3), which will eventually become numerical. In this specific case, the results obtained derived from consultation with five experts or specialists in the field: three professionals from the citrus fruit industry, one from academia, and another from government.
When methodologies involving several experts are used to determine priorities among various alternatives, as is the case here, there are two possibilities for accomplishing this. The first is to use a single matrix developed as a result of consensus among the experts. The second is to work out the Saaty matrix and the weights associated with it for each of them to finally derive a single solution from the previous values of the individual weights and which usually consists of using the arithmetic mean or the geometric mean of the values of the weights obtained for each decision-maker. Saaty recommends the geometric mean, which tends to attenuate the extreme values of the weights obtained for different experts. However, in this case, the former option was chosen.
The procedure described yielded the results shown in
Table 7, derived from the consensus reached among the experts.
The above results were then arranged in the pairwise comparison matrix shown in
Table 8, bearing in mind that the criterion chosen as most important was the row of the matrix.
The calculations to determine the weights or relative importance of each criterion are as follows. First, the columns of Saaty’s matrix are added up. A new [3 × 3] matrix is then built where each element is the initial one divided by the sum of its column. Finally, the mean value of each of the rows in this new matrix is the weight of the source. The results are shown in
Table 9.
As noted above, the calculation method originally proposed by Saaty consists of calculating the eigenvector of the pairwise comparison matrix and the eigenvalues associated with it. Given the particular structure of this matrix, there is only one eigenvector in the field of the real ones that corresponded to the weights or relative importance of the compared elements. The method used here was a simplification of the previous one, and its results matched the ones in the method proposed by Saaty when the CR (consistency ratio) value was not very large [
35].
In this case, the weighting of the three sources of information based on the preferences expressed by the experts consulted was as follows: 59.5% for information from the Regional Ministries, 34.7% for information from the MARM, and 5.8% for information from the Exchanges. This result may be a good basis for setting the weighting criteria of the different sources.
One aspect often examined in these preferences is the CR of expert estimates. In this case, the CR is 0.02, which is lower than the acceptable value of 0.10. Therefore, these comparisons were admitted as consistent and the simplified calculation method as being appropriate to the data. If the matrix does not achieve the appropriate CR, the initial data must be re-estimated until it is reached.
The above values are similar to and consistent with those found previously. Specifically, they are similar to the results for the mandarin data, where information from the Regional Ministries had a 62% weighting, and to the results for all useful data pertaining to both oranges and mandarins, where the Regional Ministries had a weight of 51%. In the case of the data for oranges, the weight assigned to the Regional Ministries stood at 43%, differing significantly from the figure now derived.
In addition, the values of the weights were calculated exactly following the method advocated by Saaty [
33]. In this case, the matrix used had a single solution for the eigenvalue in the real field (the other two solutions were in the imaginary field) and therefore a single eigenvector in the real field, whose values are [0.8623, 0.4996, 0.0827]. Thus, reconverting the previous values so that they added up to one, the values of the weightings were derived by means of the exact method and turned out to be (for Regional Ministries, MARM, and Exchanges, respectively) 0.5969, 0.3458, and 0.0573. Rounding off these values shows that the weight for the Regional Ministries would be 0.60, the weight for the MARM would be 0.35, and the weight for the Exchanges would be 0.05. These results are practically the same as those achieved previously using the approximate method.
Finally, it should be noted that, when the experts were subsequently asked for their opinion on the results previously obtained, they all agreed that they were consistent. When asked why, they mentioned two aspects: firstly, the importance of the Regional Ministries, which are in fact four independent sources and the basis of the MARM calculations; secondly, the low relative importance of the Price Exchanges as a source of information due to the fact that this source of prices has only recently been set up.
In short and according to the previous results, the weighting coefficient values of the sources of information used (coefficients
α,
β, and
γ) for all varieties are as shown in
Table 10.



{kind=link}
{kind=link}
{kind=link}


