Assessment of the Use of Geographically Weighted Regression for Analysis of Large On-Farm Experiments and Implications for Practical Application

 ,
,  ,
,
Abstract
1. Introduction
- is influenced by spatial auto-autocorrelation;
- is not due to the treatment being tested [34]; and
- is often much larger than the variation due to treatment effects.
2. Materials and Methods
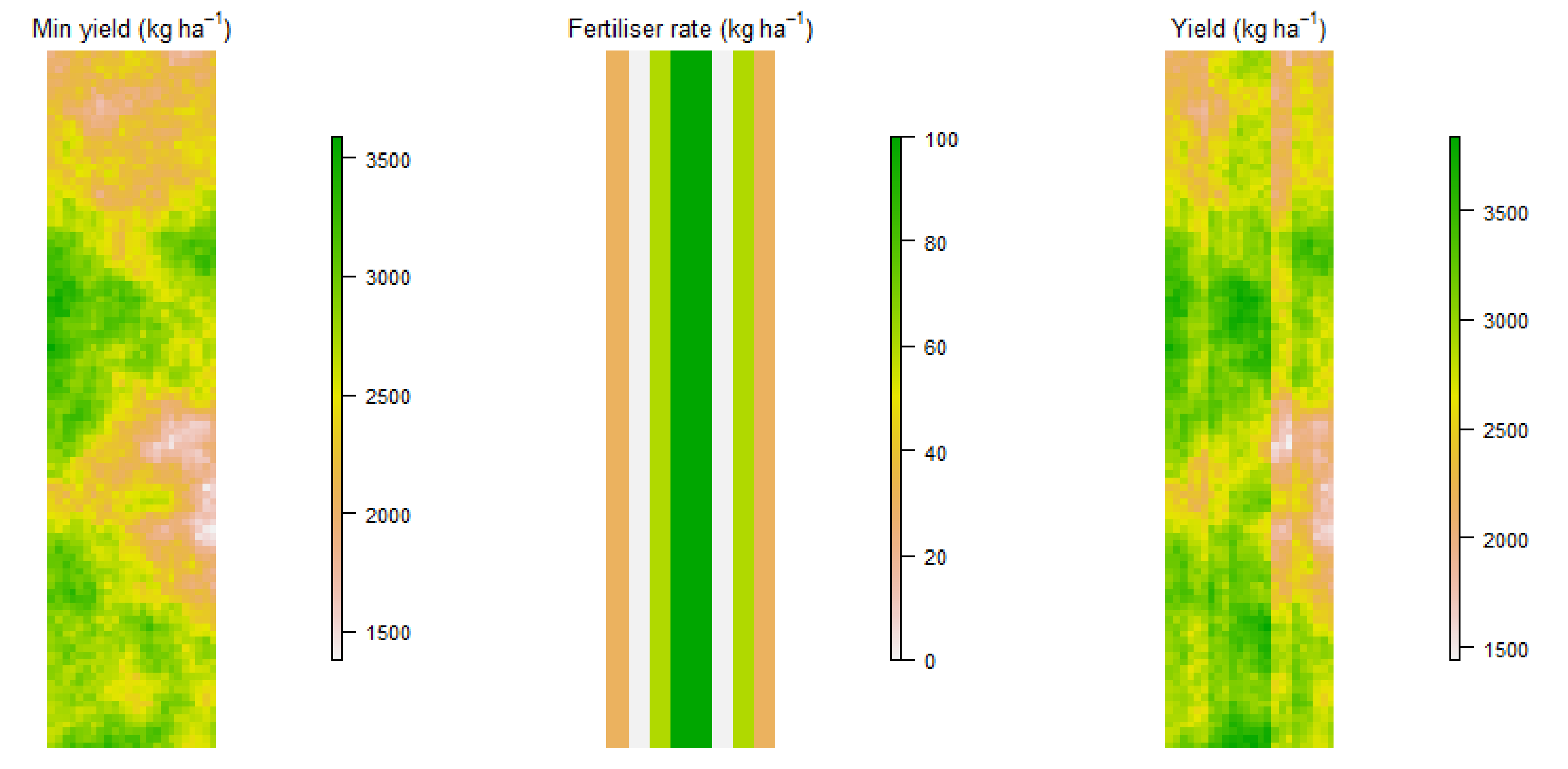
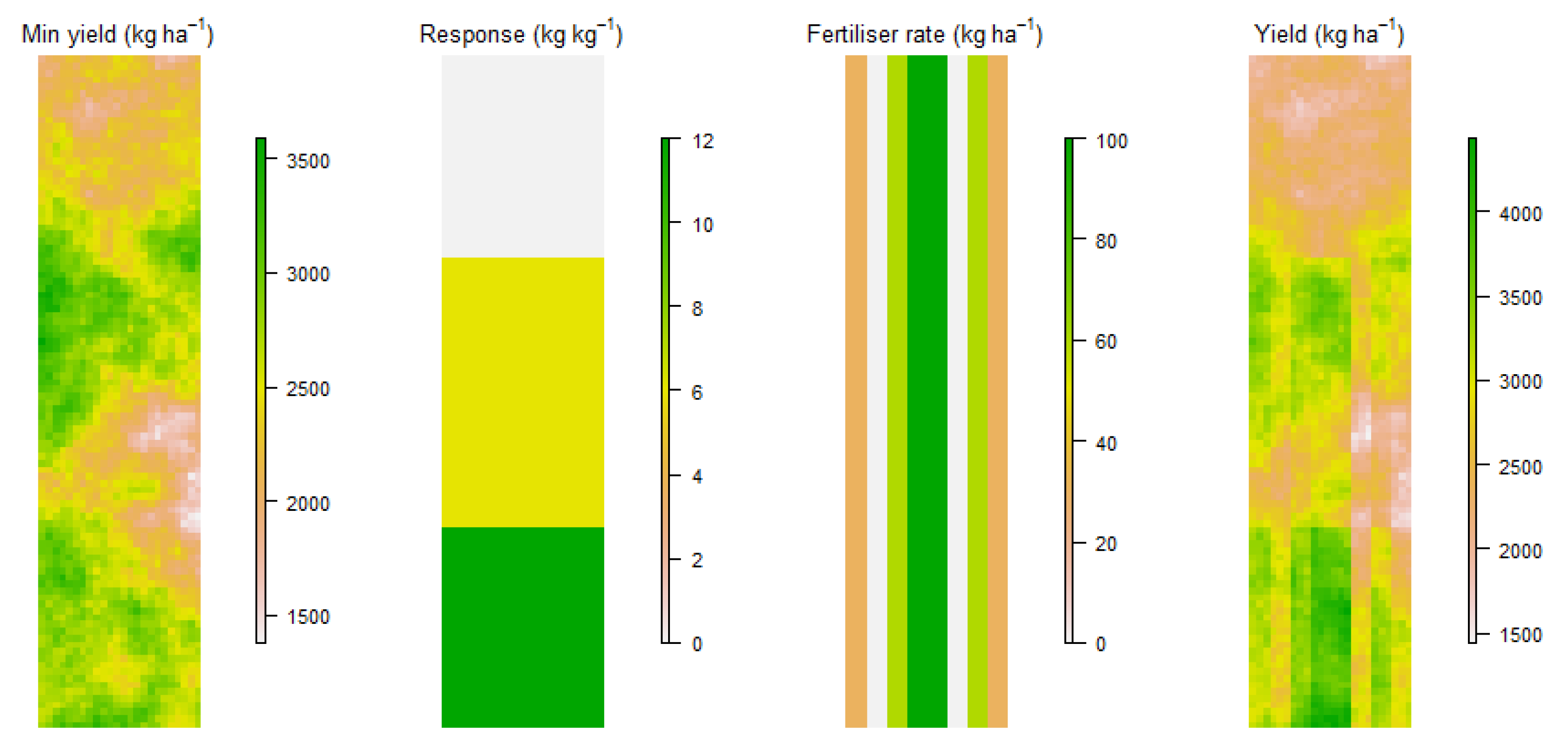
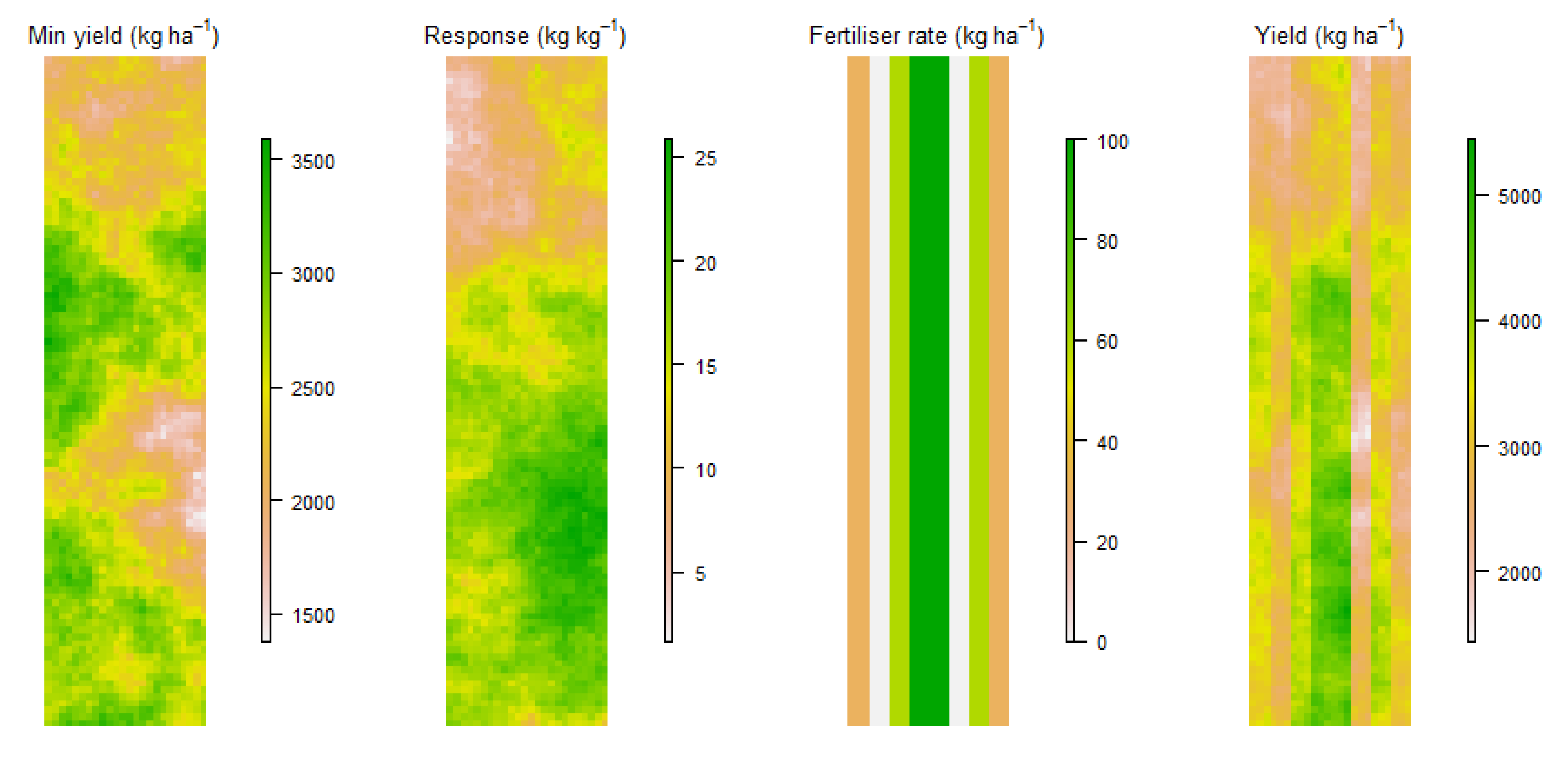
2.1. Simulated Data
- Global linear response to fertiliser
- Linear response to fertiliser that varies within spatial zones
- Locally varying linear response to fertiliser
2.1.1. Global Linear Response to Fertiliser
2.1.2. Linear Response to Fertiliser that Varies within Spatial Zones
2.1.3. Locally Varying Linear Response to Fertiliser
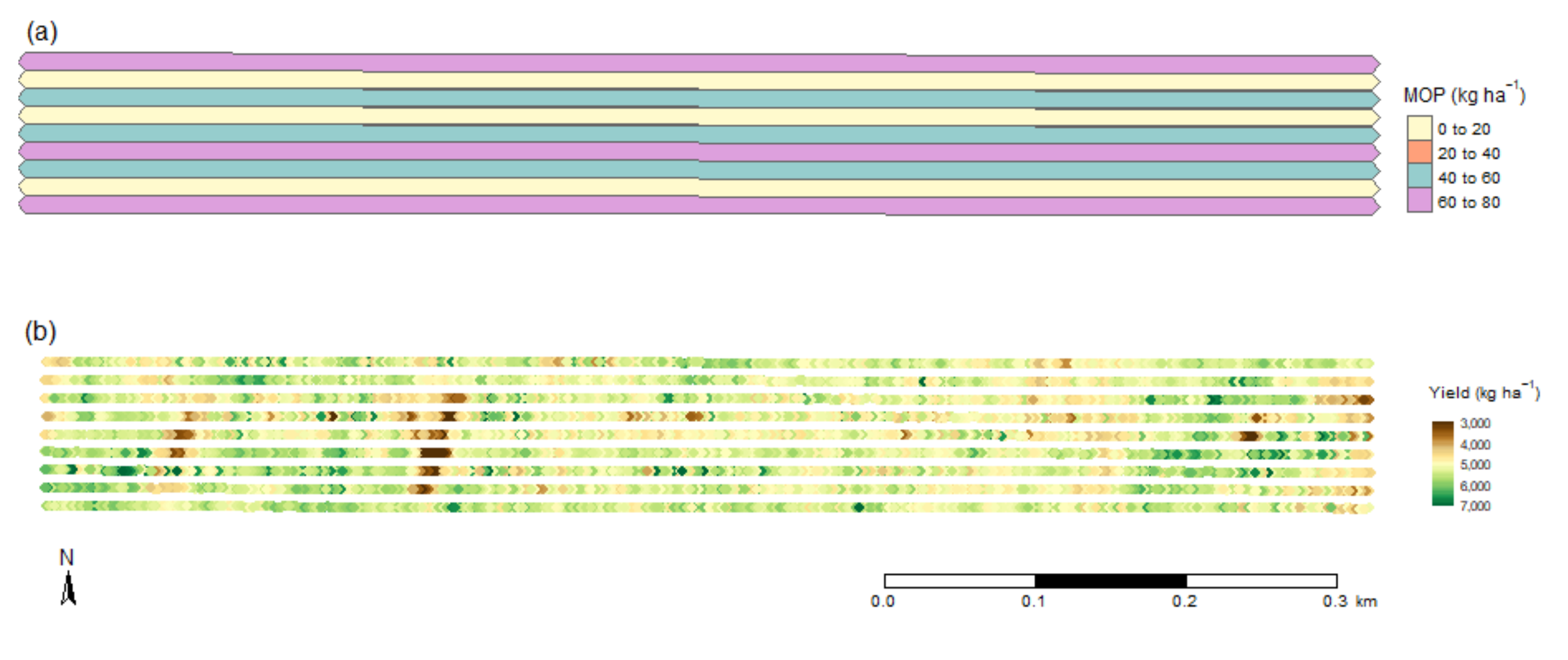
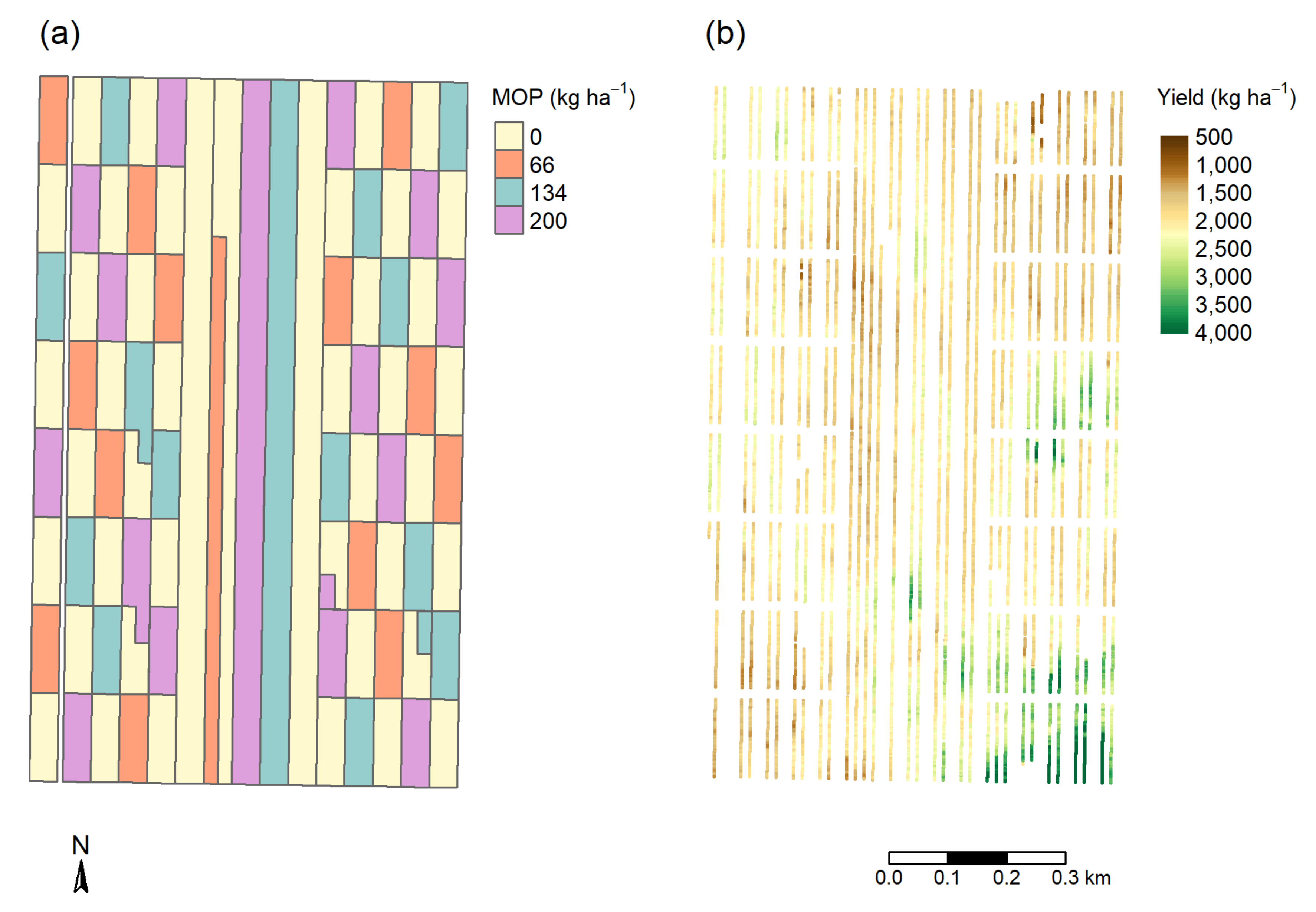
2.2. Potassium Trials
2.2.1. Cunderdin Trial
- Extreme high and low yields.
- Extreme high and low harvester speeds.
2.2.2. Narambeen Trial
2.3. Geographically Weighted Regression (GWR)
2.3.1. Basic GWR
2.3.2. Bandwidth Selection for GWR
2.3.3. Mixed GWR and Model Selection
- For each column of ,
- i.
- Regress the column against using basic GWR.
- ii.
- Compute the residual from the above regression.
- Regress y against using basic GWR.
- Compute the residual from the above regression.
- Regress the y residuals against the residuals using ordinary least squares regression to get .
- Regress against using basic GWR to get the spatially varying coefficients.
2.3.4. GWmodel R Package
3. Results
3.1. Simulated Data
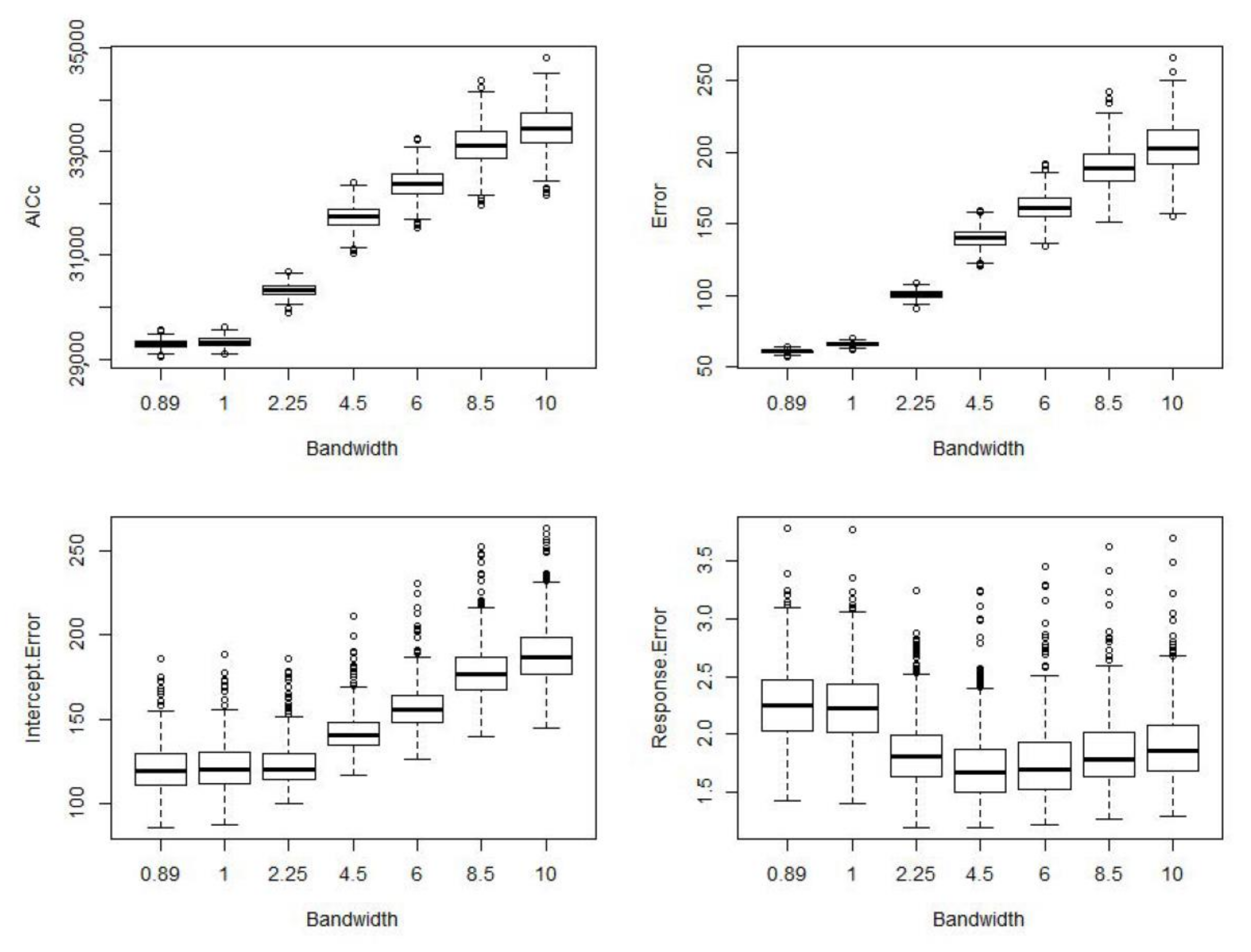
3.1.1. Bandwidth Selection
Summary of Bandwidth Selection Results and Recommended Approach to Bandwidth Selection for OFE
3.1.2. Model Selection
Summary of Model Selection Results and Recommended Approach to Model Selection for OFE
- Calculate the bandwidth that minimises AICc.
- Fit a mixed GWR that allows only the intercept to vary spatially.
- Fit a basic GWR that allows both the intercept and yield response to treatment to vary spatially.
- Select the model from 2 and 3 that has the lowest AICc.
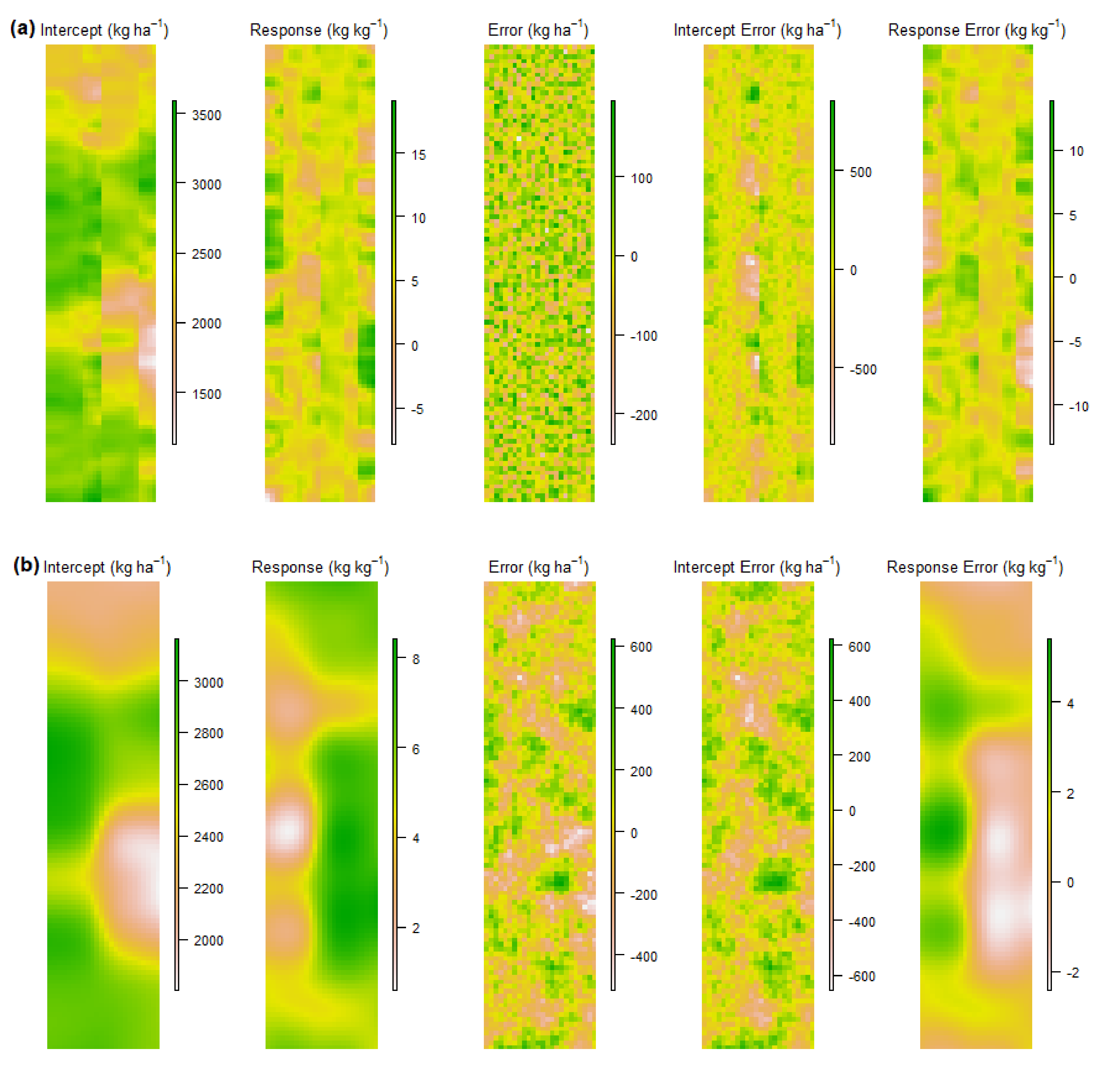
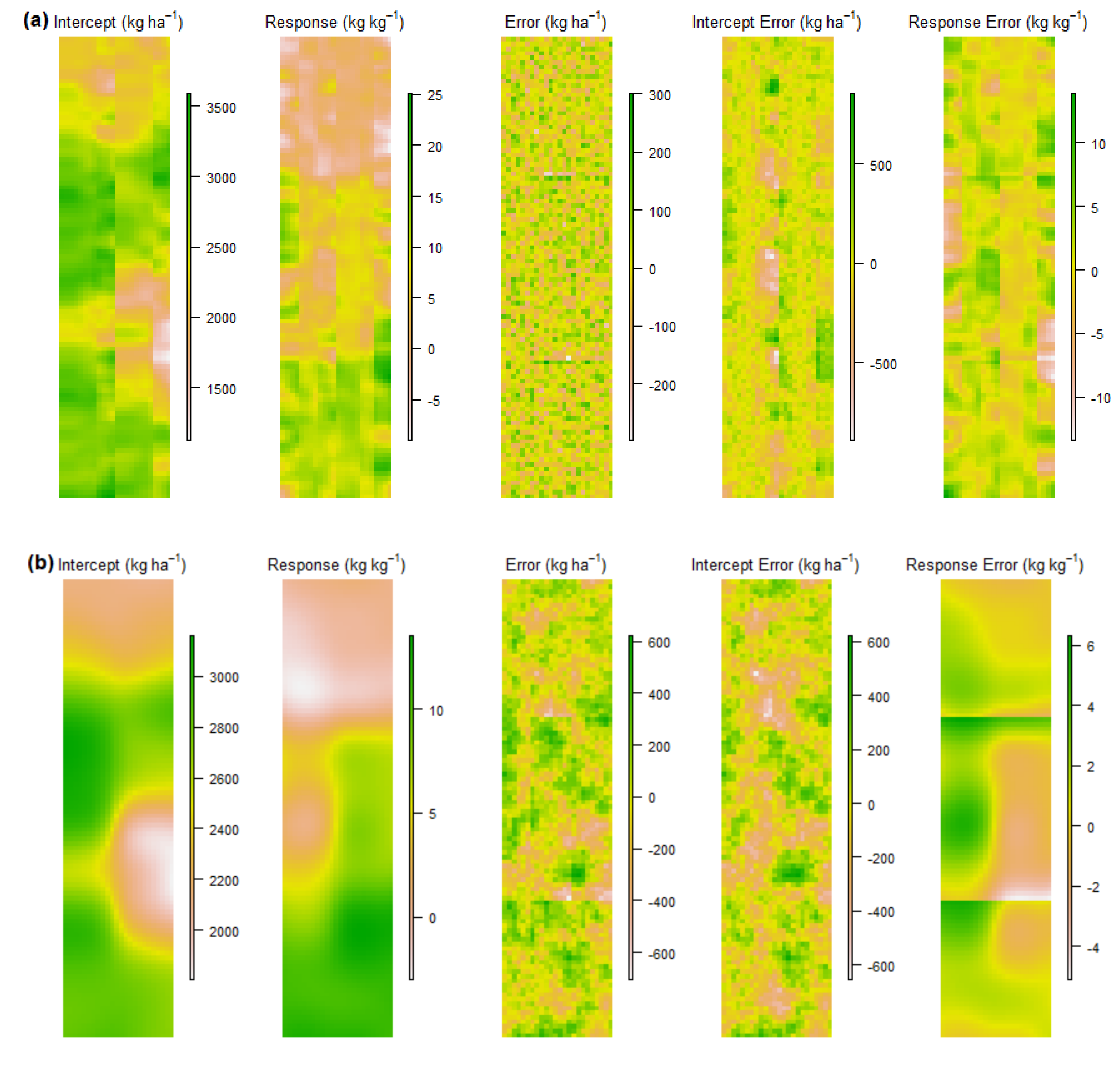
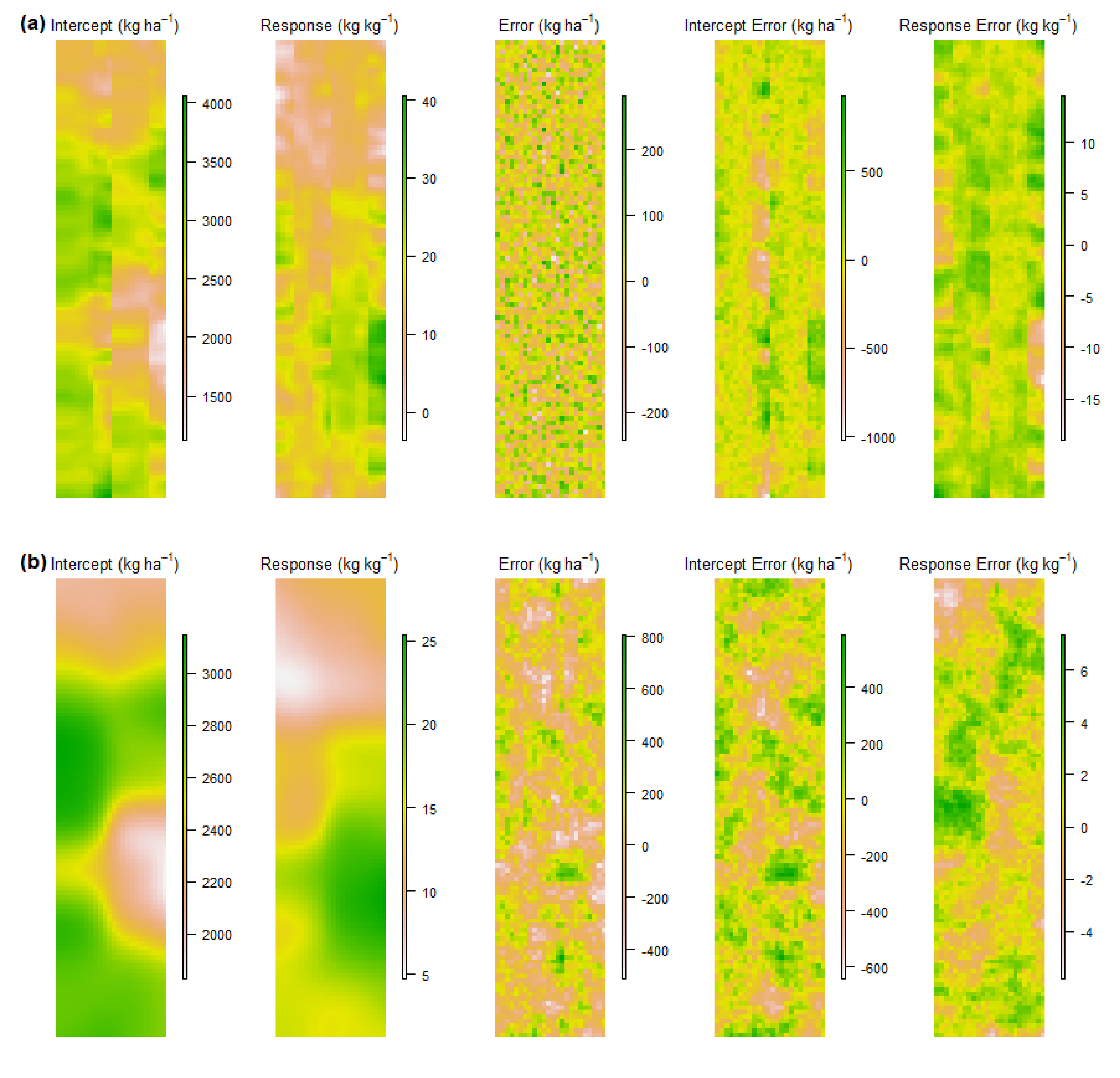
3.2. Potassium Trials
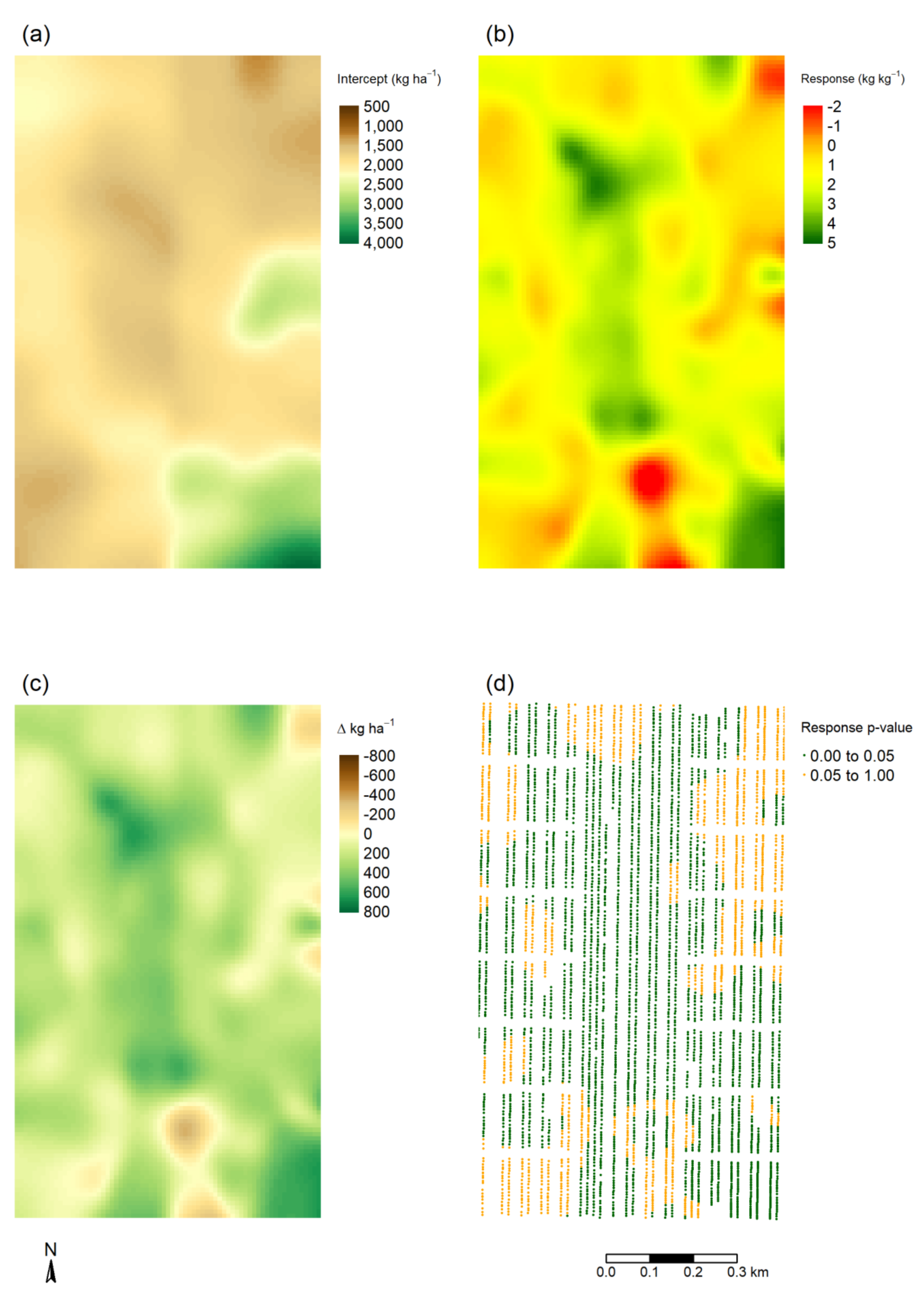
3.2.1. Cunderdin Trial
3.2.2. Narambeen Trial
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Robert, P.C. Precision agriculture: A challenge for crop nutrition management. Plant Soil 2002, 247, 143–149. [Google Scholar] [CrossRef]
- International Society of Precision Agriculture. Available online: https://www.ispag.org/ (accessed on 1 June 2019).
- Cook, S.E.; Bramley, R.G.V. Precision agriculture-opportunities, benefits and pitfalls of site-specific crop management in Australia. Aust. J. Exp. Agric. 1998, 38, 753–763. [Google Scholar] [CrossRef]
- Robertson, M.J.; Llewellyn, R.S.; Mandel, R.; Lawes, R.; Bramley, R.G.V.; Swift, L.; Metz, N.; O’Callaghan, C. Adoption of variable rate fertiliser application in the Australian grains industry: Status, issues and prospects. Precis. Agric. 2011, 13, 181–199. [Google Scholar] [CrossRef]
- McBratney, A.B.; Whelan, B.; Ancev, T.; Bouma, J. Future directions of precision agriculture. Precis. Agric. 2005, 6, 7–23. [Google Scholar] [CrossRef]
- Bramley, R.G.V.; Ouzman, J. Farmer attitudes to the use of sensors and automation in fertilizer decision-making: Nitrogen fertilization in the Australian grains sector. Precis. Agric. 2019, 20, 157–175. [Google Scholar] [CrossRef]
- Cock, J.; Oberthür, T.; Isaacs, C.; Läderach, P.R.; Palma, A.; Carbonell, J.; Victoria, J.; Watts, G.; Amaya, A.; Collet, L.; et al. Crop management based on field observations: Case studies in sugarcane and coffee. Agric. Syst. 2011, 104, 755–769. [Google Scholar] [CrossRef]
- Jimenez, D.; Dorado, H.; Cock, J.; Prager, S.D.; Delerce, S.; Grillon, A.; Andrade Bejarano, M.; Benavides, H.; Jarvis, A. From observation to information: Data-driven understanding of on farm yield variation. PLoS ONE 2016, 11, e0150015. [Google Scholar] [CrossRef]
- Lamb, D.W.; Frazier, P.; Adams, P. Improving pathways to adoption: Putting the right P’s in precision agriculture. Comput. Electron. Agric. 2008, 61, 4–9. [Google Scholar] [CrossRef]
- Pannell, D.J.; Marshall, G.R.; Barr, N.; Curtin, A.; Vanclay, F.; Wilkinson, R. Understanding and promoting adoption of conservation practices by rural landholders. Aust. J. Exp. Agric. 2006, 46, 1407–1424. [Google Scholar] [CrossRef]
- Kutter, T.; Tiemann, S.; Siebert, R.; Fountas, S. The role of communication and co-operation in the adoption of precision farming. Precis. Agric. 2009, 12, 2–17. [Google Scholar] [CrossRef]
- Paustian, M.; Theuvsen, L. Adoption of precision agriculture technologies by German crop farmers. Precis. Agric. 2016, 18, 701–716. [Google Scholar] [CrossRef]
- Pierpaoli, E.; Carli, G.; Pignatti, E.; Canavari, M. Drivers of precision agriculture technologies adoption: A literature review. Procedia Technol. 2013, 8, 61–69. [Google Scholar] [CrossRef]
- Cook, S.; Cock, J.; Oberthür, T.; Fisher, M. On-farm experimentation. Better Crops 2013, 4, 17–20. [Google Scholar]
- Cook, S.; Lacoste, M.; Evans, F.; Ridout, M.; Gibberd, M.; Oberthür, T. An on-farm experimental philosophy for farmer-centric digital innovation. In Proceedings of the 14th International Conference on Precision Agriculture, Montreal, QC, Canada, 24–27 June 2018. [Google Scholar]
- Sylvester-Bradley, R.; Kindred, D.R.; Marchant, B.; Rudolph, S.; Roques, S.; Calatayud, A.; Clarke, S.; Gillingham, V. Agronōmics: Transforming crop science through digital technologies. Adv. Anim. Biosci. 2017, 8, 728–733. [Google Scholar] [CrossRef]
- Kyveryga, P.M. On-farm research: Experimental approaches, analytical frameworks, case studies, and impact. Agron. J. 2019, 111, 2633–2635. [Google Scholar] [CrossRef]
- Bullock, D.S.; Boerngen, M.; Tao, H.; Maxwell, B.; Luck, J.D.; Shiratsuchi, L.; Puntel, L.; Martin, N.F. The data-intensive farm management project: Changing agronomic research through on-farm precision experimentation. Agron. J. 2019, 111, 2736–2746. [Google Scholar] [CrossRef]
- Schmidt, P.; Möhring, J.; Koch, R.J.; Piepho, H.P. More, larger, simpler: How comparable are on-farm and on-station trials for cultivar evaluation? Crop Sci. 2018, 58, 1508–1518. [Google Scholar] [CrossRef]
- Marchant, B.; Rudolph, S.; Roques, S.; Kindred, D.; Gillingham, V.; Welham, S.; Coleman, C.; Sylvester-Bradley, R. Establishing the precision and robustness of farmers’ crop experiments. Field Crops Res. 2019, 230, 31–45. [Google Scholar] [CrossRef]
- Cook, S.E.; Adams, M.L.; Corner, R.J. On-farm experimentation to determine site-specific responses to variable inputs. In Proceedings of the 4th International Conference on Precision Agriculture, Minneapolis, MN, USA, 19–22 July 1998; pp. 611–621. [Google Scholar]
- Lawes, R.A.; Bramley, R.G.V. A simple method for the analysis of on-farm strip trials. Agron. J. 2012, 104, 371–377. [Google Scholar] [CrossRef]
- Hall, D.; Galloway, P.; Lemon, J.; Curtis, B.; van Burgel, A.; Kong, K. The Agronomy Jigsaw: Finding the Pieces That Maximise Water Use Efficiency; Department of Agriculture and Food, Government of Western Australia (DAFWA): Kensington, Australia, 2014. [Google Scholar]
- Sela, S.; van Es, H.M.; Moebius-Clune, B.N.; Marjerison, R.; Melkonian, J.; Moebius-Clune, D.; Schindelbeck, R.; Gomes, S. Adapt-N outperforms grower-selected nitrogen rates in northeast and midwestern United States strip trials. Agron. J. 2016, 108, 1726–1734. [Google Scholar] [CrossRef]
- Whelan, B.M.; Taylor, J.A.; McBratney, A.B. A ‘small strip’ approach to empirically determining management class yield response functions and calculating the potential financial ‘net wastage’ associated with whole-field uniform-rate fertiliser application. Field Crops Res. 2012, 139, 47–56. [Google Scholar] [CrossRef]
- Bramley, R.; Cook, S.; Adams, M.; Corner, R. Designing Your Own on-Farm Experiments; Grains Research and Development Corporation: Canberra, Australia, 1999. [Google Scholar]
- Doerge, T.A.; Gardner, D.L. On-farm testing using the adjacent strip comparison method. In Proceedings of the 4th International Conference on Precision Agriculture, Minneapolis, MN, USA, 19–22 July 1998; pp. 603–609. [Google Scholar]
- Schwenke, G.; Beange, L.; Cameron, J.; Bell, M.; Harden, S.; Aitkenhead, M. What soil information do crop advisors use to develop nitrogen fertilizer recommendations for grain growers in New South Wales, Australia? Soil Use Manag. 2019, 35, 85–93. [Google Scholar] [CrossRef]
- Adams, M.L.; Cook, S.E. Methods of on-farm experimentation. In Proceedings of the ASAE Annual International Meeting, Minneapolis, MN, USA, 10–14 August 1997. [Google Scholar]
- Kindred, D.; Sylvester-Bradley, R.; Clarke, S.; Roques, S.; Smillie, I.; Berry, P. Agronōmics—An arena for synergy between the science and practice of crop production. In Proceedings of the 12th European IFSA Symposium, Harper Adams University, New Port, UK, 12–16 July 2016. [Google Scholar]
- Fisher, R.A. The arrangement of field experiments. J. Minist. Agric. Great Br. 1926, 33, 503–513. [Google Scholar]
- Oehlert, G.W. A First Course in the Design and Analysis of Experiments; University of Minnesota Digital Conservancy: Minneapolis, MN, USA, 2010. [Google Scholar]
- Kravchenko, A.N.; Snapp, S.S.; Robertson, G.P. Field-scale experiments reveal persistent yield gaps in low-input and organic cropping systems. Proc. Natl. Acad. Sci. USA 2017, 114, 926–931. [Google Scholar] [CrossRef]
- Piepho, H.-P.; Richter, C.; Spilke, J.; Hartung, K.; Kunick, A.; Thöle, H. Statistical aspects of on-farm experimentation. Crop Pasture Sci. 2011, 62, 721–735. [Google Scholar] [CrossRef]
- Tobler, W.R. A computer movie simulating urban growth in the Detroit region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Gilmour, A.R.; Cullis, B.R.; Verbyla, A.P. Accounting for natural and extraneous variation in the analysis of field experiments. J. Agric. Biol. Environ. Stat. 1997, 2, 269. [Google Scholar] [CrossRef]
- Piepho, H.-P.; Williams, E.R.; Michel, V. Beyond Latin squares: A brief tour of row-column designs. Agron. J. 2015, 107, 2263–2270. [Google Scholar] [CrossRef]
- Van Frank, G.; Goldringer, I.; Rivière, P.; David, O. Influence of experimental design on decentralized, on-farm evaluation of populations: A simulation study. Euphytica 2019, 215, 126. [Google Scholar] [CrossRef]
- Anselin, L.; Bogiovanni, R.; Lowenberg-deBoer, J. A spatial econometric approach to the economics of site-specific nitrogen management in corn production. Am. J. Agric. Econ. 2004, 86, 675–687. [Google Scholar] [CrossRef]
- Lambert, D.M.; Lowenberg-Deboer, J.; Bongiovanni, R. A comparison of four spatial regression models for yield monitor data: A case study from Argentina. Precis. Agric. 2004, 5, 579–600. [Google Scholar] [CrossRef]
- Griffin, T.W.; Dobbins, C.L.; Vyn, T.J.; Florax, R.J.G.M.; Lowenberg-DeBoer, J.M. Spatial analysis of yield monitor data: Case studies of on-farm trials and farm management decision making. Precis. Agric. 2008, 9, 269–283. [Google Scholar] [CrossRef]
- Jiang, P.; He, Z.; Kitchen, N.R.; Sudduth, K.A. Bayesian analysis of within-field variability of corn yield using a spatial hierarchical model. Precis. Agric. 2008, 10, 111–127. [Google Scholar] [CrossRef]
- Lark, R.M.; Wheeler, H.C. A method to investigate within-field variation of the response of combinable crops to an input. Agron. J. 2003, 95, 1093–1104. [Google Scholar] [CrossRef]
- Pringle, M.J.; McBratney, A.B.; Cook, S.E. Field-scale experiments for site-specific crop management. Part II: A geostatistical analysis. Precis. Agric. 2004, 5, 625–645. [Google Scholar] [CrossRef]
- Panten, K.; Bramley, R.G.V.; Lark, R.M.; Bishop, T.F.A. Enhancing the value of field experimentation through whole-of-block designs. Precis. Agric. 2010, 11, 198–213. [Google Scholar] [CrossRef]
- Bishop, T.F.A.; Lark, R.M. The geostatistical analysis of experiments at the landscape-scale. Geoderma 2006, 133, 87–106. [Google Scholar] [CrossRef]
- Rudolph, S.; Marchant, P.B.; Gillingham, V.; Kindred, D.; Sylvester-Bradley, R. Spatial discontinuity analysis, a novel geostatistical algorithm for on-farm experimentation. In Proceedings of the 13th International Conference on Precision Agriculture, Monticello, IL, USA, 31 July–3 August 2016. [Google Scholar]
- Rakshit, S.; Baddeley, A.; Stefanova, K.; Reeves, K.; Chen, K.; Cao, Z.; Evans, F.; Gibberd, M. Novel approach to the analysis of spatially-varying treatment effects in on-farm experiments. Field Crops Res. 2020, 255, 107783. [Google Scholar] [CrossRef]
- Trevisan, R.G.; Bullock, D.S.; Martin, N.F. Spatial variability of crop responses to agronomic inputs in on-farm precision experimentation. Precis. Agric. 2020, 1–22. [Google Scholar] [CrossRef]
- Brunsdon, C.; Fotheringham, S.; Charlton, M. Geographically weighted regression: A method for exploring spatial nonstationarity. Geogr. Anal. 1996, 28, 281–298. [Google Scholar] [CrossRef]
- Brunsdon, C.; Fotheringham, S.; Charlton, M. Geographically weighted regression—Modelling spatial non-stationarity. J. R. Stat. Soc. Ser. D (Stat.) 1998, 47, 431–443. [Google Scholar] [CrossRef]
- Fotheringham, S.; Brunsdon, C.; Charlton, M. Geographically Weighted Regression: The Analysis of Spatially Varying Relationships; Wiley: Hoboken, NJ, USA, 2002. [Google Scholar]
- Mitscherlich, E.A. Das gesetz des minimums und das Gesetz des abnehmenden Bodenertrages (Eng: The law of the minimum and the law of diminishing soil productivity). Landwirtsch. Jahrbücher 1909, 38, 537–552. [Google Scholar]
- Tembo, G.; Brorsen, B.W.; Epplin, F.M.; Tostão, E. Crop input response functions with stochastic plateaus. Am. J. Agric. Econ. 2008, 90, 424–434. [Google Scholar] [CrossRef]
- Bullock, D.G.; Bullock, D.S. Quadratic and quadratic-plus-plateau models for predicting optimal nitrogen rate of corn: A comparison. Agron. J. 1994, 86, 191–195. [Google Scholar] [CrossRef]
- Sylvester-Bradley, R.; Kindred, D.R.; Wynn, S.C.; Thorman, R.E.; Smith, K.E. Efficiencies of nitrogen fertilizers for winter cereal production, with implications for greenhouse gas intensities of grain. J. Agric. Sci. 2012, 152, 3–22. [Google Scholar] [CrossRef]
- Robertson, M.J.; Lyle, G.; Bowden, J.W. Within-field variability of wheat yield and economic implications for spatially variable nutrient management. Field Crop. Res. 2008, 105, 211–220. [Google Scholar] [CrossRef]
- Akaike, H. Information theory and an extension of the maximum likelihood principle. In Proceedings of the Second International Symposium on Information Theory, Tsahkadsor, Armenia, 2–8 September 1971; pp. 267–281. [Google Scholar]
- Brunsdon, C.; Fotheringham, S.; Charlton, M. Geographically Weighted Regression as a Statistical Model; Newcastle University: Newcastle, UK, 2000. [Google Scholar]
- Valavi, R.; Elith, J.; Lahoz-Monfort, J.J.; Guillera-Arroita, G.; Warton, D. blockCV: An R package for generating spatially or environmentally separated folds for k-fold cross-validation of species distribution models. Methods Ecol. Evol. 2018, 10, 225–232. [Google Scholar] [CrossRef]
- Brunsdon, C.; Fotheringham, A.S.; Charlton, M. Some notes on parametric significance tests for geographically weighted regression. J. Reg. Sci. 1999, 39, 497–524. [Google Scholar] [CrossRef]
- Mei, C.-L.; He, S.-Y.; Fang, K.-T. A note on the mixed geographically weighted regression model. J. Reg. Sci. 2004, 44, 143–157. [Google Scholar] [CrossRef]
- Gollini, I.; Lu, B.; Charlton, M.; Brunsdon, C.; Harris, P. GWmodel: An R package for exploring spatial heterogeneity using geographically weighted models. J. Stat. Softw. 2015, 63, 1–50. [Google Scholar] [CrossRef]
- Lu, B.; Harris, P.; Charlton, M.; Brunsdon, C. The GWmodel R package: Further topics for exploring spatial heterogeneity using geographically weighted models. Geo Spat. Inf. Sci. 2014, 17, 85–101. [Google Scholar] [CrossRef]
- Páez, A.; Uchida, T.; Miyamoto, K. A general framework for estimation and inference of geographically weighted regression models: 1. Location-specific kernel bandwidths and a test for locational heterogeneity. Environ. Plan. A 2002, 34, 733–754. [Google Scholar] [CrossRef]
- Da Silva, A.R.; Fotheringham, A.S. The multiple testing issue in geographically weighted regression. Geogr. Anal. 2016, 48, 233–247. [Google Scholar] [CrossRef]
- Stone, M. An asymptotic equivalence of choice of model by cross-validation and Akaike’s criterion. J. R. Stat. Soc. Ser. B 1977, 39, 44–47. [Google Scholar] [CrossRef]
- Leung, Y.; Mei, C.-L.; Zhang, W.-X. Statistical tests for spatial nonstationarity based on the geographically weighted regression model. Environ. Plan. A Econ. Space 2000, 32, 9–32. [Google Scholar] [CrossRef]
- Scanlan, C.A.; Bell, R.W.; Brennan, R.F. Simulating wheat growth response to potassium availability under field conditions in sandy soils. II. Effect of subsurface potassium on grain yield response to potassium fertiliser. Field Crops Res. 2015, 178, 125–134. [Google Scholar] [CrossRef]
- Guo, L.; Ma, Z.; Zhang, L. Comparison of bandwidth selection in application of geographically weighted regression: A case study. Can. J. For. Res. 2008, 38, 2526–2534. [Google Scholar] [CrossRef]
- Wong, M.T.F.; Corner, R.J.; Cook, S.E. A decision support system for mapping the site-specific potassium requirement of wheat in the field. Aust. J. Exp. Agric. 2001, 41, 655–661. [Google Scholar] [CrossRef]
- McCown, R.L.; Carberry, P.S.; Dalgliesh, N.P.; Foale, M.A.; Hochman, Z. Farmers use intuition to reinvent analytic decision support for managing seasonal climatic variability. Agric. Syst. 2012, 106, 33–45. [Google Scholar] [CrossRef]
- Llewellyn, R.S.; Ouzman, J. Adoption of Precision Agriculture-Related Practices: Status, Opportunities and the Role of Farm Advisers; CSIRO: Canberra, Australia, 2014. [Google Scholar]
- Bishop, T.F.A.; Lark, R.M. A landscape-scale experiment on the changes in available potassium over a winter wheat cropping season. Geoderma 2007, 141, 384–396. [Google Scholar] [CrossRef]
- Pannell, D.J. Economic perspectives on nitrogen in farming systems: Managing trade-offs between production, risk and the environment. Soil Res. 2017, 55, 473. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | GW Model Function and Formula |
|---|---|
| Spatial regression | |
| Local linear regression (SVC) |
| Kernel Name | Formula |
|---|---|
| Gaussian | |
| Exponential | |
| Bi-Square | |
| Tri-Cube | |
| Box-car |
| Model | Global Linear (gwr.mixed) | Local Linear (gwr.basic) | Global Linear (gwr.mixed) | Local Linear (gwr.basic) |
|---|---|---|---|---|
| Simulated data with global linear response | ||||
| Bandwidth (pixels) | 0.87 | 0.87 | 4.5 | 4.5 |
| AICc | 28,468 * | 28,795 | 31,397 | 31,227 * |
| Simulated data with local linear response | ||||
| Bandwidth (pixels) | 0.88 | 0.88 | 4.5 | 4.5 |
| AICc | 30,032 | 29,303 * | 33,184 | 31,973 * |
| Bandwidth | Global Response | Local Response |
|---|---|---|
| AICc-minimising | 100 | 78 |
| 45 m | <1 | 100 |
| Bandwidth | Global Response | Local Response |
|---|---|---|
| AICc-minimising | 70 | 69 |
| 45 m | 18 | 99 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Evans, F.H.; Recalde Salas, A.; Rakshit, S.; Scanlan, C.A.; Cook, S.E. Assessment of the Use of Geographically Weighted Regression for Analysis of Large On-Farm Experiments and Implications for Practical Application. Agronomy 2020, 10, 1720. https://doi.org/10.3390/agronomy10111720
Evans FH, Recalde Salas A, Rakshit S, Scanlan CA, Cook SE. Assessment of the Use of Geographically Weighted Regression for Analysis of Large On-Farm Experiments and Implications for Practical Application. Agronomy. 2020; 10(11):1720. https://doi.org/10.3390/agronomy10111720
Chicago/Turabian StyleEvans, Fiona H., Angela Recalde Salas, Suman Rakshit, Craig A. Scanlan, and Simon E. Cook. 2020. "Assessment of the Use of Geographically Weighted Regression for Analysis of Large On-Farm Experiments and Implications for Practical Application" Agronomy 10, no. 11: 1720. https://doi.org/10.3390/agronomy10111720
APA StyleEvans, F. H., Recalde Salas, A., Rakshit, S., Scanlan, C. A., & Cook, S. E. (2020). Assessment of the Use of Geographically Weighted Regression for Analysis of Large On-Farm Experiments and Implications for Practical Application. Agronomy, 10(11), 1720. https://doi.org/10.3390/agronomy10111720