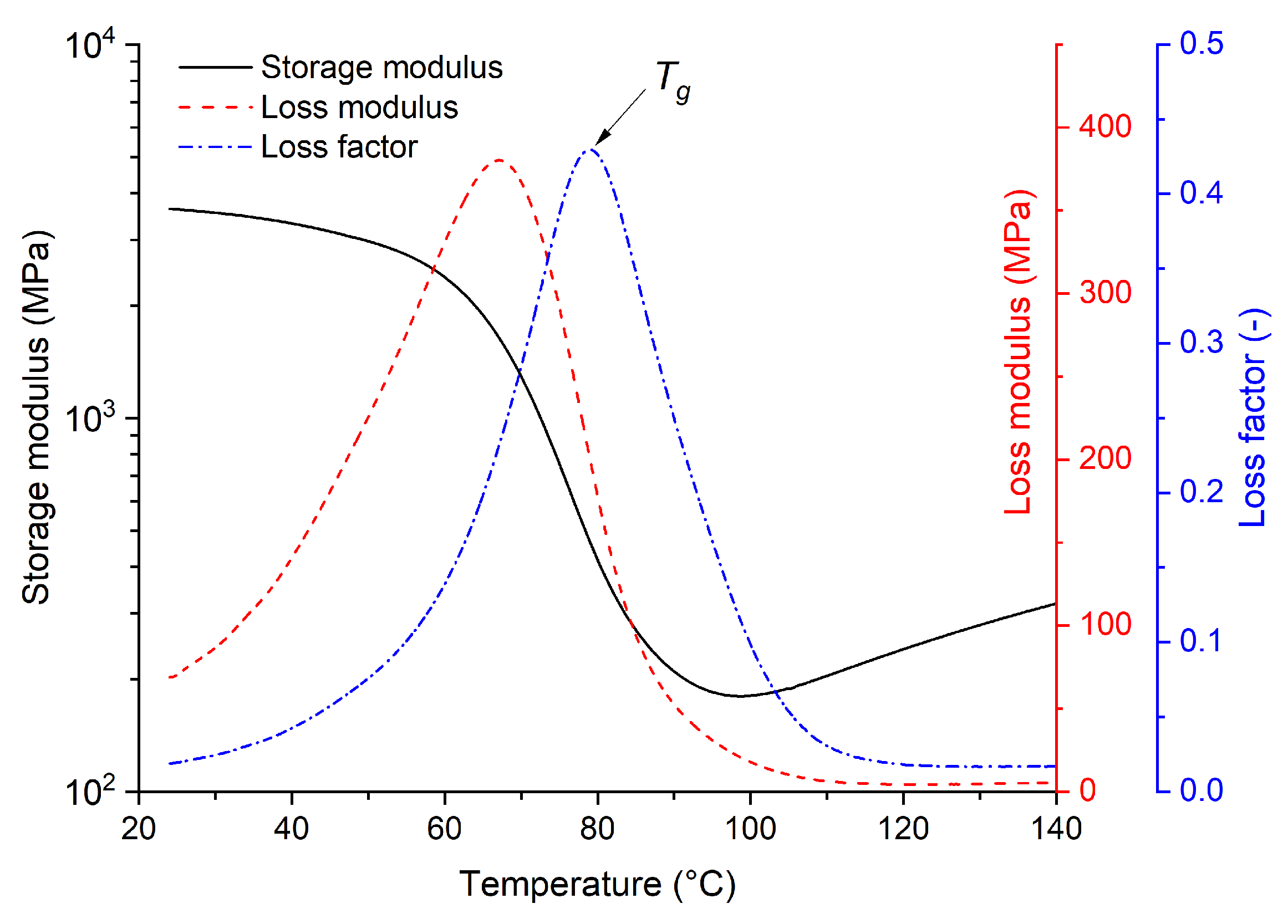
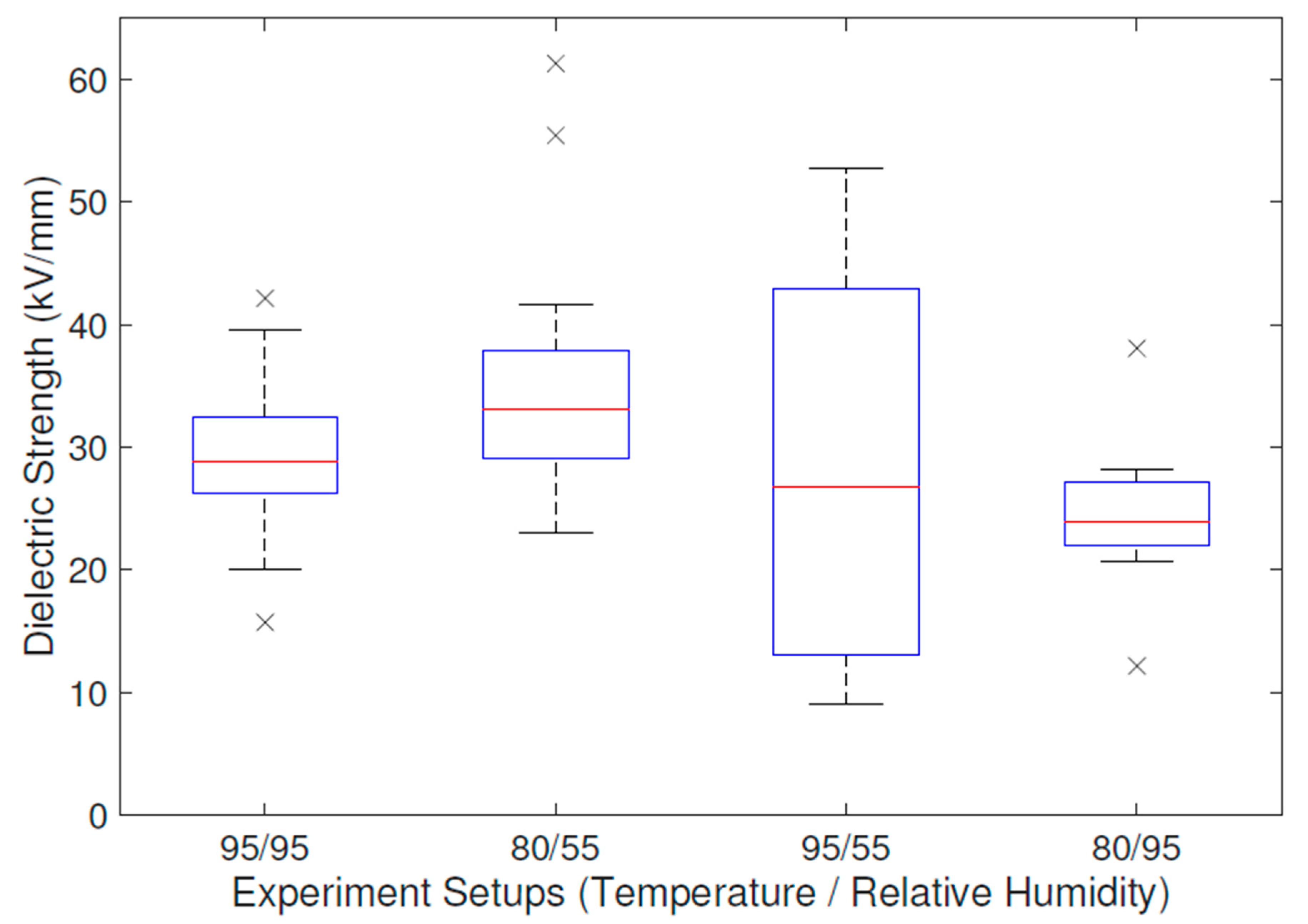
There are various procedures for acquiring an aging or degradation model. As the authors of this work, we selected (i) a physically informed empirical relation experimental design, (ii) a Response Surface Methodology experimental design using a two-factor first-order model with an interaction, and (iii) a Bayesian experimental design.
2.5.1. Physically Informed Empirical Relation
These models are based on the physical principle of a material degradation process. In some cases, direct implementation of certain physical laws is possible (e.g., Crines’ model) [
19]. However, this is not usually applicable to many degradation-related issues. Thus, empirical-based physical models were employed. These models are also based on the physical principle of degradation, but the model parameters are found by regression using measured data gathered via accelerated-aging experiments [
20,
21].
Unfortunately, a hygrothermal degradation process description within a certain material and with a characteristic response such as a dielectric strength is quite specific demand. However, a general lifespan (
) model of components under hygrothermal stress is proposed in [
21] and can be described via the following equation:
where
,
, and
are parameters obtained via regression,
represents the temperature, and
stands for relative humidity.
The benefit of this approach is the fact that the procedure is quite straightforward as the selected equation for regression is applied directly and the coefficients are determined via the ordinary least-squares method. On the other hand, the more generic degradation-related equation could be considered a significant disadvantage as the estimation of the system response might be imprecise.
2.5.2. Response Surface Methodology
A general approach used to assess the response of a system to a certain factor or multiple factors is the DoE with RSM [
25]. In this case, this study used a two-level two-factor experimental design and a first-order RSM model. This is a well-established method for many investigation issues, e.g., for investigating the impacts of temperature and alternate voltage [
26,
27]. The benefits include that one does not need to know the exact system behavior and the full factorial experimental design returns the information about factors’ interactions. The essential disadvantage is the poor scalability of this procedure for a high number of factors. Hence, for extensive experiments, it is advised to perform a pre-experiment to determine which factors and interactions are important and which are not. To make an experiment less demanding, many reduction methods might be employed, e.g., the Taguchi or Shainin method [
41] or the fractional factorial design (excluding selected higher-order interactions) [
25].
Once all values are collected, the following general two-factor first-order model equation can be used:
In Equations (
2) through (
5),
Y is the system’s response to the factors,
is the mean value,
a and
b are elements containing the factor level (
Fs and
I) and the effect strengths (
Es) according to Equation (
3), and, similarly,
t represents the same, but for interactions between the factors. The element
e represents the residual least-squares error, which is constant and might be caused by other sources of variability, for instance, measurement variability, background noise, and other unknown influences. In general, the indexes
i and
j stand for the possible applied multiple levels of acting factors, and the index
p respects the number of possible replications on the same factor level.
After completion of all of the respective experiment runs, it is possible to obtain each effect strength as follows:
These equations can be more conveniently rewritten in a matrix notation, wherein the matrix that respects the experimental setup is denoted as
:
which can be rewritten as
An example of the response of such a first-order model with interaction can be seen in
Figure 2b, among others [
25]. The
z-axis together with the label “RS” represents the respective response surfaces.
2.5.3. Bayesian Experimental Design
The empirical or physical approach introduces the model to describe degradation when the process is roughly known. On the other hand, the RSM approach suggests a very general procedure in order to describe any experiment results. If the empirical or physical model is linear in its parameters, then the regression coefficients can be easily found using the ordinary least-squares (OLS) method. However, it is not always clear from the beginning which model and which approach will be suitable. Comparing models based on the mean squared error or coefficient of determination
can then be burdened with the problem of overfitting. The Bayesian approach allows the model to be considered in probabilistic terms, and so the probabilities of the different models can be compared. Moreover, it is possible to design the experiment so that the most likely model is found with the fewest number of measurements. We selected four models, wherein the predicted value is the logarithm of the dielectric strength
and the basis functions are as follows:
Bayesian linear regression [
42] further generalizes the least-squares method by not searching a single value of parameter estimate
, but instead providing a full probability distribution of all possible values given in the data,
. This approach is closely related to the OLS formulation when both the likelihood function and the prior have Gaussian form:
where
denotes the multivariate Gaussian distribution with the mean value and covariance matrix as arguments, and
I is the identity matrix of appropriate dimensions. The prior parameter
is chosen to be the vector of zeros, and
will be estimated from the data. The mean value is then the model
, where
represents the unknown parameters and
is a vector of the basis functions. The posterior distribution is then computed via the Bayesian theorem
where
represents the measured data. The posterior distribution again has a Gaussian form,
:
Note that for
, the mean value
corresponds to the OLS solution. The key distinction between this method and the OLS method is in the predictive variance, i.e., the uncertainty of the predicted output for a new unseen value of the factors, specifically
To distinguish between multiple models
(in our case, four), we need to compute the probability that those data
were generated from this model:
where
is the prior probability of each of the four candidate models (
6), and
is given by Equation (
11), often evaluated in logarithm:
Equation (
13) provides the probability of the
m model. Since the model is uncertain, the prediction has to take this uncertainty into account and average over it:
where
is the probability (weight) of each model. This is a mixture of Gaussian predictors (
11), and is denoted as the Bayesian Model Averaging (BMA) predictor. In effect, the uncertainty about the model prediction is thus increased. The variance of the prediction (
16) is as follows:
Since this formula is sensitive to the choice of
, we estimated it together with
from the data for each model using the empirical Bayes procedure [
42].
As the experiments in this application domain might be very expensive, we explored the ability of Bayesian optimization to obtain as much information with as few experiments as possible. The theory of optimal design is a classical method [
43] with many recent applications [
31]. Formally, the next experimental point is found as a solution optimization problem:
where
is a chosen utility function. A common choice of utility is the information gain; however, this is quite expensive to evaluate and various approximations can be used [
31], such as predictive variance (
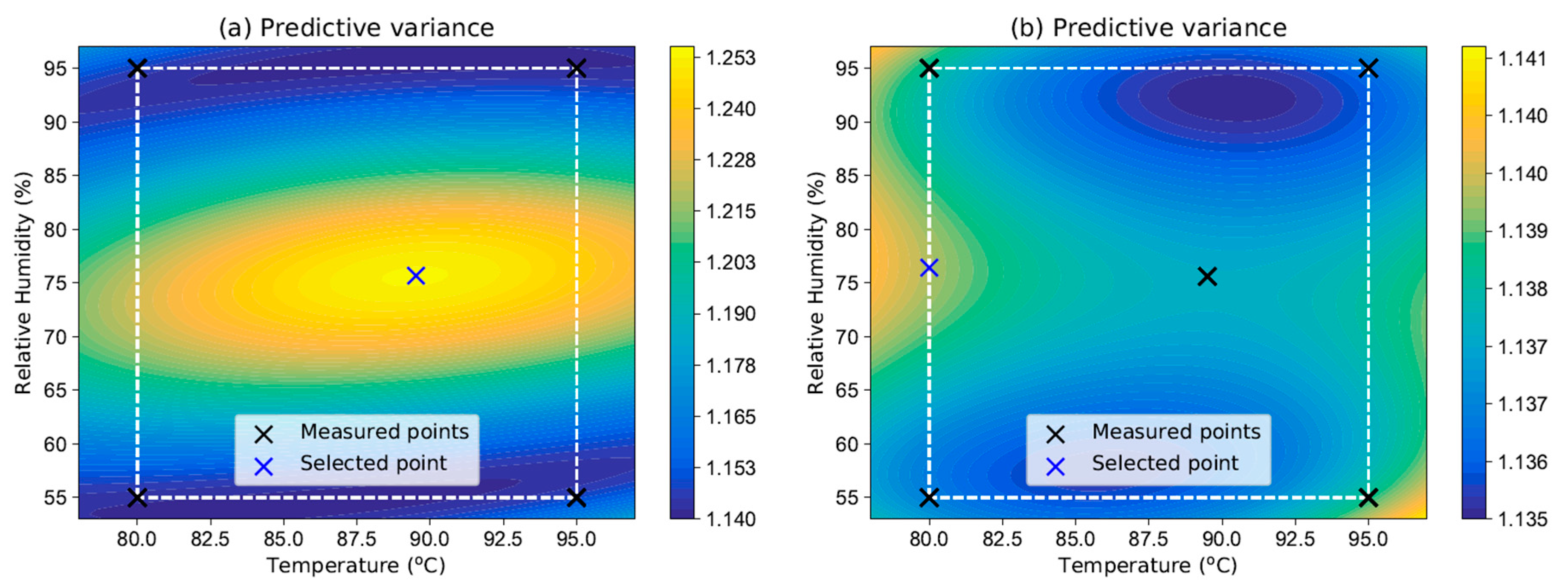
18). The summary of the approach is described in Algorithm 1.
| Algorithm 1 Summary of the Bayesian experimental design for the selection of the optimal linear model. |
Init: Choose initial specimens and measure output variable using e.g., the RSM recommendation. Set iteration counter . Iterate until convergence:
- 1.
For each model calculate coefficients ( 10) and probability using (17) for data - 2.
On the grid of candidate points compute predictive variance ( 18) - 3.
Select point with highest variance for the next measurement, - 4.
Perform measurement to obtain and extend the data sets:
|
The main benefits of this method are as follows: The method works with not one but several candidate models that can be compared based on their probability concerning the measured data. This probabilistic interpretation then leads to the use of a Bayesian optimal design, which selects experimental setups in such a way that the different models are discriminated and the most suitable one is found as quickly as possible.









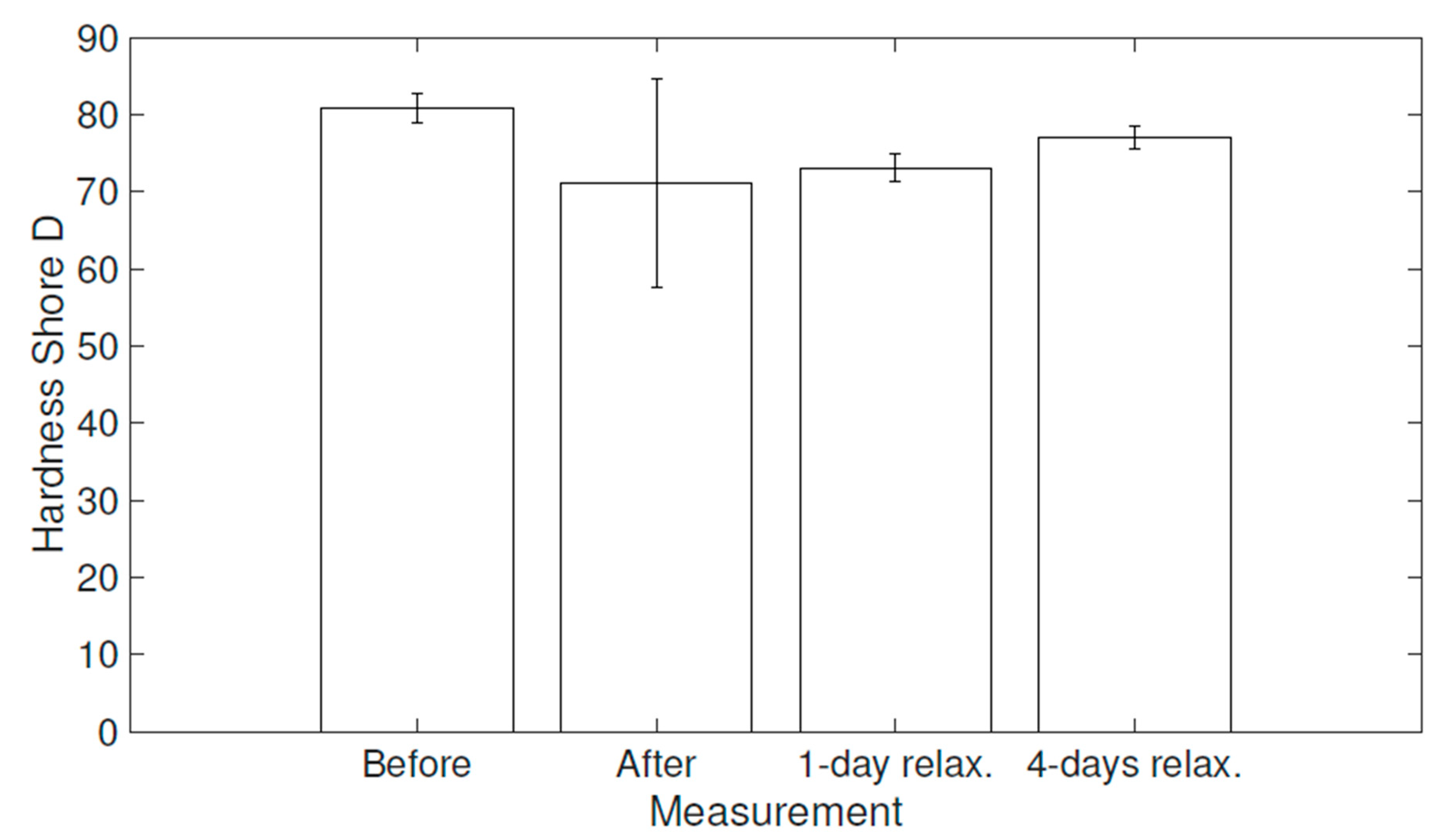
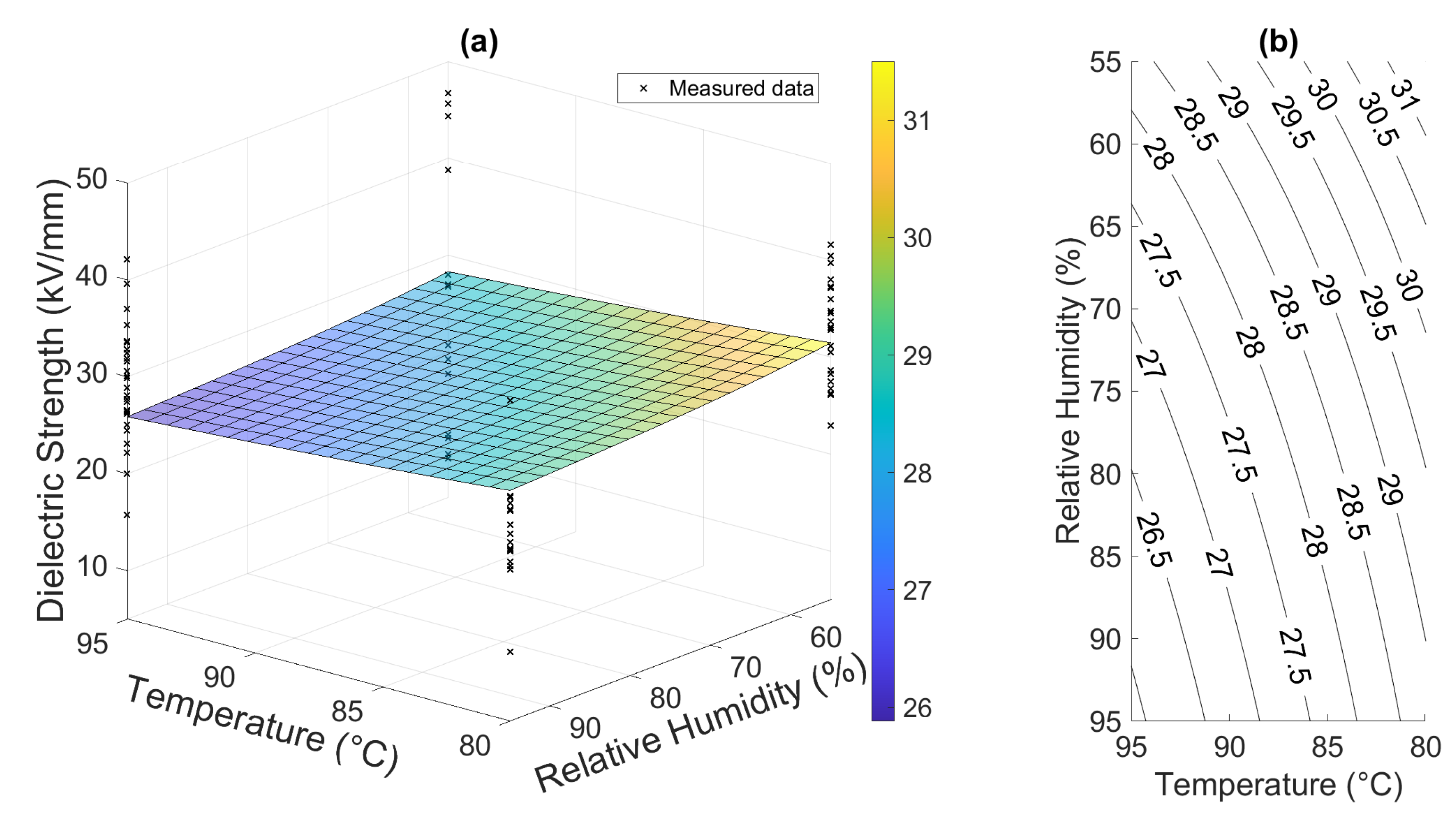

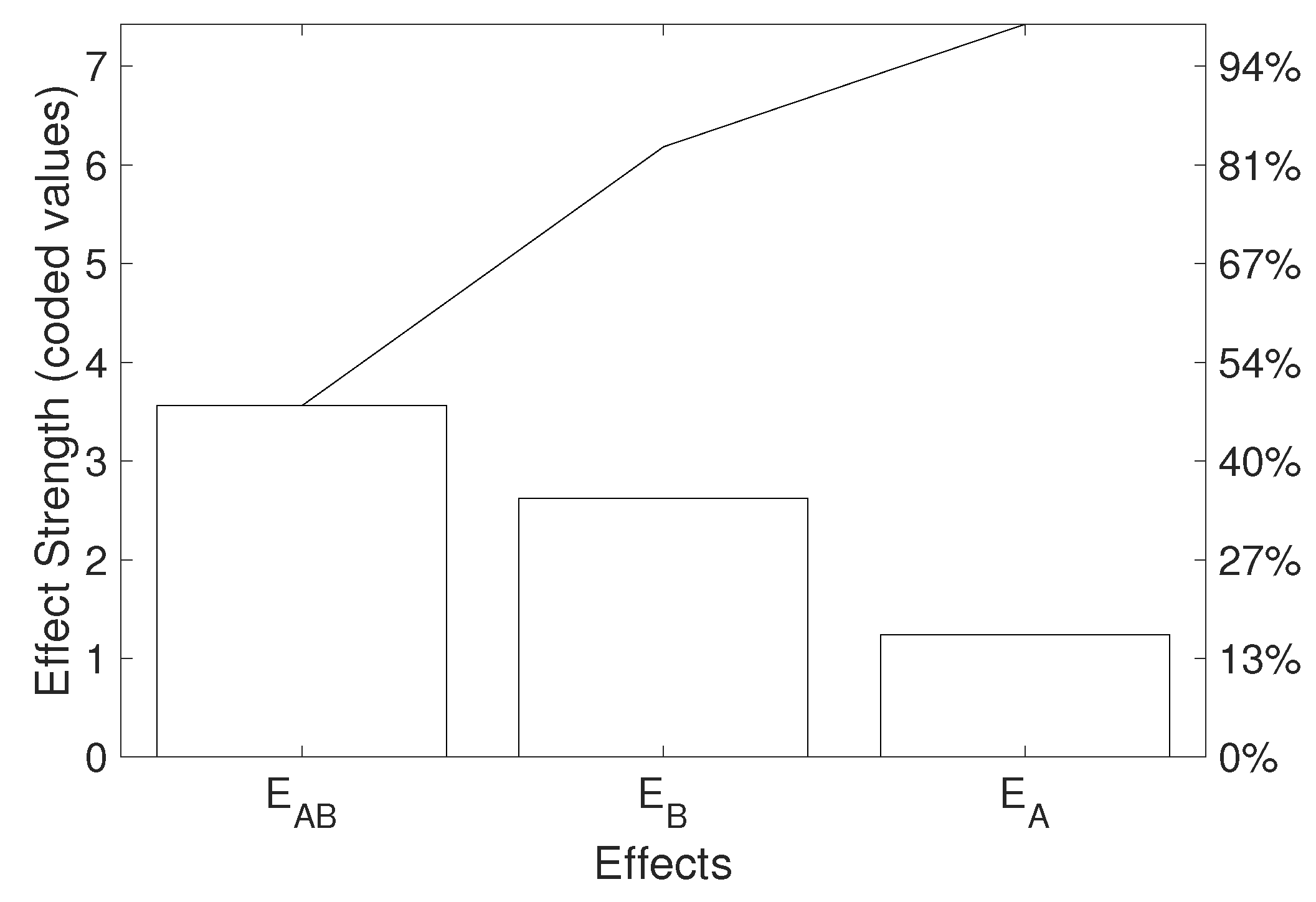
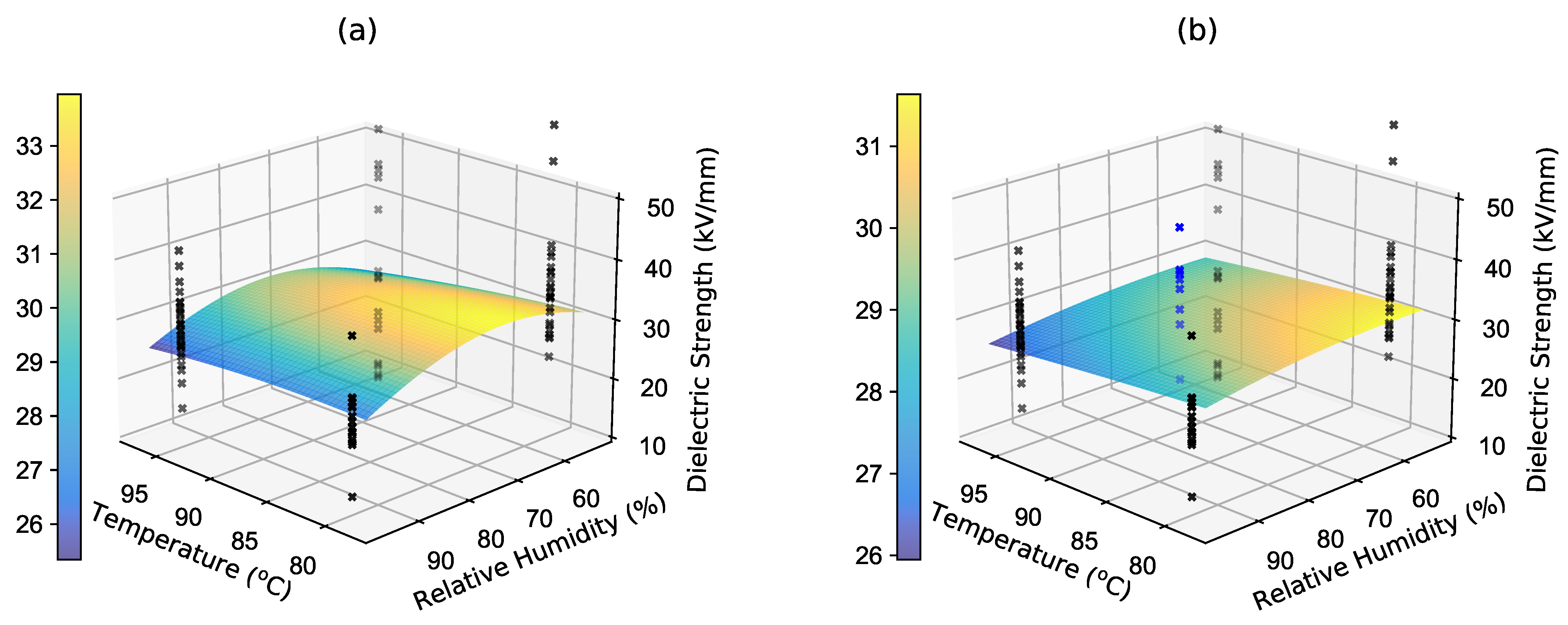


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}