
Prediction and Optimization of Process Parameters for Composite Thermoforming Using a Machine Learning Approach


Abstract
:
1. Introduction
2. Background
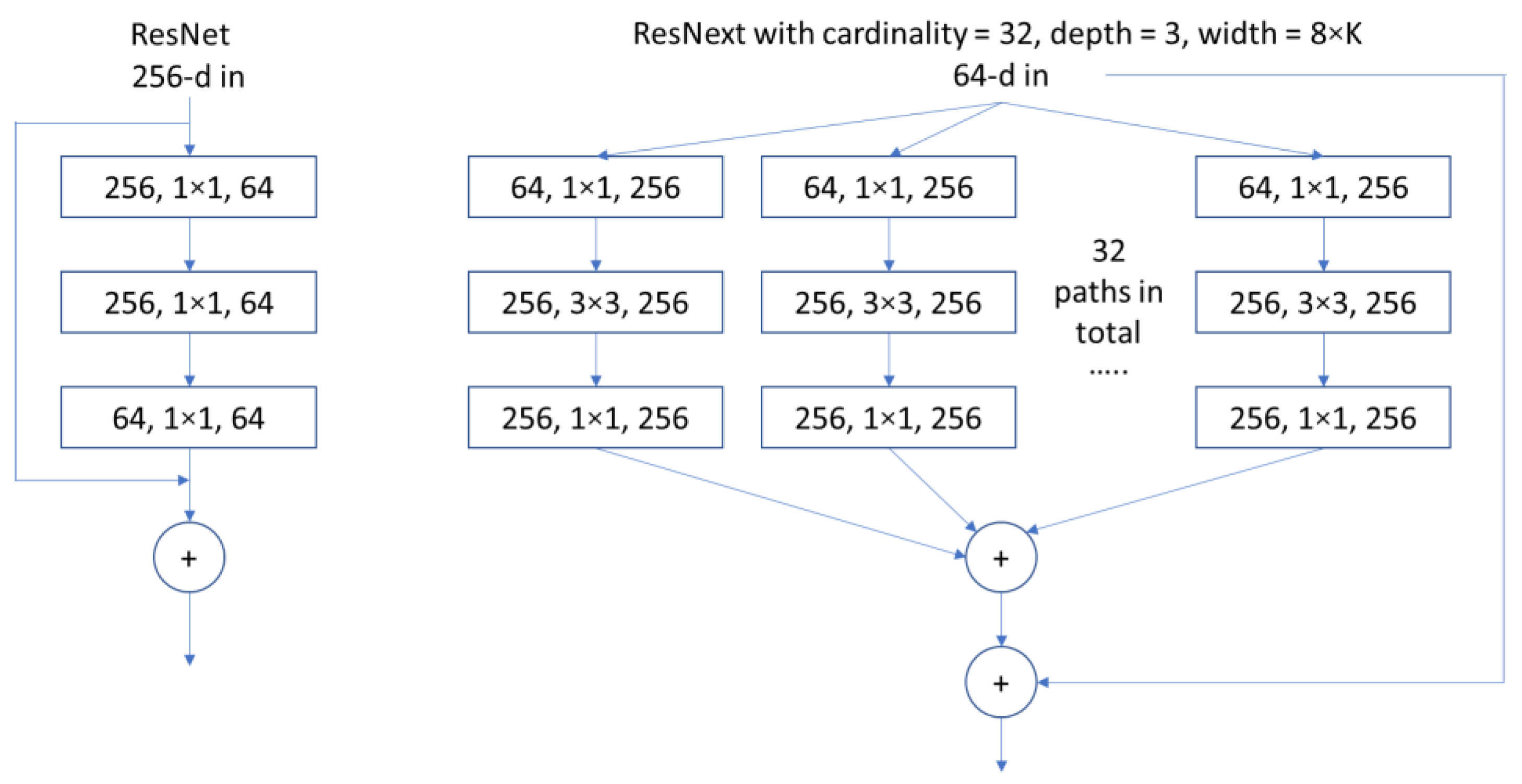
2.1. Artificial Neural Network and Convolutional Neural Network
2.2. ANN Applications in Manufacturing Research
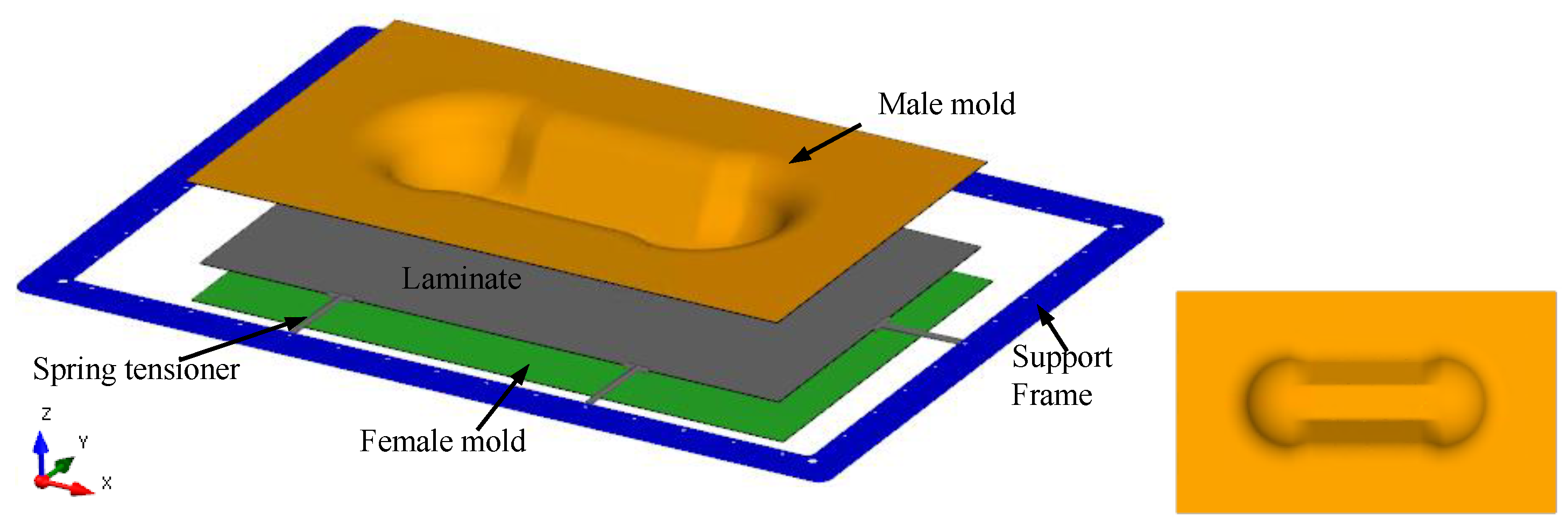
3. Model Overview and Material Properties
3.1. Part Profile
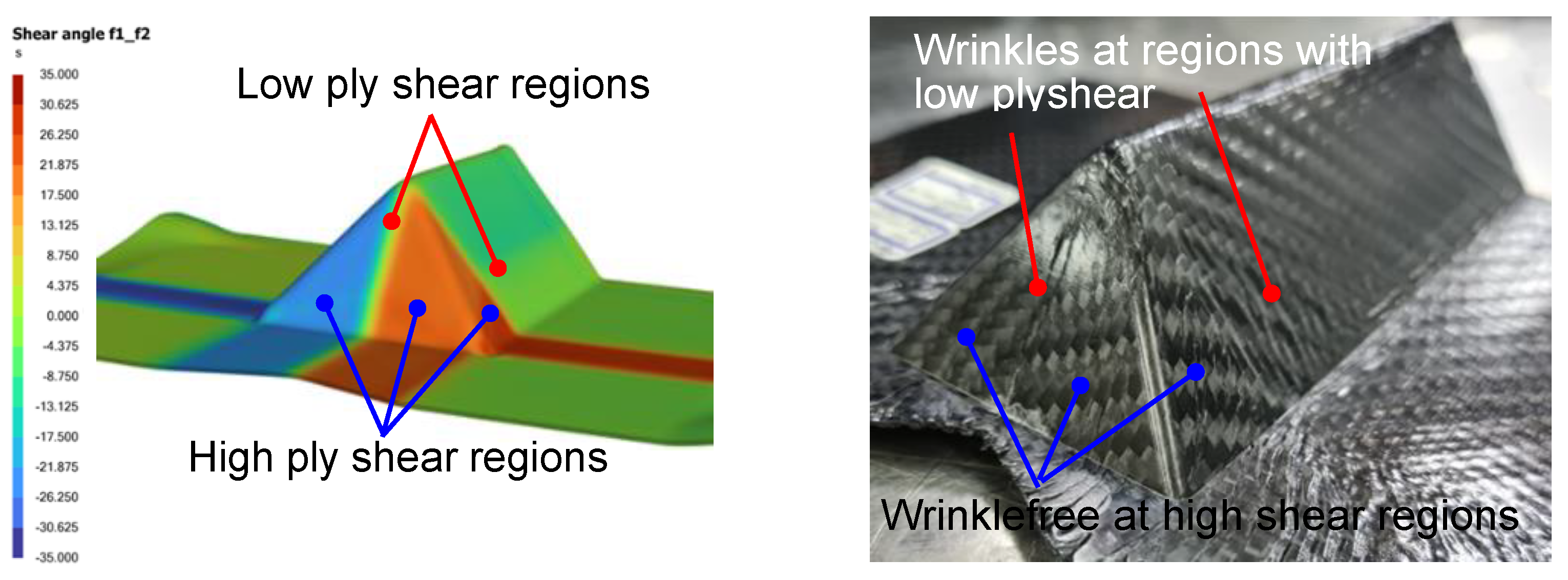
3.2. Thermoforming Parameters Studied
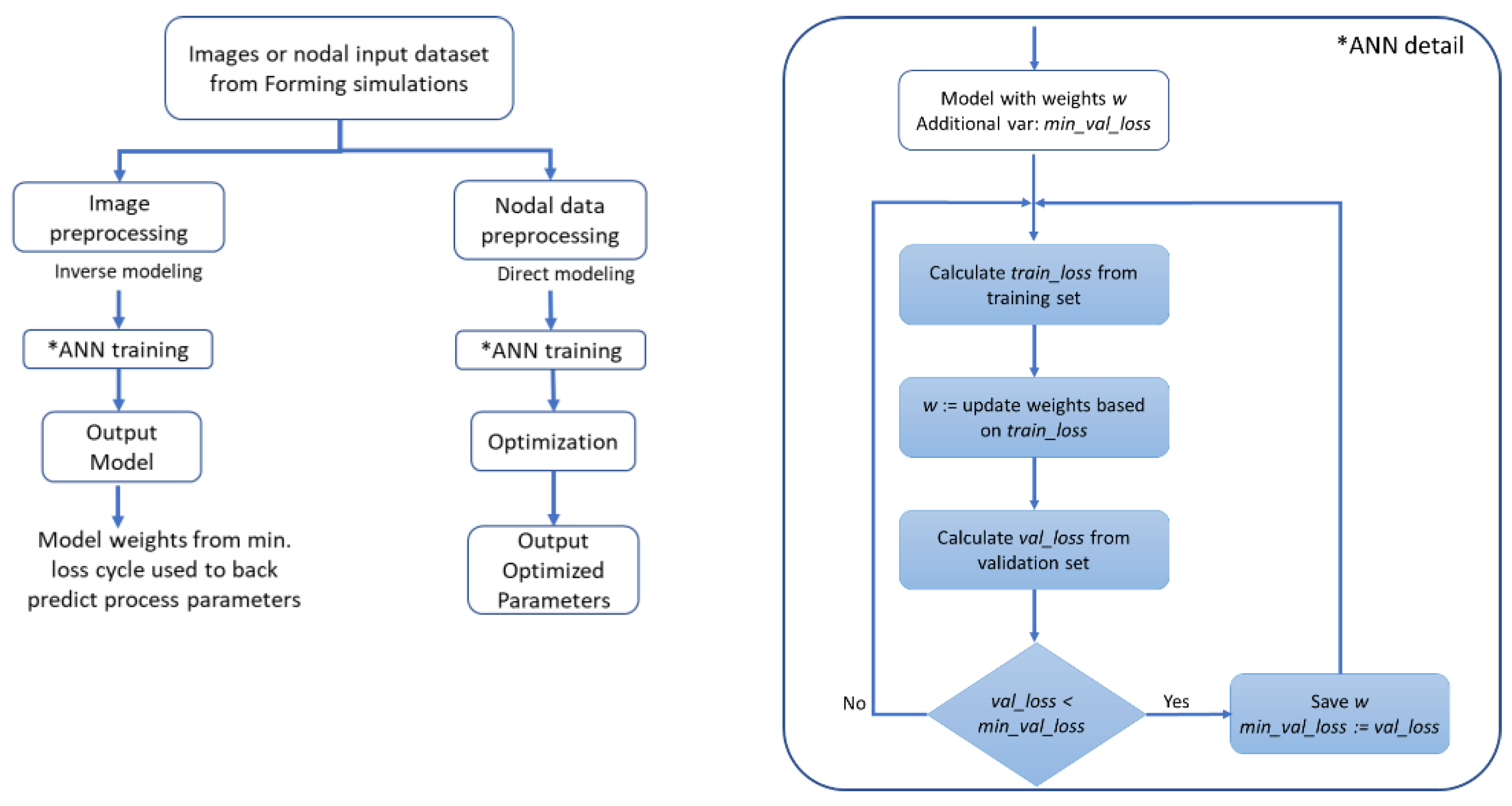
4. ANN Training Methodology
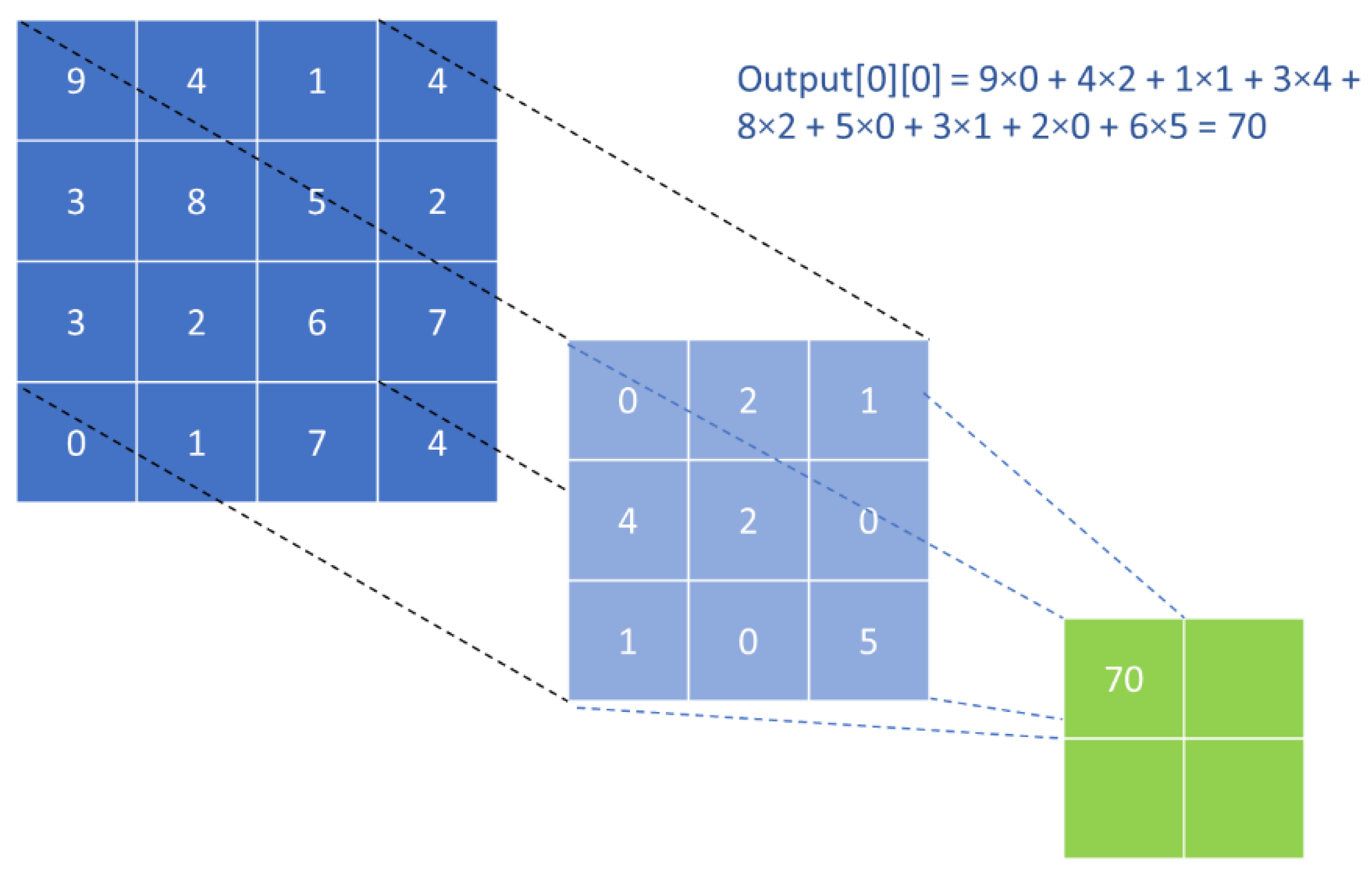
4.1. Image Data Preprocessing
4.2. ANN Architecture in Inverse Modeling
- Laminate orientation, .
- Tensioner stiffness, .
- Preload, .
- Press rate, .
- Grip size, .
- Mean absolute error (MAE):
- Mean squared error (MSE):
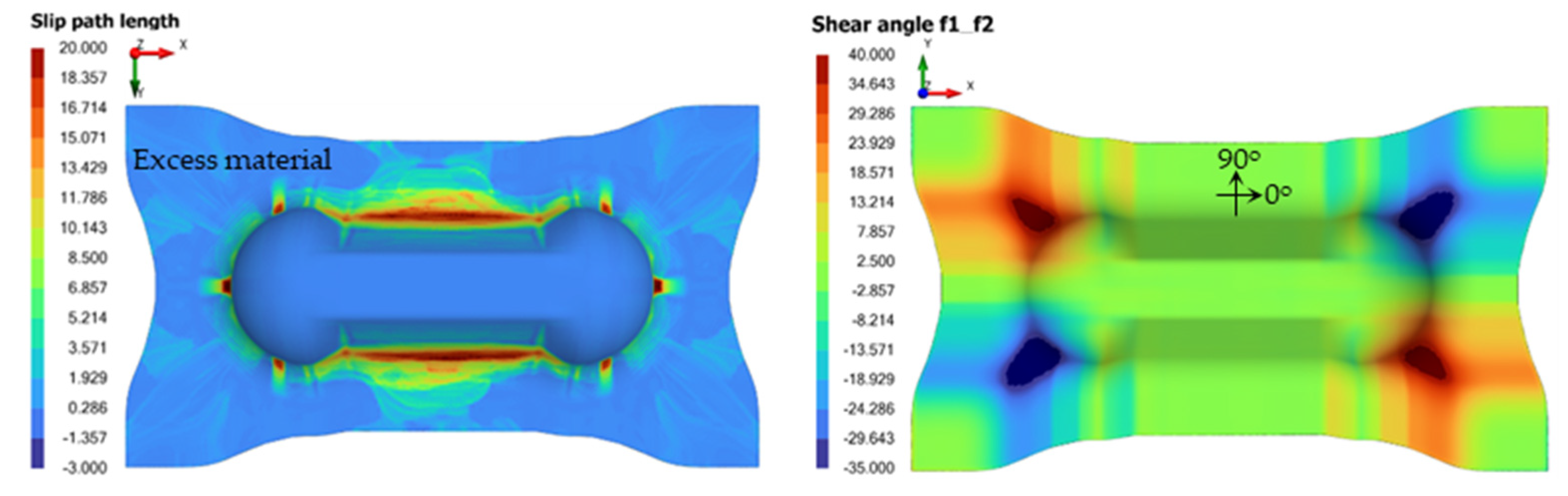
4.3. Optimization of Slip-Path Length and Shear Angle in Direct Modeling
5. Results
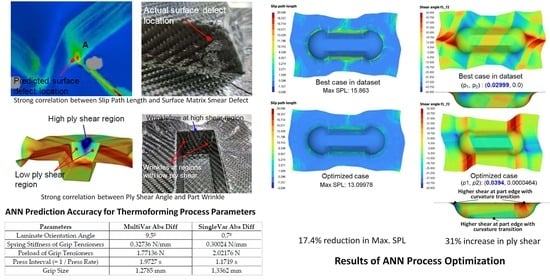
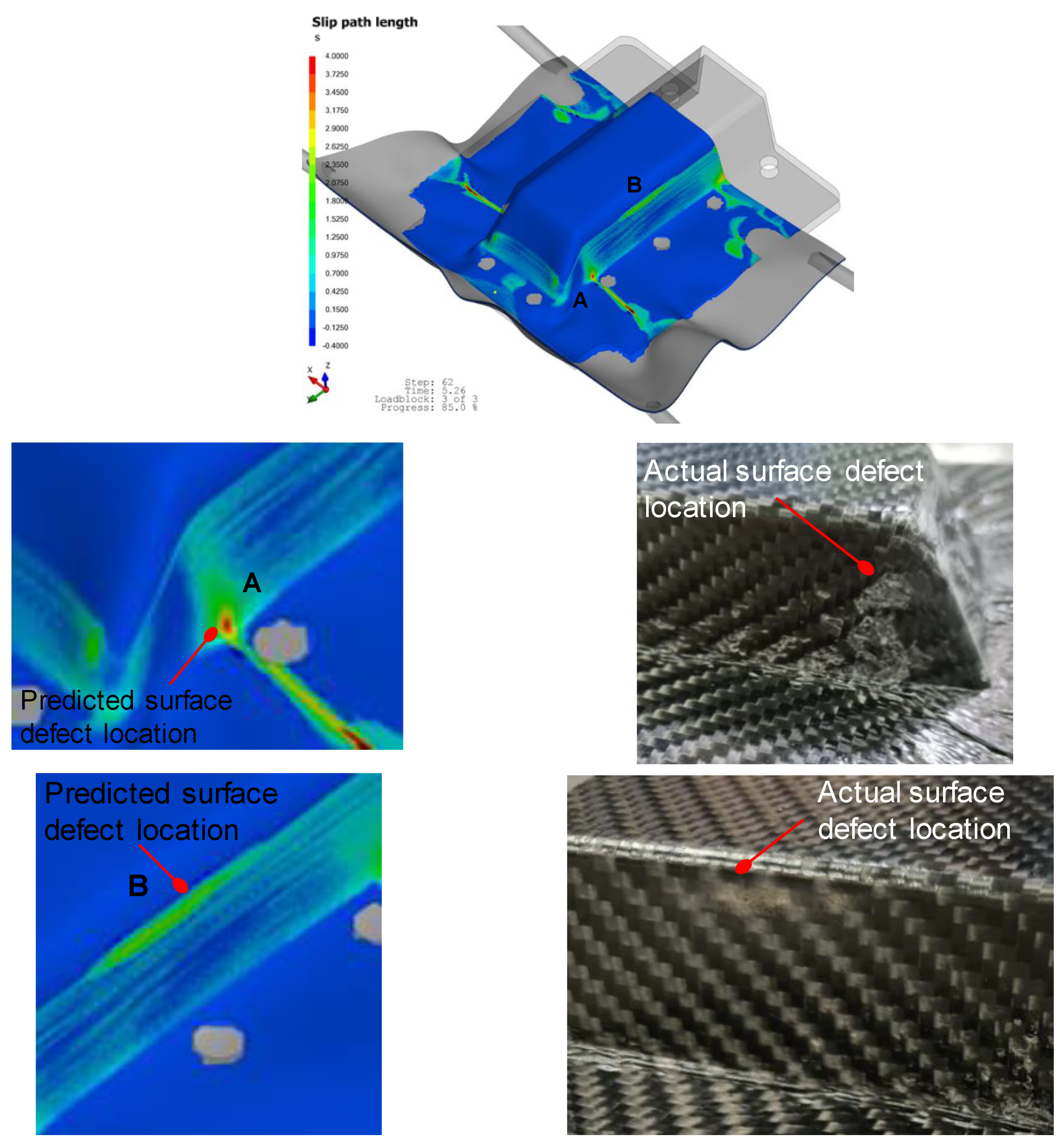
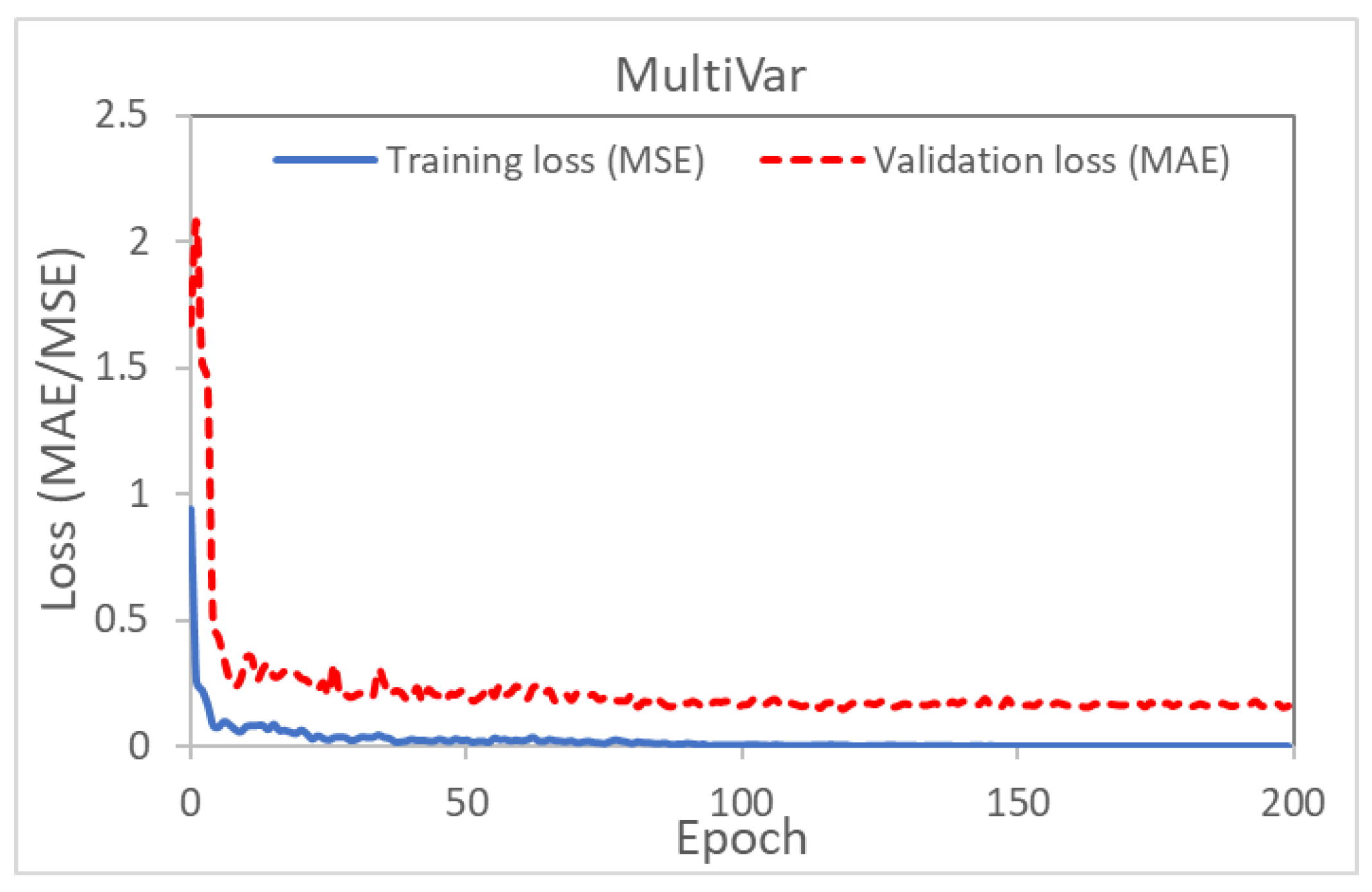
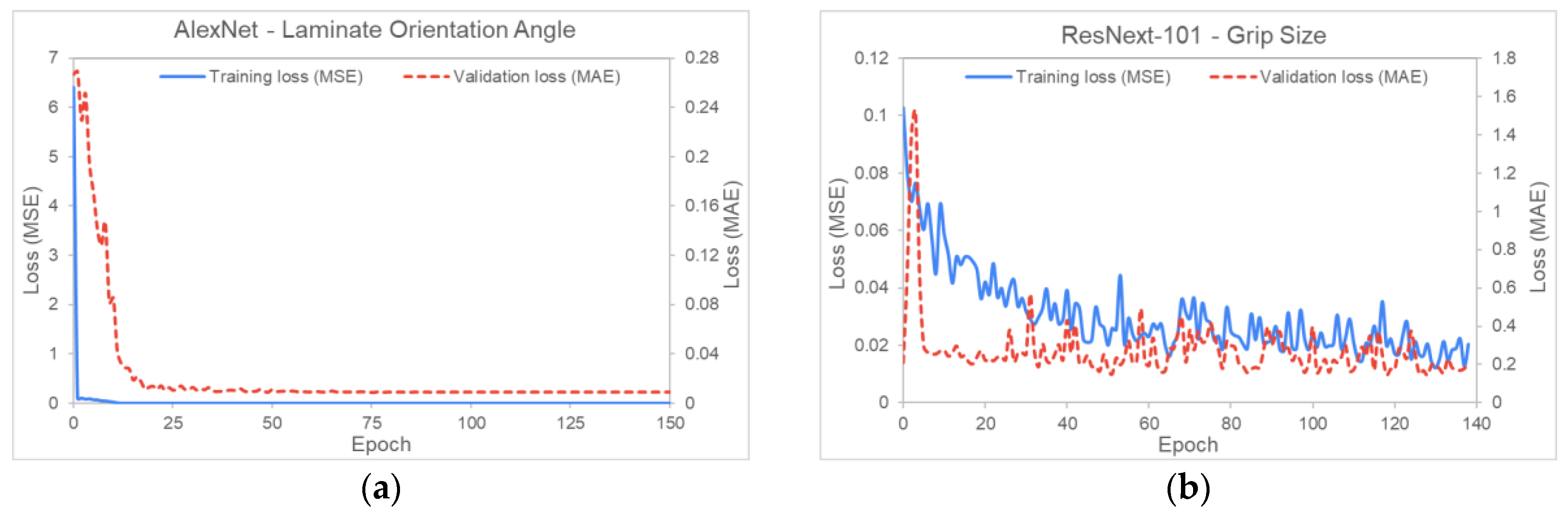
5.1. Inverse Modeling
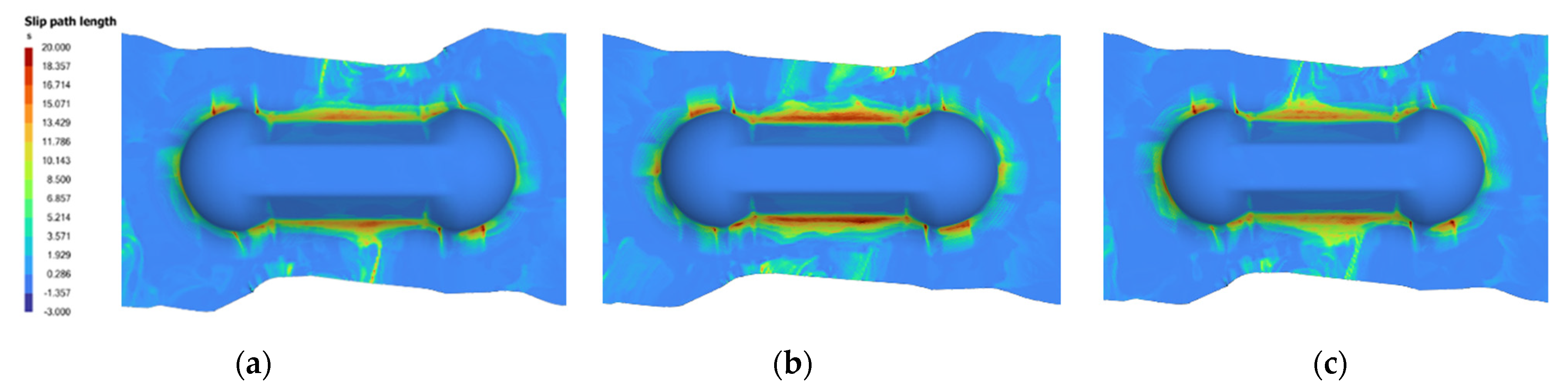
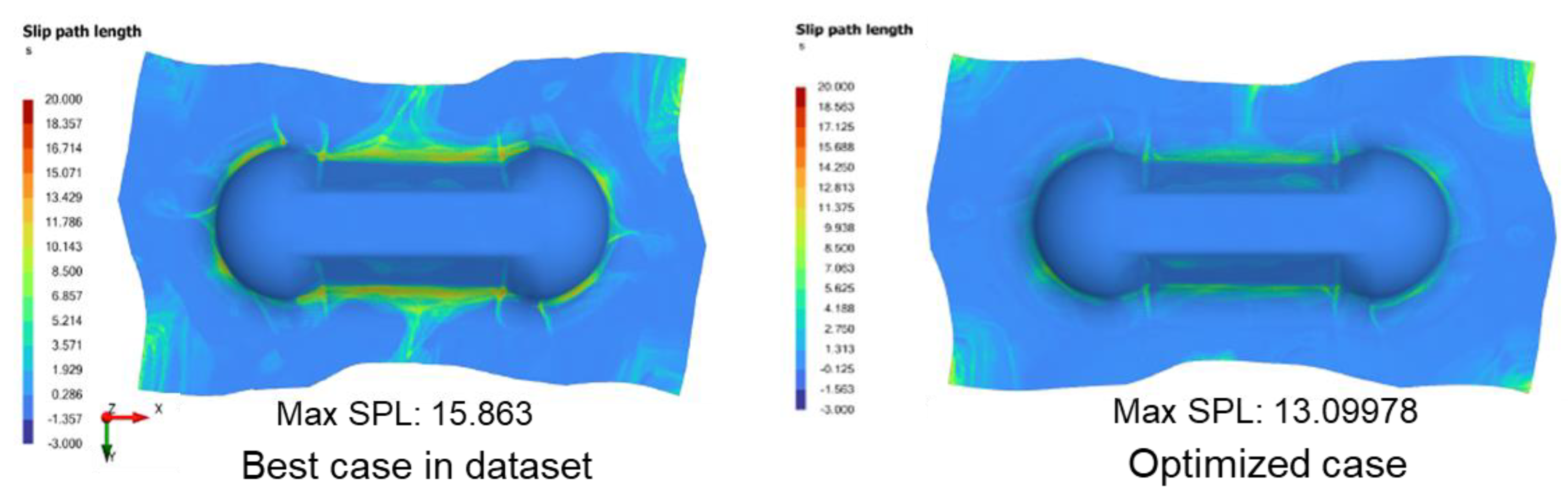
5.2. Optimizing Slip-Path Length
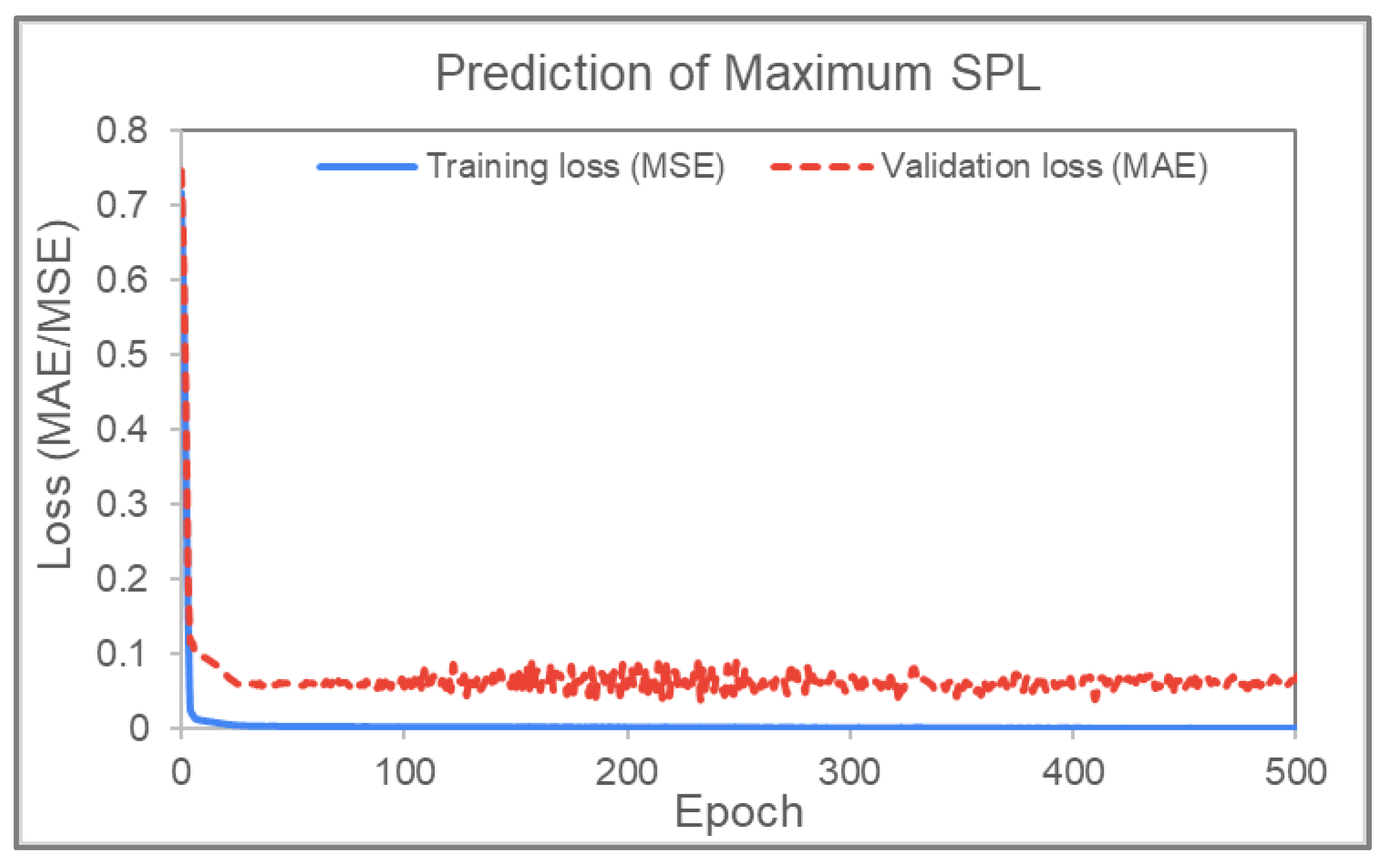
Prediction of Maximum Slip-Path Length (SPL)
- Max SPL: 14.409; Parameters: lam −34/−34, S0.18, PL1, rate 0.96 (103.87 s), grip 6.
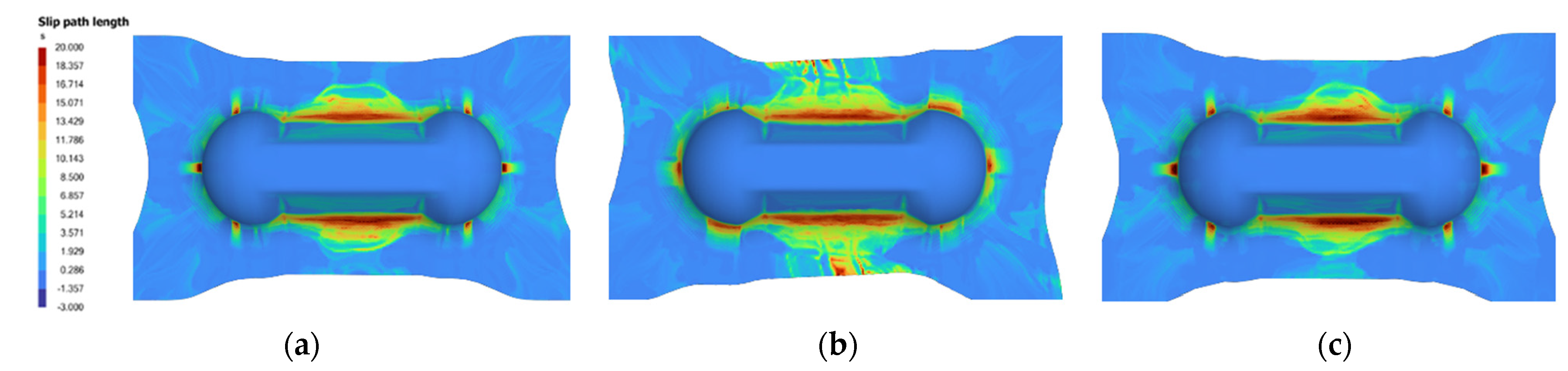
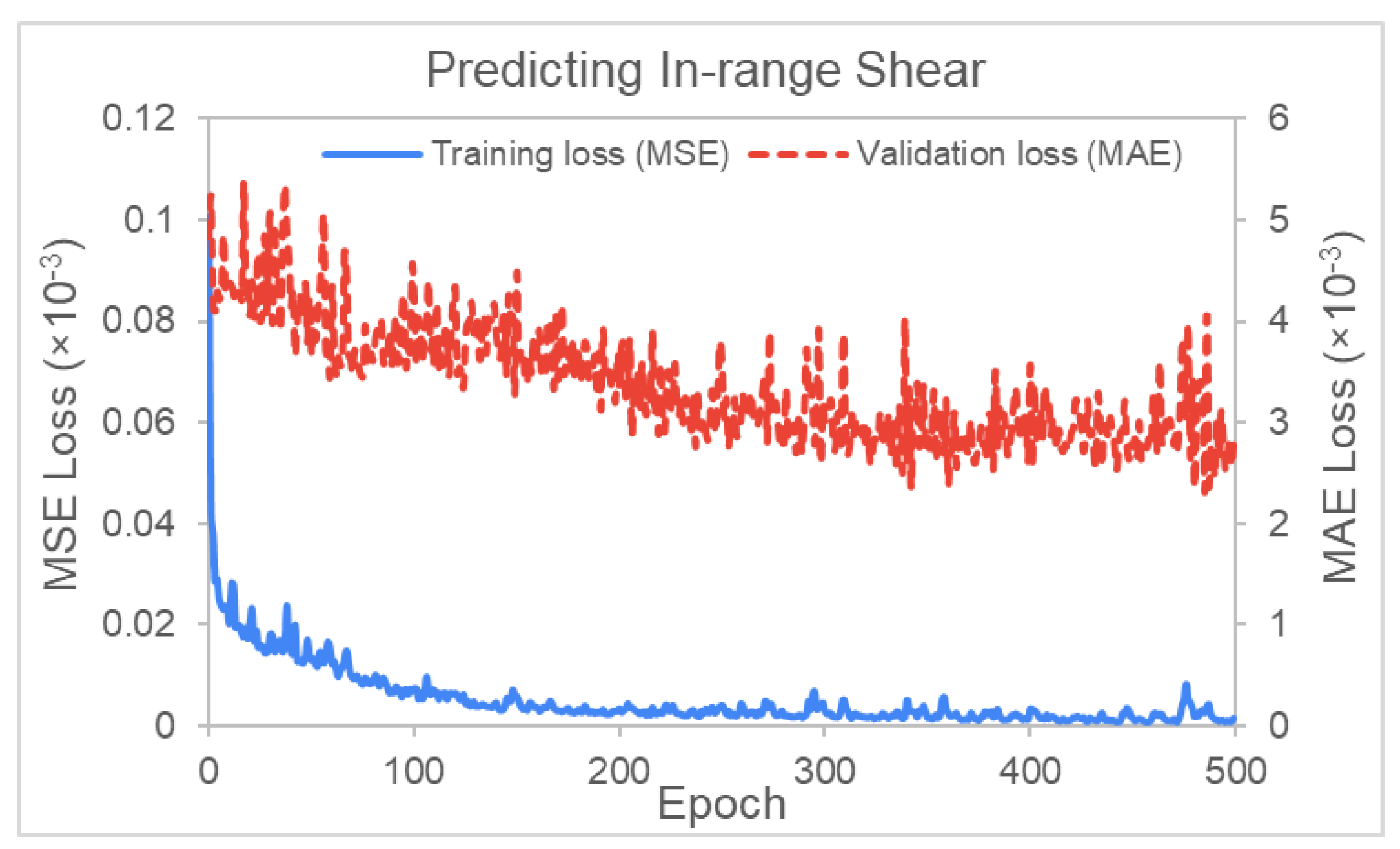
5.3. Optimizing Shear Angle
Prediction of Proportion of Nodes with Designated Shear Angle Ranges
6. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- AniForm Virtual Forming. Available online: https://aniform.com/ (accessed on 29 June 2022).
- Zhang, Z.; Friedrich, K. Artificial Neural Networks Applied to Polymer Composites: A Review. Compos. Sci. Technol. 2003, 63, 2029–2044. [Google Scholar] [CrossRef]
- Chang, Y.-Z.; Wen, T.-T.; Liu, S.-J. Derivation of Optimal Processing Parameters of Polypropylene Foam Thermoforming by an Artificial Neural Network. Polym. Eng. Sci. 2005, 45, 375–384. [Google Scholar] [CrossRef]
- Simoncini, A.; Tagliaferri, V.; Trovalusci, F.; Ucciardello, N. Neural Networks Approach for IR-Heating and Deformation of ABS in Thermoforming. Int. J. Comput. Appl. Technol. 2017, 56, 114. [Google Scholar] [CrossRef]
- Leite, W.; Campos Rubio, J.; Mata, F.; Carrasco, A.; Hanafi, I. Vacuum Thermoforming Process: An Approach to Modeling and Optimization Using Artificial Neural Networks. Polymers 2018, 10, 143. [Google Scholar] [CrossRef] [Green Version]
- Zobeiry, N.; Reiner, J.; Vaziri, R. Theory-Guided Machine Learning for Damage Characterization of Composites. Compos. Struct. 2020, 246, 112407. [Google Scholar] [CrossRef]
- Nardi, D.; Sinke, J. Design Analysis for Thermoforming of Thermoplastic Composites: Prediction and Machine Learning-Based Optimization. Compos. Part C Open Access 2021, 5, 100126. [Google Scholar] [CrossRef]
- Humfeld, K.D.; Gu, D.; Butler, G.A.; Nelson, K.; Zobeiry, N. A Machine Learning Framework for Real-Time Inverse Modeling and Multi-Objective Process Optimization of Composites for Active Manufacturing Control. Compos. Part B Eng. 2021, 223, 109150. [Google Scholar] [CrossRef]
- Wanigasekara, C.; Oromiehie, E.; Swain, A.; Prusty, B.G.; Nguang, S.K. Machine Learning-Based Inverse Predictive Model for AFP Based Thermoplastic Composites. J. Ind. Inf. Integr. 2021, 22, 100197. [Google Scholar] [CrossRef]
- Wanigasekara, C.; Swain, A.; Nguang, S.K.; Prusty, B.G. Improved Learning from Small Data Sets through Effective Combination of Machine Learning Tools with VSG Techniques. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–6. [Google Scholar]
- Melaibari, A.A.; Khetib, Y.; Alanazi, A.K.; Sajadi, S.M.; Sharifpur, M.; Cheraghian, G. Applying Artificial Neural Network and Response Surface Method to Forecast the Rheological Behavior of Hybrid Nano-Antifreeze Containing Graphene Oxide and Copper Oxide Nanomaterials. Sustainability 2021, 13, 1505. [Google Scholar] [CrossRef]
- Núria, B.; Imma, B.; Pau, X.; Pol, T.; Narcís, B. Deep Learning for the Quality Control of Thermoforming Food Packages. Sci. Rep. 2021, 11, 21887. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Macosko, C.W. Rheology Principles, Measurements, and Applications; Wiley-VCH: New York, NY, USA, 1994; ISBN 978-0-471-18575-8. [Google Scholar]
- Cao, J.; Akkerman, R.; Boisse, P.; Chen, J.; Cheng, H.; De Graaf, E.; Gorczyca, J.; Harrison, P.; Hivet, G.; Launay, J. Characterization of Mechanical Behavior of Woven Fabrics: Experimental Methods and Benchmark Results. Compos. Part A Appl. Sci. Manuf. 2008, 39, 1037–1053. [Google Scholar] [CrossRef] [Green Version]
- Sargent, J.; Chen, J.; Sherwood, J.; Cao, J.; Boisse, P.; Willem, A.; Vanclooster, K.; Lomov, S.V.; Khan, M.; Mabrouki, T. Benchmark Study of Finite Element Models for Simulating the Thermostamping of Woven-Fabric Reinforced Composites. Int. J. Mater. Form. 2010, 3, 683–686. [Google Scholar] [CrossRef]
- Rietman, B.; Haanappel, S.; ten Thije, R.H.W.; Akkerman, R. Forming Simulation Sensitivity Study of the Double-Dome Benchmark Geometry. Key Eng. Mater. 2012, 504–506, 301–306. [Google Scholar] [CrossRef]
- AniForm Suite Help Documentation, Version 4.0; AniForm Engineering B.V.: Enschede, The Netherlands, 2022.
- Pytorch/Vision. Available online: https://github.com/pytorch/vision/tree/master/torchvision/models (accessed on 29 June 2022).
- Pytorch Models and Pre-Trained Weights. Available online: https://pytorch.org/vision/main/models.html (accessed on 29 June 2022).
- Zhao, Z.-Q.; Zheng, P.; Xu, S.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.; Deng, W. Deep Face Recognition: A Survey. Neurocomputing 2021, 429, 215–244. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition 2015. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Xie, S.; Girshick, R.B.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. arXiv 2016, arXiv:1611.05431. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Robbins, H.; Monro, S. A Stochastic Approximation Method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Wilson, A.C.; Roelofs, R.; Stern, M.; Srebro, N.; Recht, B. The Marginal Value of Adaptive Gradient Methods in Machine Learning. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Zhou, P.; Feng, J.; Ma, C.; Xiong, C.; Hoi, S.; E, W. Towards Theoretically Understanding Why SGD Generalizes Better Than ADAM in Deep Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21285–21296. [Google Scholar]
- Scipy. Available online: https://scipy.org/ (accessed on 29 June 2022).
- Zhu, C.; Byrd, R.H.; Lu, P.; Nocedal, J. Algorithm 778: L-BFGS-B: Fortran Subroutines for Large-Scale Bound-Constrained Optimization. ACM Trans. Math. Softw. (TOMS) 1997, 23, 550–560. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| General Properties | ||||
|---|---|---|---|---|
| Isotropic Density | υ = 0 | E = 1 × 10−16 MPa | Rho = 2 × 10−9 | |
| In-plane Model | ||||
| Fiber | 10,000 MPa | |||
| Isotropic Elastic | υ = 0 | E = 0.02295 MPa | ||
| Mooney Rivlin | C10 = 0 | C01 = 0.0072 | ||
| Cross-Viscosity | Eta0 = 0.5 | EtaInf = 0.04 | M = 75 | N = −0.17 |
| Bending Model | ||||
| Isotropic Elastic | E = 200 MPa | |||
| Cross-Viscosity | Eta0 = 2000 MPa | EtaInf = 10 MPa | M = 7200 | N = 0.02 |
| Laminate Orientation (Deg) | Tensioner Stiffness (N/mm) | Preload (N) | Press Rate (mm/s) | Grip Size (mm) |
|---|---|---|---|---|
| 0, +/− 15, +/−30, +/−45 | 0.5, 1.0, 1.5, 1.75, 2.0 | 2, 4, 8 | 66.7, 33.3, 16.7 | 0 (point), 2, 4, 8 |
| Layer | No. of Filters/ Neurons | Filter Size | Stride | Padding | Size of Feature Map | Activation Function |
|---|---|---|---|---|---|---|
| Input | - | - | - | - | 3 × 224 × 224 | - |
| Conv 1 | 64 | 11 × 11 | 4 | - | 64 × 54 × 54 | ReLU |
| Max Pool 1 | - | 3 × 3 | 2 | - | 64 × 26 × 26 | - |
| Conv 2 | 192 | 5 × 5 | 1 | 2 | 192 × 26 × 26 | ReLU |
| Max Pool 2 | - | 3 × 3 | 2 | - | 192 × 12 × 12 | - |
| Conv 3 | 384 | 3 × 3 | 1 | 1 | 384 × 12 × 12 | ReLU |
| Conv 4 | 256 | 3 × 3 | 1 | 1 | 256 × 12 ×12 | ReLU |
| Conv 5 | 256 | 3 × 3 | 1 | 1 | 256 × 12 × 12 | ReLU |
| Max Pool 3 | - | 3 × 3 | 2 | - | 256 × 6 × 6 | - |
| FC 1 | 256 × 6 × 6 × 4096 | - | - | - | 4096 | ReLU |
| FC 2 | 4096 | - | - | - | 4096 | ReLU |
| FC 3 | 4096 | - | - | - | 1 | - |
| Parameters | MultiVar Abs Error | SingleVar Abs Error |
|---|---|---|
| Laminate Orientation Angle | 9.5° | 0.7° |
| Spring Stiffness of Grip Tensioners | 0.32736 N/mm | 0.30024 N/mm |
| Preload of Grip Tensioners | 1.77136 N | 2.02176 N |
| Press Interval (=1/Press Rate) | 1.9727 s | 1.1719 s |
| Grip Size | 1.2785 mm | 1.3362 mm |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, L.B.; Nhat, N.D.P. Prediction and Optimization of Process Parameters for Composite Thermoforming Using a Machine Learning Approach. Polymers 2022, 14, 2838. https://doi.org/10.3390/polym14142838
Tan LB, Nhat NDP. Prediction and Optimization of Process Parameters for Composite Thermoforming Using a Machine Learning Approach. Polymers. 2022; 14(14):2838. https://doi.org/10.3390/polym14142838
Chicago/Turabian StyleTan, Long Bin, and Nguyen Dang Phuc Nhat. 2022. "Prediction and Optimization of Process Parameters for Composite Thermoforming Using a Machine Learning Approach" Polymers 14, no. 14: 2838. https://doi.org/10.3390/polym14142838
APA StyleTan, L. B., & Nhat, N. D. P. (2022). Prediction and Optimization of Process Parameters for Composite Thermoforming Using a Machine Learning Approach. Polymers, 14(14), 2838. https://doi.org/10.3390/polym14142838