
Post-Consumer Textile Waste Classification through Near-Infrared Spectroscopy, Using an Advanced Deep Learning Approach




Abstract
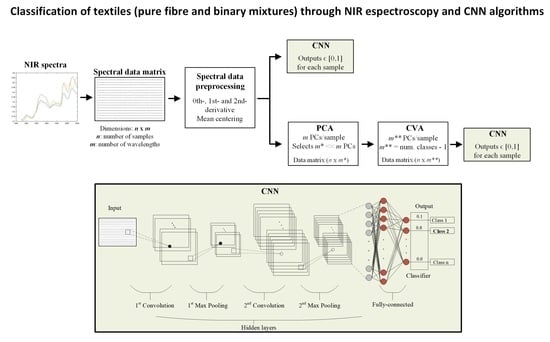
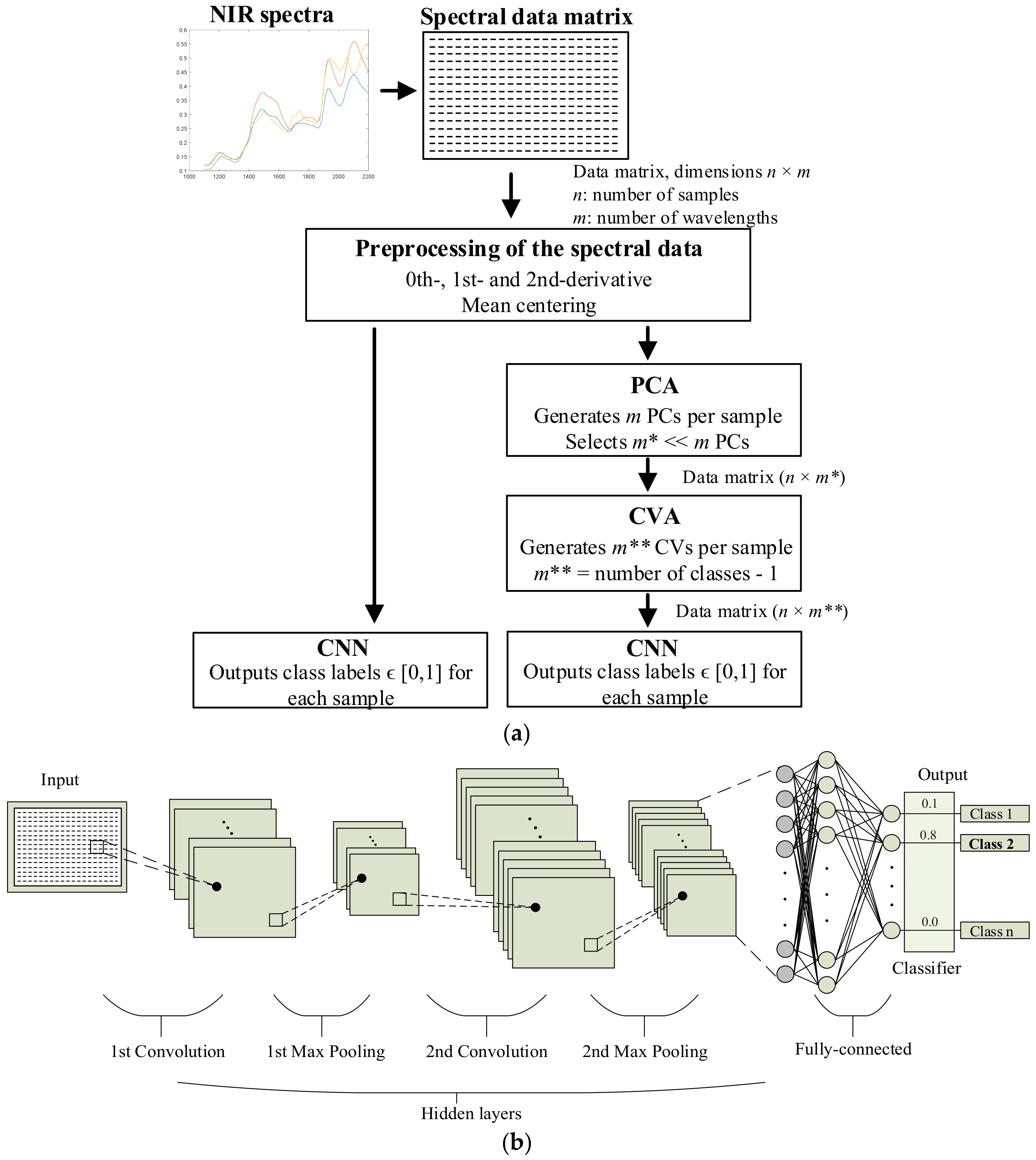
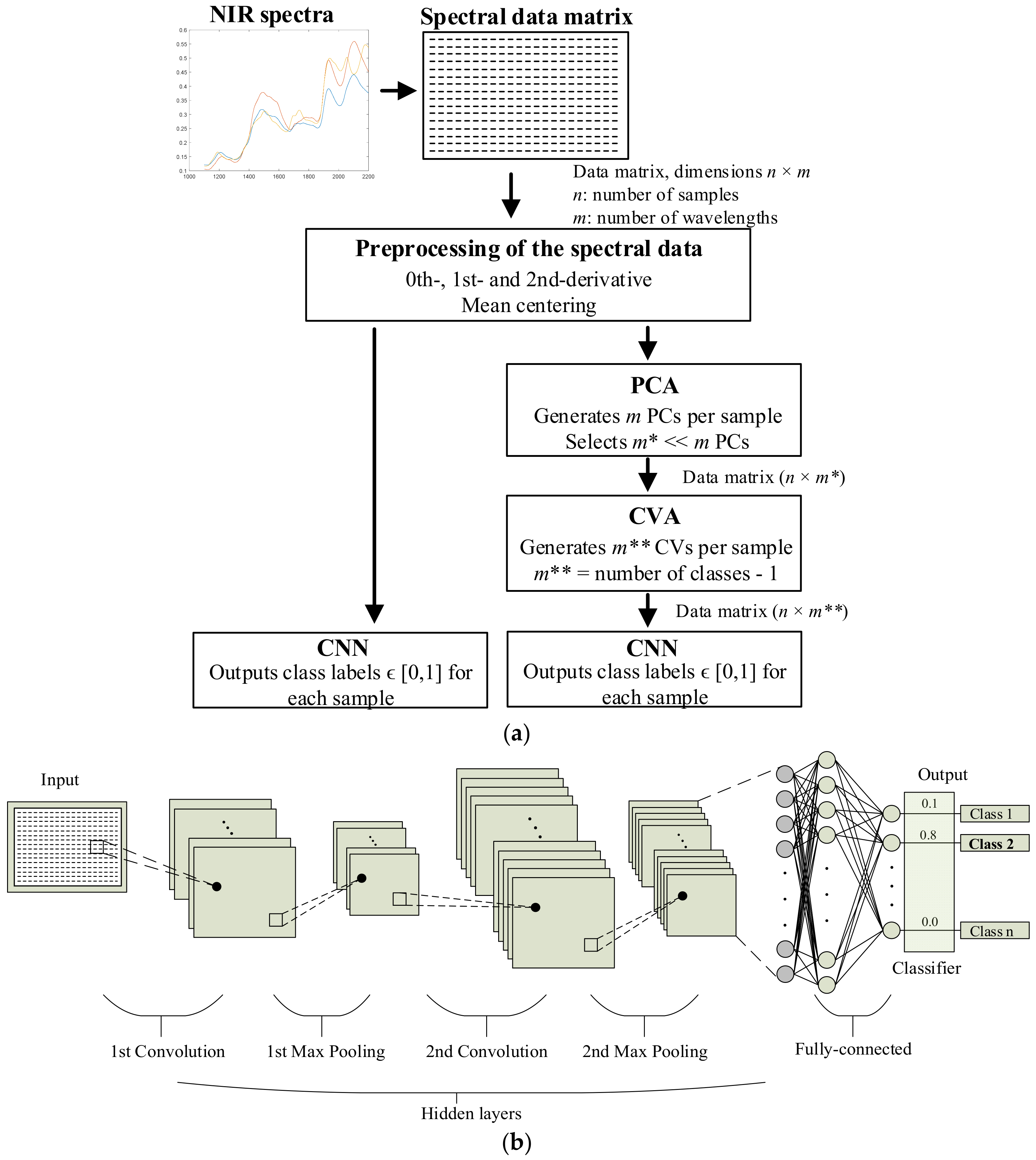
:
1. Introduction
2. The Proposed NIR–CNN Approach and the Processing Methods
2.1. Calibration and Prediction Data Subsets
2.2. Data Processing Stage
2.3. Applied Dimensionality Reduction Methods
2.4. Convolutional Neural Networks (CNNs) for Classification
2.5. Training of the CNN
3. Sample Collection and Identification
- Study #1: To classify 100% pure textile samples among seven different classes (i.e., cotton, linen, wool, silk, polyester, polyamide, and viscose).
- Study #2: To classify mixtures of viscose and polyester in different percentages.
- Study #3: To classify mixtures of cotton and polyester in different percentages.
4. The Analyzed Spectral Data
5. Experimental Results
5.1. Study #1: Analyzing Pure Textile Fibers
5.2. Study #2: Analyzing Mixed Viscose–Polyester Textile Samples
5.3. Study #3: Analyzing Mixed Cotton–Polyester Textile Samples
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ellen MacArthur Foundation a New Textiles Economy: Redesigning Fashion’s Future. Available online: https://emf.thirdlight.com/link/2axvc7eob8zx-za4ule/@/preview/1?o (accessed on 16 May 2022).
- European Environmental Agency Textiles in Europe’s Circular Economy Key Messages. Available online: https://www.eea.europa.eu/publications/textiles-in-europes-circular-economy (accessed on 16 May 2022).
- Kleinhückelkotten, S.; Neitzke, H.-P. Social Acceptability of More Sustainable Alternatives in Clothing Consumption. Sustainability 2019, 11, 6194. [Google Scholar] [CrossRef] [Green Version]
- Hole, G.; Hole, A.S. Recycling as the way to greener production: A mini review. J. Clean. Prod. 2019, 212, 910–915. [Google Scholar] [CrossRef]
- Yousef, S.; Tatariants, M.; Tichonovas, M.; Sarwar, Z.; Jonuškienė, I.; Kliucininkas, L. A new strategy for using textile waste as a sustainable source of recovered cotton. Resour. Conserv. Recycl. 2019, 145, 359–369. [Google Scholar] [CrossRef]
- Terinte, N.; Manda, B.; Taylor, J.; Schuster, K.; Patel, M. Environmental assessment of coloured fabrics and opportunities for value creation: Spin-dyeing versus conventional dyeing of modal fabrics. J. Clean. Prod. 2014, 72, 127–138. [Google Scholar] [CrossRef]
- Roos, S.; Jönsson, C.; Posner, S.; Arvidsson, R.; Svanström, M. An inventory framework for inclusion of textile chemicals in life cycle assessment. Int. J. Life Cycle Assess. 2019, 24, 838–847. [Google Scholar] [CrossRef] [Green Version]
- Piribauer, B.; Bartl, A. Textile recycling processes, state of the art and current developments: A mini review. Waste Manag. Res. J. A Sustain. Circ. Econ. 2019, 37, 112–119. [Google Scholar] [CrossRef]
- Esteve-Turrillas, F.; de la Guardia, M. Environmental impact of Recover cotton in textile industry. Resour. Conserv. Recycl. 2017, 116, 107–115. [Google Scholar] [CrossRef]
- Sandin, G.; Peters, G.M. Environmental impact of textile reuse and recycling—A review. J. Clean. Prod. 2018, 184, 353–365. [Google Scholar] [CrossRef]
- De Oliveira, C.R.S.; Júnior, A.H.D.S.; Mulinari, J.; Immich, A.P.S. Textile Re-Engineering: Eco-responsible solutions for a more sustainable industry. Sustain. Prod. Consum. 2021, 28, 1232–1248. [Google Scholar] [CrossRef]
- Dahlbo, H.; Aalto, K.; Eskelinen, H.; Salmenperä, H. Increasing textile circulation—Consequences and requirements. Sustain. Prod. Consum. 2017, 9, 44–57. [Google Scholar] [CrossRef]
- Huang, Y.-F.; Azevedo, S.G.; Lin, T.-J.; Cheng, C.-S.; Lin, C.-T. Exploring the decisive barriers to achieve circular economy: Strategies for the textile innovation in Taiwan. Sustain. Prod. Consum. 2021, 27, 1406–1423. [Google Scholar] [CrossRef]
- Hole, G.; Hole, A.S. Improving recycling of textiles based on lessons from policies for other recyclable materials: A minireview. Sustain. Prod. Consum. 2020, 23, 42–51. [Google Scholar] [CrossRef]
- Document 32018L0851; Directive (EU) 2018/851 of the European Parliament and of the Council of 30 May 2018 Amending Directive 2008/98/EC on Waste (Text with EEA Relevance). Official Journal of the European Union, 2018. Available online: https://eur-lex.europa.eu/eli/dir/2018/851/oj (accessed on 16 May 2022).
- Nørup, N.; Pihl, K.; Damgaard, A.; Scheutz, C. Evaluation of a European textile sorting centre: Material flow analysis and life cycle inventory. Resour. Conserv. Recycl. 2019, 143, 310–319. [Google Scholar] [CrossRef]
- Nunes, M.A.; Páscoa, R.N.; Alves, R.C.; Costa, A.S.; Bessada, S.; Oliveira, M.B.P. Fourier transform near infrared spectroscopy as a tool to discriminate olive wastes: The case of monocultivar pomaces. Waste Manag. 2020, 103, 378–387. [Google Scholar] [CrossRef]
- Salzmann, M.; Blößl, Y.; Todorovic, A.; Schledjewski, R. Usage of Near-Infrared Spectroscopy for Inline Monitoring the Degree of Curing in RTM Processes. Polymers 2021, 13, 3145. [Google Scholar] [CrossRef]
- Chen, X.; Kroell, N.; Wickel, J.; Feil, A. Determining the composition of post-consumer flexible multilayer plastic packaging with near-infrared spectroscopy. Waste Manag. 2021, 123, 33–41. [Google Scholar] [CrossRef]
- Huang, F.; Song, H.; Guo, L.; Guang, P.; Yang, X.; Li, L.; Zhao, H.; Yang, M. Detection of adulteration in Chinese honey using NIR and ATR-FTIR spectral data fusion. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2020, 235, 118297. [Google Scholar] [CrossRef]
- Cruz-Tirado, J.; Medeiros, M.L.D.S.; Barbin, D.F. On-line monitoring of egg freshness using a portable NIR spectrometer in tandem with machine learning. J. Food Eng. 2021, 306, 110643. [Google Scholar] [CrossRef]
- Corrêdo, L.P.; Wei, M.C.; Ferraz, M.N.; Molin, J.P. Near-infrared spectroscopy as a tool for monitoring the spatial variability of sugarcane quality in the fields. Biosyst. Eng. 2021, 206, 150–161. [Google Scholar] [CrossRef]
- Wang, Z.; Peng, B.; Huang, Y.; Sun, G. Classification for plastic bottles recycling based on image recognition. Waste Manag. 2019, 88, 170–181. [Google Scholar] [CrossRef]
- Riba, J.-R.; Cantero, R.; García-Masabet, V.; Cailloux, J.; Canals, T.; Maspoch, M.L. Multivariate identification of extruded PLA samples from the infrared spectrum. J. Mater. Sci. 2020, 55, 1269–1279. [Google Scholar] [CrossRef]
- De Maesschalck, R.; Estienne, F.; Verdu-Andres, J.; Candolfi, A.; Centner, V.; Despagne, F.; Jouan-Rimbaud, D.; Walczak, B.; Massart, D.L.; De Jong, S.; et al. The development of calibration models for spectroscopic data using principal component regression. Internet J. Chem. 1999, 2. [Google Scholar]
- Riba, J.-R.; Cantero, R.; Canals, T.; Puig, R. Circular economy of post-consumer textile waste: Classification through infrared spectroscopy. J. Clean. Prod. 2020, 272, 123011. [Google Scholar] [CrossRef]
- Pan, J.; Nguyen, K.L. Development of the Photoacoustic Rapid-Scan FT-IR-Based Method for Measurement of Ink Concentration on Printed Paper. Anal. Chem. 2007, 79, 2259–2265. [Google Scholar] [CrossRef]
- Riba, J.-R.; Canals, T.; Cantero, R. Recovered Paperboard Samples Identification by Means of Mid-Infrared Sensors. IEEE Sens. J. 2013, 13, 2763–2770. [Google Scholar] [CrossRef] [Green Version]
- Nørgaard, L.; Bro, R.; Westad, F.; Engelsen, S.B. A modification of canonical variates analysis to handle highly collinear multivariate data. J. Chemom. 2006, 20, 425–435. [Google Scholar] [CrossRef]
- Lai, W.-W.; Zeng, X.-X.; He, J.; Deng, Y.-L. Aesthetic defect characterization of a polymeric polarizer via structured light illumination. Polym. Test. 2016, 53, 51–57. [Google Scholar] [CrossRef] [Green Version]
- Younes, K.; Moghrabi, A.; Moghnie, S.; Mouhtady, O.; Murshid, N.; Grasset, L. Assessment of the Efficiency of Chemical and Thermochemical Depolymerization Methods for Lignin Valorization: Principal Component Analysis (PCA) Approach. Polymers 2022, 14, 194. [Google Scholar] [CrossRef]
- Riba Ruiz, J.-R.; Canals, T.; Cantero, R. Supervision of Ethylene Propylene Diene M-Class (EPDM) Rubber Vulcanization and Recovery Processes Using Attenuated Total Reflection Fourier Transform Infrared (ATR FT-IR) Spectroscopy and Multivariate Analysis. Appl. Spectrosc. 2017, 71, 141–151. [Google Scholar] [CrossRef]
- Bhattacharyya, N.; Bandyopadhyay, R.; Bhuyan, M.; Tudu, B.; Ghosh, D.; Jana, A. Electronic Nose for Black Tea Classification and Correlation of Measurements With “Tea Taster” Marks. IEEE Trans. Instrum. Meas. 2008, 57, 1313–1321. [Google Scholar] [CrossRef]
- Amor, N.; Noman, M.T.; Petru, M. Classification of Textile Polymer Composites: Recent Trends and Challenges. Polymers 2021, 13, 2592. [Google Scholar] [CrossRef]
- Cun, L.; Henderson, J.; Le Cun, Y.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Handwritten Digit Recognition with a Back-Propagation Network. In Advances in Neural Information Processing Systems; Touretzk, D., Ed.; Morgan-Kaufmann: Cambridge, MA, USA, 1989; Volume 2, pp. 396–404. [Google Scholar]
- Zhang, Q.; Yang, Q.; Zhang, X.; Bao, Q.; Su, J.; Liu, X. Waste image classification based on transfer learning and convolutional neural network. Waste Manag. 2021, 135, 150–157. [Google Scholar] [CrossRef]
- Cao, X.-C.; Chen, B.-Q.; Yao, B.; He, W.-P. Combining translation-invariant wavelet frames and convolutional neural network for intelligent tool wear state identification. Comput. Ind. 2019, 106, 71–84. [Google Scholar] [CrossRef]
- Ciancetta, F.; Bucci, G.; Fiorucci, E.; Mari, S.; Fioravanti, A. A New Convolutional Neural Network-Based System for NILM Applications. IEEE Trans. Instrum. Meas. 2020, 70, 1–12. [Google Scholar] [CrossRef]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Rojas-Duenas, G.; Riba, J.-R.; Moreno-Eguilaz, M. Black-Box Modeling of DC–DC Converters Based on Wavelet Convolutional Neural Networks. IEEE Trans. Instrum. Meas. 2021, 70, 1–9. [Google Scholar] [CrossRef]
- Ruder, S. An Overview of Gradient Descent Optimization Algorithms. 2016. Available online: https://arxiv.org/abs/1609.04747 (accessed on 16 May 2022).
- He, F.; Zhou, J.; Feng, Z.-K.; Liu, G.; Yang, Y. A hybrid short-term load forecasting model based on variational mode decomposition and long short-term memory networks considering relevant factors with Bayesian optimization algorithm. Appl. Energy 2019, 237, 103–116. [Google Scholar] [CrossRef]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; De Freitas, N. Taking the human out of the loop: A review of Bayesian optimization. Proc. IEEE 2016, 104, 148–175. [Google Scholar] [CrossRef] [Green Version]
- Sun, X.; Zhou, M.; Sun, Y. Classification of textile fabrics by use of spectroscopy-based pattern recognition methods. Spectrosc. Lett. 2016, 49, 96–102. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Studies | Catalogs (n°) | Classification Classes | Samples per Class | Samples per Study |
|---|---|---|---|---|
| Study #1 | 25 | Cotton; linen; wool; silk; polyester; polyamide; viscose | 30 | 210 |
| Study #2 | 11 | Viscose (100%); | 26 | 73 |
| viscose/PE (90%/10%); | 26 | |||
| viscose/PE (70–75%/30–25%) | 21 | |||
| Study #3 | 25 | Cotton (>97%); | 30 | 90 |
| cotton/PE (70–90%/30–10%); | 30 | |||
| cotton/PE (30–65%/70–35%) | 30 |
| Pure Fiber | Type of Fiber | Samples Number | ||
|---|---|---|---|---|
| Calibration | Prediction | Total | ||
| Cotton | Natural | 15 | 15 | 30 |
| Linen | Natural | 15 | 15 | 30 |
| Wool | Natural | 15 | 15 | 30 |
| Silk | Natural | 15 | 15 | 30 |
| Polyester (PE) | Synthetic | 15 | 15 | 30 |
| Polyamide (PA) | Synthetic | 15 | 15 | 30 |
| Viscose | Artificial | 15 | 15 | 30 |
| Conditions | Classification Errors | |
|---|---|---|
| CNN | PCA + CVA + CNN | |
| Mean-centering | 4/105 a | 0/105 aa |
| First derivative + mean-centering | 3/105 b | 0/105 bb |
| Second derivative + mean-centering | 4/105 c | 1/105 cc |
| Pure Fiber | Composition | Samples Number | ||
|---|---|---|---|---|
| Calibration | Prediction | Total | ||
| Viscose | 100% (Pure) | 13 | 13 | 26 |
| Viscose/PE | 90%/10% | 13 | 13 | 26 |
| Viscose/PE | 70–75%/30–25% | 10 | 11 | 21 |
| Conditions | Classification Errors |
|---|---|
| PCA + CVA + CNN | |
| Mean-centering | 1/36 a |
| First derivative + mean-centering | 0/36 b |
| Second derivative + mean-centering | 0/36 c |
| Pure Fiber | Composition | Samples Number | ||
|---|---|---|---|---|
| Calibration | Prediction | Total | ||
| Cotton | ≥97% (Pure) | 15 | 15 | 30 |
| Cotton/PE | 70–90%/30–10% | 15 | 15 | 30 |
| Cotton/PE | 30–65%/70–35% | 15 | 15 | 30 |
| Conditions | Classification Errors |
|---|---|
| PCA + CVA + CNN | |
| Mean-centering | 7/45 a |
| First derivative + mean-centering | 7/45 b |
| Second derivative + mean-centering | 4/45 c |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Riba, J.-R.; Cantero, R.; Riba-Mosoll, P.; Puig, R. Post-Consumer Textile Waste Classification through Near-Infrared Spectroscopy, Using an Advanced Deep Learning Approach. Polymers 2022, 14, 2475. https://doi.org/10.3390/polym14122475
Riba J-R, Cantero R, Riba-Mosoll P, Puig R. Post-Consumer Textile Waste Classification through Near-Infrared Spectroscopy, Using an Advanced Deep Learning Approach. Polymers. 2022; 14(12):2475. https://doi.org/10.3390/polym14122475
Chicago/Turabian StyleRiba, Jordi-Roger, Rosa Cantero, Pol Riba-Mosoll, and Rita Puig. 2022. "Post-Consumer Textile Waste Classification through Near-Infrared Spectroscopy, Using an Advanced Deep Learning Approach" Polymers 14, no. 12: 2475. https://doi.org/10.3390/polym14122475
APA StyleRiba, J.-R., Cantero, R., Riba-Mosoll, P., & Puig, R. (2022). Post-Consumer Textile Waste Classification through Near-Infrared Spectroscopy, Using an Advanced Deep Learning Approach. Polymers, 14(12), 2475. https://doi.org/10.3390/polym14122475