Personal-Data Disclosure in a Field Experiment: Evidence on Explicit Prices, Political Attitudes, and Privacy Preferences †

Abstract
:1. Introduction
2. Experimental Setting
3. Hypotheses
3.1. Main Hypotheses
3.2. Secondary Hypotheses
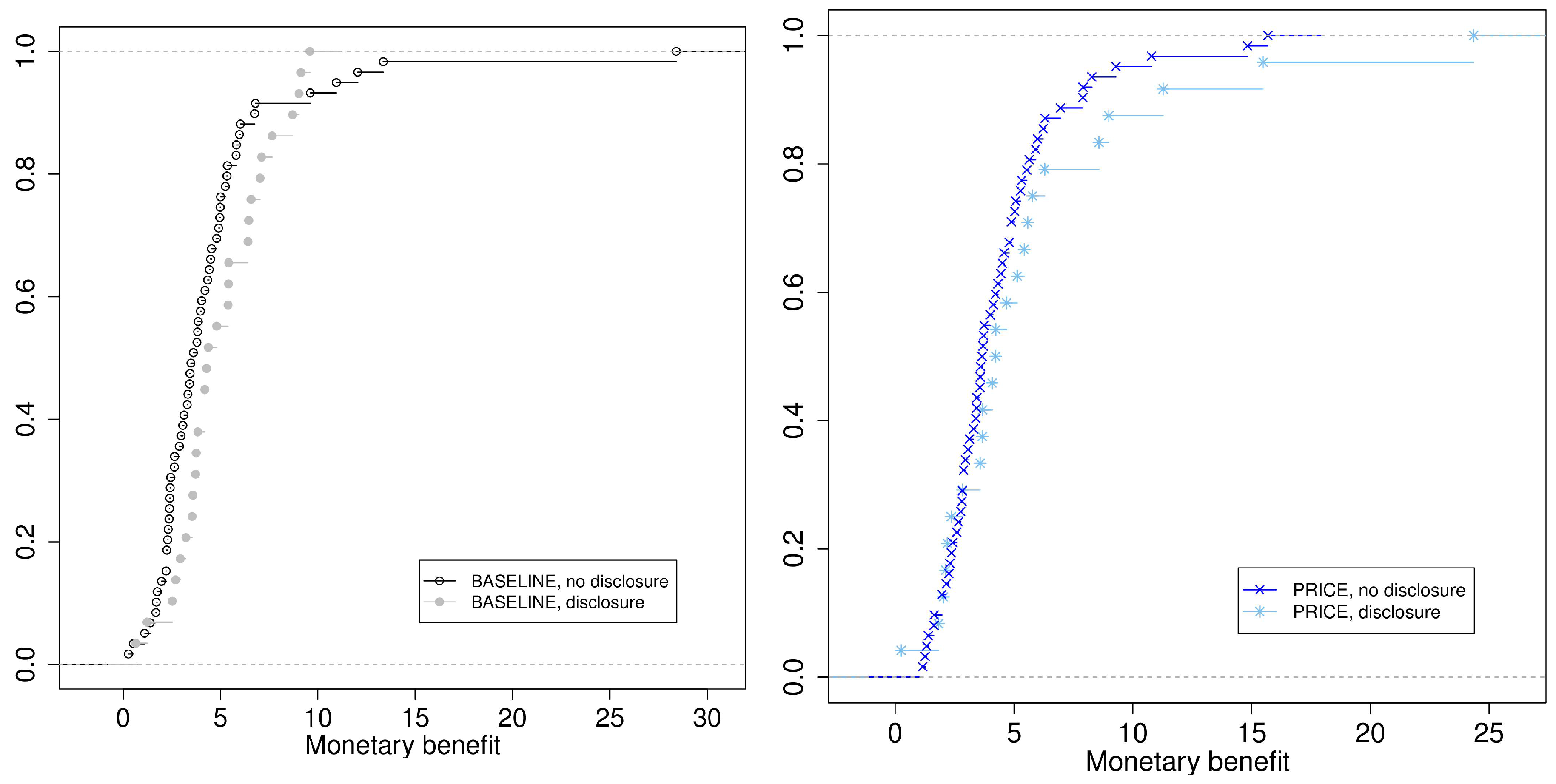
4. Results
4.1. Main Results
4.2. Exploratory Analysis: Determinants of Consent vs. Bonus-Programme Participation
5. Discussion
Author Contributions
Conflicts of Interest
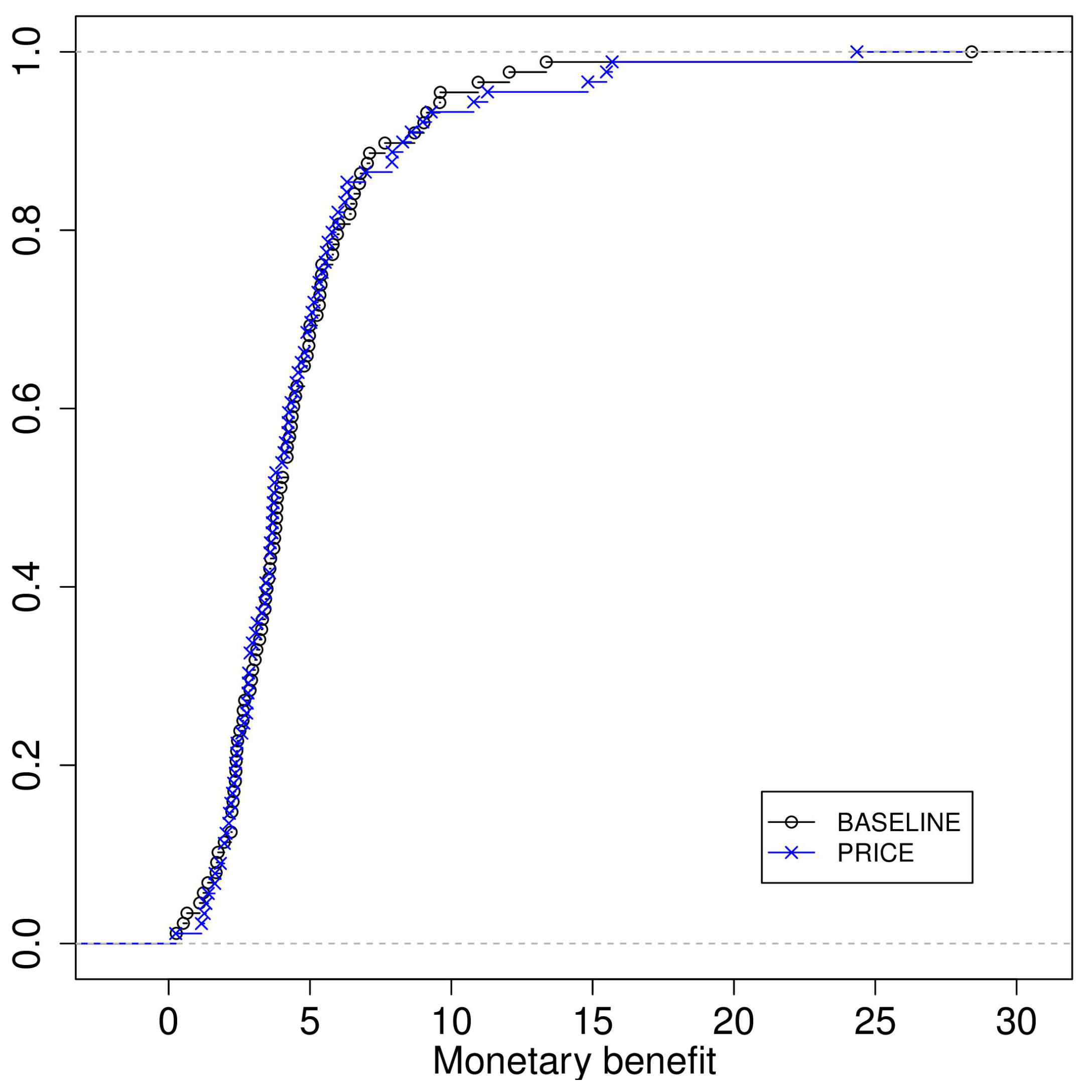
Appendix A. Supplementary Figure: Offered Benefits by Treatment

Appendix B. Script for the Guided Interview (Translated from German)
Potential inquiries:
Potential inquiries:
Potential inquiries:
- → if yes: Thank you very much, we will subtract the corresponding amount from your invoice for January.
- → if no: What a pity, but we, of course, respect that.
References
- Rotella, P. Is Data the New Oil? Forbes Magazine. 2012. Available online: https://www.forbes.com/sites/perryrotella/2012/04/02/is-data-the-new-oil/#59a92a517db3 (accessed on 28 January 2018).
- Madden, M.; Rainie, L.; Zickuhr, K.; Duggan, M.; Smith, A. Public Perceptions of Privacy and Security in the Post-Snowden Era. Pew Research Center, 2014. Available online: http://www.pewinternet.org/2014/11/12/public-privacy-perceptions (accessed on 19 March 2018).
- Tsai, J.Y.; Egelman, S.; Cranor, L.; Acquisti, A. The Effect of Online Privacy Information on Purchasing behaviour: An Experimental Study. Inf. Syst. Res. 2011, 22, 254–268. [Google Scholar] [CrossRef]
- Acquisti, A.; Taylor, C.; Wagman, L. The Economics of Privacy. J. Econ. Lit. 2016, 54, 442–492. [Google Scholar] [CrossRef]
- Acquisti, A.; John, L.K.; Loewenstein, G. What Is Privacy Worth? J. Leg. Stud. 2013, 42, 249–274. [Google Scholar] [CrossRef]
- Beresford, A.R.; Kübler, D.; Preibusch, S. Unwillingness to pay for privacy: A field experiment. Econ. Lett. 2012, 117, 25–27. [Google Scholar] [CrossRef]
- Regner, T.; Riener, G. Privacy Is Precious: On the Attempt to Lift Anonymity on the Internet to Increase Revenue. J. Econ. Manag. Strategy 2017, 26, 318–336. [Google Scholar] [CrossRef]
- Marreiros, H.; Tonin, M.; Vlassopoulos, M.; Schraefel, M.C. Now that you mention it’: A survey experiment on information, inattention and online privacy. J. Econ. Behav. Organ. 2017, 140, 1–17. [Google Scholar] [CrossRef]
- Benndorf, V.; Kübler, D.; Normann, H.-T. Privacy concerns, voluntary disclosure of information, and unraveling: An experiment. Eur. Econ. Rev. 2015, 75, 43–59. [Google Scholar] [CrossRef]
- Benndorf, V.; Normann, H.-T. The Willingness to Sell Personal Data. Scand. J. Econ. 2017. [Google Scholar] [CrossRef]
- Schudy, S.; Verena, U. You must not know about me’—On the willingness to share personal data. J. Econ. Behav. Organ. 2017, 141, 1–13. [Google Scholar] [CrossRef]
| 1 | https://www.payback.net/en/press/press-releases/detail/studie-zeigt-punkte-schlagen-geld/, last accessed on 4 October 2017. |
| 2 | A translated version of the script can be found in the Appendix B. |
| 3 | https://www.tagesschau.de/wahl/parteien_und_programme/programmvergleich datenschutz100.html, latest update: 22 August 2013; latest access on 6 October 2017. |
| 4 | While the CDU and AFD did not seem to address the issue of data privacy in their programmes at all, the FDP mainly focused on protection of citizen data against governmental intrusion. |
| 5 | Looking at marginal effects of probit regressions yields the same conclusions, but given we want to interpret interaction effects, we rather stick to a linear probability model. Using a linear probability model does not seem to be too troublesome, either. The a-priori probability of giving consent is nowhere close to the boundaries, and predicted values are rarely outside of [0, 1] for most of the models reported in the following (cf. the corresponding row in Table 2). |
| 6 | In particular, we control for the main customer’s age; for whether the customer is a long-term client (>365 days); for whether the customer asked back about data-related aspects; for whether the customer’s home is located in a development area, interacted with the standard land value and a standard land value normalised by the standard land value of the (nearby) town; and for additional area-specific characteristics by including random effects for the postal code. |
| 7 | We are grateful to an anonymous referee who suggested this approach. |
| 8 | None of the qualitative statements changes if we stick to linear probability models also in this part. However, we would have up to 9 predicted probabilities outside of [0, 1] for some of these models, which is another argument in favour of using the probit regressions reported in the text. |
| 9 | Note, however, that some of the findings of Benndorf and Normann [10] seem to contradict this conclusion. In particular, their take-it-or-leave-it treatments shows high consent rates under an offer of 5 € even though both costs and benefits are made salient (in their willingness-to-accept treatments, costs are also salient, but requested benefits are much higher). Similarly, in Acquisti et al. [5], many customers sell their data, being identifiable for as little as USD 2, but there, the costs are somewhat limited: the data are sold to the researchers only, not to a company as a third party. |
| 10 | Of course, we are not claiming that voting for the FDP causally leads to consenting to a data transfer. Our working hypothesis that would have to be substantiated in future work is that the same attitude that makes people vote for the FDP also makes them trust firms not to use people’s data to their disadvantage. |

{kind=link}
{kind=link}
| Variable | Minimum (if appl.) | Mean/Percentage | Maximum (if appl.) |
|---|---|---|---|
| Participants in price condition | na | 50.30% | na |
| consent | na | 30.50% | na |
| Offered monetary benefit | 0.25 € | 4.71 € | 28.41 € |
| Female | na | 73.00% | na |
| Age | 25 | 49 | 87 |
| Participants in other bonus programmes | na | 52.30% | na |
| Days as a client | 35 | 879 | 1241 |
| Model 1 | Model 2 | Model 3 | Model 4 | Model 5 | Model 6 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Estimate (Std.Err.) | t-Test p-Value | Estimate (Std.Err.) | t-Test p-Value | Estimate (Std.Err.) | t-Test p-Value | Estimate (Std.Err.) | t-Test p-Value | Estimate (Std.Err.) | t-Test p-Value | Estimate (Std.Err.) | t-Test p-Value | |
| Intercept | 0.281 −0.081 | <0.001 | 0.183 (0.092) | 0.048 | 0.404 (0.216) | 0.065 | 0.122 (0.156) | 0.436 | 0.027 (0.159) | 0.867 | 0.175 (0.258) | 0.498 |
| Monetary benefit | 0.010 (0.014) | 0.457 | 0.014 (0.014) | 0.328 | 0.014 (0.015) | 0.334 | 0.046 (0.044) | 0.302 | 0.042 (0.046) | 0.34 | 0.053 (0.046) | 0.248 |
| Benefit in 4th quartile | 0.630 (0.258) | 0.016 | 0.667 (0.255) | 0.01 | 0.725 (0.278) | 0.01 | ||||||
| price trmt | −0.101 −0.116 | 0.382 | −0.095 (0.115) | 0.411 | −0.124 (0.117) | 0.291 | 0.177 (0.230) | 0.443 | 0.154 (0.229) | 0.502 | 0.060 (0.236) | 0.801 |
| Another programme | 0.159 (0.071) | 0.026 | 0.171 (0.072) | 0.019 | 0.183 (0.071) | 0.011 | 0.205 (0.073) | 0.006 | ||||
| Monetary benefit × Benefit in 4th quartile | −0.074 (0.049) | 0.129 | −0.070 (0.048) | 0.146 | −0.084 (0.053) | 0.114 | ||||||
| Monetary benefit × price trmt | 0.010 (0.019) | 0.595 | 0.010 (0.019) | 0.614 | 0.014 (0.019) | 0.483 | −0.064 (0.066) | 0.33 | −0.056 (0.066) | 0.396 | −0.032 (0.068) | 0.643 |
| Benefit in 4th quartile × price trmt | −0.730 (0.375) | 0.053 | −0.697 (0.372) | 0.062 | −0.584 (0.388) | 0.134 | ||||||
| Benefit in 4th quartile × price trmt × Monetary benefit | 0.114 (0.072) | 0.116 | 0.104 (0.072) | 0.15 | 0.079 (0.076) | 0.298 | ||||||
| Controls | No | No | Yes | No | No | Yes | ||||||
| Predicted prob. out-side [0, 1] | 0 | 0 | 3 | 1 | 1 | 8 | ||||||
| Predicted prob.within [0.2, 0.8] | 98% | 84% | 71% | 92% | 72% | 69% | ||||||
| N.obs. | 177 | 172 | 172 | 177 | 172 | 172 | ||||||
| R2 | 0.02 | 0.05 | 0.07/0.20 | 0.04 | 0.06 | 0.11/0.25 | ||||||
| Model 7 | Model 8 | Model 9 | Model 10 | Model 11 | Model 12 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Marg.Ef. | t-Test | Marg.Eff. | t-Test p-Value | Marg.Eff. | t-Test | Marg.Eff. | t-Test p-Value | Marg.Eff. | t-Test p-Value | Marg.Eff. | t-Test | |
| (Std.Err.) | p-Value | (Std.Err.) | (Std.Err.) | p-Value | (Std.Err.) | (Std.Err.) | (Std.Err.) | p-Value | ||||
| Benefit in 4th quartile | 0.264 (0.089) | 0.003 | 0.249 (0.105) | 0.009 | 0.269 (0.090) | 0.003 | 0.256 (0.089) | 0.004 | 0.259 (0.089) | 0.004 | 0.259 (0.089) | 0.004 |
| Another programme | 0.211 (0.072) | 0.003 | 0.218 (0.088) | 0.007 | 0.209 (0.072) | 0.004 | 0.197 (0.072) | 0.006 | 0.195 (0.072) | 0.007 | 0.196 (0.072) | 0.007 |
| Asked back | −0.081 (0.074) | 0.272 | −0.087 (0.098) | 0.186 | ||||||||
| FDP | 0.034 (0.013) | 0.01 | ||||||||||
| SPD | −0.007 (0.010) | 0.482 | ||||||||||
| CDU | 0.004 (0.007) | 0.534 | ||||||||||
| Grüne | −0.005 (0.009) | 0.612 | ||||||||||
| Linke | ||||||||||||
| Piraten | ||||||||||||
| AfD | ||||||||||||
| Controls | No | Yes | No | No | No | No | ||||||
| R2 | 0.06 | 0.17/0.28 | 0.09 | 0.06 | 0.06 | 0.06 | ||||||
| Model 13 | Model 14 | Model 15 | Model 16 | Model 17 | Model 18 | |||||||
| Marg.Eff. | t-Test p-Value | Marg.Eff. | t-Test p-Value | Marg.Eff. | t-Test | Marg.Eff. | t-Test p-Value | Marg.Eff. | t-Test p-Value | Marg.Eff. | t-Test | |
| (Std.Err.) | (Std.Err.) | (Std.Err.) | p-Value | (Std.Err.) | (Std.Err.) | (Std.Err.) | p-Value | |||||
| Benefit in 4th quartile | 0.268 (0.090) | 0.003 | 0.257 (0.089) | 0.004 | 0.249 (0.089) | 0.005 | 0.270 (0.092) | 0.003 | 0.261 (0.104) | 0.006 | 0.260 (0.123) | 0.017 |
| Another programme | 0.193 (0.072) | 0.007 | 0.202 (0.071) | 0.005 | 0.204 (0.072) | 0.004 | 0.220 (0.074) | 0.003 | 0.229 (0.092) | 0.006 | 0.226 (0.108) | 0.018 |
| Asked back | ||||||||||||
| FDP | 0.096 (0.039) | 0.015 | 0.051 (0.024) | 0.016 | 0.100 (0.063) | 0.057 | ||||||
| SPD | 0.063 (0.040) | 0.111 | 0.053 (0.060) | 0.187 | ||||||||
| CDU | 0.053 (0.038) | 0.157 | 0.49 (0.057) | 0.195 | ||||||||
| Grüne | 0.052 (0.035) | 0.136 | 0.041 (0.056) | 0.233 | ||||||||
| Linke | −0.041 (0.024) | 0.09 | 0.004 (0.049) | 0.935 | 0.010 (0.076) | 0.447 | ||||||
| Piraten | −0.012 (0.041) | 0.772 | 0.091 (0.060) | 0.127 | 0.061 (0.086) | 0.239 | ||||||
| AfD | −0.012 (0.021) | 0.554 | 0.020 (0.045) | 0.656 | 0.014 (0.061) | 0.408 | ||||||
| Controls | No | No | No | No | Yes | Yes | ||||||
| R2 | 0.07 | 0.06 | 0.06 | 0.13 | 0.31/0.34 | 0.32/0.35 | ||||||
| Consent to a Data Transfer | Participation in a Bonus Programme | |||||||
|---|---|---|---|---|---|---|---|---|
| Linear Prob. Model | Probit Model | Linear Prob. Model | Probit Model | |||||
| Estimate (Std.Err.) | t-Test p-Value | Marg.Ef. (Std.Err.) | t-Test p-Value | Estimate (Std.Err.) | t-Test p-Value | Marg.Ef. (Std.Err.) | t-Test p-Value | |
| (Intercept) | −4.873 (3.995) | 0.224 | 1.224 (4.146) | 0.768 | ||||
| Asked back | −0.020 (0.077) | 0.792 | −0.009 (0.099) | 0.463 | 0.112 (0.083) | 0.175 | 0.106 (0.096) | 0.136 |
| E-mail contact | 0.027 (0.103) | 0.791 | 0.008 (0.129) | 0.475 | 0.246 (0.109) | 0.025 | 0.239 (0.141) | 0.045 |
| Age/100 | −0.249 (0.332) | 0.454 | −0.287 (0.377) | 0.224 | −0.125 (0.355) | 0.726 | −0.153 (0.386) | 0.346 |
| Development area | 0.106 (0.211) | 0.617 | 0.135 (0.305) | 0.329 | 0.248 (0.219) | 0.261 | 0.264 (0.268) | 0.162 |
| (Standard land value)/100 | −0.036 (0.048) | 0.452 | −0.032 (0.065) | 0.309 | 0.083 (0.049) | 0.093 | 0.086 (0.071) | 0.114 |
| FDP (absolute, not in %) | 9.438 (4.501) | 0.038 | 8.807 (6.072) | 0.074 | −4.163 (4.639) | 0.371 | −4.110 (5.431) | 0.225 |
| SPD (absolute, not in %) | 6.254 (4.391) | 0.156 | 5.625 (5.831) | 0.167 | −1.956 (4.515) | 0.665 | −1.953 (5.566) | 0.363 |
| CDU (absolute, not in %) | 6.495 (4.236) | 0.127 | 5.523 (5.415) | 0.154 | −1.862 (4.363) | 0.67 | −1.938 (5.118) | 0.352 |
| Grüne (absolute, not in %) | 5.869 (4.151) | 0.159 | 5.444 (5.590) | 0.165 | −4.212 (4.384) | 0.338 | −4.253 (5.212) | 0.207 |
| Linke (absolute, not in %) | 1.107 (5.523) | 0.841 | 0.889 (7.196) | 0.451 | −3.710 (5.810) | 0.524 | −3.763 (6.803) | 0.29 |
| Piraten (absolute, not in %) | 10.849 (6.2430) | 0.084 | 8.933 (8.422) | 0.144 | 2.096 (6.583) | 0.751 | 2.146 (7.802) | 0.392 |
| AfD (absolute, not in %) | 2.100 (4.755) | 0.659 | 1.557 (5.800) | 0.394 | 0.131 (4.962) | 0.979 | 0.232 (6.155) | 0.485 |
| Election turn-out (absolute, not in %) | −0.894 (1.065) | 0.403 | −0.815 (1.527) | 0.297 | 1.796 (1.110) | 0.108 | 1.865 (1.527) | 0.111 |
| Development area × (Standard land value)/100 | −0.072 (0.108) | 0.505 | −0.098 (0.185) | 0.299 | −0.113 (0.113) | 0.279 | −0.136 (0.142) | 0.169 |
| Predicted prob. out-side [0, 1] | 3 | 0 | 2 | 0 | ||||
| Predicted prob. within [0.2, 0.8] | 73% | 100% | 91% | 100% | ||||
| R2 | 0.09/0.16 | 0.14/0.17 | 0.13/0.13 | 0.22/0.22 | ||||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Plesch, J.; Wolff, I. Personal-Data Disclosure in a Field Experiment: Evidence on Explicit Prices, Political Attitudes, and Privacy Preferences. Games 2018, 9, 24. https://doi.org/10.3390/g9020024
Plesch J, Wolff I. Personal-Data Disclosure in a Field Experiment: Evidence on Explicit Prices, Political Attitudes, and Privacy Preferences. Games. 2018; 9(2):24. https://doi.org/10.3390/g9020024
Chicago/Turabian StylePlesch, Joachim, and Irenaeus Wolff. 2018. "Personal-Data Disclosure in a Field Experiment: Evidence on Explicit Prices, Political Attitudes, and Privacy Preferences" Games 9, no. 2: 24. https://doi.org/10.3390/g9020024
APA StylePlesch, J., & Wolff, I. (2018). Personal-Data Disclosure in a Field Experiment: Evidence on Explicit Prices, Political Attitudes, and Privacy Preferences. Games, 9(2), 24. https://doi.org/10.3390/g9020024