
Evolutionary Inspection and Corruption Games


Abstract
:1. Introduction
2. Standard Inspection Game
3. Evolutionary Inspection Game: Discrete Strategy Setting
3.1. Analysis
3.2. Linear Fine
- (i)
- If , there is additionally a unique hyperplane of fixed points,
- (ii)
- If and , there are additionally infinitely many hyperplanes of fixed points,
- (i)
- When , there is a unique satisfying . This unique is generated by infinitely many probability vectors, , forming a hyperplane of points satisfying (14).
- (ii)
- When and , every satisfies . Each one of these infinitely many is generated by infinitely many probability vectors, , forming infinitely many hyperplanes of points satisfying (14).
3.3. Convex/Concave Fine
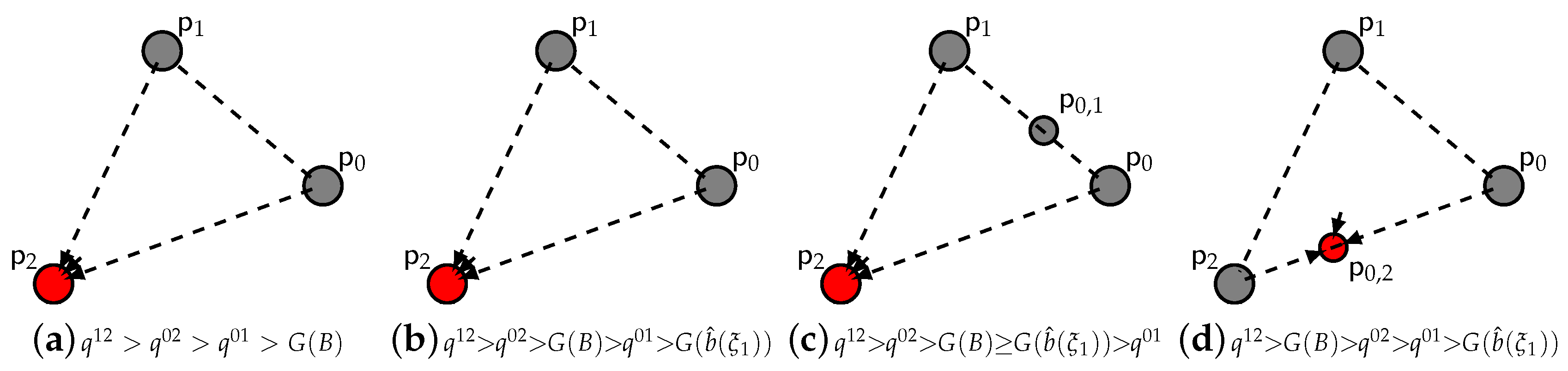
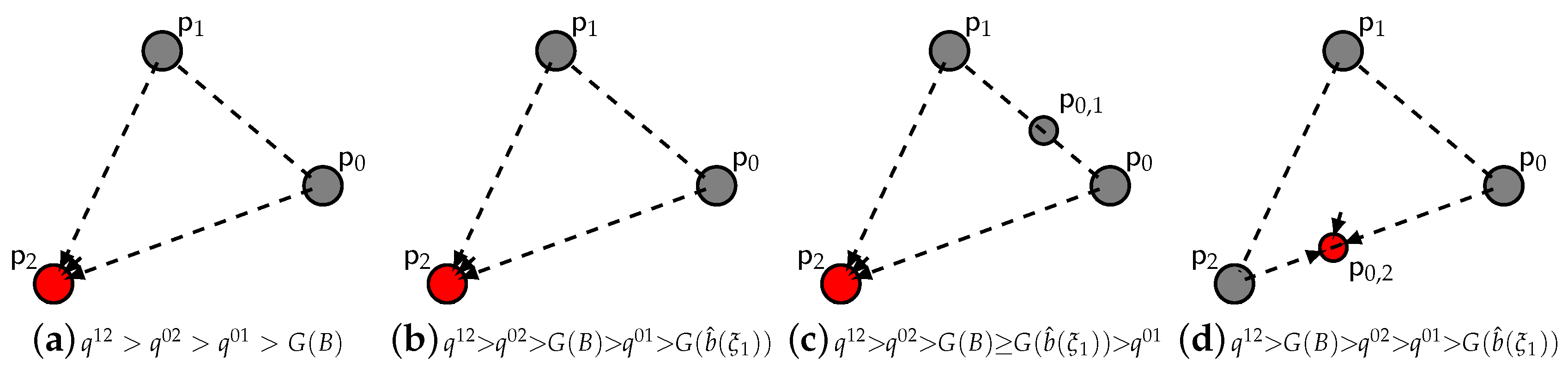
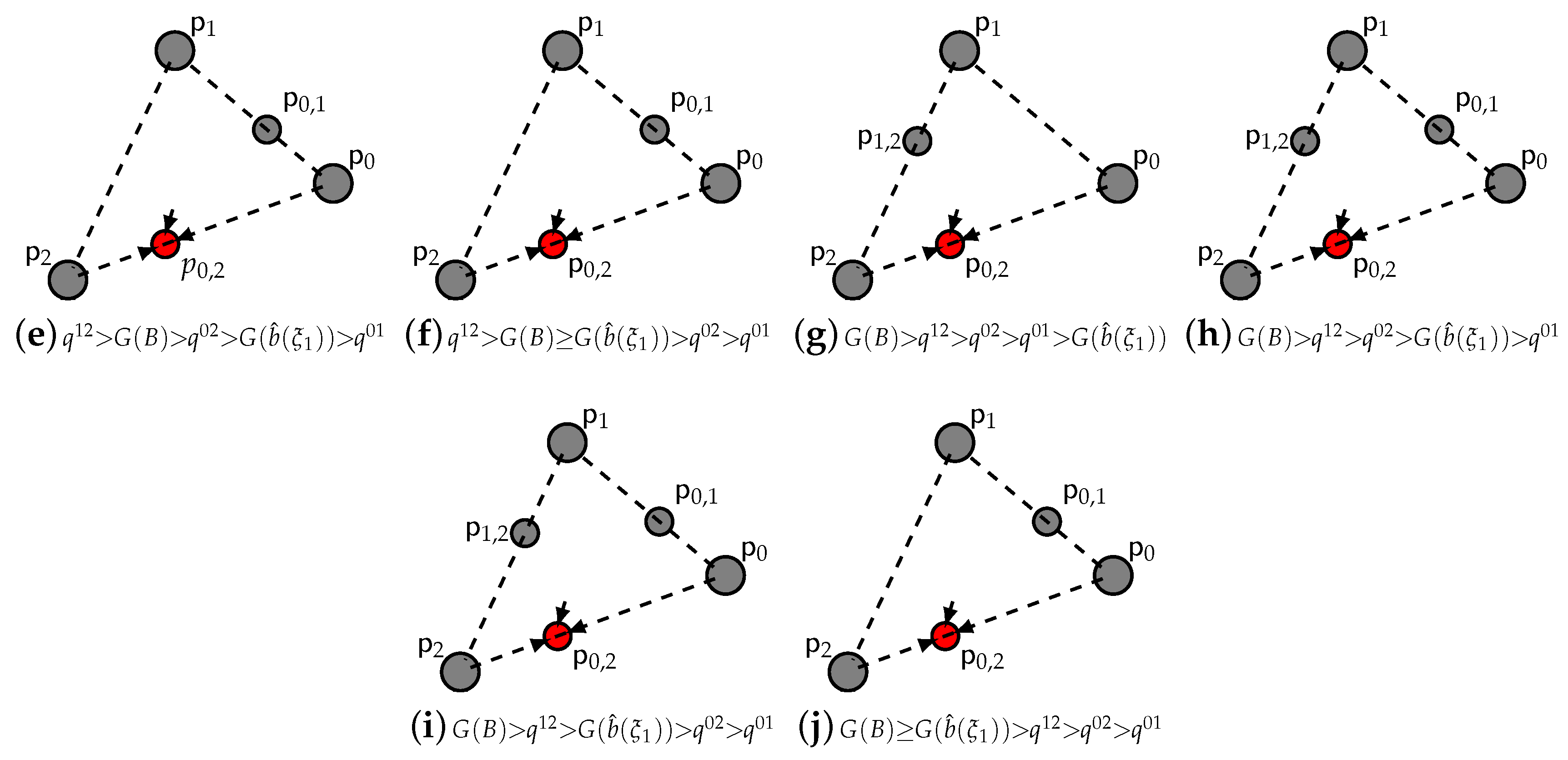
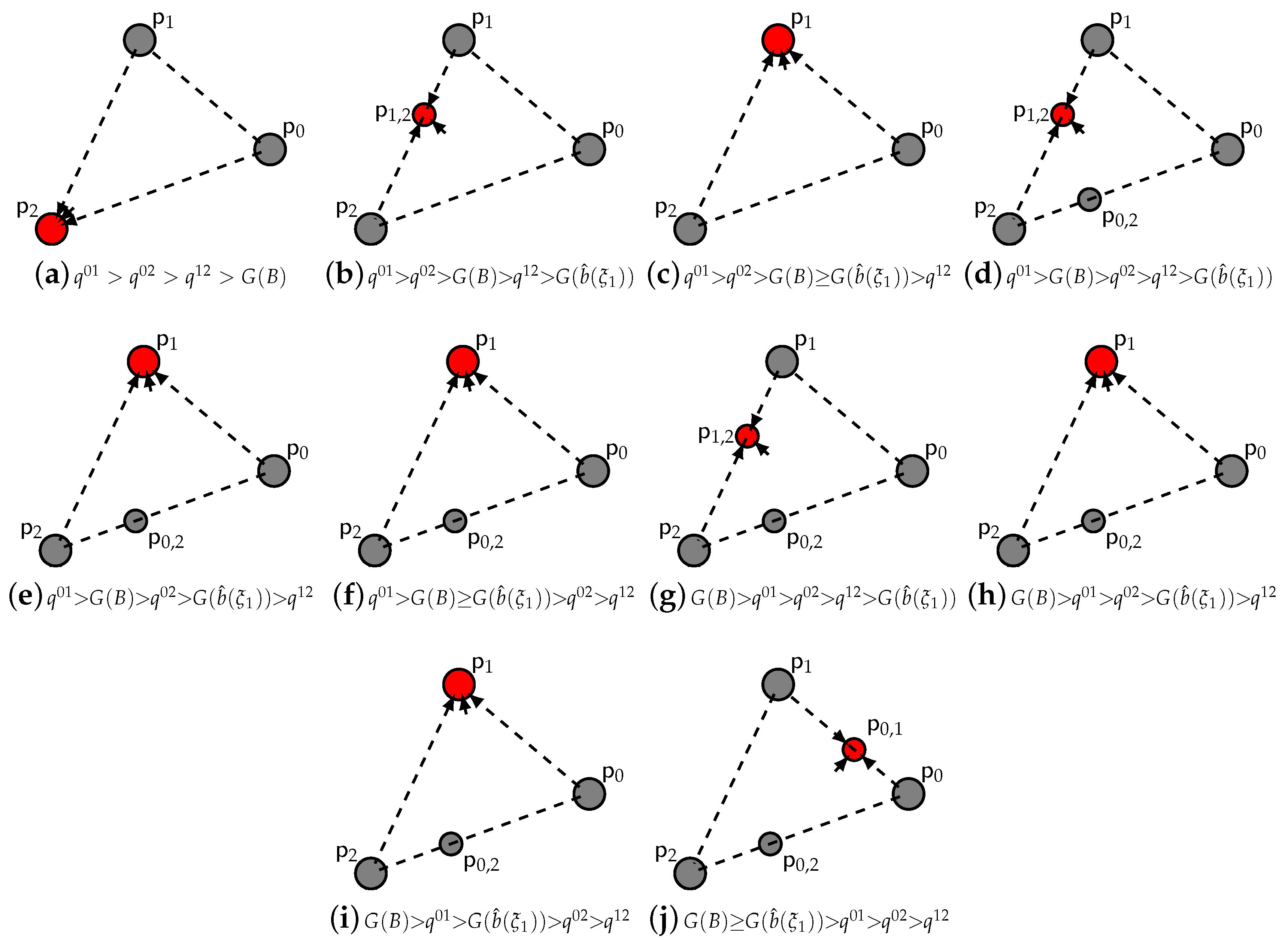
- For a concave fine: (i) the pure strategy fixed point is a source, thus unstable; (ii) the pure strategy fixed points , are saddles, thus unstable; (iii) the double strategy fixed points are saddles, thus unstable; (iv) the double strategy fixed point is asymptotically stable; (v) the pure strategy fixed point is asymptotically stable when does not exist; otherwise, it is a source, thus unstable.
- For a convex fine: (i) the pure strategy fixed point is a source, thus unstable; (ii) the double strategy fixed points , are saddles, thus unstable; the double strategy fixed points are asymptotically stable; the pure strategy fixed points , are saddles, thus unstable; the pure strategy fixed point is a source, thus unstable. * When no exists, the pure strategy fixed point satisfying (22) is asymptotically stable.
4. Evolutionary Inspection Game: Continuous Strategy Setting
4.1. Linear Fine
- (i)
- If , there is additionally a unique hyperplane of fixed points:
- (ii)
- If and , there are additionally infinitely many hyperplanes of fixed points:
- (i)
- When , there is a unique satisfying . This unique is generated by infinitely many probability measures, , forming a hyperplane of points in satisfying (25).
- (ii)
- When and , every satisfies . Each one of these infinitely many is generated by infinitely many probability measures, , forming infinitely many hyperplanes of points satisfying (25).
4.2. Convex/Concave Fine
5. Fixed Points and Nash Equilibria
6. Discussion
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
Appendix A.1. Proof of Theorem 3
- (i)
- For the pure strategy fixed point , we get:which is strictly positive . Then, is a source.
- (ii)
- For the pure strategy fixed point , we get:which is strictly negative when . Then, is asymptotically stable. Otherwise, (A5) is strictly positive, and is a source.
- (iii)
- For the pure strategy fixed points , , (A3) changes sign between and , when . Then, are saddles.
- (iv)
- For the non-isolated, non-hyperbolic mixed strategy fixed points , we resort to Lyapunov’s method. Consider the real valued Lyapunov function :
Appendix A.2. Proof of Theorem 5
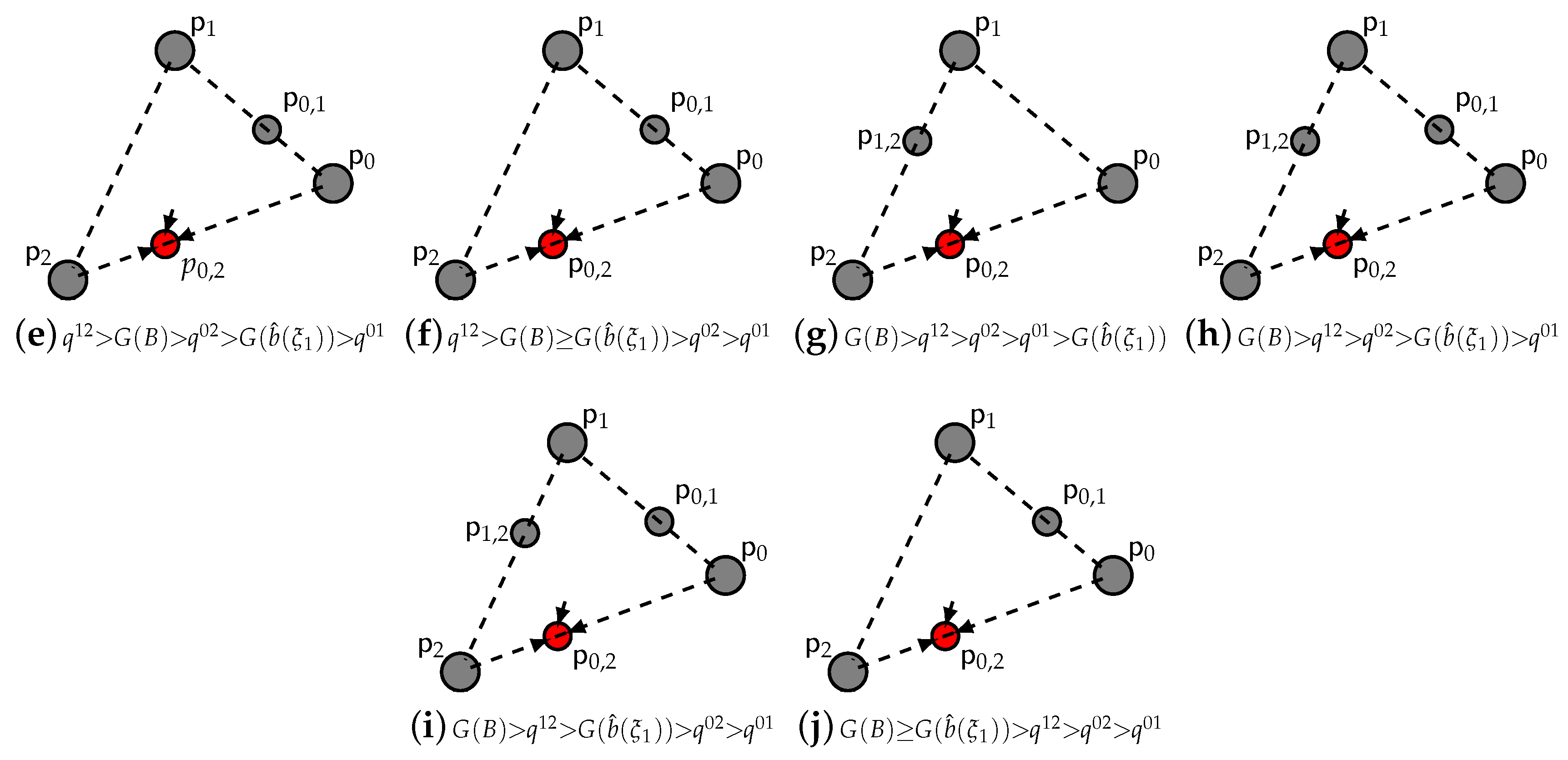
- (i)
- For the pure strategy fixed point , we get the form (A13):which is strictly positive . Then, is a source.
- (ii)
- (iii)
- For the double strategy fixed points , (A16) changes sign, indicatively between and (since is strictly increasing in i). Then, are saddles.
- (iv)
- For the double strategy fixed point , we get from (A16):which is strictly negative (since , is strictly increasing in i). Then, is asymptotically stable.
- (v)
- For the pure strategy fixed point , we get from (A13):which is strictly negative when does not exist, namely when . Then, is asymptotically stable. Otherwise, it is strictly positive , and is a source.
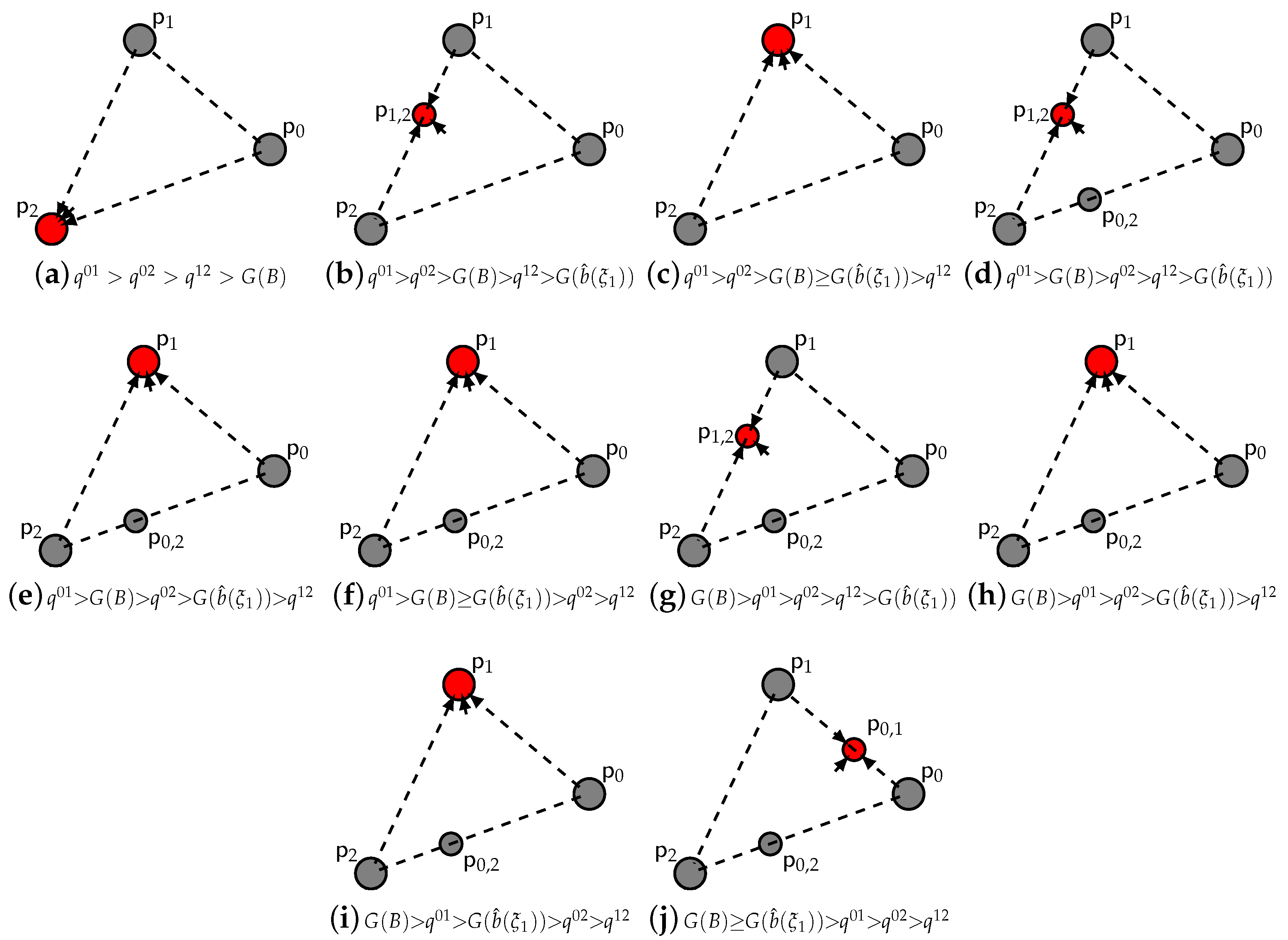
- (i)
- For the pure strategy fixed point , we get from (A13):which is strictly positive . Then, is a source.
- (ii)
- For the double strategy fixed points , (A16) changes sign, indicatively between and (since is strictly decreasing in i). Then, are saddles.
- (iii)
- For the double strategy fixed points , (A16) is strictly negative (since , is strictly decreasing in i). Then, is asymptotically stable.
- (iv)
- (v)
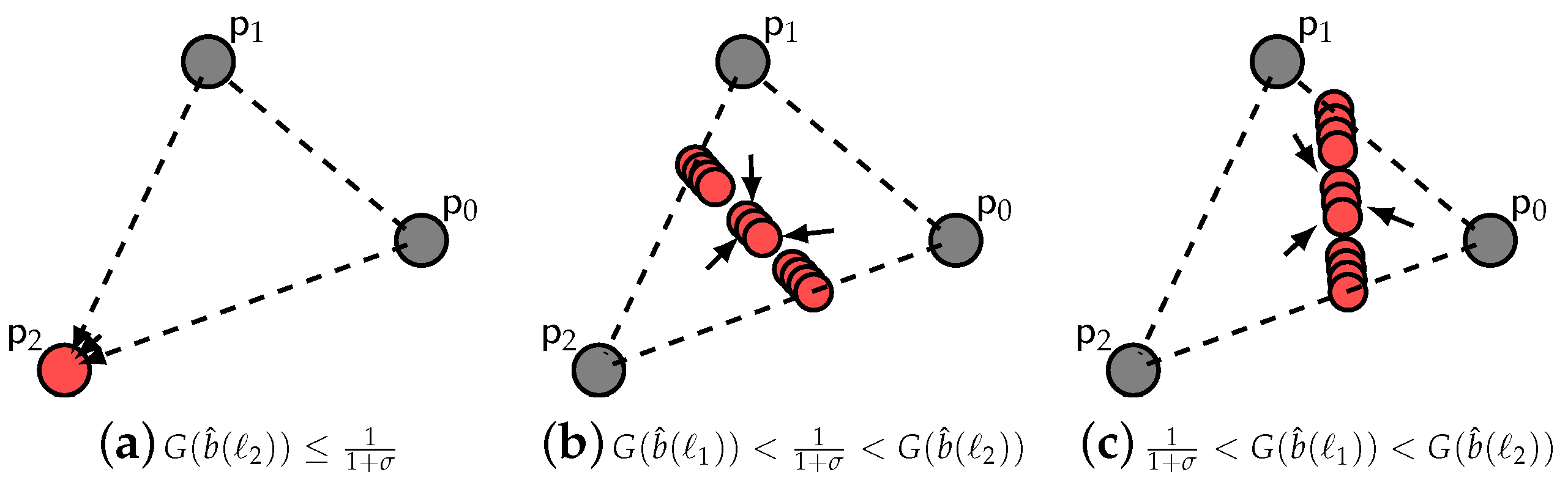
Appendix A.3. Proof of Theorem 7
- (i)
- From the proof of Theorem (3), we have seen that the pure strategy fixed points , , have at least one unstable trajectory.
- (ii)
- For the pure strategy fixed point , consider the real valued function , where E is an open subset of , with radius and centre :The total variation distance between any two is given by:thus, E does not contain any other Dirac measures. Using variational derivatives, we get:When , we have that , if and for all . Then, according to Lyapunov’s Theorem, is asymptotically stable.
- (iii)
- For the mixed strategy fixed points , take the real valued function :Using variational derivatives, we get:
Appendix A.4. Proof of Theorem 9
- (i),(ii)
- From the proof of Theorem (5), we have seen that the pure strategy fixed points and the double strategy fixed points have at least one unstable trajectory.
- (iii)
- For the mixed strategy fixed point , consider the real valued function where E is an open subset of , with radius and centre :Using variational derivatives, we get:Consider a small deviation from :where ϵ is small, and . In first order approximation, one can show that:holds, when:where:For a concave fine, it is:and from Assumption 1, is strictly increasing in and strictly increasing in . Then, overall, we have that , if and , for any small deviation from . Thus, according to Lyapunov’s theorem, is asymptotically stable.
- (iv)
- For the pure strategy fixed point , consider the real valued function , where E is an open subset of , with radius and centre (so that E does not contain any other Dirac measures):
References
- Avenhaus, R.; von Stengel, B.; Zamir, S. Inspection games. Hand. Game Theory Econ. Appl. 2002, 3, 1947–1987. [Google Scholar]
- Avenhaus, R.; Canty, M.J. Inspection Games; Springer: New York, NY, USA, 2012; pp. 1605–1618. [Google Scholar]
- Alferov, G.V.; Malafeyev, O.A.; Maltseva, A.S. Programming the robot in tasks of inspection and interception. In Proceedings of the IEEE 2015 International Conference on Mechanics-Seventh Polyakhov’s Reading, Saint Petersburg, Russia, 2–6 February 2015; pp. 1–3.
- Avenhaus, R. Applications of inspection games. Math. Model. Anal. 2004, 9, 179–192. [Google Scholar]
- Deutsch, Y.; Golany, B.; Goldberg, N.; Rothblum, U.G. Inspection games with local and global allocation bounds. Naval Res. Logist. 2013, 60, 125–140. [Google Scholar] [CrossRef]
- Kolokoltsov, V.; Passi, H.; Yang, W. Inspection and crime prevention: An evolutionary perspective. Available online: https://arxiv.org/abs/1306.4219 (accessed on 18 June 2013).
- Dresher, M. A Sampling Inspection Problem in Arms Control Agreements: A Game-Theoretic Analysis (No. RM-2972-ARPA); Rand Corp: Santa Monica, CA, USA, 1962. [Google Scholar]
- Avenhaus, R.; Canty, M.; Kilgour, D.M.; von Stengel, B.; Zamir, S. Inspection games in arms control. Eur. J. Oper. Res. 1996, 90, 383–394. [Google Scholar] [CrossRef]
- Maschler, M. A price leadership method for solving the inspector’s non-constant-sum game. Naval Res. Logist. Q. 1966, 13, 11–33. [Google Scholar] [CrossRef]
- Thomas, M.U.; Nisgav, Y. An infiltration game with time dependent payoff. Naval Res. Logist. Q. 1976, 23, 297–302. [Google Scholar] [CrossRef]
- Baston, V.J.; Bostock, F.A. A generalized inspection game. Naval Res. Logist. 1991, 38, 171–182. [Google Scholar] [CrossRef]
- Garnaev, A.Y. A remark on the customs and smuggler game. Naval Res. Logist. 1994, 41, 287–293. [Google Scholar] [CrossRef]
- Von Stengel, B. Recursive Inspection Games; Report No. S 9106; Computer Science Faculty, Armed Forces University: Munich, Germany, 1991. [Google Scholar]
- Von Stengel, B. Recursive inspection games. Available online: https://arxiv.org/abs/1412.0129 (accessed on 29 November 2014).
- Ferguson, T.S.; Melolidakis, C. On the inspection game. Naval Res. Logist. 1998, 45, 327–334. [Google Scholar] [CrossRef]
- Sakaguchi, M. A sequential allocation game for targets with varying values. J. Oper. Res. Soc. Jpn. 1977, 20, 182–193. [Google Scholar]
- Maschler, M. The inspector’s non-constant-sum game: Its dependence on a system of detectors. Naval Res. Logist. Q. 1967, 14, 275–290. [Google Scholar] [CrossRef]
- Avenhaus, R.; von Stengel, B. Non-zero-sum Dresher inspection games. In Operations Research’91; Physica-Verlag HD: Heidelberg, Gernamy, 1992; pp. 376–379. [Google Scholar]
- Canty, M.J.; Rothenstein, D.; Avenhaus, R. Timely inspection and deterrence. Eur. J. Oper. Res. 2001, 131, 208–223. [Google Scholar] [CrossRef]
- Rothenstein, D.; Zamir, S. Imperfect inspection games over time. Ann. Oper. Res. 2002, 109, 175–192. [Google Scholar] [CrossRef]
- Avenhaus, R.; Kilgour, D.M. Efficient distributions of arms-control inspection effort. Naval Res. Logist. 2004, 51, 1–27. [Google Scholar] [CrossRef]
- Hohzaki, R. An inspection game with multiple inspectees. Eur. J. Oper. Res. 2007, 178, 894–906. [Google Scholar] [CrossRef]
- Hurwicz, L. But Who Will Quard the Quardians? Prize Lecture 2007. Available online: https://www.nobelprize.org (accessed on 8 December 2007).
- Aidt, T.S. Economic analysis of corruption: A survey. Econ. J. 2003, 113, F632–F652. [Google Scholar] [CrossRef]
- Jain, A.K. Corruption: A review. J. Econ. Surv. 2001, 15, 71–121. [Google Scholar] [CrossRef]
- Kolokoltsov, V.N.; Malafeyev, O.A. Mean-field-game model of corruption. Dyn. Games Appl. 2015. [Google Scholar] [CrossRef]
- Malafeyev, O.A.; Redinskikh, N.D.; Alferov, G.V. Electric circuits analogies in economics modeling: Corruption networks. In Proceedings of the 2014 2nd International Conference on Emission Electronics (ICEE), Saint-Petersburg, Russia, 30 June–4 July 2014.
- Lambert-Mogiliansky, A.; Majumdar, M.; Radner, R. Petty corruption: A game-theoretic approach. Int. J. Econ. Theory 2008, 4, 273–297. [Google Scholar] [CrossRef]
- Nikolaev, P.V. Corruption suppression models: The role of inspectors’ moral level. Comput. Math. Model. 2014, 25, 87–102. [Google Scholar] [CrossRef]
- Lee, J.H.; Sigmund, K.; Dieckmann, U.; Iwasa, Y. Games of corruption: How to suppress illegal logging. J. Theor. Biol. 2015, 367, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Giovannoni, F.; Seidmann, D.J. Corruption and power in democracies. Soc. Choice Welf. 2014, 42, 707–734. [Google Scholar] [CrossRef]
- Kolokoltsov, V.N.; Malafeev, O.A. Understanding Game Theory: Introduction to the Analysis of Many Agent Systems with Competition and Cooperation; World Scientific: Singapore, 2010. [Google Scholar]
- Zeeman, E.C. Population dynamics from game theory. In Global Theory of Dynamical Systems; Springer: Berlin/Heidelberg, Germany, 1980; pp. 471–497. [Google Scholar]
- Kolokoltsov, V. The evolutionary game of pressure (or interference), resistance and collaboration. Available online: https://arxiv.org/abs/1412.1269 (accessed on 3 December 2014).
- Hofbauer, J.; Sigmund, K. Evolutionary Games and Population Dynamics; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar]
- Strogatz, S.H. Nonlinear Dynamics and Chaos: With Applications to Physics, Biology, Chemistry, and Engineering; Westview Press: Boulder, CO, USA, 2014. [Google Scholar]
- Jordan, D.W.; Smith, P. Nonlinear Ordinary Differential Equations: An Introduction for Scientists and Engineers; Oxford University Press: Oxford, UK, 2007. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Inspect | Not Inspect | |
|---|---|---|
| Violate | , | , |
| Comply | r, | r, 0 |
| Inspect | Not Inspect | |
|---|---|---|
| Violate | , | , |
| Comply | r, | r, 0 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Katsikas, S.; Kolokoltsov, V.; Yang, W. Evolutionary Inspection and Corruption Games. Games 2016, 7, 31. https://doi.org/10.3390/g7040031
Katsikas S, Kolokoltsov V, Yang W. Evolutionary Inspection and Corruption Games. Games. 2016; 7(4):31. https://doi.org/10.3390/g7040031
Chicago/Turabian StyleKatsikas, Stamatios, Vassili Kolokoltsov, and Wei Yang. 2016. "Evolutionary Inspection and Corruption Games" Games 7, no. 4: 31. https://doi.org/10.3390/g7040031
APA StyleKatsikas, S., Kolokoltsov, V., & Yang, W. (2016). Evolutionary Inspection and Corruption Games. Games, 7(4), 31. https://doi.org/10.3390/g7040031