
Keeping Pace with Criminals: An Extended Study of Designing Patrol Allocation against Adaptive Opportunistic Criminals

Abstract
:1. Introduction
2. Related Work
3. Motivating Example
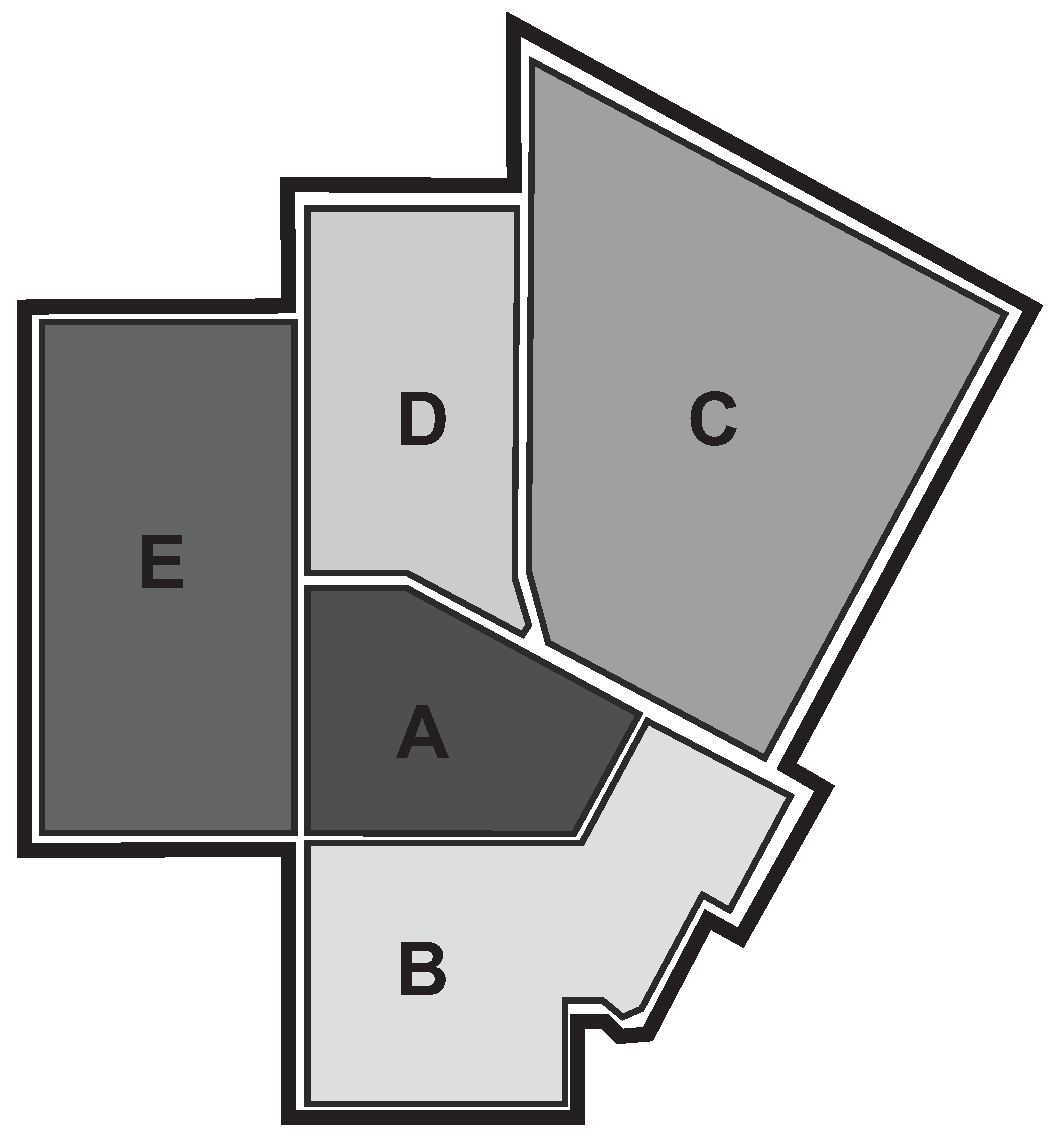
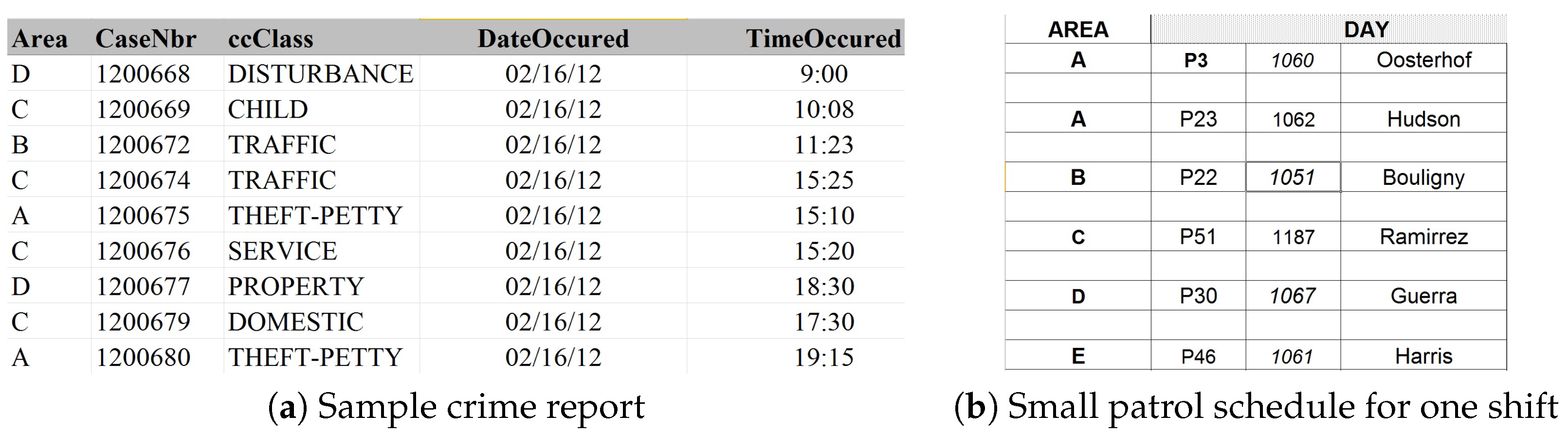
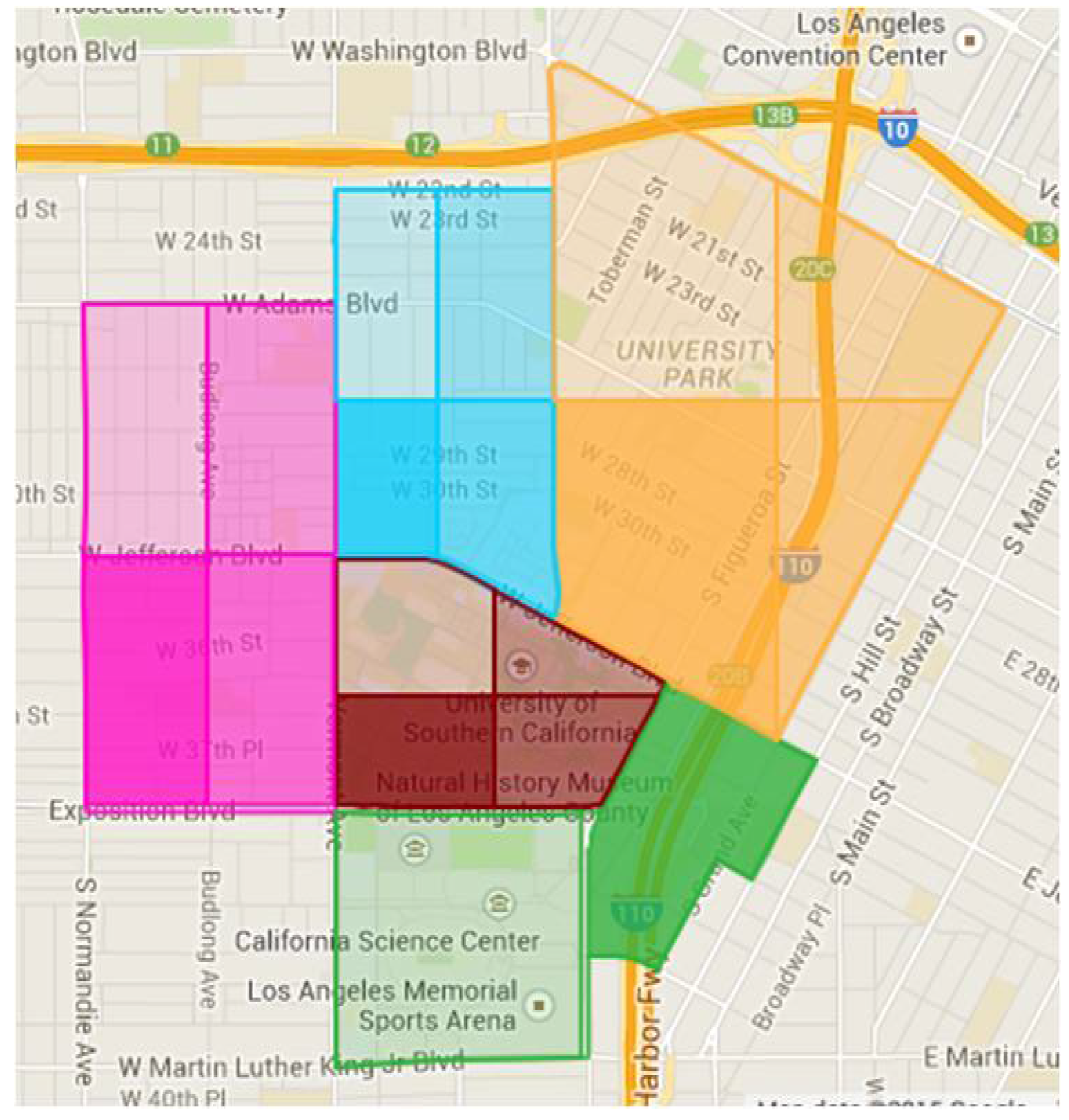
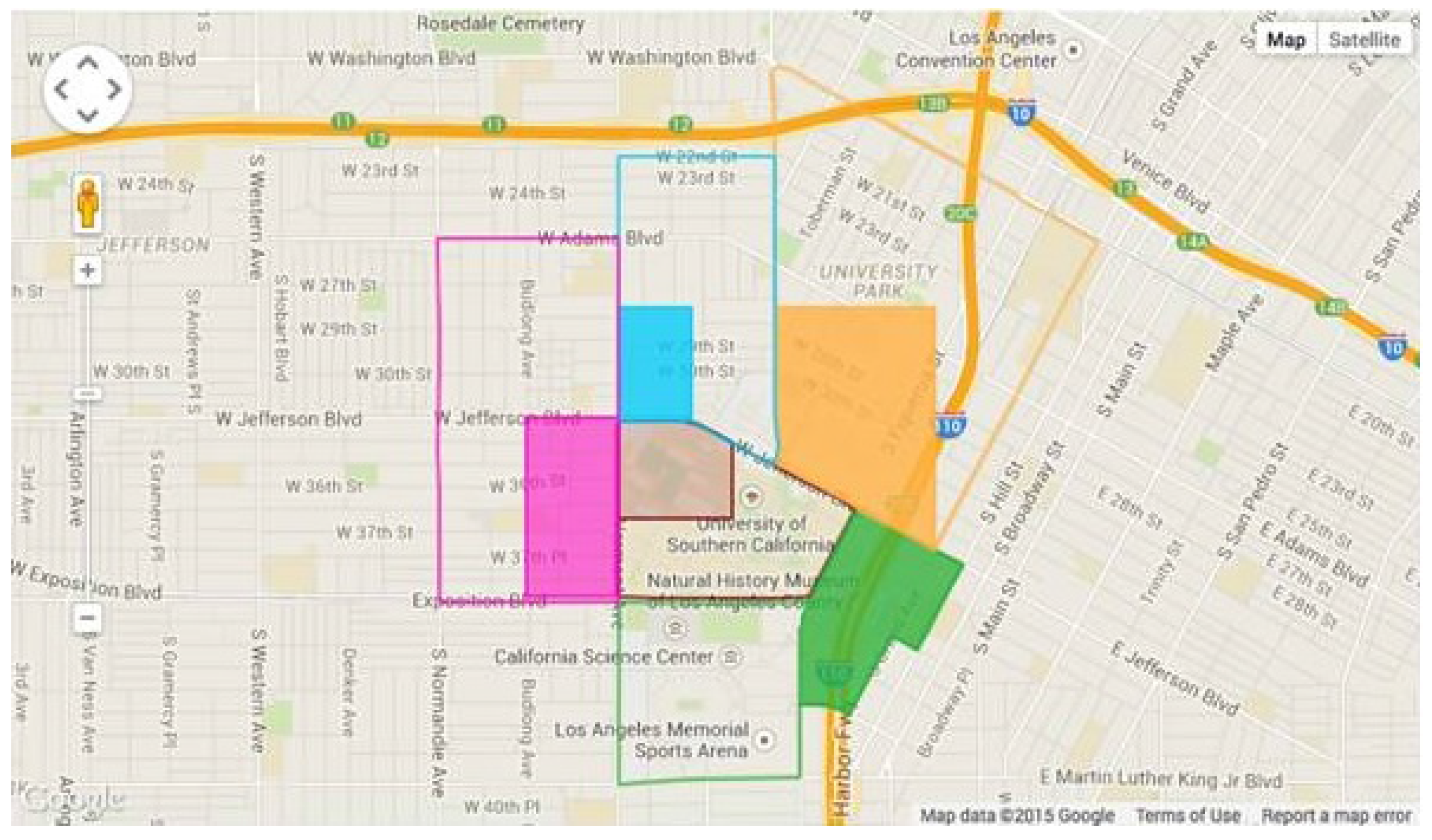
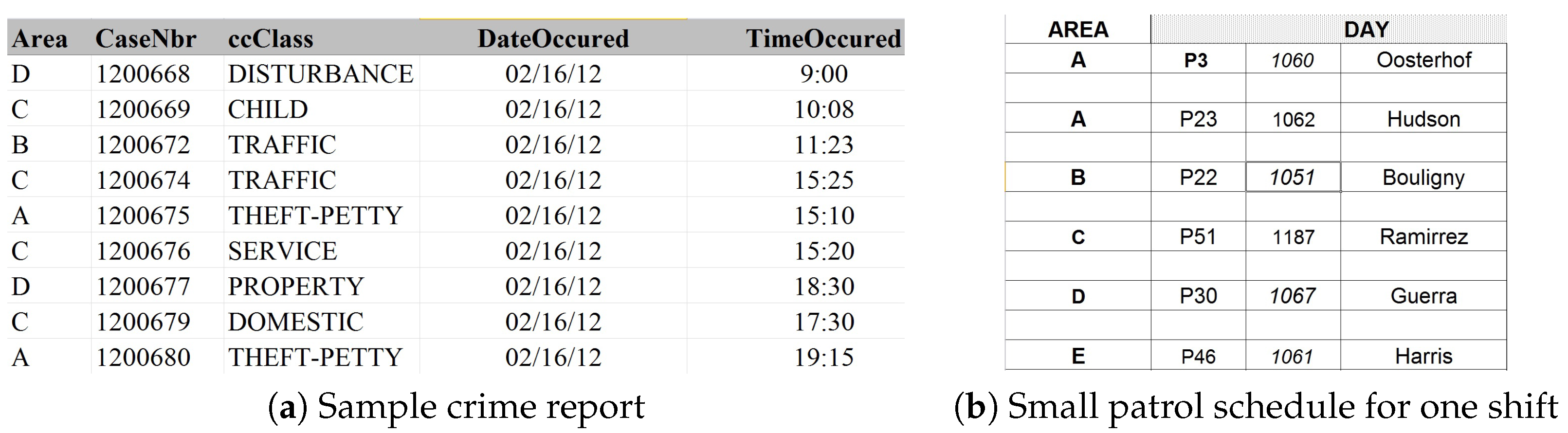
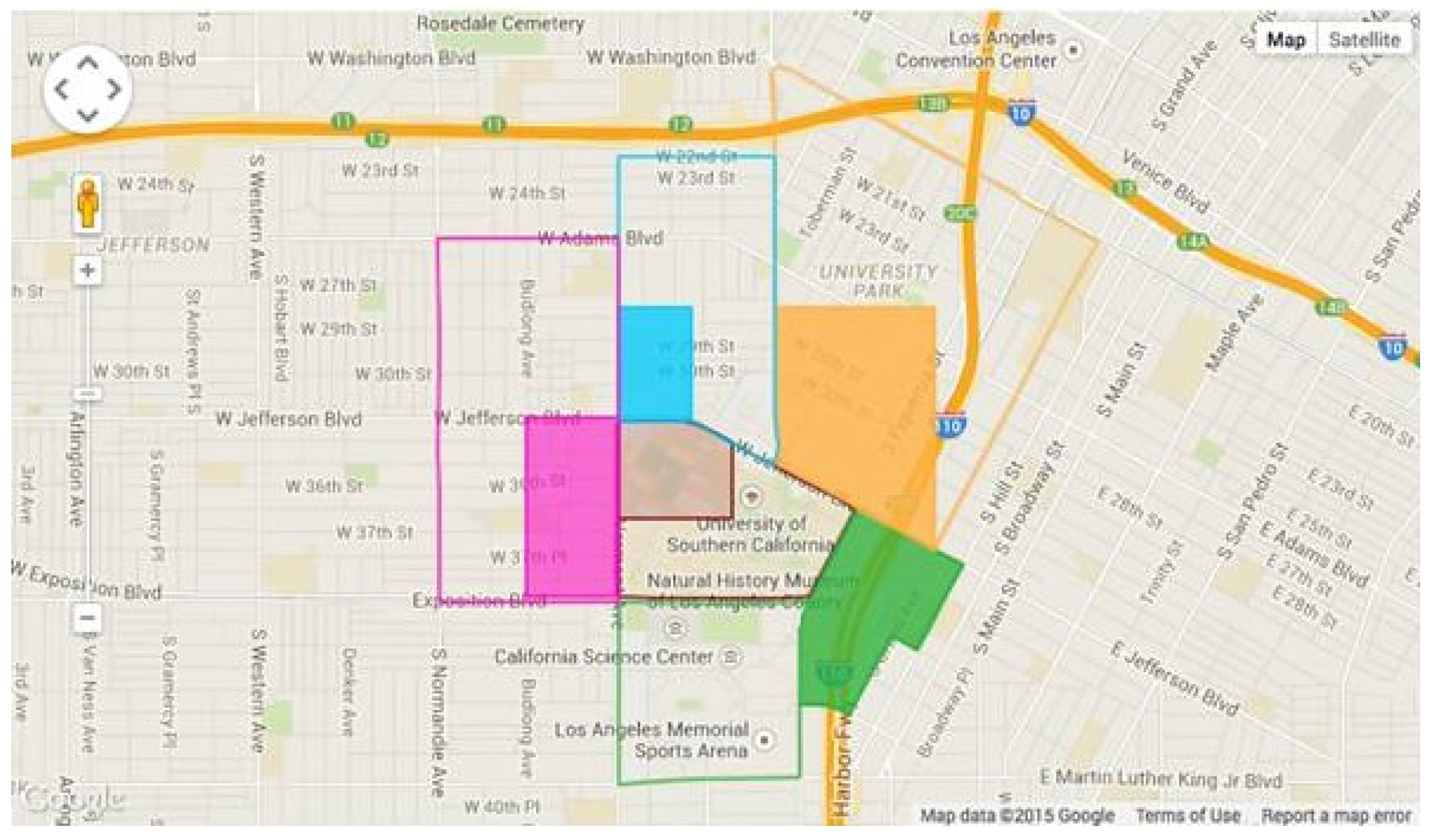
3.1. Domain Description
3.2. Problem Statement
4. Learning Model
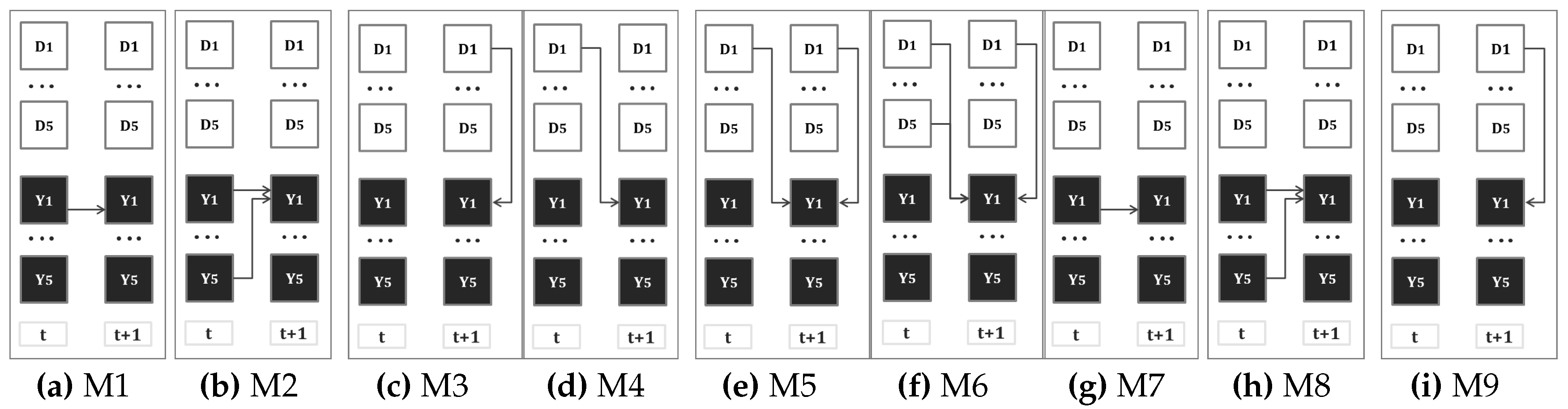
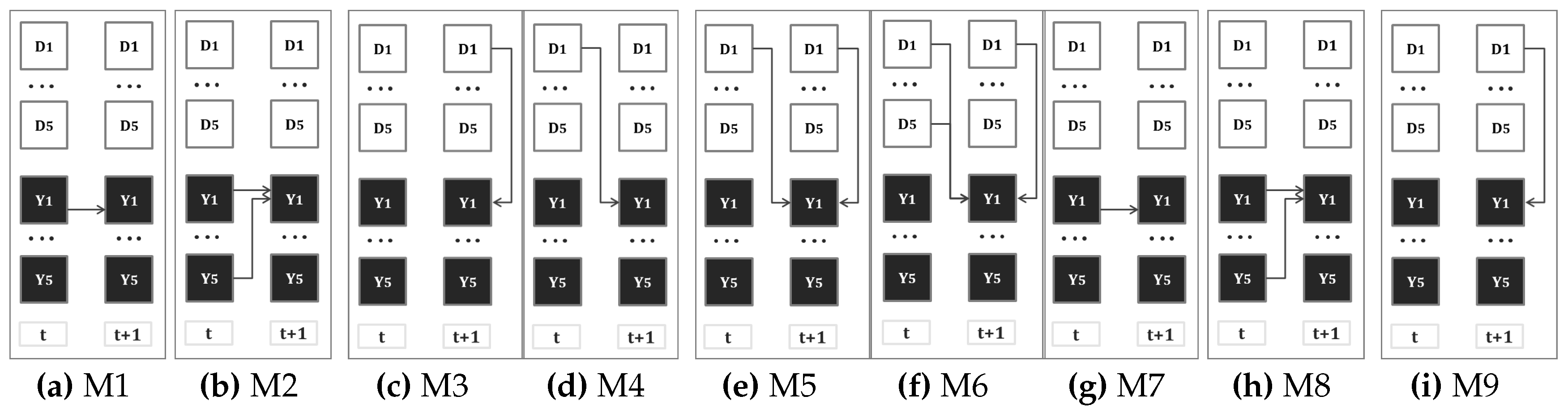
4.1. Markov Chain Models (MCM)
4.1.1. Crime Predicts Crime
4.1.2. Defender Allocation Predicts Crime
4.1.3. Crime and Defender Allocation Predicts Crime
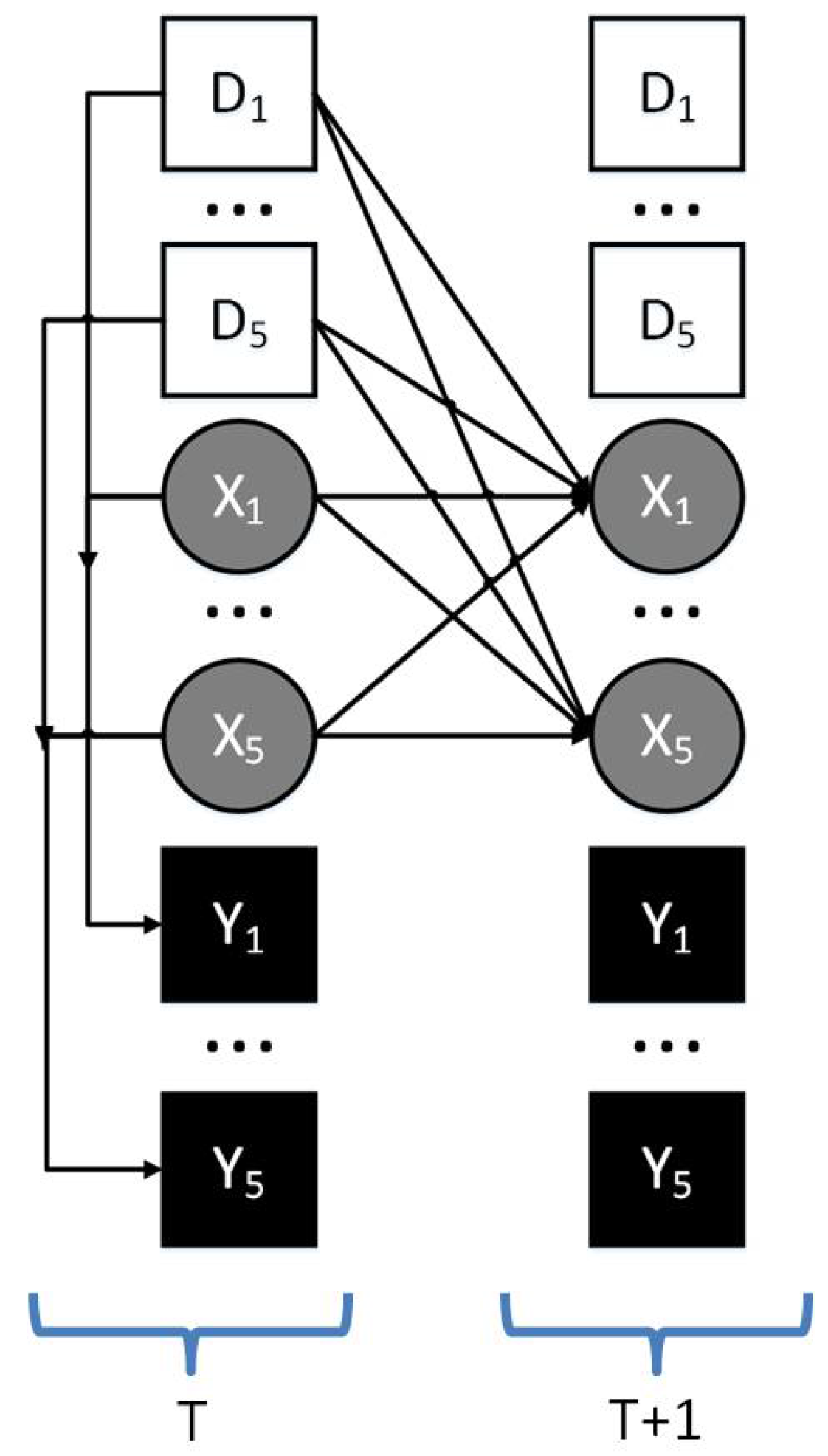
4.2. Dynamic Bayesian Network Models (DBNM)
4.2.1. DBN Parameters
- N: Total number of targets in the graph.
- T: Total time steps of the training data.
- : Defender’s allocation strategy at step t: the number of defenders at each target in step t with possible values.
- : Criminals’ distribution at step t with possible values.
- : Crime distribution at step t with possible values.
- π: Initial criminal distribution: probability distribution of .
- A (movement matrix): The matrix that decides how evolves over time. Formally, A. Given the values for each argument of A, representing A requires parameters.
- B (crime matrix): The matrix that decides how criminals commit crime. Formally, B. Given the values for each argument of B, representing B requires parameters.
- Forward prob.: α.
- Backward prob.: β.
- Total prob.: γ: γ.
- Two-step prob.: ξ.
4.2.2. Expectation Maximization
4.2.3. EM on the Compact Model
4.2.4. EMC Procedure
- Forward prob.: .
- Backward prob.: .
- Total prob.: .
- Two-step prob.: . .
5. Dynamic Planning
| Algorithm 1 Online planning (). | |
| 1: | |
| 2: | |
| 3: | while do |
| 4: | |
| 5: | |
| 6: | |
| 7: | |
| 8: | |
| 9: | end while |
5.1. Planning Algorithms
5.1.1. The Planning Problem
5.1.2. Brute Force Search
5.1.3. Dynamic Opportunistic Game Search (DOGS)
- indicates the j-th strategy for the defender from the different defender strategies at time step t.
- is the total number of crimes corresponding to the optimal defender strategy for the first t time steps that has j as its final defender strategy.
- is the criminals’ location distribution corresponding to the optimal defender strategy for the first t time steps that has j as its final defender strategy.
- is the expected number of crimes at all targets at t given the criminal location distribution and defender’s allocation strategy D at step t and output matrix B.
- is the criminal location distribution at step given the criminal location distribution and defender’s allocation strategy at t and transition matrix A.
| Algorithm 2 DOGS (). | |
| 1: | for each officer allocation do |
| 2: | ; ; |
| 3: | end for |
| 4: | for do |
| 5: | for each officer allocation do |
| 6: | |
| 7: | ; |
| 8: | |
| 9: | end for |
| 10: | end for |
| 11: | ; |
| 12: | for do |
| 13: | |
| 14: | |
| 15: | end for |
| 16: | return |
5.1.4. Greedy Search
| Algorithm 3 Greedy (). | |
| 1: | for do |
| 2: | ; |
| 3: | end for |
| 4: | return |
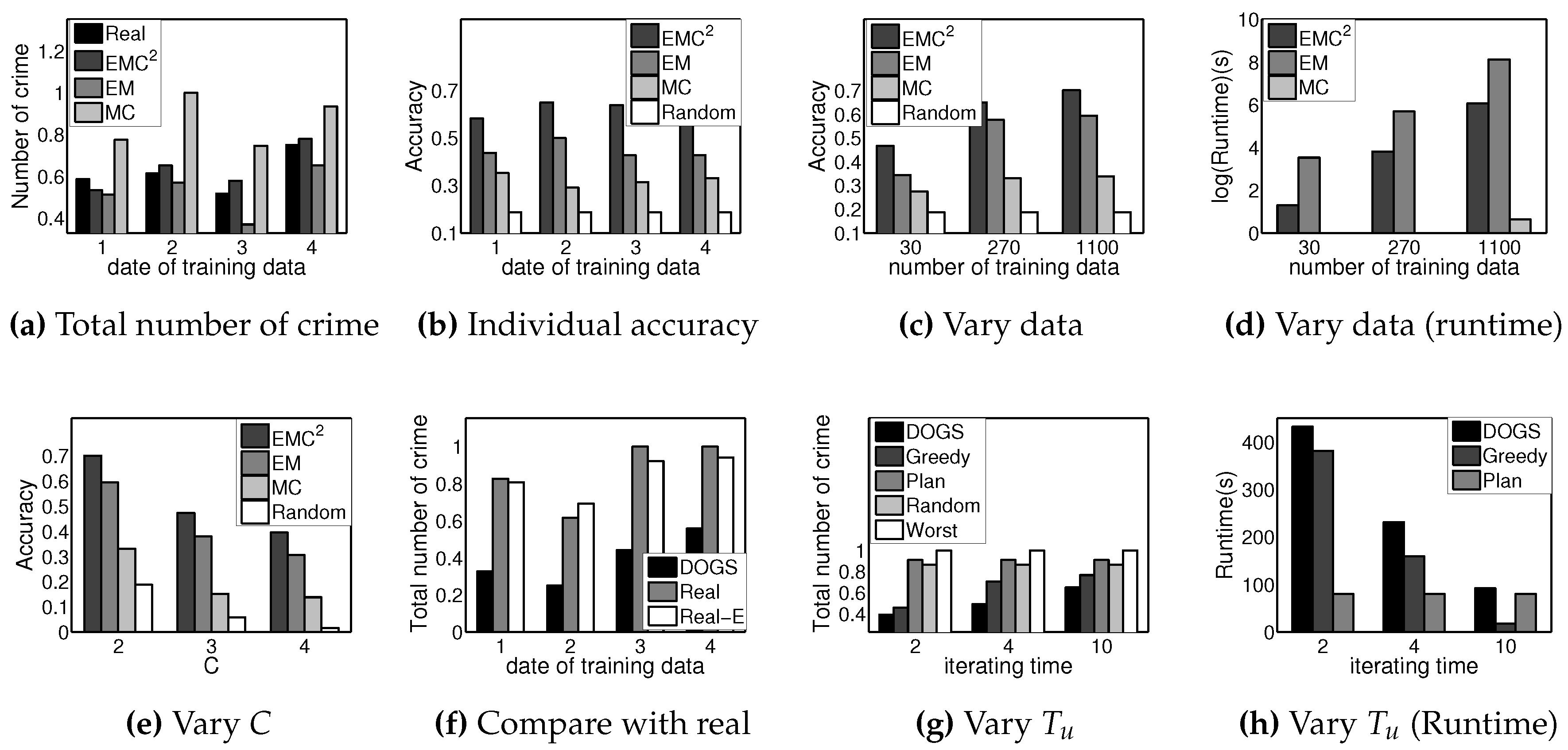
6. Experimental Results
6.1. Experimental Setup
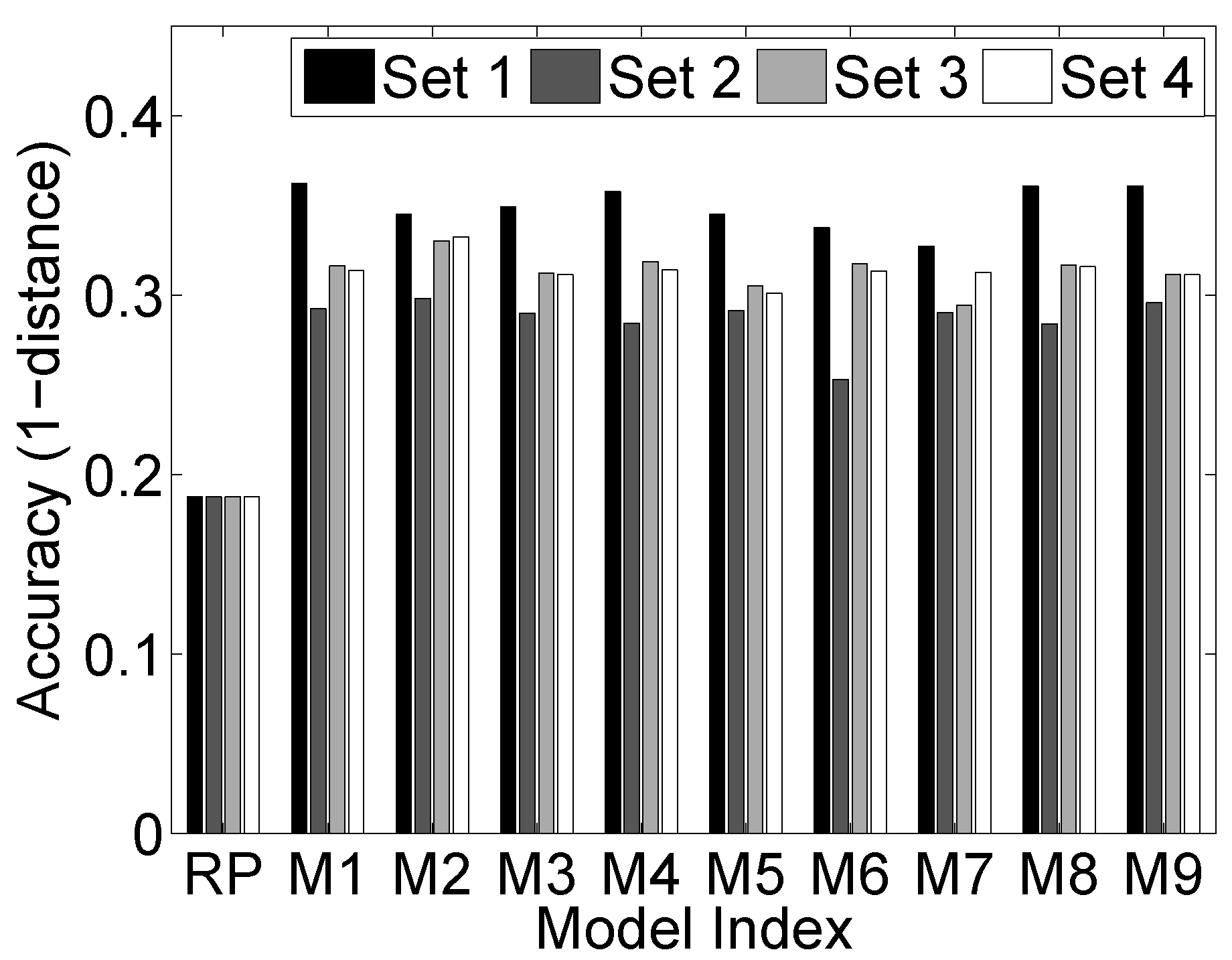
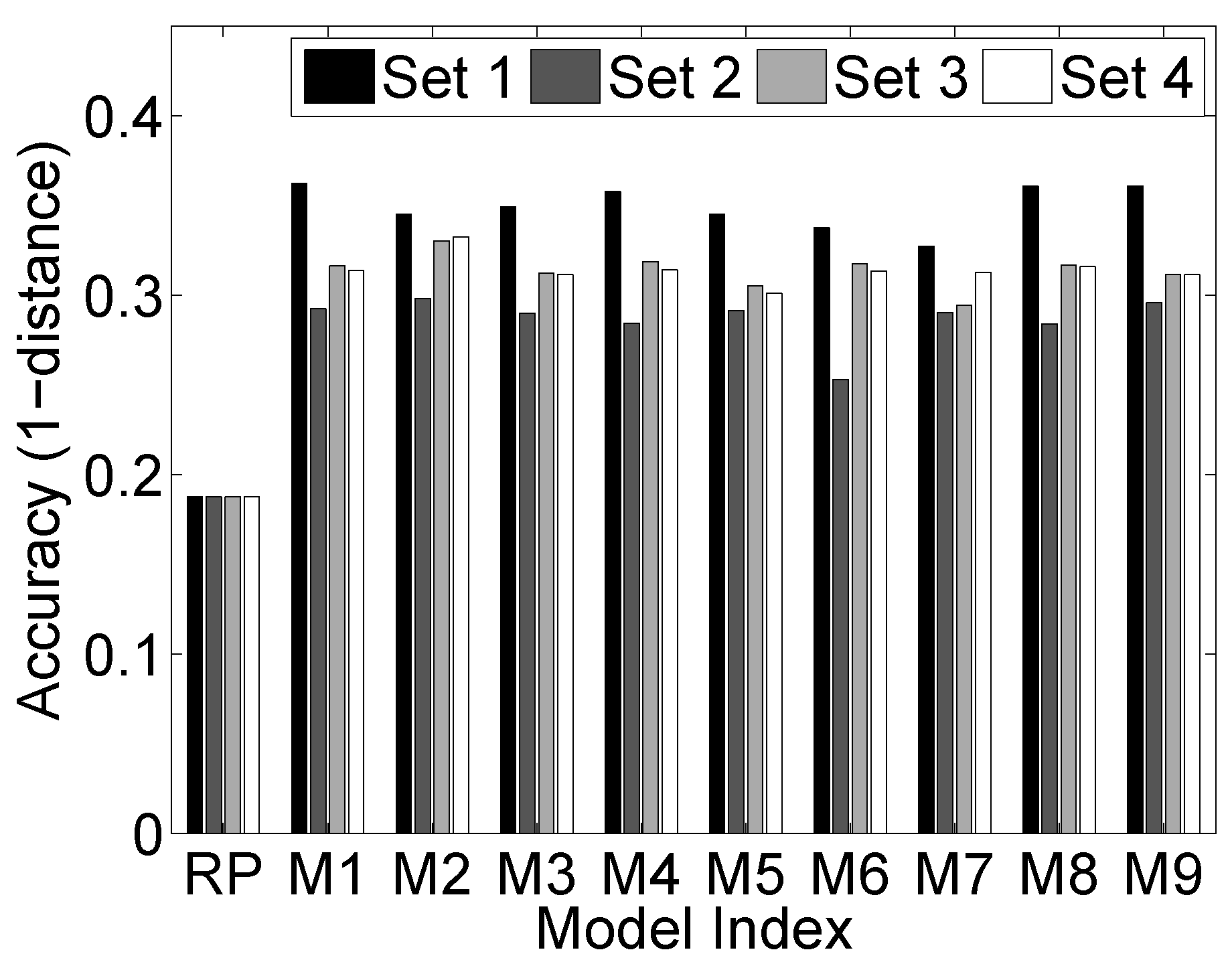
6.2. Learning (Setting)
6.3. Learning and Planning (Real-World Data)
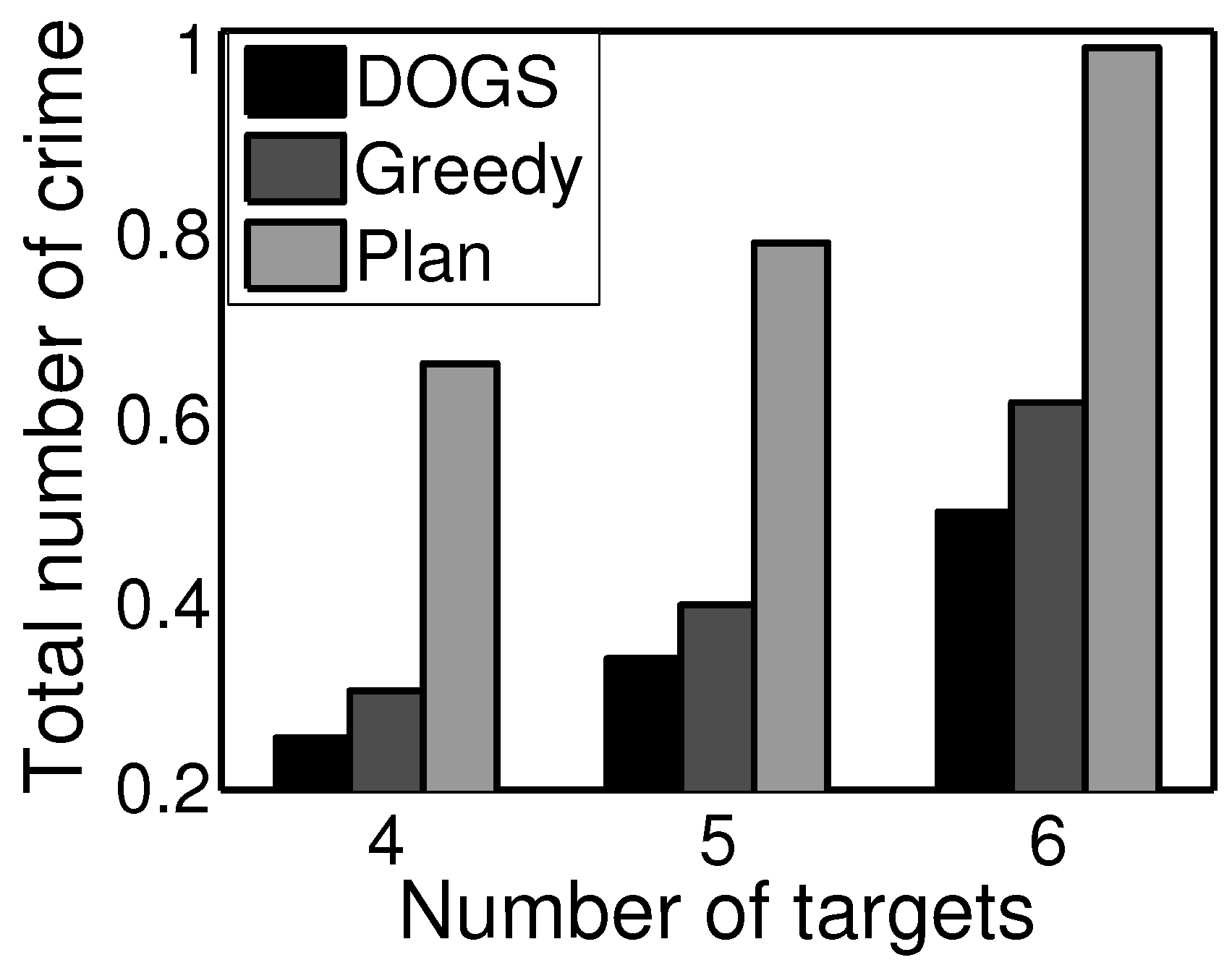
6.4. Learning and Planning (Simulated Data)
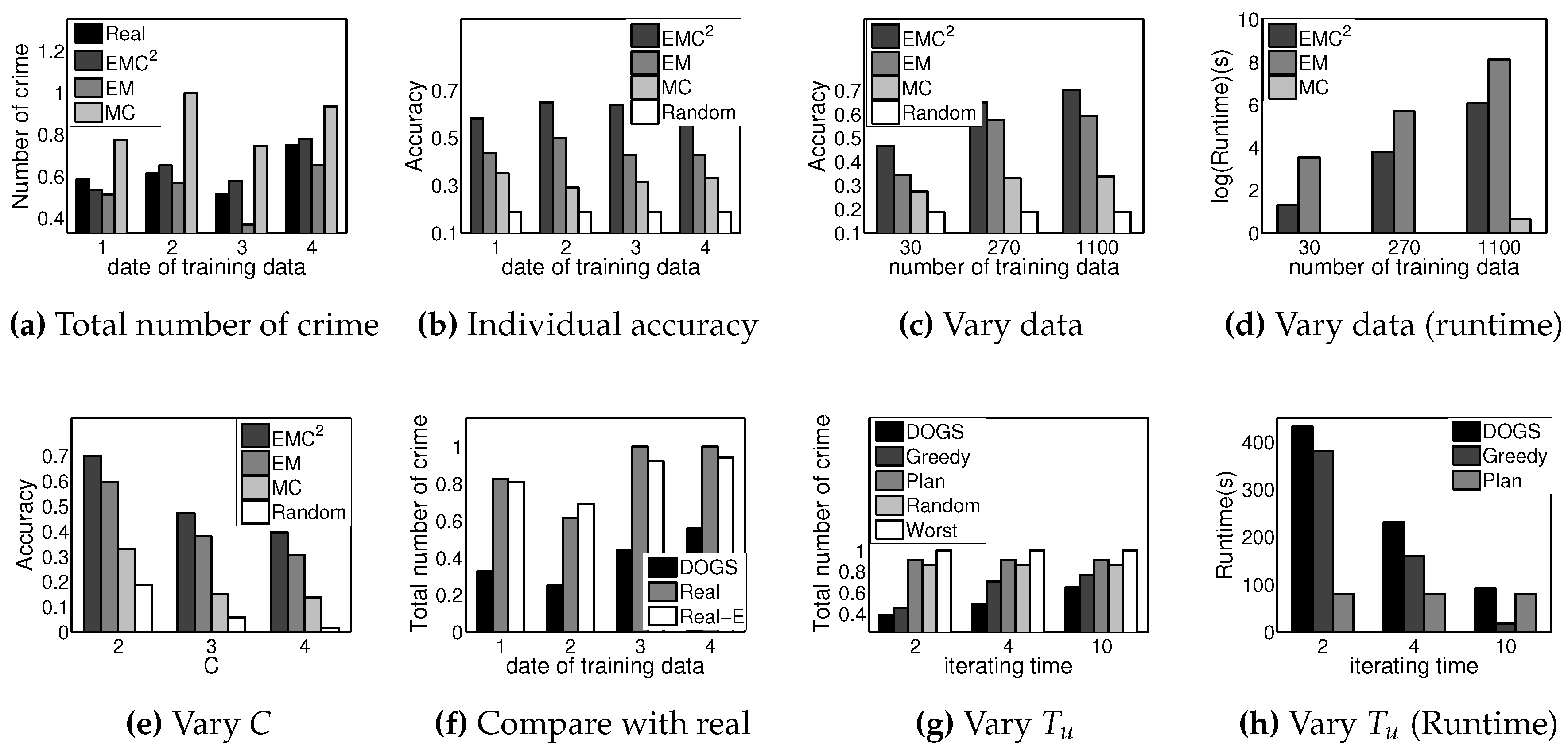
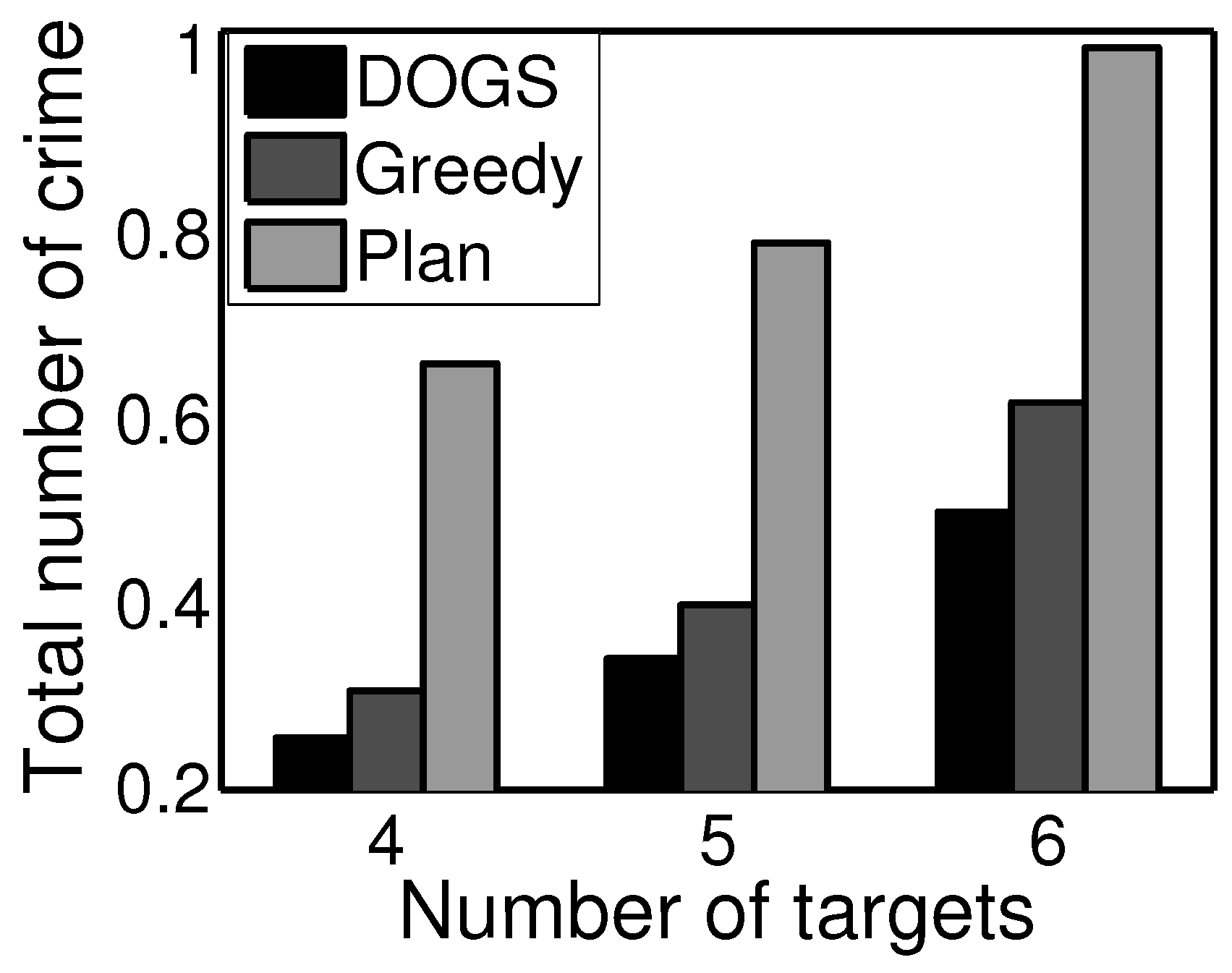
6.5. Learning and Planning Results
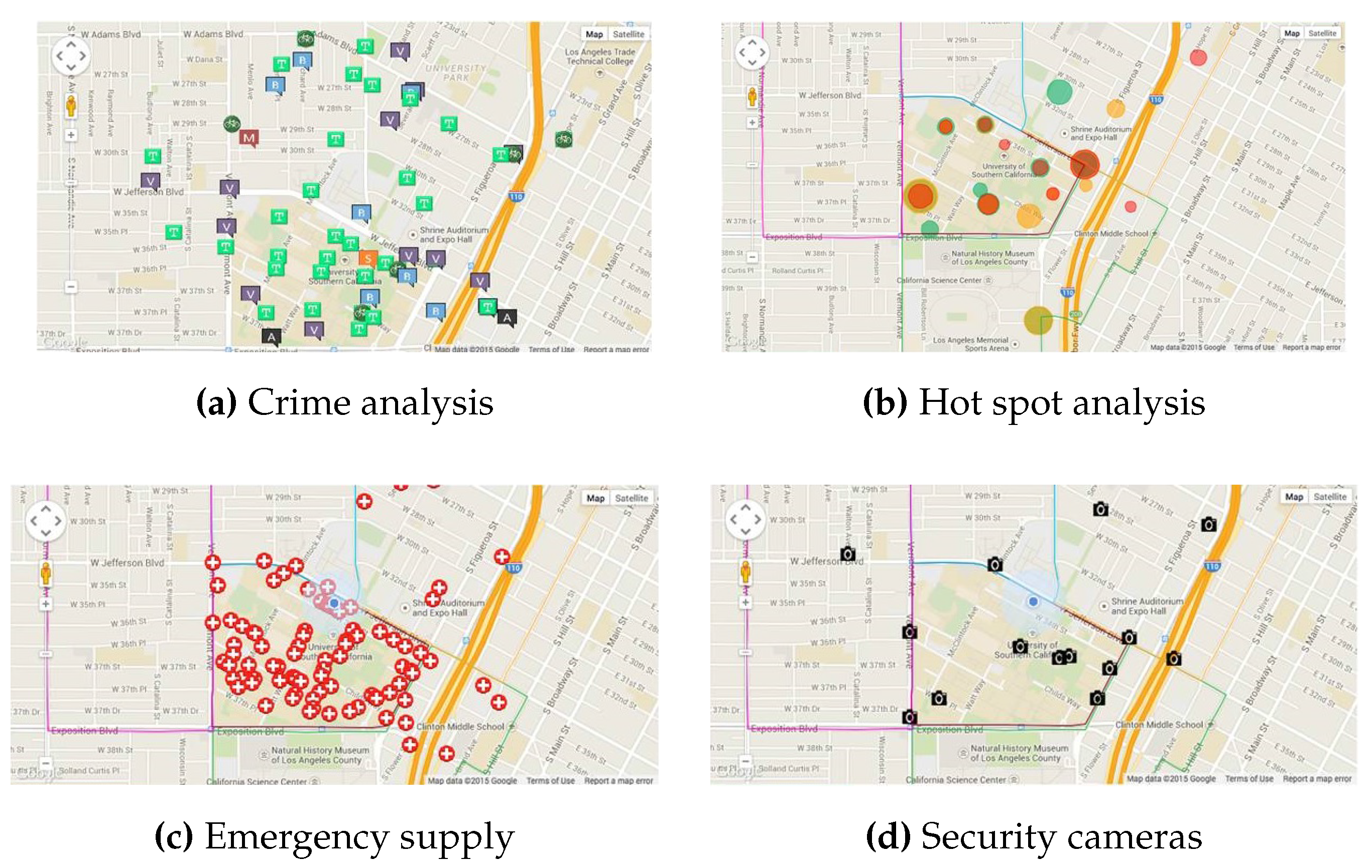
7. Real World Implementation
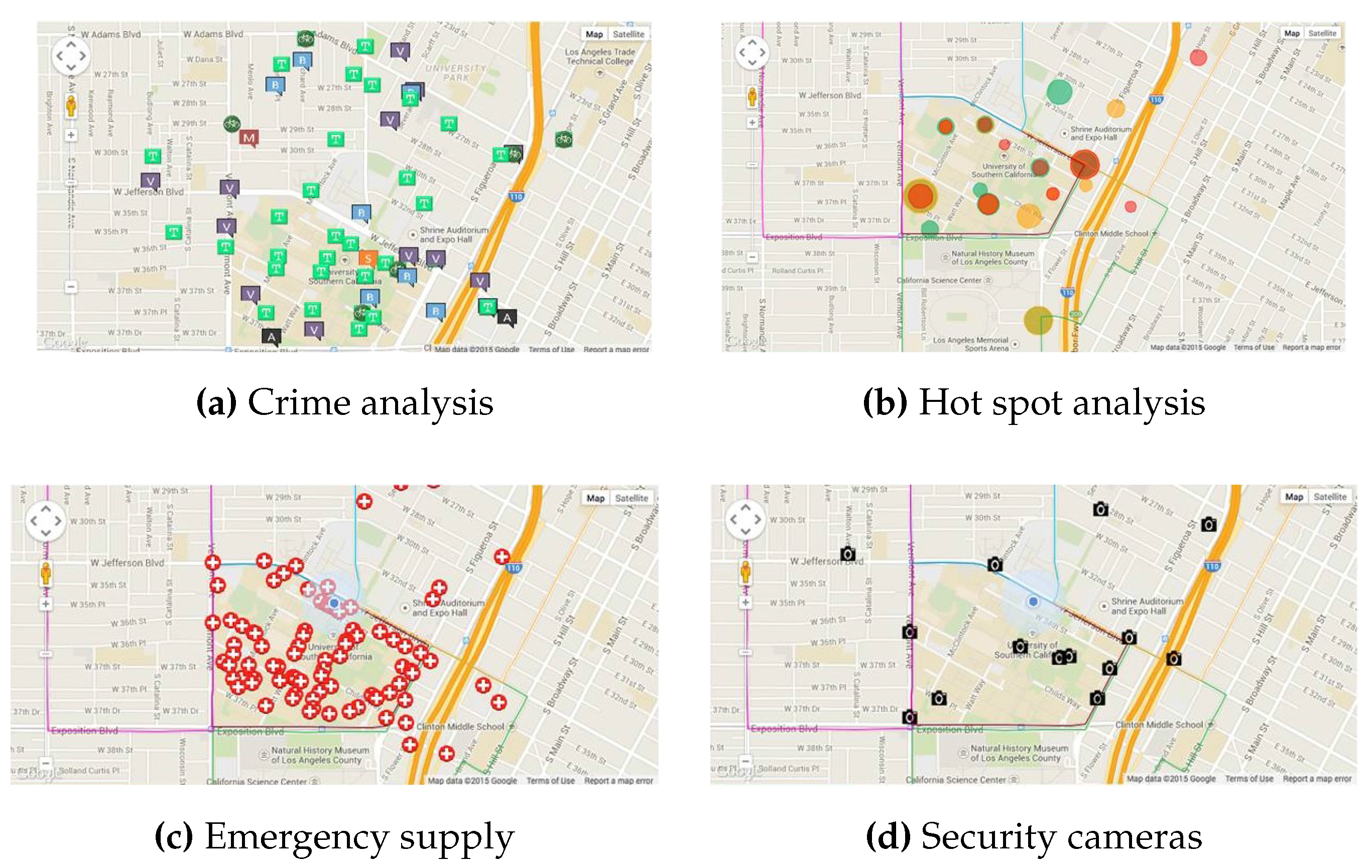
7.1. Multi-User Software
7.1.1. Data Collector
7.1.2. Patrol Scheduler
8. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
Appendix A.1. EMC Procedure Initialization Step
Appendix A.2. EM Procedure Expectation Step
References
- Short, M.B.; D’orsogna, M.R.; Pasour, V.B.; Tita, G.E.; Brantingham, P.J.; Bertozzi, A.L.; Chayes, L.B. A statistical model of criminal behavior. Math. Models Methods Appl. Sci. 2008, 18, 1249–1267. [Google Scholar] [CrossRef]
- Zhang, C.; Jiang, A.X.; Short, M.B.; Brantingham, P.J.; Tambe, M. Defending against opportunistic criminals: New game-theoretic frameworks and algorithms. In Decision and Game Theory for Security; Springer: Los Angeles, CA, USA, 2014; pp. 3–22. [Google Scholar]
- Jain, M.; Tsai, J.; Pita, J.; Kiekintveld, C.; Rathi, S.; Tambe, M.; Ordóñez, F. Software assistants for randomized patrol planning for the lax airport police and the federal air marshal service. Interfaces 2010, 40, 267–290. [Google Scholar] [CrossRef]
- Shieh, E.; An, B.; Yang, R.; Tambe, M.; Baldwin, C.; DiRenzo, J.; Maule, B.; Meyer, G. PROTECT: A deployed game theoretic system to protect the ports of the United States. In Proceedings of the 11th International Conference on Autonomous Agents and Multiagent Systems, Valencia, Spain, 4–8 June 2012; International Foundation for Autonomous Agents and Multiagent Systems: Valencia, Spain, 2012; Volume 1, pp. 13–20. [Google Scholar]
- Chen, H.; Chung, W.; Xu, J.J.; Wang, G.; Qin, Y.; Chau, M. Crime data mining: A general framework and some examples. Computer 2004, 37, 50–56. [Google Scholar] [CrossRef]
- Boyen, X.; Koller, D. Tractable inference for complex stochastic processes. In Proceedings of the Fourteenth Conference on Uncertainty in Artificial Intelligence, Madison, WI, USA, 24–26 July 1998; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1998; pp. 33–42. [Google Scholar]
- Nath, S.V. Crime pattern detection using data mining. In Proceedings of the 2006 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology Workshops, WI-IAT 2006 Workshops, Hong Kong, China, 18–22 December 2006; IEEE: Hong Kong, China, 2006; pp. 41–44. [Google Scholar]
- De Bruin, J.S.; Cocx, T.K.; Kosters, W.A.; Laros, J.F.; Kok, J.N. Data mining approaches to criminal career analysis. In Sixth International Conference on Data Mining, ICDM’06, Hong Kong, China, 18–22 December 2006; IEEE: Hong Kong, China, 2006; pp. 171–177. [Google Scholar]
- Oatley, G.; Ewart, B.; Zeleznikow, J. Decision support systems for police: Lessons from the application of data mining techniques to soft forensic evidence. Artif. Intell. Law 2006, 14, 35–100. [Google Scholar] [CrossRef]
- Hespanha, J.P.; Prandini, M.; Sastry, S. Probabilistic pursuit-evasion games: A one-step nash approach. In Proceedings of the 39th IEEE Conference on Decision and Control, Sydney, NSW, Australia, 12–15 December 2000; IEEE: Sydney, NSW, Australia, 2000; Volume 3, pp. 2272–2277. [Google Scholar]
- Tambe, M. Security and Game Theory: Algorithms, Deployed Systems, Lessons Learned; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Jiang, A.X.; Yin, Z.; Zhang, C.; Tambe, M.; Kraus, S. Game-theoretic randomization for security patrolling with dynamic execution uncertainty. In Proceedings of the 2013 International Conference on Autonomous Agents and Multi-Agent Systems, Saint Paul, MN, USA, 6–10 May 2013; International Foundation for Autonomous Agents and Multiagent Systems: Saint Paul, MN, USA, 2013; pp. 207–214. [Google Scholar]
- Yang, R.; Ford, B.; Tambe, M.; Lemieux, A. Adaptive resource allocation for wildlife protection against illegal poachers. In Proceedings of the 2014 International Conference on Autonomous Agents and Multi-Agent Systems, Paris, France, 5–9 May 2014; International Foundation for Autonomous Agents and Multiagent Systems: Paris, France, 2014; pp. 453–460. [Google Scholar]
- Basilico, N.; Gatti, N.; Amigoni, F. Leader-follower strategies for robotic patrolling in environments with arbitrary topologies. In Proceedings of the 8th International Conference on Autonomous Agents and Multiagent Systems, Budapest, Hungary, 10–15 May 2009; International Foundation for Autonomous Agents and Multiagent Systems: Budapest, Hungary, 2009; Volume 1, pp. 57–64. [Google Scholar]
- Basilico, N.; Gatti, N.; Rossi, T.; Ceppi, S.; Amigoni, F. Extending algorithms for mobile robot patrolling in the presence of adversaries to more realistic settings. In Proceedings of the 2009 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology, Milan, Italy, 15–18 September 2009; IEEE Computer Society: Washington, DC, USA, 2009; Volume 2, pp. 557–564. [Google Scholar]
- Blum, A.; Haghtalab, N.; Procaccia, A.D. Learning optimal commitment to overcome insecurity. In Proceedings of the 28th Annual Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014.
- Malik, A.; Maciejewski, R.; Towers, S.; McCullough, S.; Ebert, D.S. Proactive spatiotemporal resource allocation and predictive visual analytics for community policing and law enforcement. Vis. Comput. Graph. 2014, 20, 1863–1872. [Google Scholar] [CrossRef] [PubMed]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977, 39, 1–38. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer-Verlag New York, Inc.: Secaucus, NJ, USA, 2006. [Google Scholar]
- Blumer, A.; Ehrenfeucht, A.; Haussler, D.; Warmuth, M.K. Occam’s Razor. Inf. Process. Lett. 1987, 24, 377–380. [Google Scholar] [CrossRef]
- Aji, S.M.; McEliece, R.J. The generalized distributive law. IEEE Trans. Inf. Theory 2000, 46, 325–343. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Shift | A | B | C | D | E |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 2 | 2 | 2 |
| 2 | 1 | 1 | 1 | 2 | 1 |
| 3 | 2 | 1 | 1 | 3 | 1 |
| Shift | A | B | C | D | E |
|---|---|---|---|---|---|
| 1 | 2 | 1 | 1 | 1 | 1 |
| 2 | 1 | 1 | 2 | 2 | 2 |
| 3 | 2 | 1 | 1 | 3 | 1 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Gholami, S.; Kar, D.; Sinha, A.; Jain, M.; Goyal, R.; Tambe, M. Keeping Pace with Criminals: An Extended Study of Designing Patrol Allocation against Adaptive Opportunistic Criminals. Games 2016, 7, 15. https://doi.org/10.3390/g7030015
Zhang C, Gholami S, Kar D, Sinha A, Jain M, Goyal R, Tambe M. Keeping Pace with Criminals: An Extended Study of Designing Patrol Allocation against Adaptive Opportunistic Criminals. Games. 2016; 7(3):15. https://doi.org/10.3390/g7030015
Chicago/Turabian StyleZhang, Chao, Shahrzad Gholami, Debarun Kar, Arunesh Sinha, Manish Jain, Ripple Goyal, and Milind Tambe. 2016. "Keeping Pace with Criminals: An Extended Study of Designing Patrol Allocation against Adaptive Opportunistic Criminals" Games 7, no. 3: 15. https://doi.org/10.3390/g7030015
APA StyleZhang, C., Gholami, S., Kar, D., Sinha, A., Jain, M., Goyal, R., & Tambe, M. (2016). Keeping Pace with Criminals: An Extended Study of Designing Patrol Allocation against Adaptive Opportunistic Criminals. Games, 7(3), 15. https://doi.org/10.3390/g7030015