

Physics-Informed Graph Neural Operator for Mean Field Games on Graph: A Scalable Learning Approach

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
Related Work
2. Background
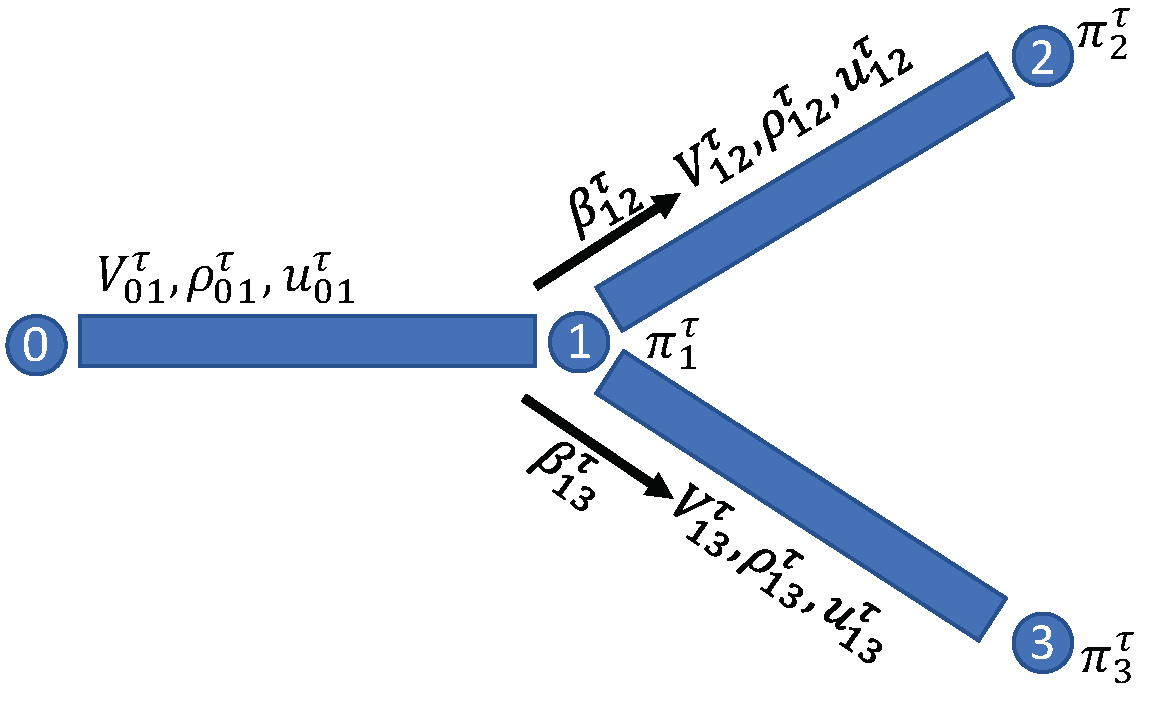
2.1. Mean-Field Games on Graphs (-MFG)
2.2. Graph Neural Operator (GNO)
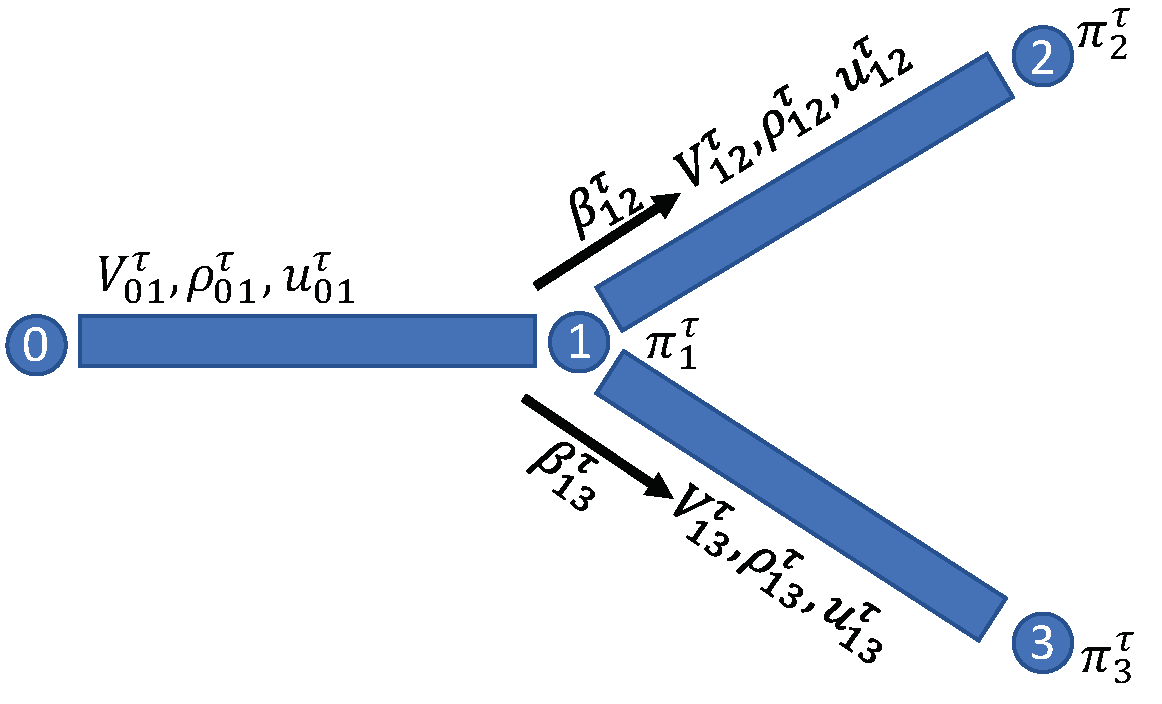
3. Scalable Learning Framework
3.1. PIGNO for Population Behaviors
3.2. PIGNO for Optimal Control
4. Solution Approach
| Algorithm 1 PIGNO-MFG |
|
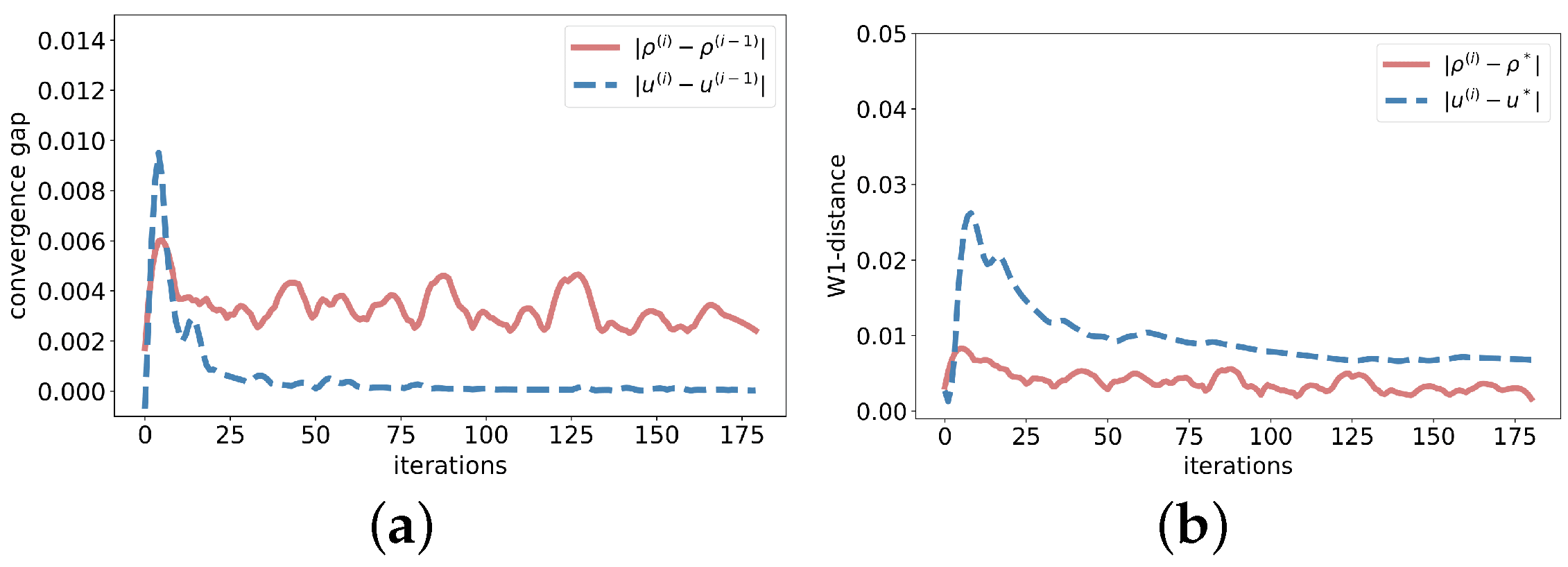
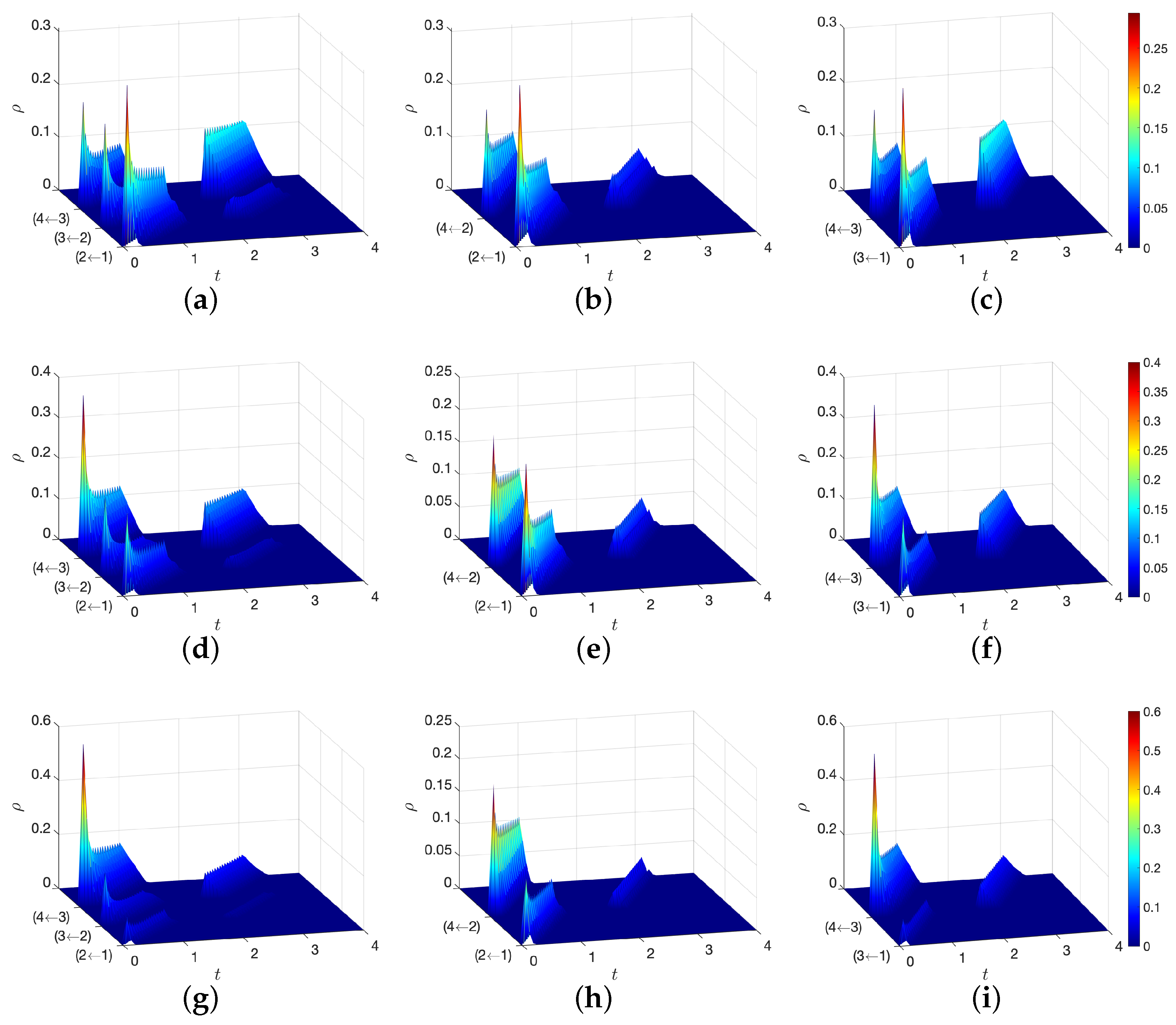
5. Numerical Experiments
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Mean Field Games on Graph
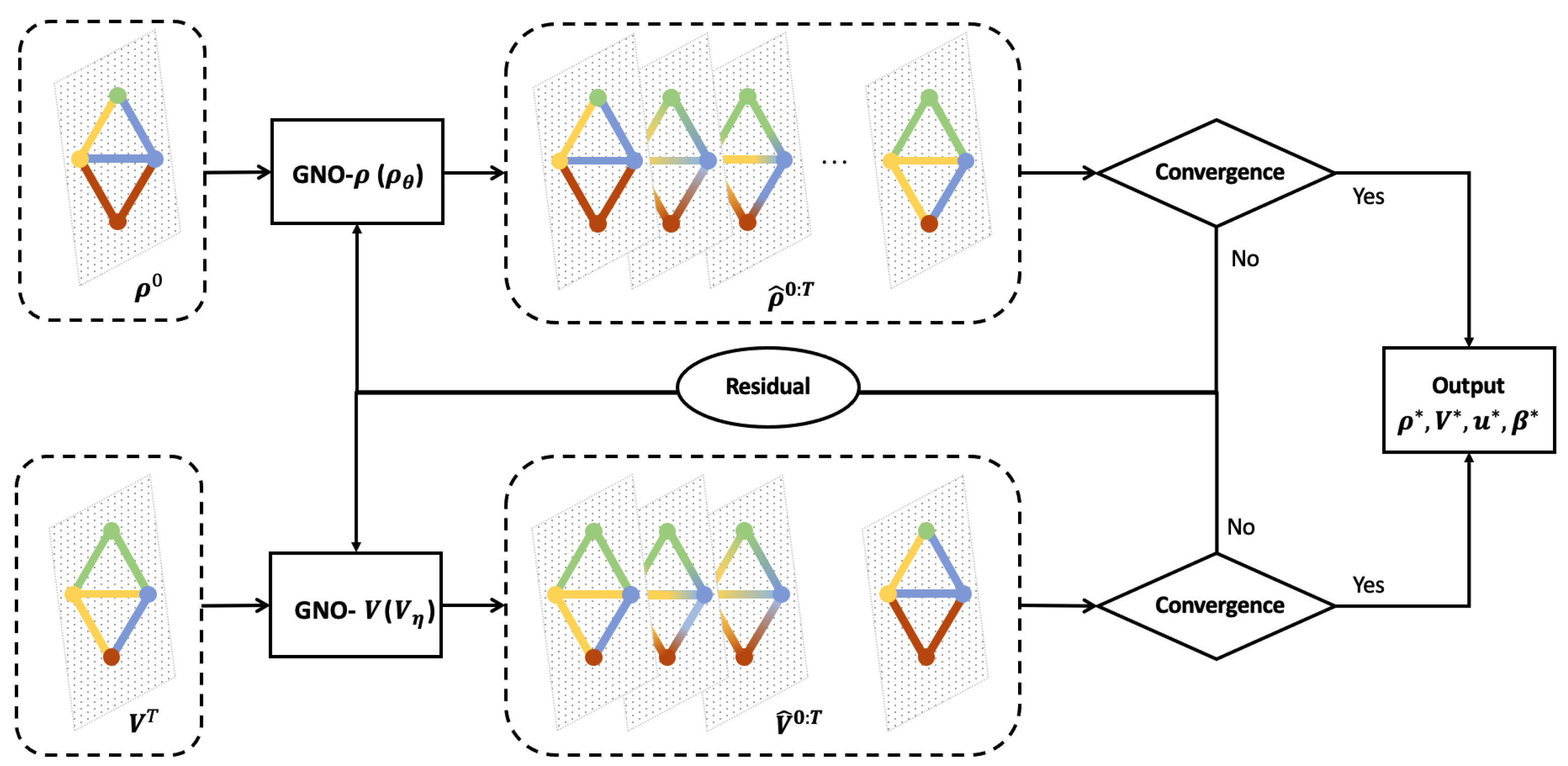
Appendix A.2. Toy Example
References
- Lasry, J.M.; Lions, P.L. Mean field games. Jpn. J. Math. 2007, 2, 229–260. [Google Scholar] [CrossRef]
- Huang, M.; Malhamé, R.P.; Caines, P.E. Large population stochastic dynamic games: Closed-loop McKean-Vlasov systems and the Nash certainty equivalence principle. Commun. Inf. Syst. 2006, 6, 221–252. [Google Scholar]
- Yang, J.; Ye, X.; Trivedi, R.; Xu, H.; Zha, H. Deep Mean Field Games for Learning Optimal Behavior Policy of Large Populations. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Elamvazhuthi, K.; Berman, S. Mean-field models in swarm robotics: A survey. Bioinspir. Biomim. 2019, 15, 015001. [Google Scholar] [CrossRef] [PubMed]
- Calderone, D.; Sastry, S.S. Markov Decision Process Routing Games. In Proceedings of the 8th International Conference on Cyber-Physical Systems, ICCPS ’17, Pittsburgh, PA, USA, 18–20 April 2017; Association for Computing Machinery: New York, NY, USA, 2017. [Google Scholar]
- Cabannes, T.; Laurière, M.; Perolat, J.; Marinier, R.; Girgin, S.; Perrin, S.; Pietquin, O.; Bayen, A.M.; Goubault, E.; Elie, R. Solving N-Player Dynamic Routing Games with Congestion: A Mean-Field Approach. In Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems, AAMAS ’22, Auckland, New Zealand, 9–13 May 2022. [Google Scholar]
- Guéant, O. Existence and uniqueness result for mean field games with congestion effect on graphs. Appl. Math. Optim. 2015, 72, 291–303. [Google Scholar] [CrossRef]
- Guo, X.; Hu, A.; Xu, R.; Zhang, J. Learning Mean-Field Games. In Advances in Neural Information Processing Systems (NeurIPS 2019); Curran Associates, Inc.: New York, NY, USA, 2019. [Google Scholar]
- Subramanian, J.; Mahajan, A. Reinforcement Learning in Stationary Mean-Field Games. In Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, AAMAS ’19, Montreal, QC, Canada, 13–17 May 2019; pp. 251–259. [Google Scholar]
- Perrin, S.; Laurière, M.; Pérolat, J.; Élie, R.; Geist, M.; Pietquin, O. Generalization in Mean Field Games by Learning Master Policies. Proc. Aaai Conf. Artif. Intell. 2022, 36, 9413–9421. [Google Scholar] [CrossRef]
- Lauriere, M.; Perrin, S.; Girgin, S.; Muller, P.; Jain, A.; Cabannes, T.; Piliouras, G.; Perolat, J.; Elie, R.; Pietquin, O.; et al. Scalable Deep Reinforcement Learning Algorithms for Mean Field Games. In Proceedings of the 39th International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; Volume 162, pp. 12078–12095. [Google Scholar]
- Ruthotto, L.; Osher, S.J.; Li, W.; Nurbekyan, L.; Fung, S.W. A machine learning framework for solving high-dimensional mean field game and mean field control problems. Proc. Natl. Acad. Sci. USA 2020, 117, 9183–9193. [Google Scholar] [CrossRef] [PubMed]
- Carmona, R.; Laurière, M. Convergence Analysis of Machine Learning Algorithms for the Numerical Solution of Mean Field Control and Games I: The Ergodic Case. SIAM J. Numer. Anal. 2021, 59, 1455–1485. [Google Scholar] [CrossRef]
- Germain, M.; Mikael, J.; Warin, X. Numerical resolution of McKean-Vlasov FBSDEs using neural networks. Methodol. Comput. Appl. Probab. 2022, 24, 2557–2586. [Google Scholar] [CrossRef]
- Chen, X.; Fu, Y.; Liu, S.; Di, X. Physics-Informed Neural Operator for Coupled Forward-Backward Partial Differential Equations. In Proceedings of the 1st Workshop on the Synergy of Scientific and Machine Learning Modeling@ICML2023, Honolulu, HI, USA, 28 July 2023. [Google Scholar]
- Chen, X.; Liu, S.; Di, X. Learning Dual Mean Field Games on Graphs. In Proceedings of the 26th European Conference on Artificial Intelligence, ECAI ’23, Kraków, Poland, 30 September–5 October 2023. [Google Scholar]
- Li, Z.; Kovachki, N.; Azizzadenesheli, K.; Liu, B.; Bhattacharya, K.; Stuart, A.; Anandkumar, A. Multipole Graph Neural Operator for Parametric Partial Differential Equations. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Online, 6–12 December 2020; Curran Associates, Inc.: New York, NY, USA, 2020. NIPS’20. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Liu, S.; Di, X. Physics-Informed Graph Neural Operator for Mean Field Games on Graph: A Scalable Learning Approach. Games 2024, 15, 12. https://doi.org/10.3390/g15020012
Chen X, Liu S, Di X. Physics-Informed Graph Neural Operator for Mean Field Games on Graph: A Scalable Learning Approach. Games. 2024; 15(2):12. https://doi.org/10.3390/g15020012
Chicago/Turabian StyleChen, Xu, Shuo Liu, and Xuan Di. 2024. "Physics-Informed Graph Neural Operator for Mean Field Games on Graph: A Scalable Learning Approach" Games 15, no. 2: 12. https://doi.org/10.3390/g15020012
APA StyleChen, X., Liu, S., & Di, X. (2024). Physics-Informed Graph Neural Operator for Mean Field Games on Graph: A Scalable Learning Approach. Games, 15(2), 12. https://doi.org/10.3390/g15020012