1. Introduction
We consider the following game with two players, A and B. There are n resources, each denoted by an integer between 1 and n. Each player selects a resource without knowledge about the other player’s selection. The state of the game is described by the random vector , where is the reward random variable of resource k. We assume to be independent random variables for each , taking non-negative real values. If both players choose the same resource k, each gets a utility of . If they choose different resources , they receive utilities of and , respectively. It is assumed that the mean and the variance of exist and are finite for each . Both players know the distribution of . Our formulation allows for an information asymmetry between the players. In particular, can be partitioned into four sets where only player A observes the realizations of for , only player B observes the realizations of for , no player observes the realizations of for , and both players observe the realizations of for .
This game can be used to model different real-world scenarios where the agents have asymmetric information regarding the involved information structure. One classic example is the problem of Multiple-Access Control (MAC) in communication systems. Here, communication channels are accessed by multiple users, and the data rate of a channel is shared amongst the users who select it [
1]. A channel can be shared using Time Division Multiple Access (TDMA) or Frequency Division Multiple Access (FDMA), where in TDMA, the channel is time-shared among the users [
2,
3], whereas in FDMA, the channel is frequency-shared among the users [
4]. In both cases, the total data rate supported by the channel can be considered the utility of the channel. The problem of information asymmetry arises since a user might have precise information regarding the total data rate offered by some channels but not others, and the known channels can be different for different users. On the other hand, the users in such a system cannot be trusted since the system may have malicious users (for instance, jammers) who focus on reducing the data rate available to genuine users.
Modified versions of this game apply to problems in economics. For instance, consider a firm that chooses a market to enter from a pool of market options. The chosen market may also be chosen by another firm. The reward of a market is the revenue it brings. Assume a simplified model where there exists a total revenue for each market, and the total revenue is divided equally among the firms entering the market. A reward known to all firms can be considered public information, while a reward known only to one firm is private information of that firm.
The game defined above can be viewed as a stochastic version of the class of games defined in [
5], which are resource-sharing games, also known as congestion games. In resource-sharing games, players compete for a finite collection of resources. In a single turn of the game, each player is allowed to select a subset of the collection of resources, where the allowed subsets make up the action space of the player. Each resource offers a reward to each player who selected the particular resource, where the reward offered depends on the number of players who selected it. The relationship between the reward offered to a player by a resource and the number of users selecting it is captured by the reward function of the resource. A player’s utility is equal to the sum of the rewards offered by the resources in the subset selected by the player. In [
5], it is established that the above game has a pure-strategy (deterministic) Nash equilibrium.
Although in the classical setting, these games ignore the stochastic nature of the rewards offered by the resources, the idea of resource-sharing games has been extended to different stochastic versions [
6,
7]. Versions of the game with information asymmetry have been considered through the work of [
8] in the context of Bayesian games, which considers the information design problem for resource-sharing with uncertainty. Similar Bayesian games have also been considered in [
9,
10]. It should be noted that in general resource-sharing games, no conditions are placed on the reward functions of the resources. The special case where the reward functions are non-decreasing in the number of players selecting the resource is called a cost-sharing game [
11]. These games are typically treated as games where a cost is minimized rather than a utility being maximized. In fair cost-sharing games, the cost of a resource is divided equally among the players selecting the resource. We consider a fair reward allocation model, where the reward of a resource is equally shared among the players selecting the resource. It should be noted that in this model, the players have opposite incentives compared to a fair-cost sharing model.
The work on resource-sharing games assumes that the players either cooperate or have the incentive to maximize a private or a social utility. It is interesting to consider a stochastic version of the game with asymmetric information between players who do not necessarily trust each other and who place no assumptions on the incentives of the opponents. In this context, the players have no signaling or external feedback and take actions based only on their personal knowledge of the reward realizations for a subset of the resource options. In this paper, we consider the above problem and limit our attention to the two-player singleton case, where each player can choose only one resource.
In the first part of the paper, we provide an iterative best response algorithm to find an
-approximate Nash equilibrium of the system. In the second part, we solve the problem of maximizing the worst-case expected utility of the first player. We solve the problem in two cases. The first case is when both players do not know the realizations of the reward random variables of any of the resources, in which case an explicit solution can be constructed. This case yields a counter-intuitive solution that provides insight into the problem. One such insight is that, while it is always optimal to choose from a subset of resources with the highest average rewards, within that subset, one chooses the higher-valued rewards with lower probability. For the second case, we solve the general version of the problem by developing an algorithm that leverages the online optimization technique [
12,
13] and the drift-plus penalty method [
14]. This algorithm generates a mixture of
pure strategies, which, when used in an equiprobable mixture, provides a utility within
of optimality on average. Below, we summarize our major contributions.
We consider the problem of a two-player singleton stochastic resource-sharing game with asymmetric information. We first provide an iterative best response algorithm to find an -approximate Nash equilibrium of the system. This equilibrium analysis uses potential game concepts.
When the players do not trust each other and place no assumptions on the incentives of the opponent, we solve the problem of maximizing the worst-case expected utility of the first player using a novel algorithm that leverages techniques from online optimization and the drift-plus penalty methods. The algorithm developed can be used to solve the general unconstrained problem of finding the randomized decision , which maximizes , where with , and are non-negative random vectors with finite second moments, and h is a concave function such that is Lipschitz continuous, entry-wise non-decreasing and has bounded subgradients.
We show our algorithm uses a mixture of only
pure strategies using a detailed analysis of the sample path of the related virtual queues (our preliminary work on this algorithm used a mixture of
pure strategies). Virtual queues are also used for constrained online convex optimization in [
13], but our problem structure is different and requires a different and more involved treatment.
1.1. Background on Resource-Sharing Games
The classical resource-sharing game defined in [
5] is a tuple
, where
is a set of
m players,
is a set of
n resources,
where
is the set of possible actions of player
j (which is a subset of
), and
, where
is the reward function of resource
i. Here, we use the notation
. Each player has complete knowledge about the tuple
, but they do not have knowledge of the actions chosen by other players. For an action profile
, the count function # is a function from
to
where
. In other words,
is the number of players choosing resource
i under action profile
. We call the quantity
the
per-player reward of resource
i under action profile
. The utility
of player
j is a function from
to
, where
. In other words,
is the sum of the per-player rewards of the resources chosen by player
j under action profile
. Resource-sharing games fall under the general category of potential games [
15]. Potential games are the class of games for which the change in reward of any player as a result of changing their strategy can be captured by the change in a global potential function.
Many game variations of the resource-sharing game have been studied [
16]. Weighted resource-sharing games [
17], games with player-dependent reward functions [
18], and games with resources having preferences over players [
19] are some of the extensions. Singleton games, where each player is allowed to choose only one resource, have also been explored explicitly in the literature [
20,
21]. Some of the extensions of the classical resource-sharing game possess a pure Nash equilibrium in the singleton case. Two examples would be the games with player-specific reward functions for a resource [
18] and the games with priorities where the resources have preferences over the players [
19].
Resource-sharing games have been extended to several stochastic versions. For instance, ref. [
6] considers the selfish routing problem with risk-averse players in a network with stochastic delays. The work of [
7] considers two scenarios where, in the first scenario, each player participates in the game with a certain probability, and in the second scenario, the reward functions are stochastic. The problem of information asymmetry in resource-sharing games has been addressed through the work of [
8,
9,
10,
22]. The work of [
22] considers a network congestion game where the players have different information sets regarding the edges of the network. Further, ref. [
8] considers a scenario with a single random state
, which determines the reward functions. The realization of
is known to a game manager who strategically provides recommendations (signaling) to the players to minimize the social cost. An information asymmetry arises among the players in this case due to the actions of the game manager during private signaling, where the game manager provides player-specific recommendations.
Resource-sharing games appear in a variety of applications such as service chain composition [
23], congestion control [
24], network design [
25], load balancing networks [
26,
27], resource sharing in wireless networks [
28], spectrum sharing [
29], radio access selection [
30], non-orthogonal multiple access [
31,
32], network selection [
33,
34], and migration of species [
35].
Our formulation differs from the literature on resource-sharing games since we consider a scenario that is difficult to be analyzed using the standard equilibrium-based approaches. This is due to the fact that the players do not trust each other and place no assumptions on the incentives of the opponents, and they take action in the absence of a signaling mechanism or external feedback by just using their knowledge of the reward random variables. This motivates our formulation as a one-shot problem tackled using worst-case expected utility maximization.
1.2. Notation
We use calligraphic letters to denote sets. Vectors and matrices are denoted by boldface characters. For integers n and m, we denote by the inclusive set of integers between n and m. Given a vector , is used to denote the k-th element of ; for represents the dimensional sub-vector of ; for a subset of integers from 1 to n represents the sub-vector of with index in . For , we use to denote the standard Euclidean norm (L2 norm) of . For a function , and , we use to denote a subgradient of f at .
3. Formulation
Denote , , , and . Recall that is known only to player A, is known only to player B, is known to both players, and is known to neither. Let us define , and . Let , , and . Therefore, . Without loss of generality, we assume , , , and .
Let
be the random variable representing the utility of player
, given that player A uses strategy
, and player B uses strategy
. General strategies for players A and B can be represented by the Borel-measurable functions,
where
are the resources chosen by players A and B, respectively. Here,
and
are independent randomization variables uniformly distributed in [0, 1) and independent of
. A pure strategy for player A is a function
that does not depend on
, whereas a mixed strategy is a function
that depends on
. Hence, we drop the randomization variable when depicting a pure strategy. Pure strategies and mixed strategies for player B are defined similarly. Let
and
denote the sets of all possible strategies for players A and B, respectively.
It turns out that our analysis is simplified when is fixed. Fixing does not affect the symmetry between players A and B since is observed by both players A and B. Hereafter, we conduct the analysis by considering all quantities conditioned on .
Note that
and
are the conditional probabilities of players A and B choosing
k given
. Define vectors
,
,
, and
. For
, define
. Hence, we have
which uses the independence of
and
when
.
Note that the utility achieved by player A given the strategies
and
can be written as
Given the strategies
and
, we provide an expression for the expected utility of player A given
, where the expectation is over the random variables
, and the possibly random actions
and
. Taking expectations of (
8) gives,
Note that given
, the random variables
and
are independent. Hence, we can split the last term (
9) as follows,
4. Computing the -Approximate Nash Equilibrium
This section focuses on finding an -approximate Nash equilibrium of the game. Fix . A strategy pair is defined as an -approximate Nash equilibrium if neither player can improve its expected reward by more than if it changes its strategy (while holding the strategy of the other player fixed).
Combining (
10) with (
9), we have that
Similarly, for player B, we have
First, we focus on finding the best response for players A and B, given the other player’s strategy is fixed.
Lemma 1. The best response for players A and B are given by , and , where and are given by, Proof of Lemma 1. We find the best response for A, and the best response for B follows similarly. Notice that we can rearrange (
11) as,
The above expectation is maximized when A chooses according to the given policy. □
Next, we find a potential function for the game. A potential function is a function of the strategies of the players such that the change in the utility of a player when he changes his strategy (while the strategies of other players are held fixed) is equal to the change in the potential function [
15].
Theorem 1. The function given by,is a potential function for the game, where , for , for and for are defined in (
5)
and (
6).
Moreover, we have that for all , . Proof of Theorem 1. The key to the proof is separating (
15) (using (
11) and (
12)) as,
Consider updating the strategy of player A while holding the strategy of player B fixed. Notice that since
is not affected in this process, from (
16), we have that the change in the expected utility of player A is equal to the change in the
H function. Similarly, this holds when player B updates the strategy while holding player A’s strategy fixed. Hence, this is indeed a potential function. The proof that
is omitted for brevity (See technical report [
36] for details). □
Using Theorem 1 with standard potential game theory (see, for example, [
37]), we have that the iterative best response algorithm with the best response found in Lemma 1 converges to an
-approximate Nash equilibrium in at most
iterations.
5. Worst-Case Expected Utility
Finding a Nash equilibrium using the above algorithm may not be desirable when the players do not trust each other and place no assumptions on the incentives of the opponent. To mitigate this issue, we consider maximizing the worst-case expected utility of player A. Similar to the case of finding the Nash equilibrium, the analysis is simplified when is fixed.
Notice that we can simplify (
10) to yield,
where
Plugging the above into (
9), we find that
The difficulty in dealing with is that it depends on the strategy of player B, which is not known to player A. Hence, given a strategy of player A, we first focus on obtaining the worst-case strategy of player B. Then we focus on finding the strategy of player A, which maximizes . This way, we can guarantee a minimum expected utility for player A irrespective of player B’s strategy.
Lemma 2. For given , the strategy that minimizes chooses =, whereand are defined in (
20).
Proof of Lemma 2. Notice that the only term of
in (
21) that depends on the strategy of player B is the last expectation. This expectation is maximized when player B chooses
k, for which
is maximized.
1 □
Hence, we have
where
is defined in (
22). We formulate a strategy for player A using the following optimization problem
where
is defined by,
Although not used immediately, we derive certain properties of f in the following theorem, which are useful later.
Theorem 2. The function f
- 1.
is concave.
- 2.
is entry-wise non-decreasing.
- 3.
satisfies,for any .
It turns out that when
, an explicit solution can be obtained to (P1), which we describe in
Section 5.1. In
Section 5.2, we describe the solution to the general case. In the technical report [
36], we provide simpler alternative solutions to the special cases
(with no restriction on
b) and
(with the additional assumption that
has a continuous CDF).
5.1. Explicit Solution for
When neither player knows any of the reward realizations, we have
, and the problem reduces to the following.
where
is the
n-dimensional probability simplex. For this section, we assume without loss of generality that
for all
k. If at least one of the
’s is zero, we could transform (P2) into a lower dimensional problem with non-zero
’s. The following lemma constructs an explicit solution for
.
2Lemma 3. Assume without loss of generality that for . Further, let,where the lowest index is chosen in the case of ties. The optimal solution for (P2) is given by where It should be noted that this solution is not unique. For instance, consider the case when , , and . In this case, the lemma finds the solution , but it should be noted that is also a solution. It is also interesting that the solution assigns positive probabilities to the r resources with the highest average reward, although within these r resources, higher probabilities are assigned to the resources with lower rewards.
It should also be noted that the worst-case strategy can be arbitrarily worse than the Nash equilibrium strategy. For instance, consider the simple scenario with two resources such that , where none of the players observe any of the reward realizations. In this case, a Nash equilibrium would be player A always choosing resource 1 and player B always choosing resource 2. Another Nash equilibrium would be player B always choosing resource 1 and player A always choosing resource 2. In either case, player A’s expected utility is . However, notice that, from Lemma 3, the maximum worst-case expected utility of player A is . Hence, can be scaled to obtain arbitrarily large deviation between the worst-case and the Nash equilibrium solutions.
5.2. Solving the General Case
In this section, we focus on solving the most general version of (P1) (with no restrictions on the sets
). In particular, we focus on finding a mixed strategy to optimize the worst-case expected utility for player A. It turns out that our optimal solution chooses from a mixture of pure strategies parameterized by
, of the following form
We name this special class of pure strategies as
threshold strategies. We develop a novel algorithm to solve this problem. Our algorithm leverages techniques from drift-plus penalty theory [
14] and online convex optimization [
12,
13]. It should be noted that our algorithm runs offline and is used to construct an appropriate strategy for player A that approximately solves (P1) conditioned on the observed realization of
. We show that we can obtain values arbitrarily close to the optimal value of (P1) by using a finite equiprobable mixture of pure strategies of the above form. It should be noted that the algorithm developed in this section can be used to solve the general unconstrained problem of finding the randomized decision
which maximizes
, where
with
,
and
are non-negative random vectors with finite second moments, and
h is a concave function such that
is Lipschitz continuous, entry-wise non-decreasing, and has bounded subgradients.
We first provide an algorithm that generates a mixture of
T pure strategies, after which we establish the closeness to the optimality of the mixture. We generate a mixture of
T pure strategies
by iteratively updating vector
for
T iterations, where
and
denote the state of
and the pure strategy generated in the
t-th iteration, respectively. In addition to
, we require another state vector
, which we also update in each iteration, and parameter
V, which decides the convergence properties of the algorithm. We provide the specific details on setting
V later in our analysis. We begin with
. In the
t-th iteration
, we independently sample
and
from the distributions of
and
, respectively, where
is defined in (
20) while keeping
fixed to its observed value. Then, we update
and
as follows. First, we solve,
to find
, where
and
. Notice that
is given by,
where
returns the lowest index in the case of ties. Notice that
is a concave function, which can be established by repeating the same argument used to establish the concavity of
f in Theorem 2. Then, we choose the action for the
t-th iteration
(See (
31)). Then, to update
, we use,
The algorithm is summarized as Algorithm 1 for clarity.
| Algorithm 1: Algorithm for the generation of the optimal mixture of T pure strategies. |
 |
After creating the mixture of pure strategies, we choose one of them randomly with probability to take the decision. In the following two sections, we focus on solving (P3) and evaluating the performance of Algorithm 1.
5.2.1. Solving (P3)
Notice that the objective of (P3) can be written as
Hence (P3) seeks to minimize a separable convex function over the box constraint
. The solution vector
is found by separately minimizing each component
over
, where
The resulting solution is,
where
denotes the projection onto
. Notice that the above solution is obtained by projecting the global minimizer of the function to be minimized onto
.
5.2.2. How Good Is the Mixed Strategy Generated by Algorithm 1
Without loss of generality, we assume that for all . The following theorem establishes the closeness of the expected utility generated by Algorithm 1 to the optimal value of (P1).
Theorem 3. Assume α is set such that , and we use the mixed strategy generated by Algorithm 1 to make the decision. Then,where
Ω
is defined in (
20),
and is the optimal value of (P1). Hence, by fixing , and using , , and , the average error is . Proof of Theorem 3. The key to the proof is noticing that
can be treated as
n queues. Before proceeding with the proof, we define some quantities. Define the history up to time
t by
. Notice that we include
in
since this will allow us to treat
and
as deterministic functions of
and
. Let us define the Lyapunov function
, and the drift
. Now, notice that
where
□
We begin with the following two lemmas, which will be useful in the proof.
Lemma 4. The drift is bounded above aswhere is defined in (
40).
The following is a well-known result regarding the minimization of strongly convex functions (see, for example, a more general pushback result in [
38]).
Lemma 5. For a convex function , a convex subset of , and , let, Now, we move on to the main proof. Notice that the objective of (P3) can be written as
where
Let
be the strategy that is optimal for (P1). Let us define
, where
where
for
is a collection of independent and identically distributed uniform
random variables. Notice that
is independent of
t and belongs to
. Hence,
is feasible for (P3). Notice that
where (a) follows from Lemma 5 for the convex function
h given by
, and
, since
is the solution to (P3) and
is feasible for (P3). Further, step 5 in each iteration of Algorithm 1 of finding the action can be represented as the maximization of
over all possible actions
at time-slot
t. Hence, comparing the scenario where
is used in the
t-th iteration with the scenario where
is used with the randomization variable
in the
t-th iteration, we have the inequality,
where the last equality follows since
is independent of
. Summing (
49) and (
51),
Adding
to both sides and using Lemma 4 yields,
where the last inequality follows from the sub-gradient inequality for the concave function
. Now, we introduce the following lemma.
Substituting the bound from Lemma 6 in (
53) we have that
The above holds for each
. Hence, we first take the expectation conditioned on
of both sides of the above expression, after which we sum from 1 to
T, which results in,
Notice that
where functions
f and
are defined in (
25) and (
33), respectively. Further, we have that
where (a) follows from the definition of
in (
33), since
is a function of
and
is independent of
. Substituting (
57) and (
58) into (
56), we have that
where (a) follows since
and the last inequality follows from Jensen’s inequality on the concave function
f. (See the definition of
and
in (
40)). Since
and
, after some rearrangements above translates to,
where
is defined in (
40). Now, we prove the following lemma.
Proof of Lemma 7. We first introduce the following two lemmas.
Lemma 8. The queues for updated according to Algorithm 1 satisfy, The following lemma is vital in constructing the bound on the queue sizes, which leads to the solution. It should be noted that an easier bound can be obtained on the queue sizes, which leads to a solution.
Lemma 9. Given that , satisfy the boundfor each . Now, we move on to the main proof. Notice that
where (a) follows from the entry-wise non-decreasing property of
f (Theorem 2-2) and (b) follows from Theorem 2-3. Combining (
64) and Lemma 8 with the bound on
given by Lemma 9, we are finished with the proof of the lemma. □
Combining Lemma 7 with (
60), we are finished with the proof of the theorem.
6. Simulations
For the simulations, we use
as exponential random variables. Notice that since we are conditioning on
to solve the problem, the objective of (P1) defined in (
25) has the same structure for the two scenarios
and
. Hence, we use
for all the simulations. Notice that the sets
and
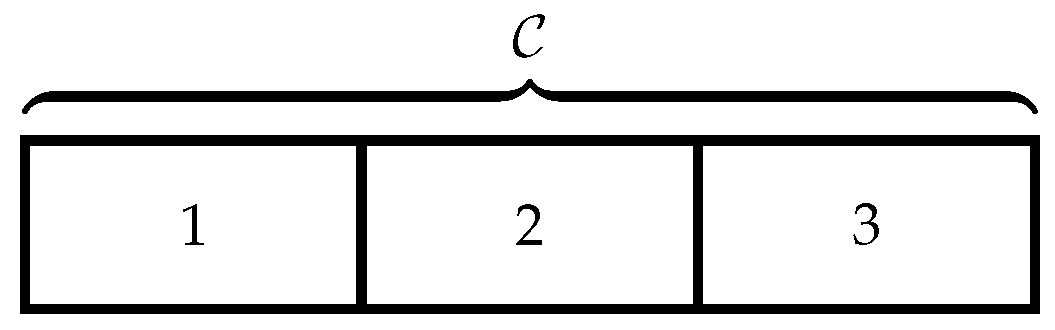
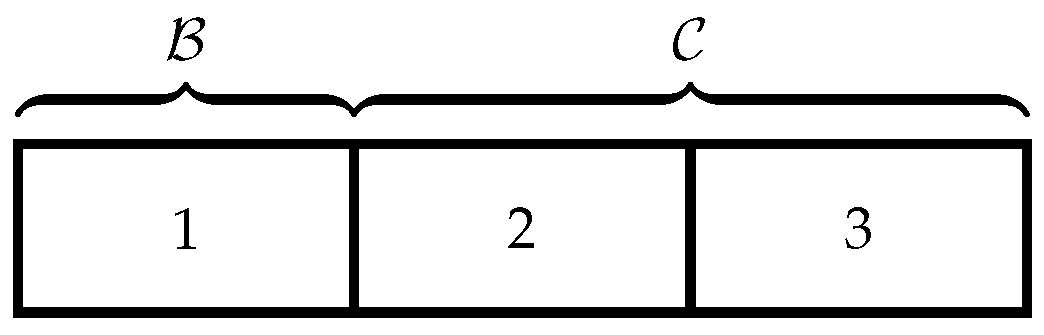
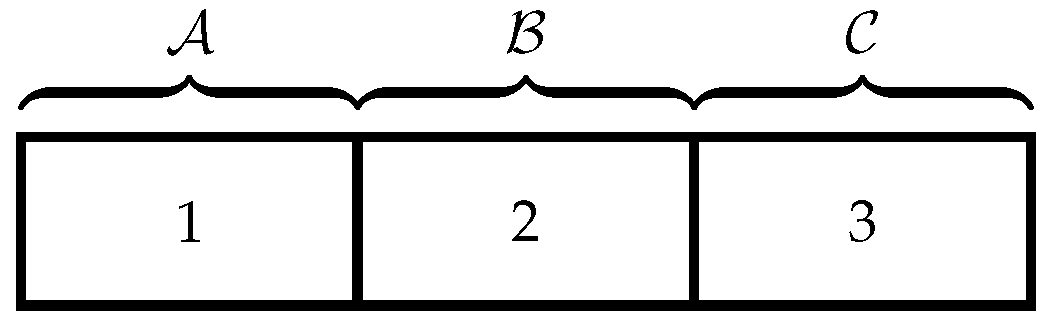
denote the private information of players A and B, respectively. We consider the three scenarios given below.
: Both players do not have private information.
: Only player B has private information.
: Both players have private information.
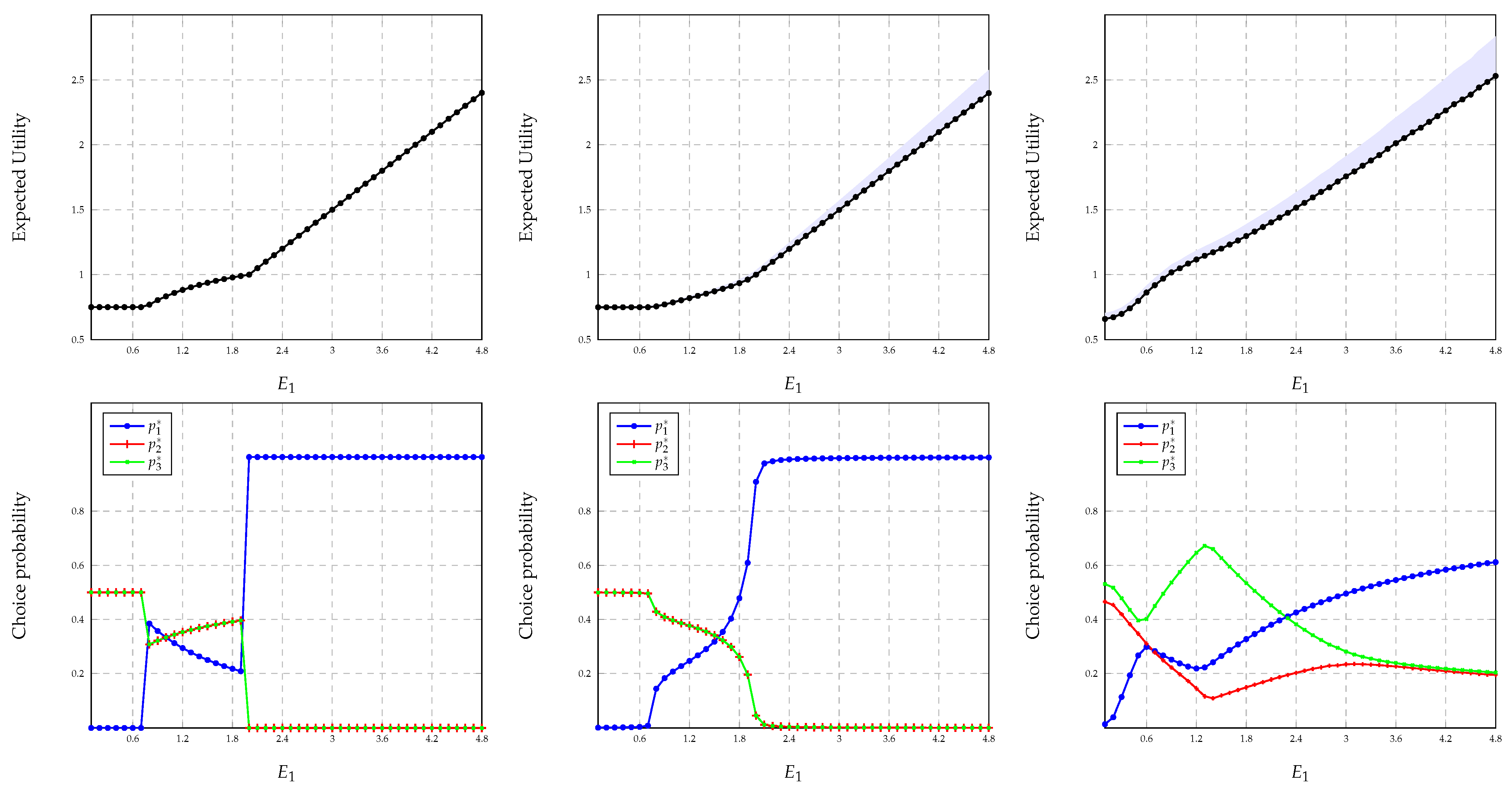
We first consider scenario 1. For
Figure 4 (top-left), we fix
and plot the expected utilities of players A and B at the
-approximate Nash equilibrium as functions of
, where
is used. For
Figure 4 (top-middle and top-right), we use the same configuration and plot a solution for the probabilities of choosing different resources as a function of
at the
-approximate Nash equilibrium for players A and B, respectively. For scenarios 2 and 3,
Figure 4 (middle) and
Figure 4 (bottom), have similar descriptions to scenario 1.
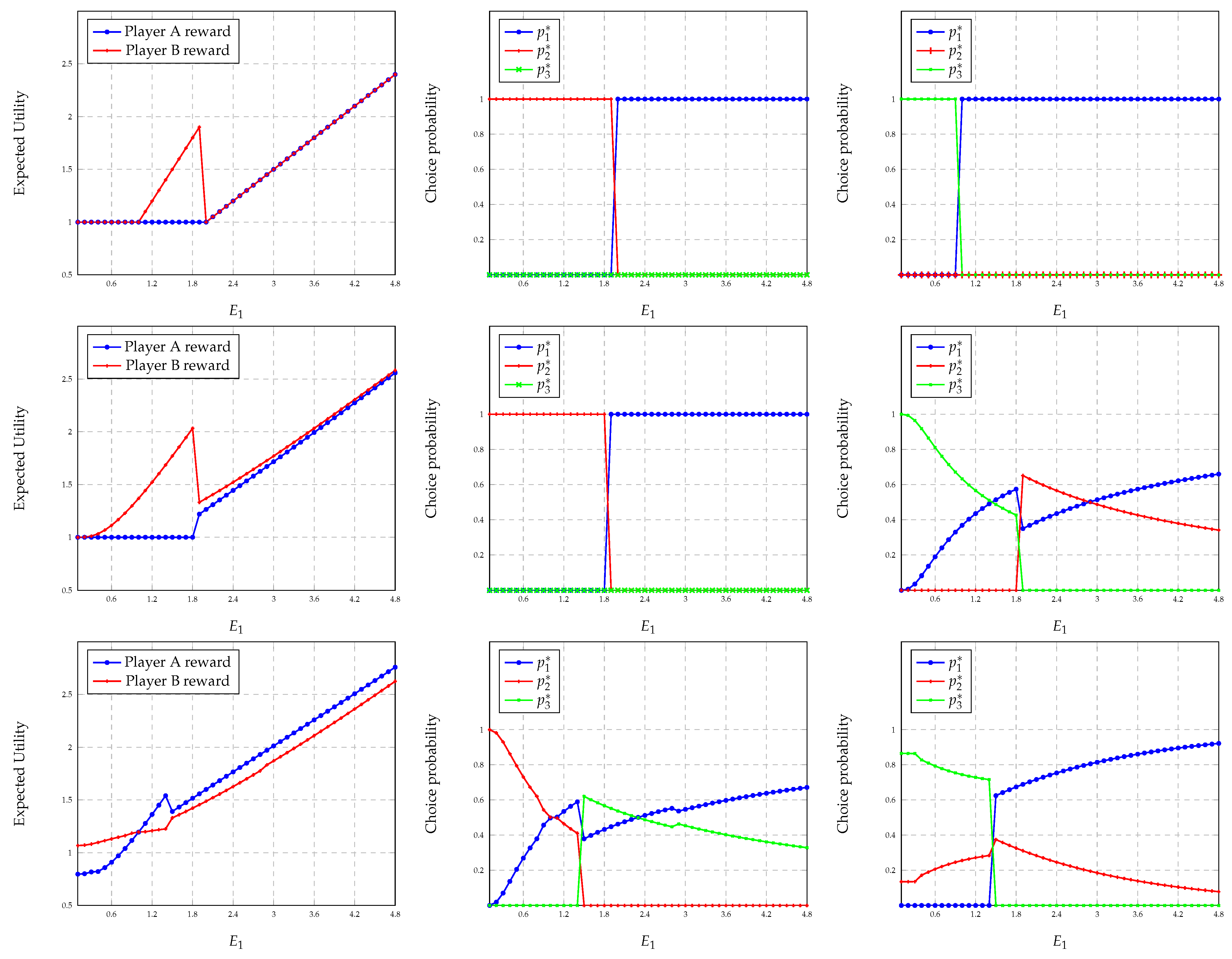
We consider the same three scenarios for the simulations on maximizing the worst-case expected utility. In each scenario, for the top figure, we fix
and plot the maximum expected worst-case utility of player A as a function of
. For the bottom figure, we use the same configuration and plot a solution for the probabilities of choosing different resources for player A as a function of
. Notice that the solutions may not be unique, as discussed in
Section 5.1. Additionally, for
Figure 5 (top-middle and top-right), we also indicate the maximum possible error of the solution calculated using the error bound derived in Theorem 3. For scenarios 2 and 3, we have obtained the solutions by averaging over
independent simulations. Further, we have used
,
, and
.
Notice that it is difficult to compare the worst-case strategy and the
-approximate Nash equilibrium strategy in general since the first can be computed without any cooperation between the players, whereas computing the second requires cooperation among players. Further, as described in
Section 5.1, the worst-case strategy can be arbitrarily worse than the Nash equilibrium strategy. Nevertheless, comparing
Figure 4 (left) and
Figure 5 (top), it can be seen that the worst-case strategy and the strategy at
-approximate Nash equilibrium yield comparable expected utilities for player A when
. For instance, in scenario 1, for
, the approximate Nash equilibrium strategy coincides with the worst-case strategy of choosing resource 1 with probability 1. However, it should be noted that our algorithm for finding the
-approximate Nash equilibrium does not necessarily converge to a socially optimal solution. For instance, in scenario 1, when
, player A chooses resource 1 with probability 1 and player B chooses resource 2 with probability 1 gives a higher utility for player A without changing the utility of player B.
In
Figure 5, it is interesting to notice the variation in choice probabilities of different resources with
. Notice that in scenario 1, the choice probability of resource 1 is non-decreasing for
, non-increasing for
, and non-decreasing for
. Similar behavior can also be observed for scenario 3. This is surprising since intuition suggests that the probability of choosing a resource should increase with the increasing mean of the reward random variable. However, notice that in scenarios 1 and 3, player B does not observe the reward realization of resource 1. This might force player A, playing for the worst case, to believe that player B increases the probability of choosing resource 1 with increasing
, as a result of which player A chooses resource 1 with a lower probability. Notice that the probability of choosing resource 1 in scenario 3 does not grow as fast as the other two. This is because player A observes
and hence can refrain from choosing it when
takes low values.
7. Conclusions
We have implemented the iterative best response algorithm to find the -approximate Nash equilibrium of a two-player stochastic resource-sharing game with asymmetric information. To handle situations where the players do not trust each other and place no assumptions on the incentives of the opponent, we solved the problem of maximizing the worst-case expected utility of the first player using a novel algorithm that combines drift-plus penalty theory and online optimization techniques. An explicit solution can be constructed when both players do not observe the realizations of any of the reward random variables. This special case leads to counter-intuitive insights.
In our approach, we have assumed that the reward random variables of different resources are independent. It should be noted that this assumption can be relaxed without affecting the analysis for the special case when both players do not observe the realizations of any of the reward random variables. An interesting question would be what happens in the general case when the reward random variables are not independent. While it is still possible to implement our algorithm in this setting, it is not guaranteed that the algorithm will converge to the optimal solution. Hence, finding an algorithm for this case that exploits the correlations between the reward random variables could be potential future work.
Several other extensions can be considered as well. One would be considering a scenario with multiple players. The general multiplayer case yields a complex information structure since the set of resources has to be split into subsets, where m is the number of players. Additionally, the idea of conditioning on the common information is difficult to be adapted for this case. Nevertheless, various simplified schemes could be considered. One example would be a case with no common information. In this case, the set of resources is split into disjoint subsets where the i-th () subset is the subset of resources of which the i-th player observes the rewards, and the -th subset is the subset of resources of which the rewards are observed by none of the players. Another interesting scenario is when no player observes any of the reward realizations. In both these cases, the expected utility can be calculated following a similar procedure to the two-player case, but finding the worst-case expected utility is difficult. Hence, we believe both cases could be potential future work. Another extension would be extending the algorithm to be implemented with a repeated game structure and in an online scenario.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





