1. Introduction
Tackling traffic congestion has been a goal of many cities for decades, to, for example, reduce travel times and decrease air pollution. The increased adoption of automatic route planners such as GPS navigation, Google Maps, Waze, etc., can potentially have a positive impact on reducing congestion by the resource allocation of routes. A recent study demonstrated, to a large extent, that intelligent transport systems have a greater effect on improving congestion than building new roads [
1]. Furthermore, the capacity for routing systems to control the flow of congestion is only increasing, and autonomous vehicle development will allow for routing control with minimal input from drivers.
Although arguably beneficial in many ways, the presence of multiple planners has important repercussions on the overall system efficiency, and the possibility for navigation applications to enforce socially desirable outcomes in transportation networks was recently listed as an open problem in Cooperative Artificial Intelligence [
2].
Due to the size and complexity of the problem, using multi-agent reinforcement learning (MARL) algorithms for network control in order to optimise congestion could be a solution, but the problem remains of how far away the learnt strategies would be from the most socially desirable outcome. Before deploying such algorithms, we need to understand the quality of the resulting equilibria.
In Distributed Artificial Intelligence (DAI), congestion games [
3] have become a reference model to analyse the inefficiency of traffic flows, with important implications for the design of better road systems [
4]. In congestion games, self-interested players travel between origin and destination nodes in a network, choosing paths that minimise their travel time. Players’ route choices constitute a Nash (or user) equilibrium when there is no incentive to unilaterally deviate, and then, they are typically compared against the total travel times, yielding the players’ social welfare. The most often used measure of inefficiency is the Price of Anarchy (PoA) [
5], which compares the worst Nash equilibrium routing with that of the optimal flow.
While Nash equilibria are important predictors, it is also well known that their assumptions on individuals’ rationality are frequently not met in practice. In large transportation networks, it is often the case that individuals have incomplete knowledge of the network (see, e.g., the bounded rationality approaches in [
6,
7]) and rely on personal route planners to figure out their optimal route. An account of this intermediate perspective, where competing controllers act on the same selfish routing network, is still missing from the multi-agent systems literature.
1.1. Our Contribution
In this paper, we study intelligent routing systems that act as distributed controllers on a traffic network and analyse their impact on the overall efficiency. We develop a two-level game, called the network control game, where route planners have control over the resource allocation of an underlying nonatomic (information-constrained) congestion game. Specifically, each route planner controls a finite predetermined fraction of the total traffic by choosing information available to vehicles with the goal of minimising the travel time incurred by that fraction only. We show that this can be seen as a distributed resource allocation problem with separable welfare functions, where the resource sets are edges on a network and the strategies of a player must correspond to their given origin and destination pair. Modelling players of the nonatomic congestion game as vehicles and route controllers or planners as optimisers for a subset of vehicles, we prove that network control games are potential games and therefore have an essentially unique equilibrium. Then, we study equilibrium efficiency, showing that the PoA is highest when the allocation of vehicles to route planners is (approximately) proportional. We also give PoA bounds over polynomial cost functions, depending on the polynomial degree and the number of controllers. Furthermore, we give an example of an MARL implementation to show that this PoA occurs in practice. Finally, we extend network control games to allow vehicles to choose their route planner, showing that the unique resulting equilibrium has the highest total cost.
1.2. Paper Outline
We begin by discussing our work in connection with the related literature in
Section 2 and outline the necessary preliminaries and notation in
Section 3. Then,
Section 4 introduces the network control games and studies the existence of equilibria.
Section 5 calculates the PoA over polynomial cost functions, with an MARL implementation shown in
Section 6. Finally, we analyse the extension where vehicles choose their route planner in
Section 7.
2. Related Literature
Our work connects to a number of research lines in algorithmic game theory, focusing on the quality of equilibria in congestion games and resource allocation, and the research in DAI studying planning and control with boundedly rational agents.
Congestion games are a class of games first proposed by Rosenthal [
3], which were utilised in research for modelling the behaviours of network systems. These were initially studied in the transportation literature by Wardrop [
8] who established the conditions for a system equilibrium to exist when all travellers have minimum and equal costs. Their applications have increased to include many other situations that can be modelled with selfish players routing flow in a network, for example, machine scheduling or communication networks [
9], as well as physical systems such as bandwidth allocation [
10] or electrical networks [
11]. However, their main application for congestion games is transportation [
12,
13,
14].
Games, where the utilities of all players can be described with a single function, are called potential games [
15], and these are, in fact, equivalent to congestion games. A useful property of potential games is that they always admit a pure Nash equilibrium. Finding a pure Nash equilibrium in an exact potential game is a PLS-complete problem [
16]. However, improvement paths [
15] converge at equilibrium for all potential games. For nonatomic congestion games, i.e., ones with continuous player sets, the maximisers of the potential function are Nash equilibria of the potential game [
17].
The PoA [
5] was proposed as a measure of inefficiency representing the cost ratio of the worst possible Nash equilibrium to the social optimum. The PoA in network congestion games is a phenomenon that is independent of network topology [
18]. The biased PoA [
7] compares the cost of the worst equilibrium to the social optimum, when players have “wrong” cost functions, i.e., differing from the true cost due to biases or heterogeneous preferences.
From the point of view of distributed control, an important related model is Stackelberg routing games, where a portion of the total flow is controlled centrally by a “leader”, while the “followers” play as selfish vehicles. Stackelberg routing was first proposed by [
19], characterising which instances are optimal. Roughgarden [
20] found the ratio between worst-case and best-case costs in these games, and the impact of Stackelberg routing on the PoA has also been established for general networks [
21]. Single-leader Stackelberg equilibria in congestion games have been looked at, and it is known that they cannot be approximated in polynomial time [
22]. Instead, multi-leader Stackelberg games are largely unexplored in this context [
23]. Our approach features multiple leaders but not Stackelberg-like “followers”, which impacts our results on the PoA.
Much of the transport literature is aimed at reducing congestion, and increasing efficiency in traffic networks focuses on introducing tolls [
24,
25,
26]. Information design, which is closely related to our approach, has more recently been considered as a mechanism to reduce congestion [
6,
7,
27]. The information-constrained variant of a nonatomic congestion game was first introduced to show that information could cause vehicles to change their departure times in such a way as to exacerbate congestion rather than ease it [
28]. The set of outcomes that can arise in equilibrium for some information structure is equal to the set of Bayes correlated equilibria [
29]. Das et al. [
30] considered an information designer seeking to maximise welfare and restore efficiency through signals using information design. Tavafoghi and Teneketzis [
31] showed that the socially efficient routing outcome is achievable through public and private information mechanisms. Moreover, Ikegami et al. [
32] consider a centralised mediator to recommend routing to users taking into account their preferences for incomplete information games. Our work differs from the private information design literature. In our model, route planners control the routing rather than provide signals, and multiple agents attempt to optimise ‘group’ welfare.
A similar game is the splittable congestion game, which was first studied in the context of communication networks [
9]. Here, each player in the congestion game assigns a weight to the possible strategies that arise when considering coalitions of players in nonatomic congestion games. The bounds on the PoA for splittable congestion games have been found for polynomial cost functions [
33], which have the same bound when there are an infinite number of route planners in a network control game.
Network control games can be seen as resource allocation games, where the resources are edges in a network and the potential function is the total cost of players’ travel times. Distributed resource allocation problems aim to allocate resources for optimal utilisation, such as distributed welfare games [
34] and cost-sharing protocols [
35]. A recent survey of game-theoretic control of networked systems highlights major advancements and applications [
4].
Additionally, distributed welfare games [
34] utilise game-theoretic control for distributed resource allocation where the distribution rule is chosen to maximise the welfare of resource utilisation. Different distribution rules can be compared by their desirable properties such as scalability, the existence of Nash equilibria, PoA, and Price of Stability. In this context, protocols have been studied to improve the equilibria of network cost-sharing games [
35], while [
36] studied welfare-optimising designers under full and partial control. We consider a distributed resource allocation problem with separable welfare functions where the resource sets are edges on a network and the strategies of player must coincide with their given origin and destination pair, i.e., on a congestion game.
Regulating the flow of traffic in complex road networks is an important application of artificial intelligence technologies usually involving distributed optimisation and multi-agent learning methods [
37,
38,
39]. Most of the literature focuses on adapting traffic lights to coordinate traffic, but MARL can also be used to improve traffic flow through resource allocation, as we show in
Section 6.
3. Preliminaries
We begin by introducing some standard definitions of nonatomic congestion games and the properties of their equilibria.
Let be a nonempty finite set of player (or vehicle) populations such that players in the same population share the same available route choices (or strategy set). For population , the demand for a population, i.e., the traffic volume associated with that population, is . Each population i has a nonempty finite resource set made up of relevant resources, i.e., those edges that are used in at least one route choice, , where is the strategy set of i. Denote E as the irredundant resource set , the set of edges used in any strategy set. Resource cost functions, such that , are assumed to be continuous, nondecreasing, and non-negative.
We assume that individuals have limited knowledge of the routing options; i.e., we assume there exist information types in each population and refer to a player from population i of type k as , where the demand for a type is . Information types can restrict knowledge of the resources; i.e., each population–type pair is associated with a known set . Formally, a nonatomic information-constrained (NIC) congestion game is defined as a tuple , with , .
The outcome of all players of type
k choosing strategies leads to a vector
satisfying
and
. A strategy distribution or outcome
is
feasible if Equation (
1) holds
and
. Then, denote the load on
e in an outcome
to be
, where
is the indicator function. In a strategy distribution,
, a player of knowledge type
incurs a
cost of
when selecting strategy
. An
information-constrained user equilibrium (ICUE) [
6] is a strategy distribution
such that all players choose a strategy of minimum cost:
and strategies
such that when
we have
. Every player of the same knowledge type has the same cost at a UE
, which is denoted
. We say that a user equilibrium is
essentially unique if all user equilibria have the same social cost. For any nonatomic congestion game, there exists a user equilibrium, and it is essentially unique [
40].
The
social cost of
is the total cost incurred by all players,
Strategy distribution
is a
social optimum (SO) if it minimises Equation (
2). Formally, a SO solves
, such that
.
In most cases, the SO solution is different to the UE solution, since players only maximise their individual utility. Pigou [
41] was the first to show this on a network with one origin and one destination and two parallel edges joining them, for a population of size 1. The cost of the first of the edges is constant at 1, and the second costs the same as the proportion of players that choose it. The UE here is for all players to use the second edge, which gives a social cost of 1, whereas the optimal routing is to split players equally along edges for a social cost of
.
The efficiency of the UE when compared with the SO is the
Price of Anarchy (PoA). It is defined as the ratio between the social cost of a SO outcome and the worst social cost of a UE,
where
is the set of user equilibria. For example, in Pigou’s network, the PoA is
.
An
exact potential game is one that can be expressed using a single global payoff function called the
potential function. More formally, a game is an exact potential game if it has a potential function
such that
,
. Here, the notation
means all players in
N excluding
i, i.e.,
. The concept of potential games was first posed by [
15] for atomic games and later extended to nonatomic games [
17,
42]. Potential games and congestion games are equivalent, where a player’s utility is their negative cost. The potential function for nonatomic congestion games is
where
is the strategy distribution of players, which is also referred to as the Beckmann function [
43]. A strategy distribution is an ICUE if, and only if, it minimises the potential function [
6] (an extension of results in [
40,
43]).
When studying the PoA in network control games, we will turn our attention to social dilemmas, i.e., games in which there exists a conflict between individual and social preferences. The classic two-player matrix game social dilemma is a game with payoffs shown in
Table 1, where we must have the conditions
,
,
, and either
or
. A social dilemma, by definition, has a PoA strictly greater than 1.
Learning algorithms can be used to find strategies in large or complex environments. In this paper, we consider the effects of using reinforcement learning algorithms to solve the problem of route control in information-constrained nonatomic congestion games.
Reinforcement learning (RL) is a framework where an agent earns rewards for taking actions in a given environment. The goal is to find a policy—a sequence of actions to take in each environmental state—in order to maximise rewards. Value functions are used to estimate long-term rewards given that the agent observes a particular state and selects actions aligning with its policy. Equivalently, this can be formalised as a single-player stochastic game where the policy is the agent’s strategy. See [
44] for a detailed introduction to RL.
The environment is represented by a state variable, , and the principle task of the agent is to select the best action, , given the current state. An optimal policy states the actions to be taken in a given state to achieve the highest expected return.
A Markov decision process (MDP) is a discrete-time stochastic control process that provides a suitable mathematical framework for modelling an agent’s reasoning and planning strategies in the face of uncertainty. It satisfies the Markov property—the probability distribution over the next set of states only depends on the current state and not its history. Formally, we write an MDP as a tuple : state space S, action set A, Markovian transition model , and reward function .
The goal of the agent is to select a sequence of actions, or policy . An optimal policy maximises the cumulative discounted return, , where is a discount factor and is the reward at step i. The state-value function, or value function, describes the expected value of following policy from state s, .
The action–value function, or
Q-function,
estimates the expected value of choosing an action
a in state
s then following policy
:
. We can write the Q-function in terms of the value function as follows:
In MARL, each agent must make assumptions about their opponents’ strategies in order to optimise their own payoff. An MDP can be generalised to capture multiple agents through the use of Markov games. Formally, a Markov game is a tuple where N is the set of agents, state space S, is the action space of , is the transition function, is the reward function, and is the discount factor.
Denote the action profile of agents at time
t is
, then we can define the value function for player
i as
For Markov games, a
Nash equilibrium is a joint policy
such that for all
and
,
Actor–critic methods [
45] are a class of algorithms where a ‘critic’ advises an ‘actor’ of the quality of each action. The actor and critic each learn separately; the critic estimates the value function, while the actor learns the policy based on feedback from the critic.
Asynchronous Advantage Actor–Critic (A3C) is a model-free policy optimisation-based MARL algorithm. It equips the actor–critic format with independent local agents (asynchronicity) whereby the critics estimate the
advantage function, which is defined as the Q-function Equation (
5) minus the value function Equation (
6). In policy optimisation, we learn the policy directly rather than the Q-values. In deep learning, we learn the parameters
of the neural network that represents the policy or value function. For further details of the algorithm, see [
46].
4. Network Control Games
Suppose that the routing choices of vehicles in an NIC congestion game are controlled by a set of route planners R, where each route planner aims at minimising the total travel cost of the (nonempty) portion of vehicles assigned to them , where and . For instance, this could occur in a setting of competing autonomous taxi companies within a city. Each taxi company wishes to minimise the journey times of their fleet for customer satisfaction and energy efficiency but does not use the same routing systems as the other companies.
The way in which the route planners have control over the routing choices is by choosing which knowledge set is available to each player, i.e., any type for a vehicle in population i. Since there exist knowledge types that have only one route available as a strategy, this action space is a superset of controlling the routes of vehicles. Thus, we allow route planners to control the demand for each knowledge type within the fraction of flow they control; i.e., they control the distribution of knowledge types within populations. Choosing this action space allows for a more generalised model than if they selected a single route for each vehicle. For instance, a navigation app would give its users a choice between only a few routes; thus, drivers have incomplete knowledge of the network available to them. For example, autonomous vehicles may not give their passengers a choice of route. In this case, the knowledge set would contain only the route that the autonomous vehicle follows.
Let the size of each population controlled by be denoted , where and , for . We can view the game as an information design problem, where a player r partitions populations in into sets of information types to minimise the social cost of . The route planner r has a strategy set denoted . Thus, a route planner chooses the information type demands , such that , . Let the strategy space for route planners be where is the set of all information sets for any . Moreover, for any and , we have , where is the indicator function. Let the combined strategy space of all route planners be denoted as , where is the set of all information types.
Now, we define a network control game to be a tuple , where is an NIC congestion game, R is the set of route planners, is the population controlled by , is the demand of population i controlled by r, and is the strategy space of r.
Let the share of control of route planner r be . If a route planner has a share of control equal to 1, then we say it has full control of the game. The control of r over a population i is defined as . If and , the control of r over population i is , then we say that the game is proportional.
Observe now that the outcome of all route planners’ strategies leads to an ICUE in the underlying game. This is true, since it is a two-level game, where route planners first choose the information types, and then, the congestion game is played by vehicles in the second stage. Given this, the cost function of a route planner is defined as , where is the ICUE from . Note that due to the notation , we can use and interchangeably.
Then, an outcome is a Nash equilibrium of the network control game if, and only if, , we have . We can show the existence of Nash equilibria in network control games by showing that these are exact potential games.
Proposition 1. A network control game is an exact potential game for potential Φ defined aswhere is the ICUE formed from . Proof. Consider a unilateral deviation
of route planner
r from an outcome
with respective ICUE profiles
and
.
Since the deviation from
to
only involves edges in
, we can rewrite the right-hand side of Equation (
7) as
Thus, the function
is an exact potential function. By definition, the network control game is an exact potential game. □
Since we have an exact potential game with nondecreasing edge costs, Corollary 1 follows directly from Acemoglu et al. [
6] (Theorem 1).
Corollary 1. For every network control game, there exists a Nash equilibrium, and it is essentially unique.
As network control games are exact potential games, all of the results known for nonatomic congestion games will also hold in the new context, e.g., [
18,
47]. Nonetheless, these games allow for insights into how the distribution of vehicle route planners will affect traffic equilibria, which is an important and novel contribution to the literature (see
Section 2 for an in-depth discussion).
We now define the PoA of a network control game as
where
is the set of Nash equilibria. Since there is a one-to-one mapping of flow to route planners, the social cost is defined the same as the underlying congestion game.
Note that our setup can be extended to incorporate vehicles that are not fully controlled by a route planner, e.g., by allowing route planners that give full information sets to their populations. However, we only consider vehicles following a route planner directly to more easily classify the best and worst-case equilibria from the full route control of populations.
We also note that for any strategy distribution in a (information-constrained) nonatomic congestion game, we can, without loss of generality, restrict ourselves to pure strategy equivalents. A route planner has no incentive to recommend multiple routes to a vehicle, since this creates uncertainty about vehicle route choice. Thus, henceforth, we study the case where all information sets chosen by the route planners contain only one strategy. As such, the profile set by the route planners has a deterministic associated ICUE .
5. Inefficiency of Route Controllers
To see how the network control game creates inefficient equilibria, first consider what happens as we change the number of route planners in a proportional game. First, suppose that a route planner has full control of the game, then all vehicles follow the same route planner. Thus, the route planner has an objective function equal to the social cost of the system: . As such, the case with will implement the socially optimal routing allocation.
Now, as we increase the number of route planners, the demand of the population controlled by a single player decreases. As and since the game is proportional, we have that , . As we now have an infinite number of agents controlling a negligible amount of flow, we are back to a simple NIC congestion game. This occurs since , when the proportion of control of r is negligible. The PoA of the game is now the same as in its underlying NIC congestion game. Thus, if there is more than one route planner in a proportional network control game, which is true by definition, there is an inefficient equilibrium if the NIC congestion game admits one.
Proposition 2. A proportional network control game has a PoA strictly greater than 1 if, and only if, the underlying NIC congestion game does.
Proof. . If the PoA of a network control game is strictly greater than 1, then there is an incentive to choose suboptimal routing at the Nash equilibrium. As the number of route planners in the proportional game tends to infinity, we approach the underlying NIC congestion game. As such, the suboptimal routing exists in the NIC congestion game, and so, the PoA for the NIC congestion game is strictly greater than 1, too.
If the PoA of an NIC congestion game underlying a proportional network game is strictly greater than 1, then we know that at the UE, there exists a suboptimal selfish routing of drivers. Let the Nash equilibrium of routing be and the SO be . Since the game is proportional, all route planners have the same strategy space. Thus, , (i) , (ii) , and (iii) .
We can write this as a two-player (r and ) normal form game with the actions , , , and . This, combined with the inequalities above, indicates that the payoffs comply with the conditions required for a social dilemma. As such, the PoA is strictly greater than 1. □
Thus, we have identified that having multiple route planners controlling the flow on any NIC congestion game with an inefficient equilibrium will not have SO equilibrium flow. We will now bound this inefficiency by finding the PoA of the route control game.
Since the PoA is independent of network topology in all nonatomic congestion games [
18], we can use the Pigou example to illustrate the inefficiency of having multiple route planners. We assume that cost functions are polynomial with maximum degree
p. To begin, let us consider linear cost functions, i.e.,
.
Example 1 (Two route planners)
. Suppose we have a total flow of 1 and two route planners 1 and 2 with respective population control of and on a Pigou network. Each route planner must solve the following minimisation problem to find their equilibrium routing defined by the variable for , as defined in Figure 1 and Figure 2.subject to . This gives us the Lagrangian function (where , ):The corresponding Karush–Kuhn–Tucker conditions are:Consider the following three cases: - 1.
First, consider the case where . Since , we must have . Route planner r plays selfishly by routing along the bottom edge only if their control is small.
- 2.
Now, suppose that and . The solution here is .
- 3.
The last possible case is where , and similarly, this occurs when .
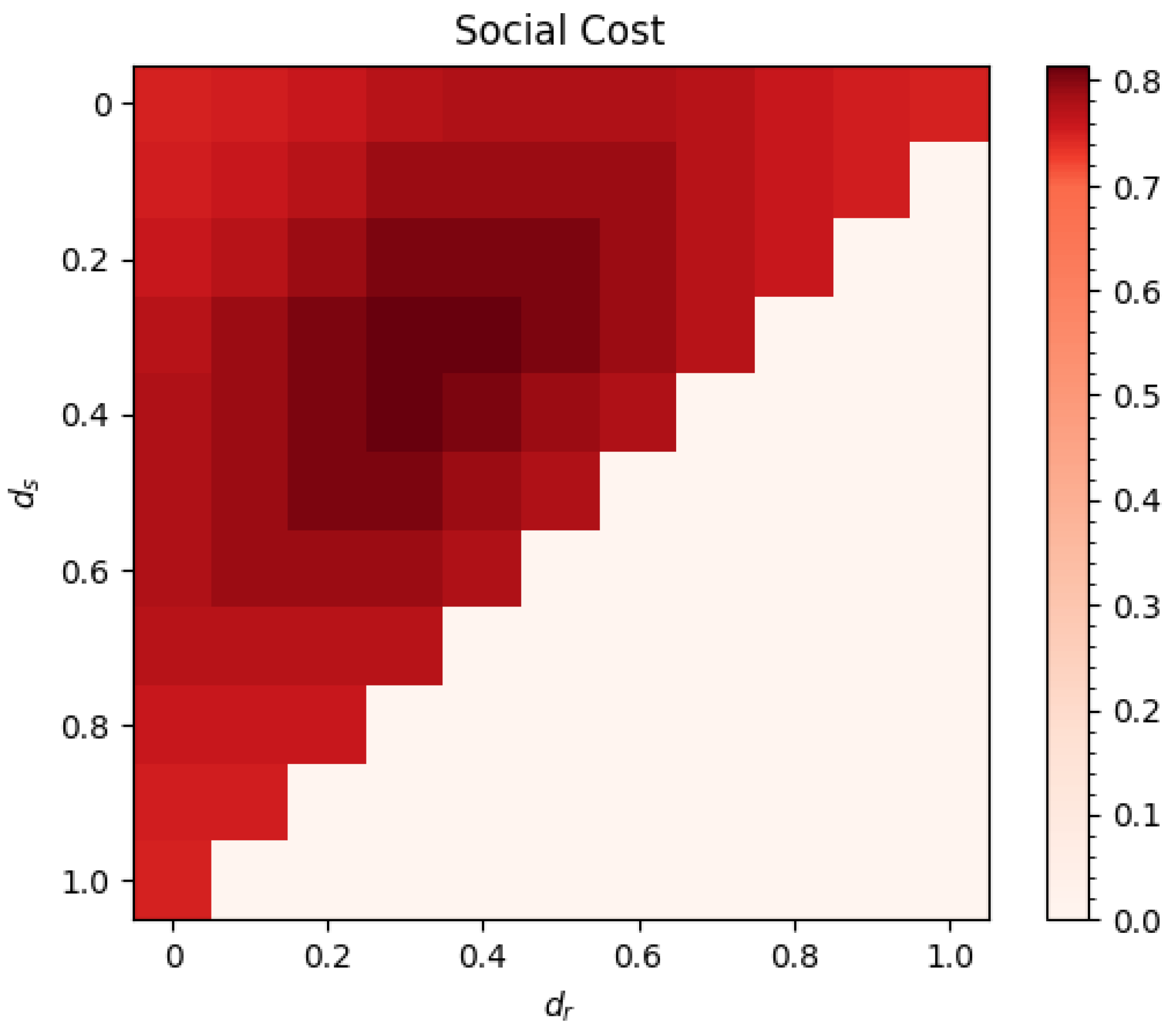
Thus, the optimal routing of splitting the vehicles equally between routes only occurs when there is one route planner with full control. The social cost of equilibria is shown in Figure 3. As choices are independent, similar reasoning applies for more route planners. The optimal routing remains the same as the three cases in Example 1, but the effect of adding another selfish agent increases the worst possible cost.
Example 2 (Three route planners)
. Now suppose three route planners control the flow on the same Pigou network. As before, each route planner performs a minimisation over their routing choice . Since they chose their routing independently of one another, the same reasoning can be used to consider more populations. The optimal routing remains the same, but the effect of adding another selfish agent increases the worst possible cost. This can be seen in Figure 4, where the same behaviour of two operating systems is seen with another dimension. Let us formalise the result that proportionality is linked to a high PoA. Once again, since the PoA is independent of network topology, we can find the worst-case example of it using the Pigou example. Thus, Examples 1 and 2 found the worst-case ratio of selfish route planners to fully cooperative route planners for two and three route planners, respectively. Let the number of route planners be . We can find the PoA using the same method as the example for general .
Proposition 3. The PoA of a network control game is highest when the game is proportional.
Proof. To find the worst-case PoA of route control, we want that no route planner is acting socially optimally. We can find the worst-case of routing on the Pigou example since it is independent of topology. Thus, we solve the minimisation problem
To do so, we use the following Lagrangian function
The corresponding Karush–Kuhn–Tucker conditions are:
For general and , the three cases remain the same as Example 1. The best response to is to choose , and when , we have . For no route planner to choose the socially optimal routing in Pigou’s example, each route planner must have a proportion of control of population i of at least and less than or equal to . For all and p, . As , . Thus, the worst-case equilibrium cost can be achieved through a proportional assignment of populations. □
The maximum social cost of Nash equilibria of the network control game also occurs for other distributions of route planner control. From
Figure 3, we see that there is a set of population controls that maximise the social cost existing around the proportional version of the game. This set is characterised by each route planner having a share of control of at least
for each population. For example, with linear cost functions and two route planners, each route planner must control at least
of each population, or for three route planners, they must control at least
.
We will now find the worst-case PoA for a network control game for polynomial edge-cost functions.
Theorem 1. The worst-case PoA for a network control game with route planners and polynomial edge-cost functions at most degree p is Proof. By Proposition 3, the worst-case equilibrium can be found when the game is proportional. Thus, we let each route planner solve the objective function
At the minimum, we have
Since the strategy spaces are symmetric and the game has an exact potential function, there exists a Nash equilibrium where each route planner plays the same strategy. The Nash equilibria of an exact potential game all have the same social cost, so this instance is also the worst Nash equilibrium. Thus,
which rearranges to
The social cost of the worst-case Nash equilibrium is
The social optimum of the game is where the total congestion on the bottom edge is
, with a social cost of
The ratio of these two costs gives us the result. □
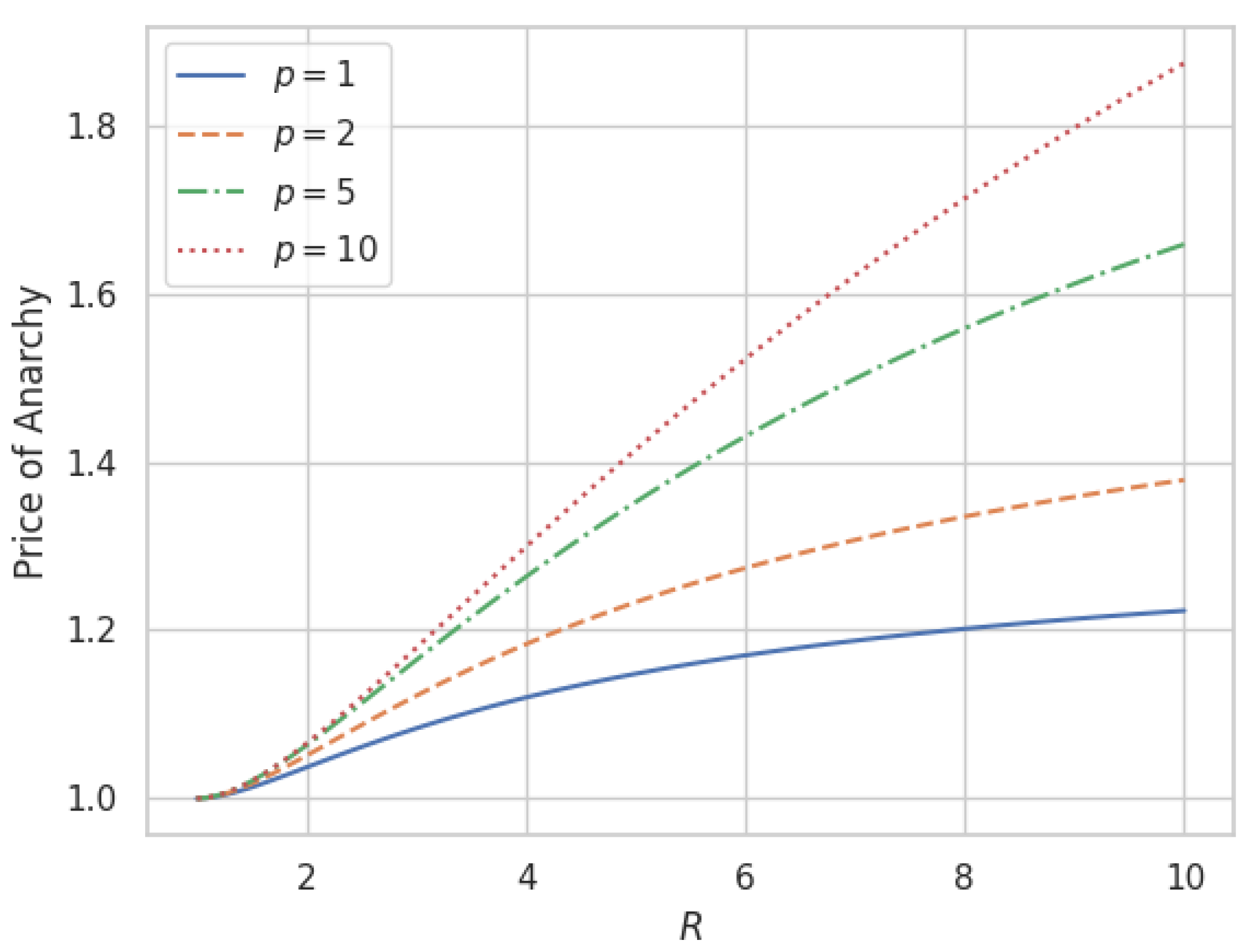
For
, by Theorem 1, the PoA is 1. Thus, the system is efficient when a route planner has full control of all vehicles. As
, Theorem 1 implies that the PoA tends to that of the NIC congestion game it controls [
18],
Figure 5 and
Figure 6 plots the PoA as a function of
p for the network control games with varying
and
p.
The PoA for the network control game is significantly better than that of the NIC congestion game (where ) for a small number of route planners . The system gets more inefficient as the number of route planners increases.
6. MARL Implementation
In this section, we consider the application of the theory of network control games to multi-agent reinforcement learning to test whether self-interested learning agents will converge to equilibrium strategies. To do so, we consider an instance of the Braess network with cost functions known to induce suboptimal selfish routing. The cost functions are shown in
Figure 7.
To show that these results align with multi-agent learning, we simulated an instance of the network control game on this example for linear and quadratic edge-cost functions. We chose a proportional game, since this case has worst-case selfish-routing as indicated by Proposition 3.
The repeated game can be seen as an MDP by defining the following state, action, rewards, and transitions. The state is the congestion of the network, i.e., the flow on each edge. Note that the route planners have full information of the network congestion. The actions of the route planners are to select the demand of knowledge types. Since we restrict our analysis to the case where recommended knowledge types have only one route available, the action space is equivalent to the demand of routes.
Figure 7 shows the four routes available to the population: along the two upper edges; along the lower two edges; and the two paths that include an upper edge, a lower edge, and the middle connecting edge. The route planners receive a reward equal to the negative of their cost function. Finally, the subsequent state is the user equilibrium of the congestion game. Thus, state change is deterministic from the actions of route planners and vehicles. Since there is no change in state that is external to the players in a repeated game, they are often referred to in MARL literature as stateless games. Note that we use a model-free algorithm which means we do not explicitly use the transition function in the learning algorithm.
We used the Asynchoronous Advantage Actor–Critic (A3C) algorithm [
46], due to its use in multi-agent RL social dilemma environments, e.g., [
48,
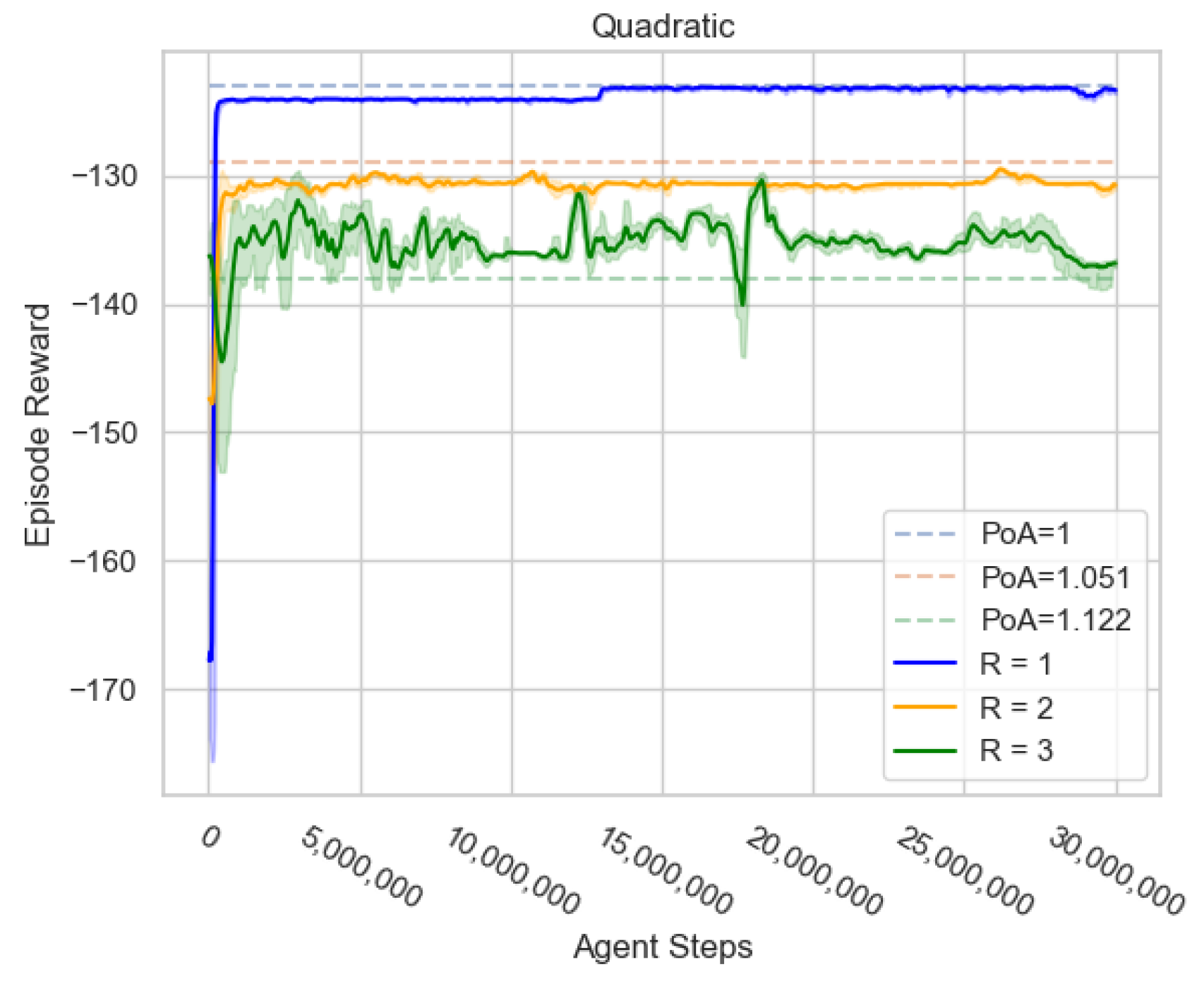
49]. We simulated instances with either one, two, or three route planner agents controlling the flow. Each game consisted of playing the network control game shown in
Figure 8 and
Figure 9 for 100 repeated rounds with no discounting (
). Thus, the SO cost is 150 or 123 for linear and quadratic costs, respectively. In both instances, the worst possible cost is 200. Each instance was averaged over three different random seeds. The neural network consisted of two fully connected layers of size 32 and a Long Short-Term Memory (LSTM) recurrent layer [
50]. This network architecture was taken from [
48]. We used the Ray library (
https://github.com/ray-project/ray, accessed 10 January 2021) for a standard implementation of A3C with default parameter settings.
The learning curves for these experiments are shown in
Figure 8 and
Figure 9. The results indicate that the agents learn to play strategies with a total cost that is close to the predicted PoA (from Theorem 1) for the edge-cost type and number of agents. Thus, reinforcement learning agents are vulnerable to choosing suboptimal routing as predicted by the theory. This suggests that the application of RL to route control requires cooperation, as with other social dilemmas, between route planners to minimise congestion.
7. Choosing Route Planners
So far, we have studied vehicles that are assigned to route planners controlling their choices. Suppose that instead, we allow vehicles to strategically select their route planner prior to their journey. In this extension, Nash equilibrium outcomes are such that no vehicle has an incentive to unilaterally deviate from the route planner they selected, given the prescribed route choices.
A
route planners game can be a tuple
, where
is an NIC congestion game, and
R is the set of route planners. Furthermore, the strategy space of players in
is
R, since their routing is selected by the route planner they choose. Let
indicate the share of control of
selected by population
. Then, a strategy profile
is feasible if
,
. Each feasible
has a corresponding network control game where
and
,
and
if
. Thus, each
has an essentially unique Nash equilibria
deciding the distribution of information. Define the cost function of a vehicle
to be
where
is the ICUE that results from
. Moreover, a Nash equilibrium is
such that
.
Proposition 4. A route planners game is an exact potential game for potential Φ defined aswhere is the ICUE formed from and . Proof. Consider the change in potential function between strategy distributions
and
for some
, with respective ICUE profiles
and
.
Rewrite as a sum over possible strategies in
S,
Rewrite as a sum over the route planners’ strategies,
Since the only difference between
and
is when
,
Thus,
is an exact potential function. By definition, the network control game is an exact potential game. □
Thus, Corollary 2 follows.
Corollary 2. For every route planners game, there exists a Nash equilibrium, and this is essentially unique.
Now, suppose we have an NIC congestion game with a socially inefficient UE and at least two route planners controlling the flow. Any route planner that has a small share of control of a population will choose the same strategy as players in a congestion game (selfish routing). Similarly, any route planner with a large share of control of a population plays by routing according to the social optimum. Since the UE of the game is socially inefficient, we know that the players choosing the route planner with a large share of control will have a strictly greater cost than those choosing a route planner with a small share of control. Thus, vehicles choosing their route planners have an incentive to choose the one with the least control. Any route planner that has less control over the population than any other route planner is more desirable to vehicles. Thus, there cannot be a route planner with strictly less control than all other route planners at the Nash equilibrium. We have ruled out the case where a route planner has no control over any population, so the flow must be proportional at the equilibrium.
Proposition 5. Each Nash equilibrium of route planner games is proportional.
Proof. Any route planner with control of a population less than will choose the same inefficient selfish routing as the vehicles of the NIC congestion game. Since this is the UE of the game, the other routing must be greater than or equal to this cost. Thus, vehicles prefer to choose a route planner with less than control over their population. Since , the best-response dynamics will end when all route planners have proportional control of all populations. □
Following from Proposition 3, we see that allowing vehicles to choose their route planner gives the worst possible PoA.
8. Conclusions
We studied multiple route planners optimising the routing of subpopulations in a nonatomic information-constrained congestion game through resource allocation. As their number grows, the equilibrium changes from achieving socially optimal routing to achieving the same inefficient routing as the original congestion game. We found the exact bound on the PoA of the induced game for polynomial edge-cost functions. Then, we used a simple example to show that MARL suffers from this PoA in practice. Additionally, we allowed vehicles to choose their route planner and showed that this only increases the overall inefficiency. Thus, companies using MARL routers to ease congestion require further incentives to cooperate with each other.
Natural extensions include analysing games with partial route planner control and the rest as selfish players with full or partial information which, we believe, could influence how autonomous vehicles design their route choice when the roads have a mix of human-driven and autonomous vehicles.
Another line of further work is to discover under what conditions is there an incentive to follow a route planner over autonomous routing. Designing incentive mechanisms for drivers to choose route planner control whilst achieving some level of fairness can impact the use of route controllers in real-world traffic. Survey research into people’s beliefs about the ethics of autonomous vehicles found that although people were in favour of a utilitarian approach of saving more lives over less, they also said that they would not purchase a utilitarian car themselves due to the risk of self-sacrifice [
51]. This phenomenon was coined “the social dilemma of autonomous vehicles”. Perhaps people would have a similar perspective of socially optimal routing—desiring a utilitarian system that is beneficial for everyone yet irrationally choosing the opposite. In which case, designing a routing system that drivers have no incentive to defect from, by choosing their own routes, would be an important extension of the work.
The results from this paper theoretically support the implementation of a centralised route planning algorithm to guide autonomous vehicles and reduce congestion. The higher the number of route planners controlling vehicles on the roads, the larger the inefficiency of the resulting routing equilibria. This is also the case for navigation apps; the more applications available to drivers, the worse the outcome of selfish routing will be. However, suboptimal routing could be mitigated if route planners cooperate with each other. The problem constitutes a social dilemma, so if route planners were able to detect if their rivals were cooperating or defecting, algorithms such as ARCTIC [
49] could be adapted and utilised for safe cooperation in route control.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}