1. Introduction
In complex sequential interactions, such as those arising in bargaining and negotiation, boundedly rational participants are often not in a position to fully calculate the consequences of their own decisions and need to make a judgment call on which move to make next. These interactions are often compared to chess, for the importance of forward thinking, opponent modelling and prediction, surprise moves and deceptive concessions (for an interesting take on the connections between chess and negotiation, see [
1]). However, the right way to analyse them is far from obvious. Game theory offers perhaps the most natural toolbox to do so, but it is important to strike a good balance between the simplicity of the solution and its applicability.
In his book
Modelling Bounded Rationality [
2], Ariel Rubinstein says:
At the beginning of the twentieth century, Zermelo proved a proposition which can be interpreted: “chess is a trivial game”.
This sentence ironically revisits the seminal result of Zermelo on the determinacy of two-player zero-sum games (for a modern and neat technical exposition see [
3]; for a comprehensive account of its historical relevance, including the original proof of the result, see [
4]) which rarely scales up to games that are played in practice, such as chess. In a way, Rubinstein notes, there is a
game theory and a
game practice, and the often idealised toy models from the former abstract away from many important features in the latter, which we should not forget about. Some games have a solution
in theory, but this solution can be very hard to find in practical play.
Rubinstein continues:
But [in games like chess] this calculation requires going through a huge number of steps, something no human being can accomplish. Modeling games with limited foresight remains a great challenge [and the frameworks studied thus far] fall short of capturing the spirit of limited-foresight reasoning.
Bounded Decision-Makers. The modern advances in Artificial Intelligence, particularly the work of the Google DeepMind team in games of perfect information and beyond (see, e.g., [
5,
6]), have shown how limited human knowledge is when it comes to decision making in complex extensive games of perfect information. However, chess, as well as many other chess-like games, is not
solved, in the sense that we do not yet know an optimal strategy from the start of the game. Even if, thanks to Zermelo, we know that either White has a winning strategy, or Black has a winning strategy, or both players at least have a drawing strategy, we still do not know which one of these disjuncts is true. In fact, even if/when found, the solution would be hard to remember or even store anywhere. Discussing Zermelo’s result [
3], Maschler, Solan and Zamir claim that, should chess be solved, it will “cease to be of interest” [
3] (p. 3). However, this is far from obvious when boundedly rational players are involved. Think of issues such as time pressure, when grandmasters and even supercomputers manage to lose theoretically won positions.
We cannot stress enough how bounded rationality is not just a “human” feature. Any decision-making agent operating in large extensive games, including supercomputers, needs to resort to heuristic assessments to make decisions. Artificial Intelligence can then provide us with stylised and testable models of boundedly rational decision-making, which we can use to support human decision-making as well—a point of view which we take in this paper.
An Issue with the Current AI Methods. When analysing complex extensive games of perfect information, where intermediate positions need to be assessed heuristically, Artificial Intelligence has come up with approximate methods, the most successful of which is Monte Carlo Tree Search (MCTS), which evaluates non-terminal positions by repeated simulation—see [
7] for a full description of MCTS methods.
MCTS constitutes an evolution from traditional
methods, which are decision-making mechanisms that assign a utility to “features” of a game position and select a continuation based on max–min solution concepts (for a detailed description of these methods, see [
8]). MCTS-based agents dominate many games of perfect information, such as Go, Checkers, Reversi, and Connect Four [
7]; witness the impressive achievements of the DeepMind team against human players [
5,
6]. Nonetheless, MCTS-based agents still trail behind their
counterparts when playing game positions requiring accurate play. Recent evidence of this fact was provided in game 6 of the 2018 Chess Championship Match between World Champion Magnus Carlsen (White) and challenger Fabiano Caruana (Black), where DeepMind’s AlphaZero missed a mate for Black following a sequence of 30 moves, found by the Sesse supercomputer running this line on the non-MTCS-based Stockfish [
9].
A key issue for MCTS’s performance in games such as chess is the presence of
trap states, where an initial move may look strong and then be followed by a forcing sequence of moves by the opponent, leading to a loss or significant disadvantage [
10]. In other words, the ubiquitous presence of reachable subgames which admit (practically) winning strategies from the opponent. Despite the breakthroughs of MCTS-based engines, the challenge still remains to equip MCTS with the capability of handling such forcing lines.
The approach we take in this paper is to formulate a generalised notion of similarity between game states to improve the performance of game-playing agents by smart search: if a trap was found after position x and we now analyse position y, which is very similar to x, then chances are we still have a trap after y. As similar strategies are likely to contain similar move sequences but not necessarily similar board positions, our measures are based on possible moves from each position, rather than the appearance of the board itself.
Our Contribution. We study the similarities of game positions in two-player, deterministic games of perfect information, looking at the structure of their local game trees, working with the set of possible moves from each position. We introduce novel similarity measures based on the intersection of move sets, and a structural similarity measure that only considers the arrangement of the local game tree and not the specific moves entailed. We analyse the formal relation of these measures and test them against benchmark problems in chess, with a number of surprising and promising findings. Notably, our structural similarity measure was able to match trap states to their child-trap states with 85% accuracy without using domain-specific knowledge. On top of this, we introduce a move-matching algorithm, which accurately pairs moves with similar strategic value from different positions. Our results are of immediate relevance to MCTS adaptations to detect and avoid trap states in gameplay.
Other Related Work. Graph comparison is one of the most fundamental problems of theoretical computer science, with graph isomorphism computation having been an open problem for quite some time [
11]. With tree structures, possibly the most commonly used metric is the
edit distance [
12]: based on the number of edits (node insertions, deletions, and substitutions) necessary to transform one tree into another, this metric works well for trees of a similar size with many shared nodes and edges. However, it tends to be less suitable when comparing multiple trees of different sizes, as large trees sharing some proportion of their nodes appear further from each other than two completely distinct smaller trees. An alternative measure is the
alignment distance [
13], an adaptation of the edit distance based on the notion of sliding one tree into another and counting the number of edits needed to transform both trees into the combined one. The alignment distance requires lower complexity to compute than the edit distance, but it is technically not a metric and suffers from similar problems comparing trees of different sizes.
In game playing, the presence of forcing continuations is identified as a key problem faced by AI engines, with more acute implications for chess-like games [
10]. Surprisingly, though, the theory of similarity metrics to aid strategic decisions in game playing is not well developed.
Similarity measures have instead been used in other areas of AI, as in the case of Siamese neural networks for one-shot learning [
14]. In this case, two symmetric convolutional neural networks were trained on same–different pairs and then shown a test instance, as well as one example from each possible classification. The output of the twin networks was then compared using a similarity measure. Here, a cross-entropy objective function was used to determine similarity, but this required the networks to be symmetric and weight tied. New similarity measures based on the structural similarity of networks could remove these requirements, but have not yet been investigated.
Paper Structure. The section “Positional Similarities” introduces our formal setup to compare game trees through a number of similarity measures. The section “Detecting Structural Similarities” uses these as the basis of a dynamic algorithm to detect structural similarities among subtrees. In the “Performance” Section, we compare these against known chess positions. We conclude by discussing potential applications and research directions.
2. Positional Similarities
Let
G be a two-player finite extensive form game of perfect information, where players, e.g., Black and White, alternate moves, with White starting the game. Formally,
G consists of a set of histories
such that
is the starting board position and each
(with
) can be reached from
with a single legal move by White whenever
k is even, and by Black otherwise (as in, e.g., [
3]).
We are interested in comparing trees that result from players exploring game continuations from a certain board position on. In MCTS, for example, these are the game trees generated by the expansion step (see, e.g., [
15]). Let
denote tree roots and
child nodes (board positions) of
and
. Then let
denote the set of all possible moves from position
and
the set of all possible moves contained in all possible move sequences of length
d from position
.
We now present three natural measures, of increasing complexity, to establish how similar such trees are: the similarity of continuations, the similarity of sequences, and the tree-edit similarity. All these measures are model free, in the sense that they can be used in all situations that can be described as two-player finite extensive games of perfect information. We analyse their formal interrelation in this section and use them as the basis of our dynamic algorithm in the subsequent one.
2.1. Similarity of Continuations
Our first measure, which we call
similarity of continuations, is calculated from the sets
,
of 1-ply atomic moves from starting positions
to their children of depth
d. The similarity is the size of the intersection of these two sets divided by the size of their union.
As can be found from a simple expansion of the game trees, computing such a measure takes time , where b is the breadth of the game tree.
At depth 1, the similarity of continuations simply calculates the proportion of children that two nodes share. When extended to a deeper search, the measure becomes less fine-grained, since a move that occurs at different depths in the trees will still count as shared, and multiple occurrences of the same move are only counted once.
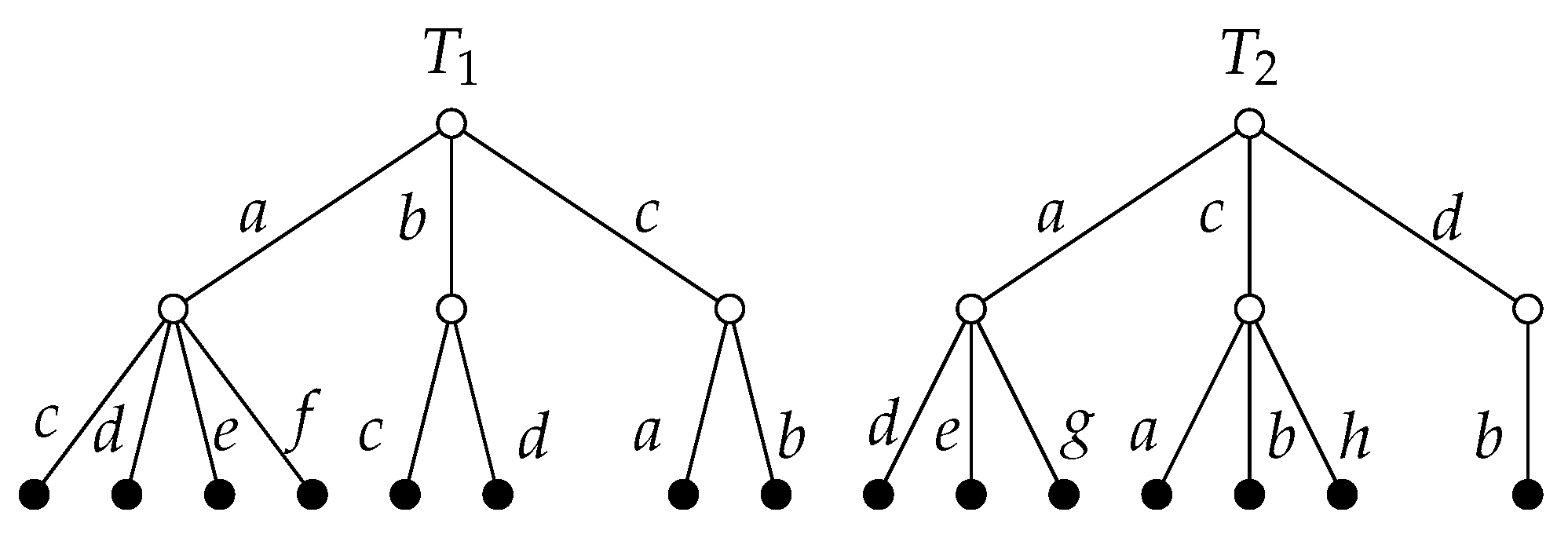
As an example, consider the trees
in
Figure 1, which have depth-2 continuation sets
,
.
2.2. Similarity of Sequences
Our second similarity measure, which we call similarity of sequences, uses longer sequences of moves rather than single plies. To ease computation, we require each possible move sequence of length d from tree root to first be rewritten according to a predetermined move, ordered as a simplified sequenceS. Formally, two sequences are simplified into one if—and only if—they are the same modulo move permutation. These simplified sequences are then stored in a structure , which we call the simplified tree of . As different move permutations can create the same simplified sequence, we also store the multiplicityk of each S in , where k corresponds to the number of ways S can be reached from the root note. Then, the similarity of sequences calculates the ratio of the intersection to the union of the simplified trees.
Let
be the multiplicity of simplified sequence
in
,
the multiplicity of
in
, and
, and the number of nodes in the larger of
,
. Then, the similarity of sequences of
and
is given by
Calculating the similarity of sequences at depth 2 on the example trees in
Figure 1 can be achieved as follows. For an alphabetical ordering, the simplified trees can be written as
where the superscript corresponds to the multiplicity of each sequence. Then
The tree simplification can be performed in one depth-first pass of each tree, taking time . Calculating the proportion of shared sequences takes , which is equal to in the worst case, the same logarithmic complexity as the similarity of continuations. It should be noted that the tree-reduction step means that the complexity coefficient is larger for the similarity-of-sequences calculation. This is a trade-off for accuracy at depth , as less information is lost when calculating from sequences rather than continuations.
Relation to Kernels. The similarity of sequences is closely related to the Tanimoto similarity measure or kernel [
16,
17] based on the intersection over the union of the inner products of two sets. The Tanimoto kernel was successfully used to calculate the similarity of molecule fingerprints in Bioinformatics from the feature map of a molecule by counting the number of paths through the map shared by different molecules [
16]. The methods used in this area can be carried over to extensive form games of perfect information, as a board position can be viewed as a fingerprint representing the game that has gone before it. The game tree and feature map can both be traversed and have their matching paths counted. Using a suffix tree data structure [
18,
19], we can compute the Tanimoto kernel in time
, for depth
d,
nodes and
edges in trees
,
. The similarity of sequences is also comparable to the random walks kernel [
20], a measure of similarity between two graphs found by counting the number of random paths they share. The main difference here is that the similarity of sequences has limited depth and is a normalised metric.
2.3. Tree-Edit Similarity
It may be the case that
is very similar to
but differs by some very shallow moves. If this is the case, the similarity of sequences measure would not detect this similarity. We therefore propose a modified version of the tree-edit distance [
21], which traditionally counts the cost-wise minimal number of operations needed to turn one tree into another. The
tree edit similarity, used to compare subtrees, is normalised, and acts as a metric on the tree-edit space. The normalised tree-edit distance [
21] gives values in the range [0, 1], and as such would be suitable as a similarity measure when subtracted from one. The normalised distance is given as
where
is the tree-edit distance between
and
, and
is the weight of edit operations. Since there is no need to weigh edit operations differently, we may take
to be one for all operations. Then, as shown by Li and Zhang [
21], the formula is valid as a metric. Since calculating the distance between two trees is equivalent to calculating their similarity and subtracting it from one, we define the tree-edit similarity as
Calculating the tree-edit similarity on the example trees in
Figure 1 is as follows:
This measure is the most fine-grained of the three detailed so far. Since calculating tree-edit distance on unordered trees is known to be NP-hard [
22], we must again order the nodes in a preprocessing step with complexity
, as above. Once we have ordered trees, the time complexity reduces to
when
, and
when
[
12]. As such, the improvements made by the tree-edit similarity over the two previous measures must be weighed against the added complexity.
2.4. Comparing Terminal States
It may sometimes be necessary to find the similarity of two terminal states. In terms of the game tree for a zero-sum game, two terminal nodes should have a value of one if they give the same reward for the agent (win–win, draw–draw, lose–lose), and zero if the reward is different. Since two terminal nodes have no children, their fractional similarity measure is undefined, so we must handle this case separately.
The normalised difference between the rewards of the two terminal nodes can be found by subtracting the reward
of one node from the reward
of the other, then dividing the result by the size of the range of possible reward values
,
. This gives a value between 0 and 1, where 1 represents rewards at opposite ends of the range, and 0 represents equal rewards. Subtracting from 1 then gives a similarity measure, formalised as
This can be used in endgame cases to prevent zero errors when calculating other similarity measures.
2.5. Relationship between Measures
At depth 1, the similarity of sequences and the similarity of continuations are equivalent, as each child move only appears once per tree. At depth 2, the similarity of sequences has greater variation, as can be seen from the following chess-inspired instance.
Example 1 (Chess trees).
Let , be nodes of a chess game tree where branching factor b is constant, and , differ only in the placement of two pieces. Then at depth twoNow consider positions , , which also differ only in the placement of two pieces, except that in the opponent has chosen a forcing move leading to checkmate at depth 2, while in the opponent has chosen otherwise. Then extends past depth two, but is truncated and only contains depth 1 moves, all of which are shared with . Then at depth two So we can see thatand thus, the similarity of sequences has greater variation than the similarity of continuations. The tree-edit similarity is yet more variable than the similarity of sequences, as can be seen from further calculations on the same examples. Modulo is the tradeoff between simplicity and complexity. The above similarity measures can be used to analyse any game trees with consistent move labelling. This would be especially useful for games with less dynamic trees; that is, those without capturing or blocking moves that change the game tree structurally between plies. For games such as Go, with the potential to use one piece to exert power over a whole area, these measures provide useful tools for analysis, which could be further explored by accounting for symmetries and abstractions of the board.
3. Detecting Structural Similarities
We may find ourselves comparing positions that do not share many continuations, e.g., those that are far away from one another in a game tree. What we can then do is to extend the previous approach to recursively check for subtree similarity.
Structural Similarity Measure
Our final similarity measure, which we call the
structural similarity measure, compares the graphical structure of two game trees without comparing their atomic moves directly. The measure is based on calculating the similarity of each starting position
to each of its child nodes
using any of the three previously defined measures, before comparing this list of similarities to the list of similarities of another starting position
to its children
. The measure uses an assignment algorithm (see Algorithm 1) to pair each child node of
to a child node of
to minimise the sum of the paired nodes’ similarities to their respective parents. If one subtree has more children than the other, each unpaired child adds one to this sum. The sum is then divided by the larger number of children and subtracted from one to provide the structural similarity of the two subtrees, where a value of 1 is identical and zero is completely distinct. Let
be the number of child nodes of
respectively. Then, for a selected similarity measure
P, the structural similarity measure can be expressed as
| Algorithm 1 Structural Similarity Detection Protocol. |
- 1:
function
StrucSim(, ) - 2:
max number of children of , - 3:
min number of children of , - 4:
for child of do - 5:
Measure(, ) - 6:
for child of do - 7:
Measure(, ) - 8:
pad smaller of with 1s - 9:
for from 1 to do - 10:
- 11:
Match() - 12:
for k from 0 to do - 13:
- 14:
return ()
|
The following calculates the structural similarity measure based on the similarity of continuations at depth 1 on the trees in
Figure 1. The similarity of each branch to its root is
There are two minimum distance matchings:
and their total distance is 0.683. So
While the structural similarity measure may calculate more accurate similarities between positions, this comes at a cost, as each calculation requires similarity computations of every child node to its parent. When the similarity of sequences or continuations at depth 1 is used as the base measure, on average it takes time to calculate the similarity of all children to their parent. Assigning children in pairs using the Hungarian algorithm takes operations, so the structural similarity algorithm runs in time . To improve the complexity, the measure could be approximated by randomly sampling child nodes and calculating their structural similarity, which warrants further investigation.
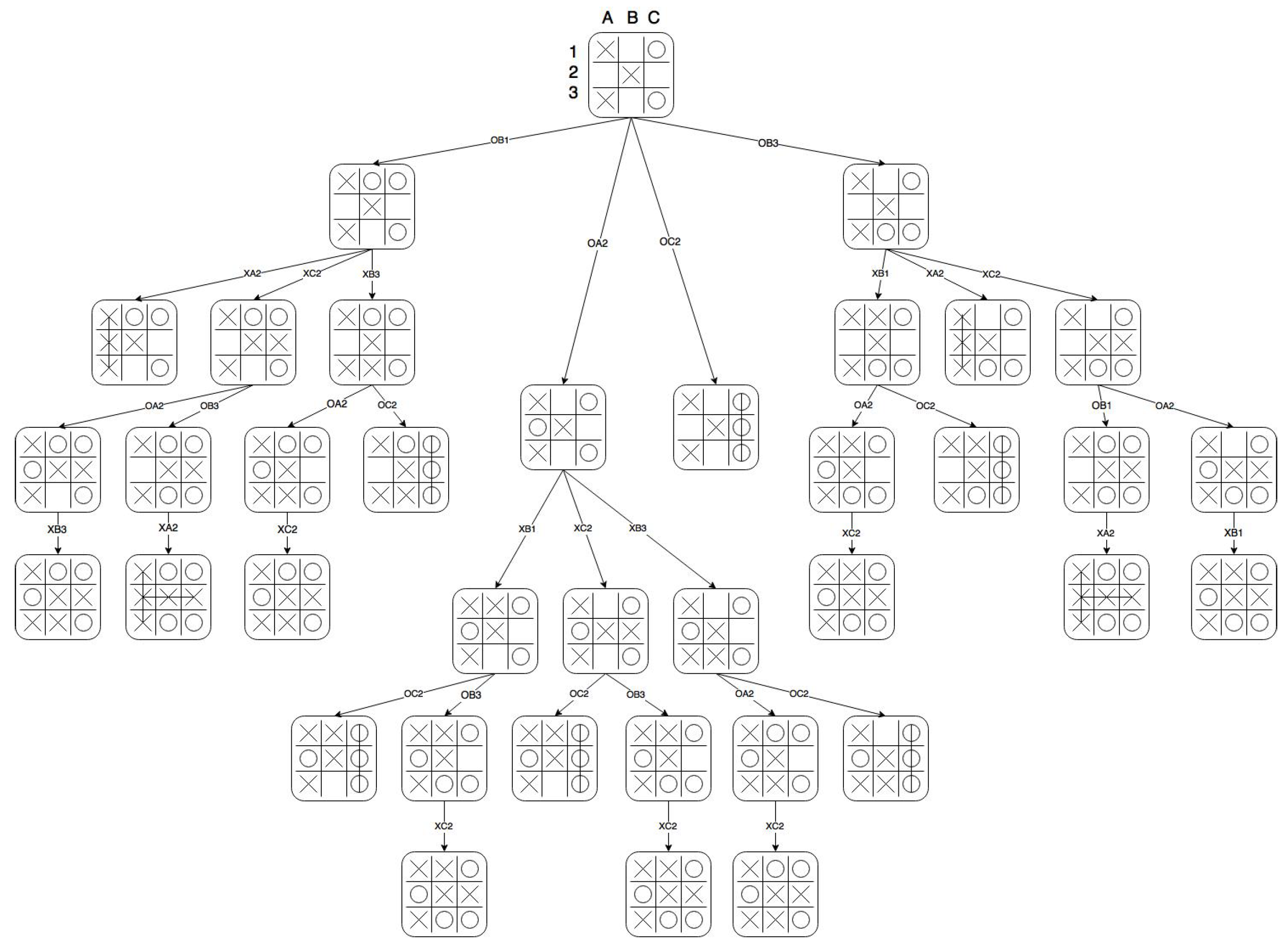
Strategic Similarity of Tic Tac Toe Positions. To investigate convergence of the structural similarity measure to an intuitive similarity of board positions based on their strategic advantage, we manually calculated the structural similarity measure on a small section of the Tic Tac Toe game tree, using the similarity of continuations measure as a basis.
Figure 2 shows the game tree for a small segment of a Tic Tac Toe game, and
Table 1 contains the results of the similarity analysis, where the branches of the game tree are labelled according to their original board position
O and the square in which the next move is made. The measure correctly identifies the rotational symmetry between branches
and
, and gives a value of zero for all comparisons of
with distinct subtrees, as
is terminal and so shares no structural similarity with any of the other depth 1 nodes. This is very promising, as it shows that the measure behaves well on a solved game, so we can be more confident in trusting it in a heuristic setting.
Move Matching. As the structural similarity measure pairs moves that are comparably similar to their parent states, this method can be used to pair moves from different board positions that may have similar strategic value. For example, if one position is known to have a killer move in two plies, leading to a win for the opponent, and this position has a high similarity to a new position, the depth 2 matches can be inspected and the move that is most frequently matched to the killer move in the known position can be identified, and this move is likely to be a killer move from the new position. We will evaluate the effectiveness of this approach in the forthcoming section.
Generalisability. The structural similarity measure is generalisable to the analysis of any two local trees with self-consistent move labellings, as the measure can be calculated independently of such labels. This means, e.g., that the structure of a local Go tree can be compared to that of a local chess tree or, alternatively, we can show how a game tree changes through the game.
Calculating how dynamic a game is, in terms of the variability of the connection density of the graph, can be very useful in indicating which gameplay heuristics to use. For example, to use the All-Moves-As-First (AMAF) heuristic, which initially updates sibling nodes with the same estimated value for each move played, an agent first assumes that a move from one node is likely to affect the game in a similar way to the same move played from a sibling node. This may be likely to work on less dynamic games, but could be less reliable for highly dynamic games, where the effect of a move on the state of the game is less consistent. Conversely, pruning may be most helpful for highly dynamic games, as these games offer a stark contrast between reward values for different branches, which is not necessarily the case for less dynamic games.
These hypotheses are supported by studies of successful AMAF use in less dynamic games such as Go [
23], Phantom Go [
24], Havannah [
25], and Morpion Solitaire [
26], successful pruning in the dynamic game of Amazons [
27] and less successful pruning in Havannah [
25].
4. Performance
We tested how effective the first three similarity measures were at detecting nearby trap states in chess, using the similarity of continuations at depth
, similarity of sequences at
and tree-edit similarity at
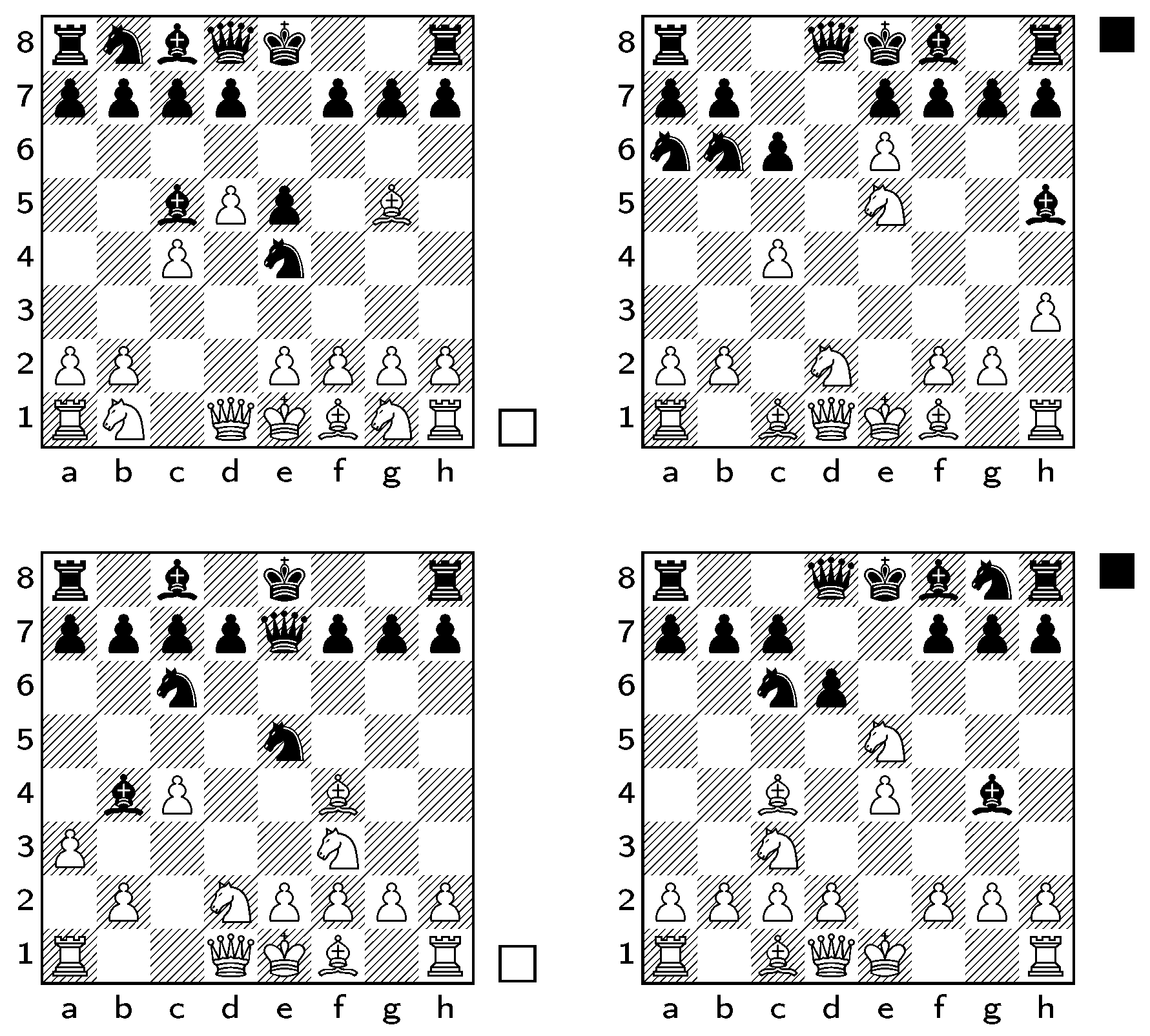
. We chose a sample of four distinct trap states which each lead to checkmate within 2 to 4 plies, as shown in
Figure 3. We used a sample of all 1000–1500 board positions that were two plies away from each trap state, and recorded whether the trap was maintained or not for each new position. The measures were calculated on each of these board positions, as was a cross-correlation measure that was used as a control, calculated by finding the number of squares where piece placement differed and dividing this number by 64. The similarity of sequences was adapted for chess by including captures in the simplified sequences. This adaptation can be generalised to any game with irreversible moves by recording the irreversible moves from each sequence as well as its standard moves.
Clearly, an effective measure should evaluate trap states as highly similar to the original position with high frequency, so we fixed a threshold value
and calculated the proportion of trap and non-trap states with similarity higher than
for each measure. For each trap state and each of our similarity measures, when
was set to the average value of the similarities, around 70% of all children that were also trap states had above average similarity to the original position, and consistently over 50% of non-trap children had below average similarity. This was not the case for the cross-correlation, where up to 87% of trap states had below average similarity, and 72% of non-trap states had above average similarity. These results can be seen in
Table 2.
In general, there was no significant difference between the proportion of false positives (non-traps with above average similarity) and false negatives (traps with below average similarity) given by the similarity of sequences, similarity of continuations and tree-edit similarity. However, the added time complexity of the similarity of sequences and tree-edit similarity at depth 2 was significant. Thus, perhaps surprisingly, the similarity of continuations is effectively better as a heuristic similarity measure for evaluating similarities of closely related board positions than the similarity of sequences.
Finally, for complexity considerations, we tested the structural similarity measure on five smaller samples of 40 randomly selected child positions from the first two trap positions. Using this measure, an average of 85% of child trap states had above average structural similarity to the original position. The high complexity of this measure makes it time intensive to compute, but results clearly show it is rather effective at picking out potential trap states from a select sample of positions.
Move Matching. The move-matching algorithm was also tested on various chess positions to detect moves with similar strategic impact. Frequent matchings were assumed to be a more reliable indicator of moves with a similar effect on gameplay, so only the top five most frequently matched pairings were assessed.
We tested the matching algorithm on three different samples, each with six pairs of board positions, all shown in
Table 3. Firstly, we used the algorithm on all traps from the trap-detection sample. For all but one of the pairings (Légal and Budapest traps), all of the five most frequent matches for each pair comprised two decisive or two non-decisive moves. In all but one pairing (Caro–Kann and Kieninger traps), the two most frequently paired moves were both checkmate moves. The second sample we used was based on the Légal and Budapest Gambit traps. We compared each trap with a sample of three child positions. This sample comprised one position containing the original trap but a difference in the placement of two pawns; one position where the bishop that had threatened the queen had been captured; and one position that was selected as the best continuation by the Stockfish chess engine. In all but one pairing, all of the top five matches comprised two decisive or two non-decisive moves. All of the most frequently paired moves were both decisive. The third sample was a selection of positions from the 2016 World Championship match between Magnus Carlsen and Sergey Karjakin, which appeared after 10, 20, 30, and 40 plies. An average of four of the top five matches for each pairing comprised two decisive or two non-decisive moves. Three of the most frequently paired moves were both check moves, and one of them comprised two equivalently unimpactful moves of the king. This sample provided less reliable pairings than the previous two samples, possibly because its positions had a more varied strategic impact than those of the other samples.
These results show that the move-matching algorithm is fairly well suited to finding similarly decisive moves from different board positions, and thus is useful for detecting possible trap states and sacrificial moves from the game-tree structure without evaluating board positions.





 f6 2. c4 e5 3.d5
f6 2. c4 e5 3.d5  c5 4.
c5 4. e7 7.a3
e7 7.a3  e7 7.
e7 7. 

{kind=link}
{kind=link}
{kind=link}
 g5+
g5+