Is Your Privacy for Sale? An Experiment on the Willingness to Reveal Sensitive Information

 ,
,
Abstract
1. Introduction
2. Related Literature
3. Method
3.1. Experimental Design
3.2. Hypotheses
3.3. Experimental Procedure
4. Results
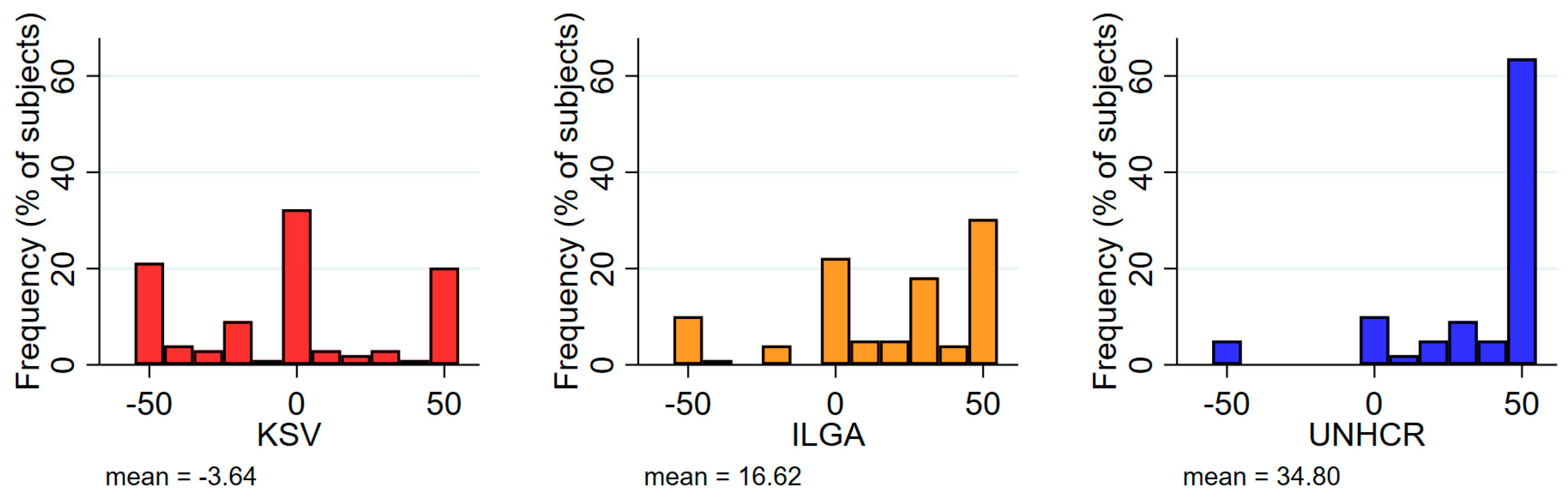
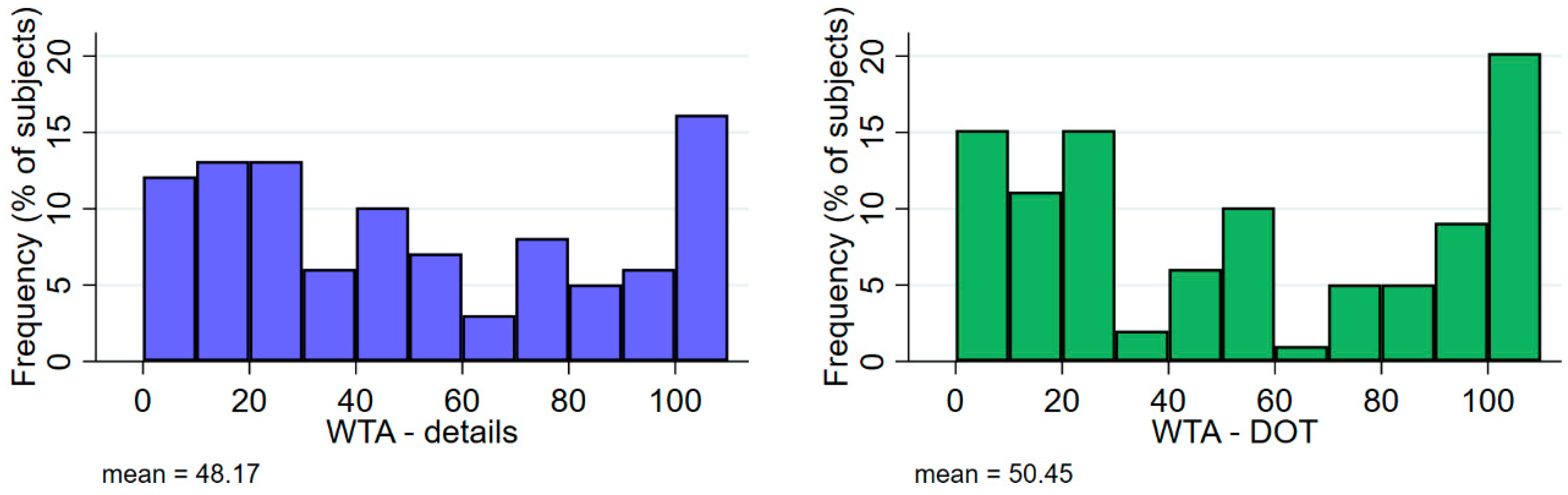
4.1. Descriptive Statistics
4.2. Main Regression Results
4.3. Robustness
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
| (1) | (2) | (3) | (4) | (5) | (6) | |
|---|---|---|---|---|---|---|
| WTAdetails | WTAdetails | WTAdetails | WTADOT | WTADOT | WTADOT | |
| privacy | 12.38 ** | 11.48 ** | 11.76 ** | 12.15 * | 12.39 * | 10.19 |
| (5.80) | (5.74) | (5.89) | (6.78) | (6.69) | (6.82) | |
| weight | 15.05 * | 17.83 ** | ||||
| (8.41) | (8.74) | |||||
| smoke | 7.98 | 7.28 | ||||
| (10.28) | (10.37) | |||||
| grade | −2.81 | −2.27 | ||||
| (7.13) | (7.19) | |||||
| KSV | 0.13 | 0.14 | ||||
| (0.14) | (0.14) | |||||
| ILGA | −0.34 ** | −0.32 * | ||||
| (0.17) | (0.18) | |||||
| UNHCR | 0.06 | 0.07 | ||||
| (0.20) | (0.20) | |||||
| age | −0.57 | 3.55 * | ||||
| (1.77) | (2.11) | |||||
| female | −4.45 | 7.81 | ||||
| (8.97) | (10.26) | |||||
| session | 10.99 | 12.44 | 11.36 | 19.91 ** | 17.20 * | 17.93 * |
| (8.41) | (8.73) | (9.43) | (9.72) | (9.75) | (10.52) | |
| Constant | 10.08 | 11.32 | 22.83 | 8.26 | 13.68 | −57.99 |
| (16.95) | (26.36) | (44.55) | (19.81) | (20.17) | (46.31) | |
| sigma | 38.95 *** | 38.06 *** | 38.09 *** | 44.66 *** | 43.64 *** | 43.27 *** |
| (3.28) | (3.20) | (3.25) | (3.92) | (3.83) | (3.85) | |
| Observations | 94 | 94 | 92 | 94 | 94 | 92 |
| pseudo R2 | 0.01 | 0.01 | 0.01 | 0.01 | 0.02 | 0.02 |
| Variable | Factor | Uniqueness |
|---|---|---|
| a1 | 0.49 | 0.76 |
| a2 | 0.26 | 0.93 |
| a3 | 0.34 | 0.88 |
| a4 | 0.53 | 0.72 |
| a5 | 0.12 | 0.98 |
| a6 | 0.67 | 0.55 |
| a7 | 0.58 | 0.66 |
| eigenvalue | 1.51 | |
| alpha | 0.54 |
| Variable | Factor | Uniqueness |
|---|---|---|
| a1 | 0.49 | 0.76 |
| a4 | 0.51 | 0.74 |
| a6 | 0.65 | 0.58 |
| a7 | 0.58 | 0.66 |
| eigenvalue | 1.25 | |
| alpha | 0.65 |
| Indices | Factor Analysis (a1–a7) | Factor Analysis (a1, a3, a6, a7) | Additive (a1–a7) | Additive (a1–a5) |
|---|---|---|---|---|
| factor analysis (a1-a7) | 1.00 | |||
| factor analysis (a1, a3, a6, a7) | 0.98 *** | 1.00 | ||
| additive (a1–a7) | 0.89 *** | 0.81 *** | 1.00 | |
| additive (a1–a5) | 0.73 *** | 0.62 *** | 0.95 *** | 1.00 |
| (1) | (2) | (3) | (4) | (5) | (6) | |
|---|---|---|---|---|---|---|
| WTAdetails | WTAdetails | WTAdetails | WTADOT | WTADOT | WTADOT | |
| privacy | 0.96 | 4.70 | 5.02 | 6.51 | 8.79 | 1.92 |
| (23.03) | (22.27) | (22.56) | (24.97) | (24.96) | (24.68) | |
| weight | 16.94 * | 19.21 ** | ||||
| (8.71) | (9.30) | |||||
| smoke | 7.74 | 7.29 | ||||
| (10.66) | (10.84) | |||||
| grade | −4.44 | −3.80 | ||||
| (7.04) | (7.11) | |||||
| KSV | 0.11 | 0.11 | ||||
| (0.14) | (0.14) | |||||
| ILGA | −0.35 ** | −0.32 * | ||||
| (0.17) | (0.18) | |||||
| UNHCR | 0.09 | 0.09 | ||||
| (0.23) | (0.23) | |||||
| age | −0.33 | 3.85 * | ||||
| (1.74) | (1.96) | |||||
| female | −1.65 | 10.69 | ||||
| (8.96) | (9.61) | |||||
| session | 12.79 | 13.51 | 13.55 | 21.42 ** | 18.38 * | 19.98 * |
| (8.47) | (8.64) | (9.16) | (9.48) | (9.62) | (10.39) | |
| Constant | 43.01 *** | 43.61* | 48.75 | 37.81 ** | 42.13 *** | −40.17 |
| (13.20) | (24.00) | (40.67) | (14.83) | (15.93) | (40.34) | |
| sigma | 40.17 *** | 39.09 *** | 39.14 *** | 45.48 *** | 44.47 *** | 43.83 *** |
| (2.98) | (3.04) | (3.14) | (3.25) | (3.28) | (3.30) | |
| Observations | 94 | 94 | 92 | 94 | 94 | 92 |
| pseudo R2 | 0.00 | 0.01 | 0.01 | 0.01 | 0.01 | 0.02 |
| (1) | (2) | (3) | (4) | (5) | (6) | |
|---|---|---|---|---|---|---|
| WTAdetails | WTAdetails | WTAdetails | WTADOT | WTADOT | WTADOT | |
| privacy | −5.82 | −1.52 | −1.34 | 5.12 | 5.65 | −0.90 |
| (22.91) | (22.35) | (22.67) | (24.18) | (24.03) | (23.77) | |
| weight | 17.03 ** | 19.10 ** | ||||
| (8.37) | (8.97) | |||||
| smoke | 5.40 | 5.04 | ||||
| (10.62) | (10.80) | |||||
| grade | −4.16 | −3.58 | ||||
| (6.71) | (6.86) | |||||
| KSV | 0.14 | 0.14 | ||||
| (0.14) | (0.14) | |||||
| ILGA | −0.39 ** | −0.36 ** | ||||
| (0.17) | (0.18) | |||||
| UNHCR | 0.09 | 0.10 | ||||
| (0.22) | (0.22) | |||||
| age | −0.41 | 3.61 * | ||||
| (1.71) | (1.90) | |||||
| female | −1.13 | 12.42 | ||||
| (8.82) | (9.23) | |||||
| session | 17.04 ** | 17.65 ** | 17.99 ** | 23.35 ** | 20.22 ** | 22.45 ** |
| (8.19) | (8.45) | (9.02) | (9.11) | (9.23) | (9.98) | |
| Constant | 44.13 *** | 43.65 * | 50.18 | 37.92 ** | 43.43 *** | −35.20 |
| (14.17) | (23.75) | (40.27) | (15.46) | (16.18) | (39.76) | |
| sigma | 40.22 *** | 39.17 *** | 39.22 *** | 45.04 *** | 43.82 *** | 43.10 *** |
| (2.88) | (2.93) | (3.02) | (3.11) | (3.13) | (3.16) | |
| Observations | 99 | 99 | 97 | 99 | 99 | 97 |
| pseudo R2 | 0.00 | 0.01 | 0.01 | 0.01 | 0.01 | 0.02 |
| (1) | (2) | |
|---|---|---|
| WTAdetails | WTADOT | |
| a1 | −0.91 | −0.70 |
| (3.58) | (3.54) | |
| a2 | 0.22 | −0.47 |
| (3.22) | (3.39) | |
| a3 | 2.71 | 0.03 |
| (2.93) | (3.02) | |
| a4 | −1.39 | 1.32 |
| (3.70) | (3.69) | |
| a5 | 8.38 *** | 7.18 *** |
| (1.94) | (2.13) | |
| Constant | 25.95 * | 29.28 * |
| (15.47) | (17.28) | |
| Observations | 94 | 94 |
| F | 4.28 | 2.35 |
| R2 | 0.19 | 0.12 |
References
- Acquisti, A.; Brandimarte, L.; Loewenstein, G. Privacy and human behavior in the age of information. Science 2015, 347, 509–514. [Google Scholar] [CrossRef] [PubMed]
- Acquisti, A.; Taylor, C.; Wagman, L. The economics of privacy. J. Econ. Lit. 2016, 54, 442–492. [Google Scholar] [CrossRef]
- Spiekermann, S.; Grossklags, J.; Berendt, B. E-privacy in 2nd generation E-commerce. In Proceedings of the 3rd Acm Conference on Electronic Commerce, Tampa, FL, USA, 14–17 October 2001. [Google Scholar]
- Acquisti, A.; Gross, R. Imagined communities: Awareness, information sharing, and privacy on the Facebook. In International Workshop on Privacy Enhancing Technologies; Springer: Berlin, Heidelberg, 2006; pp. 36–58. [Google Scholar]
- Acquisti, A.; Grossklags, J. Privacy and rationality in individual decision making. IEEE Secur. Priv. 2005, 3, 26–33. [Google Scholar] [CrossRef]
- Taddicken, M. The ‘Privacy Paradox’ in the Social Web: The Impact of Privacy Concerns, Individual Characteristics, and the Perceived Social Relevance on Different Forms of Self-Disclosure. J Comput. Mediat. Comm. 2014, 19, 248–273. [Google Scholar] [CrossRef]
- Son, J.-Y.; Kim, S.S. Internet Users’ Information Privacy-Protective Responses: A Taxonomy and a Nomological Model. MIS Quart. 2008, 32, 503–529. [Google Scholar] [CrossRef]
- Egelman, S.; Felt, A.P.; Wagner, D. Choice architecture and smartphone privacy: There’s a price for that. In The Economics of Information Security and Privacy; Springer: Berlin, Heidelberg, 2013; pp. 211–236. [Google Scholar]
- Blank, G.; Bolsover, G.; Dubois, E. A new privacy paradox: Young people and privacy on social network sites. In Proceedings of the Annual Meeting of the American Sociological Association, San Francisco, CA, USA, 17 August 2014. [Google Scholar]
- Benndorf, V.; Normann, H.-T. The willingness to sell personal data. Scand. J. Econ. 2018, 120, 1260–1278. [Google Scholar] [CrossRef]
- Tsai, J.Y.; Egelman, S.; Cranor, L.; Acquisti, A. The Effect of Online Privacy Information on Purchasing Behavior: An Experimental Study. Inf. Syst. Res. 2011, 22, 254–268. [Google Scholar] [CrossRef]
- John, L.K.; Acquisti, A.; Loewenstein, G. Strangers on a Plane: Context-Dependent Willingness to Divulge Sensitive Information. J. Consum. Res. 2011, 37, 858–873. [Google Scholar] [CrossRef]
- Plesch, J.; Wolff, I. Personal-Data Disclosure in a Field Experiment: Evidence on Explicit Prices, Political Attitudes, and Privacy Preferences. Games 2018, 9, 24. [Google Scholar] [CrossRef]
- Huberman, B.A.; Adar, E.; Fine, L.R. Valuating Privacy. IEEE Secur. Priv. 2005, 3, 22–25. [Google Scholar] [CrossRef]
- Becker, G.M.; DeGroot, M.H.; Marschak, J. Measuring utility by a single-response sequential method. Behav. Sci. 1964, 9, 226–232. [Google Scholar] [CrossRef]
- Chavanne, D. Generalized trust, need for cognitive closure, and the perceived acceeptability of personal data collection. Games 2018, 9, 18. [Google Scholar] [CrossRef]
- Schudy, S.; Utikal, V. ‘You must not know about me’ On the willingness to share personal data. J. Econ. Behav. Organ. 2017, 141, 1–13. [Google Scholar] [CrossRef]
- Dogruel, L.; Joeckel, S.; Vitak, J. The valuation of privacy premium features for smartphone apps: The influence of defaults and expert recommendations. Comput. Human Behav. 2017, 77, 230–239. [Google Scholar] [CrossRef]
- Beresford, A.R.; Kübler, D.; Preibusch, S. Unwillingness to pay for privacy: A field experiment. Econ. Lett. 2012, 117, 25–27. [Google Scholar] [CrossRef]
- Fuller, C.S. Is the market for digital privacy a failure? Public Choice 2019, 180, 353–381. [Google Scholar] [CrossRef]
- Benndorf, V. Voluntary disclosure of private information and unraveling in the market for lemons: An experiment. Games 2018, 9, 23. [Google Scholar] [CrossRef]
- Schudy, S.; Utikal, V. Does imperfect data privacy stop people from collecting personal data? Games 2018, 9, 14. [Google Scholar] [CrossRef]
- Ghosh, A.; Roth, A. Selling privacy at auction. Games Econ. Behav. 2015, 91, 334–346. [Google Scholar] [CrossRef]
- Jin, H.; Su, L.; Xiao, H.; Nahrstedt, K. Incentive mechanism for privacy-aware data aggregation in mobile crowd sensing systems. IEEE/ACM Trans. Netw. 2018, 26, 2019–2032. [Google Scholar] [CrossRef]
- Niu, C.; Zheng, Z.; Wu, F.; Tang, S.; Gao, X.; Chen, G. Unlocking the Value of Privacy: Trading Aggregate Statistics over Private Correlated Data. ACM 2018, 2031–2040. [Google Scholar] [CrossRef]
- Kokolakis, S. Privacy attitudes and privacy behaviour: A review of current research on the privacy paradox phenomenon. Comput. Secur. 2017, 64, 122–134. [Google Scholar] [CrossRef]
- Hann, I.-H.; Hui, K.-L.; Lee, S.-Y.T.; Png, I.P.L. Overcoming Online Information Privacy Concerns: An Information-Processing Theory Approach. J. Manag. Inf. Syst. 2007, 24, 13–42. [Google Scholar] [CrossRef]
- Selten, R. Die Strategiemethode zur Erforschung des eingeschränkt rationalen Verhaltens im Rahmen eines Oligopolexperiments. In Beiträge zur Experimentellen Wirtschaftsforschung; Sauermann, H., Ed.; JCB Mohr (Paul Siebeck): Tübingen, Germany, 1967; pp. 136–168. [Google Scholar]
- List, J. On the Interpretation of Giving in Dictator Games. J. Polit. Econ. 2007, 115, 482–493. [Google Scholar] [CrossRef]
- Bohm, P.; Lindén, J.; Sonnegård, J. Eliciting reservation prices: Becker-DeGroot-Marschak mechanisms vs. markets. Econ. J. 1997, 107, 1079–1089. [Google Scholar] [CrossRef]
| 1 | In Reference [12], subjects fill out surveys with questions about their sexual behavior, among other things, and can provide their email address if they want to receive an evaluation. The study finds that a different survey header design influences the contents of the answers and the willingness to provide one’s own email address. These results are consistent with a study by Reference [16], whose findings also suggest that the willingness to disclose personal data is context-specific. |
| 2 | See, https://www.uni-kassel.de/fb07/fileadmin/datas/fb07/5-Institute/IVWL/Frank/teaching/diverse_bf/Spendennachweis.pdf (accessed on 27 June 2019). |
| 3 | If we only look at the WTAs below €101, the average values are even closer to each other (WTAdetails = €41.84; WTADOT = €42.43; p = 0.380). |


| Question | Mean (sd) |
|---|---|
| a1. Some websites use special tools to identify returning users and to provide them with personalized information (such as advertisements). If a website offered you such a service, would you agree? 1,4 | 3.53 (1.17) |
| a2. How often do you use the private mode (incognito mode) of your web browser? 2 | 2.42 (1.15) |
| a3. Do you use your real name on social networks (like Facebook)? 2,4 | 2.13 (1.23) |
| a4. Do you allow apps on your smartphone, tablet or laptop to determine your location and record it if necessary? 2,4 | 3.03 (1.09) |
| a5. Do you cover up your laptop’s webcam? 2 | 2.83 (1.76) |
| a6. How important is privacy to you in general? 3 | 3.69 (0.72) |
| a7. How important is the security of your personal data to you? 3 | 4.01 (0.96) |
| (1) | (2) | (3) | (4) | (5) | (6) | |
|---|---|---|---|---|---|---|
| WTAdetails | WTAdetails | WTAdetails | WTADOT | WTADOT | WTADOT | |
| privacy | 12.07 ** | 11.33 ** | 11.56 ** | 9.73 * | 9.78 * | 7.99 |
| (4.98) | (4.89) | (4.95) | (5.84) | (5.68) | (5.87) | |
| weight | 13.63 * | 16.17 ** | ||||
| (7.46) | (7.89) | |||||
| smoke | 7.24 | 6.57 | ||||
| (8.81) | (8.93) | |||||
| grade | −2.13 | −1.53 | ||||
| (6.06) | (6.07) | |||||
| KSV | 0.06 | 0.07 | ||||
| (0.11) | (0.11) | |||||
| ILGA | −0.26 ** | −0.23 | ||||
| (0.13) | (0.14) | |||||
| UNHCR | 0.03 | 0.03 | ||||
| (0.17) | (0.17) | |||||
| age | −0.47 | 2.59 * | ||||
| (1.53) | (1.41) | |||||
| female | −4.03 | 6.11 | ||||
| (7.74) | (7.92) | |||||
| session1 | 8.08 | 9.61 | 8.66 | 13.71 * | 11.13 | 11.98 |
| (7.21) | (7.61) | (8.19) | (7.64) | (7.94) | (8.54) | |
| Constant | 9.91 | 9.71 | 19.08 | 14.41 | 19.49 | −32.87 |
| (15.46) | (24.03) | (34.86) | (17.56) | (18.53) | (30.67) | |
| Observations | 94 | 94 | 92 | 94 | 94 | 92 |
| F | 3.55 | 2.41 | 1.88 | 2.84 | 2.22 | 2.70 |
| R2 | 0.08 | 0.12 | 0.13 | 0.07 | 0.11 | 0.13 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cloos, J.; Frank, B.; Kampenhuber, L.; Karam, S.; Luong, N.; Möller, D.; Monge-Larrain, M.; Dat, N.T.; Nilgen, M.; Rössler, C. Is Your Privacy for Sale? An Experiment on the Willingness to Reveal Sensitive Information. Games 2019, 10, 28. https://doi.org/10.3390/g10030028
Cloos J, Frank B, Kampenhuber L, Karam S, Luong N, Möller D, Monge-Larrain M, Dat NT, Nilgen M, Rössler C. Is Your Privacy for Sale? An Experiment on the Willingness to Reveal Sensitive Information. Games. 2019; 10(3):28. https://doi.org/10.3390/g10030028
Chicago/Turabian StyleCloos, Janis, Björn Frank, Lukas Kampenhuber, Stephany Karam, Nhat Luong, Daniel Möller, Maria Monge-Larrain, Nguyen Tan Dat, Marco Nilgen, and Christoph Rössler. 2019. "Is Your Privacy for Sale? An Experiment on the Willingness to Reveal Sensitive Information" Games 10, no. 3: 28. https://doi.org/10.3390/g10030028
APA StyleCloos, J., Frank, B., Kampenhuber, L., Karam, S., Luong, N., Möller, D., Monge-Larrain, M., Dat, N. T., Nilgen, M., & Rössler, C. (2019). Is Your Privacy for Sale? An Experiment on the Willingness to Reveal Sensitive Information. Games, 10(3), 28. https://doi.org/10.3390/g10030028