Cloud Computing for Climate Modelling: Evaluation, Challenges and Benefits

 , ,
, ,
Abstract
1. Introduction
- the suitability of hardware to the particular computing task (e.g., massively parallel tasks, IO intensive tasks);
- the overhead from using virtualization and the ability to optimize code on cloud resources;
- the cost of computational time;
- the requirement of storing data long term and data transfers out of the cloud (and related costs);
- the ability to process and analyse data within the cloud.
- security.
- user interface and ease of use.
2. Methods and Results
2.1. Evaluation of Climate Model Performance
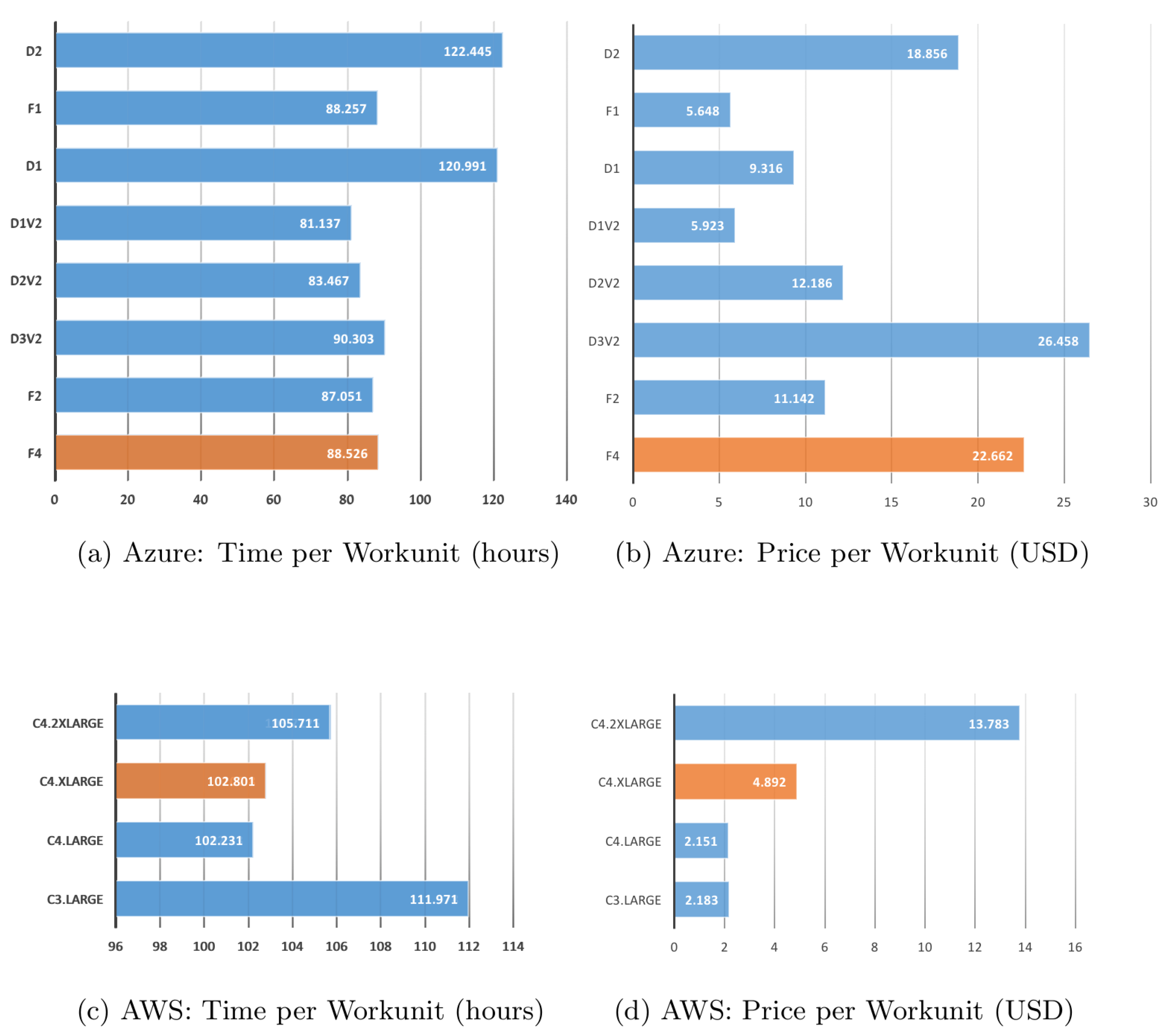
2.1.1. Single Processor Climate Simulations
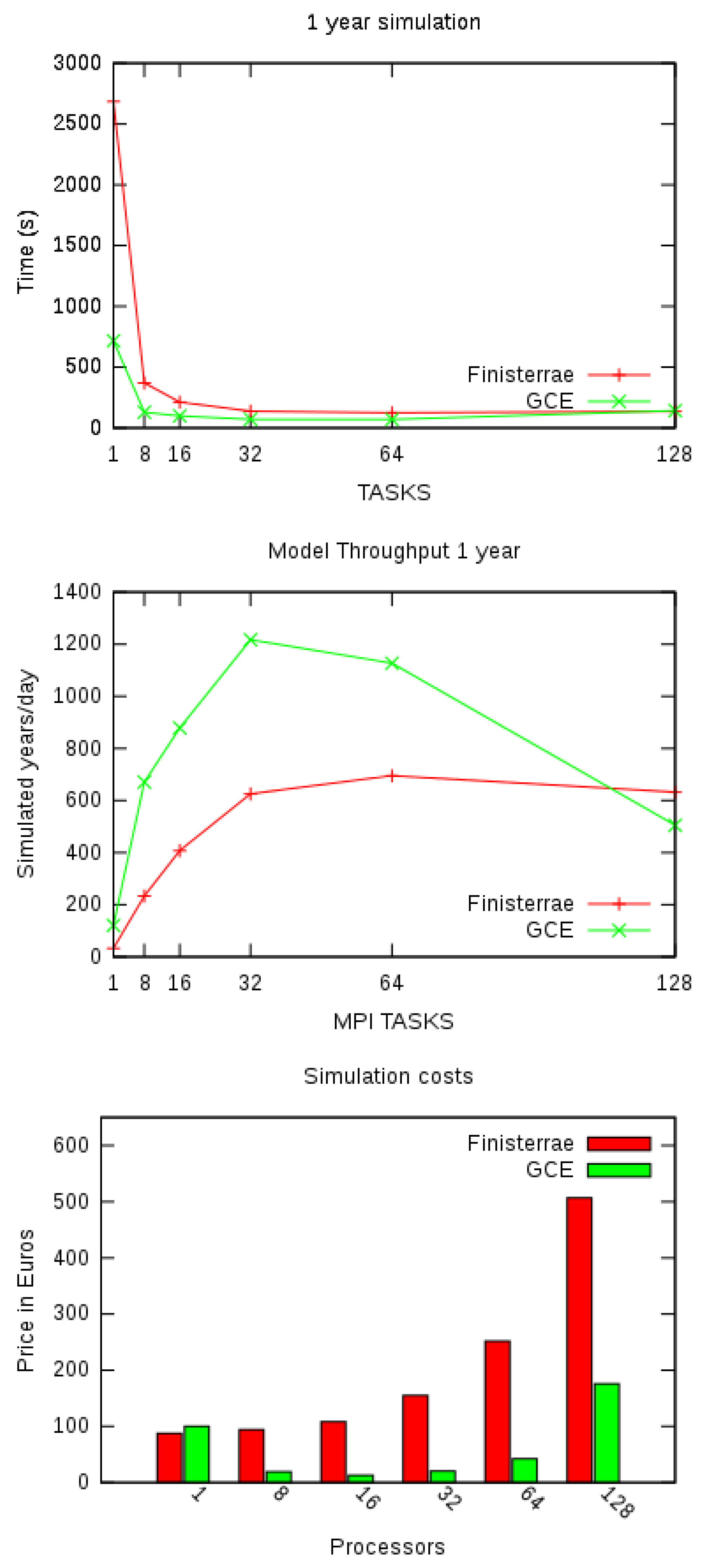
2.1.2. Multiprocessor Climate Simulations
2.1.3. User Experience of Cloud Vendors
- The prices previously described were based on standard rates; however, different discounts and specific payment plans can be discussed and negotiated directly with providers. Running simulations has costs associated with storage and transfer data. In some cases, these associated costs can be completely insignificant [17], but also can be slightly more expensive than for an SC (e.g., comparing the ARCservices (https://help.it.ox.ac.uk/arc/services) provided by the University of Oxford to AWS) [31].
- For simulations using large ensembles with BOINC, for example, the main limiting factor is the CPU, not the memory [17]. However, when running a model directly over a cloud service (as, in this case, for the GCE), constraints very similar to a supercomputer are found (parallelization, network communication and memory). However, a given vendor could provide solutions for the issue of memory and CPU without any problems. These details can be negotiated directly with providers.
- AWS API calls (and related tools) are well documented and easy to integrate (different SDKs are available). Azure’s API (and tools) have good documentation, but still have some way to go to achieve the same level as AWS.
- Writing code for Azure seems to be more oriented towards .NET developers than towards the general public, which made it difficult for us to create extensive automation for our simulations such as the agnostic/generic management of hundreds of VMs.
- In the same vein as AWS, the GCE provides an infrastructure that simplifies both the deployment of simulations and the use of VMs.
- AWS, Azure and GCP provide similar basic security mechanisms and systems: access control, audit trail, data encryption and private networks [42,43]. This was relevant for our tests as we wanted to assure the reproducibility and data validation (as well as the results’ distribution), so it was required that the data integrity was guaranteed. All the evaluated cloud providers have data encryption available for both local and distributed (AWS S3, Google Cloud Storage (GCS) and Azure Storage). The security features (for the three providers) are easy to setup (and sometimes just out-of-the-box, like on the distributed storage). It is worth mentioning that the tested providers manage and process very sensitive data (such as governments’ and medical information), so they have to comply with the highest security standards like SOC (Service Organization Control) or ISO/IEC 27001 and pass periodic audits [44,45].
3. Discussion
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Infrastructure Details for CPDN Experiments
Appendix A.1. Amazon Web Services
- Step 1: Launch Instance.
- Step 2: Select Linux Distribution (Ubuntu Server 16.04 LTS).
- Step 3: Select instance type.
- Step 4: Configure Instance Details and select Request Spot Instances, selecting the maximum price to pay.
- Step 5: In the instance details, in advance, we added the script that installs, initializes, and runs the BOINC client automatically in the instance boot time [31]. The content of the script is:
#!/bin/bash
### Main variables ### #S3 S3_BUCKET="<S3_BUCKET_FOR LOGS>" S3_REGION="us-east-1"
# EC2/instances: Get instance information from metadata TYPE=´curl http://169.254.169.254/latest/meta-data/instance-type´ EC2ID=´curl http://169.254.169.254/latest/meta-data/instance-id´ BATCH="TEST"
BOINC_CMD="/usr/bin/boinccmd" BOINC_PROJECT="http://vorvadoss.oerc.ox.ac.uk/cpdnboinc_alpha" BOINC_KEY="<PROJECT_KEY>"
# Wait seconds (for new tasks) WAIT_SECONDS="60"
# Function: Setup and Connect BOINC to CPDN project function setup_boinc { cd /var/lib/boinc-client# Boot script for AWS Ubuntu VM to run CPDN runs through BOINC
# Install required packages for Ubuntu (and 32 bit compatibility) sudo apt-get update sudo apt-get -y install awscli lib32stdc++6 lib32z1 boinc
# Print date to see how long this has taken date ${BOINC_CMD} --project_attach ${PROJECT} ${KEY}
# List Workunits running on this instance ${BOINC_CMD} --get_tasks|grep ´^\ name´ > tasks.txt# Then, prevent BOINC from getting new work ${BOINC_CMD} --project ${PROJECT} detach_when_done
echo "Polling whether BOINC is still connected" }
# Function: Check (and run) for new tasks function check_tasks { while --get_project_status|grep ´1)´; do # Check spot instance termination if curl -s \ http://169.254.169.254/latest/meta-data/spot/termination-time \ | grep -q .*T.*Z; then # Update project in case we have successful tasks # to report /usr/bin/boinccmd --project ${PROJECT} update # Report instance uptime uptime > timing.txt aws s3 cp timing.txt \ s3://${S3_BUCKET}/${BATCH}/${TYPE}/terminated_${EC2ID}.txt \ --region=${S3_REGION} aws s3 cp tasks.txt \ s3://${S3_BUCKET}/${BATCH}/${TYPE}/tasks_${EC2ID}.txt \ --region=${S3_REGION} sleep 10 /usr/bin/boinccmd --project ${PROJECT} detach fi sleep ${WAIT_SECONDS} # Wait polling secs done }# Function: Generate reports and upload to S3 function report { df -h |grep xvda1 > diskusage.txt uptime > timing.txt aws s3 cp timing.txt \ s3://${S3_BUCKET}/${BATCH}/${TYPE}/complete_${EC2ID}.txt \ --region=${S3_REGION} aws s3 cp tasks.txt \ s3://${S3_BUCKET}/${BATCH}/${TYPE}/tasks_${EC2ID}.txt \ --region=${S3_REGION} aws s3 cp diskusage.txt \ s3://${S3_BUCKET}/${BATCH}/${TYPE}/diskusage_${EC2ID}.txt \ --region=${S3_REGION} }# Function: Clean up and shut down function clean_up { sudo shutdown -h now }### MAIN ### # Workflow: Setup BOINC in instance and wait (and run) for tasks setup_boinc check_tasks
# When completed: report (to S3) and cleanup report cleanup
- Step 6: Add the necessary storage, 64 GB.
- Step 7: Give a name to the instance (for better identification).
- Step 8: Select a security group (in this case, by default, having port 22 open is enough).
- Step 9: Review parameters and Launch.
Appendix A.2. Microsoft Azure
- Step 1: Select Ubuntu Server (Ubuntu Server 16.04 LTS).
- Step 2: Select Create.
- Step 3: Give a name, user name and password (used for SSH access).
- Step 4: Select VM type/size.
- Step 5: On the VM Settings, Select Extensions, Add Extension and Custom Script for Linux, and upload the script with the content:
#!/bin/bash
### Main variables ### # Storage AZURE_ACCOUNT="<AZURE_ACCOUNT>" FS_KEY_PASSWORD="<FS_KEY_PASSWORD>" SHARE_NAME="<AZURE_SHARE_NAME>" MOUNT_POINT="<SHARED_FS_MOUNTPOINT>" MOUNT_PARAMS="-o vers=3.0,username=${AZURE_ACCOUNT}, \ password=${FS_KEY_PASSWORD},dir_mode=0777,file_mode=0777,serverino"
# VM: Get instance information from metadata VM_ID=´curl -H Metadata:true http://169.254.169.254/metadata/latest/InstanceInfo/ID´ BATCH="TEST"
BOINC_CMD="/usr/bin/boinccmd" BOINC_PROJECT="http://vorvadoss.oerc.ox.ac.uk/cpdnboinc_alpha" BOINC_KEY="<PROJECT_KEY>"
# Wait seconds (for new tasks) WAIT_SECONDS="60"
# Function: Setup and Connect BOINC to CPDN project function setup_boinc { cd /var/lib/boinc-client# Boot script for Ubuntu VM to run CPDN runs through BOINC # Install required packages for Ubuntu (and 32 bit compatibility) # and shared storage sudo apt-get update sudo apt-get -y install cifs-utils lib32stdc++6 lib32z1 boinc
# Mount shared FS sudo mount -t cifs //${AZURE_ACCOUNT}.file.core.windows.net /${SHARE_NAME} \ ./${MOUNT_POINT} ${MOUNT_PARAMS}
# Print date to see how long this has taken date ${BOINC_CMD} --project_attach ${PROJECT} ${KEY}
# List Workunits running on this instance ${BOINC_CMD} --get_tasks|grep ´^\ name´ > tasks.txt# Then, prevent BOINC from getting new work ${BOINC_CMD} --project ${PROJECT} detach_when_done
echo "Polling whether BOINC is still connected" }
# Function: Check (and run) for new tasks function check_tasks { while --get_project_status|grep ´1)´; do # Check spot instance termination if curl -s \ http://169.254.169.254/latest/meta-data/spot/termination-time \ | grep -q .*T.*Z; then # Update project in case we have successful # tasks to report /usr/bin/boinccmd --project ${PROJECT} update # Report instance uptime uptime > timing.txt cp timing.txt \ ${MOUNT_POINT}/${BATCH}/terminated_${VM_ID}.txt cp tasks.txt \ ${MOUNT_POINT}/${BATCH}/tasks_${VM_ID}.txtsleep 10 /usr/bin/boinccmd --project ${PROJECT} detach fi sleep ${WAIT_SECONDS} # Wait polling secs done }# Function: Generate reports and upload to Shared FS function report { df -h |grep xvda1 > diskusage.txt uptime > timing.txt cp timing.txt ${MOUNT_POINT}/${BATCH}/complete_${VM_ID}.txt cp tasks.txt ${MOUNT_POINT}/${BATCH}/tasks_${VM_ID}.txt cp diskusage.txt ${MOUNT_POINT}/${BATCH}/diskusage_${VM_ID}.txt }# Function: Clean up and shut down function clean_up { sudo shutdown -h now }### MAIN ### # Workflow: Setup BOINC on instance and wait (and run) for tasks setup_boinc check_tasks
# When completed: report (to Shared FS) and cleanup report cleanup
- Step 6: Add storage, 64 GB.
- Step 7: Start VM.
Appendix B. Infrastructure Details for WACCM Experiments
Appendix B.1. Finisterrae II super computer
- 143 computing nodes.
- 142 HP Integrity rx7640 nodes with 16 Itanium Montvale cores with 128 GB of RAM each.
- An Infiniband 4 × DDR 20 Gbps interconnection network.
Appendix B.2. Google Compute Engine
Appendix B.3. Cluster Creation
Appendix B.4. Simulations
- All components active: atmosphere, ocean, land, sea-ice and land-ice.
- Resolution of the grid of 1.9 × 2.5_1.9 × 2.5 (the approximately two-degree finite volume grid).
- MPI tasks of 1, 8, 16, 32, 64 and 128.
- Simulation length of one and ten years.
#!/bin/bash
NUMNODES=8
INSTANCETYPE=n1-highcpu-16
REGION=us-central1-a
#1. Verifies that Google´s utilities are installed. If not, the program
exits. command -v gcutil >/dev/null 2>&1|| { chho >&2 ´´gcutil needs \
to be installed but it couldn´t be found. Aborting.´´; exit 1;}
#2. Sets the project name.
projectID=´gcloud config list | grep project | awk ´{ print $3}^
#3. Sets the number of nodes.
numNodes=${NUMNODES}
#4. Sets machine type and image.
machTYPE=${INSTANCETYPE}
imageID=https://www.googleapis.com/compute/v1/projects/debian-\
cloud/global/images/debian-7-wheezy-v20140807
#5. Adds nodes to the cluster and wait until they are running. nodes=$(eval echo machine{0..$(($numNodes-1))}) gcutil addinstance --image=$imageID --machine_type=$machTYPE\ --zone=${REGION} --wait_until_running $nodes
#6. Uploads the file install.sh to the slave nodes. for i in $(seq 1 $(($numNodes-1))); do gcutil push machine$i install.sh . done
#7. Executes previous script in each node and checks if # the configuration ended successfully in every machine.
for i in $(seq 1 $(($numNodes-1))); do gcutil ssh machine$i "/bin/bash ./install.sh machine$i >&\ install.log.machine$i" & done
for i in $(seq 1 $(($numNodes-1))); do gcutil ssh machine$i "grep DONE install.log.machine$i" done
#8. Finally, configures ssh keys to allow the connection from #the master node without password.
clave_pub=´gcutil ssh machine0 ´´sudo cat ~/.ss/id_rsa.pub´´´ for i in $(seq 1$(($numNodes-1))); do echo ´´$clave_pub´´ | gcutil ssh machine$i ´´cat >> \ ~/.ssh/authorized_keys´´ done
cat << EOF > config Host * StrictHostKeyChecking no UserKnownHostsFile=/dev/null EOF cat config | gcutil ssh machine0 "cat >> ~/.ssh/config" rm config
References
- Palmer, T. Build high-resolution global climate models. Nature 2014, 515, 338–339. [Google Scholar] [CrossRef]
- Bell, G.; Hey, T.; Szalay, A. Beyond the data deluge. Science 2009, 323, 1297–1298. [Google Scholar] [CrossRef]
- EIU. Ascending Cloud: The Adoption of Cloud Computing in Five Industries; Technical Report. 2016. Available online: https://www.vmware.com/radius/wp-content/uploads/2015/08/EIU_VMware-Executive-Summary-FINAL-LINKS-2-26-16.pdf (accessed on 21 June 2020).
- Meinardi, M.; Smith, D.; Plummer, D.; Cearley, D.; Natis, Y.; Khnaser, E.; Nag, S.; MacLellan, S.; Petri, G. Predicts 2020: Better Management of Cloud Costs, Skills and Provider Dependence will Enable Further Cloud Proliferation; Technical Report; ITRS Group Ltd.: London, UK, 2019. [Google Scholar]
- Zhao, Y.; Li, Y.; Raicu, I.; Lu, S.; Tian, W.; Liu, H. Enabling scalable scientific workflow management in the Cloud. Future Gener. Comp. Syst. 2015, 46, 3–16. [Google Scholar] [CrossRef]
- Añel, J.A.; Montes, D.P.; Rodeiro Iglesias, J. Cloud and Serverless Computing for Scientists; Springer: Berlin, Germany, 2020; p. 110. [Google Scholar] [CrossRef]
- Ayris, P.; Berthou, J.Y.; Bruce, R.; Lindstaedt, S.; Monreale, A.; Mons, B.; Murayama, Y.; Södergøard, C.; Tochterman, K.; Wilkinson, R. Realising the European Open Science Cloud; Technical Report; Publications Office of the European Union: Luxemburg, 2016. [Google Scholar] [CrossRef]
- White, T. Hadoop: The Definitive Guide, 4th ed.; O’Reilly Media: Sebastopol, CA, USA, 2015; p. 728. [Google Scholar]
- Lawrence, B.; Bennett, V.; Churchill, J.; Juckes, M.; Kershaw, P.; Pascoe, S.; Pepler, S.; Pritchard, M.; Stephens, A. Storing and manipulating environmental big data with JASMIN. Proc. IEEE Big Data 2013, 68–75. [Google Scholar] [CrossRef]
- NOAA. Big Data Project. Available online: https://www.noaa.gov/organization/information-technology/big-data-program (accessed on 21 June 2020).
- AWS. The Met Office Case Study. Available online: https://aws.amazon.com/solutions/case-studies/the-met-office/ (accessed on 21 June 2020).
- Vance, T.; Merati, N.; Yang, C.; Yuan, M. (Eds.) Cloud Computing in Ocean and Atmospheric Sciences, 1st ed.; Academic Press: Cambridge, MA, USA, 2016; p. 415. [Google Scholar]
- Evangelinos, C.; Hill, C.N. Cloud Computing for parallel Scientific HPC Applications: Feasibility of running Coupled Atmosphere-Ocean Climate Models on Amazon’s EC2. In Proceedings of the First Workshop on Cloud Computing and its Applications (CCA’08), Chicago, IL, USA, 22–23 October 2008. [Google Scholar]
- Molthan, A.L.; Case, J.L.; Venner, J.; Schroeder, R.; Checchi, M.R.; Zavodsky, B.T.; Limaye, A.; O’Brien, R.G. Clouds in the cloud: Weather forecasts and applications within cloud computing environments. Bull. Am. Meteorol. Soc. 2015, 96, 1369–1379. [Google Scholar] [CrossRef]
- McKenna, B. Dubai Operational Forecasting System in Amazon Cloud. Cloud Comput. Ocean Atmos. Sci. 2016, 325–345. [Google Scholar] [CrossRef]
- Blanco, C.; Cofino, A.S.; Fernández, V.; Fernández, J. Evaluation of Cloud, Grid and HPC resources for big volume and variety of RCM simulations. Geophys. Res. Abtracts 2016, 18, 17019. [Google Scholar]
- Montes, D.; Añel, J.A.; Pena, T.F.; Uhe, P.; Wallom, D.C.H. Enabling BOINC in Infrastructure as a Service Cloud Systems. Geosci. Mod. Dev. 2017, 10, 811–826. [Google Scholar] [CrossRef]
- Chen, X.; Huang, X.; Jiao, C.; Flanner, M.G.; Raeker, T.; Palen, B. Running climate model on a commercial cloud computing environment. Comput. Geosci. 2017, 98, 21–25. [Google Scholar] [CrossRef]
- Zhuang, J.; Jacob, D.J.; Gaya, J.F.; Yantosca, R.M.; Lundgren, E.W.; Sulprizio, M.P.; Eastham, S.D. Enabling Immediate Access to Earth Science Models through Cloud Computing: Application to the GEOS-Chem Model. Bull. Am. Meteorol. Soc. 2019, 100, 1943–1960. [Google Scholar] [CrossRef]
- Zhuang, J.; Jacob, D.J.; Lin, H.; Lundgren, E.W.; Yantosca, R.M.; Gaya, J.F.; Sulprizio, M.P.; Eastham, S.D. Enabling High-Performance Cloud Computing for Earth Science Modeling on Over a Thousand Cores: Application to the GEOS-Chem Atmospheric Chemistry Model. J. Adv. Model. Earth Syst. 2020, 12, e2020MS002064. [Google Scholar] [CrossRef]
- Goodess, C.M.; Troccoli, A.; Acton, C.; Añel, J.A.; Bett, P.E.; Brayshaw, D.J.; De Felice, M.; Dorling, S.E.; Dubus, L.; Penny, L.; et al. Advancing climate services for the European renewable energy sector through capacity building and user engagement. Clim. Serv. 2019, 16, 100139. [Google Scholar] [CrossRef]
- Düben, P.D.; Dawson, A. An approach to secure weather and climate models against hardware faults. J. Adv. Model. Earth Syst. 2017, 9, 501–513. [Google Scholar] [CrossRef]
- Wright, D.; Smith, D.; Bala, R.; Gill, B. Magic Quadrant for Cloud Infrastructure as a Service, Worldwide; Technical Report; Gartner, Inc.: Stamford, CT, USA, 2019. [Google Scholar]
- RightScale. RightScale 2018 State of the Cloud Report; Technical Report; RightScale, Inc.: Santa Barbara, CA, USA, 2018. [Google Scholar]
- Hille, M.; Klemm, D.; Lemmermann, L. Crisp Vendor Universe/2017: Cloud Computing Vendor & Service Provider Comparison; Technical Report; Crisp Research GmbH: Kassel, Germany, 2018. [Google Scholar]
- Allen, M.R. Do-it-yourself climate prediction. Nature 1999, 401, 642. [Google Scholar] [CrossRef]
- Guillod, B.P.; Jones, R.G.; Bowery, A.; Haustein, K.; Massey, N.R.; Mitchell, D.M.; Otto, F.E.L.; Sparrow, S.N.; Uhe, P.; Wallom, D.C.H.; et al. weather@home 2: Validation of an improved global–regional climate modelling system. Geosci. Mod. Dev. 2017, 10, 1849. [Google Scholar] [CrossRef]
- Anderson, D.P. BOINC: A System for Public-Resource Computing and Storage. In Proceedings of the Fifth IEEE/ACM International Workshop on Grid Computing, Pittsburgh, PA, USA, 8 November 2004; pp. 4–10. [Google Scholar]
- Massey, N.; Jones, R.; Otto, F.E.L.; Aina, T.; Wilson, S.; Murphy, J.M.; Hassel, D.; Yamazaki, Y.H.; Allen, M.R. weather@home—Development and validation of a very large ensemble modelling system for probabilistic event attribution. Quart. J. R. Meteorol. Soc. 2014, 141, 1528–1545. [Google Scholar] [CrossRef]
- Lange, S. On the Evaluation of Regional Climate Model Simulations over South America. Ph.D. Thesis, Humboldt-Universität zu Berlin, Berlin, Germany, 2015. [Google Scholar]
- Uhe, P.; Otto, F.E.L.; Rashid, M.M.; Wallom, D.C.H. Utilising Amazon Web Services to provide an on demand urgent computing facility for climateprediction.net. In Proceedings of the 2016 IEEE 12th International Conference on e-Science (e-Science), Baltimore, MD, USA, 23–27 October 2016; pp. 407–413. [Google Scholar] [CrossRef]
- Marsh, D.R.; Mills, M.; Kinnison, D.; Lamarque, J.F.; Calvo, N.; Polvani, L.M. Climate change from 1850 to 2005 simulated in CESM1(WACCM). J. Clim. 2013, 26. [Google Scholar] [CrossRef]
- CCMVal. SPARC CCMVal Report on the Evaluation of Chemistry-Climate Models; SPARC Report No. 5, WCRP-132, WMO/TD-No. 1526; SPARC Office: Toronto, ON, Canada, 2010. [Google Scholar]
- Gettelman, A.; Hegglin, M.I.; Son, S.W.; Kim, J.; Fujiwara, M.; Birner, T.; Kremser, S.; Rex, M.; Añel, J.A.; Akiyoshi, H.; et al. Multi-model Assessment of the Upper Troposphere and Lower Stratosphere: Tropics and Trends. J. Geophys. Res. 2010, 115, D00M08. [Google Scholar] [CrossRef]
- Hegglin, M.I.; Gettelman, A.; Hoor, P.; Krichevsky, R.; Manney, G.L.; Pan, L.L.; Son, S.W.; Stiller, G.; Tilmes, S.; Walker, K.A.; et al. Multi-model Assessment of the Upper Troposphere and Lower Stratosphere: Extra-tropics. J. Geophys. Res. 2010, 115, D00M09. [Google Scholar] [CrossRef]
- Toohey, M.; Hegglin, M.I.; Tegtmeier, S.; Anderson, J.; Añel, J.A.; Bourassa, A.; Brohede, S.; Degenstein, D.; Froidevaux, L.; Fuller, R.; et al. Characterizing sampling biases in the trace gas climatologies of the SPARC Data Initiative. J. Geophys. Res. Atmos. 2013, 118, 11847–11862. [Google Scholar] [CrossRef]
- Chiodo, G.; García-Herrera, R.; Calvo, N.; Vaquero, J.M.; Añel, J.A.; Barriopedro, D.; Matthes, K. The impact of a future solar minimum on climate change projections in the Northern Hemisphere. Environ. Res. Lett. 2016, 11, 034015. [Google Scholar] [CrossRef]
- The SPARC Data Initiative: Assessment of Stratospheric Trace Gas and Aerosol Climatologies from Satellite Limb Sounders; Technical Report; ETH-Zürich: Zürich, Switzerland, 2017. [CrossRef]
- Añel, J.A.; Gimeno, L.; de la Torre, L.; García, R.R. Climate modelling and Supercomputing: WACCM at CESGA. Díxitos Comput. Sci. 2008, 2, 31–32. [Google Scholar]
- Wilson, S. (MetOffice Hadley Centre, Exeter, UK). Personal communication, 2018.
- Ranjan, R.; Benatallah, B.; Dustdar, S.; Papazoglou, M.P. Cloud Resource Orchestration Programming: Overview, Issues and Directions. IEEE Internet Comput. 2015, 19, 46–56. [Google Scholar] [CrossRef]
- Rath, A.; Spasic, B.; Boucart, N.; Thiran, P. Security Pattern for Cloud SaaS: From System and Data Security to Privacy Case Study in AWS and Azure. Computers 2019, 8, 34. [Google Scholar] [CrossRef]
- Mitchell, N.J.; Zunnurhain, K. Google Cloud Platform Security; Associaton for Computing Machinery: New York, NY, USA, 2019; pp. 319–322. [Google Scholar] [CrossRef]
- Kaufman, C.; Venkatapathy, R. Windows Azure TM Security Overview; Technical Report; Microsoft: Redmond, WA, USA, 2010. [Google Scholar]
- Saeed, I.; Baras, S.; Hajjdiab, H. Security and Privacy of AWS S3 and Azure Blob Storage Services. In Proceedings of the IEEE 4th International Conference on Computer and Communication Systems (ICCCS), Singapore, 23–25 February 2019. [Google Scholar] [CrossRef]
- Craig Mudge, J. Cloud Computing: Opportunities and Challenges for Australia; Technical Report; ASTE: Melbourne, Australia, 2010. [Google Scholar]
- Charney, J.G.; Fjörtoft, R.; von Neumann, J. Numerical Integration of the Barotropic Vorticity Equation. Tellus 1950, 2, 237–254. [Google Scholar] [CrossRef]
- Hersbach, H.; Bell, B.; Berrisford, P.; Hirahara, S.; Horányi, A.; Muñoz-Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Schepers, D.; et al. The ERA5 Global Reanalysis. Q. J. R. Meteorol. Soc. 2020. [Google Scholar] [CrossRef]
- Kay, J.E.; Deser, C.; Phillips, A.; Mai, A.; Hannay, C.; Strand, G.; Arblaster, J.M.; Bates, S.C.; Danabasoglu, G.; Edwards, J.; et al. The Community Earth System Model (CESM) Large Ensemble Project: A Community Resource for Studying Climate Change in the Presence of Internal Climate Variability. Bull. Am. Meteorol. Soc. 2015, 96, 1333–1349. [Google Scholar] [CrossRef]
- Drake, N. Cloud computing beckons scientists. Nature 2014, 509, 543–544. [Google Scholar] [CrossRef]
- Stein, L.; Knoppers, B.M.; Campbell, P.; Getz, G.; Korbel, J.O. Create a cloud commons. Nature 2015, 523, 149–151. [Google Scholar] [CrossRef]
- Critical Techniques, Technologies and Methodologies for Advancing Foundations and Applications of Big Data Sciences and Engineering (BIGDATA NSF-18-539); Technical Report. 2018. Available online: https://www.nsf.gov/pubs/2018/nsf18539/nsf18539.htm (accessed on 21 June 2020).
- EarthCube: Developing a Community-Driven Data and Knowledge Environment for the Geosciences (BIGDATA NSF 20-520); Technical Report. 2020. Available online: https://www.nsf.gov/pubs/2020/nsf20520/nsf20520.htm (accessed on 21 June 2020).
- Raoult, B.; Correa, R. Cloud Computing for the Distribution of Numerical Weather Prediction Outputs. Cloud Comput. Ocean Atmos. Sci. 2016, 121–135. [Google Scholar] [CrossRef]
- Misra, S.; Mondal, A. Identification of a company’s suitability for the adoption of cloud computing and modelling its corresponding Return on Investment. Mat. Comput. Model. 2011, 53, 504–521. [Google Scholar] [CrossRef]
- Bildosola, I.; Río-Belver, R.; Cilleruelo, E.; Garechana, G. Design and Implementation of a Cloud Computing Adoption Decision Tool: Generating a Cloud Road. PLoS ONE 2015, 10, e0134563. [Google Scholar] [CrossRef]
- CLOUDYN. Determining Your Optimal Mix of Clouds; Technical Report; Cloudyn: Rosh Ha’ayin, Israel, 2015. [Google Scholar]
- Oriol Fitó, J.; Macías, M.; Guitart, J. Toward Business-driven Risk Management for Cloud Computing. In Proceedings of the International Conference on Network and Service Management, Niagara Falls, ON, Canada, 25–29 October 2010; pp. 238–241. [Google Scholar]
- Wallom, D.C.H. Report from the Cloud Security Workshop: Building Trust in Cloud Services Certification and Beyond; Technical Report; European Commission: Brussels, Belgium, 2016. [Google Scholar]
- Kim, A.; McDermott, J.; Kang, M. Security and Architectural Issues for National Security Cloud Computing. In Proceedings of the IEEE 30th International Conference on Distributed Computing Systems Workshops, Genova, Italy, 21–25 June 2010; pp. 21–25. [Google Scholar] [CrossRef]
- Bennett, K.W.; Robertson, J. Security in the Cloud: Understanding your responsibility. In Proceedings of the SPIE 11011, Cyber Sensing 2019, Baltimore, MD, USA, 17 May 2019; pp. 1–18. [Google Scholar] [CrossRef]
- Añel, J.A. The importance of reviewing the code. Commun. ACM 2011, 54, 40–41. [Google Scholar] [CrossRef]
- Hutton, C.; Wagener, T.; Freer, J.; Han, D.; Duffy, C.; Arheimer, B. Most computational hydrology is not reproducible, so is it really science? Water Resour. Res. 2016, 52, 7548–7555. [Google Scholar] [CrossRef]
- Añel, J.A. Comment on ’Most computational hydrology is not reproducible, so is it really science?’ by Hutton et al. Water Resour. Res. 2017, 53, 2572–2574. [Google Scholar] [CrossRef]
- Perspectives on Cloud Outcomes: Expectation vs. Reality. 2020, p. 15. Available online: https://www.accenture.com/_acnmedia/pdf-103/accenture-cloud-well-underway.pdf (accessed on 18 June 2020).



{kind=link}
{kind=link}
| Instance Type | CPU | Memory | Disk |
|---|---|---|---|
| F4 | Intel(R) Xeon(R) CPU E5-2673 v3 @ 2.40GHz (4 cores) | 8 GB | 64 GB SSD |
| F2 | Intel(R) Xeon(R)CPU E5-2673 v3@ 2.40GHz (2 cores) | 4 GB | 32 GB SSD |
| D3v2 | Intel(R) Xeon(R)CPU E5-2673 v3@ 2.40GHz (4 cores) | 14 GB | 200 GB SSD |
| D2v2 | Intel(R) Xeon(R)CPU E5-2673 v3@ 2.40GHz (2 cores) | 7 GB | 100 GB SSD |
| D1v2 | Intel(R) Xeon(R)CPU E5-2673 v3@ 2.40GHz (1 core) | 3.5 GB | 50 GB SSD |
| D1 | Intel(R) Xeon(R)CPU E5-2660 0@ 2.20GHz (1 core) | 3.5 GB | 50 GB SSD |
| F1 | Intel(R) Xeon(R)CPU E5-2673 v3@ 2.40GHz (1 core) | 2 GB | 16 GB SSD |
| D2 | Intel(R) Xeon(R)CPU E5-2660 0@ 2.20GHz (2 cores) | 7 GB | 100 GB SSD |
| Instance Type | CPU | Memory | Disk |
|---|---|---|---|
| C3.LARGE | Intel(R) Xeon(R) CPU E5-2680v2 @ 2.80GHz (2 cores) | 3.75 GB | 64 GB (Standard EBS) |
| C4.LARGE | Intel(R) Xeon(R) CPU E5-2666 v3 @ 2.90GHz (2 cores) | 3.75 GB | 64 GB (Standard EBS) |
| C4.XLARGE | Intel(R) Xeon(R) CPU E5-2666 v3 @ 2.90GHz (4 cores) | 7.5 GB | 64 GB (Standard EBS) |
| C4.2XLARGE | Intel(R) Xeon(R) CPU E5-2666 v3 @ 2.90GHz (8 cores) | 15 GB | 64 GB (Standard EBS) |
| Platform | Pros | Cons |
|---|---|---|
| Supercomputer | ||
| • Well known and very predictable environment. | • Limited elasticity and scalability. | |
| • Usually, shared environment. | ||
| • Better institutional support and budget. | • Expected high queue wait times. | |
| AWS | ||
| • Public cloud providers’ leader. | • Cost optimization can be complex to understand. | |
| • Best support. Biggest number of solutions and integrations. | • Services are tailored to AWS; easy to get into a vendor lock-in situation. | |
| Azure | ||
| • Best option for Windows-based software. | • GNU/Linux-based simulations are not the ideal case for Azure. | |
| • Very competitive pricing and waivers. | • Generally speaking, less mature than AWS. | |
| GCP | ||
| • Appealing and comprehensive pricing model based on usage. | • Some of the services are still in the very early stages. | |
| • In many cases, services are easier to manage than with other providers. | • Very vanilla; this can also be seen as an advantage in some cases. | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Montes , D.; Añel , J.A.; Wallom , D.C.H.; Uhe , P.; Caderno, P.V.; Pena, T.F. Cloud Computing for Climate Modelling: Evaluation, Challenges and Benefits. Computers 2020, 9, 52. https://doi.org/10.3390/computers9020052
Montes D, Añel JA, Wallom DCH, Uhe P, Caderno PV, Pena TF. Cloud Computing for Climate Modelling: Evaluation, Challenges and Benefits. Computers. 2020; 9(2):52. https://doi.org/10.3390/computers9020052
Chicago/Turabian StyleMontes , Diego, Juan A. Añel , David C. H. Wallom , Peter Uhe , Pablo V. Caderno, and Tomás F. Pena. 2020. "Cloud Computing for Climate Modelling: Evaluation, Challenges and Benefits" Computers 9, no. 2: 52. https://doi.org/10.3390/computers9020052
APA StyleMontes , D., Añel , J. A., Wallom , D. C. H., Uhe , P., Caderno, P. V., & Pena, T. F. (2020). Cloud Computing for Climate Modelling: Evaluation, Challenges and Benefits. Computers, 9(2), 52. https://doi.org/10.3390/computers9020052