An Investigation of a Feature-Level Fusion for Noisy Speech Emotion Recognition



Abstract
1. Introduction
2. Review of Feature Level Fusion Based SER
3. Methodology
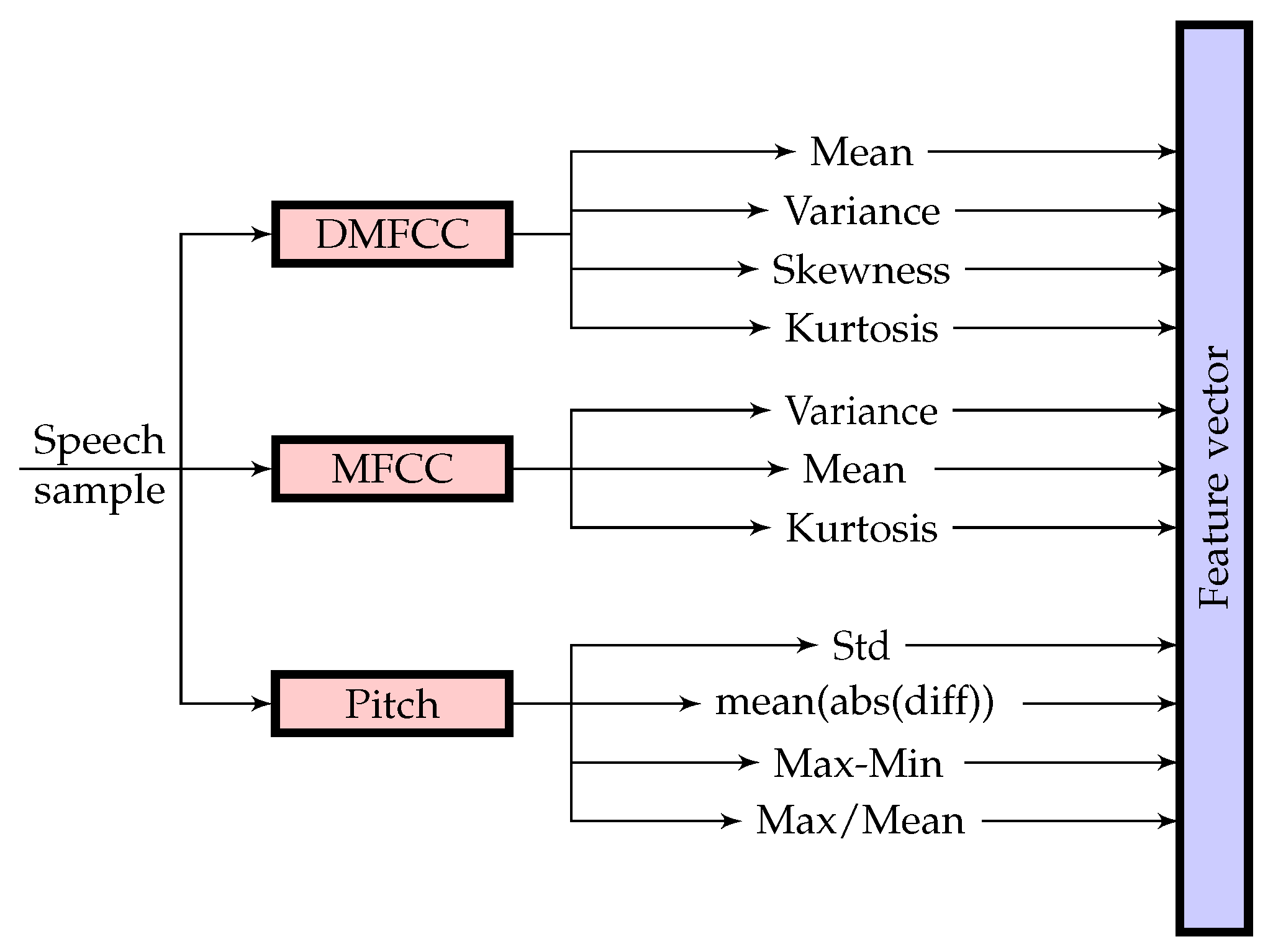
3.1. Feature Extraction
3.1.1. Pitch
3.1.2. MFCC
- Pre-emphasize the speech signal: The pre-emphasis filter is a special kind of Finite Impulse Response (FIR), and its transfer function is described as:where is the parameter that controls the slope of the filter and is usually chosen between 0.4 and 1 [29]. In this paper, its value was set to .
- Divide the speech signal into a sequence of frames that are N samples long. An overlap between the frames was allowed to avoid the difference between the frames. Windowing was then is applied over each of the frames to reduce the spectral leakage effect at the beginning and end of each frame. Here, the Hamming window was applied, which was defined as .
- Compute the magnitude spectrum for each windowed frame by applying FFT.
- The Mel spectrum was computed by passing the resulting frequency spectrum through a Mel filter bank with a triangular bandpass frequency response.
- Discrete Cosine Transform (DCT) was applied to the log Mel spectrum to derive the desired MFCCs.
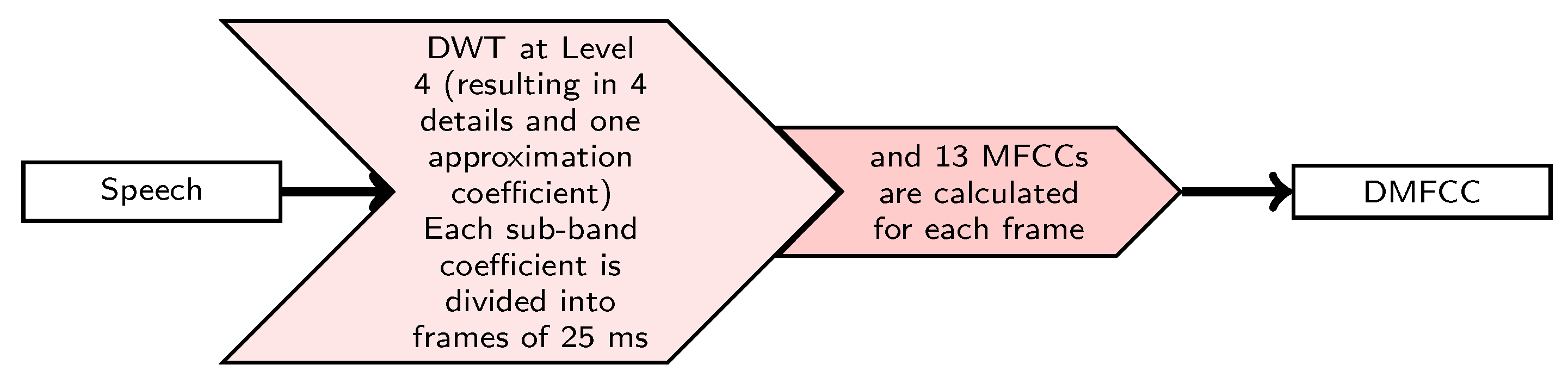
3.1.3. Wavelet Based Feature Extraction Method
3.2. Dimensionality Reduction Using LDA
3.3. Classification
3.3.1. Naive Bayes Classifier
3.3.2. SVM Classifier
4. Results
4.1. Experimental Data and Parameters
- Acted: where the emotional speech is acted by subjects in a professional manner. The actor is asked to read a transcript with a predefined emotion.
- Authentic: where emotional speech is collected from recording conversations in real-life situations. Such situations include customer service calls and audio from video recordings in public places or from TV programs.
- Elicited: where the emotional speech is collected in an implicit way, in which the emotion is the natural reaction to a film or a guided conversation. The emotions are provoked, and experts label the utterances. The elicited speech is neither authentic nor acted.
4.1.1. IEMOCAP
4.1.2. EMO-DB
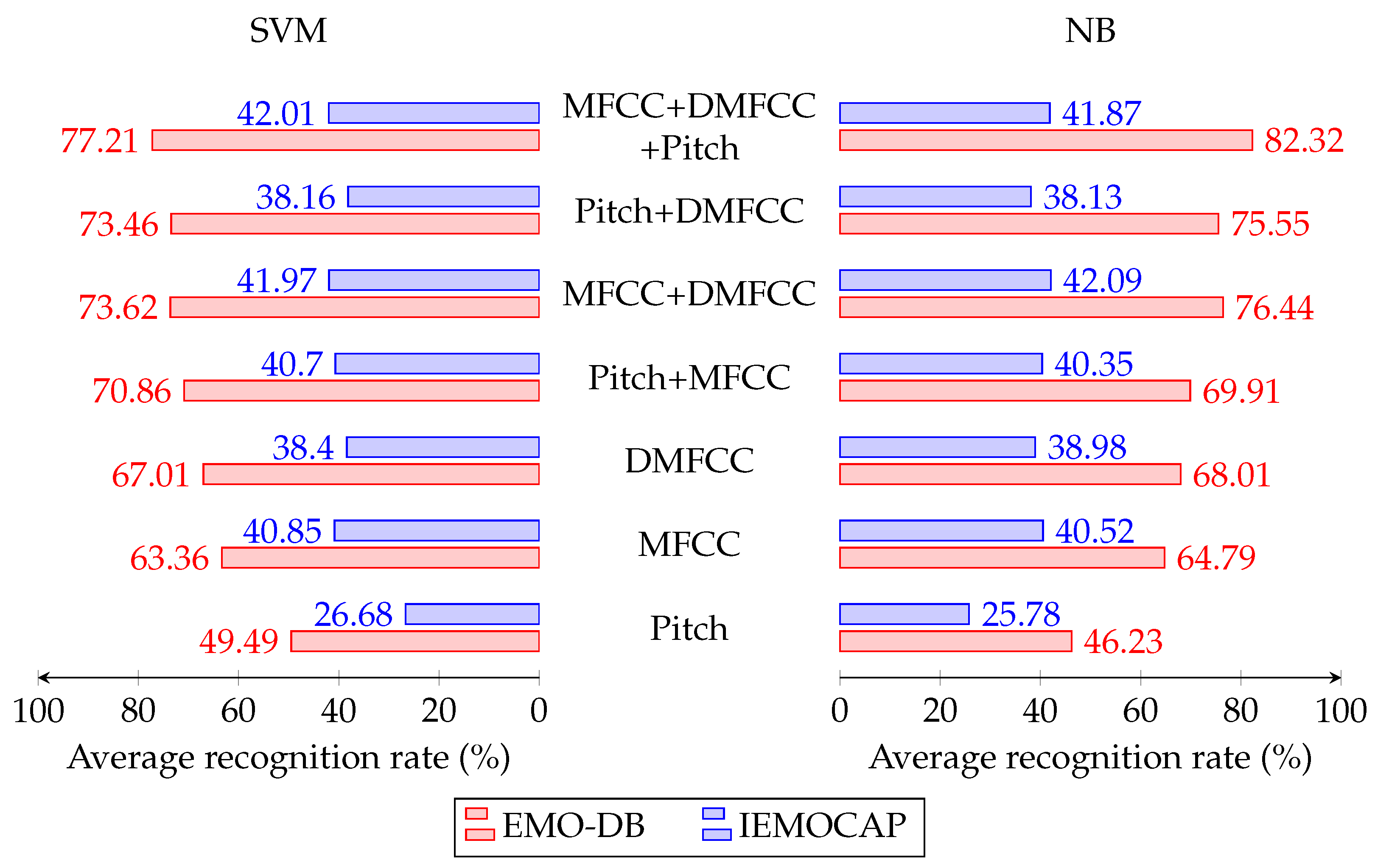
4.2. Speaker Independent Experimental Results
4.3. Comparison with Previous Related Work
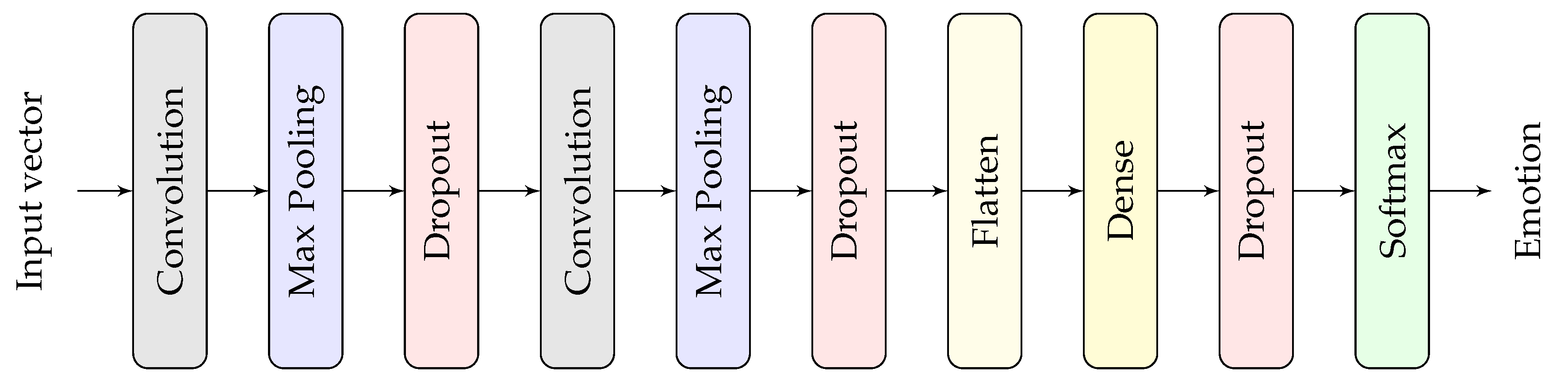
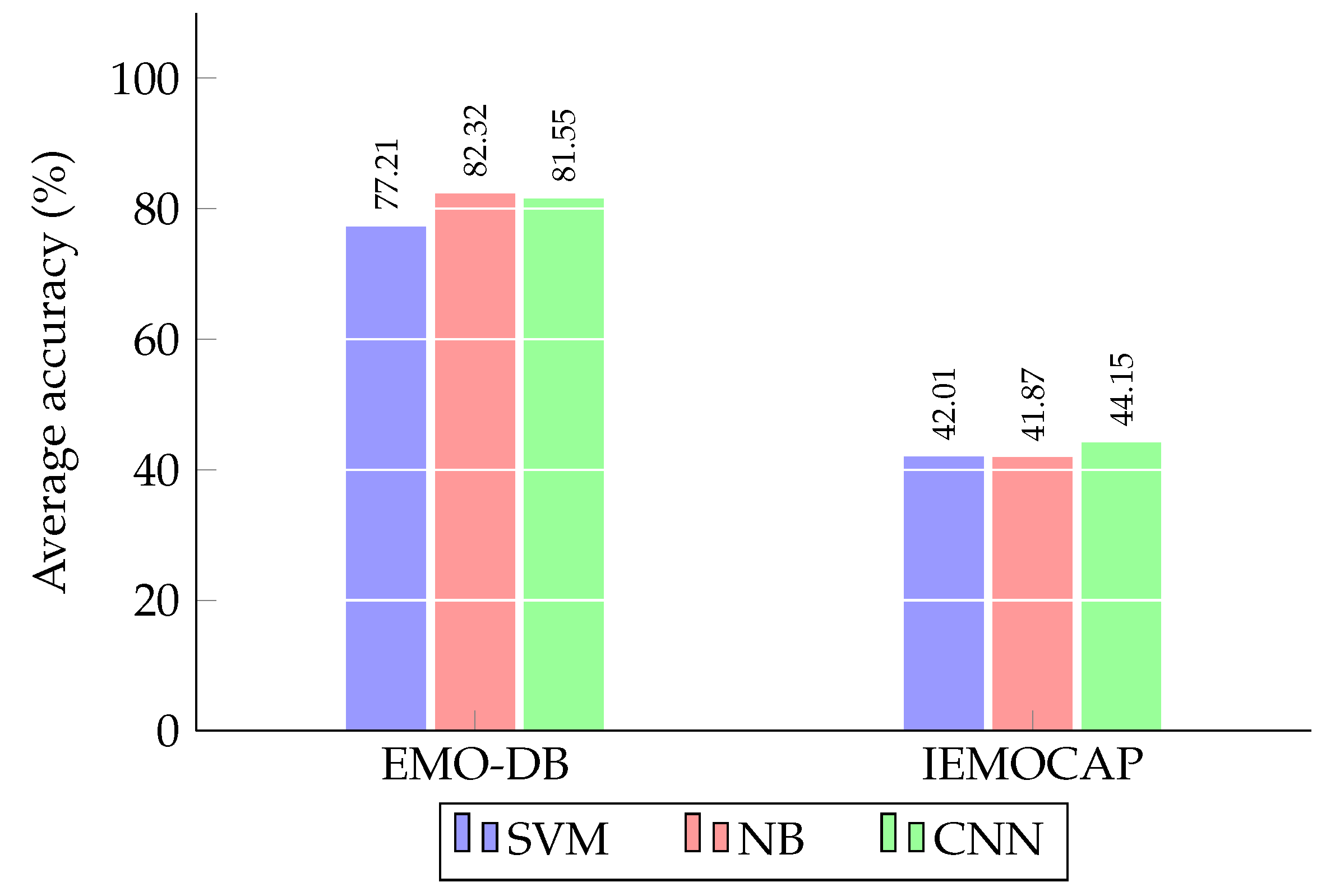
4.4. Comparison with a Deep Learning Approach
- Convolutional layer: utilizes a set of convolutional kernels (filters) to convert the input into feature maps.
- Non linearity: Between convolutional layers, an activation function is applied to the feature map to introduce nonlinearities into the network. Without this function, the network would essentially be a linear regression model and would struggle with complex data. In this paper, we used the most common activation function, which is the Rectified Linear Unit (ReLU) and defined as:
- Pooling layer: Its function is to decrease the feature maps size progressively to reduce the amount of parameters and computation in the network, hence to also control overfitting. Pooling involves selecting a pooling operation. Two common methods are average pooling and max pooling. In average pooling, the output is the average value of the feature map in a region determined by the kernel. Similarly, max pooling outputs the maximum value over a region in the feature maps. In this paper, the use of max pooling was adapted due to the property that the max operation preserves the largest activations in the feature maps.
- Softmax layer: Softmax regression is often implemented at the neural network’s final layer for multi-class classification and gives the class probabilities pertaining to the different classes. Assuming that there are g classes, then its corresponding output probability for the jth class is:
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Al-Ali, A.K.H.; Dean, D.; Senadji, B.; Chandran, V.; Naik, G.R. Enhanced Forensic Speaker Verification Using a Combination of DWT and MFCC Feature Warping in the Presence of Noise and Reverberation Conditions. IEEE Access 2017, 5, 15400–15413. [Google Scholar] [CrossRef]
- Al-Ali, A.K.H.; Senadji, B.; Naik, G.R. Enhanced forensic speaker verification using multi-run ICA in the presence of environmental noise and reverberation conditions. In Proceedings of the 2017 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuching, Malaysia, 12–14 September 2017; pp. 174–179. [Google Scholar] [CrossRef]
- Lee, M.; Lee, J.; Chang, J.H. Ensemble of jointly trained deep neural network based acoustic models for reverberant speech recognition. Digit. Signal Process. 2019, 85, 1–9. [Google Scholar] [CrossRef]
- Sekkate, S.; Khalil, M.; Adib, A. Speaker Identification for OFDM-Based Aeronautical Communication System. Circuits Syst. Signal Process. 2019, 38, 3743–3761. [Google Scholar] [CrossRef]
- Dhakal, P.; Damacharla, P.; Javaid, A.Y.; Devabhaktuni, V. A Near Real-Time Automatic Speaker Recognition Architecture for Voice-Based User Interface. Mach. Learn. Knowl. Extr. 2019, 1, 504–520. [Google Scholar] [CrossRef]
- Mallikarjunan, M.; Karmali Radha, P.; Bharath, K.P.; Muthu, R.K. Text-Independent Speaker Recognition in Clean and Noisy Backgrounds Using Modified VQ-LBG Algorithm. Circuits Syst. Signal Process. 2019, 38, 2810–2828. [Google Scholar] [CrossRef]
- Xiaoqing, J.; Kewen, X.; Yongliang, L.; Jianchuan, B. Noisy speech emotion recognition using sample reconstruction and multiple-kernel learning. J. China Univ. Posts Telecommun. 2017, 24, 1–17. [Google Scholar] [CrossRef]
- Staroniewicz, P.; Majewski, W. Polish Emotional Speech Database – Recording and Preliminary Validation. In Cross-Modal Analysis of Speech, Gestures, Gaze and Facial Expressions; Esposito, A., Vích, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 42–49. [Google Scholar]
- Tawari, A.; Trivedi, M.M. Speech Emotion Analysis in Noisy Real-World Environment. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 4605–4608. [Google Scholar] [CrossRef]
- Huang, C.; Chen, G.; Yu, H.; Bao, Y.; Zhao, L. Speech Emotion Recognition under White Noise. Arch. Acoust. 2013, 38, 457–463. [Google Scholar] [CrossRef][Green Version]
- Hyun, K.; Kim, E.; Kwak, Y. Robust Speech Emotion Recognition Using Log Frequency Power Ratio. In Proceedings of the 2006 SICE-ICASE International Joint Conference, Busan, Korea, 18–21 October 2006; pp. 2586–2589. [Google Scholar] [CrossRef]
- Yeh, L.Y.; Chi, T.S. Spectro-temporal modulations for robust speech emotion recognition. In Proceedings of the INTERSPEECH 2010, Makuhari, Japan, 26–30 September 2010. [Google Scholar]
- Georgogiannis, A.; Digalakis, V. Speech Emotion Recognition using non-linear Teager energy based features in noisy environments. In Proceedings of the 2012 20th European Signal Processing Conference (EUSIPCO), Bucharest, Romania, 27–31 August 2012; pp. 2045–2049. [Google Scholar]
- Bashirpour, M.; Geravanchizadeh, M. Speech Emotion Recognition Based on Power Normalized Cepstral Coefficients in Noisy Conditions. Iran. J. Electr. Electron. Eng. 2016, 12, 197–205. [Google Scholar]
- Schuller, B.; Arsic, D.; Wallhoff, F.; Rigoll, G. Emotion Recognition in the Noise Applying Large Acoustic Feature Sets. In Proceedings of the Speech Prosody, Dresden, Germany, 2–5 May 2006. [Google Scholar]
- Rozgic, V.; Ananthakrishnan, S.; Saleem, S.; Kumar, R.; Vembu, A.; Prasad, R. Emotion Recognition using Acoustic and Lexical Features. In Proceedings of the INTERSPEECH 2012, Portland, OR, USA, 9–13 September 2012; Volume 1. [Google Scholar]
- Karimi, S.; Sedaaghi, M.H. Robust emotional speech classification in the presence of babble noise. Int. J. Speech Technol. 2013, 16, 215–227. [Google Scholar] [CrossRef]
- Jin, Y.; Song, P.; Zheng, W.; Zhao, L. A feature selection and feature fusion combination method for speaker-independent speech emotion recognition. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 4808–4812. [Google Scholar] [CrossRef]
- Huang, Y.; Tian, K.; Wu, A.; Zhang, G. Feature fusion methods research based on deep belief networks for speech emotion recognition under noise condition. J. Ambient. Intell. Humaniz. Comput. 2017. [Google Scholar] [CrossRef]
- Palo, H.K.; Mohanty, M.N. Wavelet based feature combination for recognition of emotions. Ain Shams Eng. J. 2018, 9, 1799–1806. [Google Scholar] [CrossRef]
- Kerkeni, L.; Serrestou, Y.; Raoof, K.; Mbarki, M.; Mahjoub, M.A.; Cleder, C. Automatic Speech Emotion Recognition using an Optimal Combination of Features based on EMD-TKEO. Speech Commun. 2019. [Google Scholar] [CrossRef]
- Ruvolo, P.; Fasel, I.; Movellan, J.R. A learning approach to hierarchical feature selection and aggregation for audio classification. Pattern Recognit. Lett. 2010, 31, 1535–1542. [Google Scholar] [CrossRef]
- Yang, B.; Lugger, M. Emotion recognition from speech signals using new harmony features. Signal Process. 2010, 90, 1415–1423. [Google Scholar] [CrossRef]
- Seehapoch, T.; Wongthanavasu, S. Speech emotion recognition using Support Vector Machines. In Proceedings of the 2013 5th International Conference on Knowledge and Smart Technology (KST), Chonburi, Thailand, 31 January–1 February 2013; pp. 86–91. [Google Scholar] [CrossRef]
- Bhargava, M.; Polzehl, T. Improving Automatic Emotion Recognition from speech using Rhythm and Temporal feature. arXiv 2013, arXiv:1303.1761. [Google Scholar]
- Talkin, D. A robust algorithm for pitch tracking (RAPT). In Speech Coding and Synthesis; Klein, W.B., Palival, K.K., Eds.; Elsevier: Amsterdam, The Netherlands, 1995. [Google Scholar]
- Kasi, K.; Zahorian, S.A. Yet Another Algorithm for Pitch Tracking. In Proceedings of the 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing, Orlando, FL, USA, 13–17 May 2002; Volume 1, pp. I-361–I-364. [Google Scholar] [CrossRef]
- Davis, S.; MerMelstein, P. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 357–366. [Google Scholar] [CrossRef]
- Picone, J.W. Signal modeling techniques in speech recognition. Proc. IEEE 1993, 81, 1215–1247. [Google Scholar] [CrossRef]
- Sakar, C.O.; Serbes, G.; Gunduz, A.; Tunc, H.C.; Nizam, H.; Sakar, B.E.; Tutuncu, M.; Aydin, T.; Isenkul, M.E.; Apaydin, H. A comparative analysis of speech signal processing algorithms for Parkinson’s disease classification and the use of the tunable Q-factor wavelet transform. Appl. Soft Comput. 2019, 74, 255–263. [Google Scholar] [CrossRef]
- Mallat, S. A Wavelet Tour of Signal Processing, 2nd ed.; Academic Press: San Diego, CA, USA, 1998. [Google Scholar]
- Lee, C.M.; Narayanan, S.S. Toward detecting emotions in spoken dialogs. IEEE Trans. Speech Audio Process. 2005, 13, 293–303. [Google Scholar] [CrossRef]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Duda, R.; Hart, P. Pattern Classifications and Scene Analysis; John Wiley & Sons: New York, NY, USA, 1973. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Ververidis, D.; Kotropoulos, C. Emotional speech recognition: Resources, features, and methods. Speech Commun. 2006, 48, 1162–1181. [Google Scholar] [CrossRef]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335. [Google Scholar] [CrossRef]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A database of German emotional speech. In Proceedings of the INTERSPEECH ISCA, Lisbon, Portugal, 4–8 September 2005; pp. 1517–1520. [Google Scholar]
- Zeng, Z.; Pantic, M.; Roisman, G.I.; Huang, T.S. A Survey of Affect Recognition Methods: Audio, Visual, and Spontaneous Expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 39–58. [Google Scholar] [CrossRef] [PubMed]
- Pearce, D.; Hirsch, H.G. The Aurora Experimental Framework for the Performance Evaluation of Speech Recognition Systems under Noisy Conditions. In Proceedings of the ISCA ITRW ASR2000, Paris, France, 18–20 September 2000; pp. 29–32. [Google Scholar]
- Tang, D.; Zeng, J.; Li, M. An End-to-End Deep Learning Framework for Speech Emotion Recognition of Atypical Individuals. In Proceedings of the INTERSPEECH 2018, Hyderabad, India, 2–6 September 2018. [Google Scholar] [CrossRef]
- Zhao, J.; Mao, X.; Chen, L. Speech emotion recognition using deep 1D & 2D CNN LSTM networks. Biomed. Signal Process. Control 2019, 47, 312–323. [Google Scholar] [CrossRef]
- Hossain, M.S.; Muhammad, G. Emotion recognition using deep learning approach from audio–visual emotional big data. Inf. Fusion 2019, 49, 69–78. [Google Scholar] [CrossRef]
- Sarma, M.; Ghahremani, P.; Povey, D.; Goel, N.K.; Sarma, K.K.; Dehak, N. Emotion Identification from Raw Speech Signals Using DNNs. In Proceedings of the INTERSPEECH 2018, Hyderabad, India, 2–6 September 2018. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | Features | Classifier | Database | Speaker Dependency |
|---|---|---|---|---|
| [15] | Energy, pitch, jitter, shimmer, spectral flux, spectral centroid, spectral roll-off, intonation, intensity, formants, HNR, MFCC, VOC19 | SVM | DES EMO-DB SUSAS | SD |
| [22] | MFCC, LPCC, ZCR, spectral roll-off, spectral centroid | SVM | EMO-DB | SI |
| [23] | Energy, pitch, formants, ZCR, harmony | NB | EMO-DB | SI |
| [16] | Energy, pitch, formants, jitter, shimmer, MFCC, word-stem presence indicators, BOW sentiment categories | SVM | IEMOCAP | SI |
| [17] | Formants, pitch, energy, spectral, MFCC, PLP, LPC | NB KNN GMM ANN SVM | EMO-DB SES | SD |
| [24] | Pitch, energy, ZCR, LPC, MFCC | SVM | EMO-DB Japan Thai | SD |
| [25] | Rhythm, temporal | ANN | EMO-DB | SD |
| [18] | Intense, loudness, MFCC, LSP, ZCR, probability of voicing, F0, F0 envelope | SVM | EMO-DB | SI |
| [19] | F0, power, formants, W-WPCC, WPCC | SVM | EMO-DB | SD |
| [20] | LPCC, WLPCC, MFCC, WMFCC | RBFNN | EMO-DB SAVEE | SD |
| [21] | MS, MFF, EMD-TKEO | SVM RNN | EMO-DB Spanish | SD |
| Anger | Boredom | Disgust | Fear | Happiness | Neutral | Sadness | ||
|---|---|---|---|---|---|---|---|---|
| Anger | 92.10 | 0 | 0 | 1.60 | 5.69 | 0 | 0 | |
| Boredom | 0 | 78.39 | 2.5 | 0.27 | 3 | 10.01 | 0 | |
| Disgust | 0 | 10 | 74.25 | 1.25 | 3.75 | 3.25 | 0 | |
| Fear | 0 | 0 | 3.98 | 80.10 | 12 | 0 | 0 | |
| Happiness | 3.41 | 0 | 2.25 | 5.71 | 79.54 | 0 | 0 | |
| Neutral | 0 | 19.03 | 0 | 0.91 | 0 | 74.22 | 1.43 | |
| Sadness | 0 | 2.86 | 0 | 0 | 0 | 0 | 79.89 |
| Anger | Happiness | Neutral | Sadness | Fear | Surprise | Frustration | ||
|---|---|---|---|---|---|---|---|---|
| Anger | 41 | 11.51 | 8.18 | 2.71 | 0 | 0.70 | 35.91 | |
| Happiness | 9.07 | 30.52 | 19.23 | 9.05 | 0.12 | 0.93 | 31.07 | |
| Neutral | 0.92 | 11.81 | 38.06 | 19 | 0.13 | 0.80 | 29.27 | |
| Sadness | 0.45 | 2 | 19.06 | 63.73 | 0 | 1.28 | 13.49 | |
| Fear | 7.5 | 29.64 | 9.93 | 0 | 0 | 0 | 22.93 | |
| Surprise | 11.85 | 22.25 | 23.87 | 13.23 | 0 | 10.09 | 12.71 | |
| Frustration | 9.88 | 11.03 | 20.77 | 8.22 | 0.05 | 0.72 | 49.33 |
| NB | SVM | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 dB | 5 dB | 10 dB | 15 dB | 20 dB | 25 dB | 30 dB | 0 dB | 5 dB | 10 dB | 15 dB | 20 dB | 25 dB | 30 dB | |
| Train | 55.28 | 65.18 | 72.25 | 75.91 | 77.66 | 78.03 | 79.79 | 53.55 | 62.20 | 69.59 | 74.31 | 76.72 | 77.93 | 79.01 |
| Exhibition | 58.89 | 65.29 | 69.10 | 70.29 | 74.13 | 74.58 | 78.40 | 54.98 | 65.48 | 68.55 | 70.77 | 72.37 | 75.14 | 75.86 |
| Street | 54.60 | 66.51 | 72.25 | 76.09 | 79 | 79.65 | 81.73 | 52.60 | 62.72 | 69.69 | 72.98 | 75.56 | 78.31 | 78.90 |
| Car | 51.72 | 62.73 | 67.13 | 72.34 | 76.52 | 78.12 | 80.19 | 49.41 | 59.53 | 64.70 | 68.68 | 73.43 | 76.56 | 78.71 |
| Restaurant | 56.74 | 64.47 | 71.33 | 75.29 | 75.99 | 78.05 | 79.59 | 56.61 | 63.78 | 70.46 | 73.10 | 77.33 | 77.57 | 78.18 |
| Babble | 50.63 | 63.67 | 68.70 | 74.17 | 76.48 | 77.80 | 79.83 | 52.36 | 63.36 | 66.64 | 70.97 | 73.28 | 76.19 | 77.01 |
| Airport | 44.71 | 62.39 | 73.62 | 76.47 | 78.85 | 80.44 | 81.14 | 45.33 | 59.24 | 69.16 | 74.27 | 78.29 | 78.72 | 79.36 |
| Average | 53.22 | 64.32 | 70.63 | 74.36 | 76.95 | 78.10 | 80.10 | 52.12 | 62.33 | 68.40 | 72.15 | 75.28 | 77.20 | 78.15 |
| NB | SVM | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 dB | 5 dB | 10 dB | 15 dB | 20 dB | 25 dB | 30 dB | 0 dB | 5 dB | 10 dB | 15 dB | 20 dB | 25 dB | 30 dB | |
| Train | 36.98 | 37.99 | 39.18 | 40.17 | 40.91 | 41.36 | 41.69 | 37.22 | 38.45 | 39.77 | 40.43 | 40.97 | 41.31 | 41.84 |
| Exhibition | 33.60 | 34.78 | 35.98 | 37.12 | 37.73 | 38.69 | 39.69 | 33.95 | 34.72 | 36.00 | 36.77 | 38.08 | 38.84 | 39.66 |
| Street | 36.91 | 37.42 | 38.12 | 39.77 | 40.44 | 41.35 | 41.19 | 37.44 | 37.98 | 39.04 | 39.89 | 40.57 | 40.75 | 41.24 |
| Car | 37.02 | 37.21 | 38.10 | 38.85 | 39.42 | 39.84 | 40.65 | 37.15 | 37.18 | 37.99 | 38.78 | 39.43 | 39.90 | 40.65 |
| Restaurant | 34.95 | 35.68 | 36.68 | 37.22 | 38.33 | 39.52 | 40.42 | 36.13 | 36.63 | 37.17 | 37.42 | 38.68 | 39.86 | 40.64 |
| Babble | 34.71 | 35.98 | 37.19 | 38.58 | 39.63 | 40.34 | 41.03 | 36.06 | 36.93 | 37.97 | 38.76 | 39.56 | 40.24 | 41.03 |
| Airport | 37.00 | 38.00 | 38.97 | 39.86 | 40.96 | 41.61 | 41.56 | 37.41 | 38.54 | 39.44 | 40.16 | 40.76 | 41.18 | 41.77 |
| Average | 35.88 | 36.72 | 37.75 | 38.80 | 39.63 | 40.39 | 40.89 | 36.48 | 37.20 | 38.20 | 38.89 | 39.72 | 40.30 | 40.98 |
| Work | Anger | Happiness | Boredom | Neutral | Sadness | Fear | Disgust |
|---|---|---|---|---|---|---|---|
| [23] | 86.1% | 52.7% | 84.8% | 52.9% | 87.6% | 76.9% | - |
| [22] | 92.91% | 50% | 74.68% | 85.90% | 90.57% | 70.91% | 68.42% |
| Our approach | 92.10% | 79.54% | 78.39% | 74.22% | 79.89% | 80.10% | 74.25 |
| Layer | Value |
|---|---|
| Convolution 1 | 64@12 |
| Max Pooling 1 | 2 |
| Convolution 2 | 128@12 |
| Max Pooling 2 | 2 |
| Dense layer | 128 |
| Dropout | 0.1 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sekkate, S.; Khalil, M.; Adib, A.; Ben Jebara, S. An Investigation of a Feature-Level Fusion for Noisy Speech Emotion Recognition. Computers 2019, 8, 91. https://doi.org/10.3390/computers8040091
Sekkate S, Khalil M, Adib A, Ben Jebara S. An Investigation of a Feature-Level Fusion for Noisy Speech Emotion Recognition. Computers. 2019; 8(4):91. https://doi.org/10.3390/computers8040091
Chicago/Turabian StyleSekkate, Sara, Mohammed Khalil, Abdellah Adib, and Sofia Ben Jebara. 2019. "An Investigation of a Feature-Level Fusion for Noisy Speech Emotion Recognition" Computers 8, no. 4: 91. https://doi.org/10.3390/computers8040091
APA StyleSekkate, S., Khalil, M., Adib, A., & Ben Jebara, S. (2019). An Investigation of a Feature-Level Fusion for Noisy Speech Emotion Recognition. Computers, 8(4), 91. https://doi.org/10.3390/computers8040091