MRI Breast Tumor Segmentation Using Different Encoder and Decoder CNN Architectures



Abstract
1. Introduction
2. Related Work
3. Material and Methods
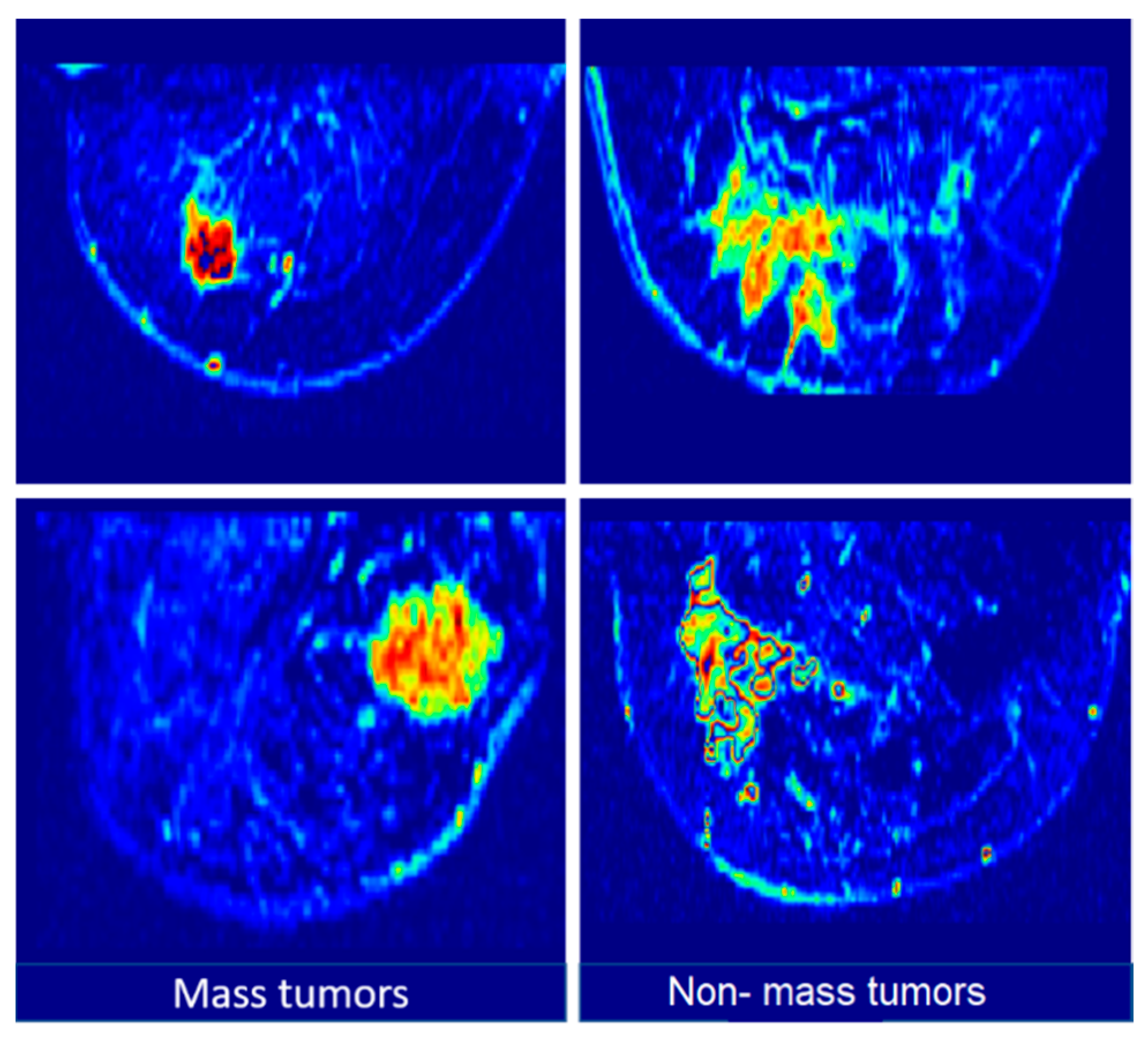
3.1. Dataset
3.2. Data-Augmentation
3.3. Encoder–Decoder Architecture
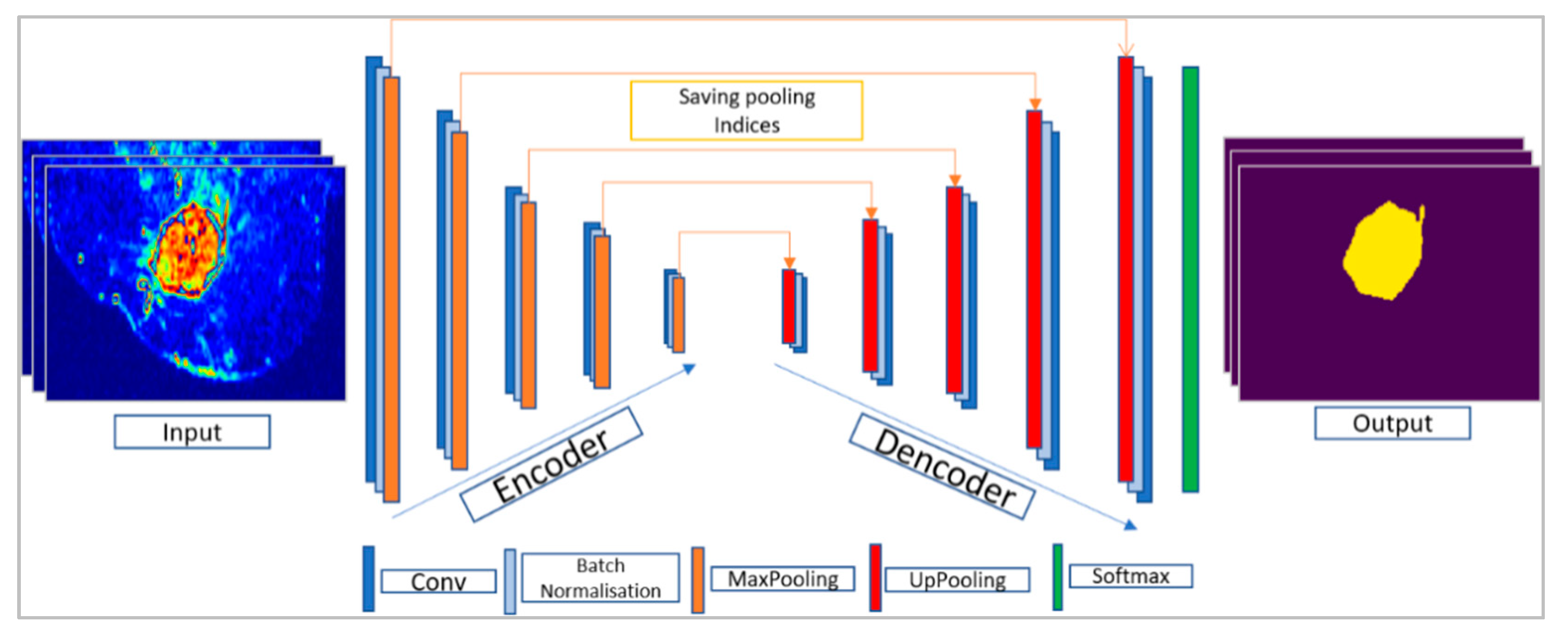
3.3.1. SegNet Architecture
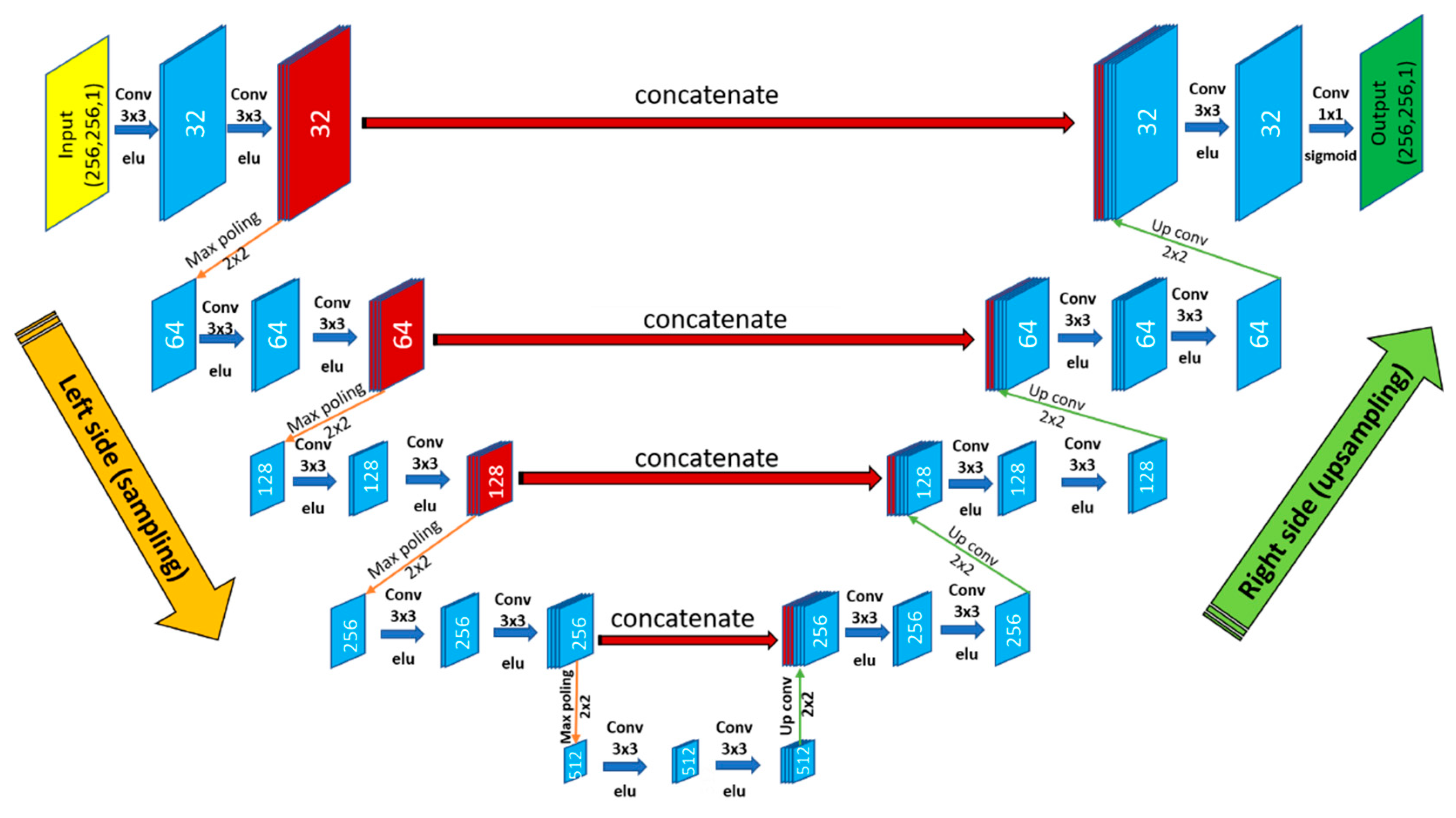
3.3.2. U-Net Architecture
3.4. HPC Software and Hardware
- CPU: 16 cores, 2.10 GHz clock speed, 128 GB of RAM memory
- 4 GPUs: Nvidia P100, 3584 CUDA cores, 10.6 TeraFLOPS (performance), 16 GB of memory.
- -
- Parallel fraction: Calculated with Amdahl’s law [31] that estimates the theoretical speedup when using N processors. This law supposes that f is the part of program that can be parallelized and (1 − f) is the part that cannot be made in parallel (data transfers, dependent tasks, etc.). Indeed, high values of f can provide better performance and vice versa.
- -
- Computation per-pixel: In fact, GPUs allow for the acceleration of image processing algorithms thanks to the exploitation of the GPU’s computing units in parallel. These accelerations increase when we apply intensive treatments since the GPU is specialized for highly parallel computation. The number of operations per pixel presents a relevant factor to estimate the computation intensity.
- -
- Computation per-image: Simply computed with the multiplication of the image resolution by the computation per pixel factor.
- -
- Dependency factor: Obtained by counting the mean number of neighbors’ pixel values that are required for calculating the output values of image pixels after treatment, such as convolution, pooling, etc.
- -
- CPU-based docker image: Including sequential (CPU) versions of the required algorithms and libraries, such as OpenCV (Open Computer Vision Library), Tensorflow, Keras (The Python Deep Learning Library) etc.
- -
- GPU-based docker image: Including parallel (GPU) versions of the required algorithms and libraries, such as OpenCV, Tensorflow, Keras, etc.
3.5. Performance Analysis
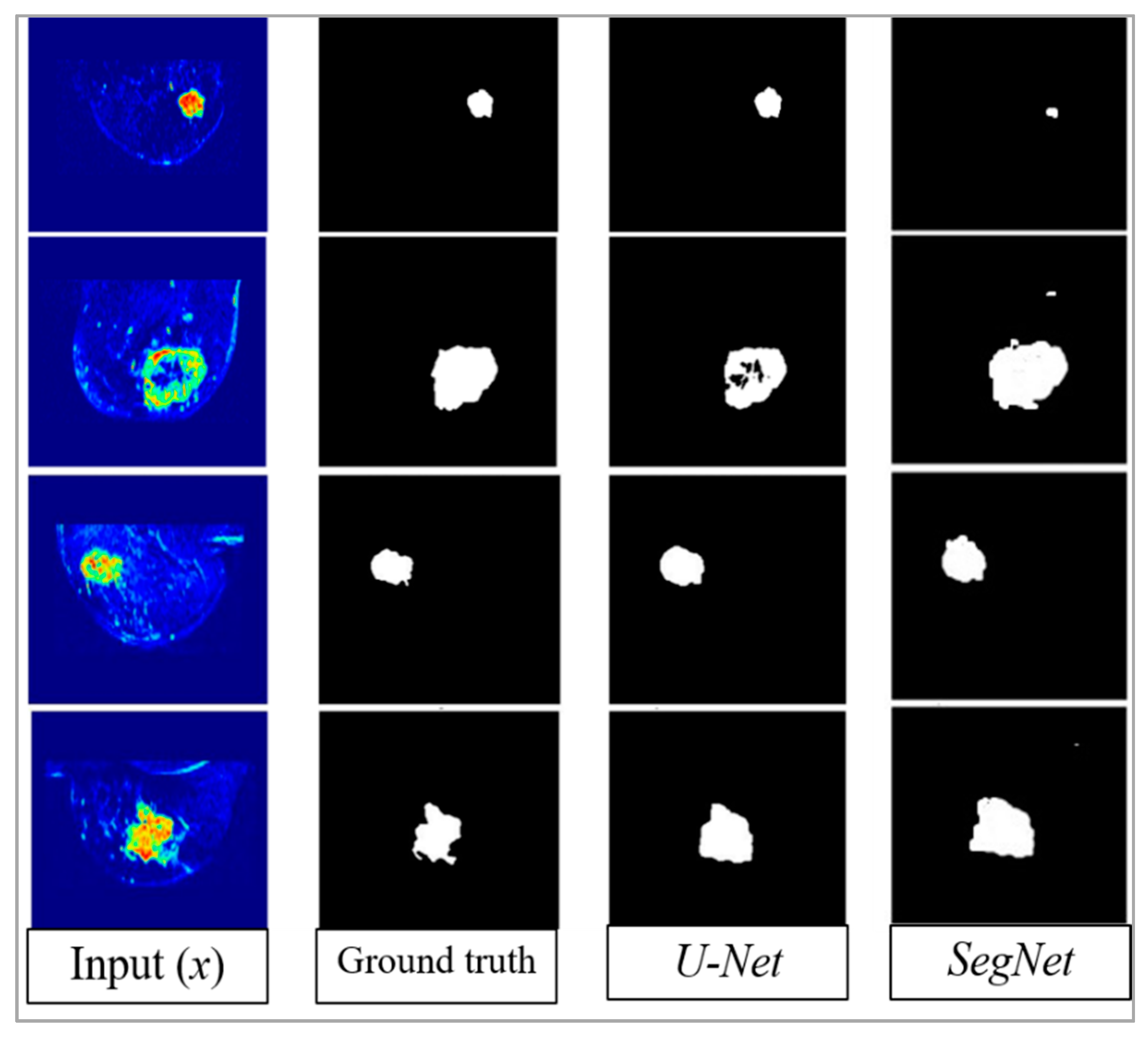
4. Results
5. Discussion
6. Conclusion and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kaufmann, M.; von Minckwitz, G.; Mamounas, E.P.; Cameron, D.; Carey, L.A.; Cristofanilli, M.; Denkert, C.; Eiermann, W.; Gnant, M.; Harris, J.R.; et al. Recommendations from an international consensus conference on the current status and future of neoadjuvant systemic therapy in primary breast cancer. Ann. Surg. Oncol. 2012, 19, 1508–1516. [Google Scholar] [CrossRef] [PubMed]
- Hamidinekoo, A.; Denton, E.; Rampun, A.; Honnor, K.; Zwiggelaar, R. Deep learning in mammography and breast histology, an overview and future trends. Med. Image Anal. 2018, 47, 45–67. [Google Scholar] [CrossRef] [PubMed]
- Zhu, W.; Lou, Q.; Vang, Y.S.; Xie, X. Deep multi-instance networks with sparse label assignment for whole mammogram classification. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2017), Quebec City, QC, Canada, 11–13 September 2017; pp. 603–611. [Google Scholar]
- Jiao, Z.; Gao, X.; Wang, Y.; Li, J. A deep feature-based framework for breast masses classification. Neurocomputing 2016, 197, 221–231. [Google Scholar] [CrossRef]
- Hu, Y.; Li, J.; Jiao, Z. Mammographic Mass Detection Based on Saliency with Deep Features. In Proceedings of the International Conference on Internet Multimedia Computing and Service, Xi’an, China, 19–21 August 2016; pp. 292–297. [Google Scholar]
- Yang, D.; Wang, Y.; Jiao, Z. Asymmetry Analysis with Sparse Autoencoder in Mammography. In Proceedings of the International Conference on Internet Multimedia Computing and Service, Xi’an, China, 19–21 August 2016; pp. 287–291. [Google Scholar]
- Li, X.; Arlinghaus, L.R.; Ayers, G.D.; Chakravarthy, A.B.; Abramson, R.G.; Abramson, V.G.; Atuegwu, N.; Farley, J.; Mayer, I.A.; Kelley, M.C.; et al. Dce-mri analysis methods for predicting the response of breast cancer to neoadjuvant chemotherapy: Pilot study findings. Magn. Reson. Med. 2014, 71, 1592–1602. [Google Scholar] [CrossRef] [PubMed]
- El Adoui, M.; Drisis, S.; Larhmam, M.A.; Lemort, M.; Benjelloun, M. Breast cancer heterogeneity analysis as index of response to treatment using MRI images: A review. Imaging Med. 2017, 9, 109–119. [Google Scholar]
- El Adoui, M.; Drisis, S.; Benjelloun, M. A PRM approach for early prediction of breast cancer response to chemotherapy based on registered MR images. Int. J. Comput. Assist. Radiol. Surg. 2018, 13, 1233–1243. [Google Scholar] [CrossRef] [PubMed]
- Benjelloun, M.; El Adoui, M.; Larhmam, M.A.; Mahmoudi, S.A. Automated Breast Tumor Segmentation in DCE-MRI Using Deep Learning. In Proceedings of the 2018 4th International Conference on Cloud Computing Technologies and Applications (Cloudtech), Brussels, Belgium, 26–28 November 2018; pp. 1–6. [Google Scholar]
- Chen, W.; Giger, M.L.; Bick, U. A fuzzy c-means (FCM)-based approach for computerized segmentation of breast lesions in dynamic contrast-enhanced MR images1. Acad. Radiol. 2006, 13, 63–72. [Google Scholar] [CrossRef] [PubMed]
- Nie, K.; Chen, J.H.; Hon, J.Y.; Chu, Y.; Nalcioglu, O.; Su, M.Y. Quantitative analysis of lesion morphology and texture features for diagnostic prediction in breast MRI. Acad. Radiol. 2008, 15, 1513–1525. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical image computing and computer-assisted intervention (MICCAI 2015), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Lo, S.C.B.; Lou, S.L.A.; Lin, J.S.; Freedman, M.T.; Chien, M.V.; Mun, S.K. Artificial convolution neural network techniques and applications for lung nodule detection. IEEE Trans. Med. Imaging 1995, 14, 711–718. [Google Scholar] [CrossRef]
- Dou, Q.; Chen, H.; Yu, L.; Zhao, L.; Qin, J.; Wang, D.; Mok, V.C.; Shi, L.; Heng, P.A. Automatic detection of cerebral microbleeds from MR images via 3D convolutional neural networks. IEEE Trans. Med. Imaging 2016, 35, 1182–1195. [Google Scholar] [CrossRef] [PubMed]
- Hwang, S.; Kim, H.E. Self-transfer learning for fully weakly supervised object localization. arXiv 2016, arXiv:1602.01625. [Google Scholar]
- Dalmıs¸, M.U.; Litjens, G.; Holland, K.; Setio, A.; Mann, R.; Karssemeijer, N.; Gubern-M´erida, A. Using deep learning to segment breast and fibroglandular tissue in MRI volumes. Med. Phys. 2017, 44, 533–546. [Google Scholar] [CrossRef] [PubMed]
- Moeskops, P.; Wolterink, J.M.; van der Velden, B.H.; Gilhuijs, K.G.; Leiner, T.; Viergever, M.A.; Iˇsgum, I. Deep learning for multitask medical image segmentation in multiple modalities. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2016), Athens, Greece, 17–21 October 2016; pp. 478–486. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Christ, P.F.; Elshaer, M.E.A.; Ettlinger, F.; Tatavarty, S.; Bickel, M.; Bilic, P.; Rempfler, M.; Armbruster, M.; Hofmann, F.; D’Anastasi, M.; et al. Automatic liver and lesion segmentation in CT using cascaded fully convolutional neural networks and 3d conditional random fields. In Proceedings of the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2016), Athens, Greece, 17–21 October 2016; pp. 415–423. [Google Scholar]
- Kamnitsas, K.; Ledig, C.; Newcombe, V.F.J.; Simpson, J.P.; Kane, A.D.; Menon, D.K.; Rueckert, D.; Glocker, B. Efficient multi-scale 3D CNN with fully connected crf for accurate brain lesion segmentation. Med. Image Anal. 2017, 36, 61–78. [Google Scholar] [CrossRef] [PubMed]
- Zhao, G.; Liu, F.; Oler, J.A.; Meyerand, M.E.; Kalin, N.H.; Birn, R.M. Bayesian convolutional neural network based MRI brain extraction on nonhuman primates. Neuroimage 2018, 175, 32–44. [Google Scholar] [CrossRef] [PubMed]
- Tustison, N.J.; Avants, B.B.; Cook, P.A.; Zheng, Y.; Egan, A.; Yushkevich, P.A.; Gee, J.C. N4ITK: Improved N3 bias correction. IEEE Trans. Med Imaging 2010, 29, 1310. [Google Scholar] [CrossRef] [PubMed]
- Adoui, M.E.; Drisis, S.; Benjelloun, M. Analyzing breast tumor heterogeneity to predict the response to chemotherapy using 3d MR images registration. In Proceedings of the 2017 International Conference on Smart Digital Environment, Rabat, Morocco, 21–23 July 2017; pp. 56–63. [Google Scholar]
- Wolf, I.; Vetter, M.; Wegner, I.; Nolden, M.; Bottger, T.; Hastenteufel, M.; Schobinger, M.; Kunert, T.; Meinzer, H.P. The medical imaging interaction toolkit (mitk): A toolkit facilitating the creation of interactive software by extending vtk and itk. In Proceedings of the Medical Imaging 2004: Visualization, Image-Guided Procedures, and Display, San Diego, CA, USA, 14–19 February 2004; Volume 5367, pp. 16–28. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Mahmoudi, S.A.; EOzkan, E.; Manneback, P.; Tosun, S. Taking advantage of heterogeneous platforms in image and video processing. High-Perform. Comput. Complex Environ. 2014, 95, 429–449. [Google Scholar]
- Mahmoudi, S.A.; Manneback, P. Efficient exploitation of heterogeneous platforms for images features extraction. In Proceedings of the 3rd International Conference on Image Processing Theory, Tools and Applications (IPTA), Istanbul, Turkey, 15–18 October 2012; pp. 91–96. [Google Scholar]
- Grama, A.; Kumar, V.; Gupta, A.; Karypis, G. Introduction to Parallel Computing. Available online: http://cse.csusb.edu/ykarant/courses/sp2006/csci525-625/slides/gramma-et-al/karypis/parbook/Lectures/GK-CS5451/Chapter%203%20-%20Principles%20of%20Parallel%20Algorithm%20Design.pdf (accessed on 18 June 2019).
- Merkel, D. Docker: Lightweight Linux containers for consistent development and deployment. Linux J. 2014, 239, 2. [Google Scholar]
- Nachar, N. The Mann-Whitney U: A test for assessing whether two independent samples come from the same distribution. Tutor. Quant. Methods Psychol. 2008, 4, 13–20. [Google Scholar] [CrossRef]
- McKnight, P.E.; Najab, J. Mann-Whitney U Test. Corsini Encycl. Psychol. 2010. [Google Scholar] [CrossRef]
- Treml, M.; Arjona-Medina, J.; Unterthiner, T.; Durgesh, R.; Friedmann, F.; Schuberth, P.; Mayr, A.; Heusel, M.; Hofmarcher, M.; Widrich, M.; et al. Speeding up semantic segmentation for autonomous driving. In Proceedings of the MLITS, NIPS Workshop, Barcelona, Spain, 9 December 2016; Volume 1, p. 5. [Google Scholar]
- El Adoui, M.; Larhmam, M.A.; Drisis, S.; Benjelloun, M. Deep Learning approach predicting breast tumor response to neoadjuvant treatment using DCE-MRI volumes acquired before and after chemotherapy. In Proceedings of the Medical Imaging 2019: Computer-Aided Diagnosis, San Diego, CA, USA, 16–21 February 2019; Volume 10950, p. 109502I. [Google Scholar]
- El Adoui, A.; Drisis, S.; Benjelloun, M. Predict Breast Tumor Response to Chemotherapy Using a 3D Deep Learning Architecture Applied to DCE-MRI Data. In Proceedings of the International Work-Conference on Bioinformatics and Biomedical Engineering (IWBBIO 2019), Granada, Spain, 8–10 May 2019; pp. 33–40. [Google Scholar]
- Vulchi, M.; El Adoui, M.; Braman, N.; Turk, P.; Etesami, M.; Drisis, S.; Plecha, D.; Benjelloun, M.; Madabhushi, A.; Abraham, J. Development and external validation of a deep learning model for predicting response to HER2-targeted neoadjuvant therapy from pretreatment breast MRI. J. Clin. Oncol. 2019, 37, 593. [Google Scholar] [CrossRef]
- Mahmoudi, S.A.; Belarbi, M.A.; Mahmoudi, S.; Belalem, G. Towards a smart selection of resources in the cloud for low-energy multimedia processing. Concurr. Comput. Pract. Exp. 2018, 30, e4372. [Google Scholar] [CrossRef]
- Mahmoudi, S.A.; El Adoui, M.; Belarbi, M.A.; Larhmam, M.A.; Lecron, F. Cloud-based platform for computer vision applications. In Proceedings of the 2017 International Conference on Smart Digital Environment, ICSDE ’17, Rabat, Morocco, 21–23 July 2017; pp. 195–200. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | CNN Approach | Segmentation Application | Modality | Accuracy (%) | Metric |
|---|---|---|---|---|---|
| 2017 [19] | 2 conductive U-Nets | Breast tissue | MRI-T1 | 93.30 | DSC |
| 2016 [20] | Standard CNN | Brain–Breast–Cardiac | MRI-T1 | 81.00 | DSC |
| 2016 [21] | V-Net (Volumetric U-Net) | Prostate | MRI-T2 | 82.39 | DSC |
| 2016 [22] | U-Net | Liver | MRI-T1 | 72.90 | IoU |
| 2017 [23] | 3D CNN | Brain lesion | MRI-T1 | 60.80 | DSC |
| 2018 [24] | Bayesian CNN | Nonhuman primate brain extraction | MRI-T1 | 98.00 | DCS |
| Parameter | Grid Search | Optimal Value for SegNet | Optimal Value for U-Net |
|---|---|---|---|
| Data augmentation | Linear, no-linear | Linear | Linear |
| Learning rate | 0.5, 0.05, 0.005, 0.0005 | 0.0005 | 0.005 |
| Batch size | 2, 4, 8, 16, 32 | 4 | 4 |
| Momentum rate | 0.8, 0.9, 0.99 | 0.99 | 0.99 |
| Weight initialization | Normal, uniform, Glorot uniform, | Normal | Normal |
| Adaptive learning rate methods | stochastic gradient descent (SGD), RMSprop, Adagrad, Adadelta, Adam | SGD | SGD |
| Learning rate decay | None, linear, exponential | Linear (0.000062) | Linear (0.000062) |
| Dropout rate | 0.1, 0.25, 0.3, 0.5, 0.75 | 0.30, 0.40 | 0.10, 0.20, 0.30 |
| Accuracy (IoU) | Loss (Binary Cross Entropy) | p-Value (U-test) | |
|---|---|---|---|
| U-Net | 76.14 | 0.002 | 0.147 (>0.05) |
| SegNet | 68.88 | 0.053 | 0.045 (<0.05) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
El Adoui, M.; Mahmoudi, S.A.; Larhmam, M.A.; Benjelloun, M. MRI Breast Tumor Segmentation Using Different Encoder and Decoder CNN Architectures. Computers 2019, 8, 52. https://doi.org/10.3390/computers8030052
El Adoui M, Mahmoudi SA, Larhmam MA, Benjelloun M. MRI Breast Tumor Segmentation Using Different Encoder and Decoder CNN Architectures. Computers. 2019; 8(3):52. https://doi.org/10.3390/computers8030052
Chicago/Turabian StyleEl Adoui, Mohammed, Sidi Ahmed Mahmoudi, Mohamed Amine Larhmam, and Mohammed Benjelloun. 2019. "MRI Breast Tumor Segmentation Using Different Encoder and Decoder CNN Architectures" Computers 8, no. 3: 52. https://doi.org/10.3390/computers8030052
APA StyleEl Adoui, M., Mahmoudi, S. A., Larhmam, M. A., & Benjelloun, M. (2019). MRI Breast Tumor Segmentation Using Different Encoder and Decoder CNN Architectures. Computers, 8(3), 52. https://doi.org/10.3390/computers8030052