Cloud-Based Image Retrieval Using GPU Platforms

 ,
,  ,
,  and
and
Abstract
1. Introduction
2. Related Work
2.1. Content-Based Image Retrieval Systems
- Indexing phase: this phase consists of designing an efficient canonical characterization of the multimedia document. This characterization is referred to as a descriptor or a signature, it serves as a key in the search process. The principal step of this phase is the features extracting. The indexing phase is the principal problematic of content-based image retrieval that scientific committee is working on. Indeed, designing an efficient canonical characterization of a given multimedia document still remains a major challenge, it is a critical kernel with a strong influence on the retrieval performances (i.e., computational efficiency and relevance of the results). The bulk of that challenge lies in the step of features extracting, which is the principal step of the indexing phase. In order to design an efficient method of features extraction, several algorithms have been proposed in the literature, [2,3,10]. Otherwise, several solutions are proposed for feature extraction using deep neural networks that consist of learning from annotated data before applying inference within the generated model [11,12]. Notice that the deep learning approach provides high precision due to the generation of very large sets of features but it requires high intensive computation and already annotated data. In this context, some GPU implementations are proposed in [13,14].
- Matching phase: this phase consists of comparing the descriptor of the query with the descriptor of each multimedia document in the database. This comparison is performed using a dissimilarity measure, that computes the distances between pairs of descriptors. The existing Multimedia content-based retrieval methods use different well known dissimilarity measurements like, K-nearest neighbor (KNN), Euclidean L2, Minkowski, KLD, etc. The reader can refer to the survey of [15] to get more details about these similarity measures. Authors in [16] proposed a content-based synthetic aperture radar (SAR) image retrieval approach for searching SAR image patches. This method is based on a similarity measure named region-based fuzzy matching (RFM) and relevance feedback for improving precision. Otherwise, one can find methods that use 3D specific measurements like the CM-BOF method [17], used for 3D shape retrieval. The latter is based on a measurement function called clock matching. In order to accelerate the matching process, several techniques based on distributed computing have been proposed in [18]. These solutions use CPUs only, while others implementations are implemented in parallel with GPU platforms [19,20]. Authors in [21] proposed a shape retrieval method using distributed databases that allowed to increase result precision.
2.2. Cloud-Based Computer Vision Platforms
- The development of an efficient method of content based image retrieval that combines the descriptors of SIFT and SURF;
- A portable GPU implementation that allows to accelerate the process of indexation and research within multimedia databases. This implementation allows to exploit both NIVIDIA and AMD/ATI cards;
- Cloud-based implementation that allows an easier exploitation of our GPU-based method without the need to download, install and configure software and hardware. The platform handles multi user connection based on docker container orchestration architecture.
3. GPU-Based Hybrid Multimedia Retrieval
3.1. Sequential Solution
- Pre-processingThe methods of image retrieval and indexation are mainly based on features extraction algorithms that allow to detect the main key points of images. In order to improve this process, we apply a pre-processing step that allows to reduce noise and consequently the number of key points. For this aim, we have tested several image filters such as median, bilateral and Gaussian filters. In our case, the Gaussian filter provided the best results for reducing the number of key points. This reduction allowed to reduce the computation time of the next steps (features extraction).
- IndexationThis step was performed offline and is so time-consuming since it is applied on the entire database. After the pre-processing step, we apply the feature extraction within SIFT and SURF descriptors. Indeed, we started by computing SIFT features for each image from the dataset, the result is represented by a matrix of (n × m) lines and 128 columns. Notice that n and m represent the weight and height of image. Secondly, we applied the same process using SURF descriptor, which requires less execution time but provides less precise results. The result of the SURF descriptor was represented by a matrix of (n × m) lines and 64 columns. Once the steps of SIFT and SURF were completed, we can combine their results (two matrices) with one matrix only. Since the two descriptors (SIFT and SURF) present a different number of columns, we have increased (using zero values) the size of SURF descriptor to 128 values in order to be compatible with the size of SIFT descriptor. Finally, we got one matrix with 2 × (n × m) lines and 128 columns. The latter was used for indexing the image database. As a result, we obtain three folders: SIFT, SURF and SIFT + SURF descriptors. This step was performed offline and was so consuming in time since it was applied on the entire database. After the pre-processing step, we applied the feature extraction within SIFT and SURF descriptors. Indeed, we started by computing SIFT features for each image from the dataset, the result is represented by a matrix of (n × m) lines and 128 columns. Notice that n and m represent the weight and height of image. Secondly, we applied the same process using SURF descriptor, which requires less execution time but provides less precise results. The result of SURF descriptor is represented by a matrix of (n × m) lines and 64 columns. Once the steps of SIFT and SURF were completed, we can combine their results (two matrices) with one matrix only. Since the two descriptors (SIFT and SURF) present a different number of columns, we have increased (using zero values) the size of SURF descriptor to 128 values in order to be compatible with the size of SIFT descriptor. Finally, we got one matrix with 2 × (n × m) lines and 128 columns. The latter is used for indexing image database. As a result, we obtained three folders: SIFT, SURF and SIFT + SURF descriptors.
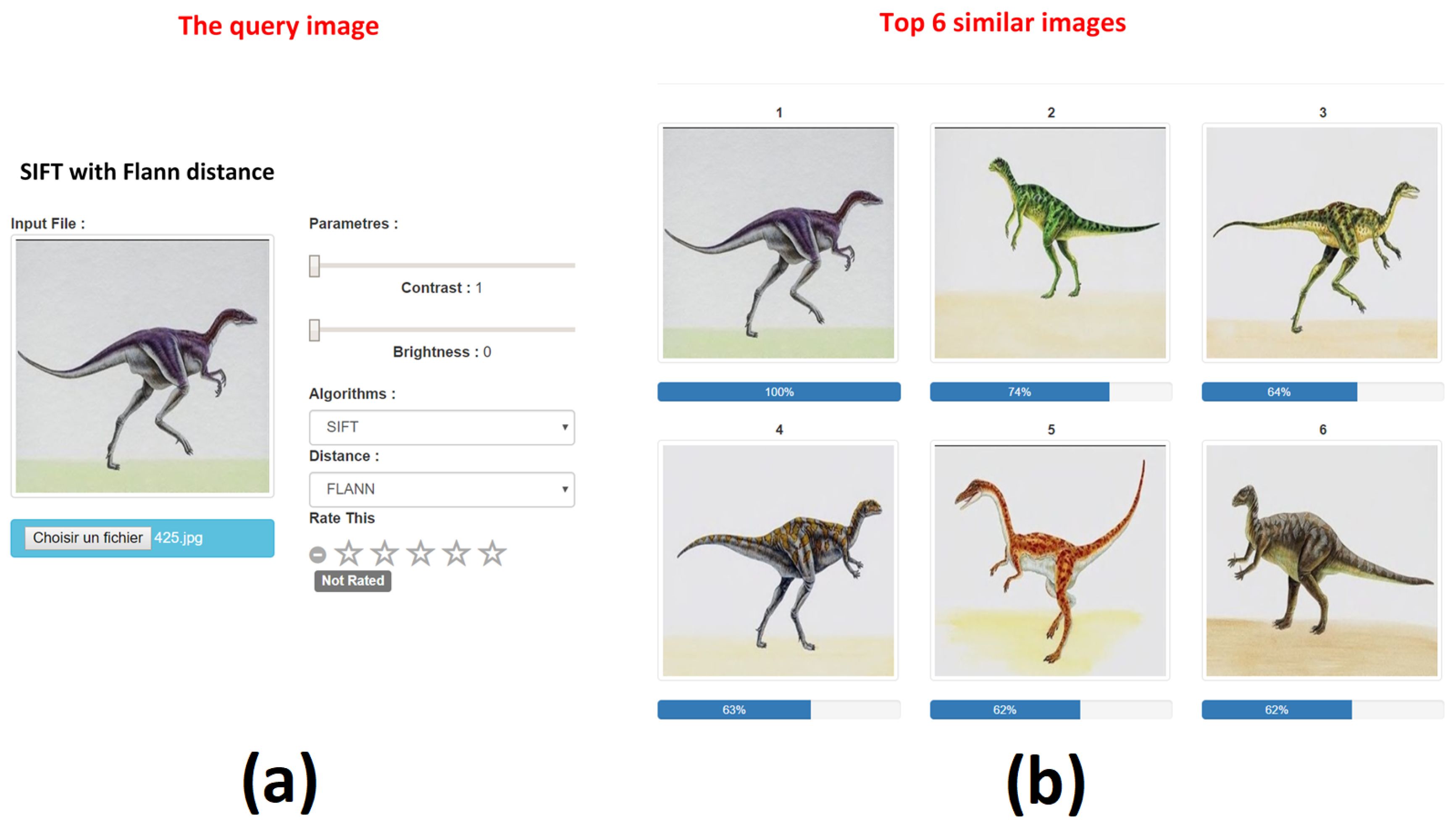
- ResearchUnlike the previous step, this phase was performed online where the user can provide its query image and choose the preferred algorithm for features extraction (SIFT, SURF or both). Once the user choice was provided, the query image was smoothed (pre-processed) within a Gaussian filter and characterized within the previously selected algorithm. The next step consisted of comparing the query image features with those of image database. The comparison was performed within two similarity matching methods: Flann based matcher and Brute force matcher [7]. Our selection of these two methods was due to their efficiency and fast execution, which is so important in our case.
3.2. Parallel Solution
- Several image processing algorithms applied for each image within the indexation phase.
- The use of high definition images that require more time for features extraction.
- The high computational intensity of features extraction and distance computation steps.
3.2.1. CUDA Implementation
- CUDA-based image indexation: we used the GPU module of OpenCV library (OpenCV GPU Module, https://docs.opencv.org/2.4/modules/gpu/doc/introduction.html) for implementing the functions of pre-processing and SURF descriptor. The CUDA implementation of SIFT descriptor is provided from [36]. These GPU functions consist of applying the operations of features extraction in parallel using the same number of CUDA threads as the number of image pixels. With this, each CUDA thread can apply its treatment on one pixel value and all the CUDA threads are launched in parallel. Since the indexation phase requires the transfer of all images (database), we use the CUDA streaming technique in order to overlap image data transfers by CUDA functions execution.
- CUDA-based image matching: the query image is also analyzed within the above-mentioned CUDA functions (pre-processing, SIFT and SURF descriptors). In addition to these functions, this step requires the computation of distance between the query image features and the database features. This distance, computed within FLANN-based matcher and Brute force matcher, is also implemented using the GPU module of OpenCV library.
3.2.2. OpenCL Implementation
- OpenCL-based image indexation: we used the OpenCL module of OpenCV library (OCL module, https://docs.opencv.org/2.4/modules/ocl/doc/introduction.html) for implementing the functions of pre-processing and SURF descriptor. The OpenCL based implementation of SIFT descriptor is provided from [37]. This implementation is so similar to the corresponding CUDA version. The main difference between CUDA and OpenCL methods is that with OpenCL, we have to create a context in order to specify the device. In this way, the same code can be used for programming either CPU or GPU. Notice that in this case, we do not overlap data transfers by execution since the streaming option is not provided in OpenCL.
- OpenCL-based image retrieval: this step is also implemented using the OpenCL module of OpenCV library for extracting features (pre-processing, SIFT and SURF descriptors) of the query image. The distance is ported on OpenCL using the Brute force matcher.
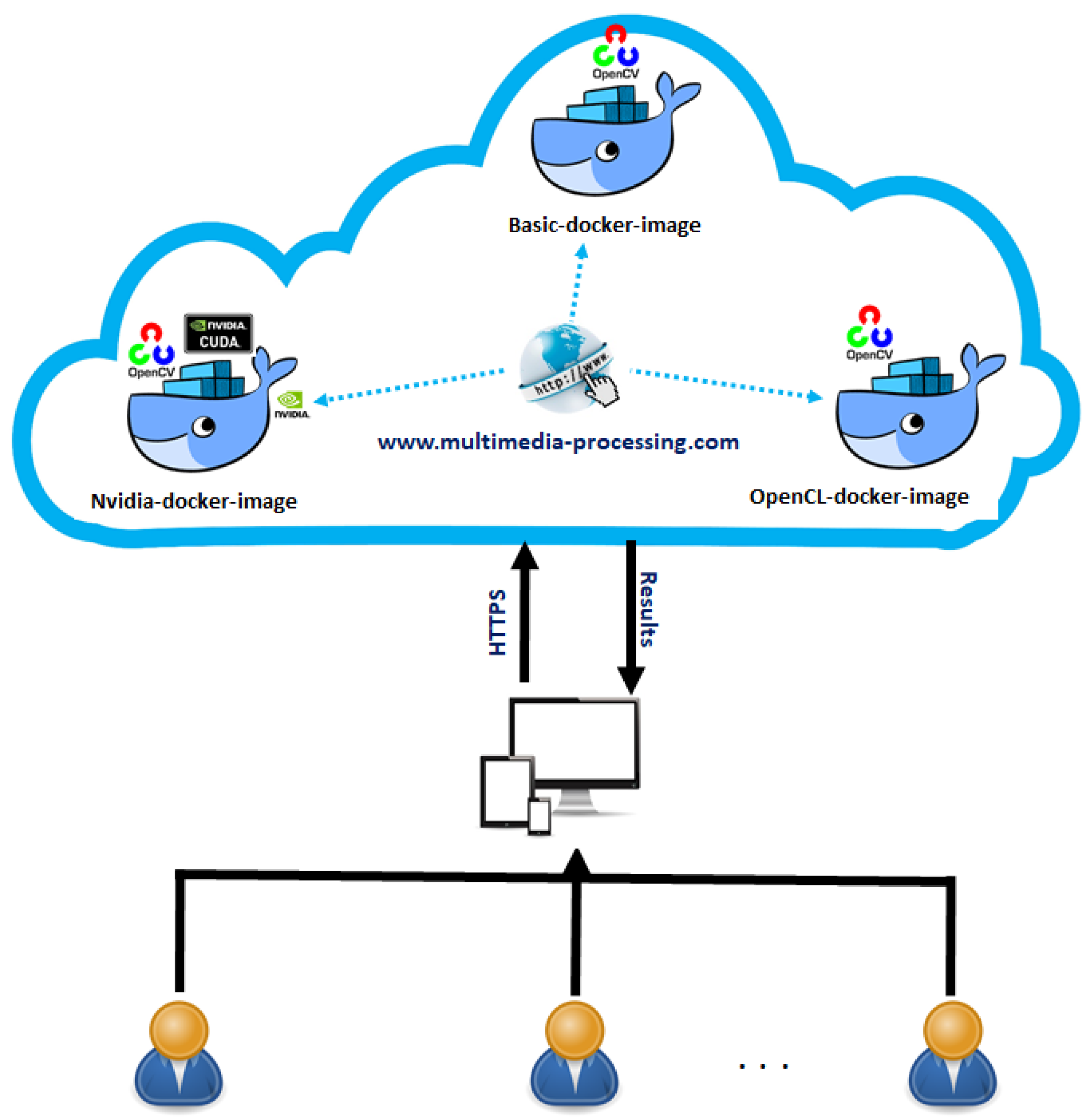
4. Cloud-Based Hybrid Multimedia Retrieval
- Web selection: the user selects the application of image retrieval within the platform.
- Input parameters uploading: the user provides the input parameters (the query image, the type of algorithm and preferred hardware) that will be sent to the web server.
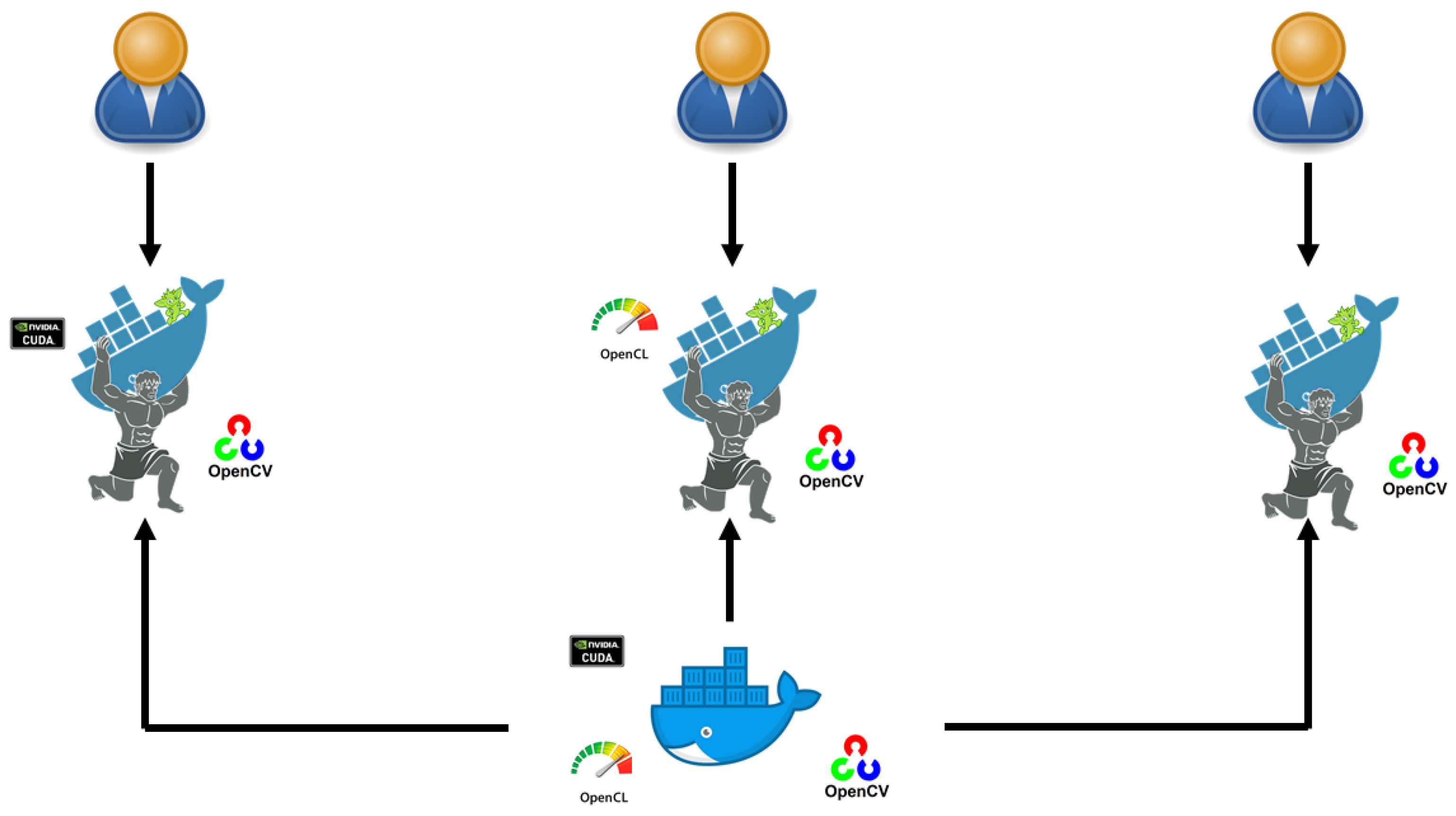
- Cloud-based execution: at this moment, the cloud platform generates the related docker container (basic, nividia or opencl) with all the parameters in order to execute the application. Notice that in case we have many users, the platform creates a container for each user.
- Results presentation: at the end of the process of research, all the containers will be removed by the cloud platform and show the results to the user. Figure 4 illustrates the general architecture of our cloud platform.
5. Experimental Results
- CPU: Intel Core (TM) i5, 2520M CPU@ 2.50 GHz, RAM: 4 GB;
- GPU NVIDIA: GeForce GTX 580, RAM: 1.5 GB, 512 CUDA cores.
- CPU: Intel(R) Xeon(R) CPU E5-2650L v4 @ 1.70 GHz, RAM: 1 GB
- GPU: 4 GPU Nvidia GTX 980, RAM: 4 GB
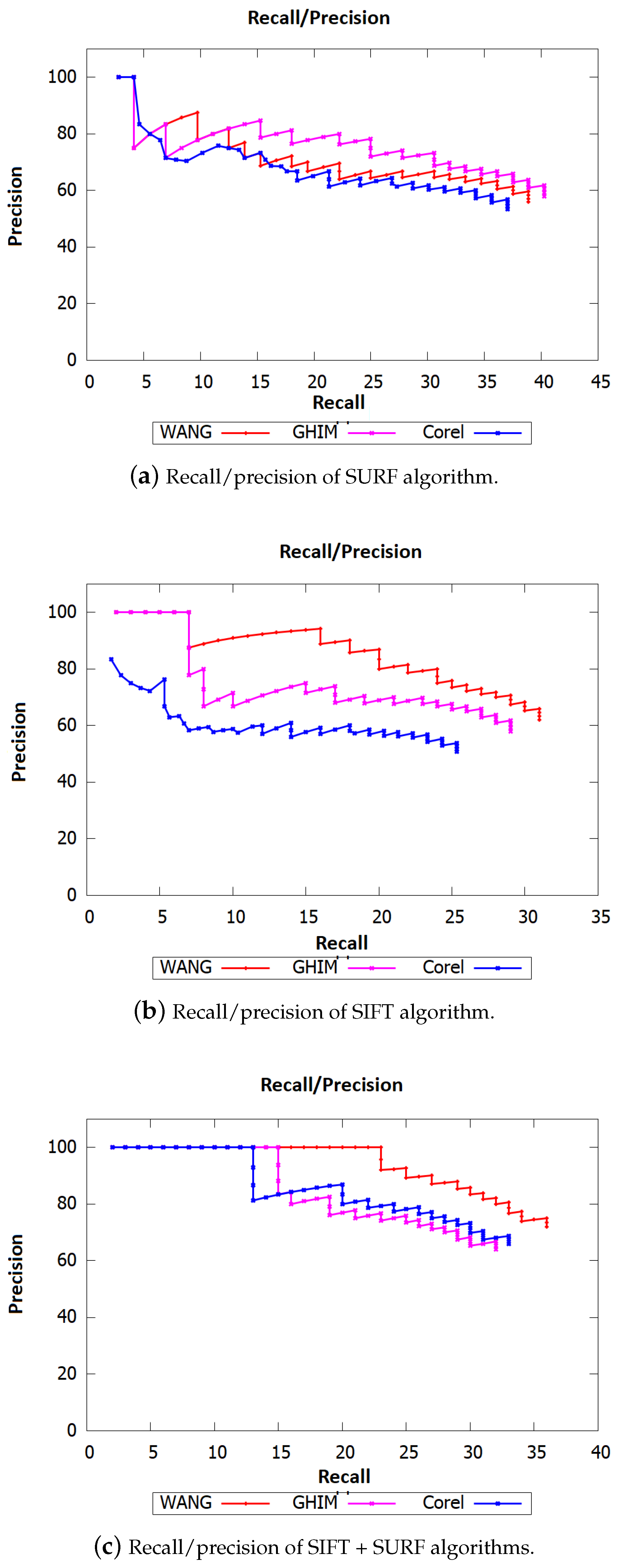
- Wang databse (Wang database, http://wang.ist.psu.edu/docs/related/): 10,000 low resolution images of size 128 × 85 classed in 100 categories, where each class contains 100 images;
- Corel-10k database (Corel-10k database, http://www.ci.gxnu.edu.cn/cbir/Dataset.aspx): 10,000 images of size 192 × 128, classed in 100 categories, where each class contains 100 images;
- GHIM-10k database (GHIM-10k database, http://www.ci.gxnu.edu.cn/cbir/Dataset.aspx): 10,000 images of size 300 × 400, classed in 20 classes where each category contains 500 images.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zahra, S.; Sulaiman, R.; Prabuwono, A.; Kahaki, S. Invariant feature descriptor based on harmonic image transform for plant leaf retrieval. Pertanika J. Sci. Technol. 2017, 25, 107–114. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded Up Robust Features. In Computer Vision—ECCV 2006, Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006, Part I; Leonardis, A., Bischof, H., Pinz, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Kusamura, Y.; Kozawa, Y.; Amagasa, T.; Kitagawa, H. GPU Acceleration of Content-Based Image Retrieval Based on SIFT Descriptors. In Proceedings of the 2016 19th International Conference on Network-Based Information Systems (NBiS), Ostrava, Czech Republic, 7–9 September 2016; pp. 342–347. [Google Scholar] [CrossRef]
- Mahmoudi, S.A.; Manneback, P.; Augonnet, C.; Thibault, S. Traitements d’Images sur Architectures Parallèles et Hétérogènes. Tech. Sci. Inform. 2012, 31, 1183–1203. [Google Scholar] [CrossRef]
- Larhmam, M.A.; Mahmoudi, S.A.; Benjelloun, M.; Mahmoudi, S.; Manneback, P. A Portable Multi-CPU/ Multi-GPU Based Vertebra Localization in Sagittal MR Images. In Image Analysis and Recognition; Campilho, A., Kamel, M., Eds.; Springer: Cham, Switzerland, 2014; pp. 209–218. [Google Scholar]
- Belarbi, M.A.; Mahmoudi, S.; Belalem, G. PCA as Dimensionality Reduction for Large-Scale Image Retrieval Systems. Int. J. Ambient. Comput. Intell. 2017, 8, 45–58. [Google Scholar] [CrossRef]
- Merkel, D. Docker: Lightweight Linux containers for consistent development and deployment. Linux J. 2014, 2014, 2. [Google Scholar]
- Mahmoudi, S.A.; Manneback, P. Multi-GPU based event detection and localization using high definition videos. In Proceedings of the 2014 International Conference on Multimedia Computing and Systems (ICMCS), Marrakech, Morocco, 14–16 April 2014; pp. 81–86. [Google Scholar] [CrossRef]
- Yang, M.; Kpalma, K.; Ronsin, J. A Survey of Shape Feature Extraction Techniques. In Pattern Recognition Techniques, Technology and Applications; IN-TECH: London, UK, 2008; pp. 43–90. [Google Scholar]
- Roy, S.; Sangineto, E.; Demir, B.; Sebe, N. Metric-Learning based Deep Hashing Network for Content Based Retrieval of Remote Sensing Images. arXiv 2019, arXiv:1904.01258. [Google Scholar]
- Tang, X.; Zhang, X.; Liu, F.; Jiao, L. Unsupervised Deep Feature Learning for Remote Sensing Image Retrieval. Remote Sens. 2018, 10, 1243. [Google Scholar] [CrossRef]
- Wu, C. SiftGPU: A GPU Implementation of Scale Invariant Feature Transform SIFT. 2007. Available online: https://github.com/pitzer/SiftGPU (accessed on 12 June 2019).
- Terriberry, T.B.; French, L.M.; Helmsen, J. GPU Accelerating Speeded-Up Robust Features. Int. J. Parallel Program. 2009, 8, 355–362. [Google Scholar]
- Cha, S.H. Comprehensive Survey on Distance/Similarity Measures between Probability Density Functions. City 2007, 1, 1. [Google Scholar]
- Tang, X.; Jiao, L.; Emery, W.J. SAR Image Content Retrieval Based on Fuzzy Similarity and Relevance Feedback. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1824–1842. [Google Scholar] [CrossRef]
- Lian, Z.; Godil, A.; Sun, X.; Xiao, J. CM-BOF: Visual similarity-based 3D shape retrieval using Clock Matching and Bag-of-Features. J. Mach. Vis. Appl. 2013, 24, 1685–1704. [Google Scholar] [CrossRef]
- Belarbi, M.A.; Mahmoudi, S.; Belalem, G.; Mahmoudi, S.A. Web-based Multimedia Research and Indexation for Big Data Databases. In Proceedings of the 3rd International Conference on Cloud Computing Technologies and Applications—CloudTech’17, Rabat, Morocco, 24–26 October 2017. [Google Scholar]
- Benjelloun, M.; Dadi, E.W.; Daoudi, E.M. GPU-based Acceleration of Methods based on Clock Matching Metric for Large Scale 3D Shape Retrieval. Scalable Comput. 2018, 19. [Google Scholar] [CrossRef]
- Belarbi, M.A.; Mahmoudi, S.A.; Mahmoudi, S.; Belalem, G. A New Parallel and Distributed Approach for Large Scale Images Retrieval. In Cloud Computing and Big Data: Technologies, Applications and Security; Springer: Cham, Switzerland, 2019; pp. 185–201. [Google Scholar]
- Benjelloun, M.; Dadi, E.W.; Daoudi, E.M. 3D shape retrieval in distributed databases. Int. J. Imaging Robot. 2016, 16. [Google Scholar]
- Calasanz, R.B.I. Towards the Scientific Cloud Workflow Architecture. In Proceedings of the 5th International Workshop on ADVANCEs in ICT Infraestructures and Services (ADVANCE’2017), Paris, France, 17–18 January 2017. [Google Scholar]
- Agrawal, H.; Mathialagan, C.S.; Goyal, Y.; Chavali, N.; Banik, P.; Mohapatra, A.; Osman, A.; Batra, D. CloudCV: Large-Scale Distributed Computer Vision as a Cloud Service. In Mobile Cloud Visual Media Computing: From Interaction to Service; Hua, G., Hua, X.S., Eds.; Springer: Cham, Switzerland, 2015; pp. 265–290. [Google Scholar]
- Limare, N.; Morel, J.M. The IPOL Initiative: Publishing and Testing Algorithms on Line for Reproducible Research in Image Processing. Procedia Comput. Sci. 2011, 4, 716–725. [Google Scholar] [CrossRef]
- Yan, Y.; Huang, L. Large-Scale Image Processing Research Cloud. Cloud Comput. 2014, 88–93. [Google Scholar]
- Mahmoudi, S.A.; Belarbi, M.A.; Mahmoudi, S.; Belalem, G. Towards a smart selection of resources in the cloud for low-energy multimedia processing. Concurr. Comput. Pract. Exp. 2018, 30, e4372. [Google Scholar] [CrossRef]
- Mahmoudi, S.A.; Belarbi, M.A.; El Adoui, M.; Larhmam, M.A.; Lecron, F. Real Time Web-based Toolbox for Computer Vision. J. Sci. Technol. Arts 2018, 10, 2. [Google Scholar] [CrossRef]
- Udit, G. Comparison between security majors in virtual machine and linux containers. arXiv 2015, arXiv:1507.07816. [Google Scholar]
- Liu, X.; Feng, C.; Yuan, D.; Wang, C. Design of secure FTP system. In Proceedings of the 2010 International Conference on Communications, Circuits and Systems (ICCCAS), Chengdu, China, 28–30 July 2010; pp. 270–273. [Google Scholar]
- Alshammari, R.H. A flow based approach for SSH traffic detection. In Proceedings of the 2007 IEEE International Conference on Systems, Man and Cybernetics (ISIC), Montreal, QC, Canada, 7–10 October 2007; pp. 296–301. [Google Scholar]
- Bhimani, A. Securing the commercial Internet. Commun. ACM 1996, 39, 29–36. [Google Scholar] [CrossRef]
- Bhimani, A. Man-in-the-Middle Attack to the HTTPS Protocol. IEEE Secur. Priv. 2009, 7, 78–81. [Google Scholar]
- Dudani, S.A. The distance-weighted k-nearest-neighbor rule. IEEE Trans. Syst. Man Cybern. 1976, 325–327. [Google Scholar] [CrossRef]
- Mahmoudi, S.A.; Manneback, P. Multi-CPU/Multi-GPU Based Framework for Multimedia Processing. In Computer Science and Its Applications; Springer: Cham, Switzerland, 2015; pp. 54–65. [Google Scholar]
- Mahmoudi, S.A.; Manneback, P. Efficient exploitation of heterogeneous platforms for images features extraction. In Proceedings of the 2012 3rd International Conference on Image Processing Theory, Tools and Applications (IPTA), Istanbul, Turkey, 15–18 October 2012; pp. 91–96. [Google Scholar] [CrossRef]
- Björkman, M.; Bergström, N.; Kragic, D. Detecting, segmenting and tracking unknown objects using multi-label MRF inference. Comput. Vis. Image Underst. 2014, 118, 111–127. [Google Scholar] [CrossRef]
- Paleo, P. An Implementation of SIFT on GPU with OpenCL. 2015. Available online: https://github.com/pierrepaleo/sift_pyocl (accessed on 12 June 2019).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | 2 CPU | GPU (CUDA) | GPU (OpenCL) | ||
|---|---|---|---|---|---|
| Time | Acc (x) | Time | Acc (x) | ||
| Pre-processing | 0.24 s | 0.002 s | 120× | 0.003 s | 80× |
| SURF descriptor | 0.54 s | 0.120 s | 4.50× | 0.15 s | 3.60× |
| SIFT descriptor | 0.69 s | 0.130 s | 5.31× | 0.16 s | 4.31× |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahmoudi, S.A.; Belarbi, M.A.; Dadi, E.W.; Mahmoudi, S.; Benjelloun, M. Cloud-Based Image Retrieval Using GPU Platforms. Computers 2019, 8, 48. https://doi.org/10.3390/computers8020048
Mahmoudi SA, Belarbi MA, Dadi EW, Mahmoudi S, Benjelloun M. Cloud-Based Image Retrieval Using GPU Platforms. Computers. 2019; 8(2):48. https://doi.org/10.3390/computers8020048
Chicago/Turabian StyleMahmoudi, Sidi Ahmed, Mohammed Amin Belarbi, El Wardani Dadi, Saïd Mahmoudi, and Mohammed Benjelloun. 2019. "Cloud-Based Image Retrieval Using GPU Platforms" Computers 8, no. 2: 48. https://doi.org/10.3390/computers8020048
APA StyleMahmoudi, S. A., Belarbi, M. A., Dadi, E. W., Mahmoudi, S., & Benjelloun, M. (2019). Cloud-Based Image Retrieval Using GPU Platforms. Computers, 8(2), 48. https://doi.org/10.3390/computers8020048