Natural Language Processing in OTF Computing: Challenges and the Need for Interactive Approaches


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
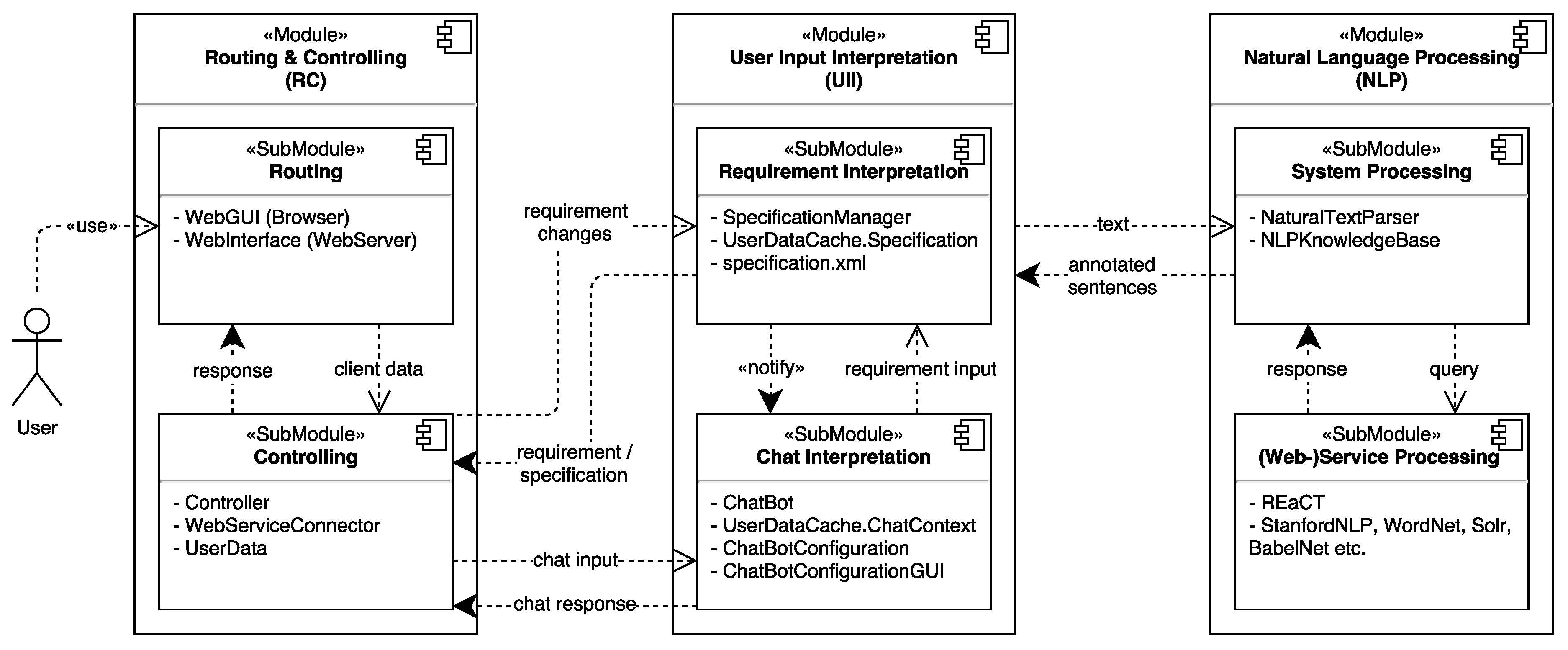
2. Service Descriptions for OTF Computing: Open Challenges
2.1. Extraction of Canonical Core Functionalities
2.2. Automatic Detection and Compensation of Inaccuracy
2.3. Explainable Results
3. State-of-the-Art
3.1. Requirements Extraction
3.2. Multiple Inaccuracy Detection and Compensation
4. Open Challenges: A Discussion
5. Domain-Specific Approaches
5.1. Knowledge Base
5.1.1. Motivation: A Domain-Specific Knowledge Base for the OTF Computing Scenario
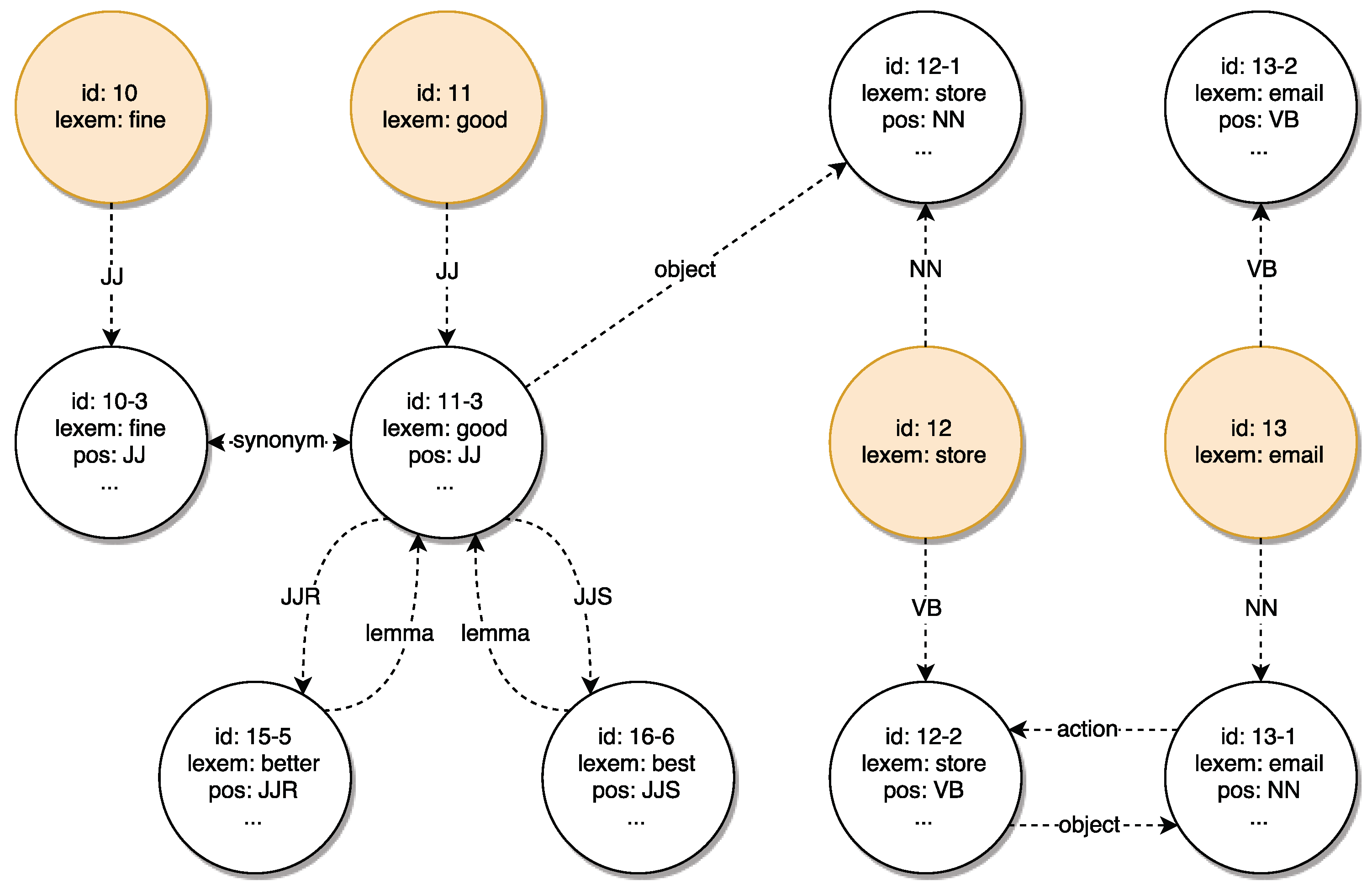
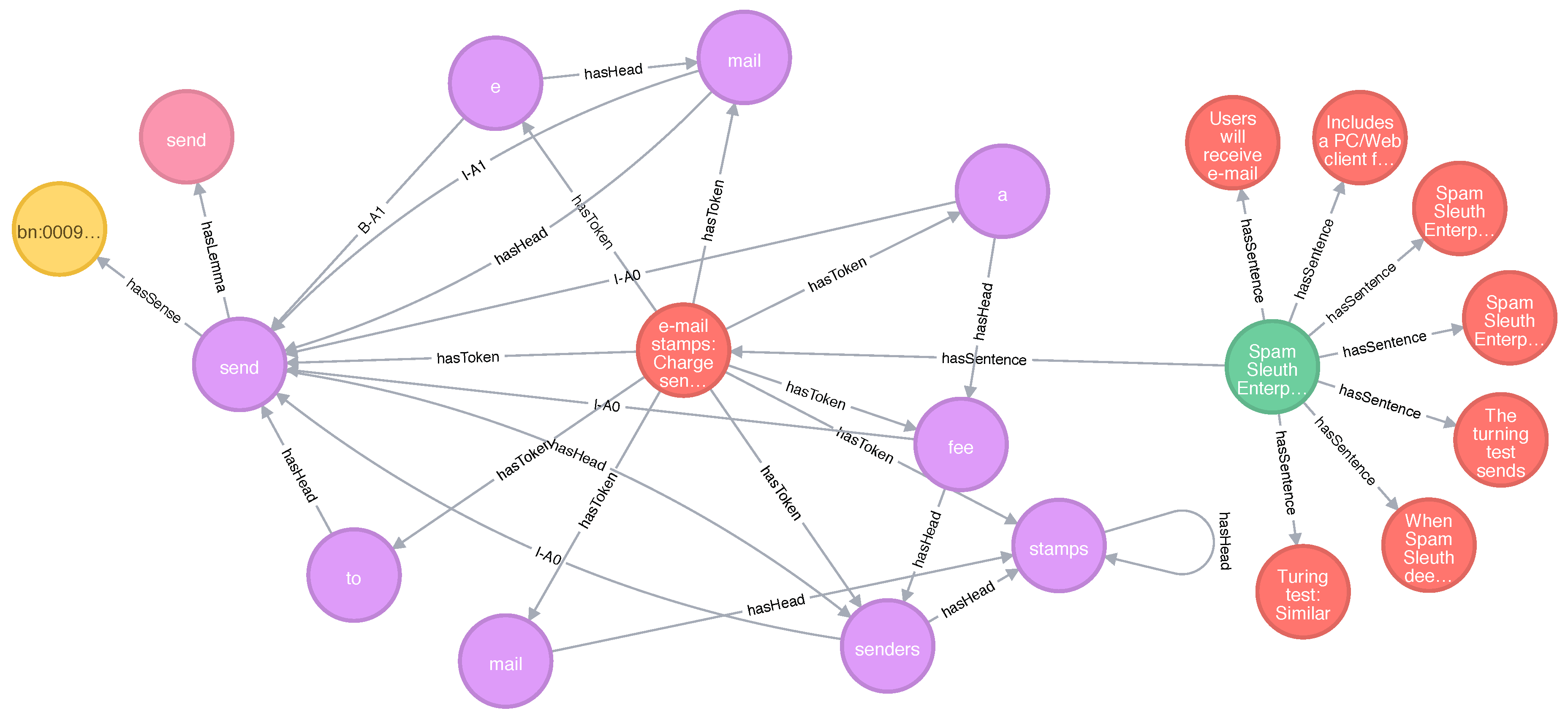
5.1.2. Development of a Linked Knowledge Base
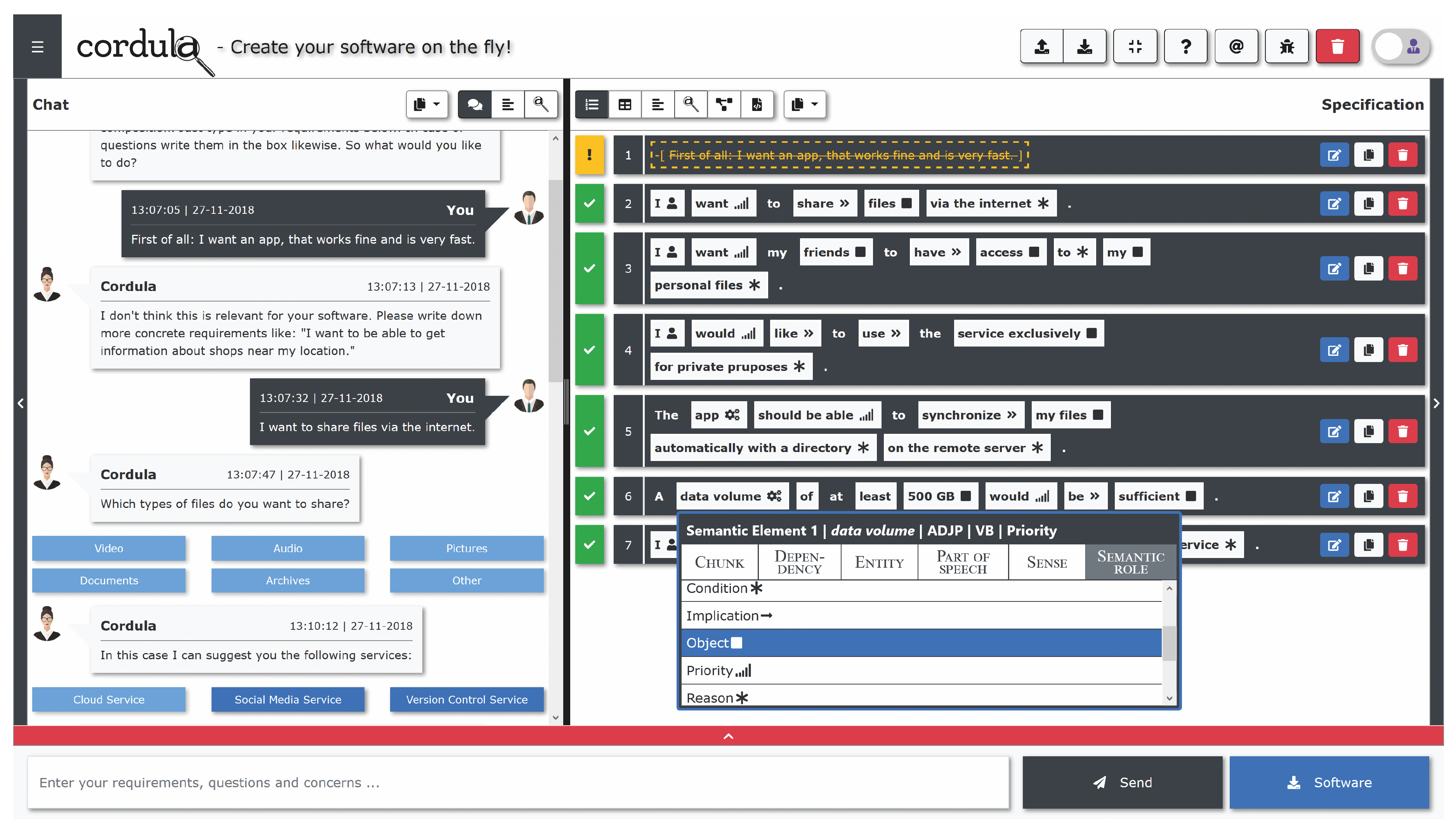
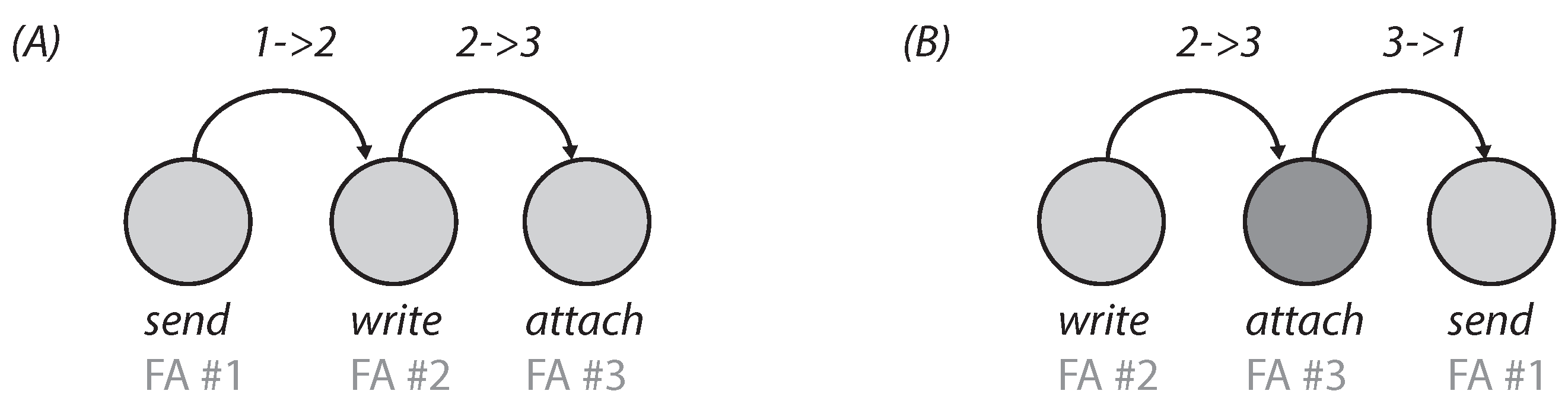
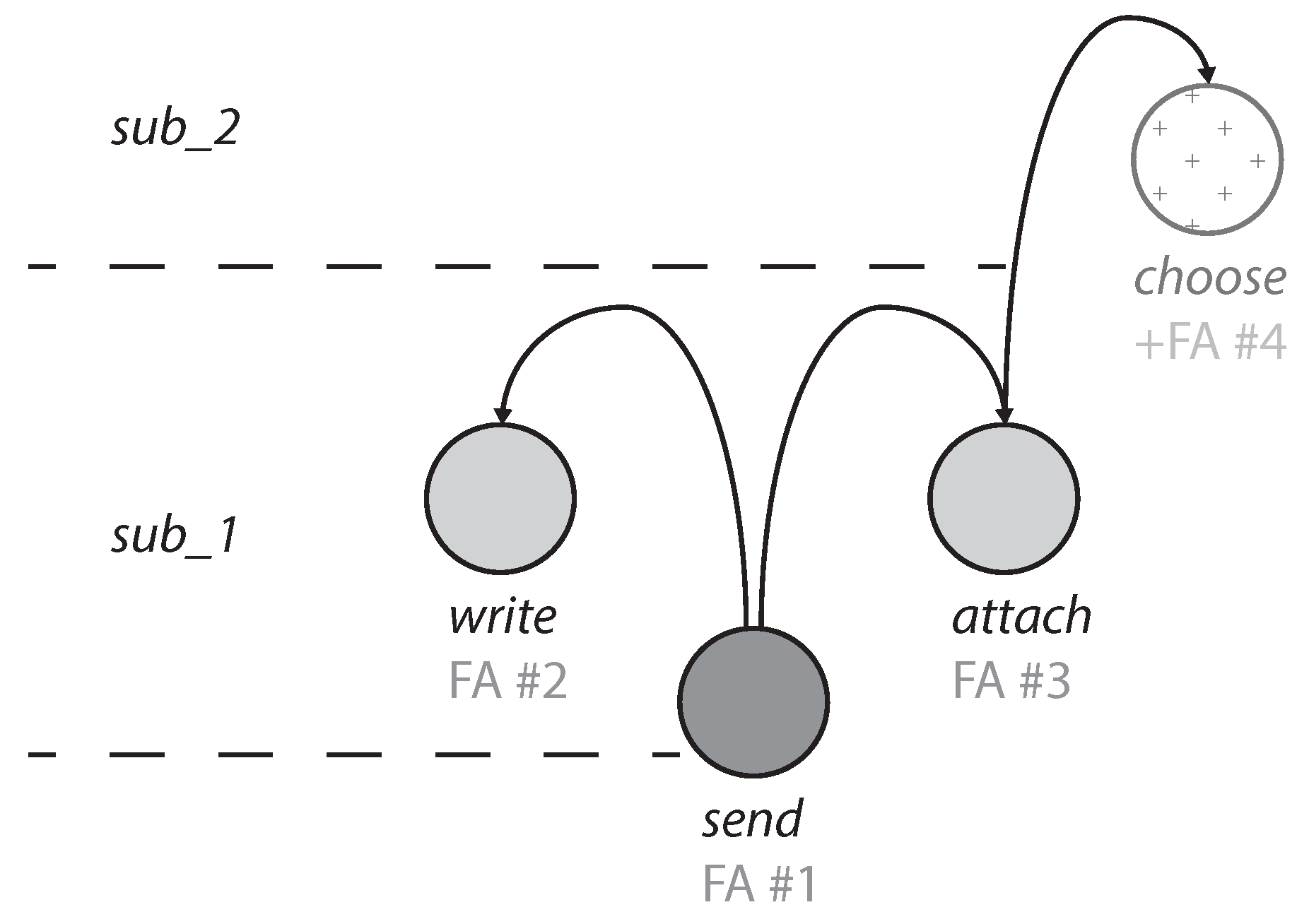
5.2. Inaccuracy Compensation by Using Domain-Specific Chat Bots
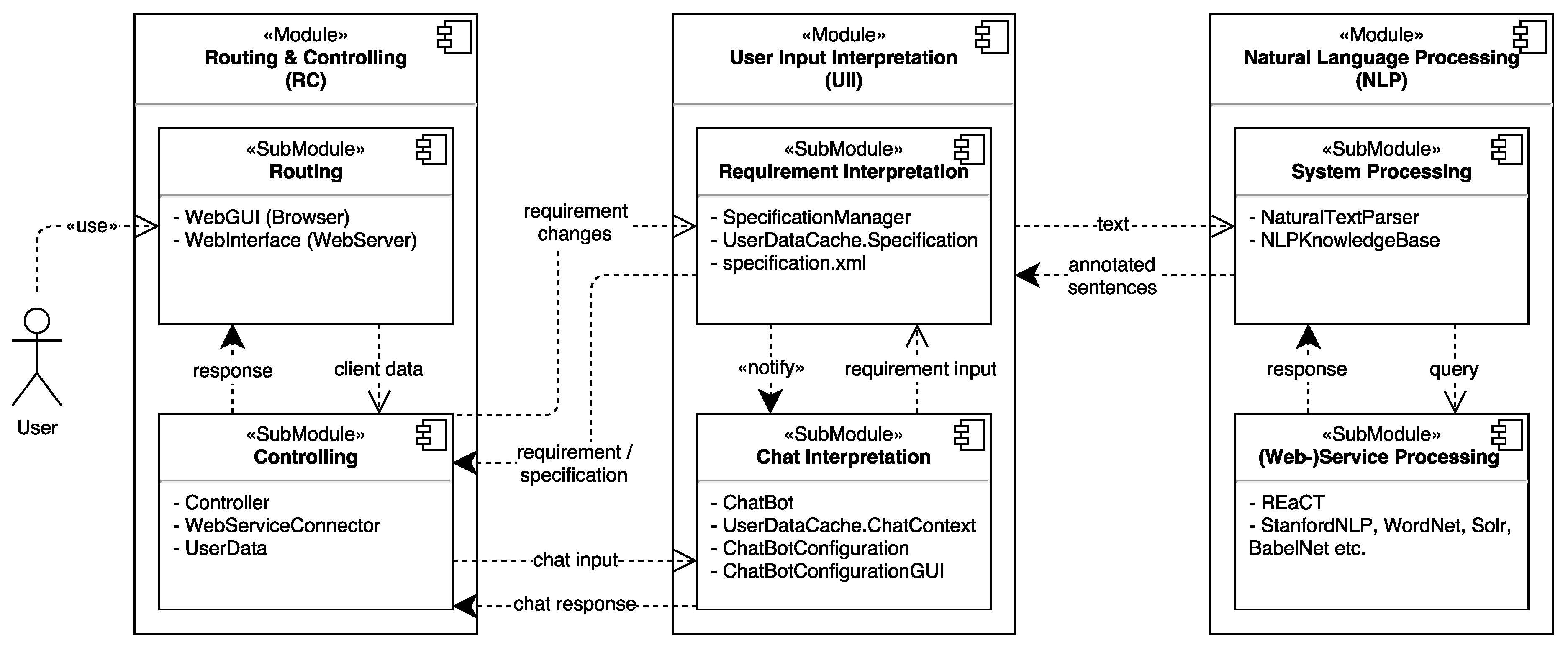
5.2.1. Concept of a Chat Bot with Dialog Control
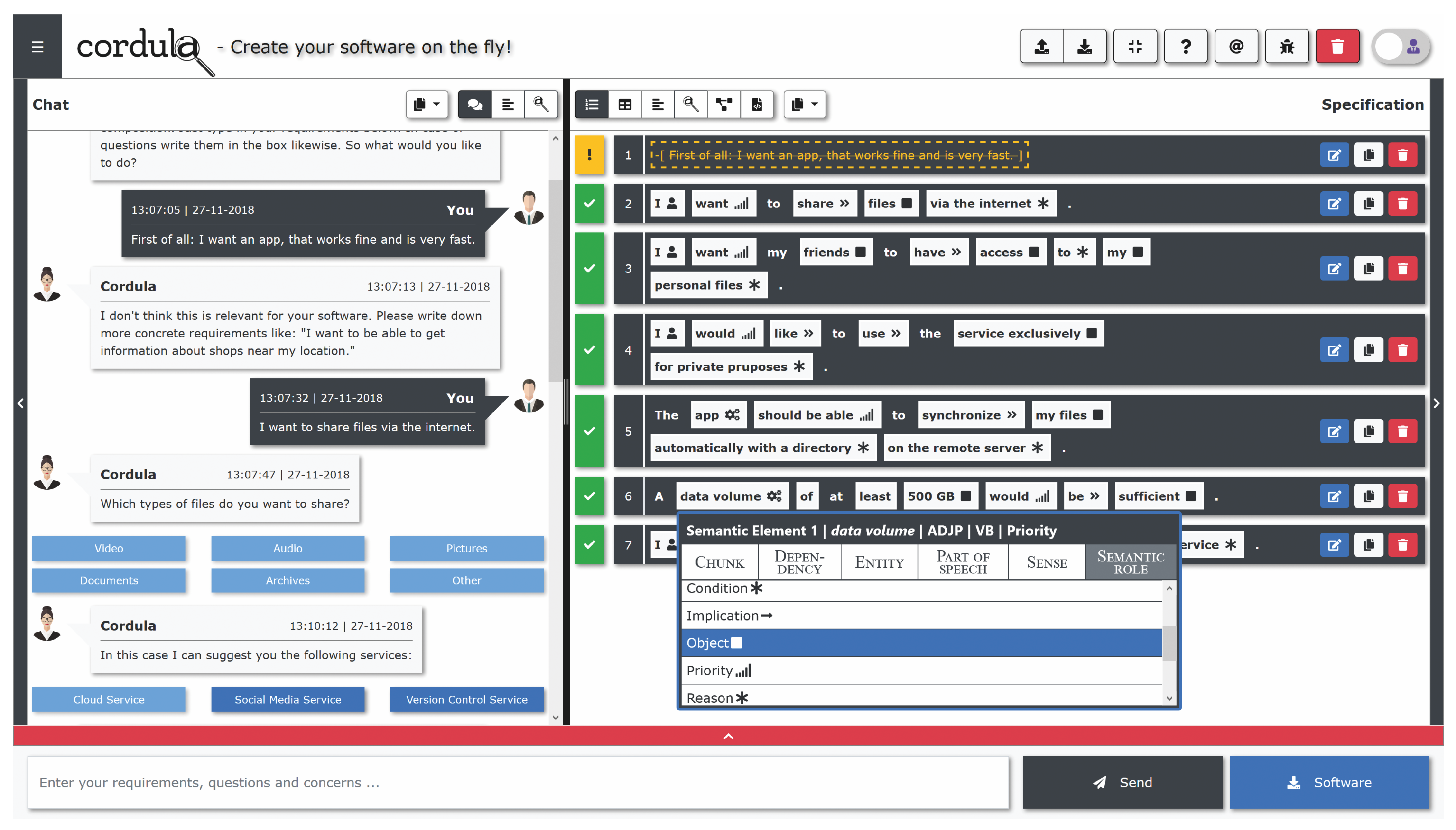
5.2.2. CORDULA: Current Prototype
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CORDULA | Compensation of Requirements Descriptions Using Linguistic Analysis |
| DFG | Deutsche Forschungsgemeinschaft (German Research Foundation) |
| I/O | Input/Output |
| NL | Natural Language |
| NLP | Natural Language Processing |
| OTF | On-The-Fly |
| POS | Part-Of-Speech |
| SFB | Sonderforschungsbereich (Collaborative Research Center) |
| SRL | Semantic Role Labeling |
References
- Bäumer, F.S.; Geierhos, M. NLP in OTF Computing: Current Approaches and Open Challenges. In Communications in Computer and Information Science; Damaševičius, R., Vasiljevienė, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 920, pp. 559–570. [Google Scholar]
- Geierhos, M.; Bäumer, F.S. How to Complete Customer Requirements: Using Concept Expansion for Requirement Refinement. In Proceedings of the 21st NLDB; Métais, E., Meziane, F., Saraee, M., Sugumaran, V., Vadera, S., Eds.; Springer: Manchester, UK, 2016. [Google Scholar]
- Moens, M.F.; Li, J.; Chua, T.S. (Eds.) Mining User Generated Content; CRC Press: Leuven, Belgium; Beijing, China; Singapore, 2014. [Google Scholar]
- Platenius, M.C.; Josifovska, K.; van Rooijen, L.; Arifulina, S.; Becker, M.; Engels, G.; Schäfer, W. An Overview of Service Specification Language and Matching in On-The-Fly Computing (v0.3); Technical Report Tr-ri-16-349; Software Engineering Group, Heinz Nixdorf Institut, Paderborn University: Paderborn, Germany, 2016. [Google Scholar]
- Geierhos, M.; Schulze, S.; Bäumer, F.S. What did you mean? Facing the Challenges of User-generated Software Requirements. In Proceedings of the 7th ICAART; Special Session on PUaNLP 2015; Loiseau, S., Filipe, J., Duval, B., van den Herik, J., Eds.; SCITEPRESS—Science and Technology Publications: Lisbon, Portugal, 2015; pp. 277–283. [Google Scholar]
- Ferrari, A.; dell’ Orletta, F.; Spagnolo, G.O.; Gnesi, S. Measuring and Improving the Completeness of Natural Language Requirements. In Requirements Engineering: Foundation for Software Quality; Salinesi, C., van de Weerd, I., Eds.; Springer: Essen, Germany, 2014; Volume 8396, pp. 23–38. [Google Scholar]
- Dollmann, M.; Geierhos, M. On- and Off-Topic Classification and Semantic Annotation of User-Generated Software Requirements. In Proceedings of the Conference on EMNLP; ACL: Austin, TX, USA, 2016. [Google Scholar]
- Bäumer, F.S. Indikatorbasierte Erkennung und Kompensation von Ungenauen und Unvollständig Beschriebenen Softwareanforderungen. Ph.D. Thesis, Paderborn University, Paderborn, Germany, 2017. [Google Scholar]
- Pekar, V.; Felderer, M.; Breu, R. Improvement Methods for Software Requirement Specifications: A Mapping Study. In Proceedings of the 9th QUATIC, Guimaraes, Portugal, 23–26 September 2014; pp. 242–245. [Google Scholar]
- Umber, A.; Bajwa, I.S. Minimizing Ambiguity in Natural Language Software Requirements Specification. In Proceedings of the 6th ICDIM, Melbourn, VIC, Australia, 26–28 September 2011; pp. 102–107. [Google Scholar]
- Kamsties, E. Understanding Ambiguity in Requirements Engineering. In Engineering and Managing Software Requirements; Aurum, A., Wohlin, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 245–266. [Google Scholar]
- Kamsties, E.; Paech, B. Taming Ambiguity in Natural Language Requirements. In Proceedings of the 13th International Conference on System and Software Engineering and Their Applications (ICSSEA’00), Paris, France, 5–8 December 2000; pp. 1–8. [Google Scholar]
- Firesmith, D. Common Requirements Problems, Their Negative Consequences, and the Industry Best Practices to Help Solve Them. J. Object Technol. 2007, 6, 17–33. [Google Scholar] [CrossRef]
- Kamsties, E.; Berry, D.M.; Paech, B. Detecting Ambiguities in Requirements Documents Using Inspections. In Proceedings of the 1st Workshop on Inspection in Software Engineering (WISE’01), Paris, France, 23 July 2001; pp. 68–80. [Google Scholar]
- Tichy, W.F.; Landhäußer, M.; Körner, S.J. nlrpBENCH: A Benchmark for Natural Language Requirements Processing; Technical Report for RECAA—Requirements Engineering Complete Automation Approach; Karlsruhe Institute of Technology (KIT): Karlsruhe, Germany, 2015. [Google Scholar]
- Bäumer, F.S.; Dollmann, M.; Geierhos, M. Studying Software Descriptions in SourceForge and App Stores for a better Understanding of real-life Requirements. In Proceedings of the 2nd ACM SIGSOFT International Workshop on App Market Analytics, Paderborn, Germany, 5 September 2017; Sarro, F., Shihab, E., Nagappan, M., Platenius, M.C., Kaimann, D., Eds.; ACM: New York, NY, USA, 2017; pp. 19–25. [Google Scholar]
- Navigli, R.; Ponzetto, S.P. Joining Forces Pays Off: Multilingual Joint Word Sense Disambiguation. In Proceedings of the 2012 Joint Conference on EMNLP and CONLL, Jeju Island, Korea, 12–14 July 2012; pp. 1399–1410. [Google Scholar]
- Navigli, R.; Ponzetto, S.P. BabelNet: The automatic construction, evaluation and application of a wide-coverage multilingual semantic network. In Artificial Intelligence; Elsevier: Essex, UK, 2012; Volume 193, pp. 217–250. [Google Scholar]
- Bäumer, F.S.; Geierhos, M. Flexible Ambiguity Resolution and Incompleteness Detection in Requirements Descriptions via an Indicator-based Configuration of Text Analysis Pipelines. In Proceedings of the 51st Hawaii International Conference on System Sciences, Waikoloa Village, HI, USA, 3–6 January 2018; pp. 5746–5755. [Google Scholar]
- Dollmann, M. Frag die Anwender: Extraktion und Klassifikation von funktionalen Anforderungen aus User-Generated-Content. Master’s Thesis, Paderborn University, Paderborn, Germany, 2016. [Google Scholar]
- Vlas, R.; Robinson, W.N. A Rule-Based Natural Language Technique for Requirements Discovery and Classification in Open-Source Software Development Projects. In Proceedings of the 2011 44th Hawaii International Conference on System Sciences (HICSS), Kauai, HI, USA, 4–7 January 2011; pp. 1–10. [Google Scholar]
- Körner, S.J. RECAA—Werkzeugunterstützung in der Anforderungserhebung. Ph.D. Thesis, Karlsruher Institut für Technologie, Karlsruhe, Germany, 2014. [Google Scholar]
- Huertas, C.; Juárez-Ramírez, R. NLARE, a Natural Language Processing Tool for Automatic Requirements Evaluation. In Proceedings of the CUBE International Information Technology Conference (CUBE’12), Pune, India, 3–5 September 2012; ACM: New York, NY, USA, 2012; pp. 371–378. [Google Scholar]
- Fabbrini, F.; Fusani, M.; Gnesi, S.; Lami, G. The Linguistic Approach to the Natural Language Requirements Quality: Benefit of the use of an Automatic Tool. In Proceedings of the 26th Annual NASA Goddard Software Engineering Workshop, Greenbelt, MD, USA, 27–29 November 2001; pp. 97–105. [Google Scholar]
- Tjong, S.F.; Berry, D.M. The Design of SREE—A Prototype Potential Ambiguity Finder for Requirements Specifications and Lessons Learned. In Requirements Engineering: Foundation for Software Quality; Doerr, J., Opdahl, A.L., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7830, pp. 80–95. [Google Scholar]
- Bajwa, I.S.; Lee, M.; Bordbar, B. Resolving Syntactic Ambiguities in Natural Language Specification of Constraints. In Computational Linguistics and Intelligent Text Processing; Gelbukh, A., Ed.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7181, pp. 178–187. [Google Scholar]
- Husain, S.; Beg, R. Advances in Ambiguity less NL SRS: A review. In Proceedings of the 2015 IEEE International Conference on Engineering and Technology (ICETECH), Coimbatore, India, 20 March 2015; pp. 221–225. [Google Scholar]
- Shah, U.S.; Jinwala, D.C. Resolving Ambiguities in Natural Language Software Requirements: A Comprehensive Survey. SIGSOFT Softw. Eng. Notes 2015, 40, 1–7. [Google Scholar] [CrossRef]
- Bano, M. Addressing the Challenges of Requirements Ambiguity: A Review of Empirical Literature. In Proceedings of the 5th International Workshop on EmpiRE, Ottawa, ON, Canada, 24 August 2015; pp. 21–24. [Google Scholar]
- Lami, G. QuARS: A Tool for Analyzing Requirements; Technischer Bericht ESC-TR-2005-014; Carnegie Mellon University: Pittsburgh, PA, USA, 2005. [Google Scholar]
- Bucchiarone, A.; Gnesi, S.; Fantechi, A.; Trentanni, G. An Experience in Using a Tool for Evaluating a Large Set of Natural Language Requirements. In Proceedings of the 2010 ACM Symposium on Applied Computing (SAC’10), Sierre, Switzerland, 22–26 March 2010; ACM: New York, NY, USA, 2010; pp. 281–286. [Google Scholar]
- Huertas, C.; Juárez-Ramírez, R. Towards Assessing The Quality Of Functional Requirements Using English/spanish Controlled Languages and Context Free Grammar. In Proceedings of the 3rd International Conference on DICTAP, Ostrava, Czech Republic, 20–22 November 2013; pp. 234–241. [Google Scholar]
- Körner, S.J.; Brumm, T. Natural Language Specification Improvement with Ontologies. Int. J. Semant. Comput. 2010, 3, 445–470. [Google Scholar] [CrossRef]
- Berners-Lee, T.; Hendler, J.; Lassila, O. The semantic web. Sci. Am. 2001, 284, 28–37. [Google Scholar] [CrossRef]
- Piedra, N.; Chicaiza, J.; Lopez-Vargas, J.; Caro, E.T. Guidelines to producing structured interoperable data from Open Access Repositories. In Proceedings of the 2016 IEEE Frontiers in Education Conference (FIE), Erie, PA, USA, 12–15 October 2016; pp. 1–9. [Google Scholar]
- Heath, T.; Bizer, C. Linked data: Evolving the web into a global data space. In Synthesis Lectures on the Semantic Web: Theory and Technology; Morgan & Claypool Publishers: San Rafael, CA, USA, 2011; Volume 1, pp. 1–136. [Google Scholar]
- Friesen, E.; Bäumer, F.S.; Geierhos, M. CORDULA: Software Requirements Extraction Utilizing Chatbot as Communication Interface. In Joint Proceedings of REFSQ-2018 Workshops, Doctoral Symposium, Live Studies Track, and Poster Track Co-Located with the 23rd International Conference on Requirements Engineering: Foundation for Software Quality (REFSQ 2018); Schmid, K., Spoletini, P., Ben Charrada, E., Chisik, Y., Dalpiaz, F., Ferrari, A., Forbrig, P., Franch, X., Kirikova, M., Madhavji, N., et al., Eds.; CEUR Workshop Proceedings (CEUR-WS.org): Essen, Germany, 2018; Volume 2075, p. 2075. [Google Scholar]
- Piedra, N.; Tovar, E.; Colomo-Palacios, R.; Lopez-Vargas, J.; Alexandra Chicaiza, J. Consuming and producing linked open data: the case of Opencourseware. Program 2014, 48, 16–40. [Google Scholar] [CrossRef]
- Collobert, R. Deep learning for efficient discriminative parsing. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics (AISTATS), Fort Lauderdale, FL, USA, 11–13 April 2011; Volume 15, pp. 224–232. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bäumer, F.S.; Kersting, J.; Geierhos, M. Natural Language Processing in OTF Computing: Challenges and the Need for Interactive Approaches. Computers 2019, 8, 22. https://doi.org/10.3390/computers8010022
Bäumer FS, Kersting J, Geierhos M. Natural Language Processing in OTF Computing: Challenges and the Need for Interactive Approaches. Computers. 2019; 8(1):22. https://doi.org/10.3390/computers8010022
Chicago/Turabian StyleBäumer, Frederik S., Joschka Kersting, and Michaela Geierhos. 2019. "Natural Language Processing in OTF Computing: Challenges and the Need for Interactive Approaches" Computers 8, no. 1: 22. https://doi.org/10.3390/computers8010022
APA StyleBäumer, F. S., Kersting, J., & Geierhos, M. (2019). Natural Language Processing in OTF Computing: Challenges and the Need for Interactive Approaches. Computers, 8(1), 22. https://doi.org/10.3390/computers8010022