ASIR: Application-Specific Instruction-Set Router for NoC-Based MPSoCs

Abstract
1. Introduction
2. Related Work
2.1. Design of NoC-Based MPSoC
2.2. High-Level Synthesis
2.3. Network-on-Chip
2.4. Programming and Task Mapping
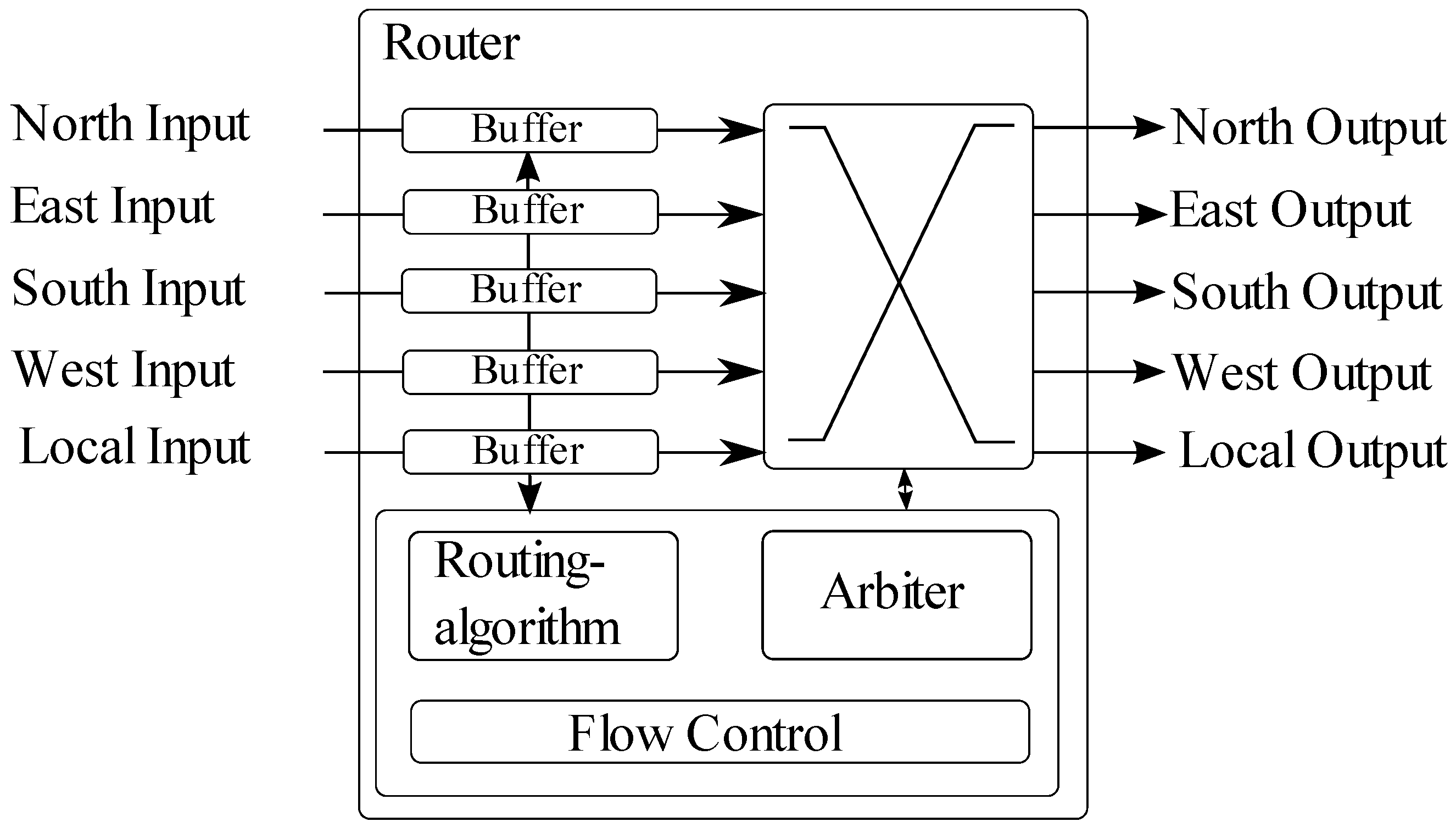
3. Hardware Architecture of ASIR
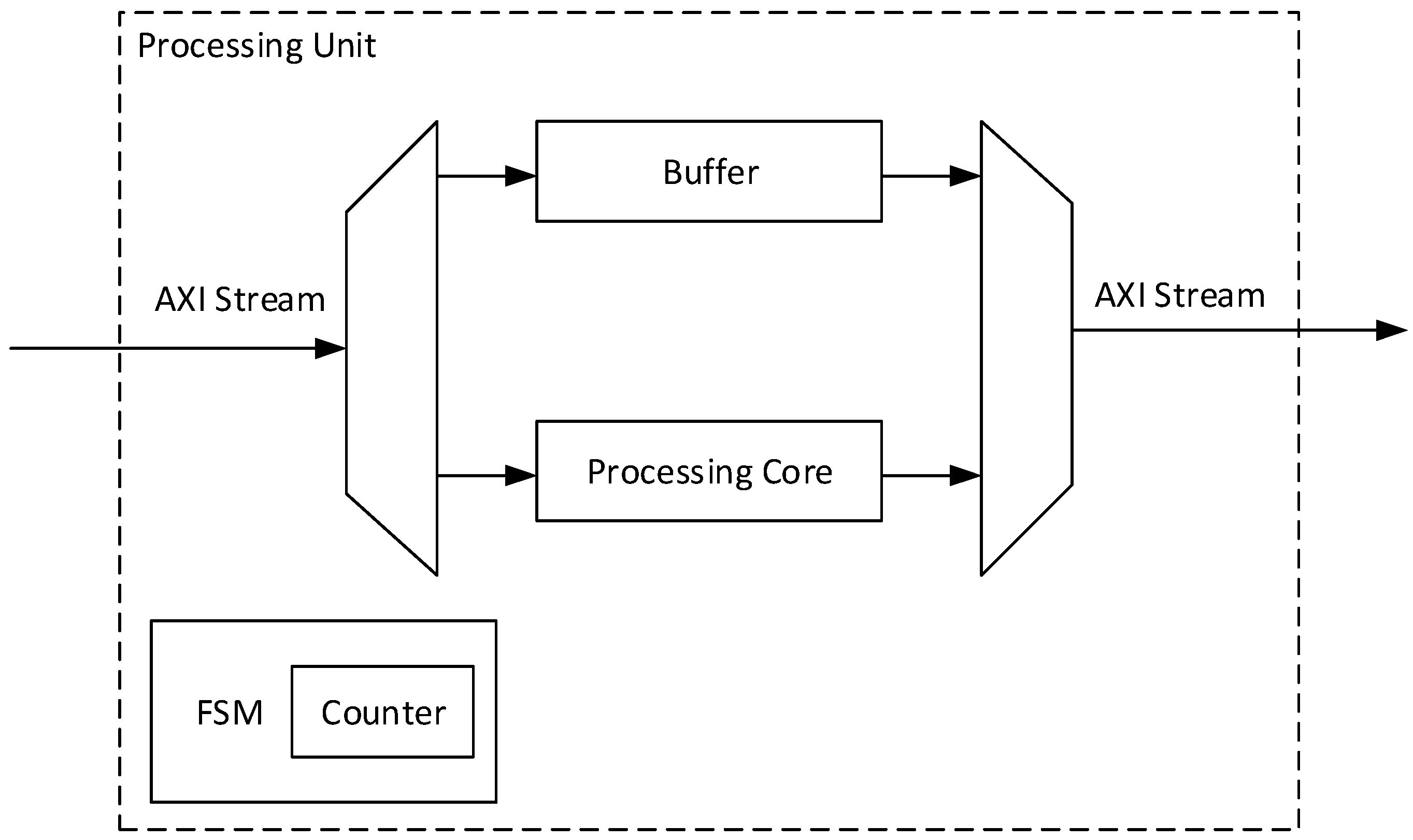
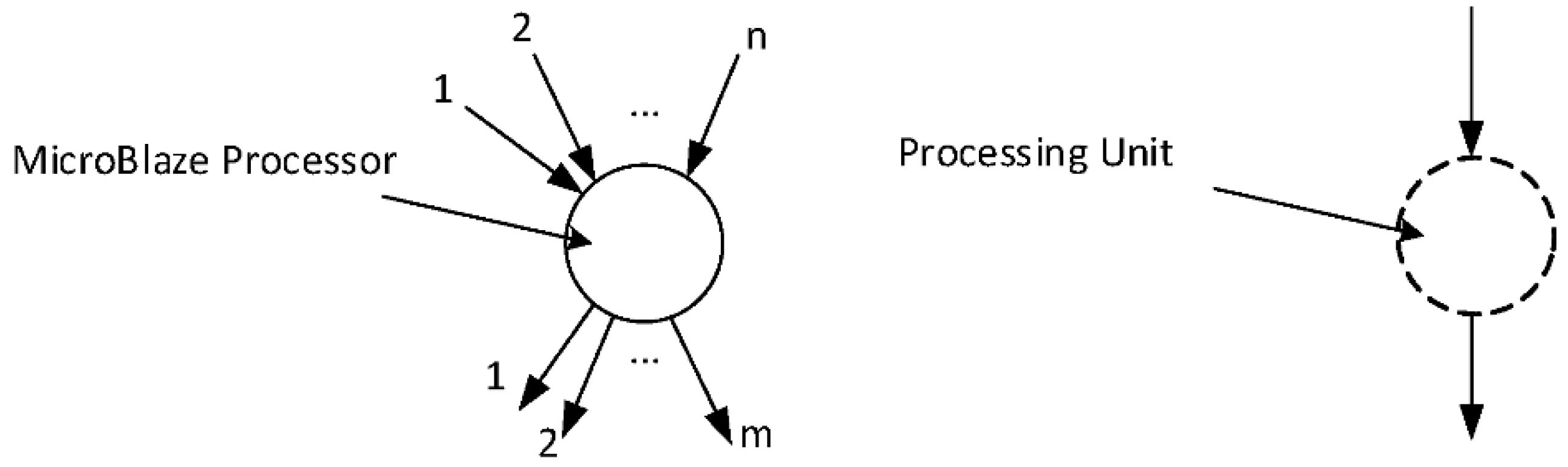
3.1. Processing Unit

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1: | void processing_core(int* A, int* B){ |
| 2: | #pragma HLS INTERFACE axis port=A |
| 3: | #pragma HLS INTERFACE axis port=B |
| 4: | //Following code is application-specific |
| 5: | int threshold=110; |
| 6: | if (*A < threshold){ |
| 7: | *B=0; |
| 8: | }else{ |
| 9: | *B=1; |
| 10: | } |
| 11: | } |
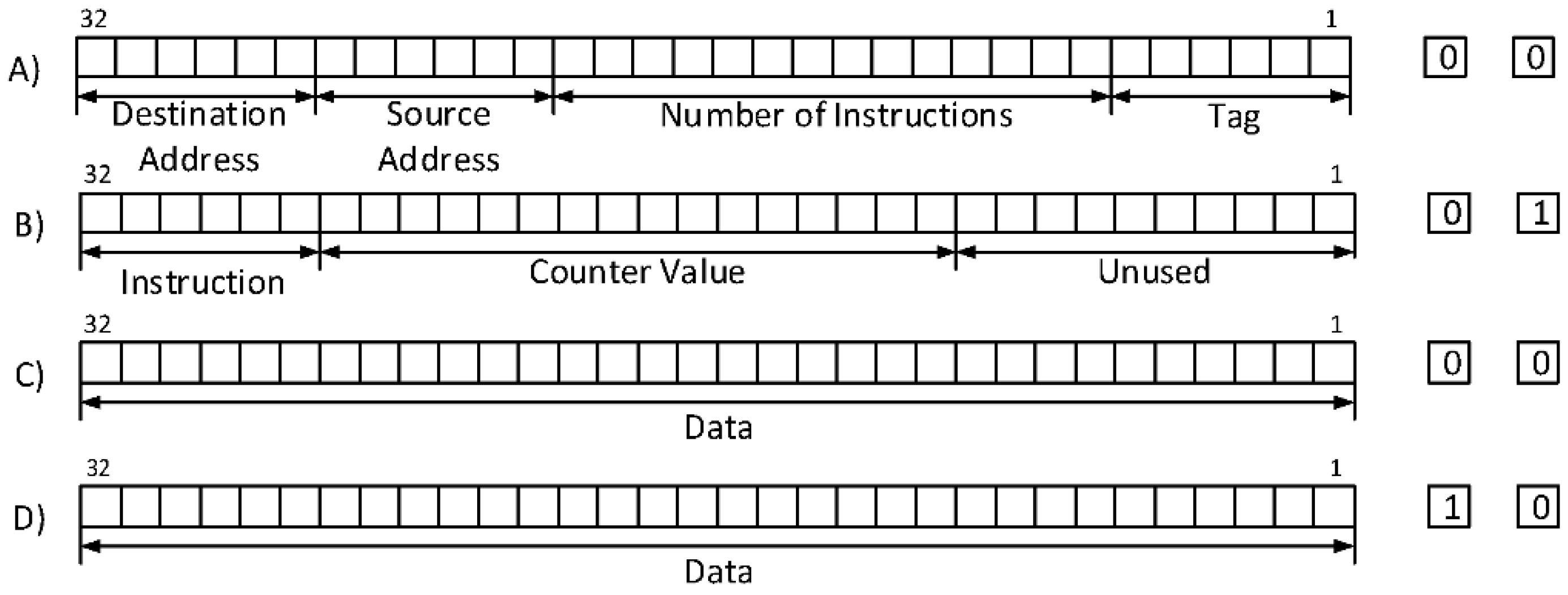
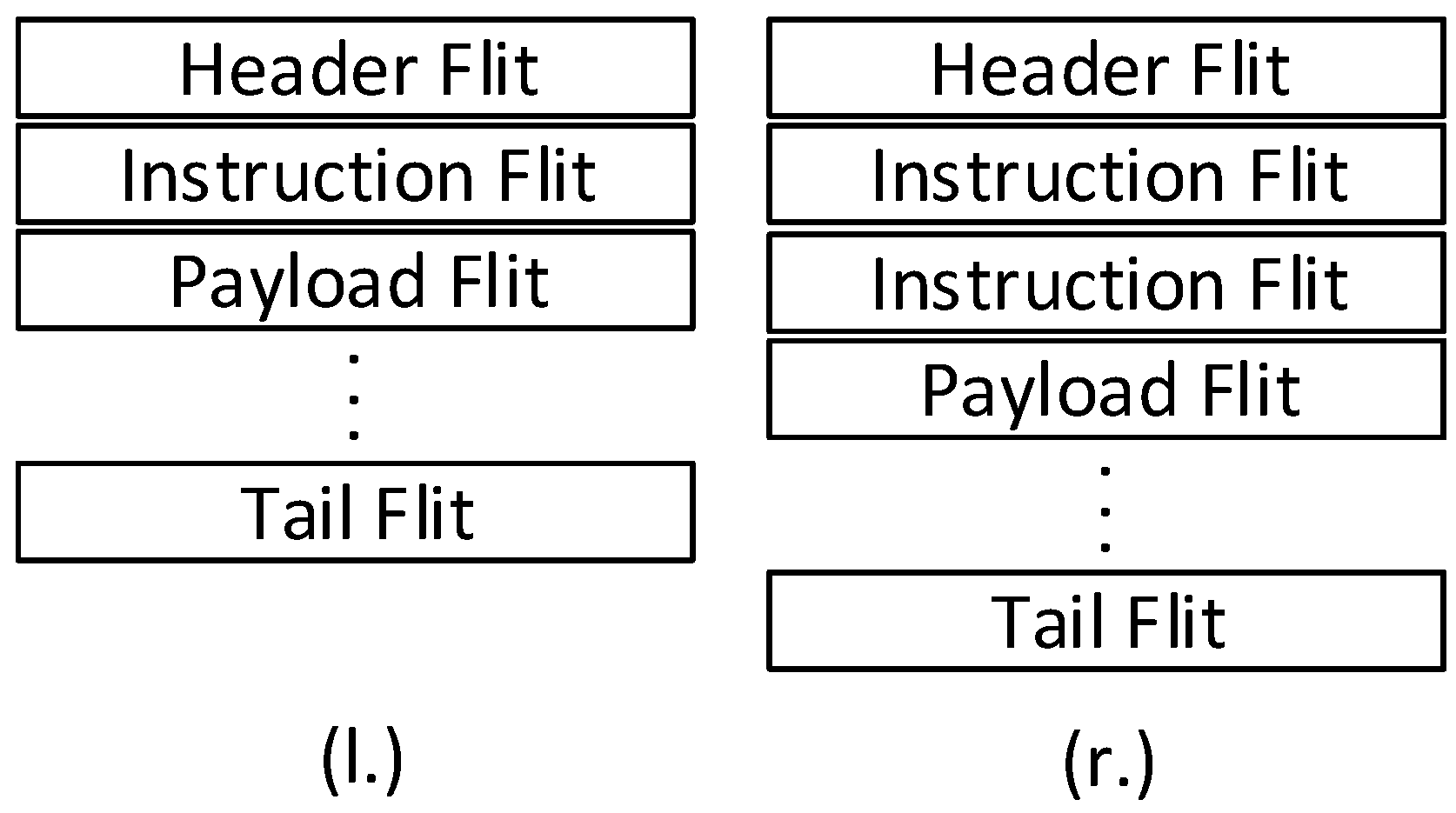
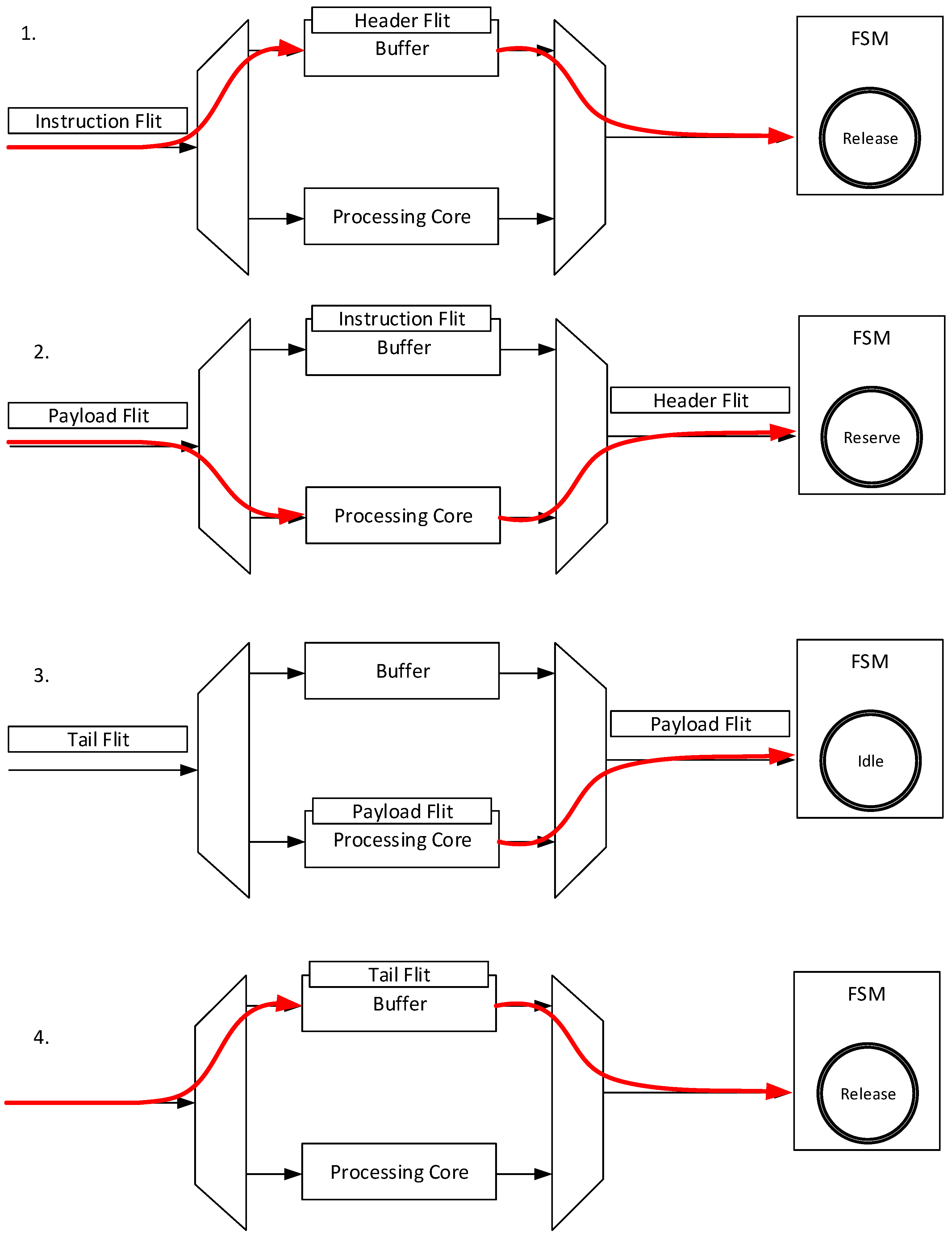
3.2. Instruction and Data Flow through the Processing Unit
- Initially, the FSM is in the Release state. The header flit of a message is forwarded through the first multiplexer to the buffer in this state. The second multiplexer transmits the output of the buffer to the crossbar. The configuration of the processing core by setting the control signals is also done in this state.
- Afterwards, the instruction flit enters the buffer, which leads to a change from the Release state to the Reserve state. This state change requires that the instruction flit contains the corresponding address of the router; otherwise, the FSM remains in the Release state. The Reserve state sets the first and second multiplexer to the processing core. In addition, the counter increments at every incoming flit until it reaches the number of flits that is specified in the instruction flit. Furthermore, the instruction flit stored in the buffer is removed.
- The FSM changes from the Reserve state to the Idle state at the moment when the counter reaches the specified number of flits. The Idle state disables the first multiplexer so that no new flit can be forwarded to the processing core, as well as the buffer.
- The Release state is active again when the last flit of the processing unit has been transmitted. In Figure 5, the tail flit, which identifies the end of the message is transmitted through the buffer. However, further payload flits can be also transmitted.
4. Programming and Mapping of ASIR-Based MPSoCs
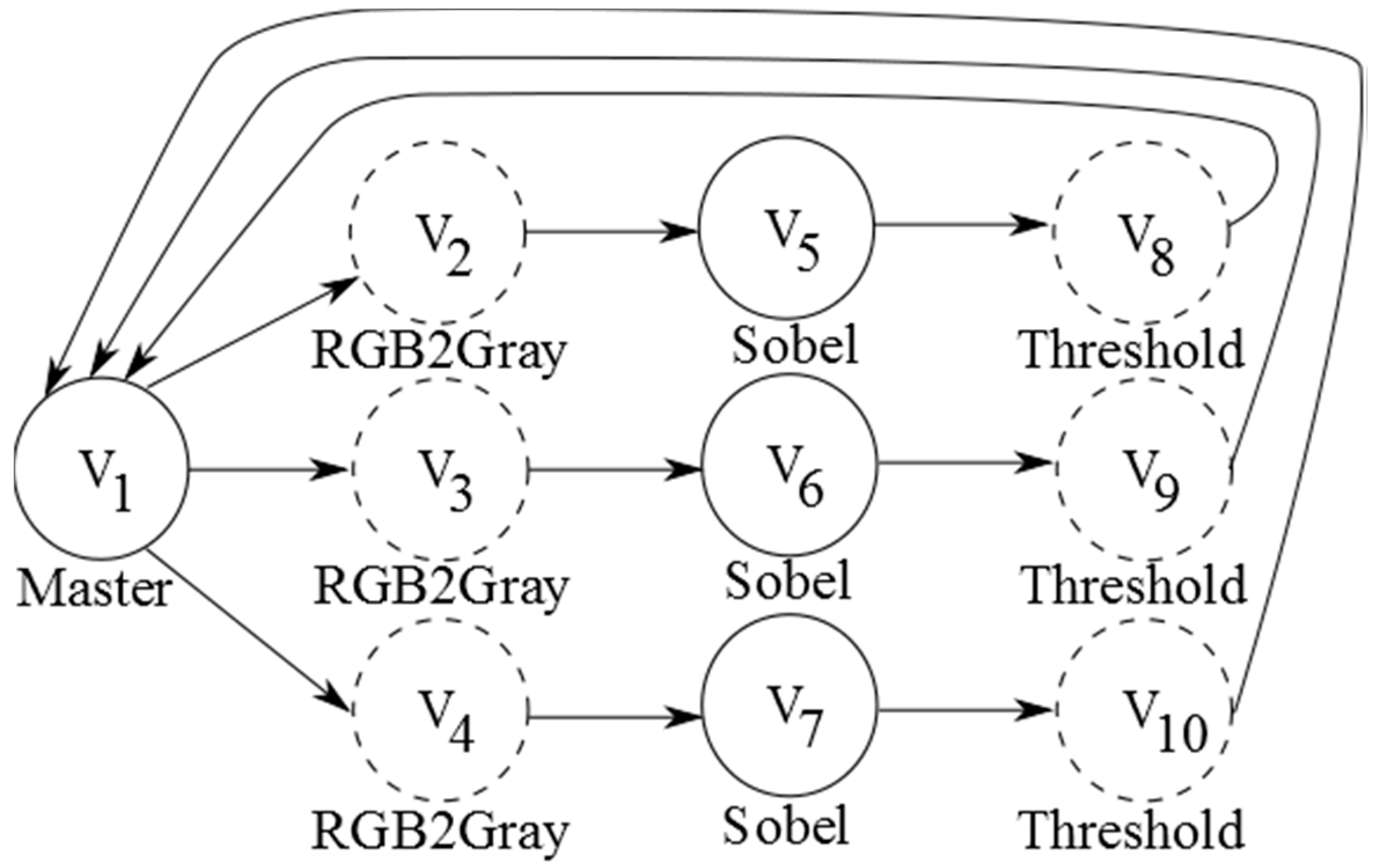
4.1. Kahn Process Networks
4.2. KPN-Based Graphs for ASIR-Based MPSoCs
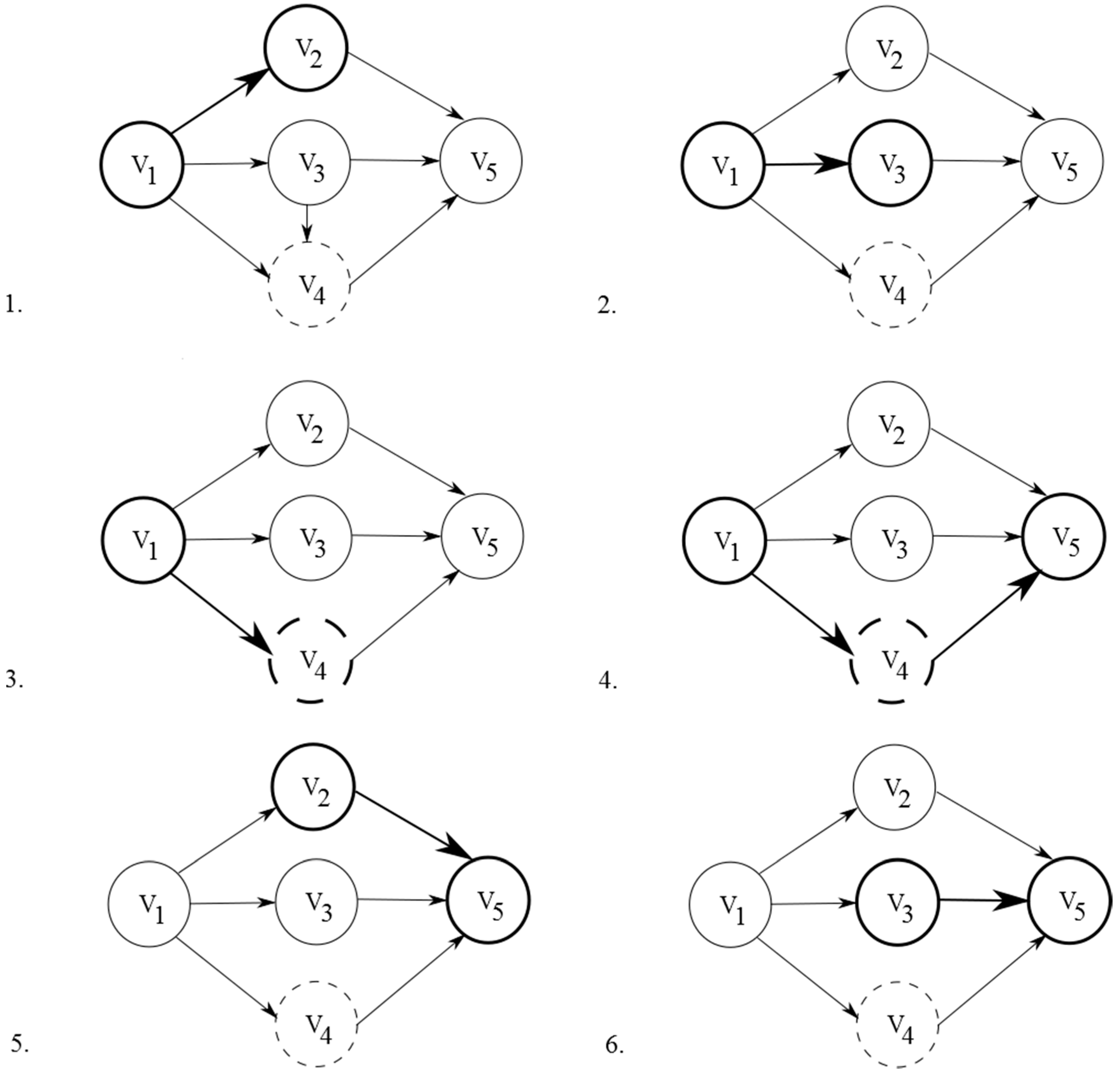
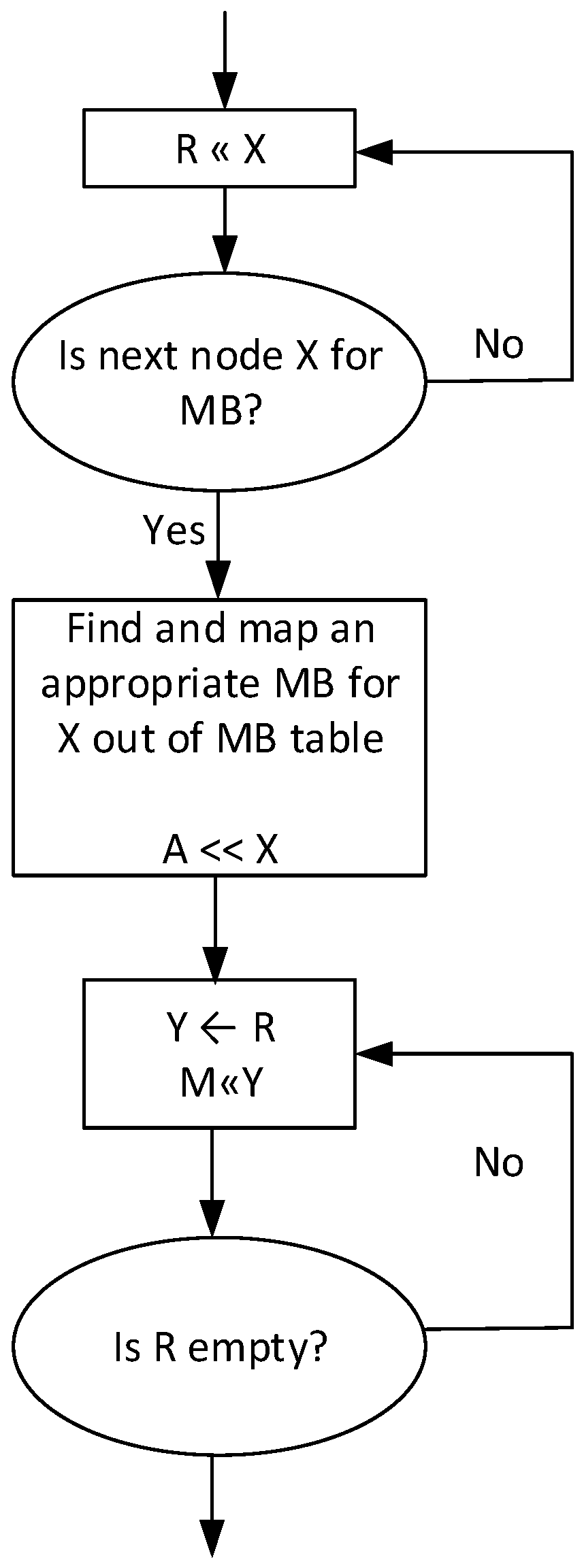
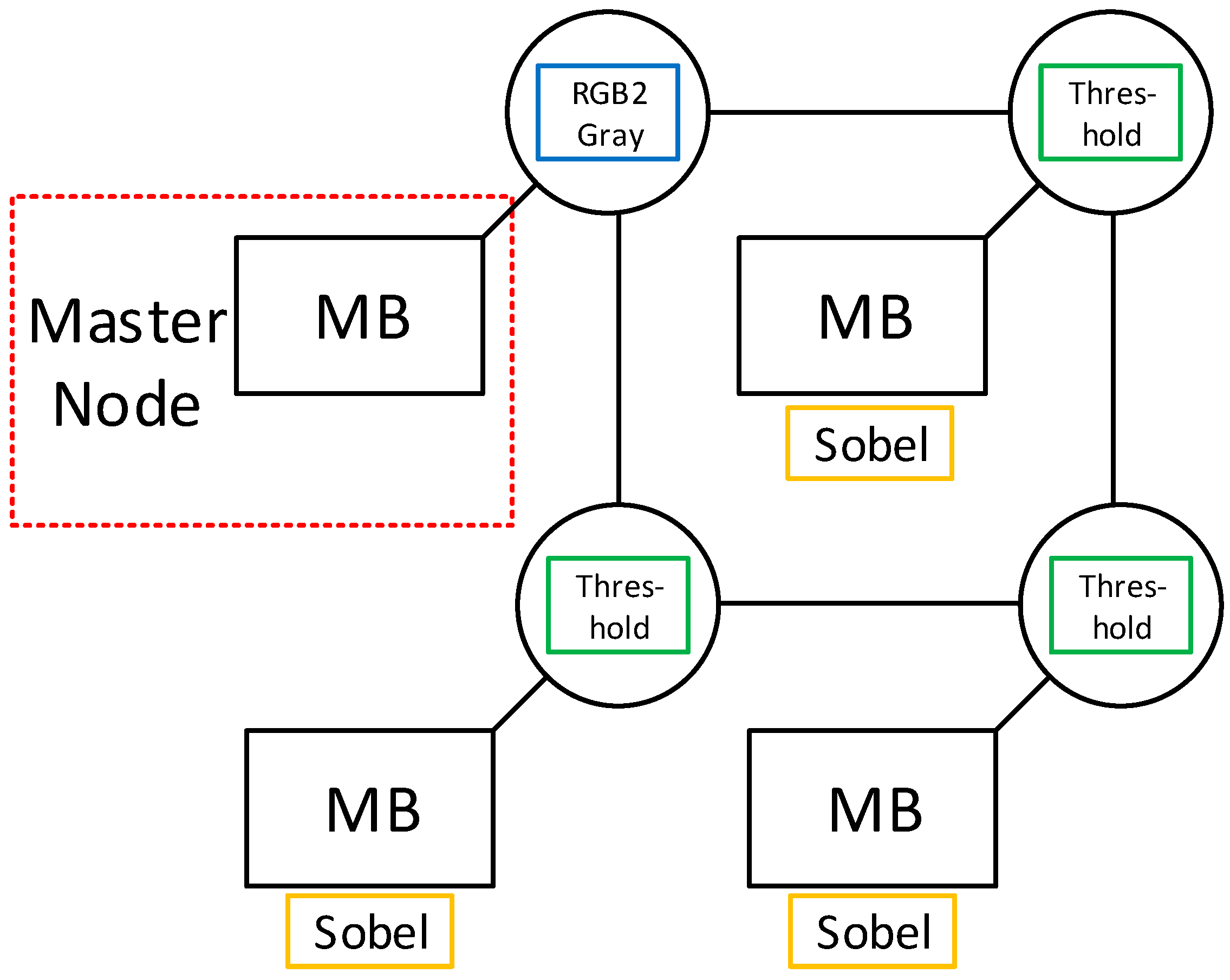
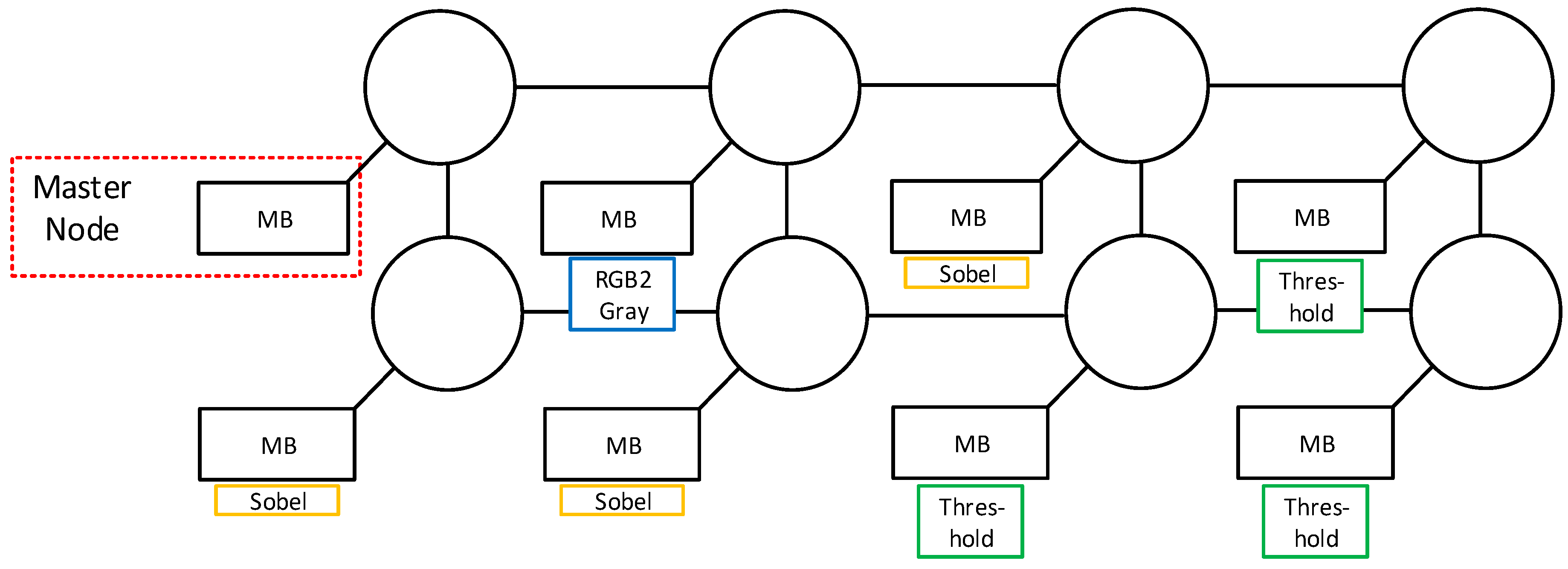
4.3. Mapping of KPN-Based Graphs on an ASIR-Based MPSoC
- The path length to the MicroBlaze processor that executes the last mapped node must be greater than the length of R.
- The routers that are used in this path must have enough available buffers free for all nodes in R.
5. Evaluation
5.1. Image Processing Algorithm
5.2. Resource Utilization
5.3. Performance Results
5.4. Discussion of Typical Use Cases
6. Conclusions and Outlook
Author Contributions
Funding
Conflicts of Interest
References
- Gaur, M.S.; Laxmi, V.; Zwolinski, M.; Kumar, M.; Gupta, N. Network-on-chip: Current issues and challenges. In Proceedings of the 2015 19th International Symposium on VLSI Design and Test, Ahmedabad, India, 26–29 June 2015; pp. 1–3. [Google Scholar]
- Nane, R.; Sima, V.; Pilato, C.; Choi, J.; Fort, B.; Canis, A.; Chen, Y.T.; Hsiao, H.; Brown, S.; Ferrandi, F.; et al. A Survey and Evaluation of FPGA High-Level Synthesis Tools. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2016, 35, 1591–1604. [Google Scholar] [CrossRef]
- Rettkowski, J.; Göhringer, D. Application-specific processing using high-level synthesis for networks-on-chip. In Proceedings of the 2017 International Conference on ReConFigurable Computing and FPGAs (ReConFig), Cancun, Mexico, 4–6 December 2017; pp. 1–7. [Google Scholar]
- Xilinx. MicroBlaze—Processor Reference Guide. UG984 (v2016.4). Available online: https://www.xilinx.com (accessed on 30 November 2016).
- Ding, H.; Ma, S.; Huang, M.; Andrews, D. OOGen: An Automated Generation Tool for Custom MPSoC Architectures Based on Object-Oriented Programming Methods. In Proceedings of the 2016 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Chicago, IL, USA, 23–27 May 2016; pp. 233–240. [Google Scholar]
- Sajjad, N.; Rettkowski, J.; Göhringer, D.; Nurmi, J. HW/SW Co-design of an IEEE 802.11a/g Receiver on Xilinx Zynq SoC using High-Level Synthesis. In Proceedings of the International Symposium on Highly-Efficient Accelerators and Reconfigurable Technologies (HEART), Bochum, Germany, 7–9 June 2017. [Google Scholar]
- Andrade, J.; George, N.; Karras, K.; Novo, D.; Pratas, F.; Sousa, L.; Ienne, P.; Falcao, G.; Silva, V. Design Space Exploration of LDPC Decoders using High-Level Synthesis. IEEE Access 2017, 5, 14600–14615. [Google Scholar] [CrossRef]
- Lucia, S.; Navarro, D.; Lucia, O.; Zometa, P.; Findeisen, R. Optimized FPGA Implementation of Model Predictive Control for Embedded Systems Using High Level Synthesis Tool. IEEE Trans. Ind. Inform. 2017, 14, 137–145. [Google Scholar] [CrossRef]
- Reiche, O.; Haublein, K.; Reichenbach, M.; Hannig, F.; Teich, J.; Fey, D. Automatic optimization of hardware accelerators for image processing. Workshop on Heterogeneous Architectures and Design Methods for Embedded Image Systems (HIS) in Proceedings of the DATE Friday. arXiv, 2015; 10–15arXiv:1502.07448. [Google Scholar]
- Kapre, N.; Gray, J. Hoplite: Building austere overlay NoCs for FPGAs. In Proceedings of the 2015 25th International Conference on Field Programmable Logic and Applications (FPL), London, UK, 2–4 September 2015; pp. 1–8. [Google Scholar]
- Underwood, K.D.; Sass, R.R.; Ligon, W.B. A reconfigurable extension to the network interface of beowulf clusters. In Proceedings of the 42nd IEEE Symposium on Foundations of Computer Science, Newport Beach, CA, USA, 8–11 October 2001; pp. 1552–5244. [Google Scholar]
- Ahmed, K.E.; Rizk, M.R.; Farag, M.M. Overloaded CDMA Crossbar for Network-On-Chip. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2017, 25, 1842–1855. [Google Scholar] [CrossRef]
- Nguyen, T.D.A.; Kumar, A. XNoC: A non-intrusive TDM circuit-switched Network-on-Chip. In Proceedings of the 2016 26th International Conference on Field Programmable Logic and Applications (FPL), Lausanne, Switzerland, 29 August–2 September 2016; pp. 1–11. [Google Scholar]
- Chen, Q.; Liu, Q. Pipelined NoC router architecture design with buffer configuration exploration on FPGA. In Proceedings of the 2015 25th International Conference on Field Programmable Logic and Applications (FPL), London, UK, 2–4 September 2015. [Google Scholar]
- Bhattacharjee, D.; Devadoss, R.; Chattopadhyay, A. ReVAMP: ReRAM based VLIW architecture for in-memory computing. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Lausanne, Switzerland, 27–31 March 2017; pp. 782–787. [Google Scholar]
- Zha, Y.; Li, J. Reconfigurable in-memory computing with resistive memory crossbar. In Proceedings of the 2016 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Austin, TX, USA, 7–10 November 2016; pp. 1–8. [Google Scholar]
- Soares, R.B.S.; Silva, I.S.; Fernandes, S.R. IPNoSys II—A new architecture for IPNoSys programming model. In Proceedings of the 2015 28th Symposium on Integrated Circuits and Systems Design (SBCCI), Salvador, Brazil, 31 August–31 September 2015. [Google Scholar]
- Singh, A.K.; Shafique, M.; Kumar, A.; Henkel, J. Mapping on multi/many-core systems: Survey of current and emerging trends. In Proceedings of the 2013 50th ACM/EDAC/IEEE Design Automation Conference (DAC), Austin, TX, USA, 29 May–7 June 2013; pp. 1–10. [Google Scholar]
- Khansanov, R.; Goens, A.; Castrillon, J. Implicit Data-Parallelism in Kahn Process Networks: Bridging the MacQueen Gap. In Proceedings of the 2018 International workshop on Parallel Programming and RunTime Management Techniques for Manycore Embedded Computing Platforms, Manchester, UK, 23–30 January 2018; pp. 20–25. [Google Scholar]
- Arras, P.A.; Fuin, D.; Jeannot, E.; Thibault, S. DKPN: A Composite Dataflow/Kahn Process Networks Execution Model. In Proceedings of the 2016 24th Euromicro International Conference on Parallel, Distributed, and Network-Based Processing (PDP), Heraklion, Greece, 17–19 February 2016; pp. 27–34. [Google Scholar]
- Orsila, H.; Salminen, E.; Hämäläinen, T.D. Parameterizing simulated annealing for distributing Kahn Process Networks on multiprocessor SoCs. In Proceedings of the 2009 International Symposium on System-on-Chip, Tampere, Finland, 5–7 October 2009; pp. 19–26. [Google Scholar]
- Peh, L.; Dally, W.J. Flit-reservation flow control. In Proceedings of the Sixth International Symposium on High-Performance Computer Architecture, HPCA-6 (Cat. No.PR00550), Touluse, France, 8–12 January 2000; pp. 73–84. [Google Scholar]
- Cabrera, R.J.A.; Legaspi, C.A.P.; Papa, E.J.G.; Samonte, R.D.; Acula, D.D. HeMatic: An automated leukemia detector with separation of overlapping blood cells through Image Processing and Genetic Algorithm. In Proceedings of the 2017 International Conference on Applied System Innovation (ICASI), Sapporo, Japan, 13–17 May 2017; pp. 985–987. [Google Scholar]
- Li, Y.; Chen, L.; Huang, H.; Li, X.; Xu, W.; Zheng, L.; Huang, J. Nighttime lane markings recognition based on Canny detection and Hough transform. In Proceedings of the 2016 IEEE International Conference on Real-time Computing and Robotics (RCAR), Angkor Wat, Cambodia, 6–10 June 2016; pp. 411–415. [Google Scholar]
















| Address | MicroBlaze | Router | Path Length | |||||
|---|---|---|---|---|---|---|---|---|
| x | y | N | E | S | W | L | ||
| 0 | 0 | v1 | v5 | - | - | - | - | 1 |
| 0 | 1 | v6 | - | - | - | - | - | 2 |
| 1 | 0 | v4 | - | - | v3 | - | - | 2 |
| 1 | 1 | v3 | - | - | - | - | - | 3 |
| LUTs | FFs | BRAMs | DSPs | |
|---|---|---|---|---|
| Buffer | 3 | 34 | 0 | 0 |
| PU (Threshold) | 109 | 146 | 0 | 0 |
| PU (RGB2Gray) | 109 | 148 | 0 | 1 |
| LUTs | FFs | BRAMs | DSPs | |
|---|---|---|---|---|
| Router | 481 | 245 | 0 | 0 |
| Router with PU (Threshold) | 600 | 361 | 0 | 0 |
| Router with PU (RGB2Gray) | 601 | 363 | 0 | 1 |
| LUTs | FFs | BRAMs | DSPs | |
|---|---|---|---|---|
| 2 × 2 MPSoC | 6916 (13%) | 5649 (5.3%) | 124 (88.6%) | 0 |
| 2 × 4 MPSoC | 14,806 (27%) | 10,973 (10.3%) | 128 (91,4%) | 0 |
| ASIR-based MPSoC | 9568 (18%) | 9815 (9.2%) | 124 (88.6%) | 1 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rettkowski, J.; Göhringer, D. ASIR: Application-Specific Instruction-Set Router for NoC-Based MPSoCs. Computers 2018, 7, 38. https://doi.org/10.3390/computers7030038
Rettkowski J, Göhringer D. ASIR: Application-Specific Instruction-Set Router for NoC-Based MPSoCs. Computers. 2018; 7(3):38. https://doi.org/10.3390/computers7030038
Chicago/Turabian StyleRettkowski, Jens, and Diana Göhringer. 2018. "ASIR: Application-Specific Instruction-Set Router for NoC-Based MPSoCs" Computers 7, no. 3: 38. https://doi.org/10.3390/computers7030038
APA StyleRettkowski, J., & Göhringer, D. (2018). ASIR: Application-Specific Instruction-Set Router for NoC-Based MPSoCs. Computers, 7(3), 38. https://doi.org/10.3390/computers7030038