1. Introduction
Understanding how a piece of data was produced, where it was stored, and by whom it was accessed, is crucial information in many processes. Insights into the data flow are important for gaining trust in the data; for example, trust in its quality, its integrity, or trust that it has not been accessed by organizations unwantedly. Especially, detecting and investigating privacy violations of personal data is a relevant issue for many people and companies. For example, personal health data should not be manipulated, if doctors base a medical diagnosis on that data. Health-related data and personal data from self-tracking (Quantified Self; QS) [
1,
2] should not be available to other people or companies, as this might lead to commercial exploitation or even disadvantages for people, such as higher health insurance contributions.
In this field, data is often generated by medical sensors or wearable devices, then processed and transmitted by smartphone and desktop applications, and finally stored and analyzed using services (e.g., web or cloud services operated by commercial vendors). Following the trace of data through the various distributed devices, applications, and services is not easy. Especially, people who are not familiar with software or computer science are often not able to understand where their data is stored and accessed.
To understand the trace of data, the
provenance [
3] of that data can be recorded and analyzed. Provenance information is represented by a directed acyclic property graph, which is recorded during generation, manipulation, and transmission of data. The provenance can be analyzed using a variety of graph analytics and visualization methods [
4]. Presenting provenance to non-experts is an ongoing research topic (
“Provenance for people”). As a new visualization technique for provenance, we present
provenance comics that we introduced and applied to trace personal data [
5].
The remaining article is organized as follows:
We shortly give an overview about provenance and our provenance model for Quantified Self data and self-tracking workflows [
6,
7] (
Section 2).
We explain the general idea of
provenance comics for provenance compliant with the PROV standard [
8] (
Section 3).
We describe a visual mapping between the provenance of Quantified Self data and their graphical representations in comic strips (
Section 4).
We briefly describe our prototype for
automatically generating provenance comics (
Section 5).
We give details and results of a qualitative user study (
Section 6).
2. Provenance of Quantified Self Data
2.1. Provenance of Electronic Data
The definition of
provenance is:
“Provenance is a record that describes the people, institutions, entities, and activities involved in producing, influencing, or delivering a piece of data or a thing. In particular, the provenance of information is crucial in deciding whether information is to be trusted, how it should be integrated with other diverse information sources, and how to give credit to its originators when reusing it. In an open and inclusive environment such as the Web, where users find information that is often contradictory or questionable, provenance can help those users to make trust judgments [8]”.
With the previous definition, World Wide Web Consortium (W3C) started in 2011 and finalized in 2013 the generic provenance model
PROV, which has specifications for a data model
PROV-DM [
8] and an ontology
PROV-O [
9], among others.
PROV was inspired by various different approaches [
10], that is adaptable to any domain. The general provenance model can be seen as a property graph with three different types of nodes:
Entities,
Activities, and
Agents. Entities represent physical (e.g., sensors or medical devices), digital (e.g., data sets), conceptual (e.g., a workflow description), or any other kinds of objects. An activity is a process that uses or generates entities and that can be associated with an agent, meaning that the agent is responsible for the activity.
Provenance is being recorded during runtime of a process. To make Quantified Self workflows provenance-aware requires to gather information that is required by the provenance model (see [
7] for some possible approaches). This information is stored in a provenance database or provenance store. For example,
ProvStore [
11] is publicly available provenance store. Large provenance graphs of long running real world workflows are stored in scalable databases more efficiently (e.g., using graph databases such as
Neo4
j [
12]).
2.2. Provenance Visualization
For analyzing data provenance, visualization is a feasible method. Several solutions to visualize provenance exist, for example, publicly available web-based tools such as
PROV-O-Viz [
13], desktop tools such as
VisTrails [
14], or numerous other graph visualization tools.
Provenance is usually represented as a directed acyclic graph (DAG). In many visualizations the graph is sorted topologically from left to right or top to bottom. Much like in a family tree, the “oldest” data can then be seen at the left or top and the “youngest,” most recent data at the right or bottom.
While these graphs may, to some extent, seem quite self-explaining to scientists, they can be rather hard to understand for laymen who are not usually concerned with graphs at all and have not been trained to read them.
Furthermore, provenance graphs can sometimes grow to enormous sizes, becoming so huge that even experts will have a hard time reading them. Since the span of immediate memory is limited to 7 ± 2 entities at a time [
15], graphs containing more than five to nine items will become gradually harder to interpret with every new item being added. However, 7 ± 2 is a value that is easily reached and exceeded by even simple examples of provenance graphs. The larger the graphs become, the more difficult it is to draw conclusions and derive new findings from the provenance data.
The possibility to view the provenance of their own data is of no value to end users, if the visualization of that provenance is unintelligible to them. It cannot be expected that they learn how to read an abstract, possibly complex graph. Instead, the visualization should be simple, self-explaining, and familiar in such a way that end users can read and understand it almost effortlessly.
2.3. Quantified Self Provenance Model
Based on a requirements study of Quantified Self workflows and analysis of documentation from breakout sessions at Quantified Self Conferences (such as the QSEU14 Breakout session on Mapping Data Access [
16]), we developed a provenance model for Quantified Self workflows [
6].
The possible activities in Quantified Self workflows are categorized into six abstract functionalities:
Input,
Sensing,
Export,
Request,
Aggregation, and
Visualization. We defined a provenance sub model for each of these abstract functionalities (
https://github.com/onyame/quantified-self-prov).
As an example,
Figure 1 show the provenance model for the
Visualize activity where data (
PROV entity “UserData”) that belongs to a human (PROV agent “User”) is visualized by method (
PROV activity “Visualize”) from a certain software (
PROV agent “Software”) which results in a graphic (
PROV entity “Graphic”). The respective
PROV elements can contain attributes, which specify meta information such as time of creation, names, or data types.
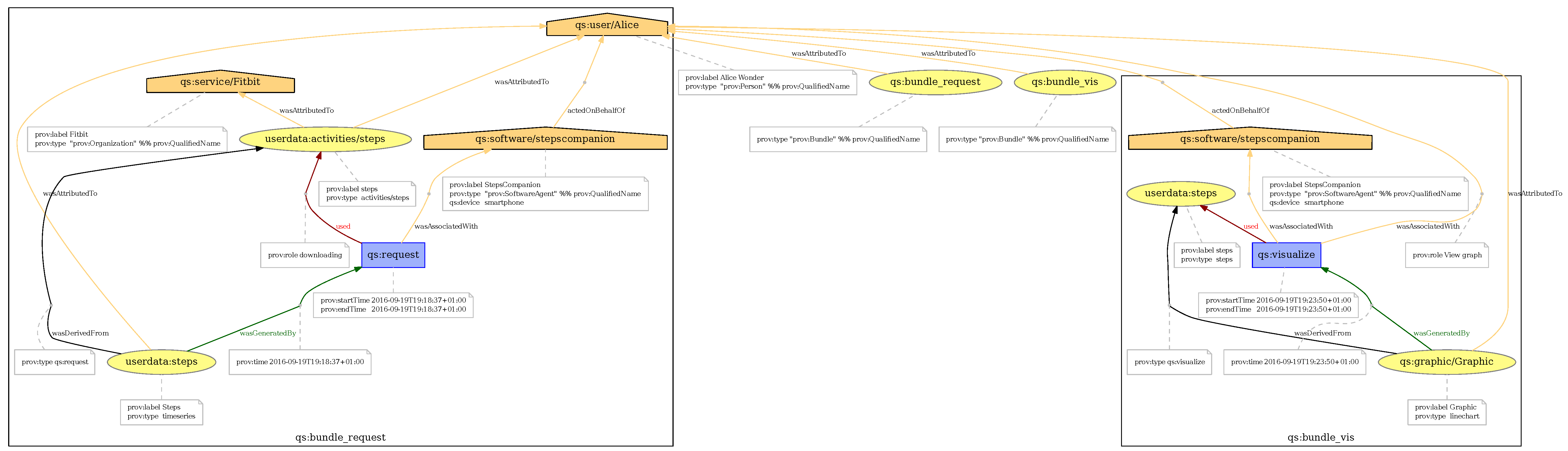
While the basic Quantified Self activities and the provenance of these activities are easy to understand conceptually, the representation of that provenance can be difficult to understand as explained in
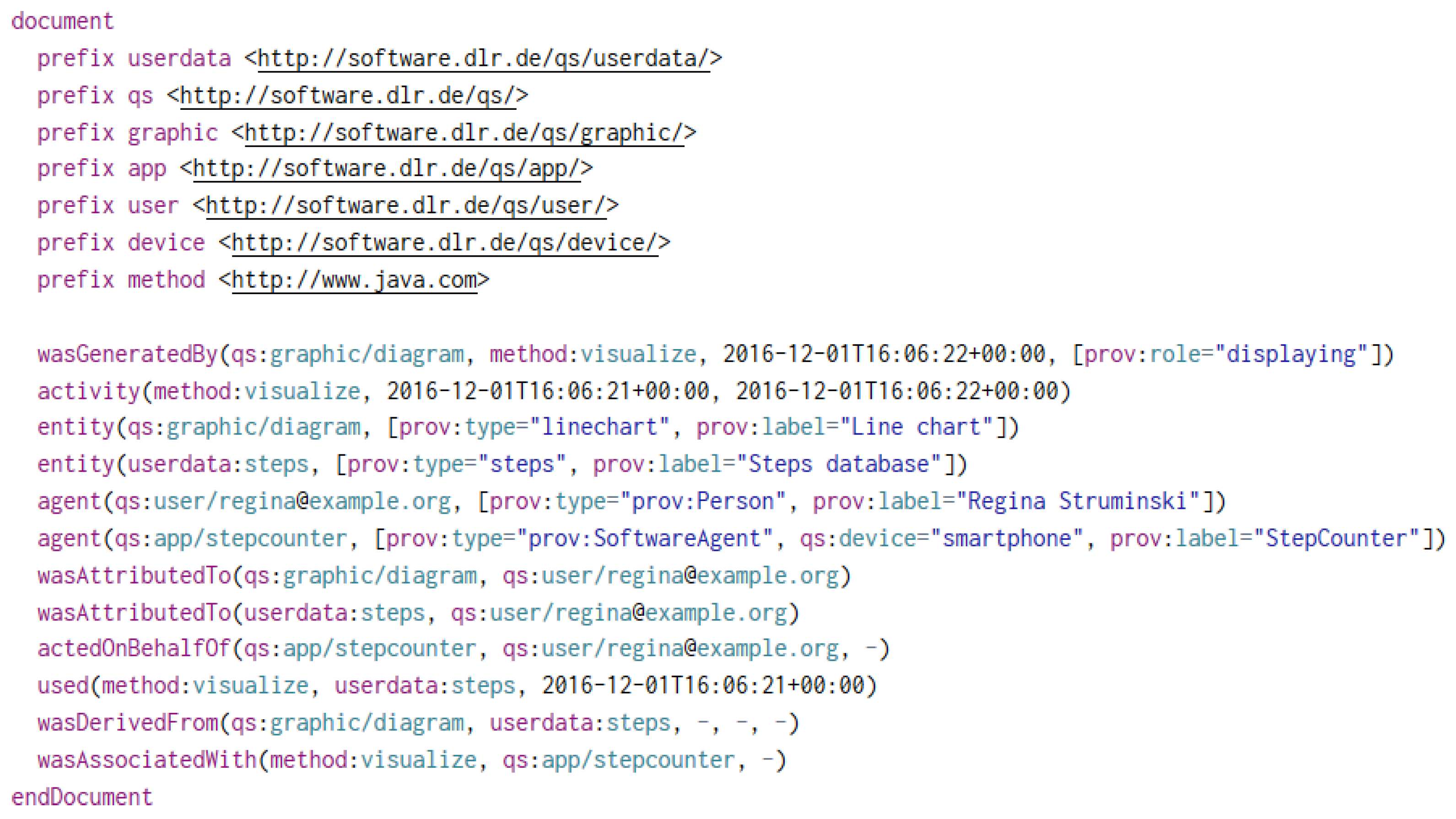
Section 2.2. For example, the two most common representations of provenance are a graphical representation as a graph (
Figure 2) and a textual representation in
PROV-N notation (
Figure 3).
3. Provenance Comics
The basic idea of provenance comics is to present the provenance information of data processes in a visual representation, which people can understand without prior instruction or training. A general advantage of comics over conventional visualizations, like node-link diagrams, is their familiarity: Almost anyone has probably seen some comics in their life. No training is required to read them, and they can transport meaning with minimal textual annotation. They are easy to interpret and not as strenuous to read as, for example, a graph or a long paragraph of continuous text.
Data provenance has a temporal aspect: origin, manipulation, transformation, and other activities happen sequentially over time. The directed, acyclic provenance graph guarantees that, while moving through its nodes, one always moves linearly forward or backward in time. It is, therefore, possible to derive a temporal sequence of happenings from the graph that can be narrated like a story.
We generate a comic strip for each basic activity in the provenance data (e.g., for the activity “Visualize” in
Figure 1 or
Figure 2). Each strip consists of a varying number of panels, which are small drawings that provide further details about the activity. The comic strip for the earliest activity in the provenance document is at the top, while the strip for the newest, most recent activity is at the bottom. The complete set of comic strips shows the “story” of the data. Of course, when there are many activities, the collection of comic strips could become quite large. In this case, one could choose a subset of the provenance, containing only those activities that are relevant in real use cases.
Some questions that the provenance comics should answer and explain are When was data generated or changed?, Where was the user?, or Where was the user’s data stored? At this time, the comics do not contain the actual data. They only represent information contained in the provenance of the user’s data. This might be extended in the future by using (parts of the) data for representing the real measurements, geographical coordinates, etc.
4. Visual Mapping
To generate the provenance comics, we defined a consistent visual language [
17]. This visual language allows to translate the provenance data into corresponding drawings. Generally speaking, we mapped elements of the
PROV standard (
Entity,
Activity,
Agent) onto three distinctive graphical features:
shapes,
colors, and
icons or texts.
4.1. Shapes
We designed and selected shapes according to several criteria. Most importantly, we created shapes that do not show much detail. Instead, they have a “flat” look without any textures, decorations, shadows, or three-dimensional elements. Flat design became popular in mobile UI and icon design [
18] and despite of the fact that study results shows a higher cognitive load for searching flat icons [
19], we stick to flat design in the first appraoch since we have use cases in mind, where the comics are incoporated into mobile applications.
Table 1 gives an overview of the shapes we selected to reflect the different types of elements in the Quantified Self
PROV model [
6]. Activities are not directly listed here. Unlike agents or entities, activities are actions that take place over time, as described in
Section 3. Thus, they are not depicted as a single graphic; instead, they represent a temporal progress and only become visible through the sequence of events in the next three to five panels of the comic.
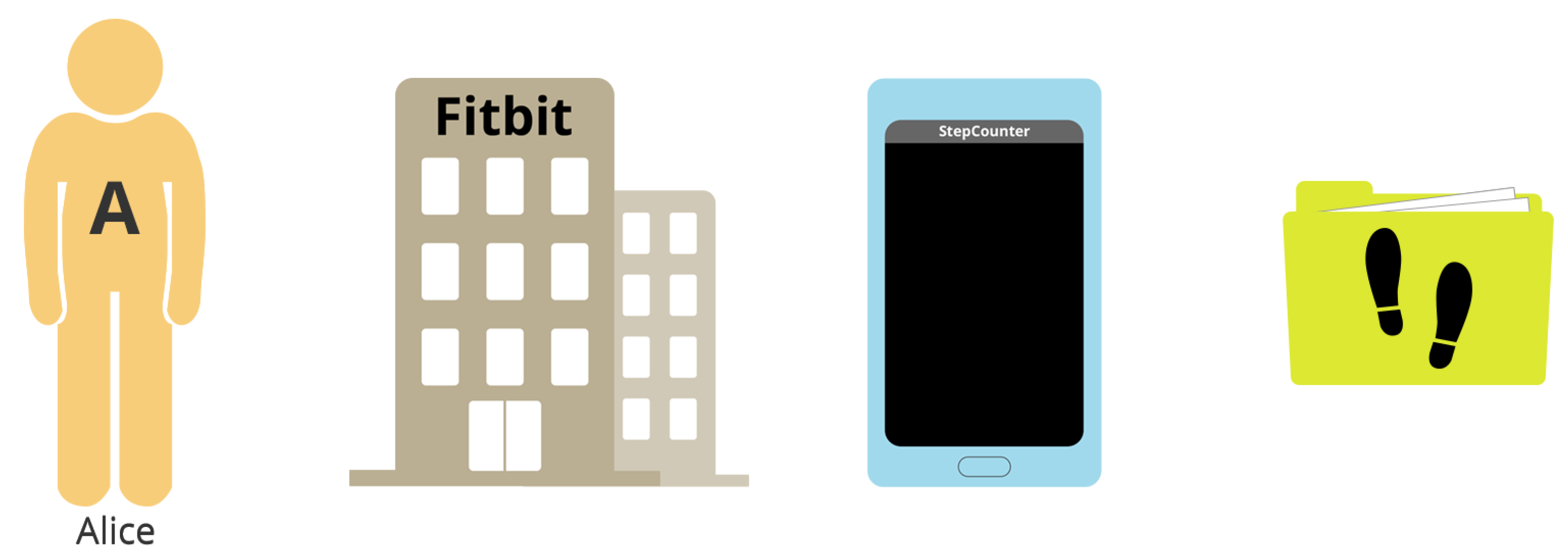
4.2. Icons, Letters, and Labels
As a second distinctive feature, all main actors in the comics carry some kind of symbol on them, whether it be an icon, a single letter, or a whole word (
Figure 4).
Person agents always wear the first letter of their name on the chest.
Organization agents display their name at the top of the office building.
SoftwareAgents show an application name on the screen.
Entities are marked by an icon representing the type of data they contain. A few icons have been defined for some types of data that are common in the Quantified Self domain (
Table 2).
4.3. Colors
We defined colors for entities as well as the different types of agents. For example, Person agents use a light orange color, while SoftwareAgents have a light blue and Organization agents a tan color. Entities are always colored in a bright yellowy green. We took care that colors are well-distinguishable even for people suffering from color vision deficiencies (pronatopia, deuteranopia, tritanopia, and achromatopsy). In the few cases where they are not, discriminability is still granted through the other two distinctive features, namely shape and icons or labels.
4.3.1. Colors for Objects of the Same Type
Alternative color shades have been defined for both agents and entities in case that two or three objects of the same type ever need to appear at once.
In a previous approach, colors had been rotated by 180, 90 and 270 to obtain well-matched second, third and even fourth colors. However, two problems arose: First of all, the whole comic would generally have become very colorful, which would possibly have led to confusion. Depending on the situation, there might, for example, have been a blue person that owns a blue phone and a pink entity, while at the same time a pink person is present owning a blue entity. Some similar items would have had very dissimilar colors, while some dissimilar items would have had very similar colors. Apart from causing a certain visual inconsistency, this might also have suggested to the reader that there were some deeper meaning to the colors, other than discriminability. For example, the reader might have thought that similar colors indicate a grouping of some kind (e.g., that a pink entity belongs to a pink person).
4.3.2. Colors for Objects of Different Types
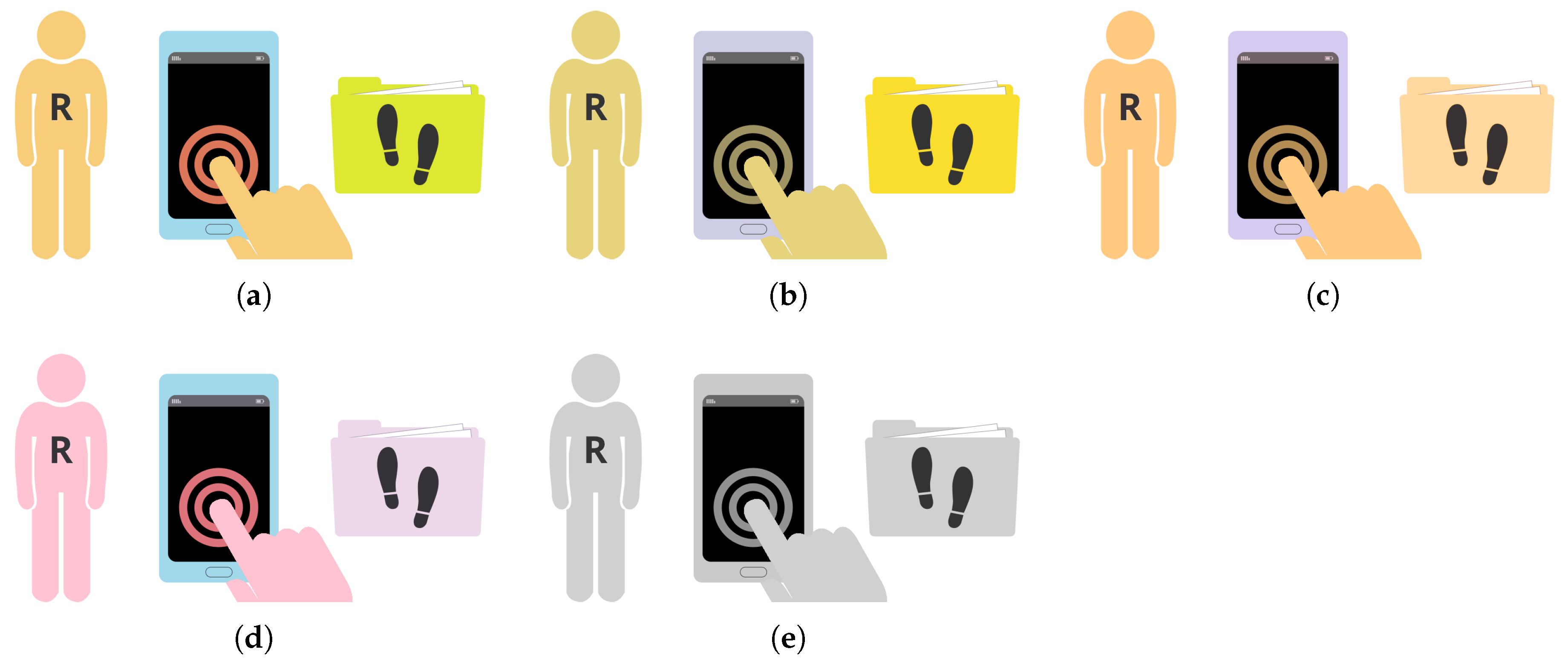
The distinctiveness between the colors of different object types is not as important as that between colors of the same types of objects. That is to say: Color is more important for distinguishing two items that have the same shape than it is for two items with different shapes. Thus, the selection and discriminability of colors need not be handled as strictly for different types of actors.
Figure 8 shows that especially the default colors of
Person agents and entities are not well distinguishable by readers suffering from color vision deficiencies. However, since shape and icon or text will be different, the weak color difference is neglectable.
Figure 9 shows that items are still well distinguishable due to their shapes and icons.
4.3.3. Text and Icon Colors
In a number of cases, agents and entities will be labeled with texts, letters or icons. To keep those recognizable on different background colors, a simple rule of thumb has been established using the colors’ equivalents in the Lab color space:
If a color’s L (lightness) value is between 0 and 49, the text or icon color is white.
If a color’s L value is between 50 and 100, the text or icon color is black.
By choosing the font color this way, a contrast ratio of at least 3:1 (often a lot higher) is achieved, which is “the minimum level recommended by
ISO-9241-3 and
ANSI-HFES-100-1988 for standard text and vision” [
20]. The
WCAG’s SC 1.4.3 (
Minimum Contrast) requires a ratio of 4.5:1 for standard text, and 3:1 for “large-scale text and images of large-scale text”, with “large-scale text” having a size of at least 18 point, or 14 point and bold style. The even stricter SC 1.4.6 (
Enhanced Contrast) requires a ratio of 4.5:1 for large-scale text and 7:1 for standard text [
20].
The majority of icons and letters used in the
PROV Comics qualify as large-scale text. By choosing the font or icon color according to the simple “black or white” rule proposed here, it is guaranteed that a contrast ratio of at least 3:1 is always achieved. In fact, when combined with the previously defined agent and entity colors, this rule yields a contrast ratio of at least 4.5:1 for all graphics containing text or icons. Thus, they even fulfill the stricter SC 1.4.6 (
Enhanced Contrast) for large-scale text.
Figure 10 shows some example graphics with high-contrast icons or letters (Contrast ratios calculated by
http://leaverou.github.io/contrast-ratio/).
4.4. Panels and Layout
All panels are perfect squares. Horizontally, they are separated from each other by a whitespace of 10% of the panel size, while the vertical distance between rows of panel is 20% of the panel size. For example, 600 × 600 pixel panels have 60 pixels of white space between them horizontally, and 120 pixels of white space vertically. By arranging them this way, panels are grouped into rows, helping the reader determine the correct reading direction. This is explained by the gestalt law of proximity: Objects that are close to each other are perceived as a group [
21].
However, no requirements are made as to how many panels each row should contain. Due to the fact that the comics are to be viewed on different devices the layout needs to be scalable. While a row may consist of four or five panels on a desktop or tablet computer, there might only be enough space for one panel per row on a smartphone.
The panels have black borders, the width of which should amount to 1% of the panel size. For example, a 600 × 600 pixel panel should use a 6 pixel border. In case a caption or introductory text is added to the top of a panel, it is separated from the rest of the panel by a bottom border with the same properties. Borders group the different graphics inside a panel together, so they are perceived as one large image. This is an application of the law of closure, which states that objects in a framed area are perceived as one unit [
21].
4.5. Captions and Text
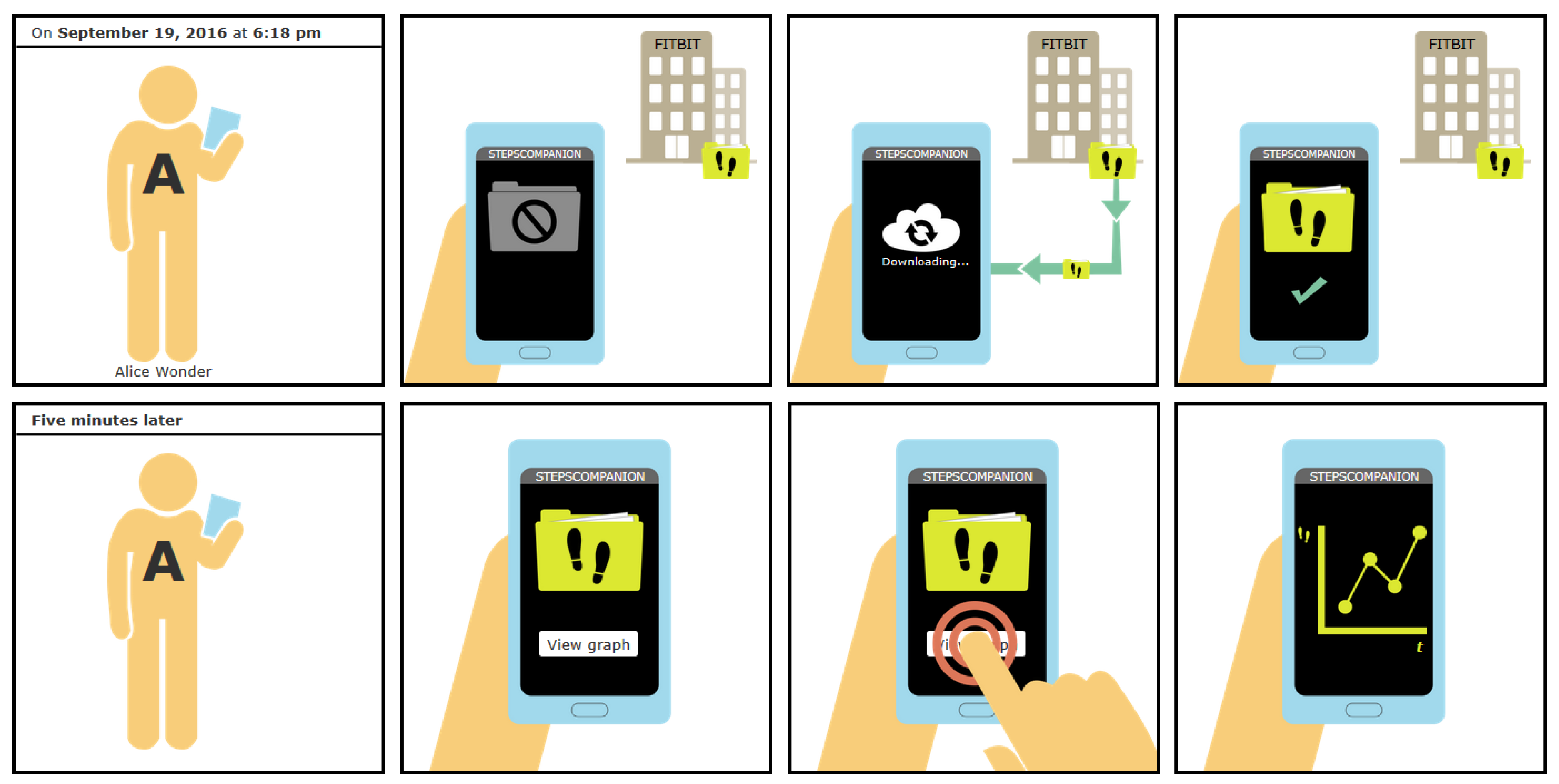
We aimed to include as little text as possible in the comics. Most of the information should be conveyed by the graphics to provide an effortless “reading” experience. However, in certain cases, a few words are useful to support the interpretation of symbols. For example, when up- or downloading data, the words “Uploading…” or “Downloading…” are added below the cloud icon. These short annotations take only little cognitive capacity to read, but may greatly help understand certain icons.
Buttons also use textual labels, as it is very difficult to convey the actions they represent in the form of graphics. The labels are only very short though, mostly consisting of only one or two words (e.g., “View graph” or “Export CSV”).
Captions are used to expose the date and time when activities took place. Every comic strip begins with such a caption in the very first panel to give the reader temporal orientation. If a relevant amount of time has passed between two activities, a caption may be used again to communicate this to the reader.
The comic depicted in
Figure 11 contains examples of these textual annotations, button labels, and captions.
4.6. Level of Detail
The comics are characterized by extreme simplicity and reduction to the essentials. The reader should never have to look for the important parts of the image. Thus, only relevant items are pictured; no purely decorative graphics are used. This includes the background, which is plain white at all times. No surroundings or other possible distractions are ever shown. By eliminating details, reducing images to their essential meaning, and focusing on specific elements, the emphasis is put on the actual information.
4.7. Recurring Image Structures
Activities will not be represented by a single graphic, but by a sequence of three to five comic panels. Similar activities should be illustrated by similar sets of panels, making use of recurring image compositions. For example, the activities of the data sub-models
Export,
Aggregate, and
Visualize are comparable in that they take one kind of data and create a different kind of data from it. They can thus be visualized in a very similar manner (see
Figure 11,
Figure 12 and
Figure 13).
Using recurring image structures whenever possible adds to the comics’ consistency, comprehensibility and learnability: Once readers have understood the Export panels, for example, they will easily be able to understand Aggregate and Visualize panels, too.
4.8. Commonly Known Symbols
Some of the graphics used in the comics rely on the reader’s experience. For example, “sheet of paper” and “document folder” icons have been used for decades to symbolize data and collections of data, and in recent years, the “cloud” icon has become a widely known symbol for external data storage space.
Conventions like these are useful when it comes to depicting rather abstract items. Concrete objects, such as a person, a smartphone, or a computer, can easily be drawn as a simplified graphic, but it is not as easy with more abstract notions like “data”. The graphics representing exported files, collections of Quantified Self data, but also data transmission and synchronization build upon icons that have been adopted into many peoples’ “visual vocabulary”.
4.9. Example
Figure 11 shows an example of two comic strips that correspond to the provenance graph in
Figure 14. The example contains the consecutive strips for two user actions:
downloading steps count data from a cloud service to the user’s smart phone (
PROV activity “request”), and
visualizing the steps data in a line chart (
PROV activity “visualize”).
5. Implementation
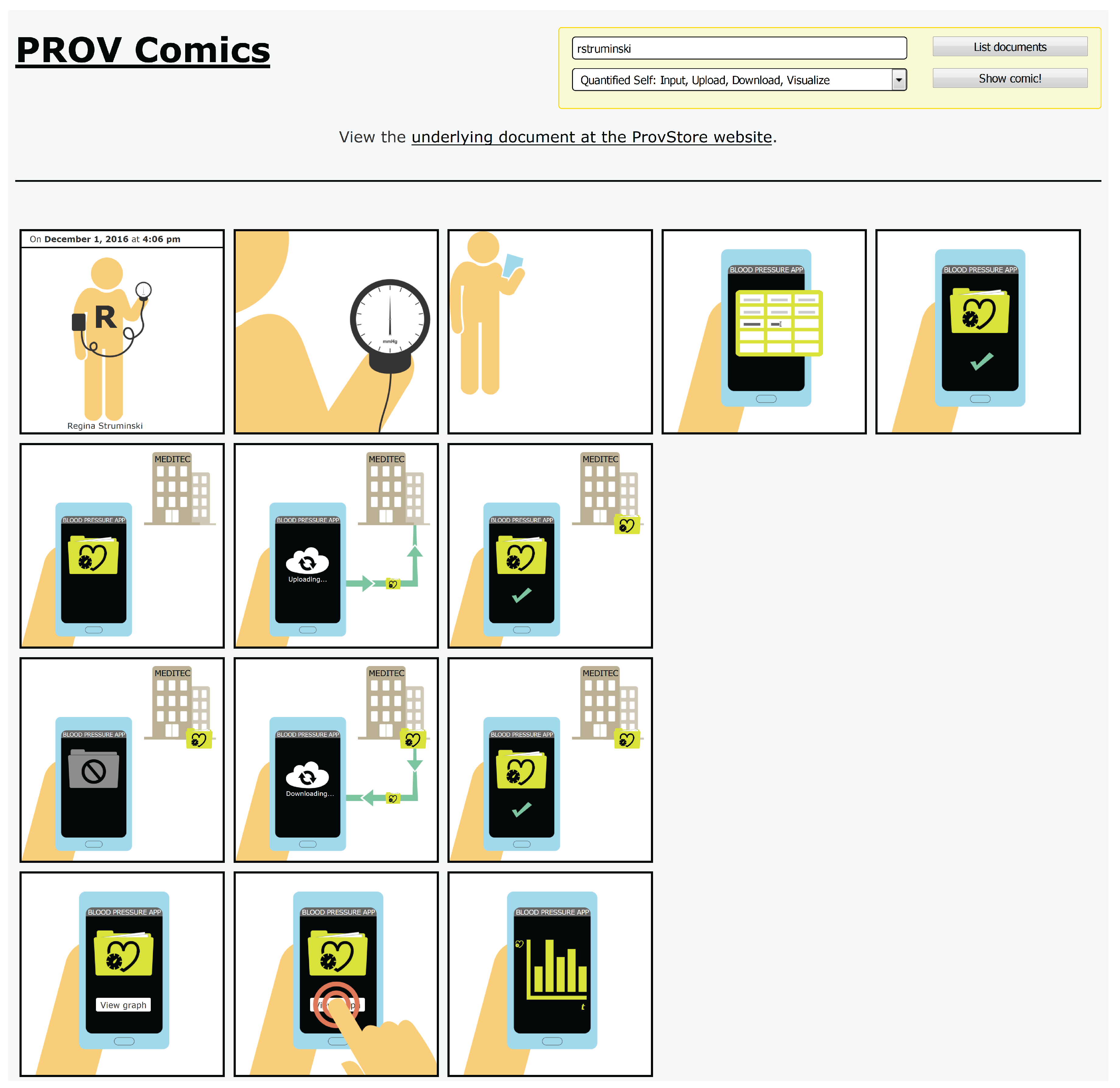
For generating the comic strips, we developed the web application
PROV Comics in JavaScript [
22] (
Figure 15). This web application fetches provenance documents directly from a provenance store. The current prototype supports the publicly available provenance store
ProvStore [
11] using the
ProvStore jQuery API to retrieve public documents from the
ProvStore for a certain user.
Within the provenance document, the script first looks for activities to determine what kinds of panels need to be displayed. If there is more than one activity, the correct order is derived from the activities’ timestamps. As mentioned earlier in
Section 4.7, activities will not be represented by a single graphic, but by a sequence of three to five comic panels. Similar activities are illustrated by similar sets of panels.
After that, the script reads the attributes of involved agents, entities, and relations to decide which graphics to include in these panels. For example, the attributes indicate whether to display a smartphone or a computer, a folder or a single document, a steps icon or a weight icon, etc.
For generating the comics, the ProvComics.js script defines three JavaScript prototypes (“classes”):
- ProvComic
serves as a frame to contain all comic panels. It is also the general starting point for creating a provenance comic inside a given HTML element. For example, if there is a <div id=“comic”> tag in the HTML, a new provenance comic may be started within the div element by declaring var comic = new ProvComic(“#comic”).
- Panel
represents a single comic panel and has all necessary abilities to create any of the panels described in the concept. For example, it provides functions to add captions, Persons, SoftwareAgents, Organizations, different types of entities, etc.
- PanelGroup
represents a predefined sequence of panels. They make it easier to insert recurring panel sequences. For example, it provides a function to add all panels depicting a download Request at once.
6. Qualitative User Study
We conducted a user study to evaluate the clarity and comprehensibility of the provenance comics. Ten test subjects were shown a number of test comics and asked to re-narrate the story as they understood it.
6.1. Study Design
We decided that a qualitative study was the better choice—in contrast to a quantitative study—in order to find out whether or not the PROV Comics are comprehensible. Different people may understand the comics in different ways, or have different problems when reading them. These can hardly be compared or measured in numbers, and creating a standardized questionnaire with closed questions would have been very difficult. Moreover, it would probably have led to further problems; for example, if asking about certain features of the comics using single or multiple choice questions, the question itself as well as the available answers might have provided hints and suggested something to the participants that they actually did not understand by themselves when they first read the comics.
Due to these considerations, we let test readers speak freely about the comics and performed a qualitative analysis afterwards. However, to make the test readers’ answers accessible to statistics and comparison, we created a list for each of the comics, containing 10 to 23 findings that participants might discover and verbalize. It was thus possible to gain quantitative data by calculating the percentage of discovered findings.
6.1.1. Research Question
The general research question that was to be answered by the study is whether the comics are comprehensible to average end users:
Are the selected graphics and the visual language they form understandable? and
Do users understand the history of their own data (i.e., when and how their data originated, what conversions and transformations it underwent, and who had access to or control over it in the course of time)?
The study was also to reveal misunderstandings that may arise from a lack of technical knowledge of the reader’s part and help determine passages where the images are not explanatory enough and need to be improved or extended.
6.1.2. Test Comics
We selected five different scenarios as test comics to be included in the user study [
17]. The first three test comics each depicted a combination of two activities (e.g.,
Input and
Visualize). The fourth and fifth comics are a little longer, combining three to four activities.
6.1.3. Questions
We decided to have test readers speak freely about the comics and do a qualitative analysis afterwards. However, to make the test readers’ answers accessible to statistics and comparison, we created a list for each of the comics, containing 10 to 23 findings that participants might discover and verbalize. It was thus possible to gain quantitative data by calculating the percentage of discovered findings.
6.1.4. Timing
Test readers were interviewed one at a time, and each reader was interviewed only once; there were no repeated interviews with the same persons. All participants were shown the same comics in the same order. The interviews took about thirty minutes each and were conducted over a period of several days.
6.1.5. Selection of Test Subjects
No special background was required of the test persons; on the contrary, it was desired that they have no previous knowledge about data provenance and no special expertise in the Quantified-Self domain. No limitations were set in terms of age, gender, or occupation.
Table 3 gives an overview about the selected participants.
6.1.6. Tasks, Rules and Instruments
For each participant, five different sheets with comic strips were printed out and handed to them on paper. To obtain comparable results, all test subjects were asked to fulfill the exact same tasks for each of the five comics: first read the comic silently for themselves, and then re-narrate their interpretation of the story. To avoid influencing the process in any way, the examiner did not talk to participants at this stage. A smartphone running a dictaphone app was used to record the participants’ re-narrations of the comics.
6.1.7. Debriefing
After all comics had been worked through, any difficult parts were revisited and analyzed in an informal conversation. Participants were encouraged to comment freely on the comics, giving their own opinion and suggestions for improvements.
6.2. User Study Results
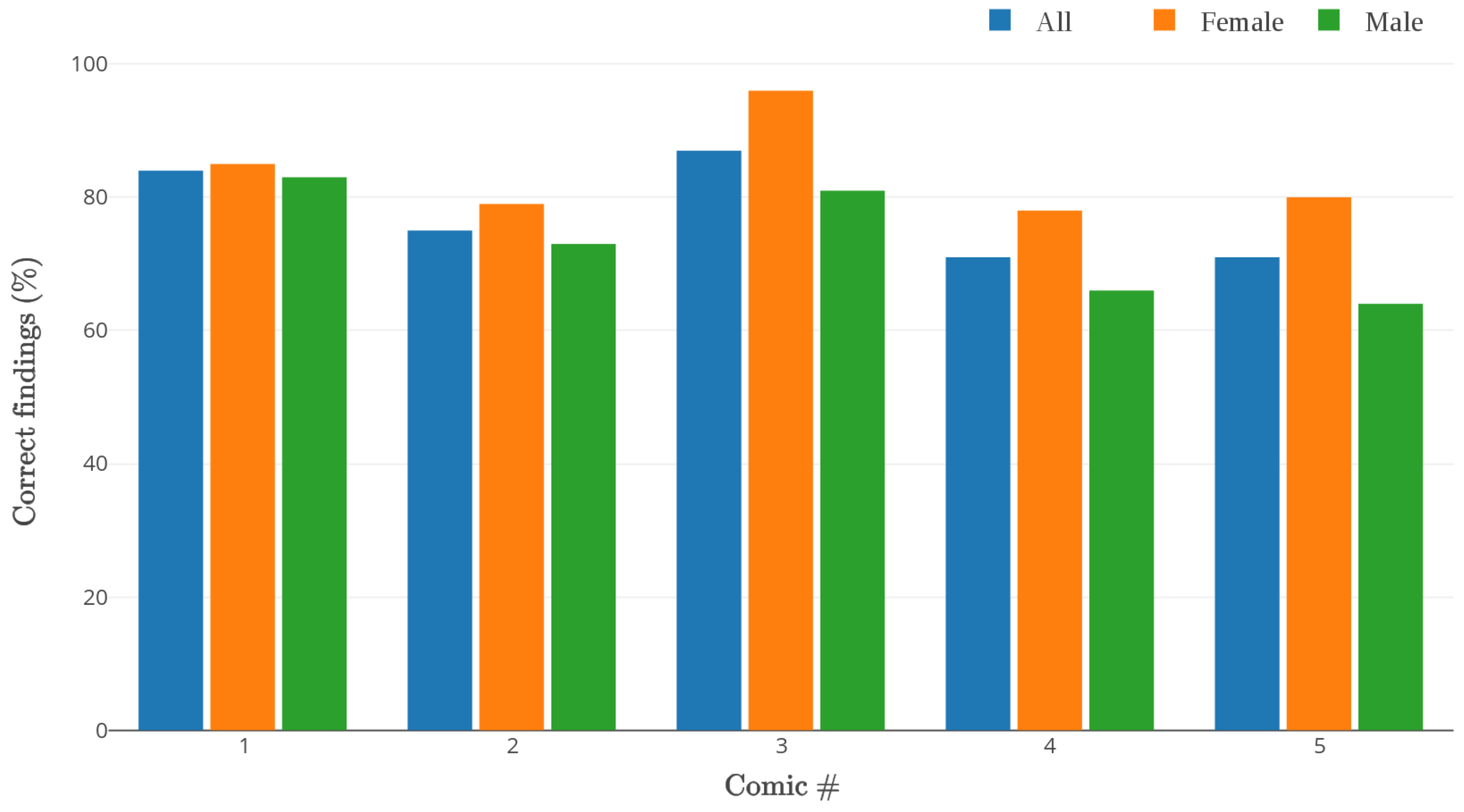
The average percentage of findings that participants verbalized over all five comics was 77%. The value was remarkably high for some particular comics, the highest one being 87%. Women showed a better overall performance than men (84% for women vs. 73% for men).
Figure 16 shows results for all test comics. However, the number of test subjects in this small study is too low to draw any general conclusions from that.
There were certain difficult parts in some of the comics, which mostly stemmed from a lack of experience with Quantified Self applications or web services. However, even in these cases, the general essence of the story was largely interpreted correctly.
Participants had no difficulties recognizing and interpreting the different icons for concrete elements, such as people, smartphones, computers, and bracelets or smartwatches. However, even more abstract notions (e.g., “transmitting data from one device to another”, “synchronizing data with a cloud”) were well-understood, since they relied on icons that are commonly used in software and web applications and were understood by most readers without any confusion.
Readers also had no problem identifying themselves with the comic figure (human silhouette). Almost every re-narration was told from a first-person point of view, using sentences like “I was walking”, “I was wearing a bracelet”, “I clicked the button”, etc.
In summary, all users were able to explain correctly the scenarios depicted in the comic strips. Some users suggested minor changes and improvements to the visual representation.
Current work includes user studies with a much broader set of people, especially with very limited knowledge about the technology behind wearable devices, smartphone applications, and services.
7. Related Work
Usually, visualization in Quantified Self focuses on the
data, where all kinds of visualization techniques are used [
23]. For example, time series visualizations or geographical visualization are very common (See visualization examples at the “Quantified Self” website:
http://quantifiedself.com/data-visualization/).
For
provenance visualization, most tools found in literature visualize provenance graphs using ordinary node-link diagrams, or tree representations similar to node-link diagrams.
Provenance Map Orbiter [
24],
Provenance Browser [
25], and
Provenance Explorer [
26] are based upon node-link diagrams. Large provenance graphs are then simplified by combining or collapsing sub-nodes or hiding nodes that are not of interest right now. The user can interactively explore the graph by expanding or zooming into these nodes.
Other tools, such as
VisTrails [
14], use a tree representation similar to node-link diagrams. Visual clutter is reduced by hiding certain nodes, limiting the depth of the tree, or displaying only the nodes that are related to the selected node.
Probe-It! [
27] and
Cytoscape [
28] basically display provenance as ordinary graphs. However, Probe-It! does not only show the
provenance of data, but also the
actual data that resulted from process executions. In
Cytoscape, users can create their own visual styles, mapping certain data attributes onto visual properties like color, size, transparency, or font type.
One work that stands out due to its completely different and novel approach is
InProv [
29]. This tool displays provenance using an interactive radial-based tree layout. It also features time-based grouping of nodes, which allows users to examine a selection of nodes from a certain period of time only.
There are some more related works, even though they are not directly concerned with provenance visualization. A non-visual approach to communicating provenance is natural language generation by Richardson and Moreau [
30]. In this case,
PROV documents are translated into complete English sentences.
Quite similar to provenance comics are
Graph Comics by Bach et al. [
31], which are used to visualize and communicate changes in dynamic networks using comic strips.
8. Conclusions and Future Work
The goal of this work was to develop a self-explaining, easy-to-understand visualization of data provenance that can be understood by non-expert end users of Quantified Self applications.
A detailed concept has been created that defines a consistent visual language. Graphics for PROV elements like different agents and entities were designed, and sequences of comic panels to represent different activities were determined. Symbols, icons, and panel sequences were specified in an exact and uniform manner to enable the automatic generation of comics.
As proof of concept, a prototypical website has been developed which is able to automatically generate comics from PROV documents compliant with the existing Quantified Self data model. The documents are loaded from the ProvStore website.
A reading study involving ten test readers has shown that a non-expert audience is mostly able to understand the provenance of Quantified Self data through provenance comics without any prior instruction or training. The overall percentage of 77% for findings verbalized by participants is deemed a good result, given that the checklists were very detailed and contained findings that some readers probably omitted, because they seemed too obvious and self-evident to them.
Future work will focus on graphical improvements. This includes suggested improvement measures that resulted from the reading study. A major step will be quantitative comics, which also show actual measured values. For example, diagrams on depicted devices could show real plots of health data, and single comic panels may include real geographical information. Another improvement could be the use of glyph-based depiction [
32], where the body shape of depicted humans represent real values such as weight. A more technical improvement will be the consequent use of
provenance templates [
33,
34], which will help to standardize the recorded provenance with templates provided to tool developers and which then helps tools for generating comic strips based on these standardized provenance.
A useful improvement of the provenance comics would be to make them application-generic to some extent, (i.e., not restricted to the Quantified Self domain). We plan to explore whether provenance comics might be useful for other application domains, such as electronic laboratory notebooks, writing news stories in journalism, or security breaches in Internet-of-Things environments. For example, using provenance comics seem to be a feasible approach to communicate hacking attempts in smart home systems, if provenance of such attacks is available (such as by the recent works of Wang et al. [
35]).




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
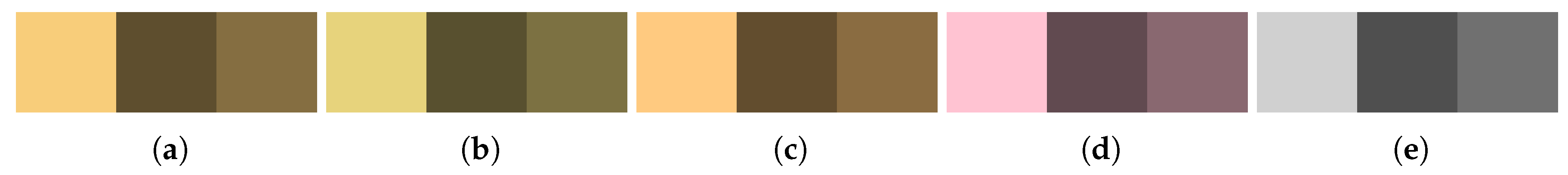{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









