
Design of a Flow Visualisation Framework

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- (1)
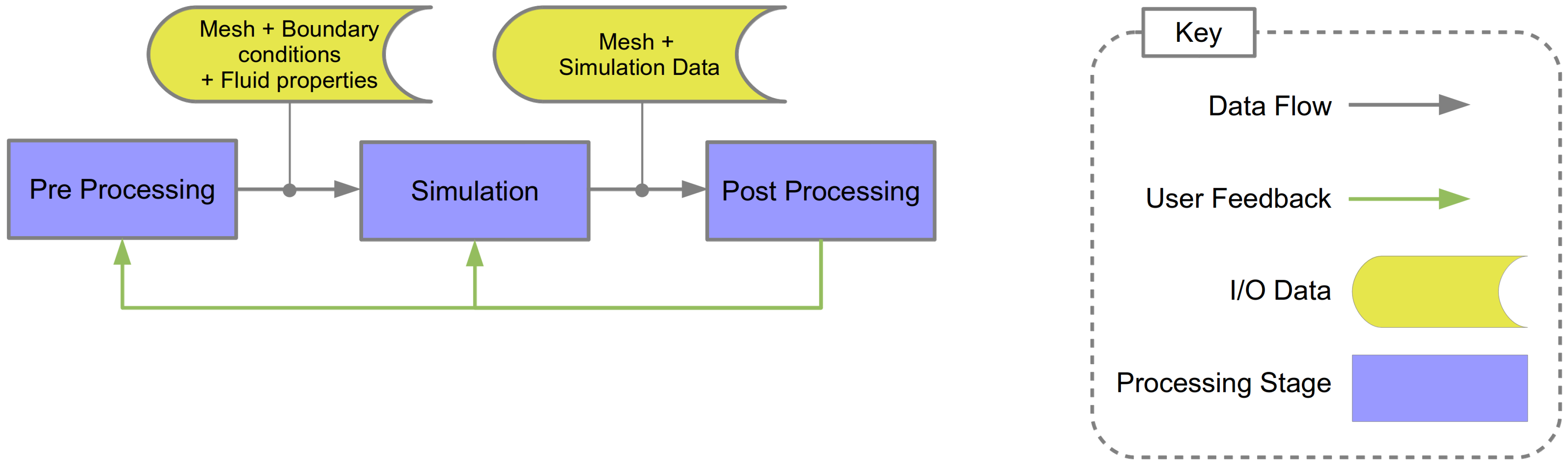
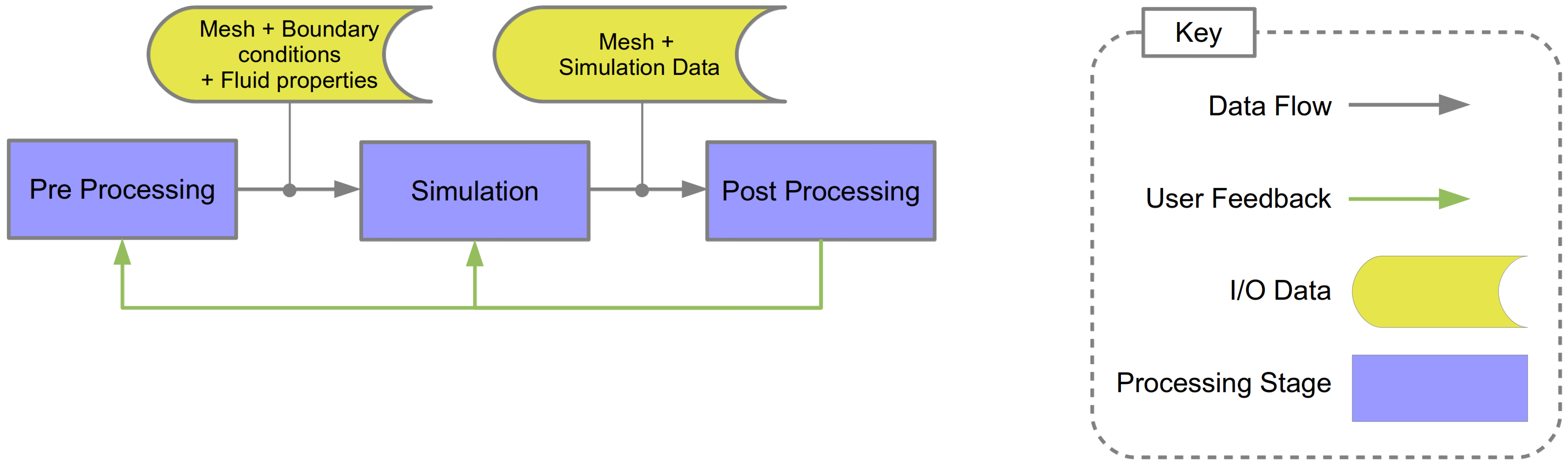
- Preprocessing: A surface and the volumetric mesh is generated to model a physical object. This mesh is generated from computer-aided design (CAD) geometry utilizing mesh generation and manipulation tools. Boundary conditions and fluid properties are defined and specified.
- (2)
- Simulation: A computational simulation of the fluid is performed using numerical methods applied to the mesh, with respect to the boundary conditions and fluid properties.
- (3)
- Post Processing: The simulation result is explored, analyzed and visualized using a range of techniques dependent on the requirements of the CFD engineer.
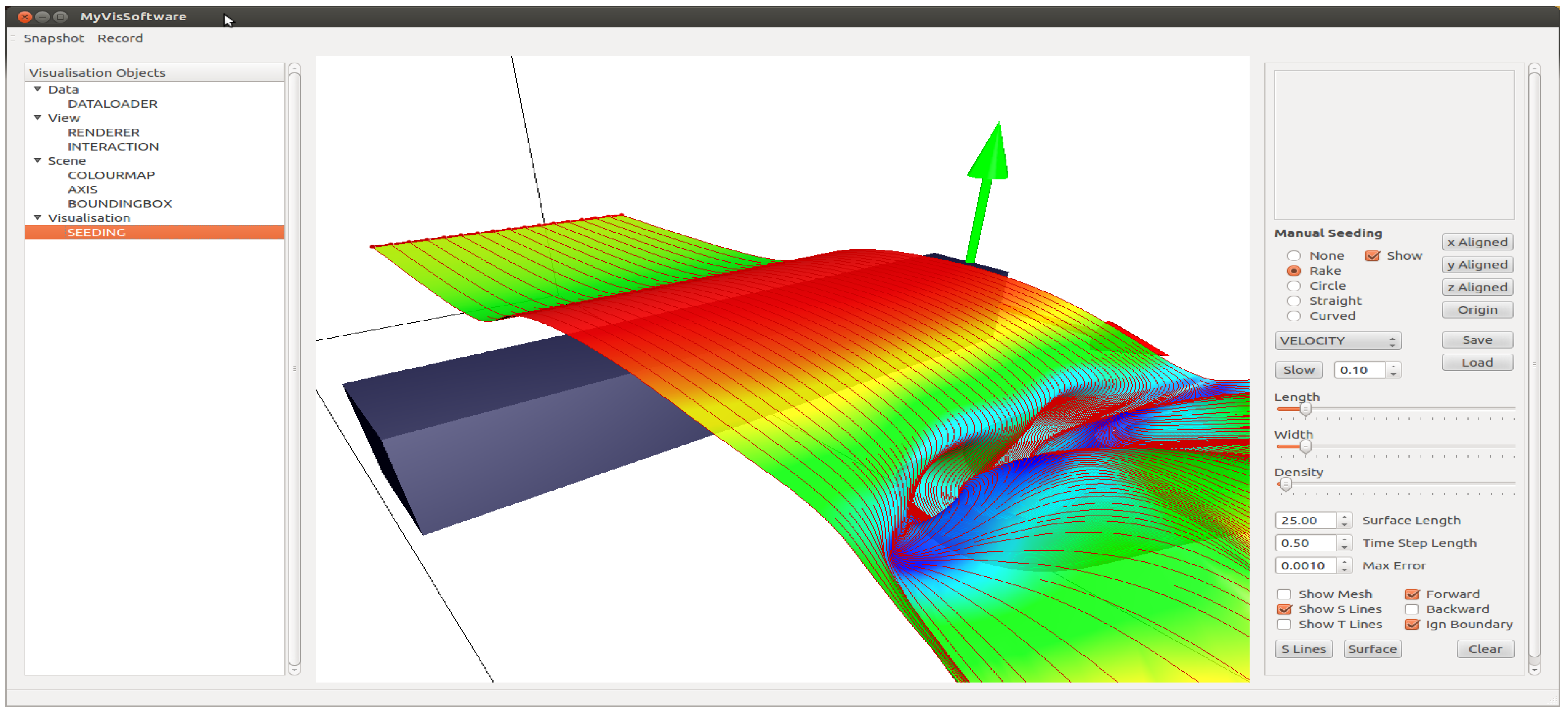
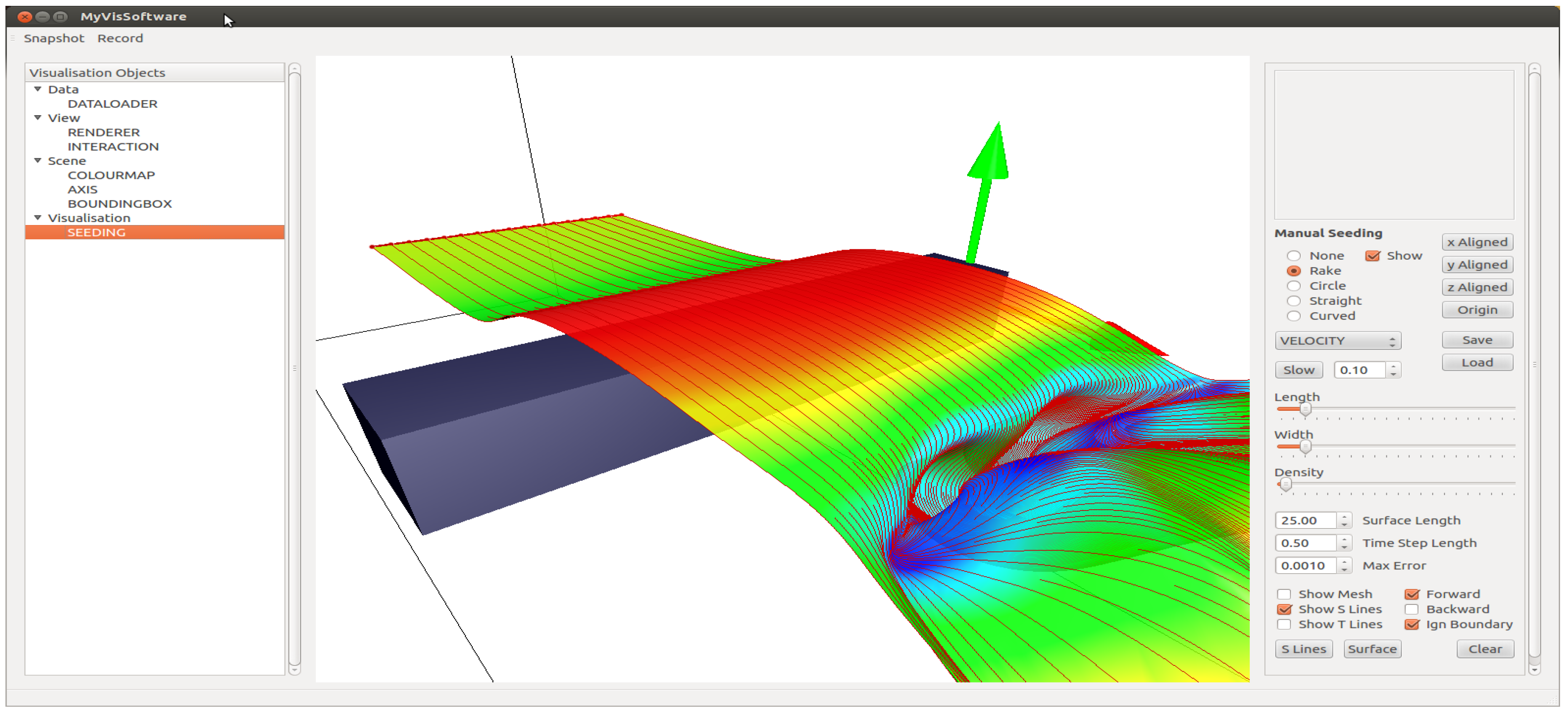
- A platform independent flexible framework, which implements state of the art research algorithms in flow visualization. In particular, stream surface seeding algorithms are incorporated, which were not available in previous systems, such as the VTK or Visit [2].
- A framework specifically designed to enable quick integration of new algorithms for study, testing and evaluation.
- A smooth and efficient threaded user interface, even when processing large data and complex algorithms.
- Simultaneous comparisons of different techniques.
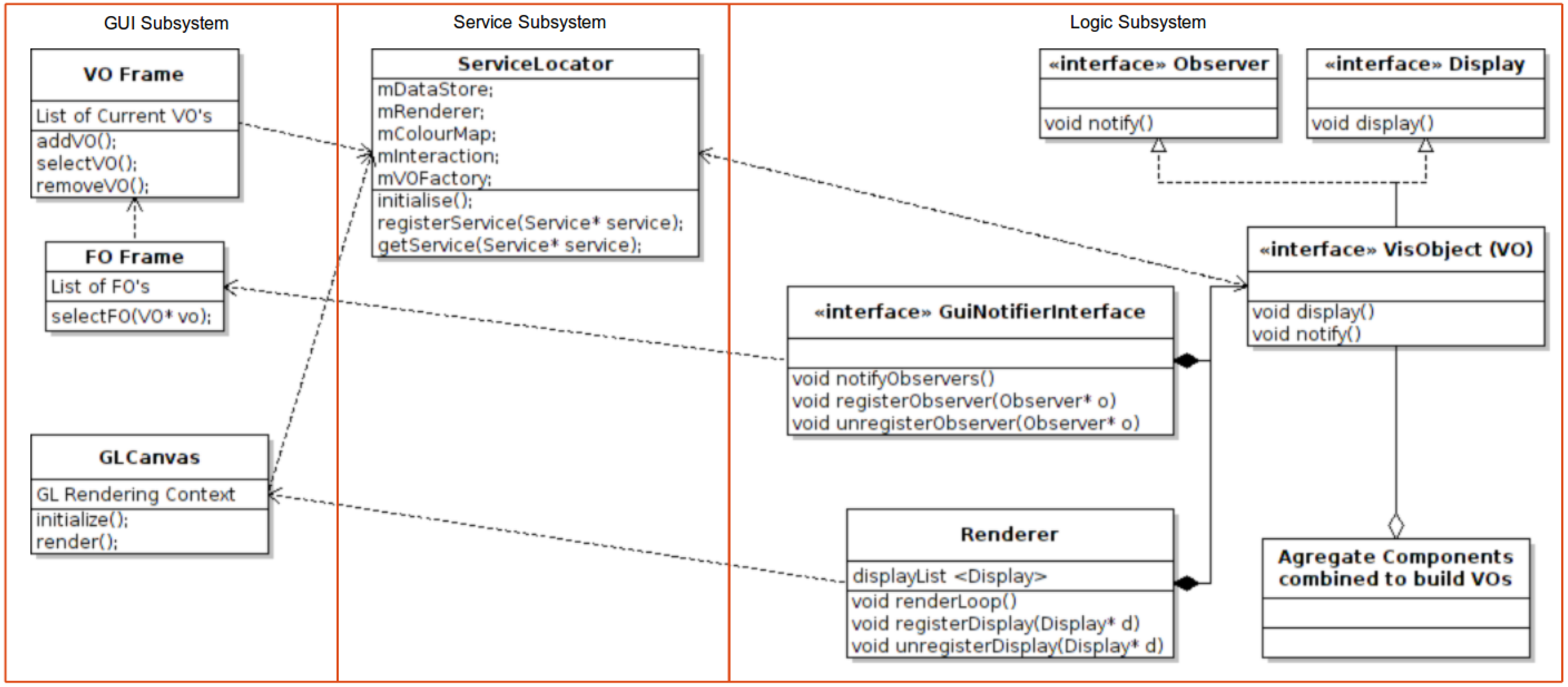
2. System Overview
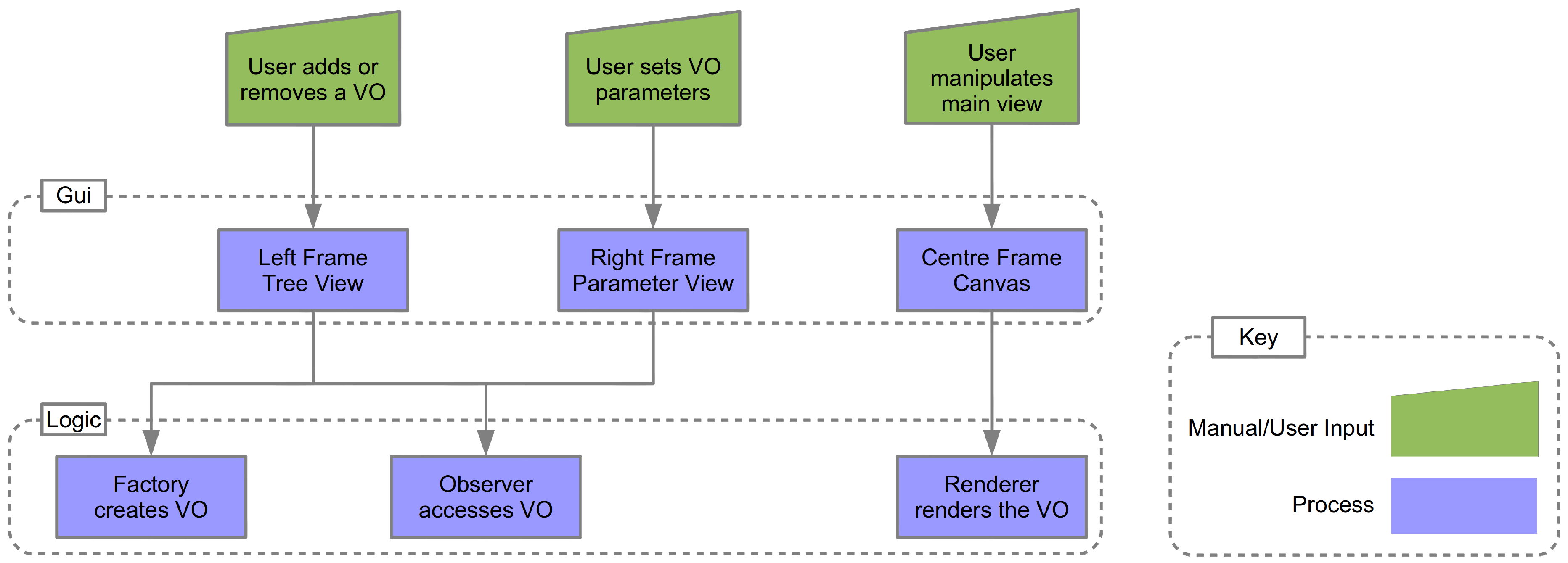
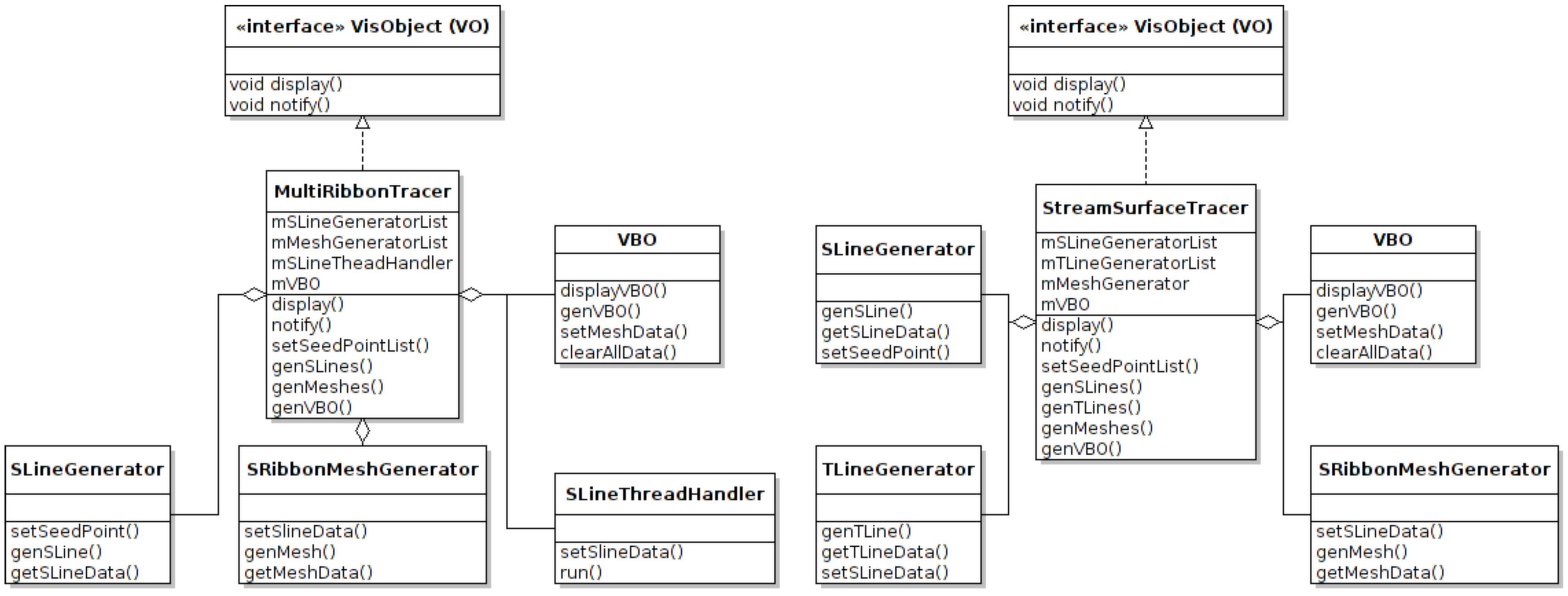
3. GUI Subsystem Design
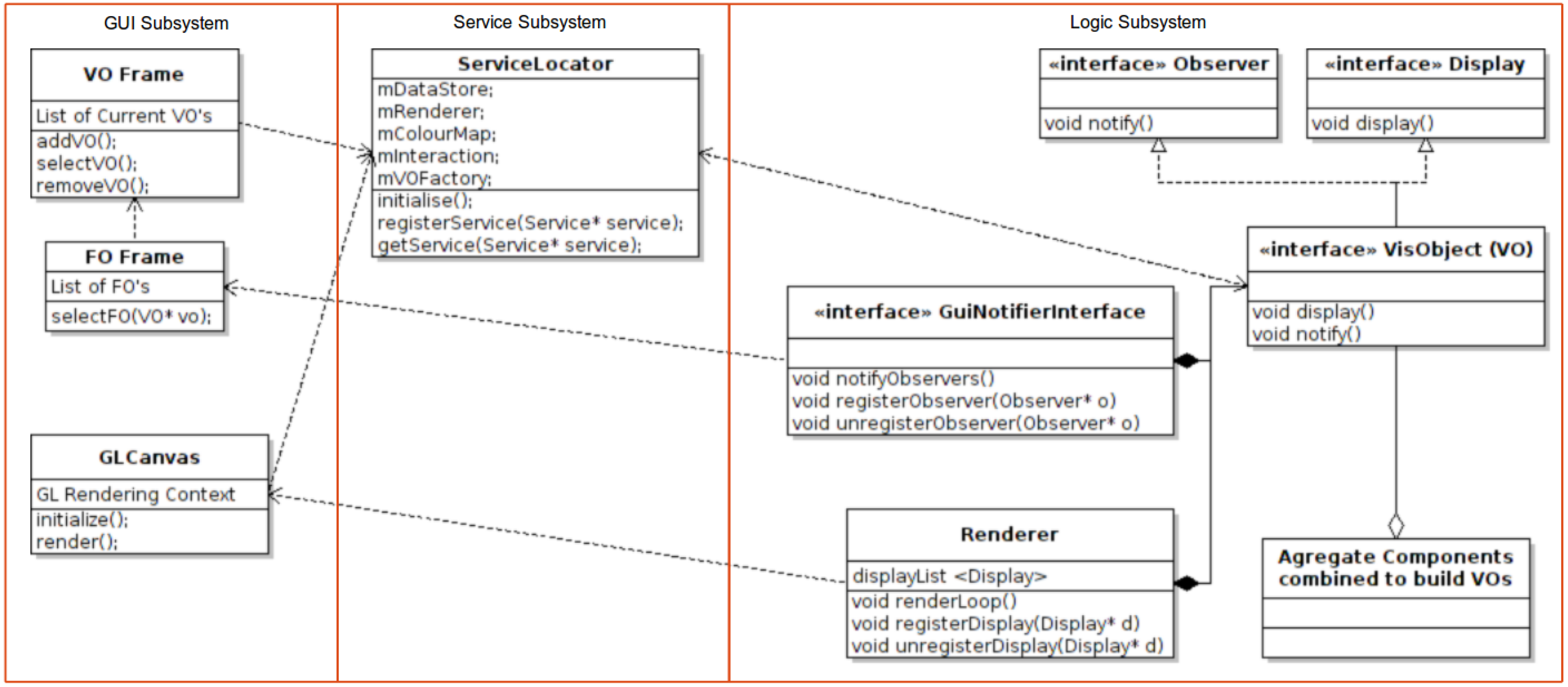
4. Services Subsystem Design

5. Logic Subsystem Design
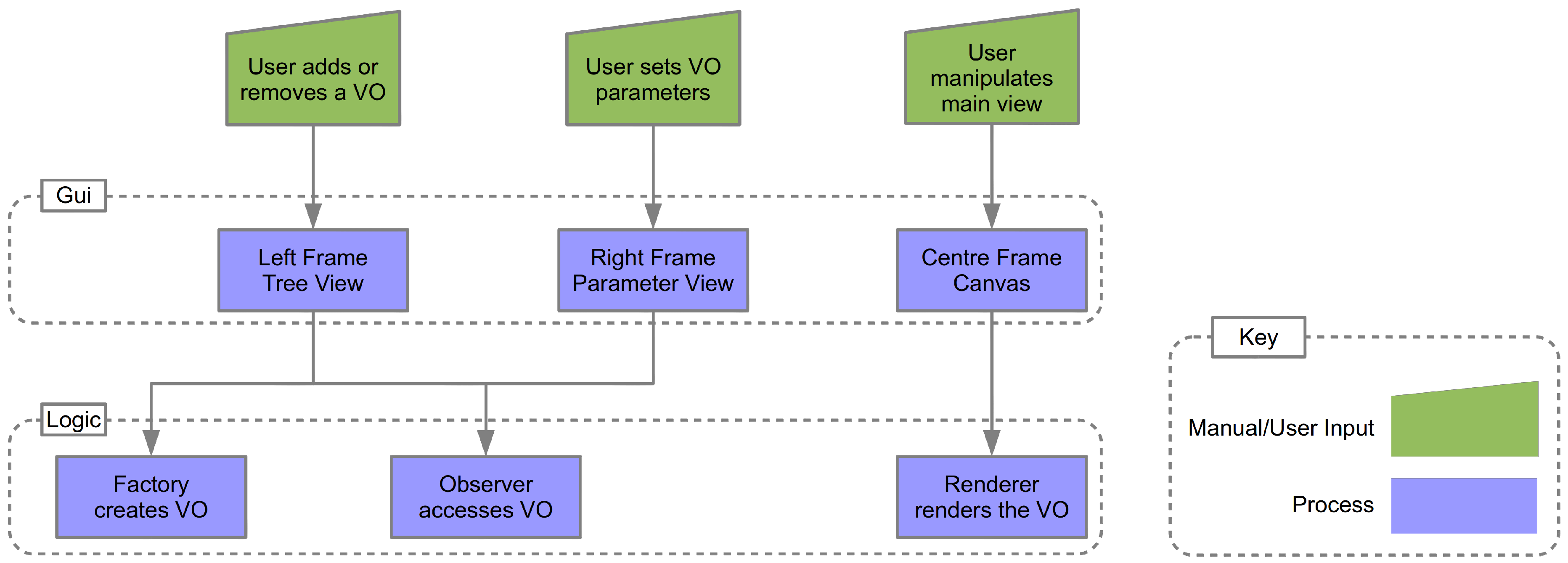
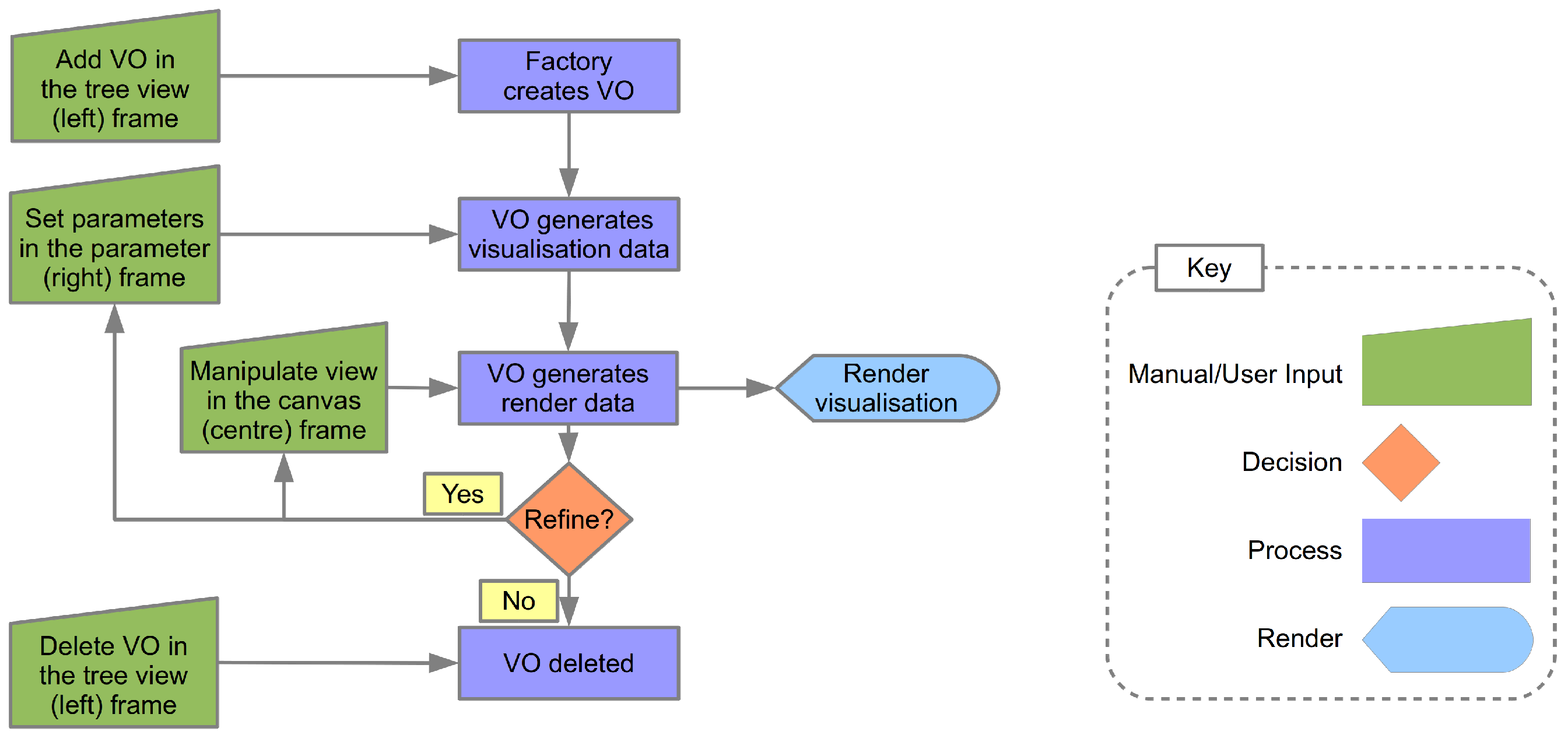
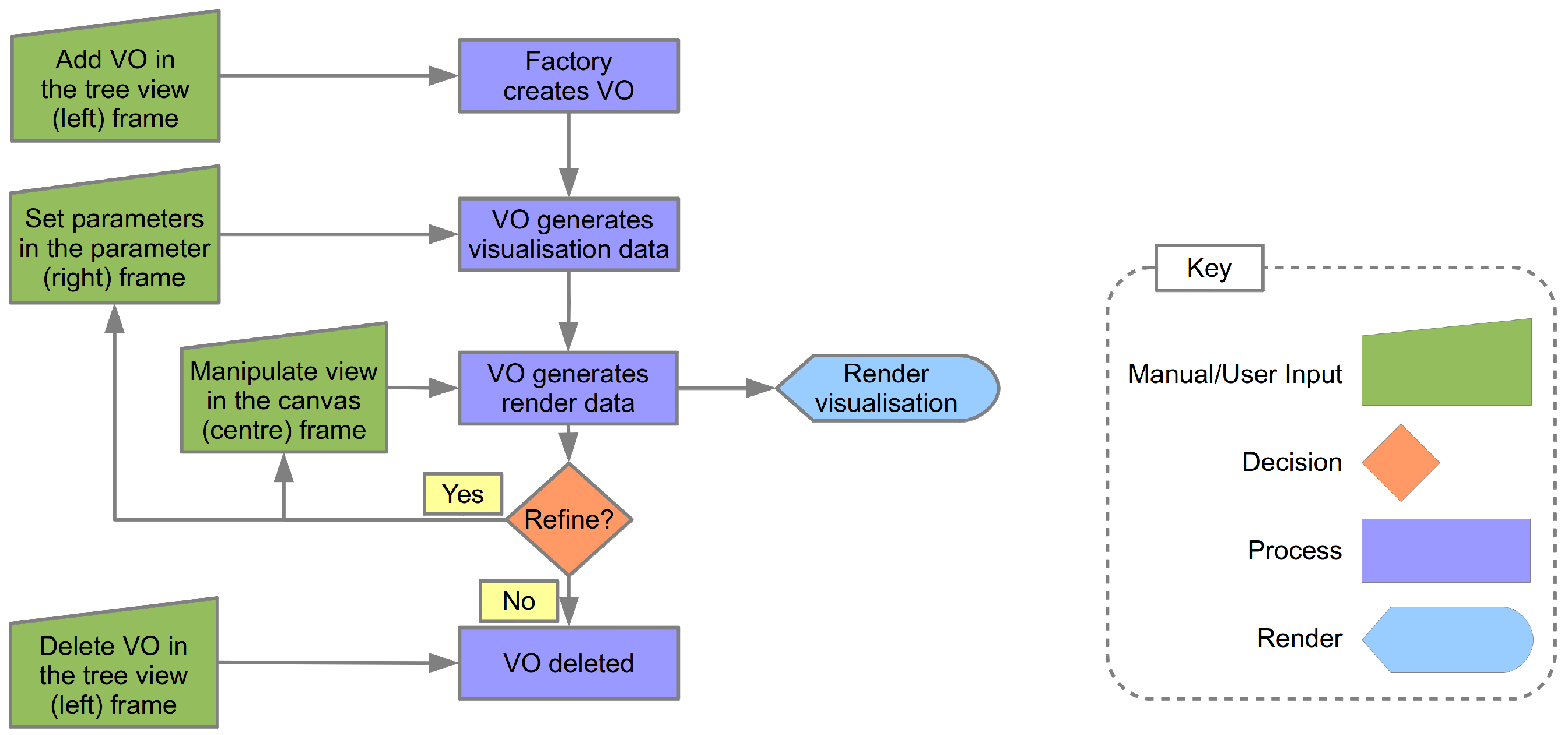
5.1. The Factory

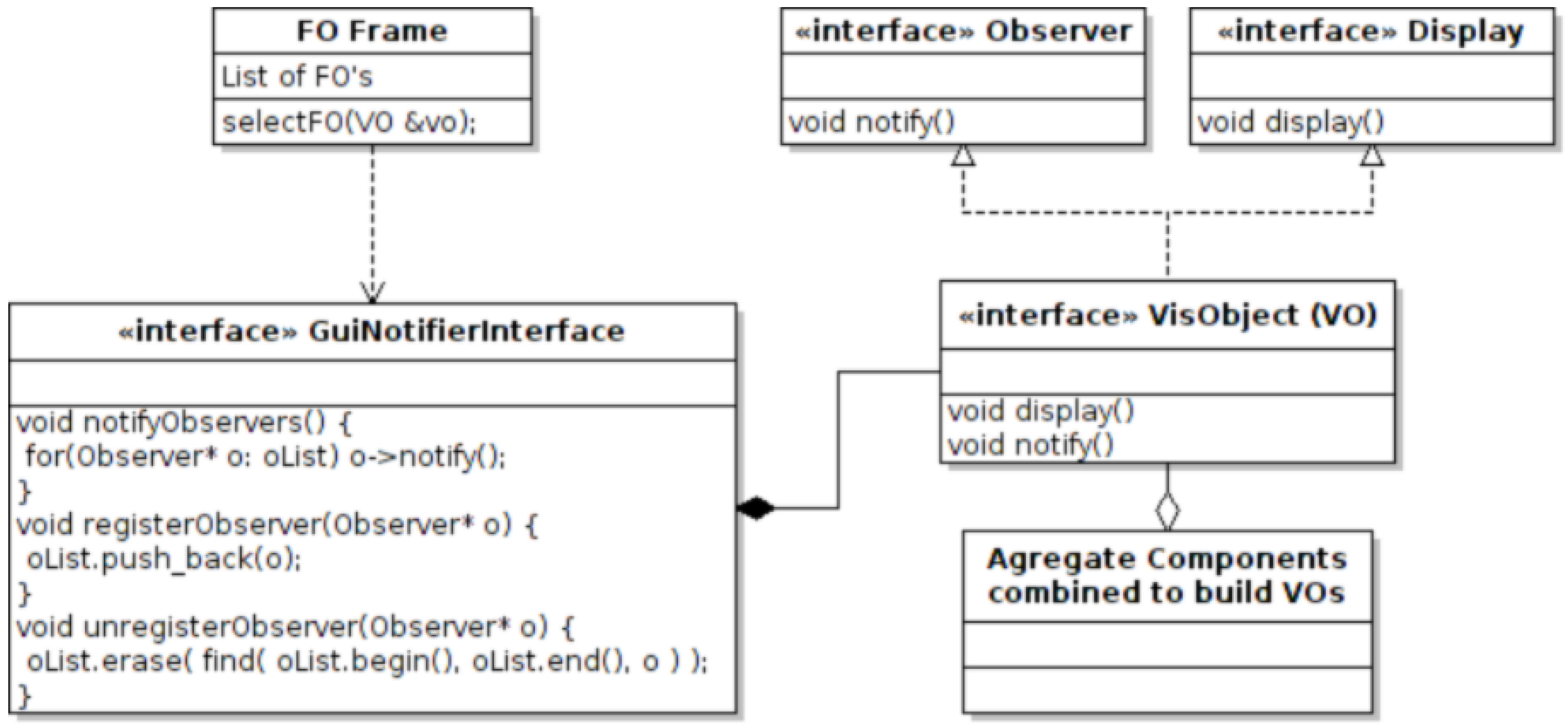
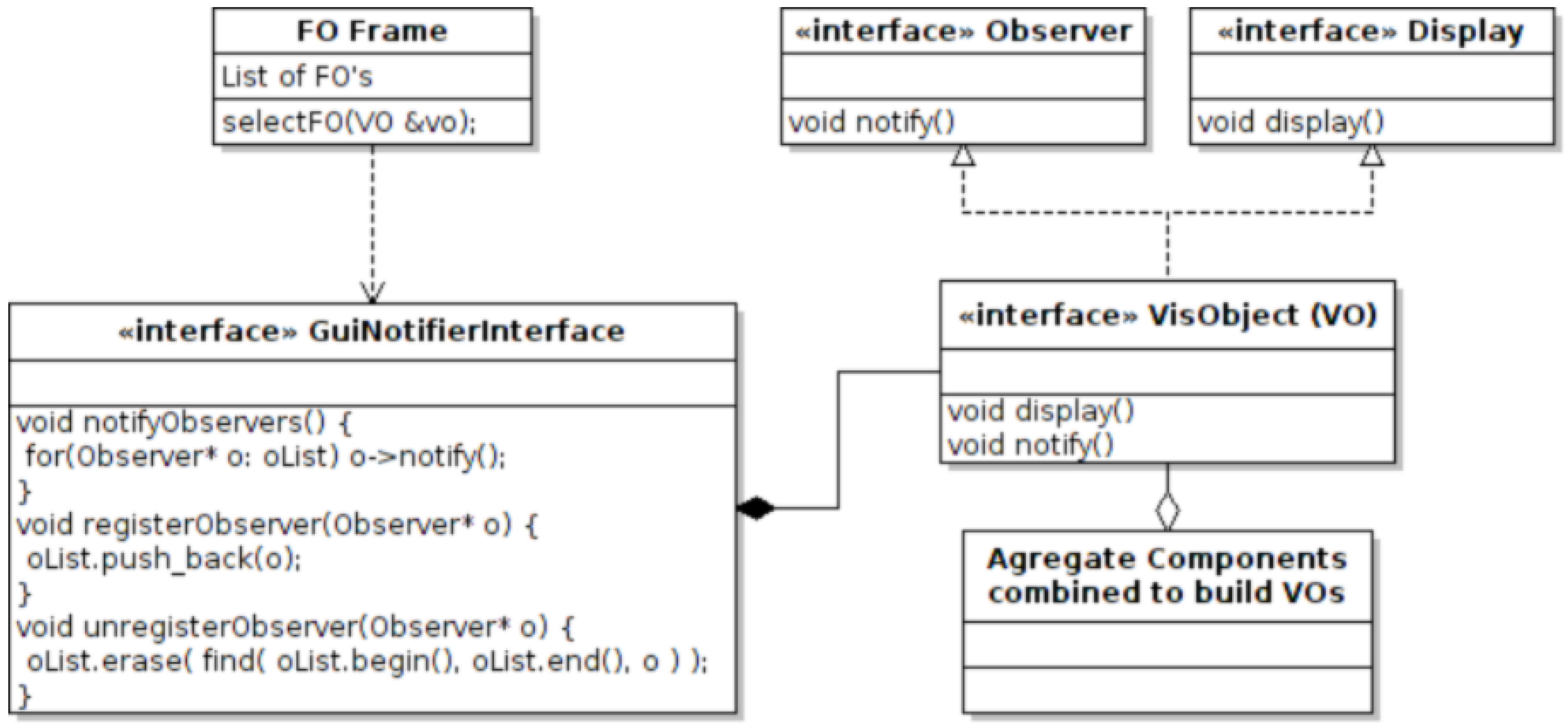
5.2. The Observer
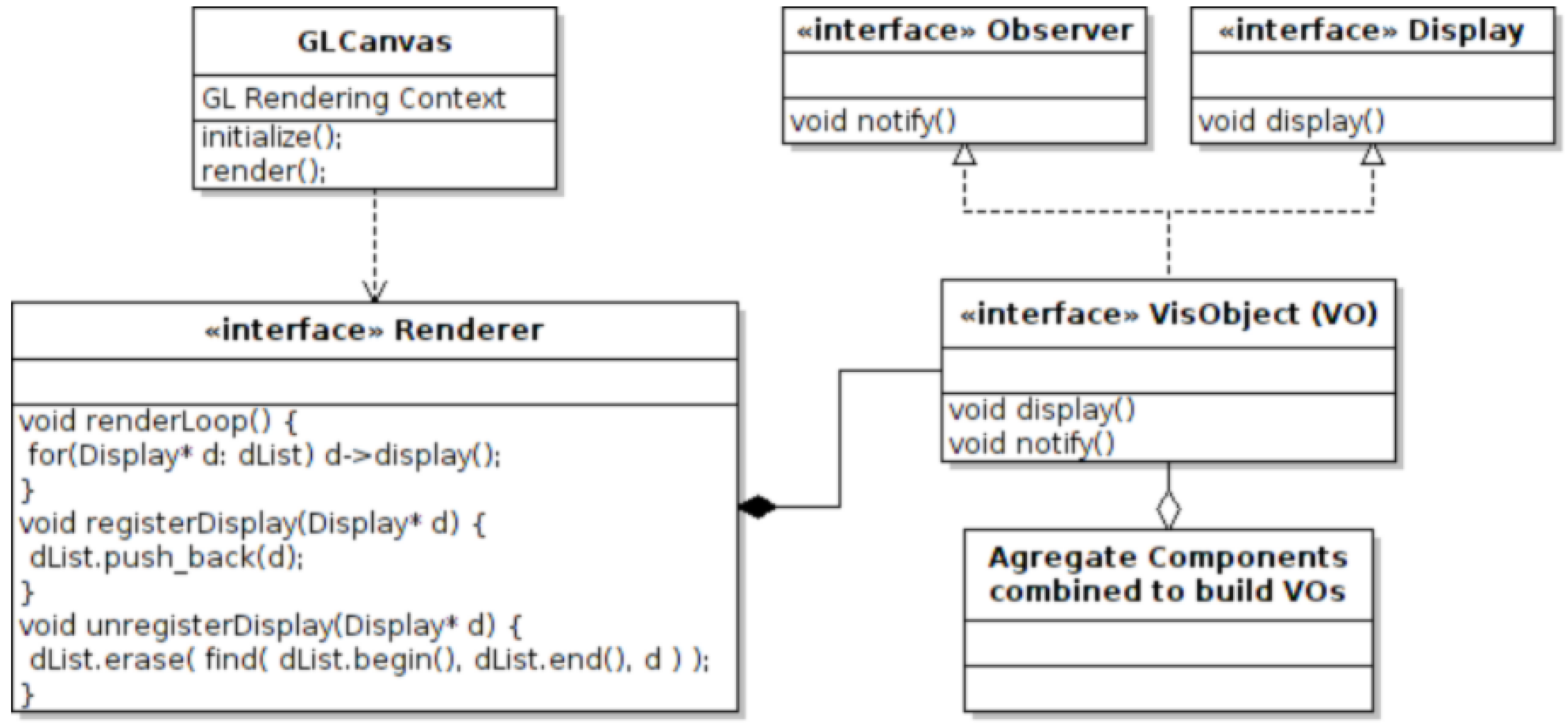
5.3. The Rendering Loop

- What is GLSL: GLSL or Graphics Library Shading Language is a high level shading language, which uses a syntax close to that of the C programming language. It was created for the purpose of providing developers with more precise control over the built-in graphics pipeline. Previously, developers would be required to use OpenGL assembly or graphics card-specific programming languages to implement modifications to the fixed functionality pipeline.
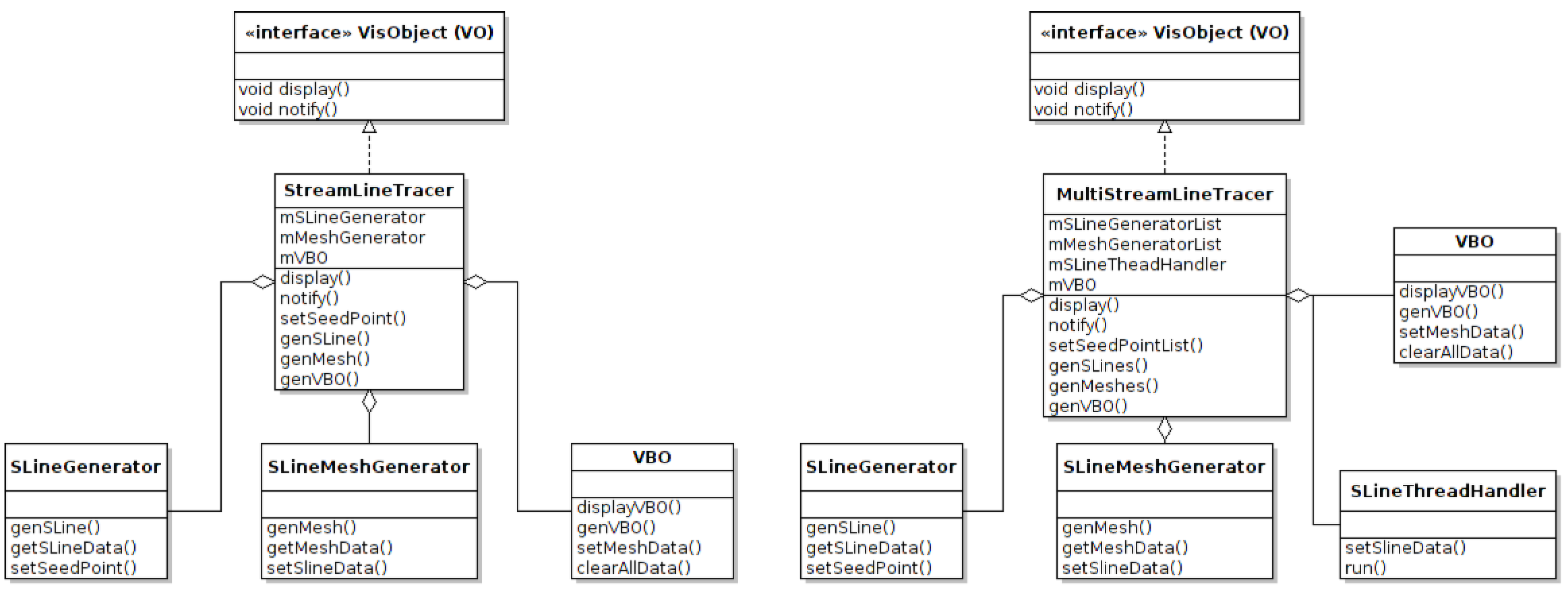
5.4. The Visualization Object (VO)
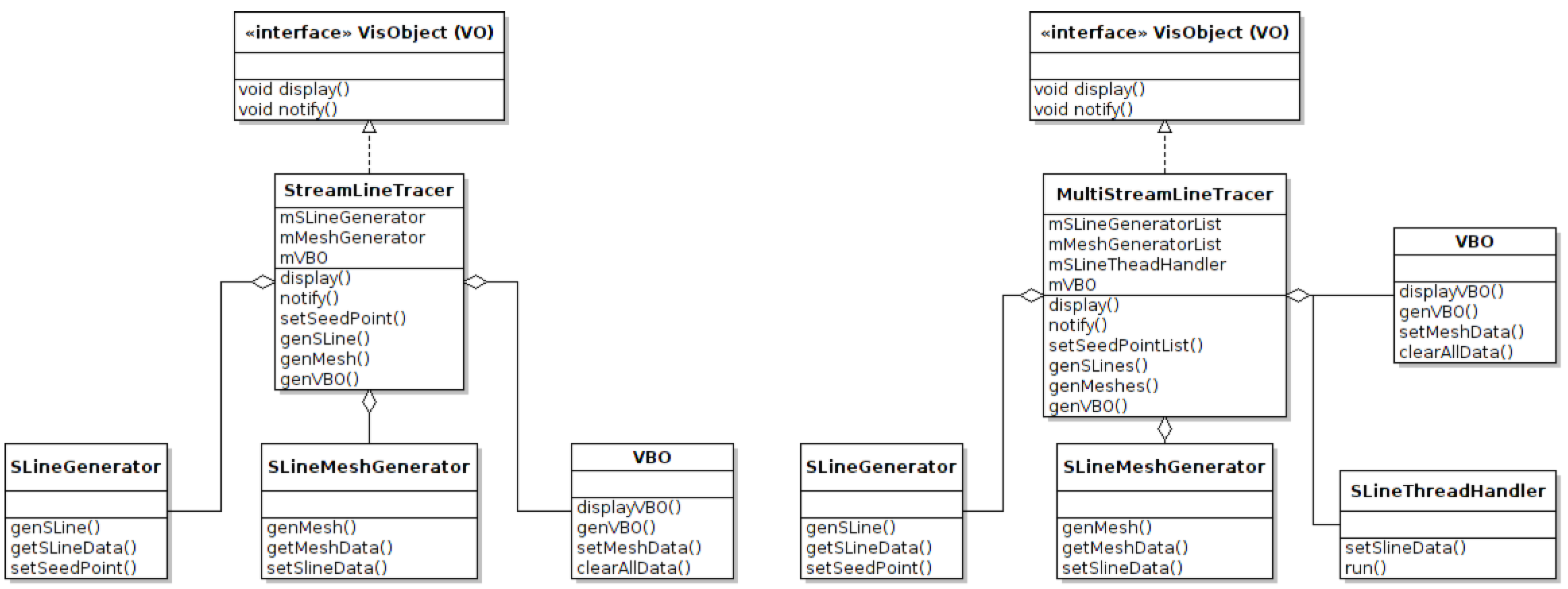

6. Conclusions
Acknowledgments
Author Contributions
Conflict of Interest
References
- ANSYS UK. Fluent Engineering Simulation. Available online: http://www.fluent.co.uk/ (accessed on 11 March 2015).
- Laramee, R.S. Comparing and evaluating computer graphics and visualization software. Softw. Pract. Exp. (SP&E) 2008, 38, 735–760. [Google Scholar]
- Edmunds, M.; Laramee, R.; Chen, G.; Zhang, E.; Max, N. Advanced, Automatic Stream Surface Seeding and Filtering. In Proceedings of Theory and Practice of Computer Graphics 2012, Didcot, UK, 13–14 September 2012; pp. 53–60.
- Edmunds, M.; Laramee, R.S.; Evans, B.; Chen, G. Stream Surface Placement for a Land Speed Record Vehicle; Technical Report; The Visual and Interactive Computing Group, Computer Science Department, Swansea University: Wales, UK, 2013. [Google Scholar]
- Laramee, R.S.; Hadwiger, M.; Hauser, H. Design and Implementation of Geometric and Texture-Based Flow Visualization Techniques. In Proceedings of the 21st Spring Conference on Computer Graphics, Budmerice, Slovakia, 12–14 May 2005; pp. 67–74.
- Piringer, H.; Tominski, C.; Muigg, P.; Berger, W. A Multi-threading Architecture to Support Interactive Visual Exploration. IEEE Trans. Vis. Comput. Graph. 2009, 15, 1113–1120. [Google Scholar] [CrossRef]
- Piringer, H.; Berger, W.; Krasser, J. HyperMoVal: Interactive Visual Validation of Regression Models for Real-Time Simulation. In Computer Graphics Forum; Blackwell Publishing Ltd.: Hoboken, NJ, USA, 2010; Volume 29, pp. 983–992. [Google Scholar]
- McLoughlin, T.; Laramee, R.S. Design and Implementation of Interactive Flow Visualization Techniques; INTECH Open Access Publisher: Rijkka, Croatia, 2012; Chapter 6; pp. 87–110. [Google Scholar]
- Peng, Z.; Geng, Z.; Laramee, R.S. Design and Implementation of a System for Interactive, High-Dimensional Vector Field Visualization. In Horizons in Computer Science Research; Nova Science Publishers: Hauppauge, NY, USA, 2013; Volume 8, pp. 175–200. [Google Scholar]
- Edmunds, M.; Laramee, R.; Malki, R.; Masters, I.; Croft, T.; Chen, G.; Zhang, E. Automatic Stream Surface Seeding: A Feature Centered Approach. Comput. Graph. Forum 2012, 31, 1095–1104. [Google Scholar] [CrossRef]
- Cppreference.com. Std::lock. Available online: http://en.cppreference.com/w/cpp/thread/lock (accessed on 11 March 2015).
- BlackWasp. Service Locator Design Pattern. Available online: http://www.blackwasp.co.uk/ServiceLocator.aspx (accessed on 11 March 2015).
- Code Project. A Basic Introduction On Service Locator Pattern. Available online: http://www.codeproject.com/Articles/18464/A-Basic-Introduction-On-Service-Locator-Pattern (accessed on 11 March 2015).
- Martin Fowler. Inversion of Control Containers and the Dependency Injection pattern. Available online: http://martinfowler.com/articles/injection.html (accessed on 11 March 2015).
- BlackWasp. Null Object Design Pattern. Available online: http://www.blackwasp.co.uk/NullObject.aspx (accessed on 11 March 2015).
- BlackWasp. Decorator Design Pattern. Available online: http://www.blackwasp.co.uk/Decorator.aspx (accessed on 11 March 2015).
- OpenGL.org. OpenGL GLSL. Available online: http://www.opengl.org/wiki/OpenGL_Shading_Language (accessed on 11 March 2015).
- Born, S.; Wiebel, A.; Friedrich, J.; Scheuermann, G.; Bartz, D. Illustrative Stream Surfaces. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1329–1338. [Google Scholar] [CrossRef]
- Hummel, M.; Garth, C.; Hamann, B.; Hagen, H.; Joy, K. IRIS: Illustrative Rendering for Integral Surfaces. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1319–1328. [Google Scholar] [CrossRef] [PubMed]
- Nystrom, R. Game Programming Patterns. Available online: http://gameprogrammingpatterns.com/component.html (accessed on 11 March 2015).
- West, M. Refactoring Game Entities with Components. Available online: http://cowboyprogramming.com/2007/01/05/evolve-your-heirachy (accessed on 11 March 2015).
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Edmunds, M.; Tong, C.; Laramee, R.S. Design of a Flow Visualisation Framework. Computers 2015, 4, 24-38. https://doi.org/10.3390/computers4010024
Edmunds M, Tong C, Laramee RS. Design of a Flow Visualisation Framework. Computers. 2015; 4(1):24-38. https://doi.org/10.3390/computers4010024
Chicago/Turabian StyleEdmunds, Matthew, Chao Tong, and Robert S. Laramee. 2015. "Design of a Flow Visualisation Framework" Computers 4, no. 1: 24-38. https://doi.org/10.3390/computers4010024
APA StyleEdmunds, M., Tong, C., & Laramee, R. S. (2015). Design of a Flow Visualisation Framework. Computers, 4(1), 24-38. https://doi.org/10.3390/computers4010024