Abstract
The increasing use of Arabic and Urdu on social media platforms, particularly Twitter, has created a growing need for robust Named Entity Recognition (NER) systems capable of handling noisy, informal, and code-mixed content. However, both languages remain significantly underrepresented in NER research, especially in social media contexts. To address this gap, this study makes four key contributions: (1) We introduced a manual entity consolidation step to enhance the consistency and accuracy of named entity annotations. In the original datasets, entities such as person names and organization names were often split into multiple tokens (e.g., first name and last name labeled separately). We manually refined the annotations to merge these segments into unified entities, ensuring improved coherence for both training and evaluation. (2) We selected two publicly available datasets from GitHub—one in Arabic and one in Urdu—and applied two novel strategies to tackle low-resource challenges: a joint multilingual approach and a translation-based approach. The joint approach involved merging both datasets to create a unified multilingual corpus, while the translation-based approach utilized automatic translation to generate cross-lingual datasets, enhancing linguistic diversity and model generalizability. (3) We presented a comprehensive and reproducible pseudocode-driven framework that integrates translation, manual refinement, dataset merging, preprocessing, and multilingual model fine-tuning. (4) We designed, implemented, and evaluated a customized XLM-RoBERTa model integrated with a novel attention mechanism, specifically optimized for the morphological and syntactic complexities of Arabic and Urdu. Based on the experiments, our proposed model (XLM-RoBERTa) achieves 0.98 accuracy across Arabic, Urdu, and multilingual datasets. While it shows a 7–8% improvement over traditional baselines (RF), it also achieves a 2.08% improvement over a deep learning (BiLSTM = 0.96), highlighting the effectiveness of our cross-lingual, resource-efficient approach for NER in low-resource, code-mixed social media text.
1. Introduction
The rapid growth of user-generated data on social media—such as text, images, audio, and video—has added new facets and complications to the discipline of Natural Language Processing (NLP) [1,2,3,4]. Named Entity Recognition (NER) is one of the important subfields of NLP [5,6,7,8]. NER is used to find and categorize real-world entities and objects mentioned in text, such as persons, locations, organizations, dates, times, numbers, and monetary amounts. Its utility in other language processing tasks is highly valuable, such as in information retrieval [9,10], question answering [11,12,13,14], data searching, opinion analysis and hope speech [15,16,17,18], and summary generation. NER gains additional significance when applied to social media platforms like Twitter, where a vast amount of novel and rapidly evolving text is posted daily.
The social media text is usually noisy, informal, and multilingual, and the entity recognition task is much more complicated than in the classical newswire or literary text. Twitter, specifically, is distinguished by brief messages (280 characters maximum), extensive usage of slang [19], abbreviations, hashtags, emojis, and frequent code-mixing (particularly in multilingual communities) [20]. Such language phenomena cause problems for traditional NER systems, which had initially been trained on clean and formal data. Consequently, the need to have more flexible and smarter NER systems, capable of operating in user-generated dynamic content, has risen.
The fundamental task behind NER systems is the ability to identify and tag named entities in free-form text. Earlier rule-based systems relied heavily on hand-crafted linguistic rules and dictionaries and were not easily scalable to new domains and languages [21]. However, the emergence of machine learning (ML) and deep learning (DL) approaches has transformed the field, enabling the development of more robust and generalizable models. Learned algorithms—primarily Conditional Random Fields (CRFs), Support Vector Machines (SVMs), and more recently, neural network-based models such as Bidirectional LSTM-CRF and Transformer-based models (e.g., BERT, XLM-RoBERTa)—have significantly improved NER performance in high-resource languages such as English. Despite these technological advancements, languages like Arabic and Urdu remain underrepresented in NER research. This disparity is particularly evident in the context of social media, where massive amounts of data are generated in these languages but remain largely unanalyzed due to the lack of annotated corpora, tools, and standard resources. Addressing this gap is essential for expanding NLP technologies to a broader linguistic and cultural scope.
The increasing popularity of Arabic and Urdu on social media platforms such as Twitter highlights the urgent need for practical Named Entity Recognition (NER) systems in these languages [22,23]. Arabic, a Semitic language spoken by over 274 million people worldwide [24], is the fourth-most-used language on Twitter, especially in MENA regions like Saudi Arabia, Egypt, the UAE, and Kuwait, where user engagement is high—Saudi Arabia alone has over 17 million active users [25]. However, Arabic presents serious challenges for NER due to its rich morphology, lack of diacritics, dialectal variation, and right-to-left script. NER systems often struggle to identify entities written in different morphological forms, or when proper nouns are inflected, prefixed, or abbreviated—especially in dialects. Named entities are frequently written without capitalization, and the omission of diacritics further introduces ambiguity. For example, in the tweet: “زار محمد بن سلمان الرياض لمناقشة مؤتمر الطاقة العالمي.”, the correct entities are “محمد بن سلمان” (person), “الرياض” (location), and “مؤتمر الطاقة العالمي” (event). Without sufficient context, an NER model may misclassify “الرياض” as a generic term rather than a location. Furthermore, dialectal expressions like “رايح دبي” (instead of the standard “سأذهب إلى دبي”) make generalization more difficult for models trained primarily on formal text.
Urdu, spoken by over 170 million people [15], mainly in Pakistan and India, faces its own unique challenges on social media, where users frequently code-switch between Urdu and English (“Urdu English”) and use both the Perso-Arabic and Roman Urdu scripts. Roman Urdu, with its non-standard spellings and phonetic variations influenced by English, complicates automated text processing. The cursive Perso-Arabic script lacks capitalization, making it harder to identify entity boundaries. These issues are magnified on social media, where informal syntax and spelling inconsistencies are common. As of 2024, over 6 million Twitter users in Pakistan actively produce Romanized and code-mixed content, which remains underutilized by current NLP tools. For example, in the tweet “آج لاہور میں عمران خان کی جلسے میں زبردست شرکت رہی۔”, “لاہور” is a place and “عمران خان” is a person, yet informal writing, lack of annotations, and script complexity often hinder NER models from correctly recognizing such entities.
In this study, we utilized two publicly available datasets—one in Arabic and the other in Urdu. We applied relatively new techniques to overcome the low-resource challenges in these languages such as a joint multilingual approach and a translation-based approach. In the joint multilingual technique, we merged the original Arabic and Urdu datasets into a single unified corpus, thereby creating a richer, linguistically diverse dataset that captures shared semantic patterns across both languages. In the translation-based technique, we used the highly reliable Google Translate API to translate the Urdu dataset into Arabic and combined it with the original Arabic data. Similarly, we translated the Arabic dataset into Urdu and combined it with the original Urdu data. This resulted in three distinct and novel datasets—joint multilingual, Arabic-translated, and Urdu-translated. We then applied a range of models to evaluate performance across these datasets: traditional machine learning models using token-based feature extraction, deep learning models with pretrained embeddings like FastText and GloVe, and advanced language-based transformer architectures leveraging contextual embeddings. This multi-strategy framework allowed us to investigate how cross-lingual data augmentation and translation influence model performance, and to what extent combining linguistically related but distinct datasets can improve generalization. The key benefit of this approach lies in its ability to overcome the limitations of monolingual data by harnessing the strengths of multiple languages, enhancing model robustness, improving generalization in multilingual contexts, and paving the way for more inclusive NLP systems that work effectively across linguistically diverse regions.
This study makes the following contribution:
- To the best of our knowledge, this is the first study that systematically investigates both joint multilingual and translation-based strategies for Named Entity Recognition (NER) in Arabic and Urdu—two linguistically rich yet underrepresented languages in NER research.
- We introduced a manual entity consolidation step to enhance the consistency and accuracy of named entity annotations. In the original datasets, named entities such as person names and organization names were often fragmented into separate tokens (e.g., first and last names labeled individually). We manually refined these annotations to represent full names and multi-word entities as single, unified tokens (e.g., combining “ عمران” and “ خان” into “ عمران خان” enhances the dataset quality and improves model training.
- We utilized two publicly available datasets—one in Arabic and one in Urdu—and generated three distinct datasets through cross-lingual translation (via Google Translate API) and data merging, offering enhanced diversity and representation for low-resource NER tasks.
- We developed, designed, and evaluated a customized XLM-RoBERTa model integrated with a novel attention mechanism, specifically optimized to accurately recognize named entities in both Arabic and Urdu, accounting for their unique morphological and syntactic properties.
- We presented a comprehensive and reproducible pseudocode-driven framework that systematically integrates translation, manual refinement, dataset merging, preprocessing, and multilingual model fine-tuning, enabling transparent replication and future extension of NER detection tasks across Arabic and Urdu.
- Based on the experiments, our proposed model (XLM-RoBERTa) achieves 0.98 accuracy across Arabic, Urdu, and multilingual datasets. While it shows a 7–8% improvement over traditional baselines (RF), it also achieves a 2.08% improvement over strong deep learning (BiLSTM = 0.96), highlighting the effectiveness of our cross-lingual, resource-efficient approach for NER in low-resource, social media texts.
2. Literature Review
This section will discuss different research initiatives and developments carried out in the Named Entity Recognition (NER) on the Urdu as well as Arabic languages. Since these languages’ present peculiar linguistic issues, including complicated morphology, script diversities, and specific vocabulary, several studies have suggested dedicated solutions to enhance the NER accuracy. We survey important datasets, annotation styles, model structures, and evaluation measures employed in recent publications, and point out the advancements in NER research, in addition to the gaps that remain in these two high-significance but low-resource languages.
Salah et al. [26] developed a new manually annotated Named Entity Recognition (NER) corpus for Classical Arabic (CA), focusing on over 7000 Hadiths. They introduced 20 domain-specific entity types relevant to Islamic texts, such as Allah, Prophet, and Paradise. The paper highlights linguistic differences between Classical and Modern Standard Arabic. It also includes a statistical analysis of factors affecting human annotation in CA.
Albahli et al. [27] proposed a novel Arabic NER model that tackles challenges like morphological complexity and nested entities. They introduced a Hybrid Feature Fusion Layer and Compound Span Representation Layer to enhance entity detection and disambiguation. Their model integrates cross-attention, GLU, RoPE, and Bi-GRUs to improve accuracy. It outperforms state-of-the-art systems on multiple datasets, achieving up to 93.0% F1-score.
El Moussaoul et al. [28] explored the impacts of various annotation schemes on Arabic NER using both general and domain-specific datasets. They tried seven schemes with three models, LR, CRF, and AraBERT. The traditional ML models performed better with simple schemes such as IO, whereas the complex schemes such as BIOES favored AraBERT. The researchers note the existence of a trade-off between the complexity of annotations and computational expense, independent of domain.
Alimi et al. [29] introduced the first multidialectal Arabic NER model, ARDIAL-BERT, which is pretrained using continuous pretraining and fine-tuning on dialect datasets grouped by region. They constructed ARDIAL-NER, a huge manually labeled multidialect corpus containing more than 53K entities. Their lifelong learning strategy makes the model incrementally better by adding new data and labels. Our findings indicate that ARDIAL-BERT surpasses its predecessors, demonstrating the advantage of the regional dialect grouping in Arabic NER.
Ahmad et al. [30] proposed U-MNER, a new framework of Multimodal Named Entity Recognition in Urdu language, overcoming problems such as small sizes of datasets and baselines. They published Twitter2015-Urdu, a marked multimodal corpus adjusted to the Urdu grammar principles. Their model concatenates the text embeddings of the Urdu-BERT and visual features of ResNet through a Cross-Modal Fusion Module. U-MNER presents state-of-the-art results, which forms a basis of Urdu MNER research.
Ullah et al. [31] introduced EDU-NER-2025, the first manually annotated Urdu NER dataset stressing on the education domain and containing 13 fine-grained entity types. Discussing the problems with labeling, they described the process and rules of annotation. Linguistic problems such as morphological complexity and ambiguity in formal Urdu were also examined in the course of the study. The work addresses a serious gap since it offers a specialized resource in Urdu education NER.
Azhar et al. [32] trained two Transformer-based models on the biggest Urdu NER corpus, MK-PUCIT, and obtained F1-scores of more than 0.94. They found critical errors of mislabeling in the data including wrong entity tags on names and punctuations. In spite of them, their work demonstrates the possibility to achieve better performance in Urdu NER by enhancing the quality of datasets.
To augment Urdu NER datasets, especially those of the Nastaliq script, Ullah et al. [33] suggested a new data augmentation technique named Contextual Word Embeddings Augmentation (CWEA). The augmented data greatly increased the coverage of entities as well as model performance. The best model according to macro F1-score was BERT-multilingual with a score of 98.2% among the models tested. They find that augmentation is an effective approach to improve the accuracy of NER in low-resource languages such as Urdu.
Unlike previous studies that focus primarily on Named Entity Recognition (NER) within either Arabic or Urdu individually, our work is the first to systematically explore joint multilingual and translation-based strategies combining these two linguistically rich but underrepresented languages. While prior research has developed domain-specific corpora, novel model architectures, or data augmentation methods for a single language, we introduce cross-lingual data augmentation by translating and merging Arabic and Urdu datasets to create enriched, diverse corpora. Moreover, we design a customized XLM-RoBERTa model enhanced with a novel attention mechanism specifically optimized to capture the unique morphological and syntactic characteristics of both languages simultaneously. Additionally, we provide a comprehensive and reproducible framework that integrates dataset translation, refinement, merging, preprocessing, and multilingual model fine-tuning, facilitating transparent replication and extension. This combined approach addresses low-resource challenges and linguistic diversity in social media text more effectively than prior monolingual or single-strategy studies.
Table 1 provides a comparative overview of various NER models applied to Arabic and Urdu datasets, demonstrating that while several high-performing models exist—such as the Morphology-aware Transformer on ANERCorp (F1: 0.93) and BiLSTM+GRU with Floret embeddings on UNER (F1: 0.98)—none of the previous studies have employed Joint Multilingual Learning (JML) or Joint Translation Learning (JTL). Existing works are language-specific, using models tailored to either Arabic or Urdu without leveraging cross-lingual synergies. In contrast, our proposed model is novel in its integration of both JML and JTL: JML enables simultaneous learning from both Arabic and Urdu data, while JTL enriches the training process by translating Arabic to Urdu and merging it with original Urdu data, and vice versa. This dual strategy not only addresses the scarcity of annotated data in low-resource languages but also enhances semantic alignment across languages. As a result, our approach utilizing custom attention mechanism achieves a state-of-the-art F1-score of 0.98, marking a significant advancement in Arabic and Urdu NER and establishing a new direction in multilingual and translation-enhanced NER research.

Table 1.
Comparison of prior work on Arabic and Urdu NER with our proposed model.
3. Methodology
3.1. Construction of Dataset
Figure 1 presents a comprehensive workflow designed for a Named Entity Recognition (NER) task involving both Urdu and Arabic languages. The process begins by separately collecting datasets from Github (https://github.com/EmnamoR/Arabic-named-entity-recognition/blob/master/ANERCorp.rar, https://github.com/javaidiqbal11/Named-Entity-Recognition-for-Urdu/blob/master/ner%20(1).txt (accessed on 15 June 2025)), one for Urdu and another for Arabic. Each dataset then undergoes translation into the other language—the Urdu dataset is translated into Arabic, and the Arabic dataset is translated into Urdu. These translated datasets are merged back with their respective original datasets, enhancing the data richness for each language.
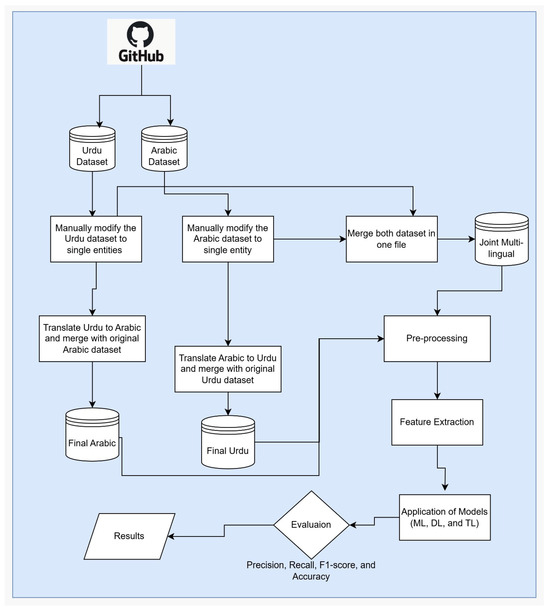
Figure 1.
Proposed methodology and design.
We incorporated a manual entity consolidation step to improve the consistency and accuracy of the named entity annotations. In the original datasets, many entities—such as person names and organization names—were fragmented into multiple tokens; for example, first and last names were often labeled separately rather than as a single entity. To address this, we followed specific merging guidelines that combined these fragmented tokens into unified entities representing the full names or multi-word organizations (e.g., merging “سرفراز” and “احمد” into “سرفراز احمد”). These guidelines emphasized preserving semantic integrity by ensuring that only tokens belonging to the same logical entity were merged, based on linguistic and contextual cues. Through this consolidation process, approximately 10,000 tokens were merged in the Urdu dataset (reducing token counts from 55,350 to 45,029) and about 20,500 tokens in the Arabic dataset (from 150,286 to 129,770), reflecting a significant improvement in annotation quality.
Following this, the combined Arabic and Urdu datasets are merged into a single unified dataset. This merged dataset undergoes a crucial preprocessing phase, which includes several cleaning steps: removing missing values to ensure data completeness, eliminating hashtags (# tags) to reduce noise from social media text, removing user mentions to anonymize the data, deleting duplicate posts to avoid bias, and correcting sentences to improve textual quality and consistency.
After preprocessing, feature extraction is performed using several advanced techniques such as token-based methods, FastText, GloVe embeddings, and language-specific models. These features serve as the input for applying various machine learning (ML), deep learning (DL), and transfer learning (TL) models tailored to the NER task.
Finally, the models’ performance is rigorously evaluated using standard metrics: accuracy, precision, recall, and F1-score. The evaluation results are stored and used to analyze and compare the effectiveness of the different approaches. This end-to-end pipeline reflects a methodical approach to handle multilingual datasets for NER, ensuring data quality, feature robustness, and thorough model assessment.
3.2. Preprocessing
We applied several preprocessing techniques to normalize and clean the raw social media text in order to prepare it for effective analysis. First, data quality was ensured by eliminating any null or empty entries. Posts consisting solely of hashtags, mentions, or URLs without actual text were removed, as they often do not carry useful information for Named Entity Recognition. Duplicate tweets were also detected and filtered out to avoid bias and redundancy in the training data. Additionally, sentence correction methods were employed to address common typing errors, grammatical issues, and the informal language typical of social media communication. Finally, all posts that did not contain significant information or were unrelated to the task were removed, leaving only informative and contextually relevant data in the dataset, which could be used to train high-quality models.
3.3. Translation-Based Approach
The purpose of the translation and joint multilingual strategies is to consolidate multilingual Twitter posts into a shared representation to enable more effective processing. Three datasets were prepared as follows: Arabic translation, Urdu translation, and a joint multilingual dataset. Google Translate API was used for initial translation, and the outputs were subsequently manually reviewed and corrected to ensure linguistic accuracy and contextual appropriateness. The corrections were carried out by the first and second authors, both native Urdu speakers, and a third annotator from our lab who is a native Arabic speaker. The reviewers cross-checked the translations for grammar, idiomatic expressions, and context alignment. This manual step ensured high-quality translations, especially important given the informal and code-mixed nature of social media texts. Table 2 presents the pseudo code of these methods.
Table 2.
Pseudo code of multilingual Named Entity Recognition task.
- First, Arabic tweets were translated into Urdu using the Google Translate API. These translations were then manually reviewed and corrected to fix any errors or inconsistencies. The refined Urdu translations were merged with the original Urdu dataset to form the enhanced Urdu dataset for further processing.
- Similarly, Urdu tweets were translated into Arabic using the same translation and manual refinement procedure. The cleaned Arabic translations were combined with the original Arabic dataset to form an augmented Arabic dataset.
- Finally, to create the joint multilingual dataset, the original Arabic and Urdu datasets were merged without translation, resulting in a unified corpus that represents both languages simultaneously.
3.4. Inter-Annotator Agreement
The annotation and consolidation process were carried out collaboratively by the first and second authors, who are native Urdu speakers and PhD students working in the NLP domain with prior experience in text annotation tasks and published research in the field [44], along with a third annotator—a native Arabic speaker from our lab with similar NLP expertise—who specifically contributed to the Arabic translations to ensure linguistic and contextual accuracy.
To ensure annotation consistency, we calculated the inter-annotator agreement (IAA) across all three annotators. The resulting Fleiss’ Kappa score was 0.81, which indicates a substantial level of agreement. Discrepancies were discussed and resolved by consensus to finalize the annotations
3.5. Application of Models
In this section, we discuss the application of various machine learning algorithms such as Support Vector Machine (SVM), Random Forest (RF), and Logistic Regression (LR) using TF-IDF features. Additionally, we employ deep learning architectures like BiLSTM and CNN with advanced pretrained word embeddings such as FastText and GloVe. Moreover, we employed language-based Transformer models, including bert-base-multilingual-cased, RoBERTa-base, and xlm-roberta-base, featuring built-in attention mechanisms to enhance Named Entity Recognition accuracy to identify the most effective solution. These models were selected due to their demonstrated strong performance in our NER task. Although traditional methods can achieve high accuracy, we chose Transformer-based models because they provide contextual embeddings that better capture the nuances of Arabic and Urdu languages. These models handle multilingual, informal, and code-mixed text more effectively, leading to improved performance in real-world scenarios. The dataset was split into 80% training and 20% testing sets. The models were trained on the training set and evaluated on the test set, as illustrated in Figure 2 Evaluation metrics including precision, recall, F1-score, and accuracy were used to assess model performance after training, providing a comprehensive measure of how well the models detect named entities (NE’s) from the Arabic, Urdu, and joint multilingual text. Figure 2 shows the overall application of models training and testing phase.
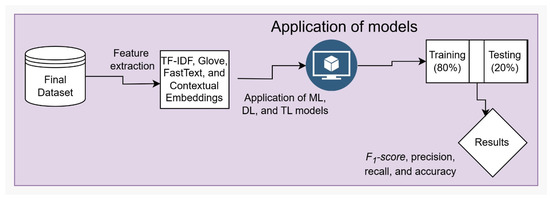
Figure 2.
Application of models training and testing phase.
Table 3 presents the key fine-tuning parameters used for a range of machine learning, deep learning (DL), and transfer learning (TL) models applied to Named Entity Recognition (NER). In the ML category, Logistic Regression is configured with L2 regularization, the ‘liblinear’ solver, a regularization strength (C) of 1.0, and 1000 maximum iterations. The Support Vector Machine (SVM) uses a linear kernel with C set to 1.0 and gamma set to ‘scale’, and employs a one-vs.-rest (ovr) strategy. Random Forest is set with 100 estimators, no maximum depth restriction, ‘gini’ as the split criterion, and a fixed random seed for reproducibility. For DL, the Convolutional Neural Network (CNN) model uses 128 filters, a kernel size of 3, ReLU activation, max pooling, and a dropout of 0.5 to prevent overfitting, and was optimized using Adam over 10 epochs with a batch size of 32. The BiLSTM model comprises 128 hidden units, dropout and recurrent dropout rates of 0.5 and 0.3, respectively, and is similarly trained using Adam for 10 epochs. We utilized popular Transformer-based models like BERT (uncased), mBERT, and XLM-R by leveraging their pretrained versions such as bert-base-multilingual-cased. Our input sequences were limited to a maximum length of 512 tokens. We trained the models using a learning rate of 3 × 10−5, a batch size of 16, and for 3 epochs with the AdamW optimizer. To enhance the model’s ability to focus on the most important words in the text, we added a custom attention mechanism on top of the Transformer outputs. Unlike the standard self-attention inside the Transformer layers, which is complex and operates across all tokens at every layer, our custom attention learns to assign explicit weights to the final token embeddings before classification. We chose this approach because it provides a simpler, interpretable way to highlight key tokens relevant to our classification task and can improve performance by directing the model’s focus more effectively than the default mechanism.
Table 3.
Fine-tuning parameters for ML, DL, and Transfer Learning Models used in NER.
4. Results and Analysis
In this section, a thorough review of the results of various machine learning and deep learning models for NER is presented on Arabic data, Urdu data, and multilingual datasets. This benchmark compares the performance of traditional classification models (such as Random Forest), deep neural networks (CNN and BiLSTM) using different word embeddings (FastText and GloVe), and the latest advanced transformer models (BERT, mBERT, and XLM-R). The results demonstrate a consistent improvement from classical to deep learning methods in evaluation metrics such as precision, recall, F1-score, and accuracy. The analysis also explores how multilingual training influences the generalization and robustness of models in low-resource and morphologically rich languages, offering critical insights into the strengths and limitations of each modeling strategy in the context of multilingual NER.
4.1. Results for Machine Learning
Table 4 presents the performance results of Named Entity Recognition (NER) models applied to three datasets: Arabic translation, Urdu translation, and a joint multilingual dataset. Three machine learning classifiers—Logistic Regression (LR), Support Vector Machine (SVM), and Random Forest (RF)—were evaluated using precision, recall, F1-score, and accuracy metrics. For the Arabic dataset, SVM and RF outperform LR, achieving the highest accuracy (0.91) with slightly higher precision and recall, indicating better generalization and detection of named entities. A similar trend is observed in the multilingual dataset, where SVM and RF again lead with 0.91 accuracy and higher precision, suggesting that combining Arabic and Urdu data enhances performance. In contrast, for the Urdu dataset, all models yield identical results (0.82 precision, 0.9 recall, 0.86 F1-score, and 0.9 accuracy), implying less model variability and possibly simpler entity structures in the Urdu translation. Overall, the results show that while all models perform well, SVM and RF consistently provide stronger performance, particularly in Arabic and multilingual settings, highlighting the benefit of multilingual training and model robustness in morphologically rich languages.
Table 4.
Results for Machine learning.
4.2. Results for Deep Learning
Table 5 compares the performance of deep learning models—CNN and BiLSTM—using two types of word embeddings, FastText and GloVe, for Named Entity Recognition (NER) across Arabic, Urdu, and multilingual datasets. Overall, the results demonstrate that FastText embeddings consistently outperform GloVe embeddings in all settings. Under FastText, the BiLSTM model performs best across all datasets, achieving remarkably high and stable results with 0.96 precision, recall, F1-score, and accuracy, indicating its strong ability to capture complex linguistic patterns, even in morphologically rich languages. CNN also shows strong performance with FastText, slightly lower than BiLSTM but still robust, achieving around 0.92–0.93 accuracy and F1-score across the datasets.
Table 5.
Results for deep learning results.
In contrast, GloVe-based models yield slightly lower performance. For the Arabic dataset, both CNN and BiLSTM achieve similar results (0.87–0.91), but BiLSTM does not outperform CNN as clearly as it does with FastText. The multilingual dataset shows a small gain for BiLSTM over CNN using GloVe (0.91 vs. 0.87 precision), but the F1-score remains around 0.87 for both. For the Urdu dataset, BiLSTM again slightly outperforms CNN with a marginal improvement in F1-score (0.88 vs. 0.87), but both still fall behind their FastText counterparts. These findings underscore that FastText embeddings are more effective for NER in Arabic and Urdu, likely due to their subword-level modeling, which helps in handling rich morphology and out-of-vocabulary words common in these languages. Furthermore, the BiLSTM architecture consistently surpasses CNN across embedding types, especially with FastText, confirming that its sequential modeling capabilities are better suited for the NER task in low-resource or linguistically complex settings. The multilingual model maintains high performance, validating that training across both Arabic and Urdu data does not degrade results and can be beneficial for generalization.
4.3. Transformers Results
Table 6 presents the evaluation of Transformer-based models—BERT, mBERT (Multilingual BERT), and XLM-R (XLM-RoBERTa)—for Named Entity Recognition (NER) across three datasets: Arabic, Urdu, and a multilingual combination of both. The performance is measured using precision, recall, F1-score, and accuracy, and the results demonstrate exceptionally high and consistent performance across all models and datasets, especially with XLM-R. For the Arabic dataset, BERT achieves strong results (0.97 across all metrics), while both mBERT and XLM-R slightly outperform it with near-perfect scores of 0.98 in every metric, reflecting excellent capability to handle Arabic morphology and context. In the multilingual setting, all three models perform equally well (0.98 across all metrics), showing that combining data from different languages does not degrade performance but rather maintains or enhances generalizability.
Table 6.
Results for Transfer learning model.
For the Urdu dataset, results are similarly strong: BERT and mBERT achieve slightly varied scores (BERT: F1-score 0.97, mBERT: precision 0.97, recall 0.98), but XLM-R again stands out with perfect consistency (0.98 in all metrics). These findings indicate that transformer models, particularly XLM-R, are highly effective for NER in both individual and cross-lingual settings. The consistent performance across datasets and languages also reflects the power of pretrained multilingual language models in capturing complex linguistic features in low-resource and morphologically rich languages like Arabic and Urdu. In summary, XLM-R proves to be the most robust and reliable model for NER tasks in this multilingual context, followed closely by mBERT and BERT.
4.4. Error Analysis
Table 7 highlights the top-performing models for Named Entity Recognition (NER) across Arabic, Urdu, and multilingual datasets by comparing a traditional machine learning model (Random Forest—RF), a deep learning model (BiLSTM with GloVe embeddings), and a transformer-based model (XLM-RoBERTa—XLM-R).
Table 7.
Top-performing models in each learning approach.
For the Arabic dataset, the Random Forest (RF) model shows solid baseline performance with an accuracy of 0.91 and an F1-score of 0.87, demonstrating its ability to identify named entities to a reasonable degree. However, RF’s performance is limited by its lack of sequence modeling, which is crucial for capturing the rich morphological and contextual dependencies in Arabic. The BiLSTM model using GloVe embeddings significantly improves upon this, achieving 0.96 across precision, recall, F1-score, and accuracy by effectively modeling the sequential nature of text. Despite these gains, the transformer-based XLM-R model surpasses both, reaching near-perfect scores of 0.98 across all metrics, showing its superior capacity for capturing long-range dependencies and multilingual features essential for handling Arabic’s complex language structure.
In the multilingual setting, which combines Arabic and Urdu data, Random Forest maintains the same moderate performance as in the Arabic-only dataset, highlighting its limitations when handling diverse languages simultaneously. BiLSTM with GloVe embeddings again delivers strong results (0.96 across all metrics), benefiting from its ability to model context and word relationships within and across languages. XLM-R continues to lead with the highest precision, recall, F1-score, and accuracy at 0.98, demonstrating its robustness and flexibility in processing and understanding multiple languages in a joint setting. This confirms the advantage of transformer models in leveraging multilingual pretraining to generalize well on diverse language datasets.
For the Urdu dataset, Random Forest shows comparatively lower performance, with an F1-score of 0.86 and accuracy of 0.90, indicating that it struggles more with Urdu’s morphological complexity and entity patterns. BiLSTM with GloVe provides a meaningful improvement (F1-score of 0.88 and accuracy of 0.91) by capturing sequential information and contextual clues better than RF. Yet, XLM-R again dominates this dataset with a consistent 0.98 score across all evaluation metrics, illustrating its strong ability to handle low-resource languages like Urdu effectively. Overall, these results highlight that while traditional machine learning and deep learning models offer competitive performance, Transformer-based models like XLM-R are the state-of-the-art choice for NER across morphologically rich and multilingual languages. Overall, the comparative analysis of Named Entity Recognition models across Arabic, Urdu, and multilingual datasets clearly demonstrates the superiority of Transformer-based models, particularly XLM-RoBERTa.
Table 8 presents the precision, recall, and F1-scores for four Named Entity Recognition (NER) classes—Location, Organization, Person, and Other—across three settings: multilingual (joint Urdu and Arabic), Arabic translation, and Urdu translation, using the top-performing XLM-R model. Overall, the Other class consistently achieves the highest scores across all settings, with near-perfect precision and recall (around 0.99), indicating excellent detection performance. The Person and Location classes also show strong performance, with F1-scores ranging from 0.85 to 0.93. The Organization class has slightly lower recall, particularly in the multilingual and Urdu settings, resulting in marginally lower F1-scores (around 0.85–0.87). These results demonstrate that the joint multilingual model performs competitively with or better than the monolingual models, effectively capturing entities across both Urdu and Arabic languages.
Table 8.
Class-wise score of our top-performing model XLM-R.
Figure 3, Figure 4 and Figure 5 show the confusion matrices of the top-performing XLM-R model on the Arabic, Urdu, and multilingual datasets, respectively; these matrices provide a detailed view of the model’s prediction accuracy and error patterns across different languages, helping to identify strengths and areas for further improvement in multilingual NER tasks. Meanwhile, Figure 6, Figure 7 and Figure 8 present the accuracy vs. epoch and loss vs. epoch curves for the same datasets, illustrating the model’s training progress, convergence, and stability throughout the learning process.
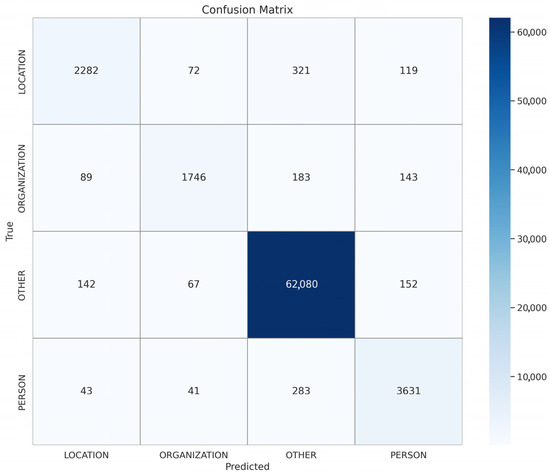
Figure 3.
Urdu translation XLM-R.
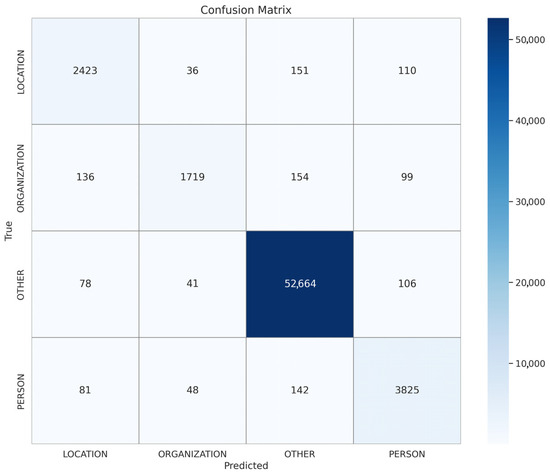
Figure 4.
Multilingual translation XLM-R.
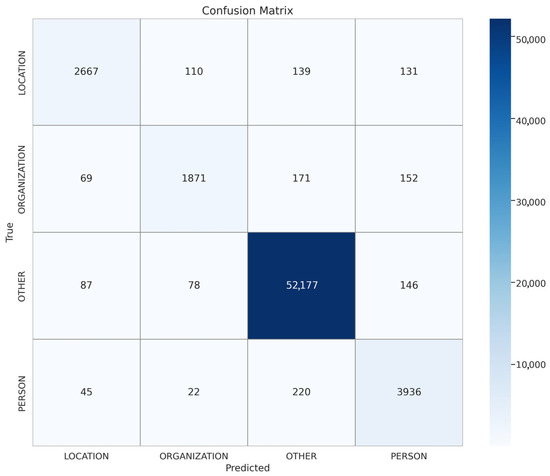
Figure 5.
Arabic translation XLM-R.
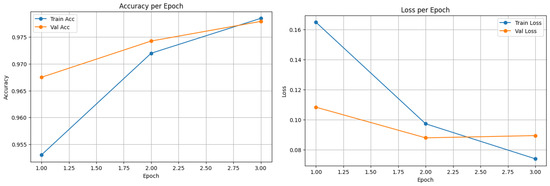
Figure 6.
Arabic translation of XLM-R.
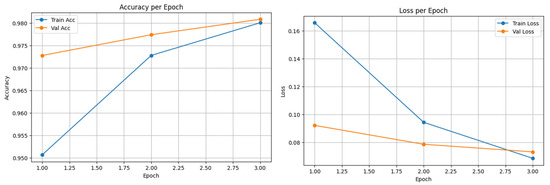
Figure 7.
Multilingual translation of XLM-R.
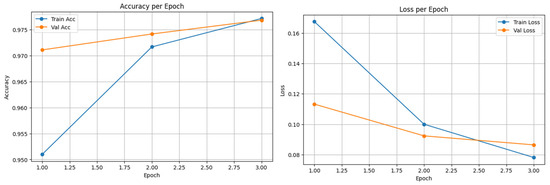
Figure 8.
Urdu translation of XLM-R.
5. Limitations
Despite the promising results and novel approaches proposed in this study, several limitations must be acknowledged. First, while the use of the Google Translate API enabled the creation of cross-lingual datasets, the translations may not always capture the nuanced, context-dependent meanings of named entities, especially in informal or dialectal social media language. This could introduce noise into the training data, potentially affecting model performance. Second, although the joint multilingual dataset improves diversity, merging datasets from different languages may lead to semantic inconsistencies, particularly when the original annotation standards or entity boundaries vary. Third, the study focuses primarily on standard Arabic and formal Urdu, leaving dialectal variants (e.g., Gulf Arabic, Punjabi–Urdu) and Roman Urdu relatively underexplored. Additionally, code-mixed content was not explicitly modeled, which limits the applicability of the system in fully capturing real-world multilingual social media behavior. Finally, while the customized XLM-R model with a novel attention mechanism showed strong performance, its training and fine-tuning require substantial computational resources, which may limit reproducibility for researchers without access to high-performance infrastructure.
6. Conclusions and Future Work
In this study, we addressed the challenges of Named Entity Recognition (NER) in low-resource languages—specifically Arabic and Urdu—by proposing two novel strategies: a joint multilingual approach and a translation-based augmentation technique. By constructing three enriched datasets and evaluating multiple model architectures, including a custom attention-based XLM-R model, we demonstrated that combining cross-lingual resources and translation techniques significantly enhances NER performance in noisy, informal, and morphologically complex social media text. Our experiments confirm that these methods not only help bridge the resource gap but also improve the generalizability of models across diverse linguistic settings. The proposed pseudocode-driven framework further ensures reproducibility and scalability, making it a valuable contribution to multilingual NLP research.
For future work, we aim to extend our joint multilingual and translation-based approaches to better handle code-mixed and Romanized content, particularly Roman Urdu and informal Arabic, which remain major challenges in social media NER. Addressing dialectal variation, especially within Arabic, could further improve model robustness in diverse regional contexts. Additionally, our framework can be adapted to other low-resource languages, enabling broader multilingual applications in underrepresented regions. Additionally, we plan to incorporate the English language into our dataset and conduct further experiments to evaluate its impact on model performance.
Author Contributions
Conceptualization, F.U. and M.A.; methodology, F.U. and M.A.; software, F.U. and M.A.; validation, A.G., G.S. and E.M.F.R.; formal analysis, M.A. and F.U.; investigation, A.G. and G.S.; resources, G.S. and A.G.; data curation, F.U.; writing—original draft preparation, F.U. and M.A.; writing—review and editing, I.B. and E.M.F.R.; visualization, M.A., I.B. and E.M.F.R.; supervision, A.G.; project administration, A.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Dataset is publicly available on GitHub.
Acknowledgments
The work was done with partial support from the Mexican Government through grant A1-S-47854 of CONAHCYT, Mexico and grants 20241816, 20241819, 20240936 and 20240951 of the Secretaría de Investigación y Posgrado of the Instituto Politécnico Nacional, Mexico. The authors thank the CONAHCYT for the computing resources brought to them through the Plataforma de Aprendizaje Profundo para Tecnologías del Lenguaje of the Laboratorio de Supercómputo of the INAOE, Mexico and acknowledge the support of Microsoft through the Microsoft Latin America PhD Award.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Pinto, A.; Gonçalo Oliveira, H.; Oliveira Alves, A. Comparing the performance of different NLP toolkits in formal and social media text. In Proceedings of the 5th Symposium on Languages, Applications and Technologies (SLATE’16), Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik, Wadern, Germany, 20–21 June 2016; p. 3. [Google Scholar]
- Camacho-Collados, J.; Rezaee, K.; Riahi, T.; Ushio, A.; Loureiro, D.; Antypas, D.; Boisson, J.; Anke, L.E.; Liu, F.; Cámara, E.M. TweetNLP: Cutting-edge natural language processing for social media. arXiv 2022, arXiv:2206.14774. [Google Scholar]
- He, L.; Omranian, S.; McRoy, S.; Zheng, K. Using large language models for sentiment analysis of health-related social media data: Empirical evaluation and practical tips. In AMIA Annual Symposium Proceedings; American Medical Informatics Association: San Francisco, CA, USA, 2024; Volume 2024, p. 503. [Google Scholar]
- Reshi, J.A.; Ali, R. Leveraging transfer learning for detecting misinformation on social media. Int. J. Inf. Technol. 2024, 16, 949–955. [Google Scholar] [CrossRef]
- Kaur, N.; Saha, A.; Swami, M.; Singh, M.; Dalal, R. Bert-Ner: A Transformer-Based Approach For Named Entity Recognition. In Proceedings of the 2024 15th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kanpur, India, 29 June–1 July 2024; pp. 1–7. [Google Scholar]
- Deshmukh, P.; Kulkarni, N.; Kulkarni, S.; Manghani, K.; Khadkikar, P.A.; Joshi, R. Named entity recognition for Indic languages: A comprehensive survey. In Proceedings of the 2024 1st International Conference on Trends in Engineering Systems and Technologies (ICTEST), Mumbai, India, 13–14 April 2024; pp. 1–6. [Google Scholar]
- Deng, Q.; Chen, X.; Yang, Z.; Li, X.; Du, Y. CLSTM-SNP: Convolutional neural network to enhance spiking neural P systems for named entity recognition based on long short-term memory network. Neural Process. Lett. 2024, 56, 109. [Google Scholar] [CrossRef]
- Li, Q.; Xie, T.; Zhang, J.; Ma, K.; Su, J.; Yang, K.; Wang, H. Enhancing named entity recognition with external knowledge from large language model. Knowl. Based Syst. 2025, 318, 113471. [Google Scholar] [CrossRef]
- Peddavenkatagari, C. EMPOWERING INFORMATION RETRIEVAL: A FRAMEWORK FOR EFFECTIVE DATA SUMMARIZATION USING NLP AND SBERT. Int. Res. J. Mod. Eng. Technol. Sci. 2024, 6. [Google Scholar]
- Le, D.V.T.; Bigo, L.; Herremans, D.; Keller, M. Natural language processing methods for symbolic music generation and information retrieval: A survey. ACM Comput. Surv. 2025, 57, 175. [Google Scholar] [CrossRef]
- Gardazi, N.M.; Daud, A.; Malik, M.K.; Bukhari, A.; Alsahfi, T.; Alshemaimri, B. BERT applications in natural language processing: A review. Artif. Intell. Rev. 2025, 58, 166. [Google Scholar] [CrossRef]
- Kuang, J.; Shen, Y.; Xie, J.; Luo, H.; Xu, Z.; Li, R.; Li, Y.; Cheng, X.; Lin, X.; Han, Y. Natural language understanding and inference with mllm in visual question answering: A survey. ACM Comput. Surv. 2025, 57, 190. [Google Scholar] [CrossRef]
- Mallikarjuna, C.; Sivanesan, S. Tweet question classification for enhancing Tweet Question Answering System. Nat. Lang. Process. J. 2025, 10, 100130. [Google Scholar] [CrossRef]
- Laugiwa, M.; Yulianti, E. Question Answering through Transfer Learning on Closed-Domain Educational Websites. J. RESTI (Rekayasa Sist. Dan Teknol. Inf.) 2025, 9, 104–110. [Google Scholar] [CrossRef]
- Ahmad, M.; Ameer, I.; Sharif, W.; Usman, S.; Muzamil, M.; Hamza, A.; Jalal, M.; Batyrshin, I.; Sidorov, G. Multilingual hope speech detection from tweets using transfer learning models. Sci. Rep. 2025, 15, 9005. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, M.; Usman, S.; Farid, H.; Ameer, I.; Muzzamil, M.; Ameer, H.; Sidorov, G.; Batyrshin, I. Hope Speech Detection Using Social Media Discourse (Posi-Vox-2024): A Transfer Learning Approach. J. Lang. Educ. 2024, 10, 31–43. [Google Scholar] [CrossRef]
- Ullah, F.; Zamir, M.T.; Ahmad, M.; Sidorov, G.; Gelbukh, A. Hope: A multilingual approach to identifying positive communication in social media. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2024), Salamanca, Spain, 18–20 September 2024. [Google Scholar]
- Albahli, S.; Nazir, T. Opinion mining for stock trend prediction using deep learning. Multimed. Tools Appl. 2025, 84, 21249–21272. [Google Scholar] [CrossRef]
- Shroff, R.; Ramesh, A. Slang Word Identification on Twitter. Int. J. Comput. Technol. Appl. 2016, 7, 420–426. [Google Scholar]
- Prakash, T.N.; Aloysius, A. Data preprocessing in sentiment analysis using twitter data. Int. Educ. Appl. Res. J. 2019, 3, 89–92. [Google Scholar]
- Saba, T.; Almazyad, A.S.; Rehman, A. Language independent rule based classification of printed & handwritten text. In Proceedings of the 2015 IEEE International Conference on Evolving and Adaptive Intelligent Systems (EAIS), Douai, France, 1–3 December 2015; pp. 1–4. [Google Scholar]
- Shoukat, E.; Irfan, R.; Basharat, I.; Tahir, M.A.; Shaukat, S. Attention based Bidirectional GRU hybrid model for inappropriate content detection in Urdu language. arXiv 2025, arXiv:2501.09722. [Google Scholar]
- Khan, J.; Ahmad, K.; Jagatheesaperumal, S.K.; Sohn, K.A. Textual variations in social media text processing applications: Challenges, solutions, and trends. Artif. Intell. Rev. 2025, 58, 89. [Google Scholar] [CrossRef]
- Wikipedia. Arabic. 2025. Available online: https://en.wikipedia.org/wiki/Arabic (accessed on 13 June 2025).
- Bagies, T.; Alsuhaimi, R.; Almasre, M.; Bafail, A. A comprehensive analysis dashboard for detecting similar saudi twitter accounts by using stylometric features. ACM Trans. Asian Low Resour. Lang. Inf. Process. 2025, 24, 20. [Google Scholar] [CrossRef]
- Salah, R.E.; Zakaria, L.Q.B. Building the classical Arabic named entity recognition corpus (CANERCorpus). In Proceedings of the 2018 Fourth International Conference on Information Retrieval and Knowledge Management (CAMP), Kota Kinabalu, Malaysia, 26–28 March 2018; pp. 1–8. [Google Scholar]
- Nhat Minh, P.Q. A Feature-Rich Vietnamese Named Entity Recognition Model. Comput. Sist. 2022, 26, 1323–1331. [Google Scholar] [CrossRef]
- El Moussaoui, T.; Loqman, C.; Boumhidi, J. Exploring the Impact of Annotation Schemes on Arabic Named Entity Recognition across General and Specific Domains. Eng. Technol. Appl. Sci. Res. 2025, 15, 21918–21924. [Google Scholar] [CrossRef]
- Daouadi, K.E.; Boualleg, Y.; Guehairia, O. Comparing Pre-Trained Language Model for Arabic Hate Speech Detection. Comput. Sist. 2024, 28, 681–693. [Google Scholar] [CrossRef]
- Ahmad, H.; Zeng, Q.; Wan, J. A Benchmark Dataset and a Framework for Urdu Multimodal Named Entity Recognition. IEEE Access 2025, 13, 100904–100919. [Google Scholar] [CrossRef]
- Ullah, F.; Ahmad, M.; Zamir, M.T.; Arif, M.; Riverón, E.M.F.; Gelbukh, A. EDU-NER-2025: Named Entity Recognition in Urdu Educational Texts using XLM-RoBERTa with X (formerly Twitter). arXiv 2025, arXiv:2504.18142. [Google Scholar]
- Azhar, N.; Latif, S.; Arshad, S. Fine-tuning Urdu NER Models Using Context-Aware Embeddings. In Proceedings of the 2024 14th International Conference on Software Technology and Engineering (ICSTE), Shanghai, China, 23–25 August 2024; pp. 133–137. [Google Scholar]
- Ullah, F.; Gelbukh, A.; Zamir, M.T.; Riverón, E.M.F.; Sidorov, G. Enhancement of Named Entity Recognition in Low-Resource Languages with Data Augmentation and BERT Models: A Case Study on Urdu. Computers 2024, 13, 258. [Google Scholar] [CrossRef]
- Ali, M.N.; Tan, G.; Hussain, A. Bidirectional recurrent neural network approach for Arabic named entity recognition. Future Internet 2018, 10, 123. [Google Scholar] [CrossRef]
- Albahli, S. An Advanced Natural Language Processing Framework for Arabic Named Entity Recognition: A Novel Approach to Handling Morphological Richness and Nested Entities. Appl. Sci. 2025, 15, 3073. [Google Scholar] [CrossRef]
- Al-Duwais, M.; Al-Khalifa, H.; Al-Salman, A. CLEANANERCorp: Identifying and Correcting Incorrect Labels in the ANERcorp Dataset. arXiv 2024, arXiv:2408.12362. [Google Scholar]
- Hamdan, N.; Hamoud, H.; Abou Chakra, C.; Al Mraikhat, O.R.; Albared, D.; Zaraket, F.A. DRU at WojoodNER 2024: ICL LLM for Arabic NER. In Proceedings of the Second Arabic Natural Language Processing Conference, London, UK, 15–16 August 2024; pp. 885–893. [Google Scholar]
- Sadallah, A.B.; Ahmed, O.; Mohamed, S.; Hatem, O.; Hesham, D.; Yousef, A.H. ANER: Arabic and Arabizi named entity recognition using transformer-based approach. In Proceedings of the 2023 Intelligent Methods, Systems, and Applications (IMSA), Tunis, Tunisia, 13–15 July 2023; pp. 263–268. [Google Scholar]
- Kanwal, S.; Malik, K.; Shahzad, K.; Aslam, F.; Nawaz, Z. Urdu named entity recognition: Corpus generation and deep learning applications. ACM Trans. Asian Low Resour. Lang. Inf. Process. 2019, 19, 8. [Google Scholar] [CrossRef]
- Malik, M.K. Urdu named entity recognition and classification system using artificial neural network. ACM Trans. Asian Low Resour. Lang. Inf. Process. 2017, 17, 2. [Google Scholar] [CrossRef]
- Haq, R.; Zhang, X.; Khan, W.; Feng, Z. Urdu named entity recognition system using deep learning approaches. Comput. J. 2023, 66, 1856–1869. [Google Scholar] [CrossRef]
- Khan, W.; Daud, A.; Alotaibi, F.; Aljohani, N.; Arafat, S. Deep recurrent neural networks with word embeddings for Urdu named entity recognition. ETRI J. 2020, 42, 90–100. [Google Scholar] [CrossRef]
- Anam, R.; Anwar, M.W.; Jamal, M.H.; Bajwa, U.I.; Diez, I.d.l.T.; Alvarado, E.S.; Flores, E.S.; Ashraf, I.; Khan, H.U. A deep learning approach for Named Entity Recognition in Urdu language. PLoS ONE 2024, 19, e0300725. [Google Scholar] [CrossRef]
- Ahmad, M.; Sidorov, G.; Amjad, M.; Ameer, I.; Batyrshin, I. Opioid Crisis Detection in Social Media Discourse Using Deep Learning Approach. Information 2025, 16, 545. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).