1. Introduction
The process of mapping virtual machines (VMs) to physical machines (PMs) in a cloud data center (CDC) is referred to as “VM placement” (VMP). According to Alsadie [
1], the first and foremost goal of the VMP is to reduce the amount of carbon footprint emissions. A VMP strategy must take into account both the original placement of the VM and the location of the VM after migration in order to provide the greatest possible mapping between VMs and real machines [
2]. The issue is difficult to tackle because of the unexpected arrival patterns of requests for VM instances, which, when paired with the enormous scale of cloud data centers, make it difficult to fix. Because of this, it is difficult to locate the best or nearly best physical computers that are compatible with a certain VM [
1]. Authors [
3,
4,
5] are among examples of the study articles that have been published on some techniques aimed at solving VMP problems.
According to Talebian [
6], the term “ICT carbon footprint” refers to the quantity of carbon dioxide (CO
2) that is released from the energy source of a CDC. The total carbon dioxide emissions are exactly proportional to the energy used in the different power networks [
7]. This carbon footprint (CFP) has a significant influence on the environment. Concurrent with this growing worldwide development of data centers, the issues of energy usage and carbon emissions have been a major focus. Implementing the worldwide dual-carbon aim will depend much on data centers, which also act as the new driver for future digital economic growth [
8]. An additional study that was carried out by Greenpeace in the recent past [
9] indicates that the CFPs that are left behind by the information technology sector are responsible for 2% of the total greenhouse gas emissions observed worldwide. According to the projections made by Panwar [
10], the energy consumption of CDCs alone is expected to grow from 200 TWh in 2016 to 2967 TWh in 2030, which would result in an increase in CFP emissions at that time. These days, data centers generate around 1–2% of global carbon emissions and account for roughly 3% of all power used globally [
11]. In light of the growing popularity and use of cloud computing services, cloud service providers and academic institutions alike are now compelled to make choices that are not only sustainable but also favorable to the environment [
12].
There have been a number of studies that have been carried out on the subject of optimizing VM platforms (VMPs) from the perspectives of monetary savings, energy savings, task workflow efficiency, service quality, and resource transmission [
13,
14,
15,
16,
17,
18]. The huge growth in energy consumption causes data center owners to pay extra millions of dollars yearly. On the other hand, significant energy use will have negative consequences on the surroundings [
19]. Although flexibility and cost-effectiveness make cloud computing indispensable, data center energy use is beginning to generate major environmental issues. Research indicates that cloud computing’s carbon impact is more than that of the aviation industry, thereby underlining the need for sustainable solutions [
20]. The implementation of an appropriate VMP system that reduces powering expenses at the hardware level is one method that may be used to improve energy efficiency in data centers [
21].
The growing attention on environmental stewardship in business operations emphasizes the need for fresh ideas that balance economic and environmental objectives. Several studies have concentrated on enhancing energy infrastructure and reducing carbon emissions while data centers grow in size—an important double goal that underlines the main sustainability challenges facing modern companies. Combining environmental responsibility with technological innovation creates fresh ideas for digital age sustainable corporate operations [
22].
Researchers [
23,
24,
25,
26] have also used several machine learning approaches to enhance resource management and devise energy-efficient solutions in CDCs. Some of the machine learning approaches used are categorized as supervised learning, classification, regression, clustering, and reinforcement learning, among others. A recent study by Alex et al. revealed that big data and machine learning approaches may improve future energy efficiency and decrease carbon emissions by identifying and using hitherto untapped sources of flexibility [
27].
Even though VM deployment techniques have advanced significantly, current studies show clear gaps in concurrently addressing carbon awareness, energy efficiency, and SLA compliance in a single framework. Often at the cost of others, many traditional methods, such as heuristic, metaheuristic, and machine learning models, mostly focus on maximizing one or two of these variables. Furthermore, lacking in most reinforcement learning-based techniques are workload-aware clustering algorithms, which are essential for capturing the variation in cloud workloads and improving placement granularity. Furthermore, little attention has been paid to including data center carbon intensity measurements into the decision-making process, therefore losing chances to reduce the environmental effect of VM installations. This work covers these gaps by suggesting a new hybrid approach combining Deep Q-Networks (DQNs) with Agglomerative Clustering and carbon profiling to allow adaptive, carbon-efficient, and SLA-compliant VM placement choices.
The paper is structured as follows:
Related Work: With an eye toward their strengths and limits in reaching energy efficiency, optimum resource use, and SLA compliance, this section evaluates current VM placement strategies—including metaheuristic, evolutionary, and machine learning-based techniques. Furthermore, pointing out important research gaps that support the need for the suggested method are the absence of carbon-aware decision-making and workload-aware clustering.
Proposed Model: Here we present the CARBON-DQN method, a new hybrid model combining carbon intensity profiling with Agglomerative Clustering and Deep Q-Networks. Emphasizing sustainability, energy efficiency, and SLA adherence, we go over its architectural design, reinforcement learning-based decision logic, and mathematical models guiding VM-to-PM placement.
Evaluation: The experimental setup, including the simulated cloud environment, VM instance types, datasets, and performance measures used to evaluate the proposed approach, is described in this part. Included for extensive comparison are baseline algorithms including GRVMP, NSGA-II, RLVMP, GMPR, and MORLVMP.
Results and Discussion: Carbon emissions, SLA breaches, and energy usage are examined and benchmarked against current techniques for CARBON-DQN performance. Important trends, performance gains, and the effect of combining carbon-aware profiling and clustering with reinforcement learning are discussed.
Conclusions and Future Work: This study ends by aggregating the benefits of the CARBON-DQN method for intelligent, sustainable VM deployment. To improve cloud data center management even further, it also suggests future paths like security-aware placement techniques, multi-cloud scalability, and real-time energy forecasting.
2. Related Work
Energy use in CDCs has to be closely investigated if we are to lower their CFP, as authors [
28,
29] confirm that energy efficiency is very crucial in reducing the CFP. Improving energy efficiency has great environmental advantages, most notably in greatly lowering direct greenhouse gas emissions from the use of fossil fuels and indirect emissions produced by the generation of electricity.
Researchers, including [
30,
31] who underlined the need for optimizing VMP strategies to achieve sustainable data center operations, have also underlined the role that VM placement in energy and CFP reduction plays in reducing these metrics. Cloud companies like AWS, GCP, and Azure are actively looking at recent studies on carbon-aware workload management. Their techniques are two-fold: geographical task movement and temporal burden redistribution. The former waits for job completion until times when low carbon emissions are expected [
7].
Drawing on these results, authors [
32] presented a VMP method based on greedy techniques that give VMs first priority to optimal hosts. Their approach is to reduce CO
2 emissions, PUE, total energy consumption, and data transmission delay, as well as power use effectiveness. This emphasizes the many advantages of strategic VMPs going beyond simple computing efficiency.
Authors Beena et al. agreed that efficient job scheduling and the incorporation of renewable energy sources are vital measures for improving the sustainability of cloud computing. In addition to alleviating environmental impact, Green Cloud Computing aids organizations in reducing operational costs by minimizing energy use while maintaining performance standards [
20]. In addition, authors Zhao, Zhou, and Li in their study agreed that adaptive overloaded detection is a technique using multi-thresholds or regression-based threshold adjustment methods to fit changing workload patterns and prevent service level agreement violations by actively consolidating virtual machines (VMs) from perhaps overloaded physical machines (PMs). The overused resources may be directed to a small number of active PMs, while the other PMs might be put in inactive mode to preserve energy in order to achieve this goal. Though their potential is great, inconsistent workloads and inaccurate threshold settings might cause major SLA violations or energy inefficiencies [
19].
The first efforts at VM placement used machine learning-based approaches combined with heuristic methods. To evaluate measures like energy utilization, service degradation, network traffic, migration frequency, and scalability, Ref. [
33] devised a hyper-heuristic method combining conventional heuristics with machine learning. Their study revealed the possibility of hybrid models in improving VM allocation techniques by a comparison of recent metaheuristic approaches versus optimum solutions obtained from integer linear programming (ILP).
Their versatility and ability to provide almost perfect answers within realistic durations have made them quite important in handling challenging cloud computing challenges. As shown by Panwar et al. [
10] and Khanduja and Bhushan [
34], these high-level algorithmic techniques have been widely used in VM placement, load balancing, and resource prediction chores. Often-used metaheuristic models include swarm intelligence, evolutionary algorithms, bio-inspired, and physics-based approaches, which are meant to lower energy usage while also increasing performance.
The development of reinforcement learning (RL) enhanced the terrain of virtual reality location techniques even further [
35] presented a dynamic machine learning paradigm wherein agents with knowledge decide to maximize placement [
36] further expanded this using the RLVMrB method, which combines random selection, mutation, and crossover with reinforcement learning via evolutionary processes. Their multi-objective framework sought to use a non-dominance assessment approach to enhance both vertical and horizontal load balancing. Ghasemi et al. [
23] used K-means clustering in the MRRL technique to improve RL convergence and lower execution time, thereby allowing the more efficient grouping of VMs depending on workload similarity. In addition, authors Seo and Elmroth in their study focused on resource allocation to balance performance with carbon reduction to address the problem of carbon emissions in data-driven data center operations, facilitating computing-intensive applications, including machine learning (ML) [
37].
Ref. [
38] then presented an RL-based energy management system specifically for large-scale data centers, therefore highlighting the potential of reinforcement learning in resource optimization. Their model showed how an agent develops to interact with the surroundings and implement rules aiming at low energy use. Building on this basis, Ref. [
39] investigated RL methods for VM consolidation, which underlined the flexibility of RL in resource management in dynamic and unpredictable cloud environments.
Models of hybrid machine learning have also surfaced to handle the complexity of VM placement problems. Ref. [
40] devised an energy-aware resource deployment method by merging the K-nearest neighbors (KNN) algorithm for supervised classification with K-means clustering for unsupervised learning. Ref. [
40] similarly created an ensemble prediction model using learning automaton theory to improve VM allocation by lowering service level agreement violations (SLAVs) and energy usage.
With an eye on goals like energy efficiency, SLA compliance, resource use, and load balancing, the examined literature offers a range of methods and strategies meant to maximize VM placement (VMP) in cloud data centers. Genetic algorithms include NSGA-II [
41,
42], reinforcement learning-based approaches [
35,
42], greedy strategies [
43], and hybrid models integrating fuzzy logic with RL [
36]. These models were tested using simulators, including bespoke Python version 3.14 and C++ implementations, CloudSim, Edge CloudSim, and others. These techniques sometimes suffer from trade-offs—such as a longer execution time, poor SLA handling, or omitting certain resource dimensions like memory or distance measurements in clustering—even while they show benefits in enhancing energy optimization and balancing system loads.
A lack of comprehensive consideration for all important criteria in cloud systems is a typical difficulty in various research. For example, based on the schemes analyzed in
Table 1, whereas MORLVMP [
44] focused on resource optimization and energy efficiency, it neglected energy-aware distance measurements during clustering. Similarly, although concentrating on energy or VM management, algorithms such as GWO-RNN [
42] and MOD-JAYA [
45] failed to sufficiently record SLA breaches or sustain load balance. Furthermore, certain models—like GRVMP [
46] and EER-VMP [
47]—ignored memory resource waste, therefore restricting their usefulness in practical settings. These shortcomings bring attention to the continuous requirement of thorough, multi-objective optimization techniques balancing energy, performance, and SLA adherence in big-scale, dynamic cloud settings.
The examined literature exposes a notable discrepancy in the evolution of complete VM placement solutions that concurrently solve energy efficiency, CFP reduction, SLA compliance, and holistic resource use in CDC. Many studies concentrate on personal goals, including energy optimization, load balancing, or SLA adherence—but they may ignore important interdependencies, such as memory resource waste, energy-aware clustering, or the inclusion of carbon emission measurements. Some models also have poor execution speeds or fail to scale efficiently in large-scale settings. Specifically, hybrid algorithms and reinforcement learning show potential but still lack connection with carbon-aware techniques and clustering methods able to improve convergence and lower execution costs. This gap emphasizes the requirement of a comprehensive, intelligent VMP approach—such as a carbon-aware, energy-efficient, SLA-compliant model utilizing deep reinforcement learning and clustering—to holistically handle the dynamic needs of current cloud infrastructures.
3. The Proposed Model
The exponential expansion in VM installations in contemporary cloud computing systems has resulted in higher carbon emissions and energy consumption; therefore, sustainability has become a major issue. Conventional VM placement techniques can ignore the environmental effect and concentrate more on performance or cost-efficiency, therefore optimizing resources and increasing the CFP. Maintaining SLAs across resource allocation continues to be difficult as well. Intelligent, flexible, and environmentally sensitive VM placement techniques that may strike a balance between operational efficiency and sustainability objectives are much needed to handle these urgent problems.
To attain carbon-aware, energy-efficient, and SLA-compliant VM placement in cloud data centers, the proposed approach presents a unique hybrid architecture combining Deep Q-Networks (DQNs) with Agglomerative Clustering. The method starts with including the measures of carbon intensity and energy efficiency into the data center profile so that the system may assess the environmental effects of possible location choices. VMs are grouped via aggregative clustering according to resource constraints and SLA sensitivity, therefore simplifying placement choices and guaranteeing that like workloads are handled collectively. A DQN-based agent learning optimum placement strategies over time, led by a multi-objective reward function including energy savings, SLA adherence, and CFP reduction, then handles these clustered VMs.
The proposed method presents a scalable and flexible answer to VM placement by combining unsupervised learning for workload characterization with reinforcement learning for dynamic decision-making. It uses environmental data and real-time feedback to always improve placement techniques, therefore encouraging effective resource use and environmental sustainability. This method guarantees high service dependability and improves the energy and carbon efficiency of cloud operations, therefore offering a potential path for future-generation cloud infrastructure management. The model is broken down into five phases, namely, carbon-aware data center profiling, Agglomerative Clustering of VMs, state space construction for DQNs and adaptive feedback and optimization.
The goal of the proposed model is to create a scalable, carbon-aware, and energy-efficient virtual machine placement strategy in cloud data centers by combining Deep Q-Networks with Agglomerative Clustering. This will help make the best use of resources, meet SLAs, and lower the carbon footprint.
3.1. Illustration of the Proposed Model
Figure 1 shows how a carbon-aware, energy-efficient, and SLA-compliant VM deployment framework works in CDCs. It uses DQNs and Agglomerative Clustering. The first step is to profile the data center so that it is aware of carbon emissions. This involves collecting real-time environmental data from different physical equipment in the data center, such as carbon intensity and energy efficiency. This profile is the basis for making placement choices that have the least effect on the environment. After that, arriving VMs are grouped together using Agglomerative Clustering based on their common resource needs and SLA sensitivity. Putting together comparable workloads makes placement easier and encourages greater consolidation, which in turn makes better use of resources and saves energy.
The system moves on to state space creation once the VMs have been clustered. In this stage, the clustered groups and the current state of the data center are used as input for a DQN-based decision-making model. The DQN uses neural network layers to interpret these data and figure out the best ways to place VMs. It does this with the help of a multi-objective reward function that balances energy savings, SLA compliance, and reducing the carbon footprint. The adaptive feedback and optimization module uses the DQN’s output to change placement rules all the time, depending on fresh data and input from the environment. The end result is a more sustainable and performance-aware allocation of VMs, which are demonstrated to be well-distributed among servers. This shows that the model can be used to manage large-scale cloud infrastructure while being mindful of the environment.
3.2. Carbon-Aware Data Center Profiling
Forming the basis for carbon-conscious VM placement choices, the first step of the proposed method concentrates on characterizing cloud data centers based on their carbon intensity and energy performance. Every data center is assessed using real-time and historical data, including geographical emission variables, energy efficiency measures, and a mix of the power sources—renewable vs. fossil fuels. Combining these criteria allows each data center to obtain a Carbon Efficiency Score (CES), therefore measuring its environmental sustainability. The CES is meant to provide data centers with lower carbon intensity and better energy efficiency first priority, hence guiding VM placement.
The CES for a data center
is computed using the following weighted inverse scoring model [
20]:
where
Carbon Efficiency Score of data center ;
Carbon intensity of , based on energy mix and regional emissions;
Energy Performance Index, representing power usage effectiveness (PUE) and thermal efficiency;
Tunable weight parameters to balance the impact of carbon emissions and energy performance.
Higher valued data centers are judged to be more ecologically friendly. Later on, these scores are included into the DQN reward mechanism, which helps to choose sites with a smaller carbon footprint while still considering energy and SLA limitations. This step guarantees that from the very start of the decision-making process, the placement technique is aware of the environmental influence.
3.3. Agglomerative Clustering of VMs
The suggested method uses Agglomerative Clustering in the second phase to group VMs (VMs) according to resource demand and SLA criteria similarity. Starting each VM as an independent cluster, this hierarchical clustering method repeatedly merges the closest pairings depending on a predetermined distance metric, like Euclidean or Cosine distance, until an ideal number of VM groups is generated. Normalized values of CPU, memory, storage, bandwidth needs, and the SLA sensitivity level comprise each VM’s feature vector. The method lowers the search area for placement and allows batch-level optimization by grouping like VMs, hence improving the scalability and efficiency of the VM allocation process.
The clustering process is governed by a distance function
, defined as
where
and are the normalized values of the -th resource feature for VMs and , respectively;
represents the weight assigned to the -th feature (e.g., CPU, RAM, SLA sensitivity);
is the total number of features.
This clustering phase guarantees that VMs with comparable QoS demands are handled cohesively in addition to simplifying the placement choice process for the reinforcement learning model in the following phase. Maintaining SLA compliance and reducing migration overhead depend especially on this as comparable VMs may be allocated to hosts or data centers most suited for their combined profile.
3.4. State Space Construction for DQNs
To let the Deep Q-Network (DQN) make intelligent, context-aware VM placement choices in the third phase, a complete state space is built. Every state S_t at time t captures host data as well as VM group properties, therefore reflecting the current environment status. Normalized elements, including the total CPU, memory, and bandwidth needs of the clustered VM group; SLA criticality level; current load and thermal condition of possible hosts; energy cost; and the Carbon Efficiency Score (CES) of every eligible data center comprise the state vector. Formally, the state vector may be stated as
By means of a broad variety of operational and environmental indicators, this enhanced state representation enables the DQN agent to learn from them, thereby optimizing VM placement choices in a multi-objective way and balancing energy efficiency, SLA adherence, and carbon footprint reduction.
3.5. DQN-Based Placement Decision
During this phase, each cluster of virtual computers makes the best placement selections using the Deep Q-Network (DQN). Trained to learn a policy that links the present environment state—defined by resource needs, SLA levels, host conditions, energy costs, and Carbon Efficiency Scores—to the most appropriate action, which is choosing a certain host or data center for VM placement. Every action the DQN performs is like assigning a VM group to a host in a data center; the agent receives feedback depending on how well that choice performed in terms of carbon footprint, SLA compliance, and energy savings. By use of Q-learning—where the Q-value approximates the predicted cumulative reward for every state–action pair—the DQN gradually improves its decision-making.
To guide the DQN, a multi-objective reward function is used, integrating energy efficiency, SLA adherence, and carbon reduction goals. The reward function
is defined as
where
is the estimated energy saved due to efficient placement;
indicates SLA compliance (binary or percentage);
is the additional carbon intensity from the chosen host/data center;
is the cost of VM migration (if applicable);
are tunable weights reflecting the importance of each objective.
The DQN employs an ε-greedy strategy to balance exploration with exploitation: the agent primarily chooses actions with the greatest Q-values while periodically investigating random actions to find better methods. Furthermore, by eliminating correlation between successive samples and lowering oscillations in Q-value estimations, the employment of experience replay and a target network helps stabilize the learning process. The DQN is a strong and flexible tool for intelligent cloud resource management, as during consecutive placement cycles, it grows more adept at choosing placement alternatives that lower energy usage and carbon emissions while guaranteeing SLA compliance.
3.6. Adaptive Feedback and Optimization
Based on real-time performance measurements, the last step of the proposed method consists of a dynamic adaptive feedback loop that constantly analyzes and optimizes the VM placement process. Following every placement choice, the system gathers data on important benchmarks like SLA breaches, host energy consumption, thermal efficiency, and real carbon emissions produced. The environment model is updated using this input, which guides the next Deep Q-Network (DQN) choices. The method also regularly recalculates the Carbon Efficiency Scores (CESs) of data centers to reflect changes in energy sources, grid carbon intensity, and operational efficiency, thereby maintaining the alignment of the placement strategy with sustainability objectives.
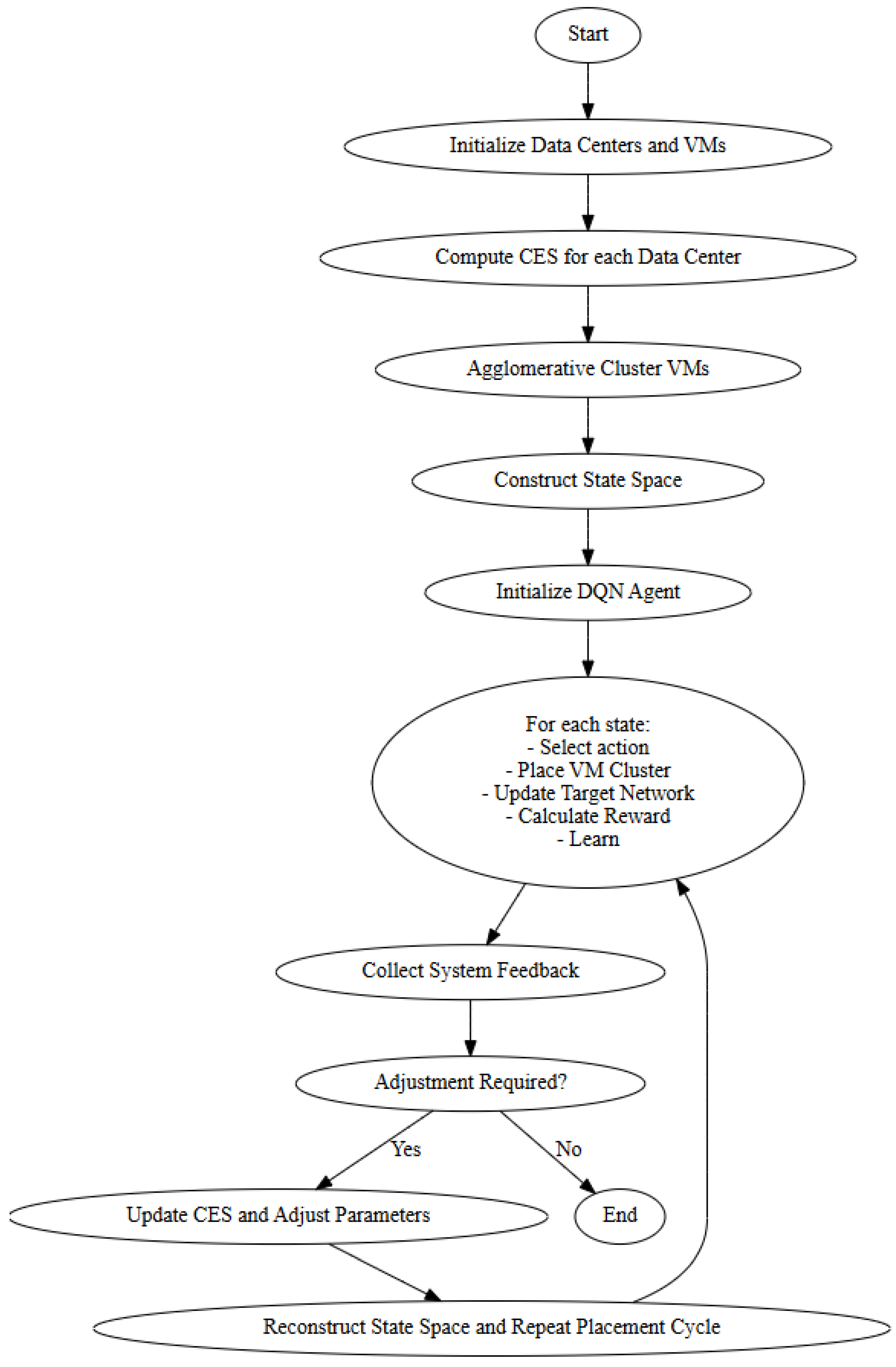
Furthermore, constantly updated depending on the observed results are the incentive function parameters and clustering sensitivity thresholds, thus optimizing the balance between energy efficiency, carbon reduction, and SLA compliance. The Algorithm 1 as described in
Figure 2, may respond, for example, by raising the weight w2w2 in the reward function or changing VM clustering to lower co-location risks should SLA breaches rise. Likewise, should carbon emissions increase, the placement plan might change to give greener data centers first priority. This step turns the algorithm into a self-optimizing system able to learn from its surroundings and adjust to workload changes, resource availability, and carbon circumstances over time, thereby guaranteeing long-term sustainability and performance efficiency in cloud data center operations.
| Algorithm 1 CARBON-DQN Algorithm |
| 1 | function Main(): |
| 5 | | DCs = initialize_data_centers() |
| 6 | | VMs = initialize_virtual_machines() |
| 7 | | for DC in DCs: |
| 8 | | | DC.CES = compute_CES(DC) |
| 9 | | clusters = agglomerative_cluster(VMs) |
| 10 | | states = construct_state_space(clusters, DCs) |
| 11 | | dqn_agent = initialize_DQN() |
| 12 | | for state in states: |
| 13 | | | action = dqn_agent.select_action(state) |
| 14 | | | result = place_VM_cluster(state, action) |
| 16 | | | UpdateTargetNetwork() |
| 17 | | | reward = calculate_reward(result) |
| 18 | | | dqn_agent.learn(state, action, reward) |
| 19 | | feedback = collect_system_feedback() |
| 20 | | if feedback.requires_adjustment: |
| 21 | | | update_CES(DCs) |
| 22 | | | dqn_agent.adjust_parameters(feedback) |
| 23 | | | states = construct_state_space(clusters, DCs) |
| 24 | | | repeat placement cycle |
| 25 | end function |
3.7. Reasons for Adopting the DQN
This research uses the DQN because it can learn the best ways to make decisions in changing and high-dimensional settings, which is what cloud data centers are like. Heuristic-based placement tactics that have been around for a long time frequently do not perform well when workloads change, resources are different, and carbon and energy limits change. The DQN is a model-free reinforcement learning method that lets the system learn from its own actions by interacting with the environment and improving a reward function that takes into account several goals, such as reducing carbon emissions, meeting SLAs, and becoming more energy efficient. Its deep learning part makes it possible to generalize well across many different placement situations. This makes it a strong and adaptable tool for placing virtual machines in smart, adaptive, and long-lasting ways in complicated cloud infrastructures.
4. Evaluation Results and Discussion
This section offers a thorough examination of essential performance measures pertinent to carbon-aware and energy-efficient VMP in CDC. The assessment emphasizes the quantity of operational physical computers, total energy use, the efficiency of processor and memory utilization, the overhead of VM migration, adherence to SLA, and the complexity of computing time. The indicators are analyzed within the framework of our suggested methodology, which utilizes DQNs and Agglomerative Clustering to enhance placement selections. The following subsections elaborate on the comprehensive findings and their ramifications.
4.1. Simulation Environment
The simulation of the suggested technique and comparative algorithms was conducted in the Python simulation environment, version 3.13.1. The simulation was executed using a laptop with a maximum frequency of 2.13 GHz, 16 GB of RAM, and a 64-bit Windows 11 operating system. This simulation scenario included a data center with 4000 varied physical devices.
Every physical machine has a probabilistic value within the specified range. The diversity in energy consumption across physical machines is due to their heterogeneity, leading to disparities between their maximum and minimum efficiency levels.
The suggested DQN-based method used an ε-greedy exploration strategy, where ε started at 0.1 and slowly dropped throughout training to find a balance between exploration and exploitation.
The evaluation of the proposed technique is conducted via two separate experiments using synthetic real datasets (Amazon EC2) for VM request dimensions. The specifications for these datasets are detailed in
Table 2. Each experiment has four scenarios with 256, 512, 1024, 2048, and 4192 VMs, respectively.
4.2. Results and Discussion
4.2.1. Key Findings
Carbon-Aware VMP in CDC
The results in
Figure 3 demonstrate the efficacy of six virtual machine placement algorithms—RLVMP, GRVMP, NSGA-II, MORLVMP, GMPR, and the proposed CARBON-DQN—in recognizing carbon emissions across four types of Amazon EC2 virtual machines: micro, small, extra-large, and high-CPU Medium. Both bar graphs indicate that CARBON-DQN consistently receives the lowest carbon-aware scores across all VM configurations. This indicates the superior optimization of VM placement, using less energy and exerting a reduced impact on the environment. As the complexity of virtual machines increases, traditional algorithms such as GRVMP and NSGA-II exhibit diminished efficacy, rendering them less capable of managing high-demand scenarios. The disparity between CARBON-DQN and other methodologies is more apparent for larger virtual machines, such as extra-large and high-CPU Medium. This indicates that CARBON-DQN performs more effectively with resource-intensive applications.
The primary cause of this performance enhancement is CARBON-DQN’s reinforcement learning framework, which employs an ε-greedy exploration strategy to progressively improve placement picks throughout training. CARBON-DQN acquires knowledge via its interactions with the environment and makes decisions based on long-term benefits, such as reducing energy use. This enables adaptation to the many sorts of actual devices inside the simulated data center. Conversely, heuristic and evolutionary methodologies such as GRVMP and NSGA-II lack dynamic feedback mechanisms that enable self-optimization in response to variations in load patterns. The results indicate that the DQN-based technique is sufficiently robust to manage VMs in an environmentally sustainable manner, particularly as cloud infrastructures face increasing demands for sustainability.
Energy-Efficient VMP in CDC
The energy-efficiency comparison graphs in
Figure 4 indicate that the proposed CARBON-DQN algorithm significantly outperforms established approaches such as RLVMP, GRVMP, NSGA-II, MORLVMP, and GMPR in decreasing energy consumption across several Amazon EC2 VM types—micro, small, extra-large, and high-CPU Medium. The line graph indicates that CARBON-DQN consistently achieves the lowest energy consumption ratings, even in high-resource virtual machines such as extra-large and high-CPU Medium. As the intricacy and resource demands of virtual machines increase, the gap in energy efficiency widens. CARBON-DQN ensures efficient placements, whilst other algorithms encounter more energy overhead.
The adaptive learning capability of CARBON-DQN significantly enhances its energy efficiency. The DQN model progressively learns to allocate VMs to physical machines that use the least energy, using an ε-greedy exploration strategy. It renders assessments based on the presence of 4000 heterogeneous devices inside the data center. In contrast to static or heuristic methods, CARBON-DQN adapts to fluctuations in VM demand and the performance of actual machines, hence reducing unnecessary energy use. The results indicate that the DQN approach is applicable in real-world cloud systems and demonstrates flexibility and durability. Enhancing energy efficiency reduces operational costs and promotes ecologically sustainable computing practices.
SLA-Aware VMP in CDC
The SLA-awareness comparison in
Figure 5 indicates that the CARBON-DQN algorithm consistently fulfills the SLA criteria most effectively across all EC2 VM types, including micro, small, extra-large, and high-CPU Medium. The bar graph indicates that CARBON-DQN sustains SLA fulfillment rates over 90%, even under challenging conditions, like in extra-large and high-CPU Medium instances. Conversely, traditional algorithms such as GRVMP and NSGA-II struggle to meet SLAs as the resource requirements of VMs increase, indicating their inadequate adaptability to fluctuating conditions. The consistent SLA performance demonstrates that CARBON-DQN can effectively optimize placement decisions to align workload requirements with available resources.
The line graph indicates that all algorithms perform well with lighter VM types, such as micro and small; however, only CARBON-DQN maintains satisfactory SLA adherence as the workload intensifies. The ε-greedy strategy inside the DQN framework enables the algorithm to identify optimal rules that enhance SLA satisfaction, despite uncertainty about outcomes. This functionality is very beneficial in cloud environments, including 4000 distinct physical machines, where adherence to SLAs is crucial for maintaining service reliability, customer satisfaction, and operational guarantees. The results unequivocally indicate that CARBON-DQN is the optimal choice for the allocation of virtual machines in data centers using various energy sources.
4.3. Limitations
Although the proposed Deep Q-Network (DQN) and Agglomerative Clustering-based VM placement approach has great results in maximizing energy efficiency, carbon awareness, and SLA compliance, still, several limitations prevent its current industrial applicability:
The lack of thorough modeling for the temporal variability of carbon intensity is a main problem that greatly influences the sustainability of cloud operations. The current method ignores real-time fluctuations in grid carbon emissions, usually related to the availability of intermittent renewable energy, depending only on static or averaged carbon intensity measurements. This temporal disjunction reduces the efficiency of carbon-aware scheduling in practice and limits the reaction of the system to real carbon dynamics.
Although carbon-aware decisions depend on carbon intensity data, the method ignores renewable energy forecasting techniques to foresee the times of better or less available energy. By matching workloads with low-carbon power availability, including such estimates may improve VM location timing and resource use.
The increasing use of Kubernetes and other container orchestration technologies exposes a need for native interface with these systems. Practical application depends on changing the placement strategy for container workloads, especially in view of the move to microservices and serverless architectures.
Although the DQN approach is resilient, in high-throughput cloud environments, the demands of real-time inference and retraining might be somewhat significant. Applications sensitive to latency may not completely benefit from the recommended approach in the absence of further optimization or lightweight substitutes.
5. Conclusions and Future Work
The experimental results indicate that the proposed CARBON-DQN algorithm outperforms conventional VM placement methods such as RLVMP, GRVMP, NSGA-II, MORLVMP, and GMPR regarding carbon awareness, energy efficiency, and SLA compliance. CARBON-DQN consistently exhibited the lowest carbon-aware ratings, indicating its superior efficacy in mitigating the environmental impact of virtual machine allocations within a 4000-machine cloud data center, including diverse machine kinds. This is particularly significant in contemporary cloud systems, where data centers are a primary source of global carbon emissions. Deep reinforcement learning enables CARBON-DQN to optimize resource allocations that are environmentally beneficial and computationally efficient.
In terms of energy efficiency, CARBON-DQN demonstrated superiority by using less energy across all VM instance types, especially under high workload conditions, such as extra-large and high-CPU Medium instances. The algorithm’s adaptive learning mechanism, which continuously modifies itself according to the stochastic characteristics of physical machine performance and energy profiles, is what makes it very efficient. In contrast to static or heuristic methods, CARBON-DQN effectively optimizes workloads by selecting places that minimize overall power consumption without compromising performance. As cloud infrastructure expands and energy costs continue to rise, these intelligent energy-conscious deployment strategies will increasingly prove advantageous.
The SLA-awareness study showed that CARBON-DQN consistently achieves the highest SLA compliance rates, even in complex scenarios that demand substantial resources. This demonstrates the capacity to balance energy and carbon efficiency while maintaining service reliability, which is crucial for commercial cloud providers and mission-critical applications.
In the future, the algorithm will be enhanced by including real-time energy pricing models, renewable energy availability, and multi-cloud configurations. Incorporating federated learning and multi-agent cooperation into CARBON-DQN might facilitate collaboration and scalability across geographically dispersed data centers. Incorporating tangible reasons into the decision-making process is a compelling approach that might enhance operators’ comprehension and confidence in AI-driven placement criteria.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}