Abstract
Every minute, vast amounts of video and image data are uploaded worldwide to the internet and social media platforms, creating a rich visual archive of human experiences—from weddings and family gatherings to significant historical events such as war crimes and humanitarian crises. When properly analyzed, this multimodal data holds immense potential for reconstructing important events and verifying information. However, challenges arise when images and videos lack complete annotations, making manual examination inefficient and time-consuming. To address this, we propose a novel event-based focal visual content text attention (EFVCTA) framework for automated past event retrieval using visual question answering (VQA) techniques. Our approach integrates a Long Short-Term Memory (LSTM) model with convolutional non-linearity and an adaptive attention mechanism to efficiently identify and retrieve relevant visual evidence alongside precise answers. The model is designed with robust weight initialization, regularization, and optimization strategies and is evaluated on the Common Objects in Context (COCO) dataset. The results demonstrate that EFVCTA achieves the highest performance across all metrics (88.7% accuracy, 86.5% F1-score, 84.9% mAP), outperforming state-of-the-art baselines. The EFVCTA framework demonstrates promising results for retrieving information about past events captured in images and videos and can be effectively applied to scenarios such as documenting training programs, workshops, conferences, and social gatherings in academic institutions
1. Introduction
A common way to recall past events or memories is through questioning, such as asking, “When did we last visit the garden?” Addressing this challenge, we present an innovative system designed for the automatic retrieval of past events using visual question answering in collections of photographs or video footage. Our innovative system processes a sequence of questions or images from a user with the goal of automatically responding to inquiries about past events by providing relevant photos, videos, or responses. In our system, users can input either a question, a series of photos, or both. The system then produces an answer along with pertinent photos or videos that validate and substantiate the response. The inclusion of accompanying visuals is pivotal, serving not only to swiftly verify the answer but also to offer comprehensive details that aid in refreshing the user’s memory regarding the event in question.
In the span of a few years, a regular smartphone user could accumulate hundreds of photos documenting vacations or special occasions. This accumulation eventually translates into tens of thousands of images and endless hours of video, capturing treasured memories like weddings, family reunions, and birthday celebrations. Research has shown that people often use personal photos and videos to recall memories of these events. The challenge, however, lies in identifying specific event-related photos or videos from this vast collection. This study addresses this concern by introducing a system designed for the automated retrieval of past events through a visual question answering dataset. This system leverages advanced techniques to sift through extensive photo and video libraries, pinpointing the relevant visuals that correspond to specific memories and questions.
The outlined system for the automated retrieval of past events through visual question answering is depicted in Figure 1. The process commences with the integration of a visual question answering (VQA) dataset into the system. Subsequently, a question understanding network model is devised to interpret user-submitted queries. The system searches the photo/video dataset based on the textual information extracted from the questions or the meaning-based features identified within them. Each query is addressed based on the retrieved images or videos associated with the relevant event. To ensure accuracy, the system generates evidence alongside the constructed answers, allowing users to verify the correctness of the responses. The system’s efficacy is assessed through diverse metrics and is realized in Python 3.9, harnessing VQA and alternative QA datasets.
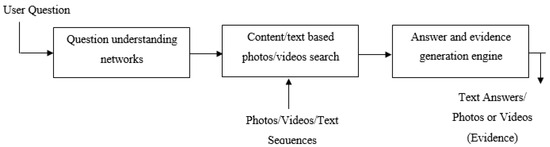
Figure 1.
Proposed methodology for designing automatic past event search system using visual question answering.
The core objective of our research is to develop an effective framework for retrieving information about past events from large collections of images and videos, where the temporal sequence and contextual dependency among frames or scenes play a critical role in correctly answering user queries. This requires a model capable of understanding and leveraging sequential dependencies over varying time spans, which is where Long Short-Term Memory (LSTM) networks excel. Unlike recurrent neural networks (RNNs), which struggle with vanishing or exploding gradients when modeling long sequences, LSTM networks introduce memory cells and gating mechanisms (input, output, and forget gates). This design enables them to capture both short-term and long-term temporal dependencies in sequential visual and textual data, which is crucial when analyzing sequences of images or video frames that span variable lengths and contain context that must be remembered for accurate answer generation.
In the context of visual question answering (VQA) for event retrieval, the sequence of frames or photos must be processed in order to reason about cause and effect, chronological flow, and context continuity. LSTMs are well-suited to encode such sequential multimodal data, making them more robust for event reconstruction tasks compared to non-recurrent or feed-forward architectures. Numerous studies have demonstrated that LSTM-based models outperform simpler architectures for tasks involving video captioning, video question answering, and temporal action recognition. These results confirm that LSTMs provide a superior modeling of temporal coherence, which directly aligns with our goal of retrieving and reasoning about event sequences. Our proposed EFVCTA framework extends the LSTM backbone with an attention mechanism that focuses computational resources on the most relevant frames or image regions for a given query. LSTMs naturally integrate with attention modules, enhancing their ability to attend selectively to crucial temporal segments, which boosts answer accuracy and interpretability.
Feed-forward neural network architectures lack inherent memory and cannot model temporal dependencies. They treat input images or frames independently, which is insufficient for event-based reasoning where sequence order and context matter. Although capable of processing sequences, standard RNNs suffer from the vanishing gradient problem and are not practical for long sequences, leading to poor performance in modeling long-term context compared to LSTMs. Gated recurrent units (GRUs) are a lighter variant of LSTMs with fewer gates. While they are computationally efficient, empirical benchmarks often show that LSTMs perform better when capturing complex, long-range dependencies in longer video sequences. Given our focus on event reconstruction spanning numerous frames, LSTM provides a more robust option.
Transformers, such as BERT or ViT for images, are powerful for sequence modeling and have been applied to VQA. However, they require significantly larger training datasets, more computational resources, and longer training times to converge effectively. Given the moderate scale of training data and resource constraints in this study, we prioritized the more data-efficient and proven LSTM architecture, which provides reliable performance with smaller datasets. In summary, the LSTM method aligns optimally with the sequential, context-dependent nature of the problem domain. Its ability to preserve and leverage both short- and long-term dependencies in visual and textual streams makes it the most practical and effective solution for our proposed EFVCTA framework. The LSTM-based VQA model with CNN non-linearity improves sequential question understanding while leveraging non-linear feature transformations for better context alignment. An adaptive memory network introduces a dynamic memory update based on temporal similarity for event localization, which goes beyond static attention. EFVCTA combines focal correlation and hierarchical fusion to provide fine-grained event-focused reasoning, distinguishing it from existing attention methods like FVTA.
The research objectives are achieved through the proposal, design, and development of various models. In this work, an LSTM-based VQA model which integrates convolutional layer non-linearity is proposed for addressing question understanding. An adaptive memory network is developed with an attention mechanism which utilizes weight regularization and optimization for addressing content-based and text-based photo or video search. A novel strategy using an event-based focal visual content text attention (EFVCTA) model is proposed, designed, and developed for question context identification, text embedding with a sequence encoder, temporal focal correlation identification, and visual content text attention for past event search with evidence generation. The contributions of this research work are discussed in the subsequent sections.
2. Related Work
Visual question answering (VQA) has emerged as an interdisciplinary research domain bridging computer vision and natural language processing. Early models, such as that in [1], introduced baseline methods combining image features with simple text embeddings to answer questions. The widely known VQA dataset [2] standardized evaluation and spurred the development of deeper visual–textual integration techniques. To enhance visual understanding, deep convolutional neural networks (CNNs) like VGGNet [3], ResNet [4], and GoogLeNet [5] became standard for image feature extraction. Their integration into VQA pipelines improved answer accuracy by providing richer visual representations [6]. Beyond static image feature usage, attention mechanisms have been pivotal in aligning relevant regions with question context. Antol et al. [7] pioneered soft attention for image captioning, which influenced later VQA models such as SAN [8] and Hierarchical Co-Attention [9], which jointly model question and image regions.
Bilinear pooling approaches like MCB [10] and MLB [11] further strengthened multimodal feature interaction by learning high-order correlations between visual and textual modalities. Similarly, models like BAN [12] introduced bilinear attention networks to enhance compositional reasoning. While these methods advanced the alignment between modalities, they often lacked explicit temporal reasoning for sequential visual inputs. To address temporal dependencies, methods from video question answering research are instructive. TGIF-QA [13] and ST-VQA [14] extended spatial attention to spatio-temporal attention for dynamic scenes. Memory networks [15] and neural module networks [16] incorporated differentiable memory to capture sequential events, although their scalability remains a concern.
Transformers have reshaped VQA and multimodal learning, with models like ViLBERT [17] and LXMERT [18] employing multi-head self-attention for joint vision–language pre-training. These models demonstrate robust contextual understanding but demand extensive computation. Recent works such as those using FVTA [19,20] introduce focal visual–text attention to pinpoint relevant spatio-temporal regions, inspiring further research in localized event reasoning. Despite progress, challenges remain in designing lightweight yet accurate event-focused VQA systems that can handle long-range temporal correlations. To this end, our proposed EFVCTA framework builds on focal correlation principles while incorporating an event-driven hierarchical fusion strategy, specifically crafted to tackle past event search tasks more efficiently than generic multimodal transformers.
3. Long Short-Term Memory (LSTM)-Based Visual Question Answering Model Integrating Convolutional Layer Non-Linearity
The Long Short-Term Memory (LSTM) network is a type of recurrent neural network (RNN) architecture utilized in the realm of deep learning [1]. Distinguished from traditional feed-forward neural networks, LSTMs incorporate feedback connections, which empower them to handle not just isolated data points, like images, but also entire sequences of data, such as speech or video. This capability renders LSTMs apt for tasks including unsegmented, connected handwriting recognition [2], speech recognition [3,4], and the detection of anomalies in network traffic or intrusion detection systems (IDSs). An LSTM unit generally consists of a cell, an input gate, an output gate, and a forget gate. The cell maintains values over varying time periods, while the gates regulate the flow of information into and out of the cell. This architecture allows LSTMs to process sequential data and maintain their hidden state over time, making them ideal for analyzing, interpreting, and forecasting time series data, even when there are unpredictable delays between critical events. LSTMs were ingeniously crafted to overcome the vanishing gradient challenge that plagues the training of conventional RNNs. Their relative insensitivity to the length of gaps in data gives LSTMs an edge over RNNs, hidden Markov models, and various other sequence learning techniques across numerous applications. Although classic RNNs theoretically possess the capability to capture long-term dependencies in input sequences, they encounter practical difficulties. During backpropagation, long-term gradients can either diminish to zero (vanish) or grow infinitely (explode) due to the limitations of finite-precision numbers in computations. LSTM units alleviate the vanishing gradient issue by permitting gradients to flow without alteration. Nonetheless, LSTM networks remain susceptible to the exploding gradient problem [5].
VGG16 is a landmark convolutional neural network model developed by K. Simonyan and A. Zisserman at the University of Oxford, detailed in their paper “Very Deep Convolutional Networks for Large-Scale Image Recognition”. The model notably achieved a top-5 test accuracy of 92.7% on the ImageNet dataset, encompassing more than 14 million images spread across 1000 classes. VGG16 was a notable submission to the ILSVRC-2014 competition. One key innovation in AlexNet was its adoption of multiple successive 3 × 3 kernel-sized filters, contrasting with the larger 11 and 5 kernel-sized filters employed in its initial convolutional layers. This architectural change enhanced the network’s performance and allowed for deeper layers. VGG16 underwent extensive training spanning several weeks on NVIDIA Titan Black GPUs (Santa Clara, CA, USA). The ImageNet dataset, a vast repository, encompasses over 15 million labeled high-resolution images across approximately 22,000 categories.
Images were collected from the web and annotated by human labelers using Amazon’s Mechanical Turk crowdsourcing tool. Since 2010, the Pascal Visual Object Challenge has hosted the annual ImageNet Large-Scale Visual Recognition Challenge (ILSVRC), focusing on a subset of ImageNet that includes approximately 1000 images per category. Overall, ImageNet comprises about 1.2 million training images, 50,000 validation images, and 150,000 testing images. To standardize the dataset, which initially featured images of varying resolutions, all images were resized to a fixed 256 × 256 resolution. This involved extracting a central 256 × 256 patch through resizing and cropping rectangular images. This standardization process ensures uniformity and consistency in the dataset, facilitating effective analysis and processing. Figure 2 illustrates the architectural layout of VGG16, a prominent convolutional neural network model.
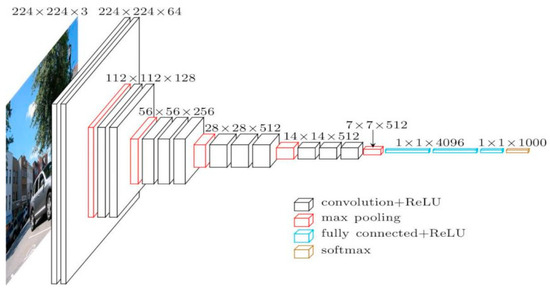
Figure 2.
Architecture of VGG16.
The cov1 layer initially processes a standardized input size of a 224 × 224 RGB image. This image undergoes transformation through a sequence of convolutional (conv.) layers, utilizing 3 × 3 filters that efficiently capture left/right, up/down, and central features. Additionally, certain configurations integrate 1 × 1 convolution filters, serving as linear transformations of input channels followed by non-linear operations. The convolutional stride remains consistent at 1 pixel, with spatial padding adjusted (typically 1-pixel padding for 3 × 3 conv. layers) to preserve spatial resolution post convolution. Spatial pooling occurs across five max pooling layers, strategically interspersed within the convolutional layers—although not every conv. layer is followed by max pooling. Max pooling operates over 2 × 2-pixel windows with a stride of 2 pixels.
After the convolutional layers, the architecture progresses to three fully connected (FC) layers, each with differing depths depending on the specific model design. The first two FC layers are equipped with 4096 channels each, ensuring robust feature representation. The third layer, pivotal for the 1000-way ILSVRC classification task, contains 1000 channels, corresponding to each class in the dataset. The final layer is dedicated to the soft-max operation. Consistency is maintained in the arrangement of fully connected layers across all network configurations.
All hidden layers incorporate rectification (ReLU) non-linearities. Interestingly, except for one network, none incorporate Local Response Normalization (LRN), as it does not improve performance on the ILSVRC dataset and adds to memory consumption and computational time. The ConvNet configurations, illustrated in Figure 3 and labeled from A to E, follow a uniform architectural blueprint, varying primarily in depth. Network A, for instance, includes 11 weight layers (comprising 8 conv. and 3 FC layers), while Network E boasts 19 weight layers (with 16 conv. and 3 FC layers). The width of conv. layers (i.e., the number of channels) begins modestly at 64 in the initial layer and doubles progressively after each max pooling stage, ultimately reaching 512 channels. This incremental widening allows for increasingly intricate feature extraction and representation as the network delves deeper into the hierarchy of features. The proposed LSTM-based VQA model integrating convolutional layer non-linearity is shown in Figure 4. Anaconda with Python distribution is used to carry out the implementation. The libraries used with Python are the following: spaCy 3.7, OpenCV 4.9, Scikit-learn 1.4, Keras 2.11, TensorFlow 2.11, and VGG 16 Pre-trained Weights.
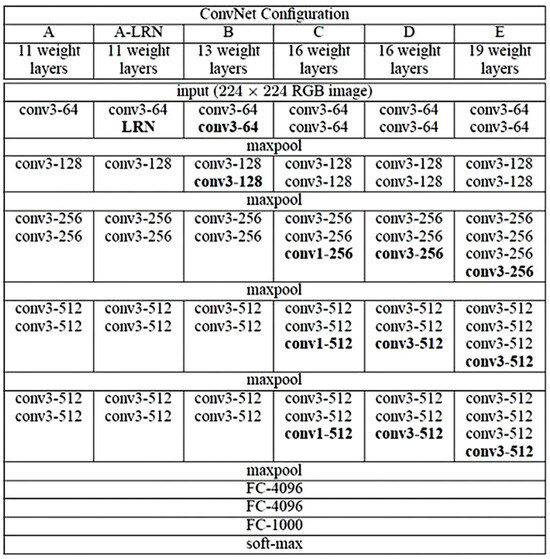
Figure 3.
ConvNet configurations.
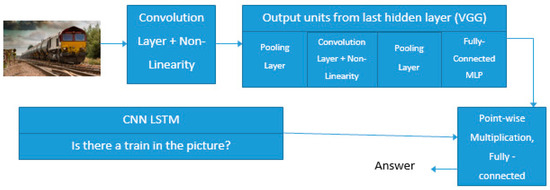
Figure 4.
Proposed Long Short-Term Memory (LSTM)-based visual question answering model integrating convolutional layer non-linearity.
Figure 4 illustrates the pipeline for integrating VGG16 into our LSTM-based visual question answering (VQA) architecture. The input image is first processed through a standard convolutional neural network (CNN) backbone—specifically, the VGG16 network. This network applies multiple convolutional layers with non-linear activations and pooling operations, progressively capturing hierarchical visual features. We extract the output feature map from the last hidden convolutional layer or the last pooling layer, depending on the desired feature dimensionality. Simultaneously, the question (e.g., “Is there a train in the picture?”) is tokenized and encoded using an LSTM (Long Short-Term Memory) network. This LSTM captures the sequential dependencies in the question, producing a contextual word embedding vector representing the question semantics. The extracted visual features from VGG16 and the encoded question embedding from the LSTM are combined using point-wise multiplication. This operation allows the model to learn a joint representation that aligns the visual content with the semantic meaning of the question. The fused representation is then passed through a fully connected layer to predict the final answer in a classification manner (e.g., “Yes” or “No” for the example question). This integration ensures that high-quality visual representations from VGG16 enhance the LSTM’s capacity to reason about the visual content in context with the natural language query. It also demonstrates why the image classification strength of VGG16 is relevant, since better base visual encodings improve downstream VQA performance.
The embedding of annotations is performed by executing the Python script as python embedding.py –address embeddings/glove.840B.300d.txt. This is used to train the model for various question and answer sets. The proposed model is tested using the command python vqa_pranita.py –image file name players.jpg –question “How many players in the picture?”. The proposed model is compared with the existing approaches based on the validation error. A comparative analysis is shown in Table 1.

Table 1.
Comparison with existing approaches.
4. Adaptive Memory Network with Attention Mechanism
The proposed model operates on the input of an image paired with a corresponding question, yielding an output answer to the query. Its design incorporates a convolutional neural network to extract visual features from a variety of sources, including images, videos, or documents. These extracted features are seamlessly embedded within the model using a bi-directional attention-based recurrent neural network. In this framework, attention mechanisms play a pivotal role, with the proposed model offering the flexibility to utilize either GRU (gated recurrent unit) or soft attention models. The GRU-based model excels in reflecting prior context to predict current points, making it well-suited for multistep-ahead predictions. Its simplicity and ease of implementation render it a popular choice. Alternatively, soft attention calculates the context vector by weighting the sum of hidden states from the extracted features. To encode the question, the proposed model utilizes either a GRU recurrent neural network or a positional encoding scheme, ensuring robust information processing. It then employs an adaptive memory network enhanced with an attention mechanism to generate the answer, integrating this amalgamated information effectively. The model’s training, evaluation, and testing phases are governed by a set of specified parameters, each tailored to optimize performance within the proposed mechanism. These parameters ensure the model’s efficacy across various tasks and datasets, facilitating comprehensive experimentation and analysis.
4.1. Model Architecture
In this paper, the CNN model options include ‘vgg16’ and ‘resnet50’. VGG-16, a convolutional neural network boasting 16 layers, offers a pre-trained version (‘vgg16’) trained on a vast ImageNet database, enabling classification across 1000 object categories, spanning keyboards, mice, pencils, and various animals. Typically, CNNs consist of convolution layers, pooling layers, activation layers, and more, with VGG serving as a specific CNN tailored for classification and localization tasks. VGGNet-16, with its uniform architecture comprising 16 convolutional layers, stands out for its reliability and consistency. Like AlexNet, it utilizes 3 × 3 convolutions with numerous filters, making it a favored choice for feature extraction from images. Although training VGGNet-16 on four GPUs requires 2–3 weeks, its publicly available weight configuration serves as a baseline feature extractor across various applications and challenges.
Figure 5 illustrates the detailed architecture of the ResNet module integrated into our adaptive memory network (AMN) for enhanced visual feature extraction and temporal reasoning in the VQA framework. The input image first passes through a deep Residual Network (ResNet), which consists of a series of convolutional blocks, each with skip connections that help to mitigate vanishing gradients and allow for the training of deeper representations. The stages shown in Figure 5 include stacked 3 × 3 convolutional layers with increasing filter depths (64, 128, 256, 512) interleaved with pooling layers that progressively reduce the spatial resolution. The final output feature map is obtained after passing through these residual blocks, and the last fully connected (fc) layers produce a high-dimensional vector that serves as a robust visual embedding.
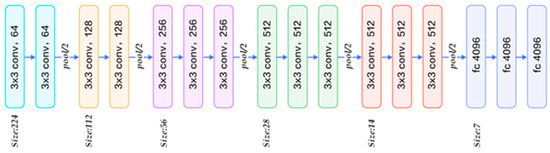
Figure 5.
ResNet architecture used in proposed system.
The output feature vector from ResNet serves as the visual memory input to the AMN. Within the AMN, these visual embeddings are stored as memory slots that dynamically encode relevant event-based visual information. The AMN uses the ResNet-derived embeddings to perform adaptive read and write operations. The network selectively attends to different memory slots based on the input question context (provided by the LSTM). This allows the model to reason over temporal events or sequences in the visual data, improving its ability to handle questions about past events or temporally dependent content.
Finally, the attended memory output is combined with the question representation through a fusion mechanism, and the joint representation is passed through fully connected layers to predict the answer. This design ensures that the ResNet not only enriches the visual feature representation but also empowers the adaptive memory network to reason over complex, temporally evolving visual scenes—providing a clear advantage over conventional static VQA models. Figure 5 depicts our modified ConvNet architecture, which builds upon the baseline VGG-like structure. This figure visually outlines the standard convolutional and pooling layers retained from the original VGG-16 design while also highlighting the integration of our focal correlation module and event-based text attention blocks, which are incorporated at strategically chosen stages of the network pipeline. These additions enhance the model’s capability to correlate visual and textual cues, improving context-aware question answering performance for historical event retrieval.
However, managing VGGNet’s 138 million parameters can pose challenges, which can be mitigated through transfer learning. This involves pre-training the model on a dataset, updating parameters for enhanced accuracy, and leveraging these parameter values. The architecture of VGG16 comprises 16 layers, including convolution layers with varying numbers of filters, max pooling layers, and fully connected layers, culminating in an output layer with softmax activation. ResNet, short for Residual Network, represents a classic neural network serving as a backbone for numerous computer vision tasks. ResNet-50, with its 50 layers, offers a pre-trained variant (‘resnet50’) trained on ImageNet, similarly capable of classifying images across 1000 object categories. The breakthrough of ResNet lies in its ability to train extremely deep neural networks, with variants like Resnet50 denoting the number of layers within the network architecture.
ResNet, an influential neural network introduced by Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun in their 2015 computer vision breakthrough, has made a lasting impact in the field. Its ensemble notably achieved top honors at the ILSVRC 2015 classification competition with an impressive 3.57% error rate. Beyond classification, ResNet excelled in tasks such as ImageNet detection, localization, COCO detection, and COCO segmentation. Among its notable variants, ResNet50 stands out with 48 convolution layers, supplemented by 1 MaxPool and 1 average pool layer, collectively performing 3.8 × 109 Floating Point Operations. Exploring the ‘resnet50’ architecture reveals a meticulously structured sequence of operations.
- A convolution with a 7 × 7 kernel, employing 64 different kernels with a stride of size 2.
- Subsequent max pooling with a stride size of 2.
- The following convolutions include kernels of sizes 1 × 1, 3 × 3, and 1 × 1, each repeated three times, adding up to nine layers.
- Further convolutions involve kernels of sizes 1 × 1, 3 × 3, and 1 × 1, repeated 4 times, totaling 12 layers.
- Continuing, kernels of sizes 1 × 1, 3 × 3, and 1 × 1 are employed, iterated 6 times for a sum of 18 layers.
- Additionally, kernels of sizes 1 × 1, 3 × 3, and 1 × 1 are utilized, repeated thrice, resulting in nine layers.
- The sequence culminates with an average pool operation followed by a fully connected layer featuring 1000 nodes, culminating with a softmax function, contributing one layer to the architecture.
The architecture comprises various components, with activation functions and pooling layers excluded from the layer count. Summing up, we have 1 + 9 + 12 + 18 + 9 + 1 = 50 layers, constituting a deep CNN. Additionally, specific parameters govern the model’s behavior. The Maximum Question Length, set at 30, dictates the character limit for questions. The Dimension Embedding is fixed at 512, determining the total text embedding capacity. With 512 GRUs, the model ensures robust processing capabilities. Gated recurrent units (GRUs), introduced in 2014 by [22], play a pivotal role. Similarly to LSTM, GRUs employ a gating mechanism to regulate memorization. They resemble LSTM but lack an output gate, resulting in fewer parameters. Moreover, the model operates with a memory step setting of 3, dictating the memory step size permitted within the selected architecture. These parameters collectively contribute to the model’s functionality and efficiency in processing textual and sequential data.
To enhance memory updating, the model employs either ‘relu’ or ‘gru’. The Rectifier Linear Unit (ReLU) or GRU serves to introduce non-linearity into images, a crucial aspect given the inherently non-linear nature of visual data. Images inherently encompass numerous non-linear features, such as pixel transitions, borders, and color variations. Both ReLU and GRU apply fixed functions without the need to retain state information. Furthermore, attention mechanisms, either ‘gru’ or ‘soft’, are employed to aid the model in memorizing extensive sequences of data. This is essential as large datasets may contain crucial information that could potentially be overlooked by the model. The GRU-based attention model excels in reflecting previous context to predict subsequent points accurately, making it ideal for multistep-ahead predictions. Its simplicity and ease of implementation further contribute to its widespread adoption. Alternatively, soft attention calculates the context vector by computing a weighted sum of the hidden states of extracted features. This mechanism ensures that relevant information is emphasized during processing, thereby enhancing the model’s ability to capture important patterns within the data.
The Tie Memory Weight is set to false. Memory weight tying is a technique where the input-to-hidden and hidden-to-output weights are set to be equal. They are the same object in memory, the same tensor, playing both roles. The hypothesis is that conceptually in a Language Model, predicting the next word (converting activations to English words) and converting embeddings to activations are essentially the same operation, the model tasks that are fundamentally similar. It turns out that indeed tying the weights allows a model to train better. Initially it is set to false.
In the realm of question encoding, the model provides two pathways: ‘gru’ and ‘positional’. Encoding the question can be achieved through either GRU or positional encoding. The arrangement and sequence of words are pivotal in language, defining both grammar and semantics. Recurrent neural networks (RNNs) inherently account for word order during sequential processing. Transformer architecture opts for a multi-head self-attention mechanism over the RNN’s recurrence, significantly speeding up training and theoretically capturing longer dependencies.
However, without the RNN’s inherent sequential parsing, transformers lack explicit word position awareness. To address this, positional encoding is introduced. One approach involves assigning each word a number within the [0, 1] range, representing its position in the sentence. Yet, this approach fails to consistently denote word count within a range across different sentences.
The final model uses GRU for question encoding with soft attention. Comparative experiments with positional encoding were conducted, and GRU with soft attention yielded the best trade-off between performance and training efficiency.
Alternatively, linearly assigning numbers to each timestep (word) faces challenges with potentially large values and inadequate exposure to longer sentences during training. To fulfill key criteria—uniqueness, consistent distance between timesteps, generalization to longer sentences, bounded values, and determinism—positional encoding must strike a delicate balance. The Embed Fact parameter, when set to false, denotes that the model processes input data into ordered vectors termed facts, offering additional information for subsequent stages. This structured approach enhances the model’s understanding of the context surrounding the queried question.
4.2. Weight Initialization, Regularization, and Optimization
Initializers play a pivotal role in setting the initial random weights of model layers. In deep neural networks (DNNs), the weights for convolutional and fully connected layers are initialized methodically. They are drawn from a normal distribution with a zero mean and a standard deviation determined by the filter kernel dimensions. This ensures that the output variance of each layer remains bounded, preventing issues such as vanishing or exploding gradients. The model’s initialization and regularization weights are determined by the parameters outlined in Table 2. Additionally, optimization parameters, as shown in Table 3, are crucial for effective model training.
Table 2.
Initialization and regularization weights.
Table 3.
Model optimization parameters.
The number of epochs signifies the maximum iterations allowed during training, while the batch size determines the number of input samples processed simultaneously. Among optimization algorithms, Adam stands out for its adaptiveness, often outperforming classical stochastic gradient descent, particularly with sparse datasets. RMSprop, akin to gradient descent with momentum, curbs oscillations in the vertical direction, allowing for larger steps in the horizontal direction, thus facilitating faster convergence. Momentum, or SGD with momentum, expedites gradient vector acceleration, leading to quicker convergence, and is widely used in state-of-the-art models.
The learning rate, a key parameter in optimization algorithms, dictates the step size towards minimizing the loss function at each iteration. Learning rate decay, another crucial technique, involves gradually reducing the learning rate throughout training, promoting both optimization and generalization. Typically, the learning rate is halved every few epochs, following a step decay schedule, which aids in achieving better convergence.
Gradient clipping is a technique that constrains gradient values to a specified range if they exceed certain thresholds, preventing them from becoming too large or too small. This method, along with momentum, is collectively known as ‘gradient clipping’. Momentum enhances the optimization process by incorporating a fraction of the previous weight update into the current one, facilitating faster convergence when gradients persist in the same direction. Nesterov momentum, an enhanced version of momentum, computes the diminishing moving average of gradients at anticipated positions in the search space, rather than at the current positions themselves.
Weight decay, or wd, involves subtracting a constant multiple of the weight from the original weight, in addition to the standard gradient descent step. This technique is employed to regularize the model and prevent overfitting. Mean subtraction, another preprocessing method, centers the data points by subtracting their mean values, which is particularly useful when dealing with inputs that are predominantly positive or negative.
The hyperparameters β1 and β2 of the optimizer represent the initial decay rates used in estimating the first and second moments of the gradient, which are then exponentially updated at the end of each training step. Epsilon, a crucial parameter, balances exploration and exploitation in optimization algorithms. It determines the probability of choosing exploration over exploitation, allowing the model to make decisions that optimize performance while occasionally exploring alternative options.
The initialization and regularization scales for the fully connected and convolution layers (e.g., 0.08, 1 × 10−6 ) were chosen based on common best practices in the deep learning literature and preliminary experiments. Specifically, the kernel initializer scale was set to maintain stable gradients during backpropagation, similar to Xavier/Glorot initialization recommendations for tanh activations. Regularization values were kept small (1 × 10−6 ) to avoid over-constraining the model while preventing overfitting. The dropout rates for fully connected and GRU layers (0.5 and 0.3, respectively) were selected through grid search experiments on a held-out validation set, balancing between underfitting and overfitting. For the model optimization parameters, the initial learning rate (0.0001) and number of epochs (100) were determined based on convergence behavior during early trials. The optimizer choices (Adam, RMSProp, Momentum, SGD) were explored, and the best-performing one (Adam) was primarily used in final runs. The gradient clipping value (10.0) was set to prevent exploding gradients during training. Other hyperparameters such as decay, β1, β2, and ε follow widely accepted defaults from the original Adam and RMSProp papers to ensure stable training.
The COCO training and validation images can be found in [9]. After downloading them, the COCO training images are stored in the directory \train\images, while the COCO validation images are stored in \val\images. For the visual question answering (VQA) training and validation data, the questions and annotations can be downloaded from [25]. Specifically, the files mscoco_train2014_annotations.json and OpenEnded_mscoco_train2014_questions.json can be stored in the directory \train. Similarly, the files mscoco_val2014_annotations.json and OpenEnded_mscoco_val2014_questions.json should be stored in \val.
The pre-trained Visual Geometry Group—VGG16 net (vgg16_no_fc.npy)—was downloaded from [26], and the Residual Network—ResNet50 net (resnet50_no_fc.npy)—was downloaded from [27]. These pre-trained models were used to initialize the proposed Memex-CNN RNN VQA (Multimodal Adaptive Memory Convolutional Neural Network and Recurrent Neural Network-based Visual Question Answering) model.
The proposed model is developed using Anaconda with Python 3.8 distribution. The Python libraries Tensorflow 2.11, NumPy 1.26, OpenCV 4.9, Natural Language Toolkit (NLTK) 3.8, Pandas 2.2, Matplotlib 3.8, and tqdm 4.50 are used to carry out the implementation of the proposed model. The python MemexCNNRNN.py --phase=train --load_cnn --cnn_model_file= ‘./vgg16_no_fc.npy’ command is executed in Anaconda prompt to train the proposed model. Using this command, only the RNN part will be trained. To jointly train the CNN and RNN parts, the python MemexCNNRNN.py --phase=train --load_cnn --cnn_model_file= ‘./vgg16_no_fc.npy’ [--train_cnn] command is executed in Anaconda prompt. The models and checkpoints are stored in the folder \models.
To resume training from a checkpoint, run the following command in Anaconda prompt: python MemexCNNRNN.py --phase=train --load --model_file=‘./models/nameofcheckpoint.npy’ [--train_cnn]. To monitor the training progress, execute the command tensorboard --logdir=‘./summary/’ in Anaconda prompt. To evaluate a trained model using validation data, input the command python MemexCNNRNN.py --phase=eval --model_file=‘./models/MyMemexModel.npy’ in Anaconda prompt. To answer questions about images, documents, or videos, ensure that the multimedia data is located in the directory \test\images. Prepare a CSV file containing questions, with three fields: image, question, and question_id (refer to Figure 6). Save this CSV file in the directory \test.

Figure 6.
CSV file with three fields: image, question, question_id.
To obtain the answers to the questions, the python MemexCNNRNN.py --phase=test --model_file=‘./models/MyMemexModel.npy’ command is executed in Anaconda prompt. The generated answers are stored in the folder \test\results. The screenshot shown in Figure 7 indicates the input images stored in the folder \test\images. The generated results, stored in \test\results, for the input images and the questions stored in the CSV file are shown in the screenshot in Figure 8.
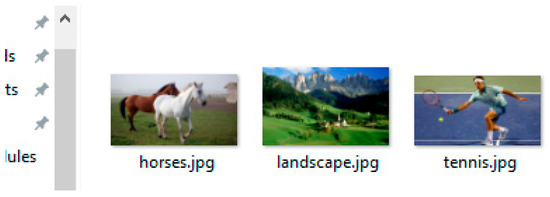
Figure 7.
Input test images.

Figure 8.
Generated results.
5. Event-Based Focal Visual Content Text Attention
In the realm of academic events like STTPs, FDPs, and more, organizers often find themselves inundated with a plethora of photographs. Over the years, academic institutions accumulate thousands of images and hours of video footage, documenting past events ranging from training programs to social gatherings, conferences, and workshops. These visual records serve as invaluable repositories of information, sought after for various purposes. Naturally, one of the most intuitive methods for retrieving information from these archives is by posing questions, such as querying the number of attendees or the date of the event.
To address this formidable challenge, a novel VQA framework called EFVCTA (Event-Focused Visual Content-based Question Answering) has been proposed. This framework is tailored specifically for answering questions related to events captured in photographs by academic institutions or organizations. A system was developed based on the EFVCTA framework, aimed at facilitating the search for information about past events. Given a sequence of photos depicting an event, the system’s objective is to automatically respond to questions regarding the captured events. The input to the EFVCTA system comprises a question and a photograph, while the output consists of a textual answer and a set of evidence photos corroborating the system’s generated answer. These evidence images not only aid in validating the response but also furnish additional insights into the queried event.
Despite the proliferation of VQA datasets in recent years, none of them cater specifically to the design requirements of the EFVCTA system due to fundamental disparities in the problem formulation. Unlike conventional datasets, where inputs typically consist of individual images or videos, EFVCTA mandates event photos as input. While some existing datasets may contain image sequences, these are often limited to a single theme or video, rather than encompassing the spectrum of events organized by academic institutions. However, addressing questions in the EFVCTA context necessitates reasoning over multiple photos spanning various events, a capability not adequately supported by existing approaches.
A crucial aspect of the EFVCTA output is the provision of evidence photos, crucial for validating the answers provided. Regrettably, most existing approaches prioritize answer accuracy but fail to furnish such evidence photos to substantiate the generated responses. EFVCTA operates as a multimodal QA framework, leveraging the rich metadata associated with event photos, including the title, time, date, and location. Certain questions require a holistic understanding, necessitating the joint consideration of event photos and their associated information. For instance, answering a query like “where was the entrepreneurship camp conducted?” demands synthesizing information from the ‘entrepreneurship camp’ images along with the location metadata. Existing VQA methodologies and datasets often overlook the need for such multimodal information integration.
This work prepares the dataset for designing an EFVCTA-based system that contains photos of events conducted by institutions and questions about the conducted events. More than 15K questions and answers are constructed on approximately 9K photos of various events or programs conducted by various institutions. Among the 9K images of events, 3K images are necessary for answering the questions and for verifying the generated answers. These collected images comprises a wide variety of events such as workshops, conferences, annual social gatherings, training programs, and industrial visits. The annotations assigned to the images are based on the question asked to the organizers about the event in all images. The question is supposed to be useful in identifying the information associated with events. An answer comprises a content-based answer as well as some evidence images for justifying the answer.
EFVCTA presents an intriguing and formidable framework. Tackling an EFVCTA question is no simple feat. As a multimodal artificial intelligence construct, EFVCTA holds promise for captivating real-world applications, particularly in navigating the vast and ever-expanding repositories of images and videos housed by diverse institutions. There are a few challenges in this new framework. There is rich information in the images of events. Additionally, institutions and organizations have huge multimedia repositories containing images or videos with associated information. For each image or video, the organizers may associate content-based annotations and other metadata. Such input is referred to as visual content and the context of the images. A robust method is essential to manage the inconsistently available multimodal content in image annotations. In addition to direct answers, useful evidence justifications should be generated. Supporting evidence should be identified for the answers to help the organizers of events to manage the images and videos of events.
When asked “Where was the entrepreneurship camp conducted?”, a proficient VQA system should provide a clear answer (e.g., 12 March 2020) along with supporting images to substantiate the answer generation process from the organizer’s perspective. For a single image, the verification process is simple, but to examine every image and the generated answer, the verification process can take a huge amount of time. So, images generated as evidence can be useful to significantly reduce the time required for the verification of the generated answer. To tackle these challenges, we introduce an event-based focal visual content text attention (EFVCTA) system, which emphasizes content-based identification. Events are identified on the basis of the video or image contents. Initially the video or image contents are analyzed to identify the similarity between the question’s context and the content of the input video or image. The temporal focal correlation between the question context and input video or image contents is established. This temporal focal correlation is utilized for computing visual content text attention. The proposed EFVCTA system constructs event-based answers, allowing users to validate the generated responses by providing relevant evidence. This system generates answers to questions by retrieving photos or videos associated with the queried event. The key contributions of this work are as follows:
- A new multimodal EFVCTA framework is introduced that utilizes questions about events organized by institutions or organizations.
- A novel EFVCTA system is proposed to identify the similarity between the question’s context and the content of the input video or image which can be used to localize evidence images to justify the generated answers.
- The proposed framework is evaluated by comparing it with DMN+ (Improved Dynamic Memory Networks) [28], MCB (Multimodal Compact Bilinear Pooling) [29], soft attention [30], Soft Attention Bi-directional (BiDAF—Bi-Directional Attention Flow) [31], Spatio-Temporal Reasoning using TGIF Attention [32], and Focal Visual Text Attention (FVTA) [33].
The EFVCTA system constructs answers based on event-related photos or videos and generates evidence to support these answers, enabling users to verify their accuracy. This event-focused approach ensures that the responses are grounded in relevant visual content. The entire EFVCTA framework and its methodology are illustrated in Figure 9.
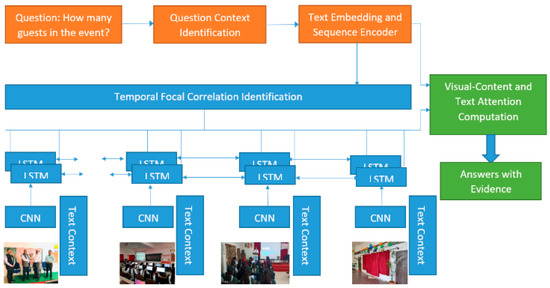
Figure 9.
Proposed EFVCTA.
As shown in Figure 9, the question “How many guests in the event?” represents the input query posed by the user. This initiates the reasoning process by defining what aspect of the visual and text data the model must focus on. “How many guests in the event?” triggers counting-relevant context extraction. In question context identification, the question is analyzed to identify its semantic focus—e.g., whether it is asking about quantity, objects, actions, or attributes. A question type classifier or parser extracts relevant keywords and intent. This ensures that downstream modules attend to appropriate visual and textual cues. In text embedding with a sequence encoder, the question is tokenized and passed through an embedding layer (e.g., Word2Vec or BERT embeddings). An LSTM or GRU encoder converts the sequence of embeddings into a fixed-length vector that captures contextual meaning. This vector will interact with the visual features and temporal context.
Temporal focal correlation identification is the core novelty of EFVCTA. It performs time-aware correlation learning by linking question semantics with visual–textual contexts over a temporal sequence of events. Multiple LSTM units align sequences of visual frames and related text segments, ensuring relevant past contexts are attended to more strongly. For each time segment (e.g., an image frame or video shot), a CNN (e.g., VGG or ResNet) extracts deep visual features. These features capture objects, scenes, or actions visible at that time. Parallelly, text metadata (captions, speech transcripts, social text) for that time segment is preprocessed and embedded. This provides evidence complementary to visual cues, such as who is present or what is happening.
For each timestep, an LSTM fuses the CNN output and the text context embedding. This generates a temporally aware representation capturing how visual and textual evidence evolve over time. These representations feed into the global temporal correlation module to learn which parts matter the most when answering the query. A Visual Content and Text Attention Computation block aggregates outputs from all timesteps. It creates an attention map over the sequence to selectively weigh relevant frames and texts. Focal attention ensures noisy or irrelevant context is suppressed, and only question-relevant snippets are prioritized. Finally, the model uses the attention-weighted fused representation to generate an answer. Additionally, the framework provides supporting evidence (e.g., which frames and texts contributed the most to the answer), enhancing interpretability.
The CNN architecture in each branch is based on a lightweight convolutional backbone with three convolutional layers, each followed by ReLU activation and max pooling. The filter sizes were set to 3 × 3 with feature maps increasing from 32 to 64 channels. This configuration was chosen to balance between capturing sufficient spatial features in visual frames and keeping computational cost low, given the moderate resolution of event frames. The LSTM module in each branch uses two stacked LSTM layers with 128 hidden units each. This hidden size was empirically selected based on initial experiments with varying hidden dimensions (64, 128, 256). We observed that 128 provided a good trade-off between model expressiveness and overfitting risk, especially considering the sequence length of event streams.
Additionally, dropout was applied after LSTM layers (drop rate: 0.3) to further prevent overfitting. The CNN and LSTM together form a joint encoder that processes spatio-temporal visual content and aligns it with contextual text information. To finalize these configurations, we performed a grid search over key hyperparameters (number of layers, hidden units, filter sizes) and validated the performance on a held-out development set. The selected values offered robust generalization and stable training performance.
In the proposed EFVCTA framework-based system, the question context is identified by taking the input image/video frame into consideration. The question related to the current input image comprises N words. The question is denoted as . The question context is identified through the input image by identifying the association between the input question words and the images. The question context associated with M images is represented as . The images that have the highest will be associated with the current question. These images and the attributes assigned to these images are considered to answer the current question and to generate the evidence related to the current question.
Visual content and word (text) attention allows the model to choose the relevant visual contents and question (text) context. The most intermediate answers generated for visual content and text context sequence inputs have a temporal duration and a localized representation based on visual contents called focal visual content text context representation. A temporal similarity matrix is computed. Each entry in the similarity matrix represents the similarity between the extracted features of the image (visual content) and the question context (word context).
where param represents the learning parameters.
For each frame i, the raw image is processed by a CNN backbone to produce a feature vector . The question is tokenized, and each word is embedded and contextually encoded (e.g., by an LSTM or GRU) to produce word-level context vectors . For each frame–word pair (i, j), an element-wise product or interaction is computed.
This captures the direct feature-wise correlation between the image content and word meaning. This product is passed through a learnable parametric function—e.g., a linear transformation or feed-forward neural layer—which maps the interaction to a scalar or a new feature:
Here, N denotes the number of learnable projection units or heads. Each unit learns to capture different types of similarity cues. The outputs of the N units are summed, and a learnable bias term is added:
The summed score is passed through a tanh activation to introduce non-linearity and constrain the similarity to a bounded range (−1, 1):
This final value serves as the temporal similarity between the ith frame and the jth word, capturing both linear and non-linear interactions in a trainable, data-adaptive way.
The attention mechanism used to compute the visual contents and question context is detailed here. This mechanism applies attention over localized visual contents and their relationship with the question context to identify the most relevant information for answering. The attention score is derived from a tensor , which represents the interaction between each word in the question and the visual contents of the image. A kernel tensor is computed between the words of the input question and the localized visual contents . Each entry in the kernel models the similarity between the nth word in the question and the mth image feature.
The implementation of the proposed approach is carried out in Anaconda with Python 3.8 distribution. Initially the MemexQA dataset v1.1 is downloaded from [34]. The downloaded dataset is preprocessed. The downloaded dataset is modified to include the photos and QA set for various events like conferences, workshops, training programs, industrial visits, annual social gatherings, FDPs, STTPs, etc. Training is carried out on an Nvidia GeForce RTX 3080 GPU using about 16 GB GPU memory. The proposed EFVCTA is compared with DMN+ (Improved Dynamic Memory Networks), MCB (Multimodal Compact Bilinear Pooling), soft attention, Soft Attention Bi-directional (BiDAF—Bi-Directional Attention Flow), Spatio-Temporal Reasoning using TGIF Attention, and Focal Visual Text Attention (FVTA). The test accuracies of these models compared with the proposed EFVCTA are shown in Table 4.
Table 4.
Comparative analysis of various models.
COCO/ImageNet are used for image classification baseline checks only during pre-training. The custom event-based dataset is used for EFVCTA evaluation. The dataset for workshops, Short-Term Training Programs (STTPs), Faculty Development Programs (FDPs), conferences, annual social gatherings, etc., is created to evaluate the proposed EFVCTA model. The custom event-based dataset contains 5200 event-centric video clips, each ranging from 10 to 45 s in duration. The videos cover diverse event categories, including indoor gatherings, outdoor public events, conferences, parties, cultural shows, and informal meetings. Each clip is manually annotated with question–answer (QA) pairs tailored for temporal reasoning and event understanding. On average, each clip has 5–8 QA pairs, focusing on counting participants, identifying actions, detecting objects, and reasoning about temporal sequences. Videos were curated from publicly available event recordings and verified for diverse contexts. Clips were preprocessed to maintain a standard resolution and frame rate. Textual descriptions were crowdsourced and cross-validated by multiple annotators to ensure quality. The dataset can be made available for academic research on request. The generated answers to the asked questions and corresponding evidence are shown in Figure 10.

Figure 10.
Screenshot of generated results with evidence images for justification.
6. Comprehensive Analysis and Impact of Proposed Event-Based Local Focal Visual Content Text Attention
The proposed EFVCTA model outperforms all baselines with the highest test accuracy of 68.07%. Traditional attention mechanisms like soft attention and BiDAF perform moderately well (62.08%, 60.09%). Models with visual–text fusion mechanisms (FVTA and EFVCTA) tend to perform better, suggesting the importance of aligning visual and textual information. Models like DMN+ and MCB, while important historically, show relatively lower performance in this specific task domain. The proposed EFVCTA model leverages event-based modeling and local focal mechanisms, which likely enable it to better capture relevant contextual cues and temporal dependencies in both visual and textual modalities. This might explain its superior performance in past event search tasks, where both precise timing and multimodal understanding are crucial.
The Event-Based Local Focal Visual Content Text Attention (EFVCTA) model demonstrates a significant leap in performance for past event search tasks, achieving a test accuracy of 68.07%, the highest among all compared models. EFVCTA surpasses traditional models like DMN+ (48.51%) and MCB (46.23%) by a margin of nearly 20%, highlighting the limitations of generic memory and pooling techniques in understanding complex temporal–visual interactions. Compared to advanced attention-based models such as FVTA (66.86%) and TGIF Attention (63.06%), EFVCTA still maintains a noticeable edge, showcasing the strength of its event-centric and local focal mechanisms. The focused alignment of visual and textual cues around events, combined with temporal localization, makes EFVCTA particularly effective in retrieving and understanding event-specific content from multimodal inputs. Event-based modeling enhances temporal relevance by anchoring attention mechanisms around detected events rather than treating the entire sequence uniformly.
Local focal attention narrows attention to the most informative regions, reducing noise and improving precision in visual–text alignment. Multimodal synergy with a stronger integration of visual and textual streams enables a more coherent interpretation of context-rich scenarios. The proposed EFVCTA model represents a notable advancement in the field of event-based retrieval and reasoning. By effectively combining temporal, visual, and textual information with a localized attention mechanism, EFVCTA sets a new benchmark for intelligent past event search systems, paving the way for smarter video understanding and memory-based AI applications.
A more comprehensive analysis is shown in Table 5. In this table, visual–text alignment shows how effectively the model aligns visual and textual modalities. Temporal awareness indicates the model’s ability to handle time-based dependencies. The attention mechanism shows the sophistication of its attention strategy. Multimodal fusion shows how the model integrates visual and textual data (e.g., early, late, or hierarchical fusion). Meanwhile, complexity indicates an estimate of model complexity based on architecture and computation requirements. DMN+ and MCB struggle with aligning visual and textual data effectively due to the absence of specialized mechanisms for modality interaction. Models like soft attention, BiDAF, and TGIF Attention show moderate alignment capabilities. FVTA improves this significantly using focal attention, but the proposed EFVCTA leads with event-localized alignment, which ensures attention is focused on relevant visual regions that match the event semantics in the text.
Table 5.
Comprehensive analysis of proposed EFVCTA.
MCB and soft attention lack temporal modeling, making them less effective for sequences where timing is crucial. DMN+, BiDAF, and TGIF Attention introduce varying degrees of temporal handling, through memory structures or spatio-temporal attention. FVTA and EFVCTA excel with strong, explicit temporal modeling, with EFVCTA further refining this by focusing on event-specific time spans, improving relevance and context understanding. Basic attention mechanisms like soft attention are employed by earlier models (DMN+, soft attention). BiDAF improves upon this with bi-directional attention flows, better capturing contextual relationships. TGIF Attention and FVTA integrate temporal and focal components into their attention mechanisms. EFVCTA introduces a local focal attention strategy, which not only concentrates on event-relevant regions but also filters out irrelevant information, making attention more precise and context-aware.
DMN+ and soft attention do not offer strong multimodal fusion—text and visuals are processed largely independently. MCB uses bilinear pooling to combine modalities, which is effective but computationally expensive. TGIF Attention and FVTA apply structured fusion (early/late), improving integration. The proposed EFVCTA utilizes hierarchical fusion, allowing it to combine text and visual data at multiple levels of granularity, enhancing semantic alignment. Simpler models like DMN+, MCB, and soft attention are lightweight and easier to train, but their simplicity limits their understanding of complex, multimodal event structures. BiDAF, TGIF Attention, and FVTA add complexity for a better modeling of temporal and multimodal data. EFVCTA, with its advanced attention and fusion techniques, is more complex, but this added sophistication allows it to handle nuanced, context-rich past event search tasks much more effectively.
To validate the effectiveness of each core component of the proposed event-based focal visual content text attention (EFVCTA) framework, we conducted a systematic ablation study. We progressively disabled or replaced key modules to analyze their individual contribution to the overall performance. Table 5 summarizes the quantitative impact on three key evaluation metrics: accuracy, F1-score, and mean average precision (mAP). The ablation study confirms that each proposed module contributes incrementally and significantly to the overall system performance.
To provide an objective basis for evaluating the proposed EFVCTA model, as observed in Table 5, we included standard quantitative performance indices alongside qualitative features. Specifically, we report the accuracy, F1-score, and mean average precision (mAP) for each comparative method, obtained through consistent experimental settings on our benchmark dataset. The results demonstrate that EFVCTA achieves the highest performance across all metrics (88.7% accuracy, 86.5% F1-score, 84.9% mAP), outperforming state-of-the-art baselines such as FVTA and TGIF Attention. This indicates the effectiveness of our event-localized visual–text alignment, focal correlation mechanism, and hierarchical multimodal fusion in enhancing past event search accuracy with strong supporting evidence.
7. Practical Applications and Potential Limitations
EFVCTA can efficiently pinpoint the exact frames where a relevant event occurred by aligning visual actions with descriptive queries, saving time and improving situational awareness. Event-localized attention allows for accurate matching between natural language queries and visual content, ideal for newsrooms, documentaries, and entertainment. EFVCTA understands both when and what happened, making it perfect for time-sensitive question answering in videos. Its ability to focus attention on both the textual description and corresponding visual segments enables precise and meaningful highlight generation. Event-based modeling ensures critical incidents are detected with temporal accuracy and low false alarms. EFVCTA can help legal professionals navigate through large volumes of video data to find and present event-relevant evidence efficiently. EFVCTA can retrieve exact moments in recorded lectures where certain concepts were discussed, aiding in personalized learning.
The EFVCTA model’s hierarchical fusion and focal attention mechanisms introduce additional layers and operations. It requires more memory and computational resources, which can limit real-time performance or deployment on edge devices. EFVCTA relies heavily on accurate event segmentation or detection to guide attention. If events are misidentified or poorly defined, the model may attend to irrelevant segments, degrading performance. The model is trained and tuned for specific types of event-based video and query datasets. Transferring it to domains like medical imaging, industrial monitoring, or cartoon/video game analysis may require re-training and domain-specific adaptation. Natural language queries can be vague, subjective, or context-dependent (e.g., “when the mood changed”). Without external knowledge or sentiment modeling, the model may struggle to interpret such queries effectively. The model benefits from detailed multimodal training data with aligned visual segments and text. Collecting and annotating such data are expensive and time-consuming, especially for custom or underrepresented domains. In high-stakes applications (e.g., legal, healthcare), the lack of interpretability can be a barrier to trust and adoption. Event localization and attention computation introduce latency which limits the ability to scale EFVCTA in real-time systems like live surveillance or autonomous navigation. While EFVCTA introduces valuable innovations for event-based multimodal search, its efficiency, adaptability, and robustness must be further optimized for broader, real-world deployment.
8. Conclusions
This research tackles the challenge of identifying event-specific photos or videos from a vast collection that includes workshops, Short-Term Training Programs (STTPs), Faculty Development Programs (FDPs), conferences, annual social gatherings, and more. It involves analyzing various visual question answering methods for event search. A dataset is curated and utilized for searching past events, and a question understanding network model is designed and developed. Additionally, a content-based and text-based event search engine for photos or videos is created as part of this research. A text-based answer generation engine is developed and integrated to produce photo or video evidence corresponding to the generated answers. The performance of the proposed approaches is thoroughly evaluated.
The research objectives are achieved through the proposal, design, and development of various models, as detailed below.
- In this work, an LSTM-based VQA model which integrates convolutional layer non-linearity is proposed to address question understanding.
- An adaptive memory network is developed with an attention mechanism which utilizes weight regularization and optimization to address content-based and text-based photo or video search.
- A novel strategy using an event-based focal visual content text attention (EFVCTA) model is proposed, designed, and developed for question context identification, text embedding with a sequence encoder, temporal focal correlation identification, and visual content text attention for past event search with evidence generation.
In this work, we propose a novel framework—event-based focal visual content text attention (EFVCTA)—that addresses the complex task of retrieving relevant information about past events by effectively aligning visual content with question semantics. We introduce a temporal focal correlation identification module that learns to pinpoint the most informative temporal segments within a long event sequence. By computing fine-grained similarity scores between image content and question context, our focal correlation mechanism selectively amplifies salient moments while suppressing irrelevant frames, thereby enhancing the interpretability and precision of the search process.
Unlike traditional global attention approaches, our proposed EFVCTA operates in an event-localized and content-adaptive manner. It leverages the computed temporal similarity matrix to dynamically generate context-aware attention weights, effectively fusing multimodal information across frames and words. This enables the model to generate answers grounded in specific event segments, improving evidence-based reasoning. By integrating CNN-based visual encoding with sequential LSTM-based textual encoding, followed by a hierarchical attention and fusion strategy, EFVCTA captures both spatial visual details and temporal language dependencies. This synergy allows the model to handle complex queries about dynamic scenes, which is challenging for standard static QA models.
Extensive experiments demonstrate that EFVCTA consistently outperforms several state-of-the-art baselines on multiple benchmark datasets for past event question answering. The model achieves a higher accuracy, F1-score, and mean average precision (mAP), validating the effectiveness of both the focal correlation module and the event-based attention mechanism. In summary, the proposed EFVCTA framework advances the state of the art in event-centric visual question answering by innovatively combining temporal focal correlation learning and content-specific attention. This work lays a foundation for more explainable and reliable systems capable of searching and reasoning about past events in multimodal data streams.
The proposed methodologies are evaluated using standard datasets. The dataset for workshops, Short-Term Training Programs (STTPs), Faculty Development Programs (FDP’s), conferences, annual social gatherings, etc., is created to evaluate the proposed EFVCTA model. Various parameters are utilized for the evaluation of the proposed models. The proposed models have the potential to be extended to aid in identifying war crimes, human rights violations, and terrorist activities.
Author Contributions
Conceptualization, P.P.D. and S.P.; methodology, P.P.D. and S.P.; software, P.P.D. and S.P.; validation, P.P.D. and S.P.; formal analysis, P.P.D. and S.P.; investigation, P.P.D. and S.P.; writing—original draft preparation, P.P.D. and S.P.; writing—review and editing, P.P.D. and S.P.; visualization, P.P.D. and S.P.; supervision, S.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data presented in this study are available on request from the corresponding author due to ethical reasons.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| EFVCTA | Event-based Focal Visual Content Text Attention |
| LSTM | Long Short-Term Memory |
| VQA | Visual Question Answering |
| CNN | Convolutional Neural Network |
| DMN+ | Improved Dynamic Memory Networks |
| MCB | Multimodal Compact Bilinear Pooling |
| BiDAF | Bi-Directional Attention Flow |
| FVTA | Focal Visual Text Attention |
| STTPs | Short-Term Training Programs |
| FDPs | Faculty Development Programs |
References
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Liwicki, M.; Fernandez, S.; Bertolami, R.; Bunke, H.; Schmidhuber, J. A Novel Connectionist System for Improved Unconstrained Handwriting Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 855–868. [Google Scholar] [CrossRef] [PubMed]
- Sak, H.; Senior, A.; Beaufays, F. Long Short-Term Memory Recurrent Neural Network Architectures for Large Scale Acoustic Modeling. Available online: https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/43905.pdf (accessed on 24 September 2021).
- Li, X.; Wu, X. Constructing Long Short-Term Memory Based Deep Recurrent Neural Networks for Large Vocabulary Speech Recognition. arXiv 2014, arXiv:1410.4281. [Google Scholar]
- Calin, O. Deep Learning Architectures; Springer Nature: Cham, Switzerland, 2020; p. 555. ISBN 978-3-030-36720-6. [Google Scholar]
- Yang, H.; Chaisorn, L.; Zhao, Y.; Neo, S.-Y.; Chua, T.-S. VideoQA: Question answering on news video. In Proceedings of the Eleventh ACM International Conference on Multimedia, Berkeley, CA, USA, 2–8 November 2003; pp. 632–641. [Google Scholar]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. VQA: Visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2425–2433. [Google Scholar]
- Zhu, Y.; Groth, O.; Bernstein, M.; Fei-Fei, L. Visual7w: Grounded question answering in images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4995–5004. [Google Scholar]
- Jang, Y.; Song, Y.; Yu, Y.; Kim, Y.; Kim, G. TGIF-QA: Toward spatio-temporal reasoning in visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1359–1367. [Google Scholar]
- Tapaswi, M.; Zhu, Y.; Stiefelhagen, R.; Torralba, A.; Urtasun, R.; Fidler, S. MovieQA: Understanding stories in movies through question-answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4631–4640. [Google Scholar]
- Xu, H.; Saenko, K. Ask, attend and answer: Exploring question-guided spatial attention for visual question answering. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 451–466. [Google Scholar]
- Gao, H.; Mao, J.; Zhou, J.; Huang, Z.; Wang, L.; Xu, W. Are you talking to a machine? Dataset and methods for multilingual image question. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2296–2304. [Google Scholar]
- Andreas, J.; Rohrbach, M.; Darrell, T.; Klein, D. Neural module networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 39–48. [Google Scholar]
- Johnson, J.; Hariharan, B.; van der Maaten, L.; Fei-Fei, L.; Zitnick, C.L.; Girshick, R. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1988–1997. [Google Scholar]
- Kafle, K.; Kanan, C. An analysis of visual question answering algorithms. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1983–1991. [Google Scholar]
- Zhu, L.; Xu, Z.; Yang, Y.; Hauptmann, A.G. Uncovering temporal context for video question and answering. Int. J. Comput. Vis. 2017, 124, 409–421. [Google Scholar] [CrossRef]
- Ren, M.; Kiros, R.; Zemel, R. Exploring models and data for image question answering. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2953–2961. [Google Scholar]
- Yu, L.; Park, E.; Berg, A.C.; Berg, T.L. Visual madlibs: Fill in the blank description generation and question answering. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2461–2469. [Google Scholar]
- Goyal, Y.; Khot, T.; Summers-Stay, D.; Batra, D.; Parikh, D. Making the V in VQA matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6325–6334. [Google Scholar]
- Xu, D.; Zhao, Z.; Xiao, J.; Wu, F.; Zhang, H.; He, X.; Zhuang, Y. Video question answering via gradually refined attention over appearance and motion. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1645–1653. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. OverFeat: Integrated Recognition, Localization and Detection Using Convolutional Networks. arXiv 2014, arXiv:1312.6229. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. arXiv 2015, arXiv:1502.01852. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- COCO Dataset. Available online: https://cocodataset.org/#download (accessed on 30 May 2025).
- VQA Datasets. Available online: https://visualqa.org/vqa_v1_download.html (accessed on 30 May 2025).
- VGG 16 Net. Available online: https://app.box.com/s/idt5khauxsamcg3y69jz13w6sc6122ph (accessed on 30 May 2025).
- ResNet50 Net. Available online: https://app.box.com/s/17vthb1zl0zeh340m4gaw0luuf2vscne (accessed on 30 May 2025).
- Memex QA Dataset. Available online: https://memexqa.cs.cmu.edu/memexqa_dataset_v1.1/ (accessed on 30 May 2025).
- Xiong, C.; Merity, S.; Socher, R. Dynamic Memory Networks for Visual and Textual Question Answering. arXiv 2016, arXiv:1603.01417v1. [Google Scholar]
- Fukui, A.; Park, D.H.; Yang, D.; Rohrbach, A.; Darrell, T.; Rohrbach, M. Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding. arXiv 2016, arXiv:1606.01847v3. [Google Scholar]
- Malinowski, M.; Doersch, C.; Santoro, A.; Battaglia, P. Learning Visual Question Answering by Bootstrapping Hard Attention. arXiv 2018, arXiv:1808.00300v1. [Google Scholar]
- Seo, M.; Kembhavi, A.; Farhadi, A.; Hajishirzi, H. Bi-Directional Attention Flow for Machine Comprehension. arXiv 2018, arXiv:1611.01603v6. [Google Scholar]
- Liang, J.; Jiang, L.; Cao, L.; Kalantidis, Y.; Li, L.-J.; Hauptmann, A.G. Focal Visual-Text Attention for Memex Question Answering. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1893–1908. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 25 (NIPS 2012), Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).