
Dark Web Traffic Classification Based on Spatial–Temporal Feature Fusion and Attention Mechanism

Abstract
1. Introduction
2. Methods
2.1. Definition and Characteristics
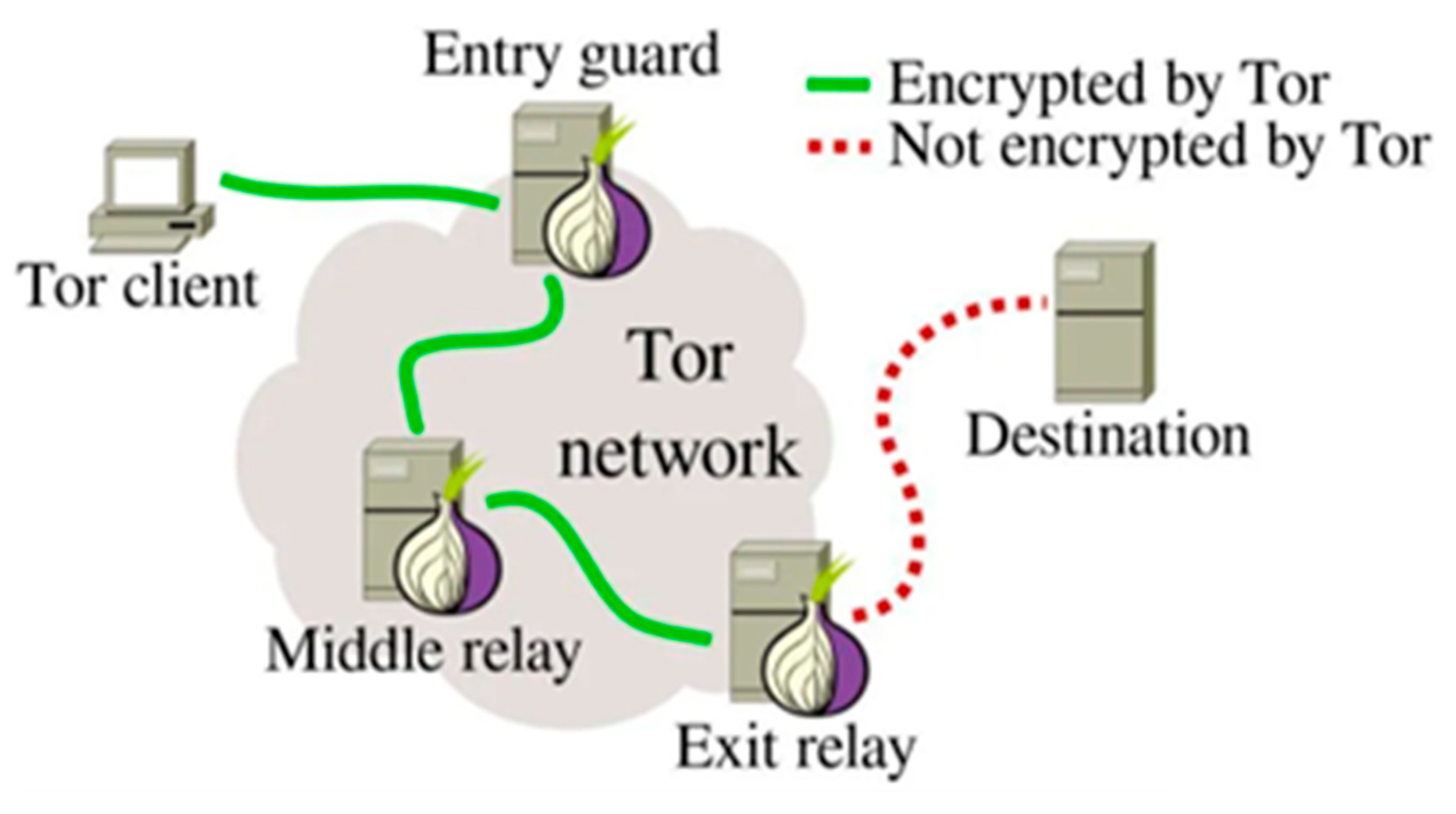
2.2. Main Applications and Threats of the Dark Web
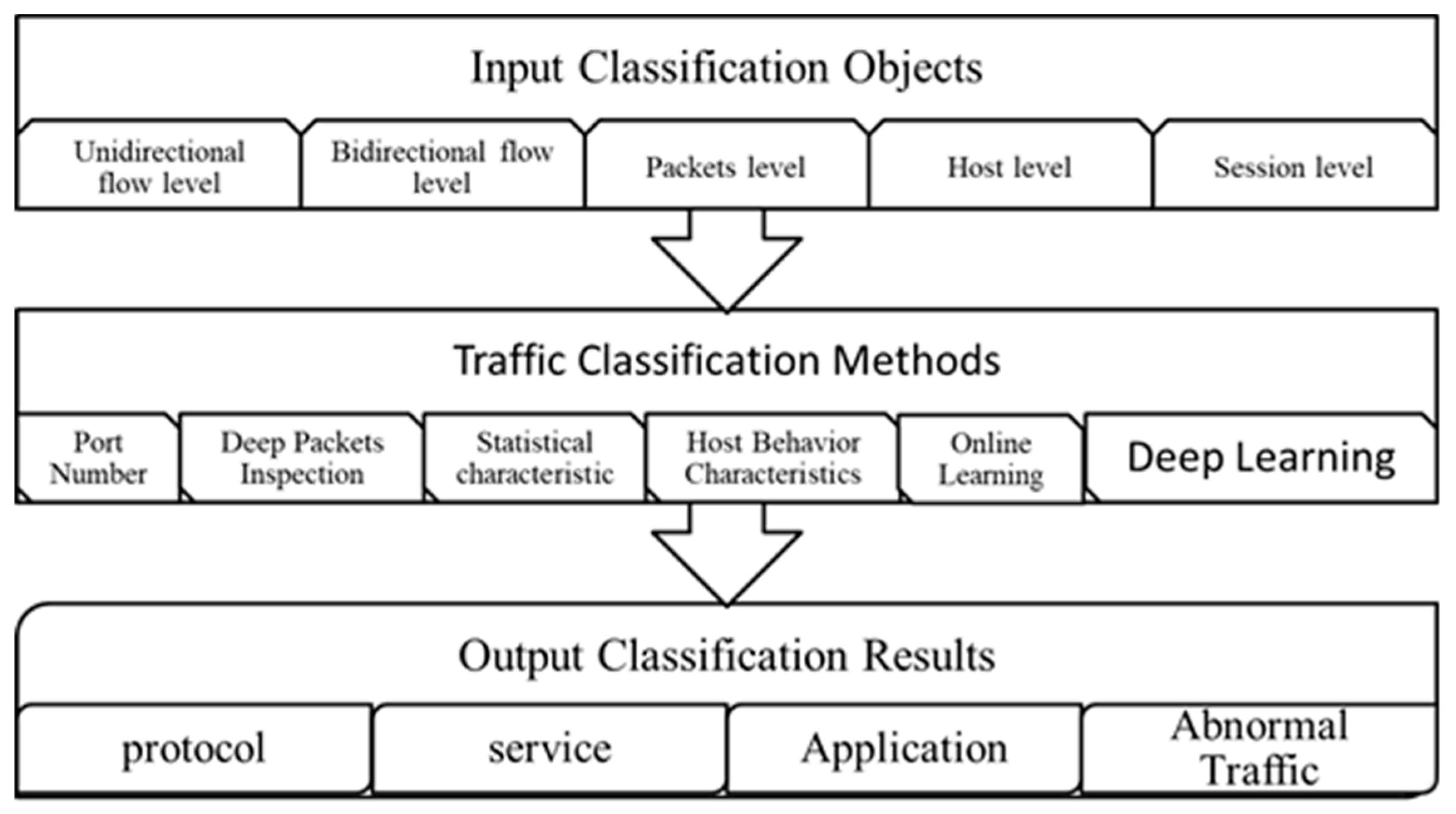
2.3. Traditional Traffic Classification Technology
2.4. Traffic Classification Technology Based on Machine Learning
2.5. Traffic Classification Technology Based on Deep Learning
2.6. The Logical Relationships of All Traffic Classification Methods
3. Experimental Setup
3.1. Data Preprocessing
3.2. Dataset Construction
3.3. Model Architecture Design
3.4. Model Training and Optimization
4. Results
4.1. Experimental Environment and Dataset
4.2. Experimental Procedures
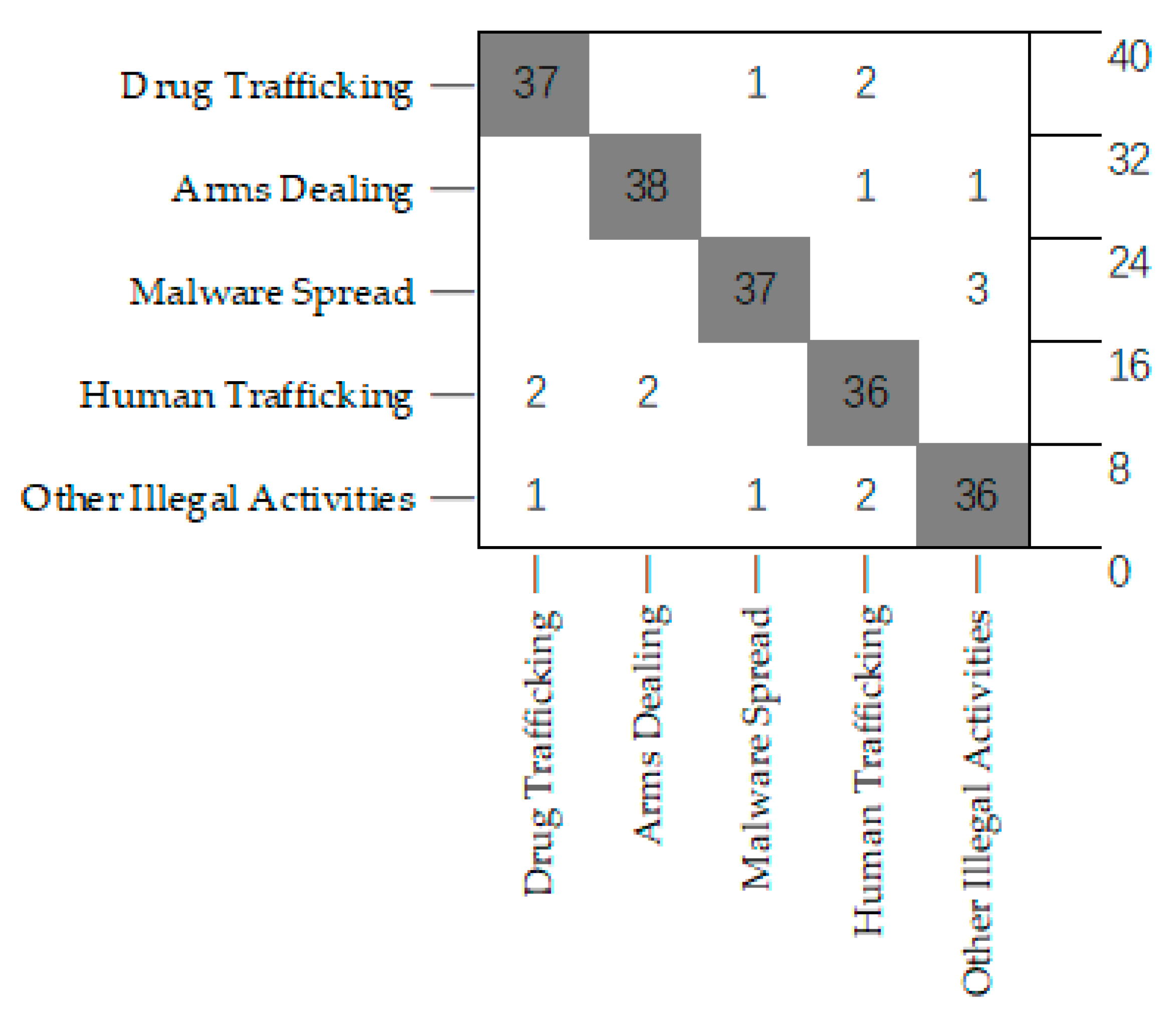
4.3. Experimental Results of Traffic Classification
4.4. Experimental Results of Contrast Experiment
4.5. Model Performance Evaluation
5. Discussion
5.1. Research Summary
- (1)
- Regarding DeepPacket, the most well-known work is “Deep Packet: A Novel Approach for Encrypted Traffic Classification Using Deep Learning” [31], published in 2020 by Lotfollahi M, Jafari Siavoshani M, Shirali Hossein Zade R, et al. in the journal “Soft Computing”. The main network structure used is SAE + CNN, without incorporating attention mechanisms.
- (2)
- Regarding DeepFlow, a frequently mentioned paper is “Network-Centric Distributed Tracing with DeepFlow: Troubleshooting Your Microservices in Zero Code” [32], co-authored by Professor Yin Xia’s team from the Department of Computer Science and Technology at Tsinghua University and the DeepFlow team at Yunsong Networks. This paper was published in the SIGCOMM 2023 conference proceedings. The system achieves zero instrumentation, full-stack coverage, and universal tagging for observability, greatly reducing the complexity of implementing observability in cloud-native applications.
5.2. Research Prospects
5.3. Future Research Directions
5.3.1. Introducing More Types of Traffic Features
5.3.2. Lightweight Design of the Model
5.3.3. Addressing the Continuous Evolution of Dark Web Technologies
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Behdadnia, T.; Deconinck, G.; Ozkan, C.; Singelee, D. Encrypted Traffic Classification for Early-Stage Anomaly Detection in Power Grid Communication Network. In Proceedings of the 2023 IEEE PES Innovative Smart Grid Technologies Europe (ISGT EUROPE), Grenoble, France, 23–26 October 2023; pp. 1–6. [Google Scholar]
- Adelipour, S.; Haeri, M. Privacy-Preserving Model Predictive Control Using Secure Multi-Party Computation. In Proceedings of the 2023 31st International Conference on Electrical Engineering (ICEE), Tehran, Iran, 9–11 May 2023; pp. 915–919. [Google Scholar]
- Ishizawa, R.; Sato, H.; Takadama, K. From Multipoint Search to Multiarea Search: Novelty-Based Multi-Objectivization for Unbounded Search Space Optimization. In Proceedings of the 2024 IEEE Congress on Evolutionary Computation (CEC), Yokohama, Japan, 30 June–5 July 2024; pp. 1–8. [Google Scholar]
- Yan, J.; Chen, J.; Zhou, Y.; Wu, Z.; Lu, L. An Uncertain Graph Method Based on Node Random Response to Preserve Link Privacy of Social Networks. KSII Trans. Internet Inf. Syst. 2024, 18, 147–169. [Google Scholar]
- Peng, Y.; Liu, Q.; Tian, Y.; Wu, J.; Wang, T.; Peng, T.; Wang, G. Dynamic Searchable Symmetric Encryption with Forward and Backward Privacy. In Proceedings of the 2021 IEEE 20th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Shenyang, China, 20–22 October 2021; pp. 420–427. [Google Scholar]
- Kabanov, I.S.; Yunusov, R.R.; Kurochkin, Y.V.; Fedorov, A.K. Practical cryptographic strategies in the post-quantum era. AIP Conf. Proc. 2018, 1936, 020021. [Google Scholar]
- Guo, C.; Katz, J.; Wang, X.; Yu, Y. Efficient and Secure Multiparty Computation from Fixed-Key Block Ciphers. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–20 May 2020; pp. 825–841. [Google Scholar]
- Zhao, J.; Jing, X.; Yan, Z.; Pedrycz, W. Network traffic classification for data fusion: A survey. Inf. Fusion 2021, 72, 22–47. [Google Scholar] [CrossRef]
- Xiang, B.; Zhang, J.; Deng, Y.; Dai, Y.; Feng, D. Fast Blind Rotation for Bootstrapping FHEs. In Advances in Cryptology—CRYPTO 2023; Handschuh, H., Lysyanskaya, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2023. [Google Scholar]
- Jain, A.; Jin, Z. Non-Interactive Zero Knowledge from Sub-exponential DDH. In Advances in Cryptology—EUROCRYPT 2021; Canteaut, A., Standaert, F.X., Eds.; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Gordon, S.D.; Starin, D.; Yerukhimovich, A. The More the Merrier: Reducing the Cost of Large-Scale MPC. In Advances in Cryptology—EUROCRYPT 2021, Lecture Notes in Computer Science; Canteaut, A., Standaert, F.X., Eds.; Springer: Cham, Switzerland, 2021; Volume 12697. [Google Scholar] [CrossRef]
- Kaur, P.; Kumar, N.; Singh, M. Biometric cryptosystems: A comprehensive survey. Multimed. Tools Appl. 2022, 82, 16635–16690. [Google Scholar] [CrossRef]
- Li, X.; Xu, L.; Zhang, H.; Xu, Q. Differential Privacy Preservation for Graph Auto-Encoders. Neurocomputing 2023, 521, 113–125. [Google Scholar] [CrossRef]
- Shiraly, D.; Eslami, Z.; Pakniat, N. Hierarchical Identity-Based Authenticated Encryption with Keyword Search over encrypted cloud data. J. Cloud Comput. 2024, 13, 112. [Google Scholar] [CrossRef]
- Li, J.; Pan, Z. Network Traffic Classification Based on Deep Learning. KSII Trans. Internet Inf. Syst. 2020, 14, 4246–4267. [Google Scholar]
- Kim, K. An Effective Anomaly Detection Approach based on Hybrid Unsupervised Learning Technologies in NIDS. KSII Trans. Internet Inf. Syst. 2024, 18, 494–510. [Google Scholar]
- Long, Z.; Jinsong, W. Network Traffic Classification Based on a Deep Learning Approach Using NetFlow Data. Comput. J. 2023, 66, 1882–1892. [Google Scholar] [CrossRef]
- Dong, S.; Su, H.; Liu, Y. A-CAVE: Network abnormal traffic detection algorithm based on variational autoencoder. ICT Express 2023, 9, 896–902. [Google Scholar] [CrossRef]
- Al-Thani, M.G.; Sheng, Z.; Cao, Y.; Yang, Y. Traffic Transformer: Transformer-based framework for temporal traffic accident prediction. AIMS Math. 2024, 9, 12610–12629. [Google Scholar] [CrossRef]
- He, S.; Luo, Q.; Du, R.; Zhao, L.; He, G.; Fu, H.; Li, H. STGC-GNNs: A GNN-based traffic prediction framework with a spatial–temporal Granger causality graph. Phys. A Stat. Mech. Its Appl. 2023, 623, 128913. [Google Scholar] [CrossRef]
- Rabbani, S.; Khan, N. Contrastive Self-Supervised Learning for Stress Detection from ECG Data. Bioengineering 2022, 9, 374. [Google Scholar] [CrossRef]
- NIST Standardization Team. CRYSTALS-Kyber: A Post-Quantum Public-Key Encryption and Key-Establishment Algorithm. NIST Spec. Publ. 2024, 800–802. Available online: https://github.com/srm1071/kyber/ (accessed on 22 June 2025).
- Sheikh, A.; Singh, K.U.; Jain, A.; Chauhan, J.; Singh, T.; Raja, L. Lightweight Symmetric Key Encryption to Improve the Efficiency and Safety of the IoT. In Proceedings of the 2024 IEEE International Conference on Contemporary Computing and Communications (InC4), Bangalore, India, 15–16 March 2024; pp. 1–5. [Google Scholar]
- Joshi, S.; Choudhury, A.; Minu, R.I. Quantum blockchain-enabled exchange protocol model for decentralized systems. Quantum Inf. Process. 2023, 22, 404. [Google Scholar] [CrossRef]
- Chia, P.H.; Desfontaines, D.; Perera, I.M.; Simmons-Marengo, D.; Li, C.; Day, W.-Y.; Wang, Q.; Guevara, M. KHyperLogLog: Estimating Reidentifiability and Joinability of Large Data at Scale. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–22 May 2019; pp. 350–364. [Google Scholar]
- Shaw, S.; Dutta, R. Post-quantum secure compact deterministic wallets from isogeny-based signatures with rerandomized keys. Theor. Comput. Sci. 2025, 1035, 115–127. [Google Scholar] [CrossRef]
- Ge, J.; Shan, T.; Xue, R. Tighter QCCA-Secure KEM with Explicit Rejection. IEEE Trans. Inf. Forensics Secur. 2022, 17, 1789–1802. [Google Scholar]
- Gurpur, S. Post-Quantum Cryptography: Preparing for the Quantum Threat. Comput. Fraud. Secur. 2024, 2024, 114–122. [Google Scholar] [CrossRef]
- Alexandru, A.B.; Pappas, G.J. Secure Multi-party Computation for Cloud-Based Control. Priv. Dyn. Syst. 2019, 16, 179–207. [Google Scholar]
- Su, T.; Wang, J.; Hu, W.; Dong, G.; Gwanggil, J. Abnormal traffic detection for internet of things based on an improved residual network. Comput. Mater. Contin. 2024, 79, 4433–4448. [Google Scholar] [CrossRef]
- Lotfollahi, M.; Jafari Siavoshani, M.; Shirali Hossein Zade, R.; Saberian, M. Deep packet: A novel approach for encrypted traffic classification using deep learning. Soft Comput. 2020, 24, 1999–2012. [Google Scholar] [CrossRef]
- Shen, J.; Zhang, H.; Xiang, Y.; Shi, X.; Li, X.; Shen, Y.; Zhang, Z.; Wu, Y.; Yin, X.; Wang, J.; et al. Network-Centric Distributed Tracing with DeepFlow: Troubleshooting Your Microservices in Zero Code. ACM SIGCOMM Comput. Commun. Rev. 2023, 53, 1–27. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
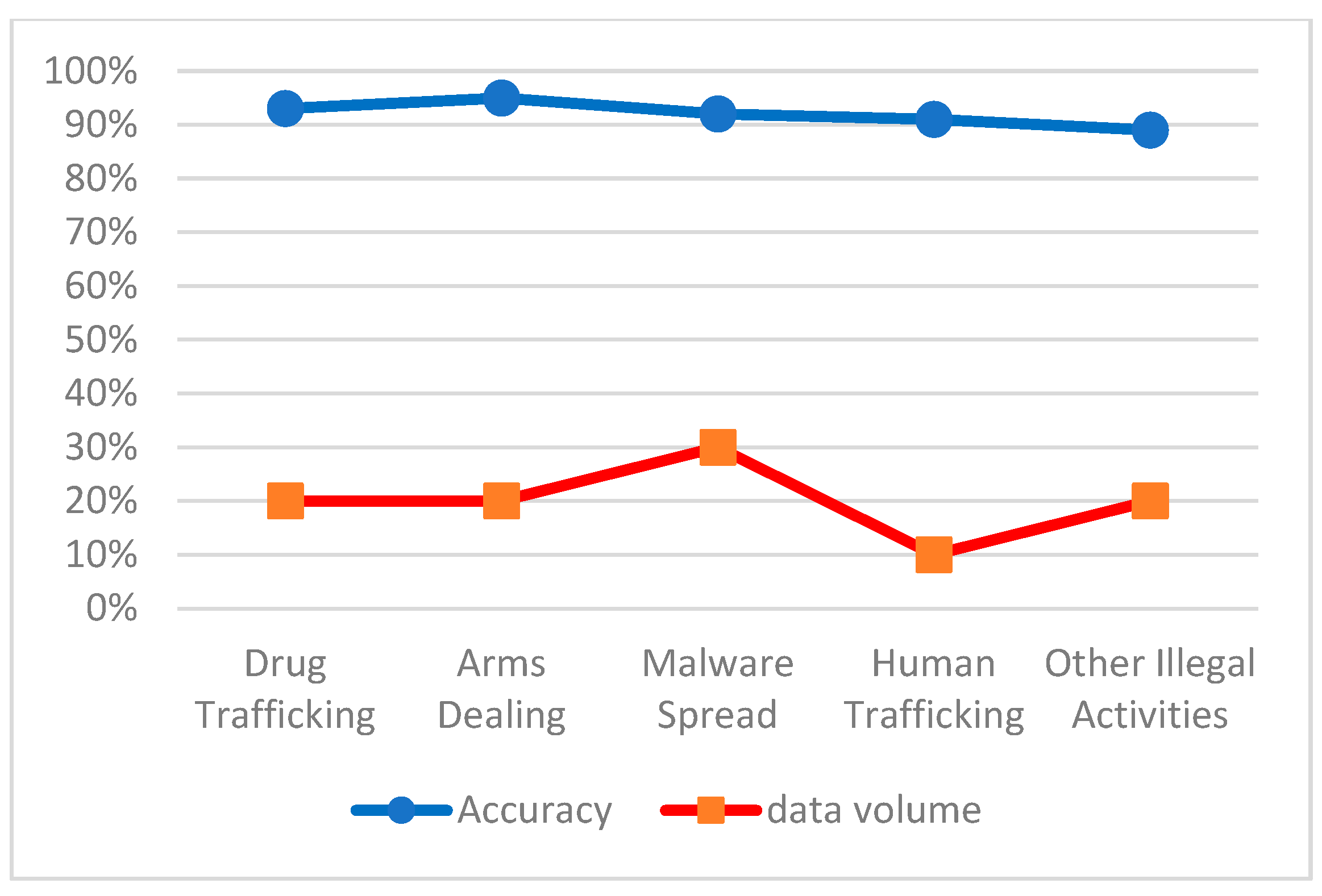
| Dark Web Traffic Category | Accuracy | Data Volume (Use ★ to Indicate the Amount of Data) |
|---|---|---|
| Drug Trafficking | 93% | ★★ |
| Arms Dealing | 95% | ★★ |
| Malware Spread | 92% | ★★★ |
| Human Trafficking | 91% | ★ |
| Other Illegal Activities | 89% | ★★ |
| Algorithms | Applicable Scenarios | Accuracy Advantage | Recall Advantage | F1 Advantage |
|---|---|---|---|---|
| SVM | High-dimensional data and limited sample classification | Stability depends on kernel function selection | Low (dependence on kernel function design) | Minimum (high precision but low recall) |
| RM | Small sample, linear and separable data | Performs well on high-dimensional data with balanced categories | Minimum (requires manual parameter adjustment for improvement) | Low (dependent on parameter optimization) |
| CNN | Image/spatial feature processing | Top in image classification | Medium (dependent on local feature capture) | Medium (high on image tasks, medium on sequence tasks) |
| LSTM | Time series data modeling | Higher in temporal tasks | High (capturing long-term dependencies) | Medium (high in temporal tasks, low in spatial tasks) |
| CLA | Multi-source information fusion | Highest (considering comprehensive spatial–temporal features) | Maximum (joint modeling for false negative reduction) | Overall performance is optimal |
| Algorithms | Feature Engineering Requirements | Performance | Generalization | Real-Time Applicability |
|---|---|---|---|---|
| The Number of ★ Indicates the Strength of Each Column Index | ||||
| SVM | ★★★ | ★ | ★ | ★★★ |
| RM | ★★★ | ★ | ★ | ★★★ |
| CNN | ★ | ★★ | ★★★ | ★★ |
| LSTM | ★ | ★★ | ★★★ | ★★ |
| CLA | ★ | ★★★ | ★★★ | ★ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Pan, Z. Dark Web Traffic Classification Based on Spatial–Temporal Feature Fusion and Attention Mechanism. Computers 2025, 14, 248. https://doi.org/10.3390/computers14070248
Li J, Pan Z. Dark Web Traffic Classification Based on Spatial–Temporal Feature Fusion and Attention Mechanism. Computers. 2025; 14(7):248. https://doi.org/10.3390/computers14070248
Chicago/Turabian StyleLi, Junwei, and Zhisong Pan. 2025. "Dark Web Traffic Classification Based on Spatial–Temporal Feature Fusion and Attention Mechanism" Computers 14, no. 7: 248. https://doi.org/10.3390/computers14070248
APA StyleLi, J., & Pan, Z. (2025). Dark Web Traffic Classification Based on Spatial–Temporal Feature Fusion and Attention Mechanism. Computers, 14(7), 248. https://doi.org/10.3390/computers14070248