1. Introduction
The exponential advancement of technology has led to an increasingly digitized society, where the demand for computing power continues to surge [
1].
However, there is a physical limitation in the vertical scalability of machine architectures. Despite ongoing improvements in central processing units (CPUs) and graphics processing units (GPUs), we inevitably encounter a ceiling that cannot be exceeded [
2]. The use of multiple computers working together is an approach that offers many more possibilities, since with horizontal scaling allows for essentially limitless growth. Although supercomputers follow this strategy, implementing them is extremely costly to implement. However, such infrastructures are accesible only by a few institutions, professionals, and, in general, users. In contrast, open and collaborative peer-to-peer (P2P) networks have emerged as a fundamental architecture that enables resource sharing and decentralized workload distribution among anonymous users [
3].
Decentralized P2P computing networks show very interesting advantages. For example, they can provide full transparency in computing tasks, as well as they are more resistant to traditional attacks such as Denial of Service (as the global network can continue to operate correctly even if several nodes are affected) [
4]. Systems such as Blockchain have demonstrated the incredible benefits of P2P networks in many critical applications: from cryptocurrencies [
5] to intellectual property [
6], resource management [
7], private communications [
8], etc. However, decentralization poses significant challenges in terms of trust, particularly in relation to the presence of malicious nodes that can compromise the integrity and reliability of the network.
In common P2P networks, nodes do not provide any evidence about the quality of the computing execution or results [
9]. Therefore, users must trust the responses. But although the P2P network is resistant to cyberattacks, individual nodes are not. And malicious behavior may arise [
10], however. As a result, computing tasks can become corrupted, and the resulting outputs may therefore be untrustworthy. Many different strategies to mitigate this problem have been proposed, but the most popular one (implemented, for example, in Blockchain or BOINC project) is the replication technique [
11,
12]. Under this scheme, any computing task is replicated and delegated to many different nodes which solves the same task independently. Then, the final result is the one which is generated by the majority of nodes. Although this approach is very sound and secure from the technological perspective, it presents some critical problems. The most critical issue is probably the waste of computing resources. However, Anderson proposed a mechanism called “adaptive replication” [
11] which seeks to minimize computational redundancy in a centralized volunteer network by considering the historical efficiency of each client, anyway, the tasks had to be fully re-executed. In any case, validity checks, when needed, are performed by executing the complete task on different nodes. As any task must be replicated and solved many different times, several unnecessary computing activities are performed by the network, which do not add any real value to the users but significantly increase, among other things, the energy consumption.
And this problem is expected to get worse. According to the state of the art in computing, this insatiable need for computing power has become even more intense with the rise of data-intensive applications such as machine learning and artificial intelligence [
13]. The reliance on these technological resources for innovation and progress in a digitized society is undeniable.
Therefore, there is a pressing need to enhance trustworthiness in P2P networks while simultaneously keeping energy consumption under control. Thus, any advances in computing architecture should also prioritize energy efficiency and sustainability to mitigate the environmental consequences of increased computational demands.
This paper fills this gap and proposes a new method for validating the computing results from P2P, for use in decentralized computing networks while ensuring energy efficiency. The solution focuses on the application of game theory, rewarding nodes that correctly solve tasks, and penalizing those that provide invalid results. To achieve this, two types of nodes are defined: workers and auditors. Workers are responsible for solving tasks, while auditors randomly select workers results and verify their validity.
The minimum number of auditor nodes required to statistically ensure network reliability has been calculated. Additionally, a Node Value is computed based on the number of tasks executed, and the number of audited tasks, both correct and incorrect. These values define the node’s reliability, and those with better performance can use this value for various purposes (beyond the scope of this article), such as accumulating points to consolidate a Blockchain block, receiving payments, or acquiring processing power for personal use within the network. To avoid issues arising from different processor architectures, each node execute its tasks in a virtual environment, ensuring that all nodes share the same virtual infrastructure.
The remainder of the paper is organized as follows.
Section 2 introduces the state of the art of computing validation mechanisms for P2P networks.
Section 3 describes the proposed solution, including the mathematical framework to weight the trustworthiness of single nodes.
Section 4 describes the experimental validation and the results. Finally,
Section 5 concludes the paper.
2. State of the Art
P2P networks represent a decentralized computing paradigm whereby orchestration, computing resources (machines, applications, data, …) are distributed throughout the network and geographically dispersed [
14]. This intricate framework facilitates the collaborative use of resources, allowing for improved computational capabilities and scalability. But this enhanced scalability introduces challenges in terms of trust and security. In the state of the art, different authors have discussed and analyzed this topic from different points of view, such as the reliability and trustworthiness of the binaries that are executed, modification of the results, and privacy concerns.
The most frequently studied topics include the following:
Binary confidence: This one applies on P2P computing networks where any node runs the received code from another node, some of the strategies used are based on the use of Virtual Machines [
15] taking into account the different security aspects [
16], but the consumed resources are relatively high and their isolation security measures are a bottleneck [
17,
18]. The rise of containers as an alternative to Virtual Machines has reduced resource consumption while still providing good isolation under Unix/Linux environments [
18,
19]. In addition, another isolation solution used are execution environments powered by JavaScript (like browsers) in which the exposed scope of the virtual machine is limited by the execution core [
20]. We also consider privacy issues. More users are realizing the importance of data privacy [
21], especially as more and more devices in home networks have access to sensitive information [
22]. So executing a binary may automatically open access to sensitive data stored on worker machine, so an isolation mechanism as previously commented, is a solution to this.
Binary truthfulness: Checking the binary to be executed with binary signing assures non-repudiation and that the binary was not modified, but does not prevent the program from reaching system resources, anyway, management of revocation and better response to abuse is required [
23].
Using an execution environment is important to maintain under control the exposed resources of the host machine.
Outcome alteration: After a peer executed the provided binary with some provided data, the outcome should be returned to the network. But if this peer wants to interfere whith or block the original project, the provided outcome could be modified. Also, if there is a bug in the peer’s processor due to overclocking or another issues [
24], operating system, etc., outcomes can be also affected.
Researchers have taken various approaches to address these issues through different projects:
Volunteer computing platforms, like BOINC, uses “adaptative replication” to deal with possible hardware errors [
11]. Estrada, Taufer and Anderson applied different replication levels (5.3 in [
25]) considering 10%, 30% and 60% probability of hardware errors.
Hardware solutions like Intel SGX [
26,
27] are used to ensure result correctness because it allows the creation of an isolated container (Intel SGX enclave) where code and data receive special hardware protections that guarantee their confidentiality and integrity with some performance penalization [
28]. Also, these solutions are not resistant to Cache Timing Attacks (6.6.6 in [
26]) nor Passive Attacks (3.7.1 in [
26]), and are vulnerable when using hyperthreading as Costan noted in the cited paper:
“SGX does not prevent hyper-threading, so malicious system software can schedule a thread executing the code of a victim enclave on an LP that shares the core with an LP.”
Blockchains are based on game theory [
29], volunteer computing solutions execute the same process into different nodes [
11] to compare results. Static code analysis [
30] is commonly used to analyze code prior to execution. It can also be applied by requesting, in real time to the worker node, for the instructions that were executed but it doesn’t assure that the outcome published had been produced by the original binary.
Energy efficiency: Different strategies have been used to try to optimize and reduce energy consumption in P2P networks [
31]. Some authors propose detecting nodes that make use of the network without contributing anything in return are penalized [
32] so that energy consumption is maximized, also, considering not only the time the network is being used, but also when it is being used [
33], i.e., detecting the moments of highest load in the electrical network to minimize the activity in the P2P network and recover it in the off-peak areas.
The energy consumption of software is not something to be overlooked [
34], and therefore in this study we have looked for the best efficiency-effectiveness ratio, furthermore, the design decisions and languages used affect consumption [
35]. When running high intensive tasks, the energy consumed by a processor increases considerably as illustrated in
Figure 1 the energy reported by Intel RAPL [
36] when starting a Boinc’s project task. Therefore, it is necessary to find more efficient methods for reducing energy consumption in P2P networks since networks like Boinc, have a system of validation results based on the repetition of the same task in multiple nodes [
11], so this approach is not efficient since it is a waste of resources.
This paper addresses these issues by introducing a novel approach based on game theory [
37] and statistical techniques.
From the infrastructure perspective, delivery content platforms (and digital entertainment services) are hosted in large datacenters with really high consumption [
38] (global datacenters energy consumption was estimated in 2022 to be around 240–340 TWh [
39] so some authors argue the use of domestic infrastructure (STB, Routers, …) for creating a P2P multimedia delivery platform will reduce the energy consumption for these datacenters [
40].
In terms of security, efficient detection of malicious nodes in a P2P network has become a critical area of research, as conventional approaches often necessitate the repetition of entire tasks, like networks running under Boinc project umbrella [
11], to ensure the veracity of results, imposing a substantial burden in terms of resources and time or penalizing nodes which consume network resources without contributing to it [
32]. Also, the use of a trust management mechanism in P2P nodes [
41], in which jobs are delivered only to trusted nodes, for which other nodes in the network are consulted, thus avoiding untrusted or dishonest nodes. The trust of an agent is associated with a numerical level measured by several nodes (multidimensional trust).
Blockchain networks are another set of decentralized P2P networks in which each peer is completely anonymous and various energy-intensive consensus methods such as PoW are applied to maintain the reliability of the network. In order to reduce consumption in this type of networks, different studies approach the problem from different points of view like the propose of a consensus approach based on PoW where a single miner is selected to mine the block [
42] instead of competing between them to get an approximate 21% improvement in energy consumption or after performing a run cycle with the PoW consensus test, the “losers” are selected for the next iteration increasing their probability of closing a block [
43] while avoiding that many nodes are trying to close a block or optimizing the PoW consensus method to reduce energy demands on low-resource devices like CWCN (Cognitive Wireless Communication Networks) [
44] reducing the complexity (defining an allowed range of values instead a number of 0 for the hash) which allows 16 times more hashes as eligible, also using smaller Blockchains with more recent transactions.
Focusing on P2P networks who manages computing resources, Blockchain [
45] ones are a good example, like the ones based on the Ethereum Blockchain [
46], that has a decentralized computing mechanism for running DApps (decentralized apps) on worker nodes (the miners) over an isolated environment called EVM (Ethereum Virtual Machine) [
47] which is Turing completeness.
This paper focuses on a novel execution environment to detect outcomes alterations to avoid wasting computational resources that could be better used for other tasks. The rate of re-execution of tasks with our method is directly proportional to the number of auditors. In our experiments (
Section 5), with a 12% task re-execution rate (instead 100%, 200%, …in models with full execution paradigm), 98% of invalid tasks have been detected and all nodes that executed those tasks were identified.
Consensus between nodes is required to accept the smart contract outcome, so “asynchronous consent” is a proposal in which smart contracts interact between them to agree on the new network status [
48] for this task, two types of contracts “client” (solve the task) and “custodian” which act as referee.
In summary, consensus mechanisms play a pivotal role in determining the performance, security, and scalability of distributed systems. While blockchain-based solutions have evolved to address different trade-offs between decentralization, energy efficiency, and fault tolerance, alternative paradigms such as BOINC’s adaptive replication offer valuable insights into achieving reliability and scalability in non-adversarial environments. Unlike traditional consensus algorithms designed to prevent malicious behavior and ensure transactional integrity, BOINC’s approach focuses on computational redundancy for scientific computing with volunteer resources. The comparative analysis presented in the
Table 1 highlights key differences and similarities among these mechanisms, providing a comprehensive overview that supports the selection and design of appropriate consensus strategies depending on the specific requirements of the target application.
3. A New Method to Evaluate Decentralized Computing Results
Figure 2 shows the proposed architecture for the new decentralized computing results evaluation mechanism. As can be seen we have a P2P network of computing nodes (green) with different roles, a decentralized storage, queues area (red) and a finished task consolidation Blockchain.
Storage area (red): This area consists of four buckets that store programs, jobs and completed tasks and subtasks: “programs” contains the platform-independent binaries needed to solve tasks. These programs are compiled or encoded into WASM binary code; “pending tasks” is based on a XOR metric binary tree index in which each leaf contains a task, i.e., the set of input data necessary to be processed by the program indicated in it, optimized to perform the search for the nearest task based on the XOR distance; “completed subtasks” contains another XOR metric binary tree index optimized for XOR distance lookups with “snapshots” of the running tasks, these snapshots represent checkpoints that the creator defines, each containing half of the solution; “completed tasks” is a queue-based storage with all finished tasks.
As previously mentioned, “pending tasks” and “completed subtasks” are stored using a binary tree index optimized for XOR distance lookups. This is because tasks, subtasks and peer nodes have a unique UUIDv4 identifier. A properly implemented UUIDv4 with a TRNG (True random number generator) ensures a uniform distribution [
49].
Since this is a decentralized architecture, it becomes difficult to inform all peers about the task a node is working on. Therefore, each node must select a task that has not been chosen by another. By looking for the ‘taskId’ closest to the ‘peerId’ (using XOR distance), the probability of collision is reduced. If two nodes happen to work on the same task, this could serve as an auditing mechanism.
Computing nodes (green): All nodes are interconnected through a kademlia-based [
50] P2P network so full communication between them is possible. Each node will take one or multiple roles, being:
“creator” the one needs to solve a problem so it will publish a platform independent program which implements the problem solution and a bulk of tasks to be solved with that program.
“workers” are the nodes in charge of solving the tasks using their computing power, they choose a pending task to be solved based on the XOR distance between their own id and taskId. Once a task is selected, it searches and obtains the necessary program to be executed and proceeds to instantiate a safe execution environment to compute it. Every task will generate “snapshots” of intermediate resolutions to be published in the “completed subtasks” area, once the task is finished, it will be published in “completed tasks” waiting to be validated by other nodes in the network and consolidated.
“auditors” will choose a randomly completed subtask, obtain the corresponding program and rerun only the selected subtask checking that the input and output data correspond to that published by the worker. On the other hand, the auditors will also monitor the queue of completed tasks, obtaining a set of tasks and only if 1 or more subtasks are successfully audited, they will proceed to the generation of a new block that will be consolidated in the Blockchain.
Consolidation Blockchain (blue): Finally, all information about nodes, tasks, auditions, …that need to be consolidated is stored on a Blockchain distributed through all nodes (creators, workers and auditors). Each node will store their information into their own node account protected by asymmetric cryptographic keys. The compute module implemented by the creator, is signed and stored with node keys.
Auditors are the nodes in charge of consolidating new blocks based on the tasks completed by worker nodes, for this purpose, they will choose a set of tasks and after checking that all of them have been audited at least once (one of their subtasks), this nodes will create a Merkle Tree [
51] with the task and target node account called dispatches.
This information is stored and signed in a block and added to the Blockchain to be validated by the other nodes.
The auditor selected to close the next block is selected among others auditors using their node valuse as weighting factor (see
Section 3.1), this method will be called Proof-of-Collaboration (PoC).
3.1. Proposed Lifecycle for P2P Nodes and Tasks
Our P2P computing network is based on Kademlia [
50], in which node distribution and task selection are based on XOR distance (Section “XOR Metric Binary Tree Index”) which is very suitable for our needs.
All the nodes of the P2P network can act with different roles being the creator those who will publish the programs to be executed as well as the different tasks to be solved by the computer network, the workers, in charge of solving these tasks making use of the associated programs and finally the auditors in charge of verifying that the workers are doing their job correctly and will sign and consolidate the solved tasks once completed and verified.
As shown in
Figure 3, creator nodes implement and publish the programs and tasks. Worker nodes will download a task (Section “XOR Metric Binary Tree Index”) to be solved, and after reading its metadata, will recover and execute the associated program. Workers will execute multiple snapshots of their execution that they shall publish on the network to be validated (as jobs/subtasks ). Finally, auditors, will get any of these jobs and re-execute only that snapshot (instead full task) to validate if the worker node is doing well their job giving a node value to each worker node.
For a voluntary computing network to succeed, it’s essential to offer incentives to users who contribute with their own resources, helping to to attract and retain participants (2.1 in [
52]). For this purpose, we have implemented a node evaluation system aligned with our vision of using game theory as in BitTorrent [
53], and in Blockchain [
29].
This mechanism ensures that honest nodes receives better evaluations, while those attempting to cheat or harm the network are heavily penalized, making such behavior unprofitable. Additionally, poorly evaluated nodes may be audited more frequently, increasing the likelihood of detecting and penalizing failures.
The evaluation system not only audits to verify the work performed by worker nodes but also incorporates a scoring mechanism to assess their quality. The score assigned to each node is based on a comparison between their results and those obtained by the auditor nodes, allowing for an assessment of the node’s reliability and accuracy.
The quality of the results, and thus the node’s reliability, will be determined using the following formula:
This measures the proportion of audited segments that have been executed correctly (bad audited segments decrease double).
The value of K is a constant for adjusting, in our tests we have set it to 10.
Good tasks are rewarded with a logarithmic function.
Finally, this is divided by the total tasks executed by the node, so if it isn’t evaluated periodically, his punctuation falls.
Each time a new subtask is audited with good result, the value of the node is increased by a logarithmic function.
If a node has more bad audited segments than good audited segments, this price is set to 0.
As equal as good task are rewarded, bad tasks are penalized with an exponential function. As seen in the equation, we limit to 128 the maximum bad tasks in order to avoid overflows (we are using
u128 variables (see
Section 4)).
Finally, the value of the node is calculated as follows:
where:
T—Number of tasks executed by the node (audited or not)
G—Number of segments audited with good result
B—Number of segments audited with bad result
K—Value drop adjustment constant for old age, in our tests adjusted to 10
3.2. Data and Task Management and Storage Strategy
As represented in
Figure 2, we define 4 storage areas being: computing modules which are decentralized using a platform like IPFS [
54], Swarm [
55] or directly on P2P nodes. Completed tasks, which is a queue of finished tasks to be consolidated into the Blockchain by the auditors (
Section 3.3) and pending tasks with new tasks to be executed and completed subtasks with each completed snapshot needed to evaluate the worker (
Section 3.1). These two storages ( pending tasks and completed subtasks) are stored into an optimized tree structure to allow workers auto assign a task to execute without any communication with other nodes and reducing the probability of running the same task by two workers, Section “XOR Metric Binary Tree Index” explains this process.
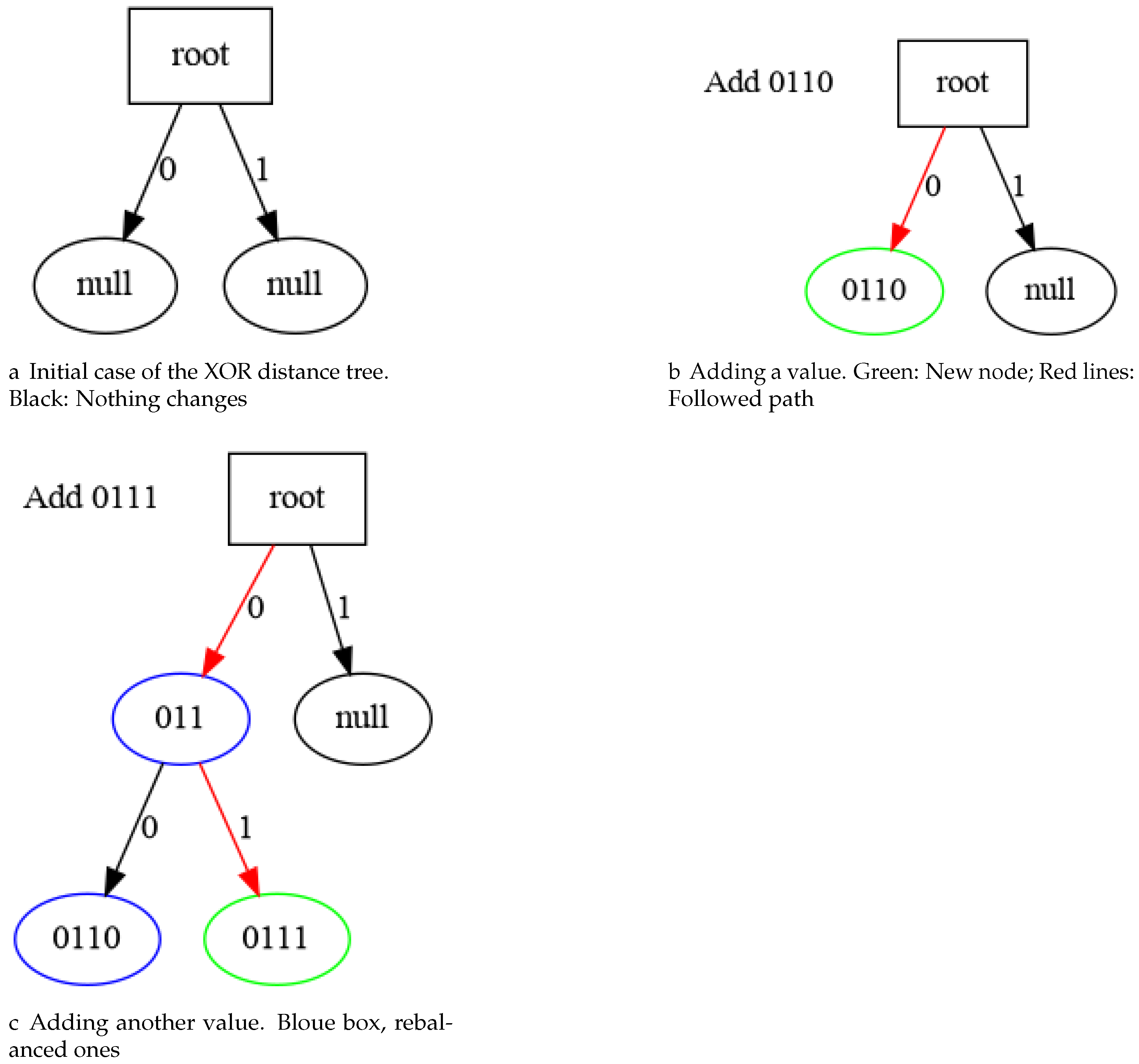
XOR Metric Binary Tree Index
Each new task created is assigned a unique 128 bits identifier (UUIDv4), ensuring uniform distribution of tasks in a field.
In parallel, all nodes in the network are assigned a unique 128 bits identifier, ensuring that they are uniformly distributed across the task field.
As we want to reduce communications between nodes, each worker should get a task to work with it, but this task shouldn’t be selected by another worker. To allow this behavior, each worker selects the taskId nearest to his own nodeId, using the XOR metric. This is defined as (Equations (
5)–(
7)):
To speed up this search, we created an index, based on the radix tree [
56] adapted to the XOR distance in order to speed up minimum distance lookups by getting a search algorithm with
complexity for any number of stored tasks.
The index consists of a binary tree where each node contains a set of bits shared with its children, by the left branch we will advance if the next non-common bit is 0, and by the right branch if it is 1.
To achieve this goal, we place newly added identifiers in the tree based on their bit patterns, from the most significant to the least. As shown in
Figure 4, if we find a node that does not share the whole sequence of common bits, then a new node will be generated with the common mask and the previous tree will become a child of it, as well as the new inserted element.
During the search process,
Figure 5, we examine each bit in turn and traverse the tree until reaching a leaf node. That element is the closest according to the XOR metric.
This process allows for an equitable distribution of tasks among available worker nodes.
3.3. Blockchain Network
Once a task is finalized, audited, and validated, it should be consolidated. Auditors are the nodes responsible for signing a new group of tasks and closing a new block in the dedicated Blockchain. This action enables the distribution of this database along all P2P nodes and assures that, once finalized, they cannot be modified.
On this Blockchain each node has its own node account defined by a private and public key based on ECC curve secp256k1. (Equation (
8)) These keys are used to sign all operations along the network ( compute modules, tasks, subtasks, auditees and dispatches).
As any other Blockchain, it needs a consensus algorithm, and instead the use of common ones like PoW (Proof-of-Work) of PoS (Proof-of-Stake) we use our own PoC (proof-of-collaboration) which avoids the energy consumption needed by PoW and does not prioritize miners who have more tokens like PoS.
Blockchain blocks, signed by auditors, store dispatches (completed tasks targeted to creator’s node account).
This consensus algorithm (PoC) will use the node value (
Section 3.1) in which the protocol selects a validator who adds the new block. The more node value of the auditor (that is, more work done on the computing network), the higher probability to be selected. This consensus method guarantees low energy consumption (like PoS) while remaining a very democratic system within the decentralized network (like PoW).
Each block contains the list of dispatches (final executed tasks sent to creator’s node account), and it is also stored in a Merkle Tree structure [
51].
3.4. Common Execution Environment
In order to increase final users trustfulness and security, we propose the use of a common execution environment for all architectures which ensures uniformity in results across diverse node architectures (trustfulness) and in which we can completely isolate our executables from other programs executed on the end-user’s machine (security).
Regarding trustfulness, as said
Section 3.2 “Some numerical applications produce different outcomes for a given work unit depending on the machine architecture, operating system, compiler, and compiler flags” [
52], a common runtime environment is needed and after state of the art study we concluded that leveraging JavaScript alongside WebAssembly, we achieve a versatile and cross-platform execution environment, promoting consistency in the outcomes of computational tasks.
WebAssembly is a binary instruction format that runs on JavaScript engines at fast speed [
57,
58] and provides a standardized runtime that transcends the idiosyncrasies of different hardware and software environments and solves the problem described by Anderson.
This approach not only enhances interoperability but also simplifies the deployment of our system across a wide range of nodes thanks to their multiplatform support and also, the use of WebAssembly offers distinct advantages, including efficient execution, broad compatibility, and a secure sandboxed environment, making it an ideal choice for ensuring consistent and reliable results in our peer-to-peer network.
A possible shortcoming is that WebAssembly is a stack-based machine instead of a register-based machine [
59]. However, it distinguishes itself with a stack based. This design choice brings forth several advantages and trade-offs. One notable advantage lies in the simplicity of the stack-based approach, making it well-suited for a portable and compact binary format. Stack architectures also tend to have a smaller set of instructions, reducing the complexity of the bytecode and facilitating efficient parsing and execution and often results in denser code, which can lead to more effective use of memory.
However, this simplicity comes with certain trade-offs and register-based architectures can sometimes outperform stack-based architectures in terms of execution speed for certain types of operations since architectures allow for a direct and more efficient interaction with the CPU’s registers, potentially leading to faster execution times in scenarios where heavy computation is involved.
Nevertheless, the stack-based approach in WebAssembly has proven to be highly effective in the context of web applications, where portability, security, and ease of implementation are paramount. As Haas proved in the article [
58], the WASM stack-based machine is near 10% of his register based version which demonstrates that currently WASM and JavaScript machines have been optimized to high levels of performance. The advantages of a compact and straightforward stack-based design align well with the goals of WebAssembly in providing a reliable and performant execution environment across diverse web platforms.
Finally, regarding energy consumption, Javascript is not bad positioned [
35] comparing to its competitors and we can consider WebASM as a step forward to JavaScript, and the consumption is lower than pure Javascript [
60].
So, after deep analysis, we decided to implement each network node with a virtual environment based on the WebASM engine (like SpiderMonkey, V8, …) [
61] with some system features exposed to the WebASM environment through programming interfaces allowing applications to have access to required network information such as generating snapshots, publishing results, etc. The advantages of this decision for our scenario:
Common environment on any platform
Really well-proven technology
No external libraries are needed. Binaries are compiled with all the necessary code.
The source code can be written with too many languages since WebASM compilers exists for most of them (C, C++, Go, Rust, …). This is the main advantage for us since we don’t force any language.
Due to the “browsers war”, WebASM virtual machines are highly optimized, so this environment runs near native performance [
62].
WebASM virtual machine is a stack based architecture [
59].
WebASM virtual machines implementations are reliable and open source (SpiderMonkey—Mozilla [
63], V8—Google/Chromium [
64], …)
3.5. Node Roles
Each node in the network can serve different roles
Figure 3, acting as a worker, auditor, and/or creator.
Creator nodes are responsible for publishing computational tasks onto the network, along with the programs to be executed. This sets the foundation for the execution of necessary operations.
Worker nodes receive both the program and the task to be executed (
Section 3.1). Upon receipt, they undertake the execution of the task and publish the obtained results (Job). Their primary function is to carry out the operations defined by the program (
Figure 6).
Auditor nodes (Nodes with higher node value
Section 3.1 as they are the most reliable) get a random Job from the “finished subtasks” store (
Figure 2) to execute it and compare results. Auditor will sign results and evaluate the worker node (Equation (
4)) (
Section 3.1).
Lastly, auditor nodes play a critical role in the process by verifying whether workers are executing their tasks correctly.
This ensures the integrity and precision of the results generated by the network.
In a continuous cycle of interaction, each worker node receives a list of pending tasks published on the network and selects one to begin processing (Section “XOR Metric Binary Tree Index”), once it finishes execution of the different subtasks, auditors select a random one an validate it (
Figure 7)
This validation ensures the reliability of the results and maintains the integrity of the system as a whole.
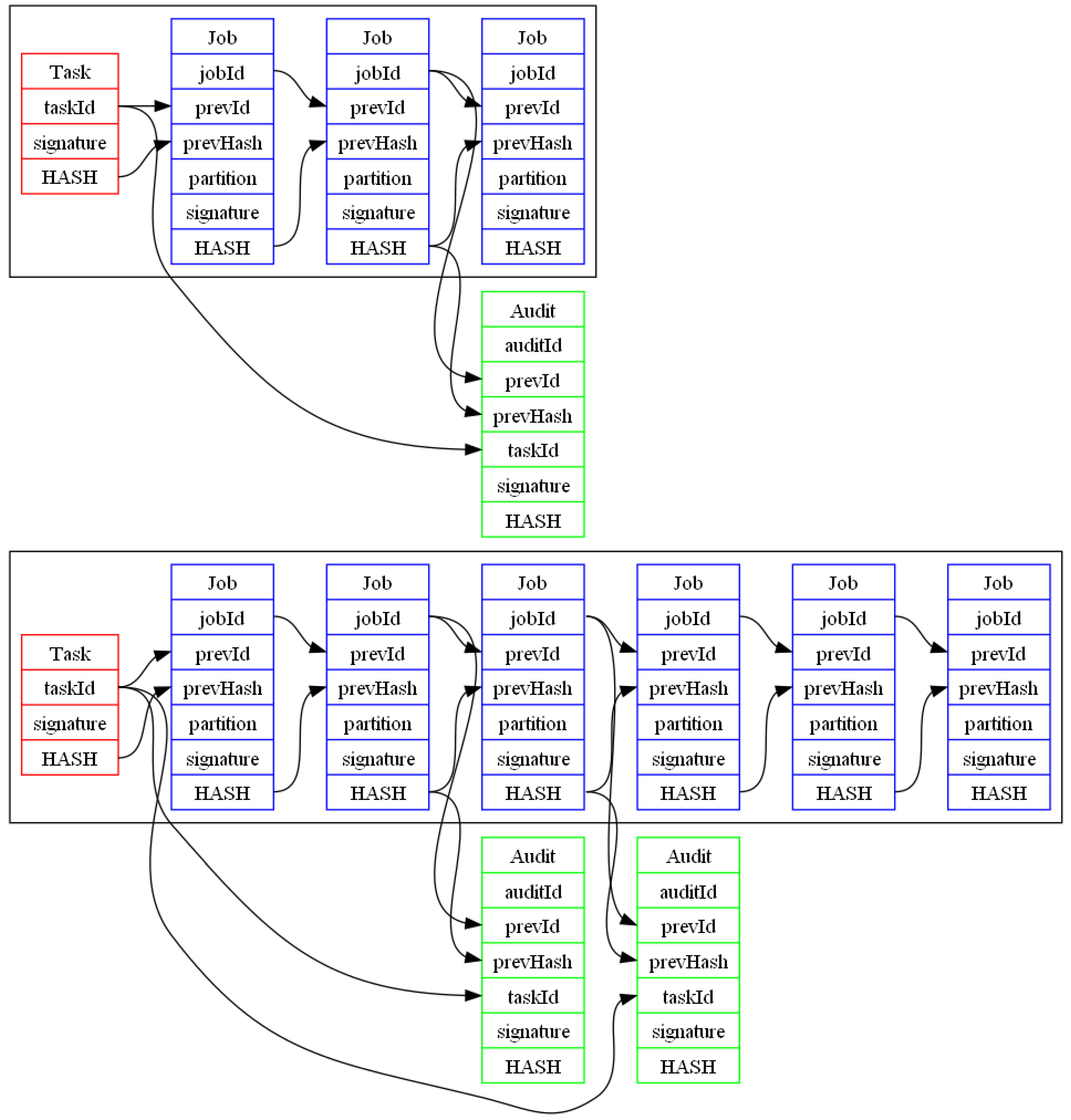
As shown in
Figure 7, from each task (red) multiple jobs (subtasks in blue) are published by workers, Auditors will select one of these jobs to be validated (green). Any task, job or auditee shall be signed by the creator, worker or auditor respectively. Also, all these nodes contain a HASH calculated over the rest of the information stored and used to assure no modifications on the chain.
This system compared to other Volunteer computing platforms can be summarized into the
Table 2.
4. Experiment Validation
4.1. Implementation
There are multiple ways to validate the results obtained by the worker nodes:
Unit tests can be used to validate the final result (ideally provided by the creator of the task).
Re-run the task in a controlled environment and compare the results obtained.
Validate the partial results obtained by the worker nodes.
Monitor the instructions that are being executed in each worker node.
In other decentralized computing solutions such as Boinc, the solution often choose to run the same task on multiple worker nodes (3.2 in [
52]).
On a first try, and considering that in our network we have control of the execution environment over WebASM (
Section 3.4), our first approach was to modify the virtual machine so that it reports in real time the instructions that are being executed on the node [
65], so that any auditor could connect at any time ask for the instructions being executing and validate they correspond to those initially provided by the task creator. However, we ultimately discarded this approach due to its high computational cost involved, since the virtual machine would have to send all the instructions that were being executed in each worker node in real time, in addition, the optimization tools of the JIT (Just In Time compilers) used will modify the instructions executed, which further complicates the auditing systems [
66].
This is why our approach eventually led to splitting the task into multiple small execution segments. Each worker node will get a task from the pool of pending tasks with the necessary input data to execute it, as well the referenced published program needed to execute it will run in the WebASM controlled environment and, as segments are completed the node will publish segment results as well as the input data used at the segment beginning (the previous segment output). A global instruction is provided inside the virtual environment to register a segment change and publish it.
This strategy serves to alleviate the workload of our auditor nodes, as they only need to re-execute specific task segments instead of the full task, in addition, this approach facilitates the early detection of potentially malicious worker nodes.
As mentioned above, in the network, we will have a number of nodes in charge of auditing the work done by the other nodes in the network. These nodes, known as auditors, select a random node to audit, and once selected, they randomly select a segment of one of the executed tasks and proceed to re-execute it, thus validating whether the execution is correct or not.
By integrating this lightweight audit method reduces the energy comsuption compared to volunteer computing networks and PoW-based consensus mechanisms, where energy inefficiency arises from redundant task execution and resource-intensive mining in three ways:
Audit layer: Subtasks validation is streamlined through probabilistic sampling.
Network layer: Volunteer nodes contribute computacional power directly to tasks.
Consensus layer: Blockchain component does not rely on energy-intensive mining while retaining democratization benefits
With this mechanism, failures may not be detected if they occur only a small proportion of the subtasks, but multiple simulations have shown us the ability to quickly identify malicious nodes.
Security and accounting are crucial to our design, so each published task shall be signed by the creator and each result shall be signed by the worker who produced it. Also, audited ones must be signed by the auditors.
The creator determines the number and size of each task partition and workers publish each partition result as soon as it is completed.
This will allow auditors to review any random partition to locate malicious workers.
To implement this way of working, all tasks define (Listing 4) not only the data to be processed but also the number of partitions into which the work is to be divided.
| Listing 4. Task struct. |
![Computers 14 00216 i004]() |
Worker nodes will acquire the nearest task using XOR distance [
50] from the task pool and the WASM program needs to process it (referenced in the task provided data). Both of them SHOULD be signed by the same creator.
After validation of signatures, the worker node will execute the program into the jailed WASM environment and, as input, will insert into the WASM shared memory the provided task data.
Worker will be running the provided code until the snapshot function (Listing 5) is invoked, which will store the result into a Job struct (Listing 6).
These Job structs maintain a linked chain (through previousId and previousHash fields) which guarantees no modifications after publishing. The last Job struct will have the final Task outcome in the outcome buffer field.
The execution environment of each of the network nodes will be formed by a native application for the platform on which it runs (implemented in C/C++ or Rust, for example) which embeds a JavaScript machine (SpiderMonkey [
63], V8 [
64], …) where the code received from other nodes in the network is executed. This ensures that the code runs within a sandboxed and controlled environment, with no access to the user’s machine’s native resources.
In order to be able to interact with the network (sign jobs, publish results, etc.), a series of functions will be exposed to the JSContext [
67] that will allow it to interact between both environments, such as the one in charge of executing a snapshot on the task in execution (Listings 5 and 8). These functions should have a limited action frame in order to limit possible attack vectors.
| Listing 8. Snapshot imported into JSContext. |
![Computers 14 00216 i008]() |
Finally, the code received by an anonymous network node will be a combination of JavaScript and WebAsm that will be executed in the JS context mentioned above.
4.2. Simulation Infrastructure
To evaluate our proposed audit mechanism, we developed a simulator that generates randomized tasks containing invalid solutions. This simulator was used to measure the effectiveness of auditors in identifying and detecting non-compliant workers. For all these simulations we used an Intel i7-12700H with 32GB RAM running Linux Debian Bookworm with kernel version 6.1.85 and an Intel Xeon E3-1231 with 32GB RAM running Linux Debian Buster with kernel version 4.19.181.
For the random number generation function, we employed a PRNG (
Figure 8) as well as two TRNGs, a Yubikey 5 (
Figure 9) and a Nitrokey HSM 2 (
Figure 10), achieving comparable results but TRNGs required excessive more time to complete a simulation while PRNG provided sufficient entropy for our requirements, consequently, we conducted multiple simulations using the PRNG.
The simulator (
Figure 11) is implemented in JavaScript for network auditee simulation and Python 3.13.2 for final graphics generation (
Section 5).
The simulator creates multiple Task, Worker and Auditor instances. Workers will randomly select one Task and split into multiple subtasks, each subtask will be randomly marked as completed or badly executed and stored on a finished list. Auditors will select a randomly subtask and check if it was badly executed. Since the number of Auditors is less than Worker ones, the number of checked subtasks is only a little proportion of the total.
The simulator will calculate and store into multiple files each Worker and Auditor “Node values” to be plotted and analyzed. Also, a resume is printed after each execution.
This simulator has allowed us to evaluate the impact of the audit on network performance and to determine the effectiveness of our scoring system.
Although the experiments used homogeneous nodes, the core mechanisms of the system (such as random audits and reputation weighting in PoC) are designed to operate in decentralized networks using probabilistic algorithms. These strategies do not depend on the uniformity of the nodes, but on their ability to respond dynamically to behavioral patterns. Networks based on random sampling or stochastic consensus tend to scale well even in heterogeneous environments, since their effectiveness is based on aggregate statistics, not on individual node properties.
The use of random audits reduces the dependence on network stability. In P2P systems with high churn, probabilistic methods (such as those employed in [
68]) have proven effective in maintaining consistency in detecting misbehavior, provided that the sampling rate is proportional to the network size. In addition, reputation weighting prioritizes nodes with verifiable history, partially mitigating the impact of new untrusted participants.
Experimental results should not be seen as limited by the simulation environment, but as evidence that the underlying theoretical principles (randomization, adaptability and feedback) are sufficient to address real challenges. The simplicity of the test environment is a methodological advantage, as it allows isolating critical variables and validating their effectiveness before facing additional complexities.
5. Results
After multiple executions of our audit simulator using different parameters (number of nodes, tasks, etc.), we can evaluate the impact of the audit proposal on a decentralized P2P network.
Different executions with equal or similar parameters ended with similar results on catched nodes so the objective is to calculate the minimum number of auditors on the network for getting a successful malicious nodes detection. The network size has no impact on the results while maintaining the same auditees proportion.
Many simulations consider a 10% fail probability as this is the worst case studied by Estrada, Taufer and Anderson (5.3 in [
25]).
Each auditor, in each iteration, will select a random worker node and a random task from among those completed by the worker node.
If it detects that the result is incorrect, the worker node will be marked as “detected”.
5.1. Malicious Worker Detection
Simulating a network in which we are going to execute 100,000 tasks with a set of between 1 and 100 subtasks each, making use of 10,000 worker nodes.
Using 10,000 worker nodes with 10% of them will execute with a probability of 10% a subtask in a wrong way.
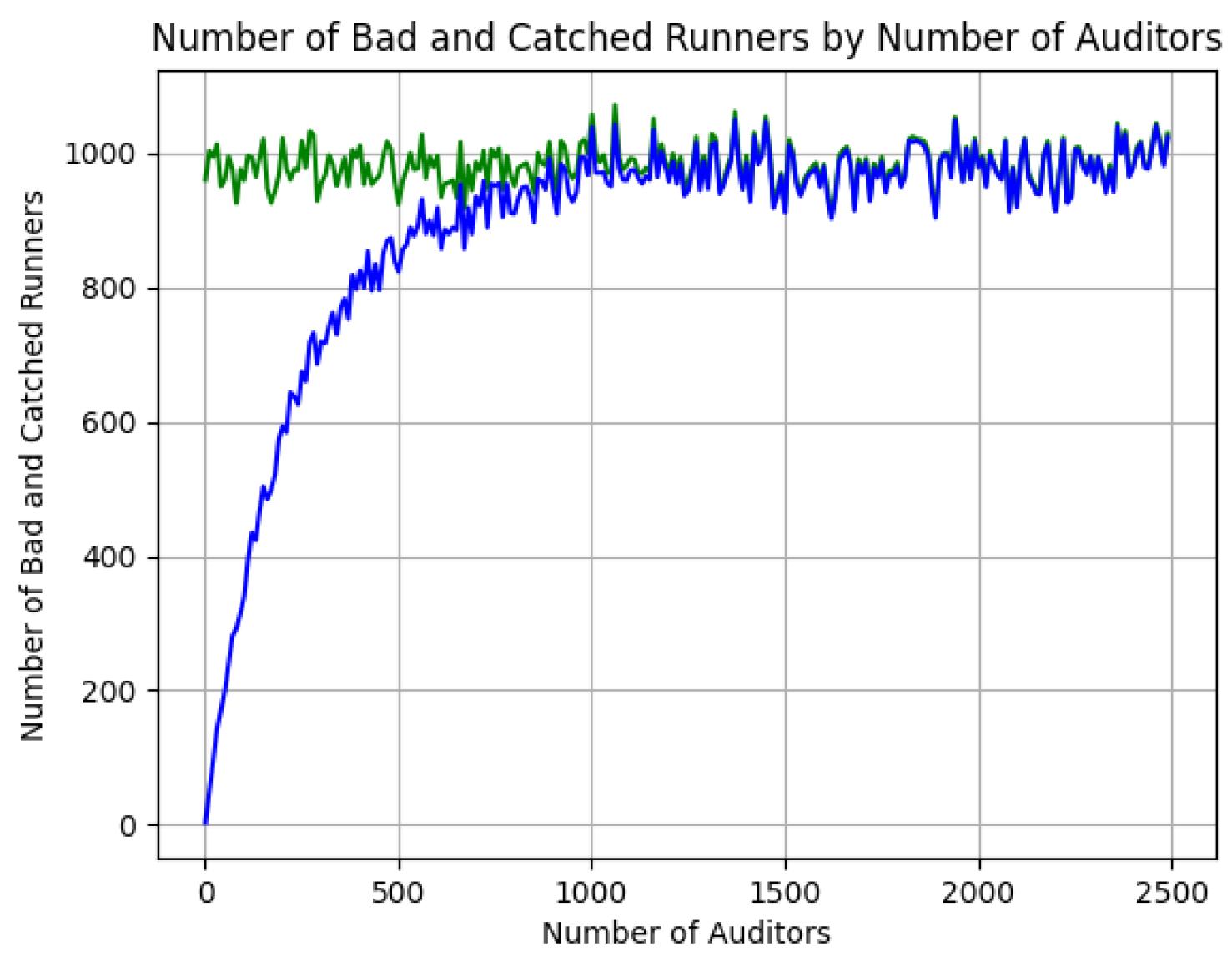
The
Figure 12 represents the number of malicious workers in each iteration (green line) and the number of detected ones in each iteration (blue line).
The x-axis represents the number of auditors running in each iteration. It can be observed that the number of malicious nodes is quickly reached by the auditor nodes.
With 50% of the number of auditor nodes compared to the number of malicious nodes, all malicious nodes in the network are detected.
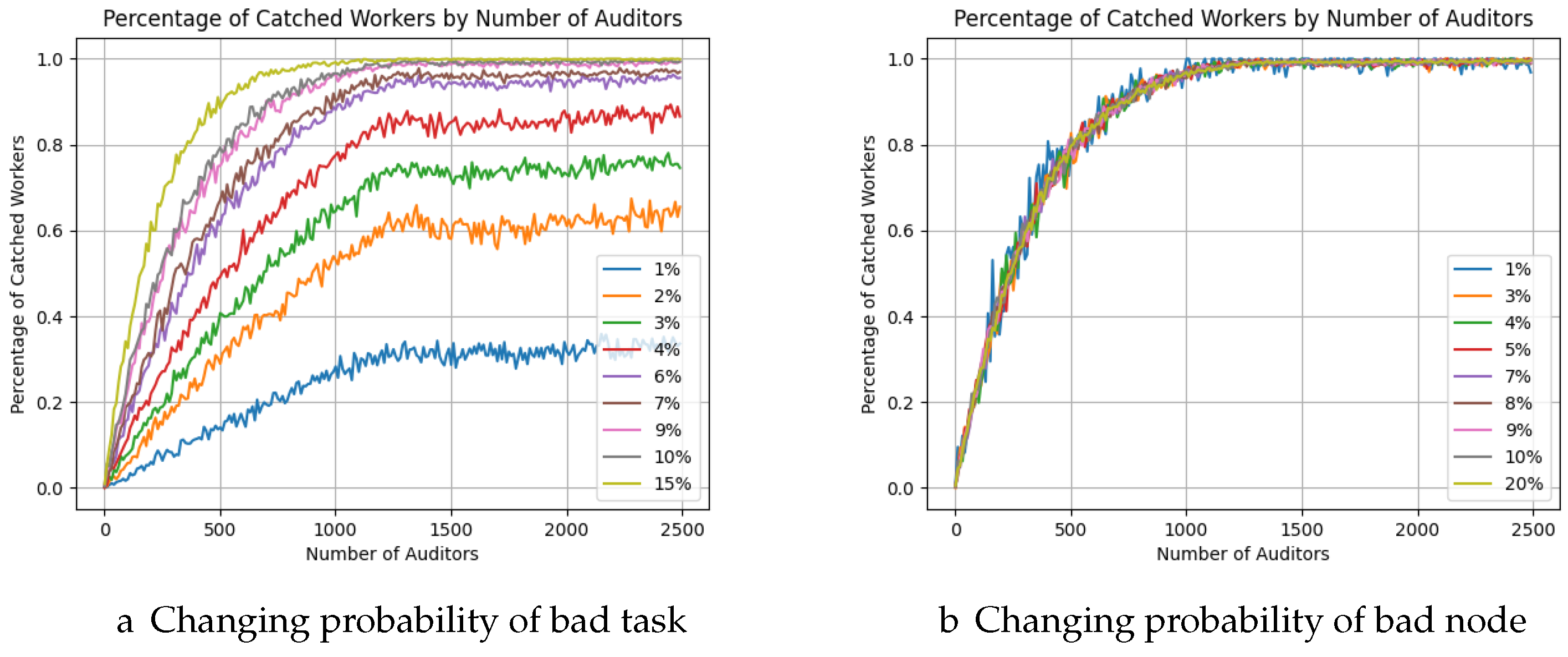
As can be observed in
Figure 13, which represents the percentage of detected malicious nodes with the increase of auditor nodes, we are approaching 90% of detected nodes. The variation in the number of bad workers does not significantly affect detection, as observed in simulation with 10,000 nodes network (
Figure 13b). In this case, the probability of bad task per bad node is always the same (10%) on all simulations while the number of malicious nodes varies. In contrast, simulation (
Figure 13a) presents a different scenario, where 10% of the nodes can execute bad tasks, but the probability of a bad task being executed varies from 1% to 20% on each simulation. In this situation, the low number of bad tasks in the network makes their detection more difficult.
Selecting appropriate values for simulations is challenging. If we aim to simulate sabotage intended to influence experimental results, unreliable workers will perform a moderate number of faulty tasks (10% or more), which, as previously noted, are more likely to be detected. However, in the case of hardware failures, determining an appropriate numerical threshold is more complex.
According to the experiments conducted by Nightingale et al. [
24], the probability of a hardware failure is very low (making it difficult for our system to capture). However, once a failure occurs, their findings suggest that affected devices are significantly more likely to experience subsequent crashes. This means that, eventually, a failing node should be detected. Considering an error rate of approximately 5%, our system is expected to detect failures with an accuracy ranging from 75% to 85%.
It must be considered that in this simulation the malicious nodes have a failure rate of 10% and that the auditing nodes randomly select a task from among those completed by the node.
The
Figure 14 illustrates the system’s behavior when both task error probability and node error probability are varied simultaneously. The asymptotic trend demonstrates that performance stabilizes as error rates increase, with optimal results achieved at lower thresholds. This supports the conclusion that scenarios with error rates exceeding 15% (not explicitly plotted) would follow the same trend, further validating the robustness of our proposal in adversarial environments.
5.2. Node Value
As discussed above in
Section 3.1, each node is also evaluated and scored at each run. The simulation also allows us to analyze the evolution of the node value if it is detected or not. On the following figures, red lines represent different worker nodes that executed some bad tasks, and blue lines represent a node who executed all tasks correctly. We can appreciate how the value of a good node differs from a bad node in the following figures (this simulation with 10% fail probability):
On
Figure 15, we can observe two common cases in which the malicious node is quickly detected, at first executions both nodes increase their values but as soon as an invalid job is detected, malicious node lost quickly his value, good ones also lost some value due to the node value characteristic in which each non audited iteration decreases its value.
If the malicious node is detected at first steps, as seen in
Figure 16, the node does not have a nice value along all the simulation.
In some situations, the bad node manages to escape the auditor, but over time it is detected, and its score is heavily penalized thanks to the exponential function used to penalize malicious nodes,
Figure 17.
These simulations demonstrate that without checking all outcomes and only a portion of them (
Figure 12), with consequent energy savings, we have a reliable P2P decentralized computing network and a tool to detect and ban problematic nodes in an effective way.
Finally, reputation scores should not grow unbounded thanks to logarithmic growth mechanisms. Also, scores would naturally decay over time if nodes cease active participation. Crucially, this decay is reinforced by the evaluation-dependent growth model: completing tasks alone does not guarantee score increases unless validated through auditees. This creates an implicit feedback loop where high-reputation nodes, having demonstrated consistent reliability, face reduced audit rates as trust in their outputs solidifies. Conversely, low-reputation nodes remain under stricter scrutiny, requiring frequent validation to prove their legitimacy. Over time, this dynamic self-regulates the system: highly trusted nodes accumulate less additional value due to minimal audits (and associated validation delays), while lower-tier nodes must continuously “earn” credibility.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}