
Detection of Fiber-Flaw on Pill Surface Based on Lightweight Network SA-MGhost-DVGG


Abstract
1. Introduction
2. Data Acquisition of Pill Image
2.1. Construction of the Experimental Device
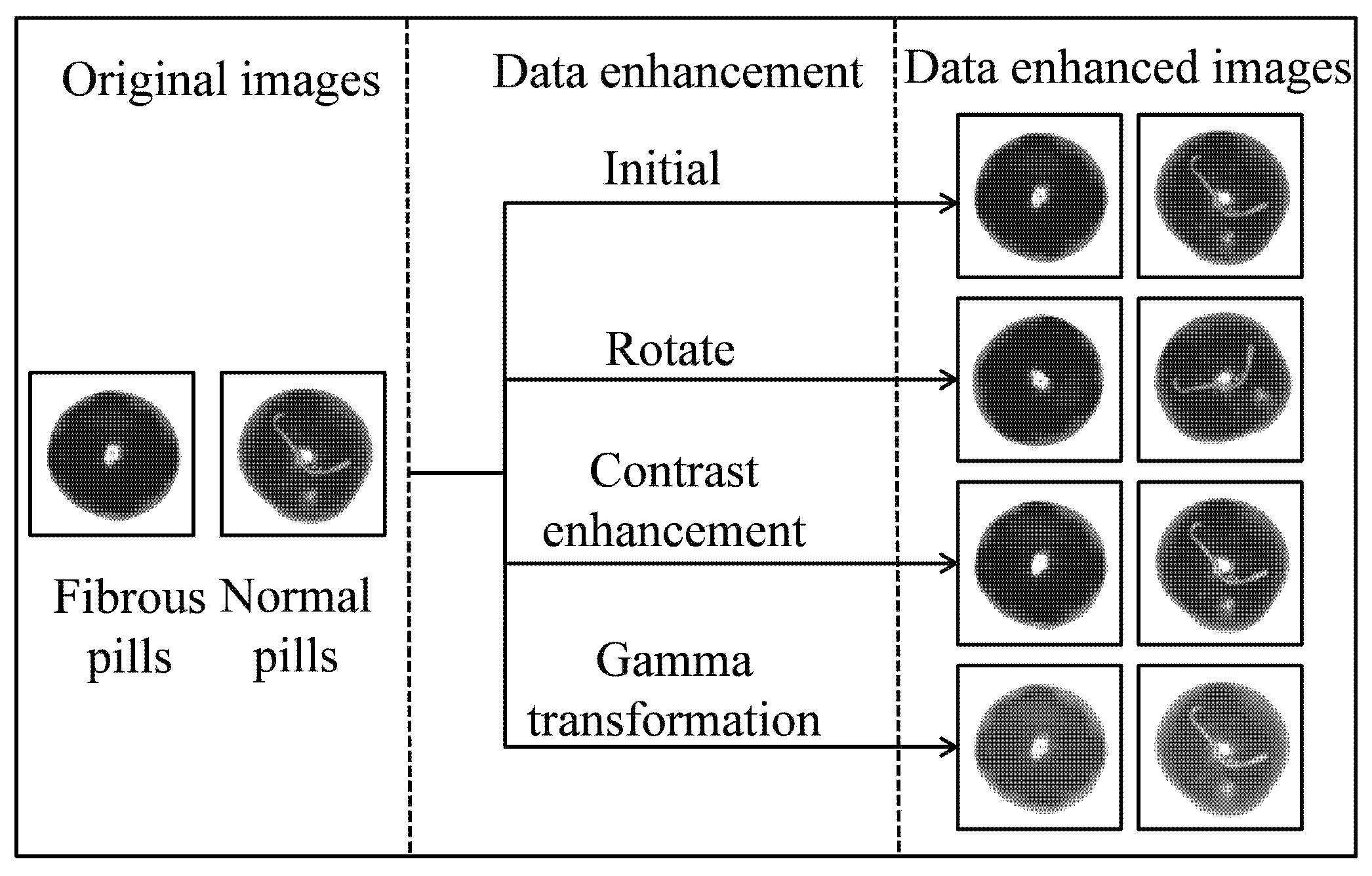
2.2. Acquisition of Pill Image Dataset
3. Classification Model of Fiber-Flaw Pills Based on SA-MGhost-DVGG
3.1. General Framework of SA-MGhost-DVGG
3.2. Lightweight Improvement
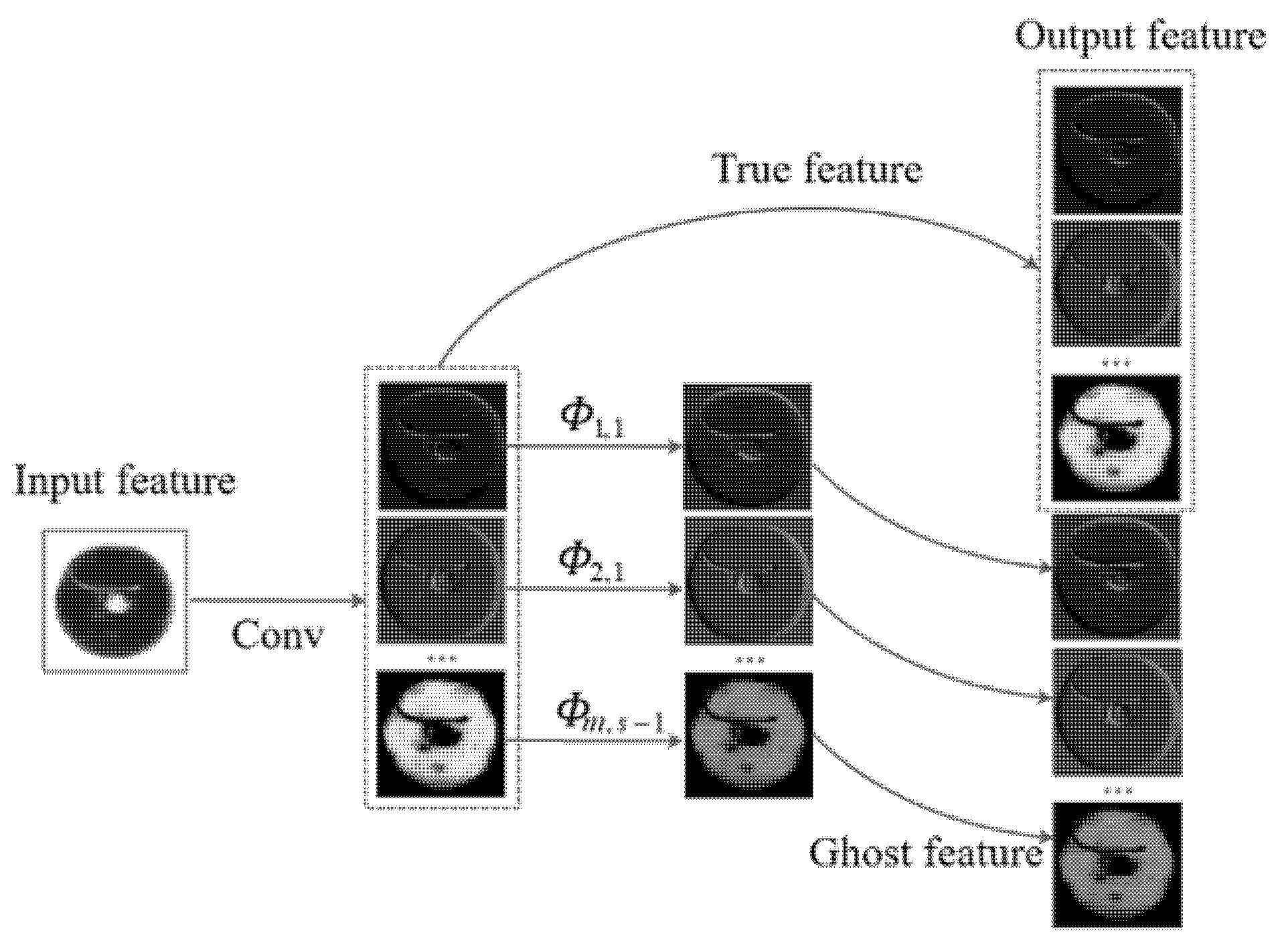
3.2.1. Ghost Module
3.2.2. MGhost Module Design
3.2.3. FLOPs Comparison of MGhost Module and Ordinary Convolution
3.2.4. Feature Visualization and Comparison
3.3. High Performance Improvement
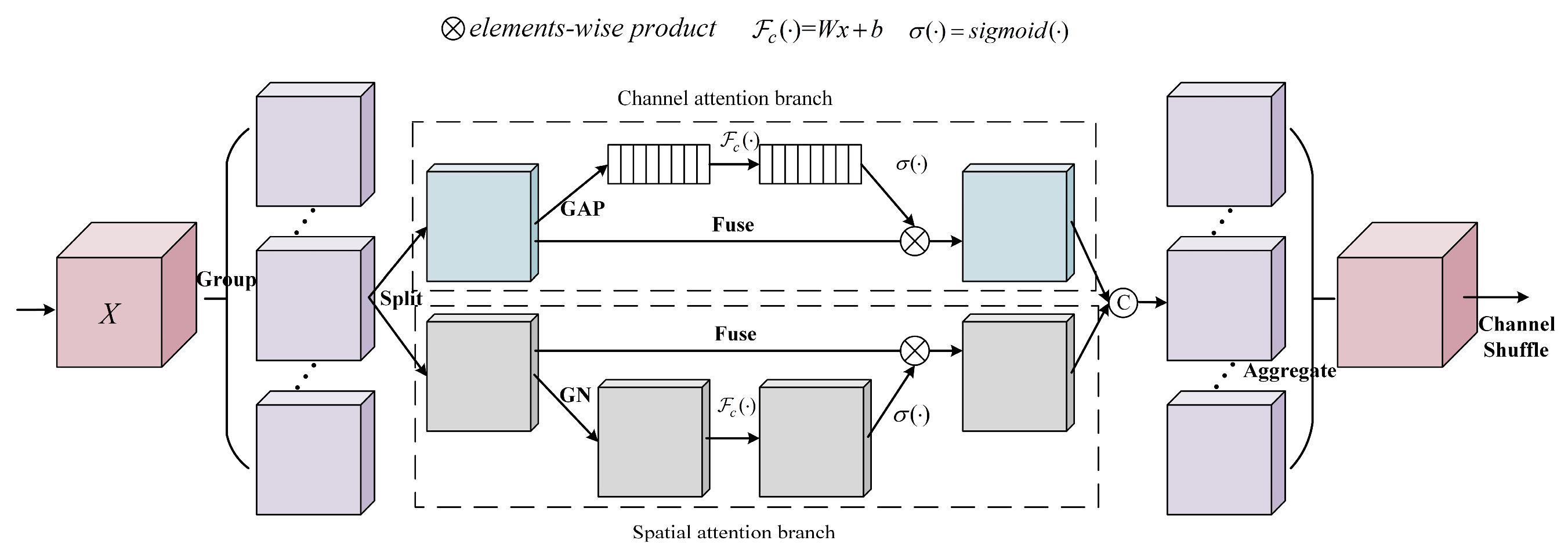
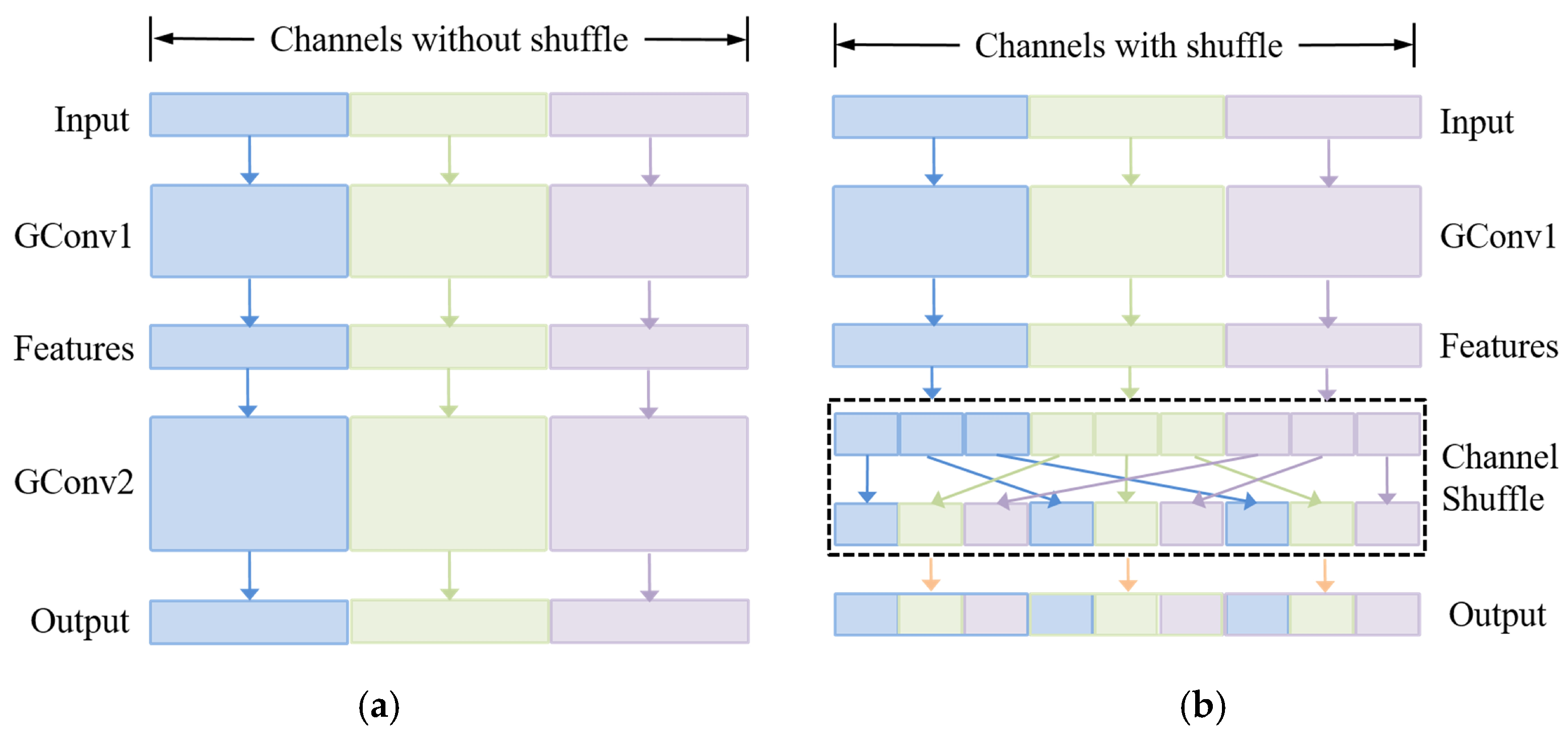
3.3.1. Spatial Attention
3.3.2. DepSepConv
4. Verification
4.1. Experimental Details and Evaluation Indicators
4.1.1. Experimental Details
4.1.2. Evaluation Indicators
4.2. Experimental Results and Analysis
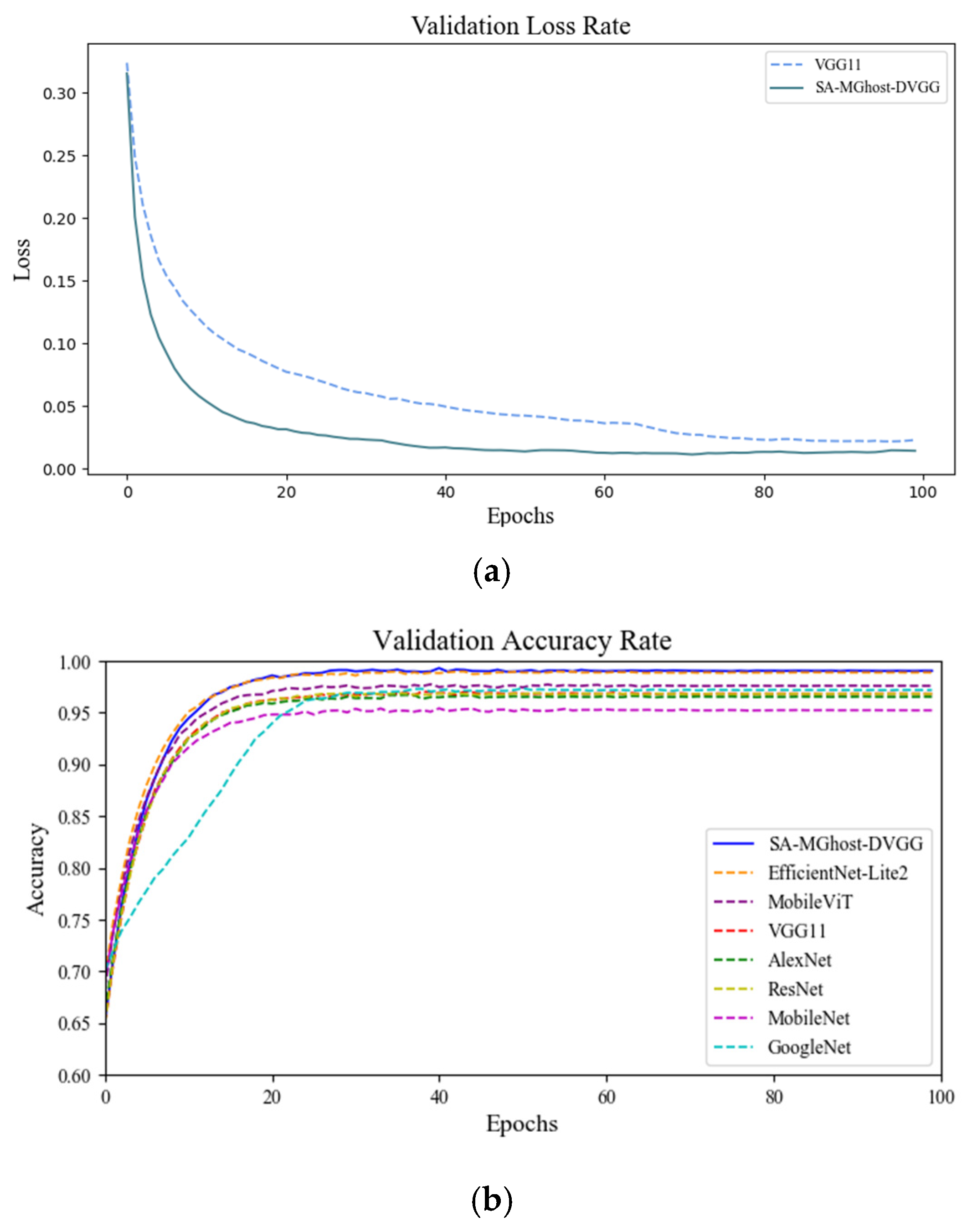
4.2.1. Comparison of Identification Results of Different Networks
4.2.2. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, Y.; Kuo, P.; Guo, J. Automatic industry PCB board DIP process defect detection system based on deep ensemble self-adaption method. IEEE Trans. Compon. Packag. Manuf. Technol. 2020, 11, 312–323. [Google Scholar] [CrossRef]
- Mittal, S.; Dutta, M.K.; Issac, A. Non-destructive image processing based system for assessment of rice quality and defects for classification according to inferred commercial value. Measurement 2019, 148, 106969. [Google Scholar] [CrossRef]
- Fan, S.; Li, J.; Zhang, Y.; Tian, X.; Wang, Q.; He, X.; Zhang, C.; Huang, W. On line detection of defective apples using computer vision system combined with deep learning methods. J. Food Eng. 2020, 286, 110102. [Google Scholar] [CrossRef]
- Wu, H.; Lei, R.; Peng, Y. Pcbnet: A lightweight convolutional neural network for defect inspection in surface mount technology. IEEE Trans. Instrum. Meas. 2022, 71, 3518314. [Google Scholar] [CrossRef]
- Wang, C.; Shu, Q.; Wang, X.; Guo, B.; Liu, P.; Li, Q. A random forest classifier based on pixel comparison features for urban LiDAR data. ISPRS J. Photogramm. Remote. Sens. 2019, 148, 75–86. [Google Scholar] [CrossRef]
- Pan, Z.; Yang, J.; Wang, X.-E.; Wang, F.; Azim, I.; Wang, C. Image-based surface scratch detection on architectural glass panels using deep learning approach. Constr. Build. Mater. 2021, 282, 122717. [Google Scholar] [CrossRef]
- Shojaeinasab, A.; Charter, T.; Jalayer, M.; Khadivi, M.; Ogunfowora, O.; Raiyani, N.; Yaghoubi, M.; Najjaran, H. Intelligent manufacturing execution systems: A systematic review. J. Manuf. Syst. 2022, 62, 503–522. [Google Scholar] [CrossRef]
- Dai, W.; Mujeeb, A.; Erdt, M.; Sourin, A. Soldering defect detection in automatic optical inspection. Adv. Eng. Inform. 2020, 43, 101004. [Google Scholar] [CrossRef]
- Cao, W.; Liu, Q.; He, Z. Review of pavement defect detection methods. IEEE Access 2020, 8, 14531–14544. [Google Scholar] [CrossRef]
- Rajesh, A.; Jiji, G.W. Printed circuit board inspection using computer vision. Multimed. Tools Appl. 2023, 83, 16363–16375. [Google Scholar] [CrossRef]
- Yu, J.; Yang, Y.; Zhang, H.; Sun, H.; Zhang, Z.; Xia, Z.; Zhu, J.; Dai, M.; Wen, H. Spectrum analysis enabled periodic feature reconstruction based automatic defect detection system for electroluminescence images of photovoltaic modules. Micromachines 2022, 13, 332. [Google Scholar] [CrossRef]
- Perez, H.; Tah JH, M.; Mosavi, A. Deep learning for detecting building defects using convolutional neural networks. Sensors 2019, 19, 3556. [Google Scholar] [CrossRef]
- Kahraman, Y.; Durmuşoglu, A. Classification of defective fabrics using capsule networks. Appl. Sci. 2022, 12, 5285. [Google Scholar] [CrossRef]
- Ho, C.-C.; Hernandez, M.A.B.; Chen, Y.-F.; Lin, C.-J.; Chen, C.-S. Deep Residual Neural Network-Based Defect Detection on Complex Backgrounds. IEEE Trans. Instrum. Meas. 2022, 71, 5005210. [Google Scholar] [CrossRef]
- Zheng, S.; Zhang, W.; Wang, L.; He, S. Special Shaped Softgel Inspection System Based on Machine Vision. In Proceedings of the 2015 IEEE 9th International Conference on Anti-Counterfeiting, Security, and Identification (ASID), Xiamen, China, 25–27 September 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 124–127. [Google Scholar] [CrossRef]
- Mac, T.T.; Hung, N.T. Automated Pill Quality Inspection Using Deep Learning. Int. J. Mod. Phys. B 2021, 35, 2140050. [Google Scholar] [CrossRef]
- Swastika, W.; Prilianti, K.; Stefanus, A.; Setiawan, H.; Arfianto, A.Z.; Santosa, A.W.B.; Rahmat, M.B.; Setiawan, E. Preliminary Study of Multi Convolution Neural Network-Based Model to Identify Pills Image Using Classification Rules. In Proceedings of the 2019 International Seminar on Intelligent Technology and Its Applications (ISITIA), Surabaya, Indonesia, 28–29 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 376–380. [Google Scholar] [CrossRef]
- Ou, Y.-Y.; Tsai, A.-C.; Wang, J.-F.; Lin, J. Automatic Drug Pills Detection Based on Convolution Neural Network. In Proceedings of the 2018 International Conference on Orange Technologies (ICOT), Nusa Dua, Bali, Indonesia, 23–26 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Yeung, C.C.; Lam, K.M. Efficient Fused-Attention Model for Steel Surface Defect Detection. IEEE Trans. Instrum. Meas. 2022, 71, 2510011. [Google Scholar] [CrossRef]
- Zhang, J.; Xu, J.; Zhu, L.; Zhang, K.; Liu, T.; Wang, D.; Wang, X. An improved MobileNet-SSD algorithm for automatic defect detection on vehicle body paint. Multimed. Tools Appl. 2020, 79, 23367–23385. [Google Scholar] [CrossRef]
- Zhang, X.; Yang, K. Transformer Fault Diagnosis Method Based on MTF and GhostNet. Measurement 2025, 249, 117056. [Google Scholar] [CrossRef]
- Long, Z.; Suyuan, W.; Zhongma, C.; Jiaqi, F.; Xiaoting, Y.; Wei, D. Lira-YOLO: A lightweight model for ship detection in radar images. J. Syst. Eng. Electron. 2020, 31, 950–956. [Google Scholar] [CrossRef]
- Zhao, B.; Dai, M.; Li, P.; Xue, R.; Ma, X. Defect detection method for electric multiple units key components based on deep learning. IEEE Access 2022, 8, 136808–136818. [Google Scholar] [CrossRef]
- Xiao, D.; Kang, Z.; Yu, H.; Wan, L. Research on belt foreign body detection method based on deep learning. Trans. Inst. Meas. Control. 2022, 44, 2919–2927. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1577–1586. [Google Scholar] [CrossRef]
- Zhang, Q.L.; Yang, Y.B. Sa-net: Shuffle attention for deep convolutional neural networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2235–2239. [Google Scholar] [CrossRef]
- Mehrish, A.; Majumder, N.; Bharadwaj, R.; Mihalcea, R.; Poria, S. A review of deep learning techniques for speech processing. Inf. Fusion 2023, 99, 101869. [Google Scholar] [CrossRef]
- Yaseen, M.U.; Nasralla, M.M.; Aslam, F.; Ali, S.S.; Khattak, S.B.A. A novel approach based on multi-level bottleneck attention modules using self-guided dropblock for person re-identification. IEEE Access 2022, 10, 123160–123176. [Google Scholar] [CrossRef]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Name | Valacc (%) | Testacc (%) | TTime (s/Epoch) | RTime (ms/pill) |
|---|---|---|---|---|
| Statistical image processing | / | 93.00 ± 0.32 | / | 2.06 ± 0.66 |
| VGG11 | 97.79 ± 0.17 | 96.85 ± 0.10 | 322 ± 22 | 5.14 ± 1.10 |
| AlexNet | 96.95 ± 0.06 | 96.54 ± 0.02 | 55 ± 6 | 2.55 ± 0.62 |
| ResNet | 95.94 ± 0.07 | 96.82 ± 0.05 | 134 ± 14 | 9.75 ± 0.72 |
| MobileNet | 94.81 ± 0.06 | 95.24 ± 0.05 | 55 ± 7 | 3.31 ± 0.71 |
| GoogleNet | 96.79 ± 0.08 | 97.19 ± 0.06 | 130 ± 14 | 15.8 ± 0.94 |
| MobileViT | 97.85 ± 0.02 | 97.60 ± 0.01 | 62 ± 5 | 4.38 ± 0.89 |
| EfficientNet-Lite2 | 98.08 ± 0.04 | 98.88 ± 0.02 | 42 ± 3 | 3.08 ± 0.23 |
| SA-MGhost-DVGG | 98.95 ± 0.03 * | 99.01 ± 0.01 * | 35 ± 4 | 2.23 ± 0.46 |
| Network Name | DSMethod | Params (M) | FLOPs (M) | TN (%) | TP (%) | Testacc (%) | RTime (ms/pill) |
|---|---|---|---|---|---|---|---|
| VGG11 | MaxPool | 15.71 | 7491.94 | 96.92 ± 0.16 | 96.78 ± 0.06 | 96.85 ± 0.10 | 5.14 ± 1.10 |
| Ghost-VGG | MaxPool | 7.02 | 485.47 | 97.04 ± 0.18 | 96.88 ± 0.12 | 96.96 ± 0.14 | 2.08 ± 0.52 |
| MGhost-VGG | MaxPool | 7.02 | 485.47 | 97.22 ± 0.12 | 96.92 ± 0.10 | 97.07 ± 0.10 | 2.07 ± 0.46 |
| SE-MGhost-VGG | MaxPool | 7.10 | 491.67 | 97.95 ± 0.15 | 98.25 ± 0.08 | 98.10 ± 0.11 | 2.16 ± 0.58 |
| BAM-MGhost-VGG | MaxPool | 7.22 | 666.86 | 98.39 ± 0.19 | 98.05 ± 0.11 | 98.22 ± 0.13 | 2.22 ± 0.63 |
| CBAM-MGhost-VGG | MaxPool | 7.10 | 498.29 | 98.48 ± 0.18 | 98.10 ± 0.15 | 98.29 ± 0.16 | 2.18 ± 0.45 |
| SA-MGhost-VGG | MaxPool | 7.02 | 488.53 | 98.92 ± 0.09 | 98.26 ± 0.05 | 98.59 ± 0.05 | 2.12 ± 0.42 |
| SA-MGhost-DVGG | DepSepConv | 7.64 | 713.02 | 99.08 ± 0.03 | 98.94 ± 0.01 | 99.01 ± 0.01 | 2.23 ± 0.46 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lou, J.; Wang, H.; Liang, H.; Wu, Z. Detection of Fiber-Flaw on Pill Surface Based on Lightweight Network SA-MGhost-DVGG. Computers 2025, 14, 200. https://doi.org/10.3390/computers14050200
Lou J, Wang H, Liang H, Wu Z. Detection of Fiber-Flaw on Pill Surface Based on Lightweight Network SA-MGhost-DVGG. Computers. 2025; 14(5):200. https://doi.org/10.3390/computers14050200
Chicago/Turabian StyleLou, Jipei, Hongyi Wang, Haodong Liang, and Ziwei Wu. 2025. "Detection of Fiber-Flaw on Pill Surface Based on Lightweight Network SA-MGhost-DVGG" Computers 14, no. 5: 200. https://doi.org/10.3390/computers14050200
APA StyleLou, J., Wang, H., Liang, H., & Wu, Z. (2025). Detection of Fiber-Flaw on Pill Surface Based on Lightweight Network SA-MGhost-DVGG. Computers, 14(5), 200. https://doi.org/10.3390/computers14050200