1. Introduction
Large language models (LLMs) [
1] are a category of deep learning models that have transformed the landscape of natural language processing (NLP), Computer Vision, and more [
1]. These models can process, generate, and understand human language at an unprecedented scale. By being pre-trained on vast amounts of text data and then fine-tuned for specific use-cases, LLMs can achieve state-of-the-art results in a variety of language-based tasks such as translation [
2,
3], summarization [
3,
4], question answering [
3,
5], and more.
The effectiveness of LLMs on downwards tasks is dependent on the quality and quantity of the training data used during training [
6,
7,
8]. Depending on their training data, these models display different levels of competence in language understanding and generation. Training on domain-specific knowledge enables improved capabilities in nuanced aspects, such as cultural references or domain-specific jargon [
9,
10,
11]. The robustness of an LLM is directly correlated to the quality, diversity, and representativeness of its training dataset [
7,
8]. The more comprehensive the data, covering a broader spectrum of topics, styles, and formats, the more capable the model is in generalising its learning to new, unseen texts or tasks. It is, therefore, important to ensure the incorporation of these models into different domains and enable professionals in various domains to incorporate their domain-specific knowledge into these models.
Despite their impressive capabilities, LLMs face significant challenges when applied to tasks that require domain-specific knowledge. One primary issue is their reliance on generalised training datasets. General datasets used in the training and fine-tuning of LLMs typically encompass a wide array of topics with the aim of providing a broad understanding of natural language and a strong capability of instruction-following [
12]. However, they often lack the depth of domain-specific knowledge necessary for tasks in specialised fields such as law, medicine, or scientific research. While an LLM trained on general information sourced from the internet might excel at everyday language tasks, it might struggle with legal document review [
11] or medical diagnostics [
9], where specialised terminology and structured reasoning are required.
This lack of understanding becomes apparent when these models are deployed in environments that require specific and specialised knowledge. Instead of providing answers with substance, LLMs trained only on general datasets generate broad answers and guesses relative to the topic of discussion [
9,
11], increasing the possibility of errors or misunderstandings by the users. This behaviour can deter professionals from using LLMs [
13]. Mistakes or misunderstandings in fields like medicine, law, or public health can have significant consequences, underscoring the inadequacy of general datasets in providing the necessary training foundation.
Moreover, attempting to bridge the lack of specialisation in LLMs through increased parameter size can lead to inefficiencies; due to the significant computational needs of such models, a domain-specific fine-tuned LLM of a smaller size can outperform a general-knowledge LLM of a larger size [
9,
11] inside its domain. These challenges underscore the need for domain-adapted models that incorporate specialised training datasets to enhance performance and reliability in targeted domains. This necessity drives the development of methodologies capable of creating, curating, and employing domain-specific datasets to fine-tune and adapt LLMs.
Curated domain-specific datasets are needed to improve the performance of LLMs in specialised fields [
9,
11]. By integrating datasets tailored to specific domains with instruction-following and general knowledge datasets, the models can learn the unique patterns, language, and knowledge used in those fields while maintaining their general capabilities, thus becoming more effective and reliable. Fine-tuning and adapting LLMs to specific domains can improve their effectiveness in answering questions inside their domain and enhance their understanding when ingesting retrieved documents [
10,
14]. Retrieval-Augmented Generation (RAG) [
15] improves a model’s accuracy on specific queries by providing a grounded context, in the form of relevant retrieved text, for the LLM to use as the base of its answer. However, it is important to ensure that the model is knowledgeable in the specific domain and can successfully utilise this supplementary information [
14]. In this respect, a model trained on domain-specific knowledge can further empower an RAG system.
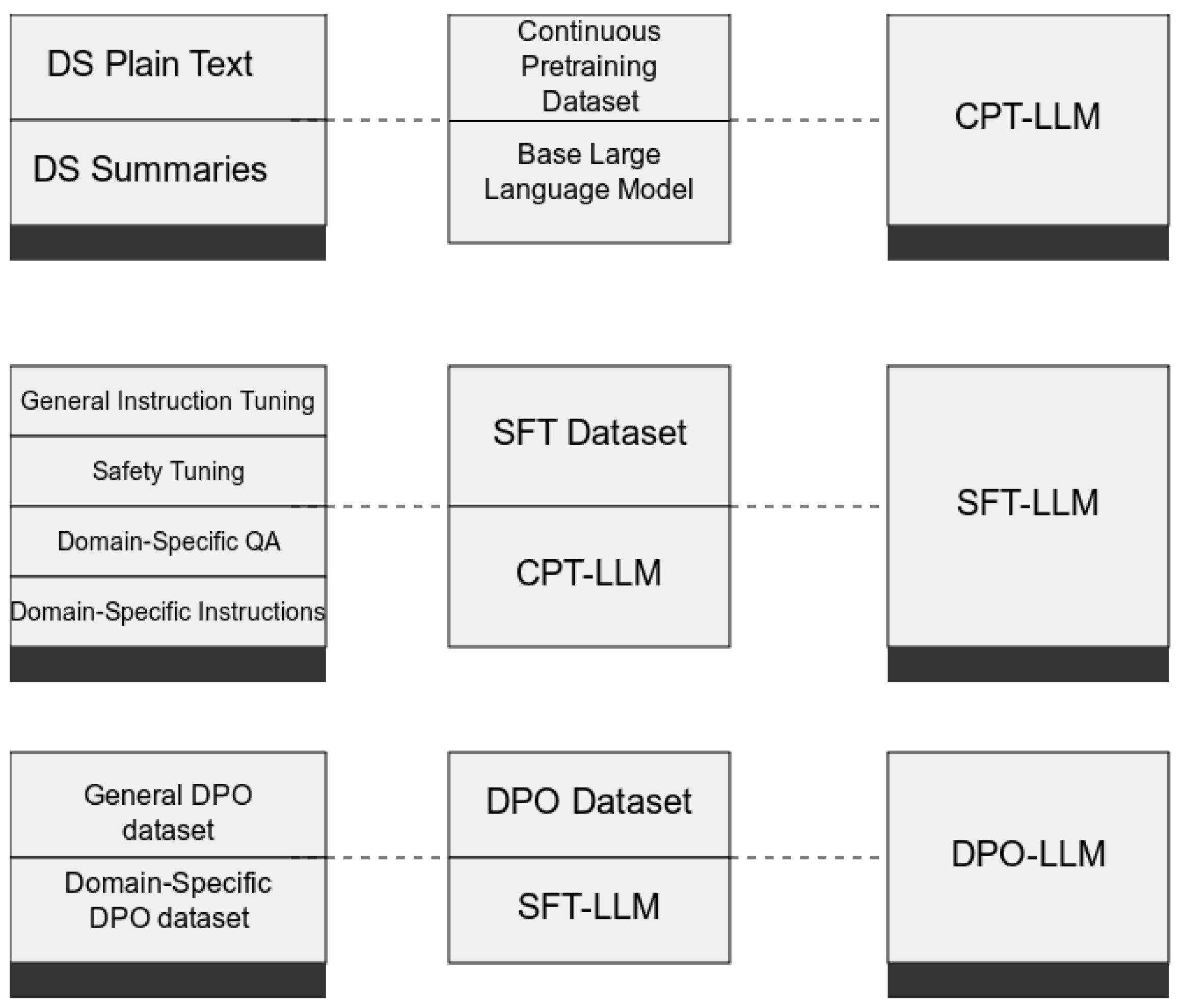
This paper presents an efficient framework for creating domain-specific datasets and fine-tuning LLMs on a configuration of open-source and private datasets based on the end-user’s discretion. The framework enables the fine-tuning and adaption of LLMs on specific domains by researchers with limited coding experience. The framework follows a three step process:
A domain dataset is created by the user based on their documents.
A multi-phase training starts where the model is fine-tuned and adapted in three stages.
An evaluation of the model occurs, where the user can utilise metrics or human annotations to evaluate the new model’s performance.
The training is conducted through a multi-phase approach: continuous pre-training for domain knowledge acquisition, supervised fine-tuning (SFT) for task-specific performance, and preference optimisation for response quality enhancement. Each phase addresses distinct aspects of model adaptation, ensuring comprehensive domain specialisation while maintaining general capabilities. To enable an easy interaction between the user and this multi-phase process, a User Interface (UI) is provided, thus enabling end-users to use, validate, and adopt the framework. The framework and its UI use a number of document formats, such as PDFs, HTML, Markdown, and LaTeX documents, as sources of knowledge to create domain-specific datasets. The framework offers integrations with Huggingface Transformers, vLLM, and other inference engines [
16,
17] to allow for text generation on local devices in tasks such as relevance evaluation, instruction, and answer generation while maintaining the privacy of the end-user’s documents. Additionally, the framework allows end-users to choose between local models or models hosted by third parties.
The framework enables integration with multiple external language model APIs, including OpenAI, Claude, Deepseek, and Groq API [
18,
19,
20,
21], allowing end-users to customize both the text generation workflow and model parameters across different stages of dataset creation according to their specific requirements. The end-users can take advantage of these integrations through the UI or through code, reducing barriers and challenges one can expect when attempting to further pre-train, fine-tune, and preference train a model. To showcase our framework and illustrate the process and benefits of customizing LLMs to meet specific domain needs, we focus on two domains: biobanking and public health co-creation.
Public health co-creation aims to address complex problems by bringing together multiple stakeholders with different and often conflicting perspectives to collaborate and design more robust solutions. By employing co-creation to bridge the gap between different stakeholders, the proposed solutions can be more effective, widely accepted by the communities and more sustainable in the long run. Additionally, the proposed solutions may face less opposition due to the high level of inclusion of relevant stakeholders. For co-creation to be successful, the various stakeholders must have an increased understanding of the co-creation process and the perspective and knowledge of the other stakeholders. LLMs can help bridge the different kinds of domain knowledge each stakeholder group possesses by facilitating more effective communication, knowledge transfer, and idea generation among diverse groups of stakeholders. Co-creation in public health is hindered by the limited availability of easily accessible and integrated literature [
22]. We can mitigate these barriers by training a domain-specific LLM, Co-creationLLM, thereby increasing the chances of a successful co-creation process. Furthermore, by training models on datasets comprising domain-specific case studies, academic papers relevant to public health co-creation, and collaborative protocols, the trained LLM is better equipped to understand and predict different stakeholders’ needs and communication styles, thereby enhancing the co-creation process. The models trained during the testing of our framework will be deployed on a web-based service to be used by co-creation facilitators and participants. Furthermore, they will also be made available online for use on edge devices during real-time co-creation sessions.
In biobanking, effective management and analysis of biological samples is critical. Biobanking research depends on public trust and solidarity, as it involves donating tissue samples and personal data. Transparent communication is essential to engage the public. An ongoing use-case aiming to improve communication between the public and biobank education through tailored training materials, developing an interactive course for students and scientists adaptable across scientific fields, has been identified, where BiobankLLM, one of the LLMs developed with the framework, is deployed and evaluated.
Furthermore, a serious game and a digital guide are being created through the identified use-case to raise public awareness and offer best practices for science outreach. BiobankLLM is used in the serious game and the digital guide to answer user queries. Large language models trained on domain-specific datasets can enhance metadata annotation, searchability, and regulatory knowledge, aiding researchers in maintaining data integrity and privacy.
This paper presents a low-to-no-cost and easy-to-use framework for creating domain-specific datasets and the continuous pre-training, supervised fine-tuning, and preference optimisation of LLMs on these datasets. Additionally, we provide an intuitive UI to help lower the barrier to using the framework, and we publish both the models and datasets we created while testing the framework. The use-cases mentioned above illustrate the framework’s capabilities in constructing and employing domain-specific datasets to train LLMs that perform generic language tasks and excel in specialised, domain-specific contexts. Given the challenges in domain-specific LLM adaptation and the need for accessible frameworks, particularly for users with limited technical expertise, this study is guided by the following research questions:
RQ1: How effective were the trained models when evaluated on domain-specific datasets created through the direct preference optimisation methodology?
RQ2: How did these models perform on general-purpose datasets compared to their performance on domain-specific tasks?
RQ3: Did training with the direct preference optimisation methodology lead to any decrease in model performance when transferring knowledge from one task to another?
2. Methods
This section presents the methods to used to address the research questions outlined in
Section 1 and how the framework is used for adapting domain-specific large language models through three main components.
It covers the processes for (1) automated dataset curation, including relevance assessment, (2) the multi-stage model adaptation framework designed to enhance domain-specific performance (RQ2), and (3) the evaluation protocols used to assess both domain-specific capabilities (RQ1) and general performance characteristics, including potential catastrophic forgetting [
23] (RQ2, RQ3).
The framework enables systematic adaptation while maintaining evaluation standards throughout development. This process incorporates components from previously well-tested dataset creation processes [
24] and document preprocessing methods, involving the design and execution of two pipelines to enhance LLMs’ comprehension and task performance within specific domains. The pipelines process documents such as PDFs using natural language processing techniques to construct structured datasets for model training, as illustrated in
Figure 1. The created datasets are then used for continuous pre-training, supervised fine-tuning, and direct preference optimisation (DPO).
Figure 2 [
25].
2.1. Dataset Preprocessing
2.1.1. Document Conversion and Segmentation
The first step in the dataset generation pipeline, DGP, is to preprocess the provided documents. In most cases, end-users cannot access domain-specific knowledge in forms that are easy for LLMs to use [
26]. To address this issue, we have incorporated several document parsers, each providing a trade-off between accuracy, respecting the document format and speed, and allowing the end-user to decide on the best configuration for their needs. We have incorporated parsers for PDFs, Markdown, LaTeX, and HTML. Our focus is on PDFs due to the prevalence of the format in professional settings and the density of information within PDF documents. The user can choose between speed with PyMuPDF, hybrid performance with Unstructured, and accuracy with Nougat [
26]. For our testing use-cases, we focus on Nougat. Nougat is a state-of-the-art Visual Transformer model [
26], that performs Optical Character Recognition (OCR) and transforms documents from incompatible formats, such as PDF to Multi-Markdown [
26]. This system provides a more accurate conversion of documents while maintaining the information’s accuracy, respecting the documents’ structures, and allowing us to extract equations and tables and convert them into Markdown or LaTeX format, thus enabling us to respect and maintain this information that would otherwise be lost.
The documents are converted into Markdown, and the converted documents are then preprocessed. The documents are split into chunks of 512 tokens (<512 tokens) while respecting paragraph and sentence boundaries. The 512-token chunk size was selected as a balance between context preservation and computational efficiency, while maintaining coherent semantic units. This segmentation strategy ensures textual coherence and maintains the integrity of sentence boundaries. Additionally, we extract metadata information, such as document titles, headers, sections of documents, paragraph numbers in the document, and more. At the end of the document conversation, we have generated the basis for our future datasets by obtaining the content around which our instructions, questions, and answers are created.
2.1.2. Relevance Assessment and Document Filtering
The next step in the dataset generation pipeline ensures that the provided documents are correctly identified as relevant. In large sets of documents, there will always be documents that are misidentified and incorrectly included. To minimise this risk and ensure the relevance of documents to the target domain, the user can choose the LLM they prefer, depending on the document’s complexity, privacy needs, and budget. The user can employ local models such as Mixtral, Mistral, phi, Zephyr, or Llama 3 [
3,
7,
24,
27,
28], through a number of inference engines, such as vLLM [
17], depending on their setup and needs. Additionally, they can use the OpenAI, Claude, Deepseek, or Groq API.
To systematically evaluate document relevance, we implemented a ranking methodology and used vLLM [
17], an efficient inference engine for LLMs that optimises memory usage through paged attention mechanisms [
17]. vLLM was selected because it enables faster inference while maintaining model accuracy, making it suitable for processing large document collections on consumer hardware. The page-based attention mechanism allows for more efficient memory usage by loading only the necessary parts of the attention matrix into GPU memory, resulting in an approximately 2–4× throughput increase while maintaining comparable latency levels over standard inference. The user can decide which local model they employ based on their preferences [
17].
For our ranking process, we employed instruction-tuned Mixtral [
27] and Llama 3 models [
3] to evaluate each paragraph on a 1-10 scale and provide a rationale for this ranking [
29]. Each paragraph that is highly rated is relevant to our domain and can serve as the “grounded context” that is then used as the basis around which the datasets are built. Therefore, the context in our approach refers to the extracted document content that provides domain-specific information against which relevance is assessed. Specifically, each paragraph is evaluated based on its semantic relevance to predefined domain criteria.
Subsequently, documents are systematically evaluated based on the aggregated scores of their constituent paragraphs. Documents and paragraphs failing to meet the predefined relevance threshold, with scores falling below 8.16 and 8, respectively, are discarded, ensuring dataset integrity and focus on domain-specific content. This process ensures the following: (a) Each paragraph receives a relevance score based on explicit domain criteria. (b) The rationale for ranking is documented, enabling transparency in dataset construction. (c) Documents failing to meet the predefined threshold (8.16 for documents, 8 for paragraphs) are excluded.
2.1.3. Summarization of Non-Textual Elements
Recognising the presence of non-textual components, such as tables, within documents, a summarisation process is initiated utilizing an instruction-tuned model. The user can choose which model they prefer, as above. In our use-cases we used a Mixtral-Instruct and a Llama 3 8B-Instruct model [
3,
27]. This process transforms non-textual elements, such as tables, into textual summaries, thus extending the constructed dataset to include previously lost information while preserving the original content for reference purposes, saved as metadata. The dataset remains comprehensive and conducive to subsequent processing stages by transforming the non-textual elements into summaries. Additionally, summarising the non-textual components of the documents addresses context problems that might arise from the large number of tokens often required to handle LaTeX components. While this might not be a critical issue during inference, it can be detrimental during the fine-tuning process of the models.
2.2. Dataset Creation
To enhance the performance of the base LLM through supervised fine-tuning on specific domains and the alignment of the SFT-LLM’s responses through DPO [
25], it is necessary to augment our base dataset with additional content. This dataset creation process directly addresses RQ1 by establishing the foundation for evaluating model effectiveness on domain-specific tasks. In the dataset creation step, the end-user can we utilise both open-source models like Mixtral, Mistral, and Llama 3 [
3,
27,
28] through vLLM or the Huggingface Transformers [
16,
17], as well as proprietary models accessed through APIs, such as GPT-4 [
12,
18]. Furthermore, reasoning models can be used, such as Deepseek R1 [
20], to generate reasoning datasets if that is better for the needs of the user. The framework offers flexibility, allowing users to select their preferred model configurations for dataset generation. It integrates various APIs, such as OpenAI, Deepseek, Claude, and local inference engines, such as HuggingFace and the vLLM inference engine [
17], enabling user freedom between a default or customizable setup. In our experiments, we have chosen smaller local models for the majority of the dataset generations to mirror the expected usage of the framework. The end-users are more likely to offload easier tasks to smaller models that can be hosted locally.
2.2.1. Instruction Generation
To construct the datasets necessary for SFT and DPO [
25], the generation of a set of instructions and questions is required. This can be carried out by humans at great expense, or it can be outsourced to LLMs. Specifically, LLMs fine-tuned for instruction-based tasks, such as the Mixtral 8x7B-Instruct model, Llama 3 8B-Instruct, phi 3 [
3,
7,
27], and more based on the preference of the user, are used to produce relevant and coherent language prompts. The paragraphs selected during the initial creation of the base dataset provide the context around which these questions and instructions are generated, thus ensuring that the content generated is relevant to the domain-specific knowledge contained within the user’s dataset.
The generation of the instructions and questions follows predefined criteria. These criteria include ensuring the answerability of questions, which involves formulating queries or instructions that the models can respond to accurately based on the text data. Additionally, there is a strong emphasis on leveraging text-based knowledge, ensuring that the questions and instructions are relevant to the domain and based on the specific content provided. The generated questions and instructions must align closely with the domain, ensuring that the models trained on these datasets can be effectively used in training models for the specific field. Furthermore, the specificity of the content in the paragraph ensures that each question or instruction directly applies to the information presented in a particular paragraph, indirectly improving the relevance of the model’s responses. These generated instructions, questions, and the context previously extracted from the base dataset form the foundation of the SFT and DPO datasets.
2.2.2. Answer Generation
Leveraging an LLM of the user’s specification, such as Mistral, Mixtral, Llama 3, or models through third-party APIs, answers are systematically generated based on the context provided by paragraphs and the instructions and questions previously generated. The answer generation process prioritizes coherence, relevance, and alignment with the overarching domain theme, ensuring responses are rooted in domain-specific knowledge and effectively address associated questions. In addition to automated generation, the framework supports direct user input of domain-expert validated responses, allowing for the integration of human expertise into the training data. This hybrid approach combines the efficiency of automated generation with the precision of expert knowledge.
Following the answer generation step, the dataset undergoes a quality assessment phase wherein rankings are assigned based on relevance and quality, utilising the UltraFeedback [
29] preference ranking methodology. To ensure the quality of the rankings, the user can choose to employ a larger and more capable LLM that is used to generate a rationale for its ranking and a ranking score between 1 and 5 with completions below three being disregarded. This evaluation process ensures that only high-quality answers progress to the training dataset After this step, we have two initial datasets, one for each use-case. The Biobank-SFT dataset has 24,410 samples, and the Co-creation-SFT dataset has 15,666 samples. The datasets can be used for SFT as they consist of the following components: generated instructions and questions, selected context relevant to the domain, and generated answers that are both relevant and high-quality.
2.2.3. Construction of DPO Dataset
To further improve the stability of our generations, a preference dataset is created to align the output of the domain-specific model to human preferences. SFT can train a model to generate answers to instructions based on the datasets used. Still, it does not prevent the generation of undesirable answers that may contain inaccurate, missing, or misleading information [
12]. Preference datasets try to align model generations to the expected preference of humans; this can be achieved through the RLFH [
12] method or more recently through the DPO method [
25]. The advantage of DPO and other such methods is that it is less complex, does not require extensive hyperparameter tuning, and is cheaper to use to generate datasets while maintaining training performance. To create a DPO dataset, we need four components: an instruction, a context, a chosen answer, and a rejected answer. As mentioned above, the framework has generated instructions and extracted context from domain-specific documents. For the rejected answers, the completions are generated using the domain-adapted SFT versions that were trained for the use-case domains of two competitive but small open-source models, Mistral 7b and Llama 3 8B [
3,
28].
To further enhance dataset quality, we repeat the steps described in the previous step, utilising GPT4-Turbo. This second completion generation step provides us with better completions to be used as the chosen answers. After the ranking is conducted, the Biobank-DPO dataset has 9346 samples, and the Co-creation-DPO dataset has 10,342 samples that we can use as the chosen answers for our respective DPO datasets. The Biobank-DPO dataset is then partitioned into an 8791-sample training set and a 555-sample test set, with due consideration given to document boundaries and dataset coherence. The Co-creation-DPO dataset is then partitioned into a 9742-sample training set and a 600-sample test set, with due consideration given to document boundaries and dataset coherence as seen in
Figure 3. Dataset partitioning was implemented with careful attention to document boundaries, ensuring dataset coherence and preventing test contamination. This approach maintains the integrity of the evaluation process by ensuring that test samples derive from documents entirely separate from those used in training.
2.3. Model Training
Our framework implements a multi-phase training approach that progressively adapts generic language models to domain-specific applications while preserving general capabilities. This methodology addresses multiple research questions through a structured adaptation process.
2.3.1. Continuous Pre-Training
We tested our training methodology in the previously mentioned use-cases, public health co-creation and biobanking. In both our use-cases, human experts were used to identify the most relevant academic literature of the respective fields, biobanking and co-creation. For the biobanking use-case, 1102 documents were identified, including academic papers, training material, and more. For the co-creation use-case, 13,000 academic papers were initially selected from the Co-Creation Database [
22]. After a second identification round, 3437 academic papers were chosen to create the training dataset. For the biobanking use-case, we decided to use a Mistral 7B model, while for the public health co-creation, we decided to use a Llama 3 model as our base model. Using the methodology described above, two datasets were created for the two use-cases. Their final states are composed of paragraphs, questions or instructions, and answers. For the continuous pre-training step, the base LLM undergoes an extended pre-training phase aimed at augmenting its understanding of domain-specific knowledge. For this step, two types of data were used: question–answer pairs and plain unstructured text. This phase serves as an initial step in enhancing the model’s comprehension and adaptability to domain-specific tasks and scenarios, laying the groundwork for subsequent fine-tuning tasks. During the pre-training step, the training objective was next-token prediction, a self-supervised objective. Given
N sequences from the co-creation and biobanking datasets, where each sequence
contains
n tokens, we defined the loss function as the sum of negative log probabilities of the next token
given the previous tokens in the sequence
, where
is the model we are training.
The models trained using the continuous pre-training technique will be denoted as continuous trained models, CPMs.
2.3.2. Supervised Fine-Tuning for Task Adherence
While the continuous pre-training stage increases comprehension of domain knowledge, the CPMs lack the capacity to adhere carefully to the requirements of specific tasks and user instructions. To combat this, a supervised fine-tuning round is necessary.
The supervised fine-tuning process combines multiple dataset types. The primary instruction dataset merges our domain-specific data with general instruction-following datasets, which are included by default to maintain the model’s basic instruction-following capabilities. End-users can modify this dataset composition according to their requirements. The framework also supports integration of additional domain-specific resources, such as PubMed for medical applications. The final training dataset incorporates all these components to fine-tune the continuous pre-trained models (CPMs).
The inclusion of both general instruction datasets, such as adherence datasets, instruction datasets, and truthfulness datasets, aims to improve and enhance the LLM’s capability to follow, understand, and generate based on instructions. This is done to mitigate the deterioration of the model on general tasks while still developing enhanced domain performance. The responses for the domain-specific datasets were generated using GPT4-preview. The user can choose whether to use a paid model such as GPT3.5 or GPT4, the models available through the Groq API, or a locally hosted LLM for instruction and completion generation. To enable the SFT of the models, we use the LoRA [
30] technique. LoRA enables the efficient and accurate fine-tuning of LLMs in a fraction of the time and compute required for a full fine-tuning. LoRA is a technique that allows the fine-tuning of LLMs by introducing low-rank matrices into the model’s architecture [
30].
The training objective during the SFT step was a supervised objective. Given
N sequences from the co-creation and biobanking merged SFT datasets, where each sequence
contains
n tokens, a number of
N prompts
were created together with a corresponding number of
responses, where
is the model we are training. We defined the loss function as follows:
The probability represents an autoregressive language model where each token is predicted based on all previous tokens in the sequence. At each step t, the model outputs a probability distribution over the entire vocabulary. This formulation follows the standard language modeling objective where the model learns to predict the next token given the preceding context, with the key distinction that the context includes both the prompt PRi and the previously generated response tokens, thus optimizing the model’s ability to generate contextually appropriate responses to domain-specific instructions, enhancing performance on specialized tasks while maintaining general language capabilities. The models trained will be denoted as the SFT models.
2.3.3. Direct Preference Optimization for Quality Enhancement
Drawing upon the DPO dataset, the LLM undergoes training to align its 342 responses with human preferences and quality standards. By systematically optimising response quality and relevance, this training methodology facilitates the generation of high-quality, contextually relevant responses in medical dialogues, thereby enhancing the overall efficacy, safety, and user satisfaction in domain-specific interactions.
To build the DPO datasets for the co-creation and biobanking use-cases, we employed GPT4-preview. The instructions and context from the previous instruction step were used, but the answers were generated using the superior GPT4-preview and SFT models. The answers from GPT4 were chosen as the preferred, while the answers from the SFT models were chosen as the rejected answers. Each training sample contains a triplet for training that consists of a prompt, a chosen answer, and a rejected answer, as well as metadata, such as the originating file, the ranking scores, and more. Again, to enable the DPO training of the model, we use the LoRA [
30] technique.
The training objective follows the one showcased in the DPO paper [
25]; the goal of the training objective was to calculate the log probabilities of the chosen and rejected responses within the current model and then fine-tune the model to increase the likelihood of the preferred responses while reducing the likelihood of the rejected responses. The loss function for this optimization process can be seen below:
The models generated from the DPO training process will be referred to as direct preference optimization models, or DPOMs.
2.4. Evaluation Methodology
The evaluation methodology implemented in our framework addresses all research questions through an assessment of both domain-specific performance and general capability preservation [
23]. This approach combines automated metrics, benchmark evaluations, and human assessment to provide an evaluation of the framework.
2.5. Testing Dataset Integrity
To ensure that the model training and evaluation was successful, a number of academic papers were identified. The identified papers were explicitly excluded from all training phases. This separation was verified through multiple approaches, including unique identifier tracking (DOI, titles, author sequences) and the application of the BM25 ranking algorithm to confirm the true separation between training and testing materials. This methodology ensures that evaluation metrics reflect genuine model capabilities rather than memorization of training content.
2.6. Evaluation Metrics
To successfully evaluate our models, we decided on using ROUGE, BLUE, and BERTScore [
31,
32,
33] for domain-specific dialogue tasks; these metrics help us identify divergences between the model-generated responses and the grounded truths. For multiple-choice questions,
True/False questions and single-word answers accuracy metrics were used.
2.7. Baseline Model Selection
We used a fine-tuned Mistral 7B model, Nous-Hermes 2 7B DPO (NH) [
28]), as the base model to run our comparisons and as our starting point for the model training of the biobanking use-case. For the public health co-creation use-case, a Llama 3 8B-Instruct model was used [
3]. NH is a 7B open-source instruction fine-tuned model that has shown promising results in both evaluation datasets and empirical testing. Llama 3 is a model of comparative size with the NH model at 8 billion parameters and has also been instruction-tuned. Different models were chosen for the two use-cases to showcase that the results of the experiments are not dependent on a specific base model. Both models provide excellent starting points due to their competitive performance relative to their small size. Due to their small size and with the right quantization techniques, they can run on a wide range of devices, including embedded devices and smartphones. The end-user can choose any of the previously mentioned local models based on their needs and preferences but are bound by computing hardware limitations. These 7 and 8B models offer a reasonable compromise between speed, generative capabilities, and the hardware needed for training and inference.
2.8. Benchmark Selection
For a baseline evaluation of general capabilities and to assess potential performance degradation after domain adaptation (addressing RQ2 and RQ3), we are evaluating the models on a split of the AGIEval, BigBench, and the GPT4ALL datasets [
34,
35,
36], as well as the testing split of the domain- specific datasets that were created throughout the methodology. We evaluate 7 tasks for the GPT4ALL dataset, 8 for the AGIEval dataset, and 14 for the BigBench dataset. This evaluation routine is commonly used to evaluate open-source LLMs. AGIEval assesses general intelligence capabilities across diverse tasks including reasoning, mathematics, and knowledge application. BigBench evaluates complex language understanding through multiple challenge tasks, while GPT4ALL specifically measures instruction-following capabilities and general task completion proficiency. These benchmarks provide a broad assessment of the general and domain-specific model capabilities and can help identify any potential degradation in general instruction-following as well as showcase the improvements made in the domain-specific areas.
2.9. Human Evaluation Protocol
To complement automated metrics and provide a qualitative performance assessment, we designed and implemented a structured human evaluation protocol utilising domain experts (RQ3). Evaluators rated model responses on a standardised 5-point scale across the entire test dataset, comparing our domain-adapted models with GPT4 using a dedicated evaluation interface. This comparative approach enables direct assessment of performance relative to current state-of-the-art systems despite significant differences in model size and computational requirements.
The evaluation protocol included detailed rating guidelines to ensure consistency across evaluators, with specific criteria for assessing accuracy, completeness, relevance, and coherence. Responses were presented in randomised order with source models anonymised to prevent bias. This structured approach provides a qualitative assessment that complements the quantitative metrics from automated evaluation.
2.10. Training Implementation Details
During the continuous pre-training phase, the NH and Llama 3 were trained on a single RTX 4090 24 GB GPU, with the following settings: 3 epochs, 16 batch size, a learning rate of 2 × 10−4, 0.01 weight decay, a warmup ratio of 0.05, a linear learning rate scheduler, and a max_length of 512. This created the Biobank-CPM and Co-creation-CPM.
For SFT, the CPM models were trained using the LoRA technique and a single Nvidia RTX 4090 24 GB GPU, with the following settings: 1 epoch, 16 batch size, a learning rate of 2 × 10−5, 0.05 weight decay, a warmup ratio of 0.05, a cosine learning rate scheduler, a max_length of 768, and a lora_rank of 16, a lora_alpha of 16, and a lora_dropout of 0.05. This produced the Biobank-SFT and Co-creation-SFT models.
Finally, the SFT models underwent preference tuning using the DPO method and the LoRA technique with the following training parameters: 4 batch size, a learning rate of 1 × 10−5, 0.05 weight decay, a warmup ratio of 0.05, a cosine learning rate scheduler, and a max_length of 1024, but with a minimal number of samples surpassing 768 length. Additionally, the LoRA settings were a lora_rank of 64, a lora_alpha of 64 and a lora_dropout of 0.05.
3. Evaluation
3.1. Domain-Specific Model Performance (RQ1)
Table 1 and
Table 2 present the evaluation results for both use-cases, comparing different training stages with GPT4-T as a reference point for domain-specific performance. These results directly address RQ1 and RQ2 by quantifying the effectiveness of models trained using our framework on domain-specific tasks.
For the biobanking domain, our evaluation demonstrates that domain adaptation produced improvements across all text generation metrics. The DPO-7B model achieved the highest performance, with ROUGE-1 scores of 0.450 compared to 0.405 for the base model, and BLEU scores of 0.190 compared to 0.145 for the base model. The improvement trajectory across training phases (Base → SFT → DPO) shows consistent performance gains, with each phase contributing to enhanced domain-specific capabilities. The SFT phase produced substantial initial improvements, while the DPO phase provided additional refinement in response quality and relevance.
In the co-creation domain, we observed improvements from the base model to the DPO model. The DPO-8B model achieved ROUGE-1 scores of 0.280 compared to 0.194 for the base model, and BLEU scores of 0.026 compared to 0.005 for the base model. These improvements demonstrate the effectiveness of our adaptation approach for domains with specialised vocabulary and concepts that may be underrepresented in general pre-training corpora. The performance differential between base and adapted models in this domain reinforces the importance of domain adaptation for specialised applications, though the relative improvement magnitude differs between metrics.
Across both domains, DPO models demonstrated improved performance on ROUGE-L, ROUGE-Lsum, and BLEU metrics compared to both base and SFT models. This pattern indicates that the preference optimisation phase successfully aligns model outputs with quality expectations, producing more accurate and relevant responses. The performance gains were more pronounced in the biobanking domain than in co-creation when compared to GPT4-preview generations, which may reflect differing levels of domain complexity or variations in dataset characteristics.
BERTScore metrics show modest but consistent improvements across adaptation phases, with the biobanking domain demonstrating an increase from 0.871 (base) to 0.879 (DPO) and the co-creation domain improving from 0.734 (base) to 0.740 (DPO). These improvements, while numerically smaller than those observed in ROUGE and BLEU metrics, indicate enhanced semantic alignment with reference responses, suggesting that adaptation improves conceptual accuracy beyond surface-level text similarity.
The biobanking dataset maintains similar lengths between context and responses (280 and 240 tokens, respectively), enabling balanced context–response relationships. In contrast, the co-creation domain implementation used Llama 3 8B-Instruct as its base model for both initial training and relevance valuation, with GPT4-preview generating DPO responses. The co-creation dataset exhibits a wider length differential, with contexts averaging 512 tokens and responses averaging 140 tokens, reflecting the domain’s requirement for processing larger contextual information to generate concise responses.
Performance measured in the biobanking domain was higher than in co-creation both for the trained models and the GPT4-preview model. This performance differential correlates with the token length relationships between context and responses in each domain. The biobanking dataset’s balanced context–response lengths (280:240 tokens) yielded stronger improvements, while the co-creation dataset’s wider ratio (512:140 tokens) showed more modest gains. The evaluation metrics assess both textual fluency and alignment with reference content. Our analysis indicates that metric magnitudes differ between domains primarily due to the inherent length sensitivity of ROUGE and BLEU scores. Consequently, direct metric comparisons between domains are less informative than comparing relative improvements against GPT4 baselines within each domain. These relative improvements provide a more accurate representation of model capabilities. While the domain-specific performance improved, we observed a minor decrease in general instruction-following capabilities. This trade-off is expected given that the baseline models (7B and 8B parameters) are production-optimised for general tasks.
3.2. General vs. Domain-Specific Performance and Knowledge Preservation (RQ2,3)
The evaluation of general capabilities alongside domain-specific performance directly addresses RQ2, providing insight into potential trade-offs between specialisation and general capabilities. As shown in
Table 1 and
Table 2, we assessed this relationship using AGIEval, BigBench, and GPT4All benchmarks to quantify general performance changes resulting from domain adaptation.
For the biobanking domain, the base NH-7B model achieved scores of 0.445 on AGIEval, 0.433 on BigBench, and 0.670 on GPT4All. Following complete domain adaptation, the DPO-7B model showed modest decreases to 0.427 on AGIEval and 0.412 on BigBench, while actually improving performance on GPT4All to 0.676. This pattern indicates minimal degradation in general reasoning and knowledge capabilities, with preservation or enhancement of instruction-following abilities. The co-creation domain exhibited similar patterns. The base Llama 3 8B model achieved scores of 0.430 on AGIEval, 0.439 on BigBench, and 0.657 on GPT4All. After complete adaptation, the DPO-8B model showed a decrease to 0.406 on AGIEval and 0.408 on BigBench, while maintaining near-equivalent performance on GPT4All at 0.653. These changes indicate a modest trade-off between domain specialisation and general capabilities, with the most substantial preservation observed in instruction-following tasks.
These results demonstrate that while domain adaptation produces improvements in domain-specific tasks (as documented in
Section 3.2), it introduces a modest trade-off in general reasoning capabilities. However, the magnitude of these reductions is relatively small compared to the substantial gains in domain performance, suggesting a favorable balance in the adaptation–generalization trade-off. The preservation of GPT4All scores across both domains indicates that basic instruction-following capabilities remain largely intact throughout the adaptation process, which is critical for maintaining usability in interactive applications. Further analysis reveals correlation between performance differentials and the token length relationships between context and responses in each domain.
3.3. Human Evaluation Results
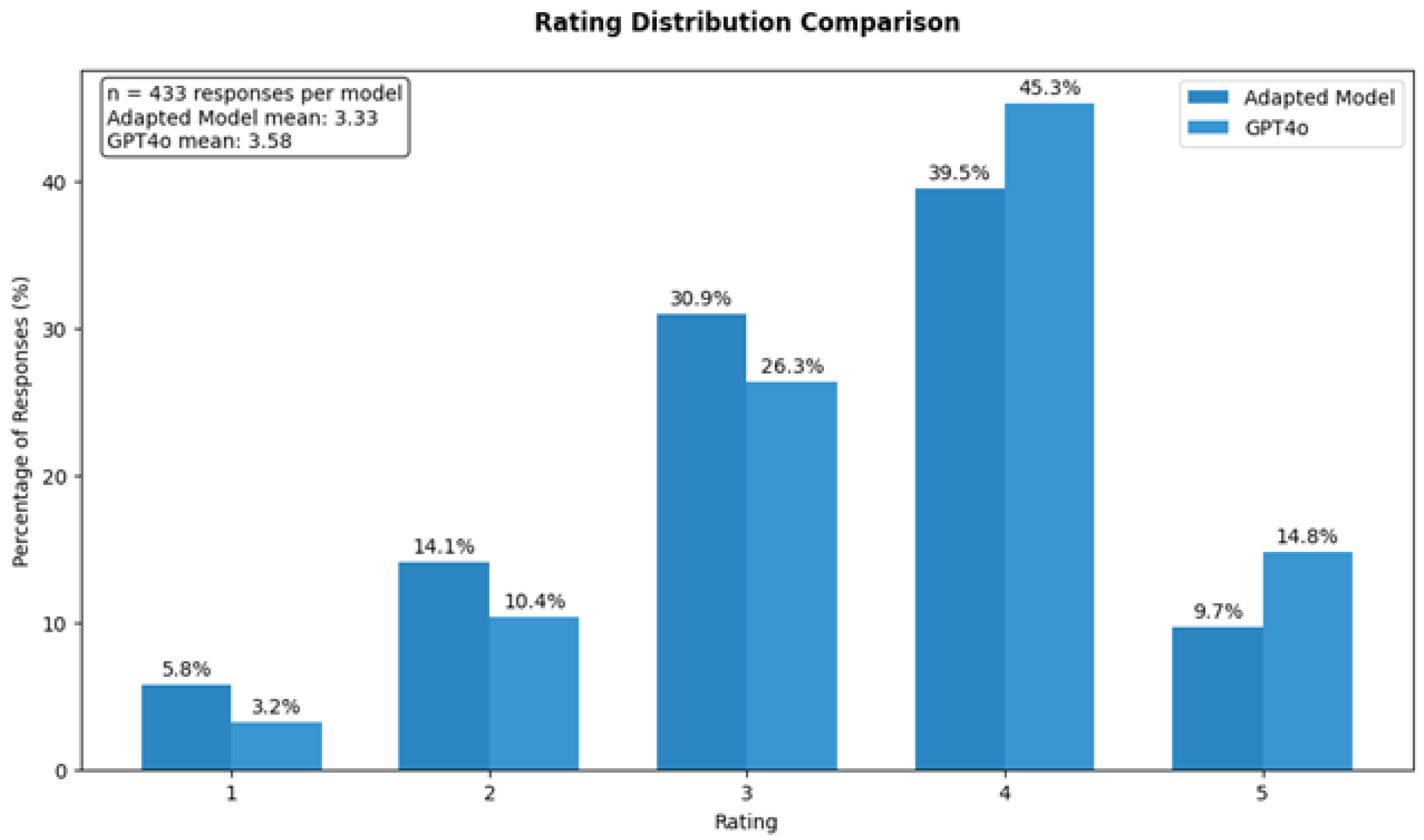
To complement the automated metrics evaluation, we conducted a human evaluation study, using domain experts to ensure the quality of the results. During the evaluation, we compared the qualitative performance of our Adapted Mistral 7B DPO model with GPT4o across 555 test samples using a dedicated evaluation interface of the framework. Evaluators rated responses from both models on a 5-point scale.
Figure 4 presents the rating distribution across both models.
The adapted model achieved a mean rating of 3.33, while GPT4 received a mean rating of 3.58. The distribution shows that both models received predominantly positive ratings, with the highest concentration in the 3–4 range. GPT4 obtained more ratings at the higher end of the scale, with 45.3% of responses rated 4 out of 5 compared to 39.5% for the adapted model. The proportion of top ratings (5/5) showed a similar pattern, with GPT4 receiving 14.8% versus 9.7% for the adapted model.
A more granular analysis of the per-answer rating differences produces a mean difference of −0.25 between the adapted model and GPT4o, with a standard deviation of 1.29. This indicates small variability in how the models performed across different test cases. The data reveal that in 119 instances, the adapted model outperformed GPT4o, while GPT4o performed better in 181 cases. Notably, both models received identical ratings in 133 cases, suggesting comparable performance in approximately 30% of the evaluations.
These results indicate that while our adapted model generally performed well, there remains a modest gap in perceived quality compared to GPT4o. The number of cases where both models received identical ratings (133 instances) suggests that our adapted model has achieved competitive performance in many scenarios, despite its significantly smaller parameter count and reduced computational requirements. Such a small model can even be deployed in mobile devices, ensuring the privacy of information. The evaluation data also highlight areas for potential improvement, particularly in achieving more consistent high-quality outputs, as evidenced by the lower proportion of top ratings compared to GPT4o. However, the relatively small mean difference in ratings (−0.25) suggests that the adapted model maintains robust performance levels that may be sufficient for many practical applications, especially when considering the trade-offs between model size, computational requirements, and output quality.
4. Discussion
This paper introduced a structured framework designed to facilitate the adaptation of LLMs for specialized domains, primarily utilizing user-provided documents. The methodology enables individuals, including those without extensive deep learning backgrounds, to generate domain-specific datasets and subsequently fine-tune models through a systematic process. Core components include automated document processing, relevance assessment, synthetic data generation, and a sequential multi-phase training approach involving CPT, SFT and DPO. Experimental results confirm the framework improves LLM performance within targeted domains, such as biobanking and public health co-creation, while maintaining general linguistic and instruction-following capabilities.
The observed performance enhancements can be attributed to the multiple phases of the training process. The initial dataset generation pipeline converts user-provided documents into a structured, relevance-filtered dataset, forming a high-quality foundation specific to the target domain. CPT then adapts the base model’s representations by exposing it to the domain’s characteristic vocabulary, discourse patterns, and knowledge structures. This foundational adaptation is important for subsequent stages. SFT subsequently aligns the model with task-specific formats by training it on instruction–answer pairs derived synthetically from the identified dataset. This stage directly optimises the model’s ability to follow instructions and generate relevant responses grounded in the provided domain context. Finally, DPO provides a further layer of refinement by optimising the model against a preference dataset. This step moves beyond simple instruction adherence, tuning the model’s output style and content selection to better align with desired quality attributes, which likely explains the consistency seen in metrics like ROUGE-L and BLEU when moving from SFT to DPO models. This sequential adaptation contrasts with simpler fine-tuning approaches, suggesting that the combination of domain exposure (CPT), task alignment (SFT), and preference tuning (DPO) build upon each other to produce more robust domain-specific models.
The marked improvement in domain-specific metrics for the adapted models compared to their base counterparts validates the effectiveness of the adaptation process. Variations in the degree of improvement between the biobanking and co-creation domains show that while improvements are derived in different domains, the quality and nature of each domain can produce different results. These variations in performance stem from multiple factors, including differences in domain complexity, the linguistic diversity within the source documents, or potentially the characteristics of the generated datasets, such as the average token length ratio between context and generated response.
The framework’s design, particularly the ability to merge multiple datasets into the final dataset and the reliance on techniques like LoRA, proved effective in mitigating catastrophic forgetting of general capabilities. By enhancing the domain-specific datasets with general instruction-following datasets, we minimise the performance degradation of the model in general instruction-following. This explains the minimal degradation observed on the general instruction-following benchmark (GPT4All), which is a critical factor for maintaining model utility across diverse queries.
The human evaluation comparing the adapted 7B parameter model to the significantly larger GPT-4o in the biobanking domain is particularly informative. Achieving comparable performance ratings in approximately 30% of evaluated cases, despite the vast difference in scale and resources, highlights the potential of specialised, smaller models. Such models offer substantial advantages regarding deployment feasibility, computational efficiency, inference speed, and the potential for privacy-preserving on-device execution. While a performance differential relative to leading proprietary models persists, attributable to differences in scale, architecture, and training data, the adapted models demonstrate considerable utility and fitness-for-purpose within their specialised domains. The choice of LLM used for synthetic data generation (e.g., GPT-4 vs. smaller open-source models) also significantly influences the quality and nature of the SFT and DPO datasets, impacting the final adapted model’s performance and potentially introducing stylistic biases from the generator model.
Despite the framework’s demonstrated utility, several potential drawbacks and operational risks require careful consideration by implementers. A primary concern involves the potential for bias propagation. Biases inherent in the source documents or in the LLMs used for relevance filtering and synthetic data generation can be incorporated and potentially amplified within the generated datasets and, consequently, the adapted model. This necessitates careful selection of source materials and awareness of the limitations of the generation models. Secondly, while adaptation enhances domain relevance, it does not guarantee factual accuracy. The risk of generating plausible sounding but incorrect information (hallucinations) persists and may even be exacerbated within a specialized domain if not rigorously monitored. Robust validation protocols, potentially involving domain expert review or cross-referencing with trusted sources, are essential, particularly in high-stakes applications. Thirdly, the quality and performance of the final adapted model are intrinsically linked to the quality, scope, and relevance of the initial documents provided by the user; errors in the source material will inevitably limit the adapted model’s capabilities. Furthermore, reliance on automated synthetic data generation, while efficient, might not fully capture the complexities and nuances of authentic human discourse or expert reasoning within the domain, potentially leading to models that perform well in the synthetic distribution but less robustly with real-world input. Overfitting to the specific style or content distribution of the synthetic data is another related risk. Finally, although the framework aims to reduce technical barriers, its effective application relies heavily on the user’s domain expertise. This expertise is critical not only for selecting appropriate source documents, but also for guiding the process, evaluating the intermediate and final outputs, and understanding the adapted model’s limitations to prevent misuse or over-reliance, meaning there is a crucial human-in-the-loop element throughout the workflow. Addressing these risks requires a combination of careful data curation, appropriate model selection for generation tasks, thorough evaluation procedures involving domain experts, and a critical perspective on the adapted model’s outputs.
The presented framework has several direct implications for research, industry practice, and broader economic participation, particularly concerning the accessibility, efficiency, and application scope of domain-specific LLMs. Reducing the technical prerequisites for dataset creation and model fine-tuning enables domain experts across various fields, including those without specialised machine learning backgrounds, to more directly contribute to the development of AI tools tailored to their unique requirements. This accessibility can facilitate the creation of specialised models for tasks such as targeted literature synthesis from niche publications, thematic analysis of qualitative research data, and the education and upskilling of personnel and students. From a broader innovation and economic standpoint, the framework lowers the barrier to entry for SMEs, which often lack the financial and human capital to fine-tune or operate large-scale LLMs. The framework empowers SMEs to leverage state-of-the-art AI without dependency on proprietary systems or significant investment in DL expertise by supporting efficient adaptation of smaller, open-source models and offering a configurable, privacy-preserving pipeline. This democratisation of AI enables SMEs to integrate intelligent tools into domain-specific workflows—from customer service and internal knowledge retrieval to compliance documentation and technical support— enhancing productivity and innovation capacity.
Furthermore, enabling SMEs to build and deploy models with competitive performance on niche or localized tasks has meaningful economic implications. It fosters a more equitable technological landscape where smaller organizations can remain competitive alongside larger enterprises. The increased accessibility to customised AI tools contributes to regional innovation ecosystems, supports digital transformation in underserved sectors, and stimulates market diversification through the creation of hyper-specialised applications that would otherwise be economically infeasible.
The demonstrated ability to achieve strong task-specific performance with smaller (7B/8B parameter) models provides significant practical advantages. This finding offers a viable strategy for organisations constrained by computational resources or operating under strict data privacy regulations that necessitate on-premise or on-device deployment. It suggests that for many domain-specific applications, targeted adaptation of smaller models can be a more efficient and feasible approach than exclusive reliance on large, general-purpose proprietary models accessed via APIs, influencing technology adoption decisions where cost, latency, or data governance are critical factors. The framework’s automated dataset creation pipeline, using user-provided documents, addresses key challenges in developing LLMs for domains with limited public data or requiring knowledge from private data. This capability allows researchers and institutions to create custom instruction-following datasets from internal knowledge bases such as standard operating procedures, institutional guidelines, or project-specific reports. It enables the development of hyper-specialised LLMs trained on information inaccessible during general pre-training, which can function as internal knowledge management systems—supporting tasks such as protocol verification, retrieval of specific internal information, or training new personnel.
The specific applications explored in biobanking and public health co-creation further exemplify the framework’s utility. In biobanking, the domain-specific model has been integrated into educational platforms, such as a serious game and digital guide, ensuring information accuracy and alignment with institutional standards. These examples demonstrate how the framework can translate domain-specific knowledge into practical, deployable AI systems, providing real-world value to both research institutions and industry stakeholders, particularly those with limited access to conventional AI development pipelines.
5. Limitations
Despite the promising results, our framework has several limitations that should be acknowledged. First, the framework’s reliance on existing LLMs for relevance assessment introduces potential biases from these models into the dataset creation process. If the base models have gaps in understanding certain domain concepts, these gaps may be introduced into the filtered datasets. This creates a potential echo chamber effect where the domain adaptation process might amplify existing model biases. Second, our evaluation primarily focused on two domains (biobanking and public health co-creation), which may not fully represent the framework’s effectiveness across broader domain types, particularly those requiring specialised reasoning (e.g., mathematical domains) rather than primarily factual knowledge. Domains with more abstract concepts or specialised logical structures might present different challenges for our adaptation approach. Third, the human evaluation sample size (555 test samples) provides a useful indicator of real-world performance but may not capture all use-case scenarios or edge cases within the domains studied. An evaluation across a wider range of query types and complexity levels would provide greater confidence in the robustness of our findings. Fourth, while our approach reduces the technical expertise required for domain adaptation, it still requires access to computational resources (e.g., GPUs) that may not be universally available, potentially limiting accessibility for some user groups. Finally, our comparison to GPT4o, while informative, represents a moving target as proprietary models continue to evolve. The performance gap may change as both commercial and open-source models advance, potentially affecting the relative value proposition of domain adaptation for smaller models.
6. Future Work
Building on this research, several directions for future work emerge. Extending the framework to support multimodal inputs and outputs would broaden its applicability to domains where visual or structured data are essential. Many specialised fields rely heavily on visual or structured data, and incorporating these modalities would significantly enhance the framework’s utility. Investigating techniques to further mitigate the trade-off between domain specialisation and general capabilities would improve overall model utility. This might include exploring more sophisticated parameter-efficient fine-tuning methods, using adaptive architecture approaches that allocate different model capacities to general versus domain-specific knowledge, or meta-learning techniques that explicitly optimise for maintaining general capabilities while acquiring domain expertise. Adopting more efficient adaptation methods that reduce computational requirements would increase accessibility for users with limited resources. This could involve adopting techniques specifically optimised for domain knowledge transfer, or exploring more efficient training regimes that require fewer computational resources while maintaining adaptation quality. Conducting studies of framework usage in real-world settings would provide insights into its practical effectiveness and guide future refinements. Understanding how domain experts actually interact with and benefit from adapted models over extended periods would help identify gaps in current approaches and inform more user-centered adaptation methodologies.
7. Conclusions
In conclusion, this framework offers a systematic approach for developing domain-specific LLMs. It successfully addresses the need for specialised models by integrating automated dataset creation with a multi-stage adaptation process, leveraging techniques like LoRA to ensure computational feasibility and mitigate knowledge degradation. This research confirms that substantial improvements in domain-specific performance are achievable, creating models that, while smaller than state-of-the-art generalist models, demonstrate competitive quality and significant practical advantages for targeted applications. For instance, the adapted BiobankLLM developed through this framework is actively being integrated into a serious game designed to enhance public understanding of biobanking principles and into an elearning course providing best practices for science outreach. These applications leverage the model’s specialised knowledge to answer user queries accurately within the context of the game or guide, demonstrating the tangible utility of creating tailored, efficient models for specific educational and engagement purposes. The framework’s flexibility regarding model choice and its support for local deployment further contribute to its potential utility across various research and operational settings, particularly where domain specificity, efficiency, or data privacy are primary concerns, thereby facilitating the broader adoption of specialised AI tools.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}