4.1. Ensembles Versus the Winner of Transformers
In this section, we will present, analyze and interpret all the results of this experimental study, based on the metrics, the specificities of the ensembles and the bibliography.
All datasets were split into 70% train, 15% test and 15% validation to coordinate the hyperparameters.
In
Table 4, we have chosen to display the Majority vote and Soft vote winners and the winner in the transformers for each dataset separately. In this way, we keep aggregated results, useful to see both the winner from the basic transformers and the percentage of improvement that the ensembles give us, avoiding the creation of chaotic results from 24 tables with 26 results in each table (12 tables for Majority vote and 12 for Soft vote). Distinguishing the cases according to the dataset, we see that the climate_3cl dataset has a slight imbalance in the classes with Positive (opportunity): 43.3%, Neutral: 33.9%, Negative (risk): 22.8%. The smallest class (risk—Negative) seems to be a more difficult classification to predict.
Majority vote combination (T5, GPT2, Pythia) is better than Soft vote combination and the best-performing model (T5) across all metrics in a consistent manner. Specifically, MV is higher in Accuracy (87.6% vs. SV’s 85.2%), F1-score (0.876 vs. 0.851), Precision (0.877 vs. 0.852), and Recall (0.876 vs. 0.851) with more accurate and consistent predictions. Furthermore, correlation-based metrics (MCC: 0.811, Kappa: 0.810) also confirm MV’s higher agreement, particularly here in this imbalanced dataset. Interestingly, both ensemble methods outperform T5 alone, with MV showing a 4.8% increase and SV 2.4%, proving the strength of ensembling.
On the cardiffnlp_3cl dataset, which is significantly imbalanced (Positive: 45.9%, Neutral: 35.1%, Negative: 19.0%), the Majority vote ensemble (Bart, Albert, GPT2) performs best, beating Soft vote and DeBERTa. MV beats SV on all of the metrics: Accuracy (0.802 vs. 0.741), F1-score (0.803 vs. 0.741), Precision (0.805 vs. 0.741), and Recall (0.802 vs. 0.742), indicating fewer false positives and more consistent predictions as illustrated in
Table 5. It also shows higher reliability in MCC (0.684) and Kappa (0.683) compared to SV (both at ~0.588). Performing worst is DeBERTa (Accuracy 0.726, F1-score 0.726, MCC/Kappa 0.565), confirming that this unbalanced dataset is vulnerable to ensemble approaches—especially in majority voting.
The Sp1786_3cl dataset, being very balanced in its distribution (Positive: 33.7%, Neutral: 29.3%, Negative: 26.6%), also shows the same trend here as illustrated in
Table 6. The Majority vote ensemble (Bart, Albert, GPT2) once again is the best one, outperforming Soft vote and DeBERTa. MV shines in all the metrics: Accuracy (0.832 vs. 0.777), F1-score (0.832 vs. 0.776), Precision (0.836 vs. 0.777), and Recall (0.832 vs. 0.776), indicating its dependability and lowered error rate. It is also more robust with higher MCC (0.749) and Kappa (0.747), compared to SV (both 0.664). DeBERTa lags even further behind with lower scores on all measures (Accuracy: 0.769, F1-score: 0.769, Precision: 0.772, Recall: 0.771, MCC/Kappa: 0.652).
In the highly imbalanced US_Airlines_3cl dataset (Negative: 62.7%, Neutral: 21.2%, Positive: 16.1%), the Majority vote ensemble (T5, GPT2, Pythia) performs the best, outperforming Soft vote and single T5 model as illustrated in
Table 7. MV possesses improved Accuracy (0.917 vs. 0.873), F1-score (0.916 vs. 0.870), Precision (0.916 vs. 0.869), and Recall (0.917 vs. 0.873), which suggests improved generalization and fewer errors. Its consistency also shows in MCC (0.833) and Kappa (0.832), which are considerably higher than SV (0.752 and 0.751, respectively). The rank of T5 is the worst, with Accuracy 0.865 (5.2% below MV), even lower F1-score (0.862), Precision (0.827), Recall (0.806), and consistency metrics (MCC: 0.737, Kappa: 0.736). MV’s better performance establishes that diversity among models enhances this kind of reliability.
In the also highly imbalanced 0shot_twitter_3cl dataset (Bullish/Positive: 64.9%, Neutral: 20.1%, Bearish/Negative: 15.0%), Majority vote ensemble (Bart, T5, GPT2) performs better than Soft vote and the standalone Bart model as illustrated in
Table 8. MV achieves highest Accuracy (0.898 compared to 0.886 for SV and 0.876 for Bart), as well as F1-score (0.898 compared to 0.885 vs. 0.877), Precision (0.899 compared to 0.885 vs. 0.840), and Recall (0.898 compared to 0.886 vs. 0.847). It is also more stable with MCC (0.810) and Kappa (0.809), both higher than SV (0.781 both) and Bart (0.766 both). Bart is lowest across the board, showing the advantage of combining various models in severely skewed settings.
In more balanced NusaX_3cl set (Positive: 23.9%, Neutral: 38.3%, Negative: 37.8%), Majority vote ensemble (Bart, DeBERTa, Albert) still leads, with improved Accuracy (0.933) over Soft vote (0.913) and single DeBERTa (0.903). F1-score, Precision, and Recall follow the same trend (MV: 0.933–0.937 range, SV: 0.913, DeBERTa: 0.904–0.897) as illustrated in
Table 9. The ensemble’s MCC (0.899) and Kappa (0.898) support its stability and improved generalization. Although DeBERTa does well, the ensemble’s lead in all measures validates its performance in moderately balanced datasets.
In the highly neutral-biased takala_50_3cl dataset (Neutral: 59.4%, Positive: 19.7%, Negative: 20.9%), Majority vote (T5, GPT2, Pythia) shows a stunning performance improvement over Soft vote and single T5 as illustrated in
Table 10. MV attains 0.917 Accuracy over 0.873 (SV) and 0.865 (T5), with F1-score and Precision both at 0.917–0.918, beating SV (0.872–0.873) and T5 (0.864–0.857). Recall also follows a similar pattern, and MCC gap (MV: 0.845 vs. SV: 0.770 vs. T5: 0.756) as well as Kappa (MV: 0.845 vs. SV: 0.768 vs. T5: 0.754) also claims higher reliability. T5 is far behind, again confirming the robustness of ensemble voting in imbalanced data sets where neutrality prevails.
In the takala_66_3cl dataset, with even greater neutral dominance (60.1%), Majority vote (T5, Albert, GPT2) again demonstrates best performance, Accuracy up to 0.941, much better than Soft vote (0.919) and DeBERTa (0.905) as illustrated in
Table 11. MV maintains this superiority in F1-score, Precision, and Recall (all 0.941), and its MCC (0.889) and Kappa (0.888) indicate even greater consistency than SV (0.853/0.852) and DeBERTa (0.826/0.825).
In the highly imbalanced takala_75_3cl dataset (Neutral: 62.1%, Positive: 18.4%, Negative: 19.5%), the Majority vote remains the best, albeit with a smaller margin as illustrated in
Table 12. MV is at 0.968 Accuracy compared to SV’s 0.963 and DeBERTa’s 0.959. F1-score, Precision, and Recall scores have the same ranking, whereas ensemble MCC (0.942) and Kappa (0.941) beat SV (0.932 both) and DeBERTa (0.926/0.925) marginally. Although all models do an excellent job, the marginal but steady improvement of the MV ensemble confirms its strength in scenarios with strong imbalance.
On the imbalanced takala_100_3cl dataset (Neutral: 61.4%, Positive: 25.2%, Negative: 13.4%), Majority vote (DeBERTa, Albert, GPT2) is marginally better than Soft vote and DeBERTa with top Accuracy (0.988), F1-score (0.988), Precision and Recall (0.988 each), MCC and Kappa (0.978) as illustrated in
Table 13. DeBERTa comes next with 0.985 Accuracy and F1-score, with SV lagging slightly at 0.982. Despite the modest size and imbalance of the dataset, classifiers performed well in general, with MV recording the most consistent and stable results.
With the well-balanced cardiffnlp_2cl dataset (Non-ironic: 52%, Ironic: 48%), Majority vote (DeBERTa, Albert, Pythia) far outperforms Soft vote and DeBERTa alone with the highest Accuracy (0.839 vs. 0.754), F1-score (0.837 vs. 0.727), Precision (0.845 vs. 0.761), and Recall (0.839 vs. 0.696) as illustrated in
Table 14. It also shows higher consistency with MCC and Kappa values of 0.680 and 0.672, respectively, compared to SV’s 0.505 and 0.503. DeBERTa is as accurate as SV but not as good in irony detection. Improved ensemble performance is backed by class balance, and therefore MV is the most effective approach.
In the large and well-balanced carblacac_2cl dataset (181,986 examples), Majority vote (DeBERTa, Albert, Pythia) significantly outperforms both Soft vote and DeBERTa. MV is the most accurate (0.905 vs. 0.857), F1-score (0.905 vs. 0.857), Precision (0.907 vs. 0.860), and Recall (0.905 vs. 0.853), indicating improved classification as illustrated in
Table 15. It also indicates higher consistency, with MCC and Kappa both at 0.811, compared to SV’s 0.715. DeBERTa’s Accuracy is 0.851—nearer to SV but still 5.4% below MV—confirming MV’s effectiveness in sentiment analysis of large, balanced samples of tweets.
4.2. The Reasons Why the Majority Vote Stands out Against the Soft Vote
4.2.1. General Conclusions of the Results
Across all datasets, the Majority vote ensemble (MV) shows the highest performance, outperforming both the Soft vote (SV) and the individual transformer models. The DeBERTa, T5, GPT2, Bart, Albert and Pythia models perform well, but never approach the accuracy of the ensemble models. Only sometimes, on very small datasets, can an individual model come close to the Soft vote ensemble.
A general principle underlying ensembles is that combining different models reduces the bias and errors of specific architectures [
35].
The simple Majority vote principle (the predominant prediction) works best on datasets where there is a strong class imbalance [
36] or specific language difficulties [
37,
38]; 10 out of 12 datasets have three classes, which are not balanced and the results showed just that, and one of the two binary datasets has specific language difficulties (ironically), cardiffnlp_2cl; again, the results justified this initial hypothesis.
Soft vote is based on the probabilities of predictions, so it is more sensitive to outliers than individual models. On very balanced datasets (e.g., carblacac_2cl), Soft vote performs quite well. Therefore, do we need to have balanced datasets to use Soft vote? Or should we generalize by assuming that Majority vote beats Soft vote in most cases?
The models may not be well-calibrated, which potentially affects Soft vote predictions and less so Majority vote predictions [
39]. The best model combinations differ between Majority and Soft Voting. If the categories (labels) are not balanced, then Soft voting may tend towards the most frequent category more than Majority vote [
40]. Soft voting uses the probabilities of the models, but if the models are not properly calibrated and biased, then the probabilities may not reflect their true confidence.
A model may give falsely high probabilities in one category, pulling the final result in that direction. That is, it can be overconfident about its predictions being right or wrong, making Soft voting work incorrectly. How can this appear in practice? If Validation Loss increases, it means the model is making more errors or becoming more confident about wrong predictions [
41]. In the experimental procedure it was observed that if the Validation Loss increases (even slightly) while the Accuracy increases, the model may become overconfident! Assuming this is hypothesis: studies [
31] show that modern deep learning models are overconfident by nature, then we see this to be true in the practice of our experimental procedure.
Overconfident means that the model gives extreme probabilities (0.95+ or 0.05−) to its predictions, when in fact it is not so confident (and of course this is not the case for all its predictions, but for many). So when this happens, Soft voting is very much affected, because it is based on probabilities and not just classes, which is not the case in Majority voting or Hard voting (hence “Hard” because it is not affected).
Here, we can say that we have the same findings about the overconfident models as other studies, but this ultimately affects ensembles. How does this work? Does using grid search in transformer models lead to the “best” parameters but also to the dilemma, small increase in (validation) loss and increase in accuracy, or at any increase in loss do we stop training and accept loss of accuracy? The first choice means that the model becomes overconfident [
31,
42] with better accuracy. The second option means we have the model with less accuracy but not as overconfident. We have to consider the trade-off between accuracy and generalization. This means that if we choose the former then Soft vote becomes vulnerable because the model becomes biased, increasing the probabilities in its prediction even if it is wrong. If we choose the second, i.e., stop training at each increase in loss, then we lose in accuracy but gain in generalization, i.e., the model is not as biased and not as confident in its predictions, i.e., it favors Soft vote schemes. All of this ultimately affects the ensemble schemes and of course their returns.
Calibration of course does not affect the accuracy, but only the reliability of the predictions [
31,
43], so sometimes some models show overconfidence in their predictions. This is reflected in the confidence charts we present below and is ultimately one of the reasons why Soft vote schemes lose to Majority vote schemes in our case.
4.2.2. Reliability Analysis
Let us look at this conclusion, namely that in datasets with strong class imbalance or specific language difficulties Majority vote works better, and at the same time consider whether these models exhibit overconfidence in its predictions, hence the superiority of the Majority vote scheme. We chose climate_3cl, a three-class dataset which has a large imbalance in its classes and cardiffnlp_2cl, a binary dataset which in its data (special language difficulties), there is or is not irony.
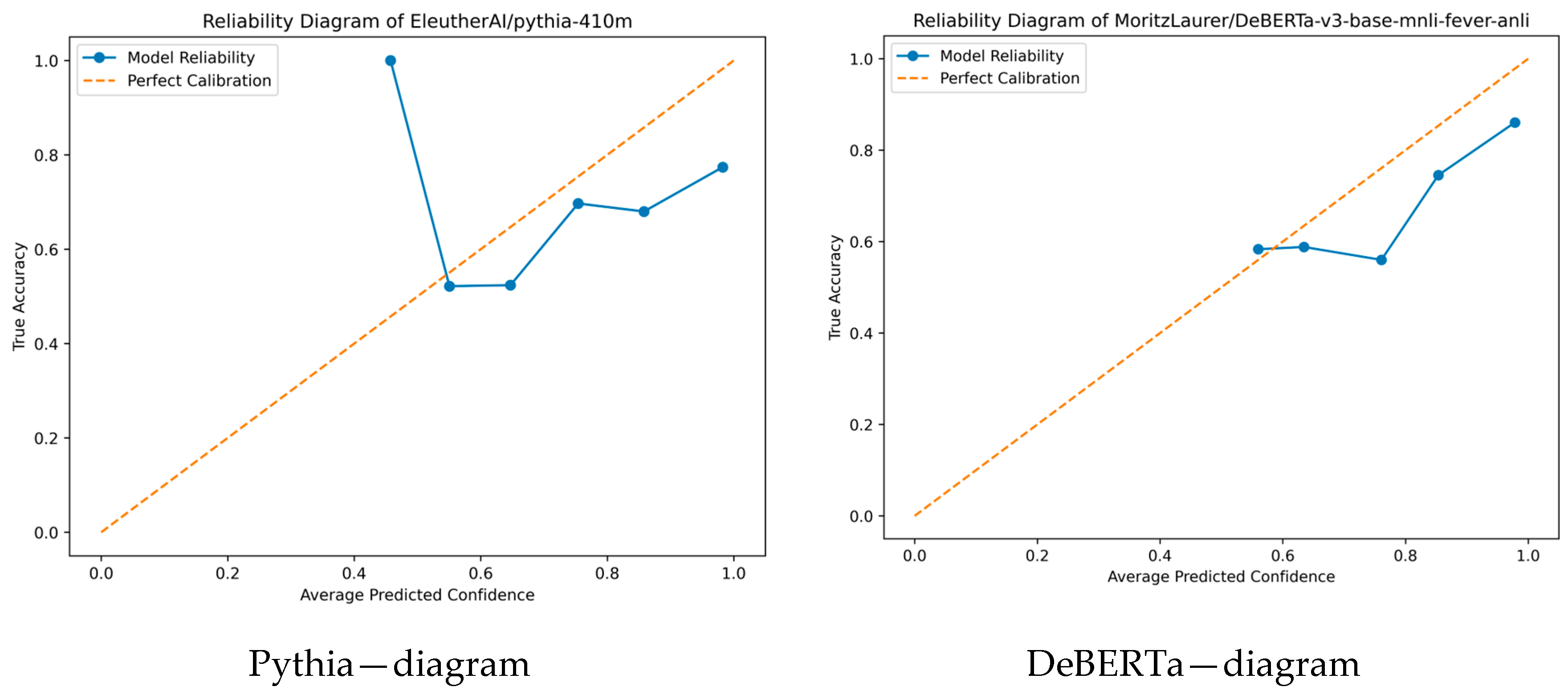
In climate_3cl, we have the winner, MV-“T5,GPT2,Pythia” and the second place, SV-”DeBERTa,T5,GPT2”, so we will consider the four different models, T5, GPT2, Pythia and DeBERTa, which are the basic models of the sets. The last two, Pythia and DeBERTa, are the ones that are not common to the two ensemble schemes, and we will consider them first, because Pythia has more characteristic sets of predictions (bins) which makes it easier to explain.
The confidence graph evaluates the accuracy of the model’s confidence after training. The meaningful information is in the bins (blue dots), which group predictions with similar confidence levels. Each bin represents a set of predictions of the model, where its coordinates (x, y) have a specific meaning.
The x-axis indicates the average probability predicted by the model for that particular group, while the y-axis shows the actual Accuracy of the predictions of that group. For example, in Pythia’s reliability diagram,
Figure 1, the first bin on the left is a group of predictions that have the following characteristics:
The model predicts with a confidence of 0.4–0.5; that is, it is quite uncertain about these predictions. The actual Accuracy in this group is close to 0.99. This means that almost all of these predictions are correct. So, the model underestimates its capabilities in these cases. So, this bin contains predictions where the model should be much more confident, but is not (underconfidence).
In general, if the points are above the dotted line, then the model is underconfident, whereas if the points are below the dotted line, the model is overconfident, displaying too much confidence in predictions that are less correct than it thinks (overconfidence in incorrect answers). If the model were perfectly calibrated, then the points would fall on the dotted line (perfect calibration: p (confidence) = p (accuracy)),
Figure 1 and
Figure 2.
We compiled the results of the charts into a table with three metrics:
Average confidence (correct): shows the average confidence of predictions that are correct. The higher this value is, the higher the confidence of the model when making correct predictions. A very high value here is usually desirable, as it means that the model is confident when it is correct.
Average confidence (incorrect): shows the average confidence of incorrect predictions. A high value for this would suggest that the model is often overconfident even when it makes an error, i.e., the model is not very well-calibrated. This should ideally be much lower than that of correct predictions, so that correct and incorrect predictions can be easily distinguished.
The Expected Calibration Error (ECE) is a metric that assesses how well-calibrated the confidence of a model’s predictions is. The ideal forecast has high confidence when it is correct and low confidence when it is incorrect. ECE is calculated by grouping forecasts into confidence intervals (bins) and comparing the average confidence of each bin to its actual Accuracy. The lower the ECE, the better the confidence rating of the model.
As we can observe from the analysis of the climate_3cl dataset in
Table 16, the average confidence of all models in correct prediction is high, from 0.9129 for GPT2 to 0.9372 for T5. Both DeBERTa and T5 have maximum confidence in correct prediction, but GPT2 has minimum confidence, i.e., this model is less confident in its estimate. In the incorrect predictions, confidence is also high but lower than in the correct predictions, from 0.8116 (GPT2) to 0.8672 (Pythia). In GPT2, the difference between confidence in correct and incorrect predictions is greater, showing that the model can better discriminate its predictions based on correctness. When compared on the basis of ECE value, GPT2 achieves the optimal calibration of 0.0894 and its predictions are the best-calibrated among the four models. T5 and DeBERTa have slightly higher ECE values (0.1092 and 0.1157, respectively), while Pythia shows the worst rating with an ECE of 0.1807, suggesting that its confidence often deviates from the actual Accuracy of predictions. Overall, GPT2 appears to be the most reliable in terms of confidence rating, while Pythia shows the largest deviation, suggesting that it may be overconfident in its estimates even when it is wrong.
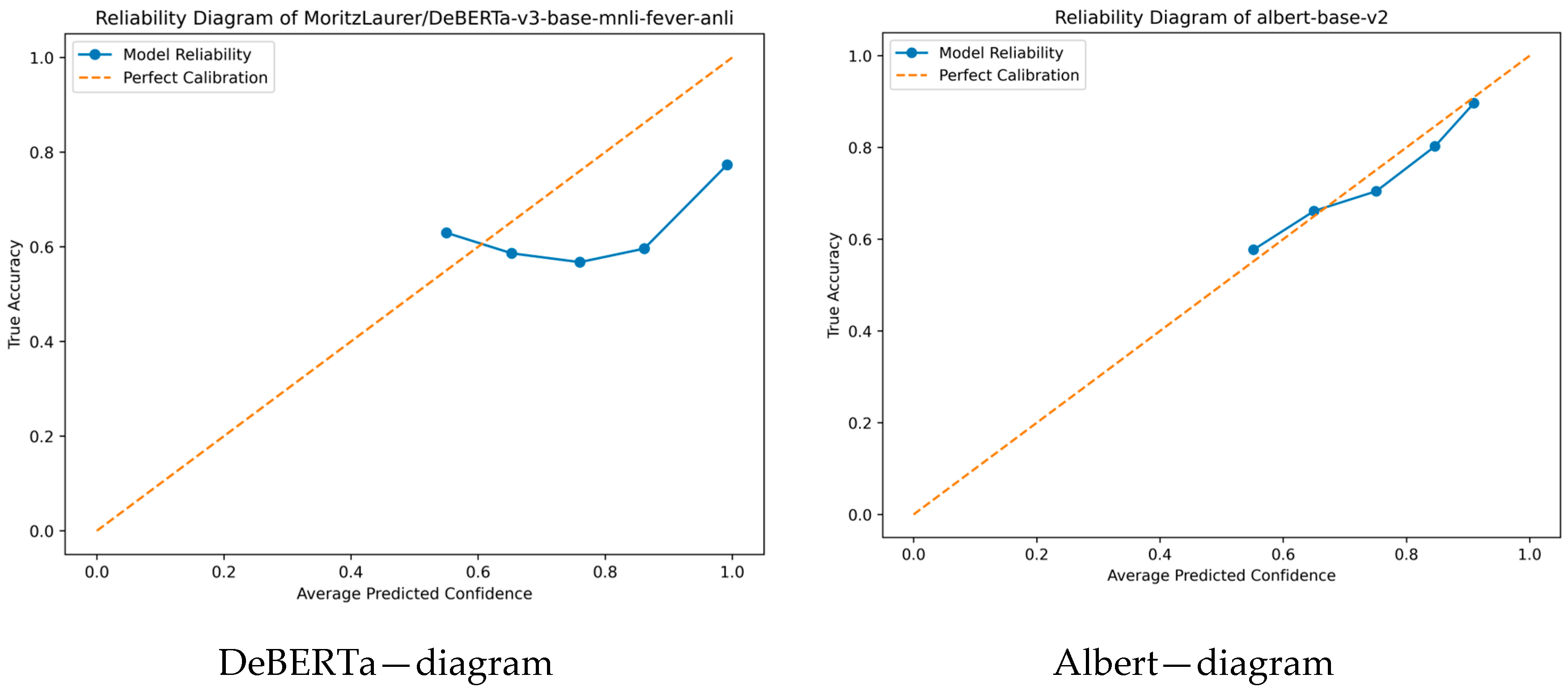
In cardiffnlp_2cl, we have MV-“DeBERTa,Albert,Pythia” as the winner, followed by DeBERTa in second place, and a very close marginal third place is SV-“DeBERTa,Albert,GPT2”, so we will consider the four different models, DeBERTa, Albert, Pythia and GPT2, which are the base models of the ensembles as illustrated in
Figure 3 and in
Figure 4.
In the analysis of results, we observe that there are significant variations between the models in their confidence in correct and incorrect predictions, and in calibration to the ECE measure as illustrated in
Table 17.
The DeBERTa model has the highest correct (0.9719) and incorrect average confidence (0.9441). This indicates the model is nearly always very confident in its predictions, both when it is correct and when it is incorrect. However, the high ECE value (0.2138) indicates that the model is poorly calibrated because the confidence does not reflect the actual performance.
On the other hand, Albert and Pythia have significantly lower average confidence in both correct and incorrect predictions. Albert has an average e-confidence of 0.7252 in correct and 0.6783 in incorrect predictions, while Pythia has 0.7066 and 0.6626, respectively. The small difference between these values shows that these models are conservative in their estimations, giving more balanced confidence values. This is evident in the extremely low values of ECE (0.0325 for Albert and 0.0420 for Pythia), which point to the fact that they are the best-calibrated models among the compared models.
GPT2 is more certain, with 0.7941 for correct and 0.7283 for incorrect predictions. GPT2 is less certain than DeBERTa but more certain than Albert and Pythia. GPT2’s ECE (0.0937) is lower than Albert and Pythia but much lower than DeBERTa, which shows its calibration is better than DeBERTa but bad in comparison to the other two models.
Overall, if the criterion is better calibration, Albert and Pythia excel, as they have lower ECE and more balanced confidence values. GPT2 is in the middle, while DeBERTa, although having the highest confidence values, has a poor rating due to its high ECE, which means that it can be overconfident even when wrong.
4.3. Final Results—Average Metric Values
By using ensembles, we maximized the performance compared to the first six models, but we still need to come up with a scheme that is the ultimate winner. We first calculated the average values of the metrics. That is, for each classifier we summed the metric scores for each dataset and then divided it by the total dataset.
Table 18 presents all the average values of the metrics for the set of classifiers. From this table, we can decide the winner over all datasets and make a general estimate of which ensemble shape is the winner on average over all datasets. But is this classifier (DeBERTa,Albert,GPT2) the undisputed winner?
It is obviously not the undisputed winner, we shall see why shortly. Following, in
Table 19 we present the Friedman ranking for the Majority and Soft vote. The Friedman ranking calculates the average position of each model on multiple datasets, and the lower the value, the better the model performs compared to the others.
The analysis of the average ranking with Friedman ranking shows that the scheme “DeBERTa, T5, GPT2” has the best performance, as it shows the lowest average ranking in Majority vote (5.333333, second column in
Table 19). The others have higher values, which means that on average they rank lower.
However, the use of the Nemenyi test for statistical comparison of the models reveals that the maximum difference between the top 18 rankings in the Majority vote (and top 16 rankings in the Soft vote) is smaller than the critical difference (CD = 10.802). This implies that the differences in performance between the models are not statistically significant at a significance level of α = 0.10, suggesting that the models have comparable performance and that the differences may be due to randomness. According to Demšar (2006) [
44], the Nemenyi test is used for multiple comparisons after the Friedman test, and when the differences do not exceed the critical value, we cannot claim that one model is objectively superior to the others.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}