This section presents two case studies showcasing the deployment of ModFPGA applied to two widely used synthesis techniques: subtractive synthesis and frequency modulation.
4.1. Subtractive Synthesis
Subtractive synthesis is a widely used technique, especially in dedicated hardware synthesisers. It involves a sound source that typically covers a broad frequency spectrum and a filter that acts as a spectrum modifier, shaping the sound produced by the source. In this approach, the sound from the source contains a wide range of frequencies, and the filter selectively removes unwanted frequencies, yielding only the desired components.
Subtractive synthesis is used for analogue emulation or virtual analogue oscillators, producing waves commonly found in analogue hardware synthesisers, such as sawtooth, pulse, and triangle waves, as well as noise generators or sampled sound sources. In our case, we focus on virtual analogue sources. The three waveform types mentioned above provide a wide range of sounds after filtering. When transitioning from analogue to digital, it is important that these sources are band-limited. This ensures that the components remain within the Nyquist frequency (half the sampling rate) to prevent aliasing artefacts.
The ModFPGA band-limited oscillator bank IP core addresses this by offering sawtooth, pulse, and triangle waveforms while also implementing band-limiting. Single-cycle waveforms are stored as wavetables in two-dimensional arrays, with the appropriate number of harmonics for each frequency range relative to the system’s 48 kHz sampling rate. The IP core selects the appropriate wavetable for the current frequency and outputs a signal within the Nyquist limit.
Various filter types can be used for spectral shaping, including low-pass filters that allow frequencies below a cutoff frequency, high-pass filters that do the opposite, and band-pass filters that yield a specific frequency range while removing everything outside of it. In our example, we use the ModFPGA four-pole filter, a low-pass filter, as the spectral modifier. Filters like four-pole also often have the capability of resonating, increasing the volume of frequencies near their cutoff frequency. Thus, they offer additional spectral-shaping possibilities.
Another key aspect of subtractive synthesis is dynamic spectral modulation. When the frequency content of a sound source changes over time, it opens up possibilities for elaborate sonic processes. In ModFPGA, the current choices for modulation sources include envelope generators and oscillators. In our example, a filter frequency envelope generator is used to modulate the cutoff frequency of the filter.
Audio effects can add texture and variation to synthesised sounds. The ModFPGA reverbsc module is used in this case to create spatial effects, adding depth and subtle pitch and phase modulations to the sound.
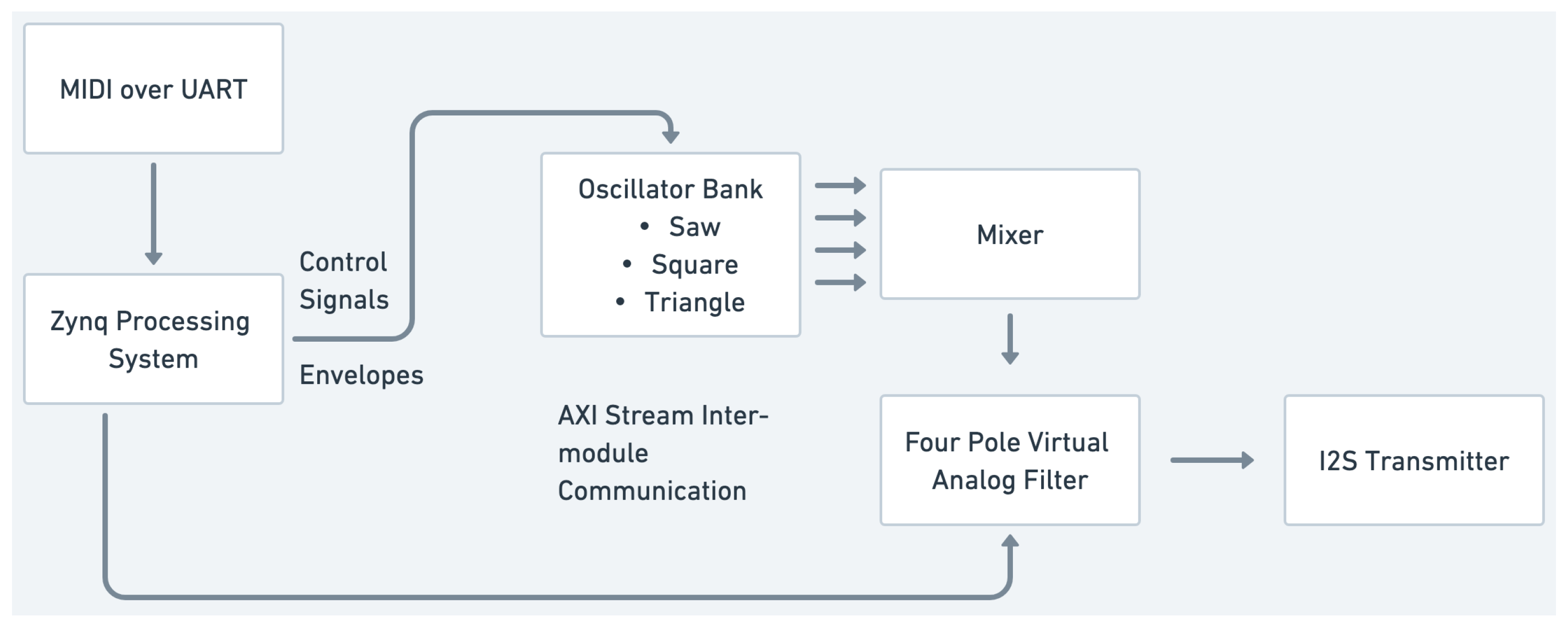
So, in terms of the plugging of IP core modules to create our subtractive synthesis examples, these are the main modules that will be interconnected. This can be carried out in monophonic or single-voice configurations, as shown in
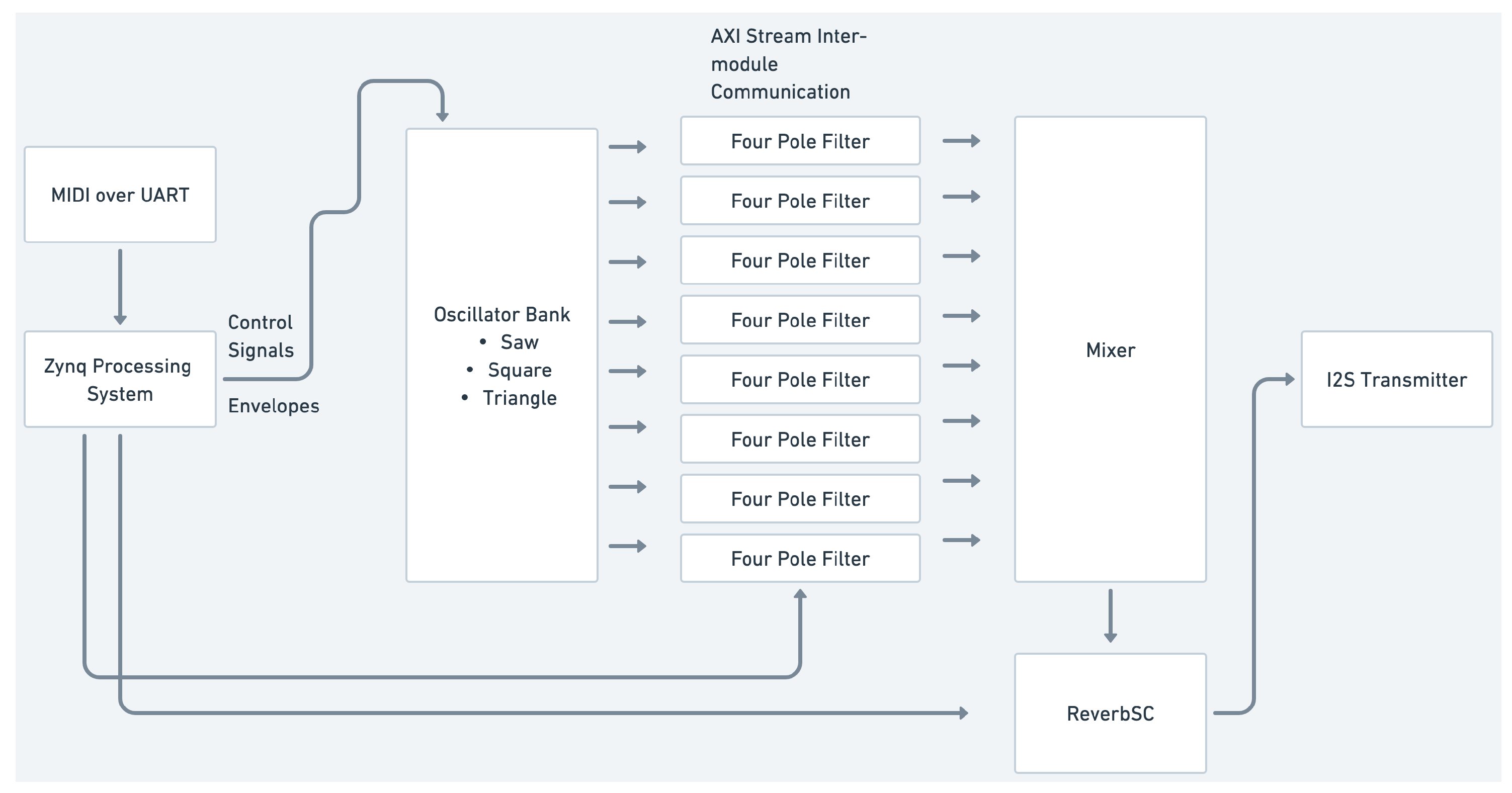
Figure 4, as well as polyphonic or multi-voice configurations, as shown in
Figure 5. In the monophonic version, a four-voice oscillator bank’s outputs are mixed and then processed by the four-pole filter. In the polyphonic version, each voice of an eight-voice oscillator bank has its own four-pole filter. The outputs of all the voices are then mixed together to be output.
Both versions feature envelope generators running on the processing system, modulating the amplitude and filter cutoff frequencies. In the case of the polyphonic design, each voice has its own amplitude and filter envelope. To control and play the synthesiser, MIDI can be used with the help of the Xilinx PS UART driver, as mentioned above. MIDI messages are received via the UART peripheral of the board. Message parsing, voice allocation, and control change/parameter processing are carried out in the C application on the processing system, providing support for MIDI controllers and keyboards. The complete polyphonic design employs about 76% of the available lookup tables of Zybo Z7020, leaving room for additional voices or effect processors in the design.
In addition to the plugging of IP cores in the block design, this subtractive synthesis example highlights a lower layer of plugging in ModFPGA in the form of porting existing audio processing algorithms and plugging them into the ModFPGA, HLS, and FPGA environment. This can be seen in the four-pole filter, which is ported from the Aurora Library, as well as the reverbs module, which was adapted from Csound. The IP cores form the basis of the plugging environment for creating different sound synthesis possibilities in the FPGA environment, and the lower layer involves the plugging of sources for the IP core itself, enabling the expansion of the higher plugging layer.
4.2. FM Synthesis
Frequency modulation (FM) synthesis involves the creation of complex harmonic spectra by modulating the frequency of sine waves at a high rate in the audio range and by a large amount [
42]. FM synthesis uses a single fundamental unit, the sine wave oscillator, which serves both as a sound source and a spectral modifier. A basic FM synthesis setup consists of two sine wave oscillators: a carrier and a modulator. A pair of carrier and modulator oscillators is referred to as an operator.
FM synthesis allows for complex configurations of carriers and modulators, enabling stacked arrangements. For instance, a second modulator can modulate the first modulator, which in turn may modulate the carrier. This capability to form various architectures using the same basic unit makes FM synthesis a versatile technique. Among the available parameters for FM synthesis, we highlight the following: carrier frequency, modulator frequency, and modulation index.
Carrier frequency: This will be the fundamental frequency of the sound produced by the synthesiser.
Modulator frequency: This should be within the audio range (above 20 Hz), and it determines the harmonic content of the resulting sound. The ratio between the carrier and modulator frequencies defines the harmonic structure; whole-number ratios result in harmonic spectra, and non-integer ratios produce inharmonic spectra.
Modulation index: This parameter relates to the amount of modulation or frequency deviation caused by the modulator. It translates to the amount of harmonics being produced in the resultant sound. This parameter is particularly important as a modulation target in creating dynamic spectra. In our design, an envelope generator modulates the modulation index to achieve this.
ModFPGA supports both monophonic and polyphonic FM synthesis designs.
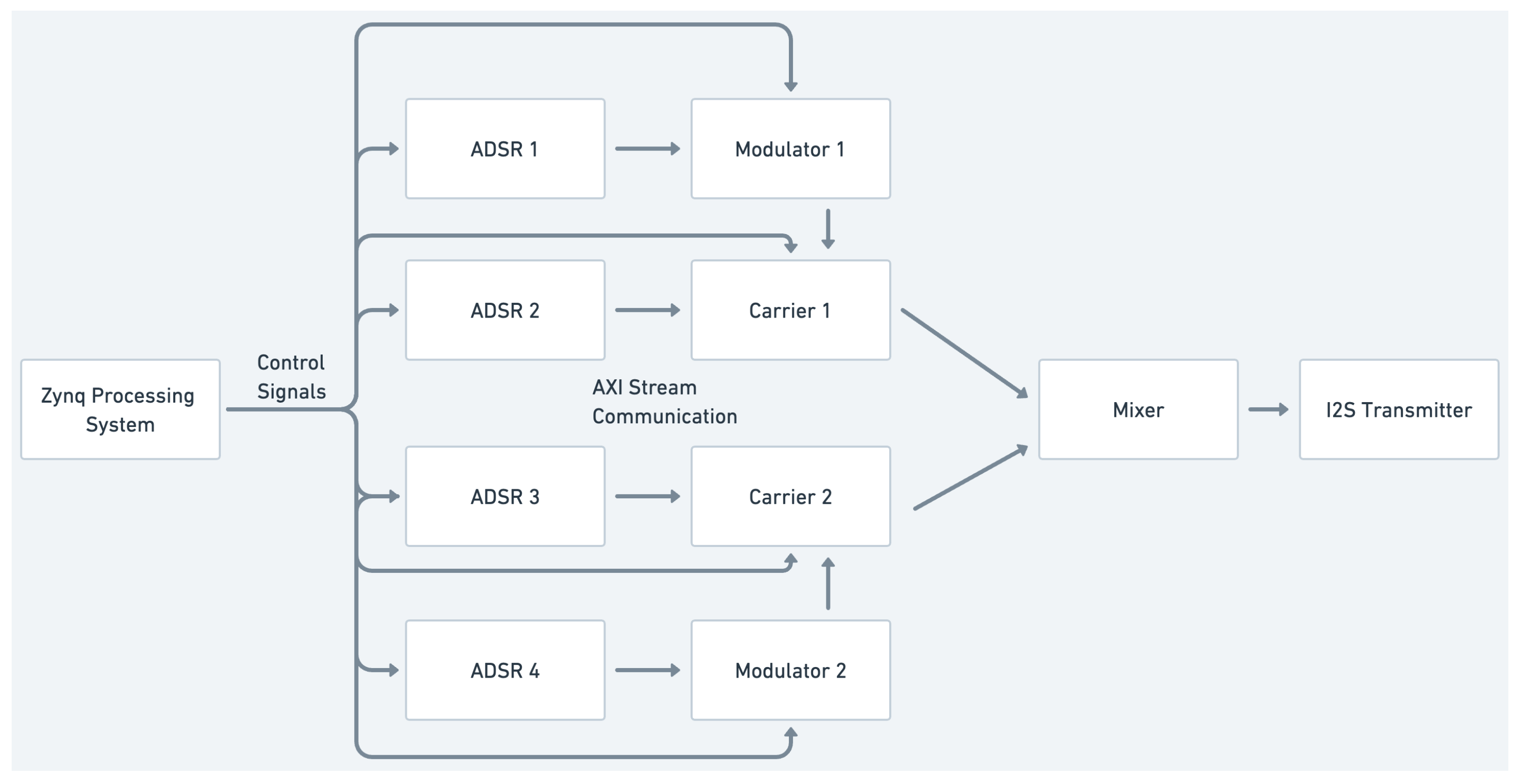
Figure 6 shows a monophonic FM synthesiser with a dual operator design made from individual fmosc modules used as carriers and modulators. In this case, there are more than enough available FPGA resources, so ADSR (attack, decay, sustain, and release) envelope generator modules are run on the programmable logic itself instead of the processing system.
Figure 7 shows a polyphonic FM synthesiser which uses eight separate FM operator IP cores (each containing a carrier and oscillator). In this design, reverbsc is also added so to conserve FPGA resources, and the envelope generators are run on the processing system. Similarly to the previous example, MIDI over UART can be used on the processing system to control or play the polyphonic FM synthesiser.
4.3. Performance Evaluation
This section presents an evaluation of key performance metrics as well as a comparison with two other established embedded audio computing platforms: Bela [
17] and Daisy [
18].
Bela is a single-board computer (SBC) audio platform based on BeagleBone Black. It is a Linux-based system optimised for low audio latency; it is open-source and supports programming with multiple open-source audio languages such as Csound, SuperCollider, PureData, and C++.
Daisy is a bare-metal platform based on the STM32 microcontroller. It features a compact form factor and various breakout boards that facilitate integration into different environments, such as effects pedals or Eurorack modules.
To enable a direct comparison, an equivalent subtractive synthesis program was implemented on each platform, replicating the structure of the ModFPGA subtractive synthesis case. Each implementation consists of eight voices, each containing two oscillators, a FourPole filter, and a ReverbSC reverberator. The Bela implementation was developed using Csound, while the Daisy implementation was written in C++ using the DaisySP library (the source code for the Bela and Daisy implementations is available in the ModFPGA repository).
4.3.1. FPGA Resource Utilisation
Table 4 highlights the resource utilisation of both synthesis cases in the programmable logic (PL) section of the Zynq-7000 SoC.
These values indicate that while both designs utilise more than half of the available resources on the Zynq PL, a substantial amount of resources remain available for further expansion. The available LUTs and FFs suggest that additional voices could be added beyond the current eight-voice configuration. The remaining BRAM capacity allows for the inclusion of additional wavetables or the use of higher-resolution wavetables for improved synthesis fidelity. One significant factor to consider is the impact of the
ReverbSC module on resource utilisation, as shown in
Table 5.
Due to the modular nature of ModFPGA, users can make trade-offs between effects processing and synthesis complexity. For instance, the ReverbSC IP alone occupies a significant portion of the available resources. Users could choose to replace it with additional voices, introduce more oscillators per voice for richer timbres, or prioritise alternative effects. In the current examples, eight voices were sufficient to demonstrate polyphony, making it feasible to include the ReverbSC IP within the available resources.
Furthermore, it is important to note that at this stage, ModFPGA HLS IPs are not fully optimised, as they rely on floating-point operations. While floating-point arithmetic facilitates the direct transfer of existing audio algorithms from other platforms to ModFPGA—as demonstrated by the FourPole module—fixed-point representation could reduce resource consumption and improve performance when deployed in hardware. However, as demonstrated in this section, even without fixed-point optimisation, the current implementation of ModFPGA achieves an acceptable level of performance and latency.
4.3.2. Computational Load Comparison
For Bela and Daisy, performance metrics are typically expressed in terms of CPU load. The
Bela platform provides real-time CPU usage monitoring within its online IDE, while the
Daisy platform reports CPU load via the
CpuLoadMeter helper class in the vendor-supplied
libDaisy hardware abstraction library. With all eight voices engaged, the measured CPU usage for both platforms is shown in
Table 6.
These results indicate that both platforms operate under considerable computational load, with
Bela nearing its maximum processing capacity. In contrast, on the Zynq platform, all audio processing occurs in the programmable logic, with resource utilisation directly quantified through implementation reports, as shown in the tables above. Additionally, only a minimal portion of the processing workload is handled by a single core of the dual-core Cortex-A9 processor, as discussed in
Section 3.5. This leaves significant headroom for additional processing tasks, offering greater scalability compared to CPU-based platforms.
4.3.3. Latency Comparison
To measure and compare latency across the three platforms, a MIDI note-on message was sent from a computer to each device, and the corresponding audio output was recorded back into the computer. The latency was measured as the time elapsed between the onset of the note-on message and the first audio sample returning to the computer. Additionally, a commercial synthesiser, the Makenoise 0-Coast semi-modular synthesiser, was also added to this comparison to provide an industrial benchmark for these measurements.
The measurement setup consisted of a computer running a Digital Audio Workstation (DAW) for sending MIDI messages and receiving audio data, an audio/MIDI interface, and the four devices. The baseline round-trip latency of the system—excluding the audio processing on the boards—was measured at 2.5 ms. Since only the audio input latency into the system is relevant to the final measurements, half of this round-trip latency (1.25 ms) was subtracted from the reported values. Each measurement represents an average of 10 trials, taken separately for monophonic and polyphonic note-on messages on each platform. The 0-Coast is a monophonic synthesiser, so only monophonic readings are included for that device.
The results in
Table 7 indicate that the FPGA-based system achieves lower latency than all the other platforms. Moreover, most of the latency in the FPGA implementation can be attributed to MIDI message processing and audio output transmission from the audio codec rather than the actual audio processing itself.
This was further confirmed by a control measurement of MIDI latency, where MIDI note-on messages were sent to a software instrument within the DAW. The time elapsed between the message and the first generated audio sample was recorded. The software instrument used was a stock synthesiser included with the DAW, Ableton Live, which is rated to have zero additional latency, ensuring an accurate MIDI latency measurement. This test yielded a latency of approximately 4 ms. Subtracting this value from the total measured FPGA platform latency results in effective latencies of 2.55 ms (monophonic) and 4.75 ms (polyphonic) for onboard audio latency resulting from the audio processing on the PL, the software application on the PS, the I2S transmitter IP, and the audio output from the onboard audio codec.
For ModFPGA-specific audio processing latency in the subtractive synthesis case, the total latency can be determined by summing the latencies of the ModFPGA IPs, which are connected in series for each voice. Since all voices are processed in parallel within the Vivado block design, the per-voice processing time represents the longest sequential path any single audio sample must traverse. As a result, the sum of latencies for a single voice can be considered the effective total latency of the entire subtractive synthesiser system. The breakdown of per-module processing latency is presented in
Table 8.
Given a clock period of 8 ns, this per-voice processing latency amounts to 6.008 µs for the complete subtractive synthesiser. Since all voices operate in parallel, this is also the overall system latency for processing an incoming audio sample. This is significantly lower than the 20.83 µs clock period corresponding to a sample rate of 48 kHz, confirming that the FPGA performs real-time sample-by-sample processing. In contrast, both Bela and Daisy process audio in blocks of eight samples to prevent glitches or dropouts, which inherently introduces additional latency. The headroom between the total processing latency of FPGA and the sample period also suggests that the system could operate at higher sample rates, further reducing overall latency. However, the achievable performance is currently constrained by the sampling rate limitations of the onboard audio codec on Zybo Z7020.
4.4. Build Replication
Both complete synthesis cases, as well as each individual IP, can be built and programmed onto the Zybo Z7020 board using the ModFPGA GitHub repository from the command line. Xilinx Software Command Line Tools (XSCTs) [
43] are utilised to automate the build process via TCL scripts.
In terms of hardware setup, both examples respond to MIDI control via the UART protocol. The UART RX signal is mapped to MIO 14 on PMOD JF Pin 9 of the board, and the TX signal is mapped to MIO 15 on Pin 10 of the same PMOD.
To safely interface with these pins and control the synthesiser designs, a standard MIDI controller can be connected using a five-pin DIN cable and an opto-isolated MIDI-to-UART interface, such as a breakout board. Detailed instructions for building, programming the board, and the hardware setup are provided in the repository’s README file.
4.5. Discussion of Results
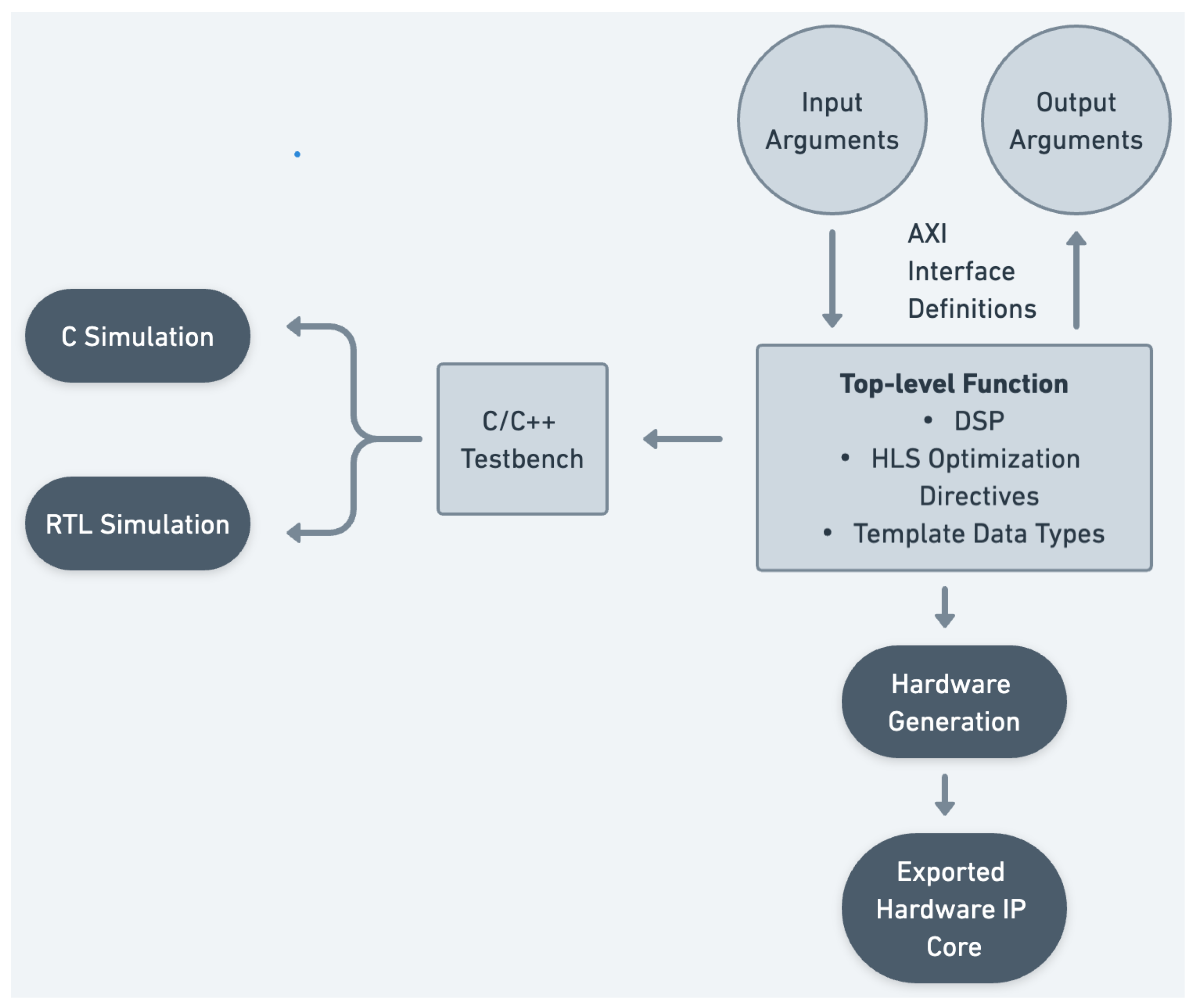
We described the development of a modular synthesis system on FPGA hardware. Our ModFPGA library takes advantage of the platform’s key features, such as low latency, parallelism, and strong processing power, to provide a portable embedded environment for musical applications. The system is designed to be programmed in C/C++ using HLS to facilitate and speed up the prototyping cycle.
A key idea behind our ubimus plugging approach involves the implementation of IP cores as independent modules for synthesis, inspired by analogue modular audio synthesisers. ModFPGA includes a growing repository of source code for these modules, tailored for FPGA hardware. Looking at the block diagram features of the FPGA development cycle, IP cores resemble modular elements within a chip, featuring input and output ports within predefined communication protocols. Their signal processing capabilities are established during the HLS programming methods. Instantiating and interconnecting these cores within the block designs reflects the support of ModFPGA for modularity. Therefore, if each of the IP cores is programmed to perform a specific audio signal processing task, it can be thought of as a synthesiser module. Its inputs and outputs can be thought of as points for plugging actions that yield multiple configurations. By approaching hardware design with a consistent methodology empowered by HLS, our ubimus plugging framework aims to provide access points to users of various skill levels.
High level: Pre-built patches are offered for various types of synthesiser and processor designs that are ready to use. Little or no requirements are imposed besides the ability to connect to hardware and flash the application.
Medium level: Pre-built IP cores are plugged together to set up custom designs. Stakeholders may require some added knowledge on how each IP core interacts and how cores can be connected while handling the tools to build an FPGA architecture.
Low level: A C++ framework is provided for the development of custom IP cores through HLS. Users are required to have audio programming and signal processing skills, as well as a practical understanding of the HLS toolchain.
ModFPGA supports the creation of audio-synthesis systems with the ability to cater to diverse musical requirements using a relatively small set of IP core modules, hence fostering aesthetic pliability, scalability, and composability.
Scalability—Modular synthesisers can be added or subtracted based on performance needs, space constraints, and artistic vision. This means that artists can have a large system with numerous modules in their home setup and have a smaller portable system containing their core modules that can be used for performances and supporting their artistic needs. In the FPGA-based ubimus plugging framework, this translates to being able to select FPGA resources. On a smaller chip with fewer resources, fewer modules are instantiated to create a ‘portable’ version of the system. A bigger chip with more resources enables a more comprehensive set. Since both designs are based on the same platform, synergy and continuity across different scenarios are supported.
Composability—Interconnecting modules to create unique signal chains, a key activity in the plugging framework, fosters the use of multiple synthesis techniques and sonic transformations without requiring an expansion of components. The deployment of just a few FPGA-based modules can result in multiple sonic results on a single chip. Due to being composable, our framework provides a complement to fixed-circuit synthesisers that tend to be tailored to limited functionality [
44].
Modularity—Being ‘field-programmable’, FPGAs allow different hardware systems to be created by reprogramming their logic units. Our modular IP core synthesis platform embraces this concept at a high level. By reconfiguring the interconnections between IP core modules, new audio synthesis systems can be created on the fly. This modularity mirrors the adaptive nature of FPGAs, allowing the practitioners to reprogram both the hardware and the signal-processing architecture without having to deal with the underlying complexities. For example, in the polyphonic FM synthesis design, each operator is processed in parallel by instantiating separate cores in the block design. Similarly, in the polyphonic subtractive synthesis example, the eight separate filters are processed in parallel. This modular approach not only harnesses both parallelism and high throughput, but it also features greater flexibility in designing complex audio processing systems.
Flexible temporalities—Latency can be further reduced by introducing parallelism through HLS pragmas. For instance, with the OscBank module, we have already observed the impact of pipelining on latency with different pipeline factors. However, latency can be further minimised by unrolling processing loops. The band-limited oscillator bank module already utilises pipelining, but it can also be configured to process each voice on separate, replicated hardware using the HLS UNROLL pragma. This directive unrolls processing loops, effectively duplicating the hardware for each voice, allowing all voices to be processed simultaneously rather than sequentially.
In our design, we chose not to unroll the loop to conserve FPGA resources, demonstrating the flexibility of managing timing, sequencing, and parallelism as needed. Unrolling increases the FPGA resource utilisation, significantly reducing latency and enhancing the system’s throughput. By processing multiple streams in parallel, the system can take full advantage of the FPGA capacity to handle a large volume of data in a very short time, thus maximising throughput. Furthermore, although the audio sample rate is limited to 48 kHz due to the onboard audio codec of the Zybo board, each IP core operates at a much higher clock speed (125 MHz). In the examples, each oscillator takes around 200 clock cycles to process one sample, with a minimum sampling period of 1.6 microseconds, allowing the core to achieve an effective sampling rate of 625 kHz. With the use of unrolling and parallelisation, as explained above, this sampling rate could be further increased, enabling the implementation of advanced synthesis techniques such as higher-order FM or virtual analogue emulations.
Aesthetic pliability—The musical examples of the two implemented prototypes highlight the ability of ModFPGA-based synthesis techniques to deliver high-quality and diverse sonic outcomes. However, this is, of course, just a small fraction of the range of applications supported by the library. In the future, the exploratory nature of fast hardware prototyping may support emerging ubimus frameworks that comprise human–computer interaction techniques and audio synthesis and processing know-how. Consider, for instance, struck-string interaction. This approach to piano-like timbre fosters the deployment of generative techniques that explore the boundaries between tuning and sonic qualities. At the time of writing, implementations of timbre-oriented tunings based on synchronous tracking of sonic information are still works in progress. ModFPGA could be deployed to enable alternative architectures involving fairly short hardware-design cycles.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}