
LLMs for Commit Messages: A Survey and an Agent-Based Evaluation Protocol on CommitBench


Abstract
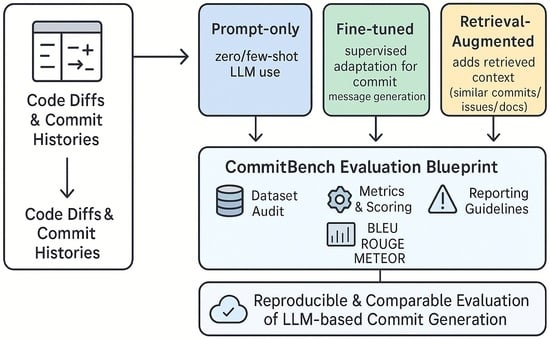
1. Introduction
2. Related Work
2.1. Commit Message Quality and Its Importance
2.2. Automated Commit Message Generation Approaches
2.3. Technical Background
2.3.1. Transformer Architectures
2.3.2. Fine-Tuning for Commit Message Generation
2.3.3. Retrieval-Augmented Generation (RAG)
2.4. Large Language Models for Commit Message Generation and Integration
2.5. Comparative Method Matrix
2.6. Tooling Examples Across Paradigms
2.7. Error Taxonomies in Commit Message Generation
2.8. Summary
Illustrative Examples
- Ideal message: states what changed and why it changed; uses clear, imperative mood; links to issues/tickets when relevant; and scopes the change precisely (no unrelated edits).
- Common pitfalls (messy): vague phrases (e.g., “fix login”), no rationale, no reference to the related issue, and overly broad or ambiguous scope.
3. Problem Statement and Research Gap
3.1. Systematic Benchmarking Deficit
3.2. Generalization and Transferability Challenges
3.3. Evaluation Metrics and Usability Limitations
3.4. Practical Integration and Deployment Barriers
3.5. Underutilization of CommitBench
- Bogomolov et al. [26] used CommitBench within a broader benchmark suite for long-context code models, without focusing on commit message generation.
- Zhao et al. [27] referenced CommitBench for evaluating LLM code understanding, but did not generate or benchmark commit messages.
- Cao et al. [28] profiled CommitBench in a meta-analysis of code-related benchmarks but did not conduct direct experiments on commit message generation.
3.6. Research Objective
4. Methodology
4.1. Walkthrough Example
- Toy Commit (input git diff)
−−− a/auth/login.py
+++ b/auth/login.py
@@ def login(user, password):
− token = issue_token(user.id)
− logger.info("login ok")
− return token
+ try:
+ token = issue_token(user.id)
+ logger.info("login ok")
+ return token
+ except TokenError as e:
+ logger.error(f"token failure: {e}")
+ return None
- Step 1—Dataset preprocessing
- Step 2—Optional retrieval (RAG)
- Step 3—Prompt construction
- Step 4—Generation
- Step 5—Evaluation
- Outcome
4.2. Dataset Collection and Preparation
4.2.1. Source: CommitBench
4.2.2. Record Schema and Example
4.2.3. Dataset Landscape
4.2.4. Preprocessing Impacts
4.3. Dataset Preprocessing Analysis
4.4. Model Selection, Training, and Evaluation
4.4.1. Modeling Paradigms
- Generic LLMs (zero-/few-shot): Prompt-engineered proprietary or open-source LLMs without repository-specific retrieval or task-specific fine-tuning.
- RAG-augmented LLMs: The model receives the current git diff plus retrieved context (similar past commits, issues, docs) from a vector index.
- Fine-tuned LLMs: Supervised training on CommitBench pairs (diff, message) to specialize the base model for CMG.

4.4.2. Model Suite
4.4.3. Training Procedure
4.4.4. Evaluation Metrics
Reference-Based Metrics
Human Evaluation
- Operational measures.
4.5. Integration and Implementation
4.5.1. System Architecture
4.5.2. Implementation Challenges
4.5.3. User Feedback and Continuous Improvement
4.6. Reproducibility Checklist
- Model identifiers, provider, and version/date (e.g., GPT-4-0613).
- Prompts: full text including few-shot exemplars and stop sequences.
- Hyperparameters: temperature, top-p, max tokens, learning rate, batch size, and sequence length.
- Tokenization and preprocessing rules (e.g., Unicode normalization and identifier preservation).
- Seed control for reproducibility.
- Dataset version and exact split recipe (CommitBench release and stratification).
- Evaluation scripts, metric variants (e.g., ROUGE-L), and postprocessing rules.
- Operational settings: latency measurement method, cost estimation (tokens × USD/1K).
4.7. Compute Resources and Constraints
4.8. Limitations and Future Directions
4.8.1. Limitations
4.8.2. Future Work
4.9. Ethical Considerations
4.10. Post-Evaluation Deployment Pipeline
Deployment Illustration
5. Discussion
5.1. Implications for Research and Practice
5.2. Protocol Design Choices and Trade-Offs
5.3. Human Evaluation Considerations
5.4. Reporting and Reproducibility
5.5. Threats to Validity
5.6. Ethical and Responsible Use
5.7. Limitations and Extensions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| LLM | Large Language Model |
| CMG | Commit Message Generation |
| NMT | Neural Machine Translation |
| RAG | Retrieval-Augmented Generation |
| BLEU | Bilingual Evaluation Understudy |
| ROUGE | Recall-Oriented Understudy for Gisting Evaluation |
| METEOR | Metric for Evaluation of Translation with Explicit ORdering |
References
- Zhang, Y.; Qiu, Z.; Stol, K.-J.; Zhu, W.; Zhu, J.; Tian, Y.; Liu, H. Automatic commit message generation: A critical review and directions for future work. IEEE Trans. Softw. Eng. 2024, 50, 816–835. [Google Scholar] [CrossRef]
- Li, J.; Ahmed, I. Commit message matters: Investigating impact and evolution of commit message quality. In Proceedings of the 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), Melbourne, Australia, 15–16 May 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 806–817. [Google Scholar]
- Tian, Y.; Zhang, Y.; Stol, K.-J.; Jiang, L.; Liu, H. What makes a good commit message? In Proceedings of the 44th International Conference on Software Engineering (ICSE ’22), Pittsburgh, PA, USA, 21–29 May 2022; ACM: New York, NY, USA, 2022; pp. 2389–2401. [Google Scholar] [CrossRef]
- Xue, P.; Wu, L.; Yu, Z.; Jin, Z.; Yang, Z.; Li, X.; Yang, Z.; Tan, Y. Automated commit message generation with large language models: An empirical study and beyond. IEEE Trans. Softw. Eng. 2024, 50, 3208–3224. [Google Scholar] [CrossRef]
- Hou, X.; Zhao, Y.; Liu, Y.; Yang, Z.; Wang, K.; Li, L.; Luo, X.; Lo, D.; Grundy, J.; Wang, H. Large language models for software engineering: A systematic literature review. ACM Trans. Softw. Eng. Methodol. 2024, 33, 1–79. [Google Scholar] [CrossRef]
- Lopes, C.V.; Klotzman, V.I.; Ma, I.; Ahmed, I. Commit messages in the age of large language models. arXiv 2024, arXiv:2401.17622. [Google Scholar] [CrossRef]
- Zhang, L.; Zhao, J.; Wang, C.; Liang, P. Using large language models for commit message generation: A preliminary study. In Proceedings of the 2024 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), Rovaniemi, Finland, 12–15 March 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 126–130. [Google Scholar]
- Jiang, S.; Armaly, A.; McMillan, C. Automatically generating commit messages from diffs using neural machine translation. In Proceedings of the 2017 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE), Urbana, IL, USA, 30 October–3 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 135–146. [Google Scholar]
- Liu, Z.; Xia, X.; Hassan, A.E.; Lo, D.; Xing, Z.; Wang, X. Neural-machine-translation-based commit message generation: How far are we? In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, Montpellier, France, 3–7 September 2018; pp. 373–384. [Google Scholar]
- Nie, L.Y.; Gao, C.; Zhong, Z.; Lam, W.; Liu, Y.; Xu, Z. Coregen: Contextualized code representation learning for commit message generation. Neurocomputing 2021, 459, 97–107. [Google Scholar] [CrossRef]
- He, Y.; Wang, L.; Wang, K.; Zhang, Y.; Zhang, H.; Li, Z. Come: Commit message generation with modification embedding. In Proceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, Seattle, WA, USA, 17–21 July 2023; pp. 792–803. [Google Scholar]
- Zhang, Q.; Fang, C.; Xie, Y.; Zhang, Y.; Yang, Y.; Sun, W.; Yu, S.; Chen, Z. A survey on large language models for software engineering. arXiv 2023, arXiv:2312.15223. [Google Scholar] [CrossRef]
- Li, J.; Faragó, D.; Petrov, C.; Ahmed, I. Only diff is not enough: Generating commit messages leveraging reasoning and action of large language model. Proc. ACM Softw. Eng. 2024, 1, 745–766. [Google Scholar] [CrossRef]
- Beining, Y.; Alassane, S.; Fraysse, G.; Cherrared, S. Generating commit messages for configuration files in 5G network deployment using LLMs. In Proceedings of the 2024 20th International Conference on Network and Service Management (CNSM), Prague, Czech Republic, 28–31 October 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–7. [Google Scholar]
- Pandya, K. Automated Software Compliance Using Smart Contracts and Large Language Models in Continuous Integration and Continuous Deployment with DevSecOps. Master’s Thesis, Arizona State University, Tempe, AZ, USA, 2024. [Google Scholar]
- Kruger, J. Embracing DevOps Release Management: Strategies and Tools to Accelerate Continuous Delivery and Ensure Quality Software Deployment; Packt Publishing Ltd.: Birmingham, UK, 2024. [Google Scholar]
- Schall, M.; Czinczoll, T.; De Melo, G. Commitbench: A benchmark for commit message generation. In Proceedings of the 2024 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), Rovaniemi, Finland, 12–15 March 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 728–739. [Google Scholar]
- Huang, Z.; Huang, Y.; Chen, X.; Zhou, X.; Yang, C.; Zheng, Z. An empirical study on learning-based techniques for explicit and implicit commit messages generation. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, Sacramento, CA, USA, 27 October–1 November 2024; pp. 544–555. [Google Scholar]
- Gao, C.; Hu, X.; Gao, S.; Xia, X.; Jin, Z. The current challenges of software engineering in the era of large language models. ACM Trans. Softw. Eng. Methodol. 2025, 34, 1–30. [Google Scholar] [CrossRef]
- Palakodeti, V.K.; Heydarnoori, A. Automated generation of commit messages in software repositories. arXiv 2025, arXiv:2504.12998. [Google Scholar] [CrossRef]
- Bektas, A. Large Language Models in Software Engineering: A Critical Review of Evaluation Strategies. Master’s Thesis, Freie Universität Berlin, Berlin, Germany, 2024. [Google Scholar]
- Liu, Y.; Chen, J.; Bi, T.; Grundy, J.; Wang, Y.; Yu, J.; Chen, T.; Tang, Y.; Zheng, Z. An empirical study on low-code programming using traditional vs large language model support. arXiv 2024, arXiv:2402.01156. [Google Scholar]
- Don, R.G.G. Comparative Research on Code Vulnerability Detection: Open-Source vs. Proprietary Large Language Models and Lstm Neural Network. Master’s Thesis, Unitec Institute of Technology, Auckland, New Zealand, 2024. [Google Scholar]
- Sultana, S.; Afreen, S.; Eisty, N.U. Code vulnerability detection: A comparative analysis of emerging large language models. arXiv 2024, arXiv:2409.10490. [Google Scholar] [CrossRef]
- Wang, S.-K.; Ma, S.-P.; Lai, G.-H.; Chao, C.-H. ChatOps for microservice systems: A low-code approach using service composition and large language models. Future Gener. Comput. Syst. 2024, 161, 518–530. [Google Scholar] [CrossRef]
- Bogomolov, E.; Eliseeva, A.; Galimzyanov, T.; Glukhov, E.; Shapkin, A.; Tigina, M.; Golubev, Y.; Kovrigin, A.; van Deursen, A.; Izadi, M.; et al. Long code arena: A set of benchmarks for long-context code models. arXiv 2024, arXiv:2406.11612. [Google Scholar] [CrossRef]
- Zhao, Y.; Luo, Z.; Tian, Y.; Lin, H.; Yan, W.; Li, A.; Ma, J. Codejudge-eval: Can large language models be good judges in code understanding? arXiv 2024, arXiv:2408.10718. [Google Scholar]
- Cao, J.; Chan, Y.-K.; Ling, Z.; Wang, W.; Li, S.; Liu, M.; Wang, C.; Yu, B.; He, P.; Wang, S.; et al. How should I build a benchmark? arXiv 2025, arXiv:2501.10711. [Google Scholar]
- Kosyanenko, I.A.; Bolbakov, R.G. Dataset collection for automatic generation of commit messages. Russ. Technol. J. 2025, 13, 7–17. [Google Scholar] [CrossRef]
- Li, Y.; Huo, Y.; Jiang, Z.; Zhong, R.; He, P.; Su, Y.; Bri, L.C.; Lyu, M.R. Exploring the effectiveness of LLMs in automated logging statement generation: An empirical study. IEEE Trans. Softw. Eng. 2024, 50, 3188–3207. [Google Scholar] [CrossRef]
- Allam, H. Intelligent automation: Leveraging LLMs in DevOps toolchains. Int. J. AI Bigdata Comput. Manag. Stud. 2024, 5, 81–94. [Google Scholar] [CrossRef]
- Ragothaman, H.; Udayakumar, S.K. Optimizing service deployments with NLP-based infrastructure code generation—An automation framework. In Proceedings of the 2024 IEEE 2nd International Conference on Electrical Engineering, Computer and Information Technology (ICEECIT), Jember, Indonesia, 22–23 November 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 216–221. [Google Scholar]
- Joshi, S. A review of generative AI and DevOps pipelines: CI/CD, agentic automation, MLOps integration, and large language models. Int. J. Innov. Res. Comput. Sci. Technol. 2025, 13, 1–14. [Google Scholar] [CrossRef]
- Coban, S.; Mattukat, A.; Slupczynski, A. Full-Scale Software Engineering. Master’s Thesis, RWTH Aachen University, Aachen, Germany, 2024. [Google Scholar]
- Krishna, A.; Meda, V. AI Integration in Software Development and Operations; Springer: Berlin/Heidelberg, Germany, 2025. [Google Scholar]
- Gandhi, A.; De, S.; Chechik, M.P.; Pandit, V.; Kiehn, M.; Chee, M.C.; Bedasso, Y. Automated codebase reconciliation using large language models. In Proceedings of the 2025 IEEE/ACM Second International Conference on AI Foundation Models and Software Engineering (Forge), Ottawa, ON, Canada, 27–28 April 2025; IEEE: Piscataway, NJ, USA, 2025; pp. 1–11. [Google Scholar]
- Cihan, U.; Haratian, V.; İçöz, A.; Gül, M.K.; Devran, O.; Bayendur, E.F.; Uçar, B.M.; Tüzün, E. Automated code review in practice. arXiv 2024, arXiv:2412.18531. [Google Scholar] [CrossRef]
- Parveen, R. Investigating T-BERT for Automated Issue–Commit Link Recovery. Master’s Thesis, University of Tampere, Tampere, Finland, 2025. [Google Scholar]
- Jaju, I. Maximizing DevOps Scalability in Complex Software Systems. Master’s Thesis, Uppsala University, Department of Information Technology, Uppsala, Sweden, 2023; p. 57. [Google Scholar]
- Kolawole, I.; Fakokunde, A. Machine learning algorithms in DevOps: Optimizing software development and deployment workflows with precision. Int. J. Res. Publ. Rev. 2025, 2582, 7421. [Google Scholar] [CrossRef]
- Zhang, X.; Muralee, S.; Cherupattamoolayil, S.; Machiry, A. On the effectiveness of large language models for GitHub workflows. In Proceedings of the 19th International Conference on Availability, Reliability and Security, Vienna, Austria, 30 July–2 August 2024; pp. 1–14. [Google Scholar]
- Fernandez-Gauna, B.; Rojo, N.; Graña, M. Automatic feedback and assessment of team-coding assignments in a DevOps context. Int. J. Educ. Technol. High. Educ. 2023, 20, 17. [Google Scholar] [CrossRef]
- Cellamare, F.P. AI-Driven Unit Test Generation. Ph.D. Thesis, Politecnico di Torino, Torino, Italy, 2025. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paradigm | Mechanism | Strengths | Limitations |
|---|---|---|---|
| Prompt-only LLMs | Zero-/few-shot prompting of proprietary or open-source LLMs. No task-specific training. | Easy to adopt; no infra; flexible across repos. | Highly prompt-sensitive; context-window limited; costly per call; privacy risks with API use. |
| Fine-tuned LLMs | Supervised training on diff–message pairs. Model specialized for CMG. | Stable performance; adapts to repo style; cheaper per inference. | High compute cost; risk of drift; licensing/IP issues; less flexible for rapid model switching. |
| RAG-augmented LLMs | Diff + retrieved similar commits/issues/docs fed to LLM. | Grounded outputs; style alignment; avoids retraining. | Extra retrieval latency; index maintenance overhead; contamination risks. |
| Paradigm | Example | Notes |
|---|---|---|
| Prompt-only | GitHub Copilot Chat; OpenCommit (OSS CLI) | Suggests commit summaries via API prompts. Sensitive to wording; no repo history. |
| Fine-tuned | CoMe model [11]; CodeT5+ finetunes | Trained on labeled diffs; stronger style control; requires compute + licenses. |
| RAG-augmented | Custom Git hooks with local vector DB; experimental CI plugins [22] | Retrieves similar past commits or issue links; latency + index maintenance are challenges. |
| Study | Dataset | Methodology | Metrics | Limitations |
|---|---|---|---|---|
| Jiang et al. [8] | Proprietary Java diffs | Seq2Seq NMT | BLEU, human | Shallow semantics; poor generalization |
| Liu et al. [9] | Proprietary diffs | NMT + AST features | BLEU | Java-specific; lacks multilingual coverage |
| Nie et al. [10] | Proprietary | Contextual code embeddings | BLEU, METEOR | No benchmark-scale evaluation |
| He et al. [11] | Proprietary | Modification embeddings | BLEU, ROUGE | Dataset tuning; weak generalization |
| Huang et al. [18] | Proprietary | Explicit/implicit CMG | BLEU | Underperforms on unseen projects |
| Schall et al. [17] | CommitBench | Multiple baselines | BLEU, ROUGE | Lacks human evaluation |
| Xue et al. [4] | Proprietary | LLM-based CMG | BLEU, ROUGE | Single LLM; low diversity |
| Beining et al. [14] | Proprietary | LLMs for config commits | BLEU, ROUGE | Domain-specific; not generalizable |
| Palakodeti & Heydarnoori [20] | Proprietary | LLM-based CMG | BLEU | No DevOps integration |
| Wang et al. [25] | Proprietary | Low-code ChatOps + LLM | BLEU, human | Peripheral CMG focus |
| This work (protocol) | CommitBench | Multi-LLM ensemble | BLEU, ROUGE, METEOR, human | Protocol only; results forthcoming |
| Research Question | Motivation |
|---|---|
| RQ1: How do modern LLMs (e.g., ChatGPT, DeepSeek, LLaMA) compare in generating high-quality commit messages? | Identify the most effective model for practical commit message generation to guide academic benchmarking and tool selection. |
| RQ2: How well do automated metrics (BLEU, ROUGE, and METEOR) align with human perceptions (clarity, informativeness, relevance)? | Test whether common metrics reflect human-centered quality; determine if additional evaluation is needed [2]. |
| RQ3: How does performance vary across commit types, domains, and languages within CommitBench? | Support generalization/robustness analysis across diverse software contexts. |
| Field | Type | Description |
|---|---|---|
| hash | string (40 chars) | Git commit SHA for traceability and deduplication. |
| diff | string (unified diff) | Normalized patch (added/removed hunks); primary model input. |
| message | string | Reference commit message (supervision/evaluation). |
| project | string | Repository identifier (stratified splitting/domain analysis). |
| split | categorical | Dataset partition: train/validation/test. |
| diff_languages | string/set | Languages inferred from changed files (e.g., py, js, php). |
| Criteria/Dataset | CommitGen | CoDiSum | CommitBERT | MCMD | CommitBench |
|---|---|---|---|---|---|
| Train size | 26,208 | 75,000 | 276,392 | 1,800,000 | 1,165,213 |
| Valid size | 3000 | 8000 | 34,717 | 225,000 | 249,689 |
| Test size | 3000 | 7661 | 34,654 | 225,000 | 249,688 |
| Repositories | 1000 | 1000 | 52 k | 500 | 72 k |
| Reproducible | ✗ | ✗ | ✓ | ✓ | ✓ |
| Deduplicated | ✗ | ✓ | ✓ | ✓ | ✓ |
| License-aware | ✗ | ✗ | ✓ | ✓ | ✓ |
| Published license | ✗ | Apache 2.0 | – | – | CC BY-NC |
| Programming languages | Java | Java | Java, Ruby, JS, Go, PHP, Python | Java, C#, C++, Python, JavaScript | Java, Ruby, JS, Go, PHP, Python |
| Step | Motivation | Observed Impact |
|---|---|---|
| Deduplication/filter merges | Remove trivial/duplicate commits | Prevents data leakage; avoids inflated BLEU from repeated examples. In our case, no duplicates were found after normalization. |
| Lowercasing + Unicode normalization | Standardize tokens across repositories/languages | Stabilizes BLEU/ROUGE; improves cross-language consistency. |
| Preserve identifiers and punctuation | Identifiers are semantically critical in CMG | Avoids semantic drift; improves human judgments even if BLEU unchanged. |
| Length bounds (min/max) | Filter trivial commits (e.g., “update”) and very large diffs | Avoids skew; improves interpretability of error taxonomy. |
| Subword tokenization (BPE) | Handle rare identifiers and compound tokens | Better generalization to unseen projects; reduces OOV errors. |
| Stratified splitting | Balance projects and languages across train/val/test | Prevents leakage; yields more reliable macro-level reporting. 1 |
| Category | Count |
|---|---|
| Raw total (after normalization) | 1,165,213 |
| Duplicates removed | 0 |
| Bot-like commits removed | 122 |
| Trivial commits removed | 9294 |
| Length-based filtering | 871 |
| Final cleaned total | 1,154,926 |
| Balanced evaluation set | 576,342 (96,057 per language) |
| Dimension | Metric | Definition/Purpose | Report as |
|---|---|---|---|
| Reference-based | BLEU-4 | 4-gram precision with brevity penalty; standard overlap proxy for short commit messages [4,5]. | Mean ± 95% CI; micro & macro. |
| Reference-based | ROUGE-Lsum | Longest common subsequence; captures sequence-level overlap robust to small reorderings [4]. | Mean ± 95% CI; micro & macro. |
| Reference-based | METEOR | Stem/synonym-aware alignment; stronger correlation on short texts [5]. | Mean ± 95% CI; micro & macro. |
| Human judgment | Clarity (1–5) | Is the message easy to read and unambiguous? Two raters per sample. | Mean, median; / for agreement. |
| Human judgment | Informativeness (1–5) | Does it capture the essential what and the relevant why? [3]. | Mean, median; /. |
| Human judgment | Relevance (1–5) | Does it accurately reflect the given diff without scope drift? | Mean, median; /. |
| Human judgment | Error taxonomy (E1–E8) | Qualitative failure modes: missing what/why, hallucination, scope drift, style violations, ambiguity, incorrect rationale, and formatting issues. | Prevalence (%), per-model breakdown. |
| Operational | Latency | End-to-end generation time (ms). | p50/p95; per-model. |
| Operational | Tokens (prompt/gen) | Token counts for input and output; proxy for cost/limits. | Mean, p95; per-model. |
| Operational | Unit cost | Estimated USD/1K tokens (if applicable). | Mean; sensitivity range. |
| Operational | Style compliance | Share of outputs meeting guidelines (imperative mood, concise, correct scope, ticket reference). | Rate (%); per-model. |
| Operational | Length (chars/words) | Distribution of output size for readability and policy checks. | Mean, p95. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trigui, M.M.; Al-Khatib, W.G. LLMs for Commit Messages: A Survey and an Agent-Based Evaluation Protocol on CommitBench. Computers 2025, 14, 427. https://doi.org/10.3390/computers14100427
Trigui MM, Al-Khatib WG. LLMs for Commit Messages: A Survey and an Agent-Based Evaluation Protocol on CommitBench. Computers. 2025; 14(10):427. https://doi.org/10.3390/computers14100427
Chicago/Turabian StyleTrigui, Mohamed Mehdi, and Wasfi G. Al-Khatib. 2025. "LLMs for Commit Messages: A Survey and an Agent-Based Evaluation Protocol on CommitBench" Computers 14, no. 10: 427. https://doi.org/10.3390/computers14100427
APA StyleTrigui, M. M., & Al-Khatib, W. G. (2025). LLMs for Commit Messages: A Survey and an Agent-Based Evaluation Protocol on CommitBench. Computers, 14(10), 427. https://doi.org/10.3390/computers14100427