1. Introduction
Face detection and analysis techniques are being targeted as a biometric verification tool to address challenging issues related to computer vision and security such as face recognition, identity verification, human–computer interactions, etc. [
1,
2]. Face recognition technology (FRT) has garnered significant attention and has been the subject of extensive research and development since the 1990s [
3,
4,
5]. The concept of face recognition technology refers to a model’s ability to distinguish a human face in an image or video stream [
6]. Face recognition involves two primary tasks: face detection, which entails finding and locating human faces, and face verification, which relies on recognizing an individual facial features to determine and confirm the identification.
Researchers initially targeted modeling FRT using concepts such as the Markov model and genetic algorithms. However, since AlexNet [
7] emerged as the winner of the ImageNet competition in 2012, the trend for modeling FRT has shifted towards using deep learning. Deep Convolutional Neural Networks (CNNs) have been widely adopted to provide intelligent solutions for complex programming scenarios since they can learn new pattern representations and make accurate decisions [
8,
9]. The use of CNNs to identify a person’s facial features has yielded impressive results [
2]. For example, the VGG group at the University of Oxford introduced VGGFace [
10] for facial features analysis. Subsequently, numerous deep neural networks (DNNs) for face detection and recognition have been developed in the field of deep learning, such as FaceNet, DeepFace, VGGFace and VGGFace2, OpenFace, ResNet Face, etc. [
11,
12]. Among these, VGGFace has shown excellent results in face recognition for various applications. This can be attributed to its good training using millions of diverse facial images [
10]. Furthermore, implementing a real-time face recognition model, i.e., VGGFace, requires an object detector to locate targeted objects and surround them within a bounding box [
13]. Several improvements of CNN-based improvements with remarkable detection performance were introduced as object detectors, such as region-based CNNs (R-CNNs), fast R-CNN, and single-shot multibox detector (SSD) [
14,
15]. However, the YOLO (you look only once) algorithm has become a leading model for object detection due to its ability to accurately detect various objects in real-time [
13]. Building on the improvements of earlier YOLO versions, YOLOv8 introduces new features and optimizations, such as incorporating an anchor-free split, to make it an excellent detector for a variety of object detection tasks across numerous applications. Additionally, it offers an optimal accuracy–speed tradeoff while delivering cutting-edge object detection performance [
16].
Additionally, tasks related to human faces, such as age estimation, hair detection and classification, gender recognition, and smile detection, have been conveyed in a variety of advanced artificial intelligence (AI) applications such as gesture recognition, pedestrian face tracking, forensic investigations, automated authentication, etc., to provide more accurate descriptions and conformations [
4,
5]. These facial-based tasks have typically been explored individually using CNNs. However, since tasks based on facial features share correlated attributes, they can be learned simultaneously to significantly reduce training and inference time [
2]. Single-task learning (STL) focuses on optimizing models for individual independent tasks. Each model is trained separately for its specific objective, which allows the model to specialize effectively in solving particular problems. Thus, it is inefficient for systems requiring solutions to multiple related tasks simultaneously. It is often used for optimizing task-specific objectives to maintain simplicity and specialization due to its suitability to solve problems with abundant labeled data. Thus, unlike single-task learning (STL), which incurs extensive training time, multitask learning (MTL) has emerged to boost learning performance by concurrently learning multiple correlated tasks [
2,
17]. The multitasking pipeline aligns more closely with the principles of MTL. In this context, MTL improves the computational efficiency of the computing architecture by enabling simultaneous face detection and analysis tasks, resulting in improved performance and further generalization of the classifiers. However, the common challenge facing MTL is that learning multiple tasks simultaneously may cause interference and increased model complexity. Interestingly, this can be addressed by balancing classes in the dataset, hyperparameter tuning, and assigning adaptive weights to the loss functions [
18].
Several scholarly studies have demonstrated that the MTL approach has improved the performance of individual tasks while also reducing training time, inference time, and computational cost [
17,
18,
19,
20]. This is due to MTL involving the simultaneous learning of multiple related tasks by sharing features and parameters across complementary classification modules. For instance, training a classifier to learn the gender and age of an individual, rather than training them separately in a sequential manner, can be accomplished in parallel as long as both attributes contribute the same extracted face feature map [
1,
2].
On the other hand, researchers are intensively concentrating on reducing the need for GPU clusters for AI inference by deploying computationally intensive operations of complicated models with a high-speed, scalable, and cost-effective architecture on CPU-based computing devices [
21]. This is due to the accelerated computational ability of a DNN architecture, which can increase its capability to perform computeationally intensive applications with a relatively short execution time, allowing for further human–machine interactions in real-time such as face detection and recognition. Moreover, significant effort has been devoted to enhancing the sophistication of DL models, particularly those deployed on resource-constrained devices [
22]. Consequently, edge computing (EC) has proven to be an efficient computing architecture for distributing DL tasks across edge devices and expediting the execution via parallel processing [
23]. However, the complexity of DL tasks presents a major burden that hinders the ability to offload computationally intensive models on resource-constrained edge devices. Hence, computation offloading has emerged as an equivalent solution that offloads intensive computations to a powerful processing unit, i.e., a CNN-based feature extraction phase. In contrast, lightweight tasks for decision-making are distributed to edge computing devices [
22].
Moreover, partitioning a multi-layer DNN network between on-device inference and edge nodes has been introduced to speed up inference time [
8]. In this case, the edge inference handles the initial layers and then uploads the intermediate result to the edge server to process the remaining layers and produce the final result. Nevertheless, when uploading an extensive task to the edge server, it requires a long processing time, impacting overall system performance [
24,
25]. Therefore, partitioning a DNN model among multiple edge computing devices allows for collaboration on DNN inference between edge devices and the edge server to improve DNN inference performance [
25].
A method of distributing DNN inference to an edge device and then dividing the task into multiple threads was presented in [
23] to enable parallel processing on a multicore edge processor to further improve processing performance. Despite mainstream adoption of the multicore architecture, there is a lack of studies exploring the use of parallel multicore architectures to speed up the training and, more importantly, inference time for DNN architectures. Therefore, in this study, we propose a novel architecture that offers an innovative approach to optimize the training of deep learning models via the use of MTL and accelerate the inference time on CPU-based resource-constrained edge devices. The proposed architecture employs pipelining and parallelism techniques among the multicores of an edge server and lightweight edge computing devices to efficiently tackle the complexity of the required operations, enabling them to overcome the expense of powerful CPUs. Our proposed parallel-multithreaded model is a fully pipelined neural network architecture that is mainly designed to accelerate the inference of deep face analysis without compromising accuracy. We leverage multitask learning, pipeline, and multithreading techniques with edge computing to optimize the training and inference time using multiple cores of processors. The proposed architecture involves multiple dependent DNN models incorporated to perform consecutive tasks for deep face analysis. Below, we list the primary contributions of this manuscript as follows:
This paper is the first to utilize multithreading to distribute face detection and analysis algorithms across multiple processing cores while exploiting pipelining and parallelism techniques.
We combine deep neural networks, computer architecture, and edge computing as complementary fields to develop an innovative computing offloading pipeline-parallel architecture for deep face analysis.
The presented model distributes and classifies face analysis tasks (algorithms) based on their level of computational complexity such that intensive computational tasks are assigned to powerful processor cores, whereas lightweight tasks are offloaded to resource-constrained edge computing devices located at the edges of the proposed framework.
We implement a unified multitask learning approach throughout the training phase, which allows the model to learn multiple correlated tasks simultaneously, thereby significantly reducing training and inference time and memory usage.
We created two custom datasets for head detection and face-age recognition. These datasets were essential for conducting parallel multiple-task training using the MTL approach.
We develop a framework architecture that employs edge computing to perform in-depth analyses of facial features. The framework can be implemented in forensic intelligence or adapted for use in human–computer interactive (HCI) applications such as measuring the concentration levels of students in educational systems.
The remainder of this paper is structured as follows. In
Section 2, we review a wide range of relevant previously presented approaches that have been developed for face analysis applications such as face detection and recognition, age estimation, hair color and hairstyle classification, gender recognition, and face smile classification. Additionally, we point out how various techniques of computer science and engineering can be combined to deliver improved performance for deep face analysis.
Section 3 covers dataset creation and preparation for our proposed face analysis model. The proposed pipeline-parallel architecture for deep learning face analysis is introduced and discussed in
Section 4.
Section 5 explains the experimental setup steps and deployment process of the required hardware equipment and software IDE environments. The results are elaborated on and deeply analyzed in
Section 6. Finally,
Section 7 summarizes the manuscript and suggests potential applications for deployment.
2. Related Work
In this section, we provide a comprehensive and up-to-date review of several deep learning networks for human face detection and verification, edge computing, and multitask learning that have been recently published in the literature. The selected prior works span different levels of abstractions, including deep learning [
26], face recognition [
3,
27], hair analysis [
5,
28], edge computing and computation offloading [
29,
30,
31,
32], parallelism approaches [
30,
33], multithreading and multi-processes [
23], and multitask learning [
1,
2,
34] to capture feature maps of faces and perform different facial analysis tasks such as face detection and verification, landmark localization, smile detection, gender recognition, age estimation, hair color and style classification, etc. Our aim is to provide a comprehensive review that is valuable for designers of cost-effective computing paradigms for face analysis based on deep neural network architectures in order to achieve high-performance computing architectures based on edge computing.
Deep CNNs have been extensively utilized in detection and recognition tasks [
35]. For instance, age estimation based on the VGGFace model was conducted in [
26] to estimate the age of individuals based on their facial features. Deep face recognition datasets including VGGFace [
10] and VGGFace2 [
36] were introduced by the VGG group to train several CNNs and deliver remarkable facial recognition accuracies. In a recent study by Hasan et al. [
3], an improved model for facial recognition is presented by training ResNet-50 using the VGGFace architecture, presented in [
10]. The proposed model addressed the issue of training a DL model with a limited number of facial images per individual. To increase its recognition performance, the authors re-trained a pre-trained facial recognition model with a different dataset. Combining VGGFace2 for facial feature extraction with PCA was explored in [
27] to reduce Gabor features, increasing recognition accuracy.
Additionally, deep learning has been widely used for hair analysis and classification across various helpful applications. For instance, human appearance can be categorized based on hair. Additionally, hair can be a crucial feature for recognizing familiar faces [
37], and more accurate gender recognition can be achieved via hair analysis [
38]. Moreover, hair color classification can be a beneficial toolkit for forensic intelligence [
39]. Therefore, DL-based hair recognition and classification have been explored across a wide range of applications. Hair detection and hairstyle classification was examined in [
28]. The authors were the first to attempt to perform hair detection and hairstyle classification to classify seven different classes. A principal component analysis (PCA) was employed to shrink the extracted feature maps into a flattened vector containing 4096 pixels. A CNN based on the CaffeNet-fc7 model with random forest (RF) provided the best-obtained hair features at the patch level, while local ternary patterns (LTP) for features with a support vector machine (SVM) for decision-making realized the best segmentation results at the pixel level. A systematic review was conducted in [
5] recently regarding hair and skin analysis. The review confirms that machine learning approaches such as artificial neural networks (ANNs) and SVMs achieved the highest prediction accuracy (95% and 90%, respectively).
A fully convolutional multi-task neural network was introduced in [
40] to extract external facial image features (baldness and hair color). The proposed framework achieved an accuracy of 92% and 93% for non-hair and average hair color prediction, respectively, using the random forest classifier. Likewise, a novel diffusion-based generative model was presented in [
41] to segment human hair and non-hair from the background of an image. The model accuracy was validated on three datasets (Figaro-1k, CeleA Mask-HQ, and Face Synthetics) and realized accurate hair segment predictions of 98.03%, 95.34%, and 98.79% for the tested datasets, respectively. However, these hair analysis models performed the tasks sequentially without using overlapping methods, such as in a pipeline, and they did not implement parallel processing to exploit multitask learning (MTL) simultaneously.
On the other hand, intrinsic attributes such as age, gender, and smile recognition have been examined in various face images. The authors in [
42] examined the relationships between age, head pose estimation, and gender recognition. Similarly, an MTL-based facial analytics framework was introduced in [
43], which integrates gender recognition and age estimation with other facial expression analyses. The hybrid learning approach for smile recognition (HLSR) was introduced in [
44]. The authors fused a CNN with the XGBoost algorithm for real-time facial smile expression recognition.
Parallel module processing was proposed in [
45] for medical diagnosis to distinguish between depressed and normal patients based on facial expression analysis. The proposed Dep-FER model is capable of distinguishing facial expressions including fear, anger, sadness, happiness, surprise, and more using three parallel modules. These module were mainly designed to identify samples, learn general similarities, and predict an intrinsic relationship between normal and depressed patients. Likewise, considering parallel computing paradigms, the study conducted by Gamatie et al. [
33] was the first to explore the integration of lightweight, low-power cores dedicated to parallel processing with high-speed processor cores designed for sequential execution. The authors investigated energy efficiency by implementing multicore architectures on resource-constrained edge computing devices, aiming to establish a cost-effective computing paradigm. Later on, energy efficiency with AI edge computing was explored in a study by Cheikh et al. [
30], which employed an interleaved multithreading approach to distribute heavy computations across multiple edge computing devices. The study demonstrated the efficacy of the presented approach by exploiting the synergy between thread-level parallelism (TLP) and data-level parallelism (DLP). It was confirmed that leveraging TLP and DLP to configure a multiple-instruction multiple-data (MIMD) architecture achieves higher speedup for more complicated 2D convolutions compared to a single-instruction multiple-data (SIMD) architecture.
On the other hand, situating computationally intensive DNN tasks on mobile edge computing devices for real-time DNN inference execution was first introduced in [
8]. The authors proposed the neurosurgeon approach, referred to as the DNN partitioning method, which partitions the computations of a DNN between the cloud and a mobile device. It achieves significant performance improvements such as reduced latency and energy consumption. To further improve inference on edge computing, an optimized deep learning model was presented to classify vehicle images and whether they were stolen [
29]. Fine-tuning the tested model reduced the model’s size, increased the model’s accuracy, and slightly improved the model loading time on edge devices. Likewise, the authors in [
46] investigated the tradeoff between computing accuracy and latency of computationally intensive deep learning applications deployed on edge devices with limited resources. Moreover, in [
47], a collaborative approach for thread-offloading was proposed to reduce the energy consumption of multithreading by provisioning optimized TLP on mobile edge computing (MEC). Similarly, the TLP was leveraged on multiple edge devices to shorten the inference time and maximize cloudlet throughput [
48]. Notably, prior research related to enabling DNN inference on the edge can be divided into three categories: cloud-assisted inference, edge-assisted inference, and multi-device collaboration [
49,
50]. Herein, we concentrate on reviewing offloading tasks on multiple edge devices. A distributed DNN computing architecture known as CoEdge was presented in [
50], in which inference tasks were divided into feature extraction and target classification. The input image is split into small patches of different sizes and distributed on the edge devices during the feature extraction phase, then the outcomes are aggregated during classification to compute the final execution. Similarly, the DNN inference was divided into two parts deployed on the user equipment (UE) and edge server [
32]. The UE performs feature extraction, then compresses the feature map and sends it to the edge server. The edge server then passes it to the remaining DNN part to provide the predicted outcome, which is then sent back to the UE. Additionally, to expedite the processing tasks of DNN models, a parallel-pipeline inference was introduced by Goel et al. [
31]. This architecture splits the DNN network into sets of hierarchical consecutive layers, and each set is run on a different device. By balancing the workload between the cooperative devices, the presented approach is capable of concurrently processing multiple video frames, thus achieving improved throughput.
Multitask learning (MTL), on the other hand, has been adopted in several computer vision problems for efficient automation of deep learning applications [
1,
2,
34,
51]. Caruana et al. [
52] were the first to introduce and generalize the MTL concept. Subsequently, MTL has expanded to enable CNN deployment for detailed facial analysis. A VGG-based unified network architecture called UberNet, expanding the training of multiple tasks on a single CNN network, was introduced in [
51] using diverse datasets. UberNet employs MTL for simultaneous training of CNNs by fusing all intermediate layers [
51]. Moreover, a region-based CNN (RCNN) model was proposed in [
34] to perform human pose estimation and action recognition. The model achieved an action mean average precision (mAP) of 70.5%. Nevertheless, action classification models are still targeted to improve their classification performance. Additionally, for images containing occlusions with faces, Zhang et al. [
1] presented a task-constrained deep learning model that performs multiple correlated tasks of facial features concurrently. The proposed task-constrained deep convolution network (TCDCN) model is utilized for facial landmark detection, gender recognition, and object detection of smile and glasses. In a similar manner, real-time facial analytics based on event surveillance cameras were presented later in [
17] to estimate individuals’ visual attention such as head pose, eye gaze, and facial occlusions for the analysis of human attention levels.
Additionally, facial feature analysis to recognize and classify multiple face-based tasks was presented in the HyperFace deep CNN model in [
2]. The model effectively exploits multitask learning, such as face detection, gender recognition, landmark localization, and head pose estimation simultaneously. The approach utilizes a diffusion method that leverages combinations of rich features among low, intermediate, and high convolutional layers; therefore, various extracted facial features are fused from different layers of the network. The authors first used a truncated AlexNet [
7] as a backbone, which consists of five convolutional layers for evolving feature maps. These fused features are then fed to five ANN classifiers that operate in parallel to perform different face tasks. Following that, the ResNet-101 [
53] model was tested with a fiducial extractor to investigate the fusion of intermediate layers with MTL, which was found to deliver more accurate prediction performance for all tasks. Using HyperFace for the AlexNet-based model, accuracies of 97% and 94% were achieved for gender recognition tested on CelebA and LFWA, respectively, whereas 98% and 94% gender prediction outcomes were realized using HyperFace ResNet as the backbone, validated on the same datasets. Moreover, using the IBUG dataset, ResNet-101 was discovered to deliver the highest landmark localization (91.82%) for 68-point. However, this achievement was realized at a high layer density, which incurs larger storage capacity costs and requires massive, computationally intensive operations. Likewise, several facial-related tasks such as face detection and recognition, age and gender estimation, and emotion prediction were addressed by a single framework in [
23]. However, this study was mainly conducted to compare employing multithreading versus multi-processes on an edge computing device for low-cost deep learning applications. The experimental results showed that when the hardware resources—i.e., the number of CPU cores and memory cells—of the edge device are limited, leveraging multithreading improves performance compared to deploying multi-processes architecture. Moreover, running two threads in parallel on two modules, each processing an image, results in an 18.87% speedup when using an NVIDIA Jetson TX2 device and a 19.83% speedup when using an AGX edge computing device. Nevertheless, employing MTL approaches for parallel facial feature analysis to detect faces, determine identity, recognize gender, and estimate age has not yet been adequately addressed. In other words, efficient employment of MTL with face analysis requires more in-depth analysis of human faces.
To summarize, these relevant prior DL networks and computing architectures offer individual benefits such as accelerated training, deployment of DL models on resource-constrained computing devices, and parallel implementation. They have confirmed the employment of a single or dual-combined specific technique, but there is no attempt to combine desirable techniques of computer science and engineering such as parallelism, pipelining, computation offloading, multitask learning, and multithreading in a single framework architecture to provide deep face analysis. Considering these aforementioned challenges, in this paper, we leverage DLP and TLP, pipelining, computation offloading, and multitask learning with edge computing paradigms to develop a pipeline-parallel architecture for deep face analysis. Primarily, our paper is the first to integrate the pipeline technique between the edge server and edge devices to maximize the throughput of DNN-based tasks. The innovative pipeline-parallel with a computation offloading architecture delivers a thorough facial analysis of the captured faces in an image taken in the wild. It can detect multiple faces in a scene, crop all detected heads surrounded by bounding boxes, and create their corresponding face images. These images are then saved in the database on the hard disk, which is then processed through the pipeline-parallel architecture for feature extraction using the VGGFace network. This involves feeding the extracted feature maps into three MTL-based classifiers (hair-module, gender-module, and faceID-module) designed for deep face analysis including hair color and style prediction, gender and smile recognition, and face identification and age estimation, respectively. Notably, these classifiers operate in parallel based on a multithreading approach that distributes tasks among seven processing units (cores); four cores are for the server edge, while the remaining three are for the edge devices to achieve a low-cost and efficient computing architecture.
4. The Developed Parallel MTL-Based Face Analysis Framework
Deep learning applications such as face analysis require billions of intensive computational operations. To run these applications in real-time, computationally efficient and low-latency architectures are desired. Therefore, pipeline and parallel implementation approaches are utilized to achieve high-speed performance for iterative computations. The pipelining technique is primarily employed to overlap the execution of DNN models to improve performance. It is used to achieve two main goals: first, to perform dependent tasks in parallel on different input data, i.e., different input images, and second, to speed up the processing performance by dividing the workload on the available processing cores. The overlap among algorithms is accomplished via multithreading, in which multiple threads (algorithms) are executed in a parallel manner. The proposed architecture performs computer-intensive operations on the server edge (core i5 processor), which employs parallelism and pipeline techniques to deliver a high throughput. Meanwhile, the lightweight tasks are offloaded to edge nodes, i.e., Raspberry Pi 4. Therefore, the input images are processed incrementally through multiple DNN models configured using pipeline and parallel techniques. The general framework of the proposed deep face analysis architecture is depicted in
Figure 4.
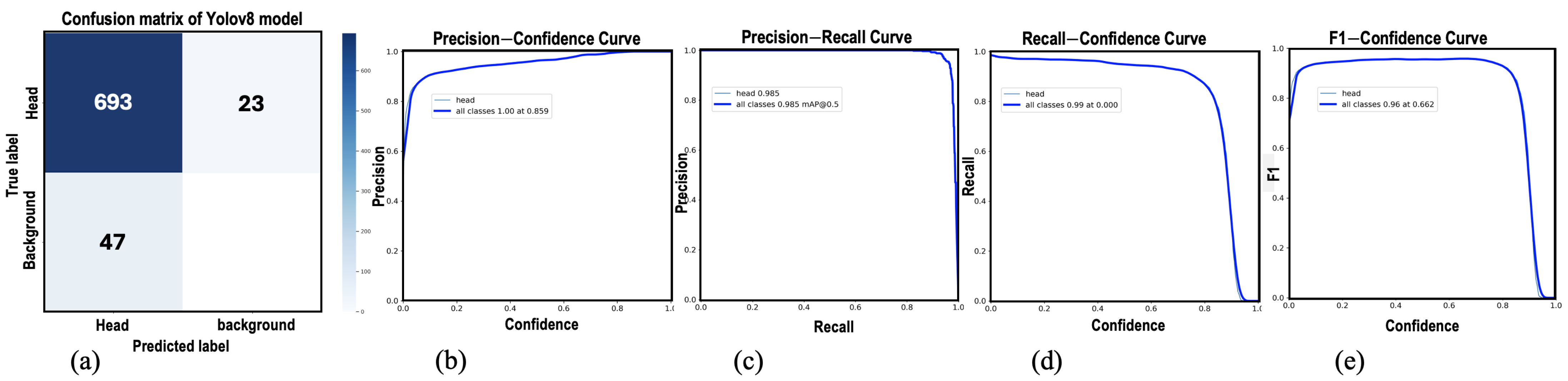
The concept of the proposed architecture is similar to the HyperFace analysis network proposed in [
2]. However, it differs in several key aspects. First, our developed architecture is based on YOLOv8 from Ultralytics [
16] and VGG-Face [
10] as backbone structures. These DNN models were implemented using pipeline and parallel techniques to realize high-computing performance. Additionally, we created a task-specific dataset, the HDDB dataset, which is tailored for head detection. Essentially, we annotated the HDDB dataset with the YOLO format for training YOLOv8 to detect heads instead of faces. The detected heads are then cropped and stored on the hard disk of the server computer to be passed through the next stage of the pipeline network for feature extraction. Second, to capture complex features of heads, small kernels need to be utilized in the convolutional layers of the CNN [
35]. Therefore, we employ a pre-trained model of VGG-Face to accomplish hair and facial feature extraction since it adopts only 3 × 3 kernels in all convolutional layers. Thus, the input to the VGG-Face network is a head image resized to a resolution of 227 × 227. In the third stage of the pipeline, feature maps are offloaded to edge computers to perform parallel multitask classification. Finally, during stage four, the classification results are sent from the edge device back to the edge server to provide detailed face analysis and decision-making. Therefore, the developed framework is designed to process four images incrementally through four pipeline stages. For instance, when all four stages become full, it indicates that the output decision-making of the first head image is in the write-back stage. The second image is being classified using three parallel MTL-based classification modules. The third image is undergoing feature extraction using VGG-Face. Lastly, YOLOv8 scans the fourth image for head detection in the first stage. These parallel incremental operations are clearly illustrated in
Figure 5.
Moreover, a producer–consumer technique, a well-known approach in concurrent programming, is adapted to maintain synchronization and temporary storage sharing between the pipeline stages. The approach is employed to handle two categories of threads: producers and consumers. A producer inserts items into the buffer, whereas a consumer takes items out of the buffer. Furthermore, to achieve efficient shared-memory allocation, a dynamic-size buffer (queue) is utilized in which the buffer size is altered depending on the number of detected individuals (heads) in the input image.
In the proposed pipeline-parallel architecture, we leveraged the producer–consumer approach to facilitate memory sharing. Initially, at stage #1, the YOLO producer thread generates paths of the cropped images and adds them to YOLO queue. During stage #2, the VGG-thread serves as both a producer and a consumer. It retrieves the paths of the cropped images from the YOLO queue and passes each head image to the VGG-Face model to generate a tensor that represents the extracted feature map for the corresponding individual. In this case, the YOLO queue is shared between the YOLO producer thread and the VGG consumer thread. The generated tensors at the output of the VGG-Face model are then placed into the offloading queue(s). Depending on the number of distributed edge devices, illustrated in
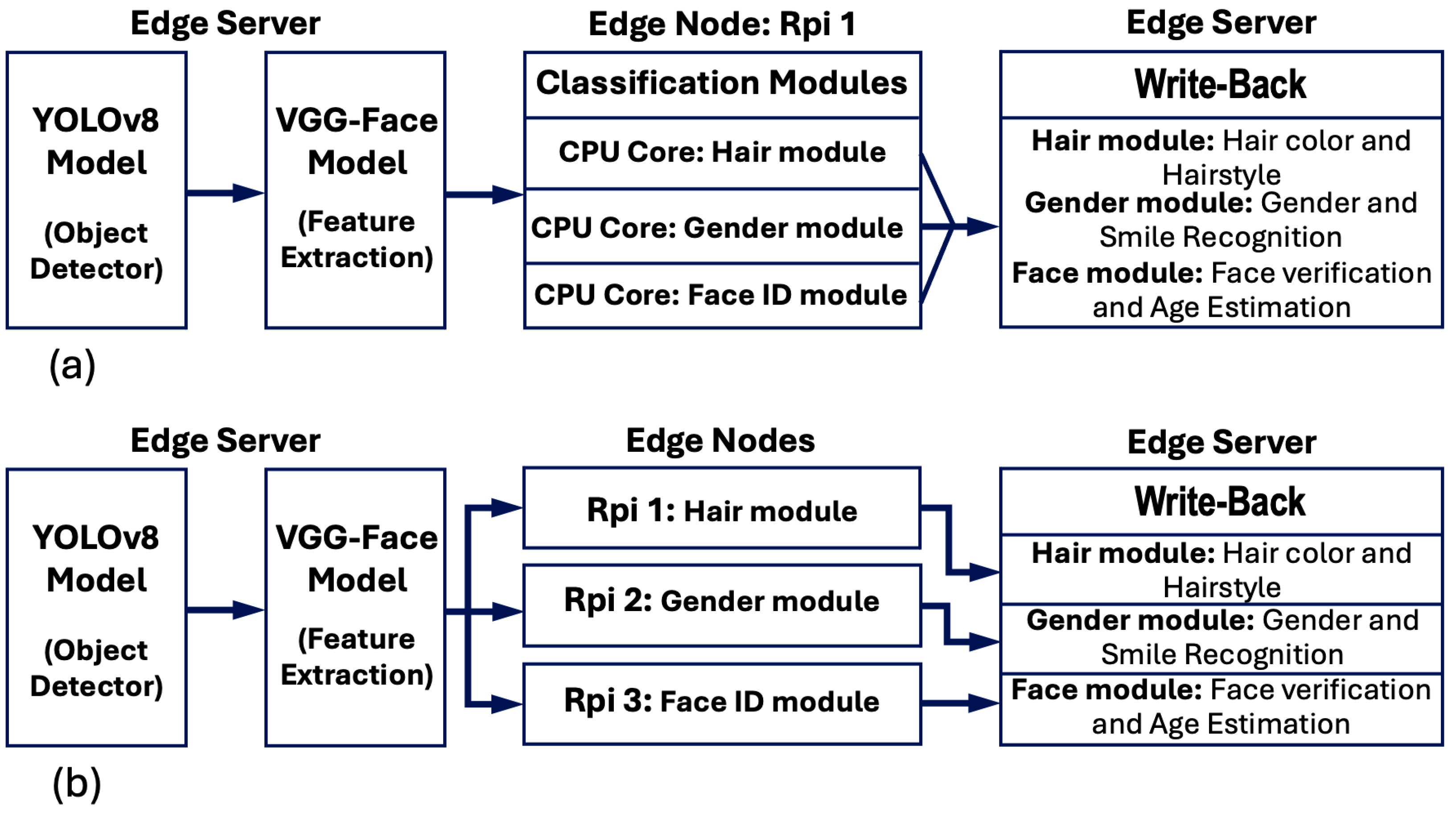
Figure 6a,b, two offloading producers were considered. For the architecture involving a multithreaded server with a single Raspberry Pi (Rpi), there exists a single offloading queue where the VGG-thread deposits the feature maps.
On the other hand, in the case of a multithreaded edge server with three Rpi devices, the VGG-thread copies the feature tensors to three offloading queues, each corresponding to an Rpi. We discuss this further in
Section 4.3. When an edge device connects to the edge server, the corresponding client thread consumes a feature map from the client’s queue and sends it to the respective device. For instance, when Rpi1 sends a request to the server asking to send an image tensor for hair color and style classification, the server accesses the feature map queue of Rpi1, retrieves an image tensor, offloads it to Rpi1, and waits for prediction outcomes. Once Rpi1 finishes predicting hair color and style, it sends the predicted classes back to the server. The server enqueues the received outcomes of hair into the prediction queue. Meanwhile, it obtains another image tensor from the tensor queue of Rpi1 and offloads it to edge node Rpi1. Thus, in stage #3, the server assigns a thread for each edge device request. However, each thread performs two sub-tasks. The first sub-task retrieves a new feature tensor from the feature map queue and offloads it to the client, while the second sub-task enqueues the received predictions into the CSV prediction queue. During stage #4, a write-back thread assigned by the server consumes predictions from the prediction queue and writes the results to a CSV file for saving. Consequently, as depicted in
Figure 5, the inference of the proposed architecture is designed to process four images (im1, 2, 3, and 4) of different individuals concurrently. This implies that when the first image (im1) reaches the write-back stage to be saved in a CSV file, the predicted classes of im2 are enqueued into the prediction queues, the tensor of im3 is inserted into the offloading queue, and the path of the cropped head (im4) from the YOLO model is placed into the YOLO queue.
The synchronization in the proposed pipeline-parallel architecture was achieved by incorporating storage units (SUs) and the producer–consumer approach between the pipeline stages. Therefore, the use of these mechanisms effectively addresses variations in processing delays, such as those induced by computationally intensive tasks like YOLOv8 for head detection and cropping or VGG-Face for feature map extraction, ensuring seamless data flow between the stages despite task dependencies or variations in execution time. To the best of our knowledge, the proposed edge computing-based architecture is the first to employ pipeline and multithreading techniques in a single framework for in-depth face analysis of multiple people. In
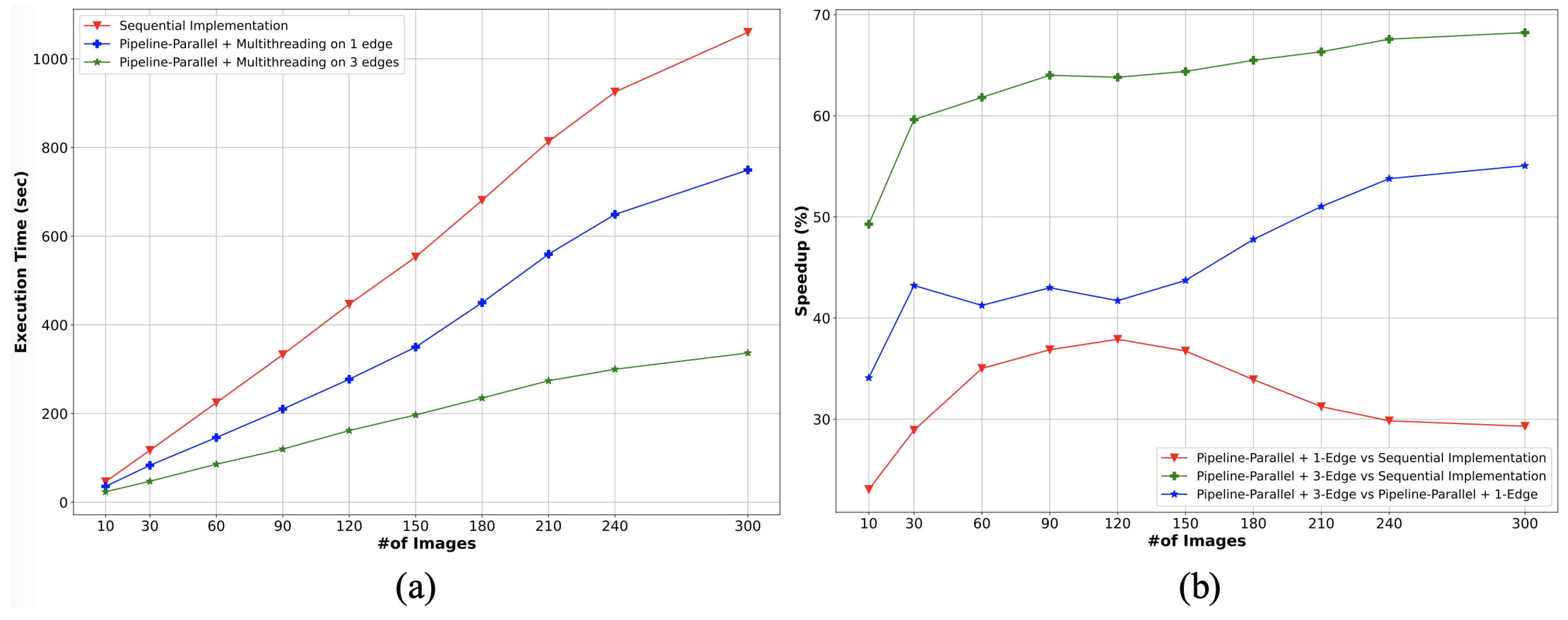
Section 6.3, we analyze the performance evaluation of the proposed pipeline-parallel architecture over the sequential design along with the STL and MTL approach. Next, we further discuss our proposed pipeline-parallel architectures.
4.1. The Proposed Pipeline-Parallel Face Analysis Architectures
In this paper, three DNN architectures for deep face analysis are presented, since the procedure of face analysis architecture is a multithreaded application. The first design is sequential-based and involves cascaded networks. It is considered as the baseline architecture. The second and third architecture designs utilize pipeline and parallel processing techniques with multithreading to expedite the computationally intensive operations of the DNN models. These developed designs are as follows:
The sequential-based architecture: It deploys a conventional fully sequential design. In this design, the processing is divided into three well-tailored cascaded modules (YOLOv8 module1, VGG-Face module2, and Classification module3), and each module must be finished before the next one can start.
Pipeline-parallel architecture with multithreading on a cluster of edge device: This employs parallel and pipeline techniques on the edge server and multithreading of the classifiers on a cluster of three homogeneous edge devices, running multiple lightweight processors to perform multiple classification tasks.
Pipeline-parallel architecture with multithreading on a single edge device: Similar to the previous parallel design, this utilizes multithreading on the server edge between module1 and module2. However, here, all classification tasks are offloaded to a single edge device. Thus, under this design, four threads run on a quad-core processor of the edge device; each core performs a single classification task at a time. Notice that one of the four cores of the edge device is allocated for the main thread, which handles the threads’ organization with other processing cores.
Figure 6 depicts the proposed pipeline-parallel architectures. As seen,
Figure 6a illustrates the design of the pipeline-parallel architecture with multithreading on a single edge node, while the design of the pipeline-parallel architecture with multithreading on three edge devices is shown in
Figure 6b. These proposed architectures employ pipeline and parallel techniques along with multithreading to realize high-speed performance for deep face analysis.
4.2. Multi-Task Learning
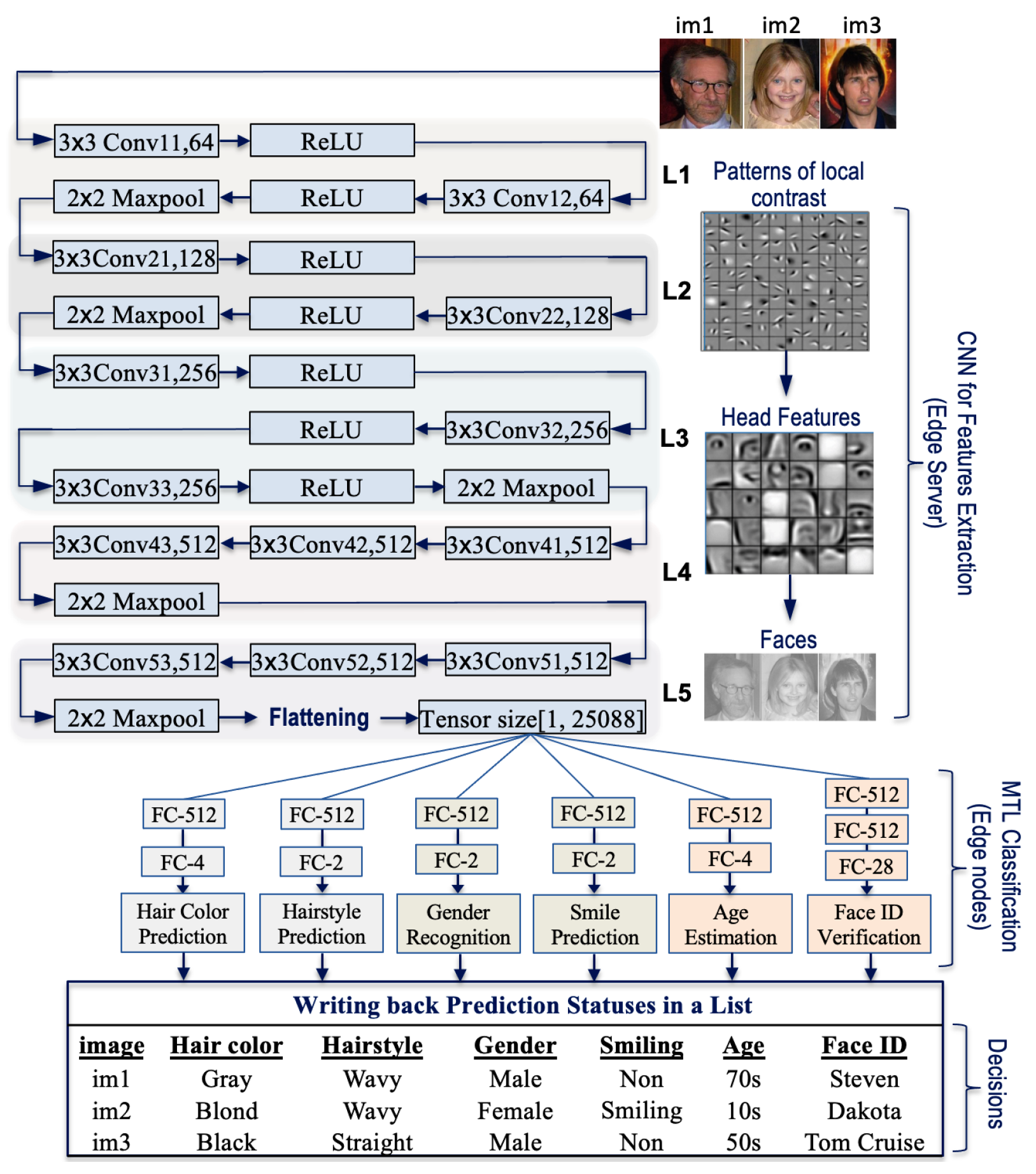
Herein, we propose an expandable pipelined and parallel implementation for deep facial feature analytics. Multitask modules are proposed to identify various facial expressions such as hairstyle, hair color, gender, smile, age, and face verification. We adapt the approach of learning multiple related face analysis tasks to train two complementary classifiers using a single MTL module simultaneously. This is because the feature maps extracted from an image are correlated among the proposed classifiers. To implement MTL for facial features, a pre-trained VGG-Face [
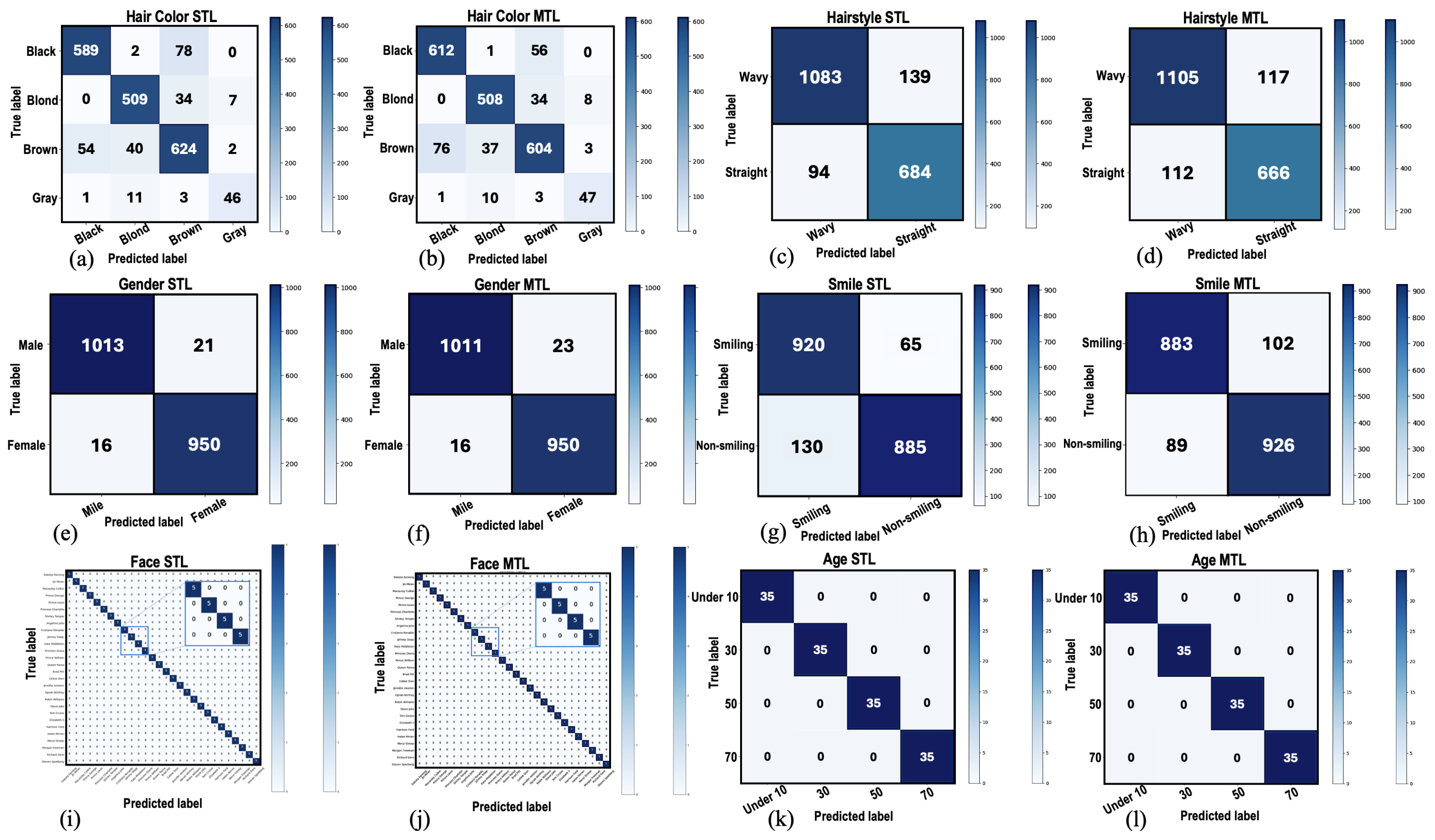
10] model is used as a backbone for hair and face feature extraction. However, only the structure of the feature map extraction was maintained without modifications. Thus, the convolutional portion of the VGG-Face architecture is employed for feature extraction in our proposed architecture. This indicates that transfer learning was used to preserve the learning of the VGG-Face network for feature extraction. Meanwhile, an additional 13 dense layers are dedicated, i.e., our modification process, to support the realization of multitask learning and to implement 6 classification tasks. Moreover, two different datasets, i.e., FDDB and FRAED, were used to train the classification modules of the modified VGG-Face network architecture. Therefore, we trained six facial attributes in parallel using three classification modules, each of which is composed of two complementary tasks.
Figure 7 illustrates the developed classification modules. These are module3-1 (hair-module), which performs hair color and hairstyle classification, module3-2 (gender-module), which detects facial smile detection and gender recognition, and module3-3 (faceID-module), which distinguishes face ID verification and age estimation.
The input to these modules is a feature map, extracted in the previous pipeline stage (module2) and fed as a flattening vector to the next stage (module3). When a classification module completes its task, the decision is sent to the edge server to complete the write-back stage (module4) for decision-making. At the server terminal, a list is used to gather decisions and write them into a CSV file as observations for all individuals detected in the input image during stage #1 (module1) using YOLOv8. It is important to note that we trained each module (hair, gender, and faceID) separately during the training phase, since the datasets are different. However, in the inference deployment, all three classification modules perform simultaneously. This indicates that when the feature maps of an inference from the previous stage (VGG-Face module) become available, all classifiers run to provide decisions, as shown in the lower portion of
Figure 7. As observed, all the classification models require two fully connected layers for decision-making, except the face recognition model, which is constructed using three fully connected layers to increase the efficiency of face recognition. It is important to note that the ability to generalize the proposed edge computing-based architecture across various models primarily relies on two factors: the capability of the tasks to be learned simultaneously through the multi-task learning (MTL) approach, and the model’s flexibility to be adapted for different tasks.
4.3. Computation Offloading of the Proposed Classification Modules
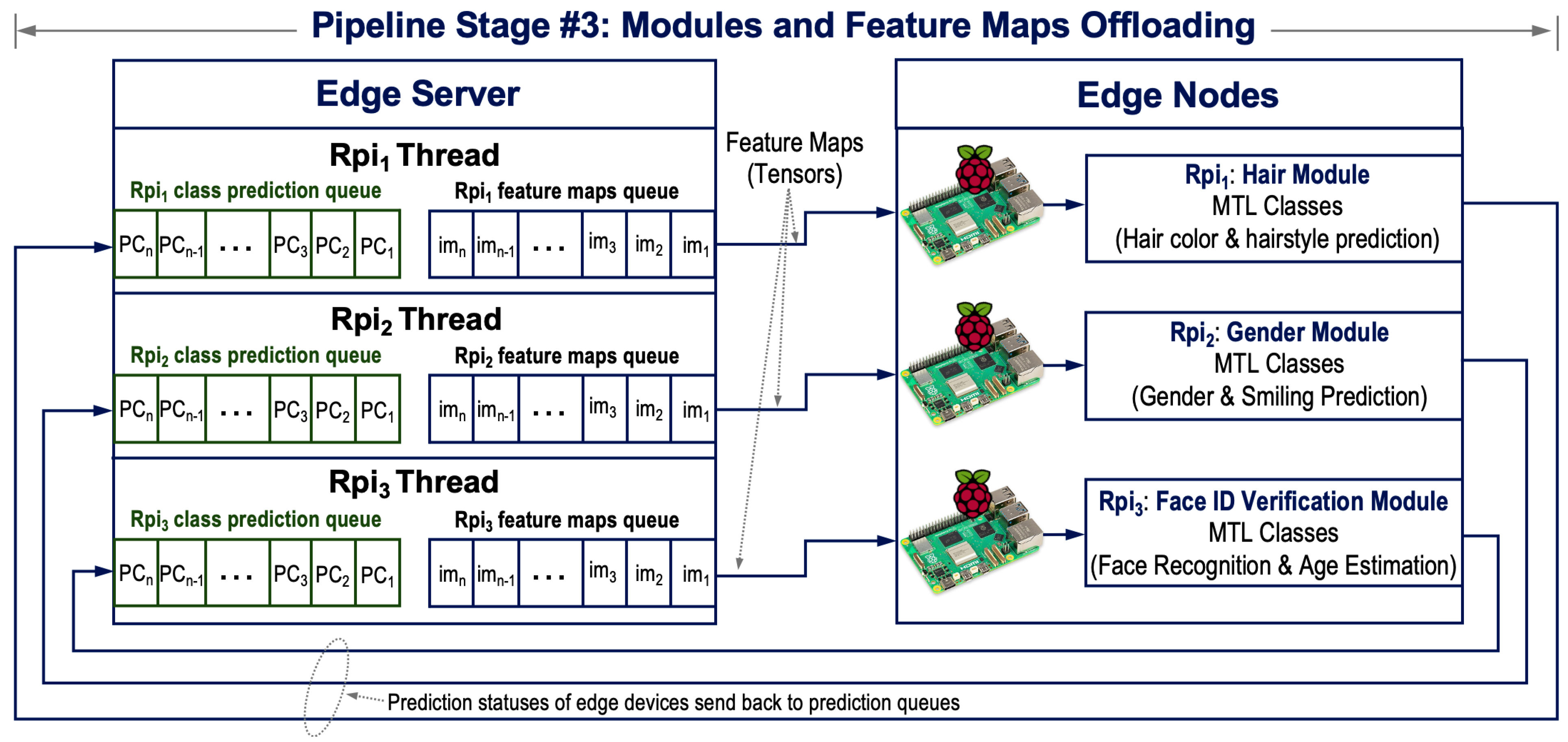
Here, we aim to implement edge intelligence, which combines AI and edge computing, in a pipeline-parallel embedded system to quickly analyze multiple individuals’ faces. Edge computing has emerged recently to accelerate the execution of heavy computations for big data streaming applications. It involves leveraging multiple lightweight processing units at the edges of the cluster. Nevertheless, the majority of existing technologies send raw data to a remote server, which can be a burden for embedded systems equipped with resource-constrained edge devices. To address this limitation hindering the ability to distribute computational-intensive tasks on edge devices, computation offloading is used, through which intensive computations are assigned to the edge server to provide processing for raw data and extract feature maps. Meanwhile, lightweight computations, i.e., the classification modules, are offloaded to the edge devices. These modules receive the extracted feature maps from the server and perform corresponding classification tasks for seamless decision-making.
Figure 8 depicts the offloading process of the proposed pipeline-parallel architecture described in
Figure 6b. The cluster involves four computing devices, including a single powerful edge server and three Raspberry Pi edge computing devices. To enable the server to handle multiple clients’ requests simultaneously, it is configured as a multithreaded server. Thus, the server assigns a thread for each edge device, and each thread works on two main temporary buffers (queues). It enqueues tensor elements to the feature map queue, whereas the received prediction outcomes for the edge nodes are inserted into the prediction queue. The two queues allocated to each edge device enable parallel processing for multiple classification tasks and parallel saving of prediction outcomes. Consequently, the deployed computation offloading approach refers to distributing face analysis computations based on task complexity and resource-rich/limited edge devices. In this context, extracted feature maps from detected heads are offloaded to the developed MTL-based classification modules, where these modules represent the dense layers of the modified VGG-Face model, illustrated in
Figure 7. The modules are embedded in three edge devices and run a multithreading approach to perform three independent threads concurrently. Next, we discuss the levels of parallelism involved in the proposed pipeline-parallel architecture.
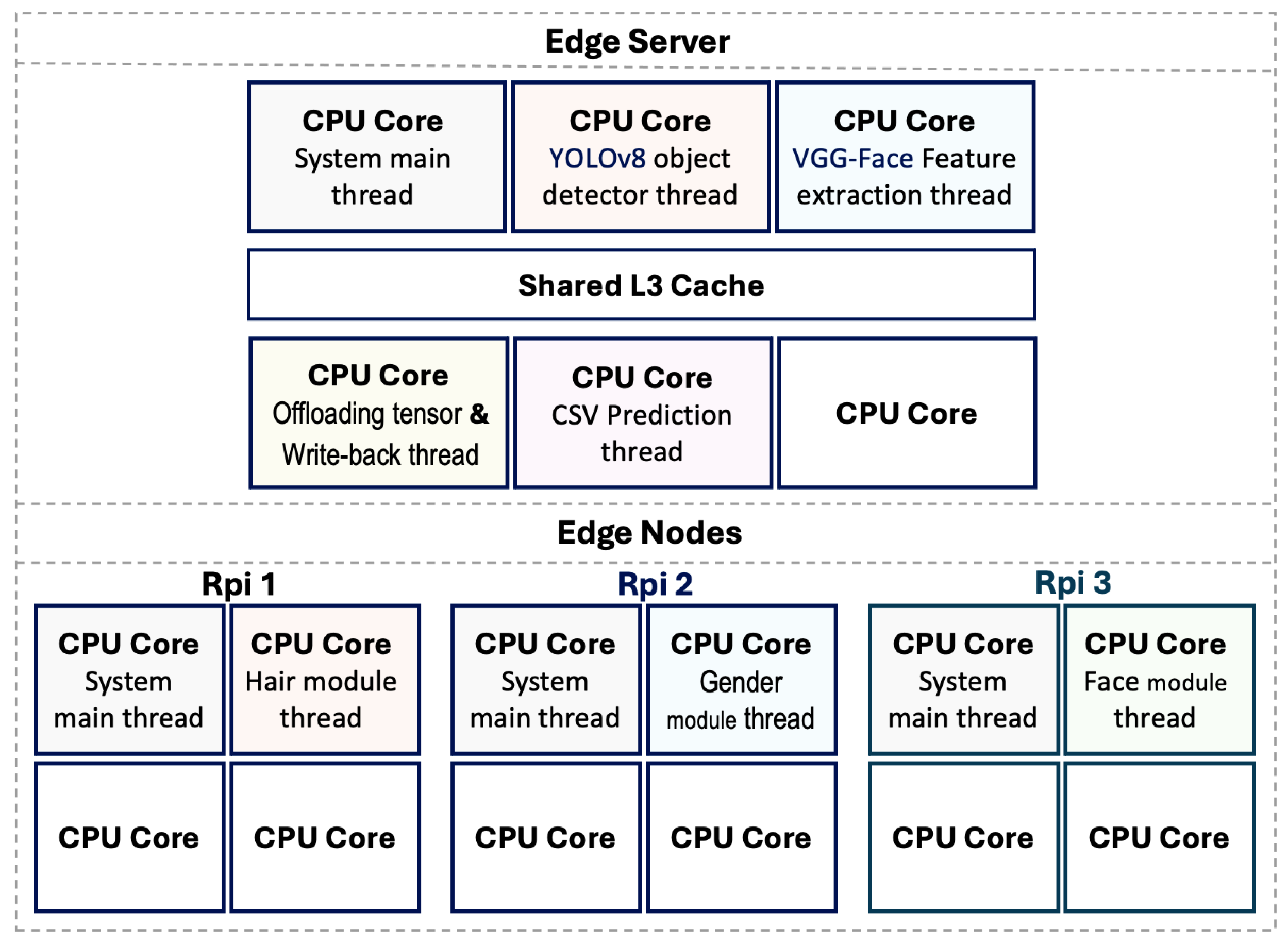
4.4. Levels of Parallelism Leveraged in the Proposed Parallel Architecture
In computing paradigms, the levels of parallelism mainly include instruction-level parallelism (ILP), data-level parallelism (DLP), and thread-level parallelism (TLP). These levels of parallelism have been efficiently exploited in the design of the proposed pipeline-parallel architecture. For example, multiplying the kernel of a CNN filter with the same size image window, i.e., a 2-dimensional (2D) array taken from the input image, is achieved via the dot product that performs ILP and DLP on the filter coefficients and elements of the selected 2D array. It produces partial products, which are then summed to provide the feature maps. This natural parallelism is carried out intra-processor (within a processor core), which indicates that ILP and DLP can be very limited to exploiting only six cores of our edge server or three similar operations performed on an edge device equipped with a quad-core processor. Consequently, it is favorable to incorporate both ILP and DLP along with TLP for ultra-fast processing. This can be achieved by using pipeline and parallelism techniques among the processors to enable cooperation between intra- and inter-processor cores, resulting in high-speed performance for DL-based complex applications. However, to enable parallelism within dependent tasks, overlapping between them is required. This has been achieved via a hybrid approach that combines pipelining and producer–consumer techniques, as discussed in
Section 4.
On the other hand, multithreading allows multiple threads to share processing units, which can be either among dependent tasks run on a single processor with an overlapping approach or among multiple independent threads run across a cluster of edge computing devices. Multithreading utilizes TLP to shrink the execution time per task. Therefore, to achieve high-speed performance with TLP, multicore processors can collaborate to run multiple independent threads simultaneously [
60,
61]. Hence, we utilize multithreading across multiple cores of processors to increase parallelism, allowing for the concurrent execution of independent threads on multiple cores of multiple processors. Moreover, the proposed pipeline-parallel design employs a multi-instruction stream multi-data stream (MIMD) architecture. This is due to multiple processing components executing various instruction streams and multiple images are processed by different processors’ cores simultaneously. In contrast, the single-instruction stream multi-data stream (SIMD) architecture is implemented within each processor core by executing the same instruction stream, i.e., multiplication or addition, on different data streams, since each image is passed through multiple pipeline processing stages. Implementing the MIMD architecture instead of the SIMD architecture for the proposed deep face analysis system is advantageous. This approach allows for the simultaneous processing of multiple distinct instructions on different data streams, making it well-suited for the diverse tasks involved in various stages of the pipeline. Our architecture utilizes a multitask pipeline-parallel strategy, where different stages of the pipeline operate concurrently on separate processors. Consequently, the MIMD architecture supports this design by enabling distinct operations, such as detection and feature extraction, to occur in parallel without the synchronization constraints that are inherent in SIMD systems. Consequently, the proposed architecture utilizes parallelism at three levels (instruction, data, and thread). Furthermore, parallelism occurs across the multicore processor of the edge server and different processors of the edge cluster, including cores for the edge server and edge computing devices. This implies that the processing mechanism of the proposed architecture has been accelerated by running multiple independent threads simultaneously. Each algorithm is forwarded to a specific core, where each core performs a single module of the proposed pipeline-parallel face analysis architecture. For instance, DNN models that involve computationally intensive operations are directed to one core of the edge server processor, i.e., YOLOv8 and VGG-Face models are assigned to run on two cores of the edge server. On the other hand, the classification modules encompass lightweight operations compared to the YOLOv8 or VGG-Face networks; thus, a single co-processor of an edge device is dedicated to each classification module, as illustrated in
Figure 9. Therefore, it perfectly aligns with the computationally intensive and task-diverse nature of the proposed edge computing-based framework.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}