1. The Evolution of Artificial Intelligence Technologies in Content Creation
Artificial intelligence is a concept that had early foundations and theoretical concepts since the 1950s, a technology focused on replicating human cognitive functions directly through programmed rules and logic [
1]. Fast forward to the 1980s, due to computational power increase, the concept saw a shift towards machine learning, where algorithms could learn from data rather than being explicitly programmed.
The growth of the internet and digital data created massive datasets that were necessary for training AI models, a period that saw various applications from search engines to personal assistants. The following years have seen groundbreaking advancements in deep learning, especially in the capability to generate complex content like text, images, videos, and audio autonomously; this is characterized by the rise of generative adversarial networks and transformer models, which have revolutionized content creation [
2].
Artificial intelligence-generated content (AIGC) has become a significant force in today’s digital landscape, driven by advancements in machine learning and artificial intelligence. This technology encompasses the creation of various types of content, including text, images, audio, and video, through sophisticated AI algorithms [
3]. Notable advancements in natural language processing (NLP) and generative models like GPT-3 (generative pre-trained transformer), GPT-4, Electra, BERT (bidirectional encoder representations from transformers) and many more have greatly enhanced AIGC capabilities, leading to its adoption across multiple sectors such as journalism, marketing, entertainment, and education.
In the realm of media and journalism, AIGC has revolutionized content creation by enabling the production of news articles, summaries, and reports with remarkable efficiency. This not only boosts productivity in newsrooms but also facilitates the personalization of news content to suit individual preferences, thereby increasing reader engagement.
However, this personalization can also contribute to the formation of echo chambers and the spread of misinformation, presenting a significant ethical challenge. In marketing and advertising, AIGC tools are employed to generate personalized ads, social media posts, and email campaigns, leveraging consumer data to create highly targeted content. This has transformed how businesses interact with their audiences, making marketing efforts more effective and personalized.
The entertainment industry has also benefited immensely from AIGC, with AI assisting in scriptwriting, storytelling, and even music composition. Furthermore, AIGC plays a crucial role in generating realistic visual effects and animations, enhancing the overall quality and appeal of entertainment products. In education, AI-generated content is used to create interactive learning materials and customized educational resources, making learning more engaging and accessible. The technology also aids in providing educational content in various languages and formats, thereby addressing diverse learning needs and improving accessibility.
The rise of AIGC presents transformative opportunities across various industries as mentioned, but it also introduces a range of complex ethical and societal concerns that warrant careful consideration. A primary concern is the potential for AIGC to amplify the spread of misinformation through fake news articles and highly realistic deepfake videos [
4]. These technologies can erode public trust in media, manipulate public opinion, and even influence political outcomes, underscoring the urgent need for robust detection and regulation mechanisms.
Intellectual property (IP) issues further complicate the AIGC landscape. Questions about the ownership and copyright of AI-generated works remain unresolved, with creators, developers, and AI systems vying for recognition and legal rights.
Equally concerning is the potential for AIGC to perpetuate biases inherent in its training data. If left unchecked, such biases can reinforce stereotypes, exacerbate social inequalities, and lead to discriminatory outcomes in fields such as hiring, education, and law enforcement [
5]. Ensuring fairness in AIGC requires rigorous scrutiny of training datasets and the adoption of ethical AI practices to mitigate these risks.
The interest in this area has seen an outstanding increase over the recent years, growth visible via the number of articles written about generative models and artificial intelligence in general. Based on the numbers found in the most common research papers, databases, and the Google Trends tool, the following graph can be reproduced (
Figure 1).
The numbers represent search interest relative to the highest point on the chart for the given region and time. These results emphasize the need for research and development in this area.
AI now plays a pivotal role in automating and enhancing content creation across various fields; this digital transformation also needs safeguarding, particularly from synthetic content and validating information authenticity. Recent developments have focused on creating synthetic data that not only alleviate bias and privacy concerns but also fulfill the requirements of being true to real data. Auditing frameworks for synthetic datasets are now being developed to ensure they meet critical socio-technical safeguards [
2].
The purpose of this research paper is to give a comprehensive understanding of the current state of AI-generated content. This paper has at its core a thorough literature review, encompassing existing research papers, articles, and reports on AIGC from academic databases, industry reports, and relevant publications. The review highlights recent advancements, key technologies like GPT-4 and GANs (generative adversarial networks), and sector-specific applications, providing a solid foundation of knowledge on the topic.
The paper delves into technological advancements, practical applications, ethical concerns, and future trends in AIGC. By capturing the perspectives of those directly involved in the field, the research can provide a nuanced understanding of the current state of AIGC. Additionally, the paper includes case studies that analyze specific instances of AIGC implementation in various sectors. These case studies will help illustrate the practical benefits and challenges of AIGC, offering concrete examples of its impact. Both qualitative and quantitative data analysis methods are employed to process the information gathered from surveys, interviews, and case studies. Qualitative analysis will involve thematic analysis of interview transcripts and open-ended survey responses to identify common themes and insights. Quantitative analysis will involve statistical examination of survey data to quantify trends, usage patterns, and impacts.
The data sources used were Cochrane Library, Scopus, Web of Science, MDPI, IEEE Xplorer, Elsevier, Cornell University Arxiv, and EBSCO. The inclusion and exclusion criteria are essential in defining the scope and quality of the research paper; the criteria (
Table 1) used for this article are based on the following:
The findings from the literature review, surveys, interviews, and case studies are synthesized into a comprehensive report; the following Prisma flow chart (
Figure 2) mentions the number of articles, case studies, registers, and databases analyzed.
The key contributions of this article are the following:
It emphasizes the evolution of artificial intelligence technologies in content creation, showcasing their applications across text, audio, image, and video modalities, and examining the key benefits and challenges associated with each.
It identifies the main challenges and limitations of detecting AI-generated content and provides a detailed categorization of these challenges to offer a clearer understanding of the current detection landscape.
The paper reviews existing detection techniques, such as stylometric analysis, watermarking, blockchain, machine learning models, and hybrid approaches while analyzing their effectiveness, limitations, and potential areas of improvement.
It suggests potential solutions, including the development of hybrid detection models and the integration of cross-modal approaches, and outlines future research directions to address gaps in this rapidly evolving field.
The paper emphasizes the ethical considerations and societal impact of AI-generated content, addressing key issues such as privacy, risks of false positives, and the importance of regulatory frameworks to ensure responsible AI use.
The paper is structured into seven sections as follows:
Section 1: The evolution of artificial intelligence technologies in content creation. This chapter provides an overview of the evolution of artificial intelligence in the area of content creation and also mentions the methodology used for this research paper.
Section 2: Characteristics of synthetic content highlights the main types of artificial intelligence-generated content and how they can be analyzed and identified as synthetic content for each category: text, audio video, and image.
Section 3: Challenges and difficulties reviews the existing literature relevant to the research topic. It identifies key theories, models, and empirical studies that have shaped the current state of the AIGC content detection tools.
Section 4: Analysis of current detection tools/algorithms details the current frameworks and their advantages and difficulties in identifying the content authenticity and validity. The methods analyzed are stylometric, watermarking and digital fingerprints, adversarial and robust detection techniques, machine learning models and the integration of the blockchain in enhancing the trustworthiness of content.
Section 5: Directions of innovation discuss the future implications of the AIGC technology. The chapter also highlights the current frameworks and offers recommendations for future research, suggesting areas where further investigation is needed.
Section 6: Ethical concerns highlights the current ethical concerns raised by the AIGC due to the concerns in regard of authenticity, misinterpretation, and privacy breaches, as well as the current regulations and legal implications.
Section 7: Conclusions summarizes the key findings of the research, drawing final conclusions based on the analysis. It provides a concise summary of what has been learned from the study and its contributions to the field.
2. Characteristics of Synthetic Content
Identifying synthetic content across different media types, such as text, audio, image, and video, involves recognizing various specific characteristics. A prominent issue in synthetic media is the lack of coherence and continuity. In natural content, there is a seamless flow across frames in videos or across sentences and paragraphs in text.
Recent research [
7,
8] also suggests the use of multimodal approaches that integrate signals from various inputs (audio, visual, textual) to improve the detection of synthetic content, highlighting the need for comprehensive analysis tools that consider all aspects of multimedia content.
However, synthetic media often exhibit abrupt changes that disrupt this flow. For instance, in synthetic videos, there might be sudden shifts in the background, lighting, or character positions that are jarring to the viewer [
9,
10,
11]. Similarly, in AI-generated text, the narrative may lack logical progression [
12,
13,
14], with sentences or ideas that do not smoothly connect. These discontinuities can break the immersion and are indicative of the artificial origin of the media.
Another common characteristic of synthetic media is the presence of detail anomalies. Fine details, such as textures, shadows, and reflections, are often not as precise or realistic as in natural content [
15,
16]. For example, in synthetic images or videos, the textures of surfaces might appear uniform or lack the intricate variations seen in real-world materials. Shadows may fall incorrectly, and reflections might not accurately correspond to the surrounding environment. These anomalies can be subtle but significantly affect the overall realism of the media. The inability to replicate these fine details accurately highlights the limitations of current synthetic media generation technologies.
Understanding these characteristics helps in developing more effective detection systems and contributes to the broader efforts in digital media forensics, ensuring the authenticity and reliability of media content.
2.1. Text
Modern AI, like OpenAI’s GPT series, can generate text that mimics human writing styles convincingly. This makes it challenging to detect AI-generated content using traditional text analysis tools. AI can subtly alter text in ways that can change meanings and spread misinformation without being overtly detectable.
One specific feature of synthetic text is the presence of unnatural syntactic patterns. Unlike human authors, who typically exhibit a rich and varied use of syntax, AI-generated text often demonstrates less variability. This can manifest in the repeated use of certain sentence structures or an over-reliance on specific grammatical forms [
17]. Additionally, AI-generated content may incorporate uncommon phrase structures that seldom appear in human writing. These syntactic peculiarities can serve as indicators of text generation by artificial intelligence.
Another characteristic of AI-generated text is the occurrence of semantic anomalies. While human writers generally maintain consistency in their use of world knowledge and facts, AI-generated text can include subtle errors or factual inconsistencies [
18]. These semantic anomalies might arise from the AI’s limited understanding of context or its reliance on incomplete data. For instance, an AI might generate statements that, while grammatically correct, contain inaccuracies or logical inconsistencies that a human writer would likely avoid. These errors, although often subtle, can provide clues about the non-human origin of the text.
Identifying AIGC text is a very challenging task, the detection methodologies rely often on statistical patterns, linguistic anomalies, and semantic consistency. The most common tool is GPTZero, which has as fundamentals the statistical detectors; this approach relies on token probability distributions and entropy analysis to flag AI-generated text. They are effective for simpler models but struggle with advanced systems like GPT-4.
Another paradigm used by OpenAI’s proprietary detector and fine-tuned BERT models are the transformer-based models, which are trained on large datasets and identify semantic inconsistencies or unnatural syntactic patterns. This paradigm has a great accuracy on domain-specific applications but faces limitations with paraphrased or heavily edited AIGC.
The best approach would be a hybrid one, combining statistical methods with deep learning frameworks and therefore improving detection accuracy, but this will increase the computational costs and complexity as well resources. Hybrid approaches combined with crowdsourcing seem to be the optimal approach due to their performance, reliability, and accuracy.
The GPTs have evolved very quickly in regard to semantic phrasing, but there are still errors of hints that can be detected.
Table 2 summarizes and analyzes a few phrases generated by a language model.
These hints are commonly identified with tools like GLTR (Giant Language Model Test Room) version 2024 (release 2024.01) or GPTZero release 2024.06, which analyze lexical features and unusual n-gram patterns to detect the synthetic text. Also, this approach is used by fact-checking systems such as OpenAI’s TruthfulQA or automated semantic analysis engines such as hugging face transformers.
2.2. Audio
One notable limitation of synthetic voices is their lack of naturalness. Unlike human speech, which is rich with subtle intonations, hesitations, and emotional expressions, AI-generated audio often falls short in these areas. Human speakers naturally vary their pitch, tone, and rhythm to convey meaning, emotion, and emphasis. In contrast, synthetic voices frequently exhibit a more monotone or mechanical quality. This absence of natural variation and emotional depth can make AI-generated speech sound less authentic and more artificial.
Another distinctive feature of synthetic audio is its consistency in tones. While human speech typically involves natural variations in pitch, speed, and volume, synthetic speech often maintains a uniform tone throughout. This can result in audio that sounds overly consistent or even robotic [
19]. Human speakers adjust their vocal characteristics dynamically in response to context, emotion, and conversational flow, whereas AI-generated voices may lack this adaptability. The uniformity in tone and pace can serve as an indicator of artificial generation, highlighting the differences between human and synthetic speech [
20].
AI-generated audio detection focuses on capturing subtle anomalies in tone, pitch, and spectral features. Spectral analysis frameworks are methods that identify unnatural consistencies in frequency and waveform patterns. For example, abrupt pitch transitions or flat intonation often signal synthetic speech. Spectrogram analysis is widely employed for this purpose.
Machine learning classifiers such as WaveNet are systems that can analyze models by focusing on monotonic rhythms and unnatural pauses. These classifiers are effective in detecting first-generation synthetic audio but struggle with advanced models like ElevenLabs, which mimic human warmth and emotional intonation.
At the moment real-time detection and multilingual capabilities remain challenges due to high computational requirements and the limitation of the current approaches. While areas such as text and image have seen impressive advancement in detection techniques and tools, audio and video remain behind due to their complexity and low popularity.
In
Figure 3, the audio waveform is interpreted and there are hints of synthetic content due to abrupt endings, instant cuts, monotone pauses or even arrhythmic steps besides the lack of intonation, emotion or human warmth.
Popular tools that are suited for this challenge are WaveNet or ASVspoof, these tools have deep learning audio models, including detectors that are specialized for exposing synthetic speech through anomaly detection. Another popular tool for audio forensics is OpenSmile, a tool that leverages forensic approaches such as intonation analysis, pitch variations, and spectral content identification.
Nevertheless, the generative models are evolving in this area, with major development being supported by large corporations that want their digital assistants to sound as human as possible.
2.3. Images
Generative adversarial networks can create highly realistic images that are difficult to differentiate from real photographs without detailed analysis. AI-generated images often carry metadata that mimics genuine content, misleading detection algorithms that rely on metadata analysis.
One of the telltale signs of synthetic images is the presence of texture irregularities. In human-created or natural images, textures typically blend seamlessly, creating a coherent and consistent visual experience.
Synthetic images often struggle with maintaining this consistency. Certain areas within these images may exhibit textures that do not match the surrounding areas, leading to noticeable discrepancies. These irregularities can disrupt the visual harmony of the image and serve as indicators of artificial generation. Such texture inconsistencies highlight the limitations of current AI techniques in replicating the complexity and subtlety of natural textures [
15].
Another common issue in synthetic images is the presence of unusual patterns in backgrounds or shadows. In real images, shadows and background elements adhere to the principles of physical lighting and environmental conditions, creating a natural and realistic appearance.
Synthetic images, however, often contain anomalies where shadows or background patterns do not align with expected physical properties. These discrepancies can manifest as incorrect shadow angles, inconsistent lighting, or patterns that defy the laws of physics. Such unnatural features can be indicative of an image’s synthetic origin, revealing the challenges faced by AI in accurately simulating real-world environments [
16,
21].
To detect AIGC images, the most prolific adaptation is based on dual-stream networks; these frameworks utilize texture analysis and low-frequency trace detection to identify synthetic images. They outperform traditional detection methods, particularly for GAN-generated content [
22]. On the other hand, the convolutional neural networks (CNNs)-based frameworks have better accuracy but require more frequent updates as generative models improve. The CNN-based image classifiers are trained on datasets containing human and AI-generated images [
23]. Another approach that offers robust protection is the watermarking one, widely implemented for content attribution; this solution is discussed in detail in the next section.
The image from
Figure 4 is a synthetic one created by the AIGC; as can be seen, the textures are not consistent throughout the entire image—the apple has some texture defects on the right side and also the texture from the rain drops is flattened wrongly on the bottom part. These pixel-level irregularities introduced by the GANs can be detected by tools like SightEngine or NVIDIA’s GANFingerprints; both tools can identify generative model traces in synthetic imagery.
By uploading the AIGC image in an image processor such as SightEngine to highlight the pixel irregularities (
Figure 5) and viewing the detailed visualization of this image, we can label it as synthetic content due to the high percentage of detections.
Even if this one is easier to identify, the new models require more attention to detail and more complex tools and frameworks to identify the synthetic content. The entanglement of multiple streams like audio and video used by the AIGC tools becomes even more difficult to identify.
2.4. Video
Tools such as DeepFaceLab [
24] and FaceSwap have popularized the creation of hyper-realistic fake videos. Detecting these requires analyzing not only the visual elements but also checking for inconsistencies in audio and behavioral patterns. Videos combine multiple streams of data (visual, audio, and metadata), each of which can be independently manipulated, complicating the detection process.
A notable issue in synthetic videos, particularly those that have been dubbed or where the audio has been generated separately, is the occurrence of lip-sync errors. In natural human speech, there is a precise synchronization between the movement of the lips and the spoken words [
20]. However, in synthetic videos, this synchronization is often imperfect. Viewers may notice mismatches where the lip movements do not align accurately with the audio, creating a disjointed and unnatural viewing experience. These lip-sync discrepancies are a clear indicator of video synthesis and highlight the challenges in achieving seamless audio–visual integration [
25].
Another characteristic of synthetic videos is the presence of facial expression inconsistencies. In real human interactions, facial expressions are closely tied to the emotional tone and content of the speech, providing visual cues that enhance communication [
11].
Synthetic videos may struggle to replicate this natural correspondence. As a result, the facial expressions displayed may not appropriately match the emotional tone or content of the spoken words. For instance, a synthetic character might smile while delivering sad news or maintain a neutral expression during an emotionally charged dialogue. These inconsistencies can detract from the video’s realism and are indicative of the current limitations in AI-driven facial animation.
One common approach in detecting synthetic videos is to search for frame-level artifacts, frame-by-frame analysis, as AI-generated videos can exhibit temporal inconsistencies, such as mismatched lighting, unrealistic shadows, or flickering between frames. Models such as instruction-tuned large language models (LLMs) generate descriptive metadata for each frame, identifying coherence anomalies in AI-generated videos [
26]. This approach is particularly effective in distinguishing deepfake videos, but the high-resolution generated videos with diffusion-based models pose significant challenges in detecting them due to their realism and fluent temporal transitions [
27].
Extracting the video in frames (visualized in
Figure 6) and analyzing them as an array of images, and therefore using the same methodology as in the case of a single image, will allow a better understanding if the content is generated or genuine [
28].
The current FaceForensics++ has the capability to detect abnormalities in facial dynamics and pixel flow; this tool can also analyze optical flow across frames and can identify unnatural transitions or glitches. Optical flow techniques focus on detecting unnatural motion or temporal artifacts in AI-generated videos. These methods are effective for identifying GAN-based or morphing techniques in video synthesis [
29].
Recognizing these characteristics is crucial for developing more accurate and efficient detection systems, which play an essential role in preserving media integrity. This effort supports the broader objectives of digital media forensics, where ensuring media authenticity and reliability is key to maintaining trust in information sources. As digital content continues to expand, such initiatives are vital not only for protecting individuals but also for defending institutions, industries, and public dialogue from misinformation and manipulation.
Detection methodologies vary widely in effectiveness depending on the modality. While text and image detection frameworks have seen substantial advancements, audio and video detection lag behind due to the complexity of their respective domains. The rapid evolution of generative AI necessitates continual refinement of these methodologies to ensure their reliability and scalability.
3. Challenges and Difficulties
To enhance the robustness of detection systems, it is crucial to propose the use of integrated systems that analyze text, image, and video data in tandem. These multimodal techniques leverage the strengths of each data type to identify inconsistencies or signs of manipulation more effectively. For instance, discrepancies between the audio and visual elements in a video, or between the text and the corresponding imagery, can serve as indicators of synthetic content. By cross-referencing multiple data streams, these integrated systems can provide a more comprehensive and accurate assessment of authenticity, significantly improving the detection of manipulated media.
In the face of rapidly evolving manipulation techniques, it is essential to develop adaptive algorithms. These algorithms should be capable of learning from new data and adapting to emerging methods of content creation and manipulation. As AI-generated fakes become increasingly sophisticated, detection systems must continuously evolve to counter these advancements. Implementing machine learning models that can update and refine their detection capabilities based on the latest manipulation techniques will be critical in maintaining the effectiveness of these systems. The adaptability of these algorithms will ensure they remain relevant and capable of identifying even the most subtle and advanced fakes.
At the moment, the rate of success in identifying artificial intelligence-generated content is very fluctuant, and human manipulation of the synthetic content makes it even more complex to differentiate the generated compared to genuine. In [
30,
31], the results of the current tools are frightening.
Legend: 1. Human-written (95%), 2. Human-written in a non-English language and automatically translated into English (80%), 3. AI-generated (70%), 4. AI-generated with multiple prompts (67%), 5. AI-generated with human/manual edits (41%), 6. AI-generated with subsequent AI/machine paraphrasing (25%).
As visible in
Figure 7 the rate of accuracy drops from 70% to 25% after the text was paraphrased, therefore increasing the difficulty of any tool and framework to identify the AIGC [
32,
33,
34,
35].
To detect manipulations in various types of media, specific machine learning models have proven highly effective. Convolutional neural networks (CNNs) are particularly well suited for detecting image manipulations. CNNs can analyze pixel-level details to identify anomalies that are not visible to the human eye, such as subtle alterations in texture or lighting that indicate tampering. The study [
8,
36,
37] highlights the efficacy of CNNs in this area comparing the application of neural networks in identifying deepfake images and videos. Similarly, recurrent neural networks (RNNs) are adept at identifying text-based inconsistencies. RNNs can analyze sequential data and detect contextual anomalies within the text, such as improbable word usage or grammatical errors that signal synthetic generation [
37,
38]. By leveraging these neural network models, detection systems can achieve high accuracy in identifying manipulated media.
Despite the advancements in AI-driven detection systems, there is a compelling argument for a hybrid approach that combines AI’s computational power with human judgment. AI systems excel at processing large volumes of data and identifying patterns that may elude human detection [
11]. However, human experts bring contextual understanding and critical thinking skills that can enhance the accuracy of these systems. By integrating human oversight into the detection process, we can improve detection rates and reduce false positives. This collaborative approach ensures that nuanced and complex cases, which may be challenging for AI alone, are evaluated with a level of discernment that only human judgment can provide. This synergy between human and AI capabilities can lead to more robust and reliable detection outcomes.
While AI-driven detection systems offer significant benefits, they also present notable challenges. One major limitation is the black-box nature of many AI systems. These systems often lack transparency in how they make decisions, making it difficult to understand and interpret their outputs. This opacity can be particularly problematic in legally sensitive contexts, where the basis for a decision must be clear and explainable. Additionally, the reliance on complex algorithms and large datasets can introduce biases and errors, further complicating their use. Addressing these challenges requires developing more transparent and interpretable AI models, as well as establishing rigorous standards for their deployment and evaluation. By acknowledging and addressing these limitations, we can work towards more reliable and ethically sound detection technologies.
Each area of the synthetic content generation faces multiple and difficult challenges, in
Table 3, there is a brief summary of the research papers that highlight these challenges.
The development of detection technologies raises significant ethical and legal considerations that must be addressed. The use of surveillance to monitor and analyze media content can impinge on privacy rights, leading to ethical dilemmas about the extent and manner of data collection. It is imperative to handle these ethical implications, ensuring that the deployment of such technologies respects individual privacy and freedoms. Additionally, there is a need for robust legal frameworks to manage and regulate the use of detection technologies. These frameworks should establish clear guidelines for responsible use, ensuring that the technologies are employed in ways that are fair, transparent, and accountable.
4. Analysis of Current Detection Tools/Algorithms
Traditional methods for detecting computer-generated content often fall short when faced with sophisticated AI-generated content. Innovations in detection technologies are crucial to address these shortcomings. One such innovation is the development of dual-stream networks that employ cross-attention mechanisms to better identify subtle anomalies distinguishing AIGC from genuine content. The research paper [
42] demonstrates that these advanced detection systems can effectively capture fine-grained inconsistencies that traditional methods might miss. By integrating multiple streams of data and focusing attention mechanisms across them, these networks enhance the capability to detect nuanced irregularities in AI-generated media [
8].
As AI content generation techniques continue to improve, so does the ability to evade existing detection systems, including those reliant on watermarks. This escalation necessitates new approaches that can withstand adversarial manipulations while maintaining high visual quality. The study [
43] suggests developing robust detection methods that are less susceptible to adversarial attacks, ensuring reliable identification of AIGC. These approaches could include adversarial training and the use of more resilient features that are less likely to be manipulated without detection. The detection of AI-generated content is increasingly moving beyond single modalities, such as text or images alone, to multimodal approaches. These approaches leverage combined cues from text, images, and possibly audio to enhance the accuracy and reliability of detection systems across various content types.
In academic contexts, distinguishing between human-written and AI-generated texts is critical for maintaining scientific integrity. As generative AI becomes more prevalent in research, there is a pressing need to develop frameworks that can reliably identify AI contributions in scientific publications. Implementing these frameworks will help preserve the credibility and trustworthiness of scholarly communication.
To keep pace with new generations of AI-generated content, incremental learning approaches are being explored. These approaches allow detection systems to adapt over time and incorporate new data, improving their effectiveness against the latest generative models. In [
44], it is highlighted that incremental learning can enhance the flexibility and responsiveness of detection systems, ensuring that they remain effective as AI technologies evolve. By continuously refining detection algorithms, it is possible to maintain robust defenses against increasingly sophisticated AI-generated content.
The following section presents approaches with their major characteristics from the literature review, highlighting the use cases, challenges, and benefits. For clarity, a summary of the findings is presented in
Table 4.
4.1. Stylometric Analysis
This approach analyzes the style of writing, including syntax, word usage, and grammar, to identify inconsistencies or anomalies that suggest content might be AI-generated. Stylometric tools can be particularly effective in cases where a specific author’s style is well documented. Stylometric analysis refers to the study of the unique stylistic choices of an author, which can be used to attribute authorship to anonymous or disputed texts. It is a method often used in literary studies, forensic linguistics, and digital text analysis, leveraging the way language is used and arranged by different authors [
45,
49]. Stylometrics focuses on quantifying and analyzing aspects such as word frequencies, sentence length, grammatical patterns, and other linguistic features that tend to be consistent and individualistic within a writer’s work.
In the context of detecting AI-generated content, stylometric analysis can be employed to distinguish between human-written and machine-generated texts. This is possible because AI models, even sophisticated ones like GPT (ChatGPT versions 3, 3.5, 4, 4o, GPT4ALL, OPT), often produce text with certain detectable patterns and anomalies that may not align with the natural linguistic style of a human author [
46,
50]. For instance, AI-generated text might show repetitive syntactic structures, unusual word choice combinations, or consistency errors in style across a text. By analyzing these features, stylometric methods can help identify whether a piece of writing was generated by a human or a machine. Stylometric analysis in practice for language models would cover elements as presented in
Table 5 [
45,
49].
Some tools focus on detecting paraphrased content or unusually high similarities to known AI-generated texts. This includes analyzing sentence structures, vocabulary, and thematic consistency across large datasets to identify potential matches with known AI outputs. Content similarity and paraphrasing detection involve identifying and analyzing texts to determine how closely they resemble each other in terms of meaning, even if their words and structures differ. These techniques are crucial in various fields such as education, where they help detect plagiarism, and in natural language processing applications, where they ensure the uniqueness and diversity of generated content.
Another type of framework [
12] is one that utilizes explainable AI (xAI) techniques to analyze stylistic features and improve the interpretability of machine learning model predictions in distinguishing AI-generated texts, showing high accuracy and identifying key attributes for classification.
Content similarity detection focuses on measuring how similar two pieces of content are. This can be carried out at different levels. The first level would be lexical which measures the overlap in vocabulary between two texts. Techniques like cosine similarity, Jaccard index, and others that analyze term frequency are commonly used. Then, on a semantic level, this goes beyond mere word overlap and assesses the meanings conveyed by the texts.
4.2. Watermarking and Digital Fingerprints
Emerging techniques involve embedding watermarks or digital fingerprints in AIGC at the time of creation. These markers are designed to be undetectable to readers but can be identified by specialized detection tools, providing a direct method for distinguishing AIGC [
54]. Watermarking and digital fingerprints are two techniques used to protect and verify the authenticity of digital content. These methods are essential in the realms of copyright protection, content authentication, and tracking the distribution of digital media.
Digital watermarking involves embedding a secret or unique mark within a piece of digital media that can be detected or extracted later to confirm its authenticity or ownership. Watermarks can be designed to be either perceptible or imperceptible to the user, depending on the application.
One of the primary applications of digital watermarking is in the realm of copyright protection. By embedding a unique watermark into digital content, the copyright owner can unequivocally prove their ownership. This watermark acts as a digital signature that is difficult to remove without compromising the content’s integrity. In the event of a copyright dispute, the presence of the watermark can serve as compelling evidence to support the copyright owner’s claims. This technique is particularly valuable in protecting intellectual property in digital media such as images, videos, and audio files.
Digital watermarking also plays a crucial role in content authentication. By embedding a watermark within the content, it becomes possible to verify its integrity over time. If the watermark remains intact, it indicates that the content has not been tampered with or altered. This capability is essential for applications where maintaining the original state of the content is critical, such as in legal evidence, news reporting, and archival preservation. Watermark verification can quickly detect any unauthorized modifications, thereby ensuring the authenticity and reliability of the content [
55].
In the media industry, digital watermarking is used for broadcast monitoring. Watermarks embedded in audio or video clips can be tracked to monitor where and how often the content is played. This information is invaluable for various purposes, including royalty calculations, audience measurement, and usage monitoring. For example, broadcasters can use watermark data to determine the reach and frequency of specific advertisements or programs, ensuring accurate and fair compensation for content creators. Additionally, this tracking capability helps in enforcing licensing agreements and preventing unauthorized broadcasts.
In
Figure 8, the watermarking process consists of adding white noise to an image in order to prove its authenticity and also include digital rights and royalty calculations for future use of this image.
Digital fingerprinting, on the other hand, involves creating a unique identifier
or fingerprint for digital content based on its characteristics or features [
63,
64]. This fingerprint is unique to each piece of content, much like a human fingerprint.
One of the primary applications of digital fingerprinting is content tracking. By generating unique fingerprints for each piece of digital content, it is possible to monitor its distribution across various channels. This ensures that the content does not appear in unauthorized locations [
56,
62]. For example, digital fingerprints can help media companies track how their videos are shared across social media platforms, identifying any instances of unauthorized uploads. This capability is essential for protecting intellectual property and ensuring that content distribution adheres to licensing agreements.
Digital fingerprinting is also a valuable tool in forensic investigations, particularly in cases of illegal content distribution. By analyzing the fingerprints embedded in digital media, investigators can trace the source or distribution path of the content. This helps identify the origin of pirated material and the individuals or networks involved in its dissemination. Digital fingerprints provide a trail of evidence that can be used in legal proceedings to prosecute those responsible for copyright infringement or other illegal activities related to digital content.
Media companies leverage digital fingerprinting for efficient content management. With large libraries of digital content, it can be challenging to organize and retrieve specific media files. Digital fingerprints enable precise identification and categorization of content, making it easier to manage extensive media archives [
63]. This technology supports the automation of content indexing and retrieval processes, improving operational efficiency and ensuring that media assets are easily accessible when needed.
On a comparison level, there are implementational, security and other key differences between watermarking and digital fingerprinting.
Table 6 summarizes the dissimilarities of those two approaches highlighting the variation in specific criteria.
4.3. Adversarial and Robust Detection Techniques
As AI models become more sophisticated, detection methods also evolve to counteract evasion tactics. This includes developing models that can detect AIGC even when it has been altered or paraphrased to evade simpler detection algorithms.
Adversarial and robust detection techniques are critical components in the field of machine learning, particularly in the context of enhancing the security and reliability of models against adversarial attacks. These techniques aim to detect and mitigate the effects of inputs specifically designed to deceive or confuse models [
67].
Adversarial detection focuses on identifying and responding to adversarial attacks, which are manipulations of input data intended to cause a machine learning model to make errors [
27,
43]. These attacks can be subtle, such as slight alterations to an image that cause it to be misclassified.
The adversarial detection follows a few key approaches, one of them being input reconstruction. This technique involves the use of autoencoders to reconstruct the input data and then compare the reconstructed input to the original. Autoencoders are neural networks designed to learn efficient codings of input data, typically for dimensionality reduction or noise removal. In the context of adversarial detection, large discrepancies between the original and reconstructed inputs may indicate the presence of adversarial manipulations [
68]. By analyzing these differences, it is possible to detect and potentially mitigate the effects of adversarial attacks on the model.
Another crucial method for enhancing adversarial robustness is adversarial training. This approach involves incorporating adversarial examples directly into the training process. By exposing the model to these challenging examples during training, the model learns to recognize and withstand adversarial inputs. Adversarial training effectively improves the model’s robustness by making it more capable of handling variations and distortions that adversarial attacks introduce. This method has been shown to significantly enhance the resilience of machine learning models against various types of adversarial manipulations [
72].
Statistical methods are also implemented to detect adversarial tampering by analyzing input data for statistical anomalies. These methods involve examining the input data’s statistical properties and identifying deviations from typical data distributions. Statistical anomalies that diverge from expected patterns can indicate adversarial interference [
75]. By leveraging statistical techniques, such as anomaly detection algorithms and distributional analysis, it is possible to identify inputs that do not conform to normal data behavior, thereby signaling potential adversarial attacks.
There are also techniques for enhancing model robustness, one of them is the regularization technique (
Figure 9). This method, including dropout, L1/L2 regularization, and data augmentation, helps prevent the model from overfitting to noise in the training data. Dropout involves randomly dropping units from the neural network during training to prevent co-adaptation of features. L1/L2 regularization adds penalty terms to the loss function to constrain the model’s complexity. Data augmentation artificially expands the training dataset by applying transformations to the original data. These techniques collectively enhance the model’s generalization capabilities, making it more resilient to noisy and adversarial inputs [
66,
71].
Robust optimization is another strategy to ensure model robustness. This approach focuses on minimizing the worst-case loss across all possible adversarial examples within a specified perturbation range of the training data. By optimizing the model to perform well under these worst-case scenarios, robust optimization techniques enhance the model’s ability to withstand adversarial attacks. This method involves formulating and solving optimization problems that account for potential adversarial perturbations, leading to models that maintain reliable performance even in the presence of adversarial inputs.
Techniques such as randomized smoothing and provable defenses based on the geometric properties of data offer good defense against adversarial attacks. Randomized smoothing involves adding random noise to the input and averaging the model’s predictions, creating a smoothed classifier that is robust to small adversarial perturbations. Provable defenses rely on the mathematical properties of the data and model to ensure robustness. These certified defenses offer a high level of assurance that the model will remain effective even under adversarial conditions [
69].
Integrating adversarial and robust detection techniques can provide a comprehensive defense mechanism for machine learning systems, particularly those deployed in security-sensitive environments. By preparing models to both recognize adversarial attempts and withstand them without degradation in performance, these integrated approaches significantly enhance the resilience of AI systems.
4.4. Machine Learning Models
Many detection methods rely on machine learning algorithms that are trained on datasets of human-written and AI-generated texts. These models learn to identify subtle differences in writing style, patterns, and other linguistic features that may not be immediately apparent to human readers.
Some detection tools leverage pre-trained language models, such as GPT-3, GPT-4, Electra or BERT, which are fine-tuned on datasets of AI-generated and human-written texts to enhance their detection capabilities [
8,
81,
82,
83]. These models are particularly effective in zero-shot or few-shot learning scenarios, where they can make accurate predictions based on minimal examples. In zero-shot learning, a model performs a task or identifies classes it has never seen before during training. Instead of relying on labeled data for the specific task, the model uses general knowledge learned from other tasks or data to make predictions. Few-shot learning allows a model to learn a new task or identify new classes from just a few labeled examples. Unlike zero-shot learning, this approach involves a small amount of task-specific data to help the model understand the new context or task requirements.
By utilizing the extensive knowledge embedded in pre-trained models, detection tools can achieve higher accuracy and reliability in distinguishing between human and AIGC, and depending on the model, it can be compared as in
Table 7.
Combining multiple detection strategies can significantly improve the accuracy and robustness of identifying AIGC. For instance, a detection tool might employ both stylometric analysis and machine learning models to cross-verify the likelihood that content is AI-generated. This hybrid approach leverages the strengths of different methodologies, reducing the risk of false positives and negatives [
18]. By integrating diverse detection techniques, it is possible to create more comprehensive and reliable detection systems.
The development of community-driven and open-source tools plays a crucial role in advancing the field of adversarial and robust detection. These efforts bring together researchers and practitioners to collaborate on the latest research and methodologies. Open-source projects provide access to cutting-edge tools and techniques, fostering innovation and facilitating the widespread adoption of effective detection strategies. Community-driven initiatives also ensure that the tools remain up-to-date with the latest advancements and are accessible to a broader audience.
Each of these options has its strengths and limitations, and their effectiveness can vary based on the context in which they are used and the sophistication of the AI models generating the content. As AI technology continues to advance, the development of detection methods remains an active area of research and innovation.
4.5. Blockchain
Blockchain technology, when combined with crowdsourcing, offers a promising approach to enhance the trustworthiness of content by providing a decentralized and secure method for validating their authenticity. The integration of these technologies can significantly reduce dependency on single sources and mitigate issues related to misinformation and biased content [
76].
Blockchain operates on a distributed ledger system where data is stored across multiple nodes, ensuring no single point of control. This decentralization makes it difficult for any one entity to manipulate information. Once data are recorded on a blockchain, it cannot be altered or deleted [
79,
80]. This feature ensures the integrity and permanence of the information, making it a reliable source of historical data. Due to that, blockchain technology has a high level of transparency, and therefore all transactions and data entries on a blockchain are visible to all participants. This transparency allows for greater accountability and traceability of information sources.
Crowdsourcing leverages the collective knowledge and expertise of a large group of people to verify the authenticity of the content. This approach can help identify synthetic information more effectively than relying on a single entity. In a crowdsourcing model, individuals can review and validate content. This peer review process helps filter out inaccurate information through consensus. Crowdsourcing involves contributions from diverse individuals, providing multiple perspectives and reducing the risk of bias.
Using this technology, the applications in the area of detection for synthetic content are unlimited, news articles or pieces of information can be submitted to a blockchain platform for validation, reducing the risk of manipulation and fake news (
Figure 10). A preliminary verification is conducted by automated algorithms or trusted nodes to check for obvious signs of misinformation. The news is then reviewed by a distributed network of individuals who assess its credibility based on various criteria such as source reliability, factual accuracy, and consistency with known information. The collective assessments are recorded on the blockchain. A consensus mechanism, such as Proof of Stake or Proof of Authority, is used to validate the majority opinion [
48,
91,
92,
93].
One big advantage of using this would be the reduced dependency on centralized authorities by decentralizing the validation process, reliance on single sources or central authorities is minimized. Also, blockchain technology has a set of cryptographic features that can protect against tampering and unauthorized modifications, therefore increasing trust due to the transparency, immutability, and collective validation.
Several studies [
76,
91,
92] have explored the integration of blockchain and crowdsourcing for validating news authenticity, the study [
76] highlights the role of blockchain in establishing trusted information systems across various domains, highlighting the technology’s ability to ensure data provenance, verifying identities, and maintain trust among collaborating entities. On top of the previous research, there is a document verification on blockchain paper [
78], which proposes also a blockchain-based model for document verification, which enhances security, reliability, and efficiency in the verification process by enabling decentralized sharing of authenticated documents between government bodies and private organizations.
Regarding certificate verification using blockchain, the most in-depth research paper is [
77], which describes a prototype for verifying the authenticity of academic certificates using blockchain, which ensures that third parties can independently verify certificates even if the issuing institution is no longer operational.
Incorporating blockchain technology with crowdsourcing can significantly enhance the trustworthiness of news by providing a decentralized, transparent, and secure method for validating authenticity. This approach not only reduces dependency on single sources but also leverages the collective intelligence of diverse individuals to filter out misinformation effectively.
4.6. Hybrid Approaches and Current Applications
In addition to the methods discussed, another direction is the one of hybridization, these approaches combine multiple detection strategies and therefore have gained prominence for their enhanced robustness and adaptability in identifying AIGC. These approaches leverage the strengths of different detection modalities, integrating features such as text analysis, audio signal processing, and image pattern recognition into unified systems. For instance, combining syntactic analysis with deep learning-based semantic understanding has shown improved accuracy in detecting AI-generated text [
94]. Similarly, multimodal frameworks that jointly analyze visual and audio features are proving effective for detecting synthetic video content, particularly in identifying inconsistencies across modalities, such as mismatching shadows, lip movements, transitions, lighting, and so on.
Hybrid approaches combine rule-based techniques, statistical metrics, and deep learning methods for more robust performance. Their strength comes from leveraging the accuracy of each individual component and therefore achieving higher precision, and higher speed, but sometimes with the downsides of higher cost and more resource consumption. On the other hand, their main weakness is the integration complexity and computational overhead [
94]. Depending on the implementation approach and architectural design, hybrid methods can struggle with their ability to generalize when faced with highly diverse datasets.
The implementation of AIGC detection systems in real-world scenarios reveals both their potential and limitations. During the last decade, when the AIGC became more popular, there were quite a few notable examples of successes and failures, shedding light on the challenges faced by these technologies and the lessons learned.
Deepfake detection tools like Microsoft’s Video Authenticator version 2023 (release 2023.06) have been employed to verify the authenticity of video content in news reporting and electoral contexts. During the 2020 U.S. presidential election, this tool was used to identify manipulated videos aimed at discrediting candidates, preventing the spread of misinformation. The tool analyzes video frames for subtle artifacts introduced during the creation of deepfakes, such as inconsistent lighting or unnatural facial movements [
95].
Facebook’s Deepfake Detection Challenge led to the development of multiple models for detecting AI-generated images and videos on its platform. These models enabled the automated removal of thousands of AI-generated fake profiles and posts, helping maintain the platform’s integrity [
96]. The challenge highlighted the importance of diverse datasets to improve model robustness against various content-generation methods.
Turnitin, traditionally known for plagiarism detection, has integrated AI-detection tools to identify student essays written by language models like GPT. These tools have been effective in flagging assignments with high probabilities of AI authorship, protecting academic standards [
97]. Turnitin’s system identifies unnatural patterns in syntax, repetition of sentence structures, and stylistic anomalies indicative of AI-generated text.
On the other side, there are times when the AIGC detection tools were not used correctly or were not implemented up to the standards and these provided a low accuracy detection. The main affected area is public security due to inconsistent detection results. Law enforcement agencies using AIGC detection tools for identifying fraudulent documents or manipulated videos have faced challenges with precision. In a high-profile case in the UK, an AI-based system failed to identify a forged passport created with sophisticated generative models, leading to the perpetrator evading detection [
98,
99]. The system struggled with adapting to newer generative models that introduced highly realistic visual details, underscoring the need for constant algorithmic updates.
Watermark-based detection of AI-generated images has proven vulnerable to adversarial attacks. Researchers demonstrated that by adding small perturbations, attackers could bypass detection in watermarked AI-generated images used in court proceedings, compromising evidence integrity. This example highlights the fragility of watermark-based methods and the need for more resilient detection strategies [
55].
In corporate environments, automated detection systems have led to reputational damages due to false positives. A multinational corporation’s internal AI detection tool falsely flagged an employee-generated report as AI-authored, leading to unnecessary disciplinary action. This incident revealed the risks of over-reliance on automated systems without human oversight and the need for integrating manual review processes [
94].
By examining these real-world examples, it is evident that while AIGC detection systems have shown significant promise, they are not without limitations. Success in this field requires a continuous refinement of methodologies and a commitment to ethical and transparent practices. Four key elements are essential for this development: adaptability—tools need regular updates to stay ahead of evolving generative technologies and ethical oversight, and systems must balance detection efficiency with considerations of privacy—accountability, fairness, and flexibility. Detection systems need to look into hybrid approaches, combining automated detection tools with human review and by this mitigating the risks of false positives and missed detections.
5. Directions of Innovation
The identification and differentiation of AIGC, including videos, photos, and text, are pivotal areas of research, given the significant advancements in artificial intelligence. AIGC encompasses a wide range of outputs such as images, text, audio, and videos. While AIGC has numerous benefits, it also presents several risks, including issues related to privacy, bias, misinformation, and intellectual property. Identifying AIGC is crucial to mitigating these risks and ensuring responsible usage [
4].
While several detection tools have shown promise, some have struggled to keep up with the rapid evolution of AI content generation. For example, early versions of OpenAI’s GPT detector faced limitations in accurately distinguishing between human-written and GPT-generated text, particularly when the text was heavily edited or mixed with human content. Similarly, Deepfake detection models like DeepTrace faced challenges in identifying high-quality deepfakes, especially when adversarial techniques were used to obscure synthetic features [
100].
Conversely, there have been significant successes in this domain. Tools like the Giant Language Model Test Room have demonstrated effectiveness in flagging synthetic text by analyzing statistical anomalies in word choices. For video detection, Sensity AI has emerged as a leading platform, employing state-of-the-art deepfake detection algorithms to analyze facial dynamics and motion inconsistencies. In image detection, the GANFingerprint approach by NVIDIA has shown great promise in tracing the generative model used to create synthetic content by identifying subtle fingerprints left in the output.
Despite the progress in detection methods, attackers continue to develop increasingly sophisticated techniques to bypass detection, such as adversarial perturbations and generative noise injection. Addressing these challenges will require the continued evolution of hybrid approaches that can adapt to new threats. Future efforts might also focus on enhancing the transparency of generative models themselves, including the implementation of tamper-proof digital watermarks that remain robust against adversarial attacks. The integration of AIGC detection into public platforms like social media and content-sharing sites will also be critical for real-world impact.
Research focused on distinguishing AI-generated images from traditional computer graphics has led to the development of a dual-stream network. This network utilizes texture information and low-frequency forged traces to identify images generated by AI, showing superiority over conventional detection methods [
42]. Studies [
53,
62] on the robustness of watermark-based AIGC detection reveal that attackers can evade detection by adding small, imperceptible perturbations to watermarked images.
Advancements in AI-generated images necessitate ongoing detection efforts. The study [
15] explores the generalization of detection methods across different AI generators and introduces pixel prediction techniques for identifying inpainted images, indicating progress in online detection capabilities.
Research [
73] proposes a framework for distinguishing between human and AI-generated text, particularly in scientific writings, using a model trained on predefined datasets to assess accuracy and reliability.
For synthetic video content, researchers proposed a framework [
28] that employs instruction-tuned large language models to generate frame-by-frame descriptions from a single user prompt, enhancing the consistency and coherence of AI-generated videos. The paper [
8] proposes using BERT and CNN models for detecting AI-generated text and images by analyzing vocabulary, syntactic, semantic, and stylistic features, alongside the use of a CNN model trained on specific datasets for image detection.
These directions showcase the breadth of approaches being explored to identify AIGC from watermarking and dual-stream networks for images to advanced text analysis frameworks and the use of large language models for video generation. The ongoing development of detection methods is critical for addressing the challenges posed by the increasing sophistication of AIGC.
6. Ethical Concerns
The rapid growth of AIGC detection systems raises complex ethical concerns. While these technologies are essential for combating deepfakes, misinformation, and other malicious uses of generative AI, their implementation must be guided by ethical principles to avoid unintended harm.
The deployment of detection systems often involves analyzing vast amounts of user-generated content, which raises significant privacy concerns. Detection systems may require access to private communications, such as emails, social media messages, or personal photos. Even when anonymized, this can lead to unauthorized surveillance or the misuse of personal data. Privacy-preserving approaches, such as federated learning or differential privacy techniques, are being explored to minimize privacy intrusions while maintaining detection efficacy [
101].
One of the most significant challenges in AIGC detection is the potential for false positives—erroneously identifying legitimate human-generated content as AI-generated. False positives can harm reputations, especially for creators falsely accused of producing AIGC. For example, academics or journalists could face unwarranted scrutiny if their work is misclassified. Detection systems may also exhibit biases based on the training data used, leading to disproportionate false positives among underrepresented groups. Addressing these biases requires diverse datasets and transparent model evaluation [
102].
The reliance on automated detection systems presents risks, particularly when these systems are treated as infallible. Overreliance can lead to complacency, with critical decisions being based solely on automated outputs. This is particularly concerning in legal or governmental contexts, where misclassification could lead to unjust penalties. Overdependence on automated systems also risks making detection efforts less adaptable to rapidly evolving evasion strategies employed by malicious actors.
There are also risks such as censorship. Detection technologies could inadvertently be used for censorship, suppressing legitimate content under the guise of combating misinformation or fraud, or even perpetuation of inequities. Unequal access to detection technologies may exacerbate existing inequities, as well-resourced organizations could use these systems disproportionately, leaving smaller entities vulnerable to AI-generated threats.
This advancement of AIGC has led to significant legal challenges, particularly concerning authenticity, privacy, and intellectual property rights. In the realm of privacy laws, one of the central concerns is the unauthorized use of personal data to train generative AI models. The use of AI to generate synthetic media often involves training models on large datasets, which may include personal data collected without explicit consent [
103]. This raises privacy issues, particularly when personal characteristics are replicated or manipulated without permission. The generation of synthetic media can infringe on intellectual property rights, as AI can produce content that closely mimics the style or substance of copyrighted works. This poses legal and ethical challenges regarding the ownership and copyright of AIGC.
In regions such as the European Union, the General Data Protection Regulation (GDPR) explicitly prohibits the processing of personal data without consent. However, cases of AI systems generating synthetic content that closely resembles private individuals, without their permission, have sparked widespread legal disputes [
104]. For example, deepfake technologies have been misused to replicate individuals’ appearances in videos without their consent, resulting in defamation claims and psychological harm. Legal frameworks like GDPR are pivotal in addressing these ethical violations, though enforcement remains challenging due to the global reach of AI technologies.
Another significant issue arises with intellectual property rights (IPRs), as generative AI models can produce works that mimic the style or content of copyrighted material [
105]. High-profile legal cases have already emerged in this area, such as Getty Images v. Stability AI, where Getty Images sued an AI company for allegedly using its copyrighted photos to train generative models without permission. The lawsuit highlighted the pressing need for clearer regulations governing the use of copyrighted materials in AI training datasets. The lack of consensus on the ownership of AI-generated works also raises questions about who holds the copyright: the developer of the AI system, the user, or neither, particularly when the output replicates pre-existing works.
The rise of deepfakes has also sparked specific legal responses aimed at curbing their misuse. For instance, in the United States, some states, including California and Texas, have enacted laws criminalizing the malicious use of deepfakes in political campaigns or non-consensual nudism. These laws aim to protect individuals from reputational harm and maintain trust in democratic processes. However, enforcement is often difficult due to the sophisticated nature of these technologies, which can evade detection systems and cross jurisdictional boundaries [
101].
Additionally, the ethical implications of false positives in AI detection systems raise potential legal and reputational risks. For example, misclassifying genuine content as AI-generated could lead to accusations of defamation or financial harm, particularly in corporate or legal contexts. In response, countries like Australia are exploring regulatory frameworks to impose stricter accountability on developers of AI-detection systems, requiring them to meet reliability thresholds and provide transparency in their algorithms. Such measures aim to balance innovation with the rights and safety of individuals affected by AIGC detection errors [
106].
There are concerns about synthetic media in regard to authenticity and misrepresentation because it is being used to create convincing yet entirely fabricated pieces of content, which can mislead, manipulate public opinion, or defame individuals. The ease of generating realistic synthetic media raises challenges in maintaining authenticity and trust in digital content [
107].
Moreover, the misuse of AIGC for misinformation campaigns has drawn the attention of global institutions. For instance, the European Commission’s Code of Practice on Disinformation has been updated to specifically address synthetic media and deepfakes [
108]. This initiative requires online platforms like Facebook and X to label AIGC clearly and take proactive measures against manipulated media designed to mislead the public. Failure to comply with these measures can result in hefty fines under the Digital Services Act (DSA), a legal framework intended to improve online safety and transparency [
109].
These legal and regulatory efforts underscore the pressing need for global cooperation in addressing the ethical and societal challenges posed by AIGC. As the technology continues to evolve, so too must the legal frameworks, ensuring they remain agile enough to address emerging threats while preserving fundamental rights such as privacy, intellectual property, and freedom of expression.
AI systems can perpetuate or even exacerbate existing social and cultural biases if they are not carefully designed. The data used to train these systems can contain biases, which the AI may then learn and replicate in its outputs, leading to stereotyping and discrimination in synthetic media [
103].
Transparent and interpretable AI models in news feeds can help combat misinformation by clarifying why certain content is flagged as false, which can also help mitigate the effects of echo chambers and filter bubbles [
91].
Deploying AI and crowdsourced systems to label false news enhances discernment among users concerning what content to share on social media. Explanations of how AI-generated warnings are produced can further improve their effectiveness, although they may not increase trust in the labels [
93].
Combining linguistic and knowledge-based approaches can significantly improve the accuracy of fake news detection systems. Features like the reputation of the news source and fact-check verifications are critical in this process [
92,
103].
The ethical challenges in detecting AIGC require a multidisciplinary approach, combining technical solutions with legal, social, and philosophical insights. Addressing these concerns is vital to ensure that detection systems not only mitigate the harms of generative AI but also uphold the principles of fairness, transparency, and privacy.
7. Conclusions
The proliferation of AIGC, encompassing audio, video, text, and images, represents a transformative development in current society. This technological advancement has opened new horizons in creative expression, communication, and information dissemination.
The importance of these technologies is underscored by their wide-ranging impact across various domains. In media and entertainment, AIGC offers unprecedented creative possibilities, enabling the production of high-quality media at scale and reducing the barriers to content creation. In education and training, AI can generate personalized and interactive learning materials, enhancing the educational experience. In business and marketing, AI-driven tools can create targeted and engaging content, driving customer engagement and brand loyalty. But AIGC has become a double-edged sword due to intellectual property theft, privacy violations, misinformation and so on.
The insights and research explored throughout this paper highlight the vast potential of this technology, as well as the complex ethical, legal, and technical landscape that surrounds its use.
One of the standout highlights is the immense utility of AIGC across diverse domains. AI-driven tools have reduced barriers to content creation, enabling individuals and organizations to produce high-quality, engaging media at scale. In education, AIGC fosters personalization and interactivity, while in marketing, it drives targeted customer engagement. However, these benefits are counterbalanced by substantial risks, including the misuse of AIGC for generating deepfakes, spreading misinformation, and violating individuals’ privacy.
The challenges inherent in detecting and mitigating the risks of AIGC cannot be overstated. As this paper discusses, existing detection systems are often outpaced by the rapid evolution of generative models, which produce increasingly sophisticated and realistic outputs. Techniques such as watermarking, dual-stream networks, pixel prediction, and stylometric analysis offer promising avenues for detecting AIGC, but each comes with limitations. For instance, watermarking can be circumvented by small perturbations, while deepfake detection struggles with generalization across different generation techniques. Moreover, the use of AI to detect AIGC raises ethical concerns, particularly around false positives, algorithmic transparency, and potential biases.
Despite these challenges, several best practices have emerged. Hybrid detection approaches that combine machine learning techniques with traditional rule-based systems have proven to be more effective in identifying AIGC across multiple modalities, such as text, images, and videos. Additionally, the integration of explainable AI models into detection frameworks enhances trust and transparency, making it easier for users to understand why certain content is flagged. In the legal sphere, emerging regulations like the GDPR, Digital Services Act, and state-level deepfake laws provide a foundation for addressing some of the ethical concerns, though enforcement and global coordination remain hurdles.
Looking to the future, it is clear that the detection and regulation of AIGC will require a multi-faceted approach involving researchers, technologists, policymakers, and civil society. As AIGC becomes more embedded in daily life, the development of robust and adaptive detection systems will be critical. Research must continue to prioritize generalizable solutions that work across various AI models and content types, while also addressing the ethical implications of detection technologies. For example, ensuring that AI-driven detection systems are unbiased, privacy-preserving, and transparent will be crucial to maintaining public trust.
At the same time, significant risks remain. The potential for misuse of AIGC in areas such as misinformation, political manipulation, and non-consensual synthetic media highlights the urgent need for global regulations and ethical oversight. Collaboration between governments, technology companies, and international organizations will be essential to establish shared standards and prevent the weaponization of AIGC.
In conclusion, as AIGC continues to integrate into the fabric of daily life, its impact on society will only grow. Ensuring the authenticity and integrity of this content is paramount to harnessing its potential benefits while mitigating associated risks by leveraging the best available technologies, fostering ethical practices, and strengthening legal frameworks, society can harness the transformative power of AIGC while mitigating its risks. The collective efforts of stakeholders across the spectrum will determine whether AIGC becomes a tool for societal progress or a source of widespread harm. Only by addressing the challenges and embracing a balanced approach can we ensure that AIGC serves humanity in a positive, responsible, and impactful way.




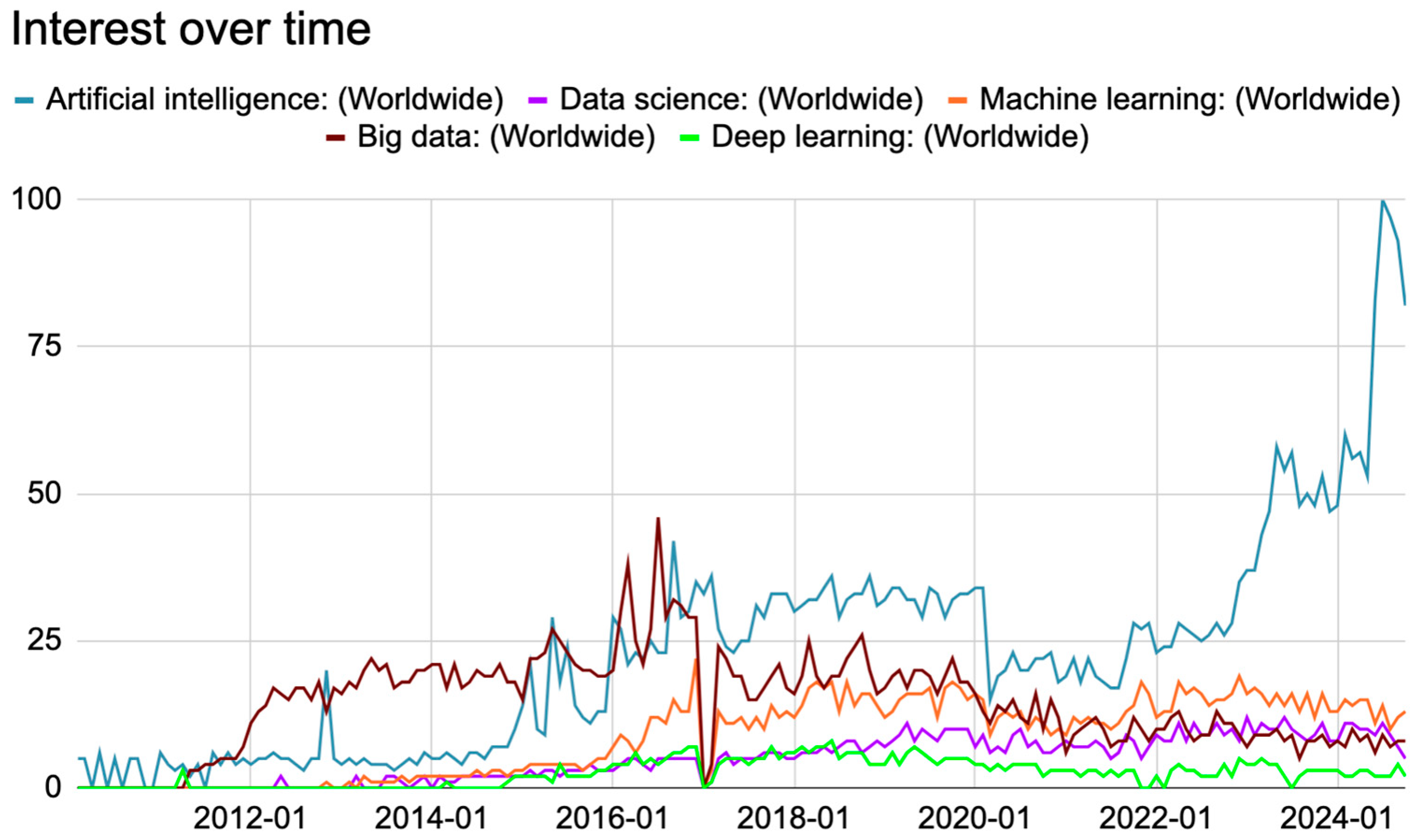
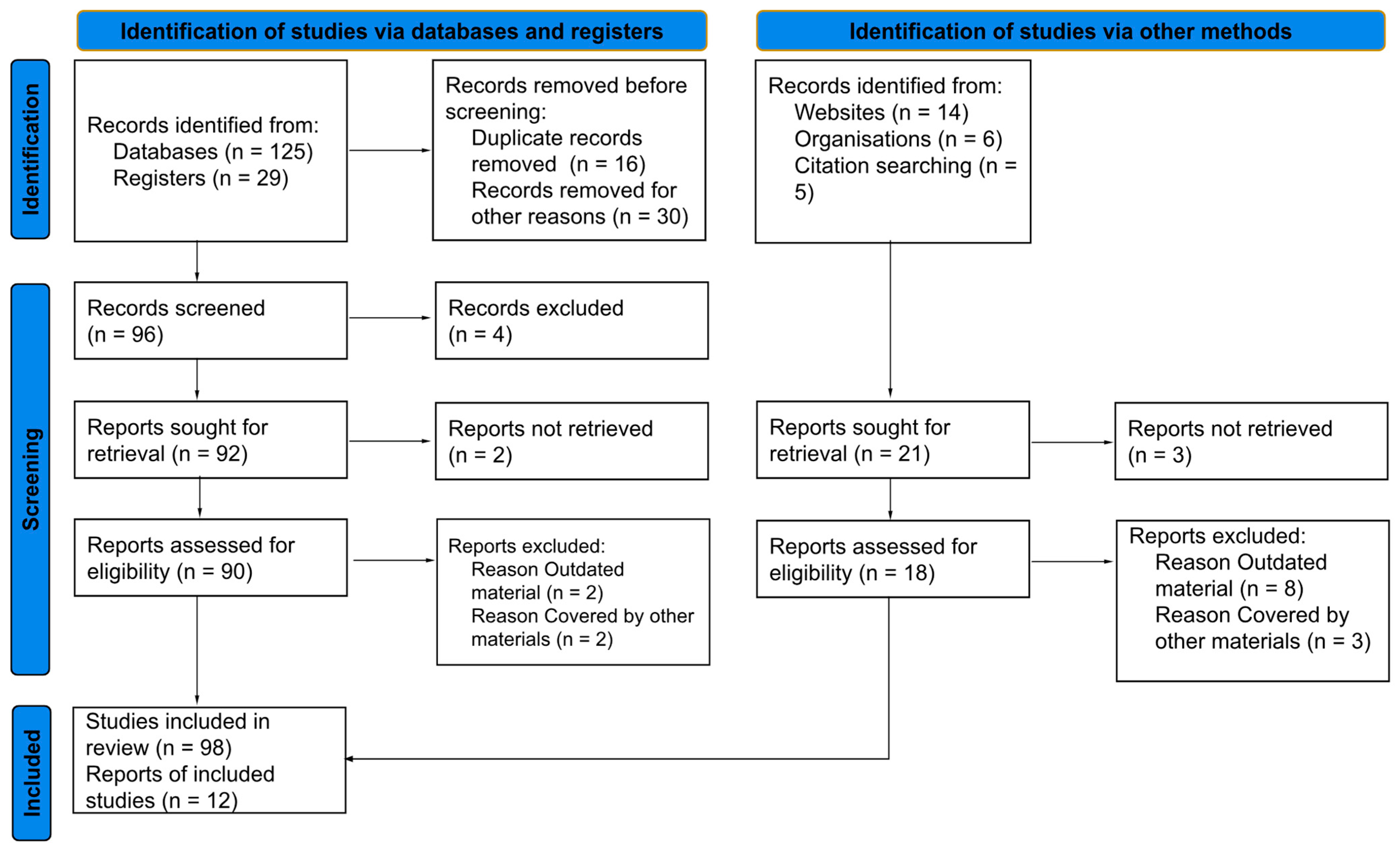
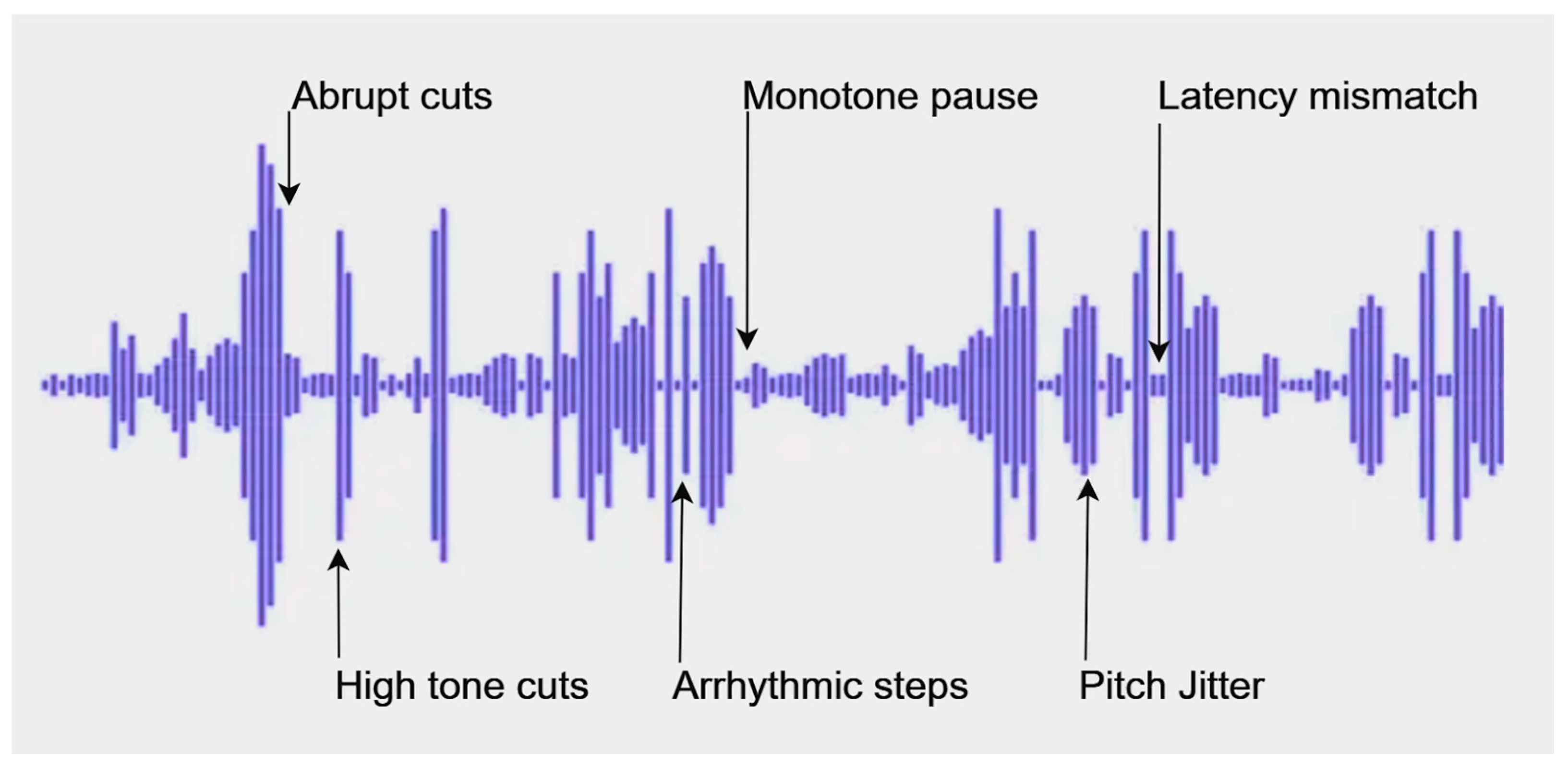



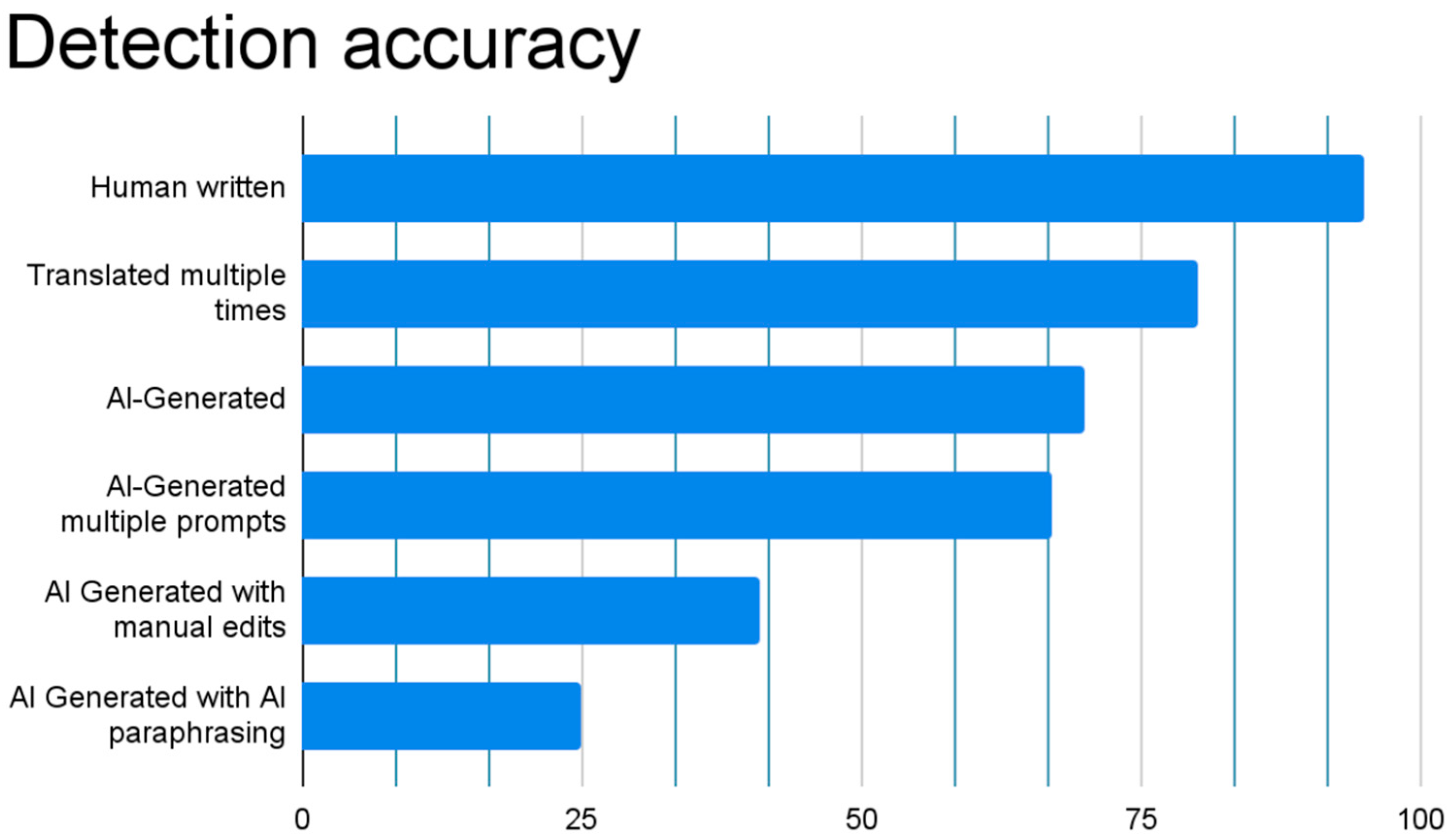

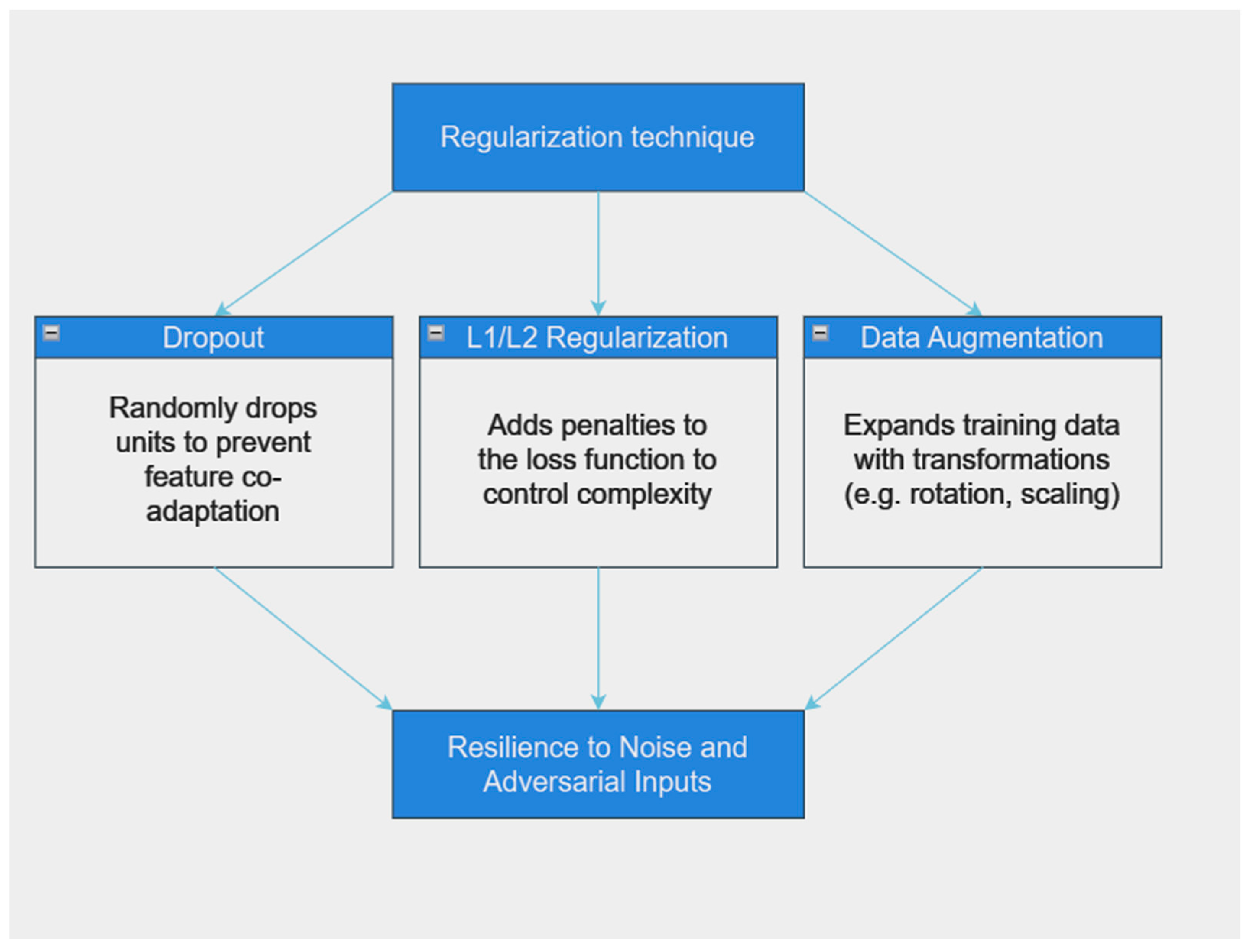
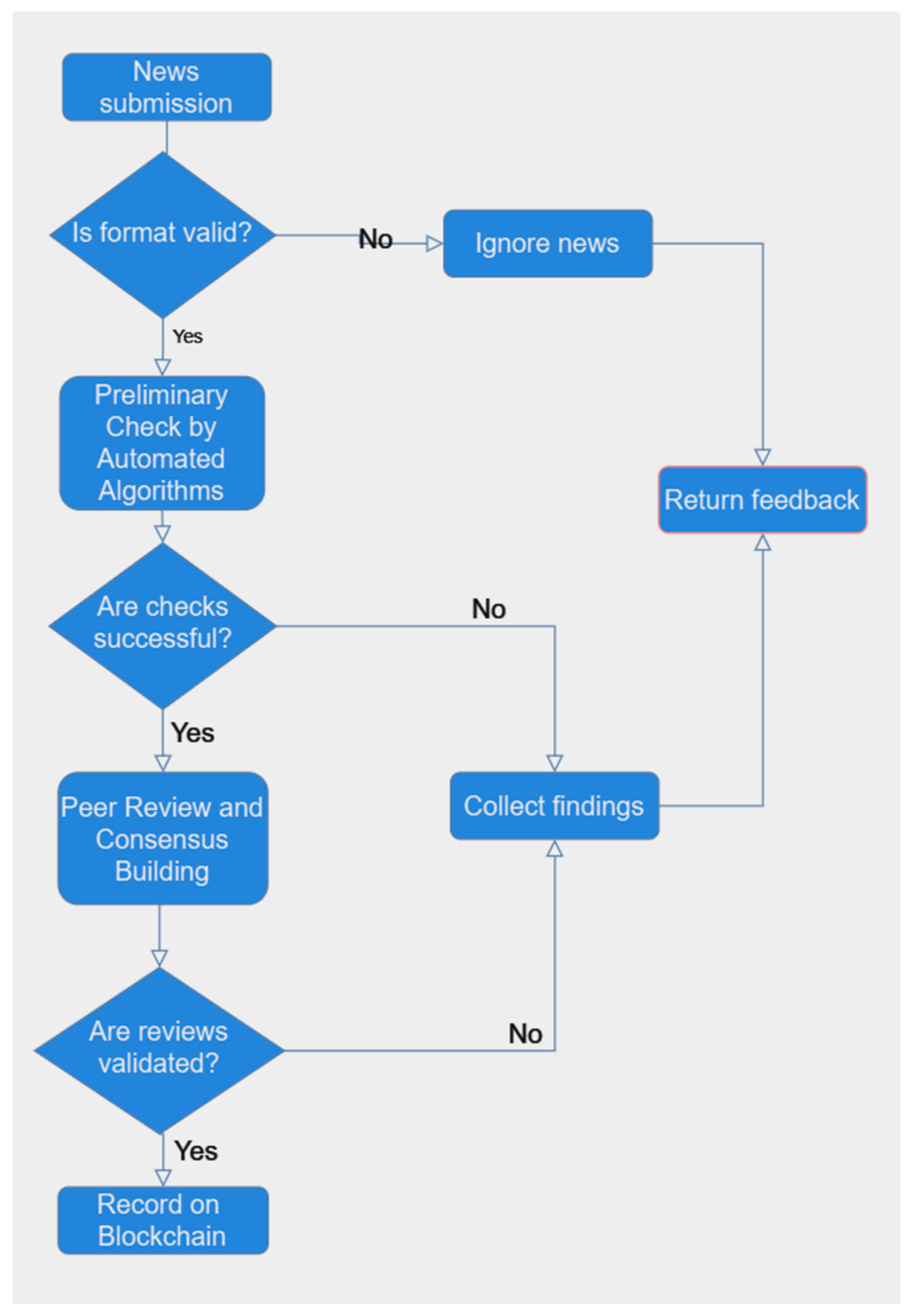

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}