1. Introduction
Android malware detection (AMD) is crucial because it protects users’ sensitive information from being compromised. Android devices often store a wealth of personal data, including financial details, personal communications, and location information. Malware can exploit vulnerabilities to steal these data, leading to identity theft, financial loss, and privacy violations. Effective malware detection helps safeguard users by identifying and mitigating threats before they can cause harm, ensuring the integrity and confidentiality of personal information.
Moreover, robust malware detection enhances the overall security of the Android ecosystem. As Android is the most widely used mobile operating system, it is a prime target for cybercriminals. Widespread malware can degrade user trust and undermine the platform’s reputation. By preventing the proliferation of malicious software, malware detection tools help maintain a secure and reliable environment for both users and developers. This encourages continued innovation and adoption of Android devices, contributing to a healthier digital landscape.
In the last decade, various artificial intelligence (AI) algorithms were applied for AMD. In [
1], the authors proposed deep convolutional neural network (CNN). Using this method, the accuracy (ACC) achieved was 98%. The authors in [
2] used an online deep-learning-based AMD engine, which can automatically detect if the application is malware or not. Using this approach, the highest ACC achieved was 96.76%. The multi-level anomaly detector for Android Malware (MADAM) was proposed in [
3]. The detector was based on the random forest classifier (RFC) that achieved 96.9%. In [
4], the robustness of the support vector machines (SVM) model for AMD against adversarial attacks was explored. It demonstrates how secure SVM can be achieved by integrating adversarial training and robust feature selection. The model achieved an ACC of 89%. Adversarial examples that can fool any deep learning model (DNN) in various domains, including AMD, were examined in [
4]. The authors discussed various attack and defense strategies. The accuracy of their adversarial trained models reached up to 92%. The paper [
5] introduces a deep learning-based approach for AMD using recurrent neural networks (RNN) to analyze API call sequences. The model effectively distinguishes between benign and malicious applications. The reported ACC is 98.2%. The paper [
6] presents MAMADroid, a tool that detects Android malware by constructing Markov chains of app behavior based on API calls. The classification was performed using different classification algorithms: RFC, artificial neural network (ANN), k-Nearest Neighbors (kNN), and support vector classifier. The reported ACC was 99%. The Deep4maldroid was introduced in [
7], a deep learning framework that uses Linux kernel system call graphs for AMD. It combines CNNs with graph embedding techniques. The model achieves an ACC of 94.6%. The paper [
8] explores the structural detection of Android malware using embedded call graphs, comparing the graphs of benign and malicious apps. The approach is effective in identifying structural anomalies. The reported accuracy is 96.5%. The paper [
9] presents a machine learning-based classification approach for Android malware, employing techniques like RFC and SVM. The study highlights the importance of feature engineering. The model achieves an ACC of 96.2%. The deep learning framework for malware detection (DL4MD) was proposed in [
10]. The DL4MD is a deep learning framework designed for intelligent malware detection in Android applications, utilizing autoencoders and deep neural networks. The framework emphasizes automatic feature learning. The reported accuracy is 95.8%. The study in [
11] presents a method for AMD based on bytecode image, transforming the app’s bytecode into images and using CNNs for classification. This novel representation aids in effective detection. The ACC reported is 94.9%.
The study presented in [
12] employs a structured pipeline for reverse engineering-based malware analysis, utilizing Call Graphs, Control Flow Graphs (CFGs), and Data Flow Graphs (DFGs) in conjunction with Deep Learning (DL) models. The authors introduce the Canonical Executable Graph (CEG) for Portable Executable (PE) files, which integrates syntactical, semantic, and structural information. Additionally, they develop the Genetic Algorithm-based Graph Explainer (GAGE) to enhance the interpretability of Explainable Artificial Intelligence (XAI). Through this innovative approach, they achieve an accuracy (ACC) of 87%, demonstrating the effectiveness of their methodology.
In [
13], the authors propose a method for Android malware detection (AMD) known as GA-StackingMD. This approach combines five different base classifiers using the Stacking technique and optimizes the framework’s hyperparameters with a Genetic Algorithm. This method addresses challenges related to high feature dimensionality and the limited accuracy of single classification algorithms. Experimental results show that GA-StackingMD achieves accuracy rates of 98.43% and 98.66% on the CIC-AndMal2017 and CICMalDroid2020 datasets, respectively, underscoring its effectiveness and practical feasibility.
The research detailed in [
14] underscores the growing importance of robust anti-malware measures in the expanding Android smartphone market. The authors develop a machine learning model designed to detect subtle malicious patterns, emphasizing the significance of coexistence patterns in malware detection. They enhance data representativeness through the use of the SMOTE technique and optimize feature selection with the Extra Trees Classifier (ETC). The proposed methodology achieves 98% accuracy using a voting classifier, representing a significant advancement in adaptable and precise Android malware detection.
In response to the rising cyber-threats associated with increased smartphone usage, the authors of [
15] introduce a Time-Aware Machine Learning (TAML) framework for Android malware detection. Utilizing the KronoDroid dataset, which comprises over 77,000 apps, their framework identifies the ’LastModDate’ feature as critical. The study demonstrates that time-aware models significantly outperform traditional machine learning models, achieving a 99.98% F1 score in a time-agnostic setting and up to a 99% F1 score in annual evaluations. Moreover, the research highlights that real-device detection surpasses emulator-based detection, underscoring the superior performance of their time-aware classifier. The results of previously described research papers are summarized in
Table 1.
The results presented in
Table 1, derived from other research studies, indicate that machine learning and deep learning methods can achieve high evaluation metrics for malware detection. However, these approaches have notable drawbacks, including the substantial computational resources required for training and model storage, as well as the inability to express them in mathematical form. This is particularly relevant for large deep learning neural networks, which consist of numerous interconnected neurons.
To address these limitations, this paper proposes the application of a Genetic Programming Symbolic Classifier (GPSC) to generate symbolic expressions (SEs) capable of detecting Android malware with high classification accuracy. The initial dataset used in this research is the publicly available Android Malware Dataset, which is inherently unbalanced. The primary challenge with an unbalanced dataset in machine learning is the bias it introduces towards the majority class, leading to suboptimal performance and inaccurate predictions, especially for the minority class.
Consequently, this paper explores whether the application of oversampling techniques can balance the dataset and, in turn, improve the GPSC’s ability to generate SEs with superior classification performance. Given the extensive range of hyperparameters associated with GPSC, a Random Hyperparameter Values Search (RHVS) method will be developed and employed to identify optimal hyperparameter combinations, enabling the GPSC to produce SEs with enhanced classification capabilities.
The GPSC training process will utilize 10-fold cross-validation (10FCV) to generate 10 SEs per training session, as each SE corresponds to one split of the 10FCV. After determining the best SE sets for each balanced dataset variation, these SEs will be integrated into a threshold-based voting ensemble (TBVE). The research will further investigate whether adjusting the threshold value can enhance the classification performance of the TBVE.
Based on the review of other research papers, the disadvantages of other research papers, and the idea and novelty in this paper, the following questions arise:
Can the Genetic Programming Symbolic Classifier (GPSC) achieve high classification performance in detecting Android malware?
Do oversampling techniques effectively balance the dataset, thereby enabling GPSC to produce symbolic expressions (SEs) with high classification performance in AMD?
Is the development and application of the Random Hyperparameter Values Search (RHVS) method justified in optimizing GPSC hyperparameters for achieving high-performance SEs in AMD?
Does the application of 10-fold cross-validation (10FCV) in training GPSC lead to the generation of robust and highly accurate SEs for AMD?
Can the combination of SEs using a threshold-based voting ensemble (TBVE) result in even higher classification performance for AMD?
The structure of this paper is organized into the following sections: Materials and Methods, Results, Discussion, and Conclusions. In the Materials and Methods section, the research methodology is detailed, including the dataset description, statistical analysis, oversampling techniques, GPSC and RHVS, evaluation metrics, training–testing procedures, and threshold based-voting ensemble. The Results section presents the optimal combinations of GPSC hyperparameter values obtained using the RHVS method, as well as the classification performance of each of the best SEs. Additionally, this section reports the classification performance of the TBVE ensemble consisting of the best SEs when applied to the original dataset.
The Discussion section provides an in-depth analysis of the proposed research methodology and the results obtained. The Conclusions section addresses the hypotheses outlined in the introduction, drawing on insights from the detailed discussion. It also highlights the advantages and limitations of the proposed research methodology and suggests directions for future research based on these limitations. Lastly, the Appendix provides supplementary information on the GPSC, along with instructions on how to download and utilize the SEs generated in this study.
2. Materials and Methods
In this section, the research methodology, dataset description and statistical analysis, oversampling techniques, genetic programming symbolic classifier, evaluation metrics, training–testing procedure, and different ensemble methods of best mathematical expressions are described.
2.1. Research Methodology
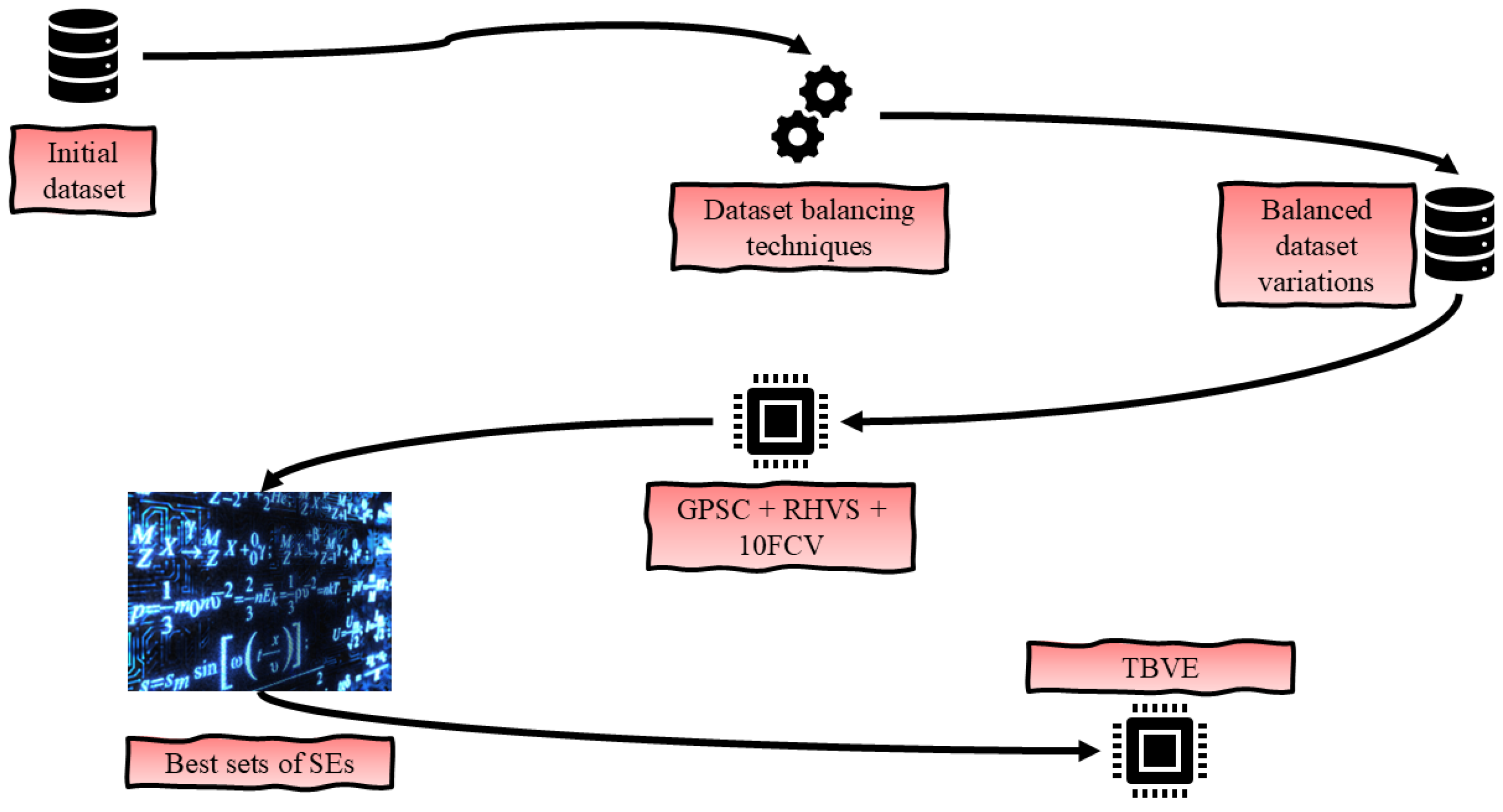
The research methodology is graphically represented in
Figure 1.
As illustrated in
Figure 1, the research methodology is composed of the following steps:
The initial dataset contains a target variable with two classes, each with a different number of samples. To address this imbalance, various oversampling techniques were employed to create balanced dataset variations, ensuring equal representation of each class in the target variable.
Once the balanced dataset variations were established, each was utilized in the GPSC to generate SEs capable of detecting Android malware with high classification performance. The datasets were split into training and testing subsets in a 70:30 ratio. The RHVS method was employed to identify the optimal combination of GPSC hyperparameters for each dataset variation. GPSC was trained using a 10FCV approach, where each of the ten splits generated one SE. In each split, the GPSC was trained on nine folds and validated on one. Following the completion of 10FCV with the optimal hyperparameters, the resulting 10 SEs were evaluated on the testing dataset. If the classification performance on the testing dataset was consistent with that on the training dataset, the training/testing procedure was deemed successful, resulting in 10 SEs with robust classification performance.
After identifying the best SEs from each balanced dataset variation, they were combined into a TBVE. The threshold was adjusted to determine if further improvements in classification performance could be achieved.
2.2. Dataset Description and Statistical Analysis
As stated, in this paper, the publicly avaliable dataset for AMD was used (for reference, see Data Availability at the end of the manuscript). The dataset consists of 327 input variables, 1 target variable, and 4644 samples. The problem with the target variable is that it consists of only strings, i.e., benign and malware values. Using the label encoder, the string values benign and malware were transformed to classes 0 and 1.
Due to an extremely large number of input variables, the initial statistical analysis will be avoided. Instead, the Pearson’s correlation analysis will be performed, and a scatter plot will be shown in which input variables that exhibit some correlation (lower than −0.3 and higher than 0.3) with the target variable will be shown. It should be noted that GPSC will automatically label each input variable from the dataset as X variable, with the corresponding index in the range of .
Pearson’s correlation analysis [
16] was performed to examine the relationship between two variables, with correlation values ranging from −1 to 1. A value of −1 indicates a perfect negative correlation, meaning that as one variable increases, the other decreases, and vice versa. Conversely, a value of 1 signifies a perfect positive correlation, where an increase in one variable corresponds to an increase in the other. A correlation value of 0 indicates no relationship between the variables, meaning that changes in one variable have no effect on the other.
Figure 2 presents the results of this analysis, showing the correlation between each input variable and the target variable.
From
Figure 2, it can be noticed that “android.permision.READ_PHONE_STATE” has the highest positive correlation value (0.76) with the target variable. This high positive correlation suggests that malware applications often request this permission, making it a significant indicator of malicious behavior. The android.permission.RECEIVE_BOOT_COMPLETED and RECEIVE_BOOT_COMPLETED variables have a 0.591 and 0.432 correlation value with the target variable. This strong correlation indicates that malware often requests to start after the device boots, likely to ensure persistence on the device. The INSTALL_SHORTCUT has a 0.4518 correlation value with the target variable. The relatively high correlation value indicates that malware apps might use this permission to place shortcuts on the home screen, possibly as part of a phishing or adware strategy. The ACCESS_COARSE_LOCATION and ACCESS_FINE_LOCATION have 0.406 and 0.39 correlation values with the target variable. Access to location data is moderately associated with malware, suggesting these apps might track user movements. The RECEIVE_SMS and READ_SMS have a bot 0.307 correlation value with the target variable. The SMS permissions are moderately correlated with malware, indicating that malicious apps might intercept or read messages. The GET_TASKS have a 0.323 correlation value with the target variable. This permission allows an app to see what tasks are running, which can be used by malware to monitor user activity or other applications. The SEND_SMS has a correlation value of 0.306 with the target variable. The ability to send SMS is associated with malware, potentially for sending premium SMS messages or spreading spam.
The negative correlation indicates that the presence of certain permissions is more common in the benign applications. The com.google.android.c2dm.permission.RECEIVE has a correlation of −0.49 with the target variable. This correlation value suggests that benign apps are more likely to use Google’s cloud messaging service, whereas malware might avoid it to evade detection. The Ljava/net/URL;->openConnection variable has a correlation value of −0.408 with the target variable. The benign apps might use standard network connections more frequently, while malware could use alternative methods to avoid detection. The Landroid/location/LocationManager;->getLastKnownLocation variable has a −0.376 correlation value with the target variable. Accessing the last known location is more common in benign apps, possibly for legitimate location-based services. The WAKE_LOCK has a −0.317 correlation value with the target variable. The benign applications might use this permission to keep the device awake for legitimate purposes, whereas malware might not use it frequently.
The number of samples per class could indicate if the dataset is balanced or imbalanced. In this dataset, there are two classes, i.e., benign (labeled 0) and malware (labeled 1). The graphical representation of both class samples are shown in
Figure 3.
As seen from
Figure 4, the initial investigation of target variable shows that class_0 has 1931 samples, while class_1 has 2533 samples. This is a huge imbalance between the minority (class_0) class and majority (class_1) class, which suggests that the application of dataset balancing techniques is mandatory.
2.3. Oversampling Techniques
In an unbalanced dataset for a binary classification problem, the two classes are typically referred to as the minority and majority classes. The minority class has fewer samples, while the majority class has a larger number of samples, leading to an imbalance. Training a machine learning algorithm on such an imbalanced dataset is generally not recommended, as it may result in the model becoming biased towards the majority class. To mitigate this, it is considered best practice to balance the classes, either by increasing the number of samples in the minority class or by reducing the number of samples in the majority class.
Increasing the number of minority class samples is achieved through oversampling techniques, while reducing the number of majority class samples is accomplished using undersampling techniques. The advantage of oversampling methods is that they generate additional samples for the minority class until its size is equal to or nearly equal to that of the majority class. This process typically does not require extensive parameter tuning and can be executed quickly, often within seconds.
In contrast, undersampling techniques reduce the number of samples in the majority class to match or approximate the number of minority class samples. However, undersampling is more time-consuming, as it involves identifying which majority class samples should be removed from the dataset. Additionally, undersampling methods usually require careful parameter tuning to achieve an appropriate balance between the classes.
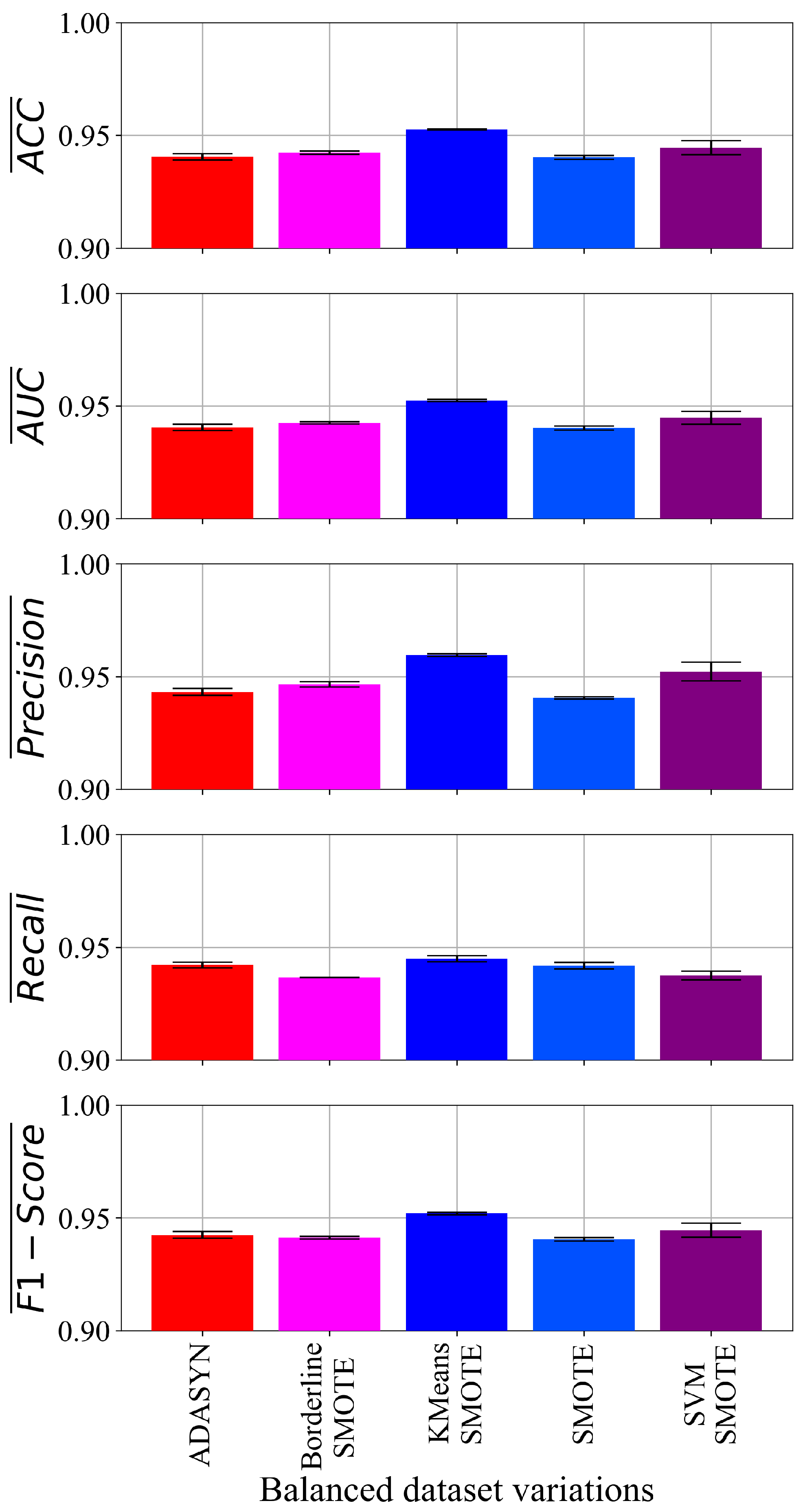
Given the ease of application, shorter execution time, and the ability to balance class samples without extensive parameter tuning, the following oversampling techniques were employed in this research: ADASYN, BorderlineSMOTE, KMeansSMOTE, SMOTE, and SVMSMOTE.
2.3.1. ADASYN
The Adaptive Synthetic Sampling (ADASYN) technique, as described in [
17], is a method designed to address class imbalance in datasets, particularly in machine learning classification tasks. ADASYN generates synthetic data samples for the minority class to achieve a more balanced class distribution. Unlike other oversampling techniques, ADASYN adaptively targets minority class samples that are more difficult to classify, producing a higher number of synthetic samples in regions where the minority class density is low and fewer samples where the density is high. This targeted approach enhances the classifier’s performance on the minority class by focusing on the areas where the model is most likely to struggle.
2.3.2. BorderlineSMOTE
The Borderline Synthetic Minority Oversampling Technique (BorderlineSMOTE) is an advanced method for addressing class imbalance in datasets. Unlike traditional oversampling techniques, BorderlineSMOTE specifically focuses on generating synthetic samples for the minority class near the decision boundary between classes [
18]. This approach is designed to improve the classifier’s performance on difficult borderline instances that are more likely to be misclassified.
BorderlineSMOTE identifies minority class samples that are at a higher risk of misclassification—those situated close to the majority class—and generates new synthetic samples around these critical points. By concentrating on these challenging regions, BorderlineSMOTE enhances the classifier’s ability to accurately differentiate between classes, making it particularly effective for complex and imbalanced datasets.
2.3.3. KMeansSMOTE
The KMeans Synthetic Minority Oversampling Technique (KMeansSMOTE) is an oversampling technique designed to handle class imbalance in datasets by combining k-means clustering with the Synthetic Minority Oversampling Technique (SMOTE) [
19]. The technique involves the following steps:
Clustering: The minority class samples are clustered using the k-means algorithm.
SMOTE Application: Within each cluster, synthetic samples are generated using SMOTE, which creates new instances by interpolating between existing minority class samples.
This clustering step ensures that synthetic samples are generated in a more structured manner, respecting the natural data distribution and improving the classifier’s performance on the minority class. By focusing on local structures within clusters, KMeansSMOTE can produce more relevant and diverse synthetic samples, enhancing the overall model accuracy.
2.3.4. SMOTE
The Synthetic Minority Oversampling Technique (SMOTE) is a widely used method for addressing class imbalance in datasets, particularly in machine learning classification tasks. SMOTE enhances class balance by generating synthetic samples for the minority class. The process begins by selecting a sample from the minority class and identifying its k-nearest neighbors within the same class [
20]. Synthetic samples are then created along the line segments connecting the original sample to its neighbors. This approach effectively increases the diversity of the minority class, avoiding mere duplication of existing samples, and thereby improving the model’s performance on imbalanced datasets.
2.3.5. SVMSMOTE
The Support Vector Machines–Synthetic Minority Oversampling Technique (SVMSMOTE) is an oversampling technique that combines the principles of SVM and SMOTE to address class imbalance in datasets [
21]. The method focuses on generating synthetic samples for the minority class, particularly around the decision boundary between classes.
The SVMSMOTE consists of the following steps:
SVM Training: An SVM classifier is trained on the dataset to identify the support vectors, which are the samples that lie closest to the decision boundary.
Sample Selection: The support vectors of the minority class are identified, as they are the most informative and challenging samples.
SMOTE Application: Synthetic samples are generated using SMOTE by interpolating between these support vectors and their nearest neighbors within the minority class.
By concentrating on the support vectors, SVMSMOTE aims to improve the classifier’s performance on the most difficult-to-classify minority class samples, thus enhancing the overall model accuracy on imbalanced datasets.
2.3.6. The Results of Oversampling Techniques
After applications of oversampling techniques, the balanced dataset variations were created. Some balanced dataset variations have a slight difference between class samples; however, these imbalances are negligible compared to the initial imbalanced dataset. The results of the application of balancing techniques is shown in
Figure 4.
As seen from
Figure 4, the application of BorderlineSMOTE, SMOTE, and SVMSMOTE generated perfectly balanced datasets. However, the ADASYN generated class_0 with 2381 samples, which is a 6% lower number of samples than the class_1 number of samples. It should be noted that, initially, class_0 has a 23.76% lower number of samples than class_1. The KMeansSMOTE oversampled class_0; however, there is a slight difference between samples: class_0 contains 2534, while class_1 contains 2533 samples.
2.4. Genetic Programming Symbolic Classifier
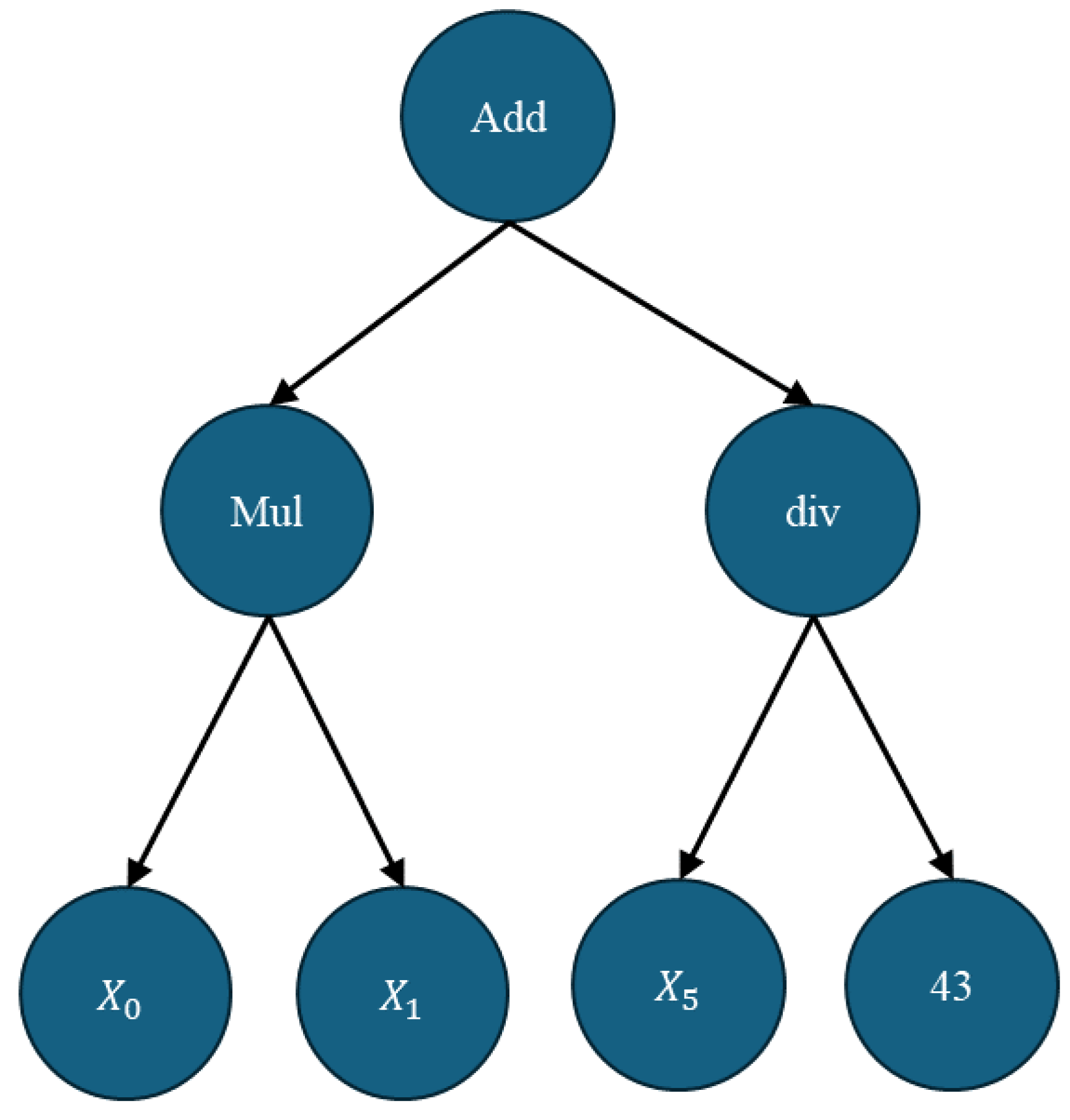
The Genetic Programming Symbolic Classifier (GPSC) is an evolutionary algorithm that begins with an initialization phase of the population. This initial population is created by randomly selecting mathematical functions, constant values, and input variables derived from the dataset. These components are organized into a primitive set, which includes terminals (i.e., input variables and constant values) and a function set (i.e., mathematical functions). The size of the initial population is determined by the GPSC hyperparameter popSize. In this study, the constant values are defined within a range specified by the GPSC hyperparameter constantRange. The mathematical functions utilized include addition, subtraction, multiplication, division, natural logarithm, absolute value, square root, cube root, and logarithms with bases 2 and 10. Notably, to ensure the correct execution of the GPSC, some functions—specifically, division, square root, and logarithms with bases 2 and 10—were slightly modified to prevent errors; details of these modifications are provided in
Appendix A. Each member of the initial population in GPSC is represented as a three-structure. For example, the symbolic expression add(mul(
,
), div(
, 43)) is illustrated in its three-structure form in
Figure 5.
In
Figure 5, the node labeled “Add” represents the root node, which is at depth 0. The functions “mul” and “div” are positioned at depth 1, while the variables
and the constant 43 are located at depth 2. The size of a symbolic expression (SE) is quantified by its length, defined as the total number of elements it contains, including mathematical functions, constants, and variables. For the SE shown in
Figure 5, which comprises 3 mathematical functions, 3 variables, and 1 constant, the total length is 7.
In GPSC, the initial population is generated using the ramped half-and-half method, which merges two traditional genetic programming methods: the full method and the grow method [
22]. The term “ramped” refers to the range of depths for the population members. For example, a depth range of 5–20 means that the initial population will include members with tree depths varying between 5 and 20.
In the full method, half of the initial population is created by selecting nodes exclusively from the function set until the maximum depth is achieved; only terminals (variables and constants) are then used to fill the remaining nodes. This method often results in trees where all leaves are at the same depth. Conversely, the grow method generates the other half of the population by selecting nodes from the entire primitive set (function set plus terminals) until the maximum depth is reached, at which point only terminals are randomly selected. The grow method tends to produce trees with greater diversity compared to the full method. The depth range used in the ramped half-and-half method is defined by the hyperparameter InitDepth, which specifies the depth range for the population members.
After the initial population is created using the random half-and-half method, the population members (SEs) are evaluated using the fitness function. This fitness function consists of the following steps:
In GPSC, there are two primary termination criteria: the fitness function threshold, known as stopCrit, and the maximum number of generations, denoted as maxGen. The GPSC execution terminates if the fitness function value of any population member falls below the stopCrit value. If this threshold is not reached, the algorithm continues until the maxGen limit is achieved. In this study, all GPSC runs were concluded upon reaching the maximum number of generations.
After evaluating the population, the Tournament Selection (TS) process is repeatedly conducted to determine which members advance to the next generation. Each TS involves randomly selecting a subset of population members, where the size of the subset is defined by the GPSC hyperparameter TS. The member with the lowest fitness value within this subset is chosen as the winner of the tournament.
Genetic operations, such as crossover and mutation, are then applied to these TS winners to produce offspring for the next generation. The crossover operation requires two TS winners. It involves randomly selecting subtrees from both winners and exchanging these subtrees to generate new population members. In GPSC, three types of mutations are utilized: subtree mutation, hoist mutation, and point mutation.
Subtree Mutation (subMute): Involves selecting a random subtree from a TS winner and replacing it with a newly generated subtree from the primitive set. This operation requires only one TS member.
Hoist Mutation (hoistMute): Randomly selects a subtree from the TS winner and replaces it with a random node, resulting in the creation of a new subtree and, consequently, a new population member.
Point Mutation (pointMute): Randomly selects nodes within the TS winner and replaces them with nodes from the primitive set. This includes replacing constants with other constants, variables with other variables, and mathematical functions with equivalent functions of the same arity (number of arguments).
The stopping criterion stopCrit is a predefined fitness value. If any population member achieves this value, GPSC terminates. In this study, stopCrit was set to a very low value to ensure that the algorithm would terminate only upon reaching maxGen.
The constant range, constRange, defines the range of constant values used in GPSC for both initializing the population and during genetic operations. The maximum samples parameter, maxSamples, specifies the percentage of the training dataset used for each generation. For example, a value of 0.99 means that 99% of the dataset is used for training, while the remaining 1% is used for additional evaluation. The fitness value obtained from the 99% of the data is compared with the out-of-bag fitness value from the remaining 1% to ensure consistency in the evolution of GPSC.
Lastly, the parsimony coefficient, parsCoeff, is a crucial hyperparameter used to manage the size of the population members and mitigate the bloat phenomenon—where members grow excessively without improving fitness. During the TS process, if a member’s length is 50 times greater than another but has a lower fitness value, its fitness is penalized by its size multiplied by the parsimony coefficient. A high parsCoeff value prevents growth, while a low value may exacerbate bloat. Thus, careful tuning of parsCoeff is essential to balance the growth of population members and maintain effective evolution.
Since the GPSC has a lot of hyperparameter values, the problem is how to find the optimal combination of its hyperparameters, in which the use of the GPSC will produce the SEs that will generate high classification performance. Developing the RHVS method from scratch consists of the following steps:
Define initial lower and upper boundary value for each hyperparameter;
Test the GPSC with each boundary and see it will successfully execute;
If the GPSC execution in the previous step fails, then adjust the boundaries.
The boundaries of GPSC hyperparameter values used in the RHVS method is shown in
Table 2.
It should be noted that the sum of genetic operations should be equal to or less than 1. If the value is lower than 1, then some population members enter the next generation unchanged. As seen from
Table 2, it can be noticed that the subMute coefficient will be a dominating genetic operation when compared to others. The initial investigation showed that the subMute greatly reduces the fitness function value. The benefit of using this genetic operation is that it does not require two TS winners, i.e., only one, and due to the large population in every GPSC execution, it is not memory intensive. On the other hand, this genetic operation can be described as more aggressive when compared to other genetic operations, such as hoistMute or pointMute, due to the fact that it replaces the entire subtree of the TS winner with a randomly generated subtree. The parsCoeff range initially proved to be a suitable range for this research since the coefficient value did not prevent the growth of the population members and the bloat phenomenon did not occur.
2.5. Evaluation Metrics
In this research, the accuracy score (), area under receiver operating characteristics curve (), precision score, recall score, , and confusion matrix were used to evaluate the obtained SEs and TBVE. Before explaining each evaluation metric, it is important to define the basic elements—which are used to calculate the aforementioned evaluation metrics—and these are true positive (), false positive (), true negative (), and false negative ().
are instances where the model (trained ML model or SE) correctly predicts the positive class. In the case of AMD, this could be a sample that is classified as Android malware (actual positive) and the model correctly identifies this is Android malware (predicted positive). is the count of such correct positive predictions.
are instances where the model (trained ML model or SE) incorrectly predicts the negative class for a true positive case. In the case of AMD, this is the sample that is classified as Android malware (actual positive) but the model fails to detect it (predicted negative). is the count of incorrect negative predictions.
are instances where the model (trained ML model or SE) incorrectly predicts the positive class for the true negative case. In this case, the sample is not classified as Android malware (actual negative) but the model incorrectly predicts the sample as being Android malware (predicted postivie). is the count of incorrect positive predictions.
are instances where the model (trained ML model or SE) correctly predicts the negative class. In this investigation, the sample is not classified as Android malware and the model correctly identifies that this is not Android malware (predicted negative). The is the count of correct negative predictions.
The
, according to [
23], can be defined as the ratio of correctly predicted observations to the total number of observations. The
is the basic evaluation metric that gives the information about the overall effectiveness of the trained ML model or obtained SE. The equation for calculating the
can be written as:
The range of
is between 0 and 1, where one is the perfect accuracy of the model or, in other words, that the trained model or obtained SE predicts all dataset samples correctly. The
score, according to [
24], is the evaluation metric used in classification problems. This is the area under the
curve, and the
is the probability curve. The
represents the degree or measure of separability. This metric provides the information of how much the model is capable of distinguishing between classes. The components of
are the true positive rate (
) or recall and false positive rate (
). The
is calculated using the expression written as:
while the FPR can be calculated using the expression
The
value can be between 0 and 1, where 1 is the perfect ML model or obtained SE. The
of 0.5 is the model with no discriminative ability, which is similar to random guessing. A higher
value indicates a better performing model in distinguishing between the positive and negative class.
According to [
25], the precision score is the ratio of correctly predicted positive observations to the total predicted positives. The precision score measures the accuracy of the positive predictions. The precision score is calculated using the expression written as:
A high precision means that the model has a low
. This evaluation metric is very important in scenarios where
are more costly than
(example: email spam detection, AMD).
According to [
25], the recall score, also known as the sensitivity or TPR, is the ratio of correctly predicted positive observations to all observations from the dataset. The recall score is calculated using the expression:
A high recall score means that the model captures most of the positive samples. This evaluation metric is crucial in situations where FN are more costly than the FP, for example, in disease detection.
The F1-score is the harmonic mean of the precision and recall score, according to [
25]. This evaluation metric is the balance between precision and recall and is useful when a single metric that balances both concerns is required.
The confusion matrix [
26] is a table used to describe the performance of a classification model on a set of test data, of which the true values are known. The components of the confusion matrix are
,
,
, and
, and are usually represented in a table, as in
Table 3.
The CM provides a complete picture of how the classification model is performing. It helps in identifying not just errors made by the model, but also provides the information on the error type ( and ).
2.6. Training–Testing Procedure
The training–testing procedure used in this research is graphically shown in
Figure 6.
The training and testing procedure (
Figure 6) outlined in this paper involves the following steps:
Dataset Splitting: Each balanced dataset variation is divided into training and testing subsets with a 70:30 ratio. The training subset is used for GPSC training with a 10-fold cross-validation (10FCV), while the testing subset is reserved for final evaluation. The SEs are tested only if the training metrics exceed a threshold of 0.9.
GPSC Training with 10FCV: Training begins after determining the GPSC hyperparameters using the Random Hyperparameter Values Search (RHVS) method. For each fold of the 10FCV, one SE is generated, resulting in a total of 10 SEs after completing all folds. Evaluation metrics, including Accuracy (ACC), Area Under the Curve (AUC), Precision, Recall, and F1-score are calculated for each SE on both training and validation folds.
Evaluation of Training Metrics: Once training is complete, the mean and standard deviation of the evaluation metrics are computed. If all metrics exceed the 0.9 threshold, the process advances to the testing phase. If any metric falls below this threshold, the procedure restarts with a new set of hyperparameters determined through RHVS.
Testing Phase: The set of 10 SEs is evaluated on the testing dataset, which was not used during training. The performance is assessed by comparing the SEs’ predictions with the actual values in the testing dataset using the same evaluation metrics. If the metrics remain above 0.9, the process concludes. If not, the procedure is restarted with new hyperparameters selected via RHVS.
2.7. Threshold-Based Voting Ensemble
After the set of best SEs are obtained using GPSC on each balanced dataset variation, the threshold-based voting ensemble (TBVE) will be formed based on these SEs [
27]. The TBVE is a method used in ensemble learning where multiple ML models/SEs (classifiers) vote on the classification of a sample, and a decision is made based on the predefined threshold of votes. The threshold could be defined as the minimum number of accurate predictions made by SEs in an ensemble per sample. This threshold must be investigated to find for which threshold value the classification performance is the highest possible.
So, the TBVE consists of multiple SEs that were, in this case, trained on multiple balanced dataset variations. Each of the SEs in the TBVE makes a prediction for a given dataset sample. The predictions are usually in the form of class labels. A threshold is set to determine how many SEs need to agree on a particular class label for it to be assigned to the sample. The threshold can be a majority vote, i.e., more than 50% of models, a plurality vote (most votes), or a fixed number of votes. However, in this paper, the threshold will be investigated from the minimum (one SE accurate prediction) to the maximum threshold (maximum number of SEs obtained). The idea is to find the threshold interval or specific threshold value for which the classification performance has the maximum value. The class label that meets or exceeds the threshold of votes is assigned to the sample.
4. Discussion
In this paper, the publicly available dataset for AMD was used in GPSC to obtain SEs that could detect Android malware with a high detection accuracy. The initial dataset consists of 328 variables, where 327 are input variables and 1 is a target variable. The dataset contains 4464 samples in total. Due to a large number of input variables, statistical analysis is almost impossible. The problem was that initially, the research was conducted with all input variables to see which one would end up in the SEs. So only the Pearson’s correlation analysis was performed, and only correlated variables with target variables are shown. From
Figure 2, the highly positive correlation permissions, permissions like READ_PHONE_STATE and RECEIVE_BOOT_COMPLETED, are strong indicators of malware. Security systems should flag apps requesting these permissions for further inspection. The moderate positive correlation permissions are permissions related to location (ACCESS_COARSE_LOCATION, ACCESS_FINE_LOCATION), SMS (RECEIVE_SMS, READ_SMS, SEND_SMS), and task management (GET_TASKS) and suggest a higher likelihood of the app being malware, warranting closer scrutiny. The negative correlation permissions are permissions and methods like com.google.android.c2dm.permission.RECEIVE, openConnection, and getLastKnownLocation and are more common in benign apps; their presence might indicate a lower risk of the app being malware. These correlations provide valuable insights into which permissions and features are most indicative of malware, helping in the development of better heuristics and machine learning models for malware detection.
The problem with this dataset is that it was imbalanced, so the application of dataset balancing methods was necessary. In this investigation, oversampling techniques were chosen due to the fact that they are easily executed and usually do not require additional parameter tuning. The chosen oversampling techniques (ADASYN, BorderlineSMOTE, KMeansSMOTE, SMOTE, and SVMSMOTE) achieved a balanced dataset variation. However, it should be noticed that ADASYN has a slight imbalance. However, this slight imbalance was over the initial imbalance, so this dataset was used in further investigations.
On each balanced dataset variation, the GPSC with the RHVS method was applied and the GPSC was trained using the 10FCV. This means that the GPSC was trained 10 times on 10 split variations of the train dataset. Each time the GPSC was trained, the SE was obtained by the GPSC; so in total, after one 10FCV training, 10 SEs were obtained. The evaluation metric values obtained during the training determine if the SEs will continue to the testing phase, i.e., where the test dataset will be applied on obtained SEs. If the evaluation metric values were all higher than 0.9, the process was completed and the best SEs for that balanced dataset variation were obtained.
The variability of optimal GPSC hyperparameter values across different balanced dataset variations shows the importance of the application of an RHVS method that can quickly find optimal GPSC hyperparameter values. As seen from
Table 4, the larger popSizes (e.g., ADASYN dataset) may help in exploring a more extensive solution space, while a higher number of generations (e.g., BorderlineSMOTE) allows more time for evolution, potentially leading to better optimization. The variation in TS and tree depth settings suggest that different datasets benefit from varying selection pressures and model complexities. This could be due to the intrinsic complexity and noise levels within each dataset. The near-constant training size implies a consistent approach to utilizing the full capacity of the training data. The wide range of constant values reflects the need for different numerical constants to fit various datasets optimally. A low parsCoeff across all datasets emphasizes the focus of enabling the growth of the population members, which could improve the diversity between population members.
So after the application of the training–testing procedure, a total of 50 SEs were obtained. These SEs were all used in TBVE to see if the classification performance could be improved. The investigation showed that using TBVE, the highest classification performance was achieved. The best SEs obtained from balanced dataset variations (
Figure 7) showed consistency across metrics. The best SEs show robust performance across all evaluated metrics (ACC, AUC, Precision, Recall, and F1-Score). The low standard deviation indicates that the best SEs’ performance is relatively stable across different datasets and oversampling techniques. The balanced dataset variations were obtained using different oversampling techniques, and from each dataset, the SEs achieved high classification performance. This suggests that the SEs can generalize well across different distributions of data achieved by these oversampling methods. The high mean values across all metrics indicate that the best SEs are effective in distinguishing between classes and making accurate predictions. This effectiveness is crucial in practical applications, where high accuracy and reliable predictions are essential.
To compute the output of TBVE, the best SEs require 101 input dataset variables, and these are: X1, X6, X7, X8, X13, X14, X17, X20, X28, X29, X31, X34, X39, X41, X47, X49, X55, X62, X72, X78, X86, X87, X89, X95, X99, X103, X105, X108, X114, X118, X119, X128, X131, X134, X138, X140, X147, X149, X152, X154, X155, X156, X165, X167, X175, X180, X181, X188, X191, X200, X213, X216, X218, X219, X220, X228, X236, X240, X246, X247, X249, X253, X254, X257, X258, X262, X266, X267, X268, X269, X270, X272, X275, X278, X280, X282, X284, X285, X286, X289, X293, X294, X295, X298, X301, X302, X303, X304, X306, X307, X308, X309, X310, X312, X313, X314, X316, X319, X322, X323, X325.
These input variables are: ACCESS_CACHE_FILESYSTEM, ACCESS_LOCATION_ EXTRA_COMMANDS, ACCESS_MOCK_LOCATION, ACCESS_MTK_MMHW, ACCESS_ SUPERUSER, ACCESS_ SURFACE_FLINGER, ACTIVITY_ RECOGNITION, ANT, BIND_ APPWIDGET, BIND_ CARRIER_ MESSAGING_ SERVICE, BIND_ DREAM_ SERVICE, BIND_ NFC_ SERVICE, BIND_ TV_ INPUT, BIND_ VPN_ SERVICE, BRICK, BROADCAST_ SMS, CAMERA, CHANGE_ NETWORK_ STATE, DEVICE_ POWER, EXPAND_ STATUS_ BAR, GET_ TASKS, GET_ TOP_ ACTIVITY_ INFO, GOOGLE_ AUTH, INSTALL_ SHORTCUT, JPUSH_ MESSAGE, MANAGE_ APP_ TOKENS, MAPS_ RECEIVE, MEDIA_ CONTENT_ CONTROL, NFC, PLUGIN, PROCESS_ OUTGOING_ CALLS, READ_ DATABASES, READ_ GMAIL, READ_ INPUT_ STATE, READ_ PHONE_ STATE, READ_ SETTINGS, REBOOT, RECEIVE_ BOOT_ COMPLETED, RECEIVE_ SMS, RECEIVE_ WAP_ PUSH, RECORD_ AUDIO, REORDER_ TASKS, SET_ ALARM, SET_ ANIMATION_ SCALE, SET_ WALLPAPER, SUBSCRIBED_ FEEDS_ READ, SUBSCRIBED_ FEEDS_ WRITE, USE_ FINGERPRINT, WAKE_ LOCK, WRITE_ EXTERNAL_ STORAGE, WRITE_VOICEMAIL, Ljava/lang/Runtime;->exec, Ldalvik/system/DexClassLoader;->loadClass, Ljava/lang/ System;->loadLibrary, Ljava/net/ URL;->openConnection, Landroid/location/LocationManager;->getLastKgoodwarewn Location, Landroid/telephony/TelephonyManager;->getSimOperator, Lorg/apache/ http/impl/client/DefaultHttpClient;->execute, android. permission. READ_ EXTERNAL_ STORAGE, android. permission. RECEIVE_ SMS, android. permission. WRITE_ SETTINGS, android. permission. WRITE_ EXTERNAL_ STORAGE, android. permission. RECORD_ AUDIO, android. permission. CHANGE_ NETWORK_ STATE, com. android. launcher. permission. INSTALL_ SHORTCUT, android. permission. READ_ PHONE_ STATE, android. permission. INTERNET, android. permission. MOUNT_ UNMOUNT_ FILESYSTEMS, com. majeur. launcher. permission. UPDATE_ BADGE, android. permission. AUTHENTICATE_ ACCOUNTS, com. htc. launcher. permission. READ_ SETTINGS, android. permission. FLASHLIGHT, android. permission. CHANGE_ CONFIGURATION, com. anddoes. launcher. permission. UPDATE_ COUNT, com. google. android. c2dm. permission. RECEIVE, com. sonymobile. home. permission. PROVIDER_ INSERT_ BADGE, android. permission. WRITE_ CALENDAR, android. permission. SEND_ SMS, com. huawei. android. launcher. permission. WRITE_ SETTINGS, android. permission. SET_ WALLPAPER, android. permission. ACCESS_ MOCK_ LOCATION, android. permission. ACCESS_ COARSE_ LOCATION, android. permission. READ_ LOGS, android. permission. SYSTEM_ ALERT_ WINDOW, me. everything. badger. permission. BADGE_ COUNT_ READ, android. permission. CHANGE_ WIFI_ STATE, android. permission. READ_ CONTACTS, com. android. vending. BILLING, android. permission. RECEIVE_ BOOT_ COMPLETED, android. permission. WAKE_ LOCK, android. permission. ACCESS_ FINE_ LOCATION, android. permission. BLUETOOTH, android. permission. CAMERA, android. permission. FOREGROUND_ SERVICE, android. permission. BLUETOOTH_ ADMIN, android. permission. VIBRATE, android. permission. RECEIVE_ USER_ PRESENT, com. sec. android. iap. permission. BILLING, android. permission. ACCESS_ NETWORK_ STATE, com. google. android. finsky. permission. BIND_ GET_ INSTALL_ REFERRER_ SERVICE, and android. permission. READ_ SMS.
The dataset variables represent various Android permissions and API functionalities. ACCESS_ CACHE_ FILESYSTEM allows an application to read from the file system cache, while ACCESS_ LOCATION_ EXTRA_ COMMANDS provides access to additional location provider commands. ACCESS_ MOCK_ LOCATION enables applications to create mock locations for testing, and ACCESS_ MTK_ MMHW is related to MediaTek hardware features, typically requiring special hardware. ACCESS_ SUPERUSER provides elevated access levels for superuser operations, and ACCESS_ SURFACE_ FLINGER allows access to low-level graphics operations. ACTIVITY_ RECOGNITION allows applications to recognize physical activities, like walking or cycling.
ANT is related to the ANT wireless protocol used in health and fitness devices. BIND_ APPWIDGET and BIND_ CARRIER_ MESSAGING_ SERVICE are used to bind to specific system services, like widgets or carrier messaging services. BIND_ DREAM_ SERVICE and BIND_ NFC_ SERVICE bind are applications for the dream service (screensavers) and NFC service, respectively. BIND_ TV_ INPUT and BIND_ VPN_ SERVICE are used for TV input and VPN services. BRICK is a dangerous permission that can permanently disable a device.
BROADCAST_ SMS allows applications to send SMS messages, and CAMERA grants access to the device’s camera. CHANGE_ NETWORK_ STATE allows applications to change network connectivity states, and DEVICE_ POWER allows for managing device power settings. EXPAND_ STATUS_ BAR lets applications expand or collapse the status bar. GET_ TASKS provides access to information about running tasks, and GET_ TOP_ ACTIVITY_ INFO provides access to information about the top activity.
GOOGLE_ AUTH is related to Google authentication services. INSTALL_ SHORTCUT allows apps to install shortcuts on the home screen, and JPUSH_ MESSAGE is specific to the JPush messaging service. MANAGE_ APP_ TOKENS allows for managing app tokens, and MAPS_ RECEIVE is used to receive map data. MEDIA_ CONTENT_ CONTROL allows controlling media playback, and NFC enables NFC communication.
PLUGIN supports plugin integration, and PROCESS_ OUTGOING_ CALLS allows for managing outgoing calls. READ_ DATABASES allows for reading databases, READ_ GMAIL allows for reading Gmail, and READ_ INPUT_ STATE allows for reading input state. READ_ PHONE_ STATE grants access to phone state information, and READ_ SETTINGS permits reading system settings. REBOOT allows the app to reboot the device, and RECEIVE_ BOOT_ COMPLETED allows apps to start after the device boots. RECEIVE_ SMS and RECEIVE_ WAP_ PUSH allow for receiving SMS and WAP push messages. RECORD_ AUDIO grants access to record audio, and REORDER_ TASKS allows for the reordering of running tasks.
SET_ ALARM allows for setting alarms, SET_ ANIMATION_ SCALE allows for setting animation scale, and SET_ WALLPAPER allows for setting wallpapers. SUBSCRIBED_ FEEDS_ READ and SUBSCRIBED_ FEEDS_ WRITE enable the reading and writing of subscribed feeds. USE_ FINGERPRINT allows for using fingerprint hardware, and WAKE_ LOCK keeps the device from sleeping. WRITE_ EXTERNAL_ STORAGE and WRITE_ VOICEMAIL allow for writing to external storage and voicemail.
API calls like Ljava/lang/Runtime;->exec, Ldalvik/system/DexClassLoader;->loadClass, Ljava/lang/System;->loadLibrary, and Ljava/net/URL;->openConnection are related to executing commands, loading classes, loading native libraries, and opening network connections. Landroid/location/LocationManager;->getLastKnownLocation provides the last known location, Landroid/telephony/TelephonyManager;->getSimOperator provides SIM operator information, and Lorg/apache/http/impl/client/DefaultHttpClient;->execute executes HTTP requests.
Permissions such as android.permission.READ_ EXTERNAL_ STORAGE, android. permission. RECEIVE_ SMS, android.permission.WRITE_ SETTINGS, and android. permission. RECORD_ AUDIO grant essential access to storage, SMS, settings, and audio recording. Other permissions like com.android. launcher. permission. INSTALL_ SHORTCUT and android.permission.MOUNT_ UNMOUNT_ FILESYSTEMS handle shortcut installation and file system mounting. Various permissions like com.majeur.launcher. permission. UPDATE_ BADGE, android. permission. AUTHENTICATE_ ACCOUNTS, and com. htc. permission. READ_ SETTINGS manage badges, account authentication, and settings for specific launchers.
android.permission.FLASHLIGHT controls the flashlight, and android.permission. CHANGE_ CONFIGURATION allows for changing system configuration. com. anddoes. launcher. permission. UPDATE_ COUNT and com. google. android. c2dm. permission. RECEIVE enable badge count updates and receive data messages. Manufacturer-specific permissions like com.sonymobile. home.permission.PROVIDER_ INSERT_ BADGE and android.permission. WRITE_ CALENDAR handle badge insertion and calendar writing.
android.permission.SEND_ SMS allows for sending SMS messages, and com.huawei. android.launcher. permission.WRITE_ SETTINGS allows for writing settings for Huawei launchers. android.permission.SET_ WALLPAPER allows for setting the wallpaper, android.permission. ACCESS_ MOCK_ LOCATION allows for creating mock locations, and android.permission. ACCESS_ COARSE_ LOCATION provides access to coarse location data. android.permission. READ_ LOGS allows for reading system logs, android.permission.SYSTEM_ ALERT_ WINDOW allows for creating alert windows, and me.everything.badger.permission. BADGE_ COUNT_ READ allows for reading badge counts.
android.permission.CHANGE_ WIFI_ STATE allows for changing the Wi-Fi state, android.permission.READ_ CONTACTS allows for reading contacts, and com.android.vending. BILLING enables in-app billing. android.permission.RECEIVE_ BOOT_ COMPLETED allows apps to start after booting, android.permission.WAKE_ LOCK keeps the device from sleeping, and android.permission.ACCESS_ FINE_ LOCATION provides access to precise location data. android.permission.BLUETOOTH and android.permission.BLUETOOTH_ ADMIN manage Bluetooth connections and settings. android.permission.CAMERA grants access to the camera, android.permission.FOREGROUND_ SERVICE allows for starting foreground services, and android.permission.VIBRATE enables vibration control.
android.permission.RECEIVE_ USER_ PRESENT detects when the user is present, and com.sec.android.iap.permission.BILLING enables in-app billing for Samsung devices. android.permission.ACCESS_ NETWORK_ STATE allows access to the network state, and com.google.android.finsky.permission.BIND_ GET_ INSTALL_ REFERRER_ SERVICE binds to the install referrer service. Finally, android.permission.READ_ SMS grants access to read SMS messages.
The final comparison of classification performance is given in
Table 6.
As seen from
Table 6, this research outperforms the majority of research reported in other literature. Although it is not the highest classification performance achieved, the benefit of utilizing this approach is that SEs are obtained that can easily be integrated and can execute using lower computational resources when compared to CNN and DNNs.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}